Variational Bayes for high-dimensional linear regression with sparse priors
Kolyan Ray, Botond Szabo

TL;DR
This paper develops a mean-field variational Bayes approach for high-dimensional sparse linear regression, providing theoretical guarantees and practical improvements over existing methods.
Contribution
It introduces a novel prioritized updating scheme for variational inference that enhances performance and offers theoretical oracle inequalities for the approximation.
Findings
VB approximation converges at the optimal rate under certain conditions
The proposed updating scheme outperforms standard coordinate-ascent in simulations
The method performs comparably to state-of-the-art Bayesian variable selection techniques
Abstract
We study a mean-field spike and slab variational Bayes (VB) approximation to Bayesian model selection priors in sparse high-dimensional linear regression. Under compatibility conditions on the design matrix, oracle inequalities are derived for the mean-field VB approximation, implying that it converges to the sparse truth at the optimal rate and gives optimal prediction of the response vector. The empirical performance of our algorithm is studied, showing that it works comparably well as other state-of-the-art Bayesian variable selection methods. We also numerically demonstrate that the widely used coordinate-ascent variational inference (CAVI) algorithm can be highly sensitive to the parameter updating order, leading to potentially poor performance. To mitigate this, we propose a novel prioritized updating scheme that uses a data-driven updating order and performs better in…
Click any figure to enlarge with its caption.
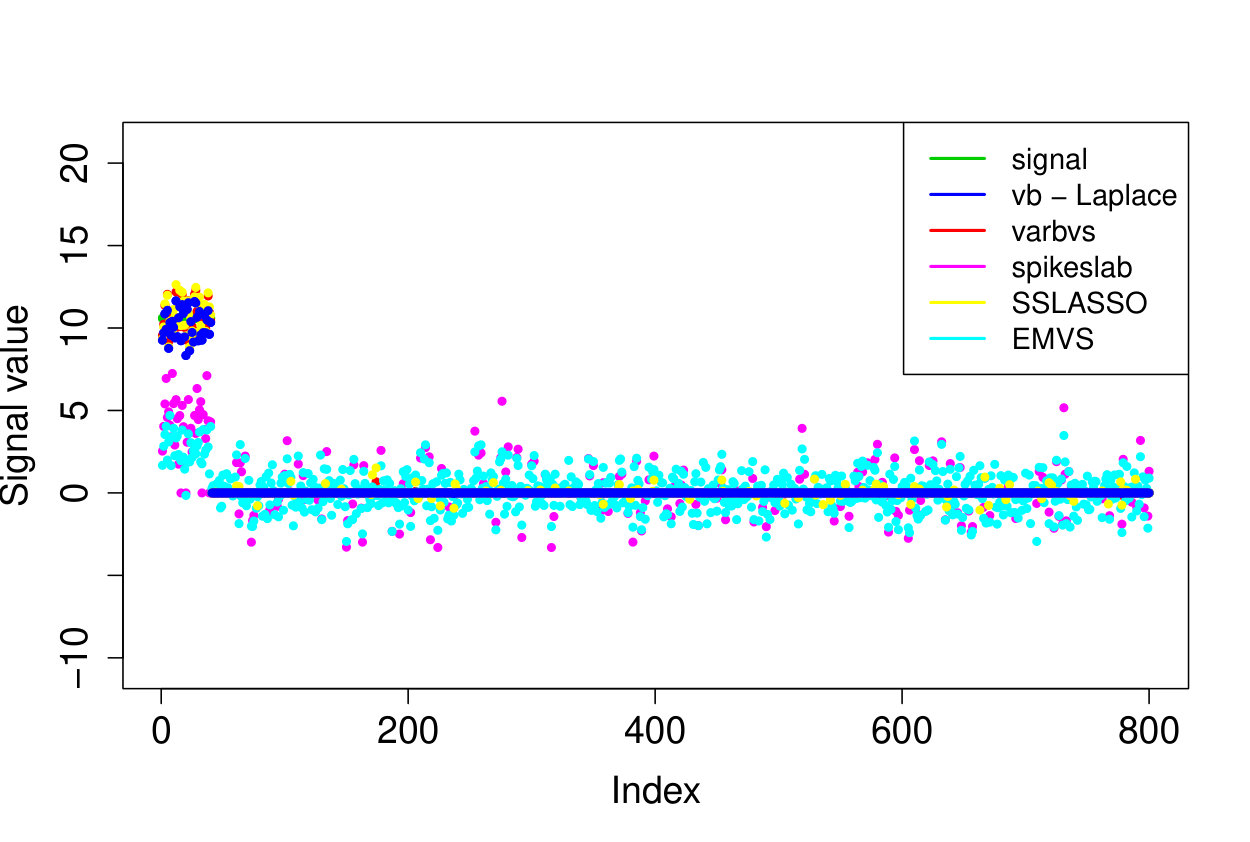 Figure 1
Figure 1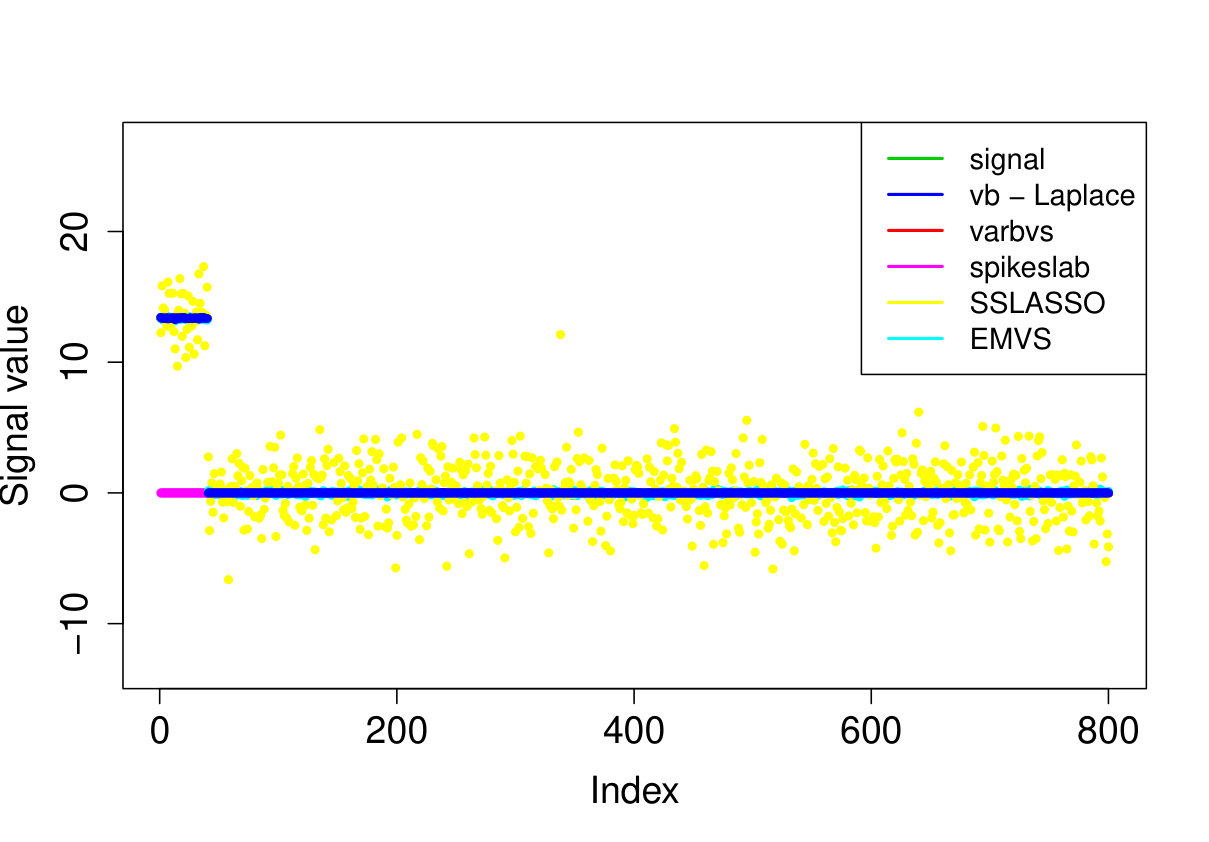 Figure 2
Figure 2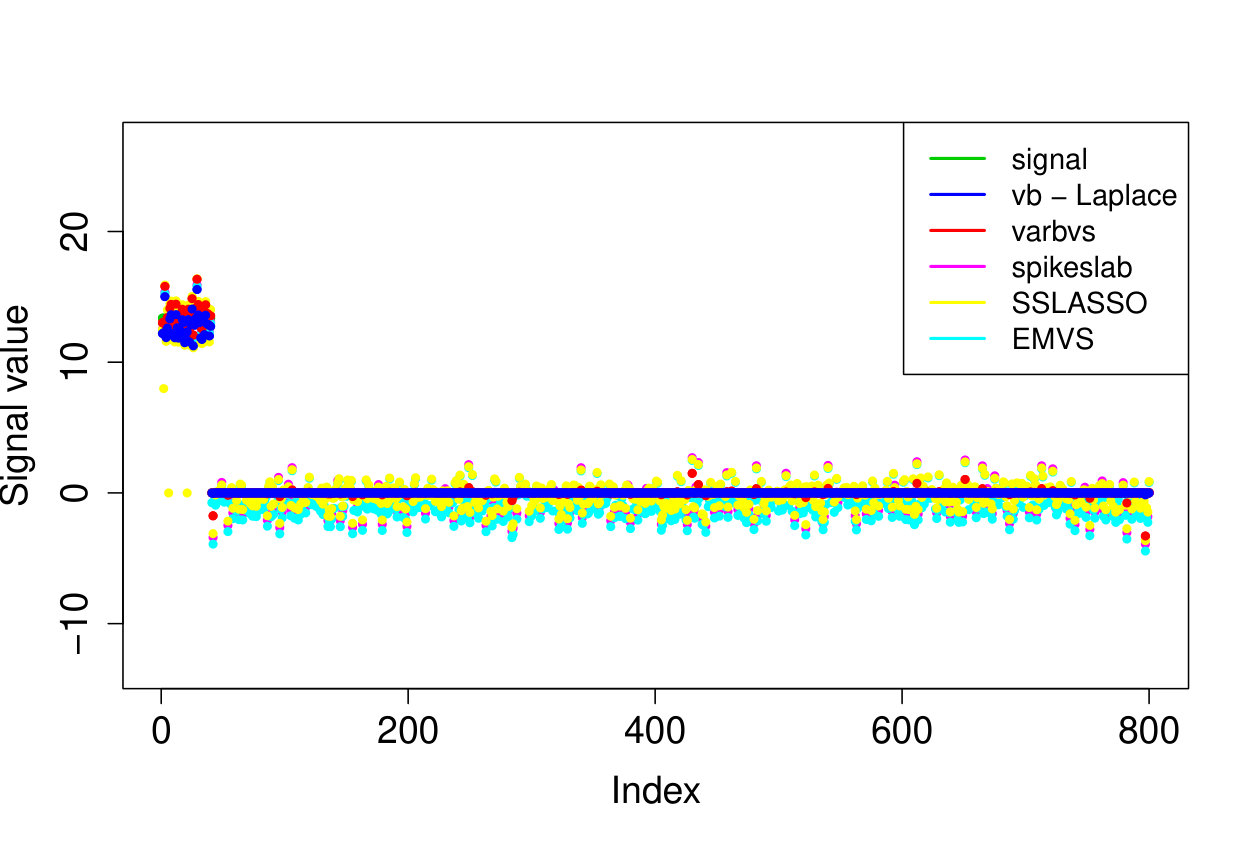 Figure 3
Figure 3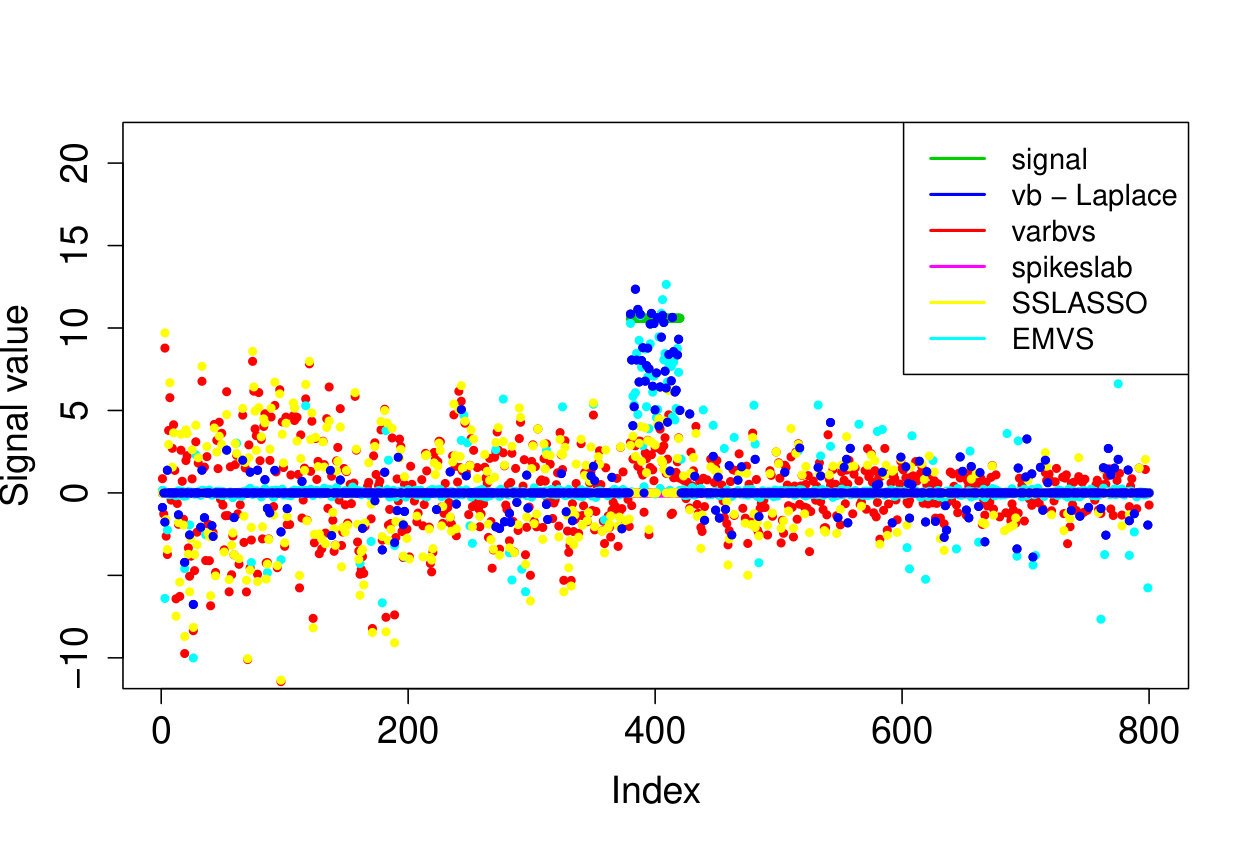 Figure 4
Figure 4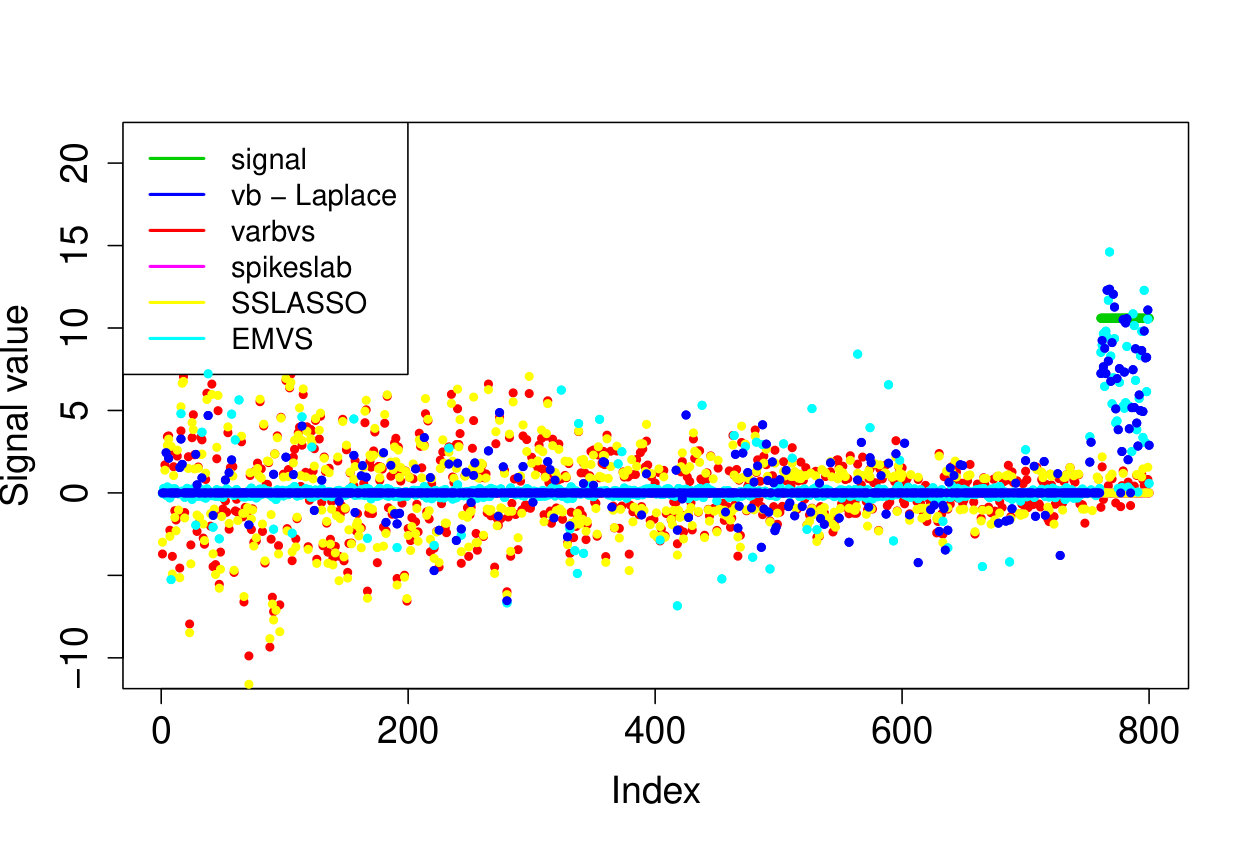 Figure 5
Figure 5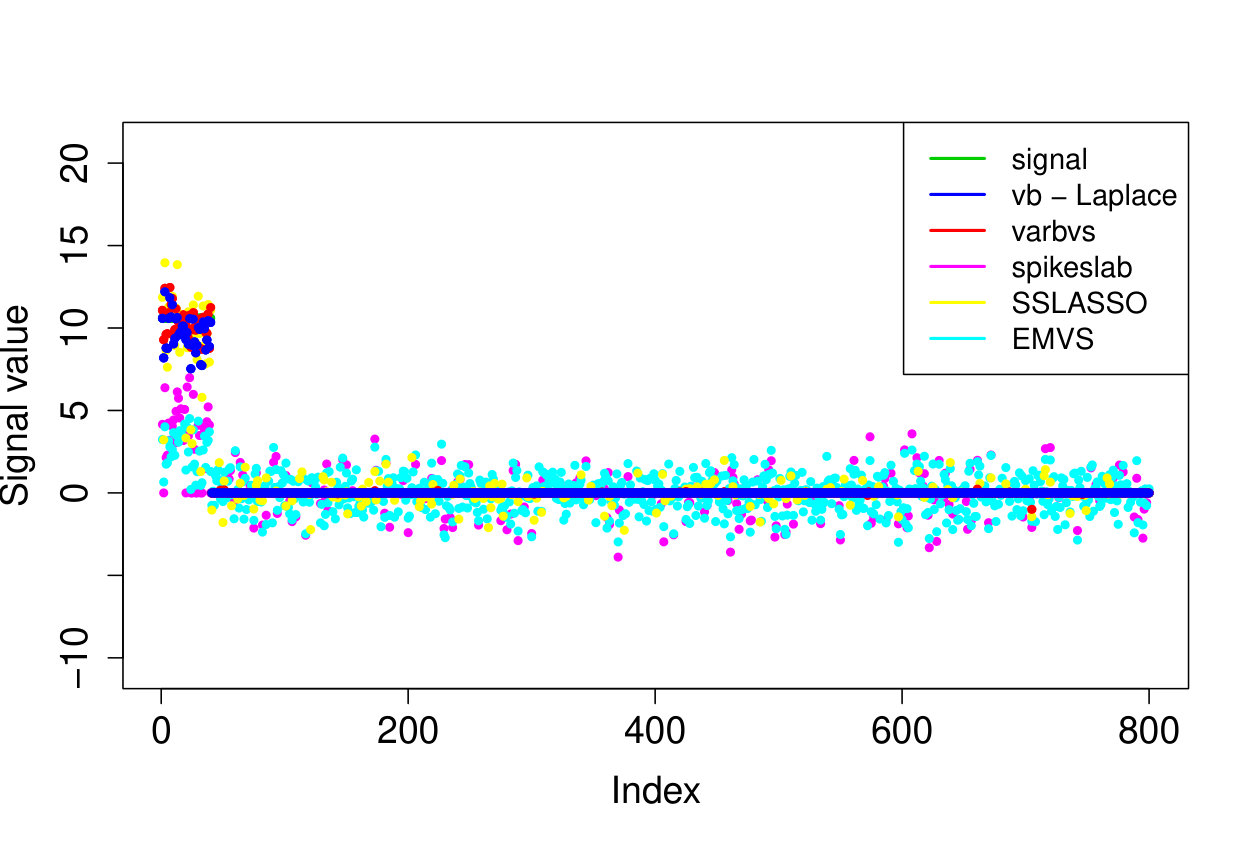 Figure 6
Figure 6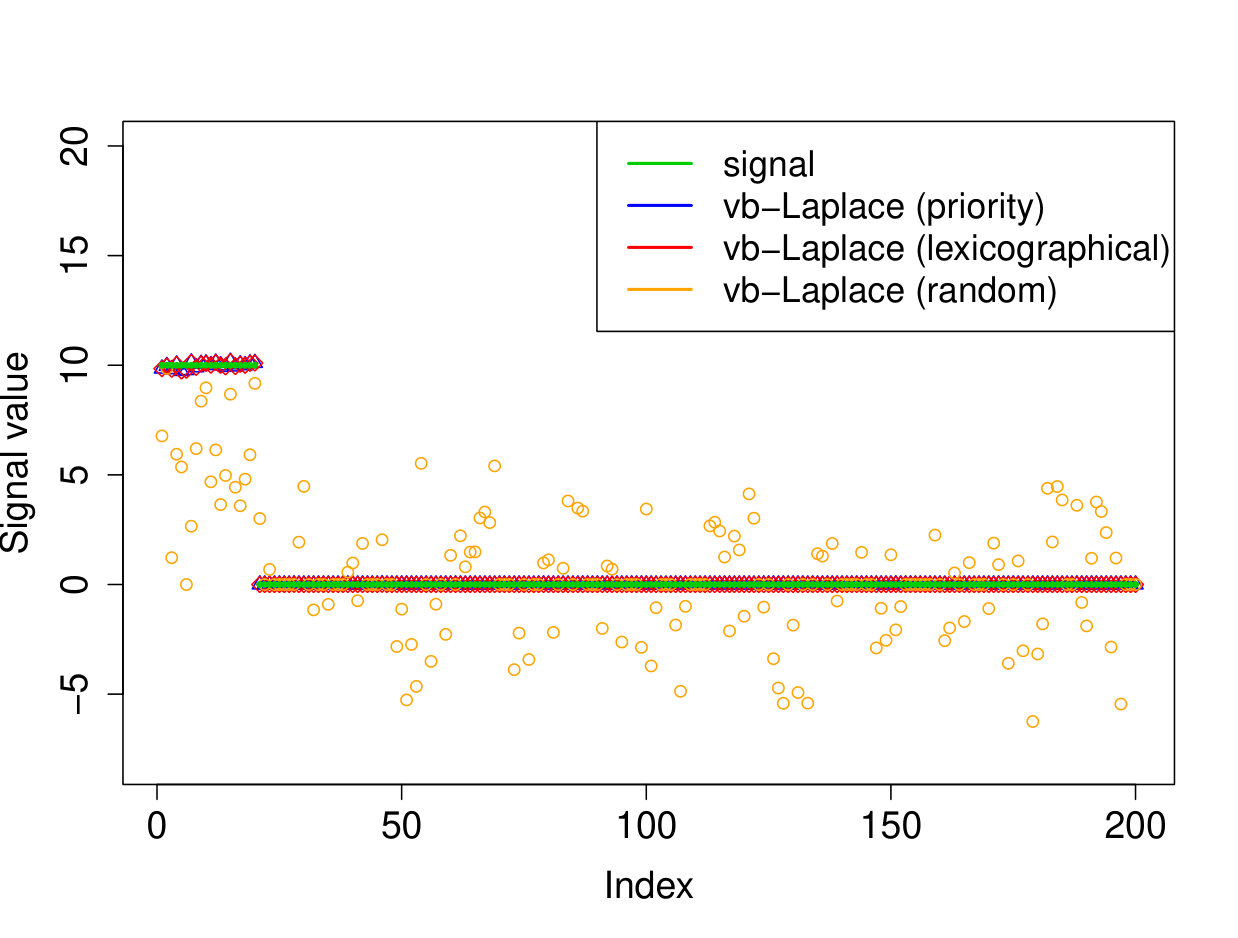 Figure 7
Figure 7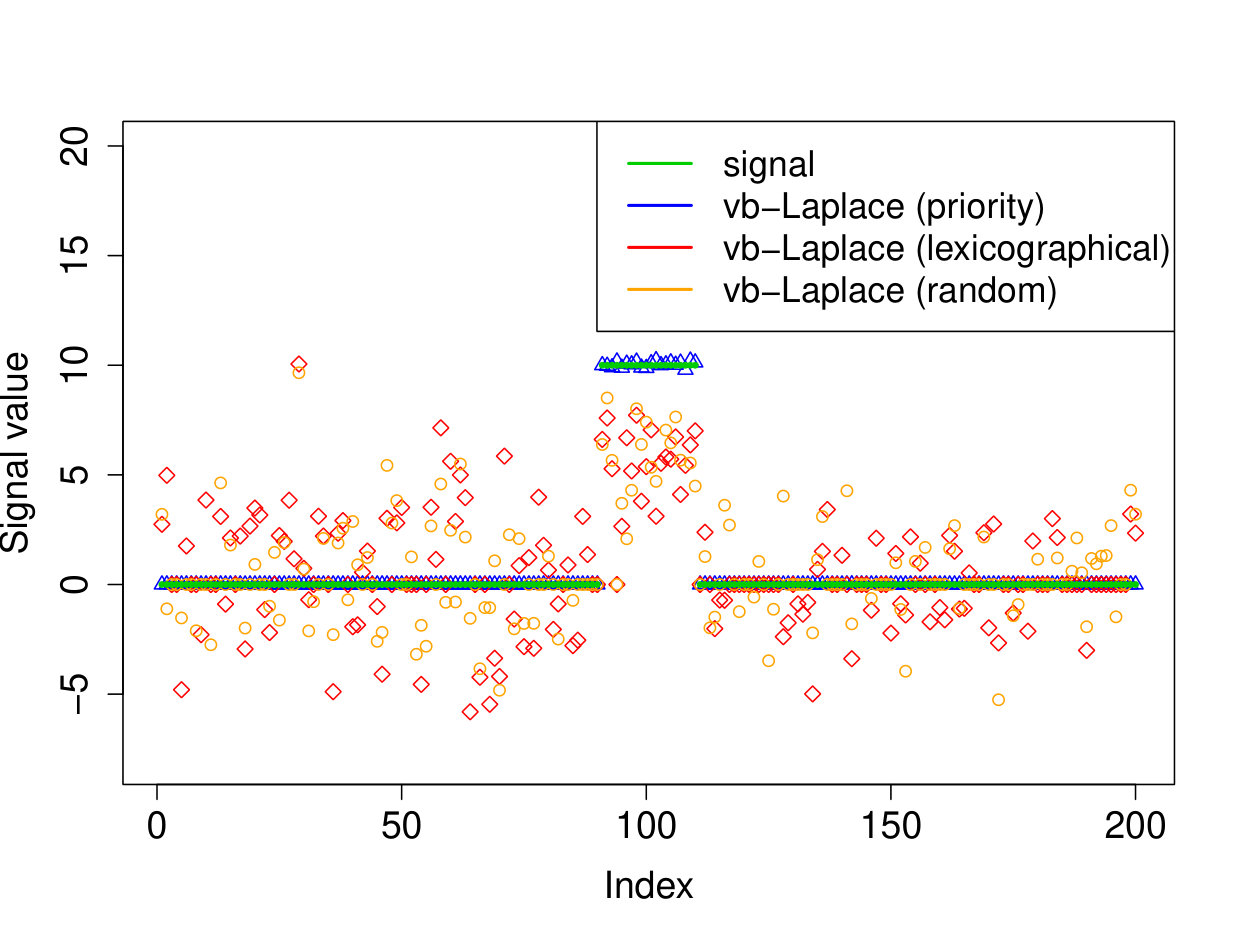 Figure 8
Figure 8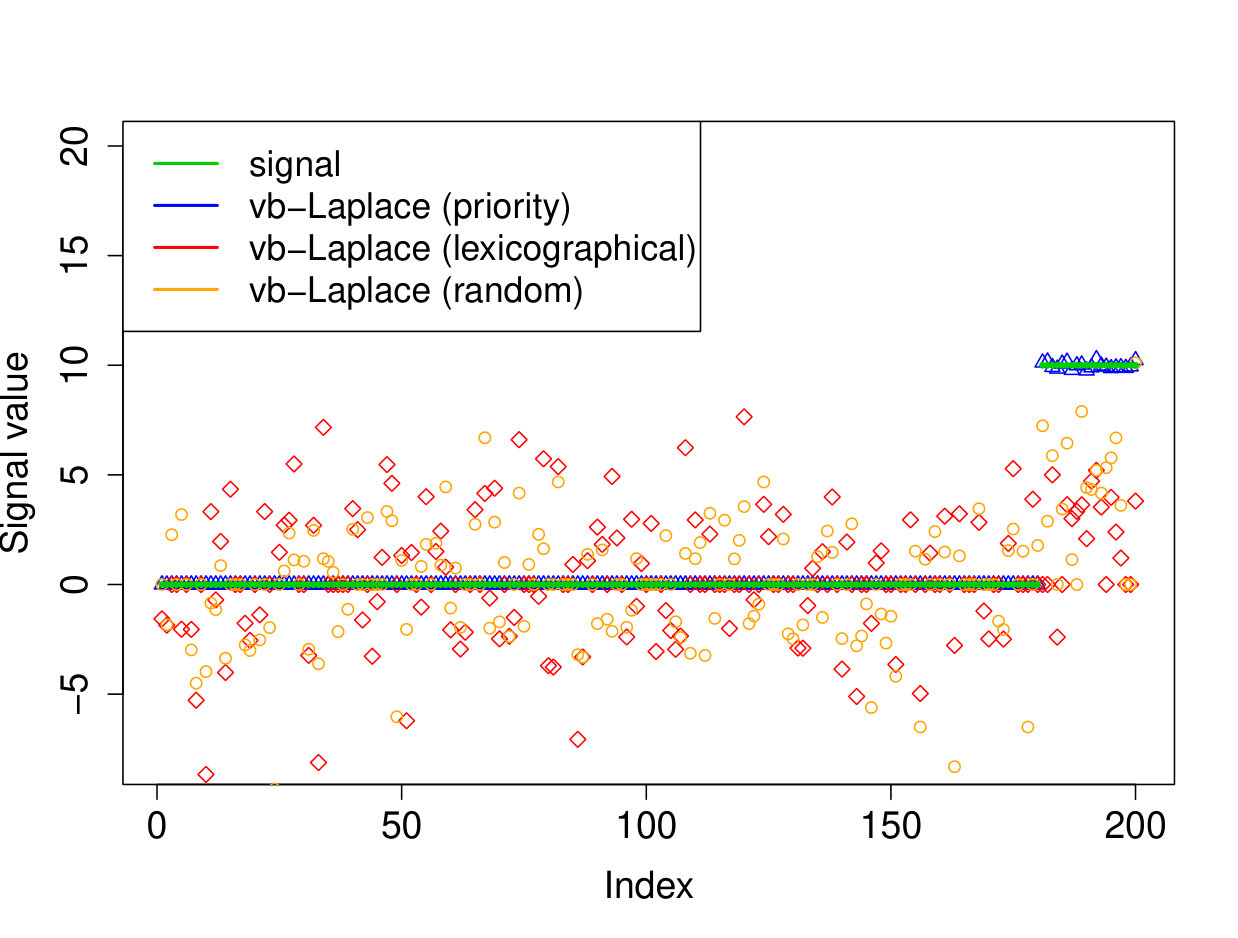 Figure 9
Figure 9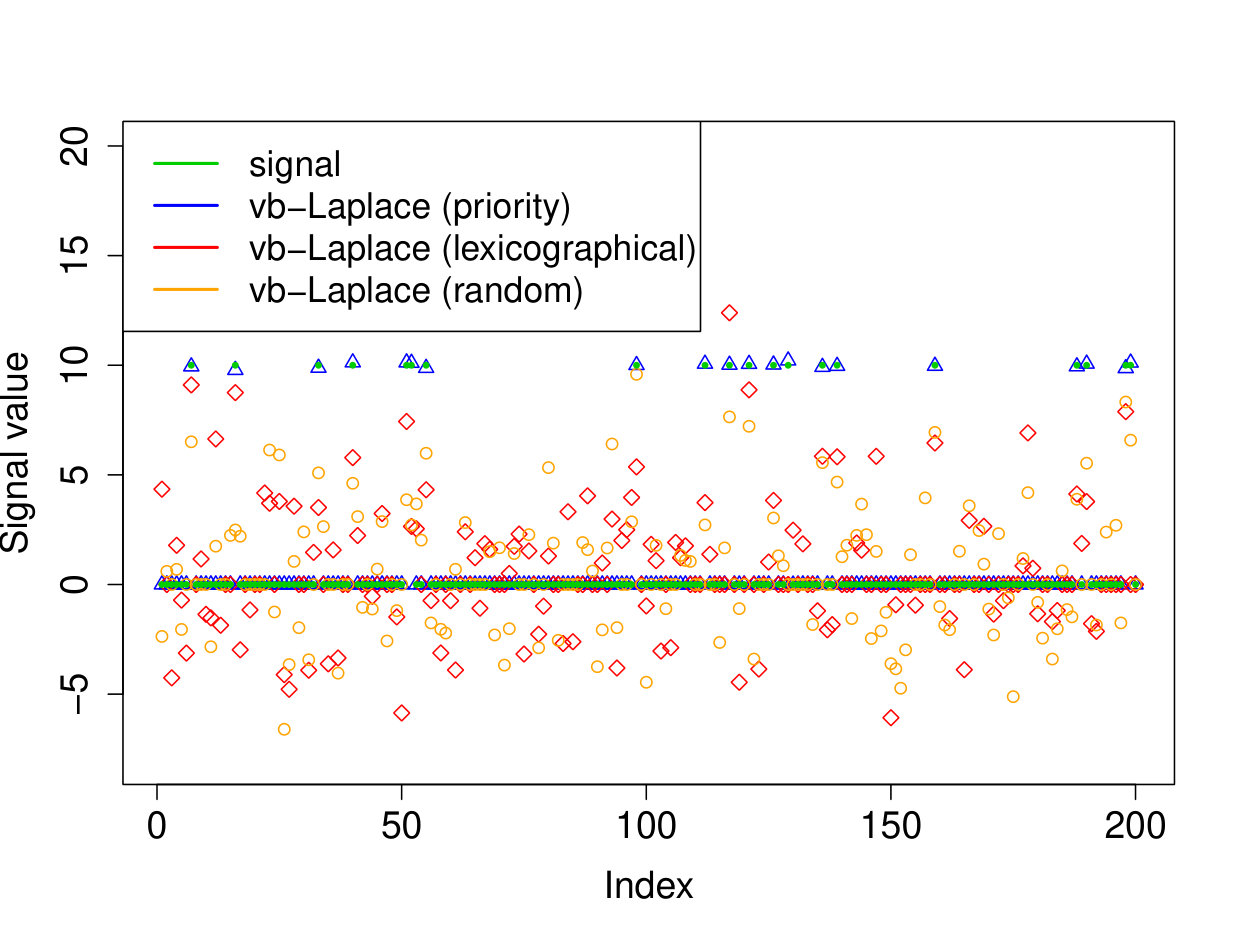 Figure 10
Figure 10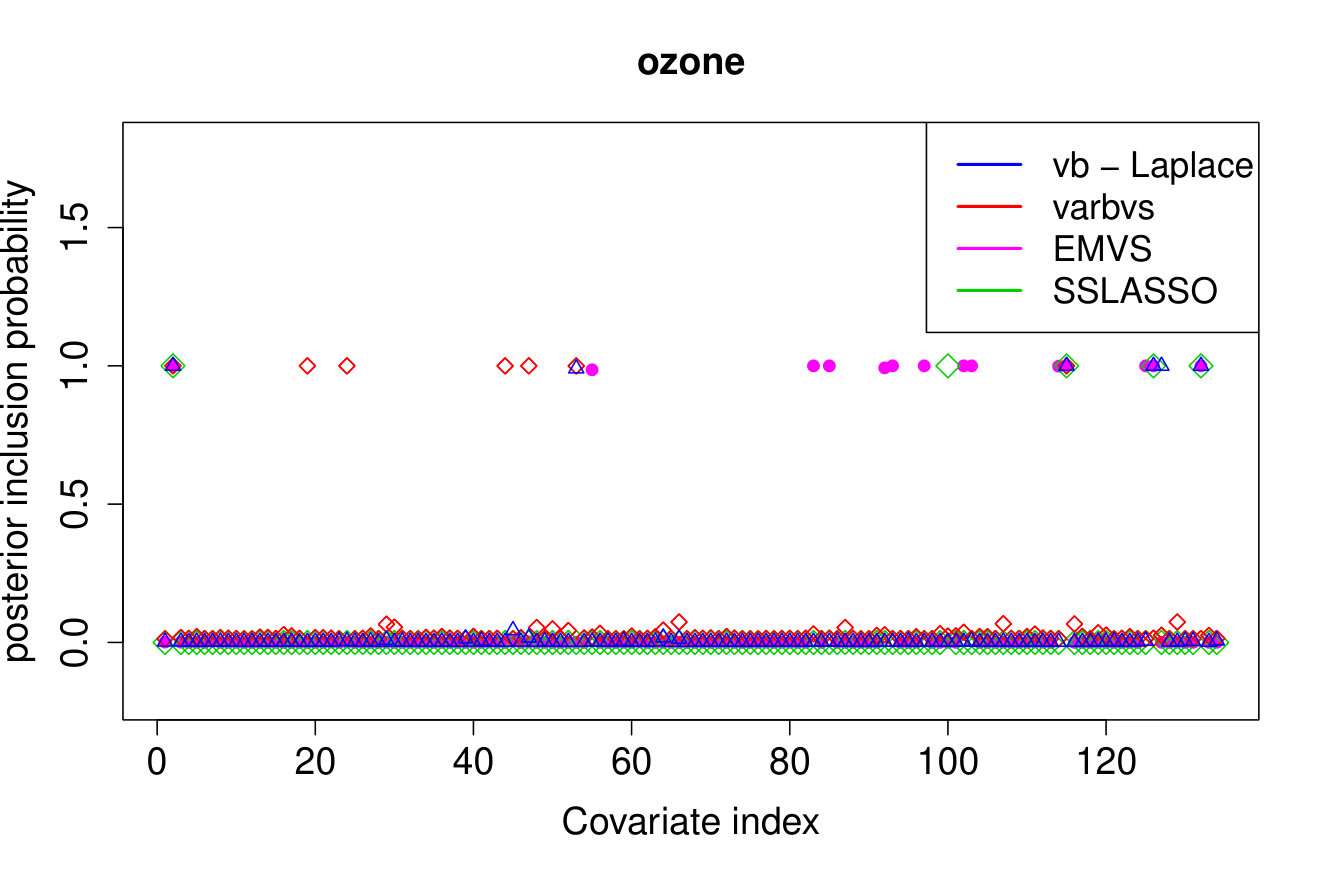 Figure 11
Figure 11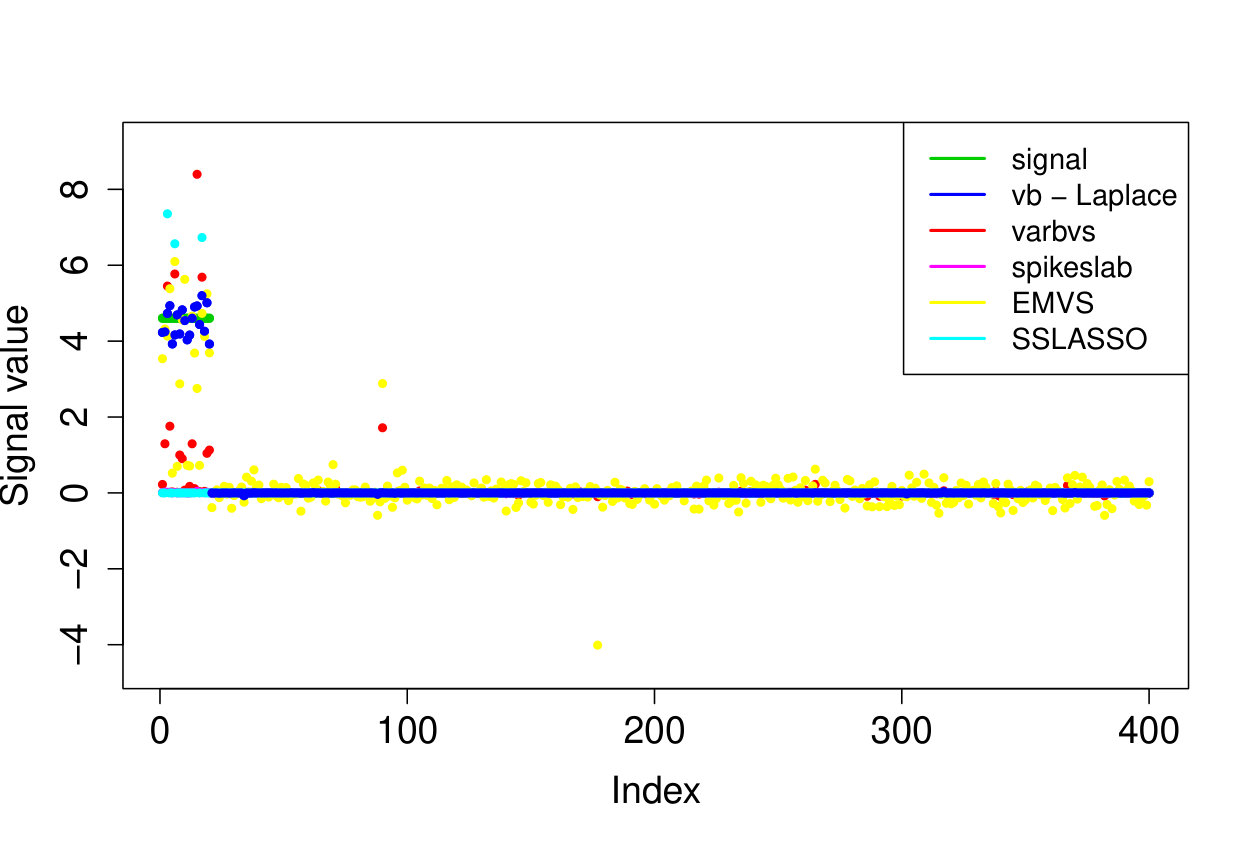 Figure 12
Figure 12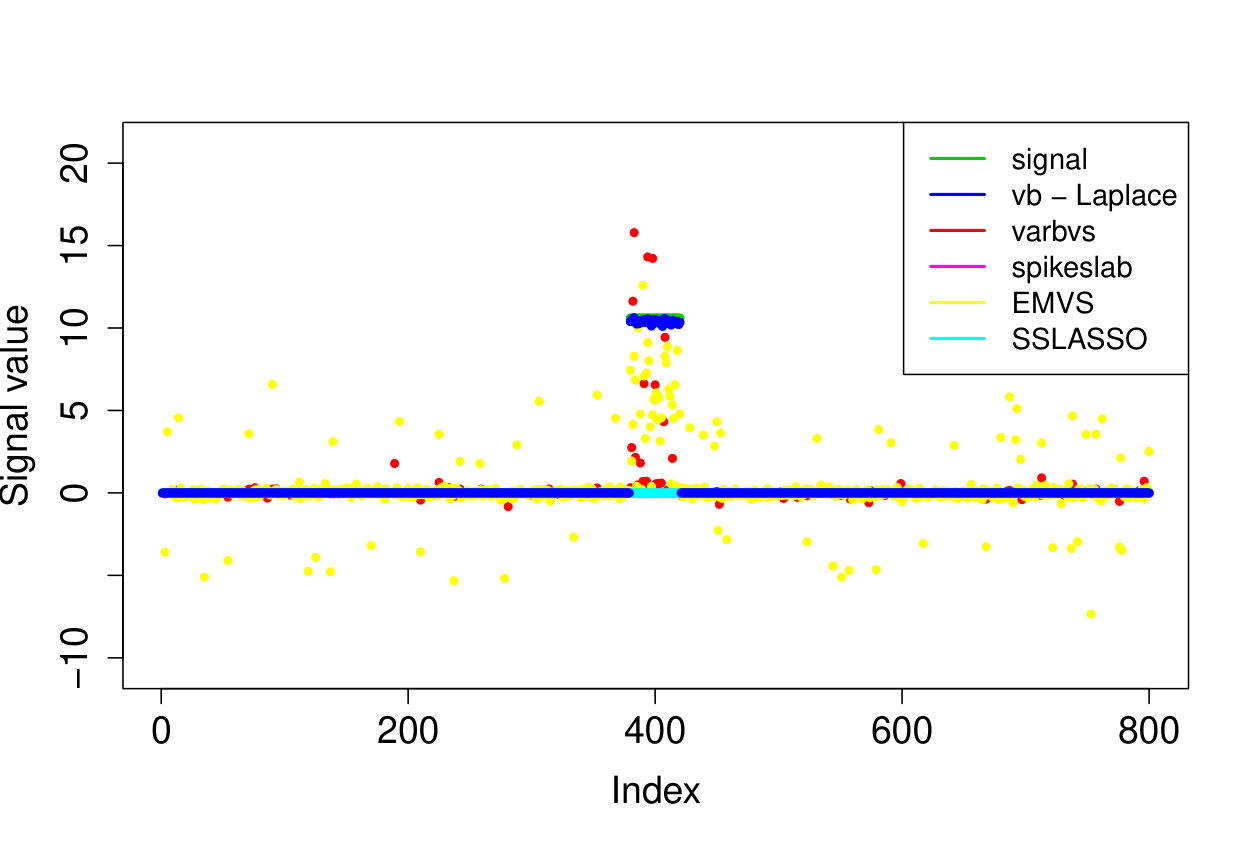 Figure 13
Figure 13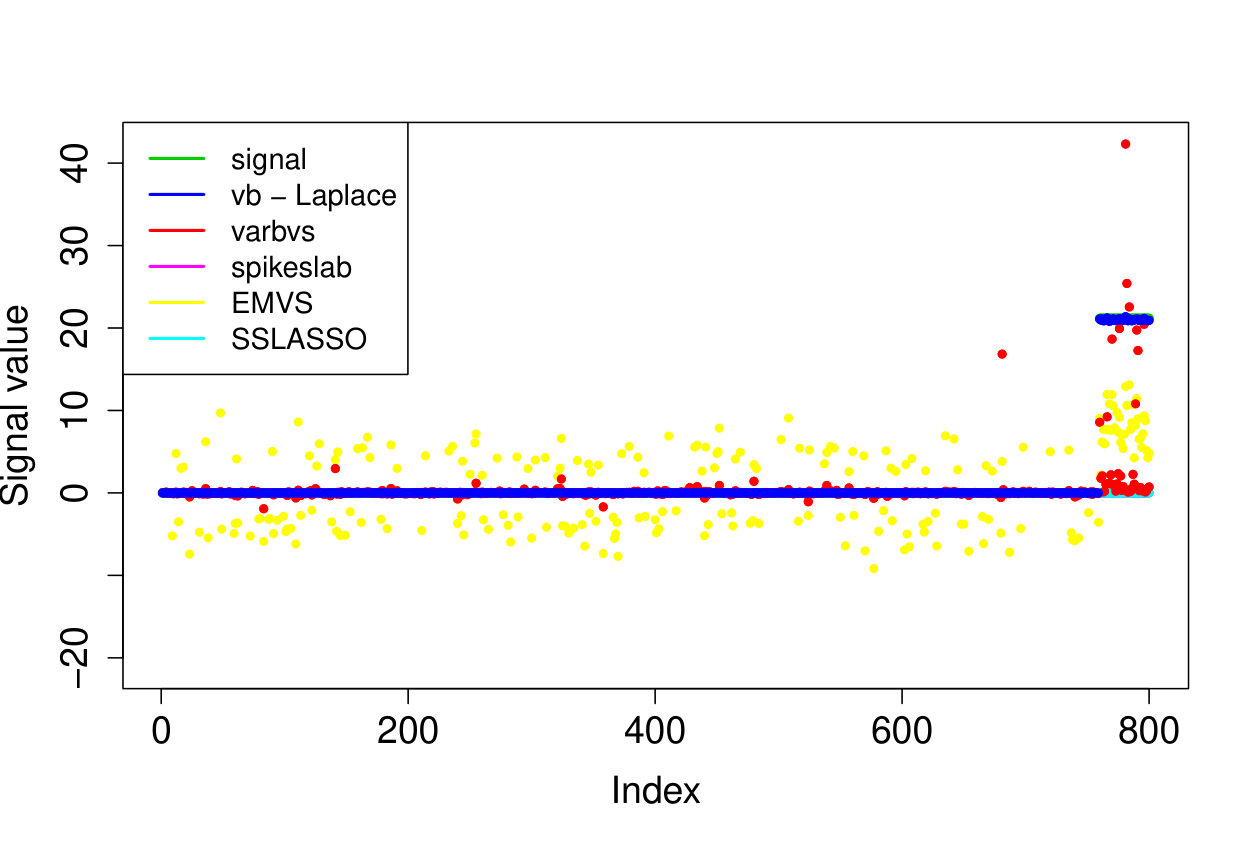 Figure 14
Figure 14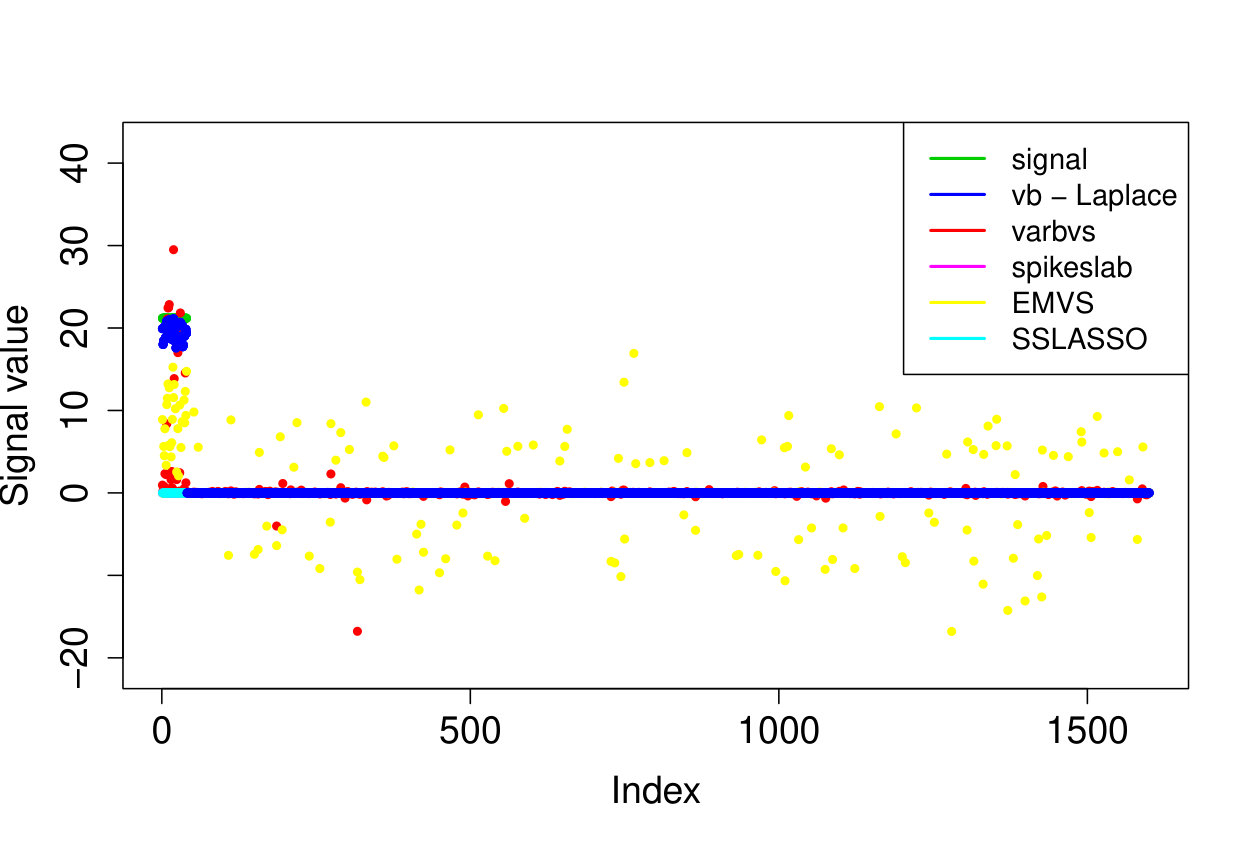 Figure 15
