Regression Concept Vectors for Bidirectional Explanations in Histopathology
Mara Graziani, Vincent Andrearczyk, Henning M\"uller

TL;DR
This paper introduces Regression Concept Vectors (RCVs) to interpret deep neural networks in histopathology, enabling concept-based explanations that improve understanding of model sensitivities in medical diagnosis.
Contribution
The work presents a novel methodology using RCVs for continuous concept measurement in neural network activation spaces, specifically applied to breast cancer grading.
Findings
Nuclei texture is identified as a key concept in tumor detection.
RCVs provide robust and consistent explanations across samples.
Directional derivatives along RCVs reveal network sensitivities.
Abstract
Explanations for deep neural network predictions in terms of domain-related concepts can be valuable in medical applications, where justifications are important for confidence in the decision-making. In this work, we propose a methodology to exploit continuous concept measures as Regression Concept Vectors (RCVs) in the activation space of a layer. The directional derivative of the decision function along the RCVs represents the network sensitivity to increasing values of a given concept measure. When applied to breast cancer grading, nuclei texture emerges as a relevant concept in the detection of tumor tissue in breast lymph node samples. We evaluate score robustness and consistency by statistical analysis.
Click any figure to enlarge with its caption.
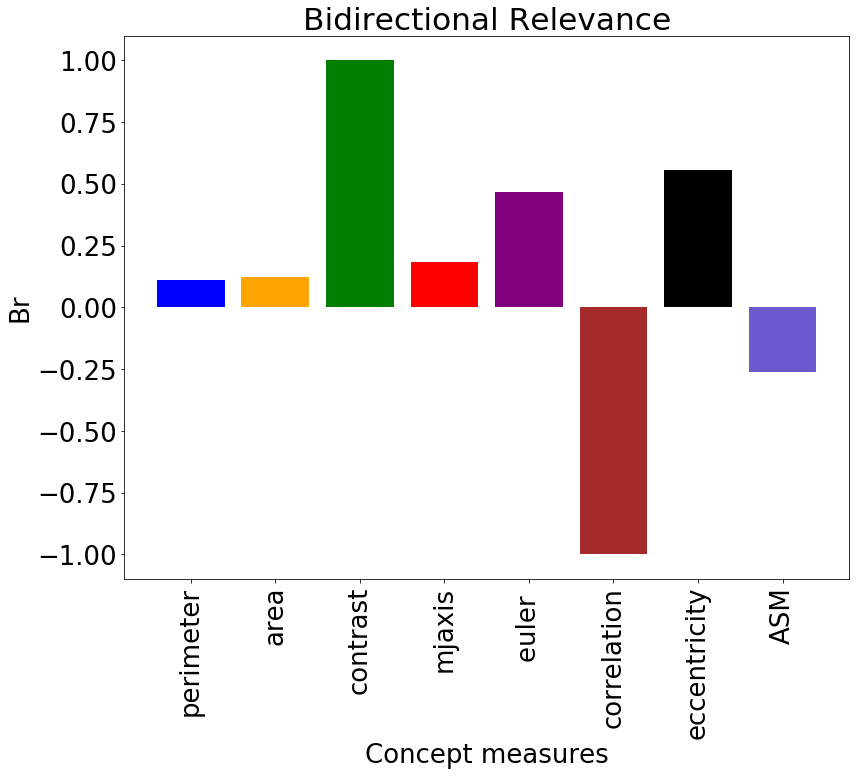 Figure 1
Figure 1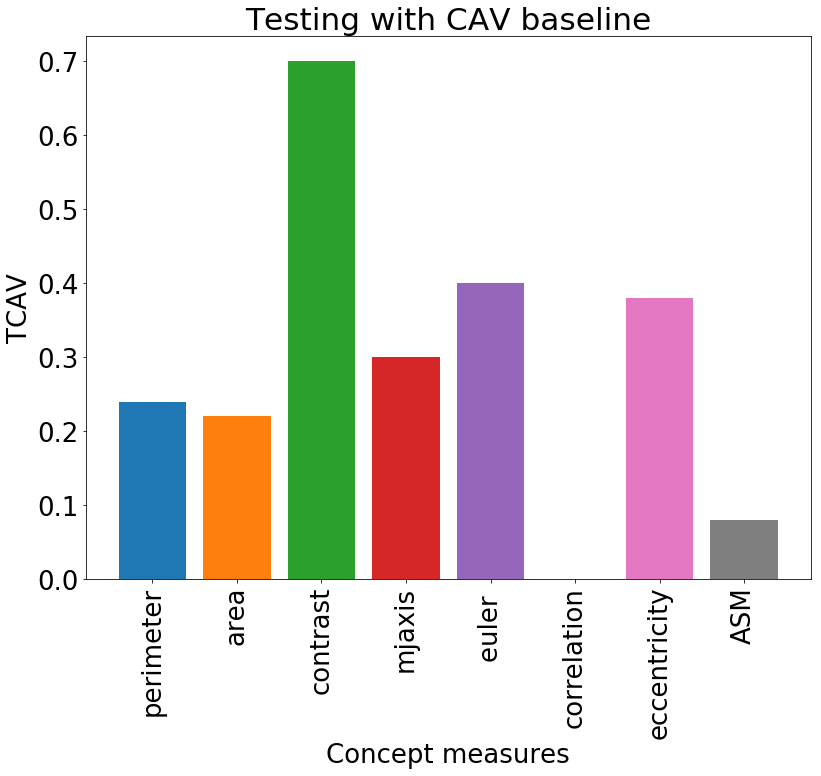 Figure 2
Figure 2 Figure 3
Figure 3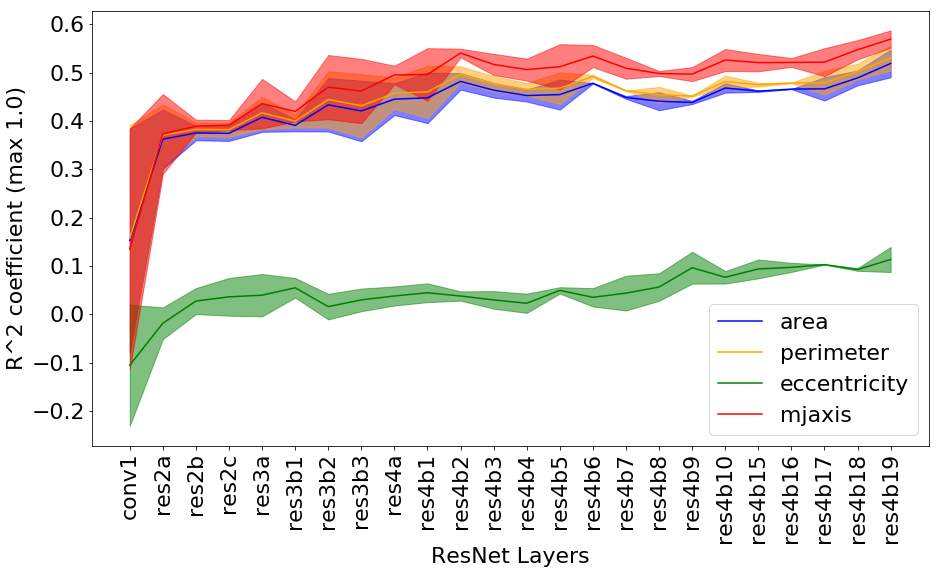 Figure 4
Figure 4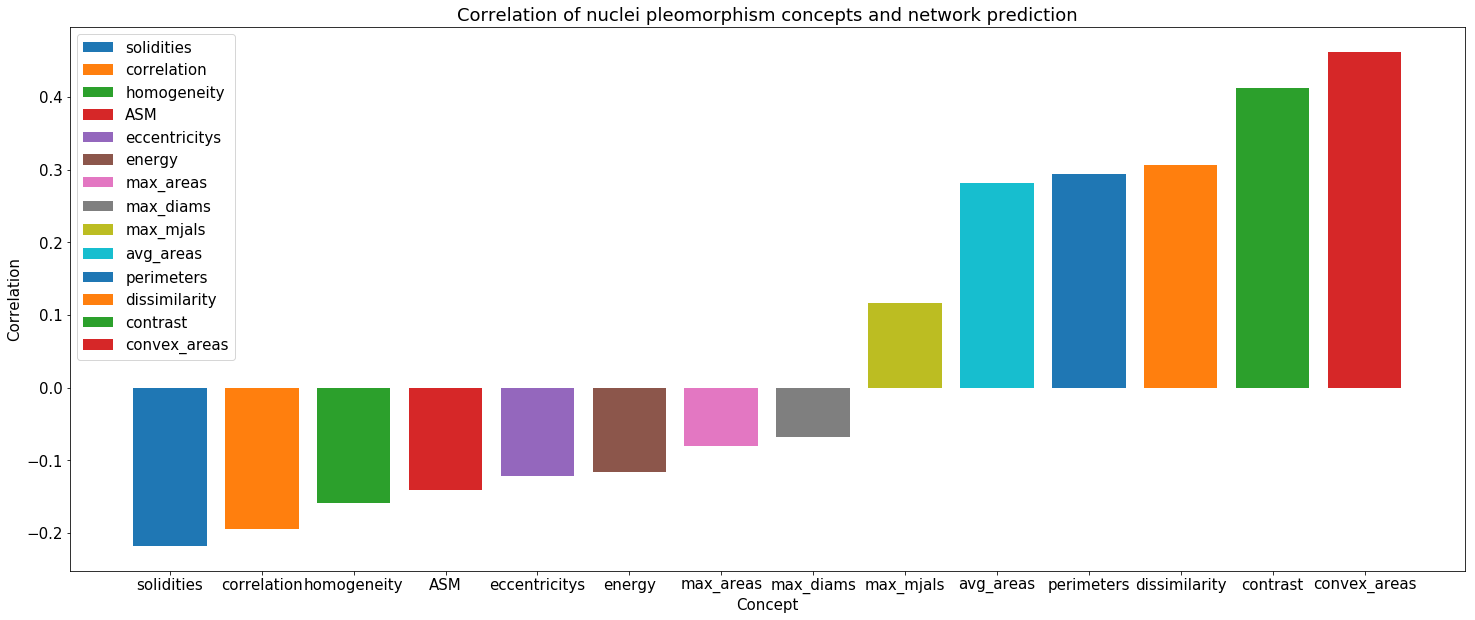 Figure 5
Figure 5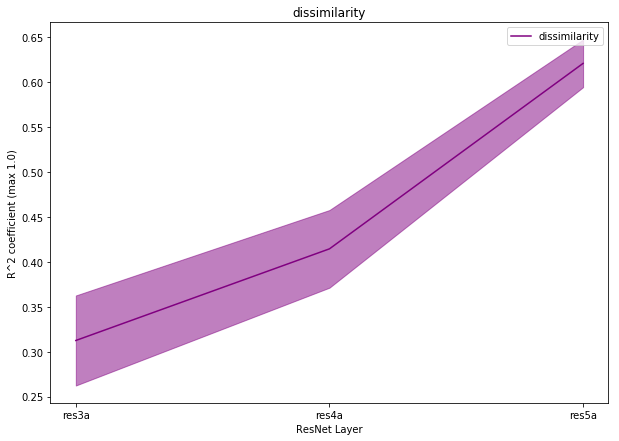 Figure 6
Figure 6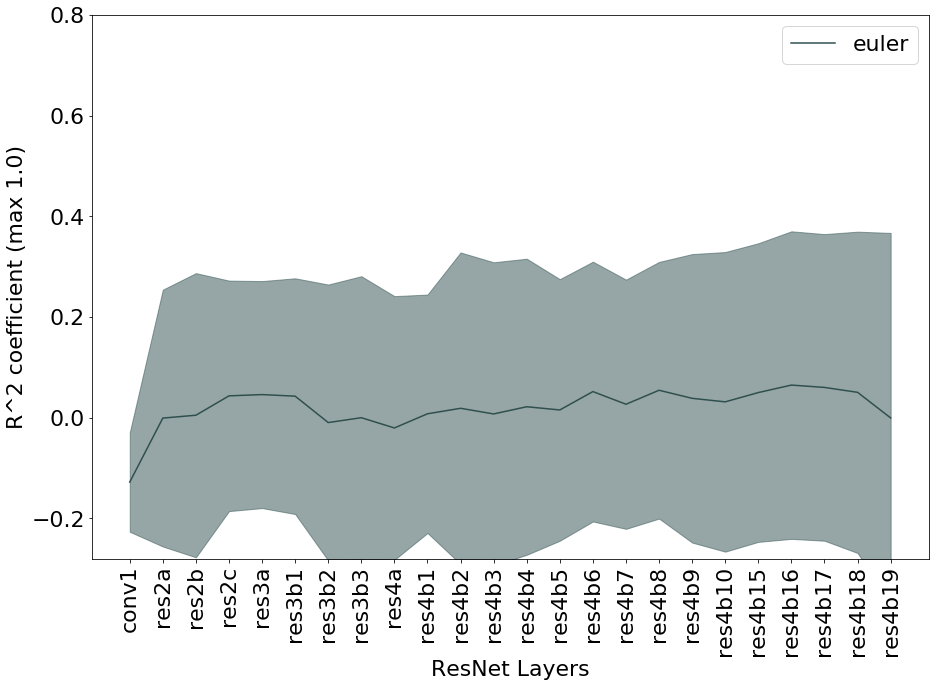 Figure 7
Figure 7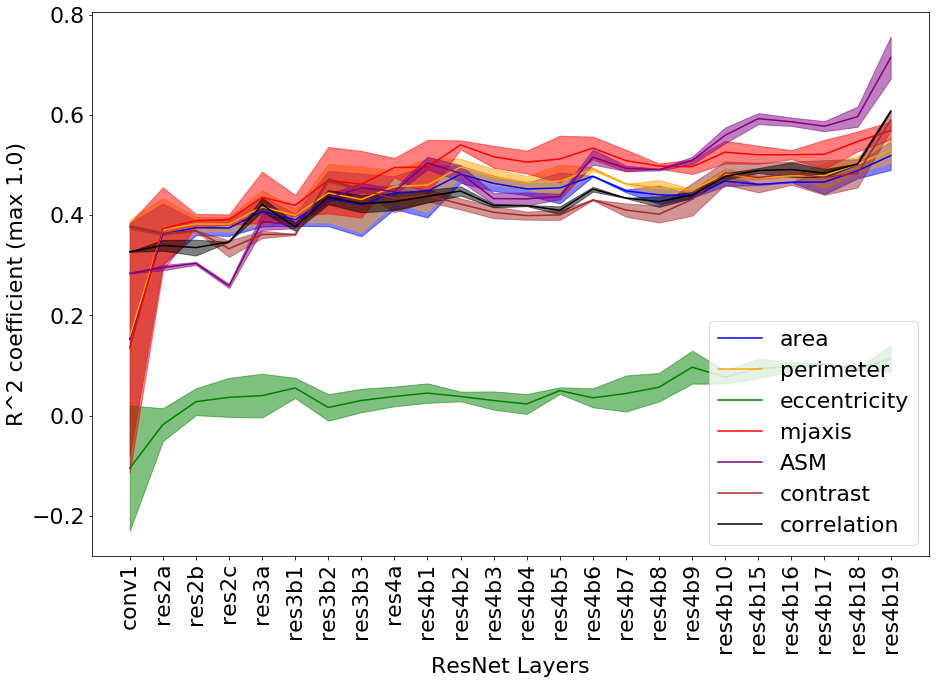 Figure 8
Figure 8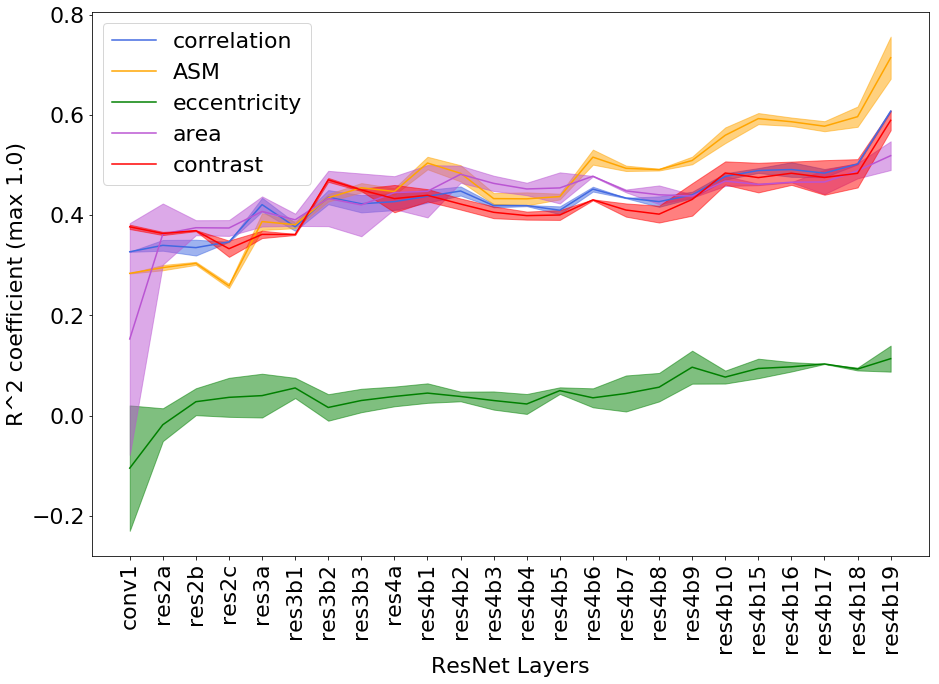 Figure 9
