On Learning Density Aware Embeddings
Soumyadeep Ghosh, Richa Singh, Mayank Vatsa

TL;DR
This paper introduces a density-aware deep metric learning algorithm that improves embedding robustness, convergence speed, and generalization by focusing on dense cluster regions, especially in noisy data scenarios.
Contribution
It proposes a novel density-aware metric learning method that enhances robustness and efficiency in deep metric learning, outperforming existing methods.
Findings
Faster convergence and higher accuracy than existing methods.
Robust to noisy training samples and outliers.
Effective across face and object recognition datasets.
Abstract
Deep metric learning algorithms have been utilized to learn discriminative and generalizable models which are effective for classifying unseen classes. In this paper, a novel noise tolerant deep metric learning algorithm is proposed. The proposed method, termed as Density Aware Metric Learning, enforces the model to learn embeddings that are pulled towards the most dense region of the clusters for each class. It is achieved by iteratively shifting the estimate of the center towards the dense region of the cluster thereby leading to faster convergence and higher generalizability. In addition to this, the approach is robust to noisy samples in the training data, often present as outliers. Detailed experiments and analysis on two challenging cross-modal face recognition databases and two popular object recognition databases exhibit the efficacy of the proposed approach. It has superior…
Click any figure to enlarge with its caption.