Figure 15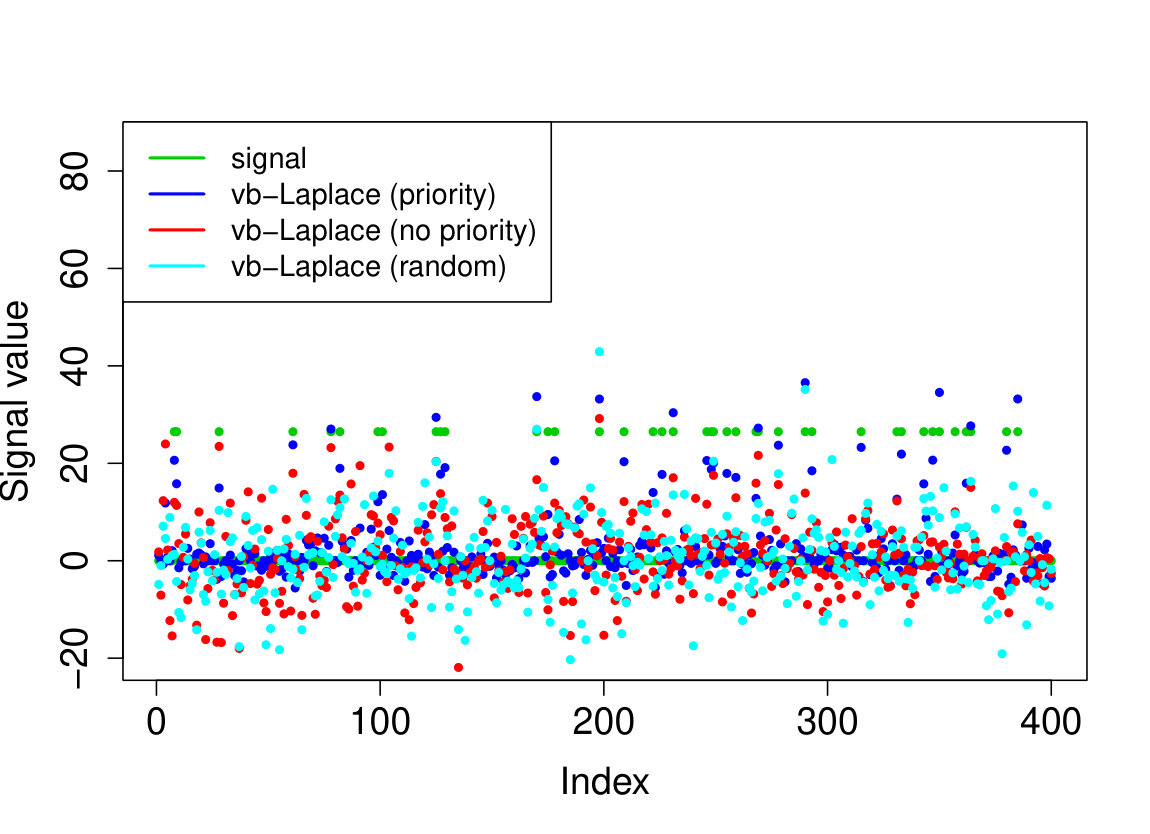 Figure 16
Figure 16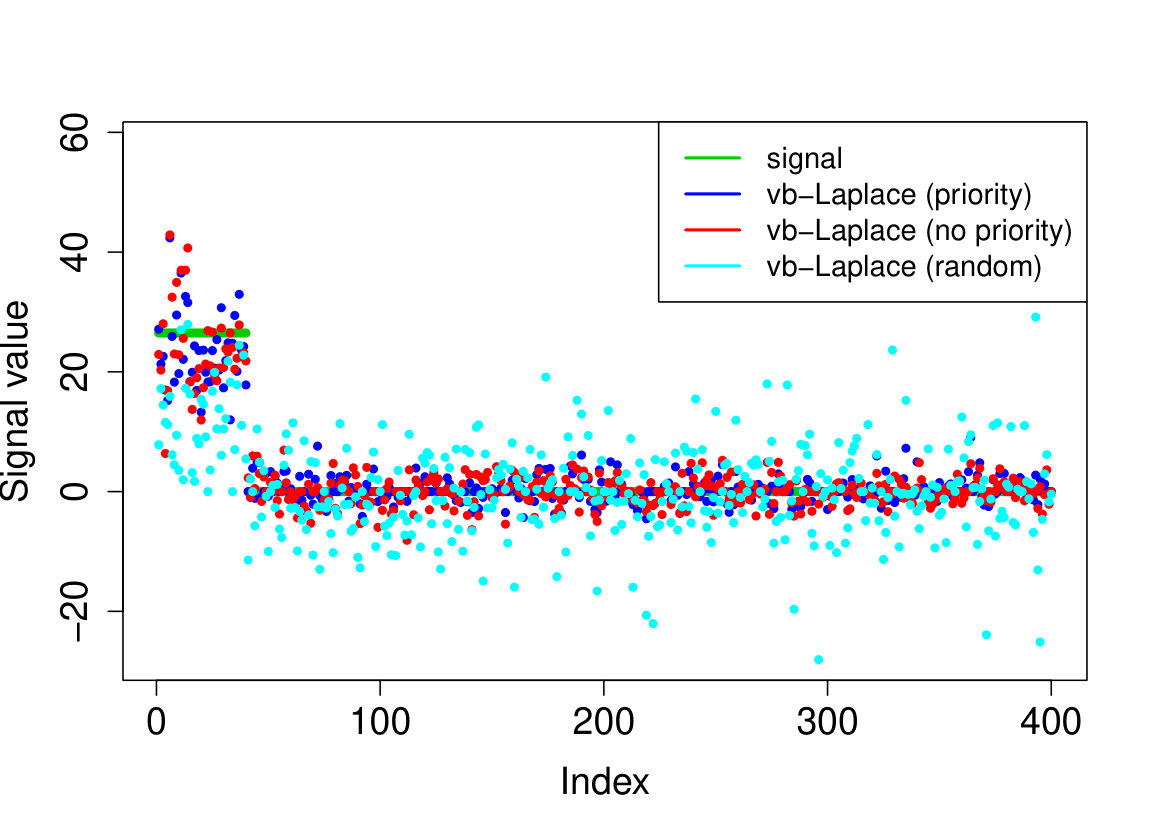 Figure 17
Figure 17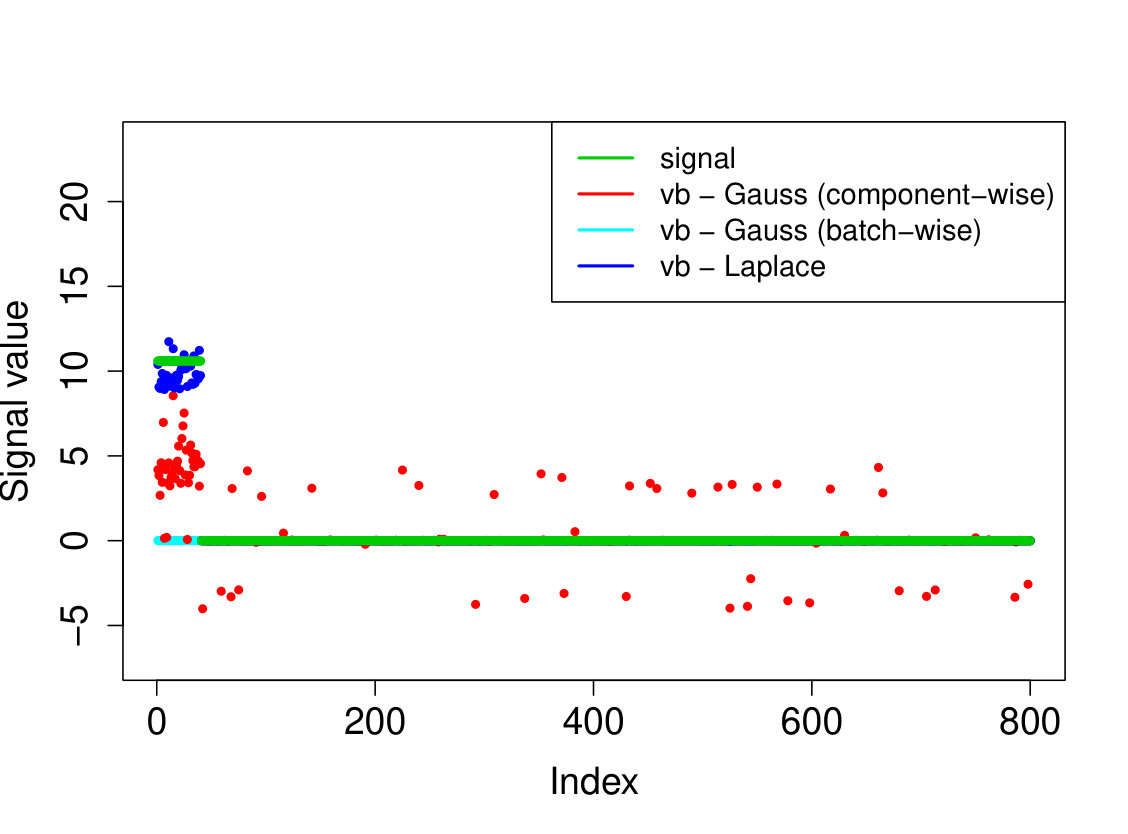 Figure 18
Figure 18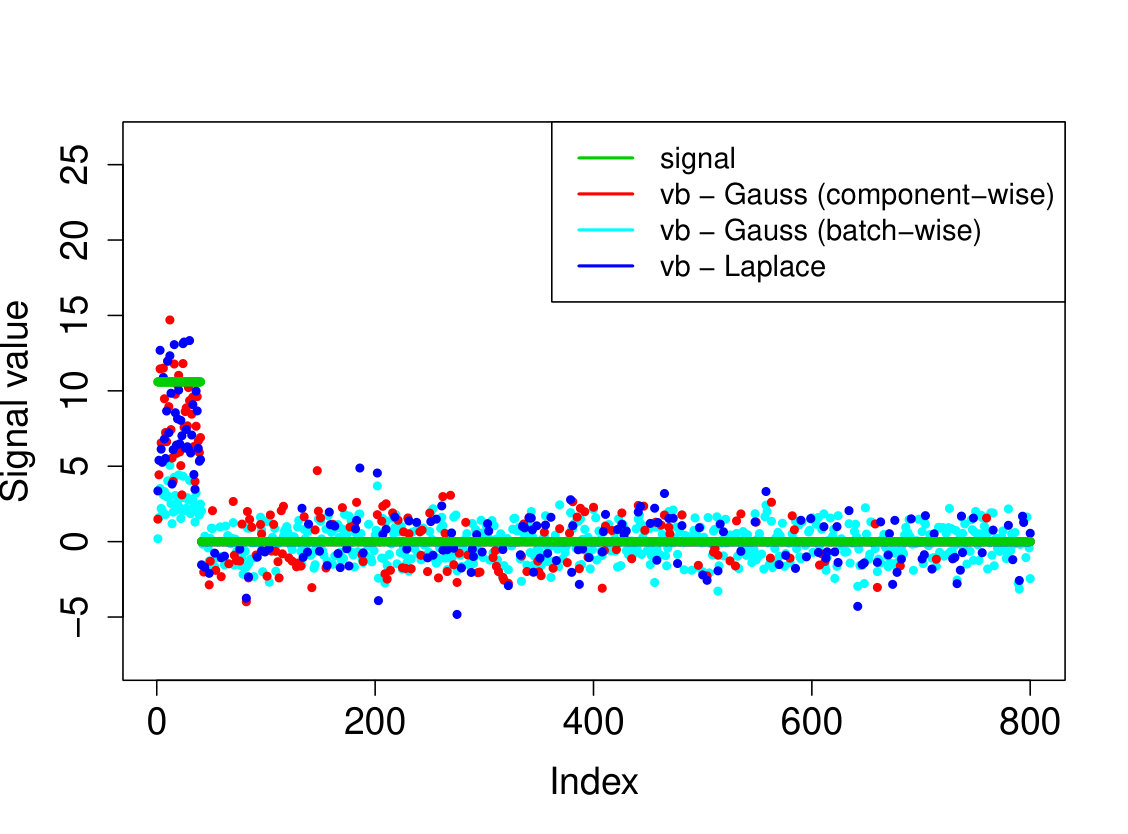 Figure 19
Figure 19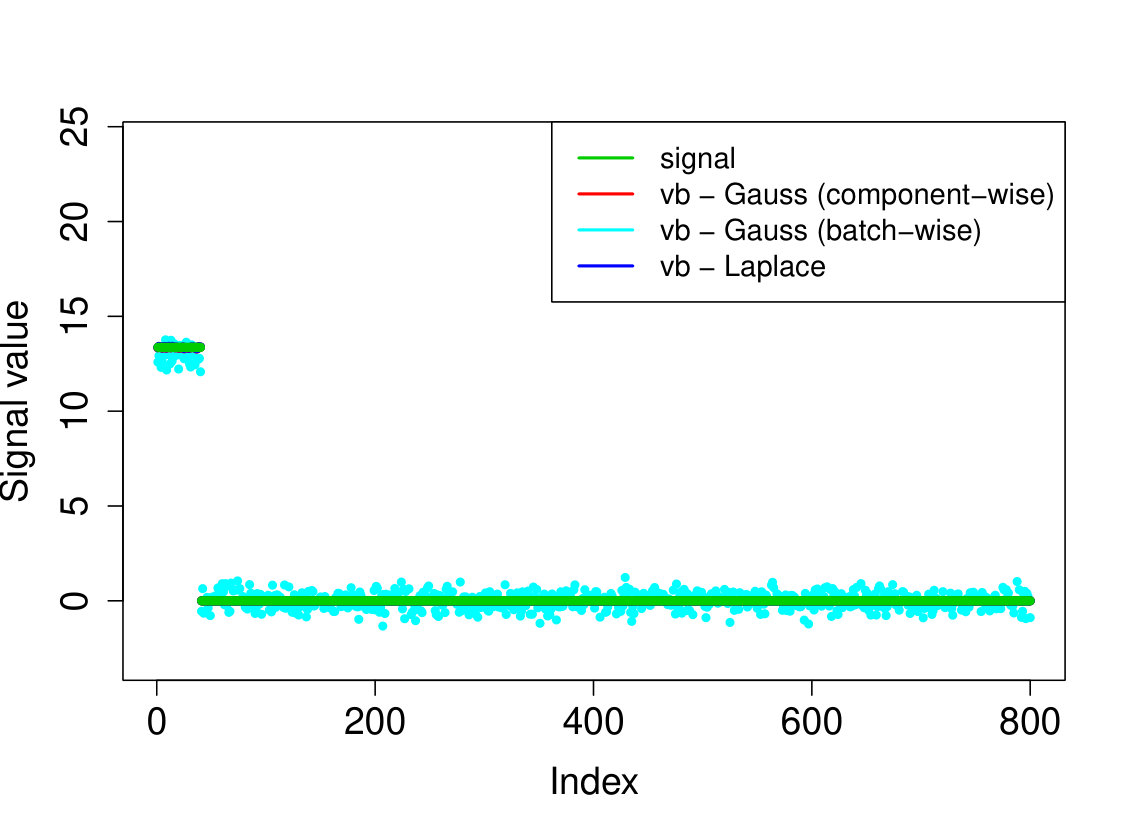 Figure 20
Figure 20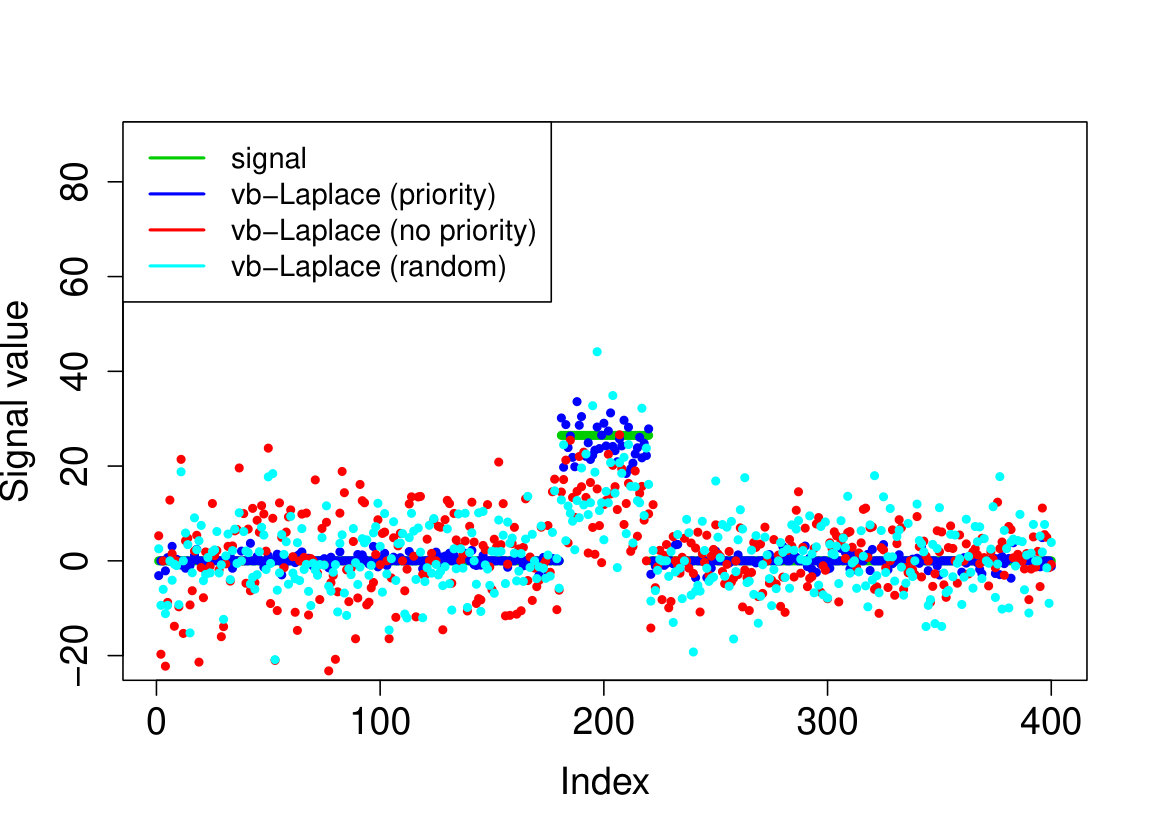 Figure 21
Figure 21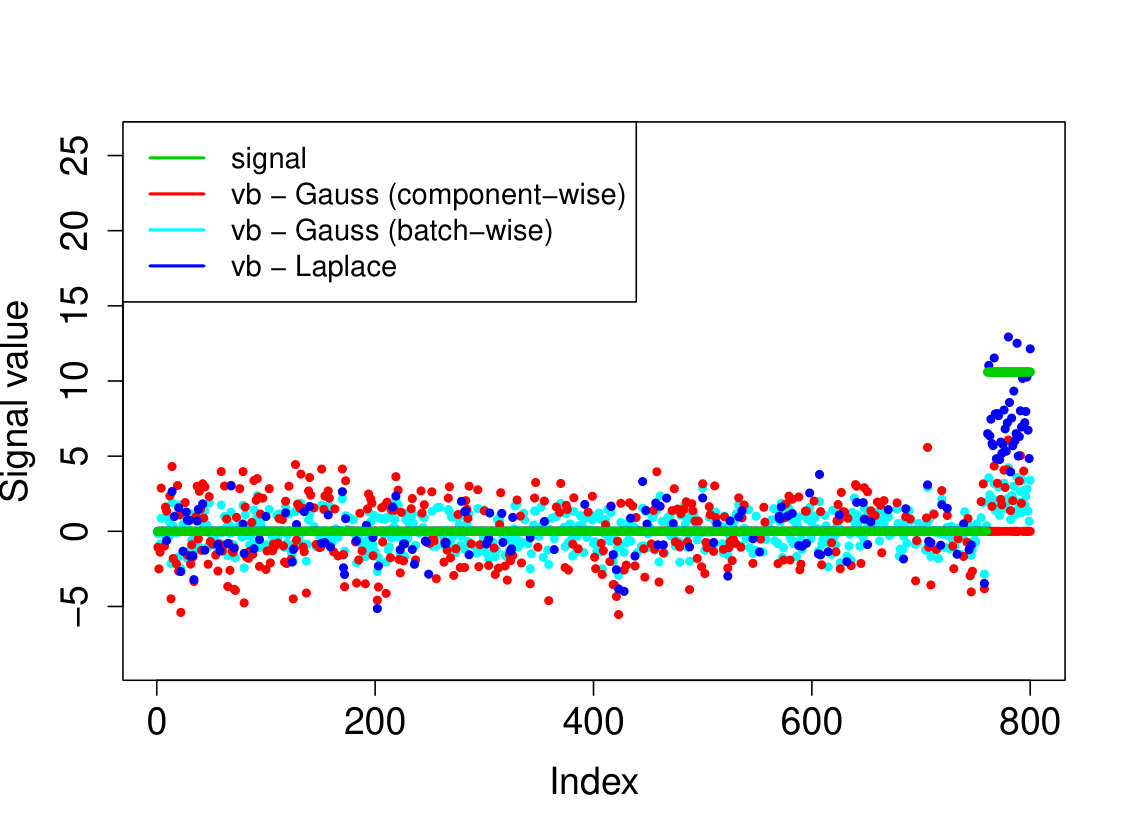 Figure 22
Figure 22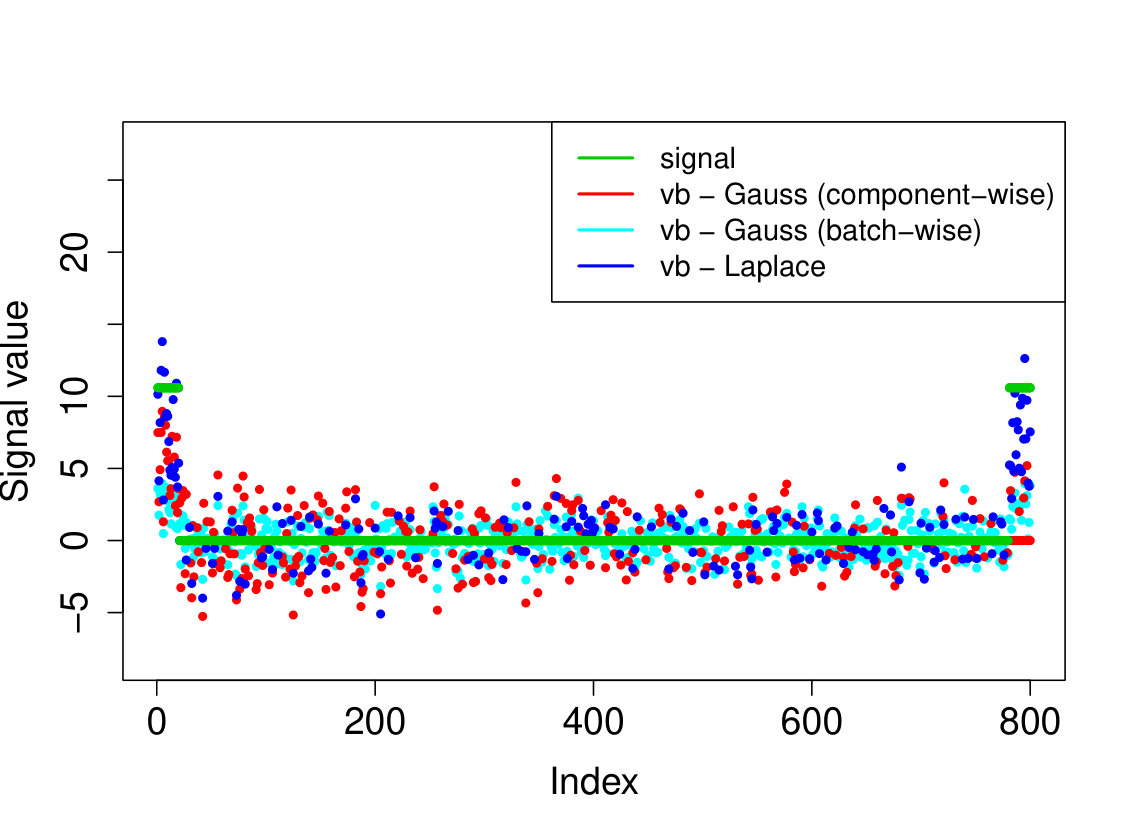 Figure 23
Figure 23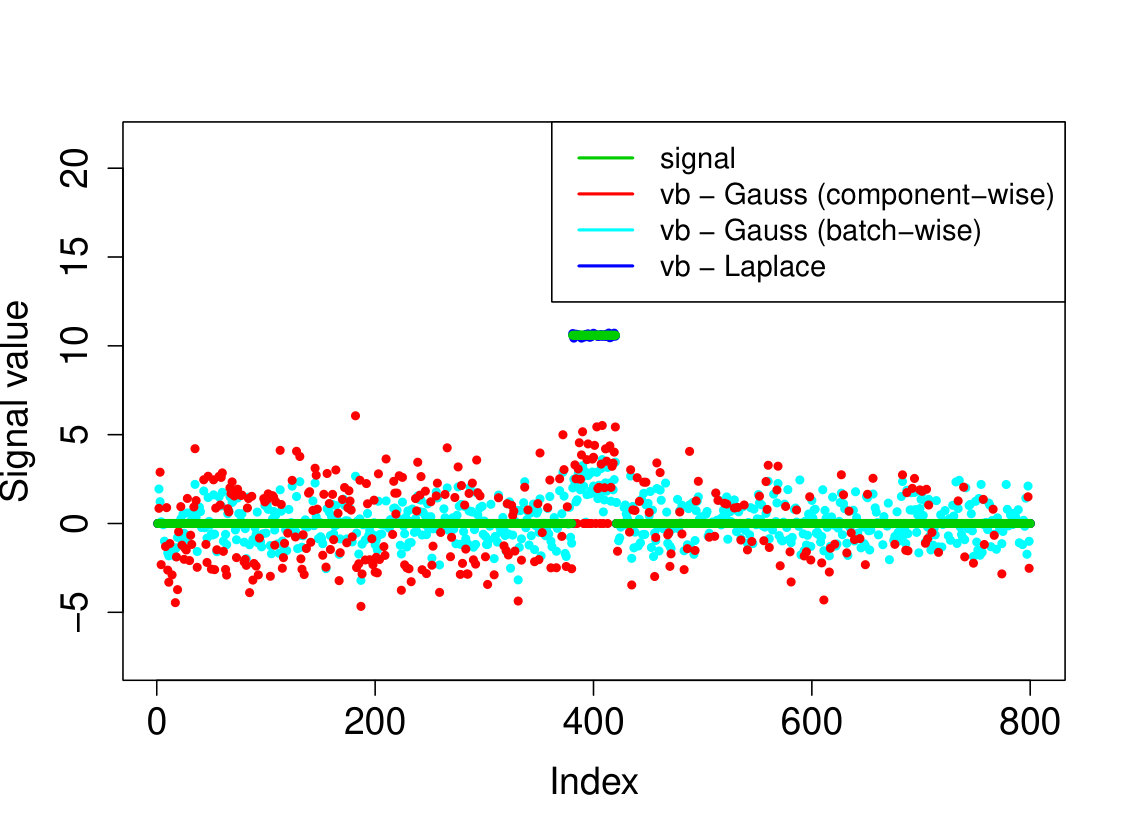 Figure 24
Figure 24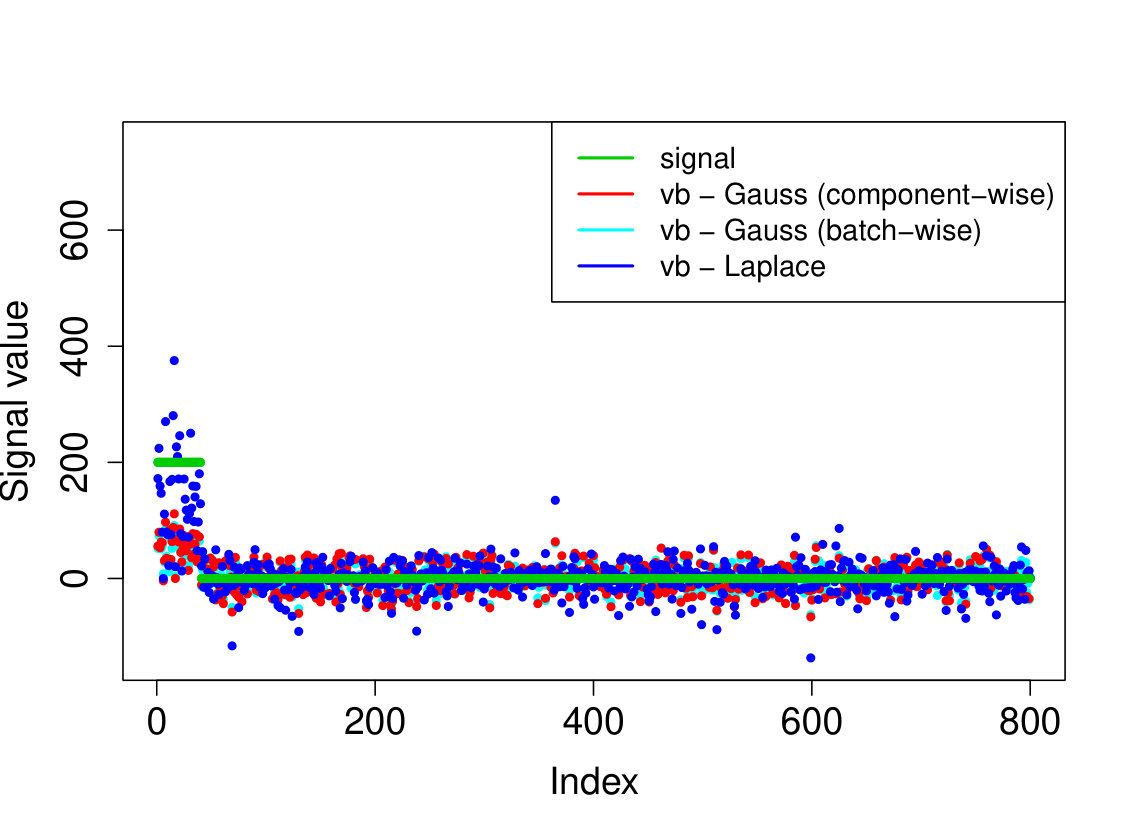 Figure 25
Figure 25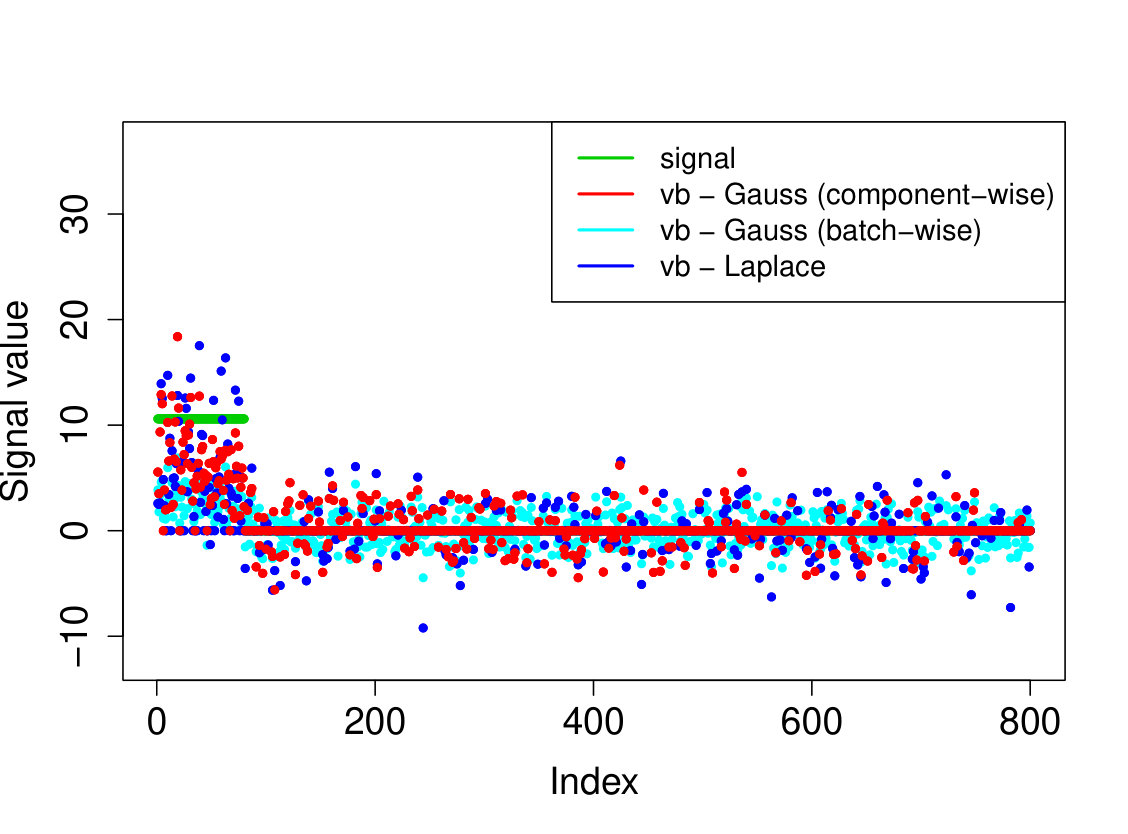 Figure 26
Figure 26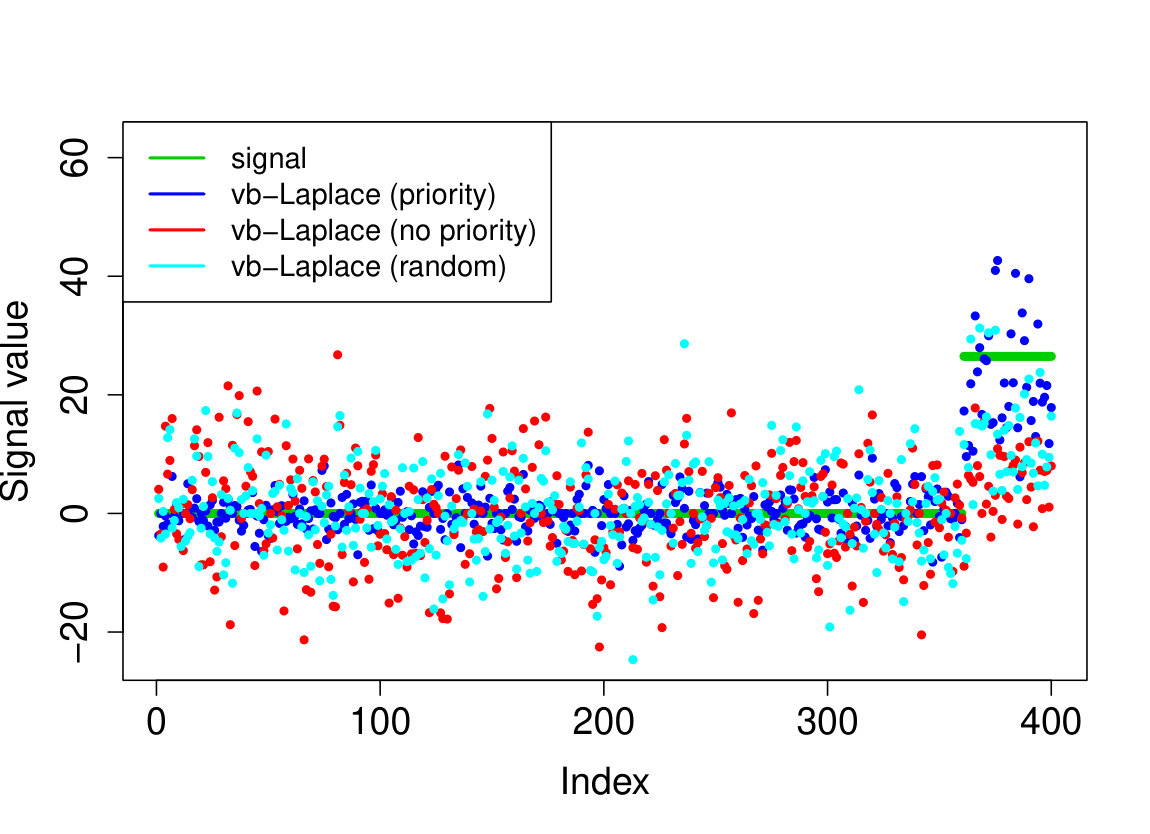 Figure 27
Figure 27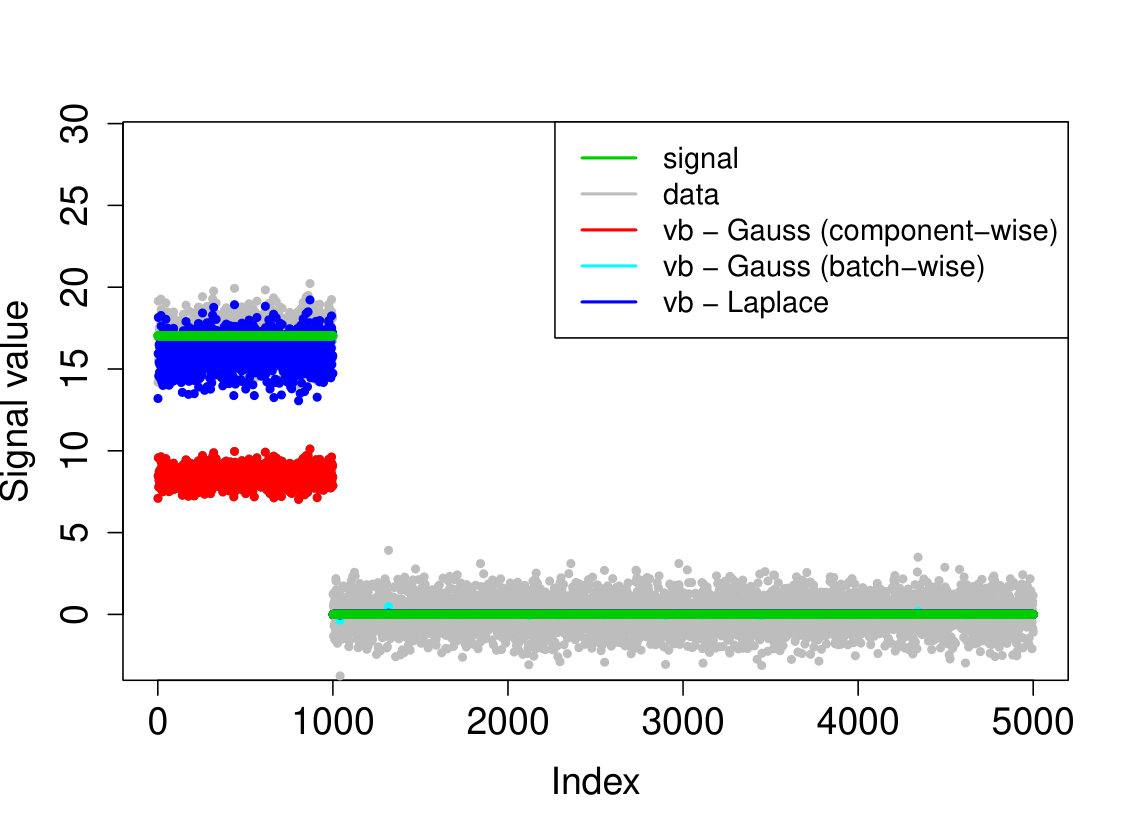 Figure 28
Figure 28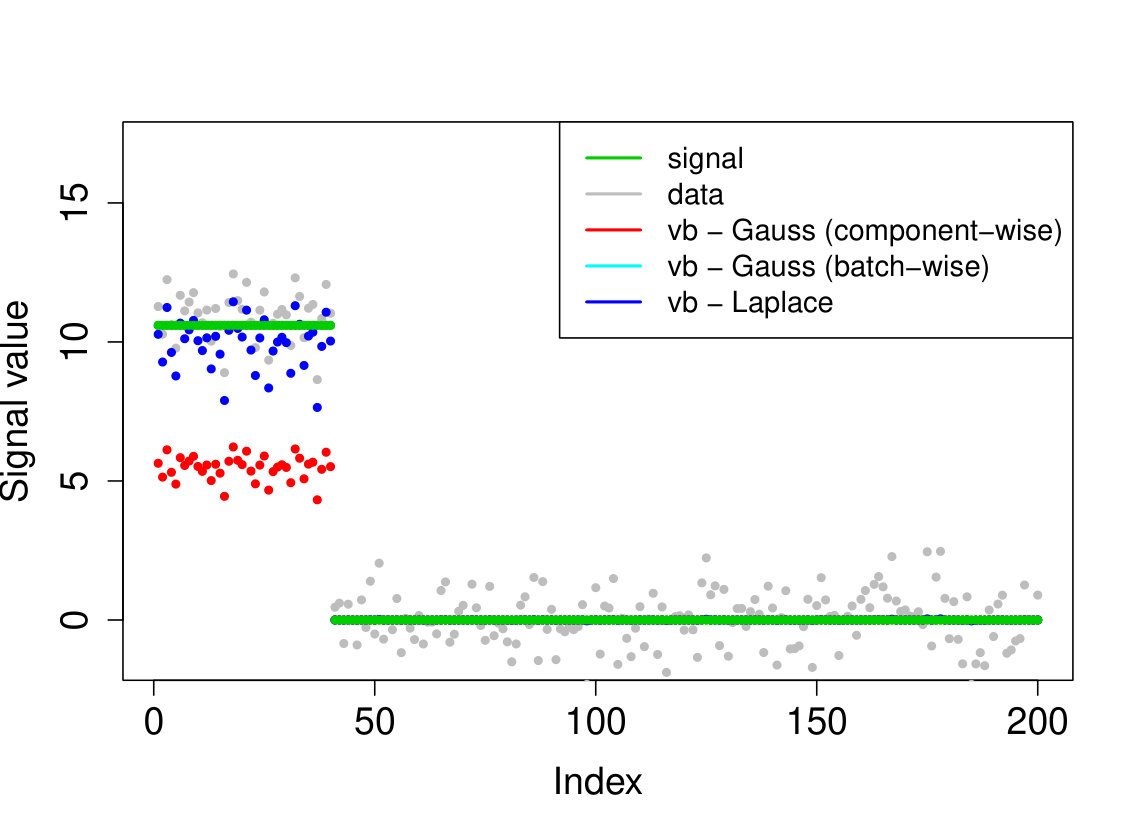 Figure 29
Figure 29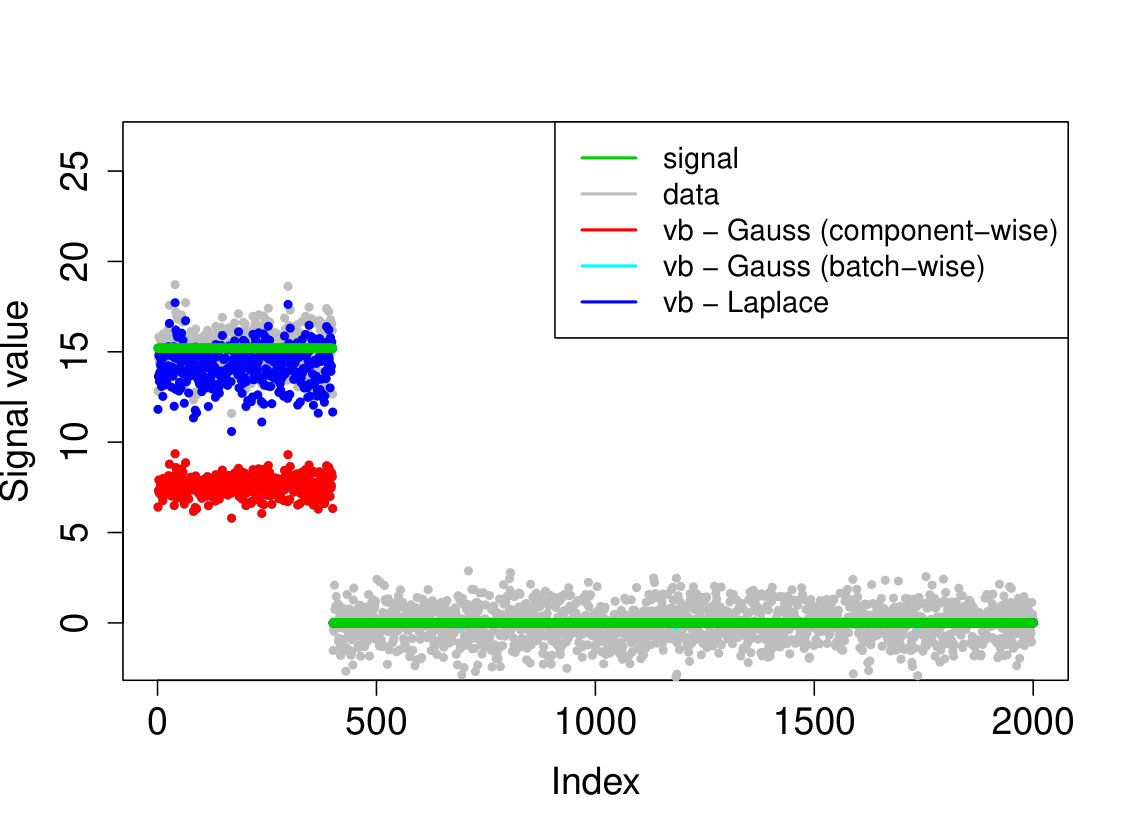 Figure 30
Figure 30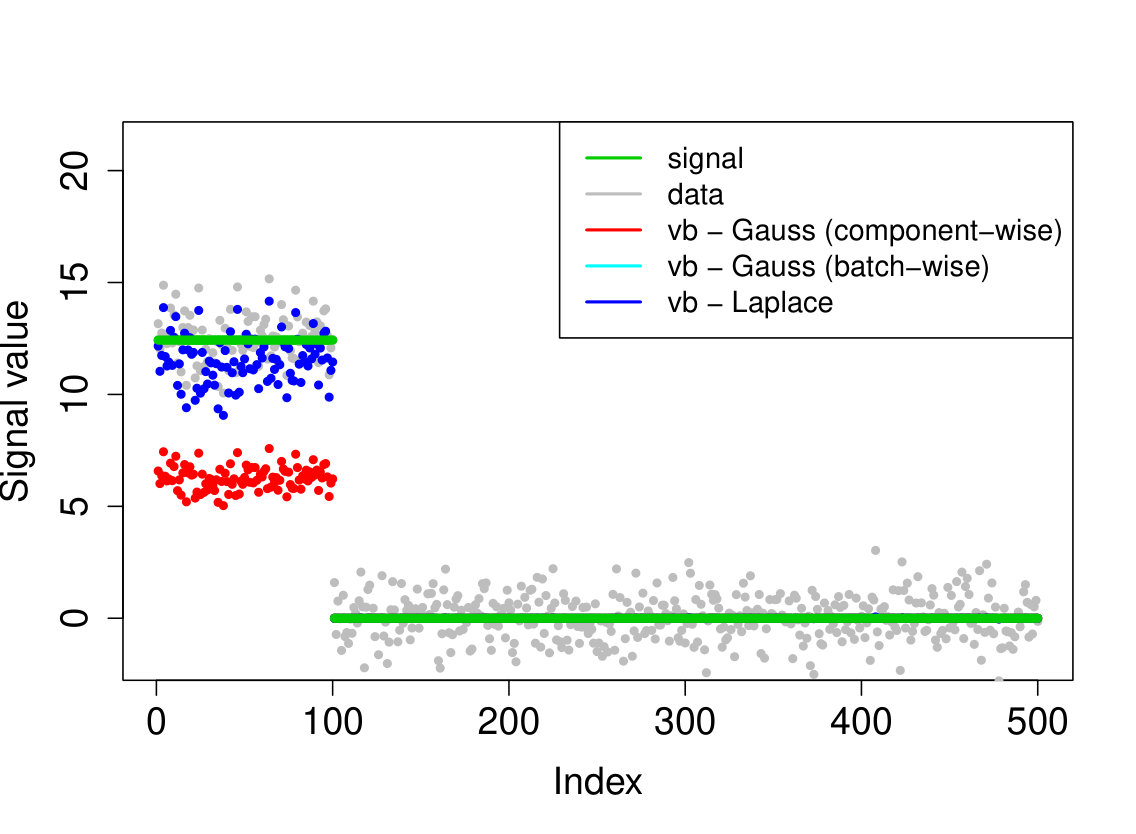 Figure 31
Figure 31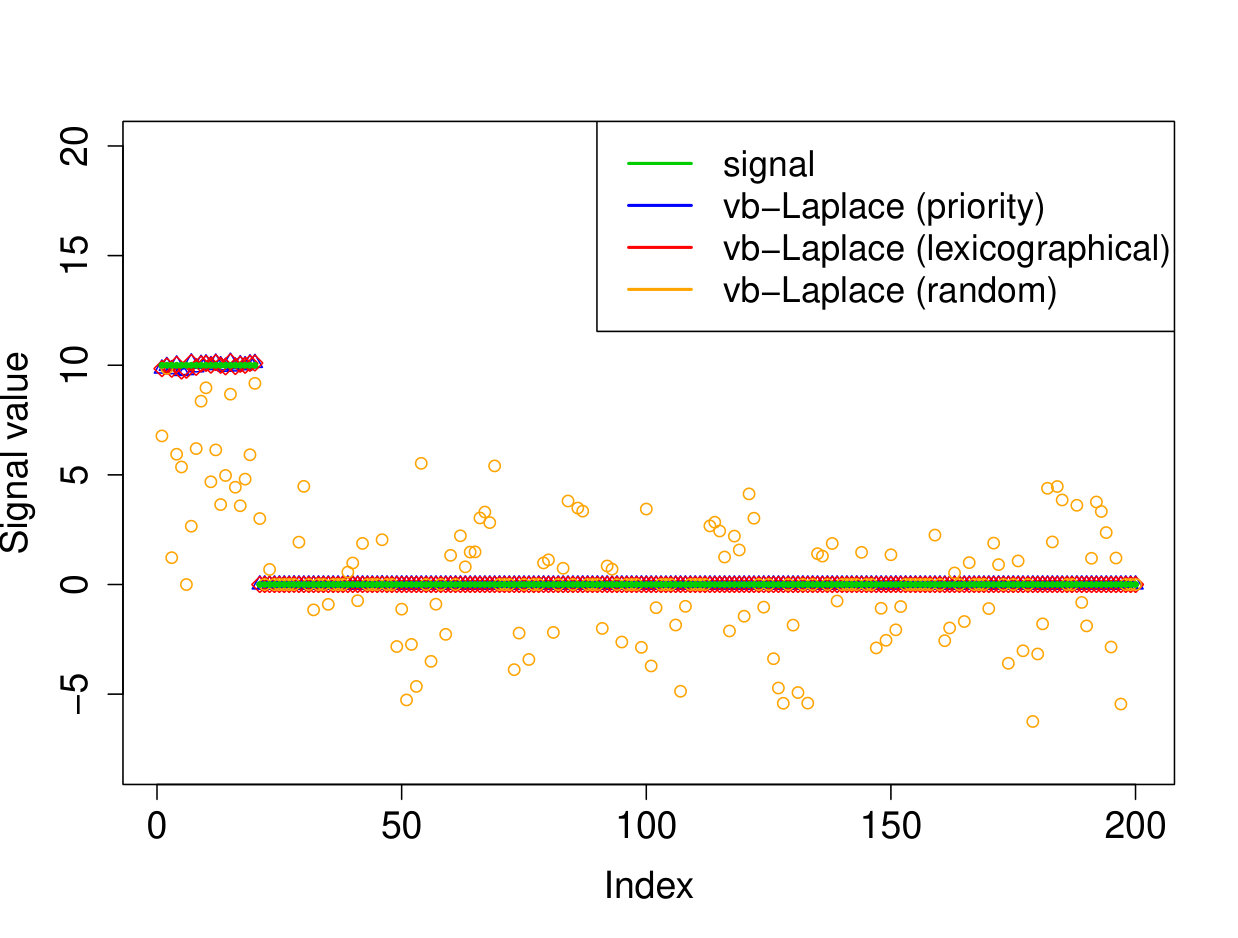 Figure 32
Figure 32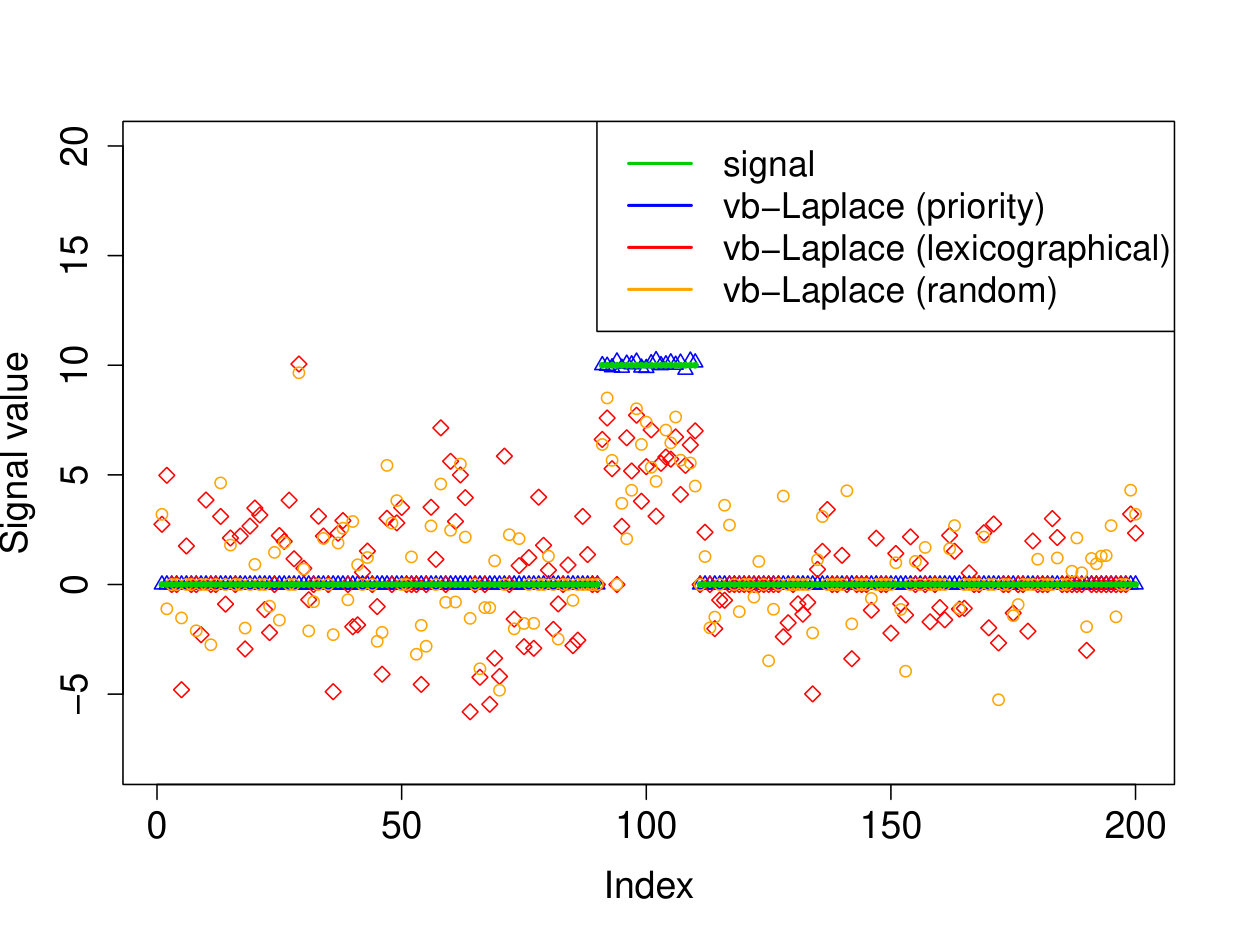 Figure 33
Figure 33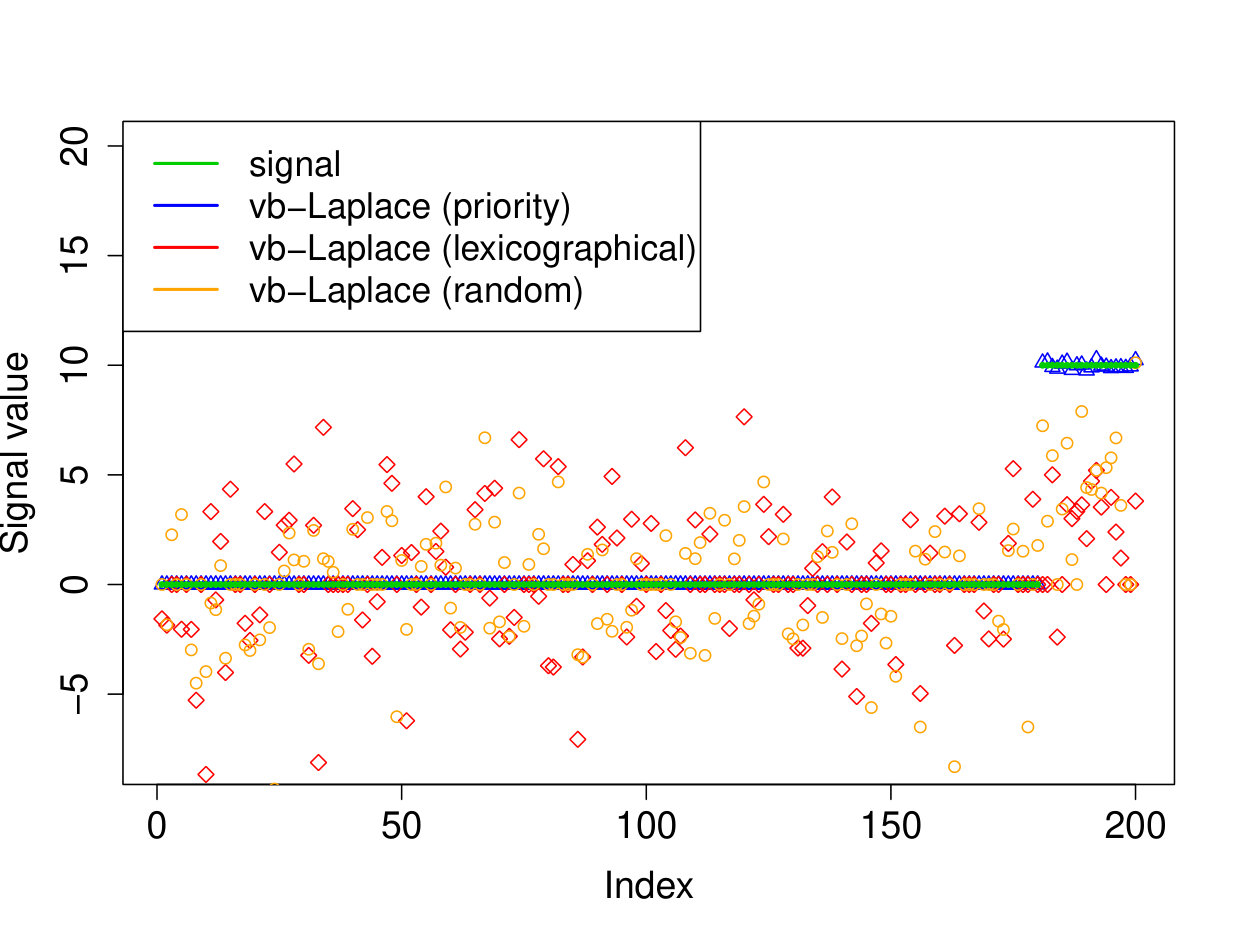 Figure 34
Figure 34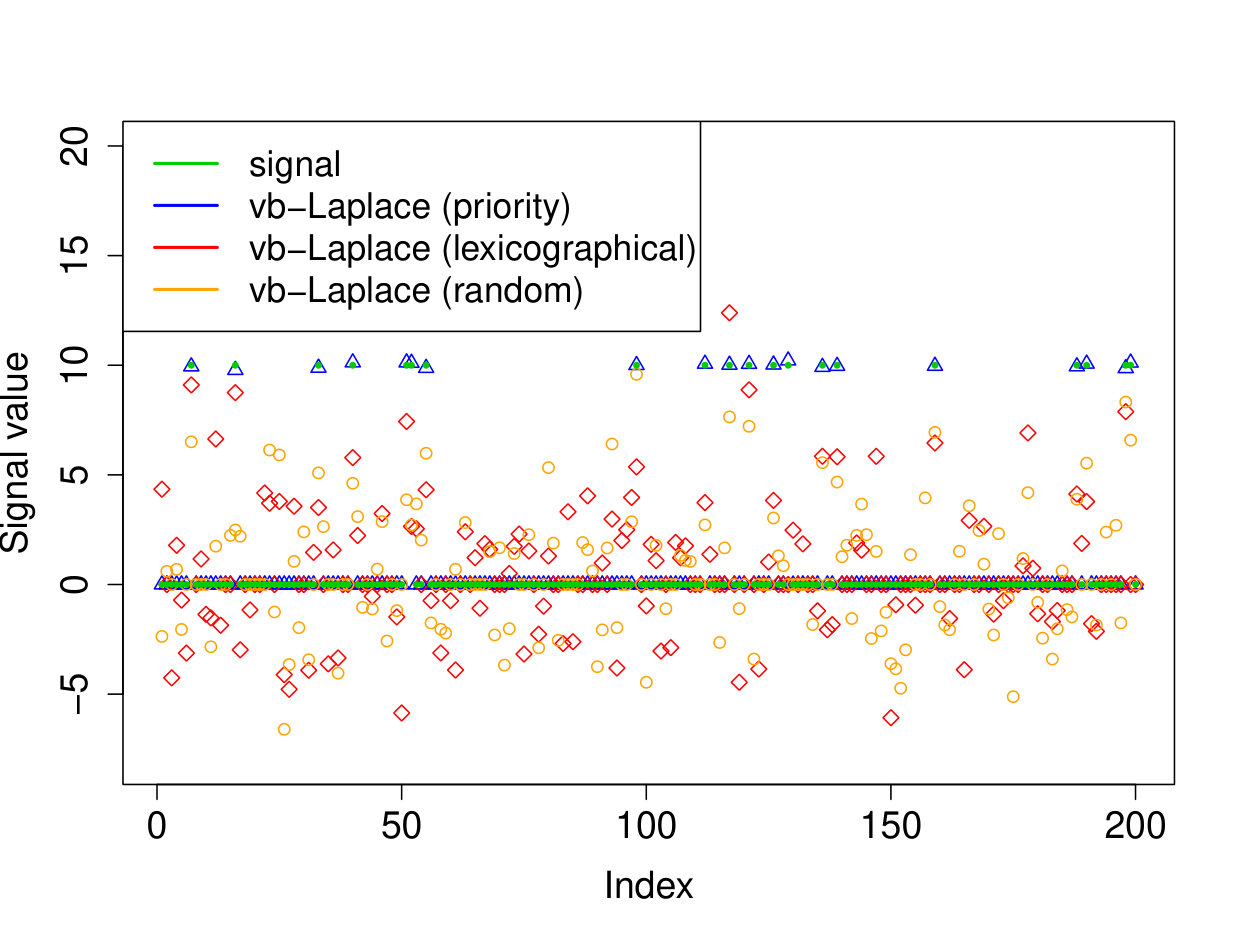 Figure 35
Figure 35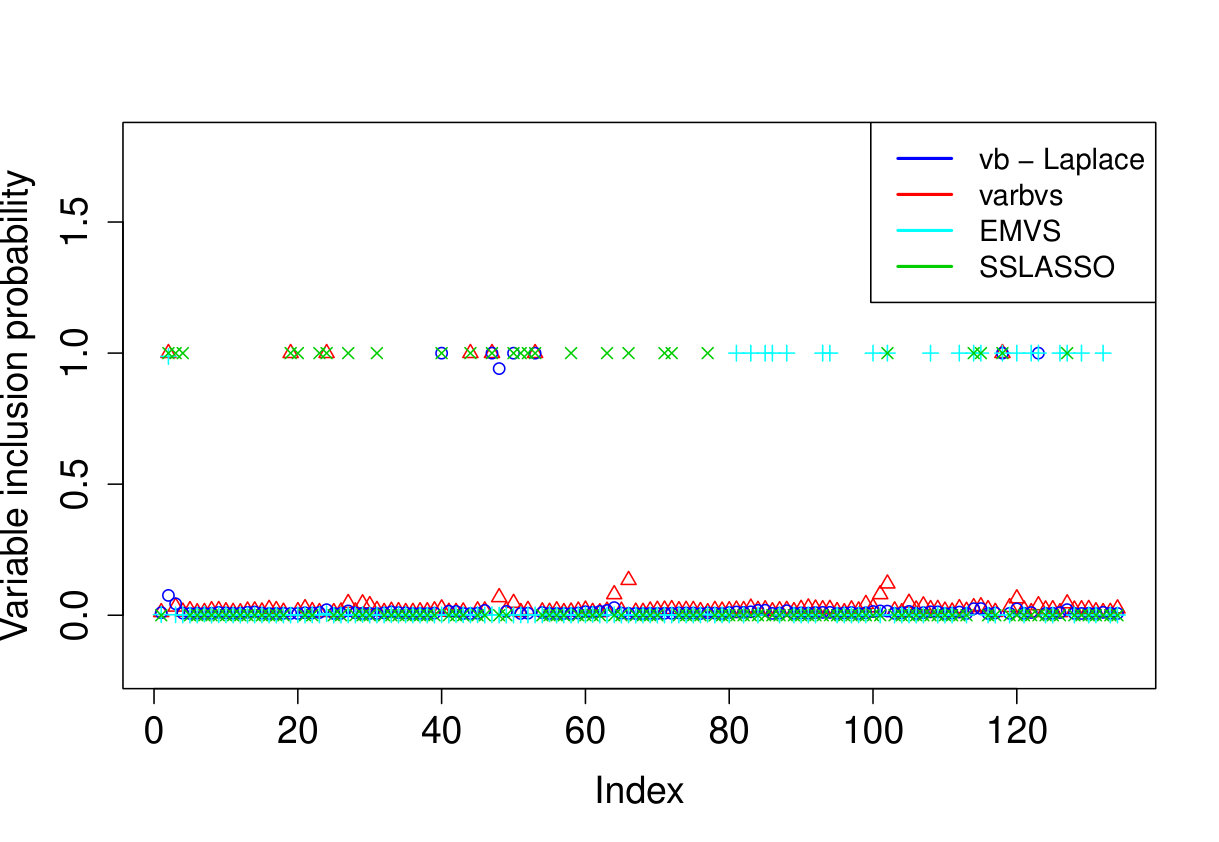 Figure 36
Figure 36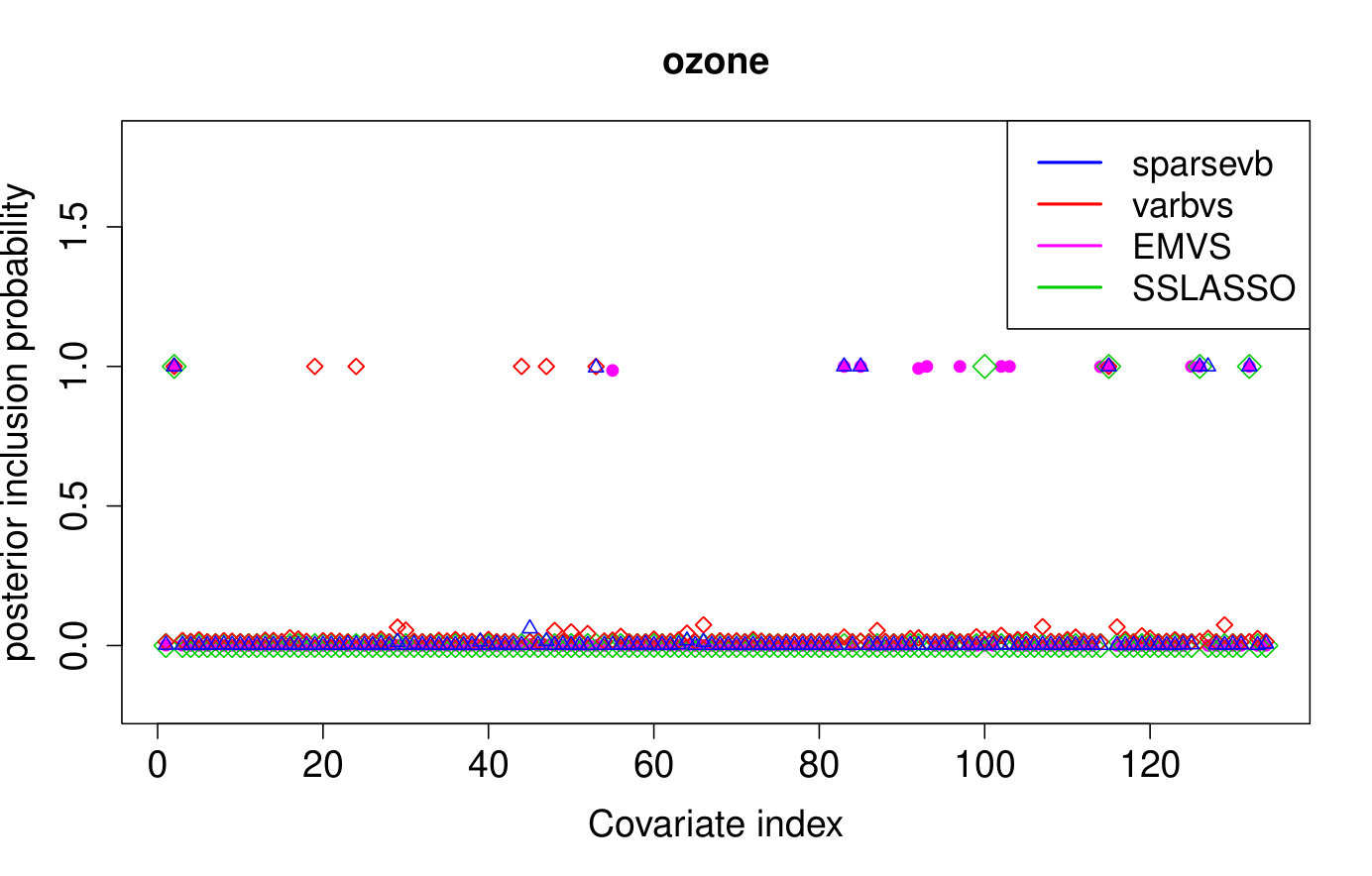 Figure 37
Figure 37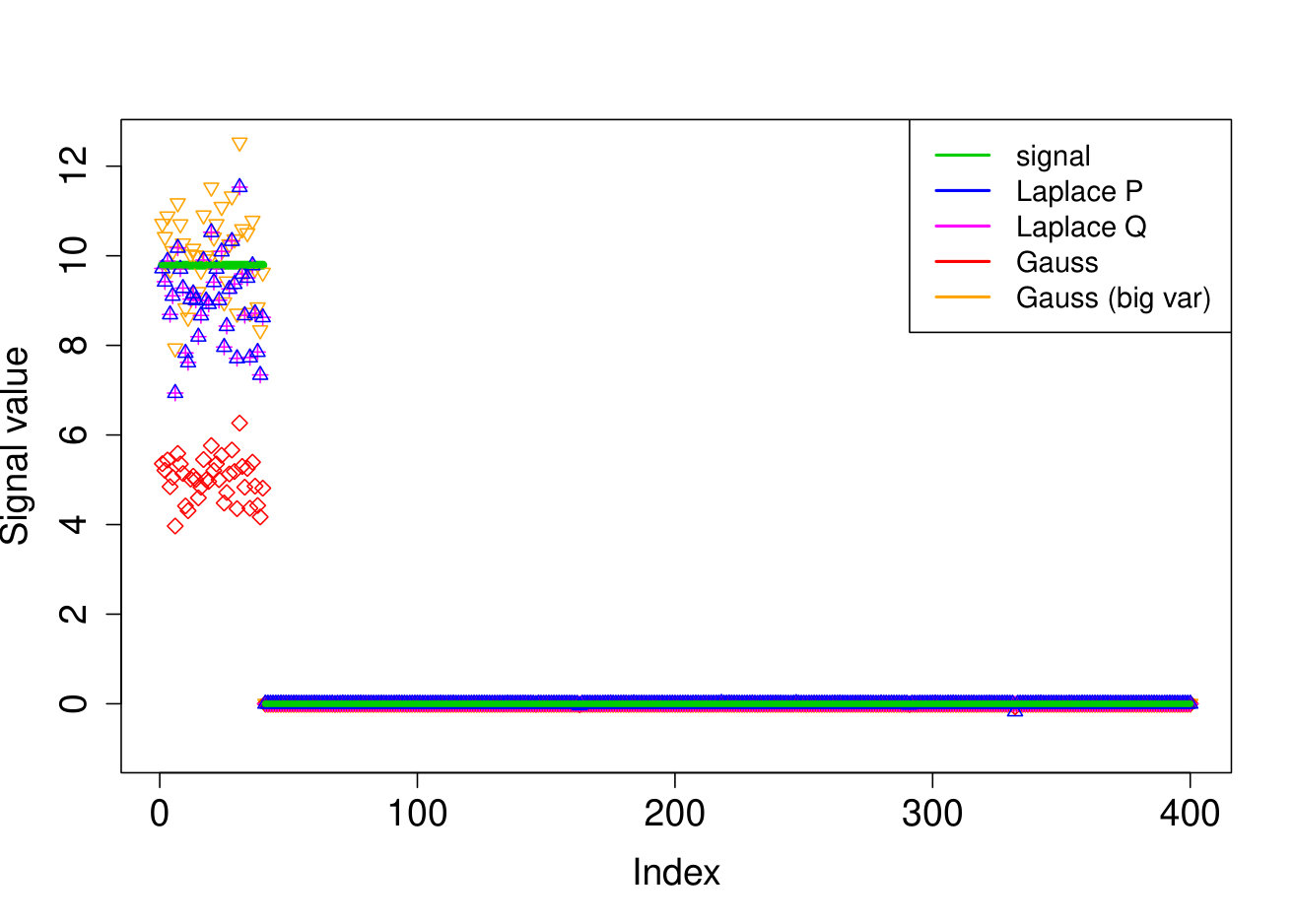 Figure 38
Figure 38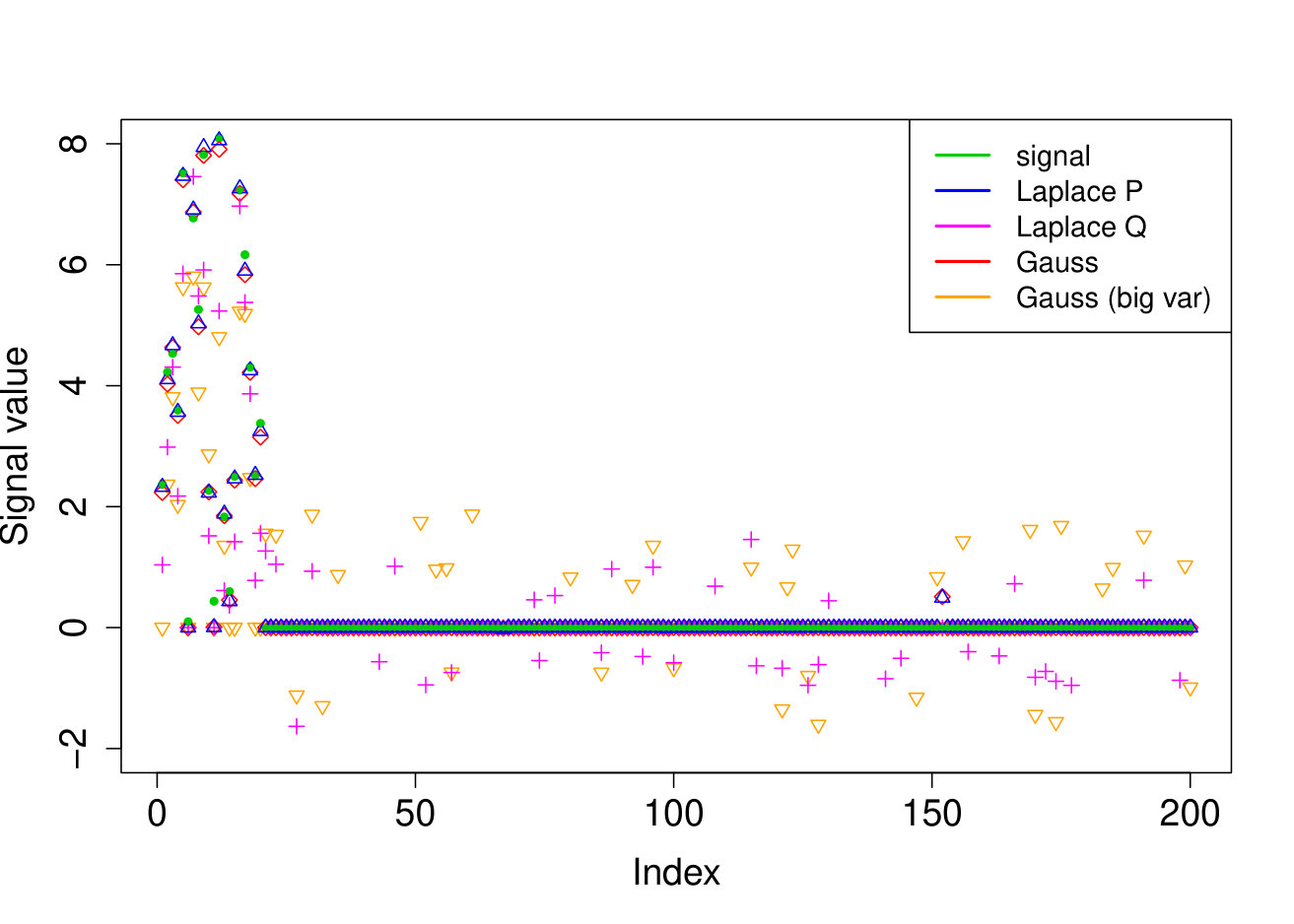 Figure 39
Figure 39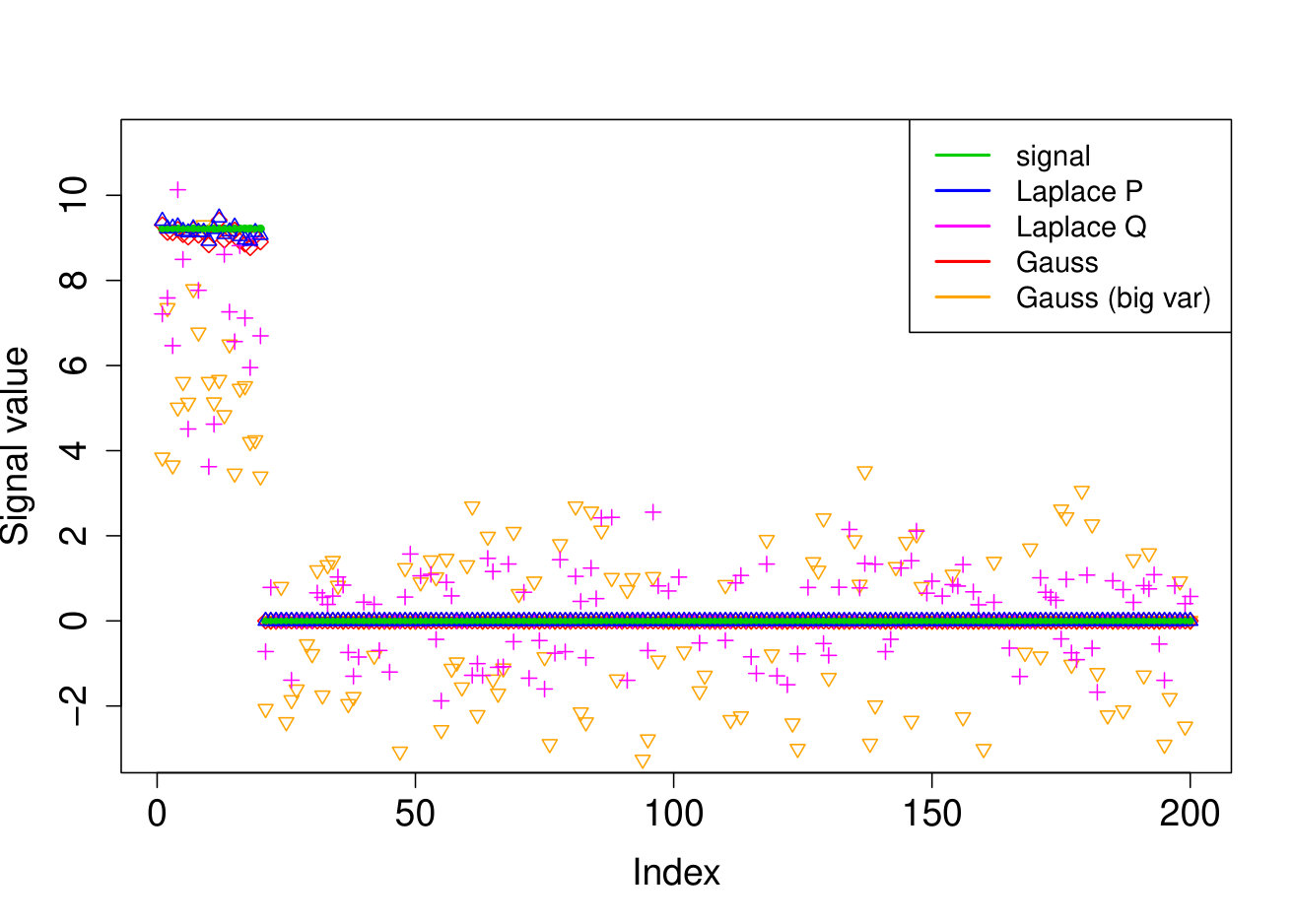 Figure 40
Figure 40| Metric | Method | (i) | (ii) | (iii) | (iv) |
|---|---|---|---|---|---|
| prioritized | 1.03 3.39 | 1.18 3.86 | 1.06 3.48 | 0.61 1.65 | |
| lexicographic | 0.71 2.14 | 26.61 15.04 | 45.72 5.45 | 37.91 5.63 | |
| randomized | 27.81 13.30 | 27.26 13.78 | 25.14 14.70 | 35.08 8.28 | |
| FDR | prioritized | 0.02 0.12 | 0.02 0.13 | 0.02 0.12 | 0.05 0.18 |
| lexicographic | 0.01 0.08 | 0.63 0.35 | 0.87 0.03 | 0.54 0.38 | |
| randomized | 0.68 0.31 | 0.66 0.32 | 0.62 0.352 | 0.69 0.30 | |
| TPR | prioritized | 1.00 0.00 | 1.00 0.01 | 1.00 0.01 | 1.00 0.01 |
| lexicographic | 1.00 0.00 | 0.93 0.06 | 0.75 0.11 | 0.95 0.05 | |
| randomized | 0.93 0.07 | 0.92 0.06 | 0.93 0.07 | 0.91 0.07 | |
| runtime (sec) | prioritized | 0.28 0.09 | 0.24 0.06 | 0.26 0.06 | 0.24 0.08 |
| lexicographic | 0.22 0.06 | 0.21 0.05 | 0.21 0.04 | 0.23 0.06 | |
| randomized | 0.24 0.08 | 0.22 0.05 | 0.23 0.05 | 0.25 0.06 |
| Metric | Method | (i) | (ii) | (iii) | (iv) |
|---|---|---|---|---|---|
| sparsevb | 10.48 6.84 | 0.21 0.14 | 0.03 0.01 | 6.55 7.80 | |
