Multi-view Vector-valued Manifold Regularization for Multi-label Image Classification
Yong Luo, Dacheng Tao, Chang Xu, Chao Xu, Hong Liu, Yonggang Wen

TL;DR
This paper introduces a novel multi-view vector-valued manifold regularization method that effectively integrates multiple features and label relationships for improved multi-label image classification.
Contribution
It proposes MV³MR, a new framework that leverages matrix-valued kernels to exploit feature complementarity and label structure in multi-label image classification.
Findings
MV³MR outperforms existing methods on PASCAL VOC'07 and MIR Flickr datasets.
The method effectively captures the intrinsic local geometry of multi-view data.
Experimental results demonstrate significant accuracy improvements.
Abstract
In computer vision, image datasets used for classification are naturally associated with multiple labels and comprised of multiple views, because each image may contain several objects (e.g. pedestrian, bicycle and tree) and is properly characterized by multiple visual features (e.g. color, texture and shape). Currently available tools ignore either the label relationship or the view complementary. Motivated by the success of the vector-valued function that constructs matrix-valued kernels to explore the multi-label structure in the output space, we introduce multi-view vector-valued manifold regularization (MVMR) to integrate multiple features. MVMR exploits the complementary property of different features and discovers the intrinsic local geometry of the compact support shared by different features under the theme of manifold regularization. We conducted…
Click any figure to enlarge with its caption.
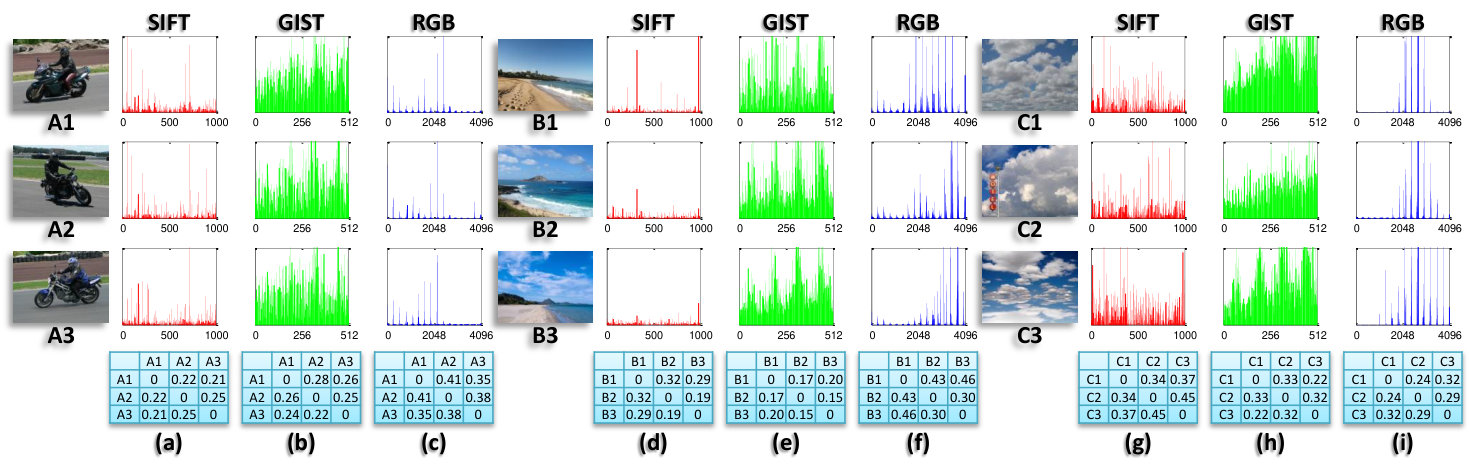 Figure 1
Figure 1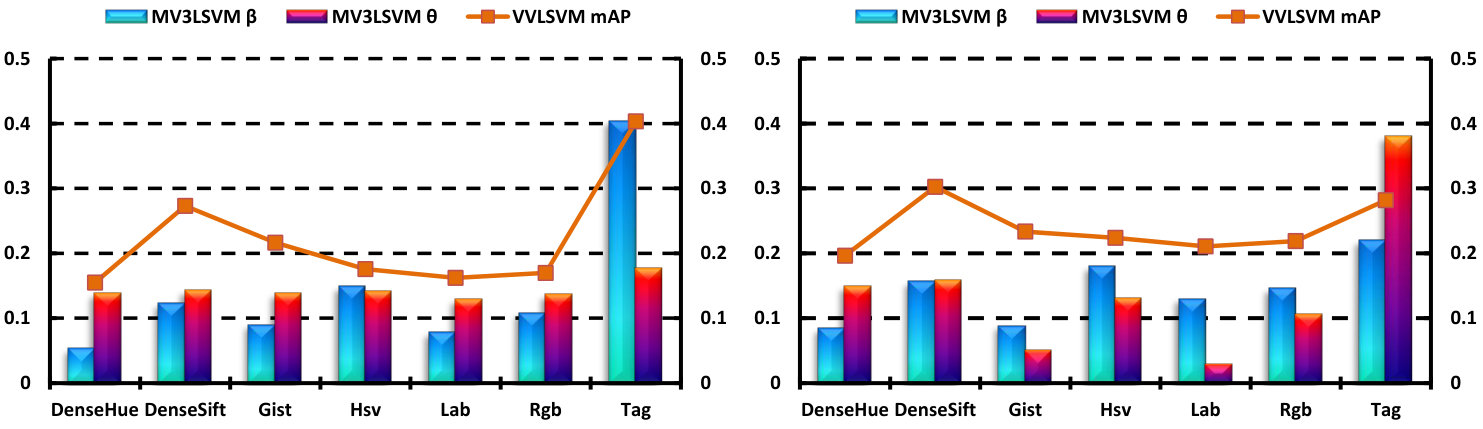 Figure 2
Figure 2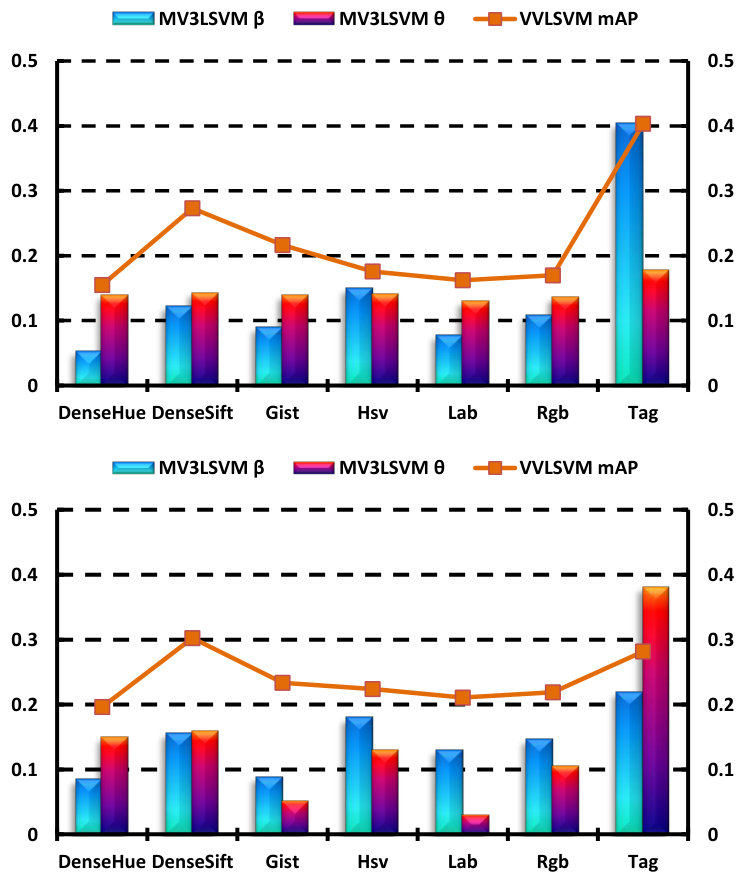 Figure 3
Figure 3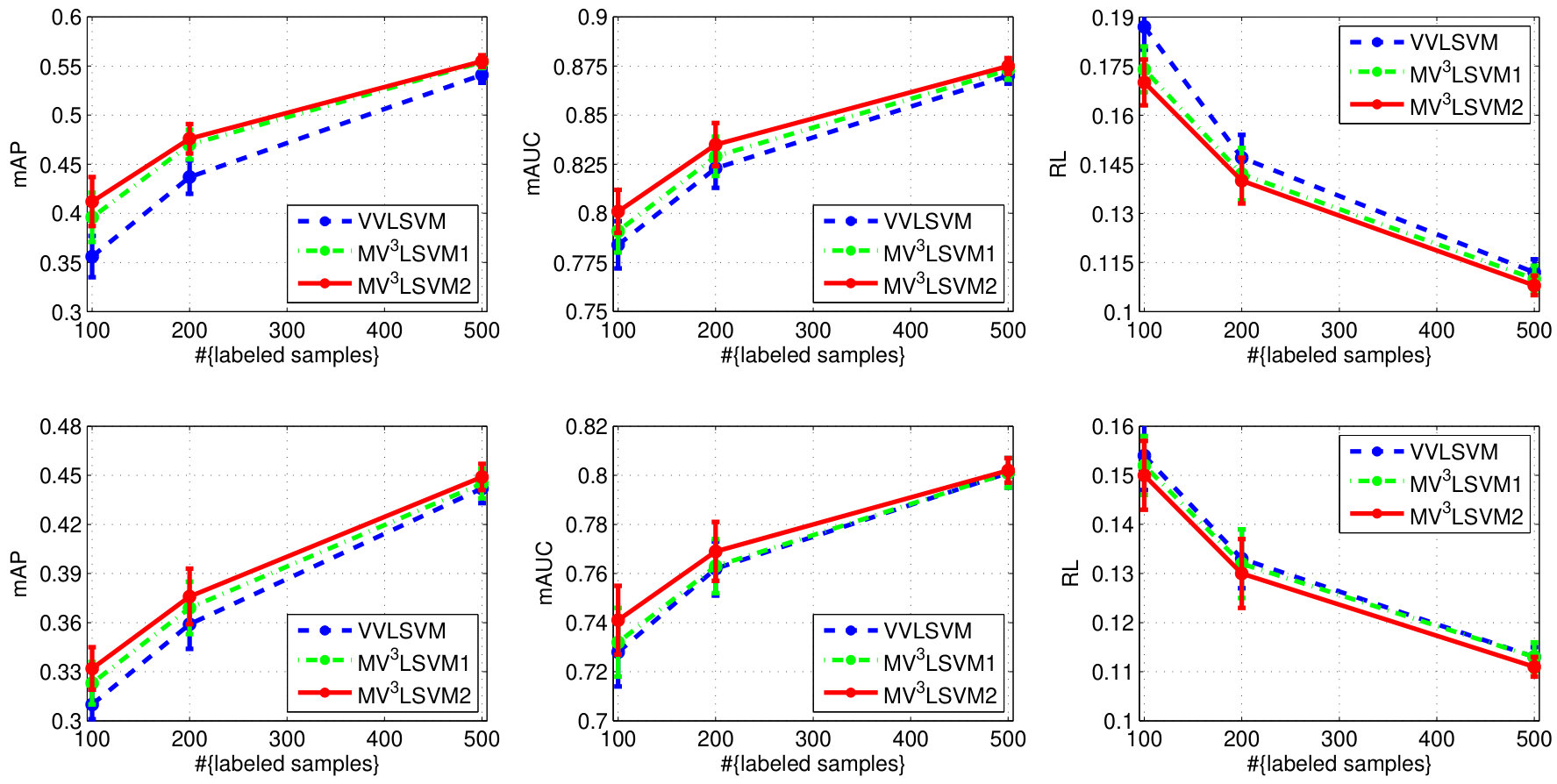 Figure 4
Figure 4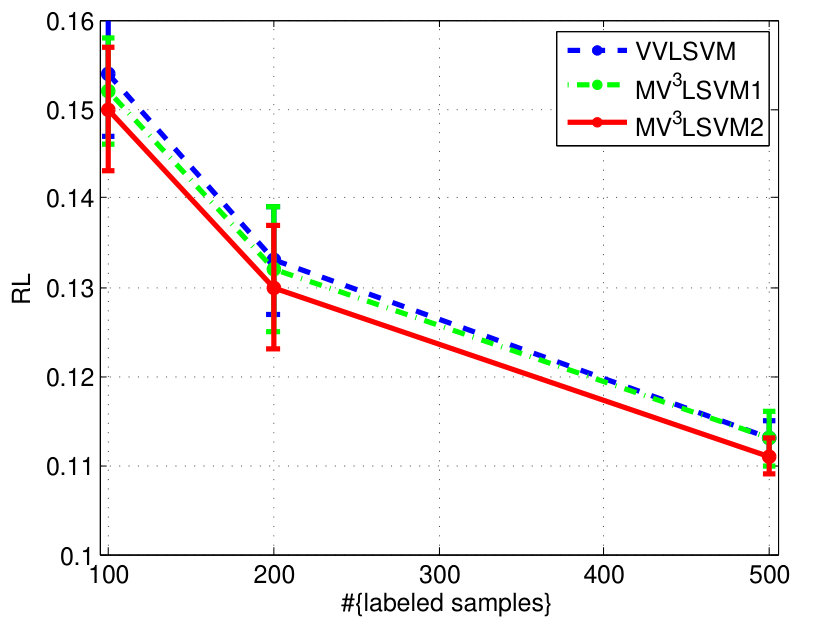 Figure 5
Figure 5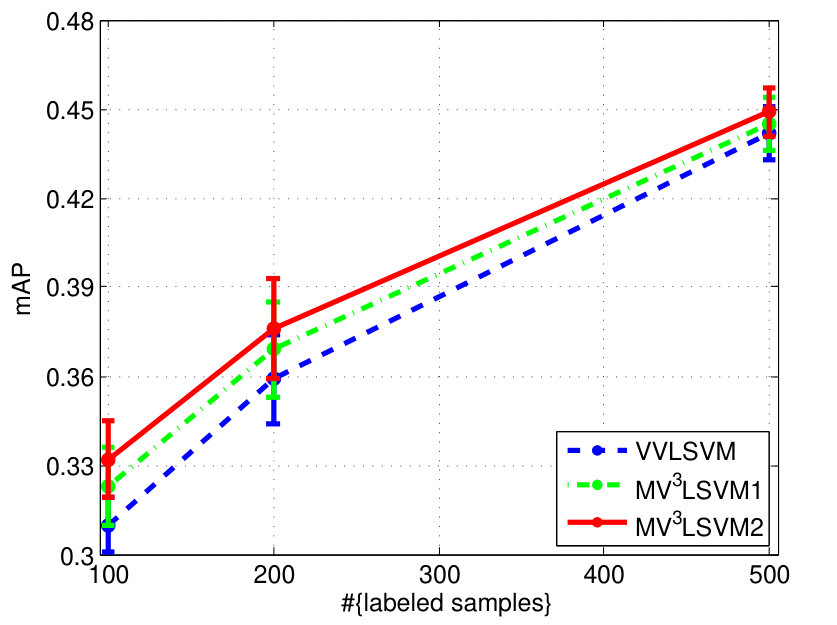 Figure 6
Figure 6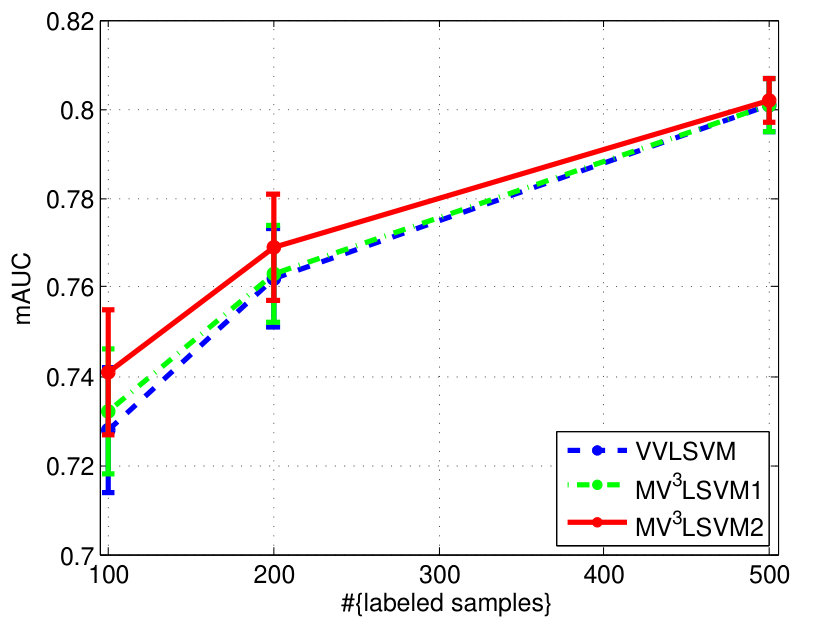 Figure 7
Figure 7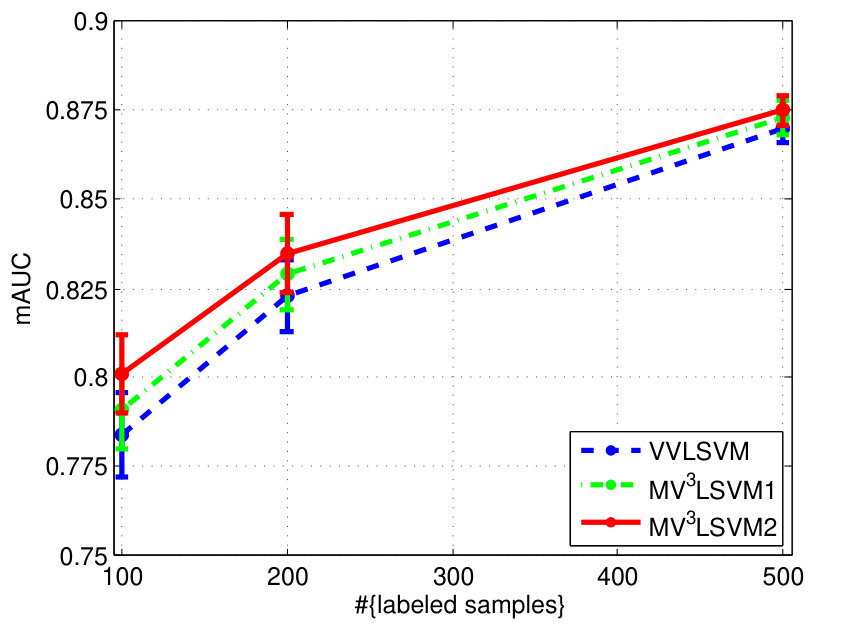 Figure 8
Figure 8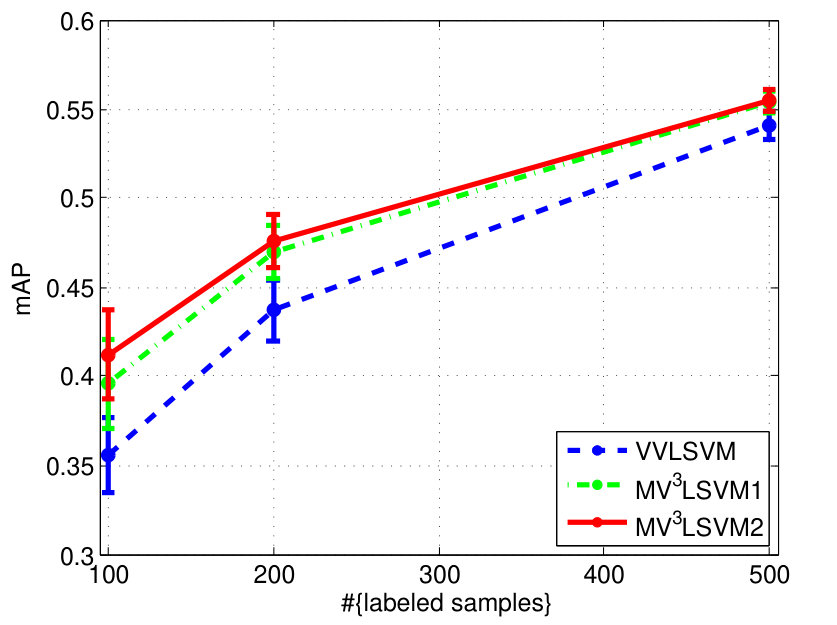 Figure 9
Figure 9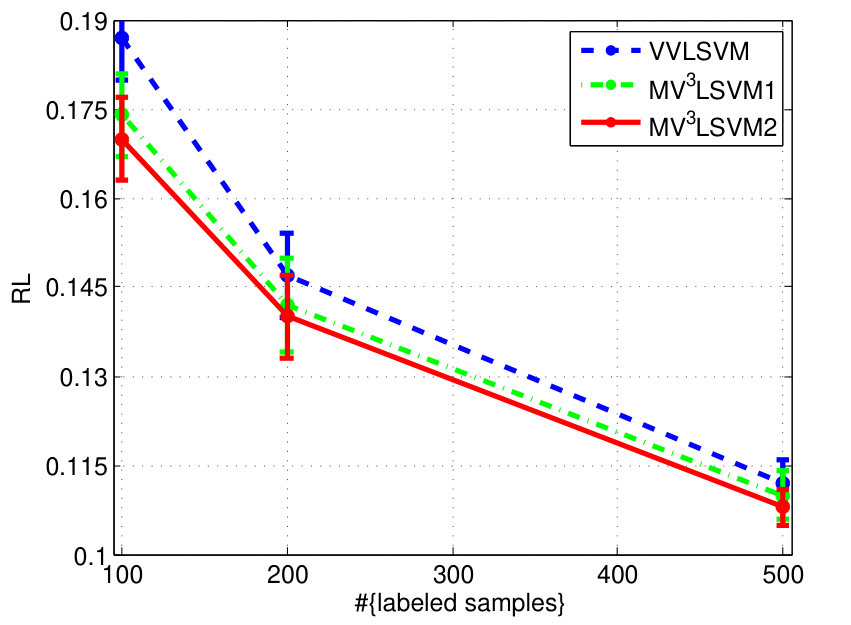 Figure 10
Figure 10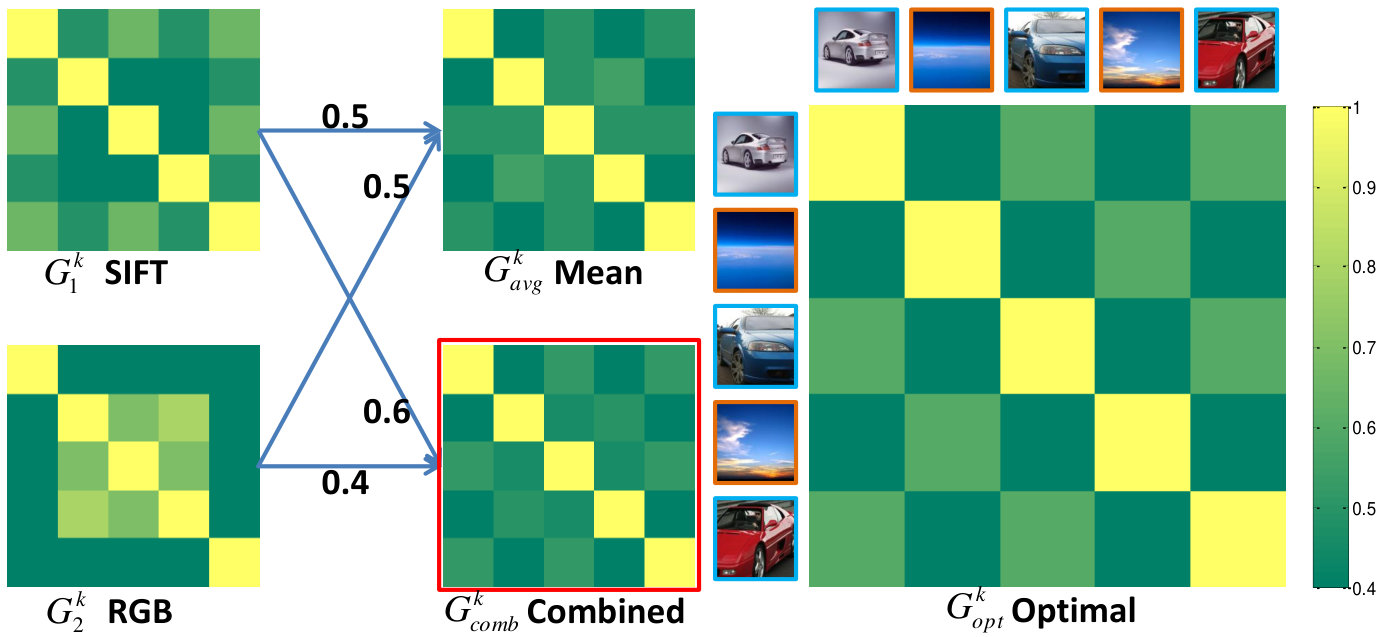 Figure 11
Figure 11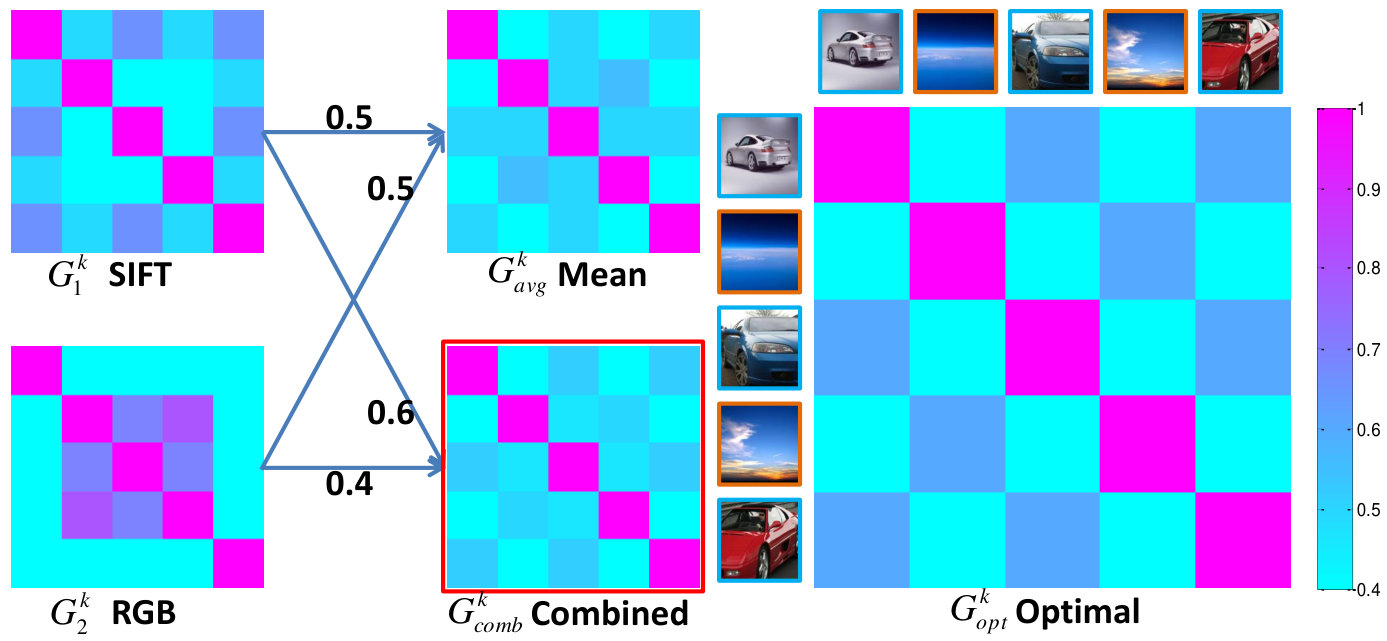 Figure 12
Figure 12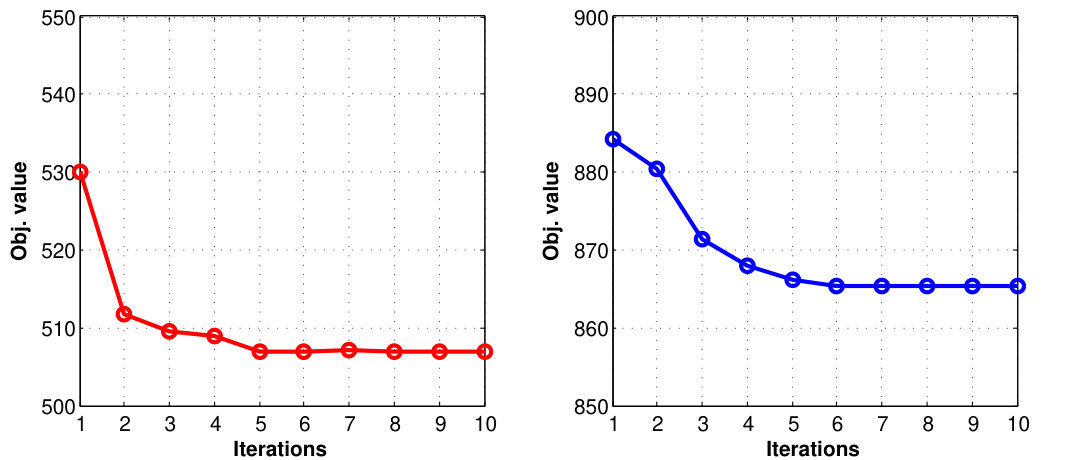 Figure 13
Figure 13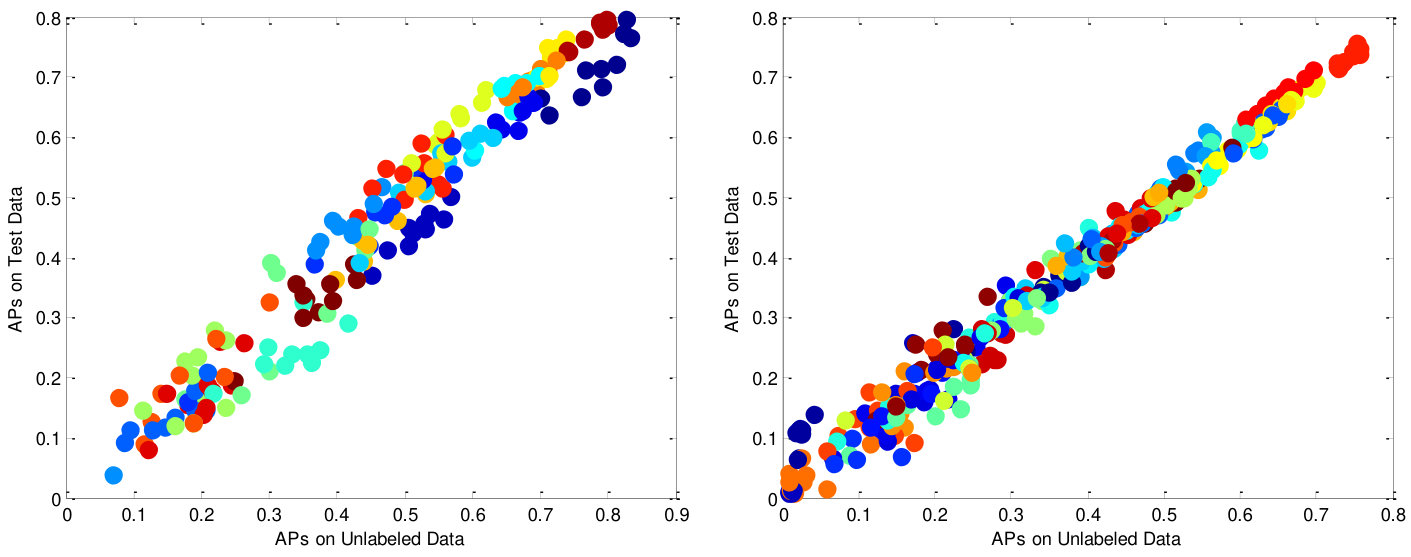 Figure 14
Figure 14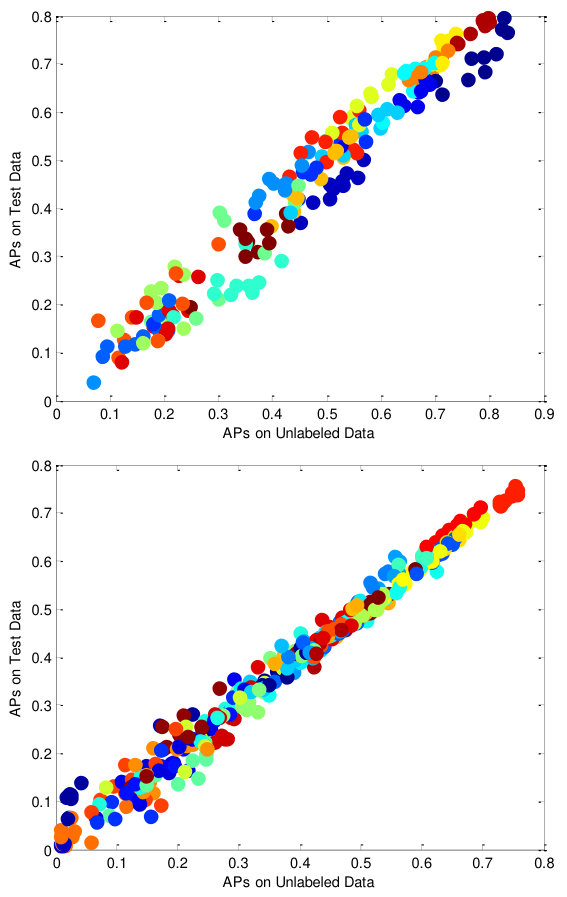 Figure 15