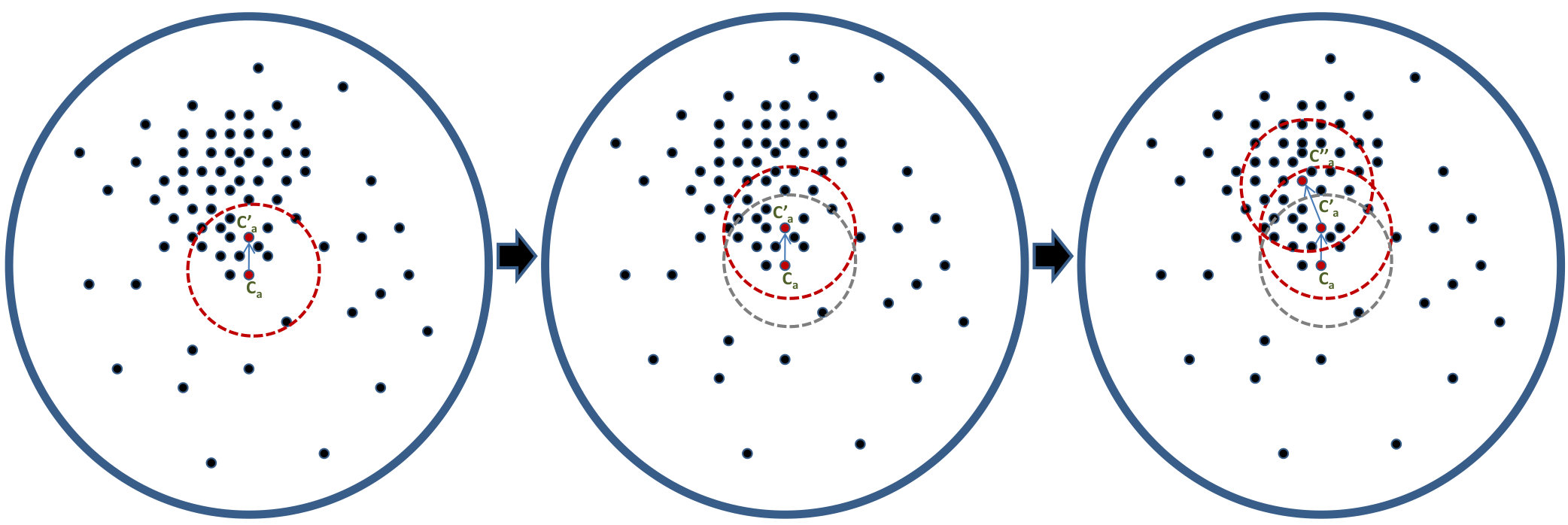 Figure 1
Figure 1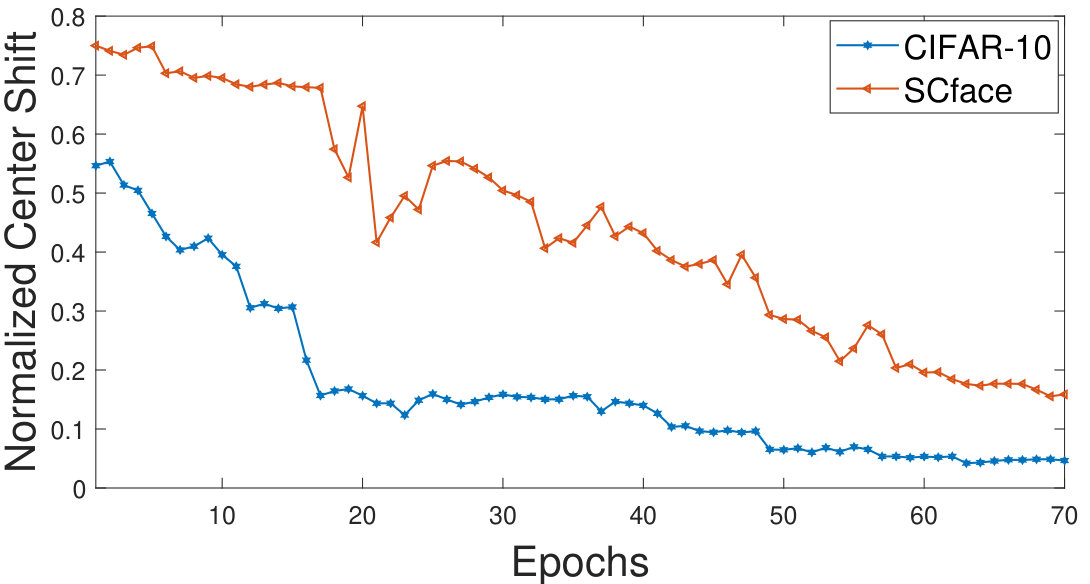 Figure 2
Figure 2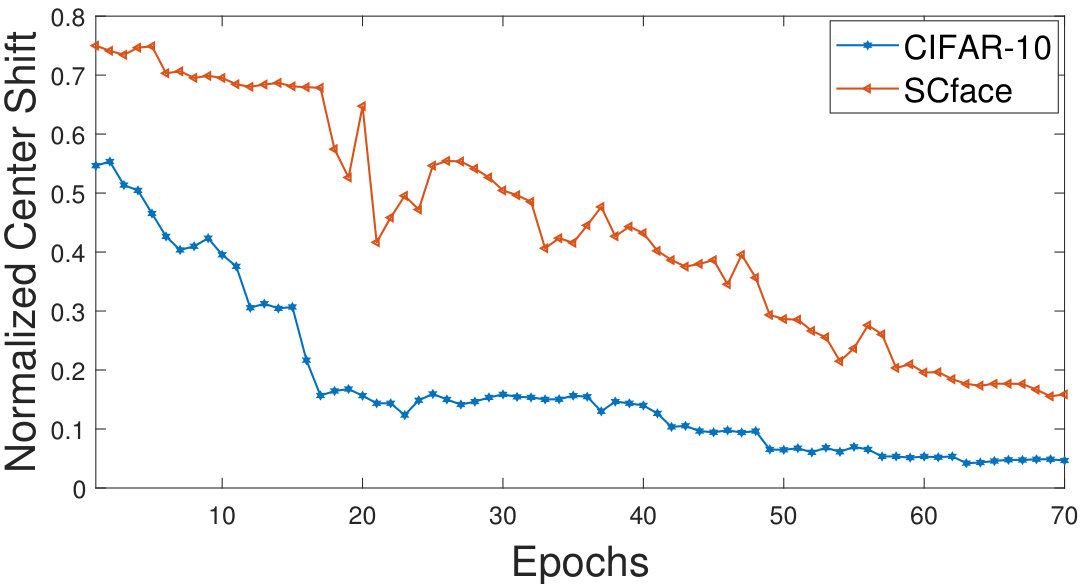 Figure 3
Figure 3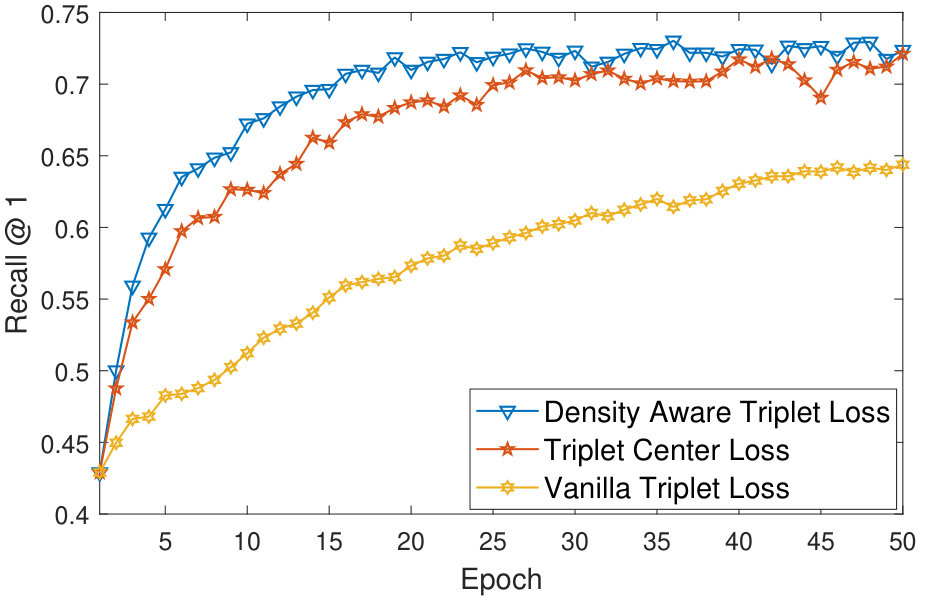 Figure 4
Figure 4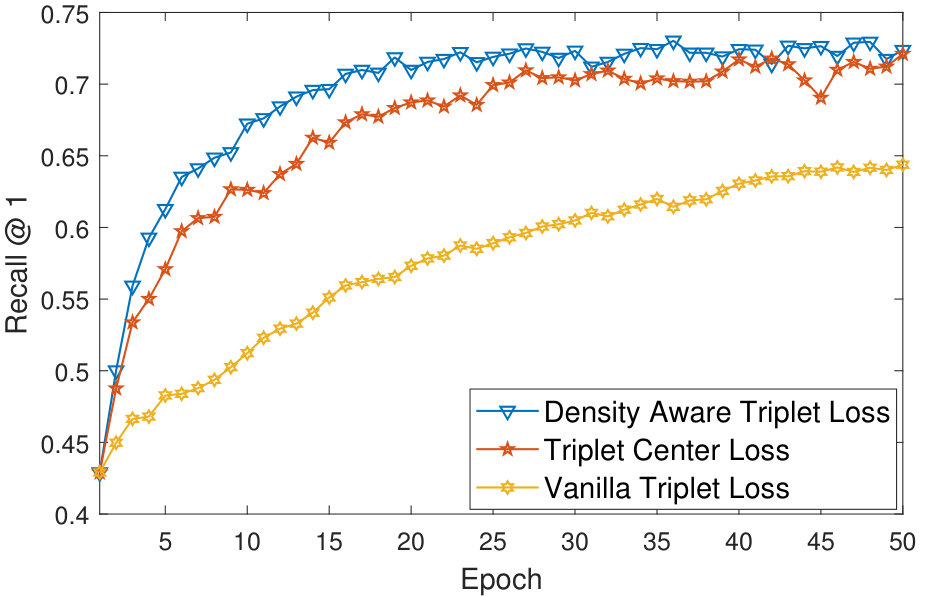 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8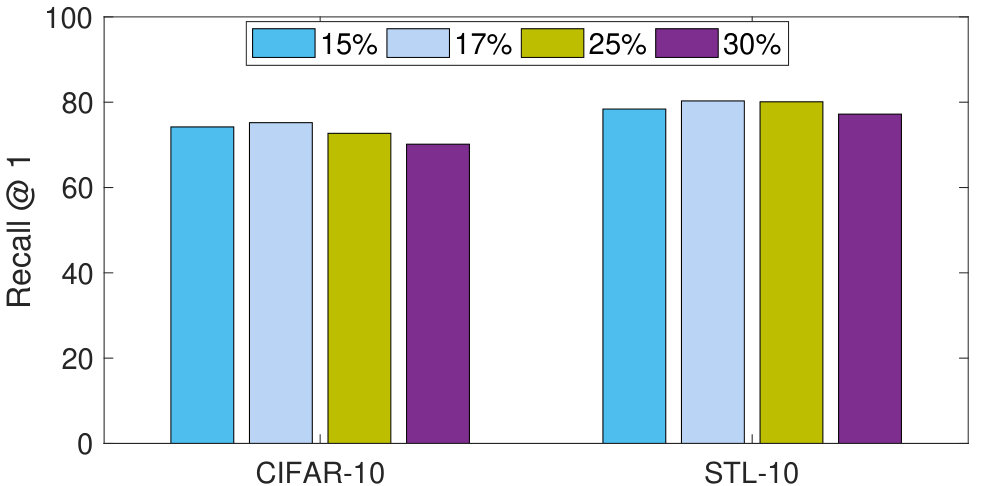 Figure 9
Figure 9 Figure 10
Figure 10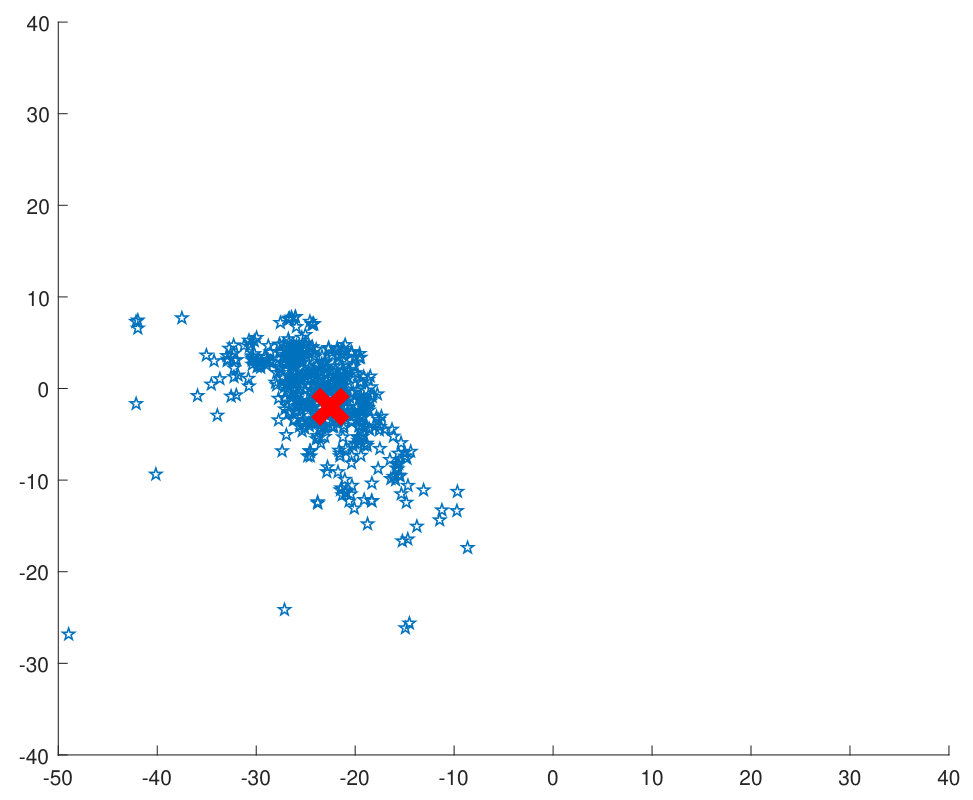 Figure 11
Figure 11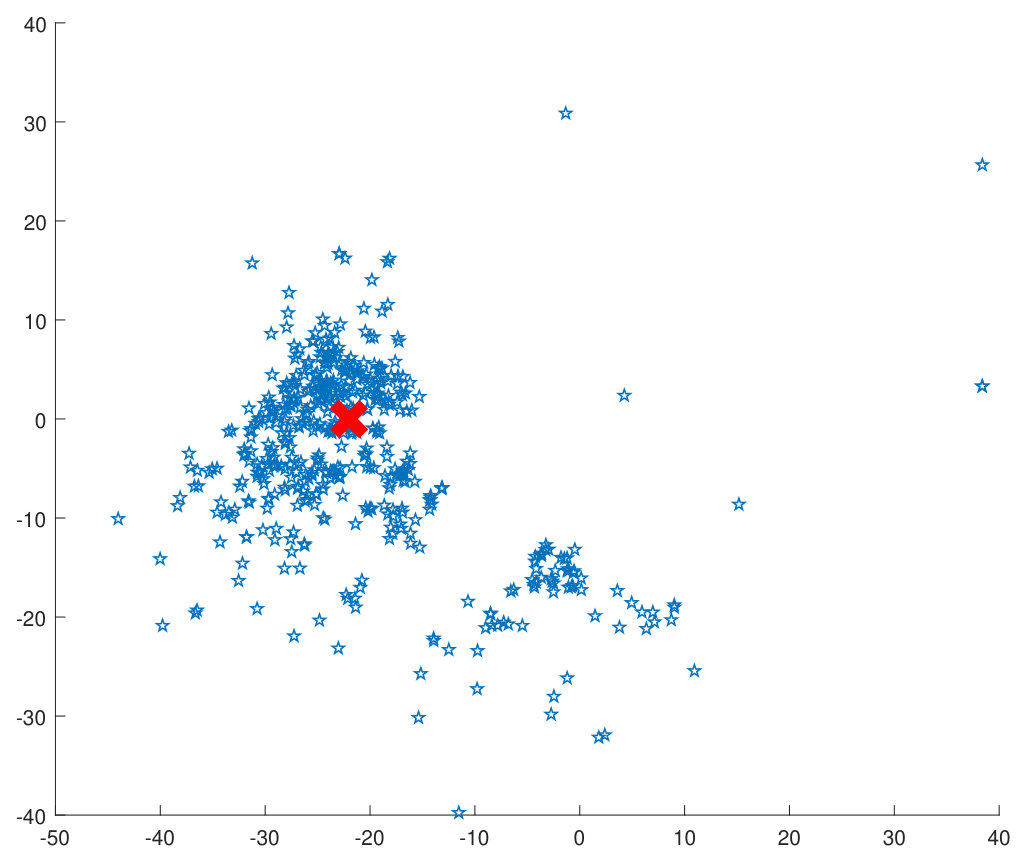 Figure 12
Figure 12