| varbvs | 14.23 6.51 | 0.18 0.07 | 0.03 0.01 | 20.43 17.15 | |
| EMVS | 14.02 2.46 | 3.57 0.03 | 5.04 0.33 | 21.52 11.29 | |
| SSLASSO | 20.62 0.17 | 0.16 0.11 | 0.09 0.12 | 37.92 9.84 | |
| ebreg | 9.38 6.05 | 0.18 0.07 | 0.17 0.04 | 7.39 7.42 | |
| FDR | sparsevb | 0.12 0.17 | 0.06 0.16 | 0.00 0.00 | 0.02 0.07 |
| varbvs | 0.06 0.11 | 0.01 0.04 | 0.00 0.00 | 0.07 0.15 | |
| EMVS | 0.24 0.13 | 0.00 0.00 | 0.00 0.00 | 0.43 0.25 | |
| SSLASSO | 0.00 0.00 | 0.00 0.00 | 0.00 0.00 | 0.00 0.00 | |
| ebreg | 0.38 0.20 | 0.01 0.02 | 0.00 0.00 | 0.28 0.16 | |
| TPR | sparsevb | 0.70 0.31 | 1.00 0.00 | 0.96 0.13 | 0.94 0.18 |
| varbvs | 0.340 0.37 | 1.00 0.00 | 0.57 0.43 | 0.53 0.44 | |
| EMVS | 0.59 0.14 | 0.00 0.00 | 0.86 0.09 | 0.88 0.10 | |
| SSLASSO | 0.01 0.01 | 0.94 0.13 | 0.10 0.29 | 0.09 0.28 | |
| ebreg | 0.88 0.18 | 1.00 0.00 | 0.98 0.07 | 1.00 0.04 | |
| runtime (sec) | sparsevb | 0.43 0.27 | 0.71 0.21 | 0.35 0.25 | 0.65 0.53 |
| varbvs | 0.60 0.28 | 2.02 0.50 | 0.51 0.38 | 0.56 0.23 | |
| EMVS | 0.20 0.07 | 1.72 0.44 | 0.21 0.05 | 0.19 0.09 | |
| SSLASSO | 0.06 0.03 | 0.37 0.11 | 0.06 0.01 | 0.07 0.03 | |
| ebreg | 35.05 7.03 | 21.20 6.05 | 31.42 4.01 | 36.33 9.13 |
| data \ Method | sparsevb | varbvs | EMVS | SSLASSO |
|---|---|---|---|---|
| CV error | 16.43 | |||
| model size | ||||
| runtime (sec) | 0.02 |
| Metric | Method Experiment | (i) | (ii) | (iii) | (iv) |
|---|---|---|---|---|---|
| Laplace | 8.80 0.85 | 1.30 0.26 | 9.25 9.73 | 1.08 0.20 | |
| Laplace | 8.80 0.85 | 6.73 1.79 | 39.98 6.88 | 6.56 1.97 | |
| Gauss | 31.06 0.49 | 1.93 0.51 | 43.58 2.94 | 1.40 0.29 | |
| Gauss (batch-wise) | 31.11 0.48 | 16.38 0.79 | 66.98 0.00 | 18.03 0.00 | |
| Gauss () | 6.26 0.72 | 1.42 0.32 | 58.12 19.01 | 2.05 3.59 | |
| FDR | Laplace | 0.00 0.00 | 0.00 0.01 | 0.03 0.11 | 0.00 0.02 |
| Laplace | 0.00 0.00 | 0.70 0.07 | 0.45 0.08 | 0.55 0.14 | |
| Gauss | 0.00 0.00 | 0.00 0.00 | 0.50 0.03 | 0.01 0.03 | |
| Gauss (batch-wise) | 0.00 0.00 | 0.87 0.01 | 0.62 0.03 | 0.82 0.03 | |
| Gauss () | 0.00 0.00 | 0.25 0.36 | 0.57 0.21 | 0.06 0.21 | |
| TPR | Laplace | 1.00 0.00 | 0.89 0.02 | 0.99 0.06 | 0.81 0.03 |
| Laplace | 1.00 0.00 | 0.81 0.06 | 0.88 0.08 | 0.74 0.07 | |
| Gauss | 1.00 0.00 | 0.89 0.02 | 0.94 0.05 | 0.81 0.03 | |
| Gauss (batch-wise) | 1.00 0.00 | 0.88 0.07 | 0.82 0.07 | 0.68 0.08 | |
| Gauss () | 1.00 0.00 | 0.81 0.10 | 0.58 0.17 | 0.78 0.10 |
| Metric | Method | (i) | (ii) | (iii) | (iv) |
|---|---|---|---|---|---|
| 0.56 0.11 | 35.81 2.17 | 2.49 0.50 | 0.09 0.02 | ||
| 0.57 0.12 | 35.28 2.32 | 2.34 0.50 | 0.08 0.02 | ||
