TL;DR
This paper introduces a variational method for uncalibrated photometric stereo under general lighting, jointly estimating shape, reflectance, and illumination directly from images, improving accuracy over previous methods.
Contribution
It presents a novel variational framework that approximates Lambertian reflectance with spherical harmonics and estimates shape without normal integration, enhancing robustness and efficiency.
Findings
Reduces mean angular error by 2-3 times compared to state-of-the-art.
Validates robustness and efficiency through extensive experiments.
Effectively estimates shape, reflectance, and lighting jointly in uncalibrated settings.
Abstract
Photometric stereo (PS) techniques nowadays remain constrained to an ideal laboratory setup where modeling and calibration of lighting is amenable. To eliminate such restrictions, we propose an efficient principled variational approach to uncalibrated PS under general illumination. To this end, the Lambertian reflectance model is approximated through a spherical harmonic expansion, which preserves the spatial invariance of the lighting. The joint recovery of shape, reflectance and illumination is then formulated as a single variational problem. There the shape estimation is carried out directly in terms of the underlying perspective depth map, thus implicitly ensuring integrability and bypassing the need for a subsequent normal integration. To tackle the resulting nonconvex problem numerically, we undertake a two-phase procedure to initialize a balloon-like perspective depth map,…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32 Figure 33
Figure 33 Figure 34
Figure 34 Figure 35
Figure 35 Figure 36
Figure 36 Figure 37
Figure 37 Figure 38
Figure 38 Figure 39
Figure 39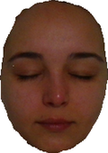 Figure 40
Figure 40| Dataset | [15] | [40] | [34] | Our approach with different initializations | |||
|---|---|---|---|---|---|---|---|
| Shape | Albedo | Hemisphere | Using [34] | Minimal surface | |||
| (Sec. 5.1) | |||||||
| Armadillo | Bars | 26.22 | 27.84 | 36.91 | 79.54 | 20.08 | 16.78 |
| Constant | 25.84 | 26.64 | 36.87 | 83.01 | 18.81 | 13.97 | |
| Ebsd | 25.34 | 26.88 | 27.80 | 82.53 | 15.99 | 14.26 | |
| Hippie | 28.21 | 27.30 | 25.82 | 79.12 | 12.56 | 14.52 | |
| Lena | 27.07 | 27.33 | 28.36 | 84.24 | 17.79 | 14.78 | |
| Pattern | 45.87 | 26.82 | 24.01 | 82.59 | 19.39 | 19.06 | |
| Rectcircle | 26.97 | 26.71 | 36.23 | 80.68 | 19.64 | 14.06 | |
| Voronoi | 25.62 | 26.91 | 50.70 | 79.65 | 55.29 | 14.07 | |
| White | 26.19 | 26.64 | 52.04 | 83.04 | 56.74 | 14.13 | |
| Joyful Yell | Bars | 21.84 | 16.26 | 31.80 | 21.21 | 28.82 | 8.69 |
| Constant | 23.95 | 14.93 | 33.47 | 16.85 | 29.31 | 5.96 | |
| Ebsd | 26.08 | 15.63 | 15.91 | 17.63 | 7.49 | 7.28 | |
| Hippie | 28.67 | 16.23 | 22.96 | 17.68 | 7.47 | 7.49 | |
| Lena | 21.33 | 16.33 | 19.70 | 20.11 | 13.16 | 9.21 | |
| Pattern | 26.07 | 18.76 | 26.67 | 18.76 | 21.03 | 16.97 | |
| Rectcircle | 35.27 | 15.19 | 52.41 | 16.27 | 61.77 | 7.34 | |
| Voronoi | 22.27 | 16.42 | 45.74 | 18.62 | 54.78 | 6.57 | |
| White | 27.12 | 14.32 | 33.06 | 17.70 | 28.99 | 6.20 | |
| Lucy | Bars | 49.13 | 21.90 | 36.51 | 40.55 | 26.15 | 8.16 |
