Copula-like Variational Inference
Marcel Hirt, Petros Dellaportas, Alain Durmus

TL;DR
This paper introduces a new family of variational distributions inspired by copulas, enabling efficient sampling and better approximation of complex posteriors in Bayesian neural networks.
Contribution
It proposes copula-like variational densities with efficient sampling and normalizing flows, improving approximation of non-Gaussian posteriors over traditional methods.
Findings
Performs comparably to state-of-the-art variational methods on benchmarks.
Can approximate non-Gaussian posteriors effectively.
Sampling complexity is linear in the dimension.
Abstract
This paper considers a new family of variational distributions motivated by Sklar's theorem. This family is based on new copula-like densities on the hypercube with non-uniform marginals which can be sampled efficiently, i.e. with a complexity linear in the dimension of state space. Then, the proposed variational densities that we suggest can be seen as arising from these copula-like densities used as base distributions on the hypercube with Gaussian quantile functions and sparse rotation matrices as normalizing flows. The latter correspond to a rotation of the marginals with complexity . We provide some empirical evidence that such a variational family can also approximate non-Gaussian posteriors and can be beneficial compared to Gaussian approximations. Our method performs largely comparably to state-of-the-art variational approximations on standard regression…
Click any figure to enlarge with its caption.
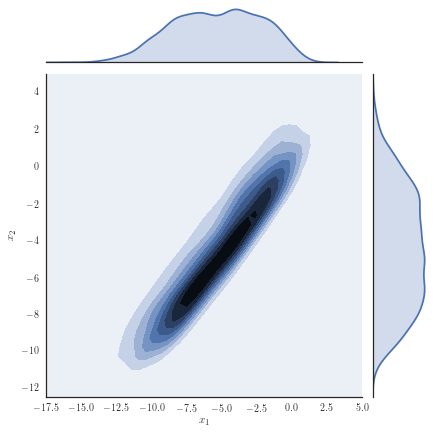 Figure 1
Figure 1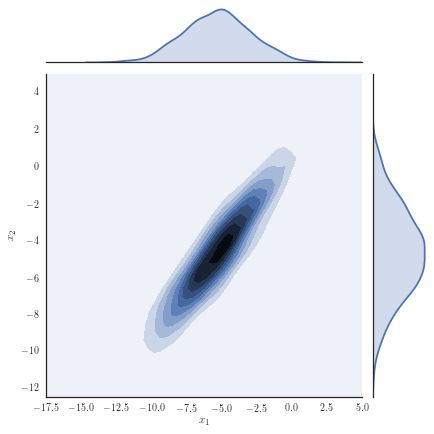 Figure 2
Figure 2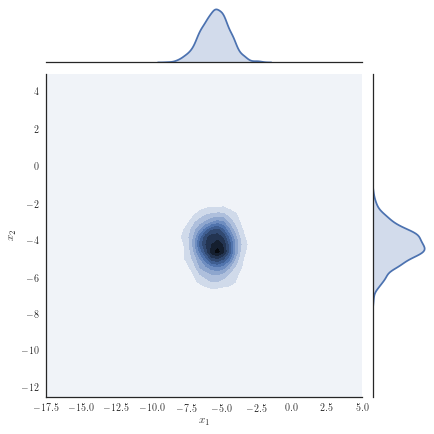 Figure 3
Figure 3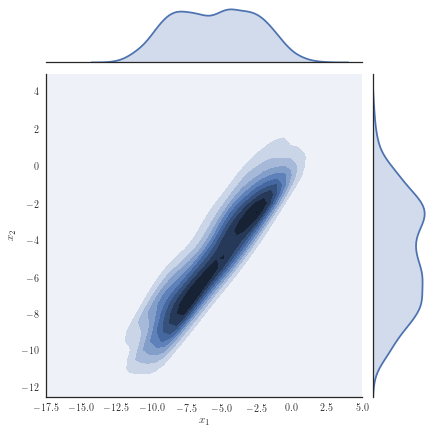 Figure 4
Figure 4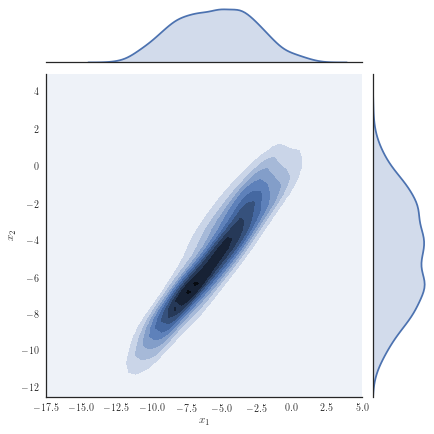 Figure 5
Figure 5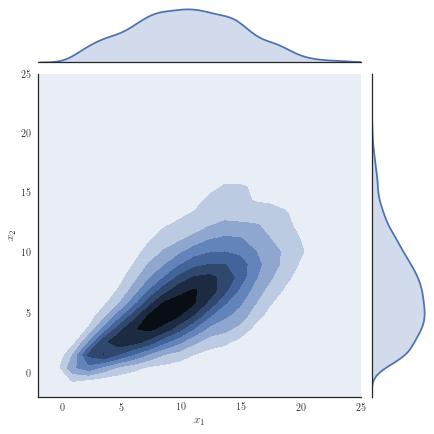 Figure 6
Figure 6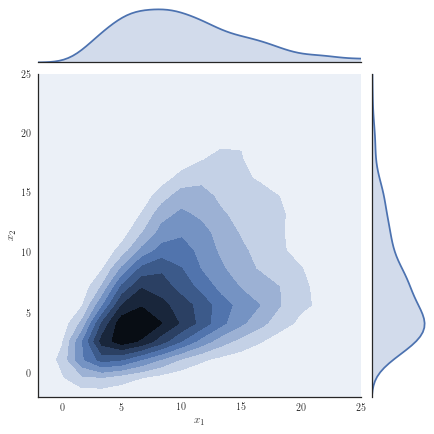 Figure 7
Figure 7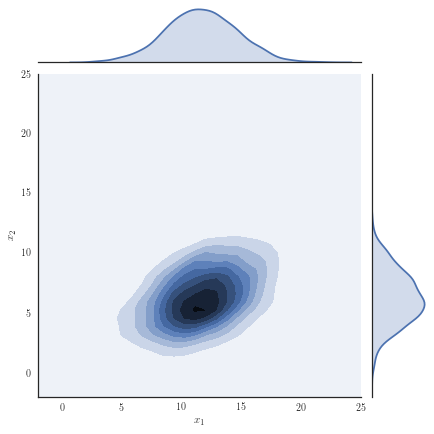 Figure 8
Figure 8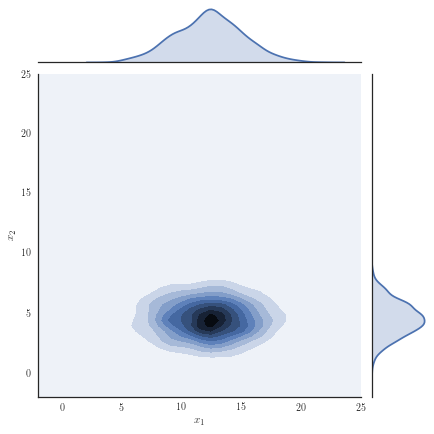 Figure 9
Figure 9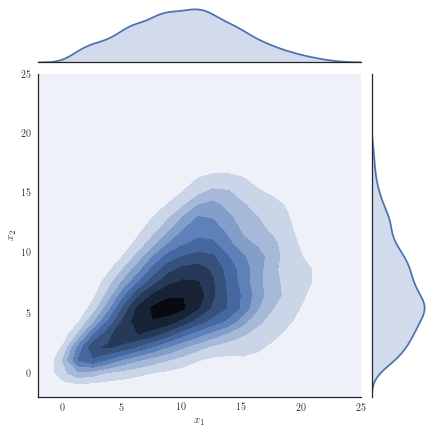 Figure 10
Figure 10| Variational family | ELBO |
|---|---|
| Mean-field Gaussian | -3.42 |
| Full-covariance Gaussian | -2.97 |
| Copula-like without rotations | -2.30 |
| Copula-like with rotations | -2.19 |
| Variational family | ELBO |
|---|---|
| Mean-field Gaussian | -1.24 |
| Full-covariance Gaussian | -0.04 |
| Copula-like | 0.04 |
| 3-mixture copula-like | 0.08 |
| Copula-like | Independent copula | Copula-like | Independent copula | |
|---|---|---|---|---|
