Unsupervised Singing Voice Conversion
Eliya Nachmani, Lior Wolf

TL;DR
This paper introduces an unsupervised deep learning approach for singing voice conversion that does not require lyrics, phonetic features, or paired samples, using a CNN encoder, WaveNet decoder, and singer embeddings.
Contribution
It presents a novel unsupervised singing voice conversion model that employs a singer-agnostic encoder, a decoder conditioned on singer embeddings, and new training protocols for small datasets.
Findings
Converted voices are natural and highly recognizable as target singers.
The method works without supervision, using only audio data.
Proposed data augmentation and training losses improve performance.
Abstract
We present a deep learning method for singing voice conversion. The proposed network is not conditioned on the text or on the notes, and it directly converts the audio of one singer to the voice of another. Training is performed without any form of supervision: no lyrics or any kind of phonetic features, no notes, and no matching samples between singers. The proposed network employs a single CNN encoder for all singers, a single WaveNet decoder, and a classifier that enforces the latent representation to be singer-agnostic. Each singer is represented by one embedding vector, which the decoder is conditioned on. In order to deal with relatively small datasets, we propose a new data augmentation scheme, as well as new training losses and protocols that are based on backtranslation. Our evaluation presents evidence that the conversion produces natural signing voices that are highly…
Click any figure to enlarge with its caption.
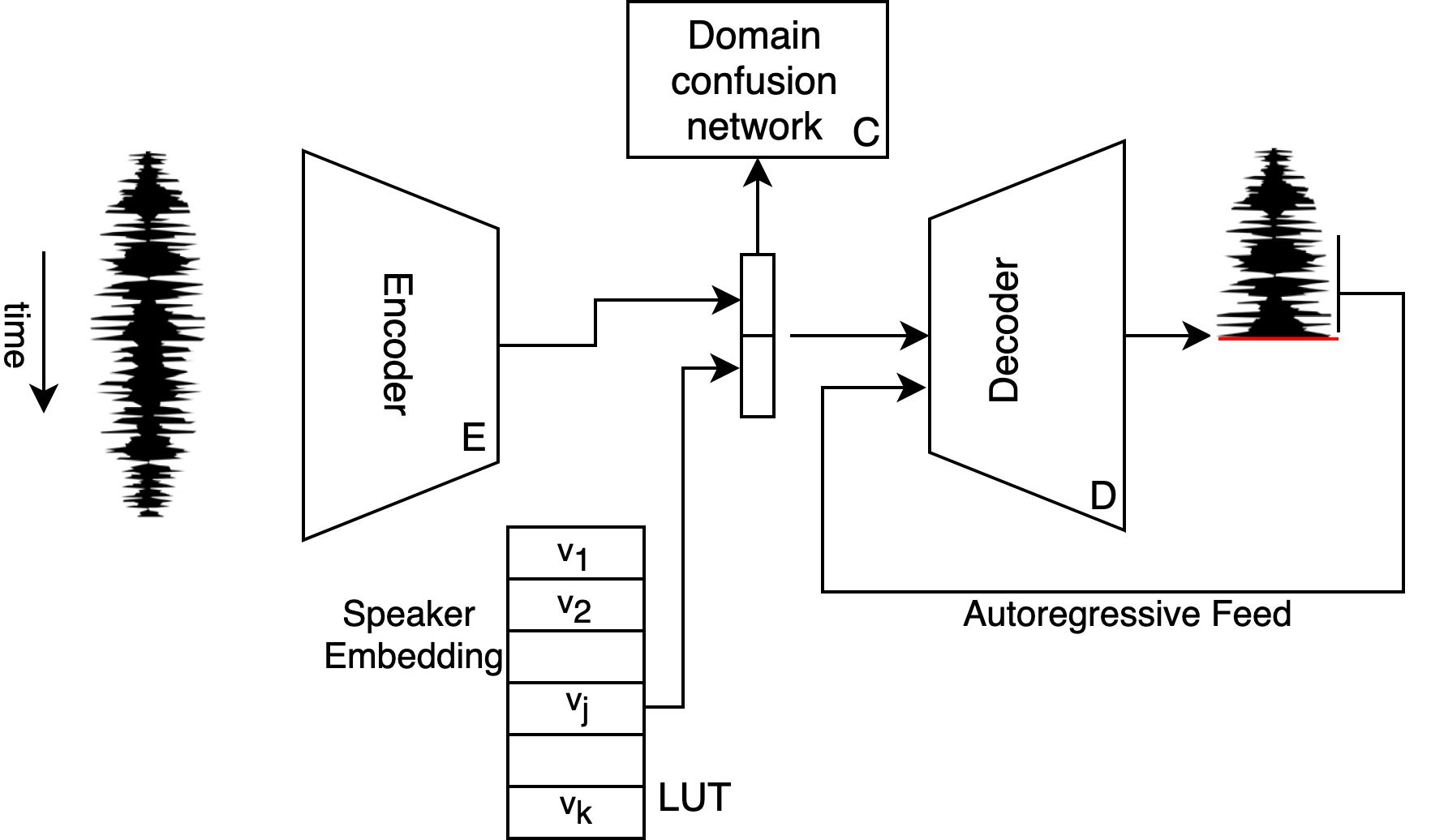 Figure 1
Figure 1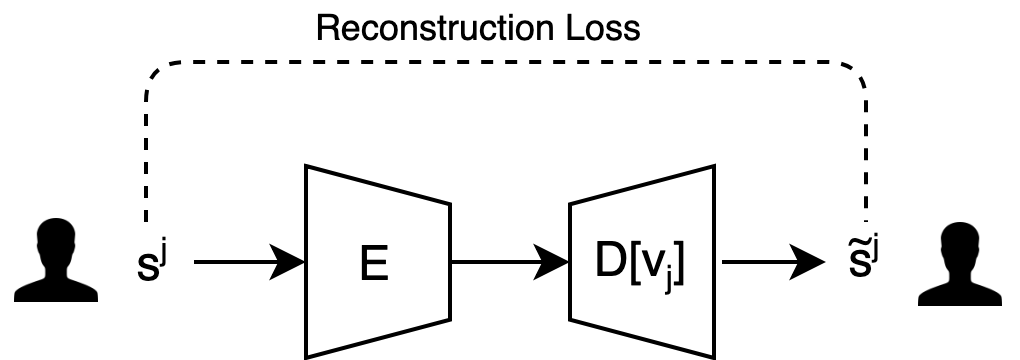 Figure 2
Figure 2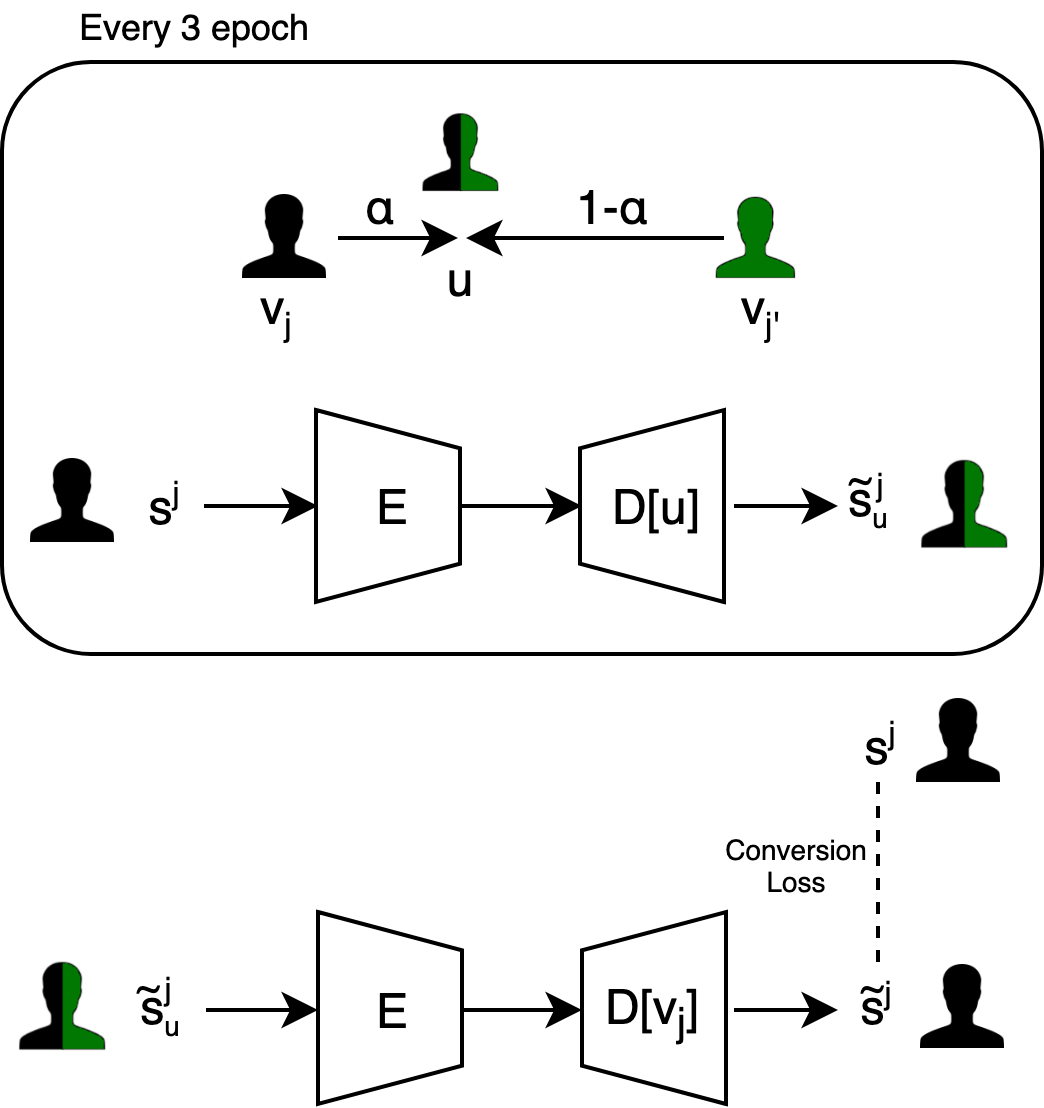 Figure 3
Figure 3| Ground truth | Reconstruction | Conversion | |
|---|---|---|---|
| DAMP | 4.300.90 | 4.010.91 | 3.990.83 |
| NUS (male) | 4.310.83 | 4.120.86 | 4.100.72 |
| NUS (female) | 4.340.73 | 4.010.73 | 0.98 |
| NUS (all) | 4.370.82 | 4.140.79 | 4.090.87 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
MethodsMixture of Logistic Distributions · Dilated Causal Convolution · WaveNet
Unsupervised Singing Voice Conversion
Abstract
We present a deep learning method for singing voice conversion. The proposed network is not conditioned on the text or on the notes, and it directly converts the audio of one singer to the voice of another. Training is performed without any form of supervision: no lyrics or any kind of phonetic features, no notes, and no matching samples between singers. The proposed network employs a single CNN encoder for all singers, a single WaveNet decoder, and a classifier that enforces the latent representation to be singer-agnostic. Each singer is represented by one embedding vector, which the decoder is conditioned on. In order to deal with relatively small datasets, we propose a new data augmentation scheme, as well as new training losses and protocols that are based on backtranslation. Our evaluation presents evidence that the conversion produces natural signing voices that are highly recognizable as the target singer.
Index Terms: Voice Conversion, Signing Synthesis
1 Introduction
The singing human voice is arguably the most important musical instrument in existence. Recently, deep neural networks have been applied successfully for synthesizing singing voices, based on the language features and the accompanying notes. In this work, we explore a related application, in which a singer’s voice is converted to another singer’s voice. This could lead, for example, to the ability to free oneself from some of the limitations of one’s own voice. While existing pitch correction methods, such as the Auto-Tune software, correct local pitch shifts, our work offers flexibility along the other voice characteristics.
