TL;DR
This paper introduces a theoretically grounded method to analyze and quantify the semantic robustness of deep neural networks, revealing differences in robustness among popular architectures.
Contribution
It develops a novel bottom-up approach for detecting robust semantic regions and formalizes the problem as optimizing integral bounds for robustness evaluation.
Findings
InceptionV3 is more accurate but less semantically robust than ResNet50.
Semantic robustness varies significantly across architectures with similar accuracy.
The proposed method provides a scalable way to evaluate semantic robustness.
Abstract
Despite the impressive performance of Deep Neural Networks (DNNs) on various vision tasks, they still exhibit erroneous high sensitivity toward semantic primitives (e.g. object pose). We propose a theoretically grounded analysis for DNN robustness in the semantic space. We qualitatively analyze different DNNs' semantic robustness by visualizing the DNN global behavior as semantic maps and observe interesting behavior of some DNNs. Since generating these semantic maps does not scale well with the dimensionality of the semantic space, we develop a bottom-up approach to detect robust regions of DNNs. To achieve this, we formalize the problem of finding robust semantic regions of the network as optimizing integral bounds and we develop expressions for update directions of the region bounds. We use our developed formulations to quantitatively evaluate the semantic robustness of different…
Click any figure to enlarge with its caption.
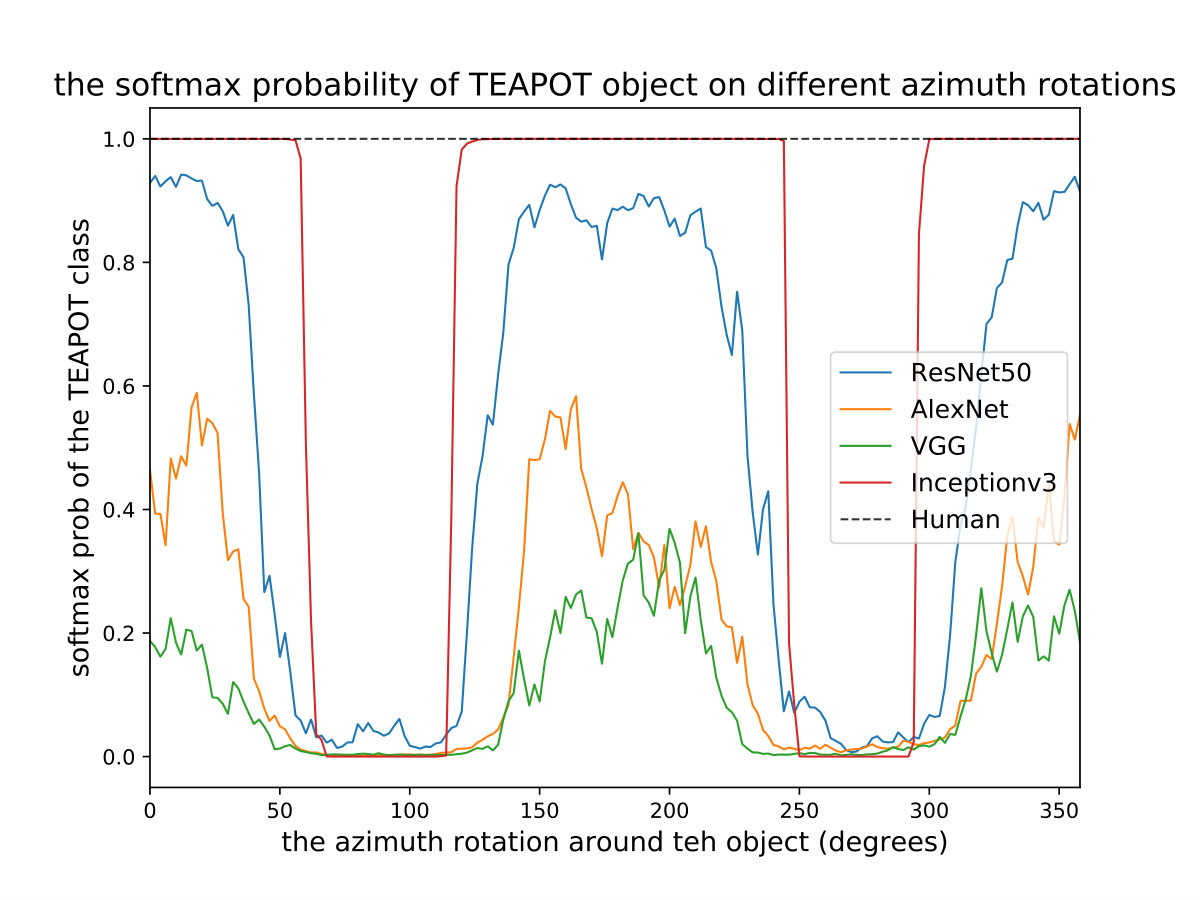 Figure 1
Figure 1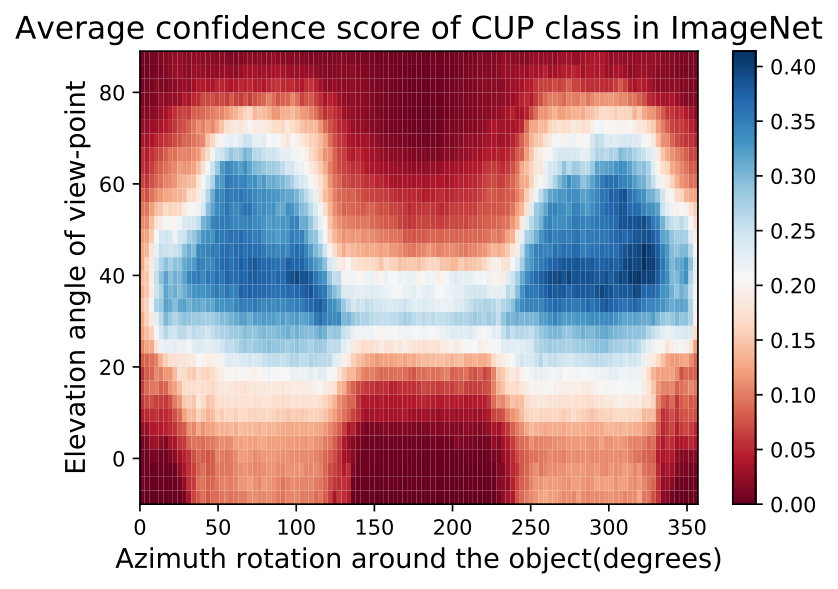 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4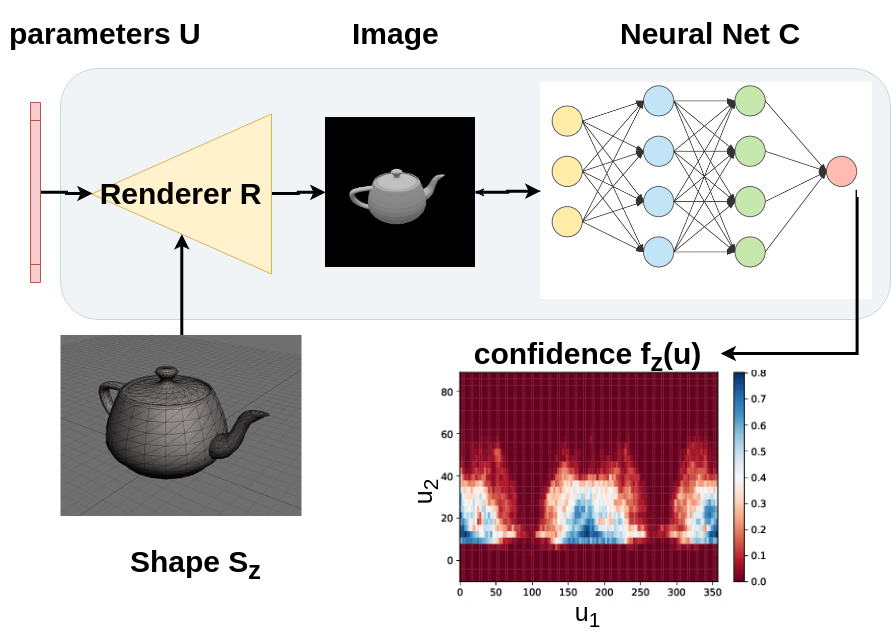 Figure 5
Figure 5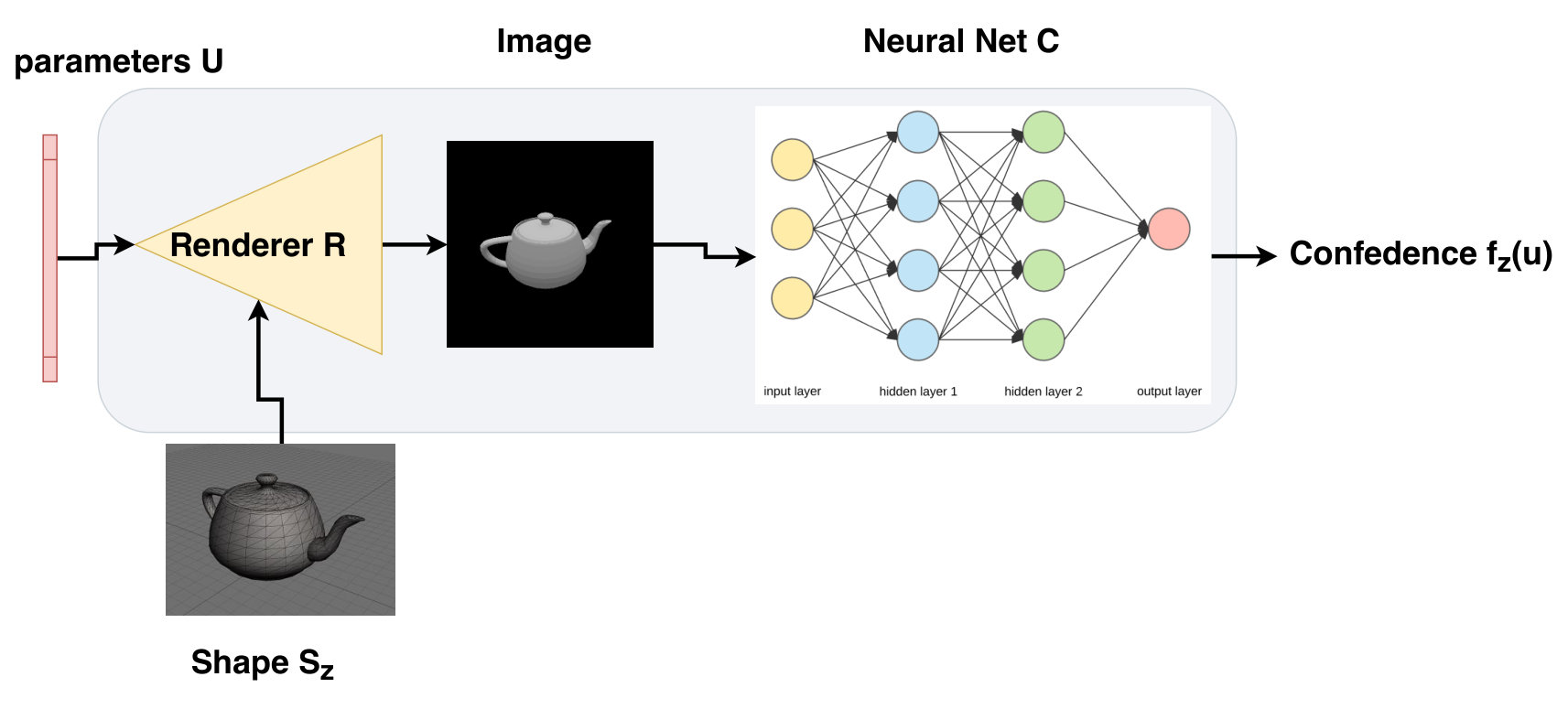 Figure 6
Figure 6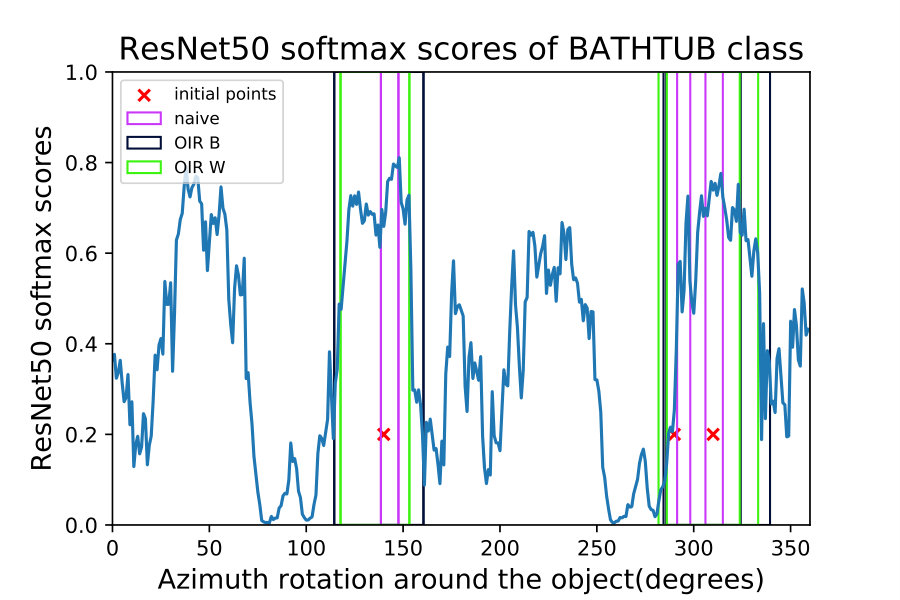 Figure 7
Figure 7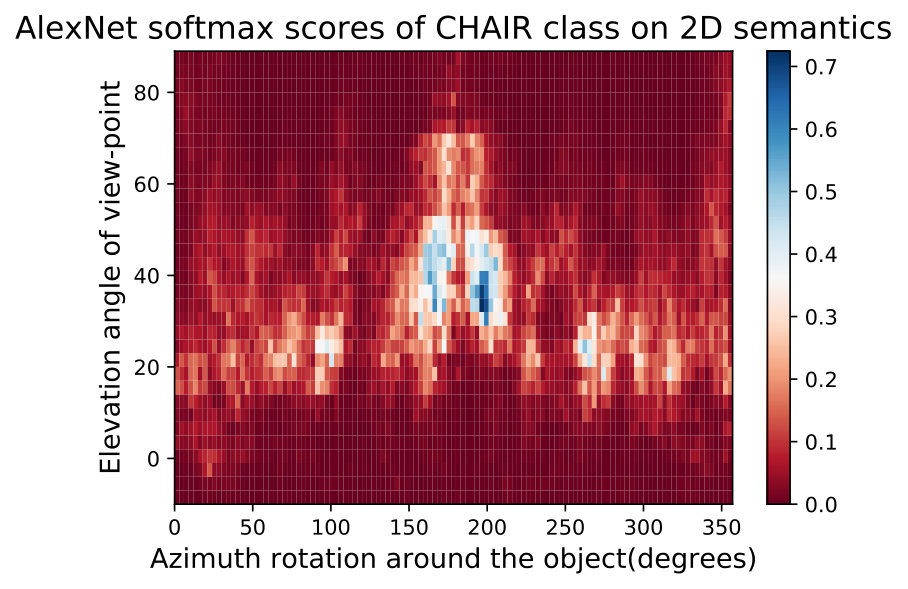 Figure 8
Figure 8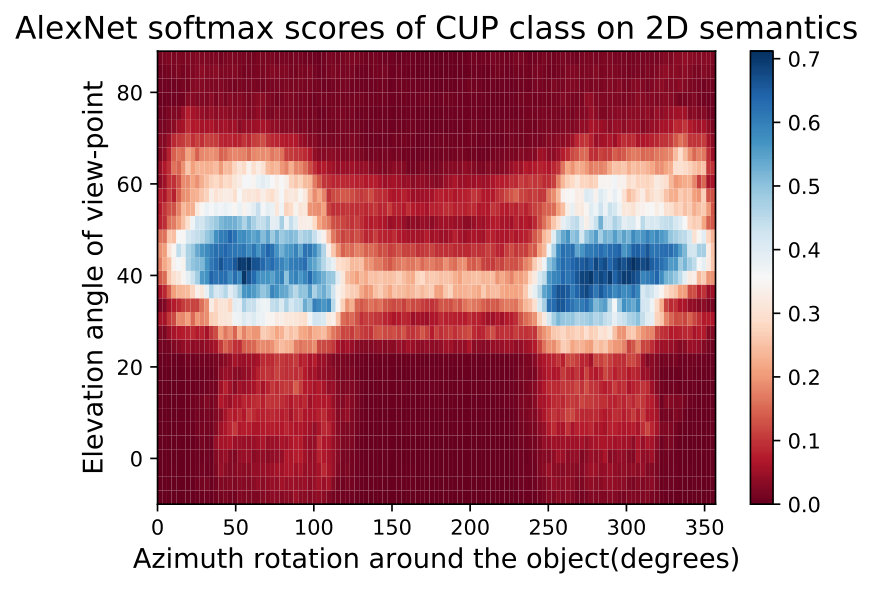 Figure 9
Figure 9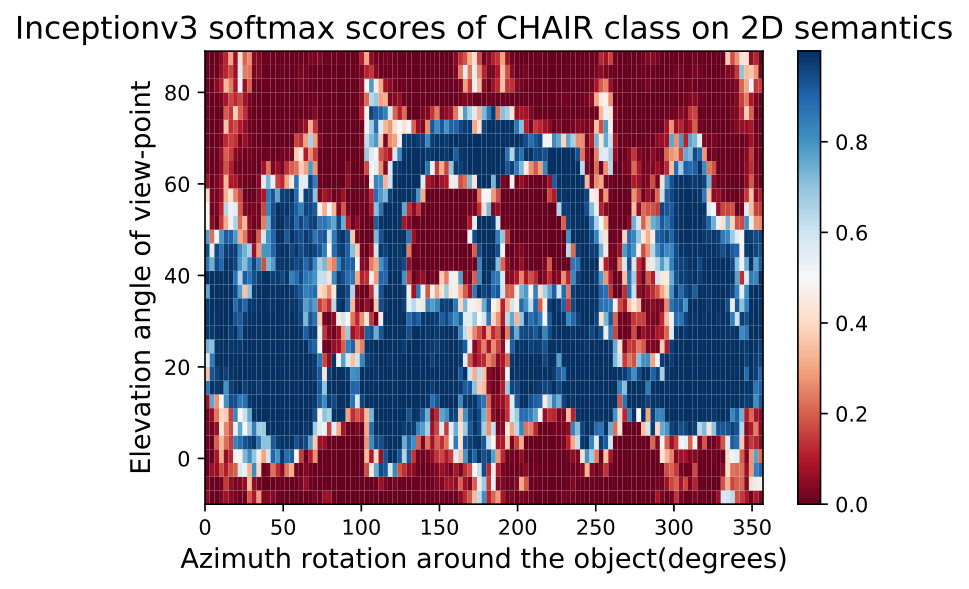 Figure 10
Figure 10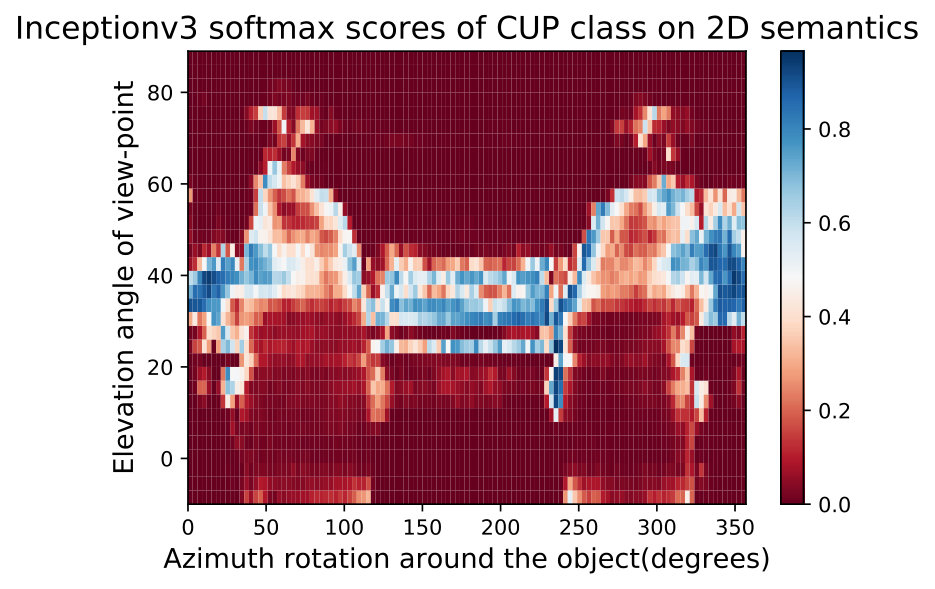 Figure 11
Figure 11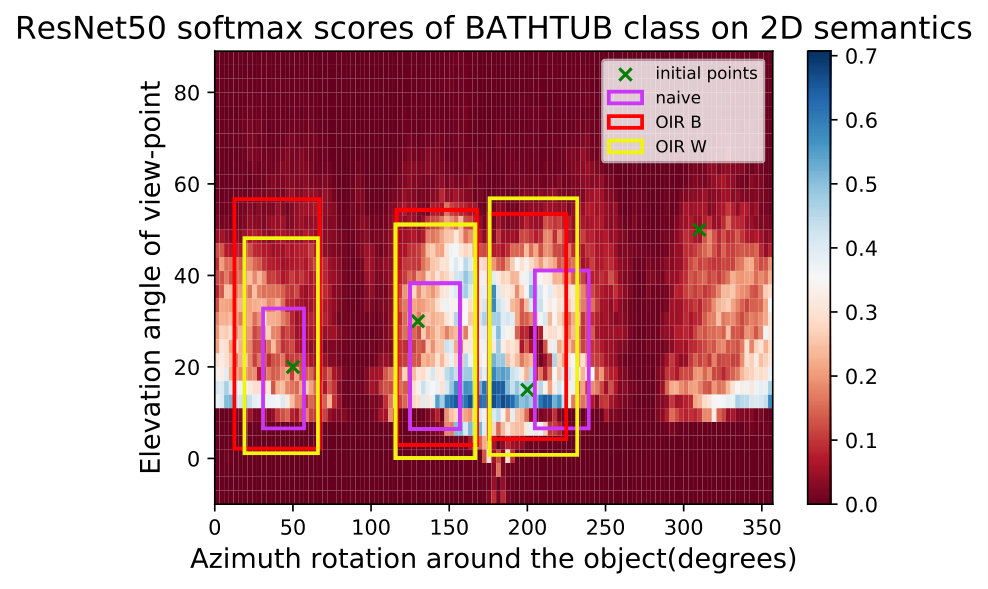 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14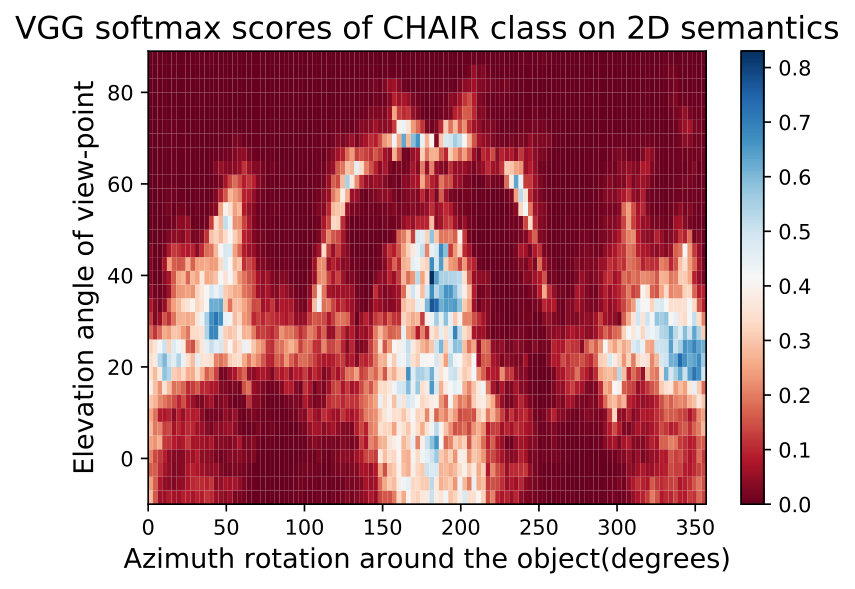 Figure 15
Figure 15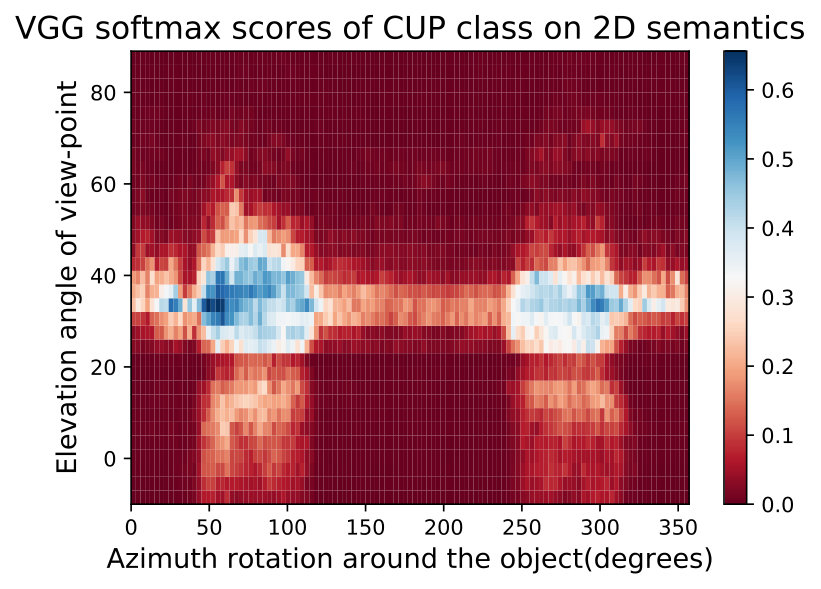 Figure 16
Figure 16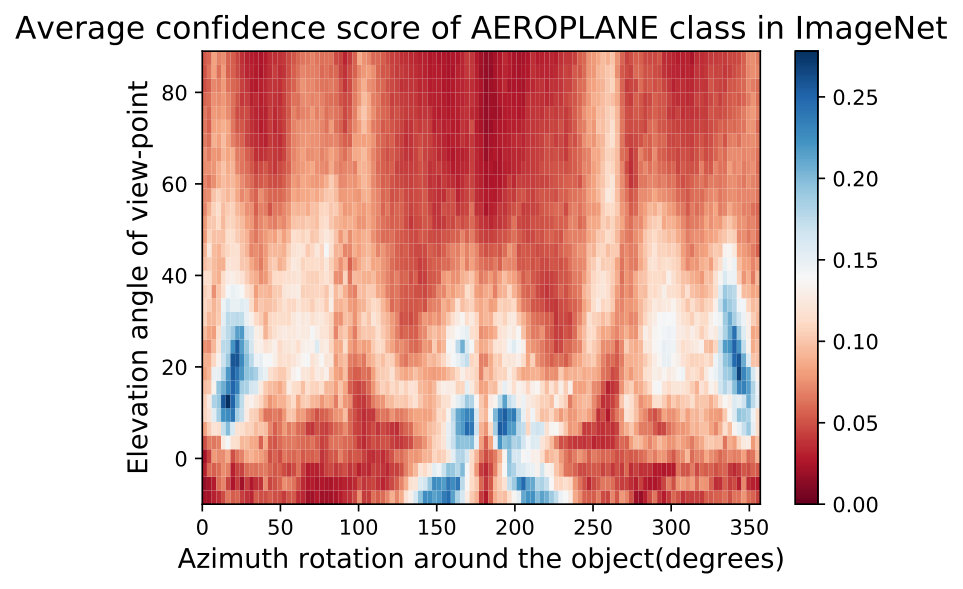 Figure 17
Figure 17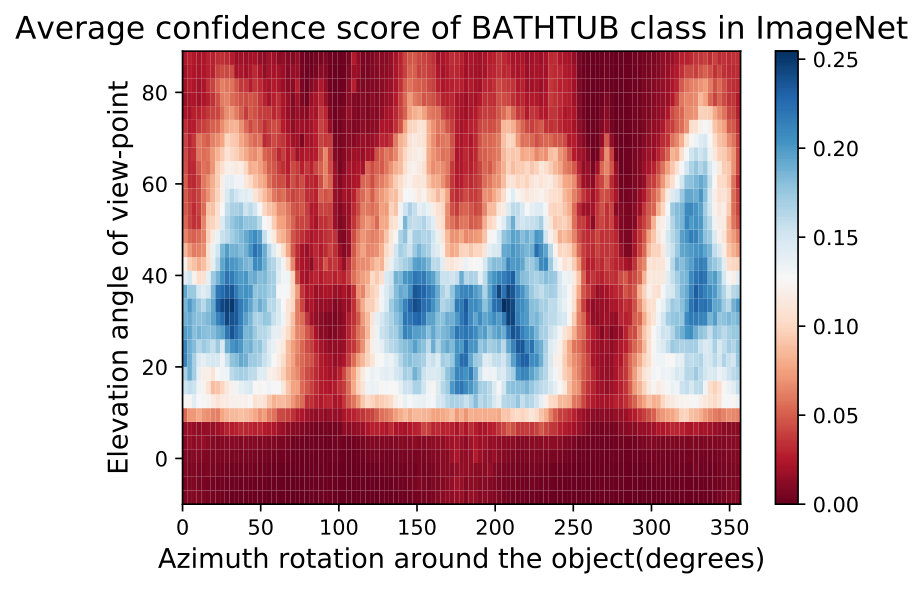 Figure 18
Figure 18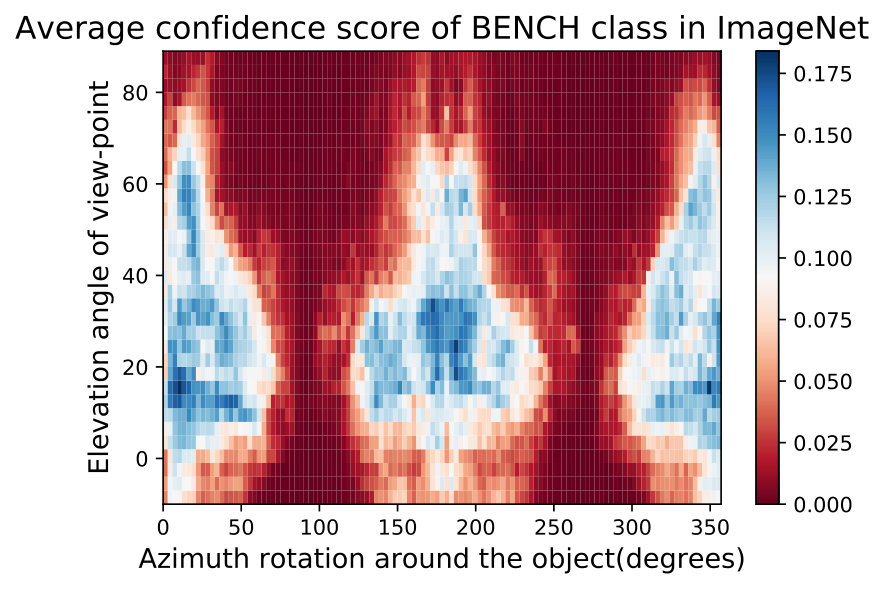 Figure 19
Figure 19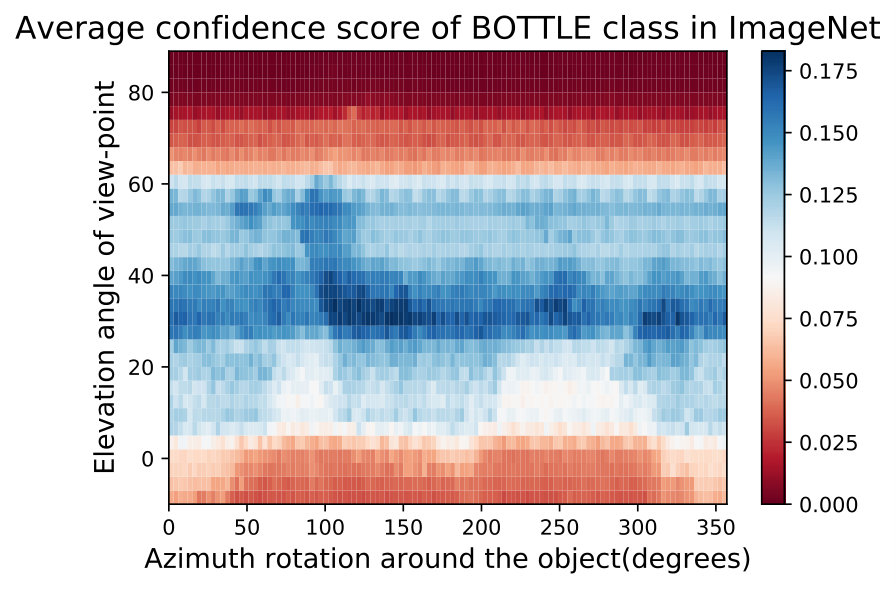 Figure 20
Figure 20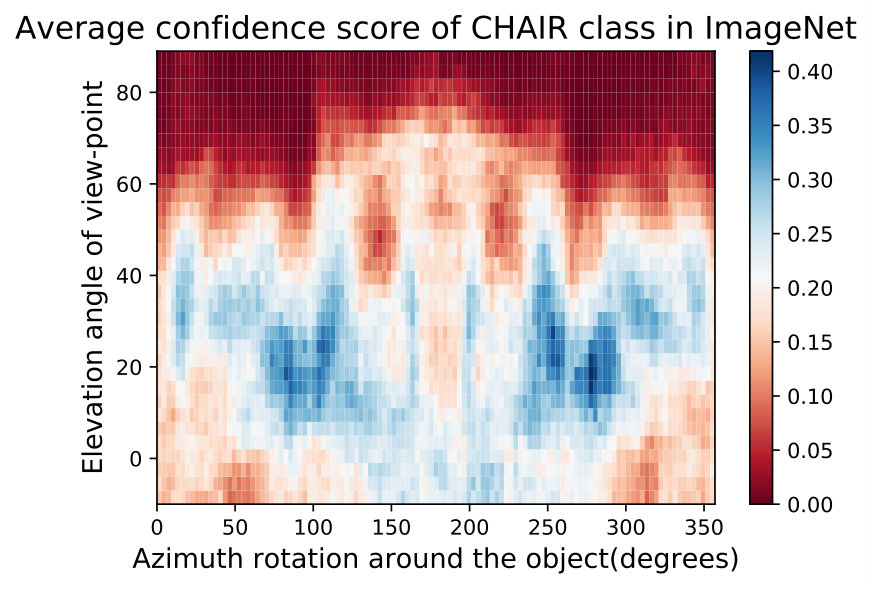 Figure 21
