Improving Distantly-supervised Entity Typing with Compact Latent Space Clustering
Bo Chen, Xiaotao Gu, Yufeng Hu, Siliang Tang, Guoping Hu, Yueting, Zhuang, Xiang Ren

TL;DR
This paper introduces a novel regularization method called Compact Latent Space Clustering (CLSC) for distantly supervised entity typing, which improves label inference and embedding quality by clustering similar mentions, leading to better classification accuracy.
Contribution
The paper proposes CLSC, a new approach that dynamically constructs mention similarity graphs and uses label propagation to enhance distantly supervised entity typing.
Findings
CLSC outperforms existing methods on standard benchmarks.
It effectively utilizes noisy data through label propagation.
The method improves mention embedding clustering and classification accuracy.
Abstract
Recently, distant supervision has gained great success on Fine-grained Entity Typing (FET). Despite its efficiency in reducing manual labeling efforts, it also brings the challenge of dealing with false entity type labels, as distant supervision assigns labels in a context agnostic manner. Existing works alleviated this issue with partial-label loss, but usually suffer from confirmation bias, which means the classifier fit a pseudo data distribution given by itself. In this work, we propose to regularize distantly supervised models with Compact Latent Space Clustering (CLSC) to bypass this problem and effectively utilize noisy data yet. Our proposed method first dynamically constructs a similarity graph of different entity mentions; infer the labels of noisy instances via label propagation. Based on the inferred labels, mention embeddings are updated accordingly to encourage entity…
Click any figure to enlarge with its caption.
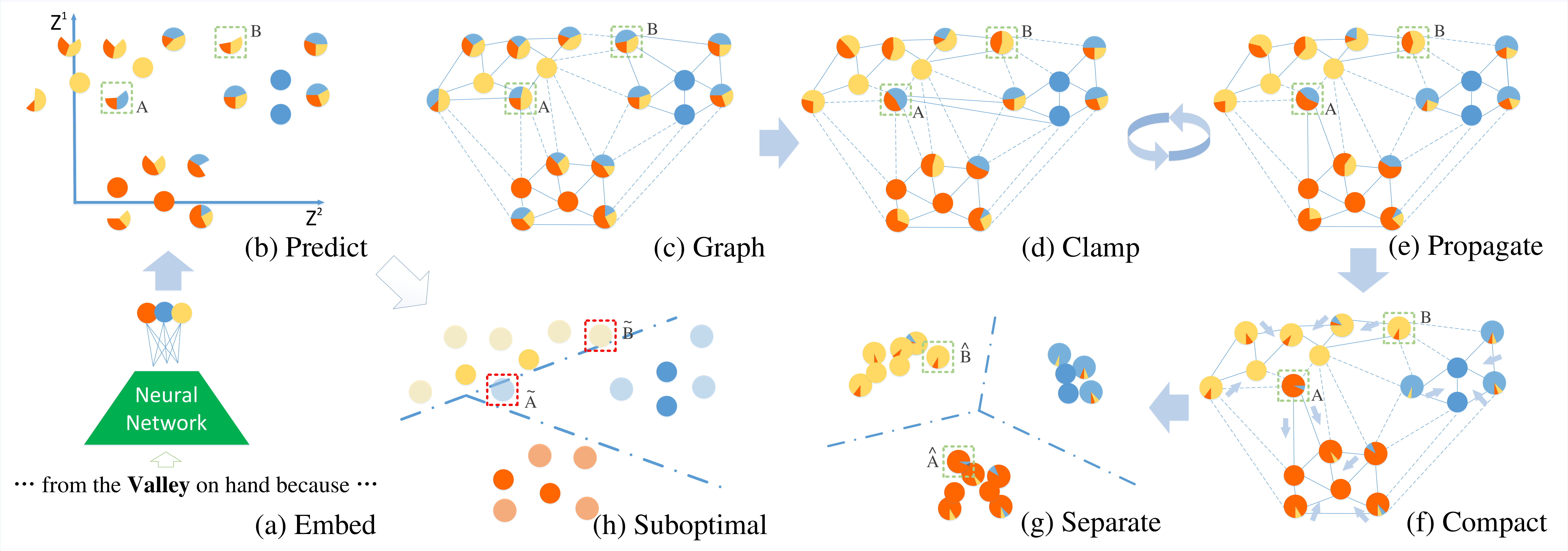 Figure 1
Figure 1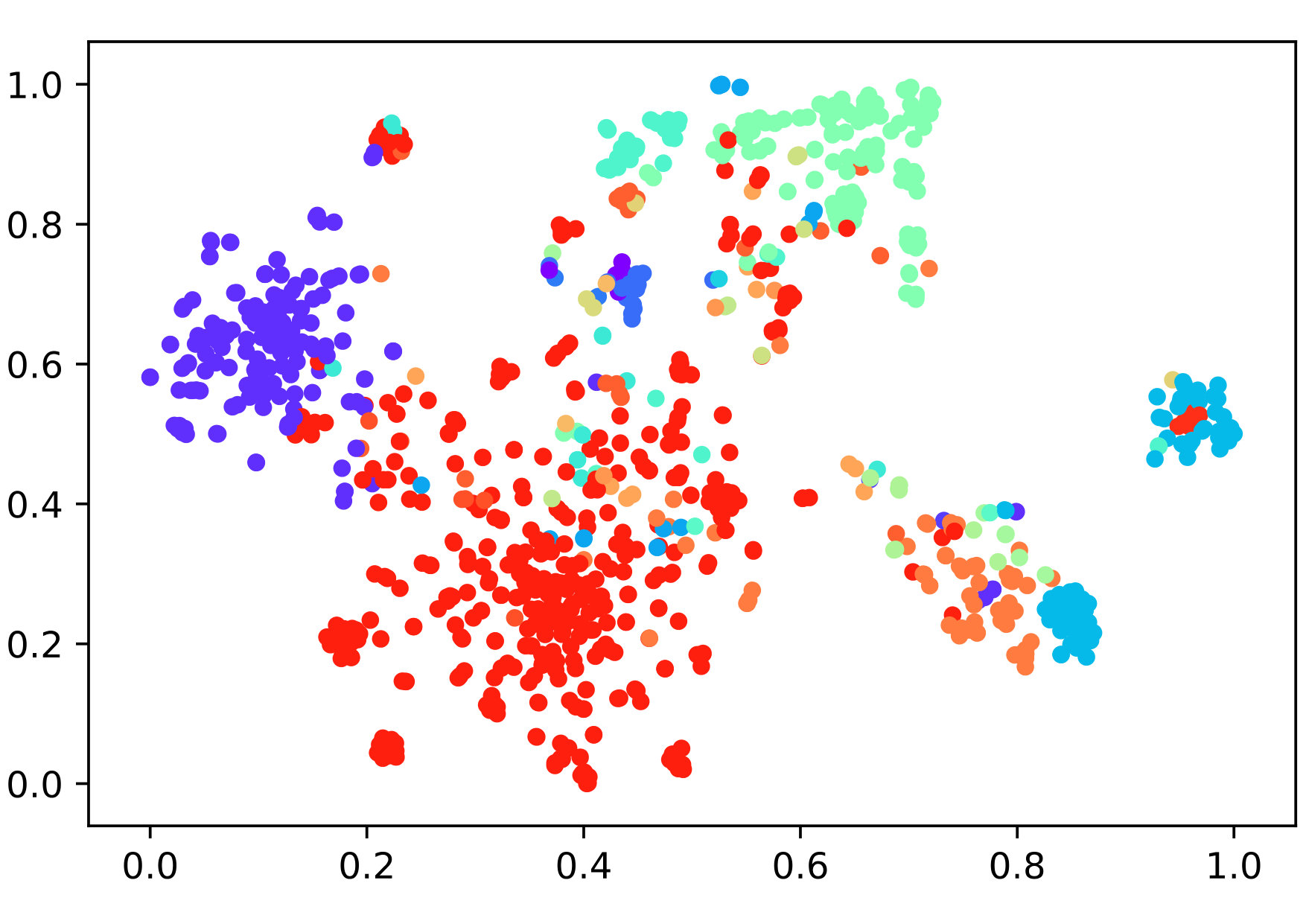 Figure 2
Figure 2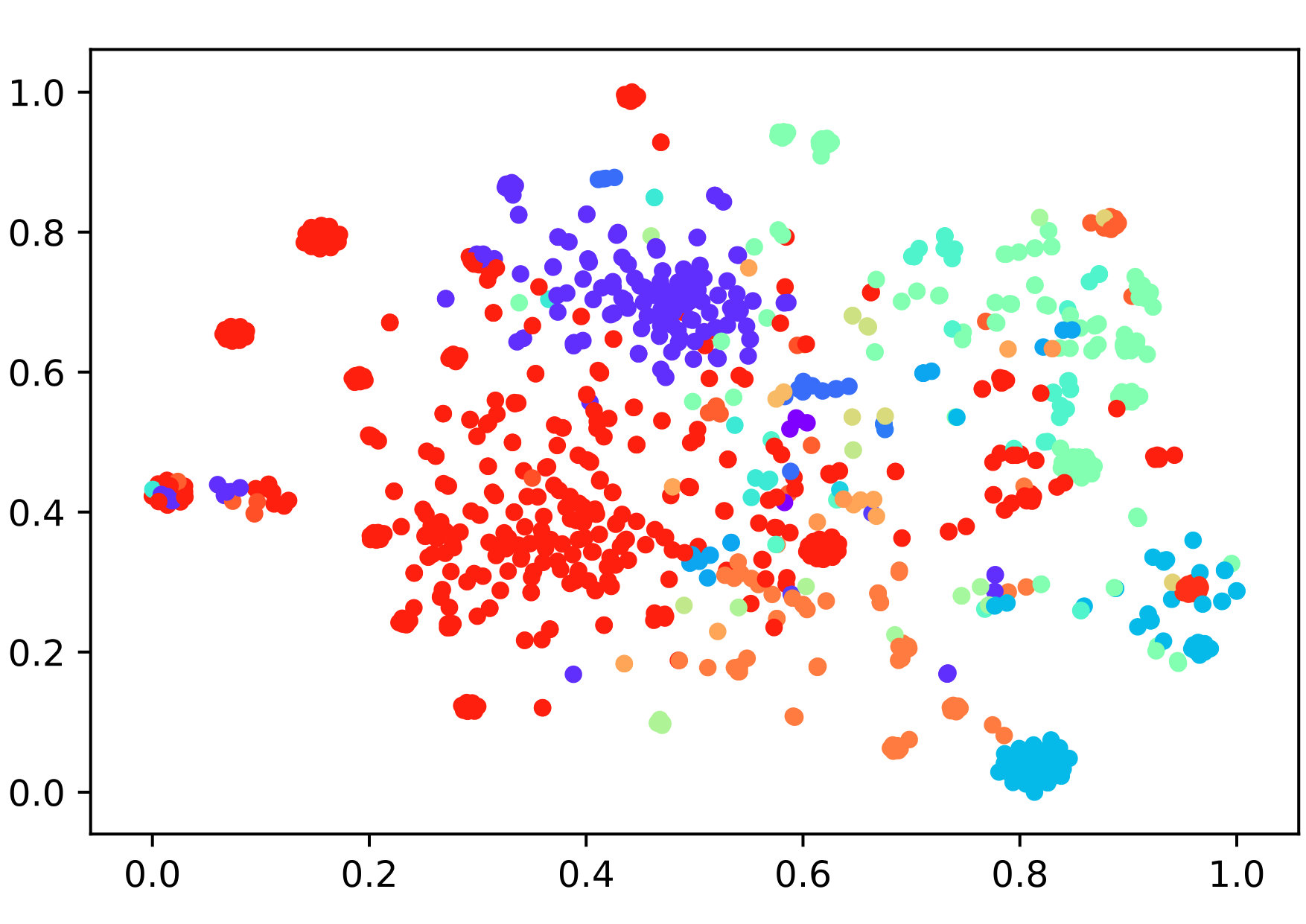 Figure 3
Figure 3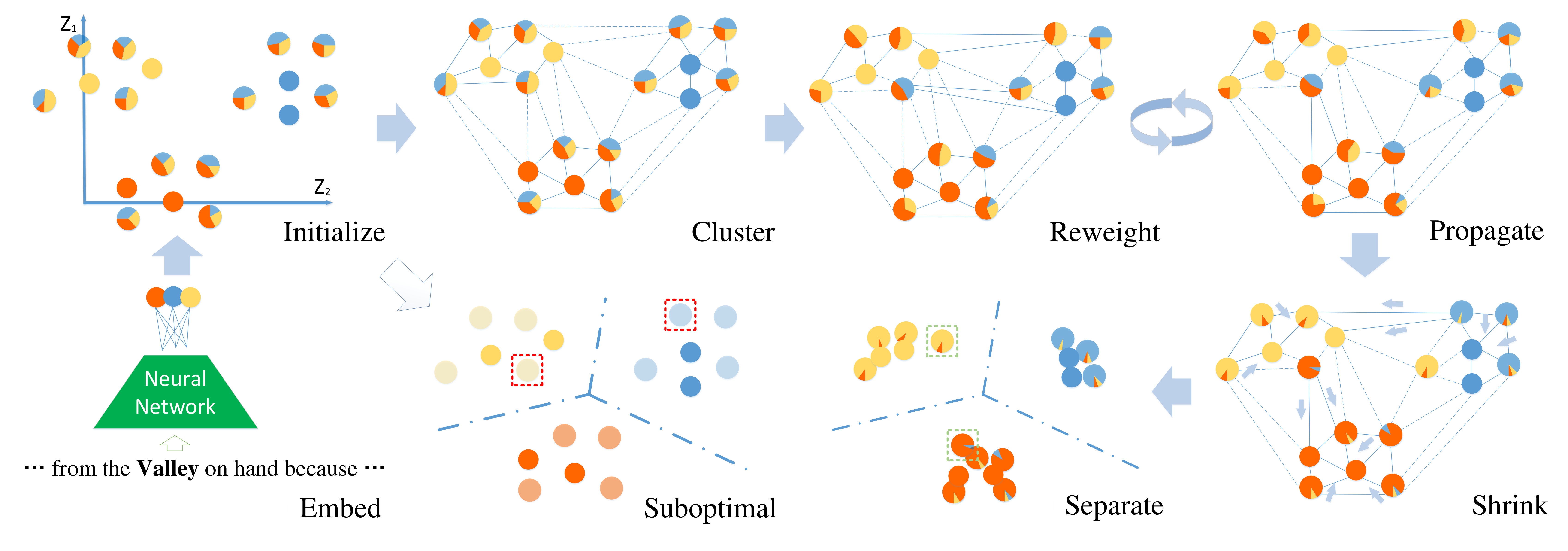 Figure 4
Figure 4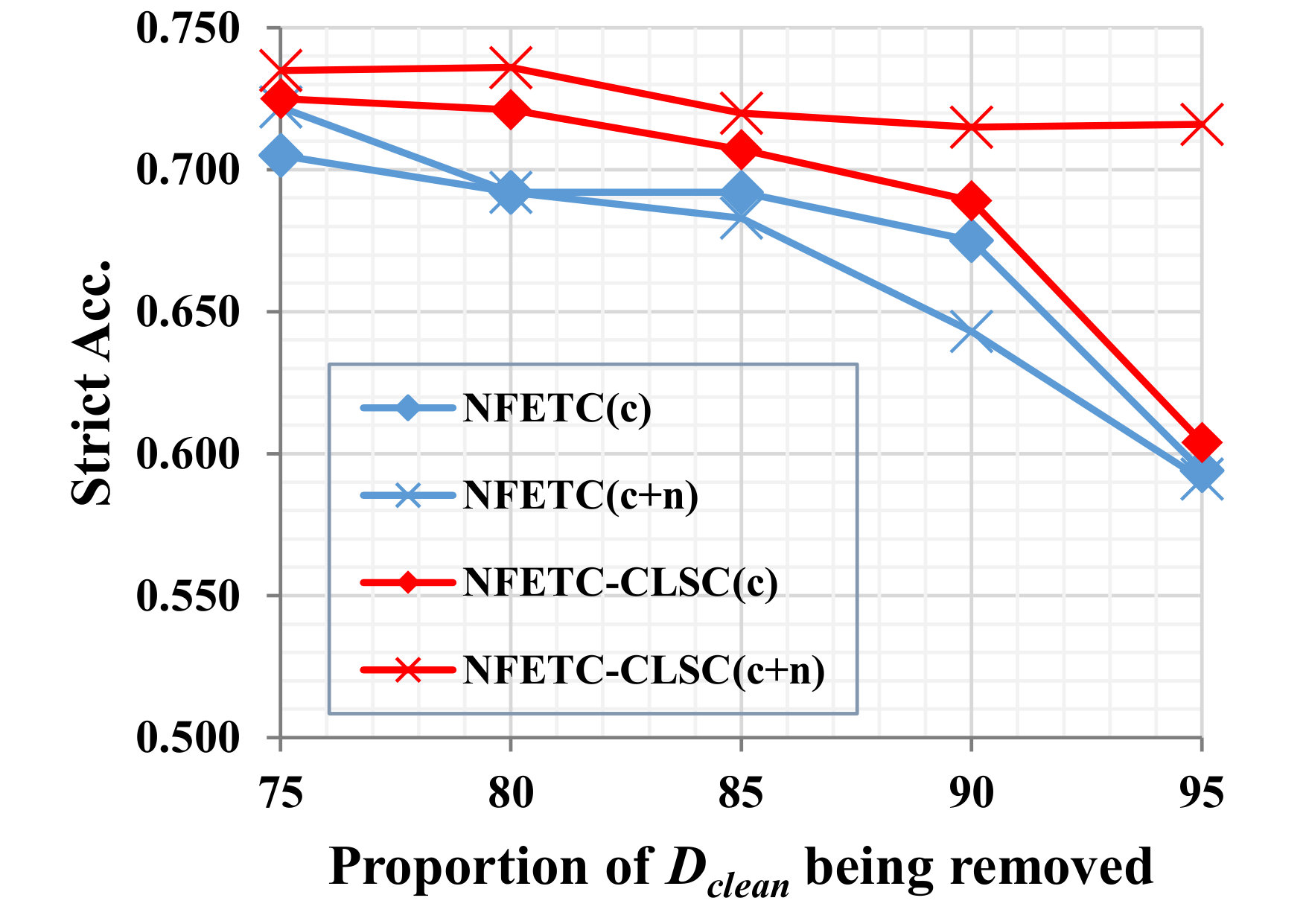 Figure 5
Figure 5 Figure 6
Figure 6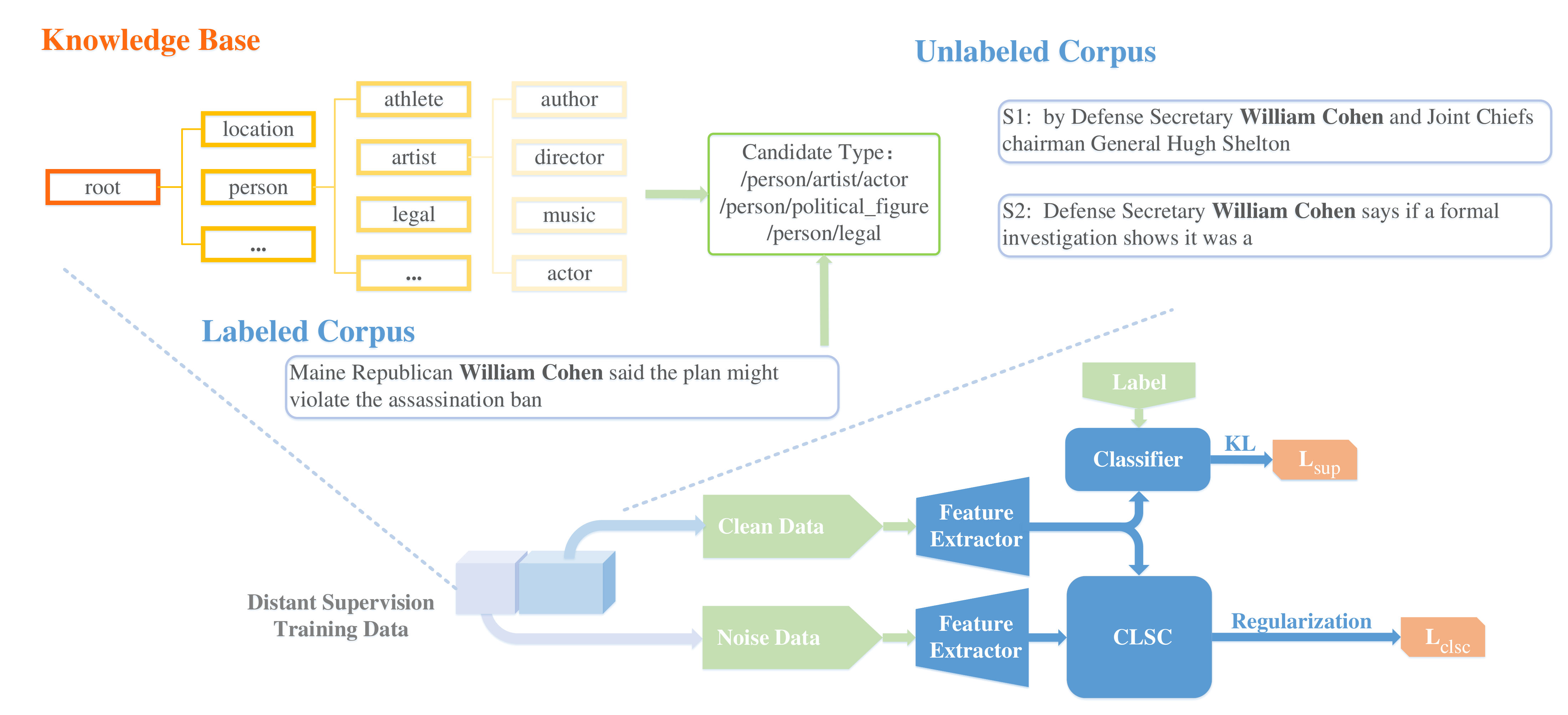 Figure 7
Figure 7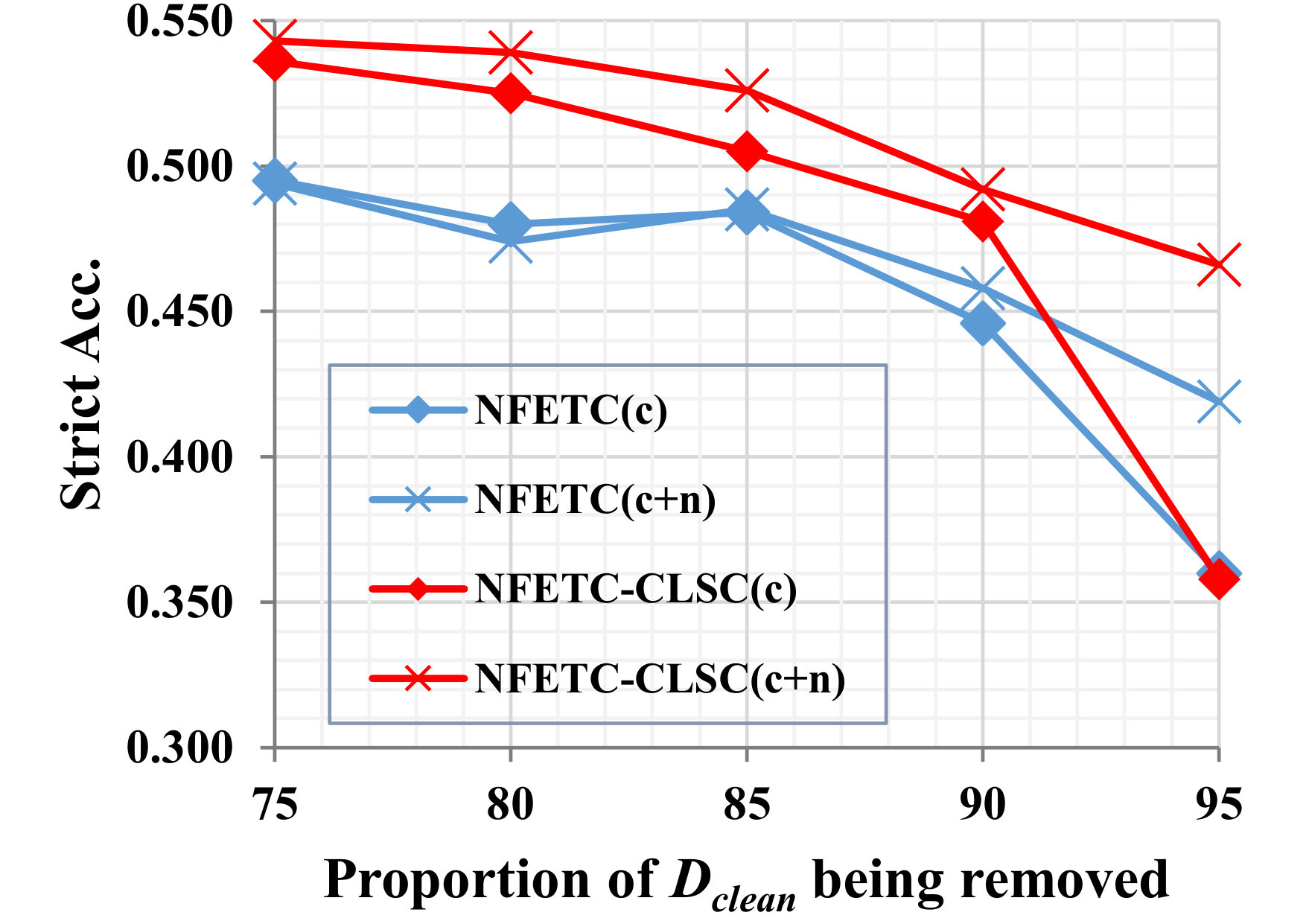 Figure 8
Figure 8 Figure 9
Figure 9| Method | OntoNotes | BBN | |||||
|---|---|---|---|---|---|---|---|
| Strict Acc. | Macro F1 | Micro F1 | Strict Acc. | Macro F1 | Micro F1 | ||
| AFET Ren et al. (2016a) | 55.3 | 71.2 | 64.6 | 68.3 | 74.4 | 74.7 | |
| AAA Abhishek et al. (2017) | 52.2 | 68.5 | 63.3 | 65.5 | 73.6 | 75.2 | |
| Attentive Shimaoka et al. (2016) | 51.7 | 71.0 | 64.91 | 48.4 | 73.2 | 72.4 | |
| PLE+HYENA Ren et al. (2016b) | 54.6 | 69.2 | 62.5 | 69.2 | 73.1 | 73.2 | |
| PLE+FIGER Ren et al. (2016b) | 57.2 | 71.5 | 66.1 | 68.5 | 77.7 | 75.0 | |
