TL;DR
This paper introduces a new method to identify the central node in complex networks by generalizing the median concept using a novel statistical data depth, applicable to networks embedded in geometric spaces, with practical relevance in social and biological contexts.
Contribution
It proposes a new median concept for complex networks based on statistical data depth, enhancing the identification of central nodes in various network types.
Findings
New median concept effectively identifies central nodes
Applicable to networks embedded in geometric spaces
Reveals socially and biologically relevant median nodes
Abstract
Centrality descriptors are widely used to rank nodes according to specific concept(s) of importance. Despite the large number of centrality measures available nowadays, it is still poorly understood how to identify the node which can be considered as the `centre' of a complex network. In fact, this problem corresponds to finding the median of a complex network. The median is a non-parametric and robust estimator of the location parameter of a probability distribution. In this work, we present the most natural generalisation of the concept of median to the realm of complex networks, discussing its advantages for defining the centre of the system and percentiles around that centre. To this aim, we introduce a new statistical data depth and we apply it to networks embedded in a geometric space induced by different metrics. The application of our framework to empirical networks allows us to…
Click any figure to enlarge with its caption.
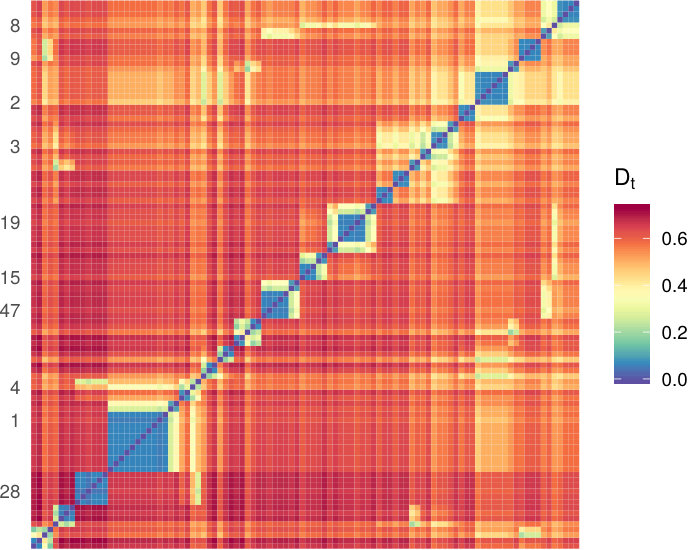 Figure 1
