Sample-Based Learning Model Predictive Control for Linear Uncertain Systems
Ugo Rosolia, Francesco Borrelli

TL;DR
This paper introduces a sample-based Learning Model Predictive Control approach for uncertain linear systems, enabling safe exploration and performance improvement despite disturbances and constraints.
Contribution
It extends LMPC to uncertain systems by using noisy data to approximate safe sets and value functions, ensuring safety and robustness.
Findings
Successfully demonstrates safe state space exploration
Iterative performance improvement under uncertainty
Robust constraint satisfaction
Abstract
We present a sample-based Learning Model Predictive Controller (LMPC) for constrained uncertain linear systems subject to bounded additive disturbances. The proposed controller builds on earlier work on LMPC for deterministic systems. First, we introduce the design of the safe set and value function used to guarantee safety and performance improvement. Afterwards, we show how these quantities can be approximated using noisy historical data. The effectiveness of the proposed approach is demonstrated on a numerical example. We show that the proposed LMPC is able to safely explore the state space and to iteratively improve the worst-case closed-loop performance, while robustly satisfying state and input constraints.
Click any figure to enlarge with its caption.
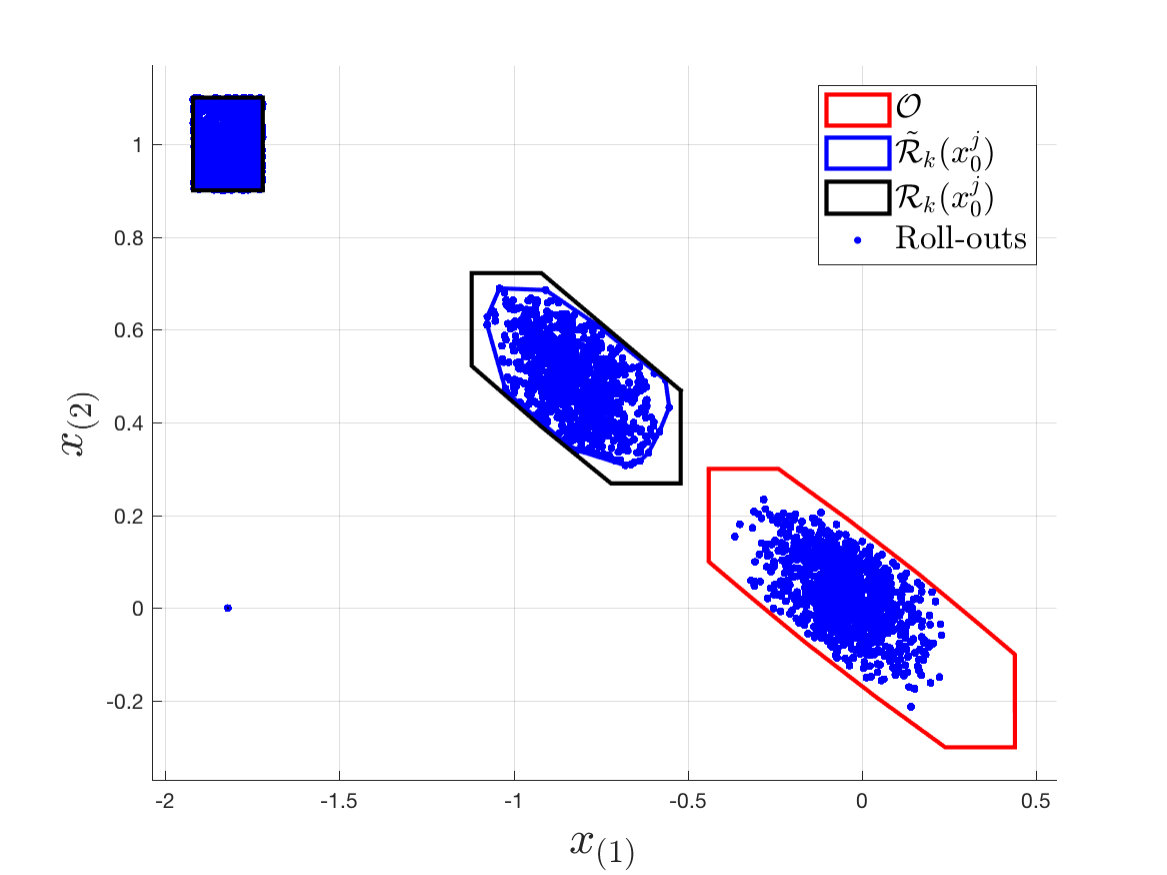 Figure 1
Figure 1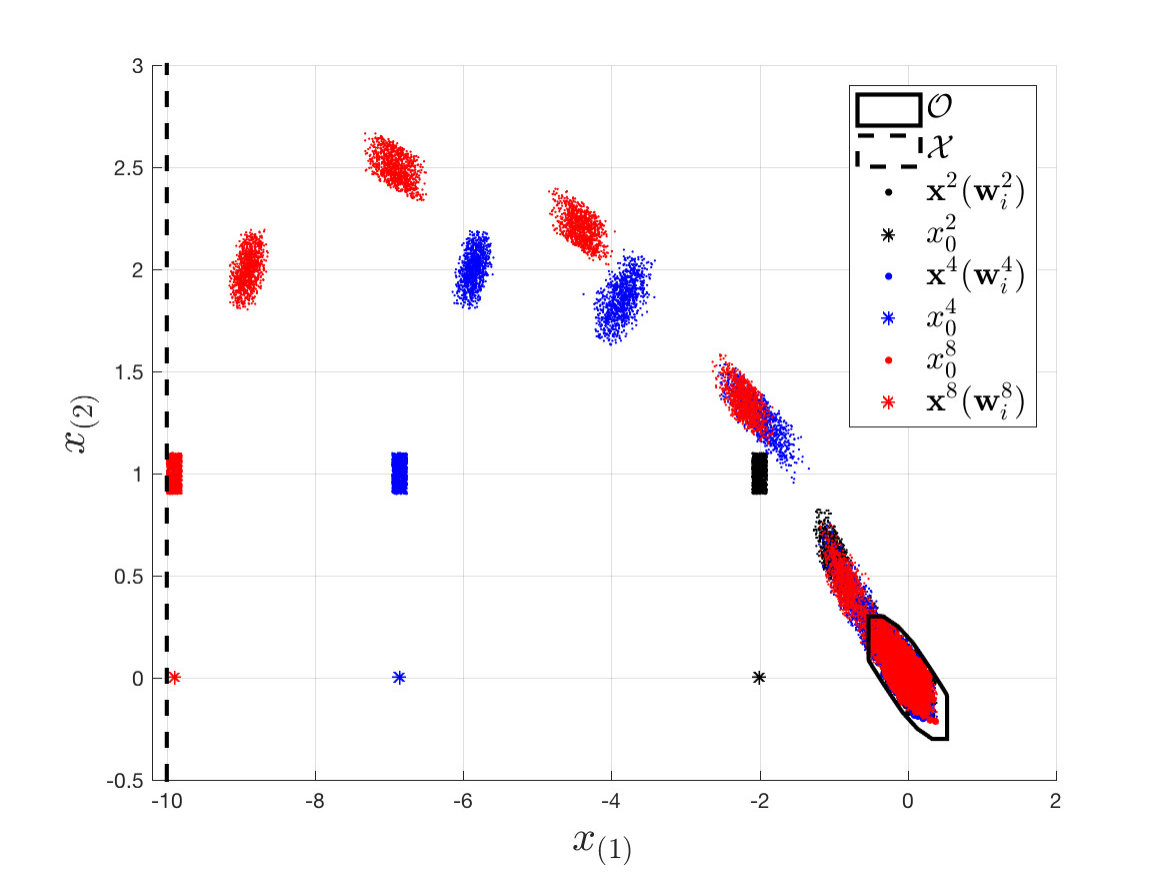 Figure 2
Figure 2 Figure 3
Figure 3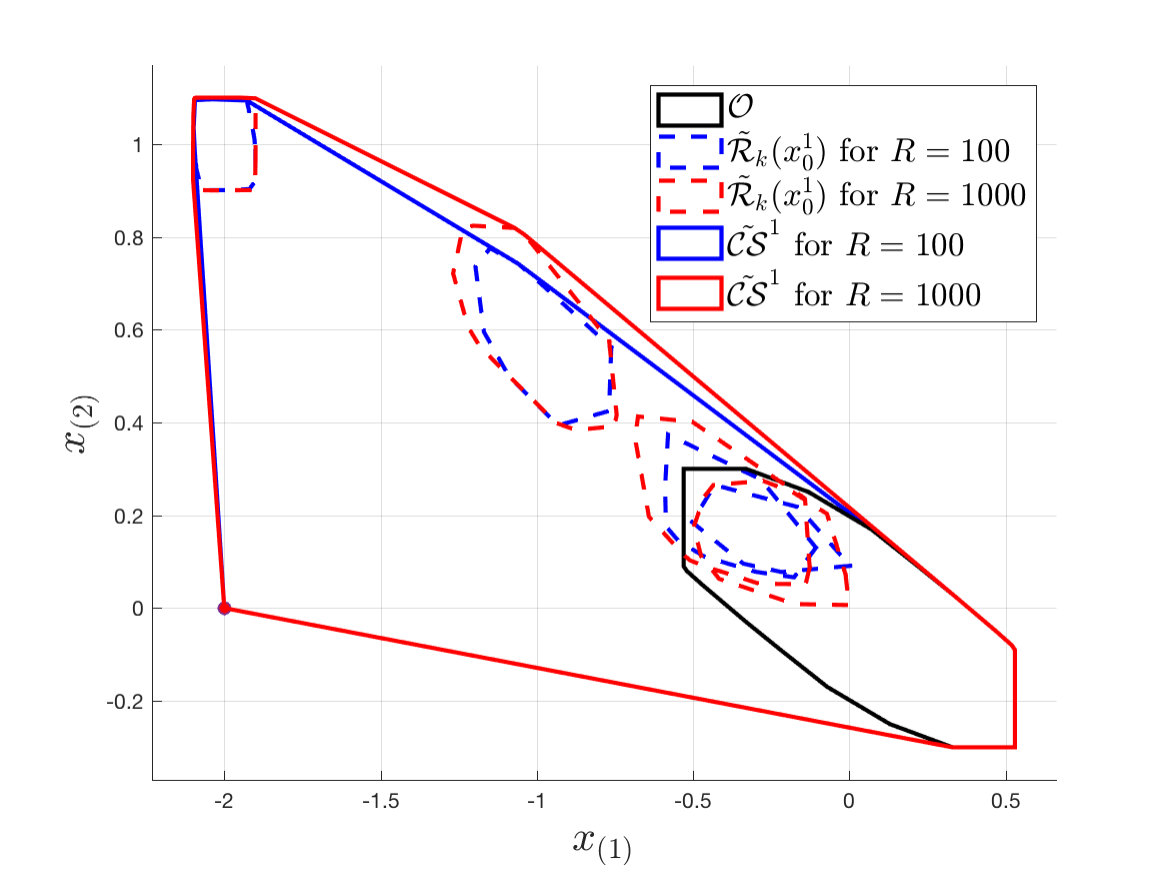 Figure 4
Figure 4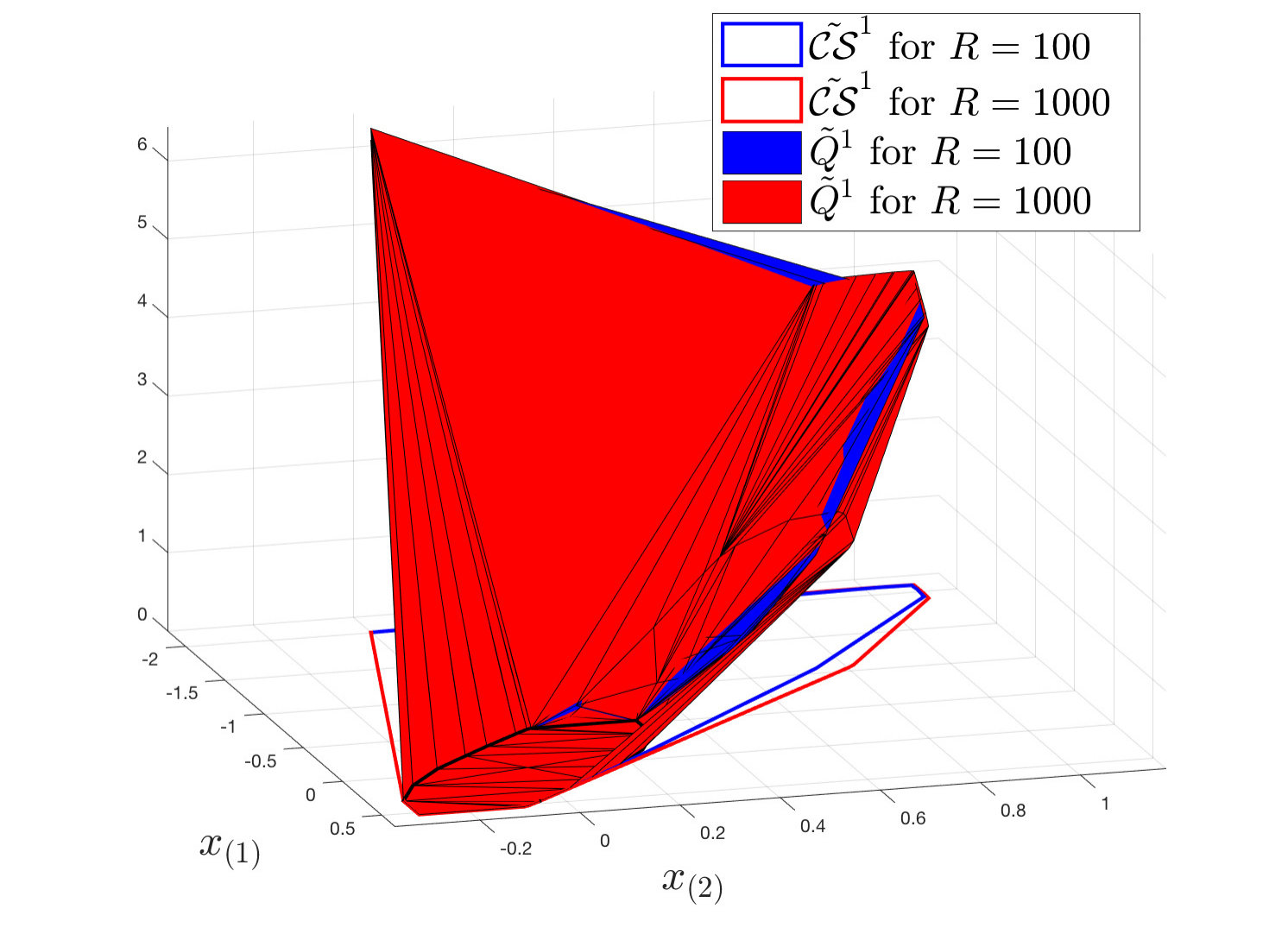 Figure 5
Figure 5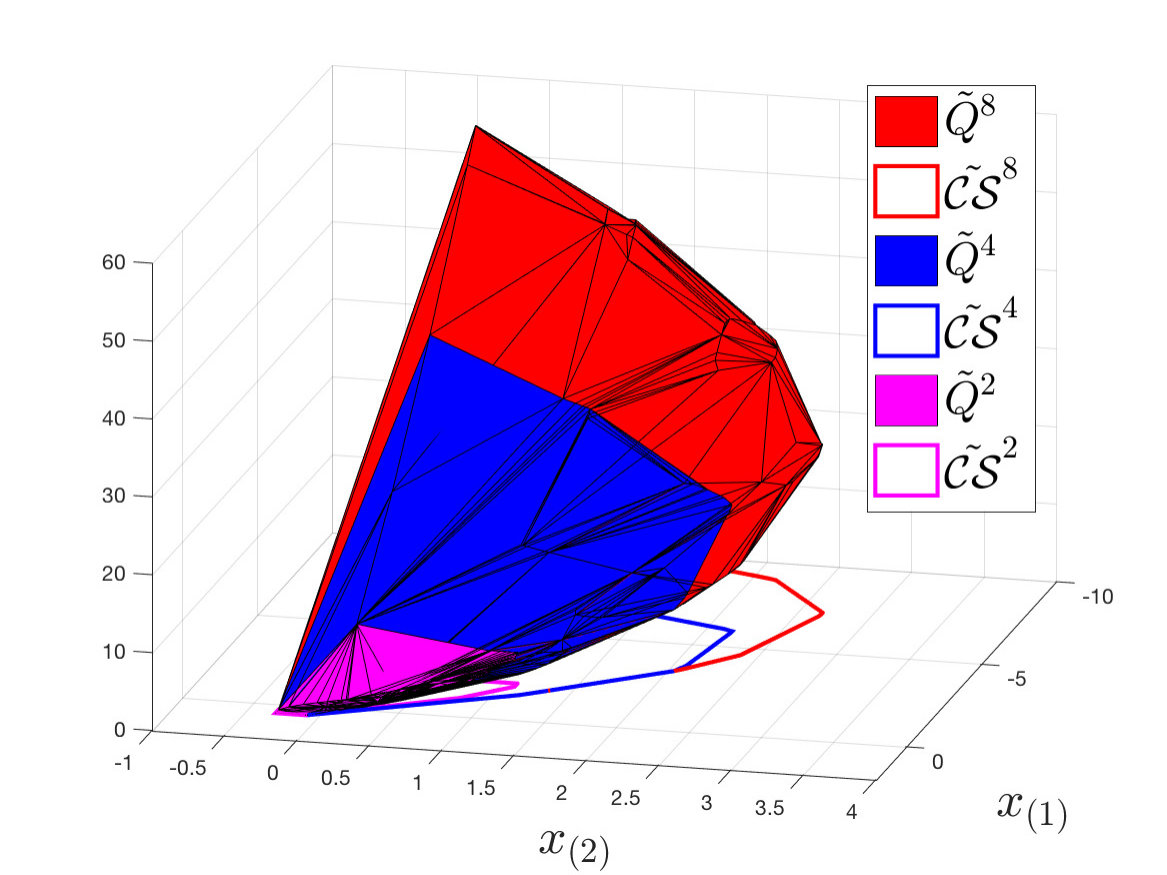 Figure 6
Figure 6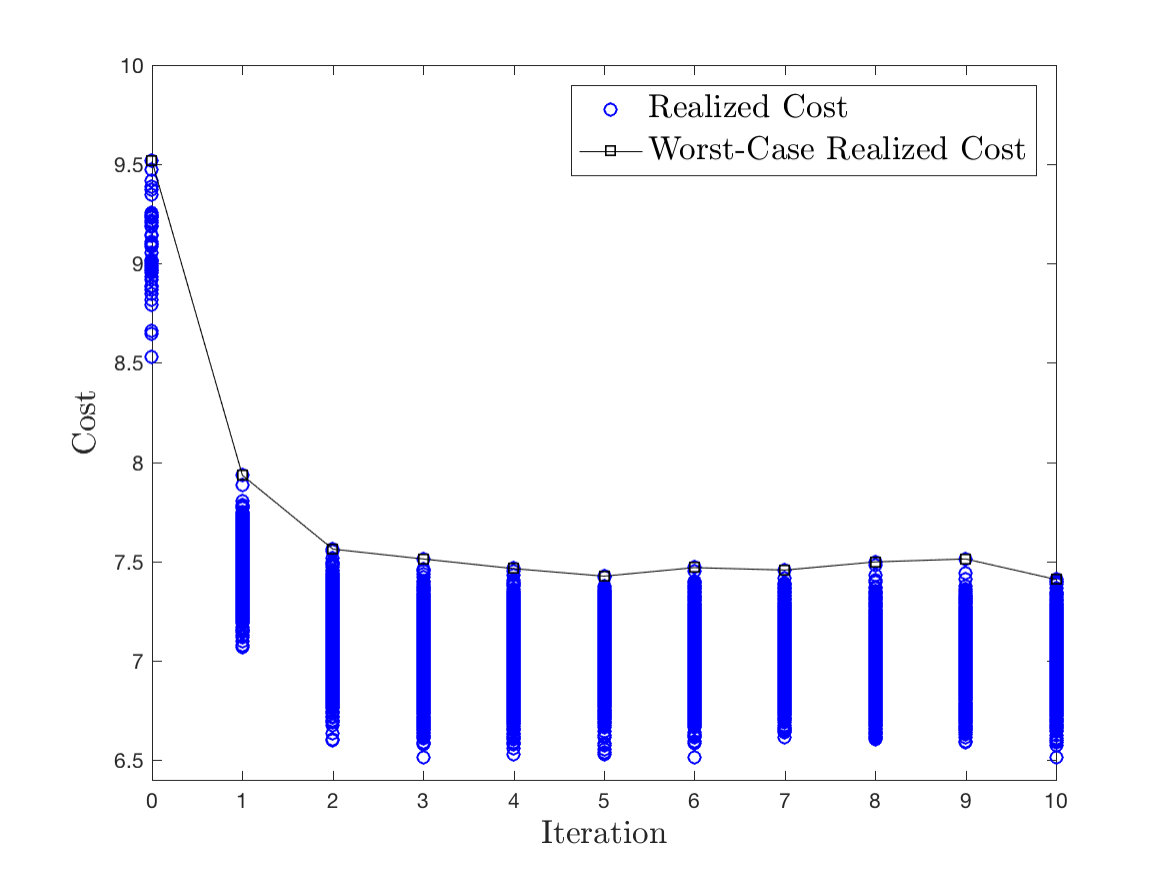 Figure 7
Figure 7Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Sample-Based Learning Model Predictive Control
for Linear Uncertain Systems
Ugo Rosolia and Francesco Borrelli U. Rosolia and F. Borrelli are with the Department of Mechanical Engineering, University of California at Berkeley , Berkeley, CA 94701, USA {ugo.rosolia, fborrelli}@berkeley.edu
Abstract
We present a sample-based Learning Model Predictive Controller (LMPC) for constrained uncertain linear systems subject to bounded additive disturbances. The proposed controller builds on earlier work on LMPC for deterministic systems. First, we introduce the design of the safe set and value function used to guarantee safety and performance improvement. Afterwards, we show how these quantities can be approximated using noisy historical data. The effectiveness of the proposed approach is demonstrated through a numerical example. We show that the LMPC is able to safely explore the state space and to iteratively improve the worst-case closed-loop performance, while robustly satisfying state and input constraints.
