TL;DR
Topic Grouper is a hierarchical agglomerative clustering method for topic modeling that creates a binary tree of topics without relying on hyperparameters, effectively handling stop words and varying topic frequencies.
Contribution
It introduces a hyperparameter-free, agglomerative approach to topic modeling that produces a hierarchical topic structure, differing from traditional probabilistic models.
Findings
Reasonable predictive power demonstrated.
Handles stop words and function words effectively.
Produces coherent and conclusive topics.
Abstract
We introduce Topic Grouper as a complementary approach in the field of probabilistic topic modeling. Topic Grouper creates a disjunctive partitioning of the training vocabulary in a stepwise manner such that resulting partitions represent topics. It is governed by a simple generative model, where the likelihood to generate the training documents via topics is optimized. The algorithm starts with one-word topics and joins two topics at every step. It therefore generates a solution for every desired number of topics ranging between the size of the training vocabulary and one. The process represents an agglomerative clustering that corresponds to a binary tree of topics. A resulting tree may act as a containment hierarchy, typically with more general topics towards the root of tree and more specific topics towards the leaves. Topic Grouper is not governed by a background distribution such…
Click any figure to enlarge with its caption.
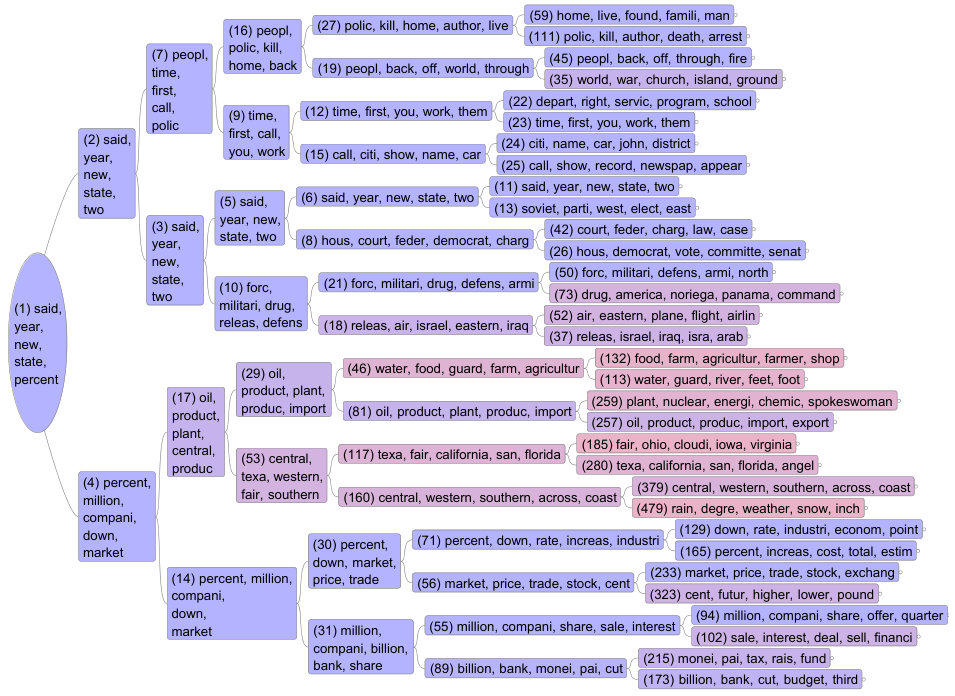 Figure 1
Figure 1 Figure 2
Figure 2Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Topic Grouper: An Agglomerative Clustering Approach to Topic Modeling
\nameDaniel Pfeifer \[email protected]
\addrDepartment of Medical Informatics
University of Heilbronn
Max-Planck-Str. 39, 74081 Heilbronn, Germany \AND\nameJochen L. Leidner \[email protected]
\addrRefinitiv Labs,
30 South Colonnade, London E14 5EP, United Kingdom
\addrUniversity of Sheffield,
Department of Computer Science,
211 Portobello, Sheffield S1 4DP, United Kingdom
Abstract
We introduce Topic Grouper as a complementary approach in the field of probabilistic topic modeling. Topic Grouper creates a disjunctive partitioning of the training vocabulary in a stepwise manner such that resulting partitions represent topics. It is governed by a simple generative model, where the likelihood to generate the training documents via topics is optimized. The algorithm starts with one-word topics and joins two topics at every step. It therefore generates a solution for every desired number of topics ranging between the size of the training vocabulary and one. The process represents an agglomerative clustering that corresponds to a binary tree of topics. A resulting tree may act as a containment hierarchy, typically with more general topics towards the root of tree and more specific topics towards the leaves. Topic Grouper is not governed by a background distribution such as the Dirichlet and avoids hyper parameter optimizations.
We show that Topic Grouper has reasonable predictive power and also a reasonable theoretical and practical complexity. Topic Grouper can deal well with stop words and function words and tends to push them into their own topics. Also, it can handle topic distributions, where some topics are more frequent than others. We present typical examples of computed topics from evaluation datasets, where topics appear conclusive and coherent. In this context, the fact that each word belongs to exactly one topic is not a major limitation; in some scenarios this can even be a genuine advantage, e.g. a related shopping basket analysis may aid in optimizing groupings of articles in sales catalogs.111A shorter version of this paper has been published by Springer-Verlag GmbH, Heidelberg (see Pfeifer and Leidner (2019)).
Keywords: Topic Modeling, Topic Analysis, Clustering, Probabilistic Topic Models, Information Retrieval, Text Collection Browsing, Exploratory Data Analysis
1 Introduction
Over the last two decades, probabilistic topic modeling (topic modeling for short) has become an active sub-field of information retrieval and machine learning. Topic modeling may be considered a refinement of document clustering and comes as an unsupervised machine learning approach in its basic versions: as opposed to pure document clustering, topic modeling allows for many topics to occur in a single document but still mandates common topics across the documents of a training collection. Hereby, each topic is typically represented via a multinomial distribution over the collection’s vocabulary. Related ideas and solutions were formed in the two seminal publications on probabilistic Latent Semantic Indexing (pLSI) (Hofmann (1999c)) and Latent Dirichlet Allocation (LDA) (Blei et al. (2003b)). Pritchard et al. (2000) proposed a model similar to LDA independently in the field of population genetics.
Besides classical text document analysis and genetics, topic modeling has turned out to be of use in bio-informatics (Liu et al., 2016), digital libraries (Griffiths and Steyvers, 2004), recommender systems (Hu et al., 2014), computing in the service of political and social studies (“digital humanities”) (Blei, 2012) and other application areas (e.g. see Boyd-Graber et al. (2017)).
Regarding pure document clustering, the two major machine learning directions are Expectation Maximization (EM) including -Means on the one hand and hierarchical clustering including agglomerative clustering on the other hand. In comparison, EM-based techniques have also been a central means for topic inference but the opportunities of hierarchical clustering for topic modeling have been overlooked to date. In this paper, we aim to partially close this gap by developing and evaluating Topic Grouper as a topic modeling approach based on agglomerative clustering.
Important benefits of agglomerative clustering for topic modeling lie in its simplicity, absence of hyper parameters, deep hierarchical structures of topics as well as the ability to find even conceptually narrow topics. A major challenge is to determine a well-founded cluster distance with reasonable predictive qualities and computational performance.
The remainder of this article is structured as follows: Section 2 describes relevant related work. It also outlines basic concepts behind topic models and summarizes the hyper parameter problem for LDA. Section 3 introduces the generative model behind Topic Grouper and derives a related cluster distance. Moreover, a corresponding algorithm for model computation is presented and its complexity is assessed. Section 4 includes a range of experiments comparing the performance of Topic Grouper with two LDA variants. A synthetic dataset allows for applying error rate as a quality measure. Regarding real-world datasets covering retailing and text, we resort to perplexity. In addition, Section 4.3 examines Topic Grouper as a feature reduction method for text classification and compares it to LDA as well as to two common text-oriented feature selection techniques. Section 4.4 discusses approaches to inspect learned models and reports on related examples for a larger text dataset. Section 5 summarizes and discusses our findings. Section 6 gives pointers to possible future work.