Figure 1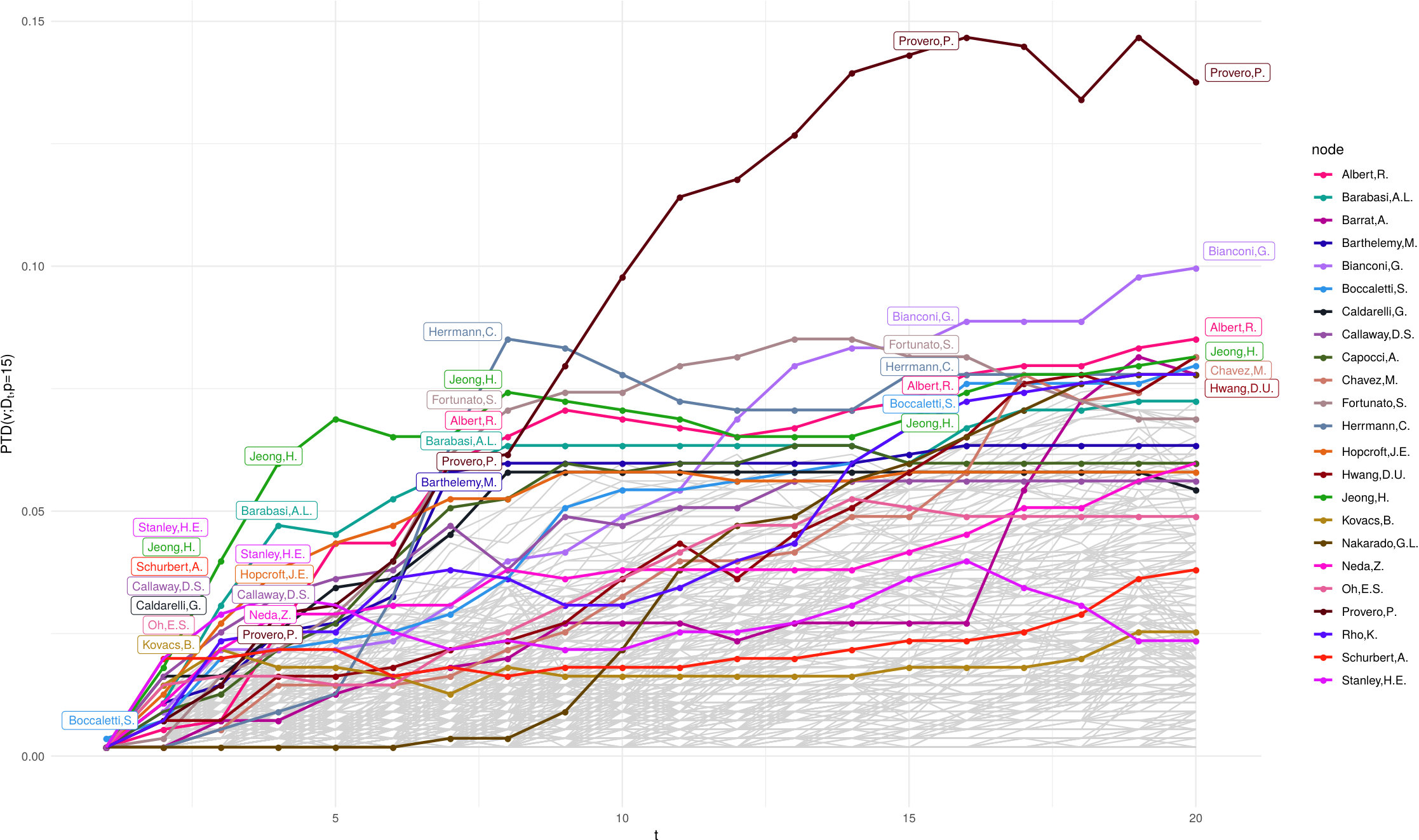 Figure 2
Figure 2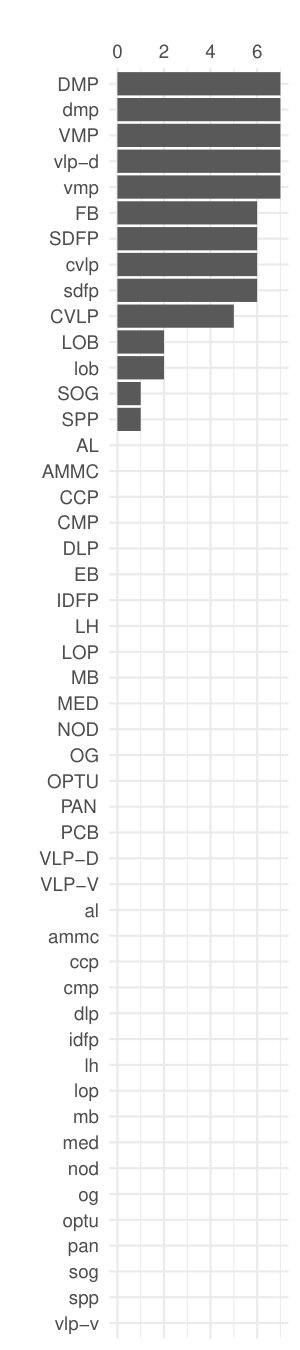 Figure 3
Figure 3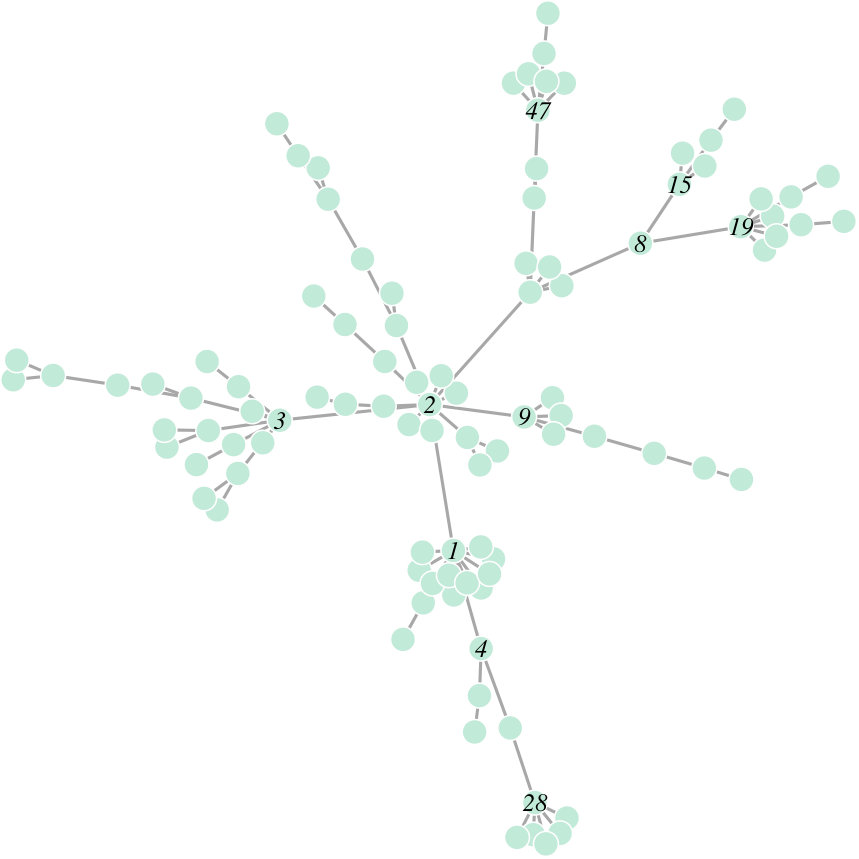 Figure 4
Figure 4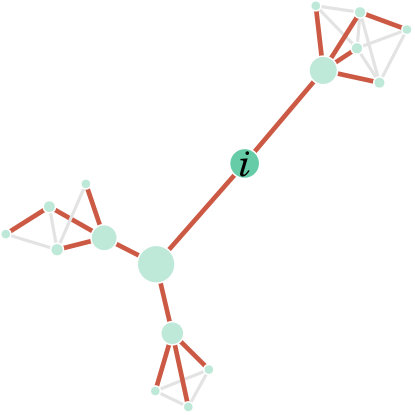 Figure 5
Figure 5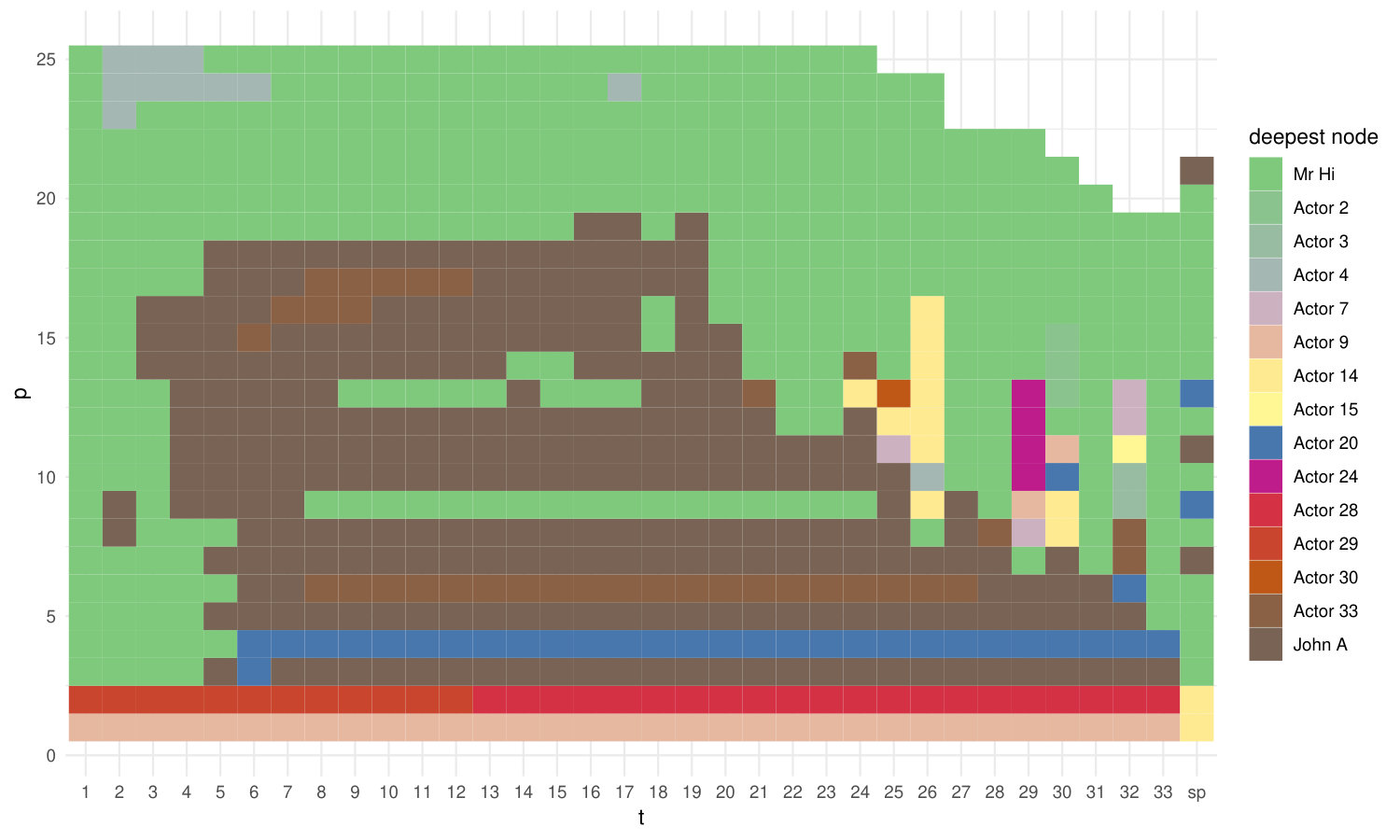 Figure 6
Figure 6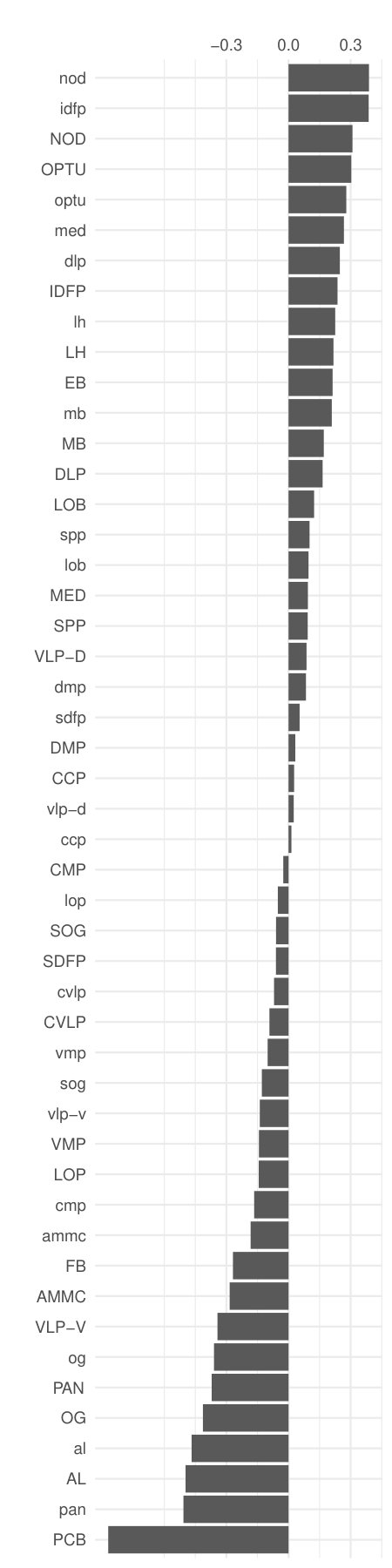 Figure 7
Figure 7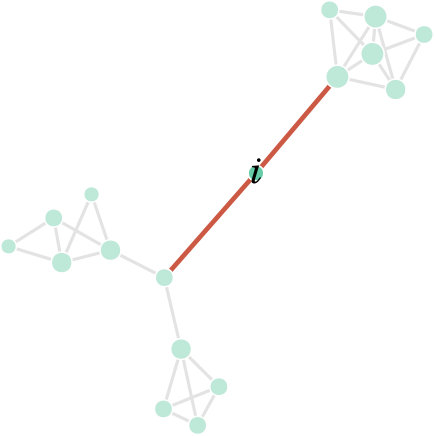 Figure 8
Figure 8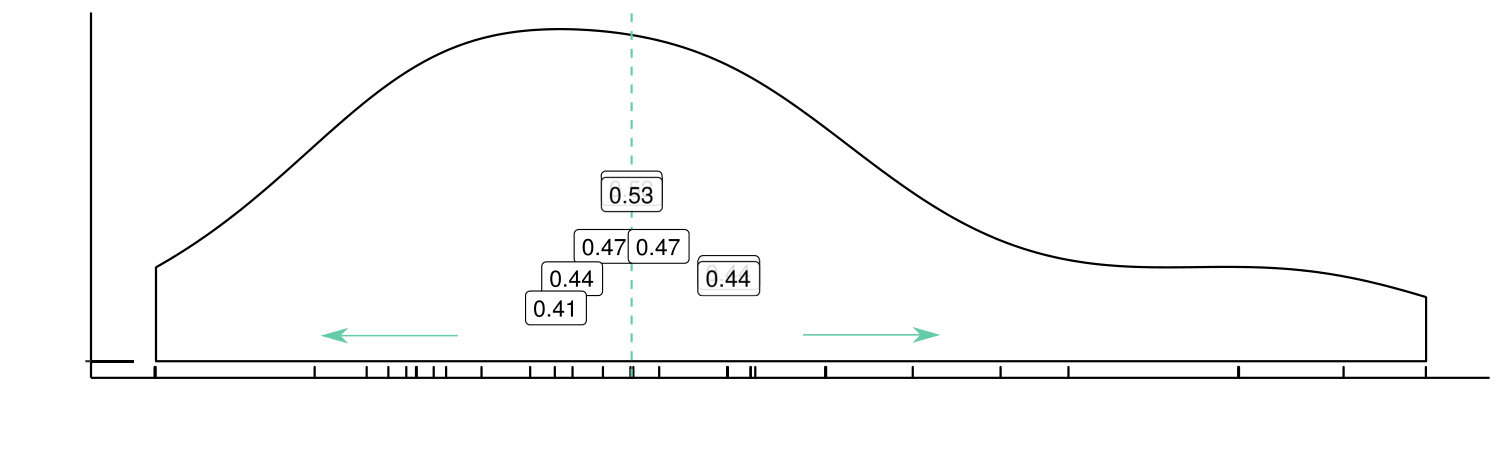 Figure 9
Figure 9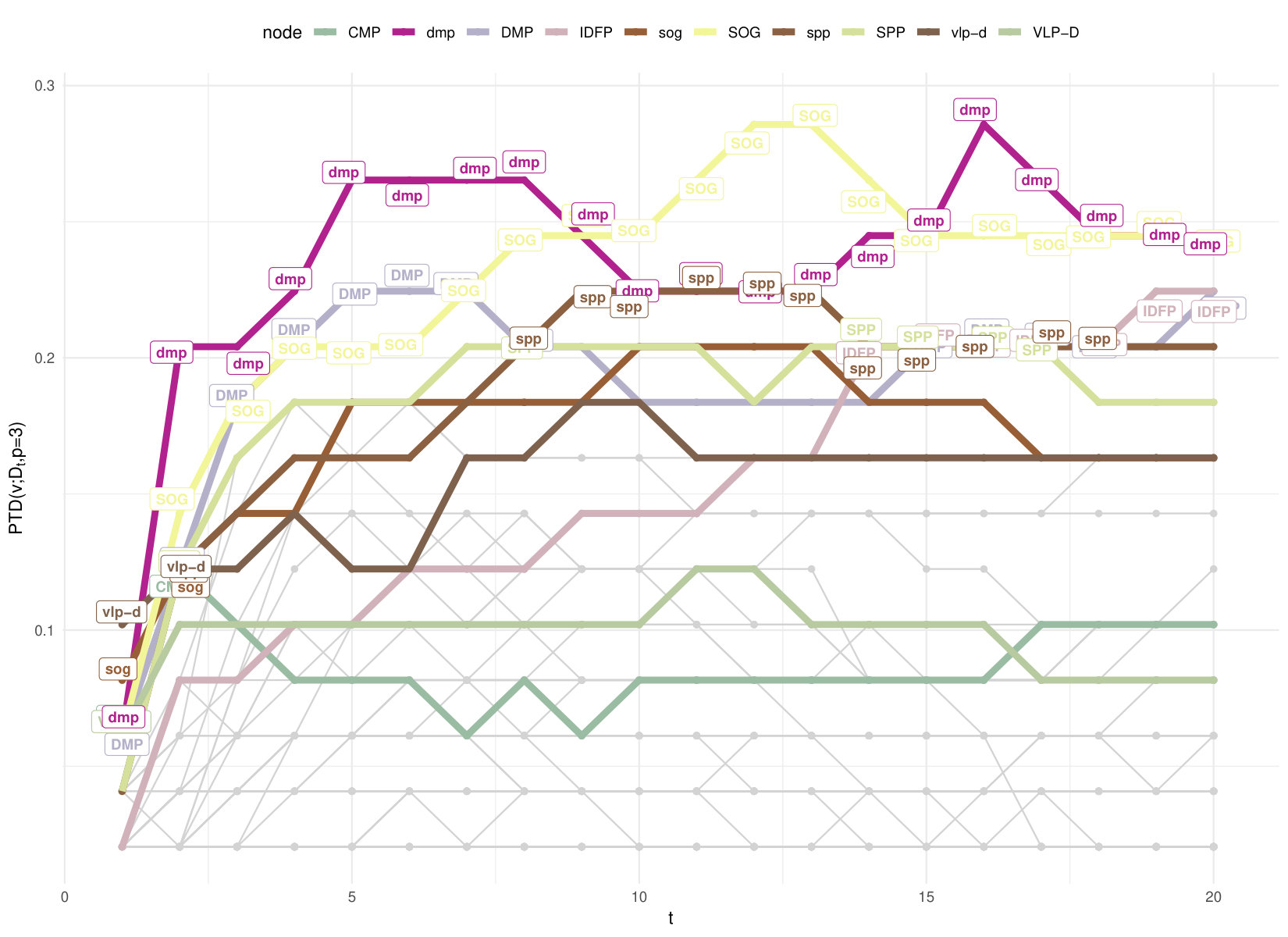 Figure 10
Figure 10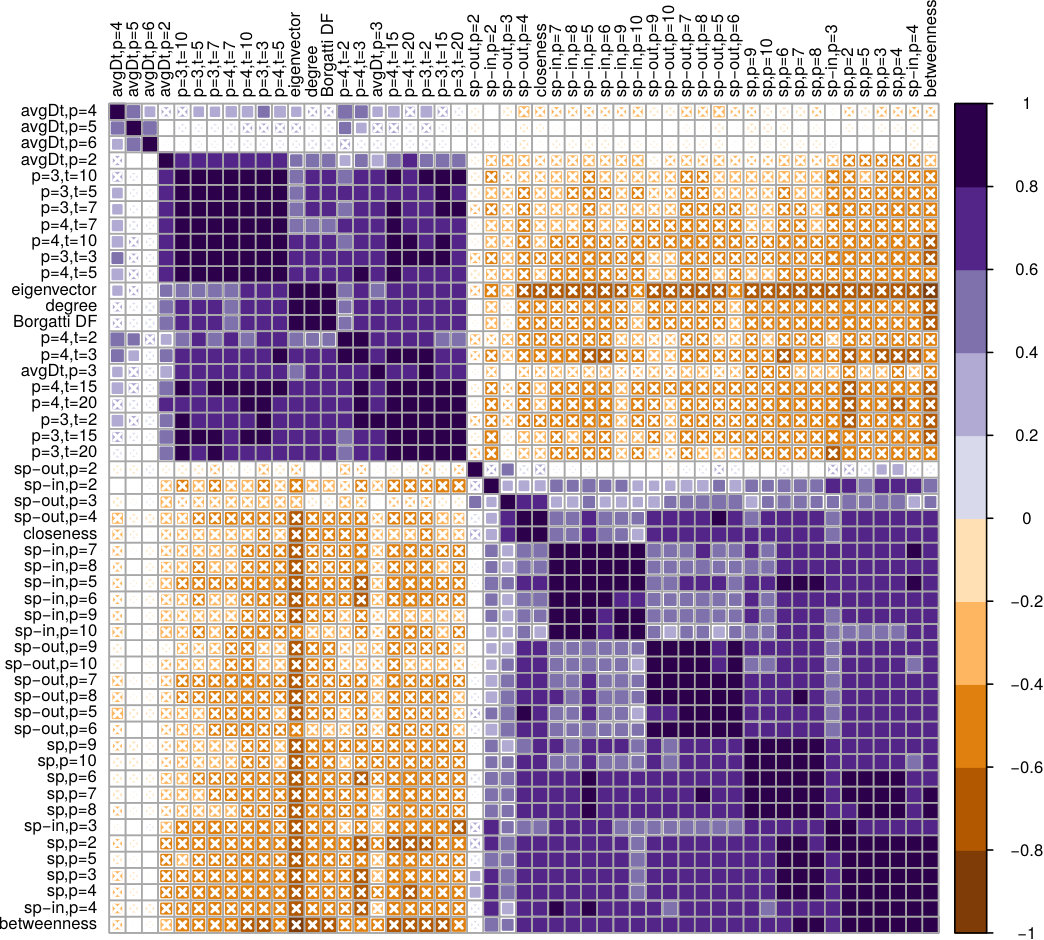 Figure 11
Figure 11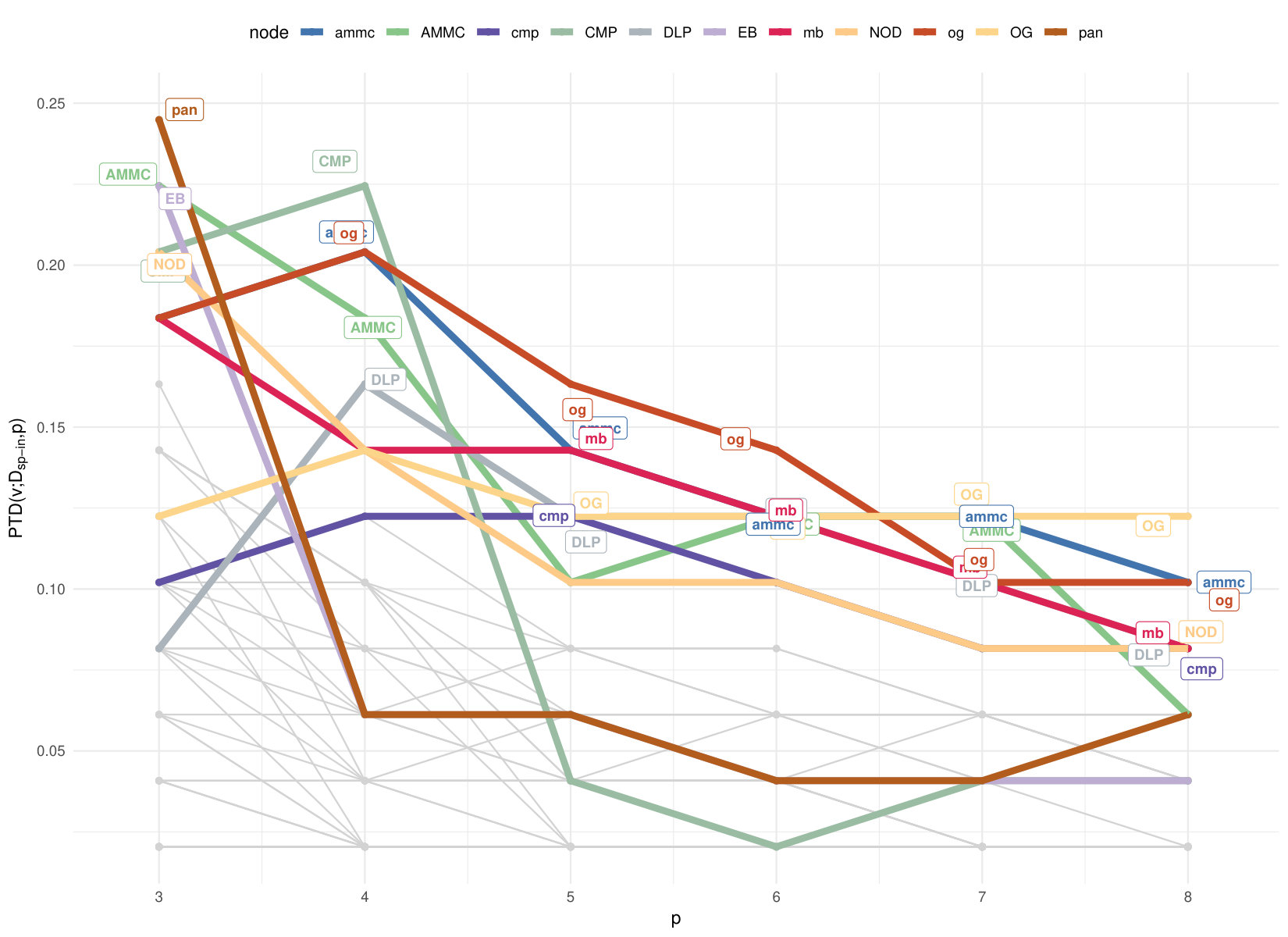 Figure 12
Figure 12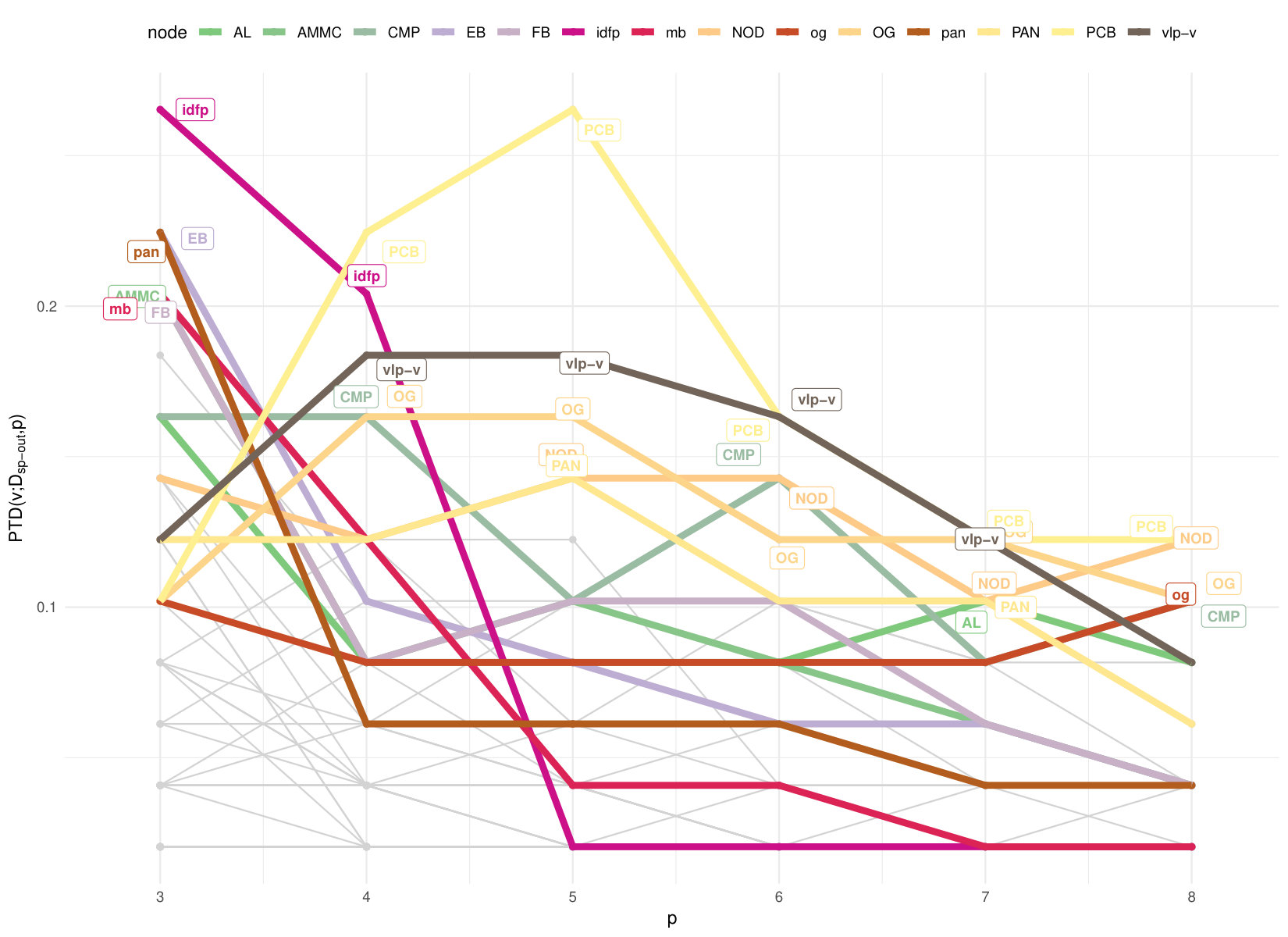 Figure 13
Figure 13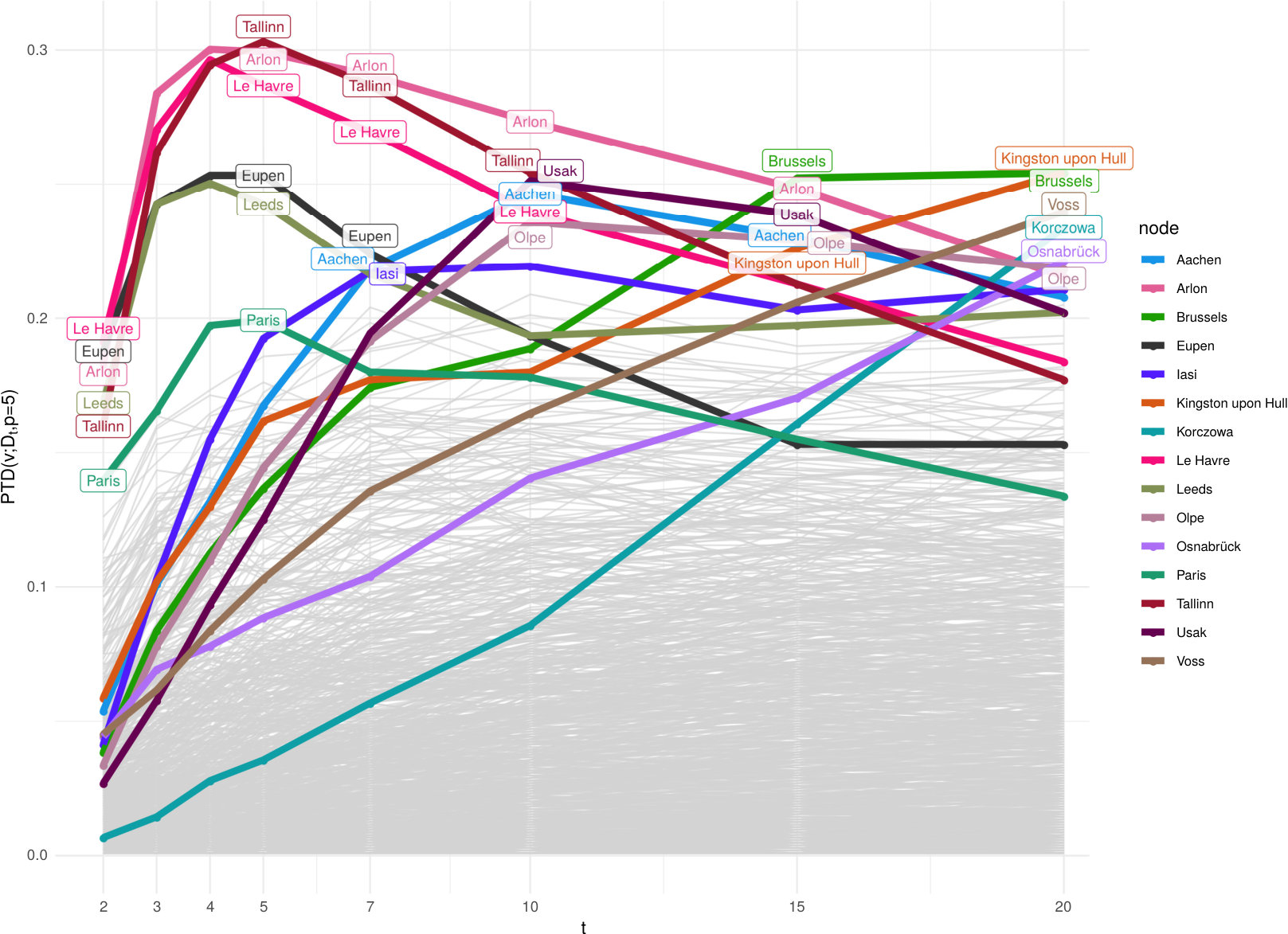 Figure 14
Figure 14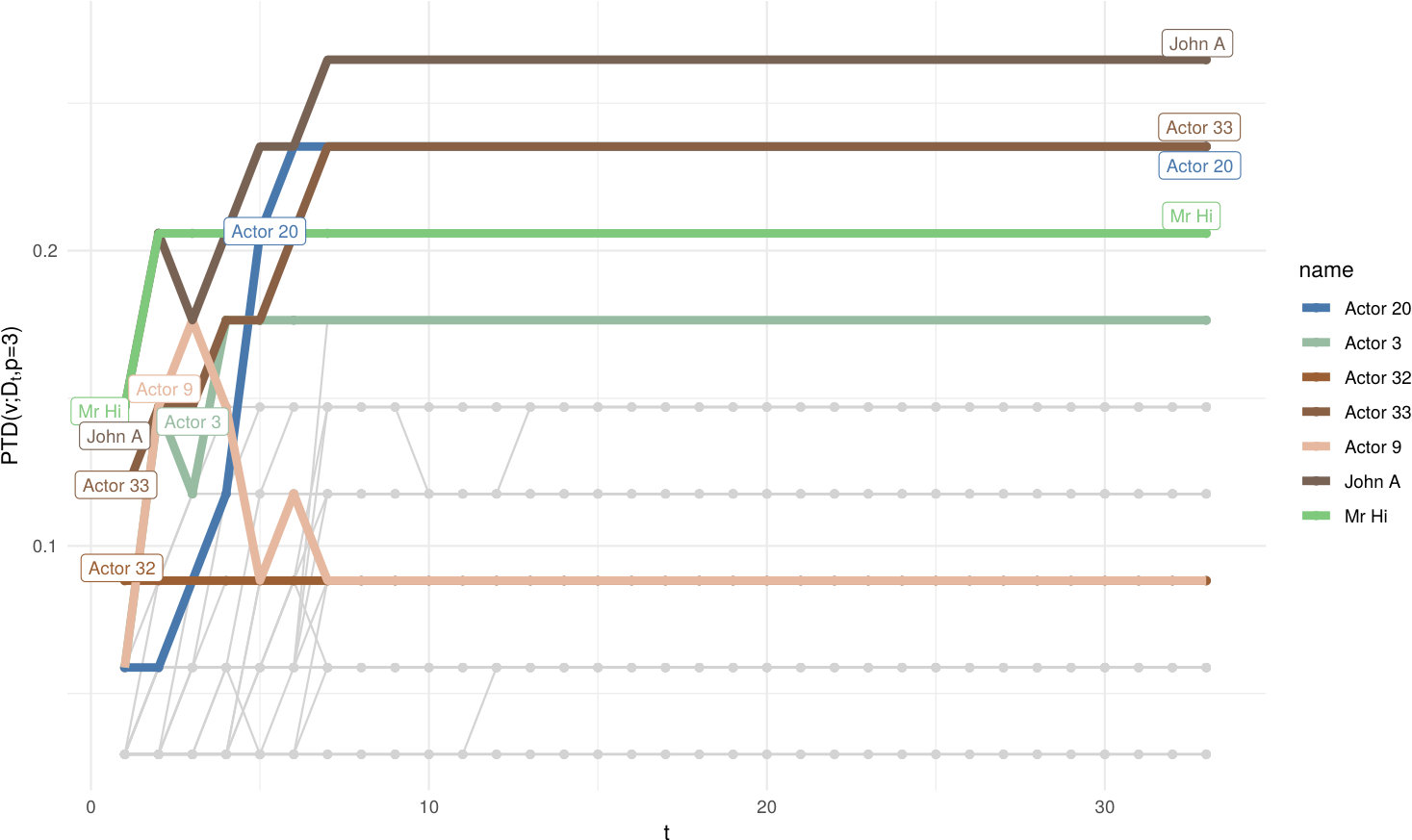 Figure 15
