TL;DR
This paper introduces a deep learning-based method for reducing metal artifacts in CT images by completing missing projection data, improving image quality efficiently for security applications.
Contribution
The paper presents a novel projection domain deep learning approach for metal artifact reduction, enabling effective and practical integration into existing CT workflows.
Findings
Effective artifact reduction on simulated data
Successful application to real CT images
Efficient end-to-end algorithm
Abstract
Filtered back projection (FBP) is the most widely used method for image reconstruction in X-ray computed tomography (CT) scanners. The presence of hyper-dense materials in a scene, such as metals, can strongly attenuate X-rays, producing severe streaking artifacts in the reconstruction. These metal artifacts can greatly limit subsequent object delineation and information extraction from the images, restricting their diagnostic value. This problem is particularly acute in the security domain, where there is great heterogeneity in the objects that can appear in a scene, highly accurate decisions must be made quickly. The standard practical approaches to reducing metal artifacts in CT imagery are either simplistic non-adaptive interpolation-based projection data completion methods or direct image post-processing methods. These standard approaches have had limited success. Motivated…
Click any figure to enlarge with its caption.
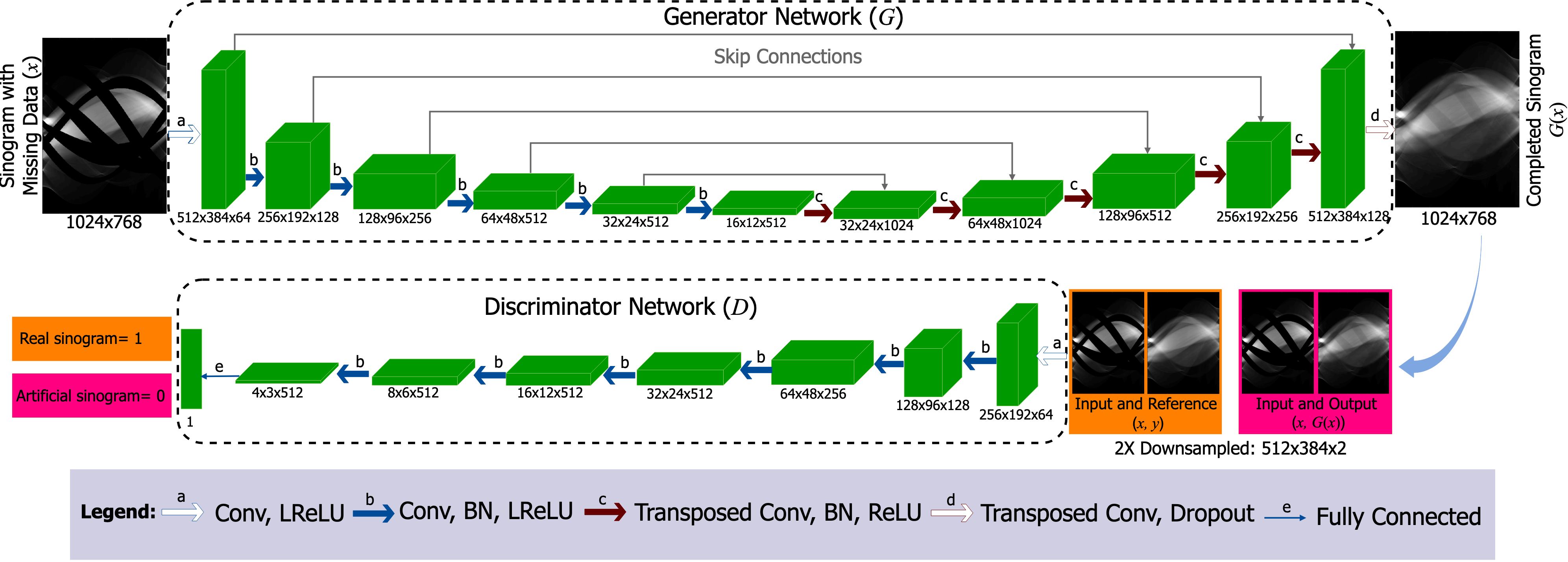 Figure 1
Figure 1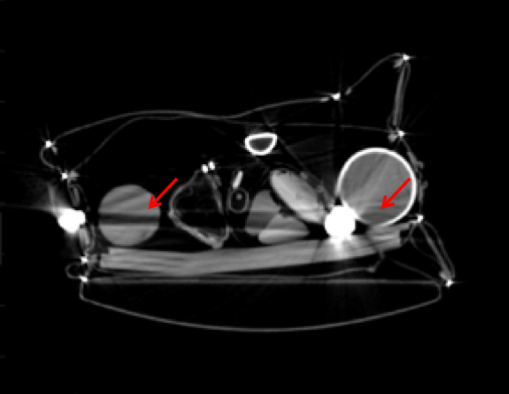 Figure 2