| NFETC | 54.40.3 | 71.50.4 | 64.90.3 | 71.20.2 | 77.10.3 | 76.90.3 | |
| 54.80.4 | 71.80.4 | 65.00.4 | 73.80.6 | 78.40.6 | 78.90.6 | ||
| NFETC | 59.60.2 | 76.10.2 | 69.70.2 | 70.30.3 | 76.80.3 | 76.60.2 | |
| 60.20.2 | 76.40.1 | 70.20.2 | 73.91.2 | 78.81.2 | 79.41.1 | ||
| NFETC-CLSC | 59.10.4 | 75.30.3 | 69.10.3 | 73.00.3 | 79.00.3 | 78.80.3 | |
| 59.60.2 | 75.50.4 | 69.30.4 | 74.70.3 | 80.70.2 | 80.50.2 | ||
| NFETC-CLSC | 61.50.3 | 77.40.3 | 71.40.4 | 70.50.2 | 78.20.2 | 78.00.2 | |
| 62.80.3 | 77.80.4 | 72.00.4 | 71.90.3 | 79.80.4 | 79.50.3 | ||
| OntoNotes | BBN | |
| #types | 89 | 47 |
| Max hierarchy depth | 3 | 2 |
| #mentions-train | 253241 | 86078 |
| #mentions-test | 8963 | 12845 |
| %clean mentions-train | 73.13 | 75.92 |
| %clean mentions-test | 94.00 | 100 |
| Average | 1.40 | 1.26 |
| Strict Acc. | |
|---|---|
| CLSC(c) | 72.00.1 |
| CLSC(c) | 73.00.3 |
| CLSC(c+n) | 73.00.1 |
| CLSC(c+n) | 74.70.3 |
| Ont.(C) | BBN(C) | BBN(N) | |
| 0.0006 | 0.0007 | 0.0007 | |
| 70 | 40 | 20 | |
| 1000 | 1000 | 240 | |
| 0.7 | 0.3 | 0.5 | |
| 0.6 | 1.0 | 0.4 | |
| 0.0000 | 0.0000 | 0.0002 | |
| 0.25/0.0 | 0.4/0.0 | 0.4/0.0 | |
| BN | FALSE | FALSE | TRUE |
| 200 | 200 | - | |
| 8 | 12 | - | |
| 2.0 | 1.5 | - | |
| 512 | 512 | 512 | |
| 2 | 1 | - | |