| Constant | 54.98 | 19.89 | 36.57 | 41.00 | 25.74 | 8.71 | |
| Ebsd | 62.33 | 20.81 | 23.56 | 40.80 | 13.36 | 9.61 | |
| Hippie | 58.61 | 21.29 | 32.38 | 39.93 | 8.10 | 7.87 | |
| Lena | 64.01 | 22.24 | 30.93 | 40.16 | 19.14 | 9.56 | |
| Pattern | 48.83 | 22.25 | 32.68 | 40.11 | 20.56 | 17.78 | |
| Rectcircle | 24.68 | 20.99 | 43.13 | 41.17 | 10.01 | 8.98 | |
| Voronoi | 61.53 | 22.10 | 48.14 | 40.39 | 71.32 | 7.59 | |
| White | 64.43 | 19.33 | 44.76 | 41.54 | 72.45 | 8.76 | |
| Thai Statue | Bars | 25.53 | 21.91 | 66.17 | 78.72 | 8.94 | 8.55 |
| Constant | 27.20 | 18.91 | 38.47 | 81.14 | 24.26 | 9.58 | |
| Ebsd | 27.85 | 20.22 | 34.11 | 79.58 | 19.23 | 9.47 | |
| Hippie | 21.91 | 21.86 | 30.62 | 77.27 | 12.78 | 8.83 | |
| Lena | 33.53 | 19.66 | 34.00 | 79.43 | 19.55 | 9.19 | |
| Pattern | 26.77 | 22.06 | 28.81 | 83.92 | 16.69 | 15.27 | |
| Rectcircle | 29.36 | 19.92 | 43.86 | 81.88 | 79.88 | 8.84 | |
| Voronoi | 30.65 | 21.56 | 36.58 | 78.92 | 25.21 | 8.69 | |
| White | 28.02 | 18.64 | 37.31 | 81.54 | 24.94 | 9.16 | |
| Median | 27.16 | 21.14 | 34.06 | 59.41 | 19.86 | 9.17 | |
| Mean | 34.15 | 21.18 | 35.53 | 55.20 | 27.43 | 10.72 | |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Variational Uncalibrated Photometric Stereo under General Lighting
Bjoern Haefner , 1 Zhenzhang Ye11footnotemark: 1 , 1 Maolin Gao2 Tao Wu1 Yvain Quéau3 Daniel Cremers1
1Technical University of Munich 2Artisense 3GREYC, UMR CNRS 6072
{bjoern.haefner, zz.ye, tao.wu, cremers}@tum.de [email protected] [email protected] Authors contributed equally.
Abstract
Photometric stereo (PS) techniques nowadays remain constrained to an ideal laboratory setup where modeling and calibration of lighting is amenable. To eliminate such restrictions, we propose an efficient principled variational approach to uncalibrated PS under general illumination. To this end, the Lambertian reflectance model is approximated through a spherical harmonic expansion, which preserves the spatial invariance of the lighting. The joint recovery of shape, reflectance and illumination is then formulated as a single variational problem. There the shape estimation is carried out directly in terms of the underlying perspective depth map, thus implicitly ensuring integrability and bypassing the need for a subsequent normal integration. To tackle the resulting nonconvex problem numerically, we undertake a two-phase procedure to initialize a balloon-like perspective depth map, followed by a “lagged” block coordinate descent scheme. The experiments validate efficiency and robustness of this approach. Across a variety of evaluations, we are able to reduce the mean angular error consistently by a factor of – compared to the state-of-the-art.
1 Introduction
Photometric stereo techniques aim at acquiring both the shape and the reflectance of a scene. To this end, multiple images are acquired under the same viewing angle but varying lighting, and a physics-based image formation model is inverted. However, the classic way to solve this inverse problem requires lighting to be highly controlled, which restricts practical applications to laboratory setups where careful calibration of lighting must be carried out.
