On barrier and modified barrier multigrid methods for 3d topology optimization
Alexander Brune, Michal Kocvara

TL;DR
This paper introduces a novel multigrid-based approach for large-scale 3D topology optimization problems, demonstrating significant computational efficiency improvements over traditional methods.
Contribution
The paper develops a PBM algorithm utilizing a special Hessian structure and multigrid preconditioning, offering a new efficient solution technique for large 3D topology optimization problems.
Findings
PBM outperforms OC and IP methods in computation time
Multigrid preconditioning effectively reduces linear system complexity
Proposed method handles large-scale problems efficiently
Abstract
One of the challenges encountered in optimization of mechanical structures, in particular in what is known as topology optimization, is the size of the problems, which can easily involve millions of variables. A basic example is the minimum compliance formulation of the variable thickness sheet (VTS) problem, which is equivalent to a convex problem. We propose to solve the VTS problem by the Penalty-Barrier Multiplier (PBM) method, introduced by R.\ Polyak and later studied by Ben-Tal and Zibulevsky and others. The most computationally expensive part of the algorithm is the solution of linear systems arising from the Newton method used to minimize a generalized augmented Lagrangian. We use a special structure of the Hessian of this Lagrangian to reduce the size of the linear system and to convert it to a form suitable for a standard multigrid method. This converted system is solved…
Click any figure to enlarge with its caption.
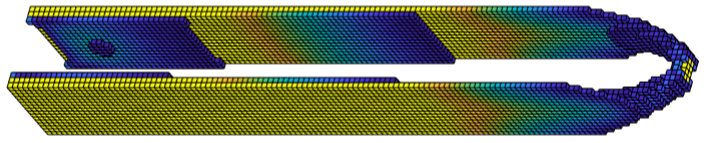 Figure 1
Figure 1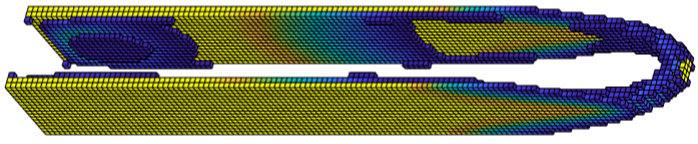 Figure 2
Figure 2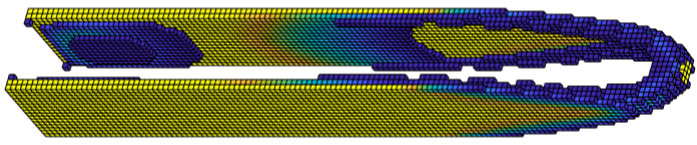 Figure 3
Figure 3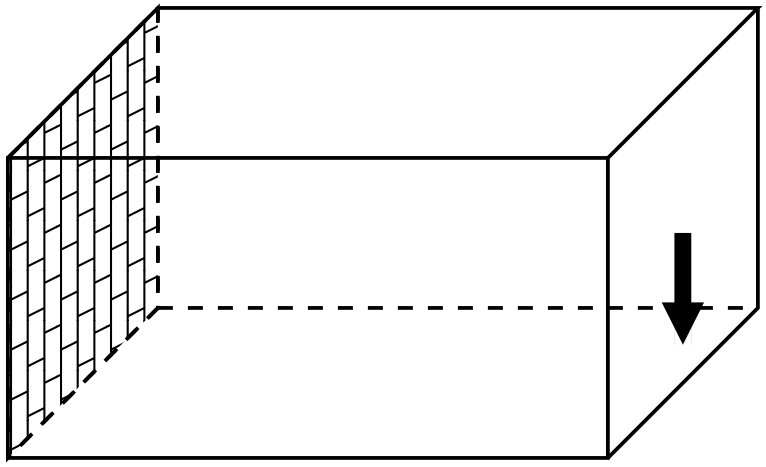 Figure 4
Figure 4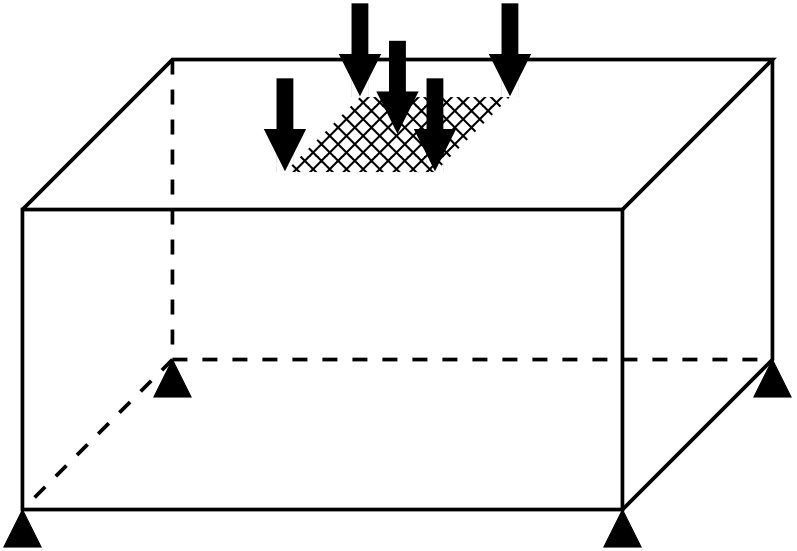 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7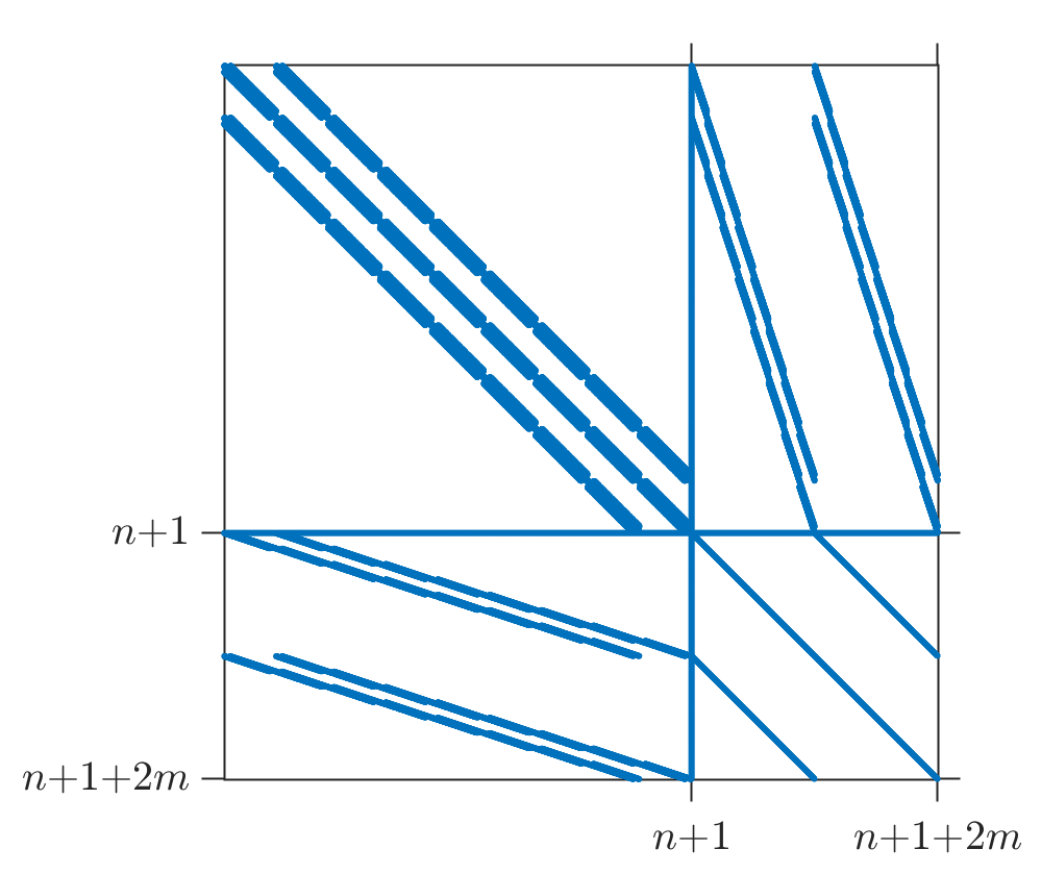 Figure 8
Figure 8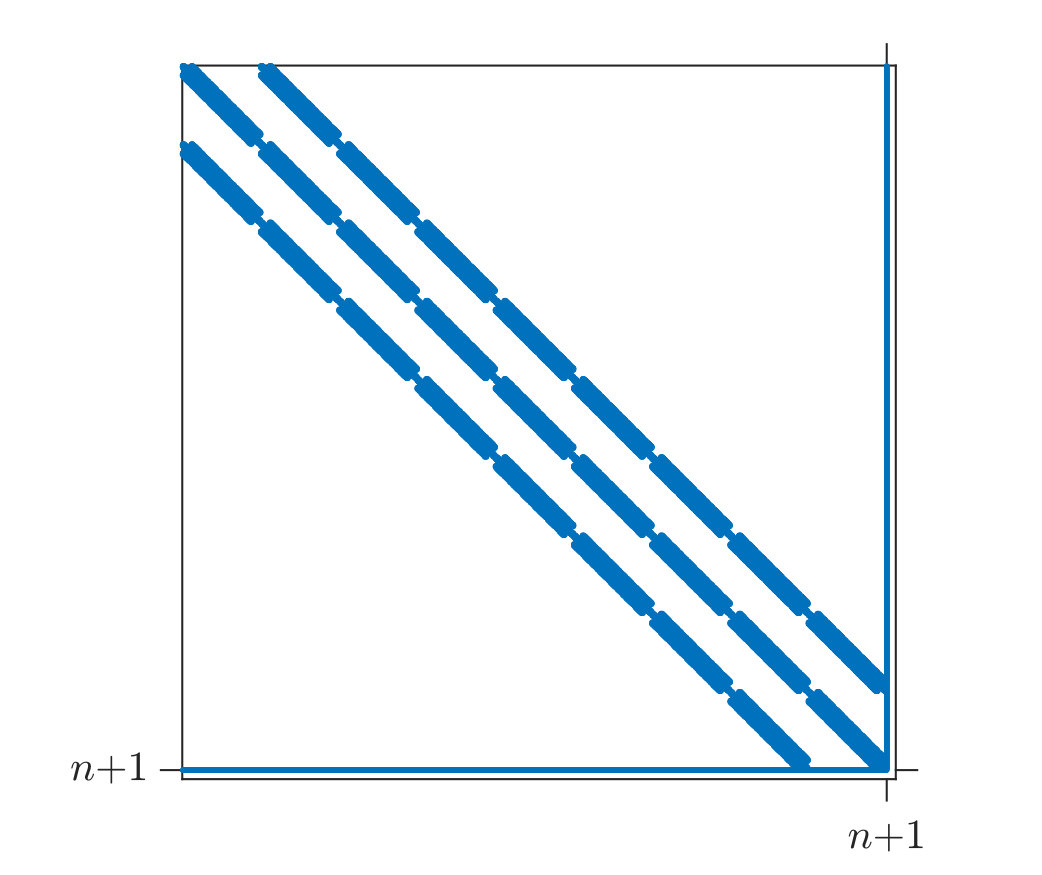 Figure 9
Figure 9| stop | iterations | CPU time [s] | ||||
|---|---|---|---|---|---|---|
| method | tol | Nwt/OC | MINRES | total | lin solv | obj fun |
| PBM | 42 | 156 | 916 | 317 | 8136 | |
| PBM | 48 | 259 | 1110 | 420 | 18 | |
| IP | 36 | 4992 | 6510 | 5670 | 49 | |
