On the construction of confidence intervals for ratios of expectations
Alexis Derumigny, Lucas Girard, Yannick Guyonvarch

TL;DR
This paper develops a generalized delta method and bootstrap techniques for constructing confidence intervals for ratios of expectations, especially in small samples or when the denominator approaches zero, with practical guidelines for reliability.
Contribution
It introduces a generalized delta method and bootstrap consistency results for ratios of expectations, addressing limitations of traditional methods in small samples and near-zero denominators.
Findings
Nonasymptotic confidence intervals are possible but not at all confidence levels.
A new index helps assess the reliability of delta method-based intervals.
Simulations and an application demonstrate practical usefulness.
Abstract
In econometrics, many parameters of interest can be written as ratios of expectations. The main approach to construct confidence intervals for such parameters is the delta method. However, this asymptotic procedure yields intervals that may not be relevant for small sample sizes or, more generally, in a sequence-of-model framework that allows the expectation in the denominator to decrease to with the sample size. In this setting, we prove a generalization of the delta method for ratios of expectations and the consistency of the nonparametric percentile bootstrap. We also investigate finite-sample inference and show a partial impossibility result: nonasymptotic uniform confidence intervals can be built for ratios of expectations but not at every level. Based on this, we propose an easy-to-compute index to appraise the reliability of the intervals based on the delta method.…
Click any figure to enlarge with its caption.
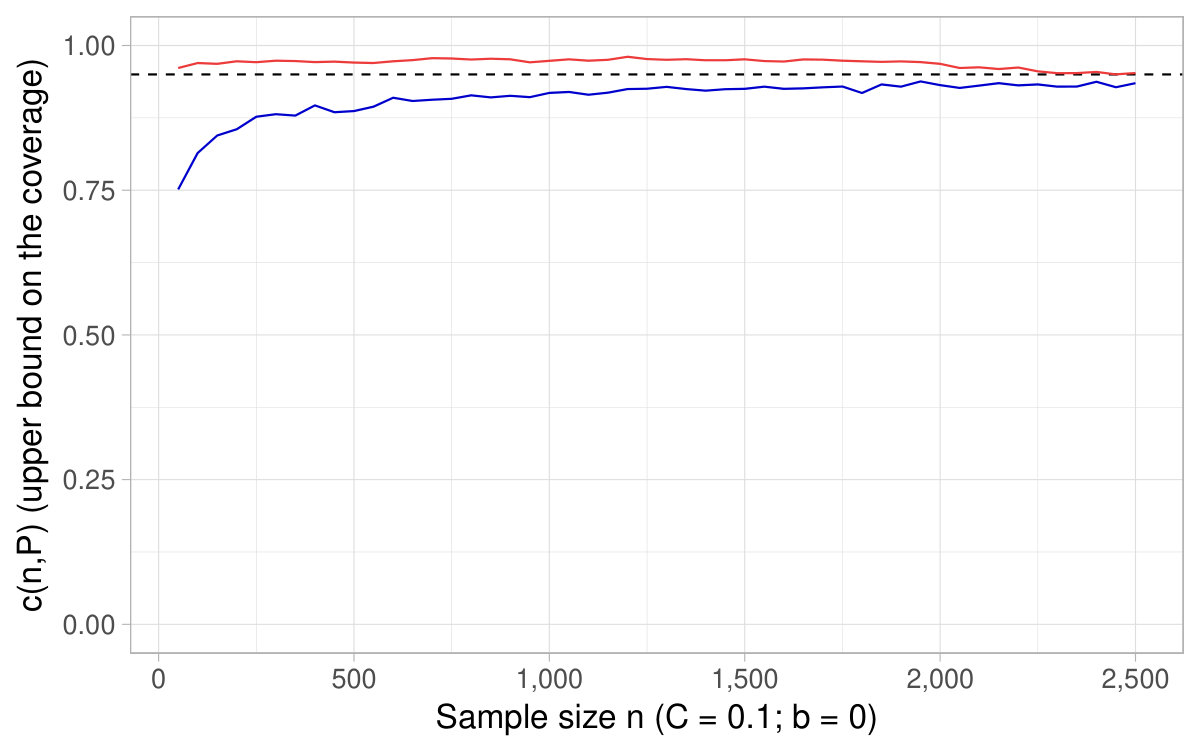 Figure 1
Figure 1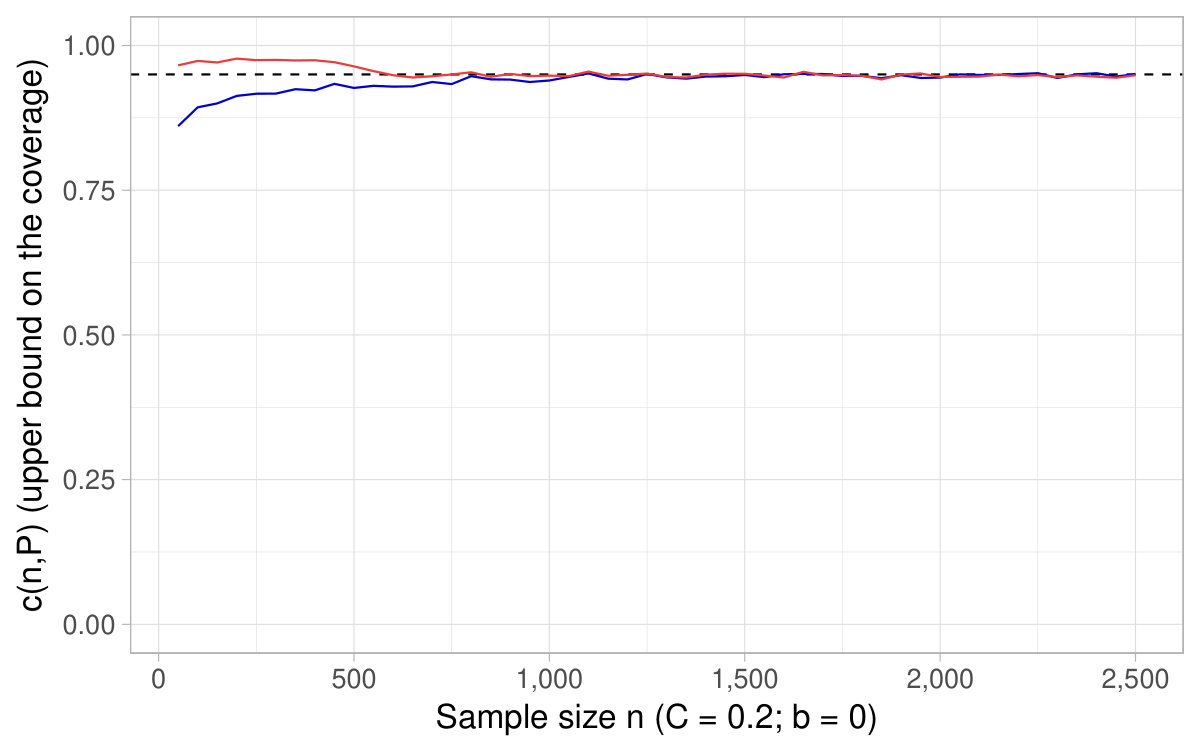 Figure 2
Figure 2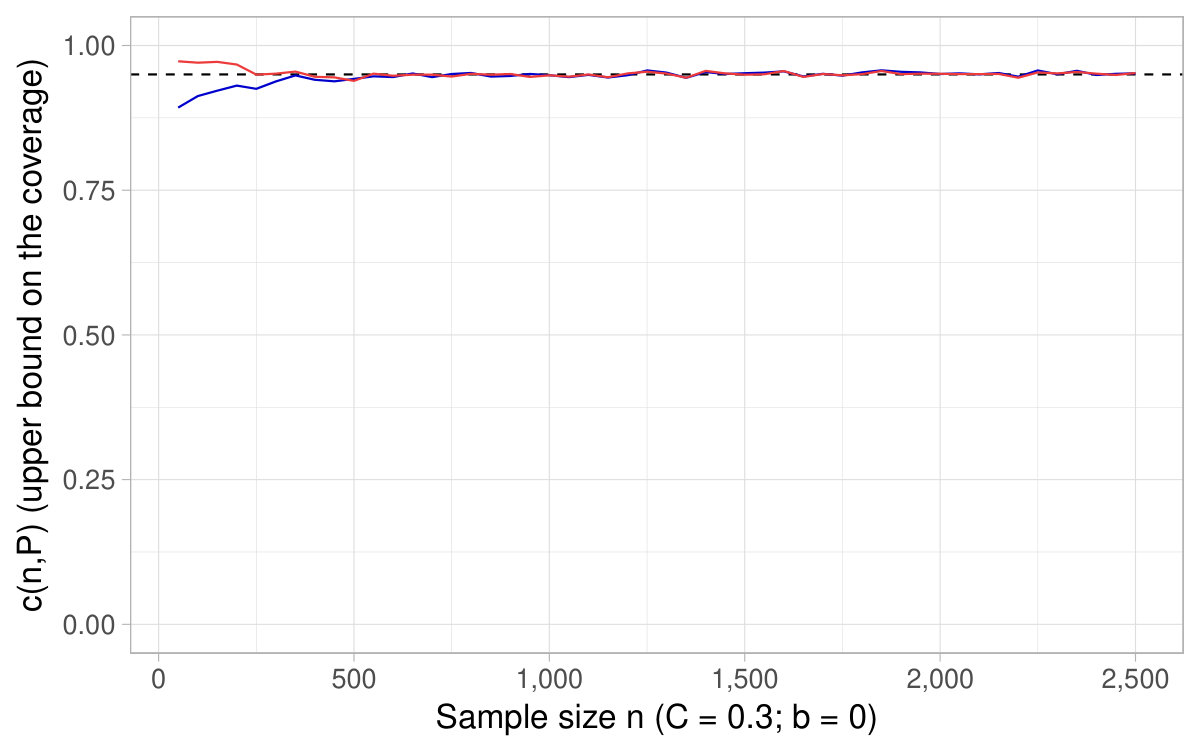 Figure 3
Figure 3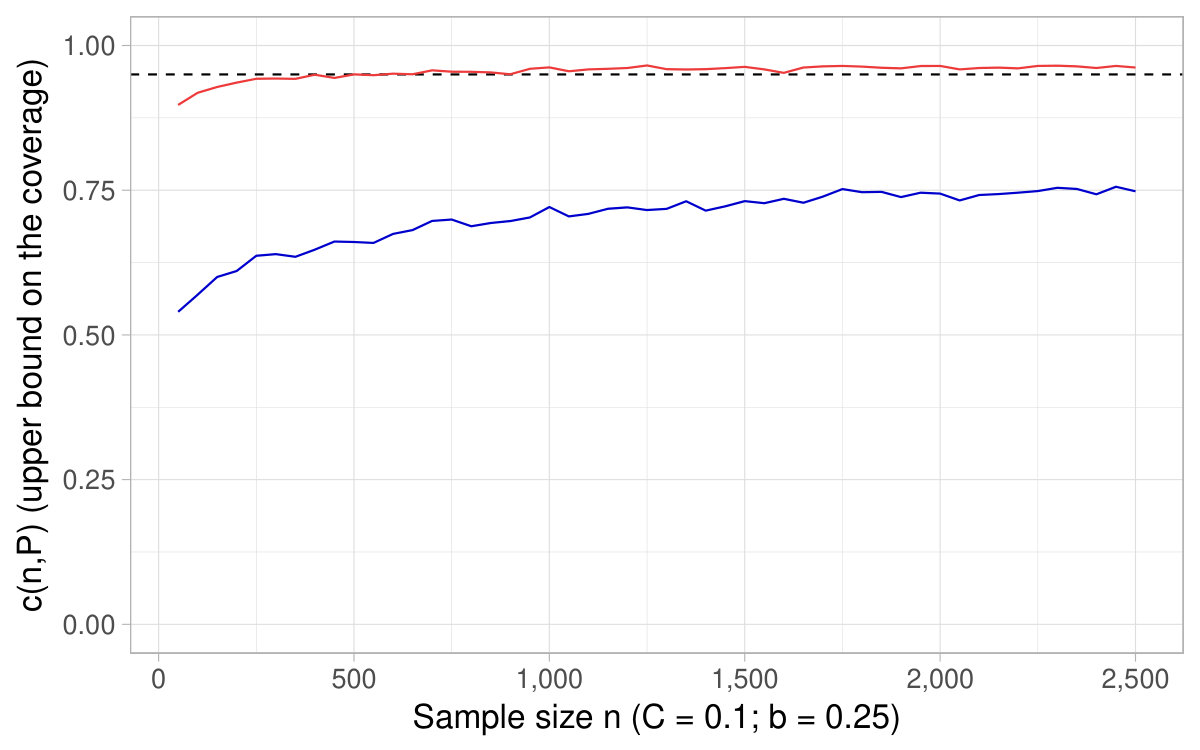 Figure 4
Figure 4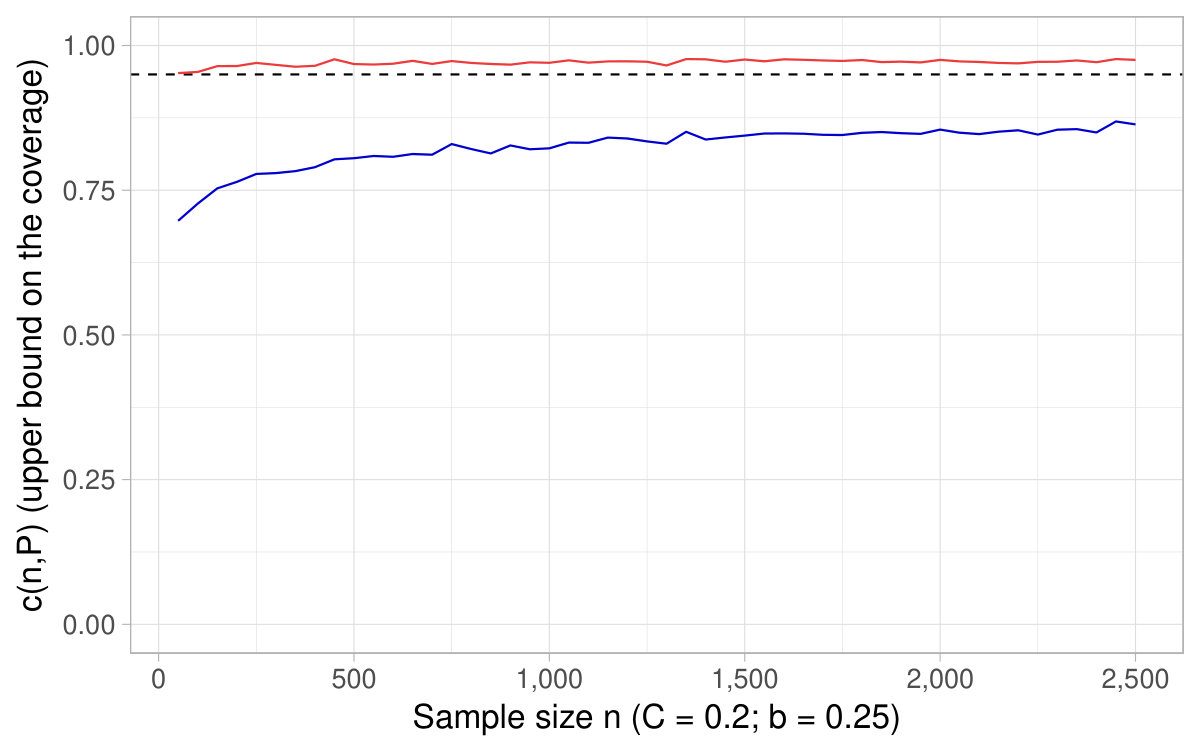 Figure 5
Figure 5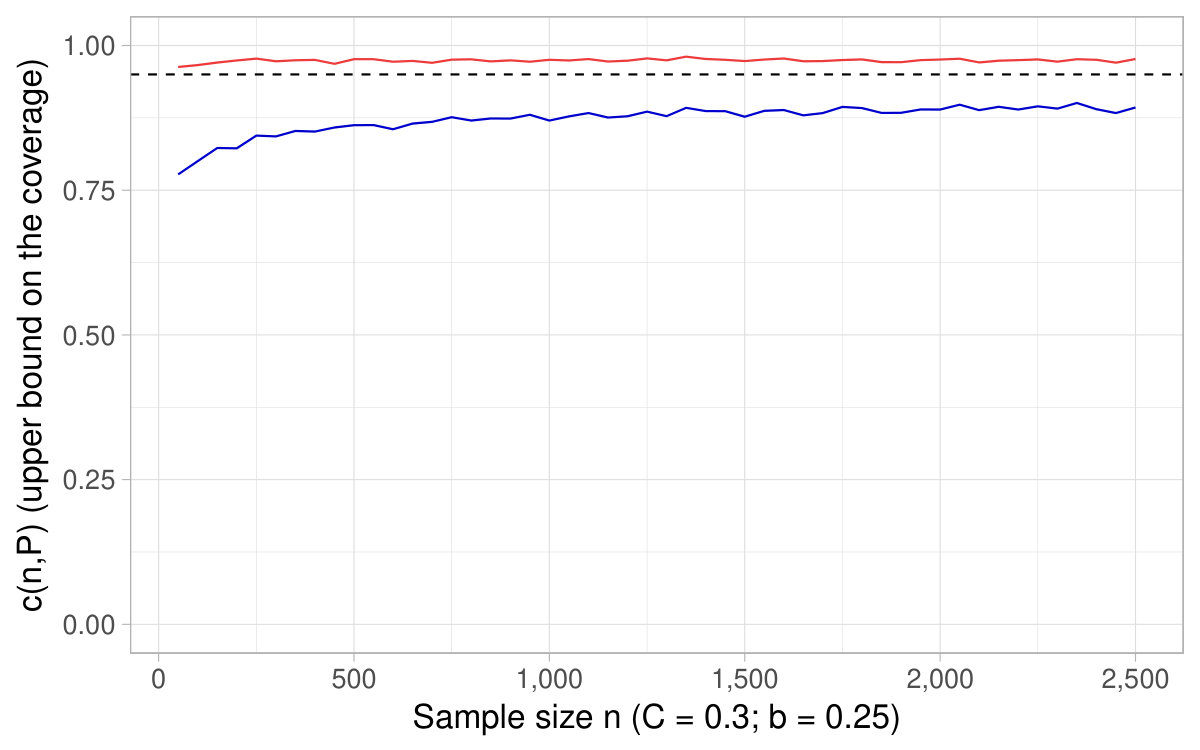 Figure 6
Figure 6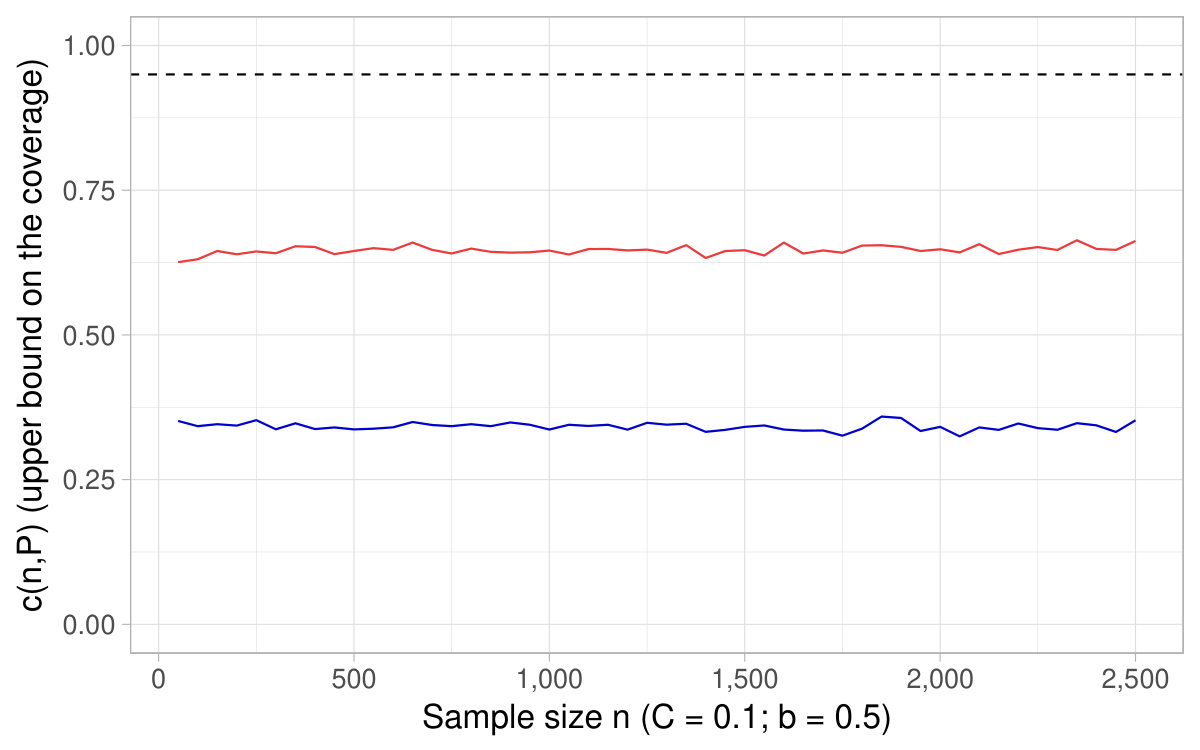 Figure 7
Figure 7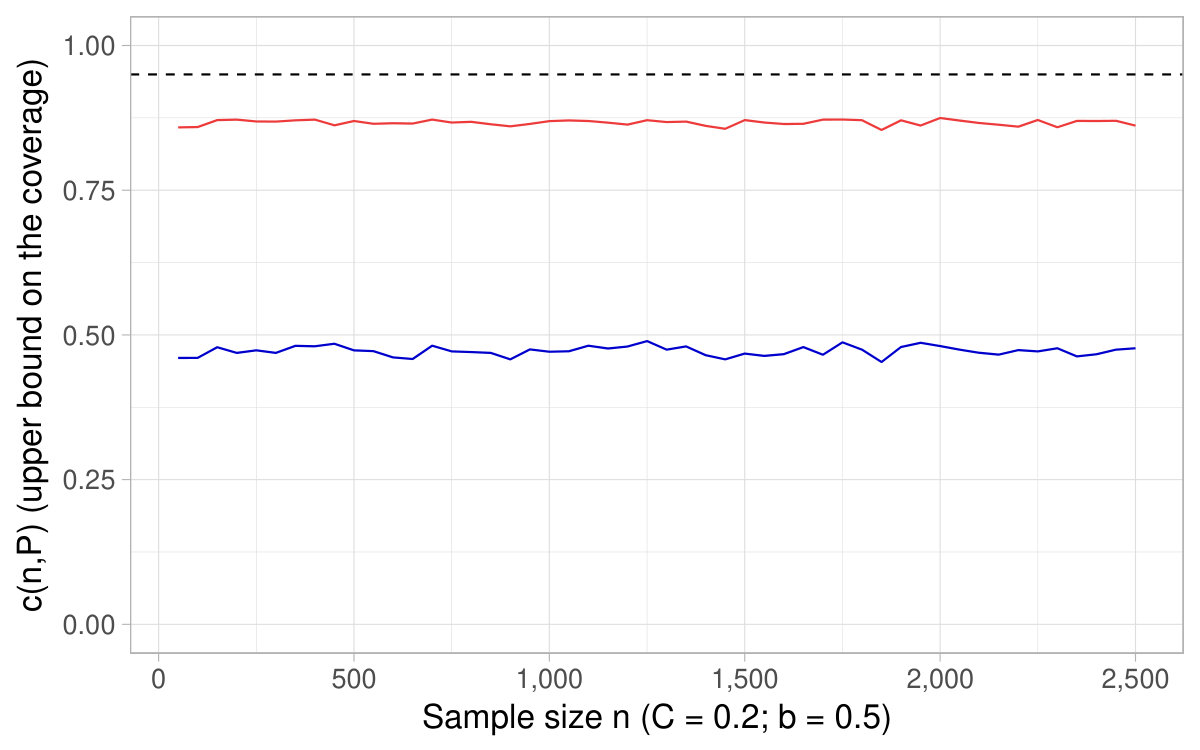 Figure 8
Figure 8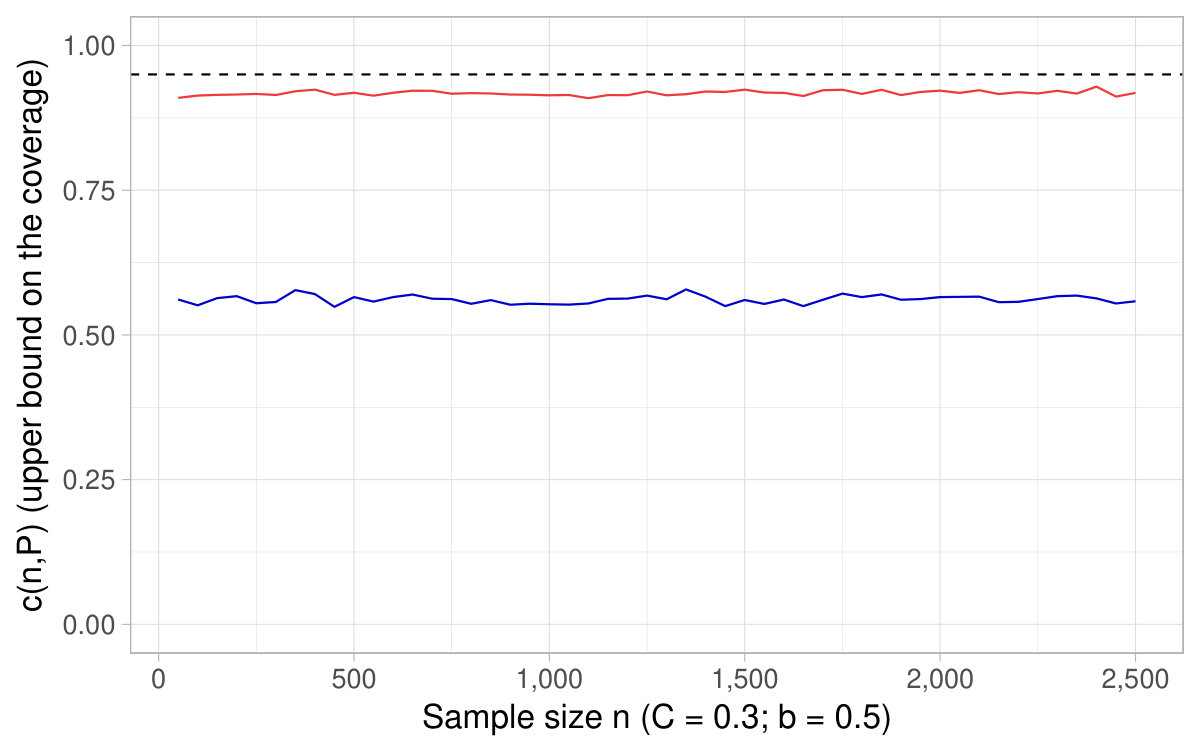 Figure 9
Figure 9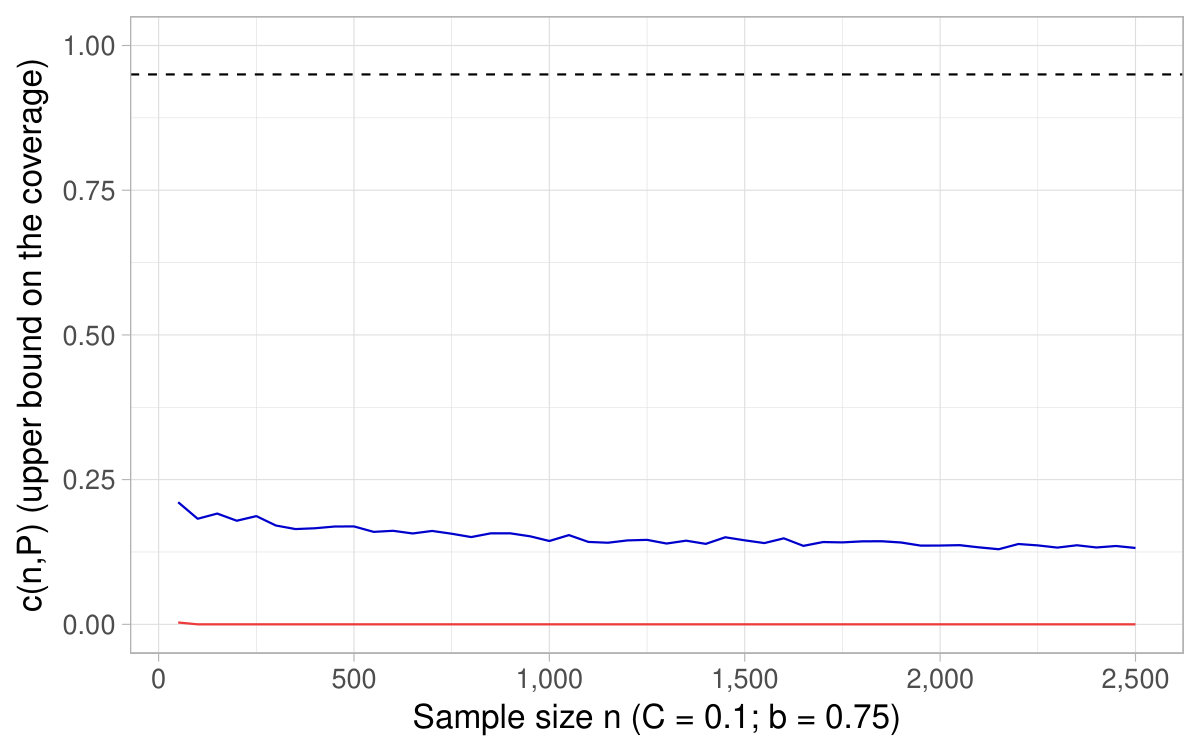 Figure 10
Figure 10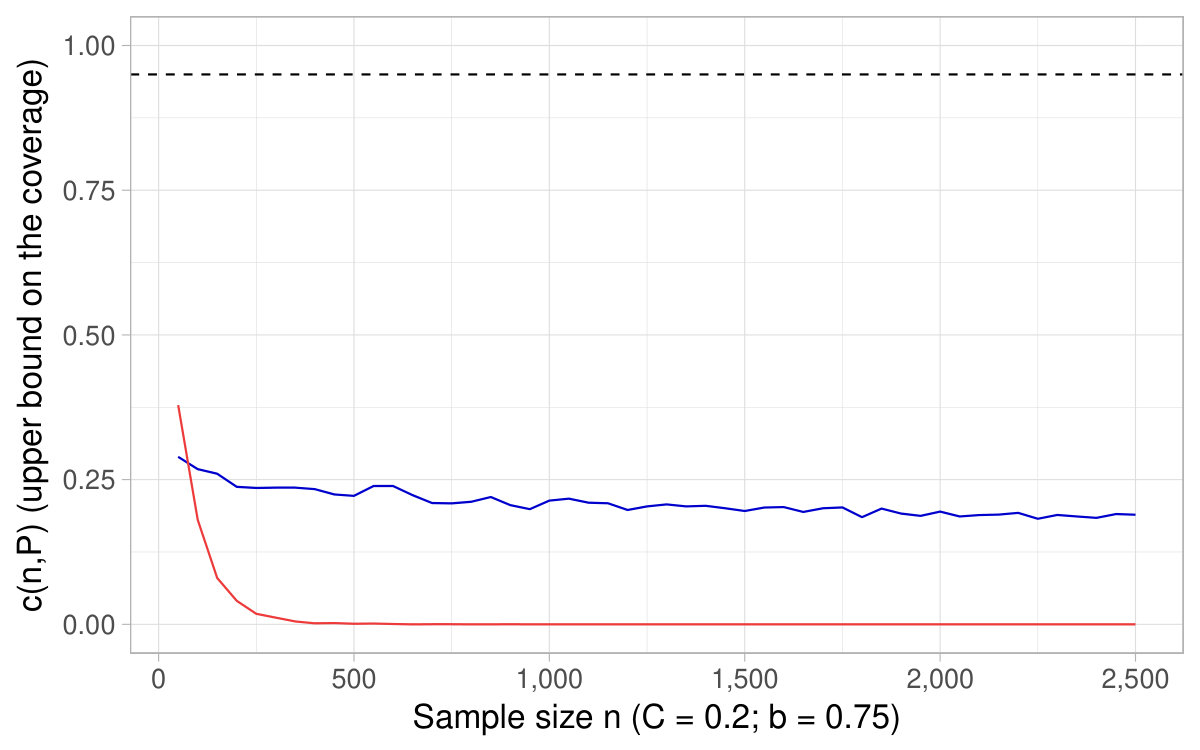 Figure 11
Figure 11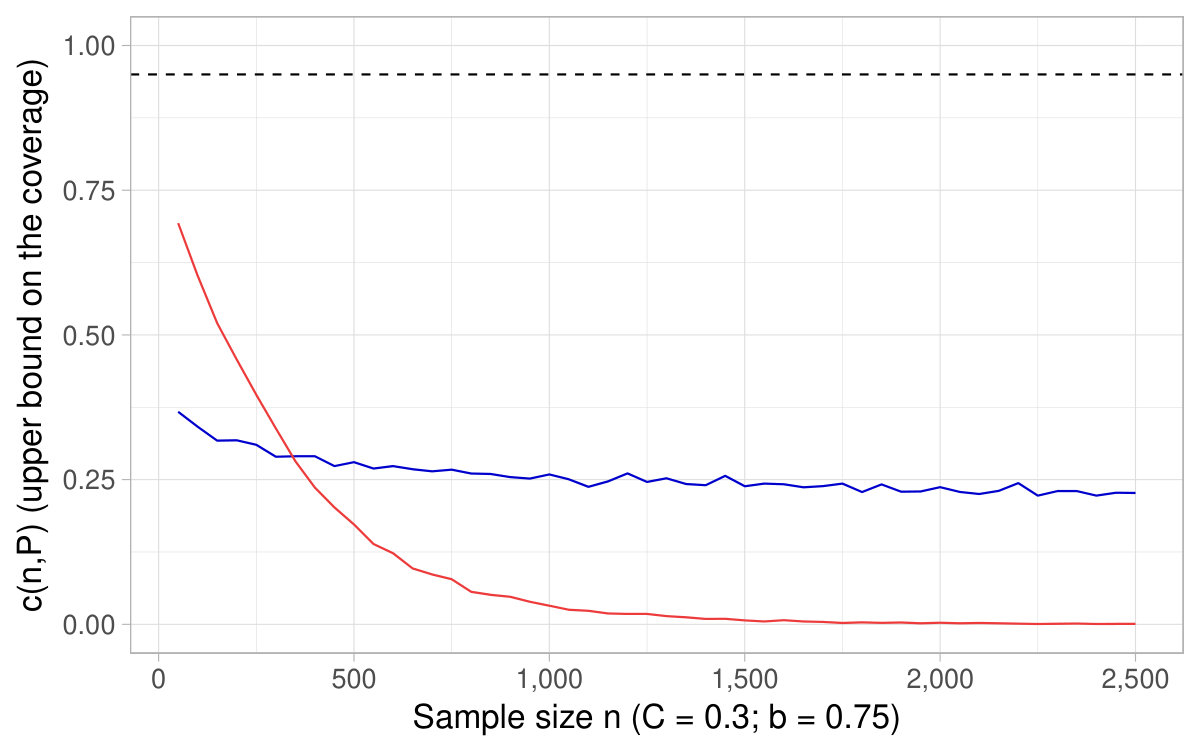 Figure 12
Figure 12 Figure 13
Figure 13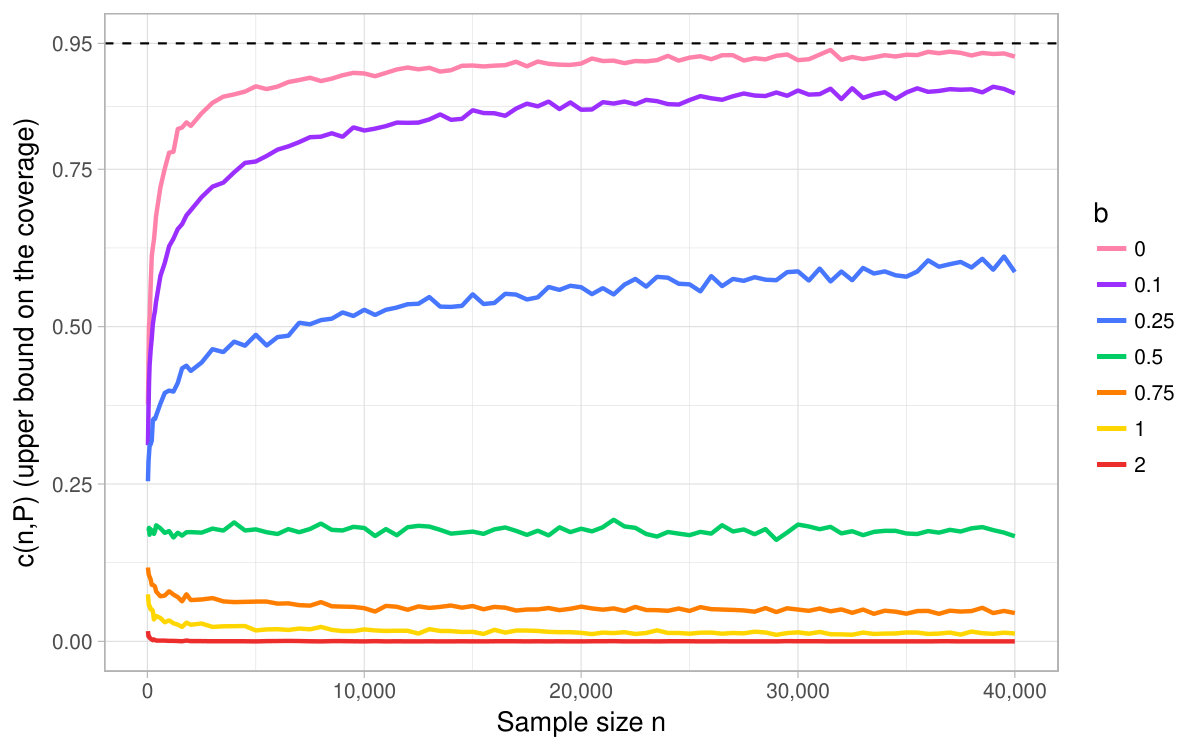 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17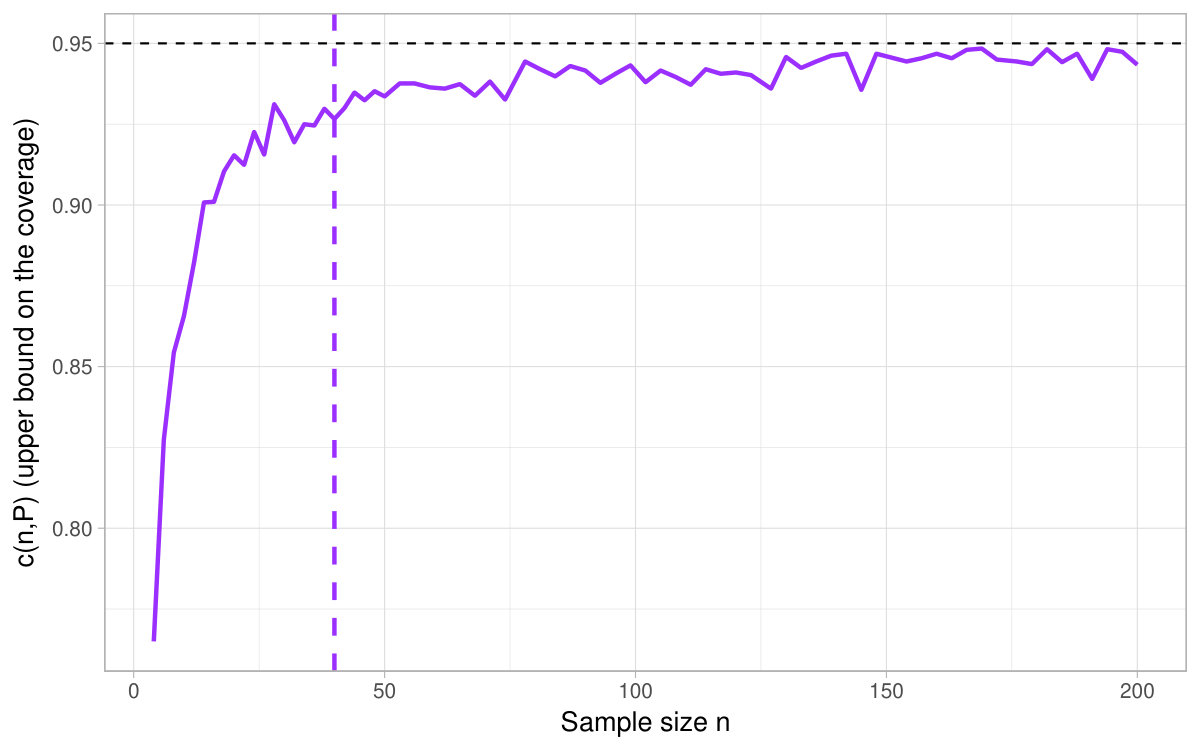 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26 Figure 27
Figure 27 Figure 28
Figure 28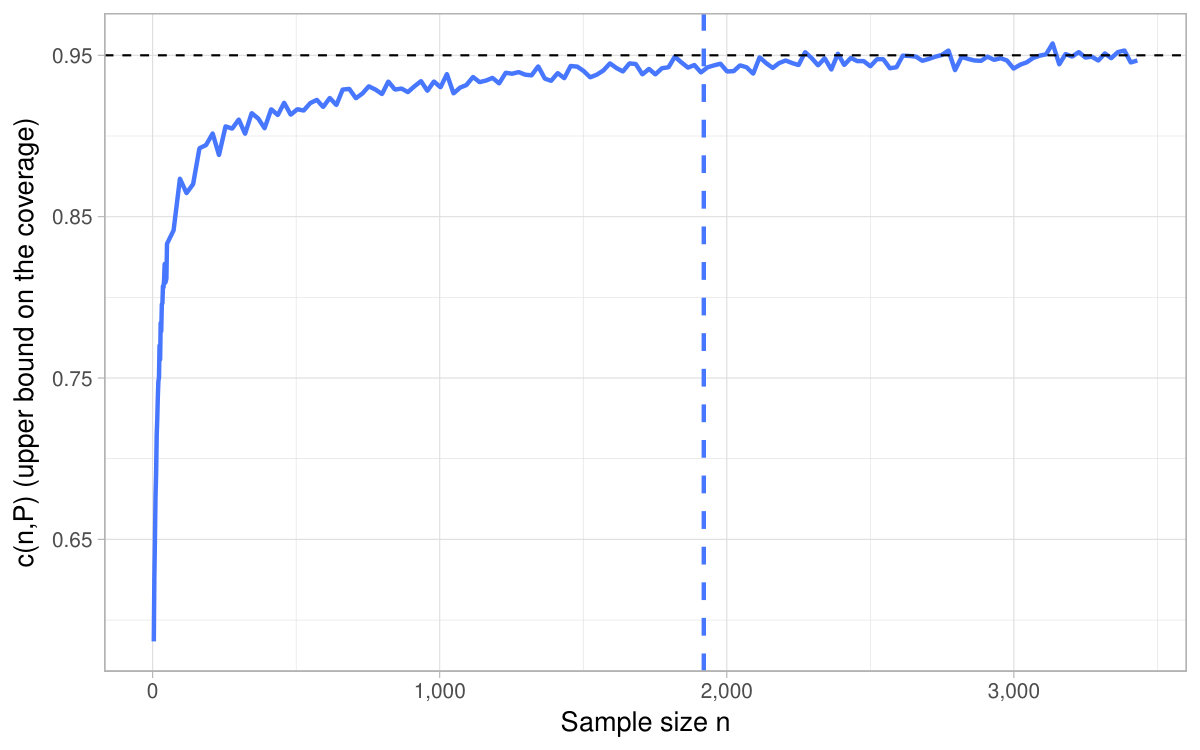 Figure 29
Figure 29 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32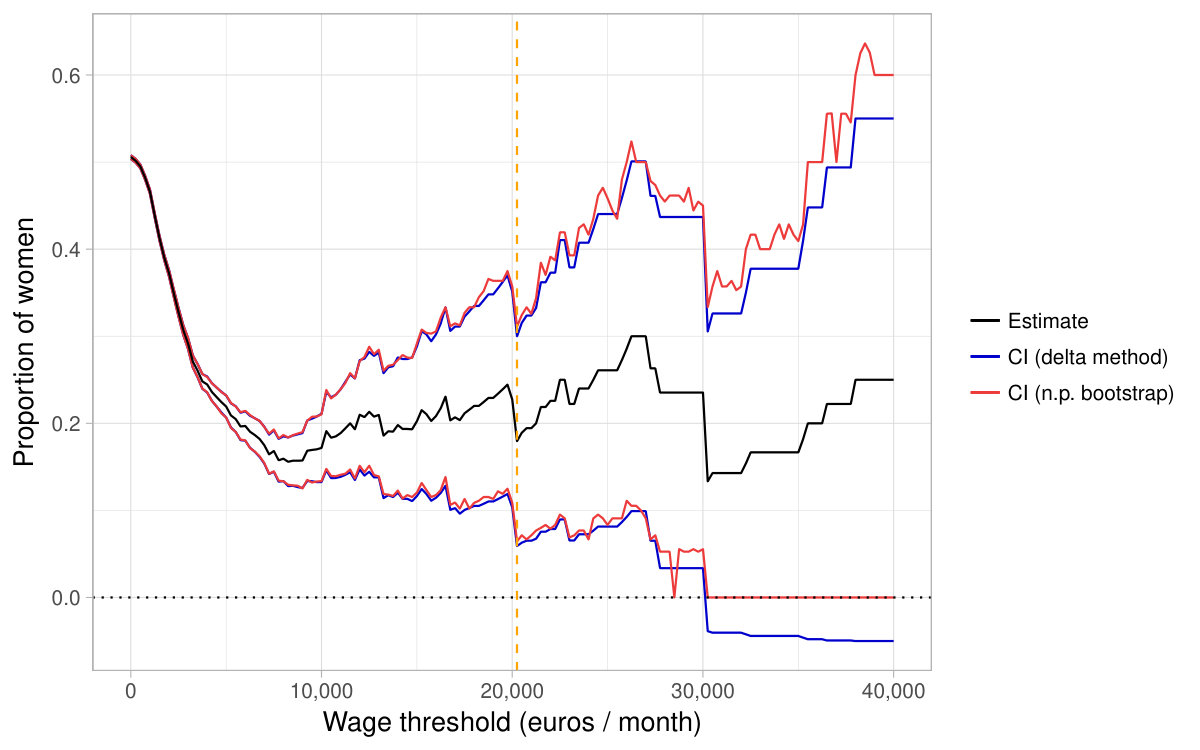 Figure 33
Figure 33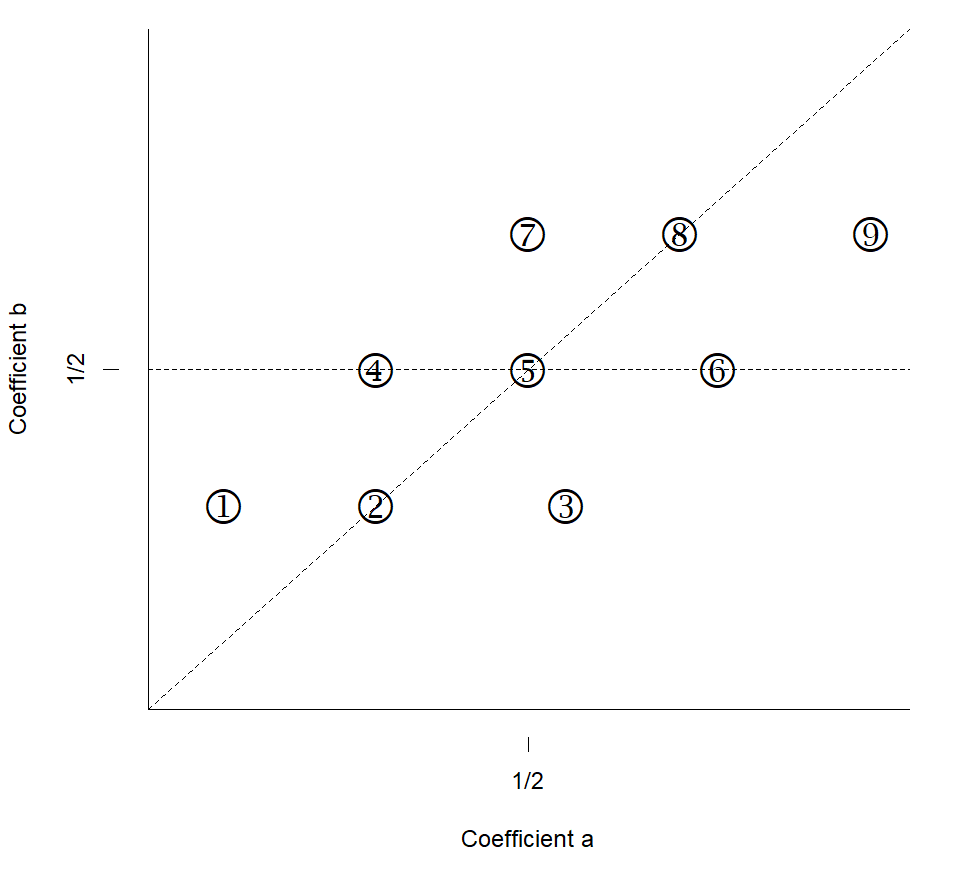 Figure 34
Figure 34 Figure 35
Figure 35Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Methods and Inference · Financial Risk and Volatility Modeling · Monetary Policy and Economic Impact
On the construction of confidence intervals for ratios of expectations††thanks:
We would like to thank Laurent Davezies, Xavier D’Haultfœuille, and the participants of the CREST internal seminar (Nov. 2018) for their valuable comments. This research has been supported by the Labex Ecodec.
Alexis Derumigny, Lucas Girard22footnotemark: 2, Yannick Guyonvarch22footnotemark: 2 CREST, 5, avenue Henry Le Chatelier, 91764 Palaiseau cedex, France.
E-mail adresses: [email protected] for the three authors.