Figure 9 Figure 10
Figure 10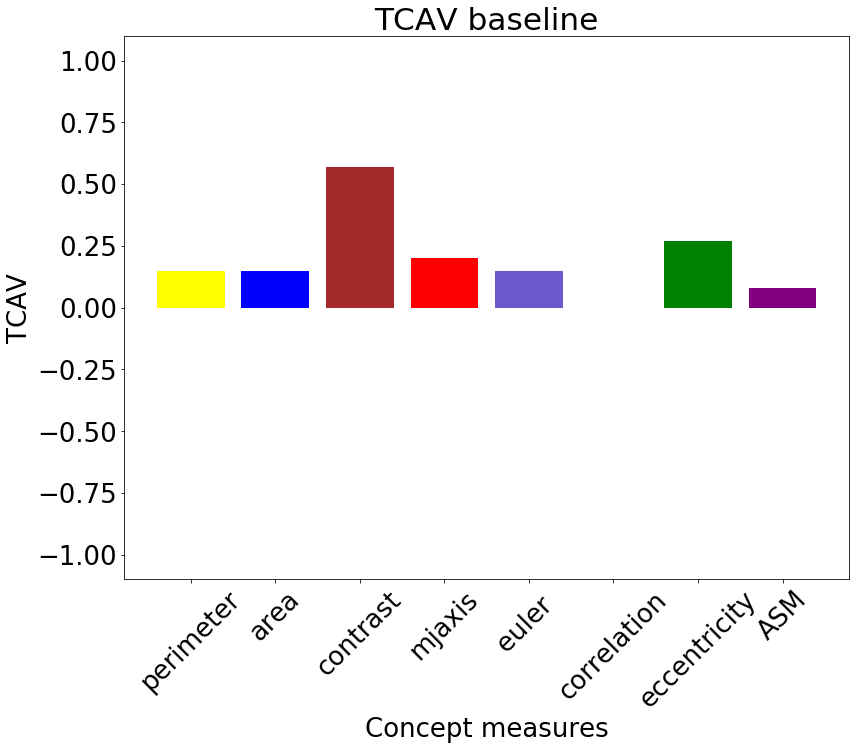 Figure 11
Figure 11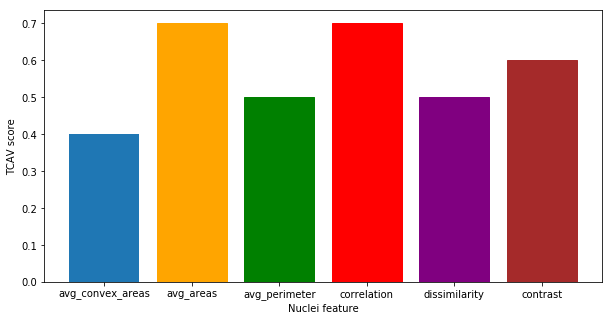 Figure 12
Figure 12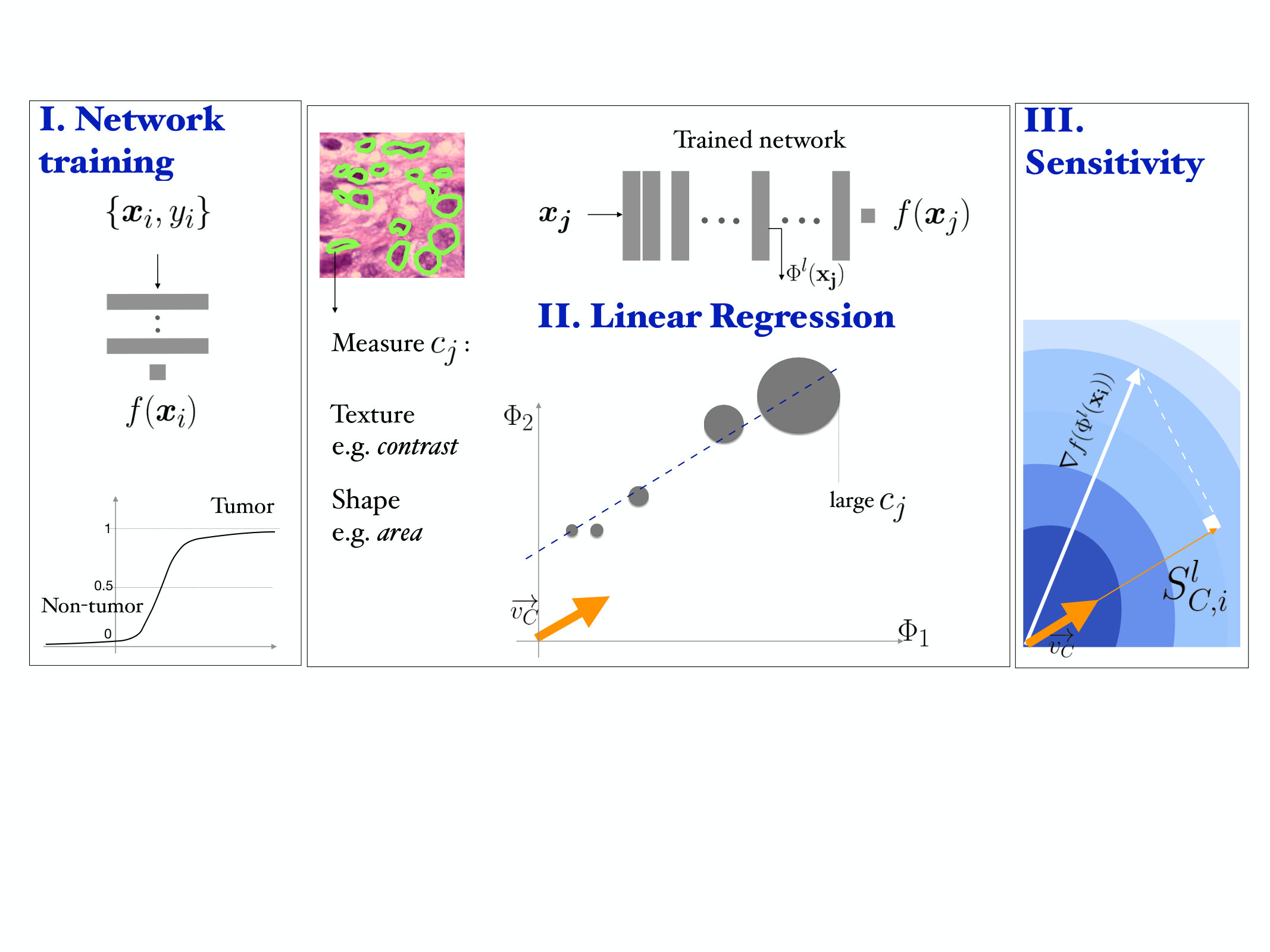 Figure 13
Figure 13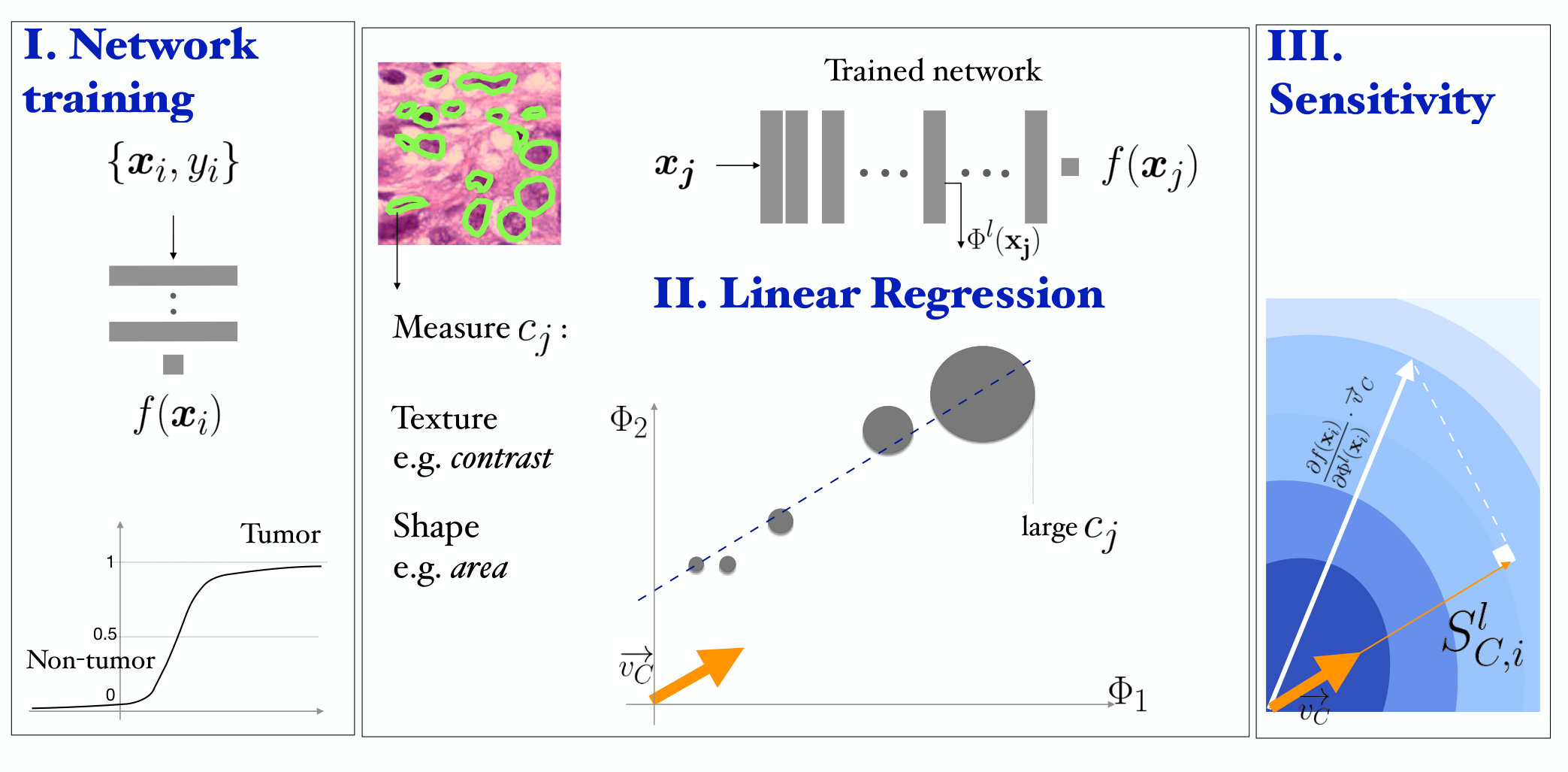 Figure 14
Figure 14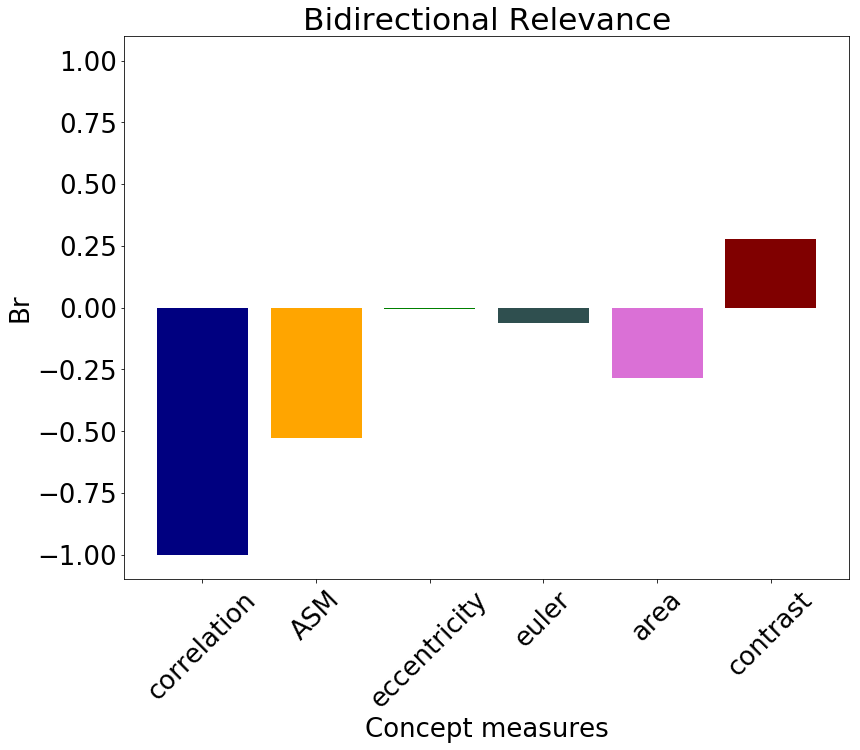 Figure 15
Figure 15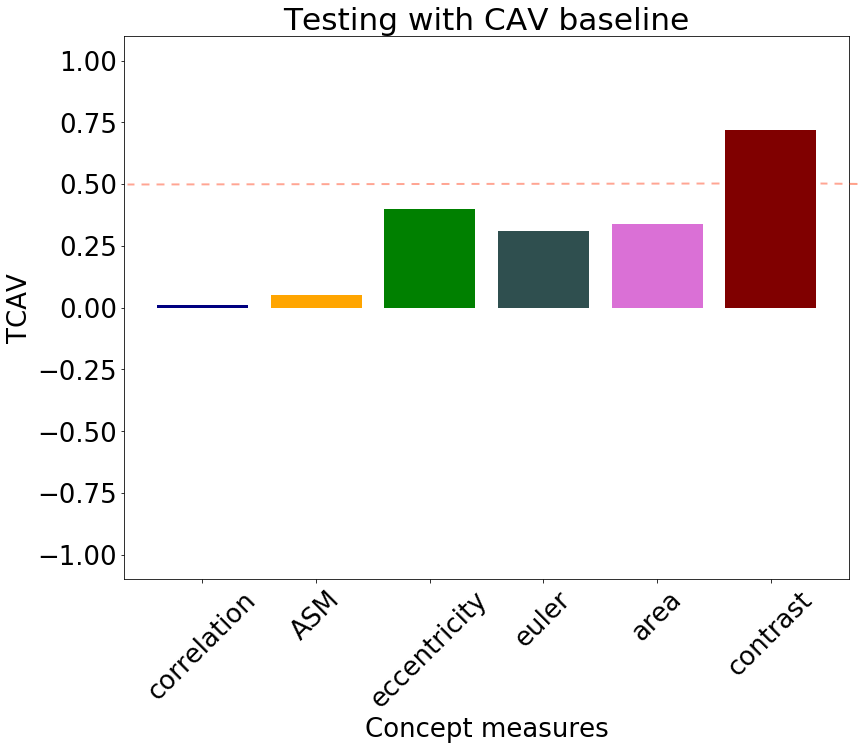 Figure 16
Figure 16 Figure 17
Figure 17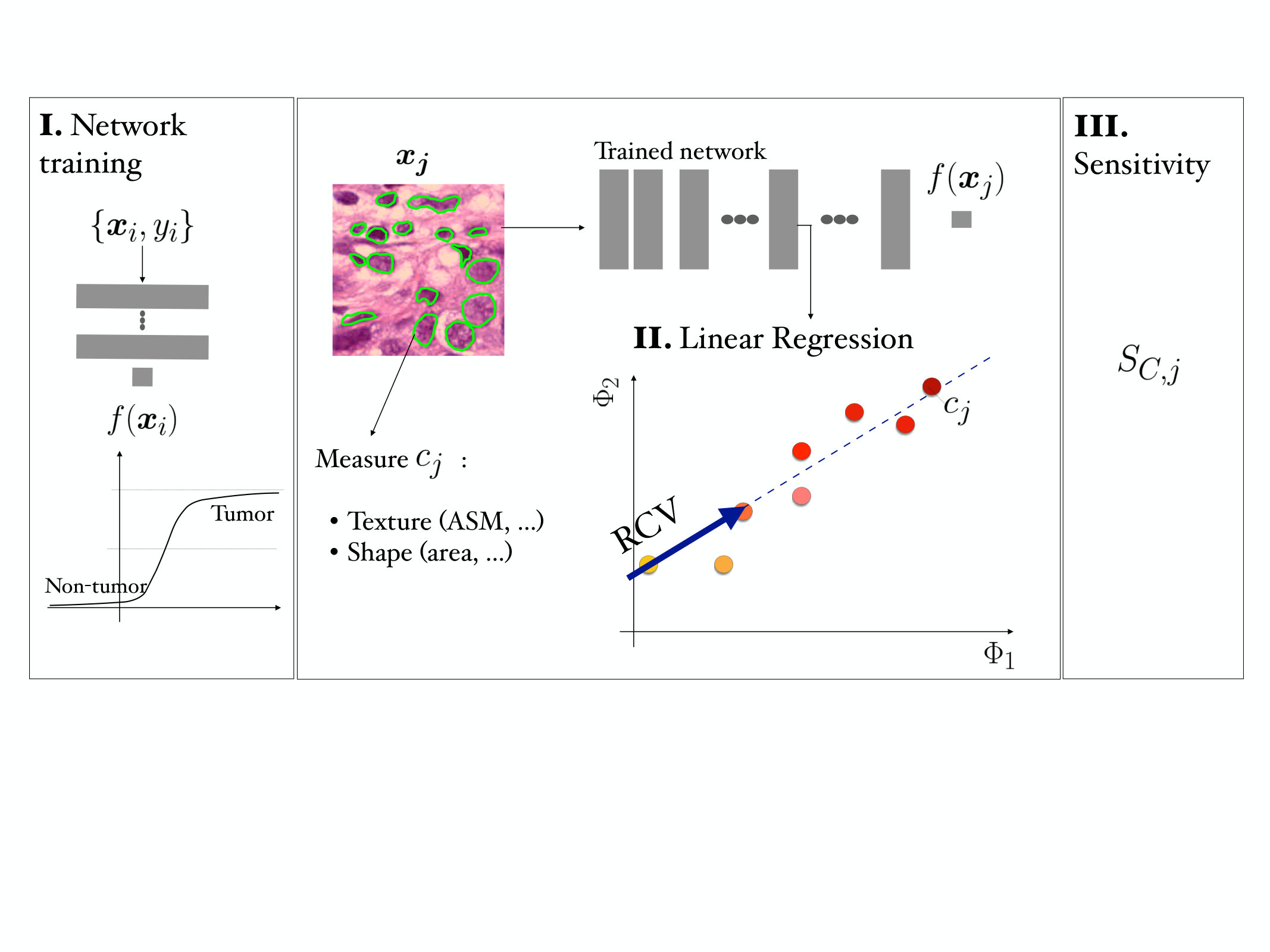 Figure 18
Figure 18| model | validation accuracy |
|---|---|
| Zanjani et al. | 98.7 |
| ResNet101 |
| correlation | ASM | eccentricity | Euler | area | contrast | |
|---|---|---|---|---|---|---|
| p-value |
| correlation | ASM | eccentricity | Euler | area | contrast | |
|---|---|---|---|---|---|---|
| TCAV | ||||||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAI in cancer detection · Explainable Artificial Intelligence (XAI) · Radiomics and Machine Learning in Medical Imaging
MethodsDynamic Time Warping
11institutetext: 1University of Applied Sciences Western Switzerland (HES-SO), Sierre, Switzerland
2University of Geneva (UNIGE), Geneva, Switzerland
Authors’ Instructions
Regression Concept Vectors for Bidirectional Explanations in Histopathology
Mara Graziani 1,2
Vincent Andrearczyk 1
Henning Müller1,2
Abstract
Explanations for deep neural network predictions in terms of domain-related concepts can be valuable in medical applications, where justifications are important for confidence in the decision-making. In this work, we propose a methodology to exploit continuous concept measures as Regression Concept Vectors (RCVs) in the activation space of a layer. The directional derivative of the decision function along the RCVs represents the network sensitivity to increasing values of a given concept measure. When applied to breast cancer grading, nuclei texture emerges as a relevant concept in the detection of tumor tissue in breast lymph node samples. We evaluate score robustness and consistency by statistical analysis.