| with rotation | with rotation | with IAF | with IAF | |
| Boston | 3.43 (0.22) | 3.51 (0.30) | 3.21 (0.27) | 3.61 (0.28) |
| Concrete | 5.76 (0.14) | 6.00 (0.13) | 5.41 (0.10) | 5.82 (0.11) |
| Energy | 0.55 (0.01) | 2.28 (0.11) | 0.53 (0.02) | 1.30 (0.10) |
| Kin8nm | 0.08 (0.00) | 0.08 (0.00) | 0.08 (0.00) | 0.08 (0.00) |
| Naval | 0.00 (0.00) | 0.00 (0.00) | 0.00 (0.00) | 0.00 (0.00) |
| Power | 4.02 (0.04) | 4.19 (0.04) | 4.05 (0.04) | 4.15 (0.04) |
| Wine | 0.64 (0.01) | 0.64 (0.01) | 0.64 ( 0.01) | 0.64 (0.01) |
| Yacht | 1.35 (0.08) | 1.38 (0.12) | 0.96 (0.06) | 1.25 (0.09) |
| Protein | 4.20 (0.01) | 4.51 (0.04) | 4.31 (0.01) | 4.51 (0.03) |
| Copula-like | Bayes-by-Backprop | SLANG | Dropout | |
|---|---|---|---|---|
| without rotation | results from [47] | results from [47] | results from [47] | |
| Boston | 3.22 (0.25) | 3.43 (0.20) | 3.21 (0.19) | 2.97 (0.19) |
| Concrete | 5.64 (0.14) | 6.16 (0.13) | 5.58 (0.12) | 5.23 (0.12) |
| Energy | 0.52 (0.02) | 0.97 (0.09) | 0.64 (0.04) | 1.66 (0.04) |
| Kin8nm | 0.08 (0.00) | 0.08 (0.00) | 0.08 (0.00) | 0.10 (0.01) |
| Naval | 0.00 (0.00) | 0.00 (0.00) | 0.00 (0.00) | 0.01 (0.01) |
| Power | 4.05 (0.04) | 4.21 (0.03) | 4.16 (0.04) | 4.02 (0.04) |
| Wine | 0.65 (0.01) | 0.64 (0.01) | 0.65 ( 0.01) | 0.62 (0.01) |
| Yacht | 1.23 (0.08) | 1.13 (0.06) | 1.08 (0.09) | 1.11 (0.09) |
| Protein | 4.31 (0.02) | NA | NA | 4.27 (0.01) |
| Variational approximation with Horseshoe prior and size | Error Rate |
|---|---|
| Copula-like with rotations | 1.70 % |
| Copula-like without rotations | 1.78 % |
| Copula-like with IAF | 2.04 % |
| Independent copula with IAF | 2.88 % |
| Independent copula with rotations | 2.90 % |
| Mean-field Gaussian | 3.82 % |
| Copula-like without rotations and for all | 5.70 % |
| Copula-like | Independent copula | Copula-like | Independent copula | |
|---|---|---|---|---|
| with rotation | with rotation | with IAF | with IAF | |
| Boston | -2.85 (0.07) | -2.84 (0.09) | -2.78 (0.1) | -2.88 (0.09) |
| Concrete | -3.29 (0.03) | -3.30 (0.02) | -3.22 (0.02) | -3.26 (0.02) |
| Energy | -1.04 (0.02) | -2.34 (0.05) | -0.93 (0.03) | -1.78 (0.07) |
| Kin8nm | 1.08 (0.01) | 1.07 (0.01) | 1.10 (0.01) | 1.03 (0.01) |
| Naval | 5.74 (0.05) | 5.23 (0.05) | 5.97 (0.05) | 5.01 (0.05) |
| Power | -2.82 (0.01) | -2.85 (0.04) | -2.83 (0.04) | -2.85 (0.01) |
| Wine | -1.01 (0.01) | -1.02 (0.02) | -1.02 (0.02) | -1.02 (0.02) |
| Yacht | -2.01 (0.04) | -2.03 (0.06) | -1.69 (0.06) | -1.94 (0.07) |
| Protein | -2.87 (0.00) | -2.94 (0.00) | -2.90 (0.01) | -2.93 (0.01) |
| Copula-like | Bayes-by-Backprop | SLANG | Dropout | |