Figure 21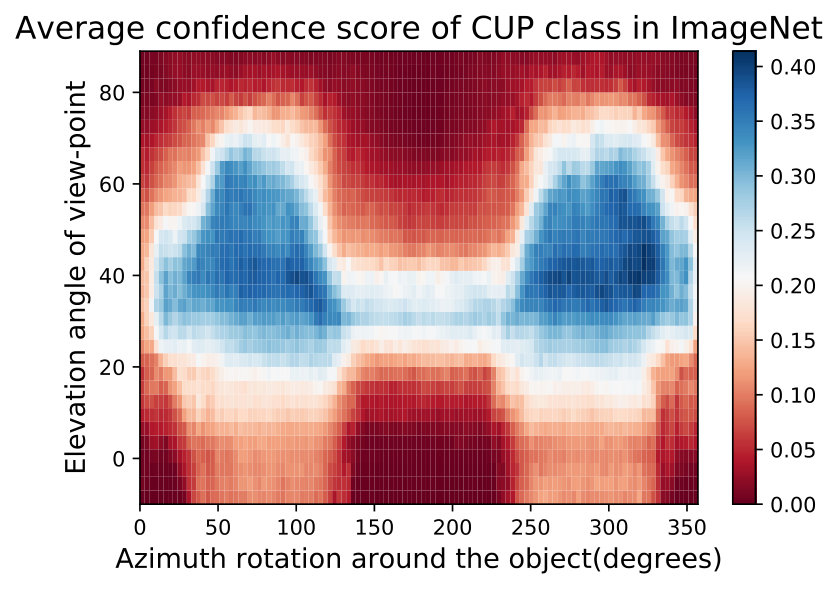 Figure 22
Figure 22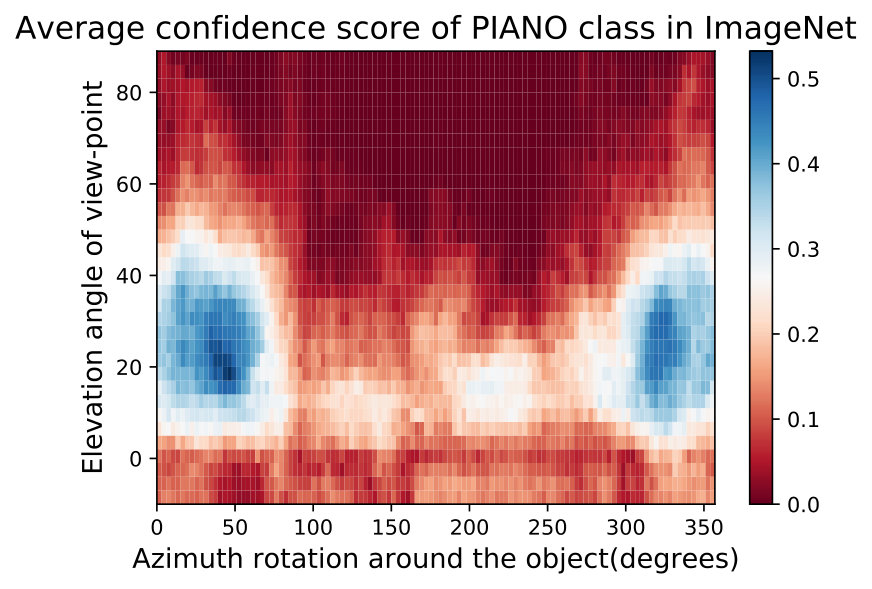 Figure 23
Figure 23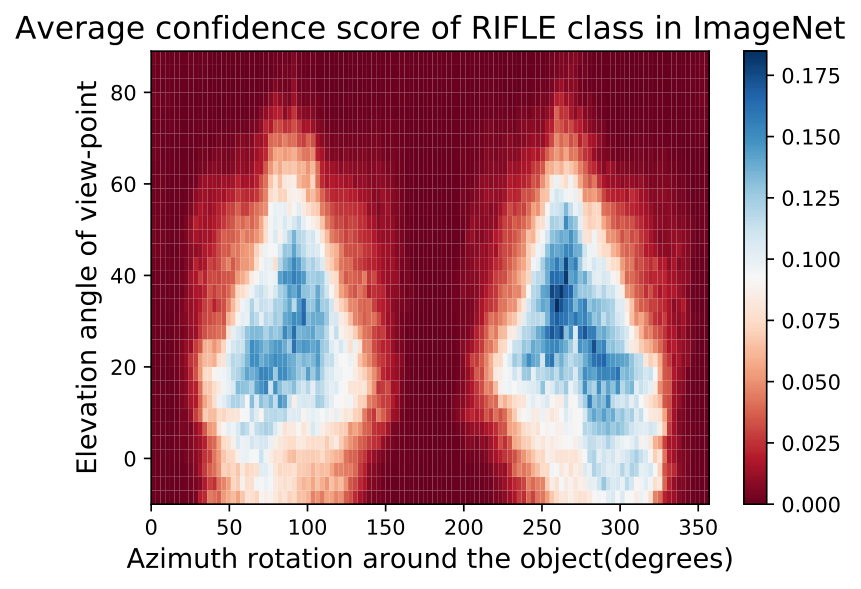 Figure 24
Figure 24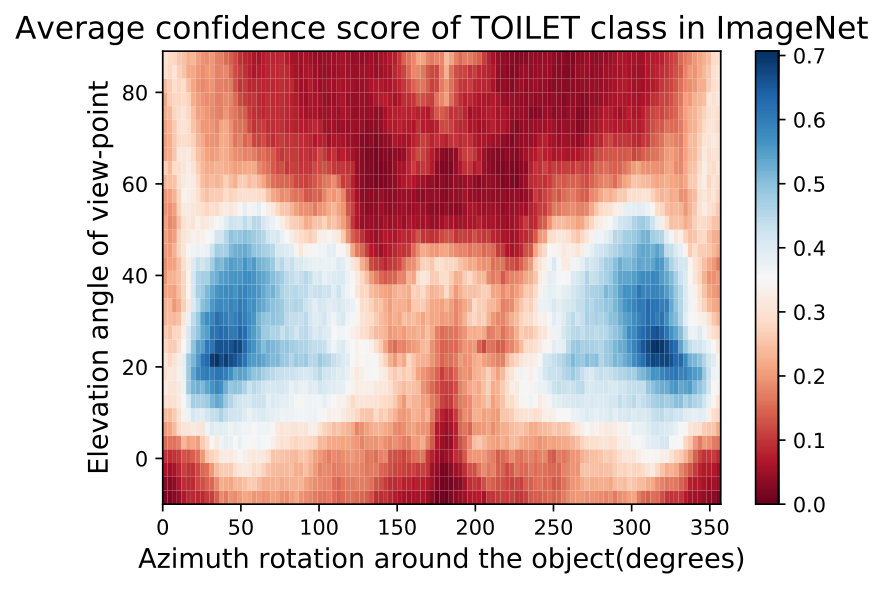 Figure 25
Figure 25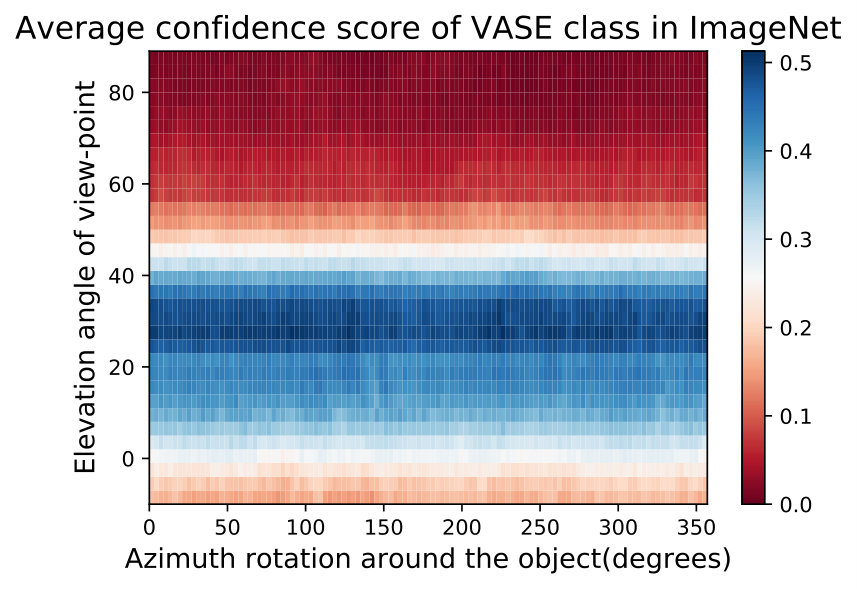 Figure 26
Figure 26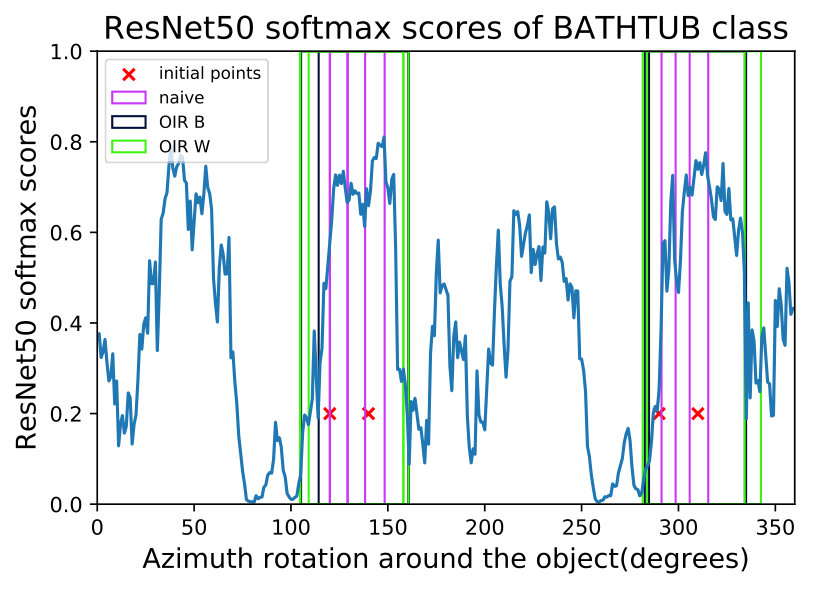 Figure 27
Figure 27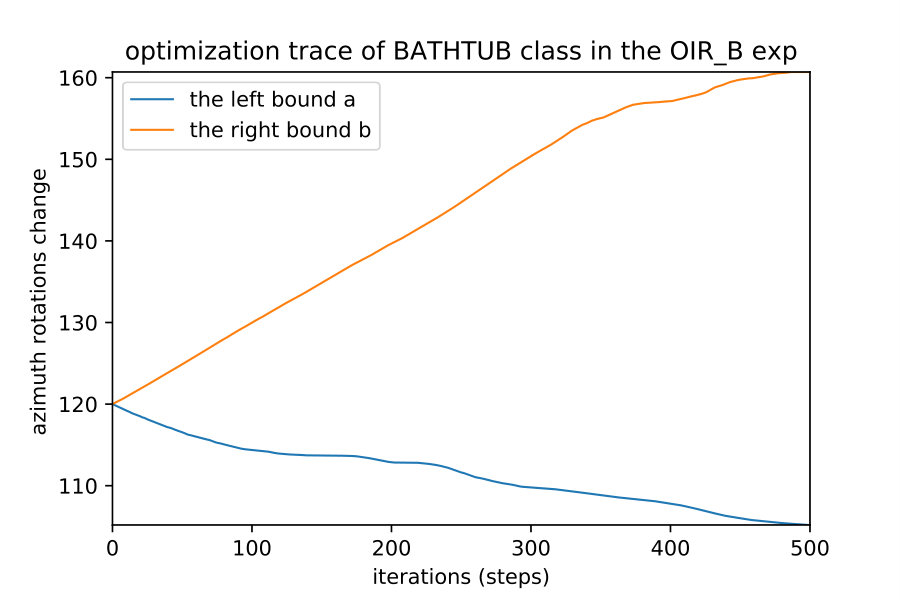 Figure 28
Figure 28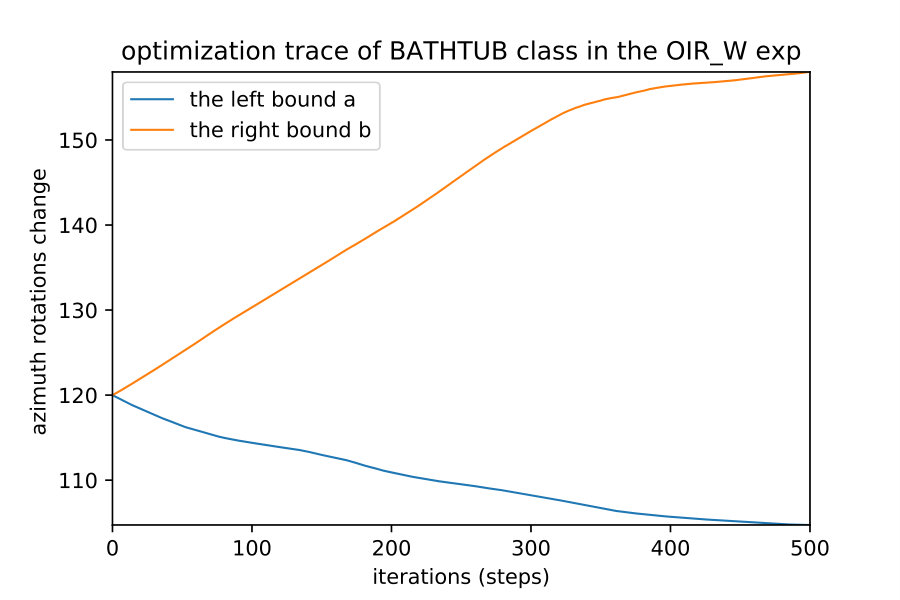 Figure 29
Figure 29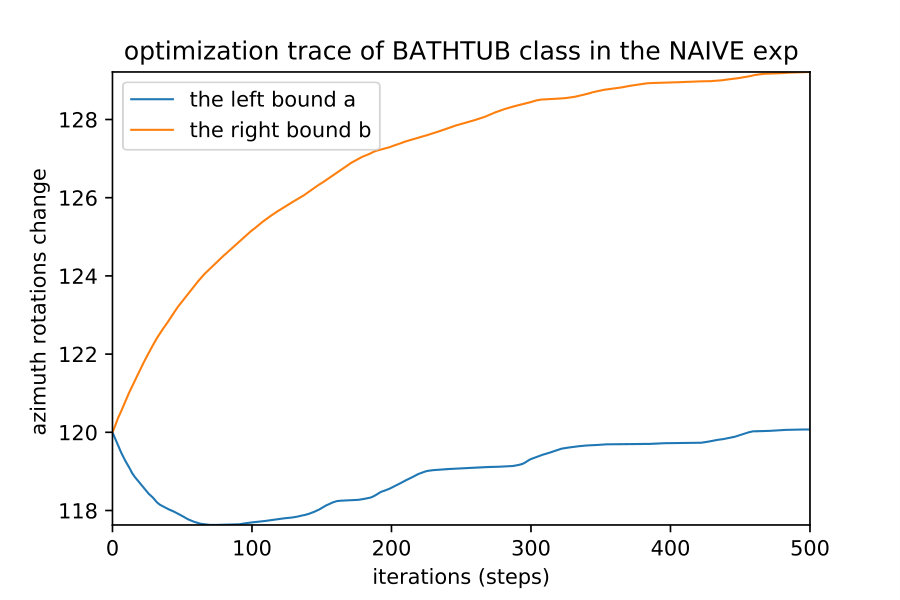 Figure 30
Figure 30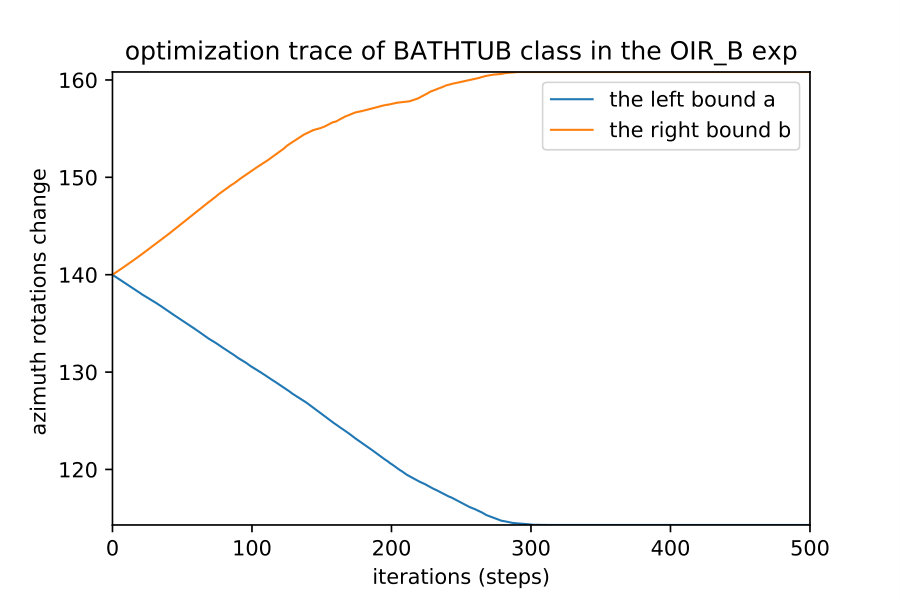 Figure 31
Figure 31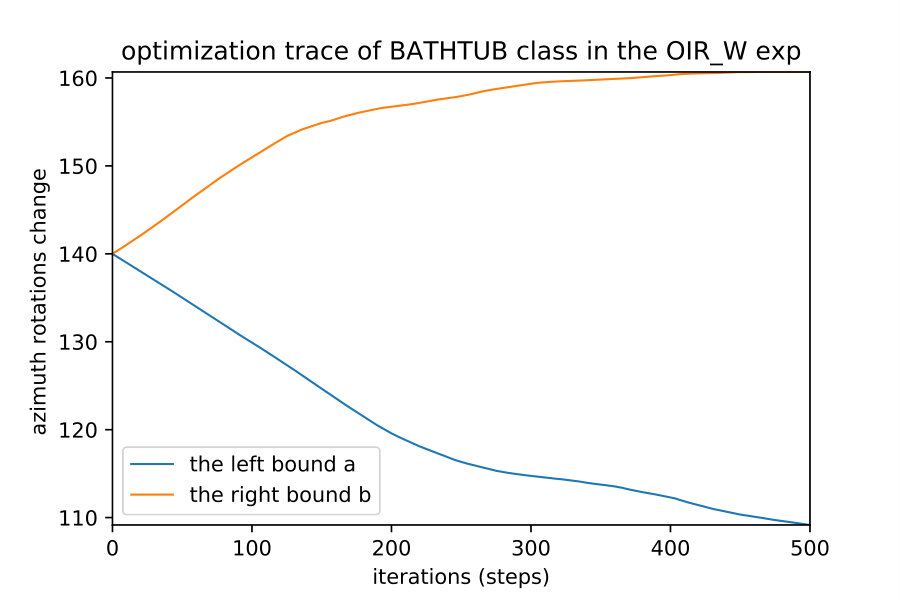 Figure 32
Figure 32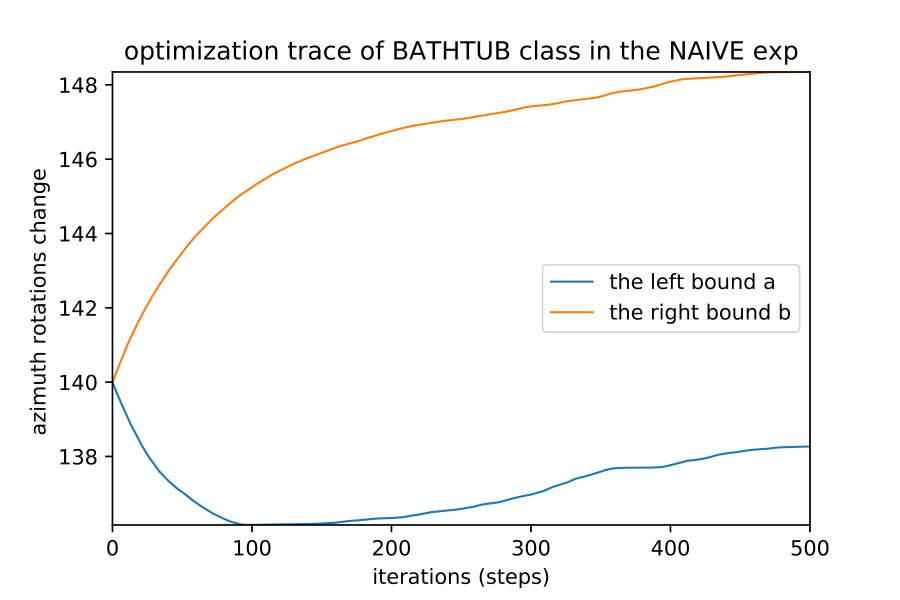 Figure 33
Figure 33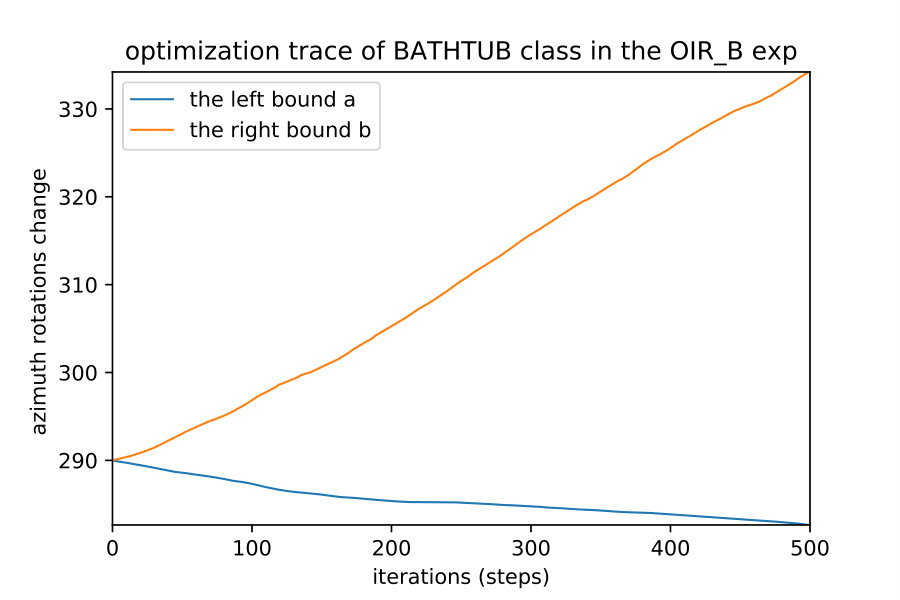 Figure 34
Figure 34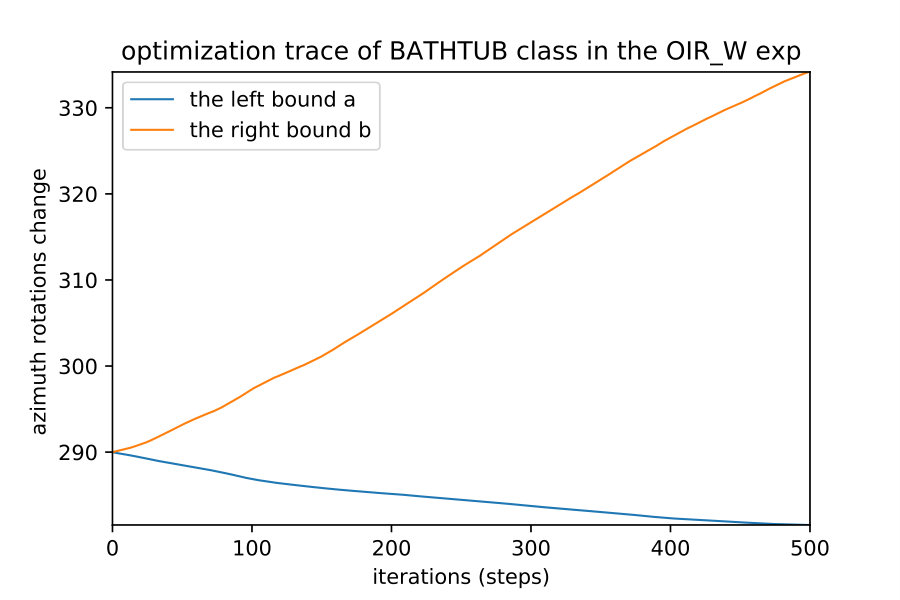 Figure 35
Figure 35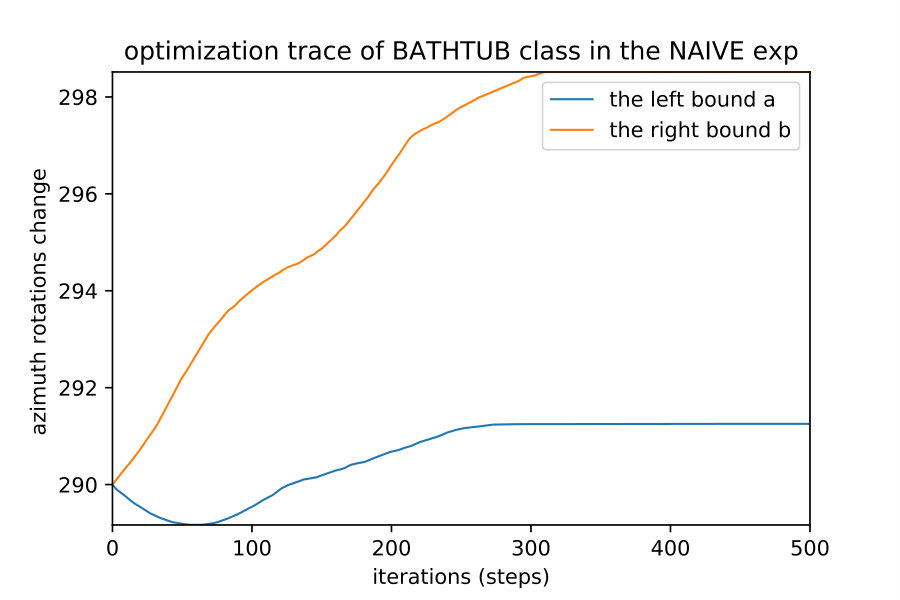 Figure 36
Figure 36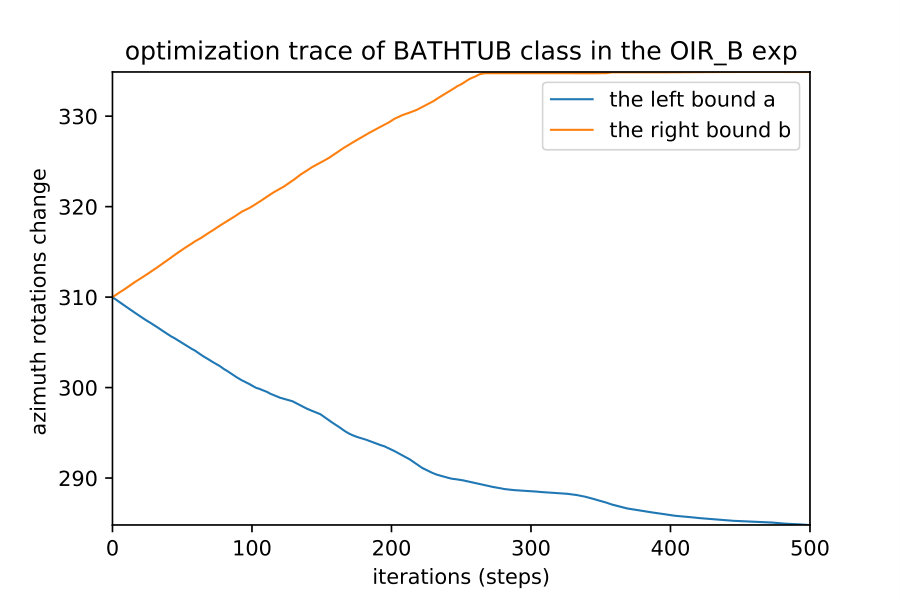 Figure 37
Figure 37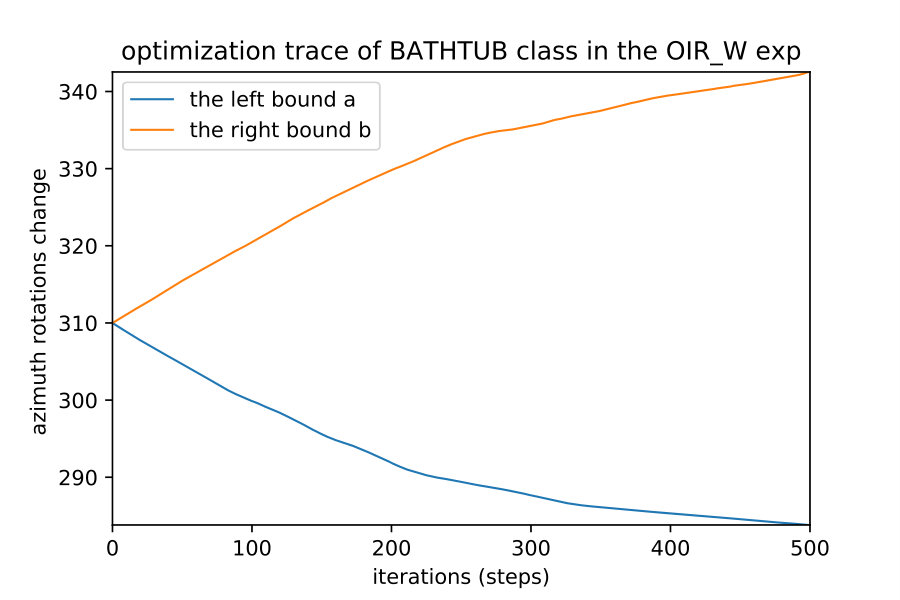 Figure 38
Figure 38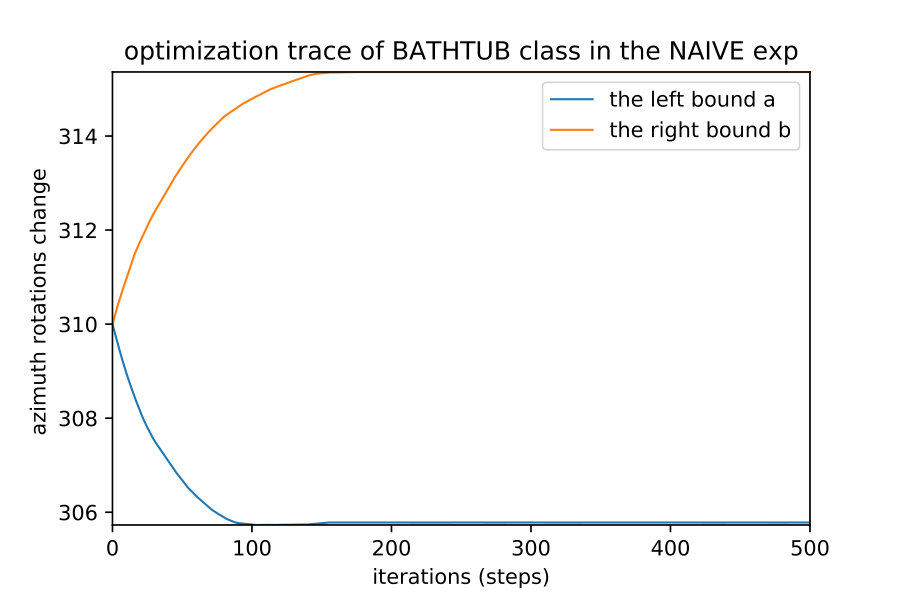 Figure 39
Figure 39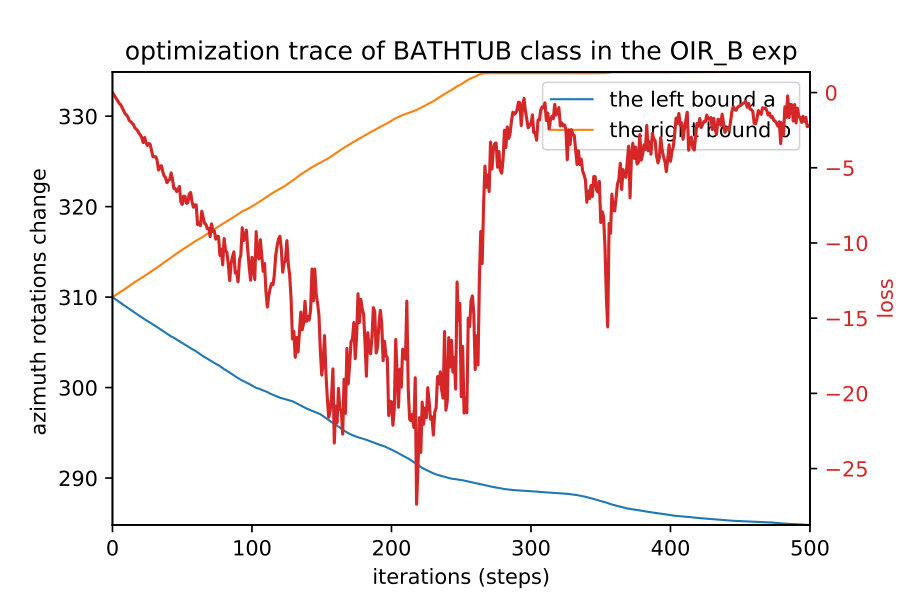 Figure 40
Figure 40
|
Paradigm |
|
|
|
|
|
||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Grid Sampling | top-down |
|
✓ | - | - |
|
||||||||||||||||
| Naive | bottom-up | ✓ | 0 |
|
||||||||||||||||||
| OIR_B | bottom-up | ✓ | 0 |
|
||||||||||||||||||
| OIR_W | bottom-up | ✖ |
|
|
Paradigm |
|
|
|
|
|
||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Grid Sampling | top-down |
|
✓ | - | - |
|
||||||||||||||||
| Naive | bottom-up | ✓ | 0 |
|
||||||||||||||||||
| OIR_B | bottom-up | ✓ | 0 |
|
||||||||||||||||||
| OIR_W | bottom-up | ✖ |
|
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
11institutetext: King Abdullah University of Science and Technology (KAUST), Thuwal, Saudi Arabia
11email: {abdullah.hamdi, bernard.ghanem}@kaust.edu.sa
Towards Analyzing Semantic Robustness of Deep Neural Networks
Abdullah Hamdi
Bernard Ghanem
Abstract
Despite the impressive performance of Deep Neural Networks (DNNs) on various vision tasks, they still exhibit erroneous high sensitivity toward semantic primitives (*e.g. *object pose). We propose a theoretically grounded analysis for DNNs robustness in the semantic space. We qualitatively analyze different DNNs semantic robustness by visualizing the DNN global behavior as semantic maps and observe interesting behavior of some DNNs. Since generating these semantic maps does not scale well with the dimensionality of the semantic space, we develop a bottom-up approach to detect robust regions of DNNs. To achieve this, we