Keywords:
interpretability concept vector histopathology.
1 Introduction
††Proceedings of the First International Workshop of Interpretability of Machine Intelligence in Medical Image Computing at MICCAI 2018, Granada, Spain, September 16-20, 2018. Copyright 2018 by the author(s)
Understanding representations learned by deep neural networks is a main challenge in medical imaging. Recent work on Testing with Concept Activation Vectors (TCAV) proposed directional derivatives to quantify the influence of user-defined concepts on the network output. As a real application example, the presence of diagnostic concepts such as microaneurysms and aneurysms was used to explain network predictions for diabetic retinopaty levels [6]. However, diagnostic concepts are often continuous measures that might be counter intuitive to describe by their presence or absence.
Intense research on network interpretability defined the distinction between global and local interpretability and proposed a taxonomy of desiderata, methods and evaluation criteria [1, 10, 12]. The relevance, or saliency, of input factors to the network decision was proposed in several gradient-based methods [12, 14, 15, 16]. Outputs of these methods are typically local explanations that are gathered in attribution maps and overlayed to the original input image. The interpretability of these approaches, however, was shown to be limited and often inconsistent [7, 13]. Research in the linearity of the latent space showed that linear classifiers can learn meaningful directions. These directions were mapped to semantic word embeddings in [11] or human-friendly visual concepts in [6]. TCAV computes the direction representative of a concept as the normal to the hyperplane which separates a set of concept images from a set of random images. The TCAV score estimates the influence of the user-defined concept on network decisions [6].
In this paper, we extend TCAV from a classification problem to a regression problem by computing Regression Concept Vectors (RCVs). Instead of seeking a discriminator between two concepts (or one concept and random inputs), we seek the direction of greatest increase of the measures for a single continuous concept. In particular, we compute RCVs by least squares linear regression of the concept measures for a set of inputs. We measure the relevance of a concept with bidirectional relevance scores, . The scores assume positive values when increasing values of the concept measures positively affect classification and negative in the opposite case.
We address breast cancer histopathology as an application for functionally grounded evaluation. The classification of high-resolution patches as tumorous and non-tumorous tissue is often used as a first step by state-of-the-art breast cancer classifiers [3]. Identifying the factors relevant to classification is essential to improve the physicians’ trust in automated grading. For this reason, we referred to the Nottingham Histologic Grading system (NHG) [2] to select nuclear pleomorphism, and especially variations in nuclei size, shape and texture as concept measures.
The main contributions of this paper are (i) the expression of concept measures as RCVs; (ii) the development and evaluation of scores; (iii) the computation of nuclei pleomorphism relevance for breast cancer.
In the following, we clarify the notations adopted in the paper. We consider the set of inputs and ground truth pairs and a deep convolutional neural network (CNN) for binary classification with prediction output . The input is a image patch and is the corresponding class label (with for the tumor class). The disjoint set is representative of a concept , with measures for each image sample . In the activation space, the output of layer for input is and the RCV for is (we will drop superscript to simplify the notation). An overview of the method is presented in Figure 1.
2 Methods
2.1 Correlation to Network Prediction
As a prior analysis, we compute the Pearson product-moment correlation coefficient between and for . If is not relevant for , their correlation should be low. In this case, should not encode information about and it should be unlikely to find a good linear regression. A high correlation could instead suggest a positive (if ) or negative () influence of the concept on the prediction.
2.2 Regression Concept Vectors
We extract and flatten the for each . The RCV is the vector in the space of the activation that best fits the direction of the strongest increase of the concept measures. This direction can be computed as the least squares linear regression fit of (see Figure 1). In the NHG, for example, larger nuclei are assigned higher grades by pathologists. If we take nuclei area as a concept, we seek the vector in the activation space that points towards representations of larger nuclei.
2.3 Sensitivity to RCV
For each testing pair we compute the sensitivity score as the directional derivative along the direction of the RCV:
[TABLE]
represents the network sensitivity to changes in the input along the direction of increasing values of the concept measures. When moving along this direction, may either increase, decrease or remain unchanged (=0). The sign of represents the direction of change, while the magnitude of represents the rate of change. TCAV computes global explanations from the sensitivities although it does not consider their magnitude. Hence, we propose as an alternative measure. scores were formulated by taking into account the principles of explanation continuity and selectivity proposed in [12]. For the former, we consider whether the sensitivity scores are similar for similar data samples. For the latter, we redistribute the final relevance to concepts with the strongest impact on the decision function. We define scores as the ratio between the coefficient of determination of the least squares regression, , and the coefficient of variation of the sensitivity scores:
[TABLE]
indicates how closely the RCV fits the . The coefficient of variation is the standard deviation of the scores over their average, and describes their relative variation around the mean. For the same value of , the for spread scores is lower than for scores that lay closely concentrated near their sample mean. After computing for multiple concepts, we scale the scores to the range [-1, 1] by dividing by the maximum absolute value.
2.4 Evaluation of the Explanations
The explanations are evaluated on the basis of their statistical significance as proposed in [6]. We compute TCAV and scores for 30 repetitions and perform a two-tailed t-test with Bonferroni correction (with significance level ), as suggested in [6]. If we can reject the null hypothesis of TCAV of 0.5 for random scores and Br of 0, we accept the result as statistically significant.
3 Experiments and Results
3.1 Datasets
We trained the network on the challenging Camelyon16 and Camelyon17 datasets††https://camelyon17.grand-challenge.org/ as of June 2018. More than 40,000 patches at the highest resolution level were extracted from Whole Slide Images (WSIs) with ground truth annotation. To extract concepts, we used the nuclei segmentation data set in [9], for which no labels of tumorous and non-tumorous regions were available. The dataset contains WSIs of several organs with more than 21,000 annotated nuclei boundaries. From this data set, we extracted 300 training patches only from the WSIs of breast tissue.