|---|---|---|---|---|
| without rotation | results from [47] | results from [47] | results from [47] | |
| Boston | -2.79 (0.08) | -2.66 (0.06) | -2.58 (0.05) | -2.46 (0.06) |
| Concrete | -3.25 (0.03) | -3.25 (0.02) | -3.13 (0.03) | -3.04 (0.02) |
| Energy | -1.00 (0.03) | -1.45 (0.02) | -1.12 (0.01) | -1.99 (0.02) |
| Kin8nm | 1.09 (0.01) | 1.07 (0.00) | 1.06 (0.00) | 0.95 (0.01) |
| Naval | 5.45 (0.12) | 4.61 (0.01) | 4.76 (0.00) | 3.80 (0.01) |
| Power | -2.83 (0.01) | -2.86 (0.01) | -2.84 (0.01) | -2.80 (0.01) |
| Wine | -1.02 (0.01) | -0.97 (0.01) | -0.97 (0.01) | -0.93 (0.01) |
| Yacht | -1.92 (0.06) | -1.56 (0.03) | -1.88 (0.01) | -1.55 (0.03) |
| Protein | -2.89 (0.01) | NA | NA | -2.87 (0.01) |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsGaussian Processes and Bayesian Inference · Bayesian Modeling and Causal Inference · Statistical Mechanics and Entropy
\newaliascnt
lemmatheorem \aliascntresetthelemma
\newaliascntcorollarytheorem \aliascntresetthecorollary
\newaliascntpropositiontheorem \aliascntresettheproposition
\newaliascntdefinitiontheorem \aliascntresetthedefinition
\newaliascntremarktheorem \aliascntresettheremark
\newaliascntexampledefinition \aliascntresettheexample
Copula-like Variational Inference
Marcel Hirt
Department of Statistical Science
University College of London, UK
&Petros Dellaportas
Department of Statistical Science
University College of London, UK
Department of Statistics
Athens University of Economics and Business, Greece
and The Alan Turing Institute, UK &Alain Durmus
CMLA
École normale supérieure Paris-Saclay,
CNRS, Université Paris-Saclay, 94235 Cachan, France.
Abstract
This paper considers a new family of variational distributions motivated by Sklar’s theorem. This family is based on new copula-like densities on the hypercube with non-uniform marginals which can be sampled efficiently, i.e. with a complexity linear in the dimension of the state space. Then, the proposed variational densities that we suggest can be seen as arising from these copula-like densities used as base distributions on the hypercube with Gaussian quantile functions and sparse rotation matrices as normalizing flows. The latter correspond to a rotation of the marginals with complexity . We provide some empirical evidence that such a variational family can also approximate non-Gaussian posteriors and can be beneficial compared to Gaussian approximations. Our method performs largely comparably to state-of-the-art variational approximations on standard regression and classification benchmarks for Bayesian Neural Networks.