I Introduction
Exploiting historical data in order to iteratively improve the performance of Model Predictive Controllers (MPC) has been an active theme of research in the past few decades [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]. The key idea is to use stored state-input pairs in order to compute at least one of the following three components used in the control design: a model which describes the evolution of the system, a safe set of states (and an associated control policy ) from which the control task can be safely completed and a value function which represents the cumulative closed-loop cost from a given point of the safe set when the policy is used. In this work, we present a strategy to build safe sets and the associated value functions by exploiting historical noisy closed-loop trajectories.
Policy evaluation strategies used to estimate value functions from historical data are studied in Approximate Dynamic Programming (ADP) and Reinforcement Learning (RL) [12, 13, 14]. For instance, direct strategies compute the estimate value function which best fits the closed-loop cost data over the stored states. On the other hand, in indirect strategies the estimate value function is computed by iteratively minimizing the temporal difference [15, 16]. A survey on policy evaluation strategies goes beyond the scope of this work, we refer the reader to [13, 12] for a comprehensive review on this topic.
The integration of MPC with system identification strategies has been extensively studied in the literature [1, 5, 3, 4, 2, 7, 6]. In [5] the authors identified the system’s model using a deep neural network, which incorporates uncertainty using an ensemble of models. Another system identification strategy consists of fitting a Gaussian Process (GP) to experimental data [3, 4, 2]. GP provides a nominal model and confidence bounds, which may be used to tighten the constraint set over the planning horizon. This strategy allows to provide high-probability safety guarantees [3, 4]. The effectiveness of GP-based strategies on experimental platform has been shown in [4], where a MPC is used to race a 1/43-scale vehicle. Regression strategies may also be used to identify the system’s model [7, 6]. For instance, the authors in [6] used linear regression to identify both the nominal model and the model uncertainty used for robust MPC design. In [7], we used local linear regression to identify the model used by the controller, which was able to drive a 1/10-scale race car at the limit of handling.
Data-based strategies to construct safe sets have been investigated in [17, 18, 19, 20, 21, 22]. The authors in [17] proposed a linear model predictive safety certification framework, where safe sets are computed exploiting closed-loop data generated by a robust controller. In [18, 19] the authors computed safe sets combining stored trajectories with polyhedron and ellipsoidal invariant sets. Another approach is proposed in [20] where the stored trajectories are mirrored to construct invariant sets. In [21, 22] we showed that data from a deterministic system can be trivially used to compute safe sets. However, these strategies cannot be used to compute safe sets for uncertain system.
In this work we present a sample-based Learning Model Predictive Controller (LMPC) for linear systems subject to bounded additive uncertainty. We refer to a control task execution as “iteration” and we iteratively update the LMPC policy. At iteration , we show how to construct a robust safe set and value function, which are used to synthesize the LMPC policy at next th iteration. We show that the proposed strategy guarantees that: i) state and input constraints are robustly satisfied, ii) the closed-loop system converges asymptotically to a neighborhood of the origin, iii) the worst-case performance of the th LMPC policy is non-increasing with the iteration index, and iv) the domain of the LMPC policy is not shrinking at each th iteration. The proposed control strategy is computationally intensive. Therefore, we propose a practical algorithm that exploits simulations of the closed-loop system, which are associated with unknown sampled disturbance realizations. These closed-loop simulations, referred to as “roll-outs”, are used to approximate the safe set and the value function used in the LMPC design.
II Problem Definition
We consider the following linear time invariant system
[TABLE]
where at time of the th iteration the disturbance , the state and input . Furthermore, the system is subject to the following convex polytopic state and input constraints, for all
[TABLE]
At each th iteration, we define the worst-case iteration cost associated with the control policy as the solution to the Bellman equation
[TABLE]
The goal of the control design is to solve the following infinite time robust optimal control problem,
[TABLE]
We present a strategy to iteratively design a feedback policy
[TABLE]
which is a feasible solution to Problem (3) for . In particular the proposed strategy guarantees: i) convergence of the closed-loop system (1) and (4) to a neighborhood of the origin , ii) safety, state and input constraints are robustly satisfied, iii) performance improvement, if the controller performs the same task repeatedly (i.e. ), then the worst-case iteration cost (2) is non-increasing (i.e. ), and iv) exploration, the domain of the policy (4) is not shrinking with the iteration index (i.e. ).
Throughout this paper we use the standard function classes , and notation (see [23]) and we define the distance from a point to a set as
[TABLE]
Furthermore, we make the following assumptions.
Assumption 1
The set is a robust positive invariant set for the autonomous system ,
[TABLE]
and we have that .
Assumption 2
The continuous stage cost is jointly convex in its arguments. Furthermore, we assume that
[TABLE]
where and .
Notice that the above assumptions imply that the optimal policy from (3) robustly steers system (1) to the goal set .
III Learning Model Predictive Control
In this section we illustrate the control design strategy. We show how to construct a safe set of states, from which the control policy can successfully complete the control task. Afterward, we define a value function which approximates the cost-to-go associated with the control policy . Finally, we exploit the safe set and the value function to synthesize the control policy at the next iteration .