The objective of this research work is to simplify the overall photometric stereo pipeline, by providing an efficient solution to uncalibrated photometric stereo under general lighting, as illustrated in Figure 1 (the code is released111https://github.com/zhenzhangye/general_ups). In comparison with existing efforts in the same direction, the proposed one has the following advantages:
- •
The joint estimation of shape, reflectance and general lighting is formulated as an end-to-end, mathematically transparent variational problem;
- •
A real 3D-surface represented as a depth map is recovered, rather than possibly non-integrable normals;
- •
It is robust, due to the use of Cauchy’s robust M-estimator and Huber-TV albedo regularization;
- •
It is computationally efficient, thanks to a tailored lagged block coordinate descent scheme initialized using a simple balloon-like shape.
After reviewing related works in Section 2, we discuss in Section 3 the image formation model considered in this work. It can be inverted using the variational approach in Section 4. A dedicated numerical solution is then introduced in Section 5 and empirically evaluated in Section 6. Section 7 eventually draws the conclusion of this research.
2 Related Work
3D-models of scenes are essential in many applications such as visual inspection [14] or computer-aided surgery using augmented reality [12]. A 3D-model consists of geometric (position, orientation, etc.) and photometric (color, texture, etc.) properties. Given a set of photographies, the aim of 3D scanning is to invert the image formation process in order to recover these geometric and photometric properties of the observed scene. This notion thus includes both those of 3D-reconstruction (geometry) and of reflectance estimation (photometry).
Many approaches to the problem of 3D-reconstruction from photographies have been studied, and they are grouped under the generic naming “shape-from-X”, where X stands for the clue which is being used (shadows [44], contours [10], texture [49], template [6], structured light [16], motion [35], focus [36], silhouettes [21], etc.). Geometric shape-from-X techniques are based on the identification and analysis of feature point or areas in the image. In contrast, photometric techniques build upon the analysis of the quantity of light received by each photosite of the camera’s sensor. Among photometric techniques, shape-from-shading is probably the most famous one. This technique, developed in the 70s by Horn et al. [25], consists in 3D-reconstruction from a single image of a shaded scene. It is a classic ill-posed inverse problem whose numerical solving usually requires the surface’s reflectance to be known [13]. In order both to limit the ambiguities of shape-from-shading and to allow for automatic reflectance estimation, it has been suggested to consider not just one image of the scene, but several ones acquired from the same viewing angle but under varying lighting. This variant, which was introduced in the late 70s by Woodham [50], is known as photometric stereo.
Among the various shape-from-X techniques mentioned above, photometric stereo is the only 3D-scanning technique i.e., the only one which is able to achieve both 3D-reconstruction and reflectance estimation. However, early photometric approaches strongly rely on the control of lighting. The latter is usually assumed for simplicity to be directional, although the case of nearby point light sources has recently regained some attention [31, 33]. More importantly, lighting is assumed to be calibrated. Indeed, the uncalibrated problem is ill-posed: the underlying normal map can be estimated only up to a linear ambiguity [20], which reduces to a generalized bas-relief one if integrability is enforced [9]. To resolve the latter ambiguity, some prior on the scene’s surface or geometry must be introduced, see [48] for a recent survey. A natural way to enforce integrability consists in following a differential approach to photometric stereo [11, 32] i.e., directly estimate the 3D-surface as a depth map instead of first estimating the surface normals and then integrating them. Such a differential approach to photometric stereo can be coupled with variational methods in order to iteratively refine depth, reflectance and lighting in a robust manner [42]. In addition to the theoretical interest of enforcing integrability in order to limit ambiguities, differential approaches to photometric stereo have the advantages of easing combination with other 3D-reconstruction methods [17, 40], and of bypassing the problem of integrating the estimated normal field, which is by itself a non-trivial problem [41]. Besides, any error in the estimated normal field might propagate during integration, and thus robustness to specularities or shadows must be enforced during normal estimation, see again [48] for some discussion.