1 Introduction
Variational inference [29, 68, 4] aims at performing Bayesian inference by approximating an intractable posterior density with respect to the Lebesgue measure on , based on a family of distributions which can be easily sampled from. More precisely, this kind of inference posits some variational family of densities with respect to the Lebesgue measure and intends to find a good approximation belonging to by minimizing the Kullback-Leibler (KL) with respect to over , i.e. . Further, suppose that with measurable and is an unknown normalising constant. Then, for any ,
[TABLE]
Since does not depend on , minimizing is equivalent to maximizing . A standard example is Bayesian inference over latent variables having a prior density for a given likelihood function and observations . The target density is the posterior with and the objective that is commonly maximized,
[TABLE]
is called a variational lower bound or ELBO. One of the main features of variational inference methods is their ability to be scaled to large datasets using stochastic approximation methods [24] and applied to non-conjugate models by using Monte Carlo estimators of the gradient [57, 35, 60, 63, 38]. However, the approximation quality hinges on the expressiveness of the distributions in and restrictive assumptions on the variational family that allow for efficient computations such as mean-field families, tend to be too restrictive to recover the target distribution. Constructing an approximation family that is both flexible to closely approximate the density of interest and at the same time computationally efficient has been an ongoing challenge. Much effort has been dedicated to find flexible and rich enough variational approximations, for instance by assuming a Gaussian approximation with different types of covariance matrices. For example, full-rank covariance matrices have been considered in [1, 28, 63] and low-rank perturbations of diagonal matrices in [1, 46, 53, 47]. Furthermore, covariance matrices with a Kronecker structure have been proposed in [42, 70]. Besides, more complex variational families have been suggested: such as mixture models [18, 22, 46, 40, 39], implicit models [45, 26, 67, 69, 64], where the density of the variational distribution is intractable. Finally, variational inference based on normalizing flows has been developed in [59, 34, 65, 43, 3]. As a special case and motivated by Sklar’s theorem [62], variational inference based on families of copula densities and one-dimensional marginal distributions have been considered by [66] where it is assumed that the copula is a vine copula [2] and by [23] where the copula is assumed to be a Gaussian copula together with non-parametric marginals using Bernstein polynomials. Recall that is a copula if and only if its marginals are uniform on , i.e. for any and . In the present work, we pursue these ideas but propose instead of using a family of copula densities, simply a family of densities on the hypercube . This idea is motivated from the fact that we are able to provide such a family which is both flexible and allow efficient computations.
The paper is organised as follow. In Section 2, we recall how one can sample more expressive distributions and compute their densities using a sequence of bijective and continuously differentiable transformations. In particular, we illustrate how to apply this idea in order to sample from a target density by first sampling a random variable from its copula density and then applying the marginal quantile function to each component of . A new family of copula-like densities on the hypercube is constructed in Section 3 that allow for some flexibility in their dependence structure, while enjoying linear complexity in the dimension of the state space for generating samples and evaluating log-densities. A flexible variational distribution on is introduced in Section 4 by sampling from such a copula-like density and then applying a sequence of transformations that include rotations over pairs of coordinates. We illustrate in Section 6 that for some target densities arising for instance as the posterior in a logistic regression model, the proposed density allows for a better approximation as measured by the KL-divergence compared to a Gaussian density. We conclude with applying the proposed methodology on Bayesian Neural Network models.
2 Variational Inference and Copulas
In order to obtain expressive variational distributions, the variational densities can be transformed through a sequence of invertible mappings, termed normalizing flows [60]. To be more specific, assume a series of -diffeomorphisms and a sample , where is a density function on . Then the random variable has a density that satisfies
[TABLE]
with . To allow for scalable inferences with such densities, the transformations must be chosen so that the determinant of their Jacobians can be computed efficiently. One possibility that satisfies this requirement is to choose volume-preserving flows that have a Jacobian-determinant of one. This can be achieved by considering transformations where is an orthogonal matrix as proposed in [65] using a Householder-projection matrix .
An alternative construction of the same form can be used to construct a density using Sklar’s theorem [62, 48]. It establishes that given a target density on , there exists a continuous function and a probability space supporting a random variable valued in , such that for any , and ,
[TABLE]
where for any , is the cumulative distribution function associated with , so for any , and is the marginal of , so for any , . To illustrate how one can obtain such a continuous function and random variable , recall that is assumed to be absolutely continuous with respect to the Lebesgue measure. Then for , the random variable , where with
[TABLE]
follows a law on the hypercube with uniform marginals. It can be readily shown that the cumulative distribution function of is continuous and satisfies (4). Note that taking the derivative of (4) yields
[TABLE]
where is a copula density function by definition of . One possibility to approximate a target density is then to consider a parametric family of copula density functions for and one parametric family of a -dimensional vector of density functions for , and try to estimate and to get a good approximation of via variational Bayesian methods. This idea was proposed by [23] and [66], where Gaussian and vine copulas were used, respectively. The main hurdle for using such family is their computational cost which can be prohibitive since the dimension of is of order . We remark that for latent Gaussian models with certain likelihood functions, a Gaussian variational approximation can scale linearly in the number of observations by using dual variables, see [54, 31].
