Learning to Generate Unambiguous Spatial Referring Expressions for Real-World Environments
Fethiye Irmak Do\u{g}an, Sinan Kalkan, Iolanda Leite

TL;DR
This paper introduces a deep learning-based two-stage method for generating natural and unambiguous spatial referring expressions in real-world environments, improving accuracy and user preference over existing algorithms.
Contribution
It presents a novel two-stage deep learning approach for generating spatial referring expressions, addressing the gap in generation methods compared to comprehension-focused research.
Findings
Generated expressions are ~30% more accurate according to user evaluation.
Users prefer the generated expressions ~32% more often.
Method outperforms state-of-the-art in ambiguous environments.
Abstract
Referring to objects in a natural and unambiguous manner is crucial for effective human-robot interaction. Previous research on learning-based referring expressions has focused primarily on comprehension tasks, while generating referring expressions is still mostly limited to rule-based methods. In this work, we propose a two-stage approach that relies on deep learning for estimating spatial relations to describe an object naturally and unambiguously with a referring expression. We compare our method to the state of the art algorithm in ambiguous environments (e.g., environments that include very similar objects with similar relationships). We show that our method generates referring expressions that people find to be more accurate (30% better) and would prefer to use (32% more often).
Click any figure to enlarge with its caption.
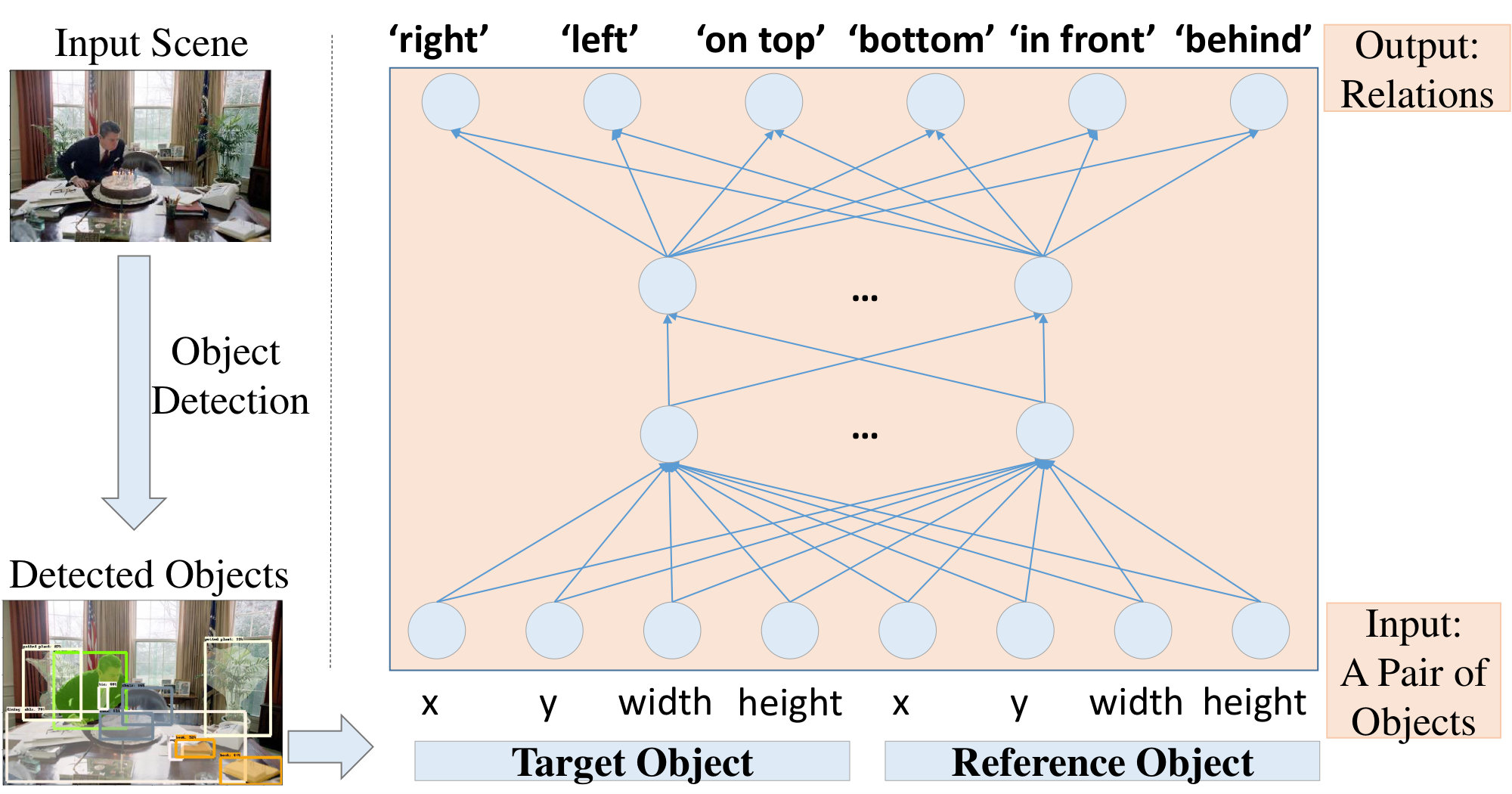 Figure 1
Figure 1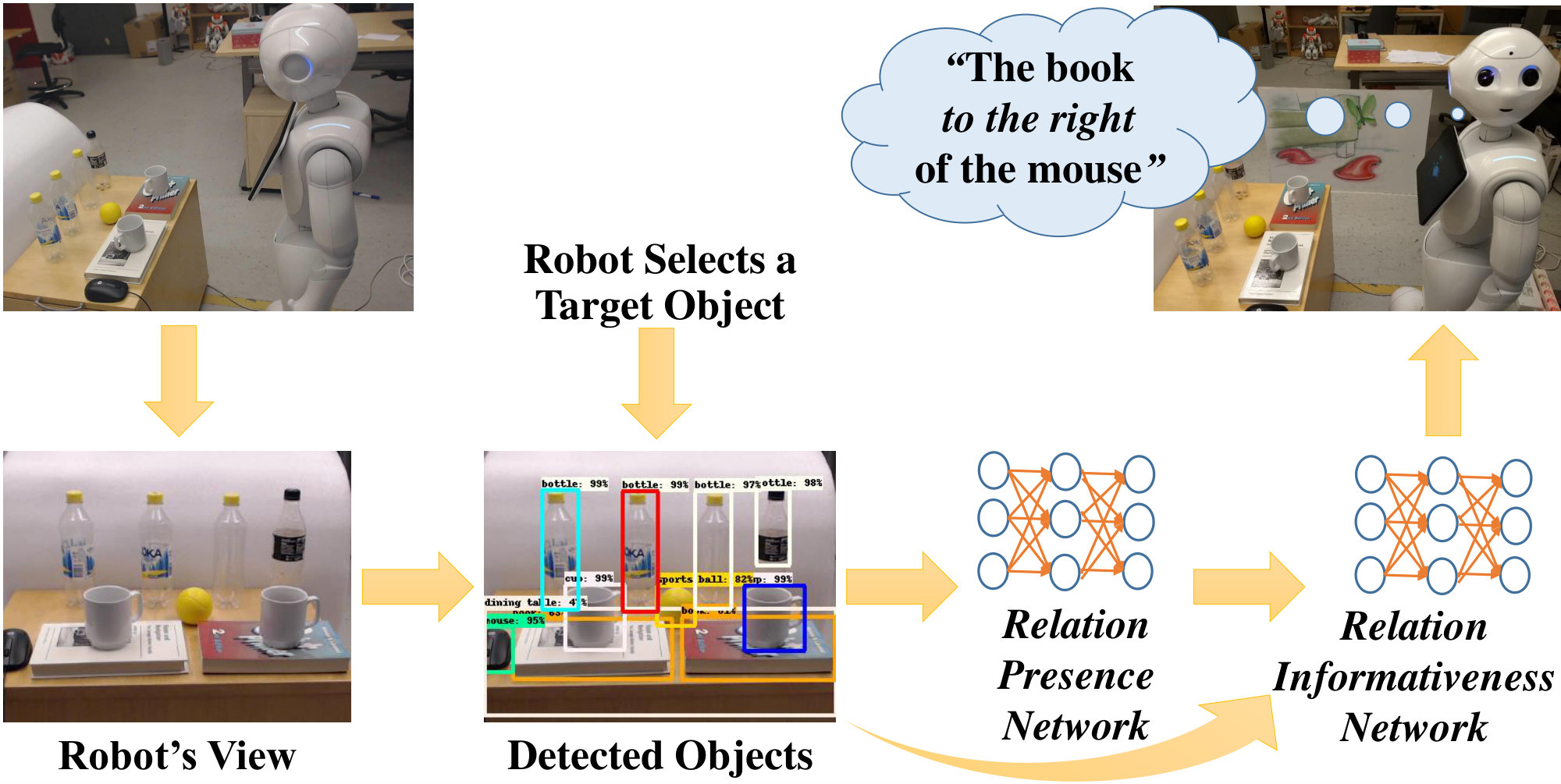 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4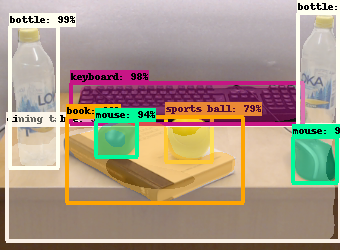 Figure 5
Figure 5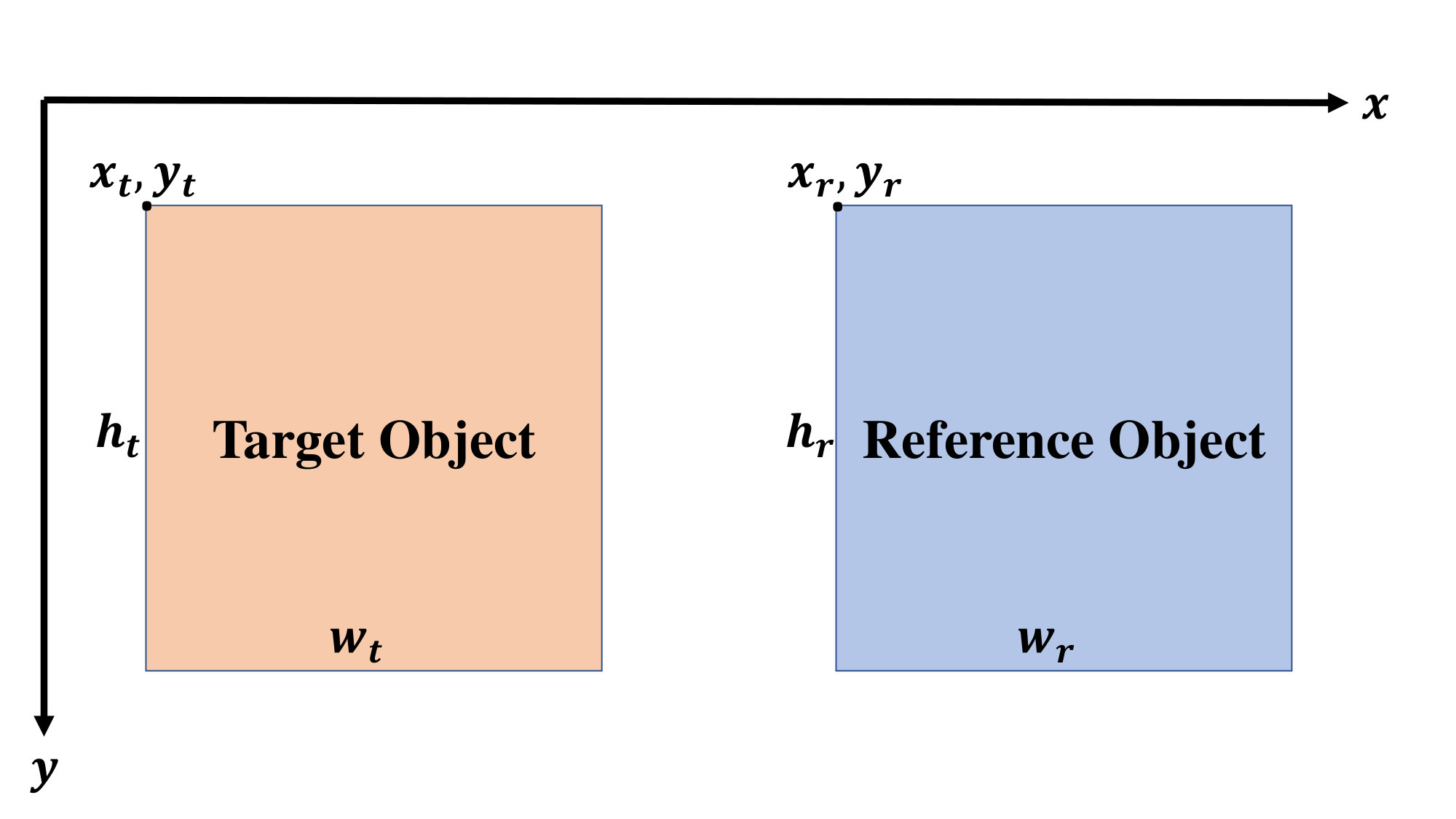 Figure 6
Figure 6 Figure 7
Figure 7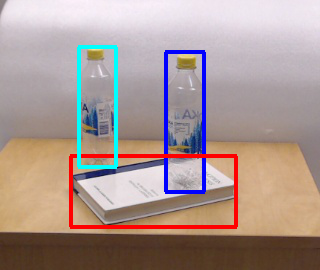 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15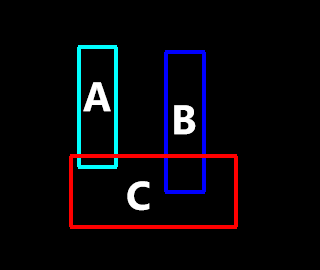 Figure 16