| IP() | 29 | 1243 | 1510 | 1070 | 66.1988863 | |
| DOC | 38 | 394 | 1160 | 883 | 107223 | |
| DOC | 226 | 2462 | 6710 | 5020 | 4912 | |
| DOC | 2759 | 30325 | 82500 | 61900 | 72 | |
| stop | iterations | CPU time [s] | ||||
|---|---|---|---|---|---|---|
| method | tol | Nwt/OC | MINRES | total | lin solv | obj fun |
| PBM | 57 | 330 | 2710 | 1020 | 2293 | |
| PBM | 62 | 423 | 3000 | 1190 | 61 | |
| IP | 49 | 2919 | 6040 | 4320 | 2076 | |
| IP() | 51 | 2965 | 6210 | 4440 | 42.0027639 | |
| DOC | 99 | 1454 | 6800 | 5330 | 14281 | |
| DOC | 278 | 4139 | 19200 | 15100 | 2175 | |
| DOC | 659 | 9854 | 45900 | 36100 | 23 | |
| Problem dimensions | IP | PBM | |||||
|---|---|---|---|---|---|---|---|
| --- | IP/Nwt | MR | PBM | Nwt | MR | ||
| 2-2-2-5 | 31 | 368 | 16 | 50 | 175 | ||
| 4-2-2-5 | 28 | 570 | 15 | 57 | 153 | ||
| 6-2-2-5 | 26 | 467 | 14 | 45 | 84 | ||
| 8-2-2-5 | 27 | 489 | 14 | 45 | 115 | ||
| 2-2-2-6 | 46 | 1195 | 18 | 60 | 141 | ||
| 4-2-2-6 | 42 | 2465 | 17 | 59 | 118 | ||
| 6-2-2-6 | 39 | 1015 | 17 | 66 | 157 | ||
| 8-2-2-6 | 39 | 1079 | 16 | 57 | 88 | ||
| 2-2-2-7 | 71 | 2383 | 22 | 66 | 70 | ||
| 4-2-2-7 | 54 | 3543 | 20 | 57 | 67 | ||
| 6-2-2-7 | 57 | 2667 | 19 | 60 | 68 | ||
| 8-2-2-7 | 58 | 2335 | 29 1 | 64 1 | 100 1 | ||
| Problem dimensions | IP | PBM | ||||||
|---|---|---|---|---|---|---|---|---|
| IP | MR | PBM | Nwt | MR | ||||
| 2-2-2-5 | 24 | 387 | 15 | 49 | 220 | |||
| 4-2-2-5 | 25 | 590 | 14 | 45 | 155 | |||
| 6-2-2-5 | 26 | 778 | 15 | 55 | 309 | |||
| 8-2-2-5 | 25 | 1050 | 13 | 47 | 184 | |||
| 2-2-2-6 | 41 | 2029 | 15 | 56 | 263 | |||
| 4-2-2-6 | 50 | 2965 | 15 | 57 | 317 | |||
| 6-2-2-6 | – | – | 15 | 61 | 466 | |||
| 8-2-2-6 | – | – | 15 | 62 | 592 | |||
| 2-2-2-7 | 91 | 4744 | 26 1 | 109 1 | 1134 1 | |||
| 4-2-2-7 | – | – | 26 1 | 99 1 | 718 1 | |||
| 6-2-2-7 | – | – | 25 1,3 | 98 1,3 | 743 1,3 | |||
| 8-2-2-7 | – | – | 25 1,2 | 97 1,2 | 707 1,2 | |||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsTopology Optimization in Engineering · Advanced Numerical Methods in Computational Mathematics · Metaheuristic Optimization Algorithms Research
On barrier and modified barrier multigrid methods
for 3d topology optimization††thanks: This work has been partly supported by Fondation mathématique Jaques Hadamard FMJH/PGMO Project No2017-0088 ”Multi-level Methods in Constrained Optimization”.