formalize the problem of finding robust semantic regions of the network as optimization of integral bounds and develop expressions for update directions of the region bounds. We use our developed formulations to quantitatively evaluate the semantic robustness of different famous network architectures. We show through extensive experimentation that several networks, though trained on the same dataset and while enjoying comparable accuracy, they do not necessarily perform similarly in semantic robustness. For example, InceptionV3 is more accurate despite being less semantically robust than ResNet50. We hope that this tool will serve as the first milestone towards understanding the semantic robustness of DNNs.
1 Introduction
As a result of recent advances in machine learning and computer vision, deep neural networks (DNNS) have become an essential part of our lives.††The code is available at https://github.com/ajhamdi/semantic-robustness. DNNs are used to suggest articles to read, detect people in surveillance cameras, automate big machines in factories, and even diagnose X-rays for patients in hospitals. So, what is the catch here? These DNNs struggle with a detrimental weakness on specific naive scenarios, despite having strong on-average performance. Fig. 1 shows how a small perturbation in the view angle of the teapot object results in a drop in InceptionV3 [37] confidence score from 100% to almost 0%. The softmax confidence scores are plotted against one semantic parameter (*i.e. *the azimuth angle around the teapot) and it fails in such a simple task. Similar behaviors are consistently observed across different DNNs (trained on ImageNet [32]) as noted by other concurrent works [1].
Furthermore, because DNNs are not easily interpretable, they work well without a complete understanding of why they behave in such a manner. A whole research direction is dedicated to studying and analyzing DNNs. Examples of such analysis include activation visualization [9, 41, 26], noise injection [12, 27, 3], and studying the effect of image manipulation on DNNs [14, 14, 13]. By leveraging a differentiable renderer and evaluating rendered images for different semantic parameters , we provide a new lens of semantic robustness analysis for such DNNs as illustrated in Fig. 2. These Network Semantic Maps (NSM) demonstrate unexpected behavior of some DNNs, in which adversarial regions lie inside a very confident region of the semantic space. This constitutes a “trap” that is hard to detect without such analysis and can lead to catastrophic failure for the DNN.
