Reduced Order Modeling for Nonlinear PDE-constrained Optimization using Neural Networks
Nikolaj Takata M\"ucke, Lasse Hjuler Christiansen, Allan Peter, Karup-Engsig, John Bagterp J{\o}rgensen

TL;DR
This paper introduces a novel solver for nonlinear PDE-constrained optimization that combines SQP, POD, and neural networks to enable faster online computations for high-dimensional problems, demonstrated on the viscous Burgers' equation.
Contribution
It presents a new integrated approach using neural networks with model reduction techniques for efficient PDE-constrained optimization.
Findings
Significant online speed-up compared to traditional methods.
Offline phase is longer but results in faster online evaluations.
Reduced accuracy is a trade-off for increased computational speed.
Abstract
Nonlinear model predictive control (NMPC) often requires real-time solution to optimization problems. However, in cases where the mathematical model is of high dimension in the solution space, e.g. for solution of partial differential equations (PDEs), black-box optimizers are rarely sufficient to get the required online computational speed. In such cases one must resort to customized solvers. This paper present a new solver for nonlinear time-dependent PDE-constrained optimization problems. It is composed of a sequential quadratic programming (SQP) scheme to solve the PDE-constrained problem in an offline phase, a proper orthogonal decomposition (POD) approach to identify a lower dimensional solution space, and a neural network (NN) for fast online evaluations. The proposed method is showcased on a regularized least-square optimal control problem for the viscous Burgers' equation. It…
Click any figure to enlarge with its caption.
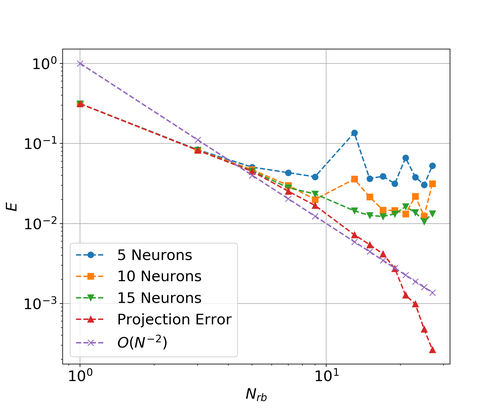 Figure 1
Figure 1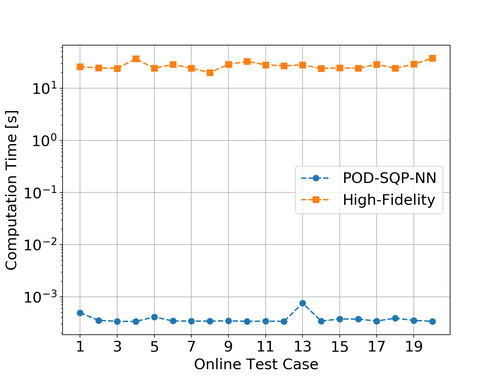 Figure 2
Figure 2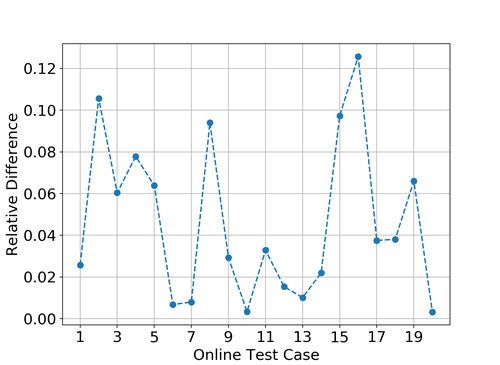 Figure 3
Figure 3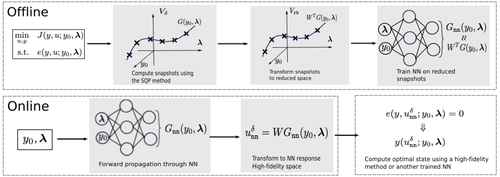 Figure 4
Figure 4Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Reduced Order Modeling for Nonlinear PDE-constrained Optimization using Neural Networks
Nikolaj Takata Mücke, Lasse Hjuler Christiansen, Allan Peter Engsig-Karup, John Bagterp Jørgensen Nikolaj Takata Mücke, Lasse Hjuler Christiansen, Allan Peter Karup-Engsig and John Bagterp Jørgensen are with the Department of Applied Mathematics and Computer Science, Technical University of Denmark, DK-2800 Kgs. Lyngby, Denmark {ntmy,lhch,apek,jbjo}@dtu.dk
Abstract
Nonlinear model predictive control (NMPC) often requires real-time solution to optimization problems. However, in cases where the mathematical model is of high dimension in the solution space, e.g. for solution of partial differential equations (PDEs), black-box optimizers are rarely sufficient to get the required online computational speed. In such cases one must resort to customized solvers. This paper present a new solver for nonlinear time-dependent PDE-constrained optimization problems. It is composed of a sequential quadratic programming (SQP) scheme to solve the PDE-constrained problem in an offline phase, a proper orthogonal decomposition (POD) approach to identify a lower dimensional solution space, and a neural network (NN) for fast online evaluations. The proposed method is showcased on a regularized least-square optimal control problem for the viscous Burgers’ equation. It is concluded that significant online speed-up is achieved, compared to conventional methods using SQP and finite elements, at a cost of a prolonged offline phase and reduced accuracy.