2 Basic Concepts and Related Work
2.1 Agglomerative Clustering
Clustering items of data, such as sets of vectors of numbers by similarity is an old idea. Hierarchical agglomerative clustering (HAC) or simply agglomerative clustering is the process of clustering the clusters in turn iteratively, based on a similarity measure between clusters from a previous iteration. It was first described in the 1960s by authors includingWard, Jr. (1963), Lance and Williams (1966, 1967), and others.
A cluster distance is usually the term for the inverse of a similarity measure underlying a clustering procedure. Standard cluster distances derived from the so-called Lance-Williams formula include single linkage, complete linkage and group average linkage, but many others have been proposed (see, Murtagh (1983); Xu and Wunsch, D. (2005)).
Cluster distances, such as the one developed here, may not necessarily meet standard mathematical distance axioms, as agglomerative clustering can do without (Ward, Jr. (1963)). Moreover, our cluster distance is model-based, as it is governed by a simple generative model. Model-based agglomerative clustering has rarely been investigated: Kamvar et al. (2002) give a model-based interpretation of some standard cluster distances and partly extend them under the same framework. Vaithyanathan and Dom (2000) develop a recursive probabilistic model for a clustering tree in order to explain the data items merged at each tree node. The model is applied to the case of pure document clustering. For efficiency reasons the authors resort to a mix of agglomerative and flat clustering.
A common critique of agglomerative clustering is its relatively high time complexity typically amounting to or more given the number of data items (Xu and Wunsch, D. (2005)). Also, space complexity is often in depending on the chosen cluster distance. In the case of our contribution and additionally in the case of text, corresponds to the vocabulary size, which can be limited even for large text collections, e.g. by simple filtering criteria such as high document frequency. This offers the potential for a reasonable computational overhead in the context of topic modeling.
A major asset of agglomerative clustering is the tree structure of its clusters often assumed to reflect containment hierarchies. Also, it is widely held that agglomerative clustering offers better and more computationally stable clusters than competing procedures such as -Means (Jain and Dubes (1988), p. 140).
For further exposition, we refer the reader to recent text books on the topic (e.g. Xu and Wunsch II. (2009); Everitt et al. (2011)) and various survey papers (e.g. Murtagh (1983), Jain et al. (1999) and Xu and Wunsch, D. (2005)).
2.2 Probabilistic Topic Modeling
Topic modeling evolved from Latent Semantic Analysis (LSA) – an algebraic dimensionality reduction technique using Singular Value Decomposition to retain the largest singular values which show the dimensions with the greatest variance between words and documents (Deerwester et al. (1990)). Latent Semantic Indexing is the application of LSA to document indexing and retrieval (Hofmann (1999b)). A drawback of LSA is the lack of a probabilistic interpretation. This was first addressed by pLSI in Hofmann (1999c).
In their influential paper, Blei et al. (2003b) describe LDA and extend pLSI by two Dirichlet priors, thus completing the generative approach and aiding in smoothing of the resulting models. In the following, we briefly reiterate such non-hierarchical or flat topic models in order to provide the foundation for our own method.
2.2.1 Non-Hierarchical Topic Models
Let
- •
be the set of training documents with size ,
- •
be the vocabulary of with size ,
- •
be the frequency of a word with regard to .
Given a set of topic references with , the goal of non-hierarchical or flat topic modeling is to estimate respectively consider topic-word distributions (one for each ) and document-topic distributions (one for each ). Together, these distributions are meant to maximize , where is the probability of all word occurrences in regardless of their order. Yet, how this is done in detail, depends on the topic modeling approach: Under pLSI (Hofmann (1999c)) we have
[TABLE]
The topic-word distributions form a corresponding topic model . Each represents the essence of a topic, where itself is just for reference.
As a more sophisticated Bayesian approach, LDA puts all potential topic-word distributions under a Dirichlet prior in order to determine (Blei et al. (2003b)). In this case, an approximation of
[TABLE]
may be considered a topic model (Blei et al. (2003b)). Hereby, is an additional Dirichlet prior to determine
[TABLE]
Alternatively to the operator, may be integrated out leading to a corresponding point estimate for (Griffiths and Steyvers (2004)).
Considering training results, plays the same role as a distribution under pLSI. With this in mind, we often use the letter for topic models regardless of the underlying modeling approach. A similar concession holds for document-topic distributions .
There exist several methods and various derived algorithms readily available to approximate under LDA including variational Bayes, MAP estimation and Gibbs sampling (e.g. see Asuncion et al. (2009)).
2.2.2 Hyper Parameter Optimization for LDA
LDA is a very successful method, but suffers from the need for setting several hyper parameters. This sections gives a brief overview of the issue as relevant for evaluations in Section 4.
Besides the number of topics , standard LDA has two hyper parameters that must be adjusted for model computation (Blei et al. (2003b); Wallach et al. (2009a); Asuncion et al. (2009)):
- •
The vector with , for all and where is called the concentration parameter: parametrizes which document-topic distributions from Equation 2 are more or less probable (regardless of ). For practical concerns is often set with . This case is called “symmetric” since the concentration parameter remains as the only degree of freedom for .
- •
The vector for all (sometimes also named ): parametrizes, which topic-word distributions from Equation 1 are more or less probable (regardless of ). is usually kept symmetric.
When applying LDA, there are different approaches to determine reasonable values for , and : is often varied via a parameter search (e.g. in Blei et al. (2003b); Griffiths and Steyvers (2004); Asuncion et al. (2009)) with a range typically between 10 and 1000 and a step size of 10. The optimization criterion is high log probability or equivalently low perplexity for held out test documents .
Regarding the optimization of , the following options are of practical relevance:
- •
If one decides for a symmetrical , a hyper parameter search may be performed (Asuncion et al. (2009)). The optimization goal is the same as for , but one does not use test documents as is considered a more integral part of the training process.
- •
A simpler approach for a symmetrical , well established in practice, is to apply a heuristic from Griffiths and Steyvers (2004) by setting .
- •
Another technique is to (re-)estimate as part of an EM procedure. E.g. in Asuncion et al. (2009), the (re-)estimation of is based on an initially computed topic model . The updated can in turn be used to compute an updated model (while using as a starting point to compute ) an so forth. After several iterations of such alternating steps, the models as well as converge. Minka (2000) provides a theoretical basis for the estimation of Dirichlet parameters via sample distribution data. In case of , these are (samples of) estimated distributions as computed along with an intermediate model . To do so, Asuncion et al. (2009) leverage Equation 55 from Minka (2000) in the EM procedure and coined for this particular E-step the name “Minka’s update”. Minka’s update can be implemented under a symmetrical as well as under an asymmetric .
Concerning , there exists similar alternatives as for . A related heuristic for a symmetrical from Griffiths and Steyvers (2004) is . Wallach et al. (2009a) report that an asymmetric optimization offers worse predictive performance than its symmetrical counter part, but they also stress the importance of the asymmetric case for topic model quality.