Figure 16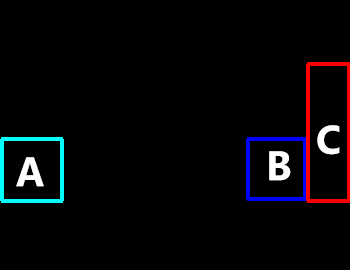 Figure 17
Figure 17 Figure 18
Figure 18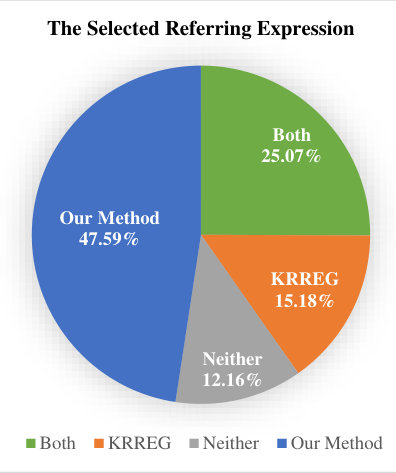 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32 Figure 33
Figure 33 Figure 34
Figure 34 Figure 35
Figure 35 Figure 36
Figure 36 Figure 37
Figure 37| Training | Validation | Testing | |
|---|---|---|---|
| RPN | 93.24% (+/- 0.41%) | 93.30% (+/- 0.69)% | 93.06% (+/- 0.63%) |
| RIN | 82.76% (+/- 0.70%) | 80.18% (+/- 0.61%) | 80.28% (+/- 0.34%) |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Learning to Generate Unambiguous Spatial Referring Expressions for Real-World Environments
Fethiye Irmak Doğan1, Sinan Kalkan2 and Iolanda Leite1 1Fethiye Irmak Doğan and Iolanda Leite are with the Division of Robotics, Perception and Learning from the School of Electrical Engineering and Computer Science at KTH Royal Institute of Technology, Stockholm, Sweden {fidogan, iolanda}@kth.se2Sinan Kalkan is with the KOVAN Research Lab at the Department of Computer Engineering, Middle East Technical University, Ankara, Turkey [email protected]
Abstract
Referring to objects in a natural and unambiguous manner is crucial for effective human-robot interaction. Previous research on learning-based referring expressions has focused primarily on comprehension tasks, while generating referring expressions is still mostly limited to rule-based methods. In this work, we propose a two-stage approach that relies on deep learning for estimating spatial relations to describe an object naturally and unambiguously with a referring expression. We compare our method to the state of the art algorithm in ambiguous environments (e.g., environments that include very similar objects with similar relationships). We show that our method generates referring expressions that people find to be more accurate (30% better) and would prefer to use (32% more often).
I Introduction