In econometrics, many parameters of interest can be written as ratios of expectations. The main approach to construct confidence intervals for such parameters is the delta method. However, this asymptotic procedure yields intervals that may not be relevant for small sample sizes or, more generally, in a sequence-of-model framework that allows the expectation in the denominator to decrease to [math] with the sample size. In this setting, we prove a generalization of the delta method for ratios of expectations and the consistency of the nonparametric percentile bootstrap. We also investigate finite-sample inference and show a partial impossibility result: nonasymptotic uniform confidence intervals can be built for ratios of expectations but not at every level. Based on this, we propose an easy-to-compute index to appraise the reliability of the intervals based on the delta method. Simulations and an application illustrate our results and the practical usefulness of our rule of thumb.
Keywords: delta method, confidence regions, uniformly valid inference, sequence of models, nonparametric percentile bootstrap.
MSC: Primary 62F25; secondary 62F40, 62P20. JEL: C18, C19.
1 Introduction
In applied econometrics, the prevalent method for constructing confidence intervals (CIs) is asymptotic: the theoretical guarantees for most CIs used in practice hold only when the number of observations tends to infinity. For a large class of parameters, the construction of asymptotic CIs also relies on the delta method. In this paper, we focus on parameters that can be expressed as ratios of expectations for which the delta method is a standard procedure to conduct inference. The objective is twofold: study the behavior of the delta method and other confidence intervals in some difficult settings and provide tools to detect cases in which the delta method may behave poorly.
Many popular parameters in economics take the form of ratios of expectations. Typical examples are conditional expectations since any conditional expectation with a discrete conditioning variable, or a conditioning event, can be written as a ratio of unconditional expectations. For instance, assume that we observe an independent and identically distributed (i.i.d.) sample of individuals indexed by with the wage of an individual and an indicator equal to whenever individual belongs to some treatment group, say a training program; [math] otherwise. Suppose you are interested in the average wage of participants in the program. We have as is binary.
Most confidence intervals used in practice are based on asymptotic justifications, hence possible concerns as regards their finite-sample reliability. For ratios of expectations, we document this issue on simulations (see Section 3.1). One of our findings is that the coverage of the CIs based on the delta method happens to be far below their nominal level, even for large sample sizes, when the expectation in the denominator is close to [math].111The definitions of coverage and other fundamental properties of confidence intervals are recalled in Appendix A with the conventions that we use. For some scenarios, these asymptotic CIs require above 100,000 observations to get reasonably close to their nominal level. Yet, denominators close to [math] are not unusual in practice. Coming back to the treatment/wage example, a small denominator would correspond to a binary treatment with a low participation rate.