All the research works mentioned in the previous paragraph assume that lighting is induced by a single light source. Nevertheless, many studies rather considered the case of more general illumination conditions, which finds a natural application in outdoor conditions [43]. For instance, the apparent motion of the sun within a day induces changes in the illumination direction which, in theory, allow photometric stereo-based 3D-reconstruction. However, this apparent motion is close to being planar, and thus the rank of the set of illumination vectors is equal or close to [45] (see also [23] for additional discussion on the stability of single-day photometric stereo). This situation is thus similar to the two-image case, which is known to be ill-posed since the early 90s [28, 37, 51], although it is still an active research area [29]. In order to limit the instabilities due to this issue, one possibility is to consider images acquired over many seasons as in [2, 3], or to resort to deep neural networks [22]. Another one is to consider a non-directional illumination model to represent natural illumination, as for instance in [26]. Modeling natural illumination is a promising track, since such a model would not be restricted to sunny days, and images acquired under cloudy days are known to yield more accurate 3D-reconstructions [23].
However, the previous approaches to photometric stereo under natural illumination assume calibrated lighting, where calibration is deduced from time and GPS coordinates or from a calibration target. The case of both general and uncalibrated lighting is much more challenging and has been fewly explored, apart from studies restricted to sparse 3D-reconstructions [46] or relying on the prior knowledge of a rough geometry [4, 27, 40, 47]. Uncalibrated photometric stereo under natural illumination has been revisited recently in [34], using a spatially-varying equivalent directional lighting model. However, results were limited to the recovery of possibly non-integrable surface normals. Instead, the method which we propose in the present paper directly recovers the underlying surface represented as a depth map. Following the seminal work of Basri and Jacobs [7], it considers the spherical harmonics representation of general lighting in lieu of the equivalent directional approximation, as discussed in the next section.
3 Image Formation Model
In photometric stereo (PS), we are given a number of observations , each representing a multi-channel image (i.e. ) over a masked pixel domain . Assuming that the object being pictured is Lambertian, the surface’s reflectance is represented by the albedo , and the general image formation model is as follows, for all , , and :
[TABLE]
Here is the unit sphere in , represents the channel-wise intensity of the incident light, and and are the channel-wise albedos and the unit-length surface normals, respectively, at the surface point conjugate to pixel . The operation in (1) encodes self-shadows. The overall integral collects elementary luminance contributions arising from all incident lighting directions . In the setup of uncalibrated PS, the quantities , , in addition to , are unknown.
Equivalent directional lighting [24] approximates (1) via
[TABLE]
where represents the mean lighting over the visible hemisphere at . The field is spatially variant but can be approximated by directional lighting over small local patches. Over each patch, one is thus faced with the ambiguities of directional uncalibrated PS [20]. State-of-the-art patch-wise methods [34] first solve this problem over each patch, then connect the patches to form a complete normal field up to rotation, and eventually estimate the rotation which best satisfies the integrability constraint. Errors may however get propagated during the sequence, resulting in a possibly non-integrable normal field.
Instead of such an equivalent directional lighting model, we rather consider a spherical harmonic approximation (SHA) of general lighting [8, 7]. By defining the half-cosine kernel as
[TABLE]
we can view (1) as an analog of a convolution:
[TABLE]
Invoking the Funk-Hecke theorem, we obtain the following harmonic expansion analogous to Fourier series:
[TABLE]
Here the spherical harmonics form an orthonormal basis of , and and are the expansion coefficients of and with respect to . Since most energy in the expansion (5) concentrates on low-order terms [8], we obtain the second-order SHA by truncating the series up to the first nine terms (i.e., ):
[TABLE]
The first-order SHA refers to the truncation up to the first four terms (i.e., ). It is shown in [8] that, for distant lighting, at least of the resulting irradiance is captured by the first-order SHA, and by the second-order SHA (cf. Figure 2 for a visualization).