Verbal communication is a key challenge in human-robot interaction. Humans are used to reasoning and communicating with the help of referring expressions, defined as “any expression used in an utterance to refer to something or someone (or a clearly delimited collection of things or people), i.e., used with a particular referent in mind.” [1]. Referring expressions are commonly used to describe an object in terms of its distinguishing features and spatiotemporal relationships to other objects.
The ability to generate spatial referring expressions is critical to many robotics applications, such as to clarify an ambiguous user request to pick up an object or to generate verbal instructions. When there are multiple objects that may fit a single description or multiple ways to describe the same target object (such as in Figure 2), it is important that the referring expression used by the robot is not only accurate but also similar to what a human would use to facilitate communication and achieve comprehension.
In this paper, we address the problem of generating unambiguous and natural-sounding spatial referring expressions by using a learning-based method that can be used by robots to describe objects in real-world environments (see Figure 1). There have been several efforts for both the comprehension and generation of referring expressions for Human-Robot Interaction (HRI). For comprehension, recent works have shown promising results by using the advances in deep learning [2, 3, 4]. Generating spatial referring expressions can be more challenging than comprehension because there can be multiple ways to refer to a target object in relation to other objects, yet some descriptions might appear unnatural to human users or not describe the target object in a unique manner. Previous research in generating referring expressions has mostly focused on hand-designed thresholds, rules or templates [5, 6, 7, 8], which makes these approaches difficult to generalize to other environments. Computer vision researchers have been addressing this problem using learning-based methods [9, 10, 11].