| 0.57 0.11 | 16.38 14.63 | 2.38 0.48 | 0.08 0.02 | ||
| 0.67 0.12 | 0.34 0.03 | 3.56 0.51 | 0.07 0.02 | ||
| 1.85 0.22 | 0.47 0.05 | 11.94 1.01 | 0.07 0.02 | ||
| FDR | 0.00 0.00 | 0.92 0.00 | 0.00 0.00 | 0.00 0.00 | |
| 0.00 0.01 | 0.92 0.00 | 0.00 0.00 | 0.00 0.00 | ||
| 0.00 0.01 | 0.51 0.45 | 0.00 0.01 | 0.00 0.00 | ||
| 0.00 0.00 | 0.00 0.00 | 0.00 0.01 | 0.00 0.01 | ||
| 0.00 0.00 | 0.00 0.00 | 0.00 0.02 | 0.00 0.00 | ||
| TPR | 1.00 0.00 | 1.00 0.00 | 0.91 0.04 | 0.95 0.03 | |
| 1.00 0.00 | 1.00 0.01 | 0.92 0.04 | 0.96 0.03 | ||
| 1.00 0.00 | 1.00 0.01 | 0.92 0.04 | 0.97 0.03 | ||
| 1.00 0.00 | 1.00 0.01 | 0.90 0.04 | 0.98 0.03 | ||
| 1.00 0.00 | 1.00 0.00 | 0.59 0.07 | 0.98 0.03 | ||
| runtime (sec) | 0.04 0.01 | 0.75 0.11 | 0.08 0.02 | 4.23 0.46 | |
| 0.04 0.01 | 0.81 0.18 | 0.08 0.02 | 4.23 0.50 | ||
| 0.04 0.01 | 1.71 0.63 | 0.08 0.02 | 4.23 0.46 | ||
| 0.04 0.02 | 1.26 0.15 | 0.08 0.02 | 4.25 0.50 | ||
| 0.04 0.01 | 0.75 0.06 | 0.08 0.01 | 4.29 0.65 |
| Metric | Method | (i) | (ii) | (iii) | (iv) Student |
|---|---|---|---|---|---|
| sparsevb | 0.18 0.05 | 0.24 0.04 | 0.21 0.03 | 0.30 0.06 | |
| varbvs | 0.17 0.03 | 0.24 0.04 | 0.21 0.03 | 0.30 0.06 | |
| EMVS | 0.59 0.03 | 1.03 0.14 | 0.89 0.16 | 1.13 0.43 | |
| SSLASSO | 5.99 0.98 | 4.07 1.02 | 4.88 0.62 | 4.87 0.78 | |
| ebreg | 0.26 0.05 | 0.26 0.07 | 0.23 0.05 | 0.23 0.05 | |
| FDR | sparsevb | 0.00 0.00 | 0.00 0.00 | 0.00 0.00 | 0.00 0.00 |
| varbvs | 0.00 0.00 | 0.00 0.00 | 0.00 0.00 | 0.00 0.01 | |
| EMVS | 0.00 0.00 | 0.00 0.00 | 0.00 0.00 | 0.00 0.01 | |
| SSLASSO | 0.00 0.00 | 0.00 0.00 | 0.00 0.00 | 0.00 0.00 | |
| ebreg | 0.01 0.02 | 0.01 0.05 | 0.01 0.05 | 0.01 0.03 | |
| TPR | sparsevb | 1.00 0.01 | 1.00 0.00 | 0.95 0.00 | 0.90 0.01 |
| varbvs | 1.00 0.00 | 1.00 0.00 | 0.95 0.01 | 0.90 0.01 | |
| EMVS | 0.95 0.02 | 0.92 0.02 | 0.89 0.02 | 0.81 0.04 | |
| SSLASSO | 0.67 0.04 | 0.72 0.05 | 0.64 0.02 | 0.64 0.04 | |
| ebreg | 1.00 0.01 | 1.00 0.00 | 0.95 0.01 | 0.90 0.01 | |
| runtime (sec) | sparsevb | 0.22 0.03 | 0.24 0.06 | 0.24 0.06 | 0.26 0.08 |
| varbvs | 0.32 0.05 | 0.32 0.05 | 0.35 0.08 | 0.35 0.09 | |
| EMVS | 1.24 0.15 | 1.19 0.24 | 1.26 0.27 | 1.31 0.34 | |
| SSLASSO | 0.16 0.03 | 0.28 0.04 | 0.22 0.05 | 0.28 0.07 | |
| ebreg | 24.37 7.10 | 24.89 3.78 | 127.72 4.51 | 28.19 4.51 |
| Metric | Method | (i) | (ii) | (iii) | (iv) |
|---|---|---|---|---|---|
| sparsevb | 0.12 0.06 | 0.89 1.40 | 1.97 0.37 | 4.85 1.29 | |
| varbvs | 0.13 0.06 | 0.30 0.10 | 2.10 0.43 | 27.18 23.59 | |
| EMVS | 4.80 0.21 | 5.29 0.26 | 4.04 0.30 | 7.04 0.98 | |