| 700 | 560 | - |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsTopic Modeling · Natural Language Processing Techniques · Domain Adaptation and Few-Shot Learning
Improving Distantly-supervised Entity Typing
with Compact Latent Space Clustering
Bo Chen1, Xiaotao Gu2, Yufeng Hu1, Siliang Tang1 , Guoping Hu3,
**Yueting Zhuang1 & Xiang Ren4
1**Zhejiang University, 2University of Illinois at Urbana Champaign
3iFLYTEK Research, 4University of Southern California,
{chenbo123, xiaofeem, siliang, yzhuang}@zju.edu.cn,
[email protected], [email protected], [email protected] Corresponding Author.
Abstract
Recently, distant supervision has gained great success on Fine-grained Entity Typing (FET). Despite its efficiency in reducing manual labeling efforts, it also brings the challenge of dealing with false entity type labels, as distant supervision assigns labels in a context-agnostic manner. Existing works alleviated this issue with partial-label loss, but usually suffer from confirmation bias, which means the classifier fit a pseudo data distribution given by itself. In this work, we propose to regularize distantly supervised models with Compact Latent Space Clustering (CLSC) to bypass this problem and effectively utilize noisy data yet. Our proposed method first dynamically constructs a similarity graph of different entity mentions; infer the labels of noisy instances via label propagation. Based on the inferred labels, mention embeddings are updated accordingly to encourage entity mentions with close semantics to form a compact cluster in the embedding space, thus leading to better classification performance. Extensive experiments on standard benchmarks show that our CLSC model consistently outperforms state-of-the-art distantly supervised entity typing systems by a significant margin.
1 Introduction
Recent years have seen a surge of interests in fine-grained entity typing (FET) as it serves as an important cornerstone of several nature language processing tasks including relation extraction Mintz et al. (2009), entity linking Raiman and Raiman (2018), and knowledge base completion Dong et al. (2014). To reduce manual efforts in labelling training data, distant supervision Mintz et al. (2009) has been widely adopted by recent FET systems. With the help of an external knowledge base (KB), an entity mention is first linked to an existing entity in KB, and then labeled with all possible types of the KB entity as supervision. However, despite its efficiency, distant supervision also brings the challenge of out-of-context noise, as it assigns labels in a context agnostic manner. Early works usually ignore such noise in supervision Ling and Weld (2012); Shimaoka et al. (2016), which dampens the performance of distantly supervised models.