Alexander Brune School of Mathematics, University of Birmingham, Edgbaston, Birmingham B15 2TT, UK
Michal Kočvara School of Mathematics, University of Birmingham, Edgbaston, Birmingham B15 2TT, UK, and Institute of Information Theory and Automation, Academy of Sciences of the Czech Republic, Pod vodárenskou věží 4, 18208 Praha 8, Czech Republic
Abstract
One of the challenges encountered in optimization of mechanical structures, in particular in what is known as topology optimization, is the size of the problems, which can easily involve millions of variables. A basic example is the minimum compliance formulation of the variable thickness sheet (VTS) problem, which is equivalent to a convex problem. We propose to solve the VTS problem by the Penalty-Barrier Multiplier (PBM) method, introduced by R. Polyak and later studied by Ben-Tal and Zibulevsky and others. The most computationally expensive part of the algorithm is the solution of linear systems arising from the Newton method used to minimize a generalized augmented Lagrangian. We use a special structure of the Hessian of this Lagrangian to reduce the size of the linear system and to convert it to a form suitable for a standard multigrid method. This converted system is solved approximately by a multigrid preconditioned MINRES method. The proposed PBM algorithm is compared with the optimality criteria (OC) method and an interior point (IP) method, both using a similar iterative solver setup. We apply all three methods to different loading scenarios. In our experiments, the PBM method clearly outperforms the other methods in terms of computation time required to achieve a certain degree of accuracy.
Keywords
topology optimization, multigrid methods, interior point methods, modified barrier functions, augmented Lagrangian methods, preconditioners
MSC2010
65N55, 35Q93, 90C51, 65F08
1 Introduction
The goal of topology optimization is to find an optimal geometry of a solid body that maximizes its performance under certain boundary conditions, by determining an optimal distribution of material in a predefined design domain. It has many applications in industry, such as in mechanical and electrical engineering. The main challenge is the high computational cost of solving large-scale systems that arise from numerical methods to solve PDEs on high-resolution meshes. A basic example of topology optimization is the minimum compliance problem, where the deformation energy of an elastic body under prescribed loading and boundary conditions is to be minimized, given an amount of material. Relating the local stiffness of the body linearly to the continuous material distribution and employing a finite element discretization leads to the so-called variable thickness sheet (VTS) problem
[TABLE]
where , with , is the stiffness matrix and is the load vector of the finite element equilibrium equations. The design variable is commonly referred to as the density, while the vector represents the nodal displacements. We assume that are symmetric and positive semidefinite and that is sparse and positive definite. We also assume that the volume and the lower and upper bounds \underaccent{\bar}{\rho}\in\mathbb{R}^{m}_{+} and are chosen such that the problem is strictly feasible. This implies \bar{\rho}>\underaccent{\bar}{\rho}, among other things. While problem (1) is not itself convex, it is equivalent to a convex problem; see [6] and Theorem 2.1 below. For a more detailed derivation of the VTS problem and a comprehensive treatment of the theory and applications of topology optimization, see for example [8].
The minimum compliance problem has been studied extensively. Still, it is the subject of ongoing research as higher design detail calls for higher mesh resolution, which in turn makes the problem more computationally demanding. Aage et al., for example, performed topology optimization on a model with more than one billion elements [1]. The bottleneck of algorithms for topology optimization is usually the solution of large linear systems. Direct solvers are not a viable option, due to their computational complexity and demand on computer memory, and iterative, most typically Krylov type solvers, are given preference. Since their convergence behavior highly depends on the condition number of the system matrix, preconditioning plays a vital role. The multigrid method, introduced by Brandt as a solver for boundary-value problems [9], has become popular as a means to precondition the system by employing it inside the iterative solvers. As early as 2000, Maar and Schulz [20] proposed a conjugate gradient (CG) method preconditioned by multigrid for topology optimization. Similar solvers were used in [2] and [15]. In [1], the authors chose a multi-layered algorithm involving two types of Krylov solvers and the geometric as well as algebraic multigrid method. We refer the reader to [10] for a comprehensive introduction to the multigrid method.
Beyond the issue of efficiently solving the linear systems arising within each iteration of the optimization algorithm, the total number of such iterations required to reach the optimal solution—and thus the choice of optimization method—also affects the overall time-efficiency of the algorithm. The most commonly used methods for the minimum compliance problem are the optimality criteria (OC) method, see [8], and the method of moving asymptotes (MMA) [25]. One of the advantages of the OC method is that it is relatively simple to implement; see in particular [3]. To our knowledge, global convergence results exist only for the MMA and it is often the algorithm of choice in commercial software or large-scale applications, such as that described in [1]. Both of these methods, however, usually rely on heuristics for their stopping criteria and, in practice, display a very similar rate of convergence.
A possible alternative to the aforementioned methods is the interior point (IP) method. It has become increasingly popular in the past twenty to thirty years, particularly for convex optimization [26]. Its theoretical advantage over the OC method or the MMA for convex problems lies in its rate of convergence, especially for convex quadratic problems such as (1). Maar and Schulz [20] used an IP algorithm for 2D topology optimization. In [14], Jarre et al. proposed an IP method for truss topology optimization. This was later extended in [15] to large 2D VTS problems, where it outperformed the OC method, in terms of both iterations and overall CPU time required to achieve optimality to within a certain precision. In one part of our paper, we build on this work and further improve the algorithm to apply it to large-scale 3D problems. The approach is described in Section 4 and results of some examples are presented in Section 7.
Going from 2D to 3D is by no means straightforward. The largest examples in [15] were based on nine regular refinements of a very coarse, e.g. , mesh. This resulted in 262 144 finite elements and 526 338 degrees of freedom (components of the displacement vector ). Such a problem could still be solved on a standard laptop. If we used the same refinement level in a 3D example starting with a coarse mesh, we would end up with a problem with more than 134 million finite elements and 405 million degrees of freedom. Moreover, while the stiffness matrix in 2D typically has 18 non-zero elements per row, in 3D problems this number typically goes up to 81 non-zeros, i.e., the stiffness matrix is considerably denser. All this makes much greater demands on the numerical linear algebra used in the optimization algorithm.