3.2 Network Architecture and Training
A ResNet101[5] pretrained on ImageNet was finetuned with binary cross-entropy loss for classification of tumor and non-tumor patches. For each input, the network outputs its probability to be tumor with a logistic regression function. We trained for 30 epochs with Nesterov momentum stochastic gradient descent and standard hyperparameters (initial learning rate , momentum ). Staining normalization and online data augmentation (random flipping, brightness, saturation and hue perturbation) were used to reduce the domain shift between the different centers. Statistics on network performance were computed from five random splits with unseen test patients.††The pretrained models and the source code used for the experiments can be found at https://github.com/medgift/iMIMIC-RCVs
3.3 Results
Classification Performance
The validation accuracy of our classifier is just below the performance of the patch classifier used to get state-of-the-art results on the Camelyon17 challenge [3], as reported in Table 1. We report the per-patch validation accuracy for both models, although details about the training setup in [3] are unknown. Bootstrapping of the false positives was not performed and the training set size was kept limited (with 40K patches instead of 600K). The obtained accuracy is sufficient for a meaningful model interpretation analysis, which may be used to boost the network accuracy and generalization. Besides this, the analysis could itself be used as an alternative to bootstrapping for detecting mislabeled examples [8].
Correlation Analysis
We expressed the NHG criteria for nuclei pleomorphism as average statistics of the nuclei morphology and texture features. From the patches () with ground truth segmentation, we computed average nuclei area, Euler coefficient and eccentricity of the ellipses that have the same second-moments as the nuclei segmented contours. We extracted three Haralick texture features inside the segmented nuclei, namely Angular Second Moment (ASM), contrast and correlation [4]. The Pearson correlation between the concept measurements and the relative network prediction is shown in Table 2. The concept measures for contrast had the largest correlation coefficient, .
Are We Learning the Concepts?
The performance of the linear regression was used to check if the network is learning the concepts and in which layers. The determination coefficient of the regression expresses the percentage of variation that is captured by the regression. We computed for all patches over multiple reruns to analyze the learning dynamics. Almost all the concepts were learned in the early layers of the network (see Figure 2(a)), with eccentricity and Euler being the only two exceptions. Figure 2(b) shows that the concept Euler is highly unstable and has almost zero mean, suggesting that the learned RCVs might be random directions.
Sensitivity and Relevance
Sensitivity scores were computed on patches () from Camelyon17. The global relevance was tested with TCAV and , as reported in Figure 3. Contrast is relevant for the classification, with TCAV and . Even stronger is the impact of correlation, which shifts the classification output towards the non-tumor class. In this case sensitivies are mostly negative, with and TCAV. These scores mirror the preliminary analysis of Pearson correlation in Table 2. Unstable concepts, such as Euler and eccentricity, lead to almost zero scores, in accordance with the initial hypothesis that the RCVs for these concepts might just be random vectors.
Statistical Evaluation
We performed a two-tailed t-test to compare the distributions of the scores against the null hypothesis of learning a random direction for the TCAV (mean ) and (mean [math]) scores. The results are presented in Table 3. There was a significant difference (with ) in the scores for all the relevant concepts, namely correlation, ASM, area and contrast. The statistical significance of correlation improves for scores. From the sensitivity and relevance analysis, we do not expect the Euler and eccentricity concepts to be statistically different from random directions. The analysis of both TCAV and scores confirms this hypothesis () for the eccentricity, although the confidence to not reject the null hypothesis is higher with . The Euler concept is not rejected by the TCAV analysis. scores, instead, reject the hypothesis of this score being relevant.
4 Discussion and Future Work
RCVs showed that nuclei contrast and correlation were relevant to the classification of patches of breast tissue. This is in accordance with the NHG grading system, which identifies hyperchromatism as a signal of nuclear atypia. Extending the set of analyzed concepts can lead to the identification of other relevant concepts. RCVs can give insights about network training. The learning of the concepts across layers is linked to the size of the receptive field of the neurons and the increasing complexity of the sought patterns (see Fig. 2 and [6]). Hence, more abstract concepts, potentially useful in other applications, can be learned and analyzed in deep layers of the network. Moreover, outliers in the values of the sensitivity scores can identify challenging training inputs or highlight domain mismatches (e.g. differences across hospitals, staining techniques, etc.).
Overall, this paper proposed a definition of RCVs and a proof of concept on breast cancer data. RCVs could be extended to many other tasks and application domains. In the computer vision domain, RCVs could also express higher-level concepts such as materials, objects and scenes. In signal processing tasks, RCVs could be used, for instance, to determine the relevance of the occurrence of a keyword in topic modeling, or of a phoneme in automatic speech recognition.
Acknowledgements
This work was possible thanks to the project PROCESS, part of the European Union’s Horizon 2020 research and innovation program (grant agreement No 777533).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Doshi-Velez, F., Kim, B.: Towards a rigorous science of interpretable machine learning. ar Xiv preprint arxiv:1702.08608 (2017)
- 2[2] Elston, C.W., Ellis, I.O.: Pathological prognostic factors in breast cancer. I. The value of histological grade in breast cancer: experience from a large study with long-term follow-up. Histopathology 19 (5), 403–410 (1991)
- 3[3] Ghazvinian Zanjani, F., Zinger, S., De, P.N.: Automated detection and classification of cancer metastases in whole-slide histopathology images using deep learning (2017)
- 4[4] Haralick, R.M., Dinstein, I., Shanmugam, K.: Textural features for image classification. IEEE Transactions On Systems Man And Cybernetics 3 (6), 610–621 (1973)
- 5[5] He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016)
- 6[6] Kim, B., Gilmer, J., Viegas, F., Erlingsson, U., Wattenberg, M.: TCAV: Relative concept importance testing with linear concept activation vectors. ar Xiv preprint ar Xiv:1711.11279 (2017)
- 7[7] Kindermans, P.J., Hooker, S., Adebayo, J., Alber, M., Schütt, K.T., Dähne, S., Erhan, D., Kim, B.: The (un) reliability of saliency methods. ar Xiv preprint ar Xiv:1711.00867 (2017)
- 8[8] Koh, P.W., Liang, P.: Understanding black-box predictions via influence functions. ar Xiv preprint ar Xiv:1703.04730 (2017)