Plugging (6) and specifics of spherical harmonics [8] into (4), we finalize our image formation model as:
[TABLE]
Here represents the second-order harmonic images, and represents the harmonic lighting vector whose entries have absorbed and constant factors of . A key advantage of the SHA (7) over the equivalent directional lighting model (2) lies in the spatial invariance of the lighting vectors , which yields a less ill-posed inverse problem [7]. The counterpart is the nonlinear dependency upon the normal components, which we will handle in Section 5 using a tailored numerical solution. In the next section, we build upon the key observations that integrability [9] and perspective projection [39] both largely reduce the ambiguities of uncalibrated PS to derive a variational approach to inverting the SHA (7).
4 Variational Uncalibrated PS
In this section, we shall propose a joint variational model for uncalibrated PS. To this end, let a 3D-frame be attached to the camera, with the optical center, the -axis aligned with the optical axis such that for any 3D point in front of the camera. Further let a 2D-frame be attached to the focal plane which is parallel to the -plane and contains the masked pixel domain . Under perspective projection, the surface geometry is modeled as a map given by
[TABLE]
with the depth map and
[TABLE]
the calibrated camera’s intrinsics matrix. In the following we denote for convenience .
Assuming that is differentiable, the surface normal at point is the unit vector oriented towards the camera such that , which yields the following parameterization of the normal by the depth:
[TABLE]
Note that the dependence of on is linear.
Based on the forward model (7) and the parameterization (11) of normals, we formulate the joint recovery of reflectance, lighting and geometry as the following variational problem:
[TABLE]
In the first term above, we use Cauchy’s M-estimator to penalize the data-fitting discrepancy:
[TABLE]
It is indeed well-known that Cauchy’s estimator, being non-convex, is robust against outliers; see for instance [42] in the context of PS. The scaling parameter is used in all experiments.
The second term in (13) represents a Huber total-variation (TV) regularization on each albedo map , with the Huber loss defined by
[TABLE]
and being fixed in the experiments. It turns out that the Huber TV imposes desirable smoothness on the albedo maps and in turn improves the joint estimation overall. Eventually, is a weight parameter which balances the data-fitting term and the Huber TV one. Its value was empirically set to (see Section 6 for some discussion).
In (13), geometry is directly optimized in terms of the depth (rather than indirectly in terms of the normal ). This both ensures integrability and avoids integration of normals into depths as a post-processing step.
5 Solver and Implementation
To solve the variational problem (13) numerically, we follow a “discretize-then-optimize” approach. There, is replaced by , being the number of pixels inside , which yields discretized vectors . To alleviate notational burden, we sometimes refer to a pixel by its index and sometimes by its position . The spatial gradient is discretized using a forward difference stencil.
We shall apply a lagged block coordinate descent (LBCD) method to find a local minimum of the objective function in (23). Due to the (highly) non-convex nature of (23), initialization of optimization variables has a strong influence on the final solution. In our implementation, we initialize for all and for all . Moreover, during the first eight iterations we freeze the second-order spherical harmonics coefficients i.e., we reconstruct using only first-order spherical harmonic approximation as a warm start. Most real-world scenes being convex, we initialize the depth as a balloon-like surface, as discussed in the following.
5.1 Depth Initialization
It is readily seen that a trivial constant initialization of the depth yields uniform vertically aligned normals and, hence, zero entries in the initial harmonic images . This would cause non-meaningful updates on albedos and lighting vectors ; cf. Figure 3 for an illustration.
To solve this issue, we specialize the depth initialization which undergoes two phases:
-
Following [38], we generate a balloon-like depth map under orthographic projection.
-
We then convert the orthographic depth to a perspective depth via normal integration [41].
Phase 1 is pursued via seeking a depth map which has minimal surface area subject to a constant volume :
[TABLE]
A global minimizer of this model can be efficiently computed by simple projected gradient iterations:
[TABLE]
where and with the spectral norm. The volume constant is a hyperparameter which is empirically chosen, see Section 6 for discussion.