3 Copula-like Density
In this paper, we consider another approach which relies on a copula-like density function on . Indeed, instead of an exact copula density function on with uniform marginals, we consider simply a density function on which allows to have a certain degree of freedom in the number of parameters we want to use. The family of copula-like densities that we consider is given by
[TABLE]
with the notation and . Therefore . The following probabilistic construction is proven in Appendix A to allow for efficient sampling from the proposed copula-like density.
Proposition \theproposition.
Let and suppose that
; 2. 2.
; 3. 3.
, where .
Then the distribution of has density with respect to the Lebesgue measure given by (6).
The proposed distribution builds up on Beta distributions, as they are the marginals of the Dirichlet distributed random variable , which is then multiplied with an independent random variable . The resulting random variable follows a Beta-Liouville distribution, which allows to account for negative dependence, inherited from the Dirichlet distribution through a Beta stick-breaking construction, as well as positive dependence via a common Beta-factor. More precisely, one obtains
[TABLE]
for some and , cf. [13]. Proposition 3 shows that one can transform the Beta-Liouville distribution living within the simplex to one that has support on the full hypercube, while also allowing for efficient sampling and log-density evaluations.
Now note that also is a sample on the hypercube if , as is the convex combination , where for any . Put differently, we can write , where
[TABLE]
and is the identity operator. It is straightforward to see that is a -diffeomorphism for from the hypercube into , where if and if . Note that the Jacobian-determinant of is efficiently computable and is simply equal to for .
We suggest to take initially at random for the transformation such that
[TABLE]
with . In our experiments, we set and . We found that choosing a different (large enough) value of tends to yield no large difference, as this choice will get balanced by a different value of the standard deviation of the Gaussian marginal transformation. The motivation to consider with was first numerical stability since we need to compute quantile functions only on the interval using this transformation. Second, this transformation can increase the flexibility of our proposed family. We found empirically that the components of tend to be non-negative in higher dimensions. However, using sometimes (more) the antithetic component of by considering , the transformed density can also describe negative dependencies in high dimensions. What comes to mind to obtain a flexible density is then to either optimize over the parameter parametrising the transformation or considering as an auxiliary variable in the variational density, resorting to techniques developed for such hierarchical families, see for instance [58, 69, 64]. However, this proved challenging in an initial attempt, since for , the transformation becomes non-invertible, while restricting on say , , seemed less easy to optimize. Consequently, we keep fixed after sampling it initially according to (8). A sensible choice was since it leads to a balanced proportion of components of equal to and . However, the sampled value of might not be optimal and we illustrate in the next section how the variational density can be made more flexible.
4 Rotated Variational Density
We propose to apply rotations to the marginals in order to improve on the initial orientation that results from the sampled values of . Rotated copulas have been used before in low dimensions, see for instance [36], however, the set of orthogonal matrices has free parameters. We reduce the number of free parameters by considering only rotation matrices that are given as a product of Givens rotations, following the FFT-style butterfly-architecture proposed in [16], see also [44] and [49] where such an architecture was used for approximating Hessians and kernel functions, respectively. Recall that a Givens rotation matrix [21] is a sparse matrix with one angle as its parameter that rotates two dimensions by this angle. If we assume for the moment that , , then we consider rotation matrices denoted where for any , contains independent rotations, i.e. is the product of independent Givens rotations. Givens rotations are arranged in a butterfly architecture that provides for a minimal number of rotations so that all coordinates can interact with one another in the rotation defined by . For illustration, consider the case , where the rotation matrix is fully described using parameters by with
[TABLE]
where and ). We provide a precise recursive definition of in Appendix B where we also describe the case where is not a power of two. In general, we have a computational complexity of , due to the fact that is a product of matrices each requiring operations. Moreover, note that is parametrized by parameters and each can be implemented as a sparse matrix, which implies a memory complexity of . Furthermore, since is orthonormal, we have and .
To construct an expressive variational distribution, we consider as a base distribution the proposed copula-like density . We then apply the transformations and . The operator in (5) is defined via quantile functions of densities , for which we choose Gaussian densities with parameter . As a final transformation, we apply the volume-preserving operator
[TABLE]
that has parameter . Altogether, the parameter for the marginal-like densities that we optimize over is and simulation from the variational density boils down to the following algorithm.
Note that we apply the rotations after we have transformed samples from the hypercube into , as the hypercube is not closed under Givens rotations. The variational density can then be evaluated using the normalizing flow formula (3). We optimize the variational lower bound in (2) using reparametrization gradients, proposed by [35, 60, 63], but with an implicit reparametrization, cf. [14], for Dirichlet and Beta distributions. Such reparametrized gradients for Dirichlet and Beta distributions are readily available for instance in tensorflow probability [9]. Using Monte Carlo samples of unbiased gradient estimates, one can optimize the variational bound using some version of stochastic gradient descent. A more formal description is given in Appendix C.