Towards overcoming out-of-context noise, two lines of work have been proposed to distantly supervised FET. The first kind of work try to filter out noisy labels using heuristic rules Gillick et al. (2014). However, such heuristic pruning significantly reduces the amount of training data, and thus cannot make full use of distantly annotated data. In contrast, the other thread of works try to incorporate such imperfect annotation by partial-label loss (PLL). The basic assumption is that, for a noisy mention, the maximum score associated with its candidate types should be greater than the scores associated with any other non-candidate types Ren et al. (2016a); Abhishek et al. (2017); Xu and Barbosa (2018). Despite their success, PLL-based models still suffer from Confirmation Bias by taking its own prediction as optimization objective in the next step. Specifically, given an entity mention, if the typing system selected a wrong type with the maximum score among all candidates, it will try to further maximize the score of the wrong type in following optimization epoches (in order to minimize PLL), thus amplifying the confirmation bias. Such bias starts from the early stage of training, when the typing model is still very suboptimal, and can accumulate in training process. Related discussion can be also found in the setting of semi-supervised learning Lee et al. (2006); Laine and Aila (2017); Tarvainen and Valpola (2017).
In this paper, we propose a new method for distantly supervised fine-grained entity typing. Enlightened by Kamnitsas et al. (2018), we propose to effectively utilize imperfect annotation as model regularization via Compact Latent Space Clustering (CLSC). More specifically, our model encourages the feature extractor to group mentions of the same type as a compact cluster (dense region) in the representation space, which leads to better classification performance. For training data with noisy labels, instead of generating pseudo supervision by the typing model itself, we dynamically construct a similarity-weighted graph between clean and noisy mentions, and apply label propagation on the graph to help the formation of compact clusters. Figure 1 demonstrates the effectiveness of our method in clustering mentions of different types into dense regions. In contrast to PLL-based models, we do not force the model to fit pseudo supervision generated by itself, but only use noisy data as part of regularization for our feature extractor layer, thus avoiding bias accumulation.
Extensive experiments on standard benchmarks show that our method consistently outperforms state-of-the-art models. Further study reveals that, the advantage of our model over the competitors gets even more significant as the portion of noisy data rises.
2 Problem Definition
Fine-grained entity typing takes a corpus and an external knowledge base (KB) with a type hierarchy as input. Given an entity mention (i.e., a sequence of token spans representing an entity) in the corpus, our task is to uncover its corresponding type-path in based on the context.
By applying distant supervision, each mention is first linked to an existing entity in KB, and then labeled with all its possible types. Formally, a labeled corpus can be represented as triples , where is the -th mention, is the context of , is the set of candidate types of . Note that types in can form one or more type paths. In addition, we denote all terminal (leaf) types of each type path in as the target type set (e.g., for , ). This setting is also adopted by Xu and Barbosa (2018).
As each entity in KB can have several type paths, out-of-context noise may exist when contains type paths that are irrelevant to in context . In this work, we argue triples where contains only one type path (i.e., ) as clean data. Other triples are treated as noisy data, where contains both the true type path and irrelevant type paths. Noisy data usually takes a considerable portion of the entire dataset. The major challenge for distantly supervised typing systems is to incorporate both clean and noisy data to train high-quality type classifiers.
3 The Proposed Approach
Overview. The basic assumptions of our idea are: (1) all mentions belong to the same type should be close to each other in the representation space because they should have similar context, (2) similar contexts lead to the same type. For clean data, we compact the representation space of the same type to comply (1). For noisy data, given assumption (2), we infer the their type distributions via label propagation and candidate types constrain.
Figure 2 shows the overall framework of the proposed method. Clean data is used to train classifier and feature extractor end-to-endly, while noisy data is only used in CLSC regularization. Formally, given a batch of samples , we first convert each sample into a real-valued vector via a feature extractor parameterized by . Then a type classifier parameterized by gives the posterior . By incorporating CLSC regularization in the objective function, we encourage the feature extractor to group mentions of the same type into a compact cluster, which facilitates classification as is shown in Figure 1. Noisy data enhances the formation of compact clusters with the help of label propagation.
3.1 Feature Extractor
Figure 3 illustrates our feature extractor. For fair comparison, we adopt the same feature extraction pipeline as used in Xu and Barbosa (2018). The feature extractor is composed of an embedding layer and two encoders which encode mentions and contexts respectively.
Embedding Layer: The output of this layer is a concatenation of word embedding and word position embedding. We use the popular 300-dimensional word embedding supplied by Pennington et al. (2014) to capture the semantic information and random initialized position embedding Zeng et al. (2014) to acquire information about the relation between words and the mentions.
Formally, Given a word embedding matrix of shape , where is the vocabulary and is the size of word embedding, each column of represents a specific word in . We map each word in to a word embedding . Analogously, we get the word position embedding of each word according to the relative distance between the word and the mention, we only use a fixed length context here. The final embedding of the j-th word is .
Mention Encoder: To capture lexical level information of mentions, an averaging mention encoder and a LSTM mention encoder Hochreiter and Schmidhuber (1997) is applied to encode mentions. Given , the averaging mention representation is :
[TABLE]
By applying a LSTM over an extended mention , we get a sequence . We use as LSTM mention representation . The final mention representation is .
Context Encoder: A bidirectional LSTM with hidden units is employed to encode embedding sequence :
[TABLE]
where denotes element-wise plus. Then, the word-level attention mechanism computes a score over different word in the context to get the final context representation :
[TABLE]
We use as the feature representation of and use a Neural Networks over to get the feature vector . has layers with hidden units and use ReLu activation.
3.2 Compact Latent Space Clustering for Distant Supervision
The overview of CLSC regularization is exhibited in Figure 4, which includes three steps: dynamic graph construction (Figure 4c), label propagation (Figure 4d, e) and Markov chains (Figure 4g). The idea of compact clustering for semi-supervised learning is first proposed by Kamnitsas et al. (2018). The basic idea is to encourage mentions of the same type to be clustered into a dense region in the embedding space. We introduce more details of CLSC for distantly supervised FET in following sections.
Dynamic Graph Construction: We start by creating a fully connected graph over the batch of samples , as shown in Figure 4c111 is a small subsample of the entire data, we didn’t observe significant performance gain when the batch size increases.. Each node of is a feature representation , while the distance between nodes is defined by a scaled dot-product distance function Vaswani et al. (2017):
[TABLE]
Each entry measures the similarity between and , can be viewed as the weighted adjacency matrix of .