Recent work in adversarial network attacks explores DNN sensitivity and performs gradient updates to derive targeted perturbations [39, 15, 6, 24]. In practice, such attacks are less likely to naturally occur than semantic attacks, such as changes in camera viewpoint and lighting conditions. The literature on semantic attacks is sparser, since they are more subtle and challenging to analyze [25, 17, 42, 1]. This is due to the fact that we are unable to distinguish between failure cases that result from the network structure, and learning, or from the data bias [40]. Current methods for adversarial semantic attacks either work on individual examples [1], or try to find distributions but rely on sampling methods, which do not scale with dimensionality [17]. We present a novel approach to find robust/adversarial regions in the n-dimensional semantic space. The proposed method scales better than sampling-based methods [17]. We use this method to quantify semantic robustness of popular DNNs on a collected dataset.
Contributions. (1) We analyze popular deep networks from a semantic lens showing unexpected behavior in the 1D and 2D semantic space. (2) We develop a novel bottom-up approach to detect robust/adversarial regions in the semantic space of a DNN, which scales well with increasing dimensionality. The method specifically optimizes for the region’s bounds in semantic space (around a point of interest), such that the continuous region offers semantic parameters that confuse the network. (3) We develop a new metric to quantify semantic robustness of DNNs that we dub Semantic Robustness Volume Ratio (SRVR), and we use it to benchmark popular DNNs on a collected dataset.
2 Related Work
2.1 Understanding Deep Neural Networks
There are different lenses to analyze DNNs depending on the purpose of analysis. A popular line of work tries to visualize the network hidden layers by inverting the activations to get a visual image that represents a specific activation [9, 26, 41]. Others observe the behavior of these networks under injected noise [12, 2, 4, 16, 38, 3]. Geirhos et. al. show that changing the texture of the object while keeping the borders can hugely deteriorate the recognizability of the object by the DNN [14]. More closely related to our work is the work of Fawzi et. al. , which shows that geometric changes in the image greatly affect the performance of the classifier [13]. The work of Engstorm et. al. [11] studies the robustness of a network under natural 2D transformations (*i.e. *translation and planar rotation).
2.2 Adversarial Attacks on Deep Neural Networks