Previous research on spatial referring expression generation has either been less focused on the naturalness of the generated expressions or has not been tested in highly ambiguous scenes. To the best of our knowledge, our method is the first in doing so, while bringing the following benefits over pure rule-based approaches: (i) being able to determine the relations between objects, (ii) learning the confidence of each spatial relation to generate the most natural referring expression for the target object. As we demonstrated with a user study in challenging indoor and outdoor scenes, our method yields more accurate referring expressions that humans would be more willing to use compared to an algorithm by Kunze et al. [7].
I-A Background
Referring expressions have been addressed in various HRI and computer vision studies, both in terms of comprehension and generation. Many of these approaches have leveraged spatial relationships.
For the comprehension of referring expressions in HRI, many studies have tried interpreting natural language descriptions from humans for finding target objects or locations. These studies primarily used natural language parsing methods or graph-based representation and search algorithms [8, 12, 13, 14]. More recently, some works have employed deep learning methods: For example, Hatori et al. [2] proposed an interactive system where a deep network processes unconstrained spoken language and maps the words to actions and objects in the scene. Similarly, Shridhar & Hu [3, 4] used recurrent neural networks to link visual features with provided referring expressions (e.g., ‘the red can next to the teddy bear’) to detect the referred object and to ask disambiguation questions. Both of these studies address comprehension of referring expressions as a learning problem, and reduce the limitations of hand-designed features and rules.