Later, when comparing LDA against Topic Grouper in Section 4, we refer to the heuristics for and from Griffiths and Steyvers (2004) as “LDA with Heuristics”. We also include an optimization for an asymmetric combined with a symmetric optimization using Minka’s update and call it “LDA Optimized”. We include both approaches in our evaluation as extreme variants for LDA hyper parametrization: the former one being straight forward and efficient; the latter one offering higher predictive performance but also incurring substantial computational overhead due to intertwined approximation procedures. We use Gibbs sampling according to Griffiths and Steyvers (2004) in order to compute intermediate topic models as described above and a final model, respectively .333Although intricate, details on hyper parameter settings matter: Some publications compare approaches to LDA but for example, leave it unclear whether is kept symmetric or if it is optimized. E.g., Tan and Ou (2010) report that “basic LDA fails” to successfully learn a solution for the kind of data we use in Section 4.1. In comparison, we found that LDA succeeds in this case if its hyper parameters are set accordingly.
2.2.3 Hierarchical Topic Models
Traditional topic models create flat topics; however, it may be more appropriate to have a hierarchy comprising multiple levels of super-topics and increasingly specialized sub-topics. To address this, topic model extensions based on trees and directed acyclic graphs have been proposed.
One of the early attempts towards hierarchical topic models is Hofmann (1999a)’s Cluster Abstraction Model (CAM), using an instance EM with annealing: Leaf nodes of a hierarchy are generated first via probabilistic soft clustering of documents. Inner nodes form latent sources of each word occurrence in a document such that a respective inner node is the ancestor of a leaf cluster in which the document is placed. The latent sources are subject to probabilistic modeling based on the hierarchy’s leaves. Experiments indicate that top probability words in inner nodes form topical abstractions of the document clusters they subsume.
Segal et al. (2002)’s Probabilistic Abstraction Hierarchies (PAH) is another model based on the EM algorithm: it jointly optimizes cluster assignment, class-specific probabilistic models (CPMs) which are taxonomy nodes and the taxonomy structure. The latter two are globally optimized. The authors state that “data is generated only at the leaves of the tree, so that a model basically defines a mixture distribution whose components are the CPMs at the leaves of the tree.” They offer a brief evaluation including a predictive performance comparison of PAH with hierarchical clustering on gene expression data.
Blei et al. (2003a) discuss an extension of the “Chinese restaurant process” (CRP) from Aldous (1985): Their so-called “nested Chinese restaurant process” (nCRP) allows for inferring hierarchical mixture models while permitting uncertainty about branching factors. Based on the nCRP, the authors propose Hierarchical LDA (hLDA) to estimate topic trees of a given depth . Documents are thought to be generated by first choosing a path of length along a tree and then mixing the document’s topics via the chosen path where each path node represents a topic to be inferred. The corresponding document-topic distribution is subject to a Dirichlet distribution with prior . Under hLDA, higher level topics tend to be common across many documents, but do not necessarily form semantic generalizations of lower level topics. I.e., the model tends to push stop words and function towards the root of tree and rather domain-specific words towards the leaves. Besides and , hLDA requires a prior affecting the branching factor of estimated trees and a prior , which is equivalent to under LDA.
The Hierarchical Dirichlet Process (HDP) by Teh et al. (2006) is a framework for two or more layered Dirichlet processes (DPs), where a first-level DP produces the parameters for second level DPs which in turn create mixture components to explain groups of data. A merit of the HDP is that the number of mixture components on the second level must not be set while still enabling a degree of sharing of mixture components between the groups. E.g. with regard to topic modeling, the authors apply the HDP in order to infer the number of flat topics on a small-sized document collection along with a respective topic model. The HDP still mandates hyper parameters similar to and under LDA. Wang et al. (2011) present a faster inference algorithm for HDP, which scales up to larger dataset sizes.
The Pachinko Allocation Model (PAM) from Li and McCallum (2006) is a hierarchical topic model based on multiple Dirichlet processes. The PAM requires a directed acyclic graph (DAG) as a prior, where leaf nodes correspond to words from the vocabulary, parents of leaf nodes correspond to flat, word-based topics and other nodes represent mixture components over their children’s mixture components. A topic for a word occurrence of a document is sampled by considering all paths from the root to the leaves’ parents. Moreover, the mixture components of all inner nodes are subject to Dirichlet distributions. Due to this structure, higher level nodes in the graph form abstractions of topic mixtures across documents and therefore capture topic correlations. As respective super-topics represent mixes over topics, the authors do not offer a labeling scheme for them. Besides the basic graph structure, the PAM has similar hyper parameters as LDA including , and the number of word-based topics . Furthermore, forms of a set vectors, one for each inner node, which are estimated as part of PAM’s inference process.
The recursive Chinese Restaurant Process (rCRP) from Kim et al. (2012) is another extension of the CRP to infer hierarchical topic structures. In contrast to hLDA, the sampling of a document-topic distribution is generalized in a way that permits a document’s topics to be drawn from the entire (hierarchical) topic tree, not just from a single path. Regarding document-topic assignments, the rCRP makes the drawing of topics deeper in the tree more unlikely and estimates the branching factor of a topic tree node similarly to a regular CRP. The topic-word distributions of a tree-node are controlled via a Dirichlet with a symmetrical prior , where and is the depth of the node. As the prior gets smaller with increasing depth, the resulting distributions get more peaked, which facilitates the production of more specific topic towards the leaves. A CRP based on a scalar prior controls how words from a document are assigned to topics and another scalar prior controls the inferred depth and branching factor of the topic tree under the rCRP. An experimental analysis and examples of inferred topics indicate that the approach alleviates well-known drawbacks of hLDA including the one mentioned above.
The Nested Hierarchical Dirichlet Process (nHDP) from Paisley et al. (2015) is perhaps the most sophisticated approach to produce tree-structured topics on the basis of DPs: Based on Blei et al. (2003a) it uses the nCRP to produce a global topic tree. Every document obtains its specific topic tree which is derived from the global tree via an HDP. Hence, the HDP ensures a degree of sharing of topics between documents and allocates document-level topics based on DPs associated with the nodes of the global topic tree. To sample of a word’s topic from the document-level topic tree the nHDP descends through that tree and may stop at any node. Stopping or progressing is a random event based on node-related probabilities drawn from a beta distribution with hyper parameters and . The approach also mandates a hyper parameter for its basic nCRP and for document-level trees. The authors provide efficient inference procedures and offer impressive results on small as well as very large text datasets, where the vocabulary on the large datasets is reduced to about 8,000 words.
An apparent commonality of the presented approaches is the need for hyper parameters—usually several scalars. This also holds for the Hierarchical Latent Tree Analysis (HLTA) from Liu et al. (2014) and the Hierarchical PAM (HPAM) from Mimno et al. (2007). An analyst applying a related approach may therefore struggle with its complexity and with setting the hyper parameters. Although some of the above-mentioned solutions scale up to large datasets, the resulting topic trees remain rather shallow. In contrast, Topic Grouper offers deep trees and requires no hyper parameters. Deeper tree nodes cover only small sets of words and tend to become more specific. The fact that word sets are disjunctive at every tree level may ease topic interpretation but it also imposes a limitation with regard to polysemic words. Related pros and cons will be addressed further in Sections 4.4 and 5.
2.3 Evaluation Regimes
Since typically, there exists no ground truth regarding topic models, a well-established intrinsic evaluation scheme is to compute the log probability for test documents withheld from the training data. In this context, estimating (the logarithm of) via an LDA topic model with its Dirichlet prior is a non-trivial problem in itself. We follow Wallach et al. (2009b), who determine this quantity conceptually as follows:
[TABLE]
Note that apart from using instead of from Section 2.2, Equation 3 and Equation 2 are the same.
Wallach et al. (2009b) also examine different approximation methods for Equation 3 and introduce their so-called “left-to-right” method. Buntine (2009) presents a refined and unbiased version of “left-to-right” named “left-to-right sequential”. Regarding LDA, we report results based on the latter algorithm since it acts as a gold standard estimation for Equation 3 (see Buntine (2009)).