Figure 15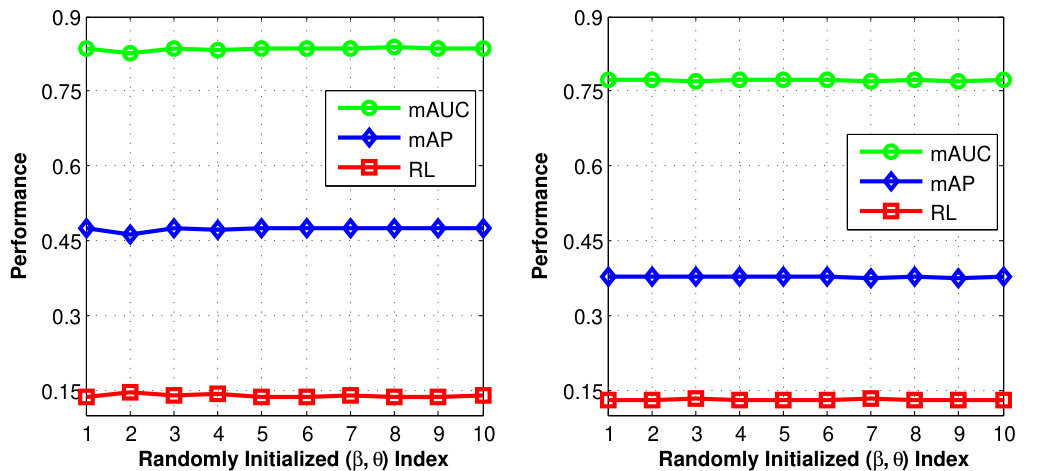 Figure 16
Figure 16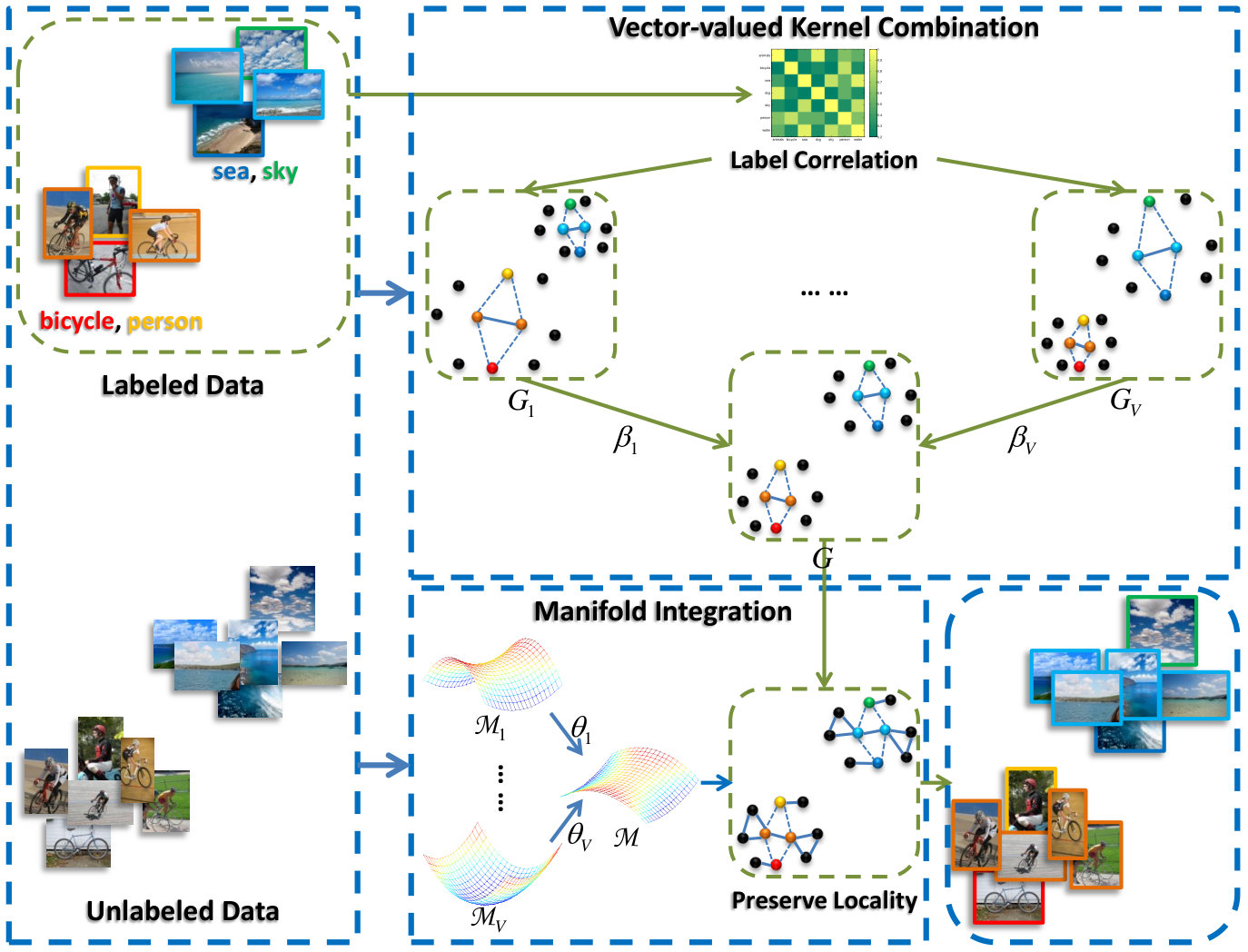 Figure 17
Figure 17| VOC mAP vs. #{labeled samples} | MIR mAP vs. #{labeled samples} | ||||||
| Methods | 100 | 200 | 500 | 100 | 200 | 500 | Ranks |
| SVM_CAT | 0.2410.011 (7) | 0.2880.013 (7) | 0.3710.007 (7) | 0.2810.009 (7) | 0.3060.007 (7) | 0.3520.008 (7) | 7 |
| SVM_UNI | 0.3470.018 (4.5) | 0.4240.014 (5) | 0.5290.006 (5) | 0.3020.011 (5) | 0.3360.013 (6) | 0.4000.009 (6) | 5.25 |
| MLCS [18] | 0.3320.017 (6) | 0.4120.016 (6) | 0.5250.007 (6) | 0.2890.010 (6) | 0.3420.011 (5) | 0.4240.010 (5) | 5.67 |
| KLS_CCA [12] | 0.3470.019 (4.5) | 0.4320.014 (4) | 0.5360.007 (4) | 0.3210.009 (3.5) | 0.3690.017 (2) | 0.4450.009 (2.5) | 3.42 |
| MV3LSVM | 0.4120.025 (1) | 0.4760.015 (1) | 0.5550.006 (1) | 0.3320.013 (1) | 0.3760.017 (1) | 0.4490.008 (1) | 1 |
| SimpleMKL [16] | 0.3810.024 (3) | 0.4530.020 (3) | 0.5380.011 (3) | 0.3210.014 (3.5) | 0.3650.017 (4) | 0.4440.011 (2.5) | 3.17 |
| LpMKL [17] | 0.3910.024 (2) | 0.4620.012 (2) | 0.5400.006 (2) | 0.3270.010 (2) | 0.3670.014 (3) | 0.4360.008 (4) | 2.5 |
| VOC mAUC vs. #{labeled samples} | MIR mAUC vs. #{labeled samples} | ||||||
| Methods | 100 | 200 | 500 | 100 | 200 | 500 | Ranks |
| SVM_CAT | 0.7440.013 (7) | 0.7850.006 (7) | 0.8320.003 (7) | 0.7220.008 (4) | 0.7450.004 (6) | 0.7830.004 (6) | 6.17 |
| SVM_UNI | 0.7830.008 (3) | 0.8240.009 (2.5) | 0.8700.003 (2.5) | 0.7180.011 (5) | 0.7420.011 (7) | 0.7820.006 (7) | 4.5 |
| MLCS [18] | 0.7730.010 (5) | 0.8190.010 (6) | 0.8690.004 (4) | 0.7010.012 (7) | 0.7490.010 (5) | 0.8050.005 (1.5) | 4.42 |
| KLS_CCA [12] | 0.7810.009 (4) | 0.8240.008 (2.5) | 0.8660.003 (5) | 0.7370.009 (2) | 0.7690.010 (1.5) | 0.8050.005 (1.5) | 2.75 |
| MV3LSVM | 0.8010.011 (1) | 0.8350.011 (1) | 0.8750.004 (1) | 0.7410.014 (1) | 0.7690.012 (1.5) | 0.8020.005 (3.5) | 1.5 |
| SimpleMKL [16] | 0.7690.017 (6) | 0.8220.013 (4.5) | 0.8700.006 (2.5) | 0.7170.013 (6) | 0.7530.010 (4) | 0.8020.005 (3.5) | 4.42 |
| LpMKL [17] | 0.7860.008 (2) | 0.8220.008 (4.5) | 0.8620.005 (6) | 0.7320.010 (3) | 0.7560.010 (3) | 0.7950.007 (5) | 3.92 |
| VOC RL vs. #{labeled samples} | MIR RL vs. #{labeled samples} | ||||||
| Methods | 100 | 200 | 500 | 100 | 200 | 500 | Ranks |
| SVM_CAT | 0.2200.008 (7) | 0.1830.006 (7) | 0.1420.003 (7) | 0.1650.005 (3) | 0.1460.004 (5) | 0.1260.002 (5) | 5.67 |
| SVM_UNI | 0.1780.008 (2) | 0.1430.006 (3) | 0.1060.003 (1.5) | 0.5490.040 (7) | 0.4370.022 (7) | 0.1770.011 (7) | 4.58 |