Figure 2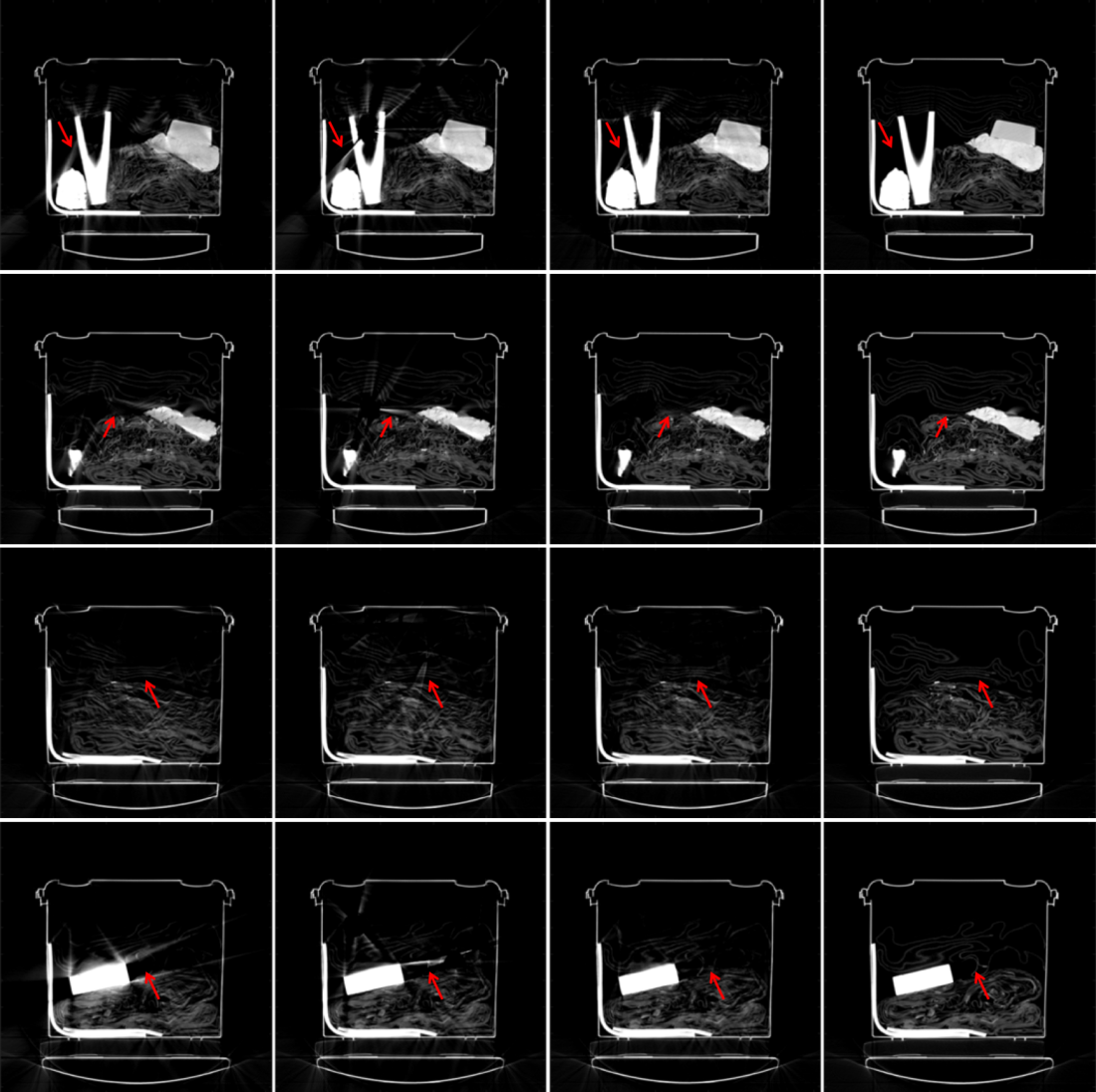 Figure 3
Figure 3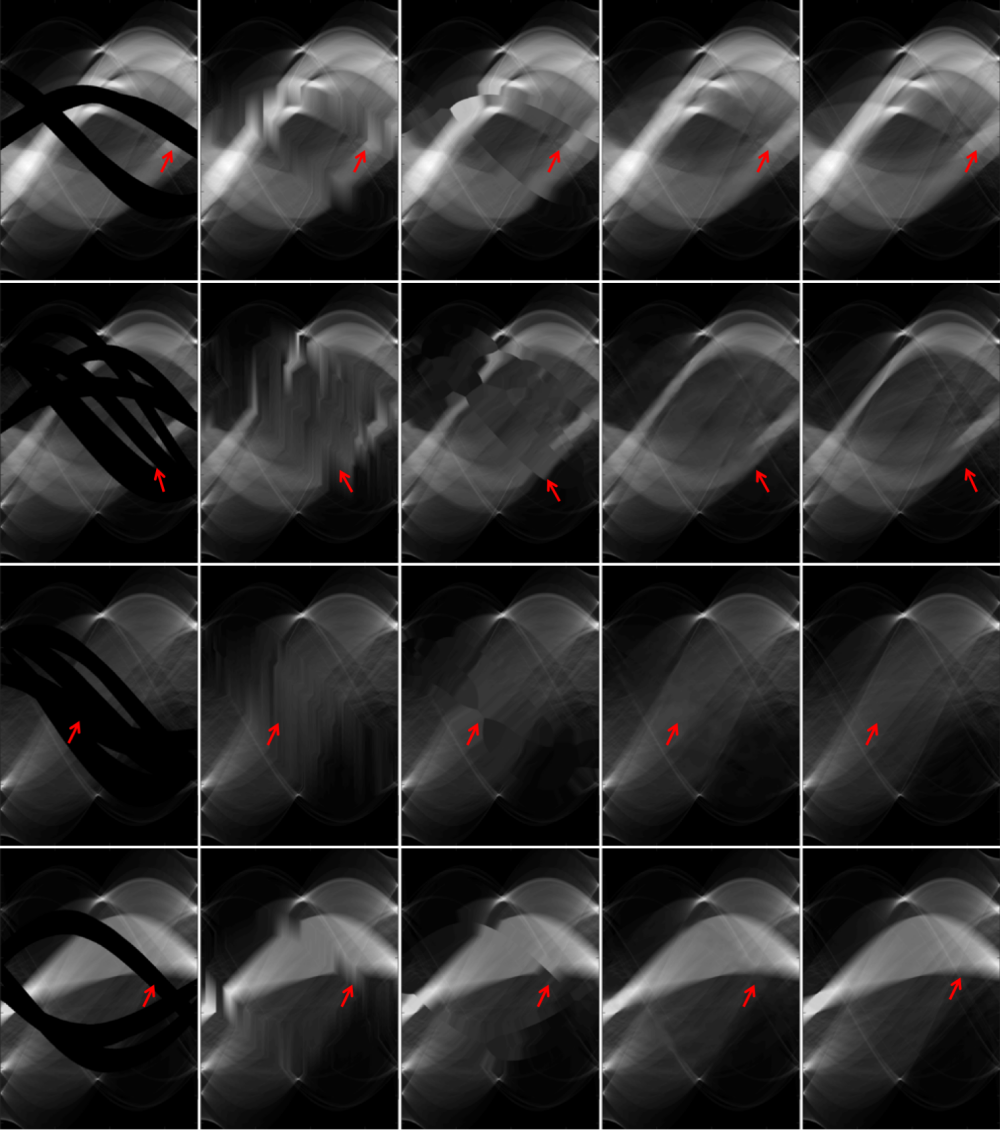 Figure 4
Figure 4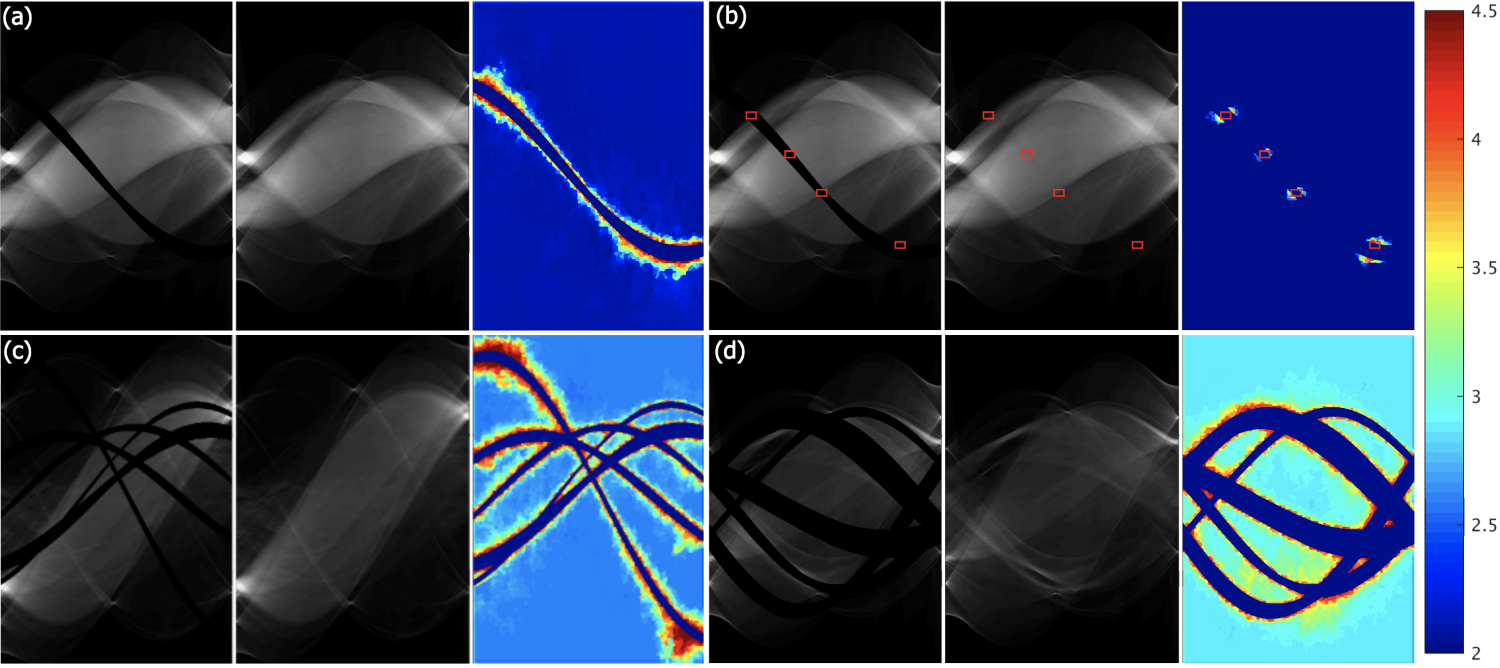 Figure 5
Figure 5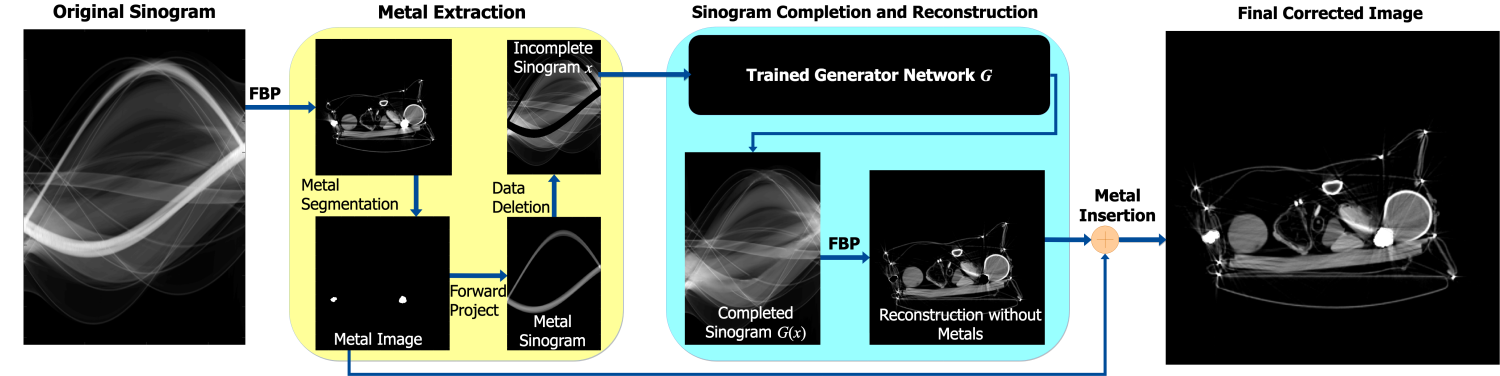 Figure 6
Figure 6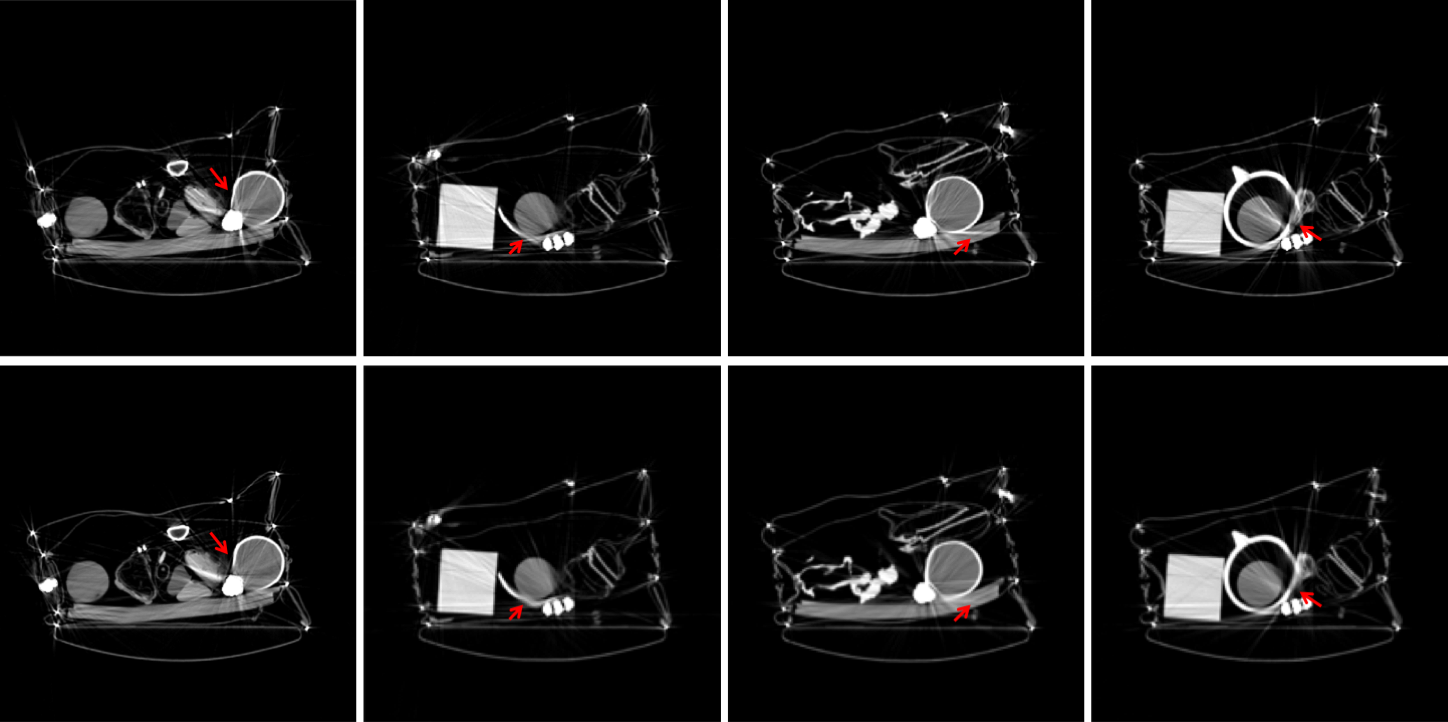 Figure 7
Figure 7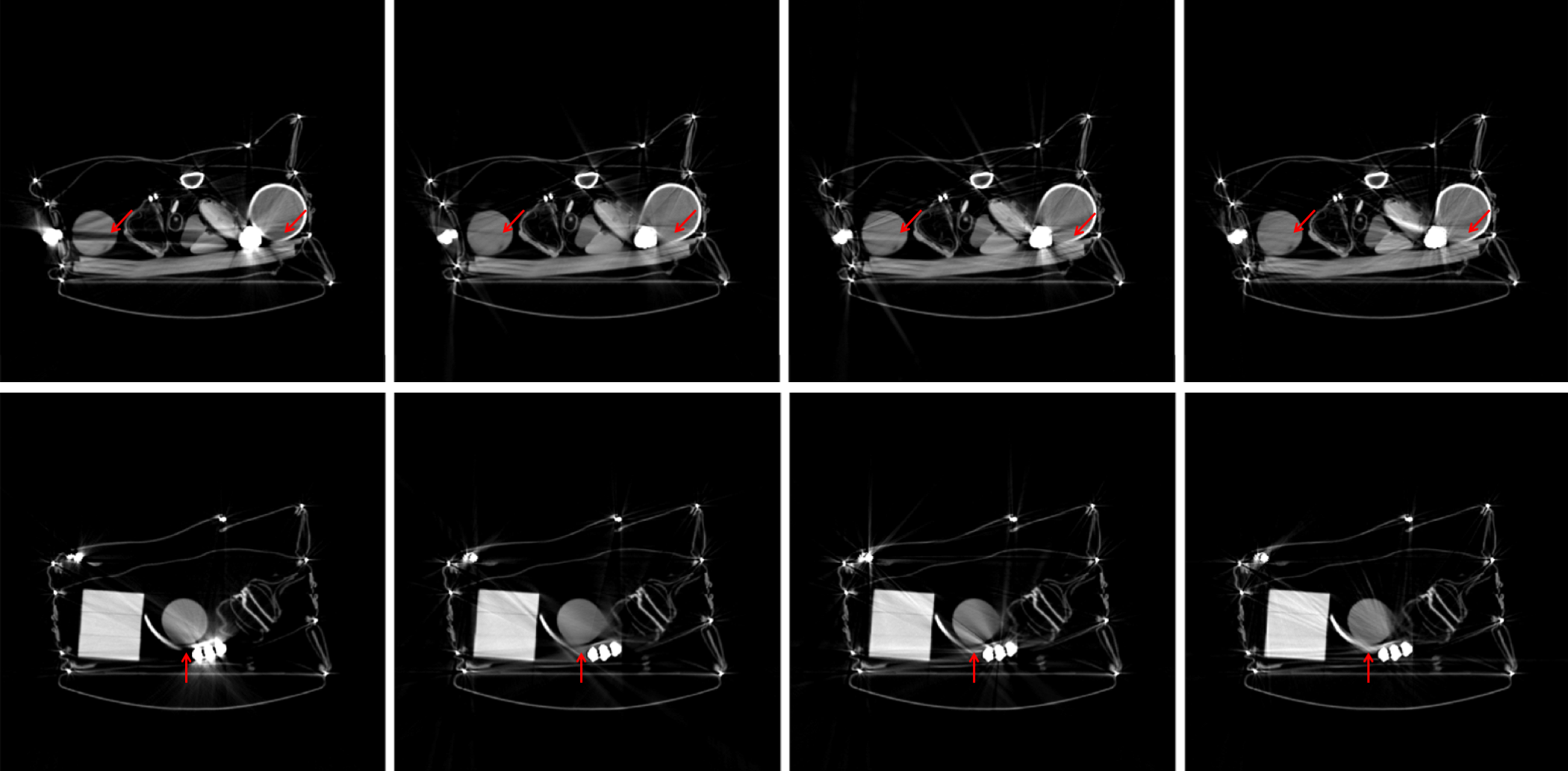 Figure 8
Figure 8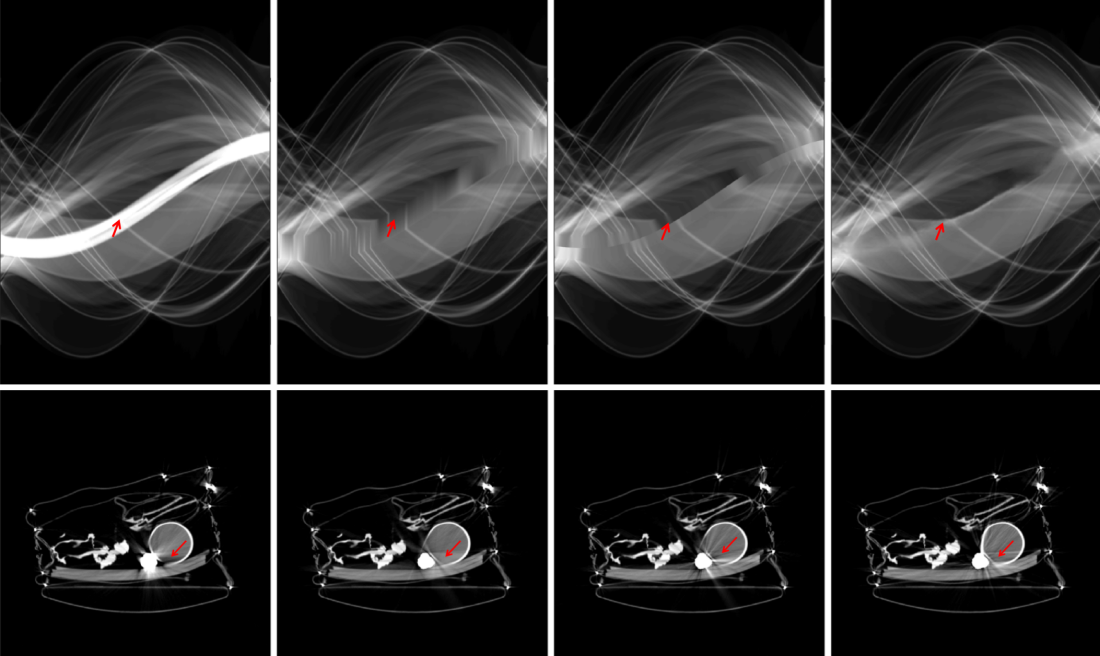 Figure 9
Figure 9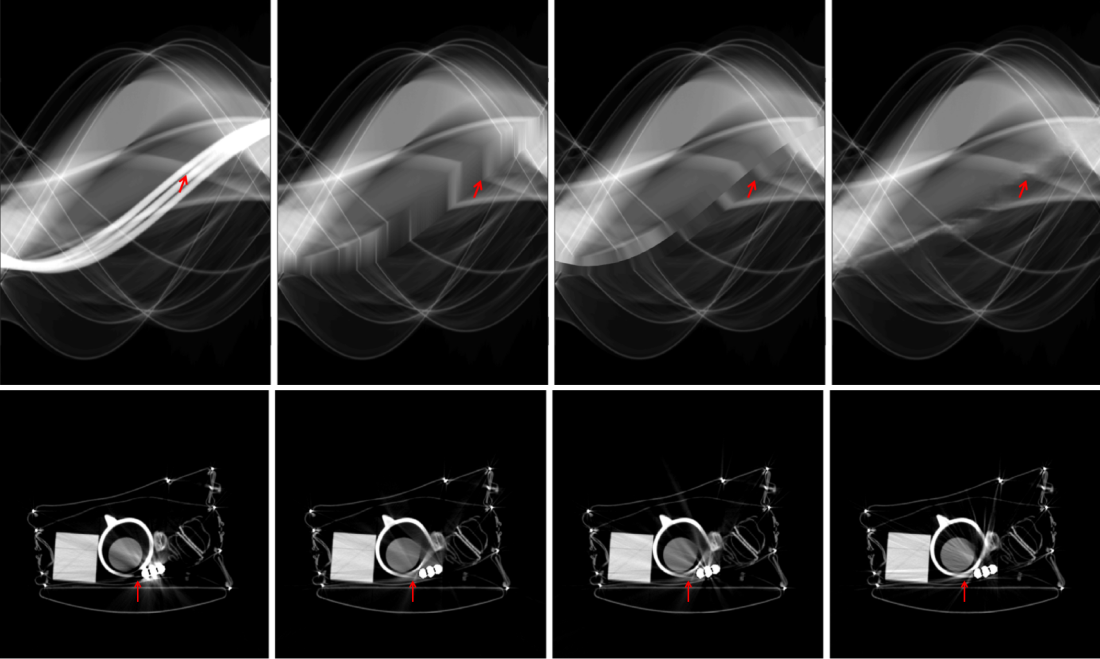 Figure 10
Figure 10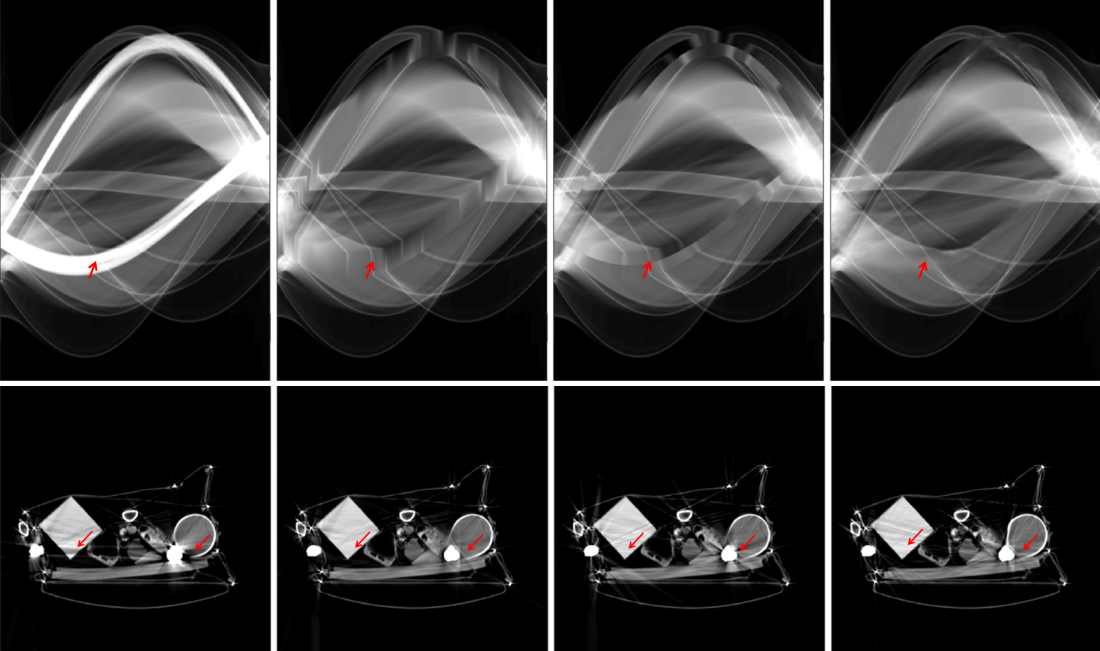 Figure 11
Figure 11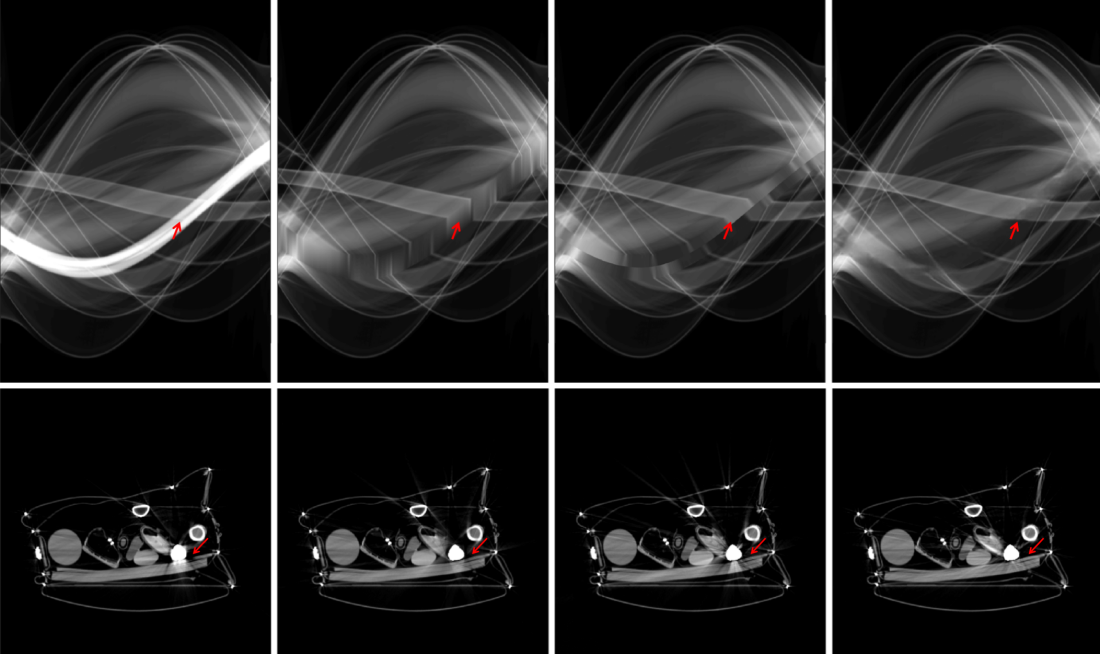 Figure 12
Figure 12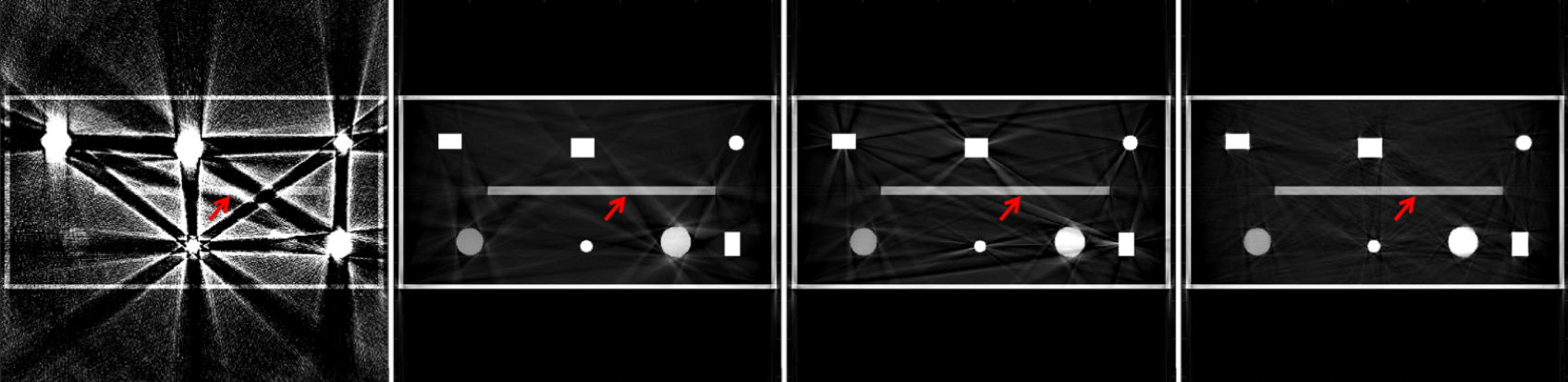 Figure 13
Figure 13 Figure 14
Figure 14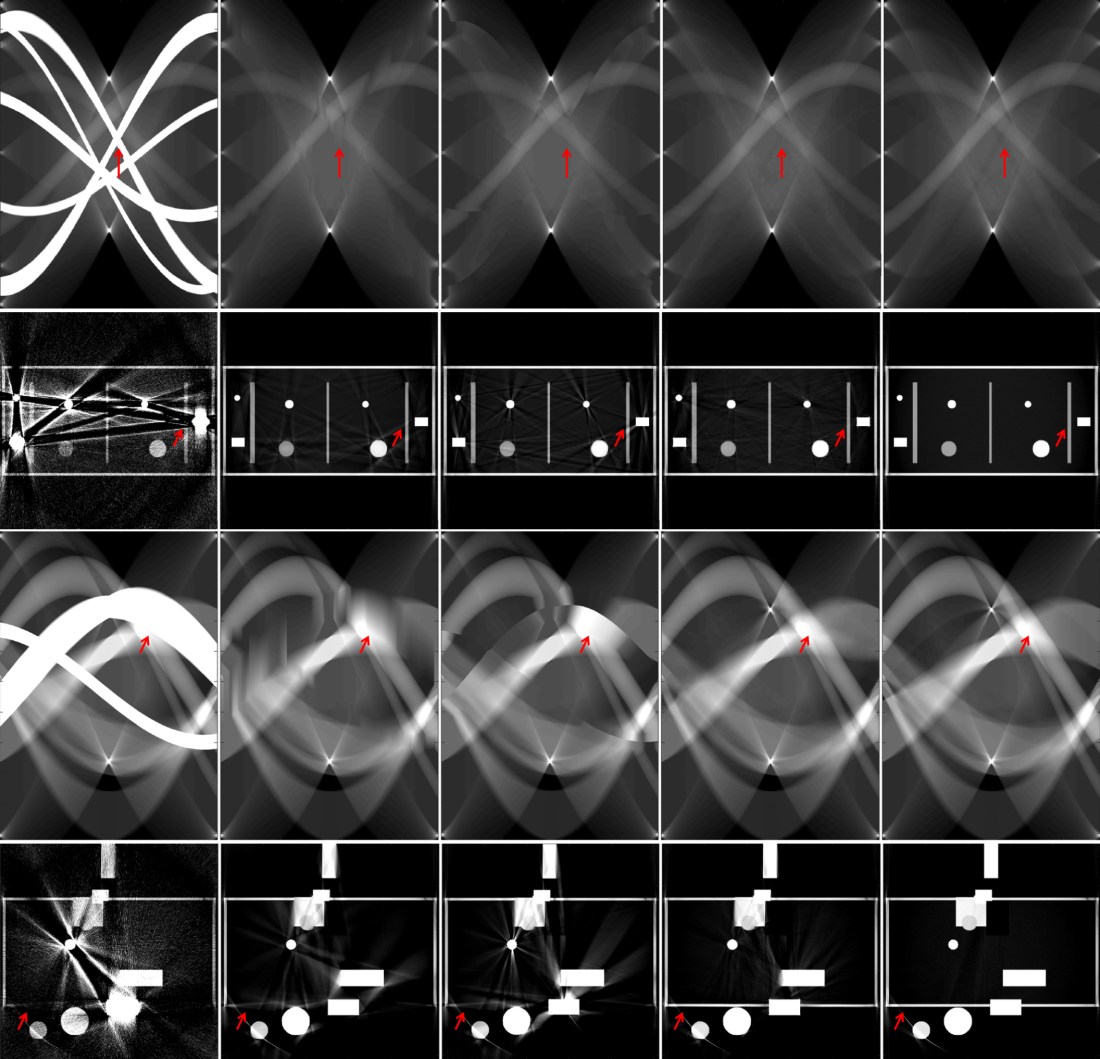 Figure 15
Figure 15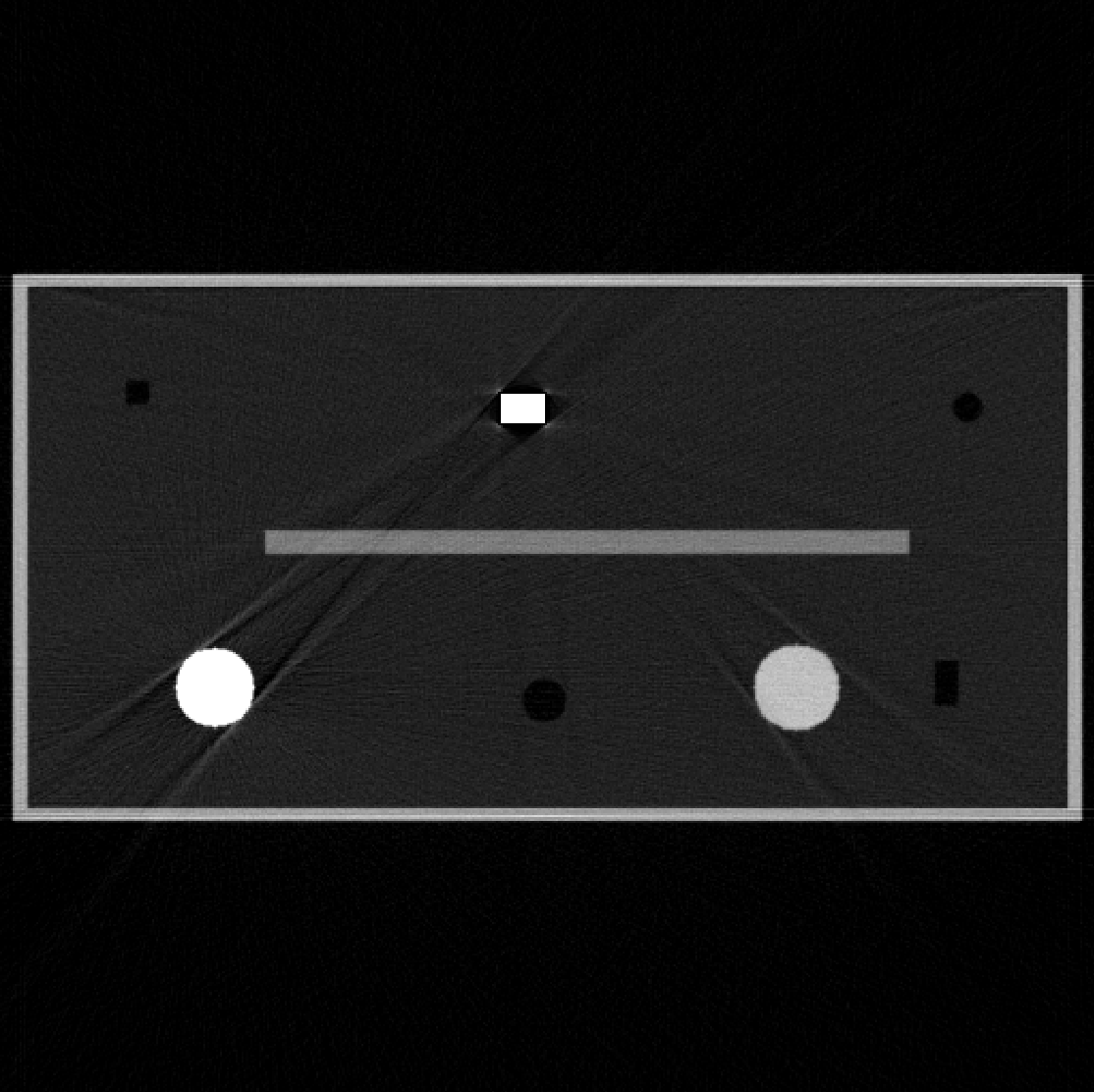 Figure 16
Figure 16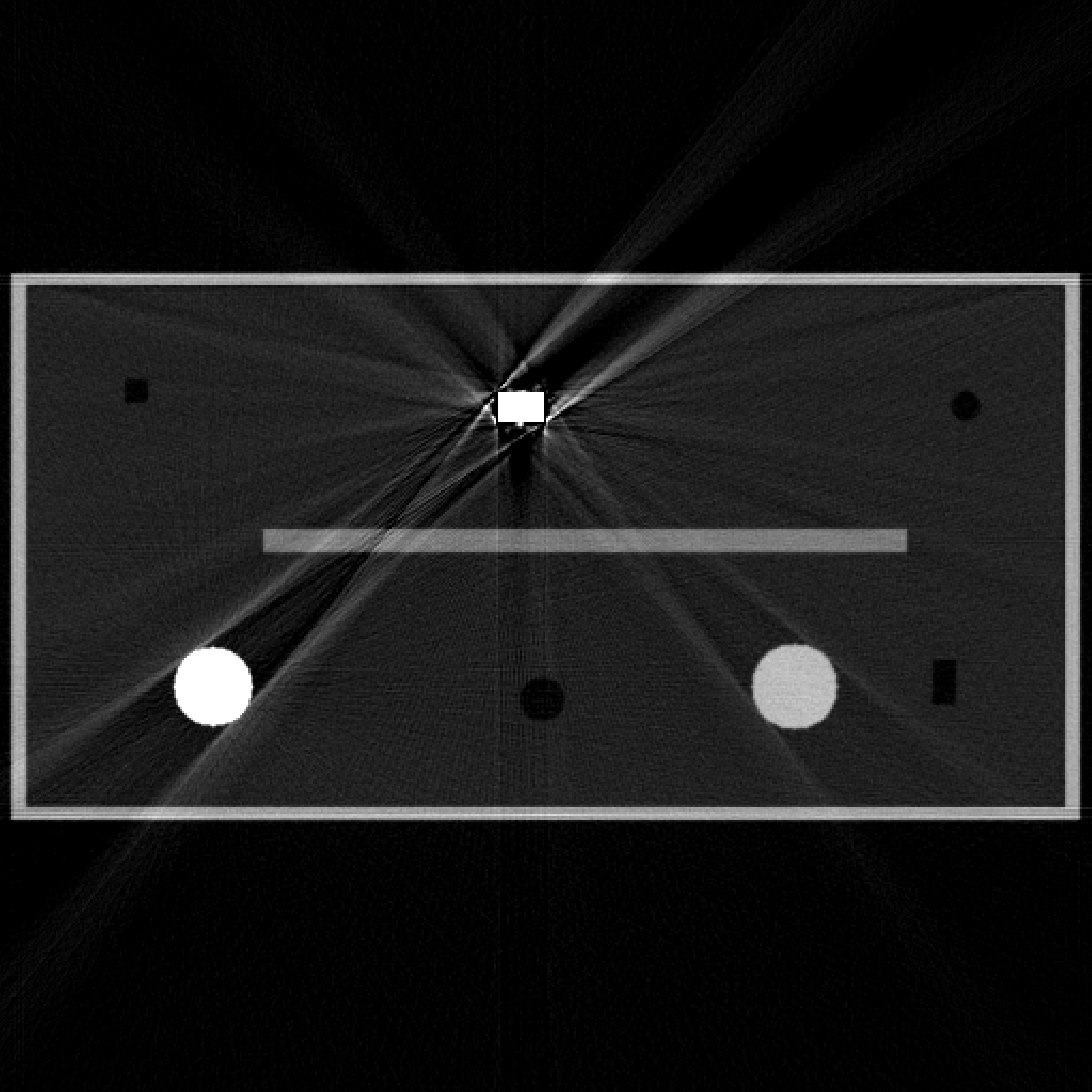 Figure 17