Like Blei et al. (2003b) and others we use perplexity as a derived measure to aggregate the predictive power of over :
[TABLE]
In doing so, only words from the training vocabulary are considered, such that the size of a test document is .
An intrinsic evaluation alone does not guarantee that learned topics coincide with human intuition and interpretability. This is particularly important when topics are consumed by humans directly rather than being utilized as an intermediate step of a machine learning or natural language processing pipeline. Extrinsic evaluations therefore resort to external resources to assess topic quality: for instance, Chang et al. (2009) describe two human experiments, one study on word intrusion and another one on topic intrusion, respectively. In the word intrusion task subjects are asked to identify which spurious (“intruder”) word was added to a topic in hindsight to “pollute” it. If subjects identify the intruder artificially injected by the experimenter, this is a sign that the other words making up the topic are of good quality. In the topic intrusion task, subjects are asked to identify a “rogue topic” that has been added to a document (i.e., topics that are not actually covered in a document). Regarding their setting the authors find that “surprisingly, topic models which perform better on held-out likelihood may infer less semantically meaningful topics”.
Newman et al. (2010) experiment with word co-occurrence measures obtained via word statistics from WordNet, Wikipedia and the Google search engine. They combine related values as obtained from each pair of a topic’s top words in order to compute topic coherence, which they define as “average semantic relatedness between a topic’s words”. Several variants of resulting quality measures matched the expectation of human annotators on respective text collections, including pointwise mutual information (PMI). Other than in the intruder scenario, annotators had to rate the coherence of topics as obtained from the training phase. Building on this work, Aletras and Stevenson (2013) compare four similarity functions for the automatic evaluation of topic coherence, including the cosine similarity, Dice coefficient and Jaccard coefficient. While Newman et al. use PMI to measure similarity between a topic’s top words directly, Aletras and Stevenson first map each word of a topic to a vector of co-occurring words as computed via word statistics from Wikipedia. Afterwards, the similarity measures are applied to such word vectors in order to estimate a topic’s coherence. An evaluation based on three document collections and envolving human judges shows that their approach performs better than using PMI directly.
Lau et al. (2014) build on the work from Chang et al. (2009) and Newman et al. (2010) and also offer a good review of extrinsic evaluations for topic models. They use machine learning to automate the detection of intruder words and to automatically assess the degree of coherence of a topic, respectively. While they solved the latter task successfully, the former task posed problems. Maybe surprisingly, they find that “the correlation between the human ratings of intruder words and observed coherence is only modest” and give a plausible example-based explanation in their paper.
This look at extrinsic evaluation methods indicates that they are manifold and that related research is still ongoing. We therefore rely on hold-out performance for now as a well-established and more standardized criterion. Numerous topic modeling contributions suggest that at least a reasonable hold-out performance is a necessary criterion also for semantically meaningful topic models. Evidence usually comes from reporting such performance results in conjunction with example topics as learned from a text collection covering general knowledge (e.g. see Mimno et al. (2007), Kim et al. (2012) or Paisley et al. (2015)). We follow this scheme, but also leverage some simple synthetic datasets in order to examine whether a modeling approach is able to recover the true topics governing that dataset.
3 Topic Grouper
3.1 Model
Let be a (topical) partitioning of such that for any , and . Further, let the topic-word assignment be the topic of a word such that . Note that in the following, we also make use of the variables , , and as specified in Section 2.2.
Our principal goal is to find an optimal partitioning for each along
[TABLE]
[TABLE]
The idea is that each document is considered to be generated via a simple stochastic process where a word in occurs by
- •
first sampling a topic according to a probability distribution ,
- •
then sampling a word from according to the topic-word distribution
and so, the total probability of generating is proportional to .
The optimal partitioning consists of pairwise disjunctive subsets of , whereby each subset is meant to represent a topic. By definition every word must be in exactly one of those sets. This may help to keep topics more interpretable for humans because they do not overlap with regard to their words. On the other hand, polysemic words can only support one topic, even though it would be justified to keep them in several topics due to multiple contextual meanings. Note that the approach considers a solution for every possible number of topics ranging between and one.
To further detail our approach, we set
- •
, since otherwise would not be in the vocabulary,
- •
, since otherwise the document would be empty,
- •
be the topic frequency in a document and
- •
be the number of times is referenced in via some word .
Concerning we use maximum likelihood estimations for and based on :
- •
, which is if ,
- •
, which is always since .
Unfortunately, constructing the optimal partitionings is computationally hard. We suggest a greedy algorithm that constructs suboptimal partitionings instead, starting with as step . At every step the greedy algorithm joins two different topics such that is maximized while must hold. Essentially, this results in an agglomerative clustering approach, where topics, not documents, form respective clusters.
For efficient computation we first rearrange the terms of with a focus on topics in the outer factorization:
[TABLE]
The rearrangement relies on the fact that every word belongs to exactly one topic and enables the “change of perspective” towards topic-oriented clustering.
We maximize instead of which is equivalent with respect to the argmax-operator. This leads to
[TABLE]
with the maximum likelihood estimation
[TABLE]
Using these formulas the best possible join of two (disjunctive) topics results in with
[TABLE]
[TABLE]
[TABLE]
From the perspective of clustering procedures is the cluster distance between and . Note though, that it does not adhere to standard distance axioms.
3.2 Joining Two Topics and
Considering the resulting algorithm, we can reuse and from prior computation steps in order to compute efficiently: Regarding expression (5) from above, let . We have , and , and so
[TABLE]
The terms and with will have been computed already during the prior steps of the resulting algorithm, i.e. when and were generated as topics. Thus, the computation of all sums over words can be avoided with respect to . This is essential for a reasonable runtime complexity.
3.3 Initialization
During initialization, the resulting algorithm generates all one-word topics . Given we have
[TABLE]
The algorithm also computes the best possible join partner for some and so
[TABLE]
The first sum in this expression is problematic because one would have to iterate over the document set to compute it. Using an inverted index, one can avoid looking at documents with and .
3.4 Algorithm and Complexity
Topic Grouper can be implemented via adaptations of standard agglomerative clustering algorithms: Listing 1 presents a related variant of the efficient hierarchical agglomerative clustering (EHAC) taken from Manning et al. (2008), which manages a map of priority queues in order to represent evolving clusters during the agglomeration process. EHAC’s time complexity is in and its space complexity in with being the initial number of clusters. However, this implies that the cost of computing the distance between two clusters is in . In the case of Topic Grouper the latter cost is in instead, because one must compute the value of from Equation 8. The factor “” from EHAC’s original time complexity accounts for access to priority queue elements – in the case of Topic Grouper this is dominated by the cost to compute -values.
Putting it together, the time complexity for Listing 1 is on the order of and its space complexity is in . In case of text, one may further assume that Heaps’ Law holds (Heaps (1978)): Without a fixed limit on the vocabulary, we then have about , leading to a simplified time complexity estimation for Topic Grouper roughly on the order of .
The stated space complexity, , can be problematic if the vocabulary is large. We devised an alternative clustering algorithm, MEHAC, whose space complexity is in but its expected time complexity is still in . A drawback of MEHAC is that in practice, it incurs a higher constant computation time factor than EHAC. So, given sufficient memory, the EHAC variant is preferable. MEHAC is detailed in Appendix B. Appendix C highlights the practical performance of both algorithms based on example datasets.
4 Experiments
4.1 Synthetic Data
This section provides a first evaluation of Topic Grouper using simple synthetically generated datasets. As the true topics are known (i.e. having gold data), this allows us to consider error rate as a quality measure and to examine some basic qualities of our approach: The idea is to compare a model against the true topic-word distributions used to generate a dataset.