| MLCS [18] | 0.1950.007 (5) | 0.1550.007 (5) | 0.1120.004 (4) | 0.1730.006 (5) | 0.1450.005 (4) | 0.1150.003 (2.5) | 4.25 |
| KLS_CCA [12] | 0.1830.008 (3) | 0.1490.006 (4) | 0.1220.005 (5) | 0.1680.013 (4) | 0.1430.005 (3) | 0.1210.004 (4) | 3.83 |
| MV3LSVM | 0.1700.007 (1) | 0.1400.007 (1) | 0.1080.003 (3) | 0.1500.006 (1) | 0.1300.007 (1) | 0.1110.003 (1) | 1.33 |
| SimpleMKL [16] | 0.2140.017 (6) | 0.1420.009 (2) | 0.1060.004 (1.5) | 0.1550.005 (2) | 0.1360.006 (2) | 0.1150.003 (2.5) | 2.67 |
| LpMKL [17] | 0.1860.011 (4) | 0.1640.010 (6) | 0.1370.007 (6) | 0.1990.014 (6) | 0.1810.007 (6) | 0.1410.004 (6) | 5.67 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Multi-view Vector-valued Manifold Regularization for Multi-label Image Classification
Yong Luo, Dacheng Tao, Chang Xu, Chao Xu,
Hong Liu, Yonggang Wen Y. Luo, C. Xu, and C. Xu are with the Key Laboratory of Machine Perception (Ministry of Education), School of Electronics Engineering and Computer Science, Peking University, Beijing, 100871, China.D. Tao is with the Centre for Quantum Computation and Intelligent Systems, University of Technology, Sydney, Jones Street, Ultimo, NSW 2007, Sydney, Australia.H. Liu is with the Engineering Lab on Intelligent Perception for Internet of Things, Shenzhen Graduate School, Peking University, China. (Email: [email protected])Y. Wen is with the Division of Networks and Distributed Systems, School of Computer Engineering, Nanyang Technological University, Singapore. (Email: [email protected])©2013 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works.
Abstract
In computer vision, image datasets used for classification are naturally associated with multiple labels and comprised of multiple views, because each image may contain several objects (e.g. pedestrian, bicycle and tree) and is properly characterized by multiple visual features (e.g. color, texture and shape). Currently available tools ignore either the label relationship or the view complementary. Motivated by the success of the vector-valued function that constructs matrix-valued kernels to explore the multi-label structure in the output space, we introduce multi-view vector-valued manifold regularization (MV3MR) to integrate multiple features. MV3MR exploits the complementary property of different features and discovers the intrinsic local geometry of the compact support shared by different features under the theme of manifold regularization. We conducted extensive experiments on two challenging, but popular datasets, PASCAL VOC’ 07 (VOC) and MIR Flickr (MIR), and validated the effectiveness of the proposed MV3MR for image classification.