Figure 17 Figure 18
Figure 18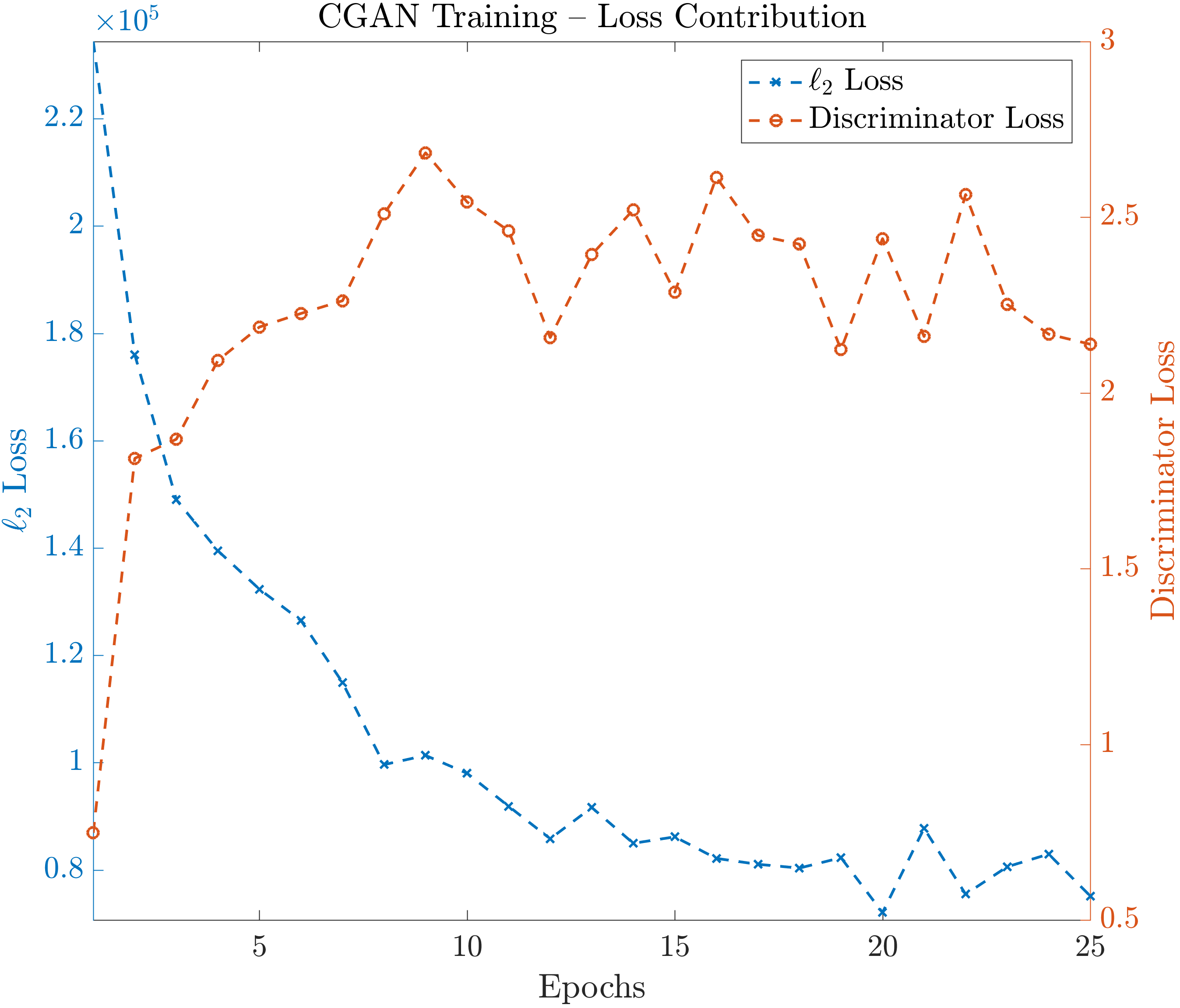 Figure 19
Figure 19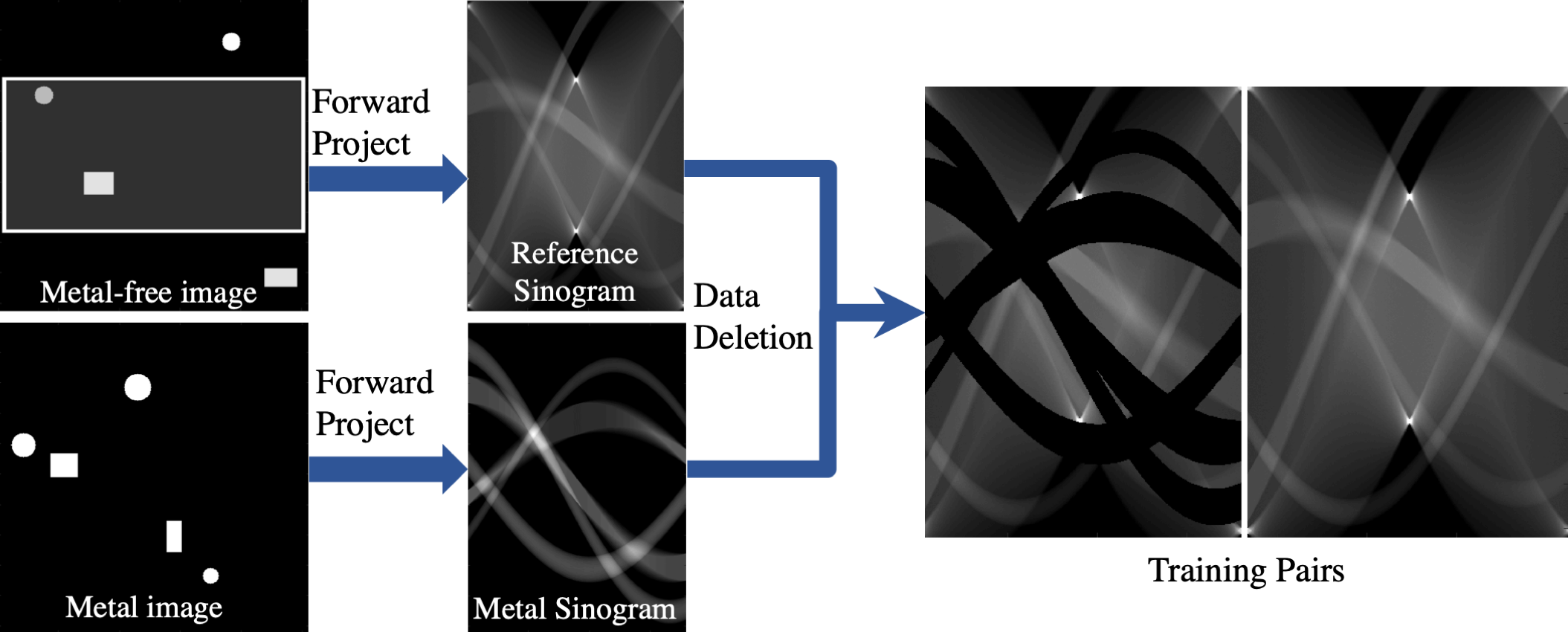 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22| LI-MAR | ||||
|---|---|---|---|---|
| WNN-MAR | ||||
| Deep-MAR | ||||
| Deep-MAR | ||||
| (Transfer Learning) | ||||
| Simulated | - | |||
| Real |
| Uncorrected | LI-MAR | WNN-MAR | Deep-MAR | |
|---|---|---|---|---|
| MSE | ||||
| SSIM | ||||
| PSNR |
| LI-MAR | ||||
|---|---|---|---|---|
| WNN-MAR | ||||
| Deep-MAR | ||||
| Deep-MAR | ||||
| (Transfer Learning) | ||||
| MSE | ||||
| SSIM | ||||
| PSNR |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Fast Enhanced CT Metal Artifact Reduction using Data Domain Deep Learning
Muhammad Usman Ghani, W. Clem Karl This material is based upon work supported by the U.S. Department of Homeland Security, Science and Technology Directorate, Office of University Programs, under Grant Award 2013-ST-061-ED0001. The views and conclusions contained in this document are those of the authors and should not be interpreted as necessarily representing the official policies, either expressed or implied, of the U.S. Department of Homeland Security.M. U. Ghani and W. C. Karl are with the Department of Electrical and Computer Engineering, Boston University, Boston, MA, 02215 USA (e-mail: {mughani, wckarl}@bu.edu).This paper has supplementary downloadable material available at http://ieeexplore.ieee.org., provided by the author. The material includes additional experimental results and information. This material is 10.3 MB in size.