In order to deal with that issue, we consider sequences of models, namely we authorize the distribution of the observations to change with the sample size. This framework enables to formalize in an asymptotic way the idea of a denominator close to [math]. Indeed, in a standard asymptotic viewpoint, with the expectation in the denominator different from [math], all parameters are fixed and well-defined. Hence, always grows large enough so that empirical means are close to their expectations and the CIs based on the delta method are valid. In other words, the signal that we want to estimate is constant while the noise goes to [math], and therefore the problem vanishes in this asymptotic perspective. We would like to model more difficult cases, in which the signal can go to [math] as well. This is precisely what the sequence-of-model set-up allows.222This can also rationalize the practice of applied social researchers (see Example 2.1). The heuristic idea is that researchers can consider narrower effects as the data gets richer. This is similar to some frameworks that have been developed for weak instrumental variables (IV), see notably [11, 12, 2].
In this literature, another approach does not consider sequences of models but designs “robust” procedures that allow to be exactly in the problematic case, namely a null covariance between the instrument and the endogenous regressor (see [1]). In this case, the parameter of interest is unidentified. In contrast with the weak IV framework, it is worth noting that for ratios in general the parameter of interest is not even defined when the denominator is exactly equal to [math]. As a consequence, such an approach seems difficult to extend to our problem.
In our setting, it is unclear, even asymptotically, what the properties of the CIs based on the delta method are when the expectation in the denominator tends to [math]. We show that usual CIs can fail and the limiting law of may not be Gaussian anymore, denoting by the ratio of expectations and its empirical counterpart. In some cases, the difference may actually have a Cauchy limit, as can be found in the weak IV literature.
We show in this sequence-of-model framework that confidence intervals provided by the nonparametric percentile bootstrap have the same asymptotic properties as the ones obtained with the delta method. Simulations support that claim and even suggest the former have better coverage than the latter in finite samples.
Even in standard settings with a fixed but small denominator, simulations document that asymptotic-based CIs may require very large sample sizes to attain their nominal level. This suggests to study more in details nonasymptotic inference. More precisely, we construct finite-sample CIs, extending old-established concentration inequalities for means to ratios of means. Concentration inequalities for the mean refer to upper bounds on the probability that an empirical mean departs from its expectation more than a given threshold. Such inequalities permit to construct confidence intervals valid for any sample size and for large classes of probability distributions (see in particular [4]). To our knowledge, there is no such result for ratios. We consider distributions within a class characterized by a lower bound on the first moment for the denominator variable, and an upper bound on the second moment for both the numerator and denominator variables.333We refer to this setting as the “Bienaymé-Chebyshev” (BC) case. In Appendix C, we present similar results for distributions whose supports are bounded (“Hoeffding” case).
One additional result highlights there exists a critical confidence level, above which it is not possible to construct nonasymptotic CIs, uniformly valid on such classes, and that are almost surely bounded under every distribution of those classes. More precisely, we exhibit explicit upper and lower bounds on this critical confidence level: the former is a threshold above which we show it is impossible to construct such CIs; the latter is a threshold below which we show how to construct them.