The following definition of error rate assumes that the perfect number of topics is already known, such that is preset for training. The order of topics in topic models is unspecified, so we try every bijective mapping when comparing a computed model with a true model and favor the mapping that minimizes the error:
[TABLE]
The measure is designed to range between 0 and 1, where 0 is perfect. Considering a mapping , every topic may contribute equally to lower the error rate. The factor avoids double counting, since a quantity exceeding will be missing for other words , i.e. will then be too low.
4.1.1 Datasets According to Tan and Ou (2010)
We use a simple synthetic data generator as introduced in Tan and Ou (2010): It is based on (artificial) words equally divided into disjoint topics . The words are represented by numbers, such that belongs to , to and so on.
Concerning the 100 words of a topic , the topic-word distribution is drawn independently for each topic from a Dirichlet distribution with a symmetric prior , such that . A resulting dataset holds 6,000 documents with each document consisting of 30 word occurrences. A document-topic distribution is drawn independently for each document via a Dirichlet with the prior , where topic 1 with is meant to represent a typical “stop word topic”, which is more likely than other topics.
To generate a word occurrence for a document , the occurrence’s topic is first drawn via . Then, the word is drawn via . For the results from below, we generated two random datasets (“1” and “2”) this way, where each has its specific topic-word distributions .
4.1.2 Results
Figure 1 shows the error rate of LDA as well as Topic Grouper for the two datasets from Section 4.1. The values were produced via a 75% random sub-sample or taken from each dataset for training, respectively. The remaining 25% were used as test data in order to compute perplexity — corresponding results can be found in Appendix A.
Regarding LDA, the depicted values are averaged across 50 runs per data point, whereby the random seed for the Gibbs sampler was changed for every run. The symmetric hyper parameter was optimized using Minka’s update (see Section 2.2.2).
LDA’s changes along the X axis such that and always hold. The results stress the importance of hyper parameter choice for model quality under LDA with regard to . This conforms to respective findings from Wallach et al. (2009a). Note that a symmetric with fails to deliver low error rates. LDA performs better as the approaches the true , which governs the datasets.
In this setting, Topic Grouper delivers good error rates right away. As its results are independent of and but also deterministic, they are included as a horizontal line.
We also added results for pLSI as an alternative approach introduced by Hofmann (1999c) (where dataset 2 is omitted for visual clarity): pLSI attains only mediocre and volatile results, heavily depending on its random initialization values. We therefore excluded it from evaluations on other datasets from below.
The unigram model simply sets for any . For completeness and for reference, we finally added a theoretically “perfect model”: It determines the topic-word probabilities on the basis of the training data while using the perfect topic-word assignment as known from data generation.
It is worth mentioning that we ran additional experiments with many other configurations for the data generator from Section 4.1.1: E.g., we varied the number of topics, words per document, vocabulary size, number of documents and but kept up the unique topic-word assignment as part of the generation. Such obtained results were analogous to the reported ones.
We also compared how LDA’s and Topic Grouper’s error rates drop with an increasing number of training documents generated according to Section 4.1.1. In favour of LDA, we set . With the number documents ranging between 500 and 10.000 both approaches attained about similar performance (not depicted).
Figure 2 illustrates how from Equation 6 can be used as a suitable measure to determine a good number of topics in the context of Topic Grouper. Here, the sudden drop of at means that at least four topics are required to model the data accordingly. A similar approach is often taken for LDA: E.g. Griffiths and Steyvers (2004) visualize the log probability for the training dataset under LDA where the number of topics is varied. While under LDA a separate training run is required for every , Topic Grouper assesses all potential values of between and 1 within a single run.
4.2 Real-World Datasets
This section reports perplexity results for two retail datasets and two text-based datasets. The log probability for test documents is estimated as described in Section 2.3 and perplexity is computed via Equation 4.
Fortunately this approach can be applied to models computed via LDA and Topic Grouper alike: In the latter case, we set with being the topic to which belongs and being the maximum likelihood estimate.444 is the Kronecker symbol. (This implies that if .) As there is no predefined prior under Topic Grouper, we simply set – the maximum likelihood estimate for . Finally, we determine a suitable value for the concentration parameter via an interval search with the optimization goal being low perplexity on the training data. The such obtained is used during test. We believe the approach is fair because it focuses on the quality of a topic model regardless of its underlying training method. Due to ’s Dirichlet, it also avoids (additional) smoothing schemes for Topic Grouper.
4.2.1 Retailing
Regarding retailing, a shopping basket or an order are equivalent to a document. Articles correspond to words from a vocabulary and item quantities transfer to word occurrence frequencies in documents. In this context, topics represent groups of articles as typically bought or ordered together. Therefore, inferred topic models may be leveraged to optimize sales-driven catalog structures, to develop layouts of product assortments (Chen and Lin (2007)) or to build recommmender systems (Wang and Blei (2011)).
The “Online Retail” dataset is a “transnational dataset which contains all the transactions occurring between 01/12/2010 and 09/12/2011 for a UK-based … online retail” obtained from the UCI Machine Learning Repository (Chen et al. (2012)).555See https://archive.ics.uci.edu/ml/datasets/Online+Retail. We performed data cleaning by removing erroneous and inconsistent orders. Item quantities are highly skewed with about 5% above 25, some reaching values of over 1,000. This is due to a mixed customer base including consumers and wholesalers. We therefore excluded all order items with quantities above 25 to focus on small scale (parts of) orders. We randomly split such preprocessed orders into 90% training and 10% test data, keeping only articles that were ordered at least 10 times in the training data. The resulting training dataset covers articles, orders and 427,150 order items. The resulting average sum of item quantities per order is about 154.
Figure 3 shows that optimized LDA and Topic Grouper are closely matched beyond 80 topics with optimized LDA performing slightly better. In comparison, the performance of LDA with heuristics begins to degrade at 80 topics. Topic Grouper is competitive although its underlying topic model is more restrained (as each article or word belongs to exactly one topic, respectively).
The “Ta Feng” dataset was published on the ACM RecSys Wiki666See http://www.recsyswiki.com.: It captures shopping baskets of consumers from a Taiwanese grocery store collected over four months between 2000 and 2001. It covers 23,812 articles and 119,578 shopping baskets but the average number of goods in a basket is only about 9.5 with about 6.8 different articles. For data cleaning, we removed unlikely item quantities above 50 from shopping baskets. Again we split the left-over data based on a 90% to 10% ratio, keeping only articles that were bought at least 20 times in the training data. This way we ended up with articles left for training.
Figure 4 shows the respective perplexity results. LDA Optimized clearly dominates but Topic Grouper surpasses LDA with Heuristics at about 180 topics. LDA with Heuristics fails at higher topic numbers due to inappropriate hyper parameter setting.
4.2.2 Text
The first of two examples is a subset of the TREC AP corpus containing 20,000 newswire articles.777See https://catalog.ldc.upenn.edu/LDC93T3A. We performed (Porter) stemming and kept every stem that occurs at least five times in the dataset. Moreover, we removed all tokens containing non-alphabetical characters or being shorter than three characters. Again we split the left-over documents on a 90% to 10% basis and only kept words occurring at least five times in the training data. This led to words left for training.
Figure 5 shows related results: Here, Topic Grouper performs generally worse than LDA but attains similar performance as LDA with Heuristics beyond about 200 topics. Despite these differences we found that related topics generated by Topic Grouper are reasonably conclusive and coherent. We will elaborate on this with regard to the AP Corpus in Section 4.4.
The NIPS dataset is a collection of 1,500 research publications from the Neural Information Processing Systems Conference. We used a preprocessed version as is of the dataset from the UCI Machine Learning Repository.888See https://archive.ics.uci.edu/ml/datasets/Bag+of+Words. It was already tokenized and had stop words removed but no stemming was performed. We split the document set on a 90% to 10% basis and only kept words occurring at least five times in the training data. This way we ended up with words left for training.