I Introduction
Nonlinear model predictive control is a well-established technique to solve optimal control problems within science, engineering and other areas [1, 2]. However, in cases where the underlying mathematical model is of high dimension, as is the case for PDEs, the optimization requires substantial computational power and time and cannot meet real-time constraints. In such mathematical models the curse of dimensionality is often a bottleneck [3]. As a consequence, black box optimizers are not sufficient and one must resort to customized solvers. The state of the art customized solvers often rely on preconditioned iterative methods [4, 5], high-performance computing [6] and/or reduced order modeling techniques [7, 8] to improve the online computation time.
The contribution of this paper towards real-time optimization of large-scale processes, is a scheme based on proper orthogonal decomposition (POD), sequential quadratic programming (SQP) and neural networks (NNs), denoted the POD-SQP-NN scheme. This approach is in the field of reduced order modeling. The work is inspired by [9], where a similar approach is presented for forward solution of nonlinear PDEs. The idea is to identify a low dimensional representation of the optimal control function, and then train a neural network to map inputs to this representation. The scheme utilizes a data driven approach to compute the low dimensional representation. One starts by exploring the solution space by computing optimal control functions, using the SQP algorithm [10], and then computes a low dimensional representation using POD [11]. The idea is closely related to that of principal component analysis for dimensionality reduction of data representations [12]. This approach exploits the often existing low dimensional structures to decrease the required computational effort and increase the accuracy of an NN.
The computation of the low dimensional representation and the training of the NN is kept in the offline stage. Thus, it is only necessary to evaluate the NN for given input in the online stage, which is an inexpensive procedure. This way one circumvents the problem associated with the curse of dimensionality in the online stage by keeping the full problem in the offline stage.
The POD-SQP-NN scheme is tested on a regularized least-square optimal control problem for the viscous Burgers’ equation to demonstrate its potential. The viscous Burgers’ equation has a nonlinear advection term. When this term is dominating shock waves will appear in the uncontrolled case, which makes it challenging to control [13].
The paper is organized as follows. Section 2 introduces the optimal control problem and the optimality system. Section 3 presents the reduced order modeling framework. Section 4 outlines the use of NNs. Section 5 presents numerical results and conclusions, as well as future prospects, are made in section 6 and 7.
II Optimal Control of Nonlinear PDEs
Consider the class of nonlinear time-dependent PDEs of the form
[TABLE]
where is a space-time cylinder, , , , , , is an external forcing, and is nonlinear operator. The initial value problem (IVP), (1), is a general form of advection-reaction-diffusion equations with linear diffusion. Processes of this type encapsulates a great amount of physical phenomena, such as chemical reactions [4], fluid flows [14], and predator-prey systems [15].
II-A The Optimal Control Problem
To control (1) towards a desired state we formulate the PDE-constrained optimization problem:
[TABLE]
The goal of problem (2) is to determine the optimal control function, , such that the state, , is as close as possible to a pre-defined desired state, . For this purpose a typical choice of the cost functional, , is given by the tracking-type functional:
[TABLE]
where denotes the standard norm and is the Tikhonov regularization parameter, ensuring that the optimal control has higher regularity [10]. The control can be restricted to a subdomain, by choosing as a characteristic function, i.e. . Note that in many real-world applications (2) is often accompanied by constraints on the control function, . However, to illustrate the ideas and principles of this paper we leave out such constraints on .