Pixel-based Adversarial Attacks. The way that DNNs fail for some noise added to the image motivated the adversarial attacks literature. Several works formulate attacking neural networks as an optimization on the input pixels [39, 15, 24, 28, 6]. However, all these methods are limited to pixel perturbations and only fool classifiers, while we consider more general cases of attacks, *e.g. *changes in camera viewpoint to fool a DNN by finding adversarial regions. Most attacks are white-box attacks, in which the attack algorithm has access to network gradients. Another direction of adversarial attacks treats the classifier as a black-box, where the adversary can only probe the network and get a score from the classifier without backpropagating through the DNN [29, 8]. We formulate the problem of finding the robust/adversarial region as an optimization of the corners of a hyper-rectangle in the semantic space for both black-box and white-box attacks.
Semantic Adversarial Attacks. Other works tried to move away from pixel perturbation to semantic 3D scene parameters and 3D attacks [42, 17, 1, 25, 18]. Zeng et. al. [42] generate attacks on deep classifiers by perturbing scene parameters like lighting and surface normals. Hamdi et. al. propose generic adversarial attacks that incorporate semantic and pixel attacks, in which an adversary is sampled from some latent distribution that is produced from a GAN trained on example semantic adversaries [17]. However, their work used a sampling-based approach to learn these adversarial regions, which does not scale with the dimensionality of the problem. Another recent work by Alcorn et. al. [1] tries to fool trained DNNs by changing the pose of the object. They used the Neural Mesh renderer (NMR) by Kato et. al. [22] to allow for a fully differentiable pipeline that performs adversarial attacks based on the gradients to the parameters. Our work differs in that we use NMR to obtain gradients to the parameters not to attack the model, but to detect and quantify the robustness of different networks as shown in Section 4.4. Furthermore, Dreossi et. al. [10] used adversarial training in the semantic space for self-driving, whereas Liu et. al. [25] proposed a differentiable renderer to perform parametric attacks and the parametric-ball as an evaluation metric for physical attacks. The work by Shu et. al. [34] used an RL agent and a Bayesian optimizer to asses the DNNs behaviour under good/bad physical parameters for the network. While we share similar insights as [34], we try to study the global behaviour of DNNs as collections of regions, whereas [34] tries to find individual points that pose difficulty for the DNN.