A common problem with IP methods is the ill-conditioning of the system as the iterates approach the optimal solution. This leads to an increase in solver iterations which can make the algorithm nonviable. A class of methods that aims to counteract this problem while otherwise following a strategy similar to that of the IP method, is the class of penalty-barrier multiplier (PBM) methods. They were first introduced in [7], building on the modified barrier methods proposed by Polyak in [23]. As part of the larger class of augmented Lagrangian methods, they have one particular convergence property which sets them apart from IP methods. The latter involve a sequence of barrier parameters which needs to tend to 0 for convergence to the optimal solution, this being the cause of the increasing ill-conditioning; the former feature a penalty parameter for which there exists a value larger than 0 such that the method still converges to the optimal solution. See, for example, [24, Corollary 6.15] for a result specific to penalty-barrier methods. PBM methods have been successfully applied to convex problems and semidefinite problems in topology optimization [17]. In Section 3 of this paper, a penalty-barrier method for (1) is introduced. In contrast to the IP method, the PBM method does not stay in the strict interior of the feasible region. This poses a problem with regard to the positive definiteness of , which depends on being strictly positive for all . We circumvent this problem by applying the PBM method to the dual of (1). The theoretical background for this is covered in Section 2. The PBM approach described in Section 3 is applied to several examples in Section 7, in order to compare it to the IP method from Section 4, as well as to the OC method, which is briefly described in Section 5.
Lastly, a remark on notation: throughout this paper, we use to denote the -th canonical unit vector and to denote the vector of appropriate dimension.
2 Dual VTS problem
Consider the variable thickness sheet problem (1). Following [5, 18] in the context of equivalent formulations for truss topology optimization, we can formulate a dual problem to (1):
[TABLE]
Theorem 2.1**.**
Problems (1) and (2) are equivalent in the following sense:
- (i)
If one problem has a solution then also the other problem has a solution and
[TABLE]
- (ii)
Let (u^{*},\alpha^{*},\underaccent{\bar}{\nu}^{*},\bar{\nu}^{*}) be a solution to (2). Further, let be the vector of Lagrangian multipliers for the inequality constraints associated with this solution. Then is a solution of (1). Moreover,
[TABLE]
- (iii)
Let be a solution of (1). Further, let \underaccent{\bar}{r}^{*} and be the Lagrangian multipliers associated with the lower and upper bounds on , respectively, and let be the multiplier for the volume constraint. Then (u^{*},\lambda^{*},\underaccent{\bar}{r}^{*},\bar{r}^{*}) is a solution of (2).
Proof 2.2**.**
We will first write (1) equivalently as
[TABLE]
Indeed, as is by assumption positive semidefinite, the necessary and sufficient optimality condition for the inner maximization problem is and, using this, the optimal value of the maximization problem is . Problem (3) is convex (actually linear) and bounded in and concave in , so we can switch “max” and “min” (see, e.g., [11]) to get an equivalent problem:
[TABLE]
Due to our assumption of strict feasibility, there exists a Slater point for the feasible set of the inner (convex) optimization problem, so we may replace it by its Lagrangian dual. The Lagrangian multipliers for the inequalities will be denoted by \underaccent{\bar}{r}\in\mathbb{R}^{m}_{+} and , that for the volume equality constraint by :
[TABLE]
We can include the non-negativity constraint on in the inner-most optimization problem because we know that the solution to (4) satisifies \rho\geq\underaccent{\bar}{\rho}\geq 0.
Now regard the dual problem (2). It can equivalently be formulated as the following min-max problem, using a partial Lagrangian function with multiplier :
[TABLE]
which can be rearranged further to give
[TABLE]
Identifying , , \underaccent{\bar}{\nu}, and with , , \underaccent{\bar}{r}, and , respectively, and changing the sign of the objective function (and thus changing “max” to “min” and “min” to “max”), we can see that (4) and (5) are equivalent. For later reference, note that the multiplier of the dual problem corresponds to the primal variable , the density.
*The second part of (ii) is obvious from the fact that \underaccent{\bar}{\nu} and are multipliers for the lower and upper bounds, so only one of them can be positive (only one bound can be active) for each component. *
Notice that (2) is a convex optimization problem, as are positive semidefinite.
We finish this section with another formulation of the dual VTS problem that allows us to easily compute the duality gap (this formulation was first derived in [5]).
Theorem 2.3**.**
Problem (2) is equivalent to an unconstrained nonsmooth problem
[TABLE]
in the following sense:
- (i)
;
- (ii)
Let (u^{*},\alpha^{*},\underaccent{\bar}{\nu}^{*},\bar{\nu}^{*}) be a solution of (2). Then is a solution of (6). Conversely, every solution of (6) is a part of a solution of (2).
Proof 2.4**.**
We will show that Eq. 2 and Eq. 6 are equivalent reformulations of each other. Introducing an auxiliary variable , problem (6) can be directly re-written as
[TABLE]
The constraints in the above problem can be written as
[TABLE]
Noting that \bar{\rho}>\underaccent{\bar}{\rho}\geq 0, we define
[TABLE]
Then the above set of constraints can also be written as
[TABLE]
Obviously, these \underaccent{\bar}{\nu}_{i},\bar{\nu}_{i} also satisfy the non-negativity constraints. Lastly, we can reformulate the objective function to match (2), since
[TABLE]
*We switch the sign of the objective function and claims (i) and (ii) follow. *
Assume that is a feasible point in the dual problem (2) such that there exist satisfying and is feasible in the primal problem (1). We then have the following formula for the duality gap:
[TABLE]
3 The penalty-barrier multilplier method for topology optimization
In this section, we describe the class of Penalty-Barrier Multiplier (PBM) algorithms and their application to the VTS problem. This class of algorithms was originally developed and analyzed by R. Polyak under the name Modified Barrier algorithms; see, among others, [22, 23]. These methods are defined for a class of “modified” barrier functions; a particular choice of a function leads to a particular algorithm. Ben-Tal and Zibulevsky [7] analyzed one such choice that proved to be computationally very efficient; see also [16]. The PBM method was first applied to topology optimization problems in [19].
3.1 Penalty-barrier multiplier methods
Consider a generic convex constraint optimization problem
[TABLE]
The idea of NR is to replace the inequalities by scaled inequalities with a penalty function and a penalty parameter . Here, is a strictly increasing, twice differentiable, real-valued, strictly convex function with dom , which has the following properties:
.
Then the “penalized” problem
[TABLE]
remains convex and has the same feasible set and thus the same solution as the original one. We formulate a standard Lagrangian function of the penalized problem that can be considered an augmented Lagrangian function of the original problem:
[TABLE]
At each iteration of the NR, we minimize the augmented Lagrangian with respect to
[TABLE]
Here is a penalty updating factor. The meaning of the “” sign in Step 1 is that the unconstrained minimization problem is only solved approximately, until , where is some prescribed tolerance.
For more details on the NR methods, analysis and numerical performance, see the references above.
In Step 1 we need to solve, approximately, an unconstrained optimization problem. For this, we will use the Newton method. Therefore, we will need formulas for the gradient and Hessian of with respect to the primal variable :
[TABLE]
and
[TABLE]
Note that, due to the convexity of the penalized problem (8), the Hessian of is positive semidefinite for any arguments , .
Ben-Tal and Zibulevsky [7] analyzed one particular choice of the penalty function defined as follows:
[TABLE]
By setting , we get a pure (not shifted) logarithmic branch. As this function combines properties of the quadratic penalty function and the logarithmic barrier function, it is called a penalty-barrier function and the resulting algorithm a penalty-barrier multiplier method. This method proved to be very efficient and we will use it to solve the dual VTS problem.