Abstract
Filtered back projection (FBP) is the most widely used method for image reconstruction in X-ray computed tomography (CT) scanners, and can produce excellent images in many cases. However, the presence of dense materials, such as metals, can strongly attenuate or even completely block X-rays, producing severe streaking artifacts in the FBP reconstruction. These metal artifacts can greatly limit subsequent object delineation and information extraction from the images, restricting their diagnostic value. This problem is particularly acute in the security domain, where there is great heterogeneity in the objects that can appear in a scene, highly accurate decisions must be made quickly, and processing time is highly constrained. The standard practical approaches to reducing metal artifacts in CT imagery are either simplistic non-adaptive interpolation-based projection data completion methods or direct image post-processing methods. These standard approaches have had limited success. Motivated primarily by security applications, we present a new deep-learning-based metal artifact reduction approach that tackles the problem in the projection data domain. We treat the projection data corresponding to dense, metal objects as missing data and train an adversarial deep network to complete the missing data directly in the projection domain. The subsequent complete projection data is then used with conventional FBP to reconstruct an image intended to be free of artifacts. This new approach results in an end-to-end metal artifact reduction algorithm that is computationally efficient textcolorredand therefore practical and fits well into existing CT workflows allowing easy adoption in existing scanners. Training deep networks can be challenging, and another contribution of our work is to demonstrate that training data generated using an accurate X-ray simulation can be used to successfully train the deep network, when combined with transfer learning using limited real data sets. We demonstrate the effectiveness and potential of our algorithm on simulated and real examples.
Index Terms:
Computed tomography, Metal artifact reduction, Sinogram completion, Deep learning.
I Introduction
Metal artifacts are common problems in conventional computed tomographic (CT) scanners using poly-energetic -ray sources coupled with energy integrating detectors. When there is a dense metallic object in the field of view, it highly attenuates or completely blocks the -rays for the corresponding detector locations. When these data are used by the conventional filtered back projection (FBP) method, the resulting image exhibits severe streaking artifacts and inaccurate CT numbers, as illustrated in Figure 1. Such streaking then leads to errors in material or tissue type identification and object segmentations that can severely degrade automated threat recognition in security settings or clinical diagnosis in medical settings. Boas *et al. *[1] reported of medical scans in their study were subject to metal artifacts. The problem is worse in security applications, where metallic objects appear in many stream of commerce items [2, 3]. Thus, metal artifact reduction (MAR) is an important problem in CT imaging.
Motivated by the security application, this paper aims to reduce metal artifacts in CT images by applying deep learning (DL) directly in the projection-domain, prior to image formation. Unlike typical image post-processing approaches, by introducing learning in the projection data domain we aim to avoid the creation of artifacts altogether. Additionally, in our approach, metal-contaminated data is completely removed, therefore the type of metal is not critical. This approach also enables our method to use the conventional and efficient FBP approach for image reconstruction, which is fast and already implemented in most of the CT systems available today. We delete the metal-contaminated projection data and train a conditional generative adversarial network (CGAN) to perform projection data completion. The resulting “enhanced” projection data is subsequently used with the FBP method to reconstruct the CT image. This new deep-learning-based MAR (Deep-MAR) approach results in an end-to-end framework that is computationally efficient and tractable, and which fits well into existing CT workflows, allowing easy adoption in existing scanners. In this initial work, we focus on -dimensional (planar) problems. A preliminary version of our learning-based sinogram completion approach was presented in [4] for sparse-view tomography.
I-A Contributions
I-A1 Deep-MAR framework
The main contribution in this work is the new Deep-MAR framework that uses state of the art deep learning (DL) methods based on convolutional neural networks (CNNs) to complete projection data in a tractable and computationally efficient way.
I-A2 CGAN-based sinogram completion
The second contribution of this work is the application of state-of-the-art conditional generalized adversarial networks (CGANs) for sinogram completion. CGANs have shown incredible power and generalizability in a variety of image processing problems and yet are relatively new to inverse problems in general and CT in particular. In order to make our work reproducible, simulated test examples, test codes, and trained models have been publicly made available111https://codeocean.com/capsule/0510438.
I-A3 Network training with simulated data and transfer learning
The availability of adequate training data is a fundamental DL challenge. This challenge is especially acute for security related CT data, where the universe of possible scenes is very large and thus limits what can be obtained through direct physical experiment. The third contribution of this work is demonstrating the use of a large set of simulated data based on accurate -ray physics coupled with transfer learning exploiting a more limited amount of real experimental data. We have made the simulation setup and simulated data prepared for this work publicly available222https://github.com/mughanibu/DeepMAR/. This will motivate and help researchers to develop new machine-learning-based methods to improve CT image reconstruction and analysis.
I-A4 Pathway to generating real training datasets
The fourth contribution of this work is the ability to generate real projection-domain training data pairs matched to our framework. By casting the learning problem as one of sinogram completion rather than direct correction we focus the deep network on the task of missing data generation. This focus means the network does not need to handle all the different possible types of metal that can appear in a sinogram, just the lower-dimensional geometric missing-data configurations. As a consequence, our network only needs matched pairs of sinograms with missing and corresponding complete (but non-metal) data for training. This structure makes it possible to generate additional real-data physical examples to train the DL-based projection-domain MAR method from existing scene data without metal objects through simple sinogram data deletion, a much easier task.
I-B Prior-Work
Existing MAR algorithms can be grouped into three categories: Model-based iterative reconstruction (MBIR-MAR), image-domain MAR (ID-MAR), and projection-domain data completion (PD-MAR). MBIR-MAR methods incorporate a physically derived observation model together with appropriate image-domain priors in an iteratively-solved optimization problem [5, 6, 7, 8, 9, 3, 10]. MBIR methods can produce excellent results and are a principled way of incorporating prior information. Unfortunately, they are typically computationally expensive, requiring repeated reconstruction and forward projection in an iterative algorithm. This computational cost has unfortunately limited their practical impact to date, especially in security applications where throughput is important.
Image-domain MAR (ID-MAR) methods rely on image-processing techniques as a post-processing strategy to reduce streaks in the reconstructions. ID-MAR methods first reconstruct images which contain unwanted artifacts, and then attempt to correct these artifact-filled images. The problem with this strategy is that once important image structure is lost to artifacts, it can be very difficult to recover it effectively. In the medical context, Soltanian-Zadeh *et al. *[11] estimate streaks by subtracting a low-pass-filtered version of an image from itself and then thresholding the difference image. Streaks are removed by subtracting this estimate from the original image. This technique involves an ad-hoc thresholding step and does not attempt to recover structure lost in the streak areas. In the security context, Karimi *et al. *[12] estimated streaks by computing the difference of penalized least squares (PLS) and penalized weighted least squares (PWLS) reconstructions where metal-contaminated projections are down-weighted and the estimated streaks are later removed from the original reconstruction using subtraction. In the medical context, Gjesteby *et al. *[13] recently proposed coupling conventional normalized MAR (NMAR) with a convolutional neural network. Their method attempts to learn a mapping from the NMAR image to an artifact-free image, with the aim of eliminating the residual artifacts of the NMAR method. Training was done on phantom images with artificially inserted metal objects. The data used appeared limited to slices of a single case, with slices held out for testing. Extending the approach to incorporate more general real data would appear challenging, since obtaining matched image pairs with and without various metal materials would be difficult. Since the nature of the artifacts will change with the nature of the metal in the scene, it would seem that the training set would need to cover the range of metal materials anticipated in addition to the configurational variability, which would be difficult to achieve in the security context.
PD-MAR approaches aim to replace the metal-corrupted projection data with data obtained using neighboring information. These methods basically treat metal-corrupted projection data as missing data and attempt to complete these projections. Kalender *et al. *[14] proposed a simple approach to replace the metal-corrupted data using the one-dimensional linear interpolation (LI) of neighboring detector channels. This approach is by far the most common MAR scheme and is considered a benchmark [15]. However, its performance deteriorates as the size and number of metal objects increases. In attempting to ameliorate the original metal streaking it can also introduce new streaking artifacts, as can be seen in the results in Section V. In an attempt to improve on the LI method, Mahnken *et al. *[16] proposed an extended, two-dimensional interpolation method that replaces the metal-corrupted projection data with a weighted sum of -nearest neighbor data points. Rivière *et al. *[17] proposed a statistical objective function-based projection data restoration method that iteratively corrects for data and model mismatch. The method is not focused on data completion or metal artifacts and can be computationally expensive.
NMAR [18] is yet another PD-MAR algorithm that relies on the presence of a prior image similar to the one of interest and combines this prior with a simple interpolation scheme. Zhang *et al. *[19] recently proposed a similar approach, in which a prior image is estimated using a trained CNN. Gjestsby *et al. *[20] trained a CNN to learn mapping from NMAR sinogram to metal-free sinogram. These approaches rely heavily on the prior image and their performance degrades if an appropriately matched prior image is not available. Such prior image-based correction methods are particularly problematic for security scenarios because a good prior image is typically not available due to the high variability of objects and materials present in such scenes.