These ideas closely relate to some impossibility results as regards the construction of confidence intervals. A large share of the research effort has concentrated on the problem of constructing confidence intervals for expectations. In an early contribution, [3] show that, when is the set of all distributions on the real line with finite expectation, the parameter of interest is the expectation with respect to a distribution and , a confidence interval built from an i.i.d. sample of observations that has uniform coverage over must contain any real number with probability at least . Broadly speaking, any confidence interval must have infinite length with positive probability for every to ensure a coverage of .
Stronger results can be derived when one further restricts or . When is taken to be the set of all distributions on the real line with variance uniformly bounded by a finite constant, it is possible to show (using the Bienaymé-Chebyshev inequality) that for every and every , there exists a confidence interval that is almost surely bounded under every and has coverage . In this case, the obtained CIs have the advantage that their length shrinks to [math] at the optimal rate . But on the downside, they are not of size , even asymptotically, except for some extreme distributions. This means that they tend to be conservative in practice.
A strand of the literature has also investigated more complex problems in which is not restricted to being an expectation. For general parameters, [7] derives a generalization of [3]. An implication of the results in [7] is the existence of an impossibility theorem for ratios of expectations. Let be a distribution on with marginals and . If , then for every , it is impossible to build nontrivial CIs of coverage when is the set of all distributions on with finite second moments and . As will be explained below, this impossibility result disappears as soon as is chosen such that is bounded away from [math] uniformly over . Interestingly, the impossibility breaks down only partly in the sense that there remains an upper bound on confidence levels (that depends on ) above which it is impossible to build nontrivial CIs.
Other interesting results can be found in [10] and [9]. [10] construct nonasymptotic valid confidence intervals that happen to be also asymptotically optimal. However, they only consider expectations. [9] study smooth functions of a vector of means and give bounds on the distance between the distribution of the normalized and centered estimator and its Gaussian limiting distribution. Nonetheless, the authors do not link their results to the construction of confidence intervals.
In the light of that existing literature, our nonasymptotic findings can be interpreted as a partial impossibility result. Indeed, even if we assume a known positive lower bound on the expectation in the denominator, the limitation on the attainable coverage of our nonasymptotic CIs remains. That point complements [7]: for a given sample size , interesting CIs can be built but not at every confidence level. By contrast, provided the expectation in the denominator is not null, the delta method gives CIs at every confidence level, but their coverage is only asymptotic.
To bridge this gap, we suggest a rule of thumb to assess the reliability of the delta method for ratios of expectations in finite samples. The heuristic idea is simply, for a given sample, to compute an estimator of the lower bound on the above-mentioned critical confidence level. This lower bound can be seen as a conservative value for the unknown critical level, which is a necessary criterion to conduct valid inference in finite samples uniformly over a given class of distributions. Hence, for any desired level higher than this bound, the CIs based on the delta method cannot reach this desired uniform level in finite samples. We illustrate the empirical usefulness of that rule of thumb on simulations and with an application to gender wage disparities in France for the years 2010-2017.