Index Terms:
Image classification, semi-supervised, multi-label, multi-view, manifold
I Introduction
Anatural image can be summarized by several keywords (or labels). To conduct image classification by directly using binary classification methods [1, 2], it is necessary to assume that labels are independent, although most labels appearing in one image are related to one another. Examples are given in Fig. 1, where A1-A3 shows a “person” rides a “motorbike”, B1-B3 indicates “sea” usually co-occurs with “sky” and C1-C3 shows some “clouds” in the “sky”. This multi-label nature makes image classification intrinsically different from simple binary classification.
Moreover, different labels cannot be properly characterized by a single feature representation. For example, the color information (e.g. color histogram), shape cue (encoded in SIFT [3]) and global structure (e.g. GIST [4]) can effectively represent natural substances (e.g. sky, cloud and plant life), man-made objects (e.g. aeroplane, motorbike and TV-monitor) and scenes (e.g. seaside and indoor), respectively, but cannot simultaneously illustrate all these concepts in an effective way. Each visual feature encodes a particular property of images and characterizes a particular concept (label), so we treat each feature representation as a particular view for characterizing images. Fig. 1 (a)-(c) indicate that SIFT representation is effective in describing a motorbike and GIST can capture the global structure of a person on the motorbike. Fig. 1 (d)-(f) shows that GIST performs well in recognizing seaside scenes, while the color information can be used as a complementary aid for recognizing the blue sea water. From Fig. 1 (g)-(i) we can see that RGB usually represents cloud well and GIST is helpful when RGB fails. For example, the RGB representations of C1 and C3 are not very similar and their GIST distance (0.22) is very small due to the sky scene structure. This multi-view nature distinguishes image classification from single-view tasks, such as texture segmentation [5] and face recognition [6].
The vector-valued function [7] has recently been introduced to resolve multi-label classification [8] and has been demonstrated to be effective in semantic scene annotation. This method naturally incorporates the label-dependencies into the classification model by first computing the graph Laplacian [9] of the output similarity graph, and then using this graph to construct a vector-valued kernel. This model is superior to most of the existing multi-label learning methods [10, 11, 12] because it naturally considers the label correlations and efficiently outputs all the predicted labels at one time.