Generating referring expressions is a more complex issue. Because the comprehension tasks have a limited number of possible solutions (i.e., they are bounded by the number of objects present), generation problems are more difficult to solve than comprehension. Consequently, generating referring expressions has mostly been resolved through hand-designed thresholds, rules, or templates [5, 6, 7, 8]. For instance, Williams & Scheutz [5, 6] proposed a method that extends an incremental algorithm [15] to generate domain-independent referring expressions under uncertainty, but they employ rules for generating expressions and pre-determined thresholds for handling uncertainties. In another study, Kunze et al. [7] used a method with five different algorithm strategies for generating spatial referring expressions and trained a classifier to determine the most appropriate one for a specific scene. Although the classifier learns to decide the algorithm strategy, each algorithm strategy depends on different rules for generating referring expressions. The main disadvantages of rule-based methods include: (i) the assumption of “perfect, complete, and accessible knowledge of all referents”, which is not always possible [5]; (ii) the impracticality of hand-designing thresholds and rules that are supposed to generalize to every possible setting; and (iii) that methods are not adaptable/extensible for a life-long learning robot.
There are promising studies on generating unambiguous referring expressions in computer vision [9, 10, 11]. However, these models have not been tested in highly ambiguous scenes (see Figure 2 for an example), and they do not focus on generating human-like referring expressions. Therefore, these models are inappropriate for real-time HRI.
Referring expressions commonly exploit spatial relations [3, 7, 16], and this approach has been employed by different HRI studies [7, 17, 18, 19]. However, studies that leverage spatial relations are generally based on rule-based approaches, limited numbers of relationships, or artificial data [16, 20, 21]. Unfortunately, rule-based approaches are not expandable for different relations and some relations are difficult to formalize in terms of rules, especially while using 2D data (Figure 8). Moreover, artificial data is not always suitable because, in real environments, the relations might satisfy different rules but one might be the dominant choice for humans. Although there are inspiring vision studies that learn spatial relations among objects [22, 23], they either assume prior knowledge about the target and reference objects or they do not have any learning on spatial relation which describes the object unambiguously and naturally.
I-B Contributions
We summarize our contributions in this paper as follows:
- •
Rather than hand-designing rules for every relation, our method is capable of learning relations between objects and deducing the dominant one when multiple relationships exist.
- •
Our method learns the informativeness of each spatial relation, i.e., the value of a relation in describing an object with respect to another without ambiguity, and generates the most natural and unambiguous referring expression to describe the target object.
- •
Our work is applicable to different indoor and outdoor environments and employable for different HRI tasks.
II Referring Expression Generation
We define the referring expression generation (REG) problem to be generating a noun phrase describing a target object with respect to a reference object in terms of their spatial relations (see Figure 6 for examples). With this problem formulation, we are limiting our approach to referring expressions involving two objects and descriptions involving spatial relations only.
We considered the following spatial relations: ‘to the right’, ‘to the left’, ‘on top’, ‘at the bottom’, ‘in front’, ‘behind’, which can easily expand if there is labeled data. By using one of these relations in , we aim to generate an unambiguous and natural referring expression for a target object, , in an encountered scene.
Given an image of a scene, we first detect and find the set of objects, , using a deep network. If there is a spatial relation of category between two objects and , we denote it by . Given the bounding boxes and the types of the objects, we use two networks to find the most informative spatial relation, , and the object to describe a target object, (see Figure 1):
- •
Relation Presence Network (RPN): The network is trained on a pair of objects using their bounding box coordinates and decides which relations exist between the pair. That is, the RPN network gives us a probability, , for the presence of spatial relation between objects and .
- •
Relation Informativeness Network (RIN): This network is trained to decide whether a given relation is informative for a pair of objects. This network yields an informativeness measure, , for the given pair of objects and and the spatial relation .
The motivation behind our two-stage approach is illustrated in Figure 3. This approach for finding an informative relation and an object for referring to a target object is similar to the two-stage object detection approaches (e.g., [24]), where one network (stage) is devoted to proposing image regions that are likely to include an object and another is employed to classify those regions into object types.
II-A Detecting Objects in the Scene
To detect the objects in a scene, we used Mask R-CNN, one of the state-of-the-art object detectors based on convolutional neural networks [24]. Our Mask R-CNN model uses the ResNet-101 as the backbone network and is trained on the MS COCO object detection dataset. This network extracts bounding boxes for each object as well as their types (e.g., book, mouse, etc.) – see Figure 4 for an example.
We describe an object as a quadruple of , where is the position of the top-left corner of the bounding box containing the object and are the box’s width and height.
II-B Relation Presence Network (RPN)
We formulated relation presence estimation as a multi-class classification problem. To this end, we trained a multilayer perceptron, as shown in Figure 5. The input of the network is a pair of objects: the target object, , and a reference object, . The input is provided as a concatenation of the sizes and locations of the bounding boxes of these two objects in an 8-dimensional input space. The network has six outputs that contain the probabilities of each possible spatial relation (i.e., ).
RPN has two hidden layers with 32 and 16 hidden neurons, respectively, with ReLU non-linearities [25]. The output layer uses a softmax function to map activations to probabilities. Multi-label cross-entropy loss is used to train the network. Moreover, dropout [26] is added between each layer including input and output layers with 0.2 probability to prevent overfitting. Early stopping is used to stop training whenever validation accuracy stop increasing.