We would like to remark that such sparse rotations can be similarly applied to proper copulas. While there is no additional flexibility by rotating a full-rank Gaussian copula, applying such rotations to a Gaussian copula with a low-rank correlation yields a Gaussian distribution with a more flexible covariance structure if combined with Gaussian marginals. In our experiments, we therefore also compare variational families constructed by sampling from an independence copula in step in Algorithm 1, i.e. are independent and uniformly distributed on for any , which results approximately in a Gaussian variational distribution if the effect of the transformation is neglected. However, a more thorough analysis of such families is left for future work. Similarly, transformations different from the sparse rotations in step in Algorithm 1 can be used in combination with a copula-like base density. Whilst we include a comparison with a simple Inverse Autoregressive Flow [34] in our experiments, a more exhaustive study of non-linear transformations is beyond the scope of this work.
5 Related Work
Conceptually, our work is closely related to [66, 23]. It differs from [66] in that it can be applied in high dimensions without having to search first for the most correlated variables using for instance a sequential tree selection algorithm [11]. The approach in [23] considered a Gaussian dependence structure, but has only been considered in low-dimensional settings. On a more computational side, our approach is related to variational inference with normalizing flows [59, 34, 65, 43, 3]. In contrast to these works that introduce a parameter-free base distribution commonly in as the latent state space, we also optimize over the parameters of the base distribution which is supported on the hypercube instead, although distributions supported for instance on the hypersphere as a state space have been considered in [7]. Moreover, such approaches have been often used in the context of generative models using Variational Auto-Encoders (VAEs) [35], yet it is in principle possible to apply the proposed variational copula-like inference in an amortized fashion for VAEs.
A somewhat similar copula-like construction in the context of importance sampling has been proposed in [8]. However, sampling from this density requires a rejection step to ensure support on the hypercube, which would make optimization of the variational bound less straightforward. Lastly, [30] proposed a method to approximate copulas using mixture distributions, but these approximations have not been analysed neither in high dimensions nor in the context of variational inference.
6 Experiments
6.1 Bayesian Logistic Regression
Consider the target distribution on arising as the posterior of a -dimensional logistic regression, assuming a Normal prior , , and likelihood function , with observations and fixed covariates for . We analyse a previously considered synthetic dataset where the posterior distribution is non-Gaussian, yet it can be well approximated with our copula-like construction. Concretely, we consider the synthetic dataset with as in [50], Section 8.4 and [32] by generating covariates from a Gaussian for instances in the first class, while we generate covariates from for instances in the second class. Samples from the target distribution using a Hamiltonian Monte Carlo (HMC) sampler [12, 51] are shown in Figure 1(a) and one observes non-Gaussian marginals that are positively correlated with heavy right tails. Using a Gaussian variational approximation with either independent marginals or a full covariance matrix as shown in Figure 1(b) does not adequately approximate the target distribution. Our copula-like construction is able to approximate the target more closely, both without any rotations (Figure 1(c)) and with a rotation of the marginals (Figure 1(d)). This is also supported by the ELBO obtained for the different variational families given in Table 2.
6.2 Centred Horseshoe Priors
We illustrate our approach in a hierarchical Bayesian model that posits a priori a strong coupling of the latent parameters. As an example, we consider a Horseshoe prior [6] that has been considered in the variational Gaussian copula framework in [23]. To be more specific, consider the generative model , with , where is a half-Cauchy distribution, i.e. has the density . Note that we can represent a half-Cauchy distribution with Inverse Gamma and Gamma distributions using , see [52], with a rate parametrisation of the inverse gamma density for . We revisit the toy model in [23] fixing . The model thus writes in a centred form as and . Following [23], we consider the posterior density on of the log-transformed variables . In Figure 4, we show the approximate posterior distribution using a Gaussian family (2(b)) and a copula-like family (2(c)), together with samples from a HMC sampler (2(a)). A copula-like density yields a higher ELBO, see Table 4. The experiments in [23] have shown that a Gaussian copula with a non-parametric mixture model fits the marginals more closely. To illustrate that it is possible to arrive at a more flexible variational family by using a mixture of copula-like densities, we have used a mixture of copula-like densities in Figure 2(d). Note that it is possible to accommodate multi-modal marginals using a Gaussian quantile transformation with a copula-like density. Eventually, the flexibility of the variational approximation can be increased using different complementary work. For instance, one could use the new density within a semi-implicit variational framework [69] whose parameters are the output of a neural network conditional on some latent mixing variable.
6.3 Bayesian Neural Networks with Normal Priors
We consider an -hidden layer fully-connected neural network where each layer , has width and is parametrised by a weight matrix and bias vector . Let denote the input to the network and be a point-wise non-linearity such as the ReLU function and define the activations by for , and the post-activations as for . We consider a regression likelihood function , and denote the concatenation of all parameters , and as . We assume independent Normal priors for the entries of the weight matrix and bias vector with mean [math] and variance . Furthermore, we assume that . Inference with the proposed variational family is applied on commonly considered UCI regression datasets, repeating the experimental set-up used in [15]. In particular, we use neural networks with ReLU activation functions and one hidden layer of size for all datasets with the exception of the protein dataset that utilizes a hidden layer of size . We choose the hyper-parameter that performed best on a validation dataset in terms of its predictive log-likelihood. Optimization was performed using Adam [33] with a learning rate of . We compare the predictive performance of a copula-like density and an independent copula as a base distribution in step 1 of Algorithm 1 and we apply different transformations in step 4 of Algorithm 1:
a) the proposed sparse rotation defined in (9);
b) ;
c) an affine autoregressive transformation , see [34], also known as an inverse autogressive flow (IAF).