Label Propagation: The end goal of CLSC is to cluster mentions of the same type to a dense region. For mentions which have more than one labeled types, we apply label propagation (LP) on to estimate their type distribution. Formally, we denote as the label propagation posterior of a training batch.
The original label propagation proposed by Zhu and Ghahramani (2002) uses a transition matrix to model the probability of a node propagating its type posterior to the other nodes. Each entry of the transition matrix is defined as:
[TABLE]
The original label propagation algorithm is defined as:
Propagate the label by transition matrix , 2. 2.
Clamp the labeled data to their true labels. Repeat from step 1 until converges
In this work is randomly initialized222We also explored other initialization (e.g. uniform initialization), but found no essential performance difference between different initialization setups.. Unlike unlabeled data in semi-supervised learning, distantly labeled mentions in FET have a limited set of candidate types. Based on this observation, We assume that can only transmit and receive probability of types in no matter it is noisy data or clean data. Formally, define a indicator matrix , where if type j in otherwise [math], where is the batch size and is the number of types. Our clamping step relies on as is shown in Figure 4d:
[TABLE]
For convenience, we iterate through these two steps times, is a hyperparameter.
Compact Clustering:
The LP posterior is used to judge the label agreement between samples. In the desired optimal state, transition probabilities between samples should be uniform inside the same class, while be zero between different classes. Based on this assumption, the desirable transition matrix is defined as:
[TABLE]
is a normalization term for class . Transition matrix derived from should be in keeping with . Thus we minimize the cross entropy between and :
[TABLE]
For instance, if is close to 1, needs to be bigger, which results in the growth of and finally optimize (Eq.4). The loss has largely described the regularization we use in for compression clustering.
In order to keep the structure of existing clusters, Kamnitsas et al. (2018) proposed an extension of to the case of Markov chains with multiple transitions between samples, which should remain within a single class. The extension maximizes probability of paths that only traverse among samples belong to one class. Define as:
[TABLE]
measures the label similarities between and , which is used to mask the transition between different clusters. The extension is given by:
[TABLE]
where is Hadamard Product, and is the probability of a Markov process to transit from node to node after steps within the same class. The extended loss function models paths of different length between samples on the graph:
[TABLE]
For , . By minimizing the cross entropy between and (Eq.11), compact paths of different length between samples within the same class. Here, is a hyper-parameter to control the maximum length of Markov chain. is added to the final objective function as regularization to encourage compact cluttering.
3.3 Overall Objective
Given the representation of a mention, the type posterior is given by a standard softmax classifier parameterized by :
[TABLE]
where is a parameter matrix, is the bias vector, where is the number of types. The predicted type is then given by .
Our loss function consists of two parts. is supervision loss defined by KL divergence:
[TABLE]
Here is the number of clean data in a training batch, K is the number of target types. The regularization term is given by . Hence, the overall loss function is:
[TABLE]
is a hyper parameter to control the influence of CLSC.
4 Experiments
4.1 Dataset
We evaluate our method on two standard benchmarks: OntoNotes and BBN:
- •
OntoNotes: The OntoNotes dataset is composed of sentences from the Newswire part of OntoNotes corpus Weischedel et al. (2013). Gillick et al. (2014) annotated the training part with the aid of DBpedia spotlight Daiber et al. (2013), while the test data is manually annotated.
- •
BBN: The BBN dataset is composed of sentences from Wall Street Journal articles and is manually annotated by Weischedel and Brunstein (2005). Ren et al. (2016a) regenerated the training corpus via distant supervision.
In this work we use the preprocessed datasets provided by Abhishek et al. (2017); Xu and Barbosa (2018). Table 2 shows detailed statistics of the datasets.
4.2 Compared Methods
We compare the proposed method with several state-of-the-art FET systems333The baselines result are reported on Abhishek et al. (2017); Xu and Barbosa (2018) in addition to performance of NFETC on BBN, we search the hyper parameters for it. Xu and Barbosa (2018) didn’t report the results on BBN:
- •
Attentive Shimaoka et al. (2016) uses an attention based feature extractor and doesn’t distinguish clean from noisy data;
- •
AFET Ren et al. (2016a) trains label embedding with partial label loss;
- •
AAA Abhishek et al. (2017) learns joint representation of mentions and type labels;
- •
PLE+HYENA/FIGER Ren et al. (2016b) proposes heterogeneous partial-label embedding for label noise reduction to boost typing systems. We compare two PLE models with HYENA Yogatama et al. (2015) and FIGER Ling and Weld (2012) as the base typing system respectively;
- •
NFETC Xu and Barbosa (2018) trains neural fine-grained typing system with hierarchy-aware loss. We compare the performance of the NFETC model with two different loss functions: partial-label loss and PLL+hierarchical loss. We denote the two variants as and respectively;
- •
NFETC-CLSC is the proposed model in this work. We use the NFETC model as our base model, based on which we apply Compact Latent Space Clustering Regularization as described in Section 3.2; Similarly, we report results produced by using both KL-divergense-based loss () and KL+hierarchical loss ().
4.3 Evaluation Settings
For evaluation metrics, we adopt strict accuracy, loose macro, and loose micro F-scores widely used in the FET task Ling and Weld (2012). To fine tuning the hyper-parameters, we randomly sampled 10% of the test set as a development set for both datasets. With the fine-tuned hyper-parameter as mentioned in 4.4, we run the model five times and report the average strict accuracy, macro F1 and micro F1 on the test set.
4.4 Hyper Parameters
We search the hyper parameter of Ontonotes and BBN respectively via Hyperopt proposed by Bergstra et al. (2013). Hyper parameters are shown in Appendix A. We optimize the model via Adam Optimizer. The full hyper parameters includes the learning rate , the dimension of word position embedding, the dimension of the mention encoder’s output (equal to the dimension of the context encoder’s ourput), the input dropout keep probability and output dropout keep probability for LSTM layers (in context encoder and LSTM mention encoder), the L2 regularization parameter , the factor of hierarchical loss normalization ( means use the normalization), BN (whether using Batch normalization), the max step of the label propagation, the max length of Markov chain, the influence parameter of CLSC, the batch size , the number of hidden layers in and the number of hidden units of the hidden layers. We implement all models using Tensorflow444The code for experiments is available at https://github. com/herbertchen1/NFETC-CLSC.