Although the vector-valued function is effective for general multi-label classification tasks, it cannot directly handle image classification problems that include images represented by multi-view features. A popular solution is to concatenate all the features into a long vector. This concatenation strategy not only ignores the physical interpretations of different features, however, but also encounters the over-fitting problem given limited training samples.
We thus introduce multi-kernel learning (MKL) to the vector-valued function and present a multi-view vector-valued manifold regularization (MV3MR) framework for handling the multi-view features in multi-label image classification. MV3MR associates each view with a particular kernel, assigns a higher weight to the view/kernel carrying more discriminative information, and explores the complementary nature of different views.
In particular, MV3MR assembles the multi-view information through a large number of unlabeled images to discover the intrinsic geometry embedded in the high dimensional ambient space of the compact support of the marginal distribution. The local geometry, approximated by the adjacency graphs induced from multiple kernels of all the corresponding views, is more reliable than that approximated by the adjacency graph induced from a particular kernel of any corresponding view. In this way, MV3MR essentially improves the vector-valued function for multi-label image classification.
Because the hinge loss is more suitable for classification than the least squares loss [13], we derive an SVM (support vector machine) formulation of MV3MR which results in a multi-view vector-valued Laplacian SVM (MV3LSVM). We carefully design the MV3LSVM algorithm so that it determines the set of kernel weights in the learning process of the vector-valued function.
We thoroughly evaluate the proposed MV3LSVM algorithm on two challenging datasets, PASCAL VOC’ 07 [14] and MIR Flickr [15], by comparing it with a popular MKL algorithm [16], a recently proposed MKL method [17], and competitive multi-label learning algorithms for image classification, such as multi-label compressed sensing [18], canonical correlation analysis [12] and vector-valued manifold regularization [8] in terms of mean average precision (mAP), mean area under curve (mAUC) and hamming loss (HL). The experimental results suggest the effectiveness of MV3LSVM.