Here and are autoregressive neural networks parametrized by and satisfying for and which can be computed in a single forward pass by properly masking the weights in the neural networks [17]. In our experiments, we use a one-hidden layer fully-connected network with width for and . Note that for a -dimensional target density, the size of the weight matrices are of order , implying a higher complexity compared to the sparse rotation. We also compare the predictions against Bayes-by-Backprop [5] using a mean-field model, with the results as reported in [47] for a mean-field Bayes-by-Backprop and low-rank Gaussian approximation proposed therein called SLANG. Furthermore, we also report the results for Dropout inference [15]. The test root mean-squared errors are given in Table 5 and Table 6; the predictive test log-likelihood can be find in the Appendix E in Table 8 and Table 9. We can observe from Table 5 and Table 8 that using a copula-like base distribution instead of an independent copula improves the predictive performance, using either rotations or IAF as the final transformation. The same tables also indicate that for a given base distribution, the IAF tends to outperform the sparse rotations slightly. Table 6 and Table 9 suggest that copula-like densities without any transformation in the last step can be a competitive alternative to a benchmark mean-field or Gaussian approximation. Dropout tends to perform slightly better. However, note that Dropout with a Normal prior and a variational mixture distribution that includes a Dirac delta function as one component gives rise to a different objective, since the prior is not absolutely continuous with respect to the approximate posterior, see [25].
6.4 Bayesian Neural Networks with Structured Priors
We illustrate our approach on a larger Bayesian neural network. To induce sparsity for the weights in the network, we consider a (regularised) Horseshoe prior [56] that has also been used increasingly as an alternative prior in Bayesian neural network to allow for sparse variational approximations, see [41, 19] for mean-field models and [20] for a structured Gaussian approximation. We consider again an -hidden layer fully-connected neural network where we assume that the weight matrix for any and any satisfies a priori
[TABLE]
where, , and for some hyper-parameters . The vector represents all weights that interact with the -th input neuron. The first Normal factor in (10) is a standard Horseshoe prior with a per layer global parameter that adapts to the overall sparsity in layer and shrinks all weights in this layer to zero, due to the fact that allows for substantial mass near zero. The local shrinkage parameter allow for signals in the -th input neuron because is heavy-tailed. However, this can leave large weights un-shrunk, and the second Normal factor in (10) induces a Student- regularisation for weights far from zero, see [56] for details. We can rewrite the model in a non-centred form [55], where the latent parameters are a priori independent, see also [41, 27, 19, 20] for similar variational approximations. We write the model as , , , , , , , and . The target density is the posterior of these variables, after applying a log-transformation if their prior is an (inverse) Gamma law.
We performed classification on MNIST using a -hidden layer fully-connected network where the hidden layers are of size each. Further details about the algorithmic details are given in Appendix D. Prediction errors for the variational families as considered in the preceding experiments are given in Table 7. We again find that a copula-like density outperforms the independent copula. Using a copula-like density without the rotation also performs competitively as long as one uses a balanced amount of its antithetic component via the transformation with parameter ; ignoring the transformation or setting for all can limit the representative power of the variational family and can result in high predictive errors. The neural network function for the IAF considered here has two hidden layers of size . It can be seen that applying the rotations can be beneficial compared to the IAF for the copula-like density, whereas the two transformations perform similarly for the independent base distribution. We expect that more ad-hoc tricks can be used to adjust the rotations to some computational budget. For instance, one could include additional rotations for a group of latent variables such as those within one layer. Conversely, one could consider the series of sparse rotations , but with , thereby allowing for rotations of the more adjacent latent variables only.
Our experiment illustrates that the proposed approach can be used in high-dimensional structured Bayesian models without having to specify more model-specific dependency assumptions in the variatonal family. The prediction errors are in line with current work for fully connected networks using a Gaussian variational family with Normal priors, cf. [47]. Better predictive performance for a fully connected Bayesian network has been reported in [37] that use RealNVP [10] as a normalising flows in a large network that is reparametrised using a weight normalization [61]. It becomes scalable by opting to consider only variational inference over the Euclidean norm of and performing point estimation for the direction of the weight vector . Such a parametrisation does not allow for a flexible dependence structure of the weights within one layer; and such a model architecture should be complementary to the proposed variational family in this work.
7 Conclusion
We have addressed the challenging problem of constructing a family of distributions that allows for some flexibility in its dependence structure, whilst also having a reasonable computational complexity. It has been shown experimentally that it can constitute a useful replacement of a Gaussian approximation without requiring many algorithmic changes.
Acknowledgements
Alain Durmus acknowledges support from Chaire BayeScale ”P. Laffitte” and from Polish National Science Center grant: NCN UMO-2018/31/B/ST1/0025. This research has been partly financed by the Alan Turing Institute under the EPSRC grant EP/N510129/1. The authors acknowledge the use of the UCL Myriad High Throughput Computing Facility (Myriad@UCL), and associated support services, in the completion of this work.
Appendix A Proof of Proposition 3
Proof.