| SSLASSO | 1.62 0.35 | 0.97 0.36 | 56.70 7.78 | 79.17 4.95 | |
| ebreg | 0.34 0.06 | 0.56 0.14 | 5.41 0.67 | 6.41 1.21 | |
| FDR | sparsevb | 0.00 0.00 | 0.18 0.34 | 0.00 0.01 | 0.00 0.00 |
| varbvs | 0.00 0.00 | 0.00 0.00 | 0.01 0.02 | 0.31 0.26 | |
| EMVS | 0.00 0.00 | 0.00 0.00 | 0.00 0.01 | 0.14 0.08 | |
| SSLASSO | 0.00 0.00 | 0.00 0.00 | 0.18 0.16 | 0.41 0.19 | |
| ebreg | 0.00 0.00 | 0.00 0.00 | 0.43 0.05 | 0.28 0.08 | |
| TPR | sparsevb | 0.96 0.05 | 0.95 0.10 | 1.00 0.00 | 1.00 0.00 |
| varbvs | 0.95 0.05 | 1.00 0.00 | 1.00 0.00 | 0.69 0.32 | |
| EMVS | 0.01 0.03 | 0.02 0.04 | 1.00 0.00 | 1.00 0.00 | |
| SSLASSO | 0.48 0.04 | 0.81 0.08 | 0.34 0.10 | 0.18 0.05 | |
| ebreg | 0.90 0.01 | 0.96 0.05 | 1.00 0.00 | 1.00 0.00 | |
| runtime (sec) | sparsevb | 0.22 0.06 | 0.30 0.06 | 0.91 0.11 | 1.28 0.17 |
| varbvs | 0.51 0.19 | 0.80 0.52 | 12.31 3.34 | 30.54 6.38 | |
| EMVS | 0.14 0.07 | 0.15 0.06 | 0.90 0.18 | 1.06 0.26 | |
| SSLASSO | 0.33 0.07 | 0.38 0.19 | 0.16 0.03 | 0.16 0.02 | |
| ebreg | 13.90 1.62 | 15.06 2.96 | 64.14 6.36 | 59.98 4.41 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Variational Bayes for high-dimensional linear regression with sparse priors
Kolyan Ray111Department of Mathematics, Imperial College London. E-mail: [email protected] and Botond Szabó222Department of Mathematics, Vrije Universiteit Amsterdam. E-mail: [email protected]
Botond Szabó received funding from the Netherlands Organization for Scientific Research (NWO) under Project number: 639.031.654.
Imperial College London and Vrije Universiteit Amsterdam
Abstract
We study a mean-field spike and slab variational Bayes (VB) approximation to Bayesian model selection priors in sparse high-dimensional linear regression. Under compatibility conditions on the design matrix, oracle inequalities are derived for the mean-field VB approximation, implying that it converges to the sparse truth at the optimal rate and gives optimal prediction of the response vector. The empirical performance of our algorithm is studied, showing that it works comparably well as other state-of-the-art Bayesian variable selection methods. We also numerically demonstrate that the widely used coordinate-ascent variational inference (CAVI) algorithm can be highly sensitive to the parameter updating order, leading to potentially poor performance. To mitigate this, we propose a novel prioritized updating scheme that uses a data-driven updating order and performs better in simulations. The variational algorithm is implemented in the R package sparsevb.