3.2 PBM for the dual VTS problem
Let us now apply the PBM method to the dual problem (2). The augmented Lagrangian for this problem is defined as
[TABLE]
with Lagrangian multipliers , \underaccent{\bar}{\mu}\in\mathbb{R}^{m} and and penalty parameters , \underaccent{\bar}{q}\in\mathbb{R}^{m} and .
To simplify the notation, let us define the aggregate variable
[TABLE]
and vectors of penalized constraints as
[TABLE]
Let denote the argument of in the definition of above. In the following, the notation will be understood as , rather than a composite derivative of with respect to . We define \underaccent{\bar}{h}^{\prime}_{i}(\cdot) and analogously, as well as , \underaccent{\bar}{h}^{\prime\prime}(\cdot) and .
According to (13), the gradient of the augmented Lagrangian with respect to the aggregate variable is
[TABLE]
To further simplify the notation, we define
[TABLE]
By (14), the Hessian of the augmented Lagrangian will take the form
[TABLE]
where
[TABLE]
By (11), the Lagrange multipliers in the PBM algorithm are never equal to zero. Hence, the matrices are diagonal and positive or negative definite, so we can easily calculate the following inverse of the lower right block of the Lagrangian, which is in turn a block diagonal matrix:
[TABLE]
with . We will require this inverse further below.
Observe that the matrix has the same sparsity structure as the “unscaled” stiffness matrix . Indeed, the only non-zero components of the vector are those corresponding to indices of non-zero elements of , hence has the same sparsity structure as . For this reason, the matrices and have the same sparsity structure as and thus . This property extends to any matrices and , where is a diagonal matrix.
We now calculate the following Schur complement matrix
[TABLE]
By the previous considerations, the principal submatrix of has the same sparsity structure as the stiffness matrix ; the last row and column of are full. Figure 1 shows typical examples of the sparsity structure of the Hessian of the augmented Lagrangian in (18) and the Schur complement matrix .
The first step of the PBM algorithm is to solve approximately the unconstrained minimization problem
[TABLE]
by the Newton method. In every step of the Newton method, we have to solve the system of linear equations
[TABLE]
where is the Newton increment and \Delta\nu:=(\Delta\underaccent{\bar}{\nu},\Delta\bar{\nu}). Equivalently, according to the above development, we can instead solve the reduced system
[TABLE]
where, by (17),
[TABLE]
Recall that the dual problem (2) is convex, hence the Hessian of is positive semidefinite and, consequently, so is the Schur complement .
The remaining component can be reconstructed from the solution to (20) as follows:
[TABLE]
After the augmented Lagrangian has been minimized, we check for convergence. For this, we use the duality gap in (7), scaled by the dual objective function, henceforth denoted by d(u,\alpha,\underaccent{\bar}{\nu},\bar{\nu}), as a measure of optimality. If convergence has not yet been achieved, the multipliers are updated, imposing the safeguard rule used in [7], followed by the penalty parameters.
The PBM method is summarized in Algorithm 1. It employs the Newton method with backtracking line search using the Armijo rule; see Algorithm 2. The stopping criterion for the Newton method uses the weighted residual term
[TABLE]
as a measure of feasibility. The stopping parameter is adjusted adaptively in each PBM iteration and this warrants some clarification. Setting the Newton method tolerance too low in early stages of the PBM method leads to an increase in Newton iterations and thus in computational time without significantly changing the convergence behavior of the PBM. A “soft” tolerance of 100 times the current optimality measure has proven to be a good choice. At the same time, however, we want to guarantee that the final solution has a certain degree of feasibility, which requires the system (20) to be solved to a certain accuracy. For this reason, after the final PBM iteration, we run the Newton method one more time with decreased tolerance and then update . For the sake of completeness, it should be noted that the solution (u,\alpha,\underaccent{\bar}{\nu},\bar{\nu}) obtained by this additional call to the Newton method is not guaranteed to still satisfy the stopping criterion on Line 4 of Algorithm 1. It is possible that it was previously only satisfied due to the inaccuracy of the solution111Note that is only a valid duality gap for feasible solutions and .. In the vast majority of our numerical experiments, however, this was not an issue and |\delta(u,\alpha)/d(u,\alpha,\underaccent{\bar}{\nu},\bar{\nu})| remained below the stopping parameter .
Our choice of parameters in Algorithm 1 was , p_{\min}=\underaccent{\bar}{q}_{\min}=\bar{q}_{\min}=10^{-8}, and . The initial values were , , \underaccent{\bar}{\nu}=\bar{\nu}=e, , for all , and \underaccent{\bar}{\mu}=\bar{\mu}=e.
Note that Algorithm 2 is an inexact Newton method, which uses a preconditioned Krylov subspace method, as described later in Section 6. Let us reiterate that the principal submatrix of in (20) has the same sparsity structure as the stiffness matrix . This will allow us in Section 6 to develop a multigrid preconditioner using the standard prolongation/restriction operators for the stiffness matrix.
4 An Interior Point method for topology optimization
In this section, we describe the primal-dual IP method used to solve (1). This involves deriving the linear system to be solved in each iteration and taking Schur complements of this system in order to obtain a system that, firstly, is symmetric positive definite and, secondly, displays a structure that allows a straightforward application of the multigrid method as a preconditioner. In this, we follow [15]. Many features of the algorithm proposed in that reference had to be changed to make it more performant and viable for 3D problems. Therefore, we include all details of the algorithm. We do not recapitulate the basics of primal-dual IP methods and instead refer the reader to [26], to name just one standard piece of literature.
Some notation from the previous section will be reused below for variables that serve a similar purpose. However, the primal and dual variables , , , \underaccent{\bar}{\nu} and have the same meaning in both sections. This is worthwhile to note because it means that the results from the PBM method described in the previous section and the IP method described below are directly comparable.
4.1 Primal-dual Interior Point method for the VTS problem
We start by setting up the KKT conditions for the VTS problem (1). Note that the problem exhibits a “hidden convexity”, i.e., it is not itself a convex problem but is equivalent to a different, convex problem [6]. The strict feasibility, given for (1) by design—see Section 1—translates to this equivalent problem. Hence, the Slater condition is satisfied and the KKT conditions are necessary and sufficient optimality conditions. They are given by the constraint equations in (1) and the equations below.
[TABLE]
Note that in the above, the Lagrange multipliers for the equilibrium equation constraint have already been eliminated, taking advantage of the fact that the minimum compliance problem is self-adjoint. This means that, due to our choice of objective function, the aforementioned multipliers also satisfy the equilibrium equation—with the the right-hand side only differing by a constant factor. Hence, we can directly identify them with . See, for example, [8] for details.
The complementarity conditions for the lower and upper bound constraints, i.e., the second and third lines in the system above, are now perturbed by replacing [math] by barrier parameters and , respectively. The resulting system of equations needs to be solved for fixed in each iteration of the IP algorithm. This is done approximately by performing one iteration of the Newton method. We get the following residual function for the Newton method:
[TABLE]
Next, we obtain the derivative of the residual function as the block matrix
[TABLE]
where is the identity matrix and we use the notation
[TABLE]
The system matrix in (23) is indefinite. Similar to the procedure in Section 3, we can reduce the above system to a positive definite one. We do this in two steps. First, we construct the Schur complement of with respect to its invertible lower right block . We then in turn form the Schur complement of the result with respect to its lower right block; see [15] for details. This leaves us with the matrix
[TABLE]
This matrix is positive definite as long as is strictly feasible and \underaccent{\bar}{\nu},\bar{\nu}>0. Recall that has the same sparsity structure as . Hence, the matrix in (24) has the same sparsity structure as that in (19) in the previous section.