4.5 Performance comparison and analysis
Table 1 shows performance comparison between the proposed CLSC model and state-of-the-art FET systems. On both benchmarks, the CLSC model achieves the best performance in all three metrics. When focusing on the comparison between NFETC and CLSC, we have following observation:
- •
Compact Latent Space Clustering shows its effectiveness on both clean data and noisy data. By applying CLSC regularization on the basic NFETC model, we observe consistent and significant performance boost;
- •
Hierarchical-aware loss shows significant advantage on the OntoNotes dataset, while showing insignificant performance boost on the BBN dataset. This is due to different distribution of labels on the test set. The proportion of terminal types of the test set is for the BBN dataset, while is only on the OntoNotes dataset. Thus, applying hierarchical-aware loss on the BBN dataset brings little improvement;
- •
Both algorithms are able to utilize noisy data to improve performance, so we would like to further study their performance in different noisy scenarios in following discussions.
4.6 How robust are the methods to the proportion of noisy data?
By principle, with sufficient amount of clean training data, most typing systems can achieve satisfying performance. To further study the robustness of the methods to label noise, we compare their performance with the presence of and clean training data and all noisy training data. Figure 5 shows the performance curves as the proportion of clean data drops. As it reveals, the CLSC model consistently wins in the comparison. The advantage is especially clear on the BBN dataset, which offers less amount of training data. Note that, with only of training data (when only leaving clean data) on the BBN dataset, the CLSC model yield a comparable result with the NFETC model trained on full data. This comparison clearly shows the superiority of our approach in the effectiveness of utilizing noisy data.
4.7 Ablation: Do Markov Chains improve typing performance?
Table 3 shows the performance of CLSC with one-step transition () and with Markov Chains () as described in Section 4. Results show that the use of Markov Chains does bring improvement to the overall performance, which is consistent with the model intuition.
5 Related Work
Named entity Recognition (NER) has been excavated for a long time Collins and Singer (1999); Manning et al. (2014), which classifies coarse-grained types (e.g. person, location). Recently, Nagesh and Surdeanu (2018a, b) applied ladder network Rasmus et al. (2015) to coarse-grained entity classification in a semi-supervised learning fashion. Ling and Weld (2012) proposed Fine-Grained Entity Recognition (FET). They used distant supervision to get training corpus for FET. Embedding techniques was applied to learn feature representations since Yogatama et al. (2015); Dong et al. (2015). Shimaoka et al. (2016) introduced attention mechanism for FET to capture informative words. Xin et al. (2018a) used the TransE entity embeddings Bordes et al. (2013) as the query vector of attention.
Early works ignore the out-of-context noise, Gillick et al. (2014) proposed context dependent FET and use three heuristics to clean the noisy labels with the side effect of losing training data. To utilize noisy data, Ren et al. (2016a) distinguished the loss function of noisy data from clean data via partial label loss (PLL). Abhishek et al. (2017); Xu and Barbosa (2018) proposed variants of PLL, which still suffer from confirmation bias. Xu and Barbosa (2018) proposed hierarchical loss to handle over-specific noise. On top of AFET, Ren et al. (2016b) proposed a method PLE to reduce the label noise, which lead to a great success in FET. Because label noise reduction is separated from the learning of FET, there might be error propagation problem. Recently, Xin et al. (2018b) proposed utilizing a pretrained language model measures the compatibility between context and type names, and use it to repel the interference of noisy labels. However, the compatibility got by language model may not be right and type information is defined by corpus and annotation guidelines rather than type names as is mentioned in Azad et al. (2018). In addition, there are some work about entity-level typing which aim to figure out the types of entities in KB Yaghoobzadeh and Schütze (2015); Jin et al. (2018).
6 Conclusion
In this paper, we propose a new method for distantly supervised fine-grained entity typing, which leverages imperfect annotations as model regularization via Compact Latent Space Clustering (CLSC). Experiments on two standard benchmarks demonstrate that our method consistently outperforms state-of-the-art models. Further study reveals our method is more robust than the former state-of-the-art approach as the portion of noisy data rises. The proposed method is general for other tasks with imperfect annotation. As a part of future investigation, we plan to apply the approach to other distantly supervised tasks, such as relation extraction.
7 Acknowledgments
This work has been supported in part by NSFC (No.61751209, U1611461), Zhejiang University-iFLYTEK Joint Research Center, Chinese Knowledge Center of Engineering Science and Technology (CKCEST), Engineering Research Center of Digital Library, Ministry of Education. Xiang Ren’s research has been supported in part by National Science Foundation SMA 18-29268.
Appendix A Hyper parameters
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Abhishek et al. (2017) Abhishek Abhishek, Ashish Anand, and Amit Awekar. 2017. Fine-grained entity type classification by jointly learning representations and label embeddings. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers , volume 1, pages 797–807.
- 2Azad et al. (2018) Amar Prakash Azad, Balaji Ganesan, Ashish Anand, Amit Awekar, et al. 2018. A unified labeling approach by pooling diverse datasets for entity typing. ar Xiv preprint ar Xiv:1810.08782 .
- 3Bergstra et al. (2013) James Bergstra, Dan Yamins, and David D Cox. 2013. Hyperopt: A python library for optimizing the hyperparameters of machine learning algorithms. In Proceedings of the 12th Python in Science Conference , pages 13–20. Citeseer.
- 4Bordes et al. (2013) Antoine Bordes, Nicolas Usunier, Alberto Garcia-Duran, Jason Weston, and Oksana Yakhnenko. 2013. Translating embeddings for modeling multi-relational data. In Advances in neural information processing systems , pages 2787–2795.
- 5Collins and Singer (1999) Michael Collins and Yoram Singer. 1999. Unsupervised models for named entity classification. In 1999 Joint SIGDAT Conference on Empirical Methods in Natural Language Processing and Very Large Corpora .
- 6Daiber et al. (2013) Joachim Daiber, Max Jakob, Chris Hokamp, and Pablo N Mendes. 2013. Improving efficiency and accuracy in multilingual entity extraction. In Proceedings of the 9th International Conference on Semantic Systems , pages 121–124. ACM.
- 7Dong et al. (2015) Li Dong, Furu Wei, Hong Sun, Ming Zhou, and Ke Xu. 2015. A hybrid neural model for type classification of entity mentions. In IJCAI , pages 1243–1249.
- 8Dong et al. (2014) Xin Dong, Evgeniy Gabrilovich, Geremy Heitz, Wilko Horn, Ni Lao, Kevin Murphy, Thomas Strohmann, Shaohua Sun, and Wei Zhang. 2014. Knowledge vault: A web-scale approach to probabilistic knowledge fusion. In Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining , pages 601–610. ACM.