II-B Optimality System
Solving (2) can be done in more than one way. This paper follows the optimize-then-discretize approach [16]. That is, we start by deriving the optimality conditions on the continuous level and then we discretize the resulting system. Utilizing the formal Lagrange method [10], we arrive at the following system:
[TABLE]
where is the adjoint state. The control is recovered by . The IVP (4) is a system of nonlinear PDEs with the state evolving forward in time and the adjoint state backwards. We use a Newton/SQP approach to overcome the nonlinearities, which first linearizes (4) and then solve the resulting system until a given stopping criteria is fulfilled [10, 13]. Denoting by , , the Newton iterates and , the next iterate, we recover the following linear system to solve for :
[TABLE]
where
[TABLE]
and with initial and boundary conditions as given in (4).
While (5) are linear, the problem of opposite time evolutions of the state and the adjoint state remains. To solve this problem we solve for all time steps at once. This is also referred to as an all-at-once approach [16].
Using the Galerkin finite element method (FEM), we aim to represent the solutions by
[TABLE]
where are the finite element basis functions and are the generalized Fourier coefficients, i.e. the degrees of freedom, to be estimated. We denote the finite dimensional solution space , introduce a time discretization, , , and define
[TABLE]
as the vectors collecting the degrees of freedom for all time steps. Thus, we solve a system of the form
[TABLE]
in each Newton iteration. Note that can potentially be a large matrix. Thus, solving (9) multiple times may be expensive, which motivates the use of specialized approaches to improve computation time.
III Reduced Order Modeling
Decreasing the size of (9) is one way to reduce the computational cost. To do so we need an efficient reduced basis, i.e. a basis comprising fewer functions without compromising the accuracy for given set of parameters. Hence, we seek solutions of the form
[TABLE]
where and is the reduced basis functions. We denote the reduced space . This also motivates naming the full-order or high-fidelity space. To derive such a basis, we utilize the POD [11, 17].
III-A Parametrized PDEs
To describe the POD method, we begin by introducing the concept of parametrized PDEs. Here, we assume that the solution does not only depend on space and time but also on the parameters. Define the vector, , to be the vector of all parameters. Such parameters could be either physical, such as the diffusion rate, characteristics of the initial condition, or geometric, such the shape and size of the domain. The input parameters will often comprise an initial state in optimal control problems. Therefore, it makes sense to decompose the parameter vector into an initial state and other parameters, .
The set of all solutions for varying parameters makes up a manifold, denoted the solution manifold:
[TABLE]
Similarly, we define and to be the solutions manifold for the high-fidelity and the reduced basis approximations, respectively.
III-B Proper Orthogonal Decomposition
The POD method to compute the reduced basis is a data driven approach. One starts by computing a series of snapshots. A snapshot is a solution of the full problem for a given set of parameters and time instance. Ideally the snapshots should make up a good representation of the solution manifold. Then we seek to minimize
[TABLE]
where is the reduced space, denotes a snapshot, i.e. the solution for a specific parameter choice and time instance, and is the number of snapshots, where and are the number of parameter samples and time steps respectively. According to the orthogonal projection theorem the minimizing reduced basis representation of is the orthogonal projection[11]:
[TABLE]
In the case one can show that minimizing (13) is equivalent to the constrained maximization problem [18]:
[TABLE]
where is the vector of coefficients of the reduced basis functions, expanded in terms of the FE functions, and is the degrees of freedom of a snapshot. By collecting all the snapshots in a snapshot matrix, , and all the reduced basis functions as columns in a matrix, , the solution to (14) is the solution to the eigenvalue problem [11]:
[TABLE]
where is a diagonal matrix with the eigenvalues, corresponding to the columns of , on the diagonal. The matrix is denoted the correlation matrix [11]. Truncating the number of eigenvectors gives us the number of reduced basis functions in use. One transforms between the degrees of freedom, in the high-fidelity basis and the POD basis, by [11]:
[TABLE]
The projection error on the snapshots corresponds to the eigenvalues of the correlation matrix of the POD modes left out [11]:
[TABLE]
Hence, the eigenvectors corresponding to the largest eigenvalues contain the most information about the solution space. Thus, one should choose the reduced basis functions by looking at the size of their respective eigenvalues.
IV Artificial Neural Networks
First, we will give a brief recap of the fundamental concepts regarding NNs. An NN can be considered a map, , that maps a vector of features to a vector of responses. In the case of a feedforward network, also denoted a perceptron, the map consists of a series of function compositions [19]:
[TABLE]
where is the number of hidden layers, is the number of neurons in each layer, is the set of weights and biases, are the activation functions, and are the propagation functions. The evaluation of a NN is called a forward propagation since it can be considered a propagation of the input features through the series of functions. The propagation function is often a linear combination with a bias term:
[TABLE]
where ’s are matrices containing the weights and ’s are vectors containing the bias terms. There are many choices for the activation functions. Recently the functions called rectified linear units (ReLUs) have gained much success due to great results. In this paper we make use of the slightly modified version called the leaky ReLU [20]:
[TABLE]
where is a small positive real number.