The rest of the paper is organized as follows. Section 2 details our framework and assumptions. In Section 3, we illustrate the weaknesses of the CIs based on the delta method with a denominator “close to 0” on simulations and detail the asymptotic behavior of the delta method and of the nonparametric percentile bootstrap in our sequence-of-model setting. Section 4 is devoted to the construction of nonasymptotic confidence intervals and presents a lower bound on the aforementioned critical confidence level. In Section 5, we derive an upper bound on the critical confidence level as well as a lower bound on the length of nonasymptotic CIs. This section also includes the description of a practical index to gauge the soundness of the CIs based on the delta method in finite samples. Section 6 present simulations and an application to a real dataset to illustrate our methods. Section 7 concludes. General definitions about confidence intervals are recalled in Appendix A. The proofs of all results are postponed to Appendix B. Additional results under an alternative set of assumptions (“Hoeffding” case) are detailed in Appendix C. Appendix D presents supplementary simulations.
2 Our framework
Throughout the paper, for any random variable and i.i.d. replications , we denote by the empirical mean of , that is . Assumption 1 defines our sequence-of-model framework and provides the basic requirements to state our asymptotic results.
Assumption 1**.**
*For every , we observe a sample , where is a given distribution on that satisfies , , and . *
Remark that indexes both the distribution of the observations in this model and the number of observations . This encompasses the standard i.i.d. set-up if the distribution does not change with : for every , for some given distribution . As we assume the existence of a finite expectation, we can consider without loss of generality.444Otherwise, we simply replace by its opposite . In order to have properly defined ratios of interest, we need to assume away a null denominator, namely suppose that for every , .
Example 2.1** (Sequences of models and the practice of applied researchers).**
Researcher may look at the average value of a variable of interest in a subgroup of the data. Subgroups could be defined as the intersections of, say, time, geographical area, gender, age, income brackets and so on. As the number of observations grows, it is possible to consider subgroups that become thinner and thinner (intersection of more and more variables for instance). This practice could be modelled as estimating where is a binary variable that is equal to 1 if an individual belongs to the subgroup . This corresponds to our framework denoting and .
To derive our nonasymptotic results, Assumption 1 has to be strengthened.
Assumption 2**.**
*For every , there exist positive finite constants , , and such that (i) , (ii) and . *
Note that in practice, the value of the constants , , and may not be available for practitioners. This is the reason why, in Section 5.3, we propose heuristic methods that palliate the lack of knowledge of those constants.
The first part of the assumption bounds the expectation of away from [math] while the second states that the second moments of and are bounded. These are necessary to derive nonasymptotic CIs with maintained coverage uniformly over a class of distributions and that are not trivial. Otherwise, if or in the absence of the upper bounds and , the impossibility theorem of [7] applies and prevents from constructing nontrivial CIs for any confidence level. In a way, given this result, Assumption 2 can be seen as close to the minimal hypothesis that allows for the possibility of nontrivial confidence intervals with finite-sample guarantees for ratios of expectations. Furthermore, the sequence-of-model framework allows to decrease to [math], which enables us to study limiting cases close to but different from the problematic case .
This set-up, where Assumptions 1 and 2 hold, is named the BC case since it is possible under these assumptions to construct nonasymptotic CIs using the Bienaymé-Chebyshev inequality. In Appendix C, we present an adapted version of our results under the assumption that and have a bounded support instead of bounded second moments; a setting we call the Hoeffding case.
To sum up, Assumptions 1 and 2 define a set of distributions for some constants , and . For a distribution in , the parameter of interest is denoted with values in . To estimate this parameter, we consider its empirical counterpart . We seek to construct confidence intervals for with nominal level based on this estimator.
In practice, it is possible that and it may even happen with a strictly positive probability for non-continuous distributions of . The estimator does not exist for such samples. In such a case, it is difficult to construct meaningful confidence intervals. Different conventions are possible:
- •
We could choose to define . This entails that belongs to by construction. We believe that such a choice would artificially improve the coverage of as it induces that the higher , the better the interval in terms of coverage.
- •
We could choose . The hypothesis would then be rejected for every using the duality between tests and confidence intervals. We would also like to avoid this situation because it may not be reasonable to always reject for the mere reason that cannot be estimated in the sample.
- •
Other choices are possible, for example , but they do not seem sensible either since there is no reason to select only [math] in our confidence interval, especially if .
For these considerations, we choose to let undefined whenever , following the convention that ratios are undefined for any real .555When facing , applied researchers may use other estimators. For instance, one could consider sub-samples (possibly several and combine them in some way) of the data for which the empirical mean in the denominator differs from [math]. Nevertheless, the construction of satisfactory estimators in this case lies beyond the scope of this paper. In practice, when given a realization and a real , we either know that belongs to , or we know that does not belong to , or is undefined. As a consequence, we have the decomposition where denotes the disjoint union of sets. This means that .
3 Limitations of the delta method: when are asymptotic confidence intervals valid?
In practice, for a sample of size , the coverage of asymptotic CIs may be well below their nominal level . Intuitively, this phenomenon should be driven by “problematic” distributions in in the following sense: when the true distribution is close to the boundary of the class , the probability may be much smaller than .666Recall that in the nonasymptotic approach, the coverage of any given confidence interval is defined as the infimum of for ranging over the studied class of distributions.
In Section 3.1, with the confidence interval based on the delta method, we illustrate on simulations that can fail to match when the expectation in the denominator is fixed close to [math]. In other words, it may require a very large number of observations to make reasonable the asymptotic approximation. In Section 3.2, we investigate a more serious issue: in the sequence-of-model framework, we let the expectation in the denominator not only be small but converge to [math] as increases. We show on simulations that depending on the speed at which the denominator goes to [math], can either converge to the nominal level (more or less quickly) or even not converge at all to this target. This sheds light on a partial failure of the delta method when the denominator goes to [math] that we derive formally in Section 3.3. Finally, in Section 3.4, we show the asymptotic consistency of the nonparametric percentile bootstrap (also known as Efron’s percentile bootstrap) in this sequence-of-model framework.
3.1 Asymptotic approximation takes time to hold
In this subsection, we consider the i.i.d. case.777For every , is identical, hence denoted . To simplify notations, we also denote by a random vector following . Under Assumption 1, asymptotic confidence intervals are easily obtained combining the multivariate central limit theorem (CLT) and the delta method:
[TABLE]
where and in practice is replaced by a consistent estimate (Slutsky’s lemma).
To assess the quality of the CI based on (1), we compute its using simulations for different sample sizes and distributions and compare it to the nominal level. By definition, the pointwise coverage forms an upper bound on the uniform coverage. In our simulations, we choose the level . For different sample sizes and values of , we draw 5,000 i.i.d. samples of size following . We compute for the interval based on the delta method for every pair using the 5,000 replications. The expectation ranges from (the denominator is close to [math]) to (the denominator is far from [math]). Figure 1 sums up the results. For every , it turns out that the closer to [math], the smaller the of the delta method. When , we observe that gets close to the nominal level only for above 300,000. Additional simulations indicate that the phenomenon is robust across different choices of the distribution (see Section D).
3.2 Asymptotic results may not hold in the sequence-of-model framework
Unlike the result displayed in (1), it is unclear how behaves asymptotically when we consider sequences of models such that the expectation in the denominator tends to [math] as increases. For a given specification, Figure 2 shows the of the CIs based on the delta method when where is set to and varies. For a speed (i.e. faster than the usual rate of the CLT), the pointwise coverage of the asymptotic CIs obtained by (1) is not good in the sense that it is far lower than the nominal level and it does not converge to the latter. Our simulations even suggest that the coverage tends to [math] for . For , the upper bound on the coverage of the delta method seems to tend to . Yet, in line with Figure 1, the validity of the asymptotic approximation requires very large sample sizes.
At this stage, Figure 2 presents some evidence that the CIs based on the delta method need to be adapted for sequences of models and that the rate of decrease toward [math] of the expectation matters. The next subsection details formal results in this set-up.
3.3 Extension of the delta method for ratios of expectations in the sequence-of-model framework
We are interested in the asymptotic distribution, as tends to infinity, of the real random variable . The following theorem states the asymptotic behavior of according to the comparison of and under a multivariate Lyapunov condition. It is proved in Section B.1.
We show that in some cases . It is then impossible to state the limiting distribution in the traditional sense. Despite that, we can still get a more precise result looking at the subsequent terms in the asymptotic expansion of . Such an asymptotic expansion is complicated to state, especially in our sequence-of-model framework, since the distributions change with without any link from one to the next. To overcome this problem, we consider equivalents in distribution of in the following sense. We say that two sequences of random variables and are equivalent in distribution if there exist a probability space and two sequences of random variables such that , and , and is equivalent to almost surely as . This means that for almost every , is equivalent to (considered as deterministic sequences of real numbers). This notion enables to formalize the link between and a simpler expression .
Theorem 3.1**.**
Let Assumption 1 hold and (i) as for some positive sequences and where is a definite positive matrix, (ii) , and (iii) as .
Denote the signal-to-noise-ratio by .
Then, the sequence of random variables satisfies as :
If , then is equivalent in distribution to:
[TABLE] 2. 2.
If there exists a finite constant such that , then is equivalent in distribution to:
[TABLE] 3. 3.
If , then is equivalent in distribution to:
[TABLE]
Theorem 3.1 can thus be interpreted as a generalization of the result given by the CLT and the delta method for ratios of expectations. The sequence-of-model framework allows both the expectation and the variance in the denominator to tend to [math]. In particular, this happens whenever follows a Bernoulli distribution with a parameter tending to [math], as detailed in Example 3.2. For instance, when we estimate a conditional expectation with a discrete conditioning variable or a conditioning event, the denominator is an average of indicator variables that follow a Bernoulli distribution. Figure 3 and its companion table highlight the different asymptotic regimes depending on the behaviors of , , and .
The main takeaway of Theorem 3.1 is that when , and for some constants , and , properly renormalized by to some power still converges in distribution to a Normal random variable. This can be explained using the signal-to-noise ratio (SNR) defined in Theorem 3.1. Indeed, in this first case, the tends to : the signal in the denominator (that is the expectation of ) is asymptotically bigger than the noise (which is up to a constant factor). Asymptotic inference based on the Normal approximation remains valid, even if the length of such confidence intervals may not decrease with the sample size .
In all other cases, when the noise dominates in the denominator, converges weakly to a non-Gaussian distribution, in some cases to a generalized Cauchy distribution with parameters that depend on the data generating process (up to a normalization of some power of ). By construction, when the noise dominates, we do not have much information and thus may not be able to conduct inference in these settings. This echoes the impossibility results presented in Section 5, notably Remark 5.3. In the next section, we provide another method for constructing confidence intervals using the nonparametric percentile bootstrap.
Example 3.2**.**
When follows a Bernoulli distribution with parameter in , we are always in the first case of Theorem 3.1, meaning that its expectation is always larger than the noise . This latter formula is obtained by remarking that the standard deviation of is so that . However, in order to satisfy the constraint , we have to impose that . Therefore, when , confidence intervals based on the delta method will be pointwise consistent if .
3.4 Validity of the nonparametric bootstrap for sequences of models
In this part, we construct confidence intervals for ratios of expectations using Efron’s percentile bootstrap. This technique relies on the nonparametric bootstrap resampling scheme that we now recall. We fix a number of bootstrap replications. For a given initial sample , and a given integer smaller than , we define the bootstrapped sample , which is obtained by i.i.d. resampling from the initial sample, i.e. with replacement. Let be the empirical mean of the numerator in the -th bootstrapped sample (resp. for the denominator).
Then, Efron’s percentile bootstrap, also known as the nonparametric percentile bootstrap, consists in using the quantiles of the bootstrapped distribution conditional on the data to conduct inference. More precisely, for every , let denote the quantile at level of , which is estimated in practice by the empirical quantile at level of the bootstrapped statistics \big{(}\overline{X}_{n}^{(b)}/\,\overline{Y}_{n}^{(b)}\big{)}_{b=1,\ldots,B}. For a given nominal level , the confidence interval we consider is defined as C_{n,\alpha}^{boot}:=\big{[}q_{\alpha/2}^{boot}\,,\,q_{1-\alpha/2}^{boot}\big{]}. The following theorem states the consistency of this interval. It is proved in Section B.2.
Theorem 3.3**.**
Let Assumption 1 hold and (i) as for some positive sequences and where is a definite positive matrix, (ii) {\sup_{n\in\mathbbm{N}^{*}}\mathbbm{E}\Big{[}(\gamma_{X,n}X_{1,n})^{4+\delta}+(\gamma_{Y,n}Y_{1,n})^{4+\delta}\Big{]}<+\infty} for some , (iii) as , and (iv) as .
Denote the signal-to-noise-ratio by .
If , then for every , the confidence interval is pointwise consistent at level , viz. \mathbbm{P}\big{(}C_{n,\alpha}^{boot}\ni\mathbbm{E}[X_{1,n}]/\,\mathbbm{E}[Y_{1,n}]\big{)}\to 1-\alpha\text{ as }n\to\infty.
The assumption is satisfied for a large set of cases, for instance when the variables are continuous or when they follow a Bernoulli distribution with a parameter decreasing to [math] not too fast (see Example 3.4 below).
Note that the moment condition of order is nearly sharp. Indeed, the proofs require the strong law of large numbers for and . As we are dealing with a triangular array of random variables, Theorem 3.1 of [8] shows that moments of order at least are necessary, even in the simpler case where the distribution does not depend on .
Example 3.4** (Example 3.2 continued).**
When follows a Bernoulli distribution with parameter for a given , the condition is satisfied when . We refer the reader to Section B.3 for a proof of this claim.
In practice, even if the theoretical results of the delta method and of the bootstrap are valid under nearly the same set of assumptions, we observe in the simulations in Figure 4 a gap between their pointwise coverage.888Additional simulations comparing the two types of asymptotic confidence intervals are presented in Appendix D.7. This fact appears even when does not depend on (i.e. . Nonetheless, the coverage gap between these two methods shrinks as increases provided . In the sequence of models where the denominator decreases slowly (i.e. ) in Figure 4, the bootstrap’s coverage is much higher than the one of the delta method. Therefore, the CI provided by the nonparametric percentile bootstrap may be an interesting alternative compared to the delta method when conducting inference with a given sample. This is all the more so as the mean in the denominator is close to [math] (in Figure 4, of the size of for a variance normalized to ) and the number of observations is moderately large (a few thousands here).