AMS 2000 subject classifications: Primary 62G20; secondary 62G05, 65K10.
Keywords and phrases: Variational Bayes, spike-and-slab prior, model selection, sparsity, oracle inequalities.
1 Introduction
Inference under sparsity constraints has found many applications in statistics and machine learning [31, 40]. Perhaps the most widely applied such model is sparse linear regression, where we observe
[TABLE]
where , is a given, deterministic design matrix, is the parameter of interest and is additive Gaussian noise. We are interested in the sparse high-dimensional setting, where and typically , and many of the coefficients are (close to) zero.
From a Bayesian perspective, perhaps the most natural way to impose sparsity is through a model selection prior, which assigns probabilistic weights to each potential model, i.e. each subset of corresponding to selecting the non-zero coordinates of . This is one of the most widely used approaches within the Bayesian community [18, 19, 31, 44] and includes the popular spike-and-slab prior, which is often considered the gold standard in sparse Bayesian linear regression. Such priors have been shown to perform well for estimation and prediction [26, 15, 13, 16], uncertainty quantification [35, 14] and multiple hypothesis testing [12], see [2] for a recent review.
However, while these priors perform excellently both empirically and theoretically, the discrete model selection component of the prior can make computation hugely challenging. For , inference using the spike-and-slab prior generally involves a combinatorial search over all possible models, a hugely expensive task for even moderate . Fast algorithms for exact posterior computation are thus usually restricted to the diagonal design case [15, 42], while Markov chain Monte Carlo methods are known to have problems mixing for typical problem sizes of interest [22].
A popular scalable alternative is variational Bayes (VB), which recasts posterior approximation as an optimization problem. One minimizes the VB objective function, consisting of the Kullback-Leibler (KL) divergence between a family of tractable distributions, called the variational family, and the posterior. Though the resulting approximation does not provide exact Bayesian inference, picking a computationally convenient variational class can dramatically increase scalability, see for example [6, 23]. An especially popular variational family consists of distributions under which the model parameters are independent, so called mean-field variational Bayes. For a nice recent review of VB, see [5].