In each iteration of the IP method, we approximately solve the nonlinear system
[TABLE]
by performing one iteration of Newton’s method. Instead of solving the Newton system
[TABLE]
we solve the equivalent system
[TABLE]
where, according to the above reduction of the system,
[TABLE]
From the solution of (25), we can reconstruct the increment for using the formula
[TABLE]
The increments for the Lagrange multipliers \underaccent{\bar}{\nu} and are computed based on the stable reduction proposed in [12], with a slight adjustment to account for the upper bound constraints not present in that paper. The multipliers are updated by the following formulas, in the following order
[TABLE]
Once the increments have been obtained, we need to determine an appropriate step length. Our algorithm employs a long step strategy [26] in that it restricts the step length mainly to guarantee feasibility of the next iterate. We do not use the same step length for all increments. Rather, and use the same step length, the step length for is always equal to 1 and different step lengths are calculated for both \Delta\underaccent{\bar}{\nu} and . For details, see Algorithm 3. This strategy proved to be the most effective in numerical experiments.
After each IP iteration, the barrier parameters are updated adaptively. For this, we compute the duality measure for the lower and upper bound constraint
[TABLE]
respectively. We then scale these measures by a constant and to update and . At this point, one unconventional feature of our algorithm should be highlighted. The new values for and are not used to construct the right hand side term for the next iteration, but rather for the iteration after that. We found that this “iteration shift”, peculiar though it might seem, makes the algorithm significantly more efficient. Indeed, without this shift this version of the code is hardly viable and one requires several Newton iterations per IP iteration instead of just one.
Finally, we require a stopping criterion for the algorithm. Just like in Algorithm 1, we use the duality gap as a measure of optimality, scaled by the current objective function—the primal objective function , in this case. On top of this, we want to ensure that our solution is feasible to within a certain accuracy. Our feasibility measure is the following sum of weighted residuum norms
[TABLE]
Furthermore, the duality gap should be (nearly) positive, as a negative duality gap points to infeasibility.
Algorithm 3 sums up our IP method. The parameter values that we used in our experiments are , . For the initial values, we chose , , for all and \underaccent{\bar}{\nu}=\bar{\nu}=e. The barrier parameters start at .
5 Optimality Condition (OC) method
To get a broader picture, we will compare the PBM and IP algorithms with the established and commonly used Optimality Condition (OC) method. We will therefore briefly introduce the OC algorithm for VTS. For more details, see [8, p.308] and the references therein.
We adapt the algorithm implemented in the popular code top88.m [3]; see Algorithm 4. We call it damped OC (DOC) method, due to the exponent that shortens the “full” OC step. We use the standard value .
Following [3], we use the stopping criterion
[TABLE]
where and are the two most recent iterates. While top88.m uses , we found that this value is too generous in many 3D examples, resulting in an image that is significantly different from an image obtained with ; see Figure 3 in Section 7, where we address the choice of in a bit more detail.
Another parameter we changed, as compared to [3], was the value of the stopping criterion for the bisection method . In Section 7, we use which leads to a more stable behaviour of the DOC and only marginal increase of total CPU time.
The reader may ask about the relation of the DOC stopping criterion (using difference of variables in two subsequent iterations) with the more rigorous criterion based on the duality gap, used in the PBM and IP algorithms. Our experiments revealed a somewhat surprising phenomenon: in most of the problems we solved, the behaviour of the two stopping measures was almost identical. This experience justifies the use of the DOC stopping criterion and, in particular, the relative fairness of our comparisons of DOC with PBM and IP.
6 Multigrid preconditioned Krylov subspace methods
In the previous sections, we have introduced three algorithms for the solution of the VTS problem, all of which have one thing in common: In every iteration, we have to solve a system of linear equations
[TABLE]
where and is a symmetric positive definite matrix. In the OC method, is the stiffness matrix of the linear elasticity problem. In algorithms PBM and IP, corresponds to the Schur complements from equations (19) and (24), respectively. These latter two matrices have the same sparsity structure. In particular, the principal submatrix of has the same sparsity structure as the stiffness matrix ; the last row and column of are full.
In this section, we will recall an iterative method that is known to be very efficient for linear elasticity problems on well structured finite element meshes. Throughout the section, we will use the notation of (30).
6.1 Multigrid preconditioned MINRES
We use standard V-cycle correction scheme multigrid method with coarse level problems
[TABLE]
where
[TABLE]
Here we assume that there exist linear operators , , with and let . As a smoother, we use the Gauss-Seidel iterative method. See, e.g., [13] for details.
Although the multigrid method is very efficient, an even more efficient tool for solving (30) may be a preconditioned Krylov type method, whereas the preconditioner consists of one V-cycle of the multigrid method222We found more than one V-cycle to not be as efficient in terms of overall CPU time.. After experimenting with several Krylov methods, we found that the MINRES algorithm [21] is the most robust for our problems in which the system matrix may converge to a positive semidefinite matrix. We use the standard implementation of MINRES from [4].
6.2 Multigrid MINRES for PBM, IP and OC
In all examples in Section 7, we use hexahedral finite elements with trilinear basis functions for the displacement variable and constant basis functions for the variable , as is the standard in topology optimization. We start with a very coarse mesh and use regular refinement of each element into 8 new elements. The prolongation operators for the variable are based on a standard 27-point interpolation scheme. For more details, see, e.g., [13]. When solving the linear systems (20) and (25) in PBM and IP, we also need to prolong and restrict the single additional variable ; here we simply use the identity.
When we use the regular finite element refinement mentioned above, the stiffness matrix will be sparse and, if a reasonably good numbering of the nodes is used, banded. The number of non-zero elements in a row of does not exceed 81. A typical non-zero structure of is shown in Figure 1(b), if we ignore the additional last column and row in that figure.
As usual, the MINRES method is stopped whenever
[TABLE]
where is the residuum and the right-hand side of the linear system, respectively. The choice of the stopping parameter varies between the different algorithms.
Multigrid MINRES for OC
The only degree of freedom in the algorithm is the stopping criterion. The required accuracy of these solutions (such that the overall convergence is maintained) is well documented and theoretically supported in the case of the IP method; it is, however, an unknown in the case of the DOC method; see [2] for detailed discussion. Clearly, if the linear systems in the DOC method are solved too inaccurately, the whole method may diverge or just oscillate around a point which is not the solution.
In all our numerical experiments, we used . In [15], it was observed that, with this stopping criterion, the number of DOC iterations was almost always the same, whether we used an iterative or a direct solver for the linear systems. Our experiments with 3D problems confirmed this observation.
Multigrid MINRES for PBM
The initial stopping parameter scales with the size of the problem, as it can otherwise be too strict for large problems or too imprecise for small problems. We initialize and update it in the following way:
- •
We start with .
- •
Let be the sum of the residua computed in the current step of the PBM Newton Algorithm 2 and let be this sum in the following step. If , we update . In other words, we increase the accuracy of the stopping parameter whenever we do not achieve a satisfactory improvement in feasibility and optimality with the current .
