Iterative Decoding of Trellis-Constrained Codes inspired by Amplitude Amplification (Preliminary Version)
Christian Franck

TL;DR
This paper introduces a novel decoding method for Trellis-Constrained Codes, inspired by quantum amplitude amplification, aiming to enhance the likelihood of the most probable codeword for improved decoding performance.
Contribution
It presents a new iterative decoding algorithm based on amplitude amplification principles, extending quantum-inspired techniques to classical coding theory.
Findings
Demonstrates improved decoding accuracy over traditional methods
Shows potential for faster convergence in decoding process
Applicable to a broad class of codes including Turbo and LDPC
Abstract
We propose a decoder for Trellis-Constrained Codes, a super-class of Turbo- and LDPC codes. Inspired by amplitude amplification from quantum computing, we attempt to amplify the relative likelihood of the most likely codeword until it stands out from all other codewords.
Click any figure to enlarge with its caption.
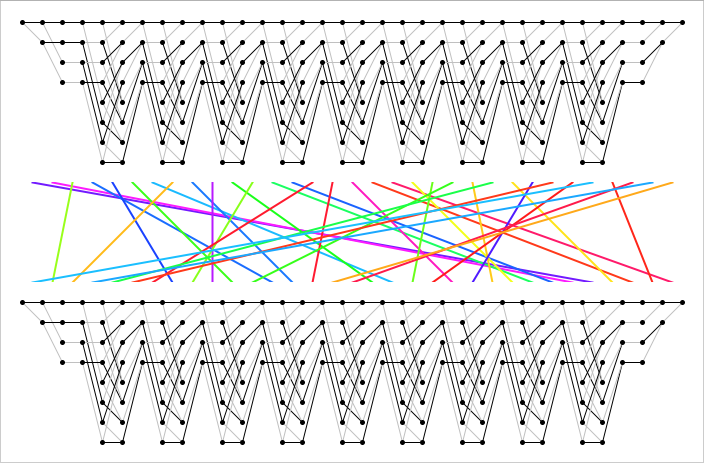 Figure 1
Figure 1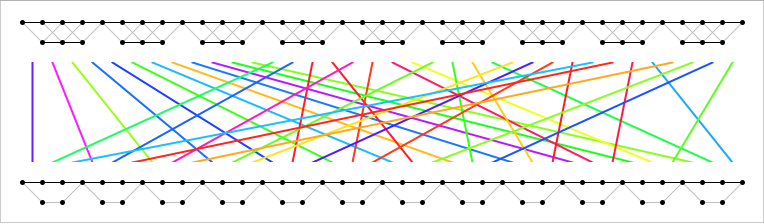 Figure 2
Figure 2Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsError Correcting Code Techniques · Quantum Computing Algorithms and Architecture · Advanced Wireless Communication Techniques
Iterative Decoding of Trellis-Constrained Codes inspired by Amplitude
Amplification
(Preliminary Version)
Christian Franck
University of Luxembourg
Computer Science and Communications Research Unit
6, Avenue de la Fonte, L–4364 Esch-sur-Alzette, Luxembourg
Email: [email protected]
Abstract
We propose a decoder for Trellis-Constrained Codes, a super-class of Turbo- and LDPC codes. Inspired by amplitude amplification from quantum computing, we attempt to amplify the relative likelihood of the most likely codeword until it stands out from all other codewords.
I Introduction
The surprising discovery of Turbo-codes [1] in the early 90’s was a major breakthrough in the field of digital communication. Two simple codes combined with an interleaver can be decoded in a nearly optimal way with loopy belief-propagation (BP) [10, 9] so that they operate close to Shannon’s channel capacity [11]. This lead to the rediscovery of LDPC codes [6] and to the investigation of more general constructions like Trellis-Constrained Codes (TCCs) [5, 4]. However, it turns out that near optimal decoding with BP only works for some specific classes of TCCs, but not in general.
In this paper we describe a method for the probabilistic computation of the most likely codeword in a TCC w.r.t. a vector of symbol likelihoods. We iteratively update the symbol likelihoods so that the relative likelihood of the most likely codeword continually increases until it hopefully stands out from all other codewords. The algorithm is insipred by amplitude amplification [2, 3] which is used in quantum algorithms like Grover search [7]. Our algorithm converges in a more controlled way than BP.