Claus *et al. *[21] recently proposed a learning-based PD-MAR approach. They trained a fully connected neural network to perform interpolation of missing data in the sinogram domain, and is thus similar in focus to the current work. Their method applies to a highly constrained problem with only a single metallic object of fixed and known size placed at the very center of the field of view. Since the network is trained for this very constrained situation, it is not clear how this method could be extended to realistic scenarios with multiple metal objects placed at arbitrary locations. In addition, its reliance on a fully connected network severely limits scaling to practical problem sizes. Overall, while there has been initial work aimed at applying learning in the CT data domain, these existing works have been limited to small, toy examples and/or highly constrained scenarios not representative of real applications.
Anirudh *et al. *[22] proposed an implicit sinogram completion method for limited angle CT application. In contrast to our approach, their method consists of a network that learns a mapping from incomplete projection data to a final complete-data image. They demonstrated that their approach produces better reconstructions and segmentations using incomplete data as compared to conventional limited angle CT methods.
Learning methods based on CNNs have had impact in a variety of applications. CNNs have demonstrated impressive performance on various image restoration tasks, including image super-resolution [23], image denoising [24], and artifact reduction [25]. However, training CNNs with a mean-square-error loss function has been shown to result in over-smoothed images [26, 27]. Adversarial training is an elegant strategy to train neural networks [28] and Isola *et al. *[26] suggest that a traditional loss coupled with an adversarial loss is a better overall loss function for image-to-image translation tasks. They proposed an approach called a Conditional Generalized Adversarial Network (CGAN) for these tasks. A CGAN consists of two networks: a generator network that learns to perform image-to-image translation, and a discriminator network that is trained to discriminate artificial from true images. The discriminator network is used as an adversarial loss for training the generator network, which forces the generator to be better and better at its job in order to fool the discriminator. We use generator and discriminator network architectures that are inspired from Isola *et al. *[26]. Different CNNs have already been successfully applied to perform missing data replacement or completion in the image domain [26, 29, 30, 31]. However, using CNNs for sinogram completion amounts to learning sinogram-to-sinogram translation, which is a different task.
The success of CNNs depends upon successful learning of internal representations, which typically requires large datasets. This need poses a major challenge for the application of CNNs to many areas where access to large datasets is not possible due to privacy or security concerns or the need for highly skilled labor to provide ground truth annotations, e.g., medical imaging, and especially security applications. A recent trend in these areas is to use transfer learning [32]. In this work, we investigate the use of transfer learning in the security context by pre-training the deep network using a large simulated dataset and then fine-tuning the network on a modestly sized real dataset.
II Learning-Based MAR Approach
In this paper, we propose a framework we term Deep-MAR to reduce metal artifacts in CT images using adversarial deep learning to perform completion of missing projection data in the sinogram domain (i.e. sinogram completion). The Deep-MAR framework is motivated by and focused on reducing the effects of metal in checkpoint security imagery.
II-A Deep-MAR Algorithm
The major steps of our Deep-MAR framework are presented in Figure 2. There are three major steps: i) identification and suppression of metal-contaminated projection data, ii) CGAN based sinogram completion, and iii) efficient FBP image reconstruction and reinsertion of metal objects back into the reconstructed image.
In order to identify the metal-contaminated projection data a conventional FBP reconstruction using the original sinogram is first generated. Thresholding followed by morphological operations are then used to segment the metallic objects in the image, which are forward projected to generate a mask, , in the sinogram domain corresponding to the metal traces. This mask is made slightly larger than the original thresholding to be sure to remove all the metal. The metal-contaminated projection data is then deleted from the original sinogram. Similar metal segmentation methods have been used in many of the MAR approaches [16, 18, 33, 12]. One could potentially use more sophisticated metal segmentation approaches, for instance a DL-based approach for object segmentation [34].
II-B Learning-Based Sinogram Projection Completion
The heart of the Deep-MAR framework is a state of the art CGAN, which is used to perform the sinogram completion task. A CGAN is composed of two distinct networks: a generator network and a discriminator network . The two networks are trained by optimizing an objective function based on a mini-max game [26, 28]. The overall mini-max objective function we use is given by:
[TABLE]
where, and represent input and ground truth pairs of incomplete-data and true complete-data sinograms, respectively; is the estimated complete-data sinogram produced by the generator; defines expectation over data density approximated by training data pairs and , denotes the discriminator network, and is a hyper-parameter used to control the balance between the two terms in the expression. The inclusion of a discriminator loss was seen to improve the overall result relative to an only loss. In the Supplementary Material, we provide more detail on the value of the and discriminator loss terms to the overall formulation.
In the optimization (1) the networks and act as adversaries – that is, attempts to make perfect sinograms while attempts to detect fakes. The first term in the objective captures this interaction through an adversarial loss between and . This loss is given by:
[TABLE]
were, defines expectation over incomplete data density, approximated by averaging over input training data samples . The presence of this loss forces the network to improve its discrimination ability and thus also forces the generator network to become better and better at completing sinograms. In other image processing tasks, such an adversarial approach has been shown to produce more robust and higher performance generator networks . The second term in the optimization (1) is the traditional loss associated with fit to the training data. In this case we use the loss because our initial experiments indicated that an loss performs better for sinogram completion, as compared to choices such as the loss.
The internal structure of the coupled generator and discriminator network architectures are presented in Figure 3. Convolutional kernels of size with a stride of are used at each layer for both the generator and discriminator networks. The generator network, , has a modified U-Net architecture with a fully convolutional architecture. Instead of using max-pooling layers for down-sampling, two-pixel strided convolutions are used. For up-sampling, transposed convolutions with two-pixel strides are used. Overall down-sampling and up-sampling layers were chosen. Additionally, there are skip connections between each layer and , where is the total number of layers. The skip connection at each layer merely concatenates outputs at layer to layer . Using stride-2 convolutions result in sub-sampling and significantly larger practical effective receptive field (ERF) as compared to stride-1 convolutions [35]. The theoretical ERF grows with the number of layers – down-sampling and up-sampling layers result in a theoretical ERF of pixels [36], so each estimate could potentially use information from very large area of the input sinogram. Kernel size selection is also guided by the theoretical ERF in that using smaller kernels would require more layers to achieve a desired ERF and larger kernels would result in many more learning parameters needing estimation. Empirical testing showed that convolutional kernels with a shallower architecture perform better than convolutional kernels with a deeper architecture. Dropout is used in the last layer to avoid over-fitting. It is used after all batch-normalization (BN) layers as suggested by Li *et al. *[37] since dropout results in variance shift when applied before BN.
The discriminator, , is based on the full sinogram image, instead of just patches. Given a ground truth or network output sinogram conditioned on the input incomplete sinogram, our discriminator network classifies the full sinogram as real or fake. The reason behind using a full-sinogram discriminator is that missing data follows sinusoidal structure, which would not be possible to accurately capture using a patch-based discriminator. Additionally, the network is trained to perform non-blind sinogram completion. The missing data are the metal-contaminated data points in sinogram, which are masked before the sinogram is input to the generator network. By using mask-specific sinogram completion our loss function is focused on the areas of most interest – where the data is missing. The generator network output is given by: , where, is the output of the last layer of the generator network, is the metal mask, and denotes element-wise multiplication. This choice retains non-metal sinogram data as is, and uses the deep network to replace only the metal traces. We use downsampled sinograms for discriminator () to speedup the training procedure.
III Network Training
A major challenge in the use of deep network architectures is having sufficient data to allow robust training of the network. In many computer vision and image processing tasks there is access to abundant samples of training data (e.g. ImageNet [38], which contains over million images). In contrast, in the security domain there is a great diversity of possible objects in a scene, yet the amount of physical CT data available for training is severely limited. To address this limitation we generated a training set for sinogram completion using physically accurate -ray simulation tools. After initial training, our networks are then refined with available physical data through transfer learning. Areas without metal are considered background (air) in this work – that is, the target replacement value for metal regions is background material and, conversely, only locations with background material are considered for virtually embedding metals in real-data. This approach makes the problem more tractable since the network can focus on a smaller space of possibilities.
III-A Simulated Training Data Generation
Most conventional CT scanners use a poly-energetic -ray source coupled with energy integrating detectors. We can accurately model the data obtained from such scanners as a sum of mono-energetic sinograms weighted by the corresponding relative strength of the source spectrum. The resulting projection output can thus be well modeled as:
[TABLE]
where is the relative -ray source intensity at energy , obtained from the energy-dependent scanner source weighting function at energy and scaled by the overall -ray source intensity or blank scan factor, . The sinogram contribution at energy for ray-path corresponding to the line is denoted by and is obtained from the Beer-Lambert law using the energy-dependent scene attenuation coefficient at location and energy integrated over the associated ray path. Note that the exponent in the Beer-Lambert expression is a line integral projection, and is approximated by discretizing the integral using standard methods. In this work we use a common ray-based projector model [9], though other models are certainly possible (e.g. distance driven projection, Fourier methods, etc.).
The projection data contributions are degraded by data-dependent and electronic noise. The data-dependent variability follows a Poisson distribution with mean corresponding to . The electronic noise is modeled as Gaussian zero-mean and variance . Since the standard CT data are log-normalized, the final -ray observation model for ray-path is defined as:
[TABLE]
where the sum is over the contributions from each of the source energies used to approximate the continuous spectrum. The term is the energy-dependent detector response or gain which captures the photon to charge conversion factor, therefore, is measured in units of current. This model is consistent with poly-energetic models used in different published studies [3, 5, 17, 39]. By incorporating a full energy aware ray model, effects such as beam hardening are inherently included. Note that one could consider other sensing models and configurations in a straightforward way by instantiating appropriate simulation models, including, for example, photon-counting detectors, Monte-Carlo-based photon scatter, etc.
Coupled with this physically accurate -ray scanner model, we also created a stochastic bag simulator. This bag or scene simulator places objects of different material composition and of varying geometric configuration at random locations in the scene. The current instantiation of the simulator uses geometric primitives including circles and rectangles and uses material attenuation coefficients drawn from the NIST XCOM database [40]. The setup for simulated training dataset generation is illustrated in Figure 4. A metal-free scene is created and then multiple metallic object areas are defined with corresponding sinogram data deletions to create multiple training pairs. These training pairs consist of sinograms with data deletions corresponding to metal object locations (incomplete sinograms) and the corresponding sinograms without the metal objects (reference completed sinograms). The entire process can be done quickly allowing the generation of tens of thousands of sinogram pairs, much more than would be possible to do physically. Other, more complex, scene generators could also be used for this purpose.
III-B Real Training Data Generation
Acquiring physical matched sinogram pairs with and without metal objects for training is a challenge, especially in security settings. What would be required in general is a real sinogram containing metal objects and the corresponding real sinogram if those objects were absent, but everything else in the scene remained the same. Such consistency is very difficult to achieve in practice.