2.3 Optimizing Integral Bounds
Naive Approach. To develop an algorithm for robust region finding, we adopt an idea from weakly supervised activity detection in videos by Shou et. al. [33]. The idea is to find bounds that maximize the inner average of a continuous function while minimizing the outer average in a region. This is achieved because optimizing the bounds to exclusively maximize the area can lead to diverging bounds of . To solve the issue of diverging bounds, the following naive formulation is to simply regularize the loss by adding a penalty on the region size. The expressions for the loss of =1 dimension is: , where is the function of interest and are the left and right bounds respectively and is a hyperparameter. The update directions to minimize the loss are: . The regularizer will prevent the region from growing to and the best bounds will be found if the loss is minimized with gradient descent or any similar approach.
Trapezoidal Approximation. To extend the naive approach to -dimensions, we face more integrals in the update directions (hard to compute). Therefore, we deploy the following first-order trapezoid approximation of definite integrals. The Newton-Cortes formula for numerical integration [36] states that: . An asymptotic error estimate is given by . So, as long as the derivatives are bounded by some Lipschitz constant , then the error becomes bounded such that .
3 Methodology
Typical adversarial pixel attacks involve a neural network (*e.g. *classifier or detector) that takes an image as input and outputs a multinoulli distribution over class labels with softmax values , where is the softmax value for class . The adversary (attacker) tries to produce a perturbed image that is as close as possible to , such that to have different class predictions through . In this work, we consider a more general case where we are interested in parameters , a latent parameter that generates the image via a scene generator (*e.g. *a renderer function ). This generator/renderer takes the parameter and an object shape of a class that is identified by . is the continuous semantic space for the parameters that we intend to study. The renderer creates the image , and then we study the behavior of a classifier of that image across multiple shapes and multiple popular DNN architectures. Now, this function of interest is defined as follows:
[TABLE]
where is a class label of interest to study and we observe the network score for that class by rendering a shape of the same class. The shape and class labels are constants and only the parameters vary for during analysis.