III-A Safe Set
In this section we show how to iteratively construct a set of states from which the control task can be safely executed. First, we recall the definition of robust reachable set [24] for the closed-loop system (1) and (4),
[TABLE]
with . The above robust reachable set collects that states which may be reached in -steps by the closed-loop system (1) and (4).
Now, we define the safe set at the th iteration as
[TABLE]
The above safe set contains the state evolution of the closed-loop system (1) and (4) at the th iteration.
Remark 1
In practical applications each iteration has a finite-time duration. It is common in the literature to adopt an infinite time formulation at each iteration for the sake of simplicity. We follow such an approach in this paper. Our choice does not affect the practicality of the proposed method. In Section IV-A, we show that if the th iteration is completed in finite time (i.e. ), then the safe set can be approximated using historical data.
Finally, we define the convex safe set as the convex hull of the safe sets for iterations ,
[TABLE]
Notice that, if the control policies for safely steer the system to the neighborhood of the origin . Then, is a robust control invariant set as stated by the following proposition.
Proposition 1
For , let be a control policy defined over . Consider system (1) in closed-loop with and assume that we have and . Then, the convex safe set is a robust control invariant set for system (1),
[TABLE]
Proof:
By assumption for in closed-loop with (1) robustly satisfies and input constraints. By definition (6), is a robust control invariant set for . Therefore, by linearity of system (1), is a robust control invariant set. ∎
III-B Q-function
In this section we define the value function , which approximates the cost-to-go from any state . Recall that the iteration cost (2) for the control policy is given by the solution to following Bellman equation
[TABLE]
and it represents the worst-case cost-to-go from any point in the state space. The solution to the above Bellman equation is hard to compute [12] and closed-form exists just for few problems [24]. For a survey on strategies to approximate the solution to Bellman equation we refer to [12, 13].
Now, we define the worst-case cost-to-go over the safe set as
[TABLE]
where . Notice that, for all , the above function coincides with the Bellman equation (8). The difference between and is that the domain of the latter is the safe set from (6). The solution equation (9) is still hard to compute, however it may be approximated using sampled closed-loop trajectories from , as shown in Section IV-B.
Finally, for all we define the function
[TABLE]
which interpolates the worst-case cost-to-go functions for . Notice that the above is simply a convexification of the cost-to-go functions (i.e. \text{epi}(Q^{j}(x))=\text{conv}\big{(}\cup_{k=0}^{j}\text{epi}(L_{\pi^{k}}(x)^{k}))). Furthermore, if the control policies for safely steer the system to the neighborhood of the origin , then the approximated value function is a robust control Lyapunov function over the convex safe set for system (1), as shown by the following proposition.
Proposition 2
For , let be a control policy defined over . Consider system (1) in closed-loop with and assume that we have and . Then, is a robust control Lyapunov function, i.e.
[TABLE]
for all .
Proof:
From definition (10), we have that there exist a set of multipliers and a set of states such that for all and for all we have , , , , and
[TABLE]
Substituting in the above equation the definition of the worst-case cost-to-go (9) evaluated at and leveraging the convexity of , we have that
[TABLE]
where , and . Definition (10) implies that and , therefore from the above equation and convexity of we conclude that
[TABLE]
∎
III-C Controller Design
In this section we illustrate the controller design which leverages the convex safe set (7) and the approximated value function (10). At each time of the th iteration, we solve the following finite time optimal control problem
[TABLE]
where the control policy and the disturbance . The optimal feedback policy from the above finite time optimal control problem safely steers system (1) from to the convex safe set, while minimizing the worst-case cost. Let
[TABLE]
be the optimal feedback policy to Problem (12). Then we apply to system (1)
[TABLE]
The finite time optimal control problem (12) is solved at time , based on the new state , yielding a moving or receding horizon control strategy.
Furthermore, we define the domain of the LMPC policy (14), which is given by
[TABLE]
The set , which collects the feasible initial conditions to Problem (12), is used to compute the initial state of the th iteration. In particular, the initial condition at the th iteration is computed solving the following convex optimization problem,
[TABLE]
where the user-defined row vector represents the direction in which the LMPC explores the state space, and is a row vector perpendicular to .
It is well-known that the solution to Problem (12) can be computed enumerating the vertices of the disturbance over the prediction horizon [25]. Therefore, the computational complexity of Problem (12) explodes with the horizon length . For this reason, it is important to construct a terminal set and terminal cost, which allow to guarantee safety and performance improvement independently on the prediction horizon length. In the result section, we show that the proposed controller is able to safely explore the state space and to improve its performance, even with a short prediction horizon.
III-D Properties
As discussed in Propositions 1-2, for every point in there exists a control policy which safely steers the system to the terminal goal set. The properties of and allow us to guarantee that the proposed strategy meets the requirements from Section II. The following theorem shows that the LMPC (12) and (14) satisfies state and input constraints while steering the system to the neighborhood of the origin .
Theorem 1
Consider system (1) in closed-loop with the LMPC (12) and (14). Let Assumptions 1-2 hold, initialize and . If , then the LMPC (12) and (14) is feasible for all and iteration . Furthermore, the closed-loop system asymptotically converges to , regardless of the disturbance realization.
Proof:
Assume that at the th iteration is a robust control Lyapunov function defined on the robust control invariant set . Then, by standard MPC arguments and the assumption on , we have that at iteration the LMPC (12) and (14) recursively satisfies state and input constraints, and the closed-loop system (1) and (14) converges asymptotically to the terminal set [24]. Consequently, the LMPC policy at iteration used to compute and satisfies the assumptions in Propositions 1-2, and therefore is a robust control Lyapunov function defined on the robust control invariant set .