Figure 6 shows that LDA Optimized performs best but Topic Grouper outperforms LDA with Heuristics beyond about 70 topics.
Together, the results of the four datasets suggest that Topic Grouper should be considered as an option especially when words incur little ambiguity. E.g., this tends to be the case for the retail examples, where words represent articles without an aspect of polysemy. Also, Topic Grouper tends to outperform LDA with Heuristics at a larger number of topics.
4.3 Feature Reduction and Document Classification
This section compares the abilities of LDA, Topic Grouper, Information Gain (IG) and Document Frequency (DF) regarding feature reduction for text classification. In the first two cases, the idea is to exchange word occurrences for topic occurrences and thus, to reduce feature space dimensionality from the vocabulary size to the number of topics . In contrast, IG and DF attain feature reduction by dropping words from the vocabulary (Yang and Pedersen (1997), Forman (2003)).
We chose Naive Bayes as a classification method since it lends itself well for all four approaches. Firstly, it allows for a straight-forward transfer from words to topics as will be shown below. Secondly, it does not mandate additional hyper parameter settings such as Support Vector Machines (SVMs), which would complicate the comparison and potentially incur bias. Moreover, approaches relying on a TF-IDF embedding (such as Roccio or SVM in Joachims (1998)) are problematic with regard to LDA because DF and IDF are undefined for topics.
Note that our goal is not to show that topic models can generally reduce the word feature space without (much) loss of classification accuracy. This has already been demonstrated in Blei et al. (2003b). Instead, we focus on the relative performance of the four feature reduction techniques. Including IG and DF allows for a direct comparison between topic modeling and word selection methods.
Let be the set of classes for the training documents . We assume that the class assignments are unique and known with regard to . We define as the subset of training documents belonging to class , so .
When using topics, Naive Bayes determines the class of a test document via
[TABLE]
with estimated from by means of .
Regarding Topic Grouper, and can be estimated via the topic-word assignments from Section 3.1. In total, this results in the following classification formula for Topic Grouper:
[TABLE]
The “” and “” in the second -expression form a standard Lidstone smoothing accounting for potential zero probabilities of the estimated . Other than that, its practical effects are effect negligible.
For best possible results under LDA, we estimate . In order to compute accurately, we resort to the so-called fold-in method: A topic-word assignment is sampled for every word occurrence in using Gibbs sampling. This involves the use of the underlying topic model and leads to a respective topic assignment vector z of length . More details on this sampling method can be found in Section 3 of Wallach et al. (2009b). The procedure is repeated times leading to vectors . Together, these results form the basis of
[TABLE]
Moreover, we estimate . In this case, an approximation of is known from running LDA on the training documents.
As known from Joachims (1998) Naive Bayes is robust against a large number of features, i.e. words, and performs best without any feature reduction. So, one cannot hope for increasing classification accuracy but only for little loss in accuracy when transferring to an ever smaller number of topics. The results are also a rough indicator of how well topics coincide with a human classification scheme: If topics tended to cover many words across classes, the probabilities would be less peaked and Naive Bayes’ classification accuracy would suffer (more).
We work with two popular datasets, namely “Reuters 21578” and “Twenty News Groups”:
- •
Reuters 21578999See http://www.daviddlewis.com/resources/testcollections/reuters21578/ (cited 2018-03-04). is text collection of business news in English with more than 120 class labels, most of them rarely occurring, and 21,578 (partly unlabeled) documents. We chose the ten most frequent labels and kept all documents with exactly one class label. Moreover, we applied the so-called ModApte split, leading to 7,142 documents for training and 2,513 for test. We performed (Porter) stemming and kept every stem that occurs at least three times in the training data. This way, we ended up with a training vocabulary of 9,567 stemmed words excluding stop words.
- •
Twenty News Groups is a collection of newsgroup messages covering twenty areas of social discussion. We used a reworked version of the collection consisting of 18,846 documents each belonging to just one class.101010See http://qwone.com/~jason/20Newsgroups/(cited2018-03-04). We applied a random split into training and test documents based on a 75% to 25% ratio. Again, we performed (Porter) stemming and kept every stem that occurs at least five times in the dataset. Moreover, we removed all tokens containing non-alphabetical characters or being shorter than three characters. This way, we ended up with a training vocabulary of 25,826 stemmed words excluding stop words.
Figures 7 and 8 present classification accuracy as a function of the number topics or words, respectively, using micro averaging. Our findings confirm the impressive abilities of LDA for feature reduction as reported in Blei et al. (2003b) when applying hyper parameter optimization. Beyond 700 topics, the heuristic setting degrades LDA’s performance. In accordance with Yang and Pedersen (1997) and Forman (2003), the results confirm that IG performs better than DF. The performance of Topic Grouper depends on the dataset and ranges below “LDA Optimized” but considerably above IG in Figure 8 whereas in Figure 7 “LDA Optimized”, IG and Topic Grouper are close above 200 topics or words, respectively.
When applying topic modeling this way, an important point to consider is the computational overhead for model generation but also the feature reduction overhead for new documents at classification time: Once a Topic Grouper model is built, its use for feature reduction incurs minimal overhead: I.e., a word from a test document can be reduced in constant time via the topic-word assignment . Thus the total feature reduction cost for a test document remains on the order of . In contrast, LDA requires the relatively complex fold-in computation of which is on the order of for a test document.
Model generation for LDA tends to become computationally expensive, when the number of topics is high because it depends linearly on . We experienced this when producing the results above about . In comparison, Topic Grouper’s computation time remained moderate even for the Twenty New Groups dataset with . As noted before, Topic Grouper assesses all values for between and one within an single run. The latter allows to adjust the degree of feature reduction in hindsight without the need for topic model recomputations.
We believe that this favorable combination of qualities places Topic Grouper as a promising alternative to IG and DG with actual practical relevance.
4.4 Model Visualization and Inspection
Topic Grouper returns hierarchical topic models by design. The hierarchy of topics may be explored interactively assuming that larger topics form a kind of semantic abstraction of contained smaller topics. Much as under LDA, the meaning of a topic may be represented by its top-most frequent words on every containment level. Analyzing results this way may give users additional insight into the nature of a document collection’s inherent topics.
Figure 9 shows a screen shot of a simple tool that we built for this purpose. The upper half of the window allows for exploring the containment structure of topics via a hierarchy of folders. The lower half of the window displays a flat topic view, which is a list of topics as they occur together during a run of Topic Grouper according to Section 3.1. The number can be changed interactively causing an instant update of the displayed topic list. Each topic from the list is displayed in one table row with the ten most frequent words included. A click on a table row selects the corresponding hierarchy node in the upper half of the window. The depicted model in Figure 9 is Topic Grouper’s result on the AP Corpus dataset from Section 4.2.
To reflect the containment hierarchy of topics, we also created tree diagrams using the mind map tool FreeMind.111111See http://freemind.sourceforge.net. Topics are represented as nodes and for reference, they are identified by the number under which they were generated. Figure 10 presents a corresponding mind map for the AP Corpus dataset from Section 4.2. All nodes below level six are collapsed in order to deal with limited presentation space. A node contains the five most frequent words of a respective topic. More frequent topics are shaded in blue (as they tend to collect low content words and stop words), whereas less frequent word sets are shaded in red.
The contents of the tree may be interpreted is as follows: The root forks into node (4) covering economy and weather as well as node (2) covering other topics and function words. Function words are mainly gathered along the path (1)/(2)/(3)/(6)/(11) and the sub-path (9)/(12)/(23). Node (4) forks into financial topics (14) and topics covering production and weather (17). Node (53) is on weather and potentially different weather regions. Node (46) covers agriculture and water supply whereas node (81) focuses on energy. Regarding node (14), we suspect that stock trading in (30) is separated from general banking and aquisitions in (31). Other topics in the tree seem equally coherent such as “home and family” (59), “public media” (25), “jurisdiction and law” (42), “military and defense” (50) and so forth. We find that such interpreted topics often meet the idea of being more general towards the root and more specific towards the leaves. However mixed topics also arise such as topic (21) combining “drug trafficking” in (73) with “military and defense” in (50).