3.1 Region Finding as an Operator
We can visualize the function in Eq (1) for any shape as long as the DNN can identify the shape at some region in the semantic space of interest, as we show in Fig. 1. However, plotting these figures is expensive and the complexity of plotting them increases exponentially with a big base. The complexity of plotting these plots of semantic maps, which we call Network Semantic Maps (NSM), is for , where is the number of samples needed for that dimension to be fully characterized. The complexity is for , and we can see that for a general dimension , the complexity of plotting the NMS to adequately fill the semantic space is . This number is intractable even if we have only moderate dimensionality. To tackle this issue, we use a bottom-up approach to detect regions around some initial parameters , instead of sampling in the entire space of parameters . Explicitly, we define region finding as an operator that takes the function of interest in Eq (1), initial point in the semantic space , and a shape of some class . The operator will return the hyper-rectangle , where the DNN is robust in the region and does not sharply drop the score of the intended class. It also keeps identifying the shape with label as illustrated in Fig. 4. The robust-region-finding operator is then defined as follows:
[TABLE]
where the left and right bounds of are and , respectively. The two small thresholds are needed to ensure high performance and low variance of the DNN in that robust region. We can define the complementary operator, which finds adversarial regions as:
[TABLE]
We can clearly show that and are related:
[TABLE]
So, we can just focus our attention on to find robust regions, and the adversarial regions follow directly from Eq (4). We need to ensure that has a positive size: . The volume of normalized by the exponent of dimension is expressed as follows:
[TABLE]
The region can also be defined in terms of the matrix of all the corner points as follows:
[TABLE]
and is the all-ones vector of size , is the Hadamard (element-wise) product of matrices, and is a constant masking matrix defined as the permutation matrix of binary numbers of bits that range from 0 to
3.2 Deriving Update Directions
Extending Naive to -dimensions. We start by defining the function vector of all function evaluations at all corner points of .
[TABLE]
Then, using Trapezoid approximation and Leibniz rule of calculus, the loss expression and the update directions become as follows:
[TABLE]
We show all the derivations for and for general in the **supplement **.
Outer-Inner Ratio Loss (OIR). We introduce an outer region with that contains the small region . We follow the following assumption to ensure that the outer area is always positive: . Here, is the small boundary factor of the outer area to the inner. We formulate the problem as a ratio of outer over inner areas and we try to make this ratio () as close as possible to 0 . We utilize the Dinkelbach technique for solving non-linear fractional programming problems [31] to transform as follows.
[TABLE]
where is the Dinkelbach factor that is the best objective ratio.
Black-Box (OIR_B). Here we set to simplify the problem. This yields the following expression of the loss , which is similar to the area contrastive loss in [33]. The update rules would be . To extend to -dimensions, we define an outer region that includes the smaller region and defined as: , where are defined as before, while is defined as the boundary factor of the outer region for all the dimensions. The inner region is defined as in Eq (6), while the outer region can be defined in terms of the corner points as follows:
[TABLE]
Let be a function vector as in Eq (7) and be another function vector evaluated at all possible outer corner points: .
Now, the loss and update directions for the -dimensional case becomes:
[TABLE]
where diag(.) is the diagonal matrix of the vector argument or the diagonal vector of the matrix argument. is the outer region scaled mask defined as follows:
[TABLE]
White-Box OIR (OIR_W). Here, we present the white-box formulation of Outer-Inner-Ratio. This requires access to the gradient of the function in order to update the current estimates of the bound. As we show in Section 4, access to gradients enhance the quality of the detected regions. To derive the formulation, We set in Eq (9), where is the small boundary factor of the outer area and is the gradient emphasis factor. Hence, the objective in Eq (9) becomes:
[TABLE]
Now, since should be small for the optimal objective as and hence the derivative in Eq (13) becomes the following:
[TABLE]
We can see that the update rule for and depends on the function value and the derivative of at the boundaries and respectively, with controlling the dependence. If , the update directions in Eq (14) collapse to the unregularized naive update. To extend to -dimensions, we have to define a term that involves the gradient of the function, *i.e. *the all-corners gradient matrix .
[TABLE]
Now, the loss and update directions are given as follows.
[TABLE]
where the mask is the special mask
[TABLE]
is a weighted sum of the gradient from other dimensions () contributing to the update direction of dimension , where .
[TABLE]
Algorithms 1, and 2 summarize the techniques explained above, which we implement in Section 4. The derivation of the 2-dimensional case and -dimensional case of the OIR formulation, as well as other unsuccessful formulations are all included in the **supplement **.
4 Experiments
4.1 Setup and Data
In this paper, we chose the semantic parameters to be the azimuth rotations of the viewpoint and the elevation angle from the horizontal plane, where the object is always at the center of the rendering. This is common practise in the literature [17, 20]. We use 100 shapes from 10 different classes from ShapeNet [7], the largest dataset for 3D models that are normalized from the semantic lens. We pick these 100 shapes specifically such that: (1) the class label is available in ImageNet [32] and that ImageNet classifiers can identify the exact class, and (2) the selected shapes are identified by the classifiers at some part of the semantic space. To do this, we measured the average score in the space and accepted the shape only if its average Resnet softmax score is 0.1. To render the images, we use a differentiable renderer NMR [22], which allows obtaining the gradient to the semantic input parameters. The networks of interest are Resnet50 [19], VGG [35], AlexNet [23], and InceptionV3 [37]. We use the official PyTorch implementation for each network [30].
4.2 Mapping the Networks
Similar to Fig. 1, we map the networks for all 100 shapes on the first semantic parameter (the azimuth rotation), as well as the joint (azimuth and elevation). We show these results in Fig. 4. The ranges for the two parameters were [[math],[math]],[[math],[math]], with a 33 grid. The total number of network evaluations is 4K forward passes from each network for every shape (total of 1.6M forward passes). We show all of the remaining results in the **supplement **.
4.3 Growing Semantic Robust Regions
We implement the three bottom-up approaches in Table 2 and Algorithms 1 and 2. The hyper-parameters were set to . We can observe in Fig. 3 that multiple initial points inside the same robust region converge to the same boundary. One key difference to be noted between the naive approach in Eq (8) and the OIR formulations in Eq (11,16) is that the naive approach fails to capture robust regions in some scenarios and fall for trivial regions (see Fig. 3).
4.4 Applications
**Quantifying Semantic Robustness.
**Looking at these NSM can lead to insights about the network, but we would like to develop a systemic approach to quantify the robustness of these DNNs. To do this, we develop the Semantic Robustness Volume Ratio (SRVR) metric. The SRVR of a network is the ratio between the expected size of the robust region obtained by Algorithms 1 and 2 over the nominal total volume of the semantic map of interest. Explicitly, the SRVR of network for class label is defined as follows:
[TABLE]
where are defined in Eq (1,2) respectively. We take the average volume of all the adversarial regions found for multiple initializations and multiple shapes of the same class . Then, we divide by the volume of the entire space. This provides a percentage of how close the DNN is from the ideal behaviour of identifying the object robustly in the entire space. The SRVR metric is not strict in its value, since the analyzer defines the semantic space of interest and the shapes used. However, comparing SRVR scores among DNNs is of extreme importance, as this relative analysis conveys insights about a network that might not be evident by only observing the accuracy of this network. For example, we can see in Table 1 that while InceptionV3 [37] is the best in terms of accuracy, it lags behind Resnet50 [19] in terms of semantic robustness. This observation is also consistent with the qualitative NSMs in Fig. 4, in which we can see that while Inception is very confident, it can fail completely inside these confident regions. Note that the reported SRVR results are averaged over all 10 classes and over all 100 shapes. We use 4 constant initial points for all experiments and the semantic parameters are the azimuth and elevation as in Fig. 3 and 4. As can be seen in Fig. 3, different methods predict different regions, so we take the average size of the the three methods used (naive, OIR_W, and OIR_B) to give an overall estimate of the volume used in the SRVR results reported in Table 1.
**Finding Semantic Bias in the Data.
**While observing the above figures uncovers interesting insights about the DNNs and the training data of ImageNet [32], it does not allow to make a conclusion about the network nor about the data. Therefore, we can average these semantic maps of these networks to factor out the effect of the network structure and training and maintain only the effect of training data. We show two such maps called Data Semantic Maps (DSMs). We observe that networks have holes in their semantic maps and these holes are shared among DNNs, indicating bias in the data. Identifying this gap in the data can help train a more semantically robust network. This can be done by leveraging adversarial training on these data-based adversarial regions as performed in the adversarial attack literature [15]. Fig. 5 shows an example of this semantic map, which points to the possibility that ImageNet [32] may not contain angles of the easy cup class.
5 Analysis
First, we observe in Fig. 4 that some red areas (adversarial regions the DNN can not identify the object within) are surrounded by blue areas (robust regions the DNN can identify the object within). These “semantic traps” are dangerous in ML, since they are hard to identify (without NSM) and they can cause failure cases for some models. These traps can be attributed to either the model architecture, training, and loss, or bias in the dataset, on which the model was trained (*i.e. *ImageNet [32].
Note that plotting NMS is extremely expensive even for a moderate dimensionality e.g. . For example, for the plot in Fig. 1, we use points in the range of degrees. If all the other dimensions require the same number of samples for their individual range, the total joint space requires samples, which is enormous. Evaluating the DNN for that many forward passes is intractable. Thus, we follow a bottom-up approach instead, where we start from one point in the semantic space and we grow an -dimensional hyper-rectangle around that point to find the robust “neighborhood” of that point for this specific DNN. Table 2 compares different analysis approaches for semantic robustness of DNNs.
6 Conclusion
We analyse DNN robustness with a semantic lens and show how more confident networks tend to create adversarial semantic regions inside highly confident regions. We developed a bottom-up approach to semantically analyse networks by growing adversarial regions. This approach scales well with dimensionality, and we use it to benchmark the semantic robustness of several well-known and popular DNNs.
Acknowledgments. This work was supported by the King Abdullah University of Science and Technology (KAUST) Office of Sponsored Research under Award No. OSR-CRG2018-3730
Appendix 0.A Analyzing Deep Neural Networks
Here we visualize different Network semantic maps generated during our analysis. In the 1D case we fix the elevation of the camera to a nominal angle of [math] and rotate around the object. In the 2D case, we change both the elevation and azimuth around the object. These maps can be generated to any type of semantic parameters that affect the generation of the image , and not viewing angle.
0.A.1 Networks Semantic Maps (1D)
In Fig. 6,7 we visualize the 1D semantic maps of rotating around the object and recording different DNNs performance and averaging the profile over 10 different shapes per class.
0.A.2 Networks Semantic Maps (2D)
In Fig. 8,9 we visualize the 2D semantic maps of elevation angles and rotating around the object and recording different DNNs performance and averaging the maps over 10 different shapes per class.
0.A.3 Convergence of the Region Finding Algorithms
Here we show how when we apply the region detection algorithms; the naive detect the smallest region while the OIR formulations detect bigger more general robust region. This result happens even with different initial points; they always converge to the same bounds of that robust region of the semantic maps. Fig. 10 show 4 different initializations for 1D case along with predicted regions. In Fig. 11,12 shows the bounds evolving during the optimization of the three algorithms (naive , OIR_B and OIR_W ) for 500 steps.
0.A.4 Examples of Found Regions ( with Example Renderings)
In Fig. 13,14 we provide examples of 2D regions found with the three algorithms along with renderings of the shapes from the robust regions detected.
0.A.5 Analyzing Semantic Data Bias in ImageNet
In Fig. 15,16, we visualizing semantic data bias in the common training dataset (*i.e. *ImageNet [32]) by averaging the Networks Semantic Maps (NSM) of different networks and on different shapes, Different classes have a different semantic bias in ImageNet as clearly shown in the maps above. These places of high confidence probably reveal the areas where an abundance of examples exists in ImageNet, while holes convey scarcity of such examples in ImageNet corresponding class.
Appendix 0.B Detailed Derivations of the Update Directions of the Bounds
0.B.1 Defining Robustness as an Operator
In our case we consider a more general case where er are interested in the , a hidden latent parameter that generate the image and is passes to scene generator (*e.g. *a renderer function ) that takes the parameter and a an object shape of a class that is identified by classifier . is the continuous semantic space for the parameters that we intend to study. The renderer creates the image , and then we study the behavior of a classifier of that image across multiple shapes and multiple famous DNNs. Now, this function of interest is defined as follows.
[TABLE]
Where is a class label of interest of study, and we observe the network score for that class by rendering a shape of the same class. The shape and class labels are constants, and only the parameters vary for . The robust-region-finding operator is then defined as follows
[TABLE]
where the left and right bounds of are and respectively. The two samll thresholds are to insure high performance and low variance of the DNN network in that robust region. We can define the opposite operator which is to find adversarial regions like follows :
[TABLE]
We can show clearly that and are related as follows
[TABLE]
So we can just focus our attentions on to find robust regions , and the adversarial regions follows directly from Eq (23).