In this work, we consider a mean field family consisting of distributions independently assigning each coordinate of an independent mixture of a Gaussian and Dirac mass at zero, thereby mirroring the form of the spike-and-slab prior (but crucially not the form of the posterior). Such a computational relaxation is significant, reducing the posterior dimension to a much more tractable . This is a natural approximation since it keeps the discrete model selection aspect and many of the interpretable features of the original posterior, for example access to posterior probabilities of submodels and inclusion probabilities of particular covariates. This sparse variational family has been applied in practice [27, 41, 11, 25, 33], but comes with few theoretical guarantees.
We study this VB procedure under the frequentist assumption that the data has been generated according to a given sparse parameter . Under standard conditions on the design matrix, we obtain refined oracle type contraction rates for the mean-field VB approximation of model selection priors. As a consequence, these imply that the VB posterior performs optimally regarding both estimation of a sparse and for prediction of the response vector. This provides a theoretical justification for this attractive approximation algorithm in a sparsity context.
While similar VB approaches have been applied in the methodological literature [27, 41, 11, 25, 33], our contribution also possesses a crucial methodological difference. These existing works typically use Gaussian slabs for the prior, which allows analytic evaluation of certain formulas in the variational algorithm leading to fast optimization. However, Gaussian slabs are inappropriate for recovering the true signal since the true underlying posterior performs excessive shrinkage causing poor performance [15]. One cannot typically expect a VB approximation based on a poorly performing underlying posterior to perform well for recovery. We instead consider Laplace slabs for the prior, which result in optimal recovery when using the true posterior [15, 13]. We are thus using a similar variational family to estimate a different posterior distribution compared to previous works. Another way to correct the original posterior is to explicitly shift the posterior mean using an empirical Bayes approach [29, 30, 3, 4].
We provide the methodological details for applying the widely-used coordinate-ascent variational inference (CAVI) algorithm [5] with Laplace slabs and investigate our method numerically on both simulated and real world ozone interaction data. As predicted by the theory, our method performs well in a number of settings and typically outperforms VB approaches with prior Gaussian slabs. In fact, we find that our approach generally performs at least as well as other state-of-the-art Bayesian variable selection methods. We have implemented our algorithm in the R-package sparsevb [17].
Our simulations also show that the CAVI algorithm is highly sensitive to the updating order of the parameters. Since the VB objective function is non-convex and typically has multiple local minima, a poorly chosen updating order can trap the algorithm near a highly suboptimal local minimum causing poor performance. To resolve this, we propose a novel prioritized update scheme where we base the CAVI parameter update order on the estimated size of the coefficients via a preliminary estimator. Our simulations indicate that such a data-driven updating order performs better than using either a naive or random update order and provides more robustness against being trapped at a suboptimal local minimum. This idea is applicable beyond the present setting and may be useful for other CAVI approaches.
Related work. Whilst VB has found increasing usage in practice, its theoretical understanding is still in the early stages. In low dimensional settings, some Bernstein-von Mises type results have been derived [28, 43], while in high-dimensional and nonparametric settings, first results have only recently appeared [47, 48, 34]. There has also been theoretical work on studying variational approximations to fractional posteriors, which down-weight the likelihood [1, 46, 45]. The papers [48, 34, 46] provide general proof methods which employ the classical prior mass and testing approach of Bayesian nonparametrics [21]. However, since it is known that posterior convergence rates, let alone oracle rates as we derive here, for model selection priors cannot easily be established using this approach [15, 13], their results do not apply to our setting. We have extended some of the present results to high-dimensional logistic regression in follow up work [36].
Organization. In Section 2 we give details of the prior, variational approximation and conditions on the design matrix. We present our main results in Section 3, details of the VB algorithm in Section 4, numerical results in Section 5 and conclusions in Section 6. In the supplementary material, we give additional numerical results in Section A, full oracle results and proofs in Section B, additional methodological details in Section C and further discussion of the design matrix assumptions in Section D.
Notation. Let be the probability distribution of the observation arising in model (1) and let denote the corresponding expectation. For two probability distributions , denotes the Kullback-Leibler divergence. For , we write for the Euclidean norm. For a vector and a subset of indices, set to be the vector in , where denotes the cardinality of . Further let be the set of non-zero coefficients of . We will often write and , where is the true vector. For the column of , set
[TABLE]
2 Prior, variational families and design matrix
2.1 Model selection priors
We first present the desirable, but computationally challenging, model selection priors that underlie our VB approximation. Consider a prior for that first selects a dimension from a prior on , then uniformly selects a random subset of cardinality and lastly a set of non-zero values from a prior density on . Since it is known that the ‘slab’ distribution should have exponential tails or heavier to achieve good recovery [15], we restrict to the case where is a product of centered Laplace densities with parameter on . This yields the hierarchical prior:
[TABLE]
where selects from the possible subsets of of size with equal probability and denotes the Dirac mass at zero. Since we wish the prior to perform model selection via the prior on the dimension rather than via shrinkage of the Laplace distribution, the choice of prior is crucial. The aim is to select a distribution which sufficiently downweights large models while simultaneously placing enough mass to the true model. Following [13], we select an exponentially decreasing prior: we assume that there are constants with
[TABLE]
Assumption (4) is satisfied by a variety of piors, including those of the form for constants (‘complexity priors’ [15]) and binomial priors. The spike-and-slab prior, where we model , falls within this framework by taking to be . The value is the prior inclusion probability of the coordinate and controls the model selection. Taking a hyperprior for also satisfies (4) ([15], Example 2.2), allows mixing over the sparsity level and gives a prior that does not depend on unknown hyper-parameters.
The regularization parameter in the slab distribution in (3) is allowed to vary with within the range
[TABLE]
where the norm is the maximal column norm defined in (2). The quantity is the usual value of the regularization parameter of the LASSO ([9], Chapter 6). Large values of may shrink many coordinates in the slab towards zero, which is undesirable in our Bayesian setup since we wish to induce sparsity via instead. Indeed, since the slab component identifies the non-zero coordinates, it is unnatural to further shrink these values. It is natural to take fixed values of or , both of which are typically allowed by (5) depending on the specific design matrix and regression setting. Specific values of for some examples of design matrices are given in Section D in the supplement.
The theoretical frequentist behaviour of the full posterior arising from prior (3) has been studied in [15, 13], who obtain oracle contraction rates amongst other things. We build on their work to show that these results extend to the scalable variational approximation.
We briefly comment on the more realistic situation that the model has unknown variance , in which case we instead observe . Since then
[TABLE]
one may first rescale the data using an estimate of and as before endow with the prior (3), thereby obtaining an empirical Bayes approach. We investigate this empirical Bayes approach numerically in Section 5.2, showing that our method continues to perform well in the more realistic scenario of unknown noise level. One can alternatively use a hierarchical Bayesian approach by endowing with a hyper-prior, common choices including the inverse Gamma distribution, or the improper prior .
2.2 Variational approximations
The posterior arising from the prior (3) and data (1) assigns weights to all the possible models, except for very special instances of the design matrix and prior. Since the posterior is difficult to compute for even moderate , we take a VB approximation using the mean-field variational family
[TABLE]
with corresponding VB posterior
[TABLE]
the minimizer of the Kullback-Leibler (KL) divergence with respect to the posterior. Under , we have independent. We thus approximate the posterior with a spike-and-slab distribution with Gaussian slabs under which every coordinate is independent. Note that while the prior may take the form (7), the posterior will in general not. The key reduction here is that we replace the model weights with the VB inclusion probabilities , thereby dramatically shrinking the posterior dimension. The VB approximation (8) forces (substantial) additional independence into the resulting distribution, breaking dependencies between the variables. For instance, pairwise information that two coefficients and are likely to be selected simultaneously or not at all is lost.
While we use Gaussian slabs in our variational family, it is crucial the true prior has slab distributions with at least exponential tails (e.g. Laplace) [15]. The reason a Gaussian approximation works well here is that the likelihood induces Gaussian tails in the posterior. We emphasize that we use the same variational family to estimate a different posterior compared to previous works [27, 41, 11, 25, 33], which use Gaussian prior slabs. While using Gaussian prior slabs is particularly efficient computationally, it can yield poor performance due to excessive shrinkage of the estimated coefficients, as we demonstrate numerically in Section A.2 in the supplement. Computing the VB estimate (8) is an optimization problem that can be tackled using coordinate-ascent variational inference (CAVI), see Section 4 for details.
While the family is our main object of interest, our proofs yield similar theoretical results for two other closely related variational families. Consider the family of distributions consisting of products of a single multivariate normal distribution with a Dirac measure:
[TABLE]
where denotes the Dirac measure on the coordinates . This family is more rigid on the model selection level than , selecting a distribution with a single fixed support set . On this set, however, the family permits a richer representation for the non-zero coefficients, allowing non-zero correlations. Next consider the mean field subclass of :
[TABLE]
This family again allows distributions with only a single fixed support set , but further forces independence of the non-zero coefficients. This class is contained in by considering distributions with inclusion probabilities restricted to . We define the corresponding VB posteriors by
[TABLE]
While all our theoretical results also apply to the VB posteriors and , these seem to perform worse in practice than , see Section A.2 in the supplement. This is potentially due to the discrete constraint for these two families, which renders the highly non-convex optimization problems (11) difficult to solve.
2.3 Design matrix
The parameter in model (1) is not estimable without further conditions on the regression matrix . For the high-dimensional case , which is of most interest to us, is not even identifiable without additional assumptions. We thus assume that there is some “true” sparse generating the observation (1) with at most non-zero coefficients:
[TABLE]
In the sparse setting, it suffices for estimation to have ‘local invertibility’ of the Gram matrix . The notion of invertibility can be made more precise using the following definitions, which are based on the sparse high-dimensional literature (e.g. [9]), and have been adapted to the Bayesian setting in [13]. We provide only a brief description, referring the interested reader to Section 2.2 of [13] for further discussion.
Definition 1** (Compatibility).**
A model has compatibility number
[TABLE]
A model is considered ‘compatible’ if , in which case for all in the above set. The number 7 is not important and is taken in Definition 2.1 of [13] to provide a specific numerical value; since we use several results from [13], we employ the same convention. The compatibility number does not directly require sparsity, but reduces the problem to approximate sparsity by considering only vectors whose coordinates are small outside . Conversely, the following two definitions deal only with sparse vectors.
Definition 2** (Uniform compatibility for sparse vectors).**
The compatibility number for vectors of dimension is
[TABLE]
Definition 3** (Smallest scaled sparse singular value).**
The smallest scaled sparse singular value of dimension is
[TABLE]
We shall require that these numbers are bounded away from zero for a multiple of the true model size. If , then is simply the smallest scaled singular value of a submatrix of of dimension . Note that Definitions 1-3 are Definitions 2.1-2.3 of [13]. Such compatibility conditions are standard for sparse recovery problems, see Sections 6.13 and 7.15 of [9] for further discussion.
These compatibility type constants are bounded away from zero for many standard design matrices, such as diagonal matrices, orthogonal designs, i.i.d. (including Gaussian) random matrices and matrices satisfying the ‘strong irrepresentability condition’ of [49]. Details of these examples are provided in Section D in the supplement.
3 Main results
We now provide the main theoretical results of this paper concerning the frequentist behaviour of the VB posterior in the asymptotic regime . While the results are obtained assuming Gaussian noise in model (1), they are in fact robust to misspecification of the error distribution, see Remark B.1 in Section B. This robustness to misspecification is reflected in practice, see Section A.4 in the supplement for numerical results.
Our first result establishes contraction rates for the VB posterior to a sparse truth in -loss, -loss and prediction error . Apart from the sparsity level, the rate also depends on compatibility. For , set
[TABLE]
In the natural case , these constants are asymptotically bounded from below by and if is bounded away from zero. Our results are uniform over vectors in sets of the form
[TABLE]
for , , and (arbitrarily slowly).
Theorem 1** (Recovery).**
Suppose the model selection prior (3) satisfies (4), (5) and . Then the variational Bayes posterior satisfies, with ,
[TABLE]
[TABLE]
[TABLE]
for any (arbitrarily slowly), defined in (13) and where depends only on the prior. Moreover, the same holds true for the variational Bayes posteriors and .
Theorem 1 follows directly from the oracle type Theorem 3 below upon setting . Recall that we are working under the frequentist model where there is a “true” generating data of the form (1). Since the above rates equal the minimax estimation rates over -sparse vectors, Theorem 1 states that the VB posterior puts most of its mass in a neighbourhood of optimal size around the truth with high -probability in terms of , and prediction loss. Thus for estimating , the VB approximation behaves optimally from a theoretical frequentist perspective. This backs up the empirical evidence that VB can provide excellent scalable estimation.
The VB posterior mean often provides a good point estimator and the VB posterior is known to typically underestimate the marginal posterior variance (see e.g. [5] - this is a result of using the KL divergence as optimization criterion). The combination of good centering point and the posterior shrinking at least as fast as the true posterior explains why the VB posterior still provides optimal recovery, despite the loss of information from using a mean-field approximation.
Since the prior and variational family do not depend on the unknown sparsity level and the VB estimate contracts around the truth at the minimax rate, the procedure is adaptive. That is, the procedure can recover an -sparse truth nearly as well as if we knew the exact level of sparsity of the unknown . However, the choice of tuning parameters still has an effect on the finite-sample performance, see Section A.3 for a numerical investigation of the effect of the hyper-parameter . Note that Theorem 1 does not imply that the VB posterior converges to the true posterior . Indeed, this is neither a typical situation nor a necessary property since the VB estimate should be substantially simpler than the true posterior to be useful.
Theorem 1 implies the variational families and also provide optimal asymptotic estimation of in , and prediction loss. However, the corresponding optimization routine seems to yield worse performance in practice, see Section A.2.
An important motivation for using model selection priors is their ability to perform variable selection. The following result shows that the variational approximation puts most of its mass on models of size at most a multiple of the true dimension, thereby bounding the number of false positives.
Theorem 2** (Dimension).**
Suppose the model selection prior (3) satisfies (4), (5) and . Then the variational Bayes posterior satisfies, with ,
[TABLE]
for any (arbitrarily slowly), defined in (13) and where depends only on the prior. Moreover, the same holds true for the variational Bayes posteriors and .
Theorem 2 follows directly from the oracle type Theorem 4 below upon setting . In the interesting case , the factor in Theorem 2 can be simplified to if the true parameter is compatible. Note also that under the conditions of Theorems 1 and 2, it is not possible to consistently estimate the true support of since one cannot separate small and exactly zero signals.
Since the variational families and contain only distributions with a single support set , the last statement says the resulting VB posteriors will select such a set of size at most a multiple times with high -probability. The VB estimates based on these two variational families perform model selection in a hard-thresholding manner, reporting only whether a variable is selected or not. On the other hand, the more flexible family quantifies the individual variable selection via the reported non-trivial inclusion probabilities , and in this regard provides a richer approximation of the target posterior. Information on pairwise variable inclusion is obviously lost given the mean-field nature of the approximation. Nevertheless, it is interesting to note that all these families still permit good estimation of .
We now provide more refined oracle-type versions of Theorems 1 and 2 as are known to hold for the true posterior [13].
Theorem 3** (Oracle recovery).**
Suppose the model selection prior (3) satisfies (4), (5) and . For , let be any vector satisfying and Then the variational Bayes posterior satisfies, for any as above,
[TABLE]
[TABLE]
[TABLE]
for any (arbitrarily slowly), defined in (13) and where depends only on the prior. Moreover, the same holds true for the variational Bayes posteriors and .
This can yield better rates than Theorem 1 for certain parameters and choices of . For example, if is the identity matrix so that for all , setting yields
[TABLE]
for any . If , this improves upon the rate in Theorem 1 by accounting for the size of the coefficients of and not only its sparsity level.
The advantage of the oracle bound is it can take into account small non-zero coefficients of and capture its ‘effective sparsity’. If , as one typically takes, the condition implies that the coordinates of in contribute on average at most to the squared prediction error. Thus if the coefficient contributes less than to the squared prediction loss, it is preferable to assign it as bias rather than pay the full term required by the squared minimax rate , which accounts only for sparsity irrespective of signal size.
Theorem 4** (Oracle dimension).**
Suppose the model selection prior (3) satisfies (4), (5),and . For , let be any vector satisfying and Then the variational Bayes posterior satisfies, for any as above,
[TABLE]
for any (arbitrarily slowly), defined in (13) and where depends only on the prior. Moreover, the same holds true for the variational Bayes posteriors and .
Theorems 3 and 4 are special cases of the finite-sample Theorems B.1 and B.2 in the supplement. Our proofs are based on the following crucial result, which allows one to exploit exponential probability bounds for the posterior to control the corresponding probability under the variational approximation.
Theorem 5**.**
Let be a subset of the parameter space, be an event and be a distribution for . If there exist and such that
[TABLE]
then
[TABLE]
Proof.
Recall the duality formula for the Kullback-Leibler divergence ([7], Corollary 4.15)
[TABLE]
where the supremum is taken over all measurable such that . In particular,
[TABLE]
Applying this inequality with and using that for ,
[TABLE]
Taking -expectations on both sides and using (14) gives the result. ∎
When deriving oracle rates for the original posterior, the exponent in (14) depends on the oracle quantity, see Section B.3. To apply Theorem 5, we must thus develop novel oracle type bounds on the KL divergence , which is the main technical difficulty in establishing our results, see Section B.2. The proof uses an iterative structure, using successive posterior localizations to eventually bound the KL divergence (see e.g. [32] for a similar idea).
4 Variational Bayes algorithm
4.1 Coordinate update equations
We now provide a coordinate-ascent variational inference (CAVI) algorithm (see for instance [5]) to compute the mean-field VB posterior based on the spike-and-slab prior with Laplace slabs. Since in the literature [27, 11, 25] the VB approximation is typically considered for Gaussian prior slabs, and can therefore take advantage of explicit analytic formulas, our algorithm requires modification.
Introducing binary latent variables , the spike and slab prior can be rewritten as
[TABLE]
The prior inclusion probability equals , the expectation of a beta random variable. In CAVI, we sequentially update the parameters , , of the VB posterior by minimizing the KL divergence between the variational class with the rest of the parameters kept fixed and the true posterior. We iterate this algorithm until convergence, measured by the change in entropy.
We now give the component-wise variational updates in the algorithm. Fixing the latent variable and all variational factors except or (i.e. using vector notation, or are all fixed), the minimizer of the conditional KL divergence between and the posterior is the same as the minimizer of
[TABLE]
respectively (see Section C.1 of the supplement for the proof of the above assertion), where denotes the cdf of the standard normal distribution. The minimizers of these functions do not have closed form expressions and hence must be computed by optimization; in our R implementation, we used the built-in optimize() function.
The minimizer of the conditional KL divergence given solves
[TABLE]
see Section C.1 of the supplement for the proof.
Following [25], we terminate the procedure once the coordinate-wise maximal change in binary entropy of the posterior inclusion probabilities falls below a prespecified small threshold (e.g. ), i.e. stop when , where , , and , are the th coordinate of the starting and updated parameters , , respectively. The full algorithm is present in Algorithm 1.
4.2 Prioritized updating order
The VB objective function is generally non-convex and so CAVI can be sensitive to initialization [5]. It turns out the algorithm is also highly sensitive to the order of the component-wise updates. In fact, naively updating the coordinates in lexicographic order is typically suboptimal in our setting. We demonstrate in the next section on various simulated data sets that, unless the significant non-zero coefficients are located at the beginning of the signal, the procedure typically converges to a poor local minimum and gives misleading, inconsistent answers. In particular, CAVI returns a solution that is far from the desired VB posterior it is trying to compute. It is clearly undesirable that the algorithm’s performance depends on the arbitrary ordering of the parameter coordinates. A natural fix is to randomize the order of the coordinate-wise updates and use different initializations, choosing the local minimum which provides the smallest overall KL-divergence to the posterior. We show, however, that due to the large number of local minima and their substantially different behaviour, this approach can also perform badly (although somewhat better than the lexicographic approach).
We instead propose a novel prioritized update scheme. In a first preprocessing step, we compute an initial estimator of the mean vector of the variational class. We then place the coefficients in decreasing order with respect to the absolute value of their estimate and update the parameters coordinate-wise in the corresponding order, i.e. denoting by the permutation of the indices such that for every , we update the coordinates in the order , .
The intuition behind this method is that when CAVI begins by updating indices whose signal coefficients are small or zero in the target VB posterior, it may incorrectly assign signal strength to such indices to better fit the data (this is especially the case if the initialization value of the signal coefficient is far from its value in the target VB posterior). Consequently, the estimates of the significant non-zero signal components may be overly small since part of the signal strength has already been falsely assigned to signal coefficients that should in fact be small under the VB posterior. This can trap the algorithm near a poor local minimum from which it cannot escape, see the corresponding simulation study in Section 5.
To avoid this, we wish to first update those coefficients which are large in the target VB posterior. Since these are unknown, the idea here is to identify them using a preliminary estimator: if the target VB posterior does a good job of estimating the signal, these large coefficients should roughly match those that are large in the true underlying signal, which can be identified using a reasonable estimator. The algorithm is given in Algorithm 1, where the function returns the indices of in descending order.
Instead of the prior (15), one can instead take the and , so that the probabilities vary with . This results in exactly the same variational algorithm since we are using a mean-field approximation. If one instead takes deterministic weights , the above algorithm can be easily adapted by using the same update steps for and , while updating as the solution to
[TABLE]
The closely related algorithm for computing the VB posterior based on the family is given in Algorithm 4 in Section C.2 in the supplement.
5 Numerical study
In this section, we empirically compare the performance of our VB method using Laplace prior slabs, implemented in the sparsevb package [17], with various state-of-the-art Bayesian model selection methods on simulated data. We also demonstrate the importance of the prioritized updating scheme compared with standard CAVI implementations.
Additional numerical results are provided in the supplementary material as follows:
Section A.1: we apply our method and other Bayesian model selection methods to real world data.
- -
Section A.2: we show that Laplace prior slabs provide better estimation and model selection than Gaussian prior slabs. We also show that the optimization problem for finding the KL-optimizer for the class is substantially harder than for the class , with the former typically ending up at a poor local minimum.
- -
Section A.3: we show that although the theory indicates that the VB approach is (asymptotically) robust to the choice of the hyper-parameter , in finite-sample cases it can still have an effect and it may be helpful to use a data-driven choice in practice (e.g. cross validation).
- -
Section A.4: we show that several Bayesian model selection methods are robust to noise misspecification
- -
Section A.5: we compare different Bayesian model selection methods when the inputs are correlated.
We ran each experiment multiple times and report the average -distance between the posterior mean (or maximum a posteriori (MAP) estimate for the SSLASSO) and the true parameter , the false discovery rate (FDR), the true positive rate (TPR) and the computational time in seconds. We also report the standard deviations of these indicators to quantify their spread. For our computations, we used a MacBook Pro laptop with 2.9 GHz Intel Core i5 processor and 8 GB memory. Throughout the numerical study, we use the hyper-parameter choices , , (except in Section A.3) and set the stopping threshold for the entropy change to , see Algorithm 1. In each experiment and for every method, we take the ridge regression estimator as initialization. Given the sparsity framework, it may be tempting to take the LASSO as initialization, however this is not recommended. The LASSO shrinks some coordinates to exactly zero and so is not suitable for , which represents the estimated coefficients given that they are included in the model, i.e. non-zero [the LASSO solution should be compared to rather than ].
5.1 Prioritized updates
We demonstrate here the relevance of our prioritized updating scheme for CAVI by comparing its performance with lexicographic and randomized updating orders, which are standard implementations for CAVI. We take , , , for the non-zero coefficients, assumed to be known, , and consider four scenarios for the locations of the non-zero signal components. We place all non-zero coordinates (i) at the beginning of the signal, (ii) at the end of the signal, (iii) in the middle of the signal and (iv) uniformly at random. We ran the experiments 200 times and report the results in Table 1 (for the FDR and TPR, the th coefficient is selected if ). We also plot the posterior means resulting from a typical run in Figure 1.
Apart from the first scenario, where the significant signal coefficients are all located at the beginning of the signal, the prioritized method substantially outperforms both the randomized and lexicographic updating schemes for parameter estimation and model selection (recall that all three methods are trying to compute the same VB estimate). The random updating order also slightly improves upon the lexicographic order, except for the first scenario, where the lexicographic order naturally updates the largest coefficients first. As well as being sensitive to initialization [5], it seems CAVI can also be very sensitive to the updating order of the parameters. Indeed, we see here that without prioritized ordering, the algorithm often terminates at poor local minima of the VB objective function. Since the VB objective is non-convex, naive (or random) update orderings may cause CAVI to return a solution that is far from the true minimizer of the KL divergence that it is trying to compute. Performing updates in a prioritized order can add some robustness against this, see Section 4 for some heuristics behind this idea. We also note that the runtime is comparable for the three updating orders.
5.2 Comparing Bayesian variable selection methods
We consider here the realistic situation of unknown noise variance , that is the model . As mentioned in Section 2 (see (6)), dividing both sides of this model by an empirical estimator for the noise standard deviation gives where , and , . Endowing with the spike-and-slab prior and if the estimator is close to , we should approximately recover the case studied above. We thus compute our VB estimator as described above based on the design matrix and data . For estimating , we have used the R package selectiveInference, see [37].
We compare the performance of our VB method with various Bayesian (based) variable selection algorithms for sparse linear regression using simulated data. We consider the varbvs R-package (variational Bayes for spike-and-slab priors with Gaussian prior slabs using an importance sampling outer circle for estimating the posterior inclusion probabilities and noise variance [11]), EMVS R-package (an expectation-maximization algorithm for spike-and-slab [38]), SSLASSO R-package (spike-and-slab LASSO [39]) and ‘ebreg.R’ R-function (a fractional likelihood empirical Bayes approach using MCMC for re-centered Gaussian slab priors [29] - the function is available on the first author’s website).