Next, we convert the orthographic depth to a perspective depth . Note that complies with the orthographic projection, under which a 3D-point is represented by
[TABLE]
and the corresponding surface normal to the surface at conjugate to pixel is given by
[TABLE]
Since is invariant to the projection model, Eq. (11) also implies that
[TABLE]
where stands for the log-perspective depth. This further implies the formula for :
[TABLE]
which can be integrated to obtain (and hence ). The overall pipeline in Phase 2 is summarized as follows:
(): Compute by (20). 2. 2.
(): Compute by (22). 3. 3.
(): Perform integration [41] to obtain . Return as the initialized (perspective) depth.
As discussed in [18] the perspective surface area depends linearly on the depth . This complicates direct perspective ballooning, since the depth is driven towards zero and hence yields numerical instability. For this reason, we opted for the two-step approach which bypasses the issue.
5.2 Lagged Block Coordinate Descent
Even with a reasonable initialization, the numerical resolution of Problem (23) remains challenging. Due to the appearances of the spherical harmonic approximation and the Cauchy’s M-estimator , the objective in (23) is highly nonlinear and nonconvex. To tackle these challenges, here we present a lagged block coordinate descent (LBCD) method which performs efficiently in practice.
To derive LBCD, we introduce an auxiliary variable such that . This enables us to rewrite (11) as . Then we formulate the following constrained optimization problem:
[TABLE]
where is the residual function defined by:
[TABLE]
Upon initialization, the proposed LBCD proceeds as follows. At iteration , we lag one iteration behind, i.e.,
[TABLE]
and then sequentially update each of the three blocks (namely , and ). In each resulting subproblem, we solve (lagged) weighted least squares problems as an approximation of the Cauchy loss and/or the Huber loss. This is detailed in the following:
- •
(Update ): We evaluate the residual
[TABLE]
and then set up the (lagged) weight factors for both the Cauchy loss and the Huber loss as
[TABLE]
The albedos are updated as the solution to the following linear weighted least-squares problem:
[TABLE]
which is carried out by conjugate gradient (CG).
- •
(Update ): The lighting subproblem is similar to the one for albedos, except for absence of the Huber TV term. Upon evaluation of the residual and the weight factor , we update by solving the following linear weighted least-squares problem via CG:
[TABLE]
- •
(Update ): The depth subproblem requires additional efforts. With and evaluated after the -update, we are faced with the following weighted least squares problem:
[TABLE]
where the dependence of on is still nonlinear. Therefore, we further linearize with respect to and arrive at the following update:
[TABLE]
where is the Jacobian of the map at . The resulting linearized least-squares problem is again solved by CG. In our experiments, we additionally incorporate backtracking line search in the -update to ensure a monotonic decrease of the energy.
6 Experimental Validation
This section is concerned with the evaluation of the proposed nonconvex variational approach to uncalibrated photometric stereo under general lighting.
6.1 Synthetic Experiments
To validate the impact of the initial volume in (16), the tunable hyper-parameter , and the number of input images in (13), we consider 36 challenging synthetic datasets. We use four different depth maps (“Joyful Yell” [1], “Lucy” [30], “Armadillo” [30] and “Thai Statue” [30]) and nine different albedo maps and each of those 36 combinations is rendered as described in (1) using different environment maps222Environment maps are downloaded from http://www.hdrlabs.com/sibl/archive.html, cf. Figure 4. The resulting 25 RGB images per dataset are used as input, along with the intrinsic camera parameters and a binary mask . A quantitative evaluation on the triplet is carried out on four randomly chosen datasets (Armadillo & White albedo, Joyful Yell & Ebsd albedo, Lucy & Hippie albedo, and Thai Statue & Voronoi albedo), comparing the impact of each value of on the resulting mean angular error (MAE) between ground truth and estimated normals.