Figure 15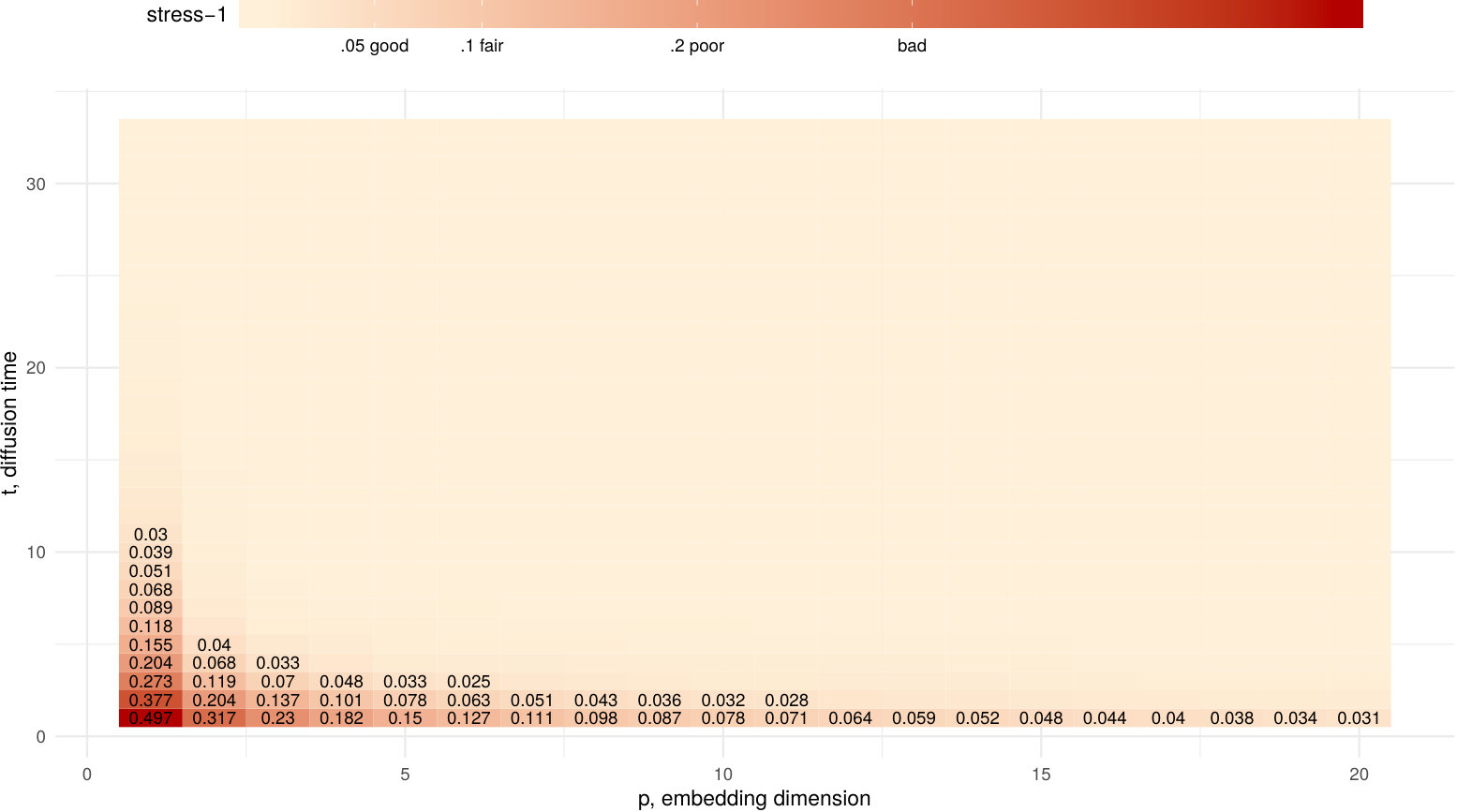 Figure 16
Figure 16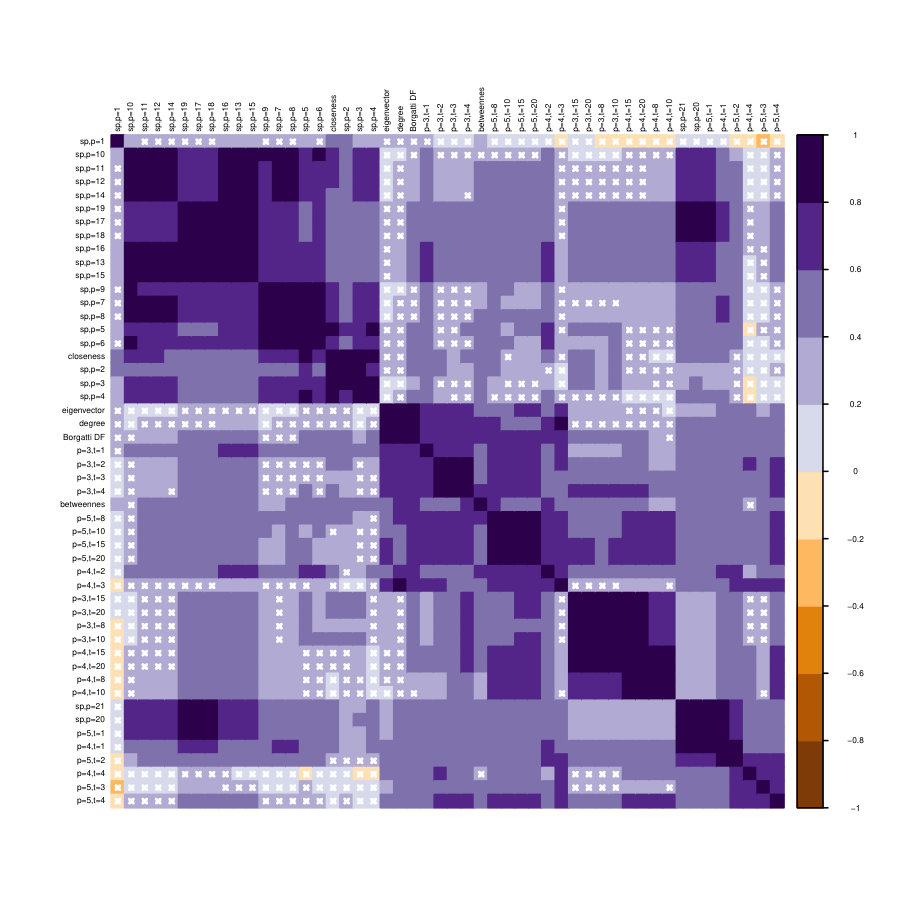 Figure 17
Figure 17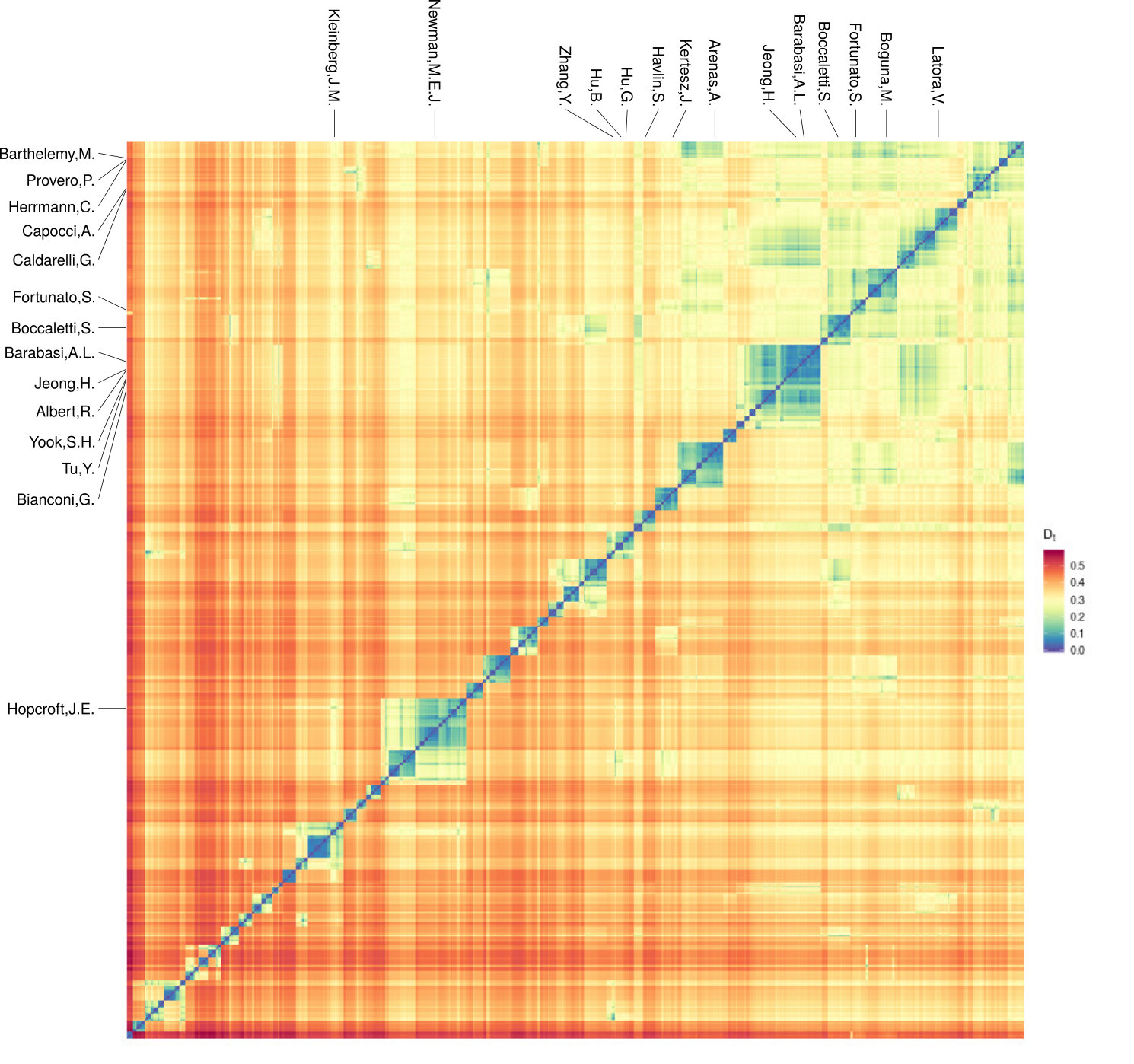 Figure 18
Figure 18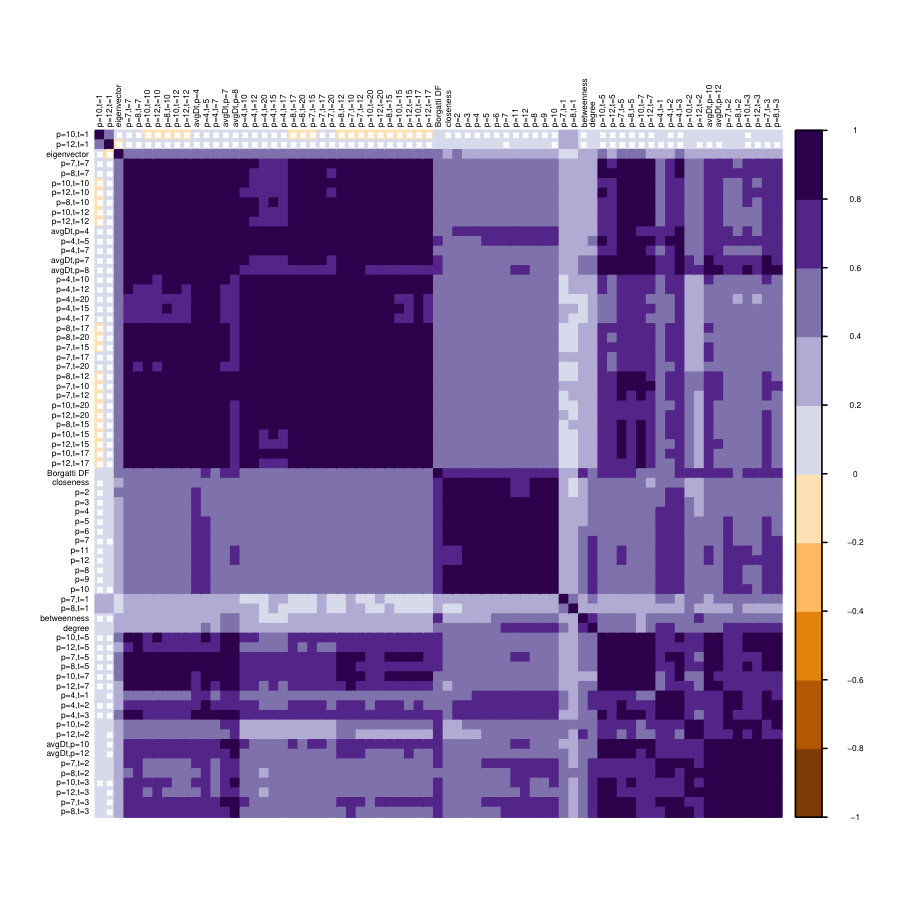 Figure 19
Figure 19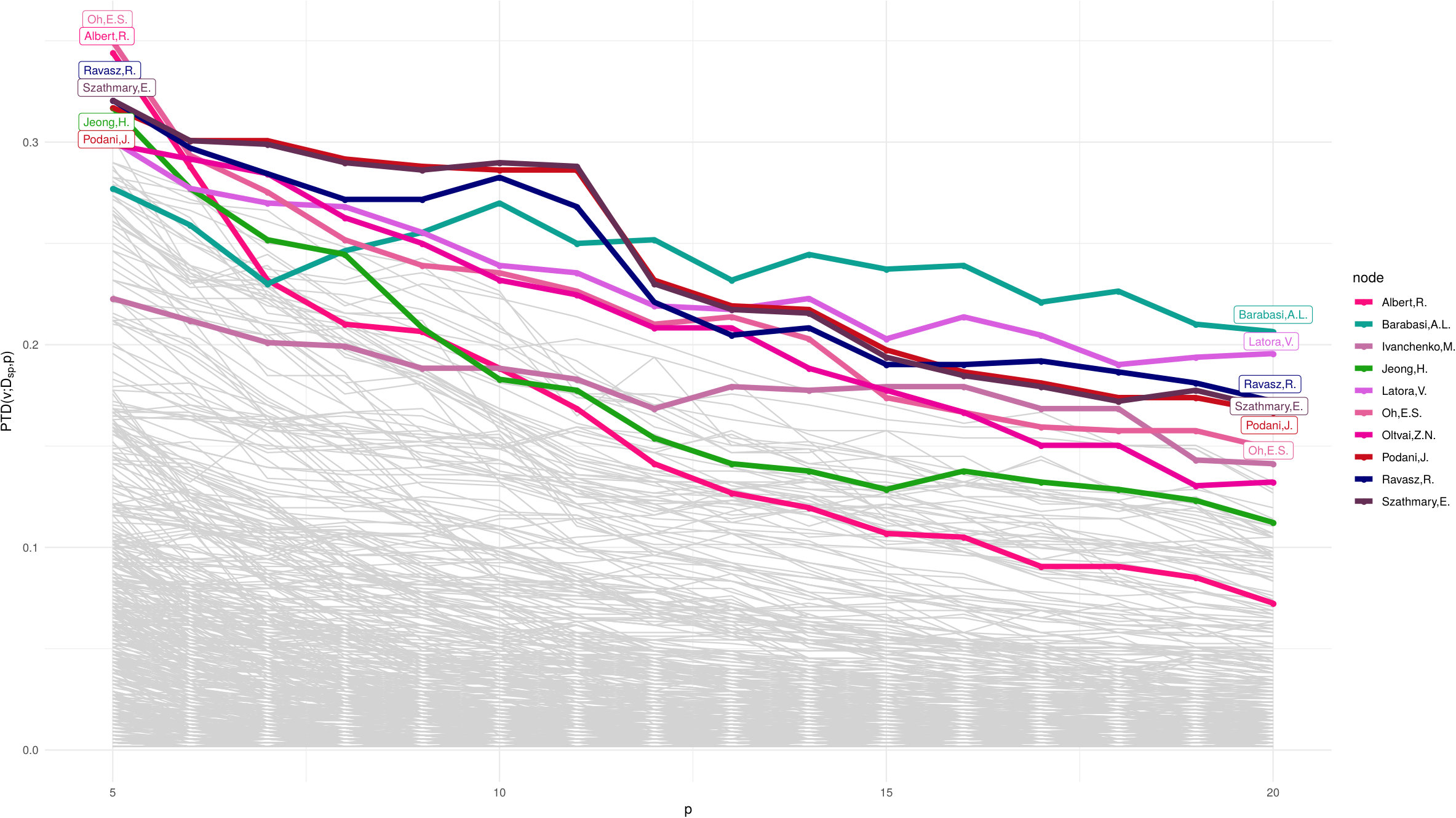 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22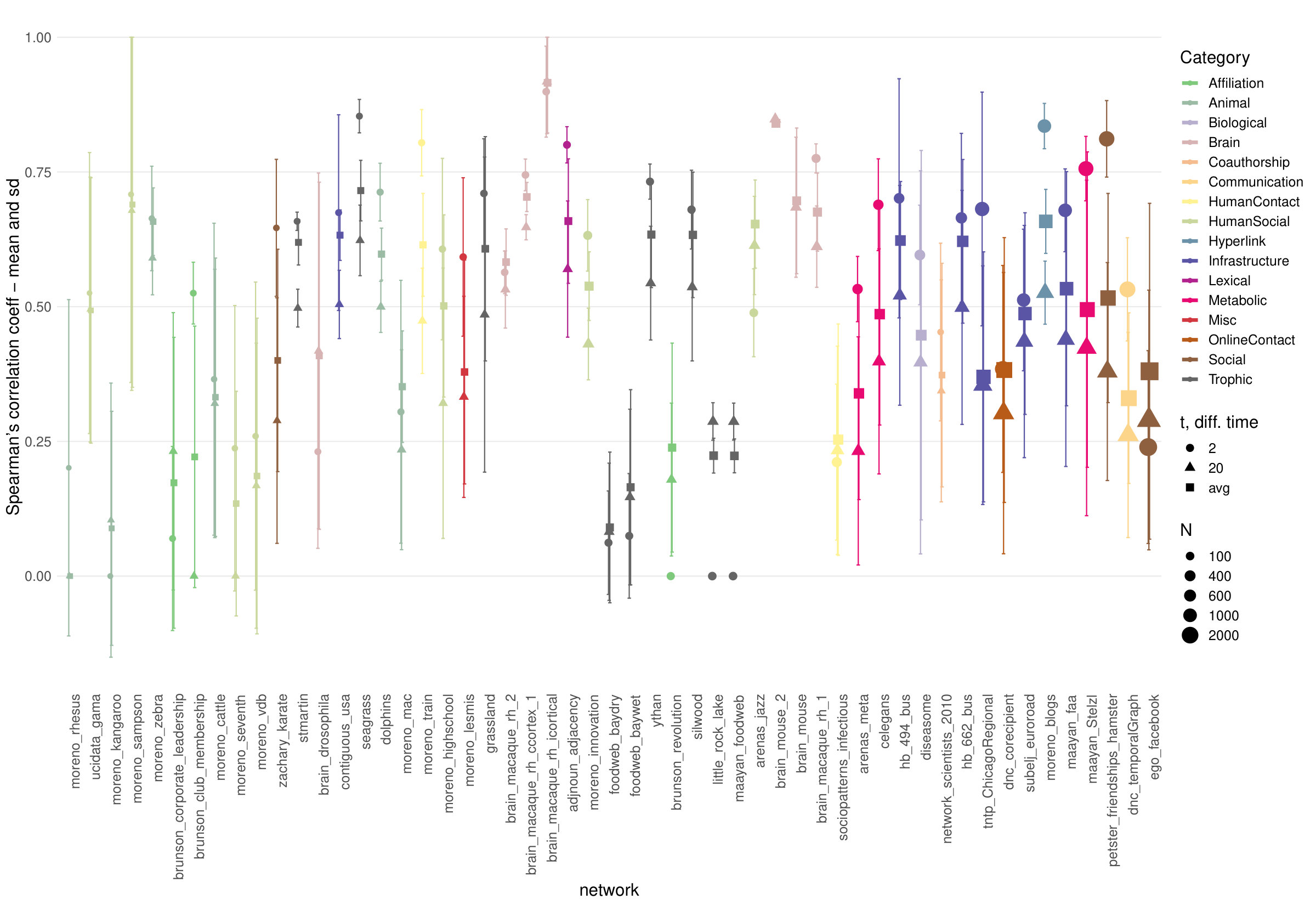 Figure 23
Figure 23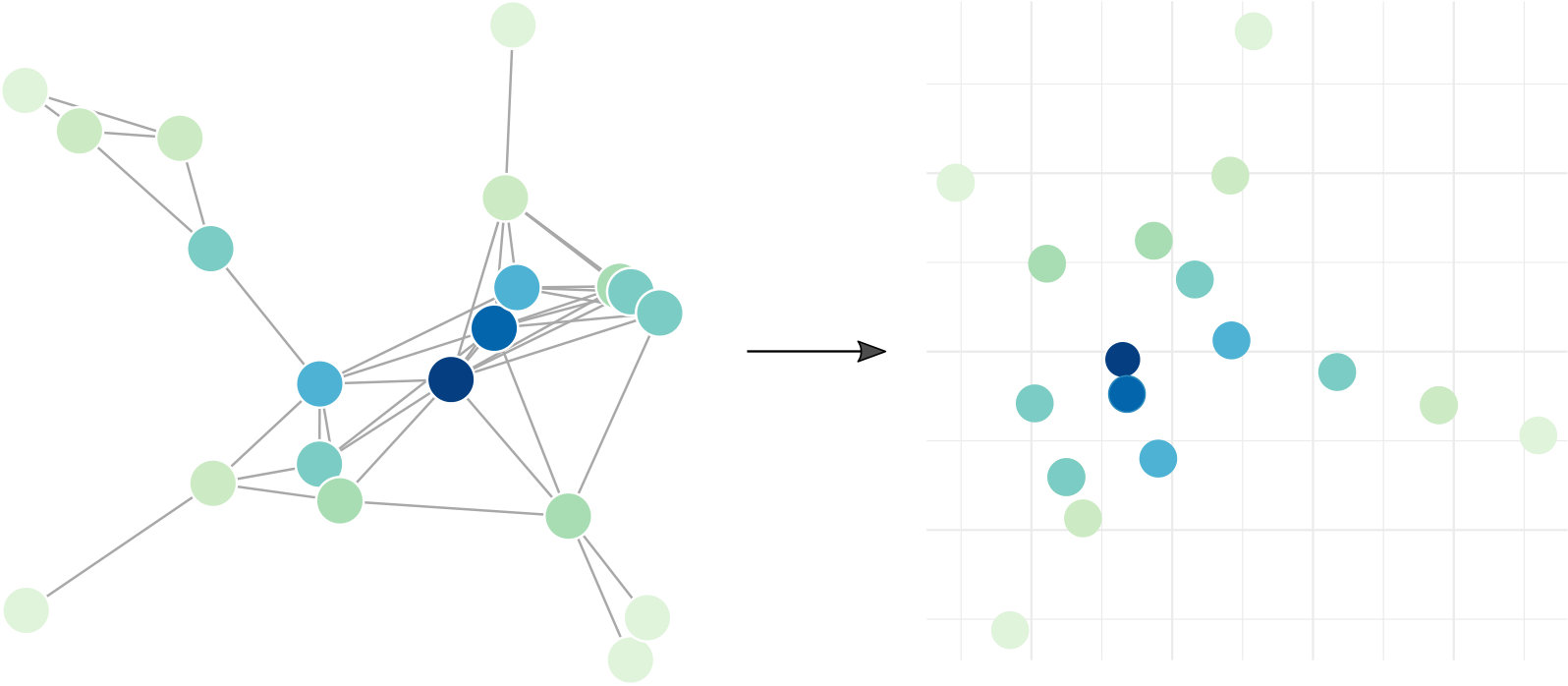 Figure 24
Figure 24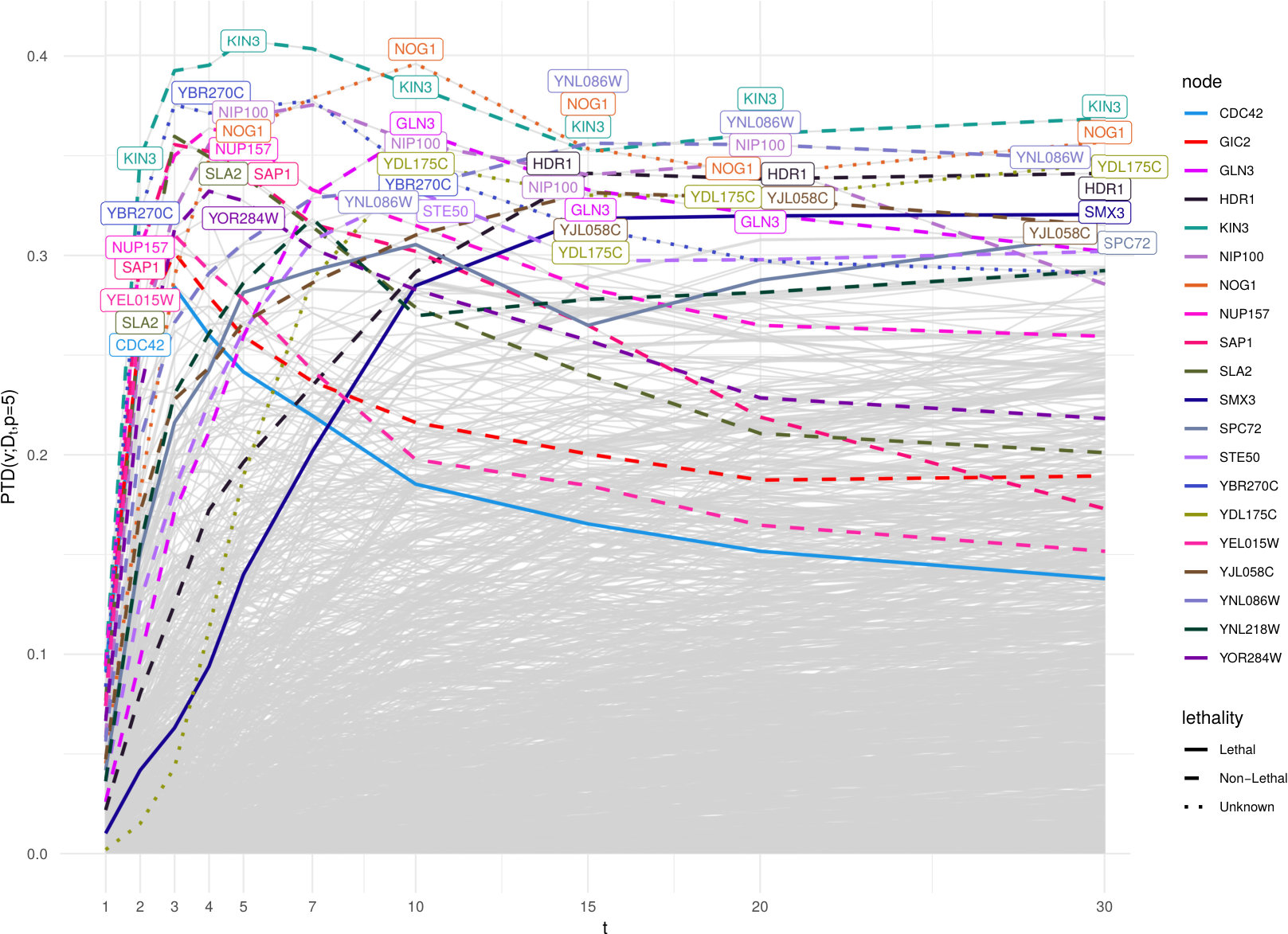 Figure 25
Figure 25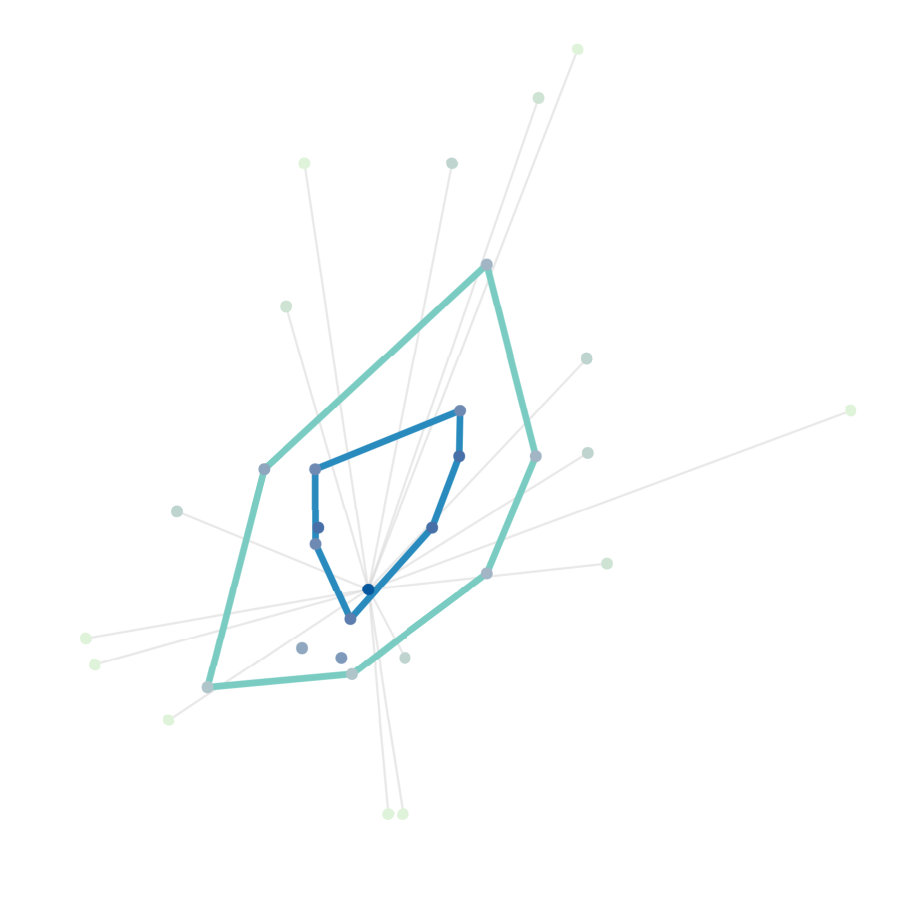 Figure 26
Figure 26| Radial | Medial | |
|---|---|---|
| Volume | Freeman degree, Bonacich eigenvector | Betweenness |
| Length | closeness | Borgatti DF |
| Eigenvector | Closeness | Betweenness | Fragmentation | |
|---|---|---|---|---|
| Kingston upon Hull | Le Havre | Leeds | Kingston upon Hull | Urziceni |
| Korczowa | Arlon | Kingston upon Hull | Stara Zagora | Ishim |
| Osnabrück | Eupen | Esbjerg | Urziceni | Memmingen |
| Kumanovo | Tallinn | Osnabrück | Leuven | Kingston upon Hull |
| Görlitz | Eindhoven | Voss | Brussels | Leeds |
| Åndalsnes | Leuven | Belgrade | Esbjerg | Irkeshtam |
| Dej | Paris | Brussels | Leeds | Stara Zagora |
| Voss | Bastogne | Panevėžys | Panevėžys | Guzar |
| Chemnitz | Székesfehérvár | Rovaniemi | Incukalns | Reni |
| Manchester | Dover | Stara Zagora | Riga | Leuven |
| Brussels | Sion | Ruse | Turku | Aarhus |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
\shortauthorlist
G. Bertagnolli, C. Agostinelli and M. De Domenico
Network depth: identifying median and contours in complex networks.