In our numerical tests, the update had to be done only in a few cases and the smallest value of needed was .
Multigrid MINRES for IP
In the IP method, we use an adaptive updating scheme for the stopping parameter, based on the complementarity of the current solution:
- •
We start with
- •
We compute
[TABLE]
and set if this new value is lower than the current . The low minimum value of for has proven to be necessary for convergence in our experiments.
7 Numerical experiments
We now present and compare numerical results for the PBM, IP and DOC methods. In Section 7.1, we focus on a rigorous comparison of the performance of the three algorithms, both in terms of CPU time and required calls to the iterative solver. For this, we look at problems where the number of finite elements is in the order of to . As we will see, the PBM method outperforms both the IP and the DOC methods. When we consider problems with over a million finite elements in Section 7.2, we only present results for IP and PBM, since DOC with our required accuracy is no longer practicable.
In the formulation of the VTS problem (1), we chose the lower bounds \underaccent{\bar}{\rho} to be positive. As far as the underlying physical model is concerned, however, \underaccent{\bar}{\rho}=0 would make the most sense, with corresponding to an element without material. A lower bound larger than zero might distort the, as it were, physically more accurate results. Yet the strict positivity is required for the positive definiteness of and to bound the condition number of the system matrices arising in the different methods. In our experiments, this turned out to be critical for the OC and IP, but not for the PBM method. Therefore, we generally set \underaccent{\bar}{\rho}=0 for PBM only.
The code was implemented in Matlab, outsourcing certain subroutines to C via MEX files. No parallelization was performed in any of our functions. While the Matlab inbuilt routines are in general parallelizable, on the BlueBEAR HPC system used to produce the large-scale results in Section 7.2, it was limited to a single core.
The design domain for each of our example problems is set up in a way that is based on a multigrid-structure. It is a cuboid defined by cubes of equal size corresponding to the coarse level finite element mesh. We refine the coarse mesh regularly times, giving us mesh levels in total; each cube element is refined into 8 new elements of equal dimensions. Hence level-2 refinement of a coarse mesh with 16 elements results in a mesh with 128 element and level- refinement of the same coarse mesh results in a mesh with elements.
We consider two sets of boundary conditions and loading scenarios, referring to the first one as “cantilever” and to the second one as “bridge”; see Figure 2 for the specifications. Cantilever problems have all nodes on the left-hand face fixed in all directions; a load in direction is applied in the middle of the right-hand face (Figure 2(a)). The bridge problems are subject to a uniform load applied on a rectangle centered on the top face; all four corners of the bottom face are fixed in all directions (Figure 2(b)).
We adopt the following naming convention for the problems solved in this paper:
CANT---- for a cantilever with a coarse mesh and mesh levels;
BRIDGE---- for a bridge with a coarse mesh and mesh levels.
7.1 Comparison of PBM, IP and OC
The problems in this section have been solved on a 2018 MacBook Pro with 2.3GHz dual-core Intel Core i5, Turbo Boost up to 3.6GHz, and 16GB RAM. This allowed us to properly compare the CPU timing; but it also prevented us from solving large scale problems, due to memory limitations. The results for those problems, run on a HPC computer, are reported in the next section.
Example CANT-16-2-2-5
In Table 1 we present results for problem CANT-16-2-2-5 with 262 144 finite elements. The lower bound for was set to zero for the PBM method and to \underaccent{\bar}{\rho}=10^{-7} for the IP and DOC methods.
Each table row shows the results for a certain method and stopping parameter. They are given in terms of the total number of linear systems solved333This is equal to the number of Newton iterations in the case of the PBM method. For the other two algorithms, there is no difference between the number of “outer” iterations and the number of Newton iterations.; the total number of MINRES iterations; the total CPU time needed to solve the problem; the CPU time spent on solving the linear systems; and the final value of the primal objective function, where the accurate digits444Digits are assumed to be accurate when the different methods all appear to converge to them. are in bold.
Because the IP method had difficulties getting below our stopping threshold , we also ran this method with \underaccent{\bar}{\rho}=10^{-3} for comparison, since this improves the conditioning of the system matrix. The resulting objective value is not comparable with the other values and is thus grayed out.
We ran the DOC method with three different stopping tolerances. While would be used to mimic the top88 code, we can see in Figure 3 that the final result delivered with this tolerance is by no means optimal and clearly differs from that obtained with (for better transparency, Figure 3 present results of a smaller problem CANT-16-2-2-4). Decreasing to improves the result but the image is still visibly different from the optimal one. This is despite the five correct significant digits in the objective function, reached by DOC with . The results produced by PBM and IP were “visually identical” to that for DOC with in Figure 3(c). (Of course, this “visual comparison” is not rigorous but, in the end, the image is the required result of topology optimization in practice; a rigorous comparison is given in Table 1.)
We also ran the PBM method with a lower stopping tolerance to demonstrate that the method can reach higher precision with only relatively few additional iterations.
The numbers in Table 1 show that PBM clearly outperforms the other two methods, both with respect to the number of MINRES iterations and to the CPU time required by the whole algorithm and the linear solver only. It is even faster than the DOC method with the very relaxed stopping tolerance , at the same time delivering a solution of much higher quality.
Below are some further, detailed observations:
- •
The PBM iterations are very robust in terms of MINRES iterations needed to solve the linear systems. Up to the very last PBM iterations, MINRES only requires 1–3 steps to reach the required accuracy. Even in the last PBM iterations, the number of MINRES steps typically does not exceed 15–20. One reason for this is presumably that the updating scheme for the MINRES tolerance (see Section 6) only rarely needs to update the value. With thus decreasing only very slowly, the linear systems never have to be solved to a very high accuracy. Still, the PBM solution displays the required optimality and feasibility.
- •
The IP method is much more sensitive to ill-conditioning. While in the first IP iterations MINRES only requires 1–2 steps, this number then quickly increases when nearing the required IP stopping criterion. In the CANT-16-2-2-5 problem with \underaccent{\bar}{\rho}=10^{-3}, the number of MINRES steps in the IP Newton iterations grew as follows: 1–1–1–1–1–1–1–1–1–1–1–2–3–3–6–5–7–11–13–23–35–49–55–25–66-466–149–314.
- •
The number of MINRES steps in every DOC iteration is almost constant. In the CANT-16-2-2-4 problem, this number was between 8 and 11 in the first 49 DOC iterations and 12 for all remaining DOC iterations, even with the stopping tolerance . The total number of DOC iterations, however, grows dramatically when higher precision in the stopping criterion is required.
- •
Because of the way that is computed in the different algorithms, the volume constraint is not satisfied to the same degree of accuracy in each case. The OC method yields the most accurate with respect to the volume constraint, while the PBM solution generally gives . The PBM solution deviation from was never more than one permille in our experiments.
Example BRIDGE-4-2-2-6
We now present some results of the BRIDGE problem. Table 2 shows the iteration numbers and CPU times for BRIDGE-4-2-2-6 with 524 288 finite elements. Compared to CANT-16-2-2-x, the stiffness matrix in these problems (and thus the Schur complement for each method) has a higher condition number, due to the different shape of the computational domain.
7.2 Large scale problems
In this section, we do not include the CPU times needed to solve the example problems. This is because they were solved on the Linux HPC BlueBEAR with 2000 cores of different types, with up to 498 GB RAM per core. We did not have any control over which cores were used for which job, so that the time statistics could not be used for reliable performance comparison. Furthermore, recall that Matlab only ran on a single core on BlueBEAR, so that the total computation time for any example would most likely not be competitive compared with any parallelized code.