Our method is unsupervised and does not employ supervision of any form. We do not require parallel training data between the various singers, nor do we employ a transcript of the audio to either text (i.e., phonemes) or to musical notes. This makes the sample collection process much simpler than what is required for most literature singer conversion methods. Singing samples are abundant, and, if needed, the technology for separating voice from instrumental music has advanced greatly, due to the advent of deep learning.
From a technical perspective, our work presents multiple technical novelties, including a new training scheme that combines backtranslation and the mixup technique, and new data augmentation techniques. Together, we are able to learn to convert between singers from 5-30 minutes of their singing voices. Our contributions are: (i) the first method, as far as we know, to perform an unsupervised singing voice conversion, where the target singer is modeled from a different song, (ii) demonstrating the effectiveness of a single encoder and a conditional decoder trained in an unsupervised way, (iii) introducing a two-phase training approach in unsupervised audio translation, in which backtranslation is used in the second phase, (iv) introducing backtranslation of mixup (virtual) identities, (v) suggesting a new augmentation scheme for training in a data efficient way.
2 Related work
Our method is based on a WaveNet [1] autoencoder. These autoencoders were used to model single musical instruments [2] and extended to perform translation between musical domains in [3] by employing a single encoder and multiple decoders. The translation is done without parallel data in a method that is similar to our first phase of training, except that we employ a single, singer conditioned, WaveNet decoder and a different data augmentation procedure. Most previous work that employ a WaveNet decoder that is conditioned on the embedding of the speaker [4, 5, 6], employ supervised learning, while we employ unsupervised learning.
In the unsupervised VQ-VAE method [7], voice conversion was obtained by employing a WaveNet autoencoder that produces a quantized latent space. The decoder is conditioned on the target speaker’s identity, using a one-hot encoding. The strong bottleneck effect achieved by discretization, leads to an embedding that is supposedly speaker-invariant. In our work, following [3, 8], we employ a domain confusion loss. As shown in [3], for the task of voice conversion, the domain confusion approach outperforms the discrete code approach of [7].
Other autoencoder-based approaches in the field of voice conversion have relied on variational auto encoders [9] to generate spectral frames. In [10], the notion of a single encoder and a parameterized decoder, where the parameters represent the identity, was introduced. The method was subsequently improved [11] to include a WGAN [12] to improve the naturalness of the output (not as a domain confusion term).
**Singing Synthesis and Conversion ** Classical singing synthesis methods are mostly concatenative (unit selection) methods [13] or HMM based [14, 15]. Blaaauw and Bonda have demonstrated very convincing singing synthesis using a WaveNet Decoder [16]. Their system receives, as input, both notes and lyrics and produces a stream of vocoder features. The method was extended [17] to adopt between singers, using the same type of note and lyrics supervision, in a data efficient manner, based on a few minutes of clean audio per target singer.
In the field of singing voice conversion, i.e., transforming an audio of a song to a target voice, almost all literature methods have used parallel data [18, 19, 20], i.e., different singers that are required to perform the same song. None of these existing methods provide code or benchmarks that can be used for a direct comparison of their results (even if supervised) to ours.
Very recently, a method that does not require parallel data was presented, in which the acoustic features of the target singer are extracted from their speech (not from a song) [21]. Vocoder features are used for synthesizing the audio. The results are demonstrated on four source singers, one target voice, and as can be heard in their sample page are still partly convincing.
**Backtranslation ** The technique of back-translation has emerged in Natural Language Processing, where it was presented as a technique for employing monolingual corpora in the supervised training of an automatic machine translation (AMT) system [22]. A sample in language , which does not have a matching translation in the target language , is automatically translated by the current AMT system to a sample in that language. One then considers the training pair (,) for translating from the language back to language .
Since our conversion system is symmetric (it can convert in both directions), we can backtranslate. However, after the first training phase of our method, the conversion offered by the network is still very limited. Synthetic samples are, therefore, created using virtual identities that are closer to the source singer than other speakers.