The proof is completed by induction. We initialized , which is a robust control Lyapunov function defined on the robust control invariant set . Therefore it follows that the LMPC (12) and (14) recursively satisfies state and input constraints, and the closed-loop system (1) and (14) converges asymotically to the terminal set . ∎
Next, we discuss the performance improvement properties. In particular, we show that if the initial condition of two subsequent iterations does not change (i.e. ), then the worst-case cost iteration cost is non-increasing.
Theorem 2
Consider system (1) in closed-loop with the LMPC (12) and (14). Let Assumptions 1-2 hold, initialize and . If the initial condition of two subsequent iterations are equal, . Then, the worst-case iteration cost (2) is non-increasing with the iteration index
Proof:
By Theorem 1, the LMPC (12) and (14) is feasible at time of the th iteration. Let (13) be the optimal policy time of the th iteration, by Proposition 2 we have
[TABLE]
The above equation and the convergence of the closed-loop system (1) and (14) from Theorem 1 imply that
[TABLE]
The above derivation holds for all disturbance realization, therefore we have that
[TABLE]
Finally we notice that the above inequality together with Equations (9)-(10) and the feasibility of the LMPC policy (14) at the next iteration imply that
[TABLE]
∎
Finally, we show that the domain of the LMPC (12) and (14) does not shrink at each iteration.
Theorem 3
Consider system (1) in closed-loop with the LMPC (12) and (14). Let Assumptions 1-2 hold, and initialize and . If . Then, the domain of which the LMPC defined in (15) does not shrink at each iteration, i.e. .
Proof:
The proof follows from the definition of the convex safe set. Notice that by definition (7) we have that . Therefore, the terminal set in (15) is not shrinking at each iteration and . ∎
IV Practical Implementation
In this section we show how the closed-loop trajectories associated with unknown sampled disturbance sequences can be used to approximate the convex safe set and the value function . At each th iteration we collect simulations of the closed-loop systems, also referred to as “roll-outs”. Afterwards, we exploit these roll-outs to approximate the robust reachable sets (5) and the worst-case cost-to-go (9).
IV-A Sample-Based Convex Safe Set
In this section we show how the data from the closed-loop system (1) and (4) can be used to approximate the convex safe set . We define the th disturbance realization sequence , where is the realized disturbance at time of the th iteration. Furthermore, we denote the stored closed-loop trajectory associated with the th disturbance realization as
[TABLE]
where is the time at which the terminal goal set is reached. The above notation emphasizes that the realized state is a function of the realized disturbance sequence . Now, we notice that at each time of the th iteration the state is contained into the -steps robust reachable set from (i.e. . Therefore, we approximate the -steps robust reachable set using roll-outs. In particular, for sampled disturbance sequences we define the approximated -steps robust reachable set
[TABLE]
Finally, we define the approximated safe set
[TABLE]
which is used to construct the approximated convex safe set,
[TABLE]
It is important to underline that the above approximated convex safe set is not invariant, as the approximated reachable sets are an inner approximation of the exact reachable sets (Figure 1). Indeed, it may exist a disturbance realization which can steer the closed-loop system (1) and (14) outside . In particular, given there is a probability that the closed-loop system evolves outside ,
[TABLE]
In the result section, we show that the above probability is a function of the number of roll-outs used to construct . In particular as more roll-outs are collected, from (19) better approximates the convex safe set from (7).
IV-B Sample-Based Q-function
In this section we show how the closed-loop trajectories may be used to approximate the cost-to-go function in (9). First, we define the realized cost-to-go associated with the stored state ,
[TABLE]
where .
The realized cost (21), associated with the realized trajectory (17), is used to approximate the worst-case cost-to-go function . We compute an hyperplane which upper-bounds the realized cost for all stored states \big{\{}\bigcup_{i=1}^{R}x_{k}^{j}({\bf{w}}^{i})\big{\}}\in\tilde{\mathcal{R}}_{k}(x_{0}^{j}). In particular, for time of the th iteration we define the hyperplane , where
[TABLE]
At the th iteration, the hyperplanes are used to approximate the worst-case cost-to-go from (9) as follows,
[TABLE]
The resulting approximated value function is defined as
[TABLE]
Finally, we underline that the above approximated value function is not a control Lyapunov function for system (1). Indeed, there is a probability that Equation (11) does not hold and is not decreasing along the closed-loop trajectory,
[TABLE]
In the result section, we show that above probability is inversely proportional to the number of roll-outs used to construct in (23).
V Results
We test the proposed control strategy on the following double integrator system
[TABLE]
where the the random disturbance is uniformly distributed on the set . The system is subjected to the following state and input constraints, and , for all . Furthermore, we compute the minimal robust positive invariant set for the autonomous system where is the LQR gain for and . Finally, we define the stage cost which satisfies Assumption 2.
The convex safe set and value function , used in the LMPC (12) and (14), are approximated as described in Section IV. In particular at each iteration , we use roll-outs to compute the approximated safe set and value function . In order to initialize the LMPC we set , and . Finally at each th iteration, the initial state is computed as the furthest point along the negative -axis which belongs to . Basically, we set in (16).
V-A Convex Safe Set and Value Function Approximation
In this section, we construct and using and roll-outs. Furthermore, we perform Monte-Carlo simulations for the closed-loop system (1) and (14), in order to estimate the properties of and .
Figure 2 shows the terminal set and the approximated robust reachable sets , which are used to construct the approximated convex safe set with and roll-outs. As expected, the approximated convex safe set constructed using trajectories contains the one constructed using trajectories. As mentioned in Section IV-A (Eq. (20)), the approximated convex safe set is not invariant. Indeed, there is a probability that, given a state , the closed-loop system evolves outside . In order to estimate the probability , we perform Monte-Carlo simulations for the closed-loop system (1) and (14) and we compute the percentage of realized states which evolved outside . As expected the probability decreases as more roll-outs are used to construct . In particular, we have that and for and , respectively.