4 Construction of nonasymptotic confidence intervals for ratios of expectations
To construct nonasymptotic confidence intervals, we rely on the possibility to ensure that with large probability (i) is close to , and (ii) is both close to and bounded away from 0. Under Assumptions 1 and 2, the Bienaymé-Chebyshev inequality can be applied to obtain (i) and (ii). On the other hand, without further restrictions, we are only able to build nonasymptotic CIs at nominal levels that are not too close to (see Section 4.2).
This limitation does not arise with nonasymptotic confidence intervals for expectations. In that sense, we can say that building nonasymptotic CIs for ratios of expectations is more demanding. Intuitively, the extra difficulty of the latter task comes from the need to ensure (ii). To stress that point, we show in the next subsection that when is bounded away from [math] and positive almost surely, we can build nonasymptotic CIs at every nominal level.
4.1 An easy case: the support of the denominator is well-separated from [math]
We present a simple framework in which it is possible to build nonasymptotic CIs, valid for every , and with coverage for every . To do so, we restrict further the set of admissible distributions with the following assumption.
Assumption 3**.**
*For every , there exists a positive finite constant such that almost surely. *
Under Assumption 3, for every , almost surely under every distribution in and is bounded from above. This assumption obviously rules out binary random variables in the denominator of the ratio, which can be quite restrictive in practice. Under this assumption, the following theorem gives a concentration inequality for our ratio of expectations. It is proved in Section B.4.
Theorem 4.1**.**
*Let Assumptions 1, 2 and 3 hold. For every , , we have *
[TABLE]
As a consequence, \inf_{P\in\mathcal{P}}\mathbbm{P}_{P^{\otimes n}}\Big{(}\mathbbm{E}[X_{1,n}]/\,\mathbbm{E}[Y_{1,n}]\in\left[\,\overline{X}_{n}/\,\overline{Y}_{n}\pm t\right]\Big{)}\geq 1-\alpha, with the choice
[TABLE]
for every .
The theorem shows that it is possible to construct nonasymptotic CIs for ratios of expectations, with guaranteed coverage at every confidence level, that are almost surely bounded under every distribution in characterized by Assumptions 1, 2 and 3. In Section 4.2, we give an analogous result that only requires Assumptions 1 and 2 to hold, so that it encompasses the case of -valued denominators. However, the cost to pay will be an upper bound on the achievable coverage of the confidence intervals.
4.2 General case: no assumption on the support of the denominator
We seek to build nontrivial nonasymptotic CIs under Assumptions 1 and 2 only. Under Assumption 1, , so that there is no issue in considering the fraction . However, without Assumption 3, has positive probability in general so that is well-defined with probability less than one. Note that when is continuous with respect to Lebesgue’s measure, there is no issue in defining anymore since the event has probability zero. This is not an easier case from a theoretical point of view though since, without more restrictions, can still be arbitrarily close to [math] with positive probability.
Theorem 4.2**.**
Let Assumptions 1 and 2 hold. For every , , we have
[TABLE]
As a consequence, \inf_{P\in\mathcal{P}}\mathbbm{P}_{P^{\otimes n}}\Big{(}\mathbbm{E}[X_{1,n}]/\,\mathbbm{E}[Y_{1,n}]\in\left[\,\overline{X}_{n}/\,\overline{Y}_{n}\pm t\right]\Big{)}\geq 1-\alpha, with the choice
[TABLE]
for every .999Equivalently, it means that for a given , the above choice of is valid for every integer .
This theorem is proved in Section B.5. It states that when , it is possible to build valid nonasymptotic CIs with finite length up to the confidence level . This is a more positive result than [7] which states that it is not possible to build nontrivial nonasymptotic CIs when is taken equal to 0, no matter the confidence level. Note that Theorem 9 is not an impossibility theorem since it only claims that considering confidence levels smaller than is sufficient to build nontrivial CIs under Assumptions 1 and 2. The remaining question is to find out whether it is necessary to focus on confidence levels that do not exceed a certain threshold under Assumptions 1 and 2. We answer this in Section 5.1.
Theorem 9 has two other interesting consequences: for every confidence level up to , a nonasymptotic interval of the form with has coverage but is unnecessarily conservative. Moreover, if the data generating process does not depend on (i.e. in the standard i.i.d. set-up), the length of the confidence interval shrinks at the optimal rate for every fixed . Note that the coefficient in the definition of defined above can be reduced to any number , at the expense of increasing the length of the confidence interval (this length actually tends to infinity when tends to ).
5 Nonasymptotic CIs: impossibility results and practical guidelines
In this section, we prove two impossibility results: a maximum confidence level above which it is impossible to build nontrivial nonasymptotic CIs and a necessary lower bound on the length of nonasymptotic CIs.
5.1 An upper bound on testable confidence levels
Proposition 5.1**.**
Let be the class of all distributions satisfying Assumptions 1 and 2 and \underline{\alpha}_{n}:=\big{(}1-l_{Y,n}^{2}/u_{Y,n}\big{)}^{n}. For every and every , if , there is no finite such that has coverage over .
This theorem asserts that confidence intervals of the form with coverage higher than under Assumptions 1 and 2 are not defined (or are of infinite length) with positive probability for at least one distribution in . This is due to the fact that is a lower bound on over all distributions in .
Remark that when , there is no impossibility result anymore: assume that and let be a distribution on that satisfies Assumptions 1 and 2. Let . We have that , which implies that almost surely. Assumption 1 further ensures that almost surely. Consequently, the results of Section 4.1 apply and allow us to conclude that under Assumptions 1, 2 and , it is possible to build nontrivial nonasymptotic CIs at every confidence level. Indeed, in that case, we are in fact only estimating a simple mean, and therefore there is no constraint on .
Proposition 5.1 is actually a corollary of the more general Theorem 5.2. It states it is impossible to construct confidence intervals that contain almost surely and are almost surely bounded over with coverage greater than . It is proved in Section B.6.
Theorem 5.2**.**
Let be the class of all distributions satisfying Assumptions 1 and 2. Let , and a random set that contains almost surely whenever it is defined and is undefined if . Then \sup_{P\in\mathcal{P}}\mathbbm{P}_{P^{\otimes n}}\big{(}I_{n}\,undefined\big{)}\geq\underline{\alpha}_{n}.
Combining Theorems 9 and 5.2, we conclude that there exists some critical level belonging to the interval such that it is impossible to build nontrivial nonasymptotic confidence intervals if and only if their nominal level is above . Finally, it is worth remarking that with a sample of size , the CIs based on the delta method with a nominal level cannot have coverage uniformly over as such CIs verify the condition of Theorem 5.2.
Figure 5 below shows the critical level and its bounds obtained in our nonasymptotic results.
Remark 5.3**.**
*In the same spirit as in Theorem 3.1, we consider a modified version of the signal-to-noise ratio defined by . When resp. as , and tend to [math] resp. . When we have enough information , the critical level tends to . Therefore, for every , nonasymptotic confidence intervals can be constructed at every level for large enough. On the contrary, when , the critical level tends to [math], which means that it is impossible to construct uniformly valid CIs for large enough. Finally, when for a positive constant , a critical level remains as in the nonasymptotic case since . *
5.2 A lower bound on the length of nonasymptotic confidence intervals
The following theorem is an extension of [6][Proposition 6.2] to ratios. It is proved in Section B.7.
Theorem 5.4**.**
For every integer , \alpha\in\big{(}0,1\,\wedge\,n/\big{(}l_{Y,n}+\sqrt{u_{Y,n}-l_{Y,n}^{2}}\big{)}^{2}\big{)}, and there exists a distribution on that satisfies Assumptions 1 and 2 such that for , we have
[TABLE]
where v_{n}:=u_{X,n}/\big{(}l_{Y,n}+\sqrt{u_{Y,n}-l_{Y,n}^{2}}\big{)}^{2}.
With this theorem, we can claim that CIs of the form cannot have uniform coverage , for every \alpha\in\big{(}0,1\wedge n/\big{(}l_{Y,n}+\sqrt{u_{Y,n}-l_{Y,n}^{2}}\big{)}^{2}\big{)}, under Assumptions 1 and 2 if they are shorter than . By a careful inspection of the proof (see Lemma B.6), we can in fact replace the value in the theorem by any number strictly larger than , at the price of assuming for large enough. It is interesting to note that the distributions that are built in the proof of the theorem are on the boundary of in the sense that they satisfy , and .
5.3 Practical methods and plug-in estimators
Nonasymptotic confidence intervals and the thresholds and based on Theorem 4.2 rely on Assumptions 1 and 2. In practice, building such CIs or computing those thresholds require the knowledge of the constants , and that determine the class of distributions we consider.101010Actually, the computation of and only require the knowledge of and . Therefore, we need to state some values for those constants. Note that constructing nontrivial and nonasymptotic CIs that overcome the limitations of having to choose some a priori class of distributions is not possible. Indeed, we would get back to [3] and [7] type impossibility results.
How to choose , and depends on the specific application. Sometimes, stating values can be sensible if researchers do have control or expert knowledge of the variables. Resuming an example started in the introduction, if the variable in the denominator is an indicator of being treated in the setting of a Randomized Controlled Trial, researchers can have intuitions about reasonable values for the lower and upper bounds of the probability of being treated.
The unknown constants are upper and lower bounds on moments that characterize the class . As such, they can never be recovered from the data since observations are by construction drawn from a single distribution . Under i.i.d. sampling, sample means converge to their corresponding theoretical moments, provided the latter are finite. Hence, without prior information, a plug-in strategy has to be used which consists in: (i) using the moments of a single distribution instead of the bounds on the class, (ii) estimating those moments with their empirical counterparts. As a consequence, this approach is valid pointwise only and not uniformly over anymore. Furthermore, it is only asymptotically justified. On the other hand, for any sample provided , this plug-in strategy enables us to construct our CIs and the quantity (or ), which can be a useful rule of thumb as explained below. We stick to that principle in our simulations and application.
For a given level and a class of distributions satisfying Assumptions 1 and 2, is the minimal sample size required to construct our nonasymptotic CIs. In other words, for a sample size , the data is not rich enough to construct the nonasymptotic CIs of Theorem 9 at this level. Heuristically, the comparison of and can be used as a rule of thumb to assess whether the coverage of the CIs based on the delta method matches their nominal level.111111Equivalently, we could compare and . As a rule of thumb, can be seen as the lowest (hence the highest nominal level ) for which the asymptotic CIs based on the delta method are reliable given the sample size . Several simulations tend to confirm the practical interest of that rule of thumb as turns out to be very close to the sample size above which the gap between the coverage of the asymptotic CIs based on the delta method and their nominal level becomes negligible. (see Section 6.1 and Appendix D).
6 Numerical applications
6.1 Simulations
This section presents simulations that support the use of , or equivalently , as a rule of thumb to inspect the reliability of the asymptotic confidence intervals from the delta method.
In Figure 6, a nominal level is fixed and we show the of the CIs based on the delta method as a function of the sample size , as well as derived in Theorem 4.2. It happens that the coverage converges toward its nominal level for sample sizes around , which supports as a rule of thumb of interest in practice.121212This fact holds across various specifications (see additional simulations in Appendix D). In Figure 7, a sample size is fixed and we show the coverage for different nominal levels, as well as the quantity . It is the converse of Figure 6 in that sense. In this simulation, turns out to fall close to the lowest (hence highest ) for which the coverage of the CIs based on the delta method attains their nominal level.
All in all, Figures 6 and 7 and additional simulations advocate the use of derived in Theorem 4.2 (or conversely ) as a rule of thumb to appraise the dependability of the CIs obtained with the delta method for ratios of expectations.
6.2 Application to real data
We illustrate our methods with an application related to gender wage disparities. The application resumes our canonical example of conditional expectations since we estimate the proportion of women within wage brackets that are defined as having a wage higher than a given threshold. We use 204,246 observations from the French Labor Survey data between 2010 and 2017.131313Enquête Emploi en continu (version FPR) – 2010-2017, INSEE [producteur], ADISP [diffuseur].
Let be a real random variable that indicates the wage of an employee (expressed in euros per month) and an indicator variable equal to if the employee is a woman and [math] otherwise. For a given threshold wage , the parameter of interest is . It can be written as a ratio of expectations with in the numerator and in the denominator. As we consider higher thresholds , the expectation in the denominator gets closer to [math]. As an illustration, out of 204,246 observations, individuals have monthly wages higher than 10,000 euros (which corresponds to a mean in the denominator equal to ); individuals above 20,000 (); and only above 30,000 ().141414To give a sense of the wage distribution, note that the empirical quantiles of at orders 90%; 95%; 99%; and 99.99% are respectively: 2,989; 3,728; 6,000; and 26,024.
For various thresholds , Figure 8 presents the estimate and two 95%-nominal-level confidence intervals for the parameter : the one based on the delta method (see Section 3.1) and the one using Efron’s percentile bootstrap (see Section 3.4). With higher thresholds, the expectation in the denominator is closer to [math] which results in wider confidence intervals. For very high thresholds, the CIs become hardly informative. In particular, the lower end of the interval based on the delta method is negative whereas the parameter of interest belongs to by construction.
The dashed vertical line relates to our rule of thumb introduced in Section 5.3. More precisely, given the level , for each threshold , we compute the plug-in counterpart of defined in Theorem 4.2: 2\left(n^{-1}\sum_{i=1}^{n}Y_{i}^{2}-\overline{Y}_{n}^{2}\right)/\big{(}\alpha\overline{Y}_{n}^{2}\big{)}. Given that is a binary variable, the latter quantity is increasing with and exceeds at some threshold represented by the dashed vertical line (here a little above 20,000). Consequently, for higher thresholds, our rule of thumb suggests that the confidence intervals obtained with the delta method might undercover as the expectation in the denominator is “too close to [math]” relative to the number of observations. Actually, in the application, it is around this vertical line that the two CIs start to differ. In particular, the upper end of Efron’s percentile confidence interval becomes larger than the upper end of the interval based on the delta method.
7 Conclusion
This paper studies the construction of confidence intervals for ratios of expectations, which are frequent parameters of interest in applied econometrics.
The most common method to do so is asymptotic and yields CIs based on the asymptotic normality of the empirical means that estimate the numerator and the denominator combined with the delta method. We document on simulations that the coverage of the confidence intervals based on the delta method may fall short of their nominal level when the expectation in the denominator is close to [math], even with fairly large sample size.
To further study the reliability of those CIs, we use a sequence-of-model framework, analogous to what a strand of the weak IV literature does. Indeed, it enables to consider limiting cases, namely here denominators tending to [math]. In the weak IV case, the equivalent is to move closer to a null covariance between the endogenous regressor and the instrument. At the limit, the coefficient of interest is not identified. Our problem differs since the parameter is not even defined in the problematic case of a null denominator. This issue underlies the impossibility type results presented in the paper.