\nameGiulia Bertagnolli∗
\nameClaudio Agostinelli
Center for Information and Communication Technology, Fondazione Bruno Kessler, Via Sommarive 18, 38123 Povo (TN), Italy
∗Corresponding author: [email protected]
Department of Mathematics, University of Trento, Via Sommarive, 14, 38123 Povo (TN), Italy
Department of Mathematics, University of Trento, Via Sommarive, 14, 38123 Povo (TN), Italy
\nameManlio De Domenico*†*
Center for Information and Communication Technology, Fondazione Bruno Kessler, Via Sommarive 18, 38123 Povo (TN), Italy
*†*Corresponding author: [email protected]
Abstract
Centrality descriptors are widely used to rank nodes according to specific concept(s) of importance. Despite the large number of centrality measures available nowadays, it is still poorly understood how to identify the node which can be considered as the “centre” of a complex network. In fact, this problem corresponds to finding the median of a complex network. The median is a nonparametric – or better, distribution-free – and robust estimator of the location parameter of a probability distribution. In this work, we present the statistical and most natural generalisation of the concept of median to the realm of complex networks, discussing its advantages for defining the centre of the system and percentiles around that centre. To this aim, we introduce a new statistical data depth and we apply it to networks embedded in a geometric space induced by different metrics. The application of our framework to empirical networks allows us to identify central nodes which are socially or biologically relevant. centrality; statistical data depths; diffusion geometry
1 Introduction
Nodes centrality is a very fundamental concept in network science, used to answer questions like “who are the most influential actors in a social network”? Or “which are the key nodes for the optimal functioning of a power grid”? Unfortunately centrality descriptors are defined upon a non-rigorous definition of importance. Consequently, there is a plethora of centrality measures and interpretations making difficult to understand which one could be used as a one-fits-all solution.
Similarly many statistical problems deal with the location, the centre of a population. Knowing very little about the underlying population, e.g. we may not know if the underlying distribution has finite first moment, we can still estimate the location through the median and set up distribution-free statistical tests for it. Nonparametric statistics largely rely on order statistic, which is fine in , but gives some problems already in , where no natural order relation is defined. As we will see in Sec. 2, statistical data depths enable the generalisation of order and order statistics, to multivariate spaces, functional spaces and, with this work, also to networks. Before moving to our new centrality, we have to summarise some key concepts about network centrality.
The need for a unified framework for centrality measures was already clear in the early days of network science, when Freeman proposed his three-fold categorisation of centralities (Freeman1978, ). More recently, Borgatti and Everett (Borgatti2006, ) approached centrality from a graph-theoretic perspective. They showed that all centralities evaluate the involvement of a node in the walkability of the network according to four features: Walk Type, Walk Property, Walk Position and Summary Type. Different Walk Types (e.g. shortest-paths or random walks) and restrictions on them (e.g. maximum length) might influence centrality as shown in Fig. 1. For instance the degree of the –th node can be seen as counting the paths of length 1 emanating from . Allowing paths of length leads to –path centrality. Another example is given by the betweenness that, as the degree, belongs to the class of measures that count walks and have volume as the Walk Property, at variance with closeness that, instead, deals with paths length.
The Walk Position can be radial, where walks emanate from a given node – as for degree and closeness – or medial, when the focus is on walks passing through that node (e.g. betweenness). Once the information based on these features is gathered in a node-by-node matrix , a summary statistic is needed to obtain a centrality score vector . represents the fourth feature: Summary Type. As observed in (Borgatti2006, ), the variation along this feature is small since usually the summary is a row sum or a (weighted) average. Table 1 places some popular centrality measures in this classification with respect to Walk Property and Position. We briefly recall the definitions of the five measures we use from now on, in bold font in Tab. 1, by using the same notation. In the following, let be the adjacency matrix of graph .
The degree of vertex is where . Observing that in some occasions one’s importance should depend on whether its neighbours are themselves important, many variations on the degree have been proposed. In 1972 Bonacich introduced the eigenvector centrality, which can be regarded as an elegant summary of Katz’s, Hoede’s and Hubbell’s measures (Borgatti2006, ). Let x be the eigenvector corresponding to the largest eigenvalue of , i.e. ; then x is the eigenvector centrality vector and for each
[TABLE]
The entries of are then and .
The closeness is obtained as the inverse of the marginals of , the shortest-path distance matrix. The elements of its centrality score vector are computed as follows
[TABLE]
Observe that is the total sp-distance from node to all others. Sometimes the average distance or (Freeman1978, ) is considered to make the scores comparable among networks with different sizes.
The betweenness centrality of node , , is the total number of shortest-paths between pairs of vertices that pass through node .
Borgatti’s Distance-weighted Fragmentation (DF)111Available in the R package “keyplayer” (An2016, ) (Borgatti2003, ) measures the extent to which the network cohesiveness depends on node . It depends both on the size of components of the network after the removal of and on the relative cohesion of each component, in terms of total sp-distance between all pairs of nodes. Let
[TABLE]
We have chosen this five measures, since they are representative of other centralities.
The remainder of this paper is organised as follows. In Section 2 we present a new centrality built upon robust, nonparametric statistics, called statistical data depths. In particular, we start introducing the statistical background of data depths and the definition of our new multivariate depth function, the Projected Tukey depth (PTD). In Subsection 2.2 we make use of the graph-theoretical framework for centralities by Borgatti and Everett, to show that the PTD evaluated on a network embedded in space defines a new centrality in the sense of networks. We call this new centrality network depth. In addition, this framework allows differences and commonalities among the network depth and other centrality descriptors to be identified theoretically. In Subsection 2.3 we examine in detail the network embedding step in our procedure and study how it reflects on the network depth. In fact, networks can be embedded in different ways. We use Multidimensional scaling (MDS), a metric preserving embedding method that depends on two parameters: a distance (or dissimilarity) matrix and an embedding dimension. This step introduces a parameter space and, consequently, a family of network depths. We provide some applications to empirical networks in Section 3, together with the heuristics that should be followed to reproduce our results and to evaluate the network depth to real data. The conclusions in Section 4 summarise our contribution to the understanding of the concept of centre-outward ordering of nodes in a network.
2 Network Depth
A statistical data depth function, or simply a depth, can be seen as a measure of the centrality or outlyingness of a given sample with respect to its underlying probability distribution. In the analysis of multivariate data, it allows us to find an overall centre of the observations, which plays the role of the median. Further, depths induce a centre-outward and probability-based ordering of sample points, which results in the ranking of the observed units.
Based on this ordering, quantitative and graphical univariate tools for data analysis have been generalised to the multivariate case (Regina1999, ). The usefulness of depths is widely recognised, indeed they have been extended to functional data as well (Nieto2016, ).
The idea underling data depths dates back to 1975 when John W. Tukey (Tukey1975, ) proposed a new approach to the problem of ordering points in . Tukey’s idea, which was further developed in (Donoho1992, ), is based on the observation that, given a univariate random variable with distribution function , a natural centre-outward ordering of points can be derived as follows: for each we can compute and and define . The median of – the value such that – is the most central (or the deepest) point, while points far away from it in both directions have smaller depth values, see Fig. 2. Then, the halfspace Tukey depth () of a point w.r.t. the distribution of a random vector X, is the least depth value of x in any one-dimensional projection of X.
Many depths and corresponding empirical estimators have been proposed since, but it was only in 2000 that statistical depth functions have been rigorously defined. In (Zuo2000a, ) Zuo and Serfling state four desirable properties a function should fulfil in order to be called a depth. These formalise the intuition that the concept of “centre” is relevant. Therefore, if a probability distribution is symmetric222There exist different definitions of symmetric probability distribution, for details see (Zuo1999, ). around a point , that ought to be also the depth centre; further, the depth should take higher values near the centre than towards the border. Properties (P2), (P3) and (P4) in the following definition are inspired precisely by this idea, while (P1) guarantees that common transformations (like standardisation) do not affect the depth of points.
Definition 2.1** (Depth function).**
Let be a point and , the probability distribution function of a random vector X on the Borel algebra . Furthermore, let the mapping be bounded, non-negative and satisfy
- P1)
* holds for any random vector , any non-singular matrix and any vector ;*
- P2)
* holds for any having centre ;*
- P3)
for any having deepest point , holds for any ;
- P4)
* as for each .*
Then is called a statistical depth function.
A last key feature of depths, is the identification of a unique centre, regardless of the distribution being uni- or multi-modal. The reason why we emphasise it will be clear in Subsection 2.2.
Currently, there exist many multivariate depth functions, fulfilling all or just some properties of the definition 2.1, differing in robustness to outliers, ease of interpretation, and computational complexity among others. The halfspace Tukey depth is one of the most famous and well studied multivariate depth functions. Given that it is based on the “projection-pursuit” methodology, it behaves well overall compared with its competitors. Unfortunately, its exact computation is challenging (or prohibitive) in high-dimensional spaces. Indeed, given a point and a p-variate random sample with empirical distribution , the (empirical) halfspace depth – – requires to consider projections along all possible such that .
Our new depth is based on the original idea of Tukey and it addresses the main drawback of : the high computational cost.
2.1 Projected Tukey depth
Definition 2.2** (Projected Tukey depth).**
Let X be a random vector in with distribution , being two independent copies and the covariance matrix333Assume that is invertible or use Moore-Penrose pseudo-inverse. of X (i.e. assume ). For a given define the univariate random variable
[TABLE]
then,
[TABLE]
Theorem 2.3**.**
The Projected Tukey depth is a statistical depth function.
Proof 2.4**.**
In the proof an equivalent444Equivalence can be easily proved writing the probability space and with associated probability measure for each Borel set . Then, is the product measure associated to . In the following we write instead of for , with a negligible ambiguity, and for . definition is also used: for each realisation define the univariate random variable
[TABLE]
and denote by the family of random variables conditioned on . Then the Projected Tukey depth of x w.r.t. is
[TABLE]
Clearly is bounded and non-negative.
- P1)
Affine invariance: we have to prove that for any non singular matrix and any vector
[TABLE]
The covariance matrix of is so we have
[TABLE]
hence ; the thesis follows since property P1 holds for .
From now on we assume w.l.o.g. that .