First, we validate the choice of the input volume using the initially fixed values of and . As the volume depends on the size of the mask, we consider a linear parametrization and evaluate a range of ratios . Figure 5 (left) indicates that the optimal value of is dataset-dependent. For synthetic datasets we always selected this optimal value, yet for real-world data no such evaluation is possible and must be tuned manually. Since the ballooning-based depth initialization can be carried out in real-time (implementation is parallelized in CUDA), the user has an immediate feedback on the initial depth and thus a plausible initial shape is easily drawn. Humans excel at estimating size and shape of objects [5] and real-world experiments will show that a manual choice of can result in appealing geometries.
Next, we evaluate the impact of , cf. Figure 5 (right). As can be seen, the depth estimate seems to deteriorate for too small and too large values of , whereas seems to provide good depth estimates across all albedo maps. Therefore we fix for all our upcoming experimental evaluation.
Unsurprisingly, the MAE is inversely proportional to the number of input images, but runtime increases (linearly) with , cf. Figure 6. We found that represents a good trade-off between runtime and accuracy, and fix for all our further experiments. Our Matlab implementation needs about – minutes on a computer with an Intel processor.
Having fixed the choice of , we can now evaluate our approach against other state-of-the-art methods. We compare our results against those obtained by an uncalibrated photometric stereo approach assuming directional lighting [15], and another one assuming general (first-order spherical harmonics) illumination yet relying on an input shape prior (e.g., from an RGB-D sensor) [40]. As this limiting assumption on the access to a sensor-based depth prior is not always given and to make comparison fair, we input as depth prior to this method the ballooning initialization described in Section 5.1. Furthermore, we compare against another uncalibrated photometric stereo work under natural illumination [34]333Code associated with [15] and [40] can be found online, and the results obtained by [34] were provided by the authors., which resorts to the equivalent directional lighting instead of spherical harmonics, cf. Section 3. Table 1 shows the median and mean MAEs over all 36 datasets (a more detailed table can be found in the supplementary material). On these datasets, it can be seen that our method quantitatively outperforms the current state-of-the-art by a factor of –. This gain is also evaluated qualitatively in Figure 7, which shows a selection of two results.
6.2 Real-World Experiments
For real-world data we use the publicly available dataset of [19]. It offers eight challenging real-world datasets of objects with complex geometry and albedo captured under daylight and a freely moving LED, along with intrinsics matrix and masks . Results are presented in Figure 8. Despite relying on a directional lighting model, the approach of [15] produces reasonable results on some datasets (Face1, Ovenmitt or Shirt), but it fails on others. As [40] assumes a reliable prior on depth in order to perform a photometric refinement, this approach is biased towards its initialization and thus, only when the depth prior is very close to the objects’ rough shape (Ovenmitt, Shirt, Tabletcase, Vase) a meaningful geometry is recovered. The approach of [34] estimates a possibly non-integrable normal field only, and it can be seen that after integration the depth map might not be satisfactory. As our approach optimizes over depth directly, such issues are not apparent and we are able to recover fine-scale geometric details throughout all tests.
7 Conclusion
We proposed a variational approach to uncalibrated photometric stereo (PS) under general lighting. Assuming a perspective camera setup, our method jointly estimates shape, reflectance and lighting in a robust manner. The possible non-integrability of normals is bypassed by the direct estimation of the underlying depth map, and robustness is ensured by resorting to Cauchy’s M-estimator and Huber-TV albedo regularization. Although the problem is nonconvex and thus numerically challenging and initialization-dependent, we tackled it efficiently through a tailored lagged block coordinate descent algorithm and ballooning-based depth initialization. Over a series of evaluations on synthetic and real data, we demonstrated that our method outperforms existing methods in terms of MAE by a factor of – and provides highly detailed reconstructions even in challenging real-world settings.
In future research, a more automated balloon-like depth initialization is desirable. Exploring the theoretical foundations (uniqueness of a solution) of differential perspective uncalibrated PS under spherical harmonic lighting and analyzing the convergence properties of the proposed numerical scheme constitute two other promising perspectives.
Appendix A Further Details on Synthetic Experiments
To provide further insights on the synthetic experiments (in Section 6.1), we visualize the environment lightings , , used to render each image. Figure 9 shows all environment maps444All environment maps were downloaded from http://www.hdrlabs.com/sibl/archive.html.