Finally, we analyze how the number of roll-outs affects the approximated value function . Figure 3 shows the approximated value function constructed with and roll-outs. First, we notice that the domain of approximated value function is enlarged as more realized trajectories are used to compute the approximation. Indeed, the domain of is the approximated safe set from Figure 2. Second, we recall that is constructed based on sampled disturbance sequences and it underestimates , which considers the whole disturbance support. Therefore, we expect that as more sample disturbance sequences are considered better approximates . This intuition is confirmed by Figure 3, we notice that constructed with trajectories upper-bounds almost everywhere the value function constructed with trajectories, therefore it better approximates . Finally, we recall from Equation (25) that is not a robust control Lyapunov function. Indeed, there is a probability that is not decreasing along the realized closed-loop trajectory. In order to estimate the probability , we use Monte Carlo simulations. As expected, the probability decreases as more closed-loop trajectories are used to construct . In particular, we have and for and , respectively.
V-B Iterative Policy Update
In this section we run the LMPC for iterations. In particular, at each th iteration we collect roll-outs which are used to compute the approximated convex safe set and the approximated value function . We show that the LMPC is able to explore the state space while safely steering the system to the terminal set .
As stated in Section V, at each th iteration we compute the initial condition as the furthest point along the negative -axis such that Problem (12) is feasible. Notice that by Theorem 3, the domain of the LMPC policy is enlarged at each iteration (i.e. for all ). As a result, the region of the state space from which the controller is able to safely complete the control task grows at each iteration. This fact is highlighted in Table I, where we report the initial condition as a function of the iteration index. Furthermore, in Figure 4 we show realized trajectories for the nd, th and th iterations. We notice that at each iteration the LMPC safely operates the system over progressively larger regions of the state space, until the closed-loop trajectory is close to saturate the state constraints.
Finally, in Figure 5 we report the approximated value function for the nd, th and th iterations. We recall that the domain of is the approximated convex safe set , which is enlarged at each iteration. Therefore, as more iterations of the control task are executed, approximates the value function over larger regions of the state space, as shown in Figure 5.
V-C Performance Improvement
In this section we empirically validate Theorem 2. We design a LMPC which minimizes the stage cost . Afterwards, we run the closed-loop system for iterations starting from the same initial condition, . In order to initialize the LMPC, we use a suboptimal controller which robustly steers system (26) to and we exploit the closed-loop data to initialize the approximated convex safe set and value function.
Figure 6 shows the closed-loop cost from (21) and the worst-case realized cost
[TABLE]
for iterations. We notice that the LMPC is able to improve the worst-case realized cost associated with the suboptimal policy used at the [math]th iteration. Furthermore, we underline that the controller performs exactly the same task at each iteration () and the worst-case realized cost (27) decreases at each iteration, until it converges within a tolerance of as stated in Theorem 2.
VI Conclusions
In this paper we proposed a sample-based Learning Model Predictive Controller (LMPC) for linear system subject to bounded additive uncertainty. First, we used the LMPC policy to construct a safe set and the associated value function. Afterwards, we showed that the proposed strategy allows to guarantee safety and worst-case performance improvement. Finally, we exploited sampled closed-loop trajectories to approximate the safe set and associated value function. We demonstrated the effectiveness of the proposed approach on a numerical example. In particular, we showed that the proposed LMPC is able to safely explore the state space while estimating the value function associated with the control task. Future work concentrates on finding probability bounds, which would allows to characterize the properties of the approximated safe set and approximate value function as a function of the sampled trajectories.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] A. Aswani, H. Gonzalez, S. S. Sastry, and C. Tomlin, “Provably safe and robust learning-based model predictive control,” Automatica , vol. 49, no. 5, pp. 1216–1226, 2013.
- 2[2] J. Kocijan, R. Murray-Smith, C. E. Rasmussen, and A. Girard, “Gaussian process model based predictive control,” in Proceedings of the 2004 American Control Conference , vol. 3. IEEE, 2004, pp. 2214–2219.
- 3[3] T. Koller, F. Berkenkamp, M. Turchetta, and A. Krause, “Learning-based model predictive control for safe exploration,” in 2018 IEEE Conference on Decision and Control (CDC) . IEEE, 2018, pp. 6059–6066.
- 4[4] L. Hewing, A. Liniger, and M. N. Zeilinger, “Cautious nmpc with gaussian process dynamics for autonomous miniature race cars,” in 2018 European Control Conference (ECC) . IEEE, 2018, pp. 1341–1348.
- 5[5] K. Chua, R. Calandra, R. Mc Allister, and S. Levine, “Deep reinforcement learning in a handful of trials using probabilistic dynamics models,” in Advances in Neural Information Processing Systems , 2018, pp. 4759–4770.
- 6[6] E. Terzi, L. Fagiano, M. Farina, and R. Scattolini, “Learning-based predictive control for linear systems: a unitary approach,” ar Xiv preprint ar Xiv:1810.12584 , 2018.
- 7[7] U. Rosolia and F. Borrelli, “Learning how to autonomously race a car: a predictive control approach,” ar Xiv preprint ar Xiv:1901.08184 , 2019.
- 8[8] K. S. Lee and J. H. Lee, “Model predictive control for nonlinear batch processes with asymptotically perfect tracking,” Computers & Chemical Engineering , vol. 21, pp. S 873–S 879, 1997.