- P2)
The proof of maximality at centre property involves probability distributions that are symmetric with around . There are several definitions of multivariate symmetry: spherical (most restrictive), elliptical, angular and halfspace (less restrictive) **(Zuo1999*, *)**; P2 can be proven in the latter, general case. Let the distribution of X be -symmetric about a unique centre , i.e. in terms of the underlying probability measure for every closed halfspace containing on its border. Assume thanks to P1. We ask if for all . From (6) and **(Zuo1999*, *, Th.2.3.2.)**
[TABLE]
similarly each projection on the line through x and is such that , hence . Since the halfspace depth satisfies the maximality at centre property and for the uniqueness of the centre of symmetry assumption, it cannot happen that .
- P3)
Monotonicity relative to deepest point: assuming w.l.o.g. we have to prove that for . The interesting case is when . The problem is that we have to compare two families of marginals and . P3) has been proved only for spherical and elliptical symmetric distributions. In the first case we use a characterisation of spherical symmetry stating that rotations around the centre do not affect the distribution, formally for orthogonal matrices . Therefore, marginals on lines through the centre are all equal and the thesis follows immediately. Elliptic symmetry reduces to spherical when so by means of P1) we ho back to previous case.
- P4)
*Vanishing at infinity – as *
Assume w.l.o.g. . Take fixed, then where is the angle between the two vectors , . If then , otherwise .
We want to show that for x sufficiently far away from the deepest point so that for each realisation. Then .
If X is bounded in , as soon as is outside the ball of finite radius containing the angle and .
If X is not bounded in , using Chebyshev’s inequality on the univariate r.v. , i.e.
[TABLE]
we have that the probability of finding a point arbitrarily distant from is small. For x such that we can then conclude that and the thesis follow.
This closes the proof. ∎
The sample version of the is built around (6). It is similar to with two important differences: first, only a subset of possible projecting directions are considered and exactly those indicated by that; secondly we do not take orthogonal but variance-scaled projections, akin in spirit to Mahalanobis distance.
Definition 2.5** (Sample PTD).**
Let be a random sample and its empirical distribution; and
[TABLE]
is the projection of the –th sample point onto the line through x and . Collecting them for all we get a univariate sample
[TABLE]
and we take the minimum probability mass carried by halflines with [math] on the boundary
[TABLE]
*In the following we denote again by .
In matrix form (8) becomes , where is obtained subtracting x from each row of .*
The set is called the depth space of X, or associated with distribution . In the empirical case the depth space is a vector whose entries are the depth value for each observation and this will be the centrality vector of nodes in graph . Another useful family of sets are the so-called depth trimmed (or central) regions , which generalise quantile-intervals, given the depth region of order is the set characterised by
[TABLE]
For instance, is the depth central region containing the 1% deepest points. The set is called depth contour of depth . The empirical version of the contour set is computed as the convex hull containing the most central fraction of sample points and it is denoted by ; becomes and the depth region . Again, as we will always deal with empirical quantities, we drop the subscript in the notation.
The Projected Tukey depth can be computed exactly also in high-dimensional spaces. Given points in , i.e. , the algorithm of the PTD requires (i) the inversion of its sample covariance matrix , which costs in the worst case and (ii) the evaluation of the matrix product , which has complexity using the naive matrix multiplication algorithm. Usually is not very high since we use dimensionality reduction techniques to embed our networks in space, so in the end the evaluation of the PTD of a point w.r.t. a cloud of points has a complexity of and of for the whole data cloud.
In the next Subsection we show how this multivariate depth function can be used to generalise the definition of median to complex networks.
2.2 The Network Depth: a New Centrality
The key step linking the Projected Tukey depth to network centralities is network embedding. A network embedded in some space is a cloud of points distributed accordingly to the connectivity of . We map the problem of finding the centrality of the node , to the problem of computing the depth of the point w.r.t. the (empirical) distribution of . The idea is that reflects the connectivity of graph , adjacent vertices should lie nearer than nodes that do not share edges. Thus, the priority for our embedding is preserving distances.
On an undirected weighted connected network, we have a distance given by length of shortest-paths, . If the graph is directed, is no longer a metric and a non-metric embedding may be needed. Another distance can always be defined on (connected) networks, that is based on diffusive random walks, the diffusion distance **(DeDomenico2017*, *)**. Let be the vector with entries representing the probability that a random walker starting at in node is found in at time . It is well known that this probability is linked to the network structure, in particular given the (random walk) normalised Laplacian , where is the diagonal matrix of node degrees, the master equation of the “continuised” random walk is
[TABLE]
The existence of a mapping from to the geometric space induced by Markov dynamics, makes it possible to define the diffusion distance at time , as shown in **(Coifman2005*, *)** and **(DeDomenico2017*, *)**
[TABLE]
which expresses how nodes and are efficient in exchanging information. In other terms, is small if there is a large transition probability from to along walks of length at most . Observe that does not assume that the spreading takes place through shortest-paths and it is robust w.r.t. small fluctuations in the structure of the network. If the network is not connected, one has to regard each component separately or can consider a more general random walk dynamics with a teleportation term, as in diffusive processes used by PageRank **(Page1999*, *)** and Infomap **(Rosvall2008*, *)**.
Given a distance matrix describing structural and/or functional properties of our network we can recover (possibly with some approximations) the position of the nodes in a space of dimension . is always a free parameter of network embedding procedures. We call perfect embedding a configuration of points in for an appropriate such that for all , where is the –th row of matrix configuration and corresponds to the coordinates of node in . For the moment, let us assume that, for a given distance matrix , we have some , such that the embedding of network in is perfect (perfect embedding assumption). In statistical terms we do not lose information passing from to and the centrality problem is equivalent to finding the depth space of .
Let us denote by the PTD centrality of node with respect to geodesic embedding of in and by the corresponding depth space, i.e. the network depth centrality vector with parameters . We do not use the initial notation because the network depth, through the embedding step, depends on some free parameters. Similarly is the depth of node in the diffusion embedding with parameters and refers to the centrality vector . If not ambiguous is omitted.
Using Borgatti’s notation, the matrix , containing the information on connectedness/social proximity, in our case is or equivalently (under our perfect embedding assumption) . Then the PTD is exactly the statistic summarising each node’s share of total cohesion, as a matter of fact . Taking the Projected Tukey depth as a Summary Type makes the centrality, not only robust to outliers, but it also enables the extension to structured data of nonparametric statistical tools based on order statistics (e.g. location and scale estimators).
The other three features characterising centralities are Walk Type, Walk Property and Walk Position. Independently on the metric, is a radial measure and, since it ignores multi-modality of distributions, it is not intended for the identification of local centres in a multi-community structure.
On the contrary Walk Type and Property depend on the distance. , like Freeman’s closeness and betweenness, takes into account only geodesics. In terms of walks, these measures assume the walker has a global knowledge of the network and it navigates it through the shortest possible paths555We do not only have a constraint on length, but also on the walks, indeed paths are sequences of unrepeated edges and nodes.. Finally, is a length measure (Walk Property) since in can be interpreted as the “tailness” of point with respect to the distribution . In other words, a point which lies deep inside the data cloud in the embedding has small values of geodesic distance with all other points. On the other side, summarises structural information gathered through random walk exploration of the network. The diffusion time sets a constraint on the length of otherwise unrestricted edges’ sequences. As observed in **(DeDomenico2017*, *)**, plays the role of a scale parameter: for small values of the micro-scale structure is revealed, see Fig. 4. In this case the network is embedded in a high dimensional space and the data cloud is very sparse with nodes with smaller lying deeper than all others, which are placed on a convex hull and have a depth of . When increases diffusion distances display two different behaviours: among nodes exchanging efficiently information tends rapidly to zero, whereas shrinks slowly if there is a small probability that two random walkers starting in and respectively meet somewhere in the network, following paths of length at most . Since the Projected Tukey depth is not affected by the magnitude of the distances, but only on the relative position of points in space, hence after a certain amount of time, the network depth spans a larger range and remains stable. Of course, in the limit for , for all pairs of nodes, here small fluctuations due to non-perfect embedding might greatly affect the depth of points.
Finally, the Walk Property of the depth w.r.t. diffusion embedding is clearly volume, as a matter of fact and are near in the diffusion manifold if there is a high probability that two random walkers starting respectively in and meet somewhere in the network. In terms of connections, is small if there are a lot of short paths connecting them.
The perfect embedding assumption is satisfied only if the original node distances are Euclidean distances in , then and the configuration matrix is reconstructed without errors. In general, and matrix is the result of a possibly non-metric Multidimensional Scaling (MDS). It is also not mandatory to have a distance matrix since MDS deals with general dissimilarity matrices . In the next subsection we will see the embedding step more in detail.
2.3 Network embedding
Multidimensional scaling is a collection of techniques aiming to find structures in multidimensional data, given a proximity matrix of observations and an embedding dimension **(Cox2000*, *)**. The MDS problem can be solved analytically or using iterative procedures, like the majorisation algorithm. The latter yields usually better results than the analytical solution, although its iterative nature may be time consuming for large . When solving MDS by means of the majorization algorithm the loss function to be minimised is Kruskal’s stress-1: given a configuration of points in with
[TABLE]
where are the original distances. If is not a proper distance matrix, are called dissimilarities and they may need to be transformed into before the scaling, for instance through a strictly increasing monotonic function such that order is preserved . This case falls under the non-metric MDS methods. Furthermore, unfolding models allow us to deal with non-symmetric matrices (which may be useful if in- and out-going geodesics have to be considered).
The dimension of the Euclidean space to which we map the network is then a free parameter of the network depth. If is very small compared to , the poor quality embedding will affect the depth too. Instead, if is very large, the statistical information of the sample is so diluted in the high dimensional space, that all nodes happen to have the same depth of , i.e. they lie on a convex hull. Take for instance a star, a simple planar graph and the geodesic distance . We may think that should be the right embedding dimension but if we perform a metric MDS without any constraint we end up with a large stress value – since every permutation of nodes different from the star centre are equivalent – and a configuration failing to match our expectations. A better approach is to use a constrained MDS on a 2D-sphere, maybe relaxing also the convergence tolerance.
In general, the most appropriate is not known a-priori and we end up with an embedding for each so that is a free parameter for the depth. First of all, embeddings with “high” stress-1 values should be removed. What is “high” depends on the data. A typically approach is to look for the “legendary statistical elbow” in the stress curve (scree-plot) or to follow Kruskal’s Rule of Thumb **(Kruskal1964*, *)** stating that stress should be less than . Whether possible, it is warmly suggested – see **(deLeeuw2009*, *)** and **(Mair2016*, *)** – to perform some additional goodness-of-fit analysis, like a permutation test to get a p-value associated with the observed stress and diagnostic plots, e.g Stress-per-point plot to see if a subset of points accounts for large values of . As we already pointed out, for the depth spans an increasingly small range since the sample of points becomes more and more sparse in , hence the principle of parsimony plays a role in determining too. Finally, as we will see in the next section there is an interval between and where the depth pattern (consequently the ranking) remains stable so that the PTD centrality score vector can be chosen among a in that interval. With the expression depth pattern we mean the ordering of nodes as a function of one free parameter. A depth pattern plot has the free parameter, e.g. on the x-axis and the values of for each node on the y-axis. This plot enables us to graphically see how the depth range evolves, if the top ranking nodes remain approximately the same (stable pattern) or if the ranking changes considerably, indicating noise in the embedding.
The network depth w.r.t. diffusion distance depends also on and the scree-plot becomes a heatmap representing the stress surface, Fig.5, still, the same considerations apply for , while makes the a multi-resolution centrality measure, as discussed in 2.2. To obtain a parameter-free centrality without having to fix the values for and/or , simply integrate over the parameter space – possibly removing those parameters leading to the worst embeddings – and look at the aggregate network depth. In the case of diffusion embedding one may also consider the average diffusion distance matrix, as in **(DeDomenico2017*, *)**, getting rid of one parameter.
We summarise the main steps the procedure as follows:
Choose a network metric, remembering that the shortest-path distance provides results which are similar to the closeness centrality and that if you choose the diffusion distance the diffusion time plays the role of a scale parameter. Compute the distance matrix (or set of matrices ).
- 1)
Embed the network in , using MDS (either solving the scaling problem analytically or through the majorisation algorithm); these statistical methods are preferred, since they give a feedback on the amount of information preserved/lost in the scaling process. Field-knowledge may suggest a dimension , a-priori. As a rule of thumb, for graphs with more than 100 nodes, avoid , remember that depends on the MDS algorithm one is using.
- 2)
For each space configuration of points , compute Kruskal’s stress function (12). It will be useful for selecting a range of reasonable dimensions . It is not mandatory to evaluate the goodness-of-fit of the embedding, but it guarantess you that the subsequent findings are not the result of chance.
- 3)
For each space configuration of points , compute the depth space , i.e. the network depth centrality vector, by means of equations (8)-(9). If the depth space reduces to just one value, , the dimension is too large, so you can focus on smaller embedding spaces. To rule out values of which are too small, plot the stress-1 values against (scree plot), values larger than 0.2 rarely lead to good results. Additionally you can look at high order depth central regions , if there is a high variability in the nodes belonging to these regions, the depth pattern is surely not stable, so you may think of removing too small dimensions as well.
- 4)
“Stable” depth patterns represent an indicator for good embedding dimensions , where stable means that there are not nodes making big jumps across the depth ranking. In other terms, high order depth regions contain more or less the same nodes (possibly swapping their order inside the region). You can either select a single and have a single depth space or aggregate the depth score vectors, integrating over the (whole or part of) parameter space.
- 5)
Given the vector of depth values, quantiles are easily computed and so you can find depth central regions , while the network median is the node with maximum depth.
3 Applications to Empirical Networks
In this section we apply the network depth to some examples of social, biological and infrastructure networks and compare it with the measures in Tab. 1: degree, eigenvector, closeness, betweenness and distance-weighted fragmentation centrality666keyplayer R package available on CRAN.. As already mentioned we compute only these five centralities, since they are representative of other measures and the goal of our work is not to provide another comparative study on centralities applied to real networks, but to propose a statistically grounded centrality measure. The novelty of our work lies in the approach to the well-studied problem of node importance inside a network: the network depth is a generalisation of statistical depth function to structured data, through network embedding. On the other hand, depths induce multivariate order relations and enable the generalisation of order statistics (median and quantiles) to high dimensional spaces.