The rest of the paper is organized as follows. Section II summarizes the recent work in multi-label learning, multi-kernel learning and image classification. In Section III, we introduce manifold regularization and its vector-valued generalization. We depict the proposed MV3MR framework and its SVM formulation in Section IV. Extensive experiments are presented in Section V and we conclude this paper in Section VI.
II Related Work
II-A Multi-label learning
Multi-label classification has received intensive attention in recent years. Some methods extend traditional multi-class algorithms to cope with the multi-label problem. AdaBoost.MH [19] adds the label value to the feature vector and then applies AdaBoost on weak classifiers. A ranking algorithm is presented in [20] by adopting the ranking loss as the cost function in SVM. ML-KNN [21] is an extension of the -nearest neighbor (KNN) algorithm to deal with multi-label data and canonical correlation analysis (CCA) has also recently been extended to the multi-label case by formulating it as a least-squares problem [12].
Other works concentrate on preprocessing the data so that standard binary or multi-class techniques can be utilized. For example, multiple labels of a sample belong to a subset of the whole label set and we can view this subset as a new class [22]. This may lead to a large number of classes and a more common strategy is to learn a binary classifier for each label [1, 2]. Considering that the labels are often sparse, a compressed sensing method is proposed for multi-label prediction [18].
Various approaches have been proposed to improve prediction accuracy by exploiting label correlations [23, 24, 11, 8]. Sun et al. [23] proposed the construction of a hypergraph to exploit the label dependencies. In [24], a common subspace is assumed to be shared among all labels, and the correlation information contained in different labels can be captured by learning this low-dimensional subspace. A max-margin method is proposed in [11], where the prior knowledge of the label correlations is incorporated explicitly in the multi-label classification model.
None of the approaches mentioned above consider the features to be used; however, an image with multiple labels usually indicates that it contains multiple objects. As far as we know, there is no single kind of feature that can describe a variety of objects very well. Therefore, how to combine different features is a critical issue in multi-label image classification and we consider MKL for this purpose in this paper.
II-B MKL: Multi-kernel learning
Classical kernel methods are usually based on a single kernel [25]. MKL [26], in which a kernel-based classifier and a convex combination of the kernels are learned simultaneously, has attracted much attention. Lanckriet et al. [26] introduces MKL for binary classification and solves it with semi-definite programming (SDP) techniques. The MKL problem is further developed by Sonnenburg et al. [27] in the presentation of a semi-infinite linear program (SILP). In [16], MKL is reformulated by using a weighted L2-norm regularization to replace the mixed-norm regularization and adding an L1-norm constraint on the kernel weights. All of these MKL formulations are based on SVM and are not naturally designed for multi-label classification. The proposed MV3MR framework extends MKL to handle the multi-label problem and model label inter-dependencies.
II-C Image classification
Image classification has been widely used in many computer vision-related applications such as image retrieval and web content browsing. In recent years, more than a dozen methods have been proposed and representative works can be grouped into three categories.
Single-view learning for image classification: This category contains many recent image classification schemes, e.g. dictionary learning [28] and spatial pyramid matching [29]. For example, Labusch et al. [30] proposed to integrate sparse-coding and local maximum operation to extract local features for handwritten digit recognition. In [31], a non-linear coding scheme was introduced for local descriptors such as SIFT. Yang et al. [32] explored the local co-occurrences of visual words over the spatial pyramid.
Multi-view learning for image classification: Schemes in this category utilize the features from different views (or multi-view features) to boost image classification performance. In this paper, the concept “views” used for learning refer to different features or attributes for depicting the objects to be classified. It should be noted that for some other applications in vision and graphics, the “views” mean different spatial viewpoints [33, 34, 35]. A semi-supervised boosting algorithm is proposed in [36], in which images measured by different views are used to construct a prior and formulate a regularization term. Guillaumin et al. [2] combined 15 visual representations (e.g. SIFT, GIST and HSV) with the tag feature for semi-supervised image classification. Combining the visual and textual information has been utilized for clustering [37] and web page classification [38].
Multi-label learning for image classification: This category is motivated by the success of multi-label learning and has demonstrated promising image classification performance. For example, Bucak et al. [39] proposed a ranking based algorithm to tackle the multi-label problem with incompletely labeled data by introducing a group lasso regularizer in optimization. Unlike traditional multi-label methods that always consider positive label correlations, a novel approach is presented in [40] to make use of the negative relationship of categories.
Although it has been widely acknowledged that both multi-view representation and label inter-dependencies are important for multi-label image classification, most of the existing approaches do not take both of them into consideration. Most existing multi-view approaches assume that different views (features) contribute equally to label prediction. In contrast to these approaches, the proposed MV3MR naturally explores both the complementary property of multi-view features and the correlations of different labels under the manifold regularization scheme.
III Manifold Regularization and Vector-valued Generalization
This section briefly introduces the manifold regularization framework [9] and its vector-valued generalization [8]. Given a set of labeled examples and a relatively large set of unlabeled examples , we consider a non-parametric estimation of a vector-valued function , where and is the number of labels. This setting includes as a special case for regression and classification.
III-A Manifold regularization
Manifold learning has been widely used for capturing the local geometry [41] and conducting low-dimensional embedding [42, 43]. In manifold regularization, the data manifold is characterized by a nearest neighbor graph , which explores the geometric structure of the compact support of the marginal distribution. The Laplacian of and the prediction are then formulated as a smoothness constraint , where and the diagonal matrix is given by . The manifold regularization framework minimizes the regularized loss
[TABLE]
where is a predefined loss function; is the standard scalar-valued kernel, i.e. and is the associated reproducing kernel Hilbert space (RKHS). Here, and are trade-off parameters to control the complexities of in the ambient space and the compact support of the marginal distribution. The Representer theorem [9] ensures the solution of problem (1) takes the form , where is the coefficient. Since a pair of close samples means that the corresponding conditional distributions are similar, the manifold regularization helps the function learning.
III-B Vector-valued manifold regularization
In the vector-valued RKHS, where a kernel function is defined and the corresponding -valued RKHS is denoted by , the optimization problem of the vector-valued manifold regularization (VVMR) is given by
[TABLE]
where is the -direct product of and the inner product takes the form
[TABLE]
The function prediction . The matrix is a symmetric positive operator that satisfies for all and is chosen to be . Here, is the graph Laplacian, is the identity matrix and denotes the Kronecker (tensor) matrix product. For , an entry of the vector-valued kernel matrix is defined by
[TABLE]
where is a scalar-valued kernel, is a parameter. Here, is the pseudo-inverse of the output labels’ graph Laplacian. The graph can be estimated by viewing each label as a vertex and using the nearest neighbors method. The representation of the ’th label is the ’th column in the label matrix , in which, if the ’th label is manually assigned to the ’th sample, and otherwise. For the unlabeled samples, .
It has been proved in [8] that the solution of the minimization problem (2) takes the form . By choosing the Regularization Least Squares (RLS) loss , we can estimate the column vector with each by solving a Sylvester Equation:
[TABLE]
where and and is a diagonal matrix with the first entries , and the others [math]. Here, is the Gram matrix of the scalar-valued kernel over the labeled and unlabeled data. We refer to [8] for a detailed description of the vector-valued Laplacian RLS.
IV MV3MR: Multi-view Vector-valued Manifold Regularization
To handle multi-view multi-label image classification, we generalize VVMR and present multi-view vector-valued manifold regularization (MV3MR). In contrast to [2], which assumes that different views contribute equally to the classification, MV3MR assumes that different views contribute to the classification differently and learns the combination coefficients to integrate different views.
Fig. 2 gives an illustrative example which suggests that different views contribute to the classification differently, and that learning the combination coefficients to integrate different views benefits the classification. Given five images from two classes, namely three cars of different colors (silvery white, blue and red) and two different sky images, the optimal Gram matrix is shown on the right side for separating these images into two classes. On the left, there are four Gram matrices, which are two single Gram matrices , obtained from two different views, and their mean , as well as their linear combination with the learned coefficients. The figure indicates that is closer to the optimal Gram matrix than .
Given a small number of labeled samples and a relative large number of unlabeled samples, MV3MR first computes an output similarity graph by using the label information of the labeled samples. The Laplacian of the label graph is incorporated in the scalar-valued Gram matrix over labeled and unlabeled data to enforce label correlations on each view, and the vector-valued Gram matrices can be obtained. Meanwhile, we also compute the vector-valued graph Laplacians by using the features of the input data from different views. Then MV3MR learns the kernel combination coefficient for as well as the graph weight for by the use of alternating optimization. Finally, the combined Gram matrix together with the regularization on the combined manifold is used for classification. Fig. 3 summarizes the above procedure. Technical details are given below.
IV-A Rationality
Let be the number of views and be the view index. On the feature space of each view, we define the corresponding positive definite scalar-valued kernel , which is associated with an RKHS . It follows from the functional framework [16] that by introducing a non-negative coefficient , the Hilbert space is an RKHS with kernel . If we define as the direct sum of the space , i.e. , then is an RKHS associated with the kernel
[TABLE]
Thus, any function in is a sum of functions belonging to . The vector-valued kernel , where we have used the bilinearity of the Kronecker product. Each corresponds to an RKHS according to the study of RKHS for the vector-valued functions [8]. Thus, the kernel is associated with an RKHS . This functional framework motivates the MV3MR framework. We will jointly learn the linear combination coefficients to integrate kernels for characterizing different views and the classifier coefficients in a single optimization problem. Moreover, to effectively utilize the unlabeled data, we construct graph Laplacians for different views and learn to combine all of them.
IV-B Problem formulation
Under the multi-view setting and the theme of manifold regularization, we propose to learn the vector-valued function by linearly combining the kernels and graphs from different views. The optimization problem is given by
[TABLE]
where and . Both and are trade-off parameters. The decision function takes the form and belongs to an RKHS associated with the kernel . We define , where each is a vector-valued graph Laplacian constructed on . It can be demonstrated that is still a graph Laplacian.
Lemma 1
* is a vector-valued graph Laplacian.*
The notation denotes a set of symmetric positive semi-definite matrices and we will use to denote a set of positive definite matrices. Then we have the following version of the Representer Theorem.