The motivation for using neural networks are their versatility. It can be shown that any continuous function can be approximated arbitrarily well by a deep neural network [19]. However, in practice it is difficult to get arbitrary precision due to various problems. These include i) a large parameter space, ii) nonlinearities, and iii) a non-convex optimization problem for determining the parameters.
Much time has gone into developing optimization algorithms for computing the weights and biases to get as close as possible to the theoretical potential. Second order methods can not, in general, be used since they only ensure local convergence and are too expensive in high dimensions. Therefore, stochastic variations of gradient descent algorithms, such as Adam, are often used [21].
V The POD-SQP-NN Scheme
For PDE-constrained optimization problems one can consider a map, that takes input parameters and maps them to the high-fidelity optimal control solution manifold:
[TABLE]
is computed using the SQP method and finite elements. The image of the mapping, , corresponds to the high-fidelity solution manifold for the control function. The general idea of the POD-SQP-NN scheme is to approximate this map in the POD space by using NNs. That is, by using the relation in (16) we aim to compute a map, , such that
[TABLE]
from which we recover the optimal control in the high-fidelity space by
[TABLE]
Consequently, the POD-SQP-NN scheme is decomposed into two stages:
- •
The offline stage.
Compute snapshots, , using SQP and finite elements. 2. 2.
Compute POD basis functions and transform snapshots to get training data: . 3. 3.
Train the neural network, , on training data.
- •
The online stage.
Input parameters, , and compute by forward propagation in NN. 2. 2.
Transform output to high-fidelity space, . 3. 3.
(Optional) Compute the optimal state by a forward solving of the state equation.
This procedure is outlined in Fig. 1. It is apparent that the offline stage is quite extensive. It consists of several steps which are all, by themselves, computationally heavy tasks and are highly dependent on the dimension of the problem. However, the online stage is not computationally demanding, which is essential for real-time applications.
By approximating the solution in the reduced space we reduce the number of output neurons and, thereby, also the number of weights to be trained significantly. This reduces training time as well as online computation time. Furthermore, it increases the accuracy of the NN since it reduces the size of the parameter space.
A typical problem when training neural networks is lack of enough data. In the proposed method, as much data as needed can be generated, given no time constraints on the offline phase. This, however, does not ensure high precision due to other constraints in neural networks such as bias-variance trade-off, irreducible errors, etc. [12]. However, it is worth discussing potential problems regarding the dimension of the input. Due to the curse of dimensionality it might be infeasible to compute the proposed map since it might require an insurmountable amount of simulations to explore the full solution manifold. However, in many cases it can be exploited that the initial state lies on a low dimensional surface parametrized by only a few parameters, which reduces this problem significantly.
We define to be the projection operator onto the reduced basis space. By using the triangle inequality, one gets rough a priori error estimate:
[TABLE]
is the error between the high-fidelity and the exact solution. is the discrepancy between the high-fidelity solution and its POD basis representation. It depends on the quality of the POD method which, in turn, depends on the how reducible the problem is and how well the solution manifold is sampled. In many cases this error decreases exponentially [17]. Lastly, is the discrepancy between the POD representation and the NN output. It depends on the quality of the training of the network and is often the most difficult to drive down through training.
VI Numerical example
As a test example, we consider the viscous Burgers’ equation as the state equation. Thus, the PDE-constrained optimization problem is:
[TABLE]
with defined as in (3) and a known forcing on the system. The well-posedness of the (25) is discussed in [13]. The resulting linear problem to be solved in each Newton iteration is
[TABLE]
For the spatial discretizations FEniCS is used [22] and for the NN the PyTorch framework is used [23]. The unconditionally stable implicit Euler is used for the time discretization.
VI-A Case Study
For the specific case study we choose , and the initial state:
[TABLE]
The desired state is to retain the initial condition over time. This problem is quite similar to the one considered in [13]. We define the vector of parameters to be varied as . It is worth noting that and parametrizes the initial condition while defines the diffusion rate. To sample the parameters the Latin Hypercube Sampling method is utilized to ensure a random distribution and that the full parameter space is explored [24].
In this paper, we use and which in total gives snapshots to compute the POD basis. Note that only 300 SQP all-at-once method solutions are needed to get all the snapshots. It is likely that that fewer snapshots would be sufficient since is static and .