The network is trained on a subset of the Visual Genome dataset [27], which includes a rich set of objects and annotations of the spatial relations among them.
II-C Relation Informativeness Network (RIN)
We formulated informativeness estimation as a binary classification problem, that is, a problem that asks whether or not a spatial relation is informative. The confidence of the answer is taken as the informativeness of the spatial relation. For this purpose, we trained another multilayer perceptron. The input for this network is 12 dimensional: the target object, , the reference object, and the relation category (one-hot vector). The network has a single output for the informativeness of the relation between these objects.
RIN has three hidden layers with 64, 16, and 8 hidden neurons. The hidden and output layers have ReLU and sigmoid nonlinearities, respectively. In RIN, dropout with 0.2 probability is added to each layer. Early stopping is used to stop training when validation accuracy stops increasing.
RIN was trained on another subset of the Visual Genome dataset. A relation is considered as ‘informative’, i.e., more natural, when the relation is annotated in the dataset. Furthermore, it is regarded as ‘non-informative’, i.e., less natural, when that relation exists but it is not annotated. The dataset used for the training of RIN is detailed in Section III-A.
II-D Forming a Referring Expression for a Pair of Objects
Given a target object () to refer to, our goal is to find the noun phrase describing in relation to a reference object, , with a spatial relation such that is as informative as possible.
First, for each object , we select the set of relations, denoted by , whose presence indicators (provided by the RPN network) are strong (i.e., above the threshold):
[TABLE]
where the threshold is set to empirically. Even in simple scenes, multiple relations turn out to be confident for each category (for an example, see Figure 9). Among these, we select the relations with the highest confidence values provided by the RIN network for each category as follows:
[TABLE]
We select a subset of , denoted by , such that contains all relations in except the relations in :
[TABLE]
where is the set of where relation holds between objects and .
For the target object , we check whether a relation with object resembles another confident relation in . In other words, we look if there is a spatial relation such that and , where is the type of the object. If there is such a relation, we remove from , the candidate relations because its description of is ambiguous.
After eliminating ambiguous relations, we pick the most confident remaining relation to refer to as follows:
[TABLE]
Given the target object , the reference object and the most informative spatial relation between them, we form a simple noun-phrase by concatenating names of their types – see Figure 6 for some examples.
The overall procedure is summarized in Algorithm 1.
II-E Kunze Et Al.’s Relative Referring Expression Generation (KRREG) Algorithm
In this section, we briefly describe the algorithm by Kunze et al. [7] with which we compared our method. This work proposed several methods for generating different types of referring expressions, including five algorithms for generating descriptions (i) involving only the object type (e.g., ‘the bottle’), (ii) relative referring expressions (e.g., ‘the bottle to the right of the book’), (iii) set-relative relations (e.g., ‘the second bottle from the right’), (iv) proximal relations (e.g., ‘the cup next to the keyboard’), and (v) distal relations (e.g., ‘the bottle furthest from you’). Because generation of the relative referring expressions (item (ii)) is closest to our work, we implemented that algorithm to compare with our method. The rest of the section describes this algorithm in detail.
In Kunze et al.’s relative referring expression generation algorithm (KRREG), the set of objects and their spatial relations in the scene are required as input. For this, as in our method, we employ Mask R-CNN to obtain and our RPN network to obtain relations between objects (threshold in Equation 1 is selected as 0.5).
KRREG’s algorithm first defines a set of distractors () as the set of objects with same type of :
[TABLE]
and the set of landmarks () as the set of objects in the scene excluding and the ones in :
[TABLE]
In KRREG’s algorithm each landmark is assigned a rank () measuring its suitability to determine the reference object. The rank of a landmark, , is defined to be proportional to ’s area in the image and inversely proportional to ’s distance to and the number of objects in :
[TABLE]
where and represent the normalized width and height of landmark ; is the number of objects in , and is the distance between and ( denotes the center of mass for object ):
[TABLE]
After calculating for each landmark , is sorted in decreasing order with respect to the values, and the distinctiveness of each for object (or if more than one relation between and , each set in the power set of relations) is checked: A candidate relation is regarded as not distinctive if there is a spatial relation for objects and such that and .
While forming a referring expression, KRREG’s algorithm assumes an ordering between relations (e.g., if is both ‘behind’ and ‘to the left’ of , ‘behind’ is prior than ‘to the left’) and checks the distinctiveness of relations according to their priority. In our implementation of KRREG, we do the same except for two relations (‘close’ and ‘distant’) that we do not have in our problem. We replace these two relations with ‘on top’ and ‘at the bottom’.
III Experiments and Results
We assess our learning-based method in terms of relation estimation accuracies and the naturalness of the generated expressions by conducting an evaluation with humans.
III-A Training Data
We use the Visual Genome (VG) dataset [27] for training the networks. This dataset contains 108,077 images of indoor as well as outdoor scenes, and 40,480 unique relations (these include other types of relations like affordances, is-a information in addition to spatial relations).