**Mixup training ** The mixup techniques for learning a function trains on an additional set of virtual samples created by combining two samples and using the same random weight that is sampled from the Beta distribution and . In the literature, the shape parameters of the Beta distribution are taken to be 0.2, which results in sampled values that are near one of the edges, i.e., a that is often close to zero or to one.
In our application of mixup, there are two modifications: first, since we employ backtranslation, we do not require the generation of a mixed audio, just the generation of a conversion to a mixed identity. Second, since we are interested in samples that are not concentrated away from the first sample, we replace the beta distribution with a uniform one.
3 Method
The singing voice conversion method employs a single encoder and a singer decoder, which is conditioned on a vector embedding of the target singer. There are two phases of training. In the first phase, a softmax-based reconstruction loss is applied to the samples of each singer separately. In the second, samples of novel singers obtained by mixing the vector embeddings of the training singers are created and the network is also trained for successfully converting these synthetic samples back to the training sample used to create them. In addition to the reconstruction losses, a domain confusion loss [23] ensures that the latent space of the encoder is singer-agnostic.
3.1 The Conversion Network
A diagram of the proposed architecture is shown in Fig. 1. Let be an input sample from any singer and be an input sample from singer , being the number of singers in the training set. The sample can be an original sample or one generated by the augmentation process of Sec. 3.2. Let be the encoder, and be the WaveNet decoder conditioned on the vector . Let be the singer classification network. Finally, let be the learned vector embedding of singer . A Look Up Table (LUT) stores the embedding vector for each of the singers. At each training iteration, each embedding vector with a norm larger than was normalized to have a norm of , making all embedding vectors lie within the unit sphere.
The confusion network predicts the singer associated with the input sample based on the latent vectors generated by the encoder. Training is done in two phases. During the first phase of training, illustrated in Fig. 2(a), the confusion network minimizes the classification loss
[TABLE]
and the autoencoder pathways , are trained with the loss
[TABLE]
where is the cross entropy loss applied to each element of the output and the corresponding element of the target separately, and is a weight factor. The decoders are autoregressive models, which are conditioned on both the singer embedding vector and the output of . During training, the autoregressive model is fed the target output from the previous time-step, instead of the generated output, i.e., it is trained using what is often called “teacher forcing”.
The network that is trained with the loss of of Eq. 2 is able to reconstruct the original signal, and its encoder produces an embedding that is (somewhat) singer-agnostic. However, it is not trained directly to perform a singer translation. Therefore, it shows only a limited success in this task.
The second phase of training is illustrated in Fig. 1(b). In this phase, backtranslation is applied in order to create parallel samples and train the network on these samples. This is done in combination with the mixup technique [24] in order to generate “in-between” singers that are easier to fit.
Every mixup sample is based on a mixup singer embedding , which is constructed based on the embedding of two different singers and , at some point during training, as:
[TABLE]
where is drawn from the uniform distribution. The sample is generated during training by transforming a sample of singer with the current network:
[TABLE]
Once the second phase of training starts, we create new mixup samples every three epochs and use them in order to add the following loss to the training of and (we do not train with these):
[TABLE]
where is the audio clip used to generate in Eq. 4.
At test time, in order to convert a sample in any singer’s voice to the voice of singer , we apply the conditioned autoencoder pathway of domain , obtaining the new sample . The bottleneck during inference is the autoregressive decoding process, which is performed in real time, using the the dedicated CUDA kernels described in [3].
3.2 Audio Input Augmentation
The audio in the network, including both input and output, follows an 8-bit mu-law encoding, as in previous work [1, 2]. This bounds the quality of the audio produced by the network, but supports efficient training in a straightforward way.
In the music translation network of [3], the pitch of the input audio clip was changed locally, in order to enforce the encoder to maintain semantic information and not memorize the input signal. We found that this augmentation is detrimental for our task and, therefore, do not employ such an augmentation.
A major obstacle for training our method is the limited amount of training data in the current datasets, which consist of 4 or 9 relatively short songs per singer. Therefore, the main goal of our augmentation scheme is to generate more data.