Let be a positive and bounded function. We have by definition, using the expression of the density of the Dirichlet and Beta distributions, see [13], and setting ,
[TABLE]
where
[TABLE]
Then by symmetry, without loss of generality, we only need to consider . Using the change of variable, , which is a -diffeomorphism from to , we get that
[TABLE]
Now using the change of variable , which is a -diffeomorphism from to
[TABLE]
we obtain since that
[TABLE]
Combining this result, (11) and (12) completes the proof. ∎
Appendix B Butterfly rotation matrices
Suppose for some and let and . For , define . Assume has been defined. Then define
[TABLE]
where has the same form as except that the and indices are all increased by . So for instance
[TABLE]
Suppose now that is not a power of and let . We construct as a product of factors as used in the construction of . For any , we then delete from the last rows and columns. Then for every in the remaining matrix that is in the same column as a deleted is replaced by . As an example, for , we have
[TABLE]
Appendix C Optimization of the variational bound
Recall that for independent random variables , for , we have , cf. [13]. Similarly, for independent random variables and , it holds that . Recall that the parameter of the rotated variational family is , where is the parameter of the copula-like base density, whereas denotes the parameters of the quantile transformation and the rotation, respectively. Furthermore, the parameter of the transformation is kept fix. Using Proposition 3 and Algorithm 1 for some fixed , we can construct a function , , that is almost everywhere continuously differentiable such that , where is the density of the proposed variational family with parameter , that is the variational density is the pushforward density of independent Gamma densities with parameter through the transport map . Differentiability with respect to can be achieved by a continuous numerical approximation for the quantile function of a standard Gaussian and applying appropriate (re)normalisation. Furthermore, there exists an invertible standardization function with continuously differentiable such that is equal to in distribution, where is a -dimensional vector of iid random variables with uniform marginals on . In particular, the distribution of does not depend on . The cumulative distribution function of say at the point is the regularised incomplete Gamma function that lacks an analytical expression though. However, one can apply automatic differentiation to a numerical method that approximates yielding an approximation of . Let us define
[TABLE]
Then , where in the first expectation, the law of the random variable depends on . For a differentiable function , we denote by the Jacobian of , that is . Following the arguments in [14], we obtain for the Jacobian of the variational bound
[TABLE]
where and can be obtained by implicit differentiation of which results in . So for instance , with being the density function of and recalling that . We can thus optimize the variational bound using stochastic gradient descent with unbiased samples from (13). We remark that for instance in tensorflow probability [9], such implicit gradients are used by default as long as one simulates from the copula-like density using Proposition 3, implements the density function from (6) and applies the bijective transformations according to Algorithm 1. In this case, optimization using the proposed density proceeds analogously as if one would use any reparametrisable variational family such as Gaussian distributions.
Appendix D Additional details for Bayesian Neural Networks with Structured Priors
In the MNIST experiments, we train the network on training points out of and report the prediction error rates for the test set of images. We used a batch-size of and used Monte Carlo samples to compute the gradients during training and Monte Carlo samples for the prediction on the test set. We used Adam with a learning rate in for iterations. The hyper-parameter for the Horseshoe prior were , , so , corresponding to a slab. Furthermore, for the global shrinkage factor, we have used . The variational parameters of the copula-like density are restricted to be positive and we have defined them as the of unconstrained parameters, initialised so that , and . We have sampled according to (8) and initialised and the log-standard deviations of the marginal-like distribution as . We aimed for an initial mean of [math] for and of for the of the remaining variables. We therefore choose so that the quantile of an initial Monte Carlo estimate for the mean of has the desired initial mean.
Appendix E Additional results for Bayesian Neural Networks with Gaussian Priors
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] David Barber and Christopher M Bishop. Ensemble learning for multi-layer networks. In Advances in neural information processing systems , pages 395–401, 1998.
- 2[2] Tim Bedford and Roger M Cooke. Probability density decomposition for conditionally dependent random variables modeled by vines. Annals of Mathematics and Artificial intelligence , 32(1-4):245–268, 2001.
- 3[3] Rianne van den Berg, Leonard Hasenclever, Jakub M Tomczak, and Max Welling. Sylvester normalizing flows for variational inference. ar Xiv preprint ar Xiv:1803.05649 , 2018.
- 4[4] David M Blei, Alp Kucukelbir, and Jon D Mc Auliffe. Variational inference: A review for statisticians. Journal of the American Statistical Association , 112(518):859–877, 2017.
- 5[5] Charles Blundell, Julien Cornebise, Koray Kavukcuoglu, and Daan Wierstra. Weight uncertainty in neural network. In Proceedings of The 32nd International Conference on Machine Learning , pages 1613–1622, 2015.
- 6[6] Carlos M Carvalho, Nicholas G Polson, and James G Scott. The horseshoe estimator for sparse signals. Biometrika , 97(2):465–480, 2010.
- 7[7] Tim R Davidson, Luca Falorsi, Nicola De Cao, Thomas Kipf, and Jakub M Tomczak. Hyperspherical variational auto-encoders. ar Xiv preprint ar Xiv:1804.00891 , 2018.
- 8[8] Petros Dellaportas and Mike G Tsionas. Importance sampling from posterior distributions using copula-like approximations. Journal of Econometrics , 2018.