The impact of each incident lighting , , is illustrated in Figure 10 showing the Joyful Yell with a White () albedo. Thus, color changes in the images are caused by lighting only, as depicted in model (1) and (7) in the main paper.
Table 2 shows the mean angular error (MAE) of each dataset on the state-of-the-art approaches [15, 34, 40] and our proposed methodology. It can be seen that our approach consistently overcomes [15, 34, 40] by a factor of –. Only the Pattern albedo seems to bias the resulting depth negatively, yet even in this case our approach estimates the geometry more faithfully than the current state-of-the-art.
Two more qualitative results on synthetic data are shown in Figure 11. While [15] gives more meaningful results on Armadillo with Constant albedo, depth deteriorates strongly on Lucy with Hippie albedo. Methods of [34, 40] both result in rather flattened shapes (cf. Lucy). Most accurate results are achieved using the proposed method where fine geometric details, as well as non flattened depth estimates are shown.
Additional to the depth results, Figure 12 shows estimated lightings and albedos along with the ground truths. Although lighting estimates show less shadowed areas and seem brighter compared to ground truths, this does not seem to affect reflectance estimations much. The estimated albedos are satisfactory, although some shading information is slightly visible.
The initialization is indeed crucial for the whole algorithm. Here, we show two different non-trivial initializations for our algorithm in Table 2: 1) Hemisphere, we first compute the circumscribed sphere for the 3D points of ground truth. The projection of each point onto this sphere is considered as initialization; 2) Initialization by [34], we simply refine the result from [34] by our algorithm. In Figure 13, we show visualized results. In certain special cases, the initialization from [34] is slightly better. However, our minimal surface strategy is stable for all cases, and our algorithm improves the results from [34]) in most cases.
Appendix B Further Details on Real-World Results
Supplementary to the real-world experiments (in Section 6.2), Figures 14 and 15 show alternative viewpoints of the real-world results. The estimated albedos, which are mapped onto the surfaces, appear satisfactory. Correspondingly, we also show the estimated albedos and lightings. In view of the multiplicative ambiguity between lightings and albedos, all visualized albedos are normalized to have maximum value 1.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] The Joyful Yell. 2015. https://www.thingiverse.com/thing:897412 .
- 2[2] Austin Abrams, Christopher Hawley, and Robert Pless. Heliometric Stereo: Shape from Sun Position. In European Conference on Computer Vision (ECCV) , volume 7573 of Lecture Notes in Computer Science , pages 357–370, 2012.
- 3[3] Jens Ackermann, Fabian Langguth, Simon Fuhrmann, and Michael Goesele. Photometric stereo for outdoor webcams. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages 262–269, 2012.
- 4[4] Jens Ackermann, Martin Ritz, André Stork, and Michael Goesele. Removing the example from example-based photometric stereo. In Trends and Topics in Computer Vision (ECCV Workshops) , volume 6554 of Lecture Notes in Computer Science , pages 197–210. 2012.
- 5[5] Joseph Baldwin, Alistair Burleigh, Robert Pepperell, and Nicole Ruta. The perceived size and shape of objects in peripheral vision. i-Perception , 7(4):2041669516661900, 2016.
- 6[6] Adrien Bartoli, Yan Gérard, Francois Chadebecq, Toby Collins, and Daniel Pizarro. Shape-from-template. IEEE Transactions on Pattern Analysis and Machine Intelligence , 37(10):2099–2118, 2015.
- 7[7] Ronen Basri, David Jacobs, and Ira Kemelmacher. Photometric stereo with general, unknown lighting. International Journal of Computer Vision , 72(3):239–257, 2007.
- 8[8] Ronen Basri and David W Jacobs. Lambertian reflectances and linear subspaces. IEEE Transactions on Pattern Analysis and Machine Intelligence , 25(2):218–233, 2003.