Theorem 1
For fixed sets of and , the minimizer of problem (6) admits an expansion
[TABLE]
where are some vectors to be estimated and . The proof of Lemma 1 and Theorem 1 are detailed in the appendix.
The hinge loss is more suitable for classification than least squares loss since the hinge loss results in a better convergence rate and usually higher classification accuracy; we refer to [13] for a comparison of different popular loss functions. We adopt the hinge loss in MV3MR and derive MV3LSVM as follows.
IV-C Multi-view vector-valued Laplacian SVM
Under the SVM formulation, the minimization problem of MV3MR is
[TABLE]
An unregularized bias is often added to the solution in the SVM formulation. By substituting (7) into the above formulation, we can see the primal problem as follows:
[TABLE]
where is the combined vector-valued Gram matrix over the labeled and unlabeled samples defined on kernel , is the integrated vector-valued graph Laplacian. Here, is the th row of the vector-valued kernel . We have three variables, i.e., , and , to be optimized in (9). To solve this problem, we consider the following constrained optimization problem:
[TABLE]
where equals to
[TABLE]
Here, and take the form as in (9). We can omit the terms and in (11) since and are fixed. By introducing the Lagrange multipliers and in (11), we have
[TABLE]
By taking the partial derivative w.r.t. , , and setting them to be zero, we obtain
[TABLE]
A reduced Lagrangian can be obtained by substituting the above equalities back into (12), which leads to
[TABLE]
where and is an identity matrix. Here, is a column vector with each , and is an all ones column vector. Taking the partial derivative of w.r.t. and letting it be zero leads to:
[TABLE]
Substituting it back into (13) we get:
[TABLE]
where the matrix . Again, the combined Gram matrix and the integrated graph Laplacian . Because of the strong duality, the objective value of problem (11) is also the objective value of (13), which is . Therefore, we can rewrite (10) as
[TABLE]
For fixed , the above problem can be rewritten with respect to as
[TABLE]
where with each and is a matrix with the entry . We can simply set the derivative of to zero and obtain . Then the computed is projected to the positive simplex to satisfy the summation and positive constraints. However, such an approach lacks convergence guarantees and may lead to numerical problems. A coordinate descent algorithm is therefore used to solve (17). In each iteration round during the coordinate descent procedure, two elements and are selected to be updated while the others are fixed. By using the Lagrangian of problem (17) and considering that will not change due to constraint , we have the following solution for updating and
[TABLE]
where . The obtained or may violate the constraint . Thus, we set
[TABLE]
From the solution (18), we can see that the update criteria tends to assign larger value to larger and smaller . Because and measures the discriminative ability and the performance of the ’th view. Let be the solution for the optimization problem of the ’th view, which is with . If all the solutions are the same, i.e., , then the objective value of the discriminative view tends to be smaller than non-discriminative view (we assume that all Gram matrices have been normalized). A smaller corresponds to a larger and a smaller , and thus our algorithm prefers discriminative view. However, the solutions may not exactly the same as . Thus the learned is in general but not strictly consistent with the performance of the ’th single view. We can see this in the experiments.
For fixed , the problem (16) can be simplified as
[TABLE]
where with each . Similarly, the solution of (19) can be obtained by using the coordinate descent and the criteria for updating and in an iteration round is given by
[TABLE]
We now summarize the learning procedure of the proposed multi-view vector-valued Laplacian SVM (MV3LSVM) in Algorithm 1.
The stopping criterion for terminating the algorithm can be the difference of the objective value, between two consecutive steps. Alternatively, we can stop the iterations when the variation of and are both smaller than a pre-defined threshold. Our implementation is based on the difference of the objective value, i.e., if the value is smaller than a predefined threshold, then the iteration stops, where is the objective value of the th iteration step. Our implementation is based on the difference of the objective value.
IV-D Convergence analysis
In this section, we discuss the convergence of the proposed MV3LSVM algorithm. We firstly prove the convexity of the problem (11), (17) and (19) as follows.
Proof:
The Hessian matrix of the objective function of (11) is . The Gram matrix and we assume that is positive definite in this paper (to enforce this property a small ridge is added to the diagonal of ). The second term is positive semi-definite since for any and . Here, we have used the property of the graph Laplacian . Then for and problem (11) is strictly convex.
For the problem (17), the Hessian matrix is . The matrix H is symmetric since the element . In addition, the Cholesky decomposition exists since . Let , we have . Thus, and for . This means that (17) is also strictly convex.
Finally, it is straightforward to verify that the problem (19) is strictly convex for . This completes the proof. ∎
Now we discuss the convergence of our algorithm. Let the objective function of problem (9) be and the initialized value be . Since the problem (11) is convex, we have . We suppose that problem (9) is exactly solved, which means that the duality gap is zero. Then . For fixed , we obtain the convex problem (17), thus we have . Similarly, due to the convexity of problem (19), we have . Therefore, the convergence of our algorithm is guaranteed.
IV-E Complexity analysis
For the proposed MV3LSVM, the complexity is dominated by the time cost of computing in each iteration, where the computation of the matrix in (15) involves an inversion and several multiplications of matrix, and the time complexity is using the Strassen algorithm [44]. Problem (15) can be solved using a standard SVM solver with the time complexity according to the sequential minimal optimization (SMO) [45]. The computations of and are quite efficient since their dimensionality is , which is usually very small (e.g., in our experiments). Suppose the number of iterations is , then the total cost of MV3LSVM is . Considering that , thus the time cost is , which is times of the case that no combination coefficients ( and ) are learned. From the experimental results shown in Section V-B, we will find that is very small since our algorithm only needs a few iterations (around five) to converge. Actually, there is a balance between the time complexity and classification accuracy. If only limited number of unlabeled samples are selected to construct the input graph Laplacians, i.e., is small. Then the time complexity can be reduced with acceptable performance sacrifice. In our experiments, we obtain satisfactory accuracy by setting , and the time cost is acceptable.
V Experiment
We validate the effectiveness of MV3LSVM on two challenge datasets, PASCAL VOC’ 07 (VOC) [14] and MIR Flickr (MIR) [15]. The VOC dataset contains 10,000 images labeled with 20 categories. The MIR dataset consists of 25,000 images of 38 concepts. For the PASCAL VOC’07 dataset [14], we use the standard train/test partition [14], which splits 9,963 images into a training set of 5,011 images and a test set of 4,952 images. For the MIR Flickr dataset [15], images are randomly split into equally sized training and test sets. For both datasets, we randomly select twenty percent of the test images for validation and the rest for testing. The parameters of all the algorithms compared in our experiments are tuned by using the validation set. This means that the parameters corresponding to the best performance in the validation set are used for the transductive inference and inductive test. From the training examples, 10 random choices of labeled samples are used in our experiments.
We use several visual views and the tag feature according to [2]. The visual views include SIFT features [3], local hue histograms [46], global GIST descriptor [4] and some color histograms (RGB, HSV and LAB). The local descriptors (SIFT and hue) are computed densely on the multi-scale grid and quantized using k-means, which will result in a visual word histogram for each image. Therefore, we have 7 different representations in total. We pre-compute a scalar-valued Gram matrix for each view and normalize it to unit trace. For the visual representations, the kernel is defined by
[TABLE]
where denotes the distance between and , . Following [2], we choose the distance for the color histogram representations (RGB, HSV and LAB), and for GIST and for the visual word histograms (SIFT and hue). For the tag features, a linear kernel is constructed.
V-A Evaluation metrics
We use three kinds of evaluation criteria. The average precision (AP) and area under ROC curves (AUC) are utilized to evaluate the ranking performance under each label. We also use the ranking loss (RL) to study the performance of label set prediction for each instance.
Average Precision (AP) evaluates the fraction of samples ranked above a particular positive sample [47]. For each label, there is a ranked sequence of samples returned by the classifier. A good classifier will rank most of the positive samples higher than the negative ones. The traditional AP is defined as
[TABLE]
where is a rank index of a positive sample and is the precision at the cut-off . In this paper, we choose to use the computing method as in the PASCAL VOC [14] challenge evaluation, i.e.
[TABLE]
where is the maximum precision over all recalls larger than . A larger value means a higher performance. In this paper, the mean AP, i.e. mAP over all labels, is reported to save space.
Area Under ROC Curves (AUC) evaluates the probability that a positive sample will be ranked higher than a negative one by a classifier [48]. It is computed from an ROC curve, which depicts relative trade-offs between true positive (benefits) and false positive (costs). The AUC of a realistic classifier should be larger than 0.5. We refer to [48] for a detailed description. A larger value means a higher performance. Similar to AP, the mean AUC, i.e. mAUC over all labels, is reported.
Ranking Loss (RL) evaluates the fraction of label pairs that are incorrectly ranked [19, 21]. Given a sample and its label set , a successful classifier should have larger value for than those . Then the ranking loss for the th sample is defined as:
[TABLE]
where is the total number of labels and denotes the cardinality of a set. The smaller the value, the higher the performance. The mean value over all samples is computed for evaluation.
V-B Performance enhancement with multi-view learning
It has been shown in [8] that VVMR performs well for transductive semi-supervised multi-label classification and can provide a high-quality out-of-sample generalization. The proposed MV3MR framework is a multi-view generalization of VVMR that incorporates the advantage from MKL for handling multi-view data. Therefore, we first evaluate the effectiveness of learning the view combination weights using the proposed multi-view learning algorithm for transductive semi-supervised multi-label classification. An out-of-sample evaluation will be presented in the next subsection. The experimental setup of the two compared methods is given as follows.
VVLSVM: vector-valued Laplacian SVM, which is an SVM implementation of the vector-valued manifold regularization framework that exploits both the geometry of the input data as well as the label correlations. We do not use the vector-valued Laplacian RLS presented in [8] for comparison because the hinge loss is more suitable for classification. The parameters and in (2) are both optimized over the set . We set the parameter in (3) to 1.0 since it has been demonstrated empirically in [8] that with a larger , the performance will usually be better. The mean of the multiple Gram matrices and input graph Laplacians are pre-computed for experiments. The number of nearest neighbors for constructing the input and output graph Laplacians are tuned on the sets and respectively.