For our first model, i.e., RPN, we collected an arbitrary set of instances, where , and are as introduced in Section II. In total, we had 5,940 such instances (990 for each relation ) from the VG dataset.
For the second network, i.e., RIN, we gathered a set of instances, where is a binary label indicating whether is an informative relation between and or not. From the VG dataset, we formed 2,057 informative and 2,057 uninformative such instances for each , yielding a dataset of 24,684 different relation pairs in total. The ‘informative’ relations are determined directly by using the annotations from the VG dataset; i.e., if there is a labeled relation between objects and in the VG dataset, we set as ‘informative’. On the other hand, for collecting ‘uninformative’ relations, we defined simple geometrical rules for each – see Figure 7. If a relation between two objects is suggested by these rules but not annotated in the VG dataset, is set to ‘uninformative’. Because humans annotated only the most prominent relations of the scene (rather than all possible ones) in the VG dataset, an unannotated relation between two objects suggests that that relation is not natural for describing these objects.
III-B Analyzing the Networks
In this section, we analyze the training and testing accuracies of our networks as well as the probability and confidence estimations of the relations.
III-B1 Accuracy Results
We present the training, validation, and testing performances of RPN and RIN in Table I. We observe that the networks do not exhibit any over-fitting because there are no significant differences among the training, validation, and test scores. Moreover, we note that the accuracies of RIN are lower than those of RPN, suggesting that determining the informativeness of a relation compared to its presence is a more challenging task.
III-B2 Analyzing RPN and RIN in detail
In this section, we analyze the performance of RPN and RIN on two example scenes in order to better illustrate the necessity of the two-stage approach and the challenge of the problem.
First, we examine RPN on a challenging example in Figure 8 where we want to analyze the relations between the book (object C) and the bottles (object A and object B). In the figure, object C is ‘in front’ of object A, and ‘at the bottom’ of the object B. When we want to describe object C, both of these relations (‘in front’ and ‘at the bottom’) might be valid for object A and object B if we only consider the bounding boxes of the objects. However, for referring to object C, RPN successfully suggests the ‘in front’ relation for object A and ‘at the bottom’ relation for object B.
In another example in Figure 9, we analyze and compare the behavior of RPN and RIN. We expect RPN to estimate the relations and RIN to assess their informativeness. To see this visually, ‘to the right’ relation is analyzed to describe the bottle (object C) in Figure 9. Object A is spatially further away from object C compared to object B, and hence, RPN outputs a higher ‘to the right’ relation probability. However, when the informativeness of this relation is examined, object B has a higher relation confidence (i.e., more informative) because it is closer to object C.
III-C User Study
In this section, we compare our method and KRREG in scenes where referring expressions can be ambiguous (i.e., more than one object may satisfy the description). For this, we conduct a user study with 61 human judges (27 females and 34 males between 22-41 years old – average age is 28) blind to our research questions evaluated the generated expressions from both methods in terms of (i) correctly finding the referenced objects (Experiment 1), and (ii) the naturalness of the expressions (Experiment 2).
For this purpose, we collected a dataset that consisted of three parts: (i) 32 challenging table scenes that we collected from various configurations of objects. The scenes illustrate commonly encountered settings for collaborative tasks performed at a table in order to appropriately test whether a robot in these scenarios would be able to direct people to find the correct object when there are ambiguities. (ii) 20 indoor scenes from 10 different spatial contexts (including a living room, bedroom, furniture store, classroom, playroom, study room, office, bathroom, kitchen, and dining room) from the SUN-RGBD dataset [28] that contain ambiguities. (iii) 13 ambiguous outdoor scenes from the SUN dataset [29]. Note that none of the models is trained on this dataset.
Among these 65 scenes, our method and KRREG generate the same expressions for 35% of cases (23 scenes), and for 17% of cases (11 scenes), KRREG could not generate any expression to describe the target. This happens when none of the relations between landmarks and the target is considered to be distinctive by the algorithm (distinctiveness is explained in Section II-E) (see Figure 10 for an example). However, because our model does not consider all spatial relations in the scene as informative, it successfully eliminates the ambiguous ones and describes the target for these 17% of cases as well. The results reported below show the cases when two methods generate different expressions for the same scene (31 scenes).
III-C1 Experiment 1: Correctly finding the referred object
In this experiment, we compare the methods on their ability to yield unambiguous referring expressions in ambiguous cases. For this purpose, the 61 human judges were asked to select the referred object from the generated referring expressions. They were requested not to select an object if the generated expression is unclear or they were not able to decide on an object according to the generated expression. For a fair comparison, a test instance is provided to a user two times: once for our method and once for the KRREG algorithm. The order of the images with an expression from our method or KRREG was selected randomly by ensuring the same image does not appear successively for different expressions.
The results of this experiment are shown in Figure 11. We observe that the judges were more likely to pick the correct object when the referring expression was generated by our method (80.70%) compared to KRREG (50.34%). Moreover, the judges found our generated referring expressions less unclear (13.75%) than those from the KRREG algorithm (44.16%).