First, in an asymptotic perspective, the possibility of a denominator arbitrarily close to [math] explains why we need a sufficiently slow rate of convergence of the expectation in the denominator to [math] to conduct meaningful inference. More precisely, our main asymptotic results basically show that the CIs based on the delta method are valid, as well as those obtained by Efron’s percentile bootstrap, when this speed is lower than (the standard speed of the CLT). Furthermore, on simulations, Efron’s percentile bootstrap CIs reach their nominal level sooner (namely for smaller sample sizes) than the CIs based on the delta method. It suggests that beyond the sequence-of-model rationalization, when confronted in practice to a mean in the denominator close to [math] relative to the size of the sample at hand, Efron’s percentile bootstrap CIs may be more trustworthy than the delta method’s ones.
Obviously, those cases where the coverage of the CIs based on the delta method can be well below their nominal level do not self-signal to practitioners. This is why the second part of the paper proposes a rule of thumb to detect those cases and thus assess the dependability of the asymptotic CIs based on the delta method on finite samples. This index is based on the construction of nonasymptotic confidence intervals and on impossibility results that stem from the problematic null denominator case.
In substance, even if we bound away from [math] the expectation in the denominator, there remains a partial impossibility result. Indeed, we show that there exists a critical nominal level above which the coverage of any nonasymptotic confidence interval that is undefined when cannot uniformly attain its target level. More precisely, we derive explicit upper and lower bounds on this critical level as a function of the characteristics of the considered class of distributions. Then, the heuristic of our rule of thumb consists in estimating by plug-in a lower bound on this critical level (or equivalently, for a given level, an upper bound on the minimal required sample size). The resulting index can thus be computed immediately on any sample. In addition to its theoretical foundations, various simulations and an application to real data attest the practical usefulness of this rule of thumb.
This paper can be seen as a first step towards nonasymptotic inference in econometric models where the issue of close-to-zero denominators arises. Notable examples may include weak IV, Wald ratios, and difference-in-difference estimands.
Appendix A General definitions about confidence intervals
A standard situation in statistics or econometrics can be modelled as the observation of a sample of i.i.d. observations valued in some measurable space . The statistical model is therefore with some specified set of distributions on . For every distribution , let be a parameter of interest and the map be valued in a metric space .
We denote by a confidence set for . Formally, a confidence set can be defined as a measurable map from to the measurable space , where is the family of all closed subsets of and is the sigma-algebra generated by for running through the family of compact subsets of .
As the vocabulary may somewhat fluctuate between authors, we define below classical objects to fix the notations and terminology used in this paper. The goal is to build confidence sets for a targeted confidence level (also termed nominal level of the confidence set). For , for , we say that a confidence set or a sequence of sets has:
- i.
coverage over if:
[TABLE] 2. ii.
size over if the inequality is an equality:
[TABLE] 3. iii.
asymptotic coverage pointwise over if:151515Respectively pointwise asymptotic size when the inequality is replaced by an equality.
[TABLE] 4. iv.
asymptotic coverage uniformly over if:161616Respectively uniform asymptotic size when the inequality is replaced by an equality.
[TABLE]
A confidence set with coverage but size different from over is said to be conservative over 171717Similarly, a confidence set is said to be asymptotically conservative pointwise over (respectively uniformly over ) if property iii. (resp. property iv.) holds with a strict inequality.. We further define a nontrivial confidence set as a confidence set that is almost surely strictly included in (whenever it is defined) under every distribution in . For instance, if is the expectation under , and is the set of all distributions that admit a finite expectation, a nontrivial CI is any CI that is almost surely bounded under every distribution in . For ratios of expectations, too and we will use the term almost surely bounded as a synonym of nontrivial, without stating “under every distribution in ” when there is no ambiguity as regards the class considered.
A family of confidence intervals is said to be pointwise (resp. uniformly)* consistent* if for every , the sequence has pointwise (resp. uniformly) asymptotic coverage at level .
Appendix B Proofs of the results in Sections 3, 4 and 5
B.1 Proof of Theorem 3.1
Let , . Let and be the centered and normalized versions of and . We first rewrite Theorem 3.1 using this notation.
Theorem B.1**.**
Let Assumption 1 hold. Assume that for some positive sequences and where is a definite positive matrix, that , as and that
Then the sequence of random variables satisfies as :
If , then is equivalent to
[TABLE] 2. 2.
If there exists a finite constant such that as , then is equivalent to
[TABLE] 3. 3.
If , then is equivalent to
[TABLE]
Let us define and remark that whenever . By assumption , therefore . Moreover, by Lyapunov’s central limit theorem applied to
[TABLE]
using and the boundedness of \mathbbm{E}\big{[}|X_{1,n}|^{3}\big{]}\gamma_{X,n}^{3} and \mathbbm{E}\big{[}|Y_{1,n}|^{3}\big{]}\gamma_{Y,n}^{3}, we obtain . We also obtain by Slutsky’s Lemma. We can therefore apply Skorokhods’s almost sure representation theorem, see [13, Theorem 2.19]. It means that there exists a probability space , a sequence of random vectors such that for every , , and a random vector following the distribution such that , where the convergence is to be seen as of a sequence of random vectors defined on . Let us define
[TABLE]
Moreover, we have and almost surely. We can define
[TABLE]
By the almost sure convergence of , we get , and for every , and for every large enough. This means that for every given , and for every large enough, is well-defined. In the rest of the proof, we will fix such a , so that all random variables may be considered as deterministic. By the almost sure representation theorem, this means that the equivalents and limits that will be obtained will still be valid in law in the original spaces .
**First case: ** We have
[TABLE]
as claimed.
**Second case: ** We have
[TABLE]
We factorize by in the latter expression, which completes the proof.
**Third case: ** We have
[TABLE]
and the result follows from the fact that is negligible compared to .
B.2 Proof of Theorem 3.3
For , let (resp. ), and , where is the -th bootstrap replication of (resp. ).
Lemma B.2**.**
We have
By the Central Limit Theorem, we have with and by Lemma B.2 (proved in Section B.2.1) and the triangle inequality, we get . Combining both results, Lemma 2.2 in [5] gives us
[TABLE]
Let us define and remark that whenever . By assumption , therefore we have . We define also so that whenever . In the same way as previously, holds by assumption. Let be a random vector of size , and let be a random vector of size following .
By Slutsky’s lemma, we have with our new notation. Using Skorokhods’s almost sure representation theorem [13, Theorem 2.19], there exists a probability space , a sequence of random vectors and a vector defined on such that , and . Let us use the notation
[TABLE]
where are random vectors of dimension and are random vectors of dimension . We define
[TABLE]
and respectively their counterparts and defined on . The following lemma, proved in Section B.2.2, ensures the existence of an event of probability on which every quantity is well-defined.
Lemma B.3**.**
There exists an event such that and such that for every , and for all large enough, , , and , and are well-defined.
In the next step, we fix and let and
[TABLE]
We restrict ourselves to the case . Theorem 3.1 therefore yields
[TABLE]
Furthermore, the same tools as those used in the proof of Theorem 3.1 plus the fact that imply
[TABLE]
We can also remark that when
[TABLE]
When \theta_{X,n}+h_{X,n}^{+}(\omega)/(\sqrt{n}\gamma_{X,n})=O\big{(}h_{X,n}^{+}(\omega)/(\sqrt{n}\gamma_{X,n})\big{)}, we have and we find again that
[TABLE]
Let (resp. , and ), which corresponds to the dominant terms in Equations (4), (7) and (8) above. By construction of and , we have , so that the continuous mapping theorem ensures that , where for every , we define where (resp. ) is the first (resp. second) component of the vector . Combining the triangle inequality, Equations (4), (7) and (8), we get
[TABLE]
Using the fact that for all we obtain
[TABLE]
Therefore, d_{BL}\Big{(}P_{\big{(}\sigma_{n}A_{n},\,\sigma_{n}A_{n}^{(1)},\,\sigma_{n}A_{n}^{(2)}\big{)}}\,,\,P_{U_{1}^{+}}^{\otimes 3}\Big{)}\to 0 as and . Applying Lemma 2.2 of [5], we can conclude that
[TABLE]
The conclusion follows from Lemma 23.3 in [13].
B.2.1 Proof of Lemma B.2
Let , and denote for and its bootstrap counterpart. Let also and . We start by showing that for every , converges weakly to almost surely conditionally on in the sense of the Lévy criterion for weak convergence, i.e.
[TABLE]
To do so, we have to check the steps of the proof of Theorem 23.4 in [13]. We have
[TABLE]
The first requirement is to ensure almost sure convergence to [math] of both quantities and . Under the assumption that , observe that all the conditions of Theorem 2.2 in [8] are satisfied with . We can thus conclude that and . Now using the fact that
[TABLE]
as well as and , to conclude that .
The second requirement is to check the Lindeberg condition for the bootstrap which writes
[TABLE]
Let be some function of to be defined later that does not depend on and satisfies . For such a function, there exists for every , a such that for every ,
[TABLE]
By the triangle inequality,
[TABLE]
The first term in the upper bound converges to 0 almost surely for every under the assumption thanks to Theorem 2.2 in [8]. The second term in the upper bound can be bounded with the Cauchy-Schwarz and Markov inequalities
[TABLE]
Picking , we get that for every
[TABLE]
Letting go to 0, we see that the Lindeberg condition is satisfied. This entails that (9) is satisfied.
Arguments underpinning the Cramer-Wold device are valid as well so that we can claim that for every
[TABLE]
where S_{n}^{(1)}:=\sqrt{n}\Bigg{(}\gamma_{X,n}\left(\overline{X}_{n}^{(1)}-\overline{X}_{n}\right),\gamma_{Y,n}\left(\overline{Y}_{n}^{(1)}-\overline{Y}_{n}\right)\Bigg{)}.
Let be the set of probability one on which (10) occurs. For every ,
[TABLE]
is a sequence of nonrandom probability measures for which all weak convergence criteria are equivalent. In particular, for every , the validity of the Lévy criterion due to (10) ensures that
[TABLE]
This is enough to conclude.
B.2.2 Proof of Lemma B.3
The vector \big{(}W_{n}^{+},W_{n}^{(1)+},W_{n}^{(2)+}\big{)} converges almost surely to . As a consequence, there exists an event of probability such that \forall\omega\in\tilde{\Omega}^{1},\,\big{(}W_{n}^{+}(\omega), W_{n}^{(1)+}(\omega),W_{n}^{(2)+}(\omega)\big{)}=(0,0,0) for large enough. As \big{(}h_{Y,n}^{+},h_{Y,n}^{(1)+},h_{Y,n}^{(2)+}\big{)} converges almost surely to a continuous vector, there exists an event of probability such that , the components of \big{(}h_{Y,n}^{+}(\omega),h_{Y,n}^{(1)+}(\omega),h_{Y,n}^{(2)+}(\omega)\big{)} are all non-zero for large enough. We finally define , which is of probability and satisfies the stated conditions.
B.3 Proof of Example 3.4
We have
[TABLE]
where . Therefore, for any ,
[TABLE]
Let \tilde{S}_{n}:=\big{(}S_{n}-n(1-p_{n})\big{)}/\sqrt{np_{n}(1-p_{n})}=O_{P}(1) be the renormalized version of and choose for . Then
[TABLE]
which completes the proof.
B.4 Proof of Theorem 4.1
We fix arbitrary and . Combining the triangle inequality, the bound and Assumptions 1 to 3, we get
[TABLE]
Consequently, the event considered in Theorem 4.1 is included in the event
[TABLE]
If both and are inferior or equal to , event (B.4) cannot happen. By contraposition, we obtain:
[TABLE]
where we use the union bound for the last inequality. The first conclusion follows from using twice Bienaymé-Chebyshev’s inequality applied to the variables and and the fact that under Assumptions 1 and 2 and Jensen’s inequality, and . The second conclusion follows from solving .
B.5 Proof of Theorem 4.2
We start by introducing and proving an intermediate lemma that is also used to prove Theorem 19. For a random variable , , and we define the following events:
[TABLE]
Lemma B.4**.**
Assume that Assumption 1 holds. Then for every , and , we have
[TABLE]
We fix arbitrary , and . By Lemma B.4, we have
[TABLE]
Using Jensen’s inequality and Assumption 2, we have , and Assumption 1 entails . Consequently, we get
[TABLE]
Using Bienaymé-Chebyshev’s inequality twice gives the bounds
[TABLE]
For the numerator, using Assumption 2. For the denominator, Assumption 1 immediately entails that is an upper bound on and a lower bound on . Therefore
[TABLE]
where the second inequality uses Assumption 2.
Combining the two bounds yields the following upper bound on the probability considered in Theorem 4.2
[TABLE]
as claimed.
For the second part of Theorem 4.2, for a fixed , we equalize each of the two terms in (12) to and solve for and , which yields:
[TABLE]
The bound comes from the fact that needs to be smaller than .
B.5.1 Proof of Lemma B.4
We fix arbitrary and . Without loss of generality, we can assume that and .
First, using the union bound, note that the event holds with a probability bigger than . Hence, its complement is of probability lower than .
Second, we show that the event considered in Lemma B.4 is included in the complement of , which concludes the proof. To do so, we reason by contraposition and do the following computations on the event .
By the triangle inequality, we get
[TABLE]
We now bound the first term using the mean value theorem applied to the function
[TABLE]
where the first inequality uses the following observation: on the event , a lower bound on with varying between [math] and is . Therefore, on ,
[TABLE]
where we use the triangle inequality to get the second line. It is indeed the complement of the event considered in the statement of Lemma B.4.
B.6 Proof of Theorem 5.2
This theorem relies crucially on the following lemma.
Lemma B.5**.**
For each in the interval \Big{(}0,1\wedge\big{(}u_{Y,n}/l_{Y,n}^{2}-1\big{)}\Big{)}, there exists a distribution such that where \tilde{\alpha}_{n}(\xi):=\big{(}1-(1+\xi)l_{Y,n}^{2}/u_{Y,n}\big{)}^{n}.
Note that the interval \Big{(}0,1\wedge\big{(}u_{Y,n}/l_{Y,n}^{2}-1\big{)}\Big{)} is not empty since we have assumed .
By Lemma B.5, for every \xi<1\wedge\big{(}u_{Y,n}/l_{Y,n}^{2}-1\big{)}, there exists a distribution such that Taking the supremum over , we deduce that
[TABLE]
Using the assumption that is undefined whenever , we deduce that \mathbbm{P}\big{(}I_{n}\,undefined\big{)}\geq\underline{\alpha}_{n}.
B.6.1 Proof of Lemma B.5
We consider the following distribution on
[TABLE]
where is some constant to be chosen later, and . Let . Observe that and \mathbbm{E}[Y_{1,n}^{2}]=l_{Y,n}^{2}(1+\xi_{n})/\big{(}1-(c/n)^{1/n}\big{)}. With the choice
[TABLE]
we have . Note that is strictly positive, because is positive. This is equivalent to , which is true by assumption.