3.1 Social Networks
3.1.1 Zachary’s Karate Club.
The first example we propose is the famous Zachary’s Karate Club network **(Zachary1977*, *)**, it is a small () social network where Actors are members of a university karate club and weighted edges represent interactions among them outside the club in a period of three years. It has a modular structure with two main communities, the factions with heads Mr. Hi, the president, and the coach John A, into which the group split after a conflict. The plot in Fig. 5 shows the stress-1, , for embeddings with parameters , which is in general low (stress-1 depends also on the sample size , **(Mair2016*, *)**), with higher values for small . The pattern visible in the heatmap is found also for the other networks we analysed. Diffusion embeddings for short diffusion times tend to have a larger stress value since there are many nodes equally far away from each other according to and these are interchangeable in terms of configuration (similarly to a star graph). As increases decreases, but remember that the sample becomes more and more diluted in high-dimensional spaces.
We then move to analyse the depth patterns plotting the depth value of each node as a function of or . These plots represent a well suited graphical tool to study the centrality range, scores and ranking, their stability and relation with the free parameters. Statistics is known to make a massive use of graphics, in particular our idea of depth pattern plots draws inspiration from forward plots in Forward Search analysis for outliers detection, see **(Atkinson2010*, *)**. The key idea there is to monitor quantities of interest, e.g. test statistics, as the model is fitted to data subsets of increasing size. In our case, we study depth values as space dimension or diffusion time increase.
We can find as a function of , in Fig. 6 For the depth space has a small range , while for it remains stable, with little variations on depth levels. Mr. Hi and John A. are the most central nodes until , after which Actors 20 and 33 gain the second position in the depth ranking. These two nodes have high centrality scores for betweenness and closeness (20) and degree (33). The last Fig. 7 shows the node of the Zachary Karate Club network that has the top score (i.e. the generalised median), according to diffusion distance embedding (and its parameters ) and shortest-path distance embedding with parameter .
3.1.2 2010 Network Scientists Network.
The second social network analysed in this work is the network of Network Scientists from 2010 **(Edler2013*, *)**. It is a co-authorship network, where 522 scholars are linked by weighted edges representing the relation if and only if there is a paper with among the authors. The weight of edge depends on the number of papers co-authored by .
Depth patterns in embeddings depending on and (Fig. 8-9) are, as expected, very different. summarises the information enclosed in the matrix , as closeness centrality. As a matter of fact, if we look at the five nodes with top scores according to closeness – Ravasz, R. Jeong, H. Podani, J. Szathmary, E. and Barabasi A.L. – we already find a strong overlap. The correlation analysis in subsection 3.4 highlights this pattern.
On the other hand, the ranking based on may appear quite counterintuitive unless we have a clear picture of the information summarised by our network depth. Fig. 10, together with the four dimensions topology characterisation of our , shades light on the results: the diffusion distance quantifies how difficult it is that two random walkers generated in two different nodes meet somewhere in the network. In terms of this co-authorship network, a node which is sufficiently near to all others corresponds to a scholar which has a multifaceted co-authoring history. Several blocks are clearly visible in the heatmap Fig. 10, but remember that depths ignore multi-modality, exactly as the usual median.
3.2 Biological Networks
3.2.1 Drosophila’s Connectome
The Drosophila connectome **(Shih2015*, *)** is a directed weighted network with 49 nodes, 43 of which are local processing units (LPUs), while the remaining 6 are interconnecting units. Edge weights represent the strength of total connections in terms of neuronal fibres between neurons inside LPUs. LPUs have their own local interneurons populations (LNs) whose fibres are limited to that region and exchange information with other LPUs via bundled tracts. Interconnecting units lack an LNs population and appear to relay information to other LPUs unmodified by any local network interactions. In **(Shih2015*, *)** the authors show that this has a modular structure with five functional clusters: four of them correspond to sensory modalities and the fifth (called “pre-motor centre”) is the integration centre for visuo-locomotor behaviours, which is important for decision-making. The inter-modular connectors are SPP, DMP, VLP-D, IDFB.
In Fig.11 we show the depth patterns in in-going and out-going geodesic embeddings with . Since the directed shortest-path distance matrix is no more symmetric we get the space configuration of nodes through unfolding **(Cox2000*, *)**. Lines carry a label if the corresponding node belongs to the depth region of order . We can compare the centrality patterns with the ranking based on node polarity, the difference between in- and out-strength; positive and negative values indicate “recievers” and “senders” respectively. Like degree, this is a very local measure, instead the PTD depends on the global distance induced space configuration. Observe that the aggregate depth trimmed region of order contains the following LPUs: PCB, AL, CMP, NOD and vlp-v; while for the deepest LPUs are mb, og, NOD, AMMC, ammc. PCB, protocerebral bridge, and noduli(NOD), belong to the integration center for visuo-locomotor behaviours in all anthropods; antennal lobes (AL) and antennal mechano-sensory and motor center (AMMC) (with their respective counterparts in the opposite hemisphere) are first-layer sensory (resp. for olfaction and hearing) LPUs, while OG, Optic Glomerulus, is one of six interconnecting units in the Drosophila’s brain, which appear to relay information to other LPUs unmodified by any local network interactions **(Shih2015*, *)**. It is thus not surprising that OG/og is among the deepest node both w.r.t. in-coming and out-going connectivity. AMMC is a strong sender according to node polarity, but it also in the downstream of ammc and other senders (PAN/pan, AL/al, OG/og among others) and of LPUs with high degree/strength like DMP/dmp.
A different scenario appears if we look at depth patterns w.r.t. diffusion embeddings in Fig.12a: the top of the depth is quite stable with dmp (Dorsomedial Protocerebrum) being the deepest node for most of the time. If we average over the whole parameter space, so that we do not even need to decide which pair to use, and look at the aggregate the depth trimmed region of level consists of: DMP, FB (Fanshaped Body), IDFP (Inferior Dorsofrontal Protocerebrum), SOG (Subesophageal Ganglion), SPP (Superpenduncular Protocerebrum), VLP-D (Ventrolateral Protocerebrum, Dorsal part), ccp (Caudalcentral Protocerebrum), dmp, idfp, sog, spp, vlp-d, vmp (Ventromedial Protocerebrum). Interestingly there is a large overlap with Shih’s Global Centrality (GC), the result of a consensus among centralities: for each type of measure the top 12 out of 49 nodes (top quartile) earned 1 point and then by summing up one gets the node GC. One significant methodological difference between aggregate and GC is that we do not arbitrarily bestow points, we use sample depth quantiles, getting a continuous measure that can be interpreted in the same way as all other depths.
3.2.2 Protein-protein network
Protein-protein interaction network of the yeast S. cervisiae **(Jeong2001*, *)**. This is a medium size network (1870 nodes, from which 1458 in the largest connected component), edges are undirected and unweighted, while nodes carry metadata on the protein lethality. According with lethality-centrality hypothesis, central nodes are important for cellular functioning. Nodes with highest degree (top 0.5%) are YDL100C (Non-Lethal), YLR423C (Non-Lethal), STE50 (Non-Lethal), SNP1 (Lethal), TEM1 (Unknown), LSM8 (Lethal), SEC17 (Lethal), Nup1 (Unknown).
Fig. 13 shows the depth patterns for . Without a detailed field knowledge it is meaningless to discuss on the importance of these proteins, however from the data we can infer that the protein-protein interaction network is disassortative, which means that Lethal protein are not necessarily connected only to other Lethal proteins. This implies that the spatial distribution of points embedded according to diffusion (or shortest-path distance) does not reflect the Lethality-communities.
3.3 Infrastructure Networks
The Euro Roads infrastructure network **(Subelj2011*, *)** is the international E-road network, located mostly in Europe. It is an undirected network, with nodes representing cities and edges between nodes denoting E-road connections. We focus on its largest connected component, containing (over the total 1177) vertices.
This real network lives in , but as we try to embed it into , solving analytically the classical MDS problem with distance matrix and , the result is poor with an explained variance of 74.9%. This agrees with our expectations, since the shortest-path distance is not equivalent to the Euclidean distance. Using the majorisation approach described in 2.3 and the non-metric MDS, a more appropriate embedding dimension according to stress evaluation is , which yields a stress-1 of 0.038. The cities in the depth region (top 1%) based on are reported in Tab. 2, together with the top 1% of the common centrality measures used in this study.
We also embed the Euro-road network based on diffusion distance, with and . Fig. 14 shows the depth patterns for the network depth in and a subset of diffusion times. We can see a claer shift from “local” to “global” centrality of cities as grows. For small the nodes in the top 0.5% are Le Havre, Eupen, Arlon, Leeds, Tallinn and Paris (this remains true also for other values of ), with a high overlap with the eigenvector centrality. There is, however, a second stack of lines (nodes) with low depth values for small , which gain depth as grows. When the depth central region of level looks very different: the median nodes are Kingston upon Hull and Brussels, followed by Voss, Korczowa, Osnabrück and Olpe. This ranking is more similar to the rankings given by the betweenness, closeness and even .
The similarity between and is a consequence of the sparsity of the network. The diffusion distance between two nodes is small if they are connected by many or by short paths and since the network has a low edge density, the two metrics have similar patterns.
3.4 Correlations Analysis of Centrality Measures
In this subsection we perform a simple correlation analysis, by means of Spearman’s rank correlation coefficients. For three of the previously studied networks and for each pair of centrality measures, we compute the Spearman’s rank correlation coefficient ; additionally a two-sided statistical test of level for , see **(Hollander2013*, *, Sec. 8.5)** for statistical details.
Fig. 15 shows the correlation matrices for the three networks analysed in this paper, which share a common pattern. Indeed, blocks of strongly correlated measures emerge: for different values of parameters and the families and have strong inter-family correlations and weak or even non-significant intra-families correlations. Further, closeness falls generally in the group while degree and eigenvector correlate more with , as expected from the categorisation of centralities using the graph-theoretic framework of centrality measures **(Borgatti2006*, *)**.
Fig. 16 shows an extensive comparison in terms of mean Spearman’s correlation between the network depth in different diffusion embeddings and common centralities, on more than 50 real networks (mostly from KONECT **(KONECT*, *)** repository). Correlations coefficients for which the value for is larger than 0.05 have been set to zero. The correlations do not show clear category- or size-based patterns. Correlations are generally moderate (below 0.7). One network stands out particularly: the interareal cortical network of the macaque **(Markov2013*, *)**.
4 Conclusions
We have shown that it is possible to extend the definition of median to structured data like networks, through a newly defined statistical data depth. This also provides a continuous centrality measure, the network depth, which depends on a network embedding step. This step introduce one parameter – in case of an embedding based on geodesics – or two parameters if we use the diffusion distance. The dimension of the embedding space affects the quality of the network depth, but a reasonable can be selected without much effort, as we have shown at the end of Sec. 2.3 and in the applications. The diffusion time is more than a free-parameter, it is a resolution parameter, it allows us to move from the micro to the macro-scale, underlying locally central nodes, e.g. centres of communities, or community connectors (see Drosophila’s connectome in Sec. 3).
The network depth arises from an unprecedented approach: the definition of the centrality does not follow the definition of the importance a node, it is the application of a pure statistical methodology, the generalisation of order relations through depth functions. For this reason and to prove that the network depth is a network centrality measure, we place it in the graph-theoretical taxonomy of centralities by Borgatti and Everett, theoretically inferring its properties. We have shown that the is a radial measure and hence it looks for a global centre. Furthermore, which distance we choose to evaluate on the network has an important role in determining the distribution of points in space. Therefore, the depth-based node ranking has to be interpreted in light of the metric considered.
In this work we have analysed different social, biological and infrastructural systems to understand if the centrality score induced by the Projected Tukey depth reveals nodes with special or relevant meaning not detected by more traditional centrality measures, such as degree and eigenvector – radial, volume measures –, closeness – a radial, length centrality summarising information given by length of shortest paths –, or betweenness and Borgatti’s fragmentation, two medial measures of centrality focusing on paths passing through each node. When diffusion geometry is used to embed the networks, we find our depth to unveil central nodes with a heterogeneous connectivity across the network. In other words, nodes that, instead of having a strong belonging to a community, are well-mixed inside the network structure.
Our results provide a grounded framework for the definition of median node and contours in complex networks.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1(1) An, W. & Liu, Y.-H. (2016) keyplayer: An R Package for Locating Key Players in Social Networks.. R Journal , 8 (1).
- 2(2) Atkinson, A. C., Riani, M. & Cerioli, A. (2010) The forward search: Theory and data analysis. Journal of the korean statistical society , 39 (2), 117–134.
- 3(3) Borgatti, S. P. (2003) The Key Player Problem. 241-252 in Dynamic Social Network Modeling and Analysis: Workshop Summary and Papers, R. Breiger, K. Carley, P. Pattison. .
- 4(4) Borgatti, S. P. & Everett, M. G. (2006) A Graph-theoretic perspective on centrality. Social Networks , 28 (4), 466–484.
- 5(5) Coifman, R. R., Lafon, S., Lee, A. B., Maggioni, M., Nadler, B., Warner, F. & Zucker, S. W. (2005) Geometric diffusions as a tool for harmonic analysis and structure definition of data: diffusion maps.. Proceedings of the National Academy of Sciences of the United States of America , 102 (21), 7426–31.
- 6(6) Cox, T. F. & Cox, M. A. (2000) Multidimensional scaling . Chapman and hall/CRC.
- 7(7) De Domenico, M. (2017) Diffusion geometry unravels the emergence of functional clusters in collective phenomena. Physical review letters , 118 (16), 168301.
- 8(8) de Leeuw, J. & Mair, P. (2009) Multidimensional Scaling Using Majorization: SMACOF in R. Journal of Statistical Software, Articles , 31 (3), 1–30.