To train the neural network in the POD-SQP-NN scheme a training set of 2500 optimal control solutions is used. For the architecture we train a feedforward network with three hidden layers with neurons in each. Furthermore, the Adam optimizer was utilized using mini-batches of size 32 together with early stopping and the mean squared error with -regularization as the loss function. Furthermore, the weights were initialized according to the standard Gaussian distribution.
The error is measured to be the relative difference of the neural network response and the high-fidelity solution:
[TABLE]
From Fig. 2 it is clear that the accuracy is increasing with the number of POD basis functions. Furthermore, more neurons in each layer gives a better approximation until a certain point at which the error stagnates. However, it is worth noting that the error is not decreasing monotonically, but is rather noisy. This points to the fact that the networks are not trained well enough in every configuration. In the best cases we reach an accuracy in the order of magnitude seconds.
In Fig. 3 we see the online computation time for the high-fidelity as well as for the POD-SQP-NN scheme. The high-fidelity scheme takes between 10 and 100 seconds while the POD-SQP-NN scheme is of the order of seconds. This does not come as a surprise, since the online phase is just a single forward propagation for the POD-SQP-NN scheme.
Whether an accuracy of is sufficient is highly dependent on the problem at hand. However, for many problems it is enough. In Figure 4 the relative difference in the objective functional,
[TABLE]
is plotted. In all online test cases the discrepancy is no larger than 0.12, which suggests that an increase in accuracy will not yield significant changes in the objective functional. Whether such differences are acceptable depends on the problem at hand.
VII Conclusions
A new and efficient scheme for online computations of nonlinear PDE-constrained optimization problems is proposed in the paper. We first showed that the problem at hand can be projected onto a lower dimensional manifold using the POD method, which lays the foundation for the POD-SQP-NN method. The scheme significantly decreases the online computation times for the case involving the viscous Burgers’ equation. It did, however, come with a decrease in accuracy and a prolonged offline phase. Regarding the decrease in accuracy it is possible that it does not pose any practical limitations due to the minor discrepancies in the objective functions. For these reasons, we see a potential in this method to be used to solve problems that are currently intractable in real-time.
VIII Future Prospects
What was not discussed in sufficient detail is how the method performs on very high dimensional problems. In many NMPC applications it is not necessarily possible to parametrize the initial conditions by a small set of parameters, as was done here. In such cases the entire initial state must be the input, which could potentially cause problems. Furthermore, the reliability is not addressed as no rigorous a posteriori error bounds exists. This was, however, not a problem in the examples given.
In ongoing work, we will, furthermore, explore different NN architectures such as residual networks, and reinforcement learning which has shown to be well-suited for time dependent data. Alternatively, instead of using NN other new approaches can be utilized to address the curse of dimensionality, such as spectral tensor train decompositions [25].
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] S. J. Qin and T. A. Badgwell, “A survey of industrial model predictive control technology,” Control engineering practice , vol. 11, no. 7, pp. 733–764, 2003.
- 2[2] E. F. Camacho and C. Bordons, “Nonlinear model predictive control: An introductory review,” in Assessment and future directions of nonlinear model predictive control . Springer, 2007, pp. 1–16.
- 3[3] R. E. Bellman, Adaptive control processes: a guided tour . Princeton university press, 2015, vol. 2045.
- 4[4] L. H. Christiansen and J. B. Jørgensen, “A new lagrange-newton-krylov solver for pde-constrained nonlinear model predictive control,” IFAC-Papers On Line , vol. 51, no. 20, pp. 325–330, 2018.
- 5[5] J. W. Pearson and M. Stoll, “Fast iterative solution of reaction-diffusion control problems arising from chemical processes,” SIAM Journal on Scientific Computing , vol. 35, no. 5, pp. B 987–B 1009, 2013.
- 6[6] G. Biros and O. Ghattas, “Parallel lagrange–newton–krylov–schur methods for pde-constrained optimization. part i: The krylov–schur solver,” SIAM Journal on Scientific Computing , vol. 27, no. 2, pp. 687–713, 2005.
- 7[7] B. Haasdonk, “Reduced basis methods for parametrized pdes–a tutorial introduction for stationary and instationary problems,” Model reduction and approximation: theory and algorithms , vol. 15, p. 65, 2017.
- 8[8] L. T. Biegler, O. Ghattas, M. Heinkenschloss, and B. van Bloemen Waanders, “Large-scale pde-constrained optimization: an introduction,” in Large-Scale PDE-Constrained Optimization . Springer, 2003, pp. 3–13.