Consider now the following product measure on defined by Let . These random vectors satisfy , and . The next step is to build a lower bound on the event .
The assumption that and the construction of imply that
[TABLE]
B.7 Proof of Theorem 5.4
To prove Theorem 5.4, we need the following lemma.
Lemma B.6**.**
For every integer and every , .
We start using arguments developed in the proof of [6][Proposition 6.2]. We detail those for the sake of clarity. For every and , let us define the following distribution on , which will be used for the variable in the numerator181818The notation denotes the Dirac distribution.:
[TABLE]
This distribution is symmetric, centered and has variance . As shown in [6], every i.i.d. sample drawn from satisfies
[TABLE]
Note further that for every integer , becomes a strict inequality strict and for every . As a result, if , for every , we have
[TABLE]
The following steps do not show up in [6] since they are specific to controlling ratios of expectations and sample averages. For every , let us define the following distribution on , which will be used for the variable in the denominator
[TABLE]
Let . Observe that and . Furthermore, almost surely. This implies that for every and , the following holds
[TABLE]
For fixed and , we choose . Combining the above inclusion with (13), and Lemma B.6 (with the choice ), we conclude that there exists a distribution on , namely , that fulfills Assumptions 1 and 2 such that
[TABLE]
which completes the proof.
B.7.1 Proof of Lemma B.6
Under our assumptions on and , is well-defined. Using Taylor-Lagrange formula on the function yields:
[TABLE]
for some . Using the fact that , and , we get that under our assumptions . This bound is actually valid for every and every . The computation of shows that the latter is larger than whenever and larger than whenever .
Appendix C Adapted results for “Hoeffding” framework
Assumption 4**.**
For every , there exist finite constants , , , and such that (respectively ) lies -almost surely in the interval (resp. ) and .
The support of and is allowed to change with , even though in many examples of interest, the former can be chosen independent from . Assumptions 1 and 4 together correspond to the Hoeffding case because under these two assumptions, we can use the Hoeffding inequality to build nonasymptotic CIs.
C.1 Concentration inequality in an easy case: the support of the denominator is well-separated from [math]
Assumption 5**.**
For every , the lower bound is strictly positive.
Theorem C.1**.**
Let and . Under Assumptions 1, 4 and 5, we have for every and
[TABLE]
As a consequence, \inf_{P\in\mathcal{P}}\mathbbm{P}_{P^{\otimes n}}\Big{(}\mathbbm{E}[X_{1,n}]/\,\mathbbm{E}[Y_{1,n}]\in\left[\,\overline{X}_{n}/\,\overline{Y}_{n}\pm t\right]\Big{)}\geq 1-\alpha, with the following choice for :
[TABLE]
for every .
The theorem shows that it is possible to construct nonasymptotic CIs for ratios of expectations at every confidence level that are almost surely bounded. However, it requires the additional Assumption 5, that in particular does not allow for binary random variables in the denominator which may limit its applicability for various applications. In Section C.2, we give an analogous result that only requires Assumptions 1 and 4 to hold, so that it encompasses the case of -valued denominators. However, the cost to pay will be an upper bound on the achievable coverage of the confidence intervals.
C.2 Concentration inequality in the general case
We seek to build nontrivial nonasymptotic CIs under Assumptions 1 and 4 only. Under Assumption 1, , so that there is no issue in considering the fraction . However, without Assumption 5, has positive probability in general so that is well-defined with probability less than one and undefined else. Note that when is continuous wrt to Lebesgue’s measure, there is no issue in defining anymore since the event has probability zero. This is not an easier case to establish concentration inequalities though, since without more restrictions, can still be arbitrarily close to [math] with positive probability.
Theorem C.2**.**
Assume that Assumptions 1 and 4 hold. For every , , we have
[TABLE]
where and .
As a consequence, \inf_{P\in\mathcal{P}}\mathbbm{P}_{P^{\otimes n}}\Big{(}\mathbbm{E}[X_{1,n}]/\,\mathbbm{E}[Y_{1,n}]\in\left[\,\overline{X}_{n}/\,\overline{Y}_{n}\pm t\right]\Big{)}\geq 1-\alpha, with the choice
[TABLE]
for every .191919Equivalently, it means that for a given level , the choice of is valid for every integer .
This theorem is proved in Section C.4. It states that when , it is possible to build valid nonasymptotic CIs with finite length up to the confidence level . This is a more positive result than [7] which claims that it is not possible to build nontrivial nonasymptotic CIs when is taken equal to 0, no matter the confidence level. Note that Theorem 19 is not an impossibility theorem since it only claims that considering confidence levels smaller than is sufficient to build nontrivial CIs under Assumptions 1 and 4. The remaining question is to find out whether it is necessary to focus on confidence levels that do not exceed a certain threshold under Assumptions 1 and 4. We answer this in Section C.3.
Theorem 19 has two other interesting consequences: for every confidence level up to , a nonasymptotic CI of the form with has good coverage but is too conservative. What is more, if the DGP does not depend on (i.e in the standard i.i.d. set-up), for every fixed , the length of the confidence interval shrinks at the optimal rate .
C.3 An upper bound on testable confidence levels
Theorem C.3**.**
For every , and every where \underline{\alpha}_{n,H}:=\big{(}1-l_{Y,n}/(b_{Y,n}-a_{Y,n})\big{)}^{n}, if , there is no finite such that has coverage over , where is the class of all distributions satisfying Assumptions 1 and 4 for a fixed lower bound and fixed lengths and .
This theorem asserts that confidence intervals of the form with coverage higher than under Assumptions 1 and 4 are not defined (or are of infinite length) with positive probability for at least one distribution in . The additional restriction is rather mild in practice: it is equivalent to and is satisfied as soon as and . This encompasses all DGPs where the denominator is -valued and the probability that the denominator equals 1 is bounded from below by .
Note that for Theorems C.1 and C.2, it is required to know not only the length but also the actual endpoints of the support, and . On the contrary, Theorem C.3 does not require the latter. In that respect, the class of Theorem C.3 is larger than the one of the two preceding theorems.
C.4 Proof of Theorems C.1 and 19
The proofs are identical to those of Theorems 4.1 and 9, except for the Bienaymé-Chebyshev inequality that has to be replaced with the Hoeffding inequality. The latter can be used under Assumption 4. Note also that is now bounded by .
C.5 Proof of Theorem C.3
We need the subsequent lemma.
Lemma C.4**.**
For each in the interval \Big{(}0,1\wedge\big{(}(b_{Y,n}-a_{Y,n})/l_{Y,n}-1\big{)}\Big{)}, there exists a distribution such that where \tilde{\alpha}_{n,H}(\xi):=\big{(}1-(1+\xi)l_{Y,n}/(b_{Y,n}-a_{Y,n})\big{)}^{n}.
Note that the interval \Big{(}0,1\wedge\big{(}(b_{Y,n}-a_{Y,n})/l_{Y,n}-1\big{)}\Big{)} is not empty since we have assumed .
By Lemma C.4, for every \xi<1\wedge\big{(}(b_{Y,n}-a_{Y,n})/l_{Y,n}-1\big{)}, there exists a distribution satisfying Assumptions 1 and 4 such that . Denote its marginal distributions by and . Therefore, satisfies Assumptions 1 and 4, and is undefined with probability greater than . Taking the supremum over , we deduce that
[TABLE]
This means that the random interval cannot have coverage higher than since it may be undefined with a probability higher than .
C.5.1 Proof of Lemma C.4
We consider the following distribution on
[TABLE]
where is some constant to be chosen later, and . Let . Observe that . With the choice
[TABLE]
we have . Note that is strictly positive, because . This is equivalent to , which is true by assumption.
Consider now the following product measure on defined by P_{n}:=\big{(}0.5\delta_{\left\{0\right\}}+0.5\delta_{\left\{b_{X,n}-a_{X,n}\right\}}\big{)}\otimes P_{n,l_{Y,n},c_{n},\xi}. Let . These random vectors satisfy , and . The next step is to build a lower bound on the event .
The assumption that and the construction of imply that
[TABLE]
Appendix D Additional simulations
This section complements the simulations presented in the main body of the article using different distributions for the variables in the numerator and in the denominator.
In this setting of simulations, we use the best bounds by setting the constants and that define our class of distributions equal to the actual corresponding moments (respectively the expectation for and the second moment for ). That is we use or . In practice, our rule-of-thumb uses the plug-in version of those quantities replacing the theoretical unknown moments by their empirical counterparts as explained in Section 5.3.
The following Figures are similar to Figures 6 and 7. They show the of the asymptotic CIs based on the delta method as a function of the sample size and also reports , with chosen according to the desired nominal level (equal to ) and , . Consequently, the titles of the figures only indicate the specification used for , the nominal pointwise asymptotic level , and the number of repetitions used to approximate the probability .
With discrete distributions for the variable in the denominator, it may happen that , all the more so as the expectation and the sample size are low typically. As discussed at the end of Section 2, confidence intervals are said to be undefined when . In such cases, for any value , it is undefined whether belongs or not to the CIs. Consequently, whenever the sample drawn is such that in the simulations, we count the draw as a no coverage occurrence in the Monte Carlo estimation of . In other words, this quantity is approximated as an average over repetitions and the repetitions for which account for [math] in this average.202020Note that in some specifications, a substantial part of the repetitions yield . For instance, with Bernoulli distributions, for smaller than and the expectation at the denominator equal to , around 10% only of the repetitions display .
D.1 Gaussian distributions
D.2 Student distributions
The specification here is two Student distributions, both in the numerator and in the denominator. Standard Student distributions are centered. We use therefore translated versions by simply adding the expectations in order to avoid a null denominator for the ratio of expectations of interest. Below, denotes the distribution of a translated standard Student variable: where is distributed according to a Student distribution with degrees of freedom. To satisfy Assumption 1, we need finite variance: we use degrees of freedom strictly higher than for this purpose.
D.3 Exponential distributions
The specification here is two exponential distributions, both in the numerator and in the denominator. The case of the exponential is specific as a unique parameter determines both the expectation and the variance of the distribution.
More precisely, the variance is equal to the square of the expectation. Consequently, whatever the parameter of the exponential distribution in the denominator, we have . Previous simulations suggest that the closer the expectation in the denominator to [math], the larger the sample size required for the asymptotic approximation to hold. At first sight, we might thus be worried for the usefulness of our rule-of-thumb to obtain independent of . Yet, with exponential distributions, the lower the expectation, the lower is the variance too. Intuitively, the lower variance will compensate having an expectation closer to [math]. The previous statement that links the closeness to [math] of the expectation in the denominator and the sample size required to reach the asymptotic approximation presupposes keeping fixed the variance. It cannot be anymore for exponential distributions.
The simulations reveal that the convergence of the coverage of the asymptotic confidence intervals toward their nominal level happens for around one hundred fifty and has the same pattern whatever the expectation of the exponential distribution in the denominator. Our rule-of-thumb appears to be a bit small. Nonetheless, it is coherent that it is constant across the value of .
D.4 Pareto distributions
The specification here is two Pareto distributions, both in the numerator and in the denominator. Pareto distributions have support in . They would fall in the easier case when the support of the denominator is well separated from [math]. To assess the dependability of our rule-of-thumb in the general case, we use translated Pareto distributions. In what follows, the notation denotes the distribution of a random variable that follows a Pareto distribution with shape parameter equal to translated such that its support is and its expectation is . A variable that is distributed according to is equal in distribution to with and a usual Pareto distribution with support or scale parameter and shape parameter , that is has the density with respect to Lebesgue measure.
D.5 Bernoulli distributions
Figure 20 is the equivalent of Figure 1 with Bernoulli distributions. The following graphs illustrate the use of to appraise the reliability of the asymptotic confidence based on the delta method. In practice a plug-in strategy has to be used to compute and, in the setting of simulations, we simply use the known moments and bounds of the DGP used in the simulation. With two Bernoulli variables in the numerator and the denominator, we are both in the BC and the “Hoeffding” cases. Thus, we show both the one obtained in the BC case with a dashed vertical line (Theorem 4.2) and the one obtained in the “Hoeffding” case , setting here , and , with a dotted vertical line (Theorem C.2).
D.6 Poisson distributions
The specification here considers two variables distributed according to a Poisson distribution, both in the numerator and in the denominator.
A Poisson distribution is entirely defined by its positive real parameter, which is equal to both its expectation and its variance. Consequently, to have denominator close to [math], we would need small variance too, as in the exponential specification (see Section D.3). In order to disentangle expectation and variance, we use below translated Poisson variables. More precisely, the notation , , , denotes a distribution alike to a Poisson, with parameter and variance equal to but translated such that its expectation is . That is a variable distributed according to is equal in distribution to with a standard Poisson distribution with parameter - that is with density with respect to the counting measure equal to for every . Thus, a has expectation and variance .
D.7 Delta method and nonparametric percentile bootstrap confidence intervals
The two following figures are the equivalent to Figure 4 with different values of . They illustrate that the lower , the lower the signal-to-noise ratio in the denominator, hence the more difficult in some sense is the estimation of . This is illustrated by the fact that, all other things equal, larger basically translates upward as revealed by the series of Figures 4, 25, and 26.
These three figures all report the of the CIs based on the delta method (in blue) and of the CIs constructed with Efron’s non parametric bootstrap using 2,000 bootstrap replications (in red) with the specification , with . For the three of them, the nominal pointwise asymptotic level is set to and for each pair , the coverage is obtained as the mean over 5,000 repetitions.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] T. W. Anderson and H. Rubin. Estimation of the parameters of a single equation in a complete system of stochastic equations. The Annals of Mathematical Statistics , 20(1):46–63, 1949.
- 2[2] I. Andrews, J. Stock, and L. Sun. Weak instruments in IV regression: Theory and practice. To appear in Annual Review of Economics , 2019.
- 3[3] R. R. Bahadur and L. J. Savage. The nonexistence of certain statistical procedures in nonparametric problems. The Annals of Mathematical Statistics , 27(4):1115–1122, 1956.
- 4[4] S. Boucheron, G. Lugosi, and P. Massart. Concentration inequalities: A nonasymptotic theory of independence . Oxford university press, 2013.
- 5[5] A. Bücher and I. Kojadinovic. A note on conditional versus joint unconditional weak convergence in bootstrap consistency results. To appear in Journal of Theoretical Probability , 2019.
- 6[6] O. Catoni. Challenging the empirical mean and empirical variance: a deviation study. Annales de l’Institut Henri Poincaré, Probabilités et Statistiques , 48(4):1148–1185, 2012.
- 7[7] J.-M. Dufour. Some impossibility theorems in econometrics with applications to structural and dynamic models. Econometrica , 65(6):1365–1387, 1997.
- 8[8] A. Gut. Complete convergence for arrays. Periodica Mathematica Hungarica , 25(1):51–75, 1992.