As a consequence of formulating the PD-MAR problem as one of sinogram completion, our approach only requires metal-trace masked and corresponding metal-free complete sinograms for CGAN training since we are focusing our learning on missing data completion. We can use sinogram data from scenes which do not contain metal objects, and then create matched sinograms by deleting data in the sinogram that corresponds to geometric configurations of embedded objects. We define these object configurations at locations of the image associated with voids or background. In this way we can manually generate a modest a number of real pairs of incomplete and complete sinograms to train our CGAN. The security scans used for this data generation were obtained from the ALERT Center of Excellence (http://www.northeastern.edu/alert/transitioning-technology/alert-datasets/)
III-C Real Data Transfer Learning
We combine our two sources of training data (that generated by accurate -ray physics simulation and that derived from real scans) through transfer learning from the larger simulated data set. Transfer learning involves transfer of knowledge from a learned function, , that solves a task in a source domain to achieve improved performance in learning a function, , to perform a task in a target domain [41, 32]. The most common use of transfer learning in DL research involves learning a function, , in the form of a deep network from a large set of training data and then copying the first layers of this network to a target network as an initialization. In general, and the target task may or may not be the same as the source task [32]. The initial network then undergoes additional refinement or training using a smaller set of training data from the new task. Transfer learning has been shown to provide improved performance, generalization, and robustness to over-fitting as compared to random initializations combined with limited training for various image classification tasks even when and are very different from each other [32, 42, 43, 44].
In this work transfer learning from a larger set of simulated data to a smaller set of real data is used. The learning task (sinogram completion) remains same in our case, i.e., , however, the nature of the training data is changed, i.e., . Additionally, we use the same network architecture for both source and target tasks, and we copy all layers of to . We first train the network on a large simulated dataset acquired by the physically accurate simulation setup previously described. This trained network, , is later fine-tuned using a smaller amount of real data. This strategy allows us to achieve good performance on real data even with a small real dataset.
IV Experiments
This section describes the details of our experiments, networks, and training. For simplicity, we restrict our experiments to 2-D parallel-beam geometry in this work. Training deep networks is a challenging and time-intensive task, but once trained, inference is very fast. Note that in the examples considered here our proposed Deep-MAR method is very efficient; our generator network takes approximately milliseconds to perform sinogram completion on an NVIDIA Tesla P100 GPU at test time, which makes it attractive in real world contexts. We use a CPU implementation of FBP which has not been optimized for efficiency, and on average it takes seconds using an Intel Xeon ( GHz) processor on a Linux system with MATLAB R2017b to reconstruct the 2-D images considered in this work.
IV-A Metal Artifact Dataset
IV-A1 Simulated Dataset
Our simulated data model is based on the Imatron C scanner. Equation 4 was used to simulate poly-energetic CT with a weighting function and detector response pA/quanta estimated by Crawford *et al. *[3], source intensity set to photons per ray, and using uniformly sampled energy levels between KeV and KeV. The electronic noise variance is modeled as counting statistics of photons detected at KeV following [3]. Photon scatter could certainly be included in our simulation setup in a straight forward way. However, accurate Monte Carlo scatter simulation methods are computationally very expensive () [45]. This additional computational load would limit the amount of simulated training data we could generate. We decided a simpler ray-based simulation was sufficient for sinogram completion training that was required and therefore, in this initial work, we do not include scatter in our simulation setup. Attenuation images of size were generated with attenuation coefficients from the NIST XCOM database [40]. The list of metallic and non-metallic materials used is presented in the Supplementary Material (Section S1). Sinograms at each of the energy levels were generated using uniformly sampled projection angles between and , and detector channels per projection angle. In order to match the network input and output size, zero-padding was performed to result in a sinogram of dimensions . We generated example images using the stochastic bag simulator with non-metallic objects, and placed up to metallic objects in each instance resulting in a training dataset of sinograms. An additional suitcase scenes with different configurations of cylinder and sheet objects (similar to the ones in the ALERT Task Order dataset [3]) were manually generated and included in the training dataset. For each of these images, matched pairs of sinograms without and with metallic objects in the scene were generated. We used horizontal flips of this data as a data augmentation strategy. The ASTRA toolbox [46] was used for accelerated forward projection in the training data preparation. We used our stochastic bag simulator to generate reference metal-free scenes and inserted up to metals to result in test dataset sinogram pairs which were used for qualitative and quantitative analysis of our approach on simulated dataset.
IV-A2 Real Training Dataset
Additional real training data was generated from real sinogram data acquired by an Imatron scanner. The data was part of a collection effort supported by DHS [47]. The scans were performed with a field of view (FOV) of with a peak -ray source energy level of KeV. Data was re-binned to a parallel geometry with projection angles and detector channels. Further, to match the network input and output size, zero-padding was done to result in a sinogram of dimensions . In order to create the pairs of sinograms for training of the CGAN, different slices which did not contain significant metal objects were manually identified from the scanned bags. The strategy described in Section III-B was used to generate pairs of real data sinograms for training with sinogram missing data corresponding to up to virtual metallic objects. Horizontal flips of this data were also used as a data augmentation strategy. This real data was used for transfer learning as previously described.
IV-A3 Real Testing Dataset
For quantitative analysis of performance on real data, pairs of sinograms were generated by selecting metal-free images from the ALERT Task Order dataset [47] using the strategy described in Section III-B. This strategy was used for quantitative analysis since the reference artifact-free images without any metal objects are available in this settings. For qualitative analysis on real data, slices were selected from the ALERT Task Order dataset [3] which contained metals and caused severe artifacts in the reconstructions. FBP reconstructions were generated for selected slices, and a metal mask identified by applying a threshold of Modified Hounsfield Units (MHU , where ) [3, 12]. Thresholded mask results were eroded and then dilated with a disk-shaped structuring element of radius and pixels respectively to obtain a final metal mask. Erosion was used to remove very small objects, and a small dilation was used to over-segment the metals. Selected sinograms were input to our Deep-MAR framework and final reconstructions were used during testing for qualitative analysis of our proposed method.
IV-B CGAN Training
To optimize our CGAN sinogram completion network, the original GAN training strategy [28] was followed, where alternations between one gradient descent step on and one step on were performed, with the exception that for the first epochs , iterations on were done for each gradient descent iteration on . Mini-batch stochastic gradient descent with batch size was used for both simulated data and real data transfer learning. The standard Adam optimizer [48] was used with learning rate of and momentum parameters , . The value of the hyper parameter was decided empirically. For simulated data, the CGAN was trained for epochs on examples using the training scheme just described. Real data was used for transfer learning from the simulated data trained network with just pairs of real sinograms. We trained our model on the real dataset for epochs. In order to show effectiveness of transfer learning, we also trained a model without pre-training on the simulated dataset, i.e., training the model from scratch on the real dataset. At test time, the trained generator network was used to perform sinogram completion. The network was implemented in Tensorflow [49] heavily borrowing code from the Tensorflow implementation of CGAN333http://github.com/yenchenlin/pix2pix-tensorflow.
V Results and Discussion
In this section Deep-MAR results are shown and its performance is compared to similar computationally light sinogram completion approaches suitable for use in practical settings. Comparison is made to LI-MAR [14], and WNN-MAR [16] on both simulated and real data. For a fair comparison, we set the weight of the original data for WNN-MAR, and use default values for the rest of the parameters suggested in [16]. The performance of our trained CGAN is also analyzed using attention maps and latent space analysis. The performance of our generator network architecture is compared to a popular CNN architecture VDSR [23] in Supplementary Material. This comparison demonstrates the effectiveness of U-net like architectures as generator network. Furthermore, we present additional experimental results in the Supplementary Material.
V-A Sinogram Completion Experiments
Since a key element of our proposed approach is sinogram completion we first focus on the ability of Deep-MAR to successfully perform this task. Qualitative sinogram completion results on simulated data are shown in Figure 5. Each row corresponds to a different sinogram completion case. The first row shows the original uncorrected sinograms, the second row shows the results obtained using LI-MAR [14], the third row shows the results obtained using WNN-MAR [16], and the fourth row shows the results obtained using the proposed learning-based completion approach Deep-MAR. Column (a) in Figure 5 corresponds to a simulated example, while column (b) and (c) correspond to two different real data examples obtained from the ALERT TO3 dataset [3]. The reference metal-free sinogram for the simulated data example in column (a) is presented in Supplementary Material. The images corresponding to these cases are shown in Figures 6 and 7. LI-MAR and WNN-MAR use limited neighboring data in -D and -D respectively coupled with spatially invariant weights to produce sinogram completion results. While this limited information is adequate in simple cases with few, small metallic objects, these methods struggle in more realistic security scenarios containing larger areas of missing data and complex configurations. As highlighted by the red arrows, the proposed Deep-MAR approach produces sinograms with fewer visual artifacts, such as discontinuities at metal trace edges compared to methods widely used in practice. Additional sinogram completion results presented in Supplementary material show that the proposed Deep-MAR based completion results are closer to the ground truth sinograms compared to LI-MAR and WNN-MAR completed sinograms.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Boas, F Edward and Fleischmann, Dominik, “Evaluation of two iterative techniques for reducing metal artifacts in computed tomography,” Radiology , vol. 259, no. 3, pp. 894–902, 2011.
- 2[2] Martin, Limor and Tuysuzoglu, Ahmet and Karl, W Clem and Ishwar, Prakash, “Learning-Based Object Identification and Segmentation Using Dual-Energy CT Images for Security,” IEEE Transactions on Image Processing , vol. 11, no. 24, pp. 4069–4081, 2015.
- 3[3] Crawford, C and Martz, H and Karl, WC, “Research and development of reconstruction advances in CT-based object detection systems–Final report, Dept. Homeland Security Center Excellence, ALERT, Boston,” Tech. Rep., MA, Tech. Rep. HSHQDC-12-J-00056, 2013.
- 4[4] Ghani, Muhammad Usman and Karl, W Clem, “Deep Learning-Based Sinogram Completion for Low-Dose CT,” in 2018 IEEE 13th Image, Video, and Multidimensional Signal Processing Workshop (IVMSP) . IEEE, 2018, pp. 1–5.
- 5[5] Elbakri, Idris A and Fessler, Jeffrey A, “Statistical image reconstruction for polyenergetic X-ray computed tomography,” IEEE transactions on medical imaging , vol. 21, no. 2, pp. 89–99, 2002.
- 6[6] Wang, Ge and Snyder, Donald L and O’Sullivan, Joseph A and Vannier, Michael W, “Iterative deblurring for CT metal artifact reduction,” IEEE transactions on medical imaging , vol. 15, no. 5, pp. 657–664, 1996.
- 7[7] De Man, Bruno and Nuyts, Johan and Dupont, Patrick and Marchal, Guy and Suetens, Paul, “Reduction of metal streak artifacts in x-ray computed tomography using a transmission maximum a posteriori algorithm,” IEEE transactions on nuclear science , vol. 47, no. 3, pp. 977–981, 2000.
- 8[8] Hamelin, Benoit and Goussard, Yves and Gendron, David and Dussault, Jean-Pierre and Cloutier, Guy and Beaudoin, Gilles and Soulez, Gilles, “Iterative CT reconstruction of real data with metal artifact reduction,” in Biomedical Imaging: From Nano to Macro, 2008. ISBI 2008. 5th IEEE International Symposium on . IEEE, 2008, pp. 1453–1456.