To observe whether the method affects the accuracy of the expressions, we analyzed the statistical significance of the evaluations with the Chi-Square test. To do so, we considered the total number of correct, false and unclear selections made by judges for the two different methods. This analysis shows that our results are statistically significant, . Therefore, our method is significantly more likely to yield an unambiguous referring expression than the KRREG algorithm.
III-C2 Experiment 2: Naturalness of the expressions
In the first task, we were looking for accuracy of selecting the referred object; in the second task, we wanted to understand whether the expressions generated by our method are considered more natural (i.e., whether people would be more likely to use that expression to refer to the target object) than the KRREG algorithm.
For this purpose, the 61 judges were asked to select which of the two generated referring expressions (one from our method and one from the KRREG algorithm) they would be more likely to use while describing a target object. That selection was then considered the more natural of the two. The human judges were also given the option of selecting neither of them or both of them. The order of the expressions generated by two different methods was chosen randomly for each image to avoid bias.
The results of the experiment are presented in Figure 12. We observe that the expressions generated by our method are preferred significantly by the human judges: they selected 47.59% of our referring expressions and only 15.18% of the KRREG algorithm expressions. In 25.07% of the cases, results of both methods were usable, whereas both methods failed to produce suitable results 12.16% of the time.
IV Discussion and Conclusion
In this paper, we have proposed a learning-based method for estimating informative spatial relations to generate unambiguous and natural referring expressions for collaborative human-robot interaction. Our approach contains two distinct models, one for learning relations between objects and another one to decide a relation’s informativeness.
Through our user study, we have shown that our method is capable of generating unambiguous referring expressions for indoor and outdoor scenes that humans prefer over the state-of-the-art KRREG algorithm. The relation probabilities shown in Figure 8 demonstrate that the proposed RPN is capable of estimating the most dominant relation when only the objects’ bounding boxes are provided. Moreover, RIN determines the informativeness of the relations with high accuracy, as shown in Figure 9. We have demonstrated in Figure 10 that using the uniqueness of informative relations can reduce ambiguity in very challenging scenes that the KRREG algorithm fails to generate an expression. Therefore, by utilizing RIN’s informativeness measure to select among relations proposed by the RPN, our method generates referring expressions for describing target objects more precisely, as presented in Figure 11. Moreover, generating the referring expressions with regard to their informativeness yields more natural results, as demonstrated in an evaluation with human judges in Figure 12.
In summary, we have demonstrated that our method is applicable to different indoor and outdoor environments, which is crucial for use by a robot operating in the real world. Moreover, we have evaluated our results regarding two fundamental aspects of HRI tasks, communicating unambiguously and naturally in different environments. The promising results indicate that our method can be employed successfully in various collaborative HRI tasks, e.g., helping people to find ingredients while preparing a recipe or to determine which pieces to use during furniture assembly.
Our work can be extended in multiple ways. First, more relations, such as ‘inside’ and ‘next to’, can be added to those we considered in this work if we provide additional labeled training data. Another possibility is to provide the objects’ depth distances, which could improve the training and test accuracies in Table I. Another avenue worth exploring would be employing RPN to replace the rules in Figure 7. Using RPN while labeling the non-informative relations could potentially increase the training and test performances of RIN, and it is part of our future research plans.
Acknowledgment
This work was partially funded by a grant from the Swedish Research Council (reg. number 2017-05189). We are grateful to participants for their voluntary contributions to evaluate the referring expressions and Liz Carter for her valuable comments.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] J. R. Hurford, B. Heasley, and M. B. Smith, Semantics: a coursebook . Cambridge University Press, 2007.
- 2[2] J. Hatori, Y. Kikuchi, S. Kobayashi, K. Takahashi, Y. Tsuboi, Y. Unno, W. Ko, and J. Tan, “Interactively picking real-world objects with unconstrained spoken language instructions,” in ICRA . IEEE, 2018.
- 3[3] M. Shridhar and D. Hsu, “Grounding spatio-semantic referring expressions for human-robot interaction,” RSS Workshop on Spatial-Semantic Representations in Robotics , 2017.
- 4[4] ——, “Interactive visual grounding of referring expressions for human-robot interaction,” in RSS , 2018.
- 5[5] T. Williams and M. Scheutz, “Referring expression generation under uncertainty: Algorithm and evaluation framework,” in INLG , 2017.
- 6[6] ——, “Referring expression generation under uncertainty in integrated robot architectures,” in RSS Workshop on Human-Centered Robotics: Interaction, Physiological Integration and Autonomy , 2017.
- 7[7] L. Kunze, T. Williams, N. Hawes, and M. Scheutz, “Spatial referring expression generation for hri: Algorithms and evaluation framework,” in AAAI Fall Symposium on AI and HRI , 2017.
- 8[8] H. Zender, G.-J. M. Kruijff, and I. Kruijff-Korbayová, “Situated resolution and generation of spatial referring expressions for robotic assistants,” in IJCAI , 2009.