We present results for the PBM and IP algorithms only. As we have seen in Section 7.1, they are both several times faster than the DOC method for the same degree of accuracy. This does not improve with larger problem sizes, which means that the OC method might take several days to solve a problem which is solved in just a few hours by the PBM method. To solve the BRIDGE---- and BRIDGE---- problems, for example, the OC method requires roughly 17 times as much CPU time as the PBM method. This factor is even larger for CANT---- and CANT----. Comparisons for CANT---- and CANT----, which are not included here, gave a factor of over 20.
As before, we set \underaccent{\bar}{\rho}=0 for the PBM method. For IP, we chose \underaccent{\bar}{\rho}=10^{-3}, as ill-conditioning becomes critical in the large-scale problems covered in this section. Even with this lower bound, IP was not able to solve all of the examples we considered. When it failed, no convergence was apparent once the duality gap had gotten below a certain threshold, which was typically still two or three orders of magnitude too large for the stopping criterion.
The same two problems are considered as in the previous section, namely CANT---- and BRIDGE----. In this section, we fix the width and height of the design domain to and vary the length . We ran the code with mesh levels. Tables 3 and 4 show the results for CANT---- and BRIDGE---- in terms of iteration numbers.
The optimal designs produced by the PBM method can be seen in Figures 4 and 5. The VTS solution typically has a large “gray area”, i.e., is well within the interval [\,\underaccent{\bar}{\rho},\bar{\rho}\,] for the majority of elements. This makes it less straightforward to interpret the solution as a discrete design than it is in the case of the SIMP formulation [8]. We must determine a cut-off value such that all elements with are ignored. As the design domain is elongated, the density distribution further does not change in a linear fashion. Rather, the gray area is spread disproportionately more thin while most solid elements are clustered along the boundary. Therefore, instead of choosing a constant cut-off value, we found that the most consistent way to plot the results was to consider only the densest elements which add up to a fixed proportion of allowed volume, where we chose .
To solve some of the examples by the PBM method, we had to deviate from the choice of parameters specified earlier. For some examples with refinement levels, we set , rather than . Otherwise, the penalty parameters are scaled down too fast for these largest examples, so that the system becomes too ill-conditioned before we reach optimality. For the specific example CANT-8-2-2-7, we set the initial , because this additional accuracy was required for convergence. Such non-default parameter choices are indicated in Tables 3 and 4.
It needs to be said that even with such adjustments, the PBM algorithm did not solve all problems to the specified accuracy. For all BRIDGE---- examples with , it failed either close to or in the last iteration, after had dropped below and had been set to . The residual term , defined in (22), did not go below as required. This was because at a certain point, the approximate solutions of the reduced Newton system (20) were no longer directions of descent, presumably due to numerical errors. In these cases, we accepted the, as it were, nearly optimal solutions at which the algorithm stalled. The iteration numbers we list in the table are those after which no further change in residual values is seen. Note that was well below for all cases except BRIDGE-8-2-2-7, and the scaled duality gap of the accepted solution was always below .
It is evident from Tables 3 and 4, that the PBM method is both more efficient and more robust than the IP method. In both cases, the use of a multigrid preconditioner for the MINRES solver achieves the desired result in that the number of MINRES iterations grows sublinearly with the size of the system, if at all. The CANT---- example even displays a decrease in MINRES iterations with larger system size in some cases. However, this is probably not representative and a possible explanation involves the parameter : since its initial value scales with the problem size, it might simply be chosen lower than necessary for the smaller problems.
8 Conclusion
In this paper, we proposed a PBM method to solve the dual of the VTS formulation of the minimum compliance topology optimization problem. We compared it with the DOC method, one of the most popular methods for topology optimization, on the one hand, and with the IP method as an established method for general convex problems, on the other. The implementations of both the PBM and IP algorithms were tailored to the specific problem. All three methods used a multigrid preconditioned MINRES solver for the linear systems arising in each iteration.
In our numerical experiments, the PBM method clearly came out on top. It was around 20 times faster in terms of CPU time than the OC method when requiring the same degree of optimality. Even when using a very generous stopping criterion in the OC method—one that yields visibly sub-optimal results—PBM was still faster.
The IP method suffers from the characteristic ill-conditioning of the system matrix, which in some of our experiments prevented convergence altogether. Here, PBM proved to be much more robust, in addition to being considerably faster. Still, convergence was not guaranteed for all large-scale examples when sticking to the strictest stopping criterion. Judging by the symmetry and smoothness of the final design, the results were still satisfactory. Overall, the convergence behavior of the PBM method seems to be sensitive to changes in parameters such as stopping tolerances or scaling parameters. A thorough parameter study might further improve the algorithm.
We did not consider the DOC method for such large-scale problems, as its expected computation time simply disqualified it as a competitor. It is however possible that it would eventually converge even for those problems where PBM does not. Note that this would most likely take days or even weeks, as compared to the typical (successful) PBM run which took less than 12 hours. Since the DOC does not feature multipliers or barrier-/penalty-parameters tending to 0, it is not as susceptible to ill-conditioning as the PBM or IP method. This means that the advantage of DOC, when compared with PBM, could be reliability, albeit at the price of serious inefficiency.
Acknowledgements
The authors would like to thank Michael Stingl for the use of the Matlab routines used to visualize the results in Section 7.1.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Aage et al. [2017] N. Aage, E. Andreassen, B. S. Lazarov, and O. Sigmund. Giga-voxel computational morphogenesis for structural design. Nature , 550(7674):84–86, Oct 2017. ISSN 1476-4687.
- 2Amir et al. [2014] O. Amir, N. Aage, and B. S. Lazarov. On multigrid-CG for efficient topology optimization. Structural and Multidisciplinary Optimization , 49(5):815–829, 2014.
- 3Andreassen et al. [2011] E. Andreassen, A. Clausen, M. Schevenels, B. S. Lazarov, and O. Sigmund. Efficient topology optimization in MATLAB using 88 lines of code. Structural and Multidisciplinary Optimization , 43(1):1–16, 2011.
- 4Barrett et al. [1994] R. Barrett, M. W. Berry, T. F. Chan, J. Demmel, J. Donato, J. Dongarra, V. Eijkhout, R. Pozo, C. Romine, and H. Van der Vorst. Templates for the solution of linear systems: building blocks for iterative methods , volume 43. SIAM, 1994.
- 5Ben-Tal and Bendsøe [1993] A. Ben-Tal and M. P. Bendsøe. A new method for optimal truss topology design. SIAM Journal on Optimization , 3(2):322–358, 1993.
- 6Ben-Tal and Teboulle [1996] A. Ben-Tal and M. Teboulle. Hidden convexity in some nonconvex quadratically constrained quadratic programming. Mathematical Programming , 72(1):51–63, 1996.
- 7Ben-Tal and Zibulevsky [1997] A. Ben-Tal and M. Zibulevsky. Penalty/barrier multiplier methods for convex programming problems. SIAM Journal on Optimization , 7(2):347–366, 1997.
- 8Bendsøe and Sigmund [2003] M. Bendsøe and O. Sigmund. Topology Optimization. Theory, Methods and Applications . Springer-Verlag, Heidelberg, 2003.