MV3LSVM: an SVM implementation of the proposed MV3MR framework that combines multiple views by constructing kernels for all views and learning their weights. We tune the parameters and as in VVLSVM and is set to 1.0. The additional parameters and are optimized over . We firstly only learn kernel combinations and set the graph weights to be uniform (MV3LSVM1 in Fig. 4). Then we learn both and in MV3LSVM2. We use and nearest neighbor graphs to construct the input and output normalized graph Laplacians respectively for the VOC dataset, while and nearest neighbor graphs are used in the experiments on MIR. We set these hyperparameters to be the same as those in VVLSVM and no further optimization was attempted.
The experimental results on the two datasets are shown in Fig. 4. We can see that learning the combination weights using our algorithm is always superior to simply using the uniform weights for different views. We also find that when the number of labeled samples increases, the improvement becomes small. This is because the multi-view learning actually helps to approximate the underlying data distribution. This approximation can be steadily improved with the increase of the number of labeled samples, and thus the significance of the multi-view learning to the approximation gradually decreases. Besides, we observe that has more influence on the final performance overall.
We show the behavior of the objective values by increasing the iteration number in Fig. 5. From the figure, we can see that only a few iterations (about five) are necessary to obtain a satisfactory solution. Thus the time complexity is only a little more than the VVLSVM algorithm and can justify the performance enhancement.
Finally, our algorithm is not sensitive to different initializations, as shown in Fig. 6. In particular, we run our algorithm with 10 random choices of and . We show the performance in terms of mAP, mAUC and RL on the two datasets in Fig. 6. It can be observed that the performance curves do not vary a lot with different initializations.
V-C Out-of-sample generalization
The second set of experiments is to evaluate the out-of-sample extension quality of the MV3MR framework and the SVM implementation is utilized. Fig. 7 compares the transductive performance to the inductive performance when using labeled samples. We show a scatter plot of the AP scores for each label on the two datasets by using 10-random choices of labeled data. We can see that our algorithm generalizes well from the unlabeled set to the unseen set. The MV3MR framework inherits a strong natural out-of-sample generalization ability that many semi-supervised multi-label methods do not naturally have [8]. Besides, most graph-based semi-supervised learning algorithms are transductive and additional induction schemes are necessary to handle new points [49].
V-D Analysis of the combination coefficients in multi-view learning
In the following, we present empirical analyses of the multi-view learning procedure. In Fig. 8, we select and present the view combination coefficients and learned by MV3LSVM, together with the mAP by using VVLSVM for each view. From the results, we find that the tendency of the kernel and graph weights are both consistent with the corresponding mAP in general, i.e., the views with a higher classification performance tend to be assigned larger weights, taking the DenseSIFT visual view (the 2nd view) and the tag (the last view) for example. However, a larger weight may sometimes be assigned to a less discriminative view; for example, the weight of Hsv (the 4th view) is larger than the weight of DenseSift (the 2nd view). This is mainly because the coefficient is not optimal for every single view, in which only and are utilized. The learned minimizes the optimization problem (8) by using the combined Gram matrix and integrated graph Laplacian , which means that the learned vector-valued function is smooth along the combined RKHS and the integrated manifold. In this way, the proposed algorithm effectively exploits the complementary property of different views.
V-E Comparisons with multi-label and multi-kernel learning algorithms
Our last set of experiments is to compare MV3LSVM with several competitive multi-label methods as well as a well-known MKL algorithm in predicting the unknown labels of the unlabeled data. The out-of-sample generalization ability of our method has been verified in our second set of experiments.
We specifically compare MV3LSVM with the following methods on the challenging VOC and MIR datasets:
SVM_CAT: concatenating the features of each view and then running standard SVM. The parameter is tuned on the set . The time complexity is [45].
SVM_UNI: combining different kernels by combining them with uniform weights and then running standard SVM. The parameter is tuned on the set . The time complexity is [45].
MLCS [18]: a multi-label compressed sensing algorithm that takes advantage of the sparsity of the labels. We choose the label compression ratio to be 1.0 since the number of the labels n is not very large. The mean of the multiple kernels from different views is pre-computed for experiments. Suppose the length the compressed label vector (for each sample) is . Then the training cost is if we choose the regression algorithm to be the least squares [50], and the reconstruction complexity is if the least angle regression (LARS) algorithm [51] is utilized. Considering that in this paper, the time complexity of MLCS is .
KLS_CCA [12]: a least-squares formulation of the kernelized canonical correlation analysis for multi-label classification. The ridge parameter is chose from the candidate set . The mean of multiple Gram matrices is pre-computed to run the algorithm. According to the discussion presented in [12], the time complexity is , where is the feature dimensionality and is the number of iterations.
SimpleMKL [16]: a popular SVM-based MKL algorithm that determines the combination of multiple kernels by a reduced gradient descent algorithm. The penalty factor is tuned on the set . We apply SimpleMKL to multi-label classification by learning a binary classifier for each label. According to the Algorithm 1 presented in [16], there is an outer loop for updating the kernel weights, as well as an inner loop to determine the maximal admissible step size in the reduced gradient descent. Suppose the number of outer and inner iterations are and respectively, then the time complexity of SimpleMKL is approximately , where we have ignored the time cost of the SVM solver in the inner loop since it has warm start and can be very fast [16].
LpMKL [17]: a recent proposed MKL algorithm, which extend MKL to -norm with . The penalty factor is tuned on the set and we choose the norm from the set . According to the Algorithm 1 presented in [17], the time complexity is since the kernel combination coefficients can be computed analytically, where is the number of iterations.
The performance of the compared methods on the VOC dataset and MIR dataset are reported in Table I. The values in the last column of Table I are average ranks. From the results, we firstly observe that the performance keeps improving with the increasing number of the labeled samples. Second, the performance of the simpleMKL algorithm, which learns the kernel weights for SVM, can be inferior to the multi-label algorithms with the mean kernel in many cases. MV3LSVM is superior to multi-view (SimpleMKL and LpMKL) and multi-label algorithms in general and consistently outperforms other methods in terms of mAP. The average rank of our algorithm is smaller than all the other methods in terms of all the three criteria. According to the Friedman test [52], the statistics of mAP, mAUC and RL are , , and respectively. All of them are larger than the critical value , so we reject the null-hypothesis (the compared algorithms perform equally well). In particular, by comparing with SimpleMKL, we obtain a significant mAP improvement on VOC when using 100 labeled samples. The level of improvement drops when more labeled samples are available, for the same reason described in our first set of experiments.
VI Conclusion and Discussion
Most of the existing works on multi-label image classification use only single feature representation, and the multiple feature methods usually assume that a single label is assigned to an image. However, an image is usually associated with multiple labels and different kinds of features are necessary to describe the image properly. Therefore, we have developed a multi-view vector-valued manifold regularization (MV3MR) for multi-label image classification in which images are naturally characterized by multiple views. MV3MR combines different kinds of features in the learning process of the vector-valued function for multi-label classification. We also derived an SVM formulation of MV3MR, which results in MV3LSVM. The new algorithm effectively exploits the label correlations and learns the view weights to integrate the consistency and complementary properties of different views. We evaluate the proposed algorithm in terms of three popular criteria, i.e. mAP, mAUC and RL. Intensive experiments on two challenge datasets PASCAL VOC’07 and MIR Flickr show that the support vector machine based implementation under MV3MR outperforms the traditional multi-label algorithms as well as a well-known multiple kernel learning method. Furthermore, our method provides a strategy for learning from multiple views in multi-label classification and can be extended to other multi-label algorithms.
Appendix A PROOF OF LEMMA 1
Proof:
The matrix , where is defined as a convex combination of the scalar-valued graph Laplacians constructed from different views. since each , and thus we have according to the positive definite property on the Kronecker product. Here, can be computed by using the following adjacency graph
[TABLE]
where denotes a set that contains the -nearest neighbors of and is the similarity between the th and th point from the th view. Thus is a graph Laplacian and is the corresponding vector-valued graph Laplacian. ∎
Appendix B PROOF OF THE REPRESENTER THEOREM
Proof:
It has been presented in Section IV-A that there is an RKHS associated with the vector-valued kernel . The probability distribution is assumed to be supported on a manifold in the manifold regularization framework. We now denote as a linear space spanned by the kernels centered at the points on . Any function can be decomposed as , with and . It has been proved in Lemma 1 that is a graph Laplacian. Thus we can use to induce an intrinsic norm , which satisfies for any , . According to the reproducing property, it concludes that vanishes on [9]. This means that for any , we have and then . Besides , and thus we conclude that the minimizer of the problem (6) must lie in for fixed and . Furthermore, because is approximated by the Laplacian of the graph constructed by the labeled and unlabeled samples, we have . This completes the proof. ∎
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] M. Boutell, J. Luo, X. Shen, and C. Brown, “Learning multi-label scene classification,” Pattern recognition , vol. 37, no. 9, pp. 1757–1771, 2004.
- 2[2] M. Guillaumin, J. Verbeek, and C. Schmid, “Multimodal semi-supervised learning for image classification,” in IEEE conference on Computer Vision and Pattern Recognition , 2010, pp. 902–909.
- 3[3] D. Lowe, “Distinctive image features from scale-invariant keypoints,” International Journal of Computer Vision , vol. 60, no. 2, pp. 91–110, 2004.
- 4[4] A. Oliva and A. Torralba, “Modeling the shape of the scene: A holistic representation of the spatial envelope,” International Journal of Computer Vision , vol. 42, no. 3, pp. 145–175, 2001.
- 5[5] E. Çesmeli and D. Wang, “Texture segmentation using gaussian-markov random fields and neural oscillator networks,” IEEE Transactions on Neural Networks , vol. 12, no. 2, pp. 394–404, 2001.
- 6[6] D. Masip and J. Vitrià, “Shared feature extraction for nearest neighbor face recognition,” IEEE Transactions on Neural Networks , vol. 19, no. 4, pp. 586–595, 2008.
- 7[7] C. Micchelli and M. Pontil, “On learning vector-valued functions,” Neural Computation , vol. 17, no. 1, pp. 177–204, 2005.
- 8[8] H. Minh and V. Sindhwani, “Vector-valued manifold regularization,” in Proceedings of the 28th International Conference on Machine Learning , 2011, pp. 57–64.