For varbvs, we set and . For EMVS we took , (these quantities were used in one of the examples provided in the package), , and and report the posterior mean corresponding to the case. For SSLASSO, we took , an arithmetic series between and with 200 elements, set the variance “unknown”, , , and penalty=“adaptive”, and report the results corresponding to the stabilized value as recommended by the authors [39]. In the ebreg algorithm, we took the default parameters , , and used the selectiveInference R-package for the estimation of . We note that for most of these methods, additional careful hyper-parameter tuning beyond the default settings can often lead to improved performance, see Section A.3 for our VB method or Section 5 of [20] for discussion concerning the SSLASSO.
We first consider (i) , , , with the non-zero signal coefficients set to , with , and located at the end of the signal. The entries of the design matrix are taken to be iid normal random variables . In the other experiments, we take equal to (ii) (with non-zero coefficients at the beginning of the signal) and set the non-zero parameters to be ; (iii) (in the middle) and take ; (iv) (at the end) and take . We ran each algorithm 100 times and report the results in Table 2. Our method performs well compared to the other methods, in some cases providing substantially better estimation and model selection.
6 Conclusion
We studied theoretical oracle contraction rates of a natural sparsity-inducing mean-field VB approximation to posteriors arising from widely used, but computationally challenging, model selection priors in high-dimensional sparse linear regression. We showed that under compatibility conditions on the design matrix, such an approximation converges to a sparse truth at an oracle rate in , and prediction loss, implying optimal (minimax) recovery, and also performs suitable dimension selection. This provides a theoretical justification for this approximation algorithm in a sparsity context. Minimax guarantees for this VB method extend to high-dimensional logistic regression, as we show in the follow up work [36].
We investigated the empirical performance of our algorithm via simulated and real world data and showed that it generally performs at least as well as other state-of-the-art Bayesian variable selection methods, including existing VB approaches. We also demonstrated how the widely used coordinate-ascent variational inference (CAVI) algorithm can be highly sensitive to the updating order of the parameters. We therefore proposed a novel prioritized updating scheme that uses a data-driven updating order and performs better in simulations. This idea may be applicable for CAVI approaches in other settings. Our variational algorithm is implemented in the R-package sparsevb [17].
Acknowledgements. We would like to thank two referees for valuable comments that helped considerably improve this manuscript.
SUPPLEMENTARY MATERIAL
Supplementary material.
In Section A, additional numerical results are given. First, we provide a real world data example, where we compare Bayesian model selection methods. We then consider various VB methods, demonstrating the advantages of using Laplace instead of Gaussian prior slabs, investigate the effect of the hyper-parameter and further study Bayesian variable selection methods under noise misspecification and correlated inputs. Section B contains full oracle results and all proofs, Section C contains additional methodological details and Section D contains further discussion of the design matrix assumption, including examples.
Appendix A Additional numerical results
A.1 Ozone interaction data
We apply our method to the real world ozone interaction data investigated in [8]. The dataset contains readings of maximal daily ozone measured in the Los Angeles basin and variables modeling the pairwise interaction of 9 meteorological and 3 time variables. We firstly normalize the design matrix by centering and rescaling each column to have Euclidean norm equal to and then add a column vector of ones to add an intercept to the model.333Except for EMVS, since adding an intercept resulted in an error message. We apply the four methods investigated above (i.e. our method sparsevb [17], varbvs, EMVS, SSLASSO) with unknown noise variance , using the method settings described in Section 5.2. We also tried to apply the ebreg method, but due to the highly co-linear nature of the design matrix, the code gave errors when trying to compute the Cholesky decomposition.
As we do not know the underlying truth, we consider the 10-fold cross validation prediction error, i.e. we use nine folds to compute the posterior mean or MAP and then use the 10th fold to compute the prediction error . We report the averaged out cross-validation errors in Table 3, together with the runtimes and number of selected covariates. Our method outperforms the other approaches in cross-validated prediction loss. Furthermore, while there is some overlap between the models selected by the various methods, the results are quite different, see Figure 2.
A.2 Comparing the VB algorithms
We compare our VB method with Laplace slabs (Algorithm 1) with different variations of the VB algorithm. First, we consider the other mean-field VB posterior derived from the variational class (Algorithm 4 in Section C.2). Next, we consider the VB method with Gaussian prior slabs, which is the standard choice in the literature, see for instance [27, 11, 25], both with component-wise and batch-wise computational approaches, see Algorithms 2 and 3 in Section C.2. To compensate for the over-shrinkage of the posterior mean caused by the light tail of the Gaussian slabs, we also consider centered Gaussian prior slabs with standard deviation set to the (unknown) oracle , as proposed by [15] for the sequence model (i.e. the identity matrix).
In all experiments, we placed the non-zero signal components at the beginning of the signal. In the first experiment, (i) we take the identity design matrix and set , , . In the other three experiments, we consider a Gaussian design matrix with entries and vary the parameters and . We take (ii) , ; (iii) , ; (iv) , . In all experiments, we take assumed to be known. The results over 200 runs are reported in Table 4 and we plot the outcome of a typical run in Figure 3.
Our Laplace VB method (sparsevb) with variational class typically outperforms the other VB algorithms. From the identity design case (i), it is clear that Gaussian prior slabs provide suboptimal recovery for unless the prior slab variance is rescaled by the norm of . However, the rescaled Gaussian slabs perform much less well in the Gaussian design cases (ii)-(iv). The other mean-field variational class performs similarly to our main method in the identity design case, but significantly worse in the more complicated Gaussian design cases. This is due to discrete nature of the variational parameter in this family, which makes the optimization problem even more difficult, causing the method to frequently get stuck at a poor local minimum. We do not report run times as the sparsevb R-package is optimized for computation and therefore runs substantially faster than the other methods, which are more simply implemented.
A.3 The effect of the hyper-parameter
Theorem 1 states that for a wide range of hyper-parameter values , our VB algorithm has good asymptotic properties. However, the finite-sample performance depends on as we now investigate. We ran our algorithm for different choices of , ranging from to , on simulated data similar to that in the preceding subsections.
We consider four different settings, each with Gaussian design with entries , non-zero signal components set to and noise variance assumed to be known. We take (i) , ; (ii) , ; (iii) , ; and (iv) , . In all cases, the non-zero signal components are located at the beginning of the signal. We ran each algorithm 200 times and report the results in Table 5. The choice of can indeed significantly influence the finite-sample behaviour of the algorithm (e.g. cases (ii) and (iii)), but not always ((i) and (iv)). There was not clear evidence to support a particular fixed choice of , since larger values sometimes performed better ((ii) and (iv)) and sometime worse ((i) and (iii)). This suggests using a data-driven choice of may be helpful in practice. As expected, larger choices for , which cause more shrinkage, result in smaller FDR and TPR. The runtime across hyper-parameter choices were broadly comparable.
A.4 Noise misspecification
We investigate the robustness of the Bayesian model selection methods to misspecification of the noise distribution in practice. Note that our theoretical results are also robust to some misspecification, see Remark B.1 in Section B below. We consider Gaussian design , set the model parameters , , , and take non-zero signal coefficients located in the beginning of . We compare the correctly-specified Gaussian noise case (i) in model (1) with the misspecified noise cases: (ii) Laplace noise ; (iii) uniform noise ; (iv) Student noise with 3 degrees of freedom . We apply the same parametrizations of the methods as in Section 5.2. We ran each experiments 200 times and collect the results in Table 6. Our method (sparsevb) gave similar results to varbvs, ebreg and EMVS, while the SSLASSO performed slightly worse. The noise distribution does not seem to have a major effect on the results, hence these algorithms seem robust to noise misspecification. It is worthwhile to further investigate this phenomenon both empirically and analytically.
A.5 Bayesian variable selection methods under correlated inputs
We lastly consider the common situation of correlated input variables. We take each row with for and , giving standard normal predictors with non-zero correlation . We take (i) , correlation and non-zero coefficients at the beginning of the signal; (ii) the same setting as in (i), but with higher correlation ; (iii) , correlation and non-zero coefficients at the end of the signal; (iv) the same setting as in (iii), but with higher correlation . We apply the same parametrizations of the methods as in Section 5.2. The results are summarized in Table 7.
One might expect that mean-field VB methods should not perform so well under correlated inputs due to their factorizable structure. This was not the case in our simulations, where the VB methods perform competitively with the other methods, often providing the best results (except perhaps in (iv), where varbvs sometimes sometimes gave large error). The correlated design also does not seem to substantially influence the run time.
While our simulations are certainly not extensive, they suggest that mean-field VB can perhaps still be effective in certain correlated input settings and understanding the exact effect of correlation on VB seems to be a subtle question. It is currently not well understood how VB, or indeed even the true posterior, behaves in general correlated design settings. This important and practically very relevant setting requires further investigation, both theoretically and empirically.
Appendix B Proofs
B.1 Full oracle results
The proofs of the full oracle results in Theorems B.1 and B.2 below rely on Theorem 5, which allows one to exploit exponential probability bounds for the posterior to control the corresponding probability under the variational approximation. To prove our results, it therefore suffices to show that on a suitable event, one can (a) control the KL divergence between the variational approximation and the true posterior and (b) establish the appropriate posterior tail inequality (14). Part (a) is dealt with in Section B.2 and (b) in Section B.3 below. Define the events
[TABLE]
and
[TABLE]
for . The middle event in says that the posterior puts most of its mass on models of dimension at most ; the number is unimportant and any number less than suffices. The third event says the posterior places all but exponentially small probability on an -ball of radius about the truth and is used for a localization argument when bounding the KL divergence. The proof uses an iterative structure, using successive posterior localizations to eventually bound the KL divergence in Section B.2. This idea is a useful technique from Bayesian nonparametrics, see e.g. [32].
For parameters , set and and define
[TABLE]
This quantity appears in the posterior exponential probabilities, which take the form . We require the following parameter choices for the event in (B.2):
[TABLE]
for some large enough depending only on .
Lemma B.1**.**
(i) The event defined in (B.1) satisfies
[TABLE]
(ii) Suppose the prior satisfies (4) and (5). For , let be any vector satisfying ,
[TABLE]
Then the event given in (B.2) with parameters chosen according to (B.4) satisfies
[TABLE]
uniformly over all and as above.
Proof.
(i) Under , . Since and for all , a union bound and the standard Gaussian tail inequality give
[TABLE]
(ii) Applying Markov’s inequality and Lemma B.5 below with gives
[TABLE]
Since the right-hand side does not depend on or , the probability tends to zero uniformly as required.
Under the assumptions on ,
[TABLE]
Therefore, applying Lemma B.6 with yields
[TABLE]
Using Markov’s inequality and the last display with ,
[TABLE]
Since the right-hand side again does not depend on or , the probability tends to zero uniformly as required. ∎
Theorem B.1** (Full oracle recovery).**
Suppose the model selection prior (3) satisfies (4) and (5). For , let be any vector satisfying and Then the variational Bayes posterior satisfies, uniformly over all and as above,
[TABLE]
for any , where are given in (B.4). Moreover, both
[TABLE]
[TABLE]
satisfy the same inequality. Furthermore, the exact same inequalities hold for the variational Bayes posteriors and .
Proof.
Suppose first that . Let denote the event in (B.2) with parameters (B.4), which by Lemma B.1(ii) satisfies uniformly over all in the theorem hypothesis. Set
[TABLE]
and note We now apply Theorem 5 with this choice of on the event . For defined in (B.3), it holds that by (B.5). Using Lemma B.6 below with thus gives
[TABLE]
for large enough depending on , and where also depend only on the prior parameters. Since by (B.2), condition (14) is satisfied on with . Applying Theorem 5 gives
[TABLE]
Note that the parameters (B.4) satisfy and . Using this and Lemma B.4 below,
[TABLE]
as required.
If then The desired inequality then immediately follows from the stronger inequality with just established above. The results for and loss follow exactly as above by using the respective inequalities for the and oracle contraction rates in Lemma B.6 to establish (14).
Similarly, the results for the variational Bayes posteriors and based on the mean-field variational families (9) and (10) follow identically upon using Lemmas B.2 and B.3 instead of Lemma B.4 to control the Kullback-Leibler divergence. ∎
Theorem B.2** (Full oracle dimension).**
Suppose the model selection prior (3) satisfies (4) and (5). For , let be any vector satisfying and Then the variational Bayes posterior satisfies, uniformly over all and as above,
[TABLE]
for any , where are given in (B.4). Furthermore, the exact same inequality holds for the variational Bayes posteriors and .
Proof.
The proof follows similarly to that of Theorem B.1 by applying Theorem 5 with
[TABLE]
again taking the event and using Lemma B.5 with instead of Lemma B.6 to verify (14). ∎
Remark B.1** (Misspecification of the error distribution).**
The Gaussian error distribution is assumed in model (1) for concreteness and can be relaxed. For recovery and dimension control (Theorems 1 and 2), inspection of the contraction rate proofs in [13] and the KL bounds in Section B.2 show that it suffices that there exists a constant such that
[TABLE]
which holds for much more general noise distributions. This condition is commonly imposed when studying the LASSO, see e.g. [9]. For the full oracle bounds, we further need that Lemma 3 of [13], which concerns a change of measure, holds. This indeed holds under a wider range of noise distributions, see Remark 1 of [13]. The results for VB in this paper are thus robust under noise misspecification as for the true posterior [13], see also Section A.4 for an empirical study of noise misspecification for our method.
B.2 Kullback-Leibler divergences between variational classes and the posterior
We now show that on the event in (B.2), we can bound the (minimized) Kullback-Leibler divergences between the posterior and the approximating variational classes. In particular, we need oracle-type bounds on the KL divergence to obtain our oracle results. This is the major technical difficulty in establishing our result. We first consider the family of distributions (9), which consists of products of non-diagonal multivariate normal distributions with Dirac delta distributions for a single fixed support set .
For a given model , let denote the -submatrix of the full regression matrix , where we keep only the columns , . Let be the least squares estimator in the restricted model . If the restricted model were correctly specified, then would have distribution under . We approximate the posterior with a distribution, where is a suitable approximating set to which the posterior assigns sufficient probability.
Lemma B.2**.**
If , then the variational posterior arising from the family (9) satisfies
[TABLE]
Proof.
We construct our posterior approximation on the event in (B.2). The posterior takes the form
[TABLE]
where the weights lie in the -dimensional simplex and is the posterior for in the restricted model . Since
[TABLE]
it follows that on ,
[TABLE]
for all since . Note further that
[TABLE]
Together, the last two displays show that on and for all , there exists a set satisfying
[TABLE]
Since an distribution is only absolutely continuous with respect to the term of the posterior (B.6),
[TABLE]
where the last Kullback-Leibler divergence is over -dimensional distributions. On , . It thus remains to bound the second term in (B.8).
Let denote the expectation under the law . Setting
[TABLE]
one can check that the resulting normal distribution has density function proportional to , . Therefore,
[TABLE]
with and the normalizing constants.
We firstly upper bound . Define
[TABLE]
Let denote the extension of a vector to with for and for . On , using (B.6) and (B.7),
[TABLE]
where the last inequality holds by assumption. Using Bayes formula, this yields
[TABLE]
almost surely. In particular, on . Therefore on ,
[TABLE]
where in the fourth inequality we have applied Cauchy-Schwarz.
We now turn to the first term in (B.10). On , using the triangle inequality and Cauchy-Schwarz,
[TABLE]
since . Let and denote the smallest and largest eigenvalues, respectively, of a symmetric, positive definite matrix . Using the variational characterization of maximal/minimal eigenvalues ([24], p. 234), for any ,
[TABLE]
Therefore,
[TABLE]
Under , using (1) and (B.9), the bias term can be decomposed as
[TABLE]
For , note first that the -operator norm of is bounded by by (B.12). On , using Cauchy-Schwarz,
[TABLE]
Together with (B.7), this gives
[TABLE]
Using the same bound on the -operator norm and (1), on the event it holds that
[TABLE]
Combining all of the above bounds and using that , on the event ,
[TABLE]
Together with (B.10), the bound derived above and that , this yields
[TABLE]
Combining this with (B.8) and that completes the proof. ∎
We next consider the mean-field subclass of given by (10). This again selects a single fixed support but further requires the fitted normal distribution to have diagonal covariance matrix. We consider a diagonal version of considered in Lemma B.2.
Lemma B.3**.**
If , then the variational posterior arising from the family (10) satisfies
[TABLE]
Proof.
We showed in the proof of Lemma B.2 that on the event given in (B.2), there exists a set satisfying (B.7). Arguing as in (B.8),
[TABLE]
where the last Kullback-Leibler divergence is over the -dimensional distributions and ranges over diagonal positive definite matrices. On and for all , we have by (B.7).
The latter Kullback-Leibler divergence equals
[TABLE]
for any covariance matrix . For the first term in (B.13), the formula for the Kullback-Leibler divergence between two multivariate Gaussians gives
[TABLE]
where denotes the determinant of a square matrix . Set now , as in (B.9) and define the diagonal matrix via . This gives , so that it remains to control . For our choice of ,
[TABLE]
while for and the smallest and largest eigenvalues, respectively, of a matrix and using (B.12),
[TABLE]
This yields that .
Note that the second term in (B.13) is identical to the expression (B.10), except that the expectation is taken under instead of . One may therefore use the exact same arguments as in Lemma B.2 with the only difference occurring in the second term in (B.11), where one instead has . For the unit vector in ,
[TABLE]
so that . Combining the bounds as in Lemma B.2 then gives the result. ∎
Lemma B.4**.**
If , then the variational posterior arising from the family (7) of spike-and-slab distributions satisfies
[TABLE]
Proof.
Since , we have . The result then follows from Lemma B.3. ∎
B.3 Oracle contraction rates for the original posterior distribution
Oracle type contraction rates for the original posterior were established in Castillo et al. [13]. However, their results are not stated with exponential bounds as needed in (14), so we must reformulate them in order to apply our Theorem 5. The required exponential bounds in fact follow from their proofs; we recall here the required results and, since [13] is a rather technical article, we provide a brief explanation why the exponential bounds hold.
Lemma B.5** (Theorem 10 of [13]).**
Suppose the prior satisfies (4) and (5). Then for large enough depending on , any and any ,
[TABLE]
where and is the event in (B.1).
Proof.
Following the proof of Theorem 10 of [13], one obtains using (6.3) and the second display on p. 2008 of [13] that for , any and any measurable set ,
[TABLE]
Setting now for , the third display on p. 2008 of [13] shows that
[TABLE]
for large enough that . Substituting this into the second last display and using that ,
[TABLE]
Choosing , the right-hand side equals
[TABLE]
Further picking and , the right-hand side is bounded by
[TABLE]
for large enough depending on , as required. ∎
The following result is a modified version of the oracle inequality in Theorem 3 of [13] with . Since it is stated somewhat differently in [13], we sketch why this is true.
Lemma B.6** (Theorem 3 of [13]).**
*Suppose the prior satisfies (4) and (5). Then there exists a constant such that for large enough, both depending only on , any , and uniformly over all with , *
[TABLE]
where , and . Moreover, both
[TABLE]
[TABLE]
satisfy the same inequality.
Proof.
Unless otherwise stated, we use here the notation from [13]. As on p. 2008 of [13], define the event for
[TABLE]
where and is the same expression with replaced by . Note that we take different constants than in (6.7) of [13] to obtain the required exponential tail bound. Lemma B.5 yields, with and since ,
[TABLE]
for every , so we can intersect the desired set with in what follows.
From definition (12), we have . Continuing through the proof, the third last display on p. 2009 of [13] (note that up to this point, the definitions of and only affect the definition of the compatibility type constants) gives
[TABLE]
where again . By condition (4), for large enough. Using this and taking , the last display is bounded by
[TABLE]
where we have also used for any . Using the definition (B.14) of , that and the inequality for any ,
[TABLE]
for a constant depending only on , yielding
[TABLE]
Combining this with the third last display gives
[TABLE]
for some large enough depending only on . Using and the definition (B.14), the probability in the last display is smaller than that in (B.15) if . Considering these two cases separately establishes the required inequality for the prediction error .
For -loss, the result follows from that for prediction error and the first display on p. 2010 of [13].
For -loss, note that for any . The result then follows from that for prediction error and that by Lemma D.1. ∎
Appendix C Additional methodological details
C.1 Proofs for the variational algorithm
We provide here the derivations of the formulas used in the CAVI update equations of our variational algorithm in Section 4.
Proof of (16): We compute the Kullback-Leibler divergence between and the posterior , conditional on , as a function of and . Since the variational probability distribution of conditional on (i.e. ) is singular to the Dirac measure , in the Radon-Nikodym derivative , where is the prior for , it suffices to consider only the continuous part of the prior measure in the denominator. Write with the normalizing constant. Using all of these and the prior product structure, equals, as a function of and ,
[TABLE]
where is independent of and is the prior mean for . Recall that the expected value of the folded normal distribution with parameters and is . Using this and explicitly evaluating the expectation of the first term, the last display equals
[TABLE]
where is again independent of . Minimizing the last display with respect to either or (but not jointly) gives the same minimizers as minimizing and in (16).
Proof of (17): Similarly to the derivation of (16) above, the KL divergence between and as a function of equals
[TABLE]
where is independent of and . Since on an event of -probability one, if and only if , the last display equals
[TABLE]
where may change from line to line and is independent of . Setting the derivative with respect to of this last expression equal to zero and rearranging gives (17).
C.2 Algorithms for Gaussian slabs
We collect here for completeness the variational algorithms for the spike-and-slab prior with Gaussian slabs with which we have compared our method. First we give the component-wise update of the parameters as in [27], see Algorithm 2 below.
In [25] the authors argue that coordinate-wise parameter updates can accumulate error from each step leading to a suboptimal optimization procedure. To resolve this, they propose simultaneously updating the entire parameter vectors and without using a CAVI type of algorithm. A version of their proposed algorithm is given in Algorithm 3, where , , creates a diagonal square matrix in with diagonal elements (see also Algorithm 1 of [46] with , and for a related implementation). As in the other cases, we have taken the ridge regression estimator as our initialization for .
Lastly, we provide the VB algorithm for the mean-field variational class using Laplace slabs in the prior.
Appendix D Examples of compatible design matrices
In addition to the compatibility type constants defined in Section 2.3, we also consider a stronger invertibility condition involving the ‘mutual coherence’ of the design matrix, which is the maximal correlation between the different predictors in .
Definition D.1** (Mutual coherence).**
The mutual coherence number is
[TABLE]
While we do not actually use the mutual coherence in our results, it provides an easy way to understand the compatibility constants in Definitions 1-3 in several well-studied design matrix examples below. The following result relates these notions.
Lemma D.1** (Lemma 1 of [13]).**
, .
By evaluating the infimum in Definition 2 at the unit vectors, one obtains , which is bounded away from zero if the columns of have comparable Euclidean norms. In this case, Lemma D.1 implies that the compatibility numbers and sparse singular values are bounded away from zero for models of size . The mutual coherence condition is thus the strongest of these notions. These conditions are illustrated via the following well-studied examples.
(Sequence model). We observe a vector of independent random variables with . This corresponds to model (1) with and the identity matrix, so that for all , the compatibility numbers are 1 and . In this setting, all results below are valid for all sparsity levels. 2. 2.
(Sequence model, multiple observations). We observe independent random variables with . Defining as times the original observations, this falls within the framework of model (1) with , so that for all , the compatibility numbers are 1 and , similar to Example 1. 3. 3.
(Regression with orthogonal design). If is an orthogonal design matrix such that for , the regression problem can be transformed into a sequence model. 4. 4.
(Response model). Suppose the entries of the original regression matrix are i.i.d. random variables . We may then normalize the entries of the design matrix by defining , so that the column lengths satisfy for all . If for a constant and , or for some and , then Theorems 1 and 2 of [10] show that as . Since , this shows that for any , . Thus with probability approaching one, the compatibility numbers are bounded away from zero for sparsity levels .
A classic example is . In this case, the above bound on the mutual coherence holds as long as . 5. 5.
By rescaling the columns of , one can set the matrix to take value one for all diagonal entries. Then for all and the elements , , are the correlations between columns. For some , if for a constant and all or for every , then [49] show that models up to dimension satisfy the ‘strong irrepresentability condition’ and are hence estimable. In particular, and hence the compatibility numbers are bounded away from zero for sparsity levels .
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Alquier, P., and Ridgway, J. Concentration of tempered posteriors and of their variational approximations. Ann. Statist. 48 , 3 (2020), 1475–1497.
- 2[2] Banerjee, S., Castillo, I., and Ghosal, S. Survey paper: Bayesian inference in high-dimensional models.
- 3[3] Belitser, E., and Ghosal, S. Empirical Bayes oracle uncertainty quantification for regression. Ann. Statist., to appear (2020).
- 4[4] Belitser, E., and Nurushev, N. Needles and straw in a haystack: Robust confidence for possibly sparse sequences. Bernoulli 26 , 1 (2020), 191–225.
- 5[5] Blei, D. M., Kucukelbir, A., and Mc Auliffe, J. D. Variational inference: a review for statisticians. J. Amer. Statist. Assoc. 112 , 518 (2017), 859–877.
- 6[6] Blei, D. M., Ng, A. Y., and Jordan, M. I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 3 (Mar. 2003), 993–1022.
- 7[7] Boucheron, S., Lugosi, G., and Massart, P. Concentration inequalities: A nonasymptotic theory of independence . Oxford University Press, Oxford, 2013.
- 8[8] Breiman, L., and Friedman, J. H. Estimating optimal transformations for multiple regression and correlation. J. Amer. Statist. Assoc. 80 , 391 (1985), 580–619.