0.B.2 Divergence of the Bounds
To develop an algorithm for , we deploy the idea by [33] which focus on maximizing the inner area of the function in the region and fitting the bounds to grow the region bounds. As we will show , maximizing the region by maximizing the integral can lead to divergence , as follows :
Lemma 1
Let be a continuous scalar function , and let be the function defining the definite integral of in terms of the two integral bounds , i.e. . Then, to maximize , and are valid ascent directions for the two bounds respectively.
Proof
a direction is an ascent direction of objective if it satisfies the inequality .[5].
To find , we use Leibniz rule from the fundamental theorem of calculus which states that
Therefore, . Similarly, . By picking , then . This proves that is a valid ascent direction for objective .
Theorem 0.B.1
Let be a positive continuous scalar function , and let be the function defining the definite integral of in terms of the two integral bounds , i.e. . Then, following the ascent direction in Lemma 1 can diverge the bounds if followed in a gradient ascent technique with fixed learning rate .
Proof
If we follow the direction , with a fixed learning rate , then the update rules for will be as follws. . for initial points , then , and . We can see now if , then as , the bounds . This leads to the claimed divergence.
To solve the issue of bounds diverging we propose the following formulations for one dimensional bounds , and then we extend them to n- dimensions , which allows for finding the n-dimensional semantic robust/adversarial regions that are similar to figure 2 . some of the formulations are black-box in nature ( they dint need the gradient of the function in order to update the current estimates of the bound ) while others .
0.B.3 Naive Approach
[TABLE]
using Libeniz rule as in Lemma 1, we get the following update steps for the objective L :
[TABLE]
where is regularizing the boundaries not to extend too much in the case the function evaluation wa positive all the time.
Extension to n-dimension:. Lets start by . Now, we have , then we define the loss integral as a function of four bounds of a rectangular region as follows.
[TABLE]
We apply the trapezoidal approximation on the loss to obtain the following expression.
[TABLE]
to find the update direction for the first bound by taking the partial derivative of the function in Eq (26) we get the following update direction for along with its trapezoidal approximation in order to able to compute it during the optimization:
[TABLE]
Doing similar steps to the first bound for the other three bounds we obtain the full update directions for ()
[TABLE]
Now, for , we define the inner region hyper-rectangle as before .Here , we assume the size of the region is positive at every dimension , i.e. . The volume of the region normalized by exponent of dimension is expressed as follows
[TABLE]
The region can also be defined in terms of the matrix of all the corner points as follows.
[TABLE]
where is the all-ones vector of size , is the Hadamard product of matrices (element-wise) , and is a constant masking matrix defined as the matrix of binary numbers of n bits that range from 0 to defined as follows.
[TABLE]
We define the function vector as the vector of all function evaluations at all corner points of
[TABLE]
We follow similar steps as in and obtain the following loss expressions and update directions :
[TABLE]
0.B.4 Outer-Inner Ratio Loss (OIR)
We introduce an outer region with bigger area that contains the small region . We follow the following assumption to insure that outer area is always positive.
[TABLE]
where is the small boundary factor of the outer area to inner area. We formulate the problem as a ratio of outer over inner area and we try to make this ratio as close as possible to 0 . By using DencklBeck technique for solving non-linear fractional programming problems [31]. Using their formulation to transform as follows.
[TABLE]
where is the DencklBeck factor and it is equal to the small objective best achieved.
Black-Box (OIR_B).
Here we set to simplify the problem. This yields the following expression of the loss
[TABLE]
using Libeniz ruloe as in Lemma 1, we get the following update steps for the objective L :
[TABLE]
Extension to n-dimension:. Lets start by . Now, we have , and with the following constrains on the outer region.
[TABLE]
we define the loss integral as a function of four bounds of a rectangular region as follows.
[TABLE]
We apply the trapezoidal approximation on the loss to obtain the following expression.
[TABLE]
to find the update direction for the first bound by taking the partial derivative of the function in Eq (40) we get the following update direction for along with its trapezoidal approximation in order to able to compute it during the optimization:
[TABLE]
Doing similar steps to the first bound for the other three bounds we obtain the full update directions for ()
[TABLE]
[TABLE]
[TABLE]
[TABLE]
Now, for , we define the inner region hyper-rectangle as before , but now define an outer bigger region that include the smaller region and defined as follows : , where are defined as before, while is defined as the boundary factor of the outer region in all the dimensions equivilantly. The inner and outer regions can also be defined in terms of the corner points as follows.
[TABLE]
where is the all-ones vector of size , is the Hadamard product of matrices (elemnt-wise) , and is a constant masking matrix defined in Eq (32). Now we define two function vectors evaluated at all possible inner and outer corner points respectively.
[TABLE]
Now the loss and update directions for the n-dimensional case becomes as follows .
[TABLE]
wheere is the outer region mask defined as follows.
[TABLE]
White-Box OIR (OIR_W.) The following formulation is white-box in nature ( it need the gradient of the function in order to update the current estimates of the bound ) this is useful when the function in hand is differntiable ( *e.g. *DNN ) , to obtain more intelligent regions, rather then the regions surrounded by near 0 values of the function . We set in Eq (36), where is the small boundary factor of the outer area, is the emphasis factor (we will show later how it determines the emphasis on the function vs the gradient). Hence, the objective in Eq (36) becomes :
[TABLE]
using Libeniz ruloe as in Lemma 1, we get the following derivatives of the bound :
[TABLE]
now since should be small for the optimal objective , then as and hence the derivative in Eq (52) becomes the following.
[TABLE]
We can see that the first term is proportional to the derivative of at , and hence the expression becomes :
[TABLE]
we can see that the update rule depends on the function value and the derivative of at the boundary with controlling the dependence. Similarly for the boundary we can see the following direction
[TABLE]
If , the update directions in Eq (54,55) collapse to the unregularized naive update in Eq (25) .
Extension to n-dimension.. Lets start by . Now, we have , and with the following constrains on the outer region.
[TABLE]
we follow similar approach as in Eq (LABEL:eq:loss-oir2-sup) to obtain the following expression.
[TABLE]
We apply the trapezoidal approximation on the loss to obtain the following approximation.
[TABLE]
to find the update direction for the first bound by taking the partial derivative of the function in Eq (40) we get the fol owing update direction for along with its trapezoidal approximation in order to able to compute it during the optimization:
[TABLE]
grouping the terms which are divided by together and then taking the limit of (as explained in the 1-d case ), we get the following expressions.
[TABLE]
Noting that the first term is related to the directional derivatives of , we get the following limit expression
[TABLE]
Doing similar steps to the first bound for the other three bounds we obtain the full update directions for ()
[TABLE]
[TABLE]
[TABLE]
[TABLE]
Now, for Following previous notations we have the following expressions for the loss and update directions for the bound
[TABLE]
where the mask is the special mask
[TABLE]
Where diag(.) is the diagonal matrix of the vector argument or the diagonal vector of the matrix argument. is a weighted sum of the gradient from other dominions () contributing to the update direction of dimension , where .
[TABLE]
0.B.5 Trapezoidal Approximation Formulation
Here we use the trapezoidal approximation of the integral, a first-order approximation from Newton-Cortes formulas for numerical integration [36]. The rule states that a definite integral can be approximated as follows:
[TABLE]
asymptotic error estimate is given by -\frac{(b-a)^{2}}{48}\left[f^{\prime}(b)-f^{\prime}(a)\right]+\mathcal{O}\Big{(}0.125\Big{)}. So as long the derivatives are bounded by some lipschitz constant , then the error becomes bounded by the following . The regularized loss of interest in Eq (24) becomes the following .
[TABLE]
taking the derivative of approximation directly with respect to these bounds , yields the following update directions which are different from the expressions in Eq (25)
[TABLE]
note that it needs the first derivative of the function evaluated at the bound to update that bound.
**Extension to n-dimensions.
**Lets start by . Now, we have , and we define the loss integral as a function of four bounds of a rectangler region and apply the trapezoidal approximation as follows.
[TABLE]
Then following similar steps as in the one-dimensional case we can obtain the following update directions for the four bounds
[TABLE]
[TABLE]
[TABLE]
[TABLE]
Where . extending the 2-dimensional to general n-dimensions is straight forward. For , we define the following. Let the left bound vector be and the right bound vector define the n-dimensional hyper-rectangle region of interest. The region is then definesd as follows : , Here, we assume the size of the region is positive at every dimension , i.e. . The volume of the region normalized by exponent of dimension is expressed as in Eq (30), the region is defined as in Eq (31), is defined as in Eq (32), and is defined as in Eq (33). now we can see that the loss integral in Eq (72) becomes as follows .
[TABLE]
Similarly to Eq (33), we define the gradient matrix as the matrix of all gradient vectors evaluated at all corner points of
[TABLE]
The update directions for the left bound and the right bound becomes as follows by the trapezoid approximation
[TABLE]
Where is the complement of the binary mask matrix .
Appendix 0.C Analysis
0.C.1 Detected Robust Regions
We apply the algorithms on two semantic parameters ( the azimuth angle of the camera around the object, and the elevation angle around the object) that are regularly used in the literature [17, 1]. When we use one parameter ( the azimuth), we fix the elevation to [math]. We used two instead of larger numbers because it is easier to verify and visualize 2D, unlike higher dimensions. Also, the complexity of sampling increase exponentially with dimensionality for those algorithms ( albeit being much better than grid sampling, see Table 3). The regions in Fig. 13,14 look vertical rectangles most of the time. This is because the scale of the horizontal-axis (0,360) is much smaller than the vertical axis (-10,90), so most regions are squares but looks rectangles because of figure scales.
0.C.2 hyper-parameters
How to select the hyper parameters in all the above algorithms? The answer is not straight forward. For the in the naive approach, it is set experimentally by trying different values and using the one which detects some regions that known to behave robustly. The values we found for this are . The learning rate is easier to detect with observing the convergence and depends on the full range of study. A rule of thumb is to make 0.001of the full range. For the OIR formulations, we have the boundary factor which we set to 0.05. A rule of thumb is to set it to be between , where is the number of samples needed for that dimensions to adequately characterize the space. In our case , so . The only hyperparameter with mathematically established bound is the emphasis factor of the OIR_W formulation . The bound shown in Table 3 which is can be shown as follows. We start from Eq (67). This expression is the actual expression for the special masks ( we apologize in the typos in the main paper ). As we can see, the most important term is . IT dictates how the function at the boundaries determine the next move of the bounds. Here should always be positive to ensure the correct direction of the movement for positive function evaluation.
[TABLE]
0.C.3 Detest
The data set used is collected from ShapeNet [7] and consists of 10 classes and 10 shapes eaach that are all identified by at least ResNet50 trained on ImagNet. This criteria is important to obtain valid NSM and DSM. The classes are [’aeroplane’,"bathtub",’bench’, ’bottle’,’chair’,"cup","piano",’rifle’,’vase’,"toilet"]. Part of the dataset is shown in Fig. 11,12. 4 shapes faced difficulty of rendering during the SRVR experiments , therefore , they were replaced by another shapes from the same class.
0.C.4 Possible Future Directions
We analyze DNNs from a semantic lens and show how more confident networks tend to create adversarial semantic regions inside highly confident regions. We developed a bottom-up approach to analyzing the networks semantically by growing adversarial regions, which scales well with dimensionality and we use it to benchmark the semantic robustness of DNNs. We aim to investigate how to use the insights we gain from this work to develop and train semantically robust networks from the start while maintaining accuracy. Another direct extension of our work is to develop large scale semantic robustness challenge where we label these robust/adversarial regions in the semantic space and release some of them to allow for training. Then, we test the trained models on the hidden test set to measure robustness while reporting the accuracy on ImageNet validation set to make sure that the features of the model did not get affected by the robust training.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Alcorn, M.A., Li, Q., Gong, Z., Wang, C., Mai, L., Ku, W.S., Nguyen, A.: Strike (with) a pose: Neural networks are easily fooled by strange poses of familiar objects. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2019)
- 2[2] An, G.: The effects of adding noise during backpropagation training on a generalization performance. Neural computation 8 (3), 643–674 (1996)
- 3[3] Bibi, A., Alfadly, M., Ghanem, B.: Analytic expressions for probabilistic moments of pl-dnn with gaussian input. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2018)
- 4[4] Bishop, C.M.: Training with noise is equivalent to tikhonov regularization. Training 7 (1) (2008)
- 5[5] Boyd, S., Vandenberghe, L.: Convex Optimization. Cambridge University Press, New York, NY, USA (2004)
- 6[6] Carlini, N., Wagner, D.: Towards evaluating the robustness of neural networks. In: IEEE Symposium on Security and Privacy (SP) (2017)
- 7[7] Chang, A.X., Funkhouser, T., Guibas, L., Hanrahan, P., Huang, Q., Li, Z., Savarese, S., Savva, M., Song, S., Su, H., Xiao, J., Yi, L., Yu, F.: Shape Net: An Information-Rich 3D Model Repository. Tech. Rep. ar Xiv:1512.03012 [cs.GR], Stanford University — Princeton University — Toyota Technological Institute at Chicago (2015)
- 8[8] Chen, P.Y., Zhang, H., Sharma, Y., Yi, J., Hsieh, C.J.: Zoo: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models. In: Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security. pp. 15–26. AI Sec ’17, ACM, New York, NY, USA (2017)