In order to perform the augmentation, we make use of the well-known fact that when a signal is played backward, the energy spectrum does not change [25]. Another fact that we rely on, is that the audio signal presents the change of pressure amplitude at a certain point in space, known as acoustic wave. The human perception for monaural audio is not affected by the phase of the signal, hence one can shift the phase by 180 degrees (multiply by -1) without any effect on auditory perception.
The augmentation method we propose increases by four fold the size of the dataset. This is done by first playing each song both forward and backward in time, and second, by multiplying the values of the raw audio signal by -1. The first augmentation creates a gibberish song that is nevertheless identifiable as the same singer; the second augmentation creates a perceptually indistinguishable but novel signal for training.
3.3 The Architecture of the Sub-Networks
The autoencoder network consists of a WaveNet-like dilated convolution encoder and on a WaveNet decoder . The decoder is conditioned on the latent representation produced by the encoder and on a vector embedding of the singer. The architecture of the encoder, decoder, and confusion network mostly reuse the successful WaveNet autoencoder architecture [2, 3].
The encoder is a fully convolutional network, which contains three blocks of ten residual-layers, a total of thirty layers. Each residual-layer comprises of a RELU nonlinearity, a non-causal dilated convolution, a second RELU, and a convolution followed by the residual summation of the activations before the first RELU. A fixed width of 128 channels is employed. After the three blocks, an additional layer passes the data to an average pooling layer, with a kernel size of 50 milliseconds (800 samples). The resulting encoding in , has a temporal down sampling factor of .
In order to condition the WaveNet decoder, the audio encoding, given by the encoder, is concatenated to the target singer embedding , resulting in a vector of dimensinality 128. The first half of this vector varies in time, while the second part is fixed as long as the singer does not change. The encoding is then upsampled temporally to the original audio rate.
The conditioning signal is passed through a layer and fed multiple times to the WaveNet decoder, where each residual layer of the WaveNet receives the conditioning signal after a different layer. The WaveNet decoder has four blocks of 10 residual-layers as in [2], leading to a receptive field of 250 milliseconds (4,093 raw samples). Each residual-layer contains a causal dilated convolution with an increasing kernel size, a gated activation, a convolution followed by the residual summation of the layer input, and a convolution layer which introduces a skip connection. The summed skip connections, together with the conditioning signal, are passed through two fully connected layers and a softmax activation to output the probability of the signal in the next timestep.
The architecture of the confusion network follows the architecture of [3], and applies three 1D-convolution layers, with the ELU [26] nonlinearity. The last layer projects the vectors to dimension (the number of singers) and the vectors are subsequently averaged to a single vector.
4 Experiments
Since we are unaware of public implementations of singing voice conversion systems (supervised or unsupervised), nor of suitable public benchmarks, we focus our empirical validation on a comparison to the ground truth songs.
We employed two publicly available datasets. The first is the Smule DAMP Dataset [27, 28] https://ccrma.stanford.edu/damp, accessed April 1, 2019. From the “DAMP-multiple” section of this dataset, we selected five singers at random (ID 84955650, 84032291, 102087231, 101442956, 100881623), after excluding several singers with low quality audio. Each singer has vocal songs, out of which songs are used for training, and the tenth for validation.
The second dataset is NUS-48E [29]. The dataset contains singers with four songs for each singer, all of which are used for training our unsupervised method, disregarding the speech files from the dataset. The audio in this dataset is significantly cleaner than in the DAMP dataset and we train three networks with it: one network for the 12 singers, one network for the six male singers, and one for the six female singers.
When evaluating the results, we use both automatic and user-study based success metrics: (i) Mean Opinion Scores (MOS) of the quality, on a scale between 1–5. These were computed using the “same_sentence” option of crowdMOS, following [30] (personal communication). (ii) MOS of the similarity of the generated voice to the target singing voice, on a scale between 1–5. (iii) Automatic identification by employing a CNN trained for speaker recognition.
Sample results are shared in our supplementary material and online https://enk100.github.io/Unsupervised_Singing_Voice_Conversion/. Tab. 4 presents MOS scores for quality. As can be seen, both the reconstructed (no translation) audio and the converted audio present scores of about 4, which is considered good quality. Interestingly, the converted results are not significantly lower in quality than the reconstructed ones.