Table 11 lists topics from for the AP Corpus dataset. To save presentation space only every second topic in order of frequency is shown: Topics 47 and 69 gather function words and therefore have high frequency. Most topics seem conclusive but obviously, a more objective coherency analysis would be necessary. A corresponding study with human judges may follow the approach in Chang et al. (2009) but is beyond the scope of this article.
5 Summary and Discussion
We have presented Topic Grouper as a novel and complementary method in the field of probabilistic topic modeling based on agglomerative clustering: Initial clusters or topics, respectively, each consist of one word from the vocabulary of the training corpus. Clusters are joined on the basis of a simple probabilistic model assuming that each word belongs to exactly one topic. Thus, topics or clusters form a disjunctive partitioning of the vocabulary.
After developing a related cluster distance we have adapted an existing clustering algorithm, EHAC, in order to compute related cluster trees as models. Dendrogram cuts in the tree serve as flat topic views where a fixed number of topics may be chosen in the range of the vocabulary size and one. The adapted clustering algorithm makes use of the dynamic programming principle leading to a time complexity in and a space complexity in , where is the number of training documents. Since memory consumption may be of an issue, we devised an additional algorithm, MEHAC, with an expected time complexity in but space complexity only on the order of .
Using simple synthetic datasets, where each word belongs to just one original topic, we examined some basic qualities of topic modeling methods: Topic Grouper manages to recover related original topics at low error rate even when their a-priori probabilities are rather unbalanced. pLSI fails under these conditions. LDA is able to recover the original topics but only if its vectorial hyper parameter is adjusted accordingly.
Regarding various real world datasets, Topic Grouper’s predictive performance matched or surpassed LDA with Heuristics at larger topic numbers but was still dominated by LDA Optimized, where only the latter includes an optimization for the LDA-specific hyper parameters and but the former applies a commonly used heuristic for them. The results also suggest that Topic Grouper performs the better the less polysemy there is in the vocabulary. This is consistent with Topic Grouper’s simplifying topic models. It makes the approach appealing, for instance, for shopping basket analysis where articles stand for themselves: Related models may then aid in forming sales-driven catalog structures or layouts of product assortments since in both cases, a clear-cut to decision on where to place an article is customary.
We also investigated Topic Grouper as a means for feature reduction in the field of supervised text classification: The results suggest that it outperforms standard techniques in the field such as Information Gain (IG) and Document Frequency (DF) but is dominated by LDA Optimized. However, LDA incurs a considerable runtime overhead at classification time, where Topic Grouper does not. Also Topic Grouper allows for a dynamic change of the number of topics after training, whereas LDA would require retraining.
Based on a corpus of news wire articles (AP Corpus) we showed how a tree model produced by Topic Grouper may be visualized and explored interactively. The presented corpus results exhibit the descriptive qualities of such deep tree models as well as the potential of related drill downs from more general to more specific topics. Alternatively, flat views of an arbitrary number of topics between and one may be derived instantly from the generated model. Although this is a subjective impression, we found corresponding topics to be conclusive and coherent in both tree views and flat topic views. Obviously, this assessment demands a more objective study to follow, potentially in similarity to Chang et al. (2009), Newman et al. (2010) or Lau et al. (2014).
For all text corpora we found that Topic Grouper tends to push stop words and or function words into separate topics. Therefore, it can do without stop word or function word filtering as a preprocessing step.
The practical performance of our straight forward implementation ranged between several minutes to several hours for larger datasets of this report and substantiated the theoretical complexity. A simple and effective means to increase time and space performance is obviously to reduce the vocabulary size , e.g. by keeping only a few thousand topmost frequency words from the dataset. The approach is well in line with the standard practice to focus on high probability words or in case of Topic Grouper, on high frequency words, when displaying and inspecting a topic model’s topic-word distributions.
In conclusion, we see Topic Grouper as a complementary approach in the tool set of topic modeling methods with a unique mix of pros and cons. The tree-based model also offering flat topic views is an important asset. It allows for deep tree structures to be produced even on small-sized datasets. Another benefit is the method’s simplicity and that it requires no configuration or hyper parametrization and no stop word filtering. The fact that each word is in exactly one topic is a considerable limitation and falls short for polysemic words and for words applied in multiple topical contexts. Nevertheless, we found actual topic models for text corpora to be conclusive as reported in Section 4.4. In some cases, a clear-cut decision on where to place words may even be in accordance with an analysts interests—we mentioned examples regarding shopping basket analysis.
The results of this paper can all be reproduced via a prototypical Java library named “TopicGrouperJ” published on GitHub.121212See https://github.com/pfeiferd/TopicGrouperJ. The library features implementations of the corresponding algorithms MEHAC and EHAC. Amongst other things, it contains an LDA Gibbs Sampler with options for hyper parameter optimization and an implementation to compute perplexity as discussed in Section 2.3. The code to regenerate any result file of the above-described experiments is also available.
6 Future Work
Future research directions may include the parallelization of the Topic Grouper algorithms MEHAC and EHAC along with other computational optimizations. Note that the parts of EHAC affecting data structure updates after joining two topics are straight forward to parallelize.
An important concern for further work is model smoothing, i.e. on how to relax the constraint of each word being in exactly one topic: Regarding flat topic views, we experimented with a combination of Topic Grouper and LDA, where LDA acts as post-processing step. To do so, a flat topic view from Topic Grouper is used to set the LDA hyper parameter then formed as a matrix in where each column corresponds to a designated topic . Higher values for a matrix element in ’s column will be given if a corresponding relation holds. A resulting LDA model will then be close to the original topics from Topic Grouper but allows for other words to be included to a certain degree in each distribution . Compiling related experimental results is work in progress. Alternatively, topics produced by Topic Grouper may provide useful initialization values for an EM procedure under pLSI.
Another line of research may be the early detection of polysemic words in order to address them in a special manner during the clustering process. I.e., if and according to Equation 7 are similar and high, then the topics and are both good join candidates for . This may trigger a special treatment of .
We have already mentioned the need to substantiate model quality via extrinsic evaluation methods as described to in Section 2.3.
Our tool from Section 4.4 allows for just a basic exploration of learned tree models. A more sophisticated system may include complementary visualization methods and the aforementioned smoothing procedures for flat topic views. Also, navigational links from topics to their underlying documents are to be included. Tool support for the exploration of document collections is an ongoing area of research and many solutions have been suggested—several of them exploiting LDA topic models (e.g., Chaney and Blei (2012), Gretarsson et al. (2012), Lee et al. (2012) or Sievert and Shirley (2014)). Corresponding insights and concepts should be considered and potentially adapted when leveraging results from Topic Grouper. In this context, a particular question is how take advantage of related tree models as opposed to the established use of flat topics. Note that topic trees are demanded by certain clientele: E.g., Brehmer et al. (2014) stress their importance when reporting about the Overview system – a successful document analysis tool developed with a focus on investigative journalism.
Wei and Croft (2006) have employed LDA to improve document ranking models for ad-hoc document retrieval. Their approach may be adapted to use models from Topic Grouper instead. The efficiency of determining and under Topic Grouper may generally be useful to improve retrieval results: E.g., query expansion may be performed on the basis of small topics containing all or most of the entered search terms . In this regard, best matching topics may be chosen from the entire topic tree – not just a flat view of topics.