II Preliminaries
An intersection code is defined as
[TABLE]
where are chosen such that the code and the interleaved code have a low trellis complexity. Some examples of TCCs are represented in Fig. 1.
For a memoryless binary channel defined by , a received word and a word , we define the log-likelihood ratio
[TABLE]
and we use Iverson brackets [8]
[TABLE]
to define the code-constrained likelihoods
[TABLE]
More details on the channels can be found in the Appendix.
III Likelihood Amplification
The objective of an ML decoder is to determine
[TABLE]
To reflect the structure of , with the two contituent codes and the symbol constraints, we can equivalently write
[TABLE]
where with .
III-A Overview
During the decoding process we iteratively update and , and in this description we denote the corresponding values in iteration as and . Further we consider
- •
the likelihood of the most likely codeword
[TABLE]
- •
the cumulated likelihood of all words in
[TABLE]
Initially, we set
[TABLE]
and we estimate
[TABLE]
Note that for the BEC we have . Then, in iterations where is even we compute
[TABLE]
and in iterations where is odd we compute
[TABLE]
The corresponding and are chosen so that
[TABLE]
which means that the relative likelihood of the most likely codeword stays the same or increases in every step. Details and stopping criteria are expained in the following sections.
III-B Choice of
In order to chose so that (3) holds, let us investigate the relation between and , and between and in (1).
First, we have
[TABLE]
for any . The same holds for all codewords in , so that the most likely word in under also remains the most likely word under and .
Then, to understand the relation between and let us assume
[TABLE]
with a single possibly non zero value at position and
[TABLE]
where
[TABLE]
It follows from (1) that
[TABLE]
Thus, for we have , and for equal to
[TABLE]
we obtain a minimal for which
[TABLE]
Hence, we can pick a position and compute so that (4) and (6) hold. This implies that (3) must also hold. Like in quantum computing the decoder does not care whether the symbols are both 0 or both 1, the relative likelihood of both states are increased. The effect of a such an optimization is illustrated in Figure 2.
In practice it can be more efficient to compute for all symbols at once, according to (5), and to use , where is a scaling factor that is used to prevent a too big step that could result from correlations.
III-C Choice of
In order to chose so that (3) holds, let us investigate the relation between and , and between and in (2).
First, we have
[TABLE]
The same holds for all words in and as exponentiation is monotonous, the most likely codeword for remains also the most likely codeword for .
Concerning the relation between and , it is obvious that for we have , but there is no simple expression for . However, as one can always compute for a given , one can try to optimize using e.g. a gradient technique. Most importantly, one can always ensure that (3) holds, by computing and for a given . We propose and investigate two simple approaches in the context of our experiments in Section IV.
III-D Stopping Criteria
Decoding is successful when with
[TABLE]
is contained in and .
IV Experiments
TBD
V Conclusions
TBD
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Claude Berrou and Alain Glavieux. Near optimum error correcting coding and decoding: Turbo-codes. IEEE Transactions on communications , 44(10):1261–1271, 1996.
- 2[2] Gilles Brassard and Peter Hoyer. An exact quantum polynomial-time algorithm for simon’s problem. In Proceedings of the Fifth Israeli Symposium on Theory of Computing and Systems , pages 12–23. IEEE, 1997.
- 3[3] Gilles Brassard, Peter Hoyer, Michele Mosca, and Alain Tapp. Quantum amplitude amplification and estimation. Contemporary Mathematics , 305:53–74, 2002.
- 4[4] Christian Franck and Uli Sorger. Some properties of homogenous trellis-constrained codes. In 2016 9th International Symposium on Turbo Codes and Iterative Information Processing (ISTC) , pages 266–270. IEEE, 2016.
- 5[5] Brendan J Frey, David JC Mac Kay, et al. Trellis-constrained codes. In Proc. of annual Allerton conference on communication control and computing , volume 35, pages 691–700. University of Illinois, 1997.
- 6[6] R. Gallager. Low-density parity-check codes. Information Theory, IRE Transactions on , 8(1):21–28, 1962.
- 7[7] Lov K Grover. A fast quantum mechanical algorithm for database search. In Proceedings of the twenty-eighth annual ACM symposium on Theory of computing , pages 212–219. ACM, 1996.
- 8[8] D.E. Knuth. Two notes on notation. American Mathematical Monthly , pages 403–422, 1992.