The MOS scores for similarity are shown in Tab. 4. As can be seen, the identity similarity of the converted music is relatively high (3.0–3.7) and is higher in the NUS dataset in comparison to the noisier DAMP dataset.
The similarity of the generated voices to the target voices is also evaluated automatically, using the same type of classification network that was used to verify voice identifiability in previous work [30, 31, 32, 33]. A multi-class CNN is trained on the ground-truth training set of the multiple singers, and tested on the generated samples. The network employs the world vocoder features [34], stacked across the time domain to form an “image”. Its architecture consists of five convolutional layers of 33 filters with 32 batch-normalized and ReLU activated channels, followed by max-pooling, average pooling over time, and two fully-connected layers. The final layer has a softmax output as large as the number of training singers.
Since the NUS dataset is small (4 songs per singer), we train the identification network with the entire the dataset. Note, however, that we are testing identification on the converted samples. For DAMP dataset, we use the same training-validation split as used to train the proposed architecture. The identification results are shown in Tab. 4. As shown, the identification accuracy of the generated samples is almost as high as those of the reconstructed samples.
An ablation analysis to highlight the contribution of the various components of our system. The major challenge is not to reconstruct relatively high quality audio but to perform conversion that results in the target speaker. Therefore, our ablation analysis focuses on identification, which is also easier to test automatically. As can be seen from Tab. 4, mixup provides an advantage in comparison to backtranslating between dataset speakers and (the phase II no mixup row). When eliminating the 2nd phase altogether, i.e., continuing to train without backtranslation, performance greatly suffers. We also observe a significant gap in the accuracy when training the conversion model without the data augmentation (tested only for phase I).
5 Conclusions
Our unsupervised method is shown to produce high quality audio, which is recognizable as the target voice. The method is based on a single CNN encoder and on a single conditional WaveNet decoder. A confusion network encourages the latest space to be singer-agnostic and new types of augmentation are applied in order to overcome the limited amount of available data. Crucially, training is done in two phases, by employing a backtranslation method that employs mixup identities.
As future work, we would like to find out whether a similar method can perform the conversion in the presence of background music. We believe that this can be done in an unsupervised way, without relying on a supervised voice separation technique for preprocessing.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] A. v. d. Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals, A. Graves, N. Kalchbrenner, A. Senior, and K. Kavukcuoglu, “Wavenet: A generative model for raw audio,” ar Xiv preprint ar Xiv:1609.03499 , 2016.
- 2[2] J. Engel, C. Resnick, A. Roberts, S. Dieleman, M. Norouzi, D. Eck, and K. Simonyan, “Neural audio synthesis of musical notes with Wave Net autoencoders,” in ICML , 2017.
- 3[3] N. Mor, L. Wolf, A. Polyak, and Y. Taigman, “A universal music translation network,” in International Conference on Learning Representations , 2019.
- 4[4] W. Ping et al. , “Deep voice 3: 2000-speaker neural text-to-speech,” in ICLR , 2018.
- 5[5] J. Shen et al. , “Natural TTS synthesis by conditioning wavenet on mel spectrogram predictions,” in ICASSP , 2017.
- 6[6] Y. Chen, Y. Assael, B. Shillingford, D. Budden, S. Reed, H. Zen, Q. Wang, L. C. Cobo, A. Trask, B. Laurie, C. Gulcehre, A. van den Oord, O. Vinyals, and N. de Freitas, “Sample efficient adaptive text-to-speech,” in International Conference on Learning Representations , 2019. [Online]. Available: https://openreview.net/forum?id=rkzj Uo Ac FX
- 7[7] A. van den Oord, O. Vinyals, and K. Kavukcuoglu, “Neural Discrete Representation Learning,” in NIPS , 2017.
- 8[8] A. Polyak and L. Wolf, “Attention-based wavenet autoencoder for universal voice conversion,” in ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2019, pp. 6800–6804.