Finally, topic modeling has been applied to the field of recommender systems (e.g. see Wang and Blei (2011); Hu et al. (2014)). Consequently, it might be interesting to assess the potential of Topic Grouper for this purpose as it produces even very small topics and may therefore, play a similar role for recommendation as the Apriori method (Sandvig et al. (2007)).
A Perplexity on Datasets According to Tan and Ou (2010)
Figure 12 depicts the same scenario as Figure 1 but with a focus on perplexity (as computed according to Section 4.2). Interestingly, it suggests that perplexity is not necessarily a good “substitute measure” for error rate:
- •
Although error rate and perplexity are correlated the relative difference in perplexity with regard to low and high error rates is small.
- •
The base values for perplexity differ considerably for the two datasets (although they have been generated under the same data generator based on identical hyper parameters).
- •
The low error rate of Topic Grouper does not transfer to a correspondingly low perplexity, while the one of LDA does.
B Memory Efficient Agglomerative Clustering for Topic Grouper (MEHAC)
This algorithm for Topic Grouper offers a small memory footprint on the order of and expected time complexity in . For every topic it keeps only the best possible join partner according to from Equation 7. All respective pairs are stored in a single priority queue sorted by descending values.
The code includes an important optimization in line 59, which considerably improves its practical performance, but does not affect its order of complexity. It will be discussed at the end of this section.
The process starts by computing the one-word topics and the best possible join partner for every topic with (lines 15 to 32). (The runtime of the lines 23 to 32 can be halved by exploiting the symmetry . For simplicity, this is omitted in the code.) 2. 2.
At each step the algorithm picks an from the top of the priority queue. If is valid (concerning validity, see point 4), it joins and and updates related data structures (line 39 to 47). Moreover, it recomputes the best possible join partner for with potential join partners available (line 48). This includes inserting the pair according to its -value. 3. 3.
Next, it adjusts the best possible join partners for all topics with (line 49). It does so by checking whether is a better join partner for than . If so, then is removed from list and is inserted as unmarked on the basis if its -value. 4. 4.
If ’s best possible join partner so far was or , then the algorithm defers the computation of ’s new best possible join partner by marking ’s current entry in the queue and setting to (lines 58 to 61). The position of the corresponding pair in the queue remains unchanged, though (line 59). The mark ensures that the pair will be considered invalid in case it is picked as from the top of the queue according point 2) (line 35). If this happens, then will be removed but and will not be joined. Instead, the best possible join partner for will be recomputed and will be inserted into the priority queue according to its -value (line 36).
According to Section 3.3, the complexity of point 1) is on the order of .
The computational cost of a step is on the order of : To determine the new best possible join partner for , every other topic in with must be considered and must be computed by iterating over (lines 68 and 73). Similarly, checking whether is potentially a better join partner for any with is on order of (lines 49 and 60). Adding up over all steps , the complexity remains on the order of .
One might wonder whether the complexity is worsened by the number of invalid pairs getting picked from the top list (line 36): But note that the update in line 36 represents a deferred computation that could have as well been done right away in line 59: If the update was not deferred, the probability of the condition from line 57 to be true is expected to be less than where is a constant depending on the data. Given so, the expected number of respective non-deferred updates in the loop from line 49 would be less than . We found that by deferring related updates, a substantial fraction of it can be avoided and thus performance be improved, since an update must only be executed if a corresponding tuple appears at the top of queue.
We also tested the frequency of related updates for the deferring case with regard to various datasets including all the ones from Section 4. The results confirmed that the frequency remains in the order . As the computation of the procedure call from line 36 is in the order of , the total order of complexity of the algorithm remains in .
Another point to mention is that for a marked and thus invalid pair , its position in the sorted list remains “optimistic”, i.e., rather too close to the top of queue (line 59). Therefore, ’s join partner will not be recomputed too late and no other pair of join partners will accidentally be given preference to be joined.
The algorithm can be readily adjusted for other agglomerative clustering tasks, while keeping its low memory footprint.
C Practical Performance
This section gives a brief impression of the runtime performance of Topic Grouper. We measured related times using a Java implementation of both algorithms EHAC and MEHAC (see Section 3.4 and Appendix B). A regular virtual computing environment was used (Intel Xeon E5-2690 processor, 2.9 GHz, 96 GB RAM, Ubuntu Server 16, Java 1.8) and output was minimized to the essentials.
Figure 13 shows runtimes in minutes with regard to text-based datasets from Section 4.2 and 4.3 depending on the squared number of training documents . Related documents were randomly drawn from the original training datasets. A data point is an average over 10 runs whereby the random subsample changed for each run. For each graph the number of documents ranged between 0 and 3000. The graphs substantiate that MEHAC is generally slower than EHAC. Also, the results are consistent with the simplified complexity from Section 3.4 incorporating Heaps’ Law. However, we found that Heaps’ Law, i.e. the relation , does not hold for the for retail datasets from Section 4.2.
To enable runtime prediction per dataset , we determined a least squares regression function for data points such as in Figure 13 (not shown). The regression function has been chosen in concordance with the stated time complexity, , from Section 3.4. Table 14 shows the actual and estimated runtimes for several larger sized datasets used elsewhere in this report. The estimates are based on the regression parameters , which may vary considerably not only between the two algorithms but also between the datasets. It is worth noting why the latter is the case: Regarding both EHAC and MEHAC Equations 8, 9 and 10 (as used in Listing 1) refer to dataset specific subsets of documents incurring different runtimes of related loops. On top, MEHAC has a relevant dataset specific condition in Line 36 of Listing 2.
We shunned a direct performance comparison with LDA and its derivatives, since it is rather unclear what to compare against in detail. There are many factors of LDA which have no counterpart in Topic Grouper such as hyper parameters and number of training iterations. Also, there are several approximization algorithms for LDA with different performance characteristics (Asuncion et al. (2009)).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Aldous (1985) D. J. Aldous. Exchangeability and related topics. In École d’Été St Flour , volume 1117 of Lecture Notes in Mathematics , pages 1–198. Springer, 1985.
- 2Aletras and Stevenson (2013) Nikolaos Aletras and Mark Stevenson. Evaluating topic coherence using distributional semantics. In Proceedings of the 10th International Conference on Computational Semantics (IWCS 2013) – Long Papers , pages 13–22. Association for Computational Linguistics, 2013.
- 3Asuncion et al. (2009) Arthur Asuncion, Max Welling, Padhraic Smyth, and Yee Whye Teh. On smoothing and inference for topic models. In Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence , UAI ’09, pages 27–34, Arlington, VA, USA, 2009. AUAI Press. ISBN 978-0-9749039-5-8.
- 4Blei (2012) D. Blei. Topic modeling and digital humanities. Journal of Digital Humanities , 2012.
- 5Blei et al. (2003 a) David M. Blei, Michael I. Jordan, Thomas L. Griffiths, and Joshua B. Tenenbaum. Hierarchical topic models and the nested Chinese restaurant process. In Proceedings of the 16th International Conference on Neural Information Processing Systems , NIPS ’03, pages 17–24, Cambridge, MA, USA, 2003 a. MIT Press.
- 6Blei et al. (2003 b) David M. Blei, Andrew Y. Ng, and Michael I. Jordan. Latent Dirichlet allocation. J. Mach. Learn. Res. , 3:993–1022, 2003 b. ISSN 1532-4435.
- 7Boyd-Graber et al. (2017) Jordan Boyd-Graber, Y. Hu, and D. Mimno. Applications of topic models. Foundations and Trends in Information Retrieval , 11(2–3):143–296, 2017.
- 8Brehmer et al. (2014) M. Brehmer, S. Ingram, J. Stray, and T. Munzner. Overview: The design, adoption, and analysis of a visual document mining tool for investigative journalists. IEEE Transactions on Visualization and Computer Graphics , 20(12):2271–2280, 2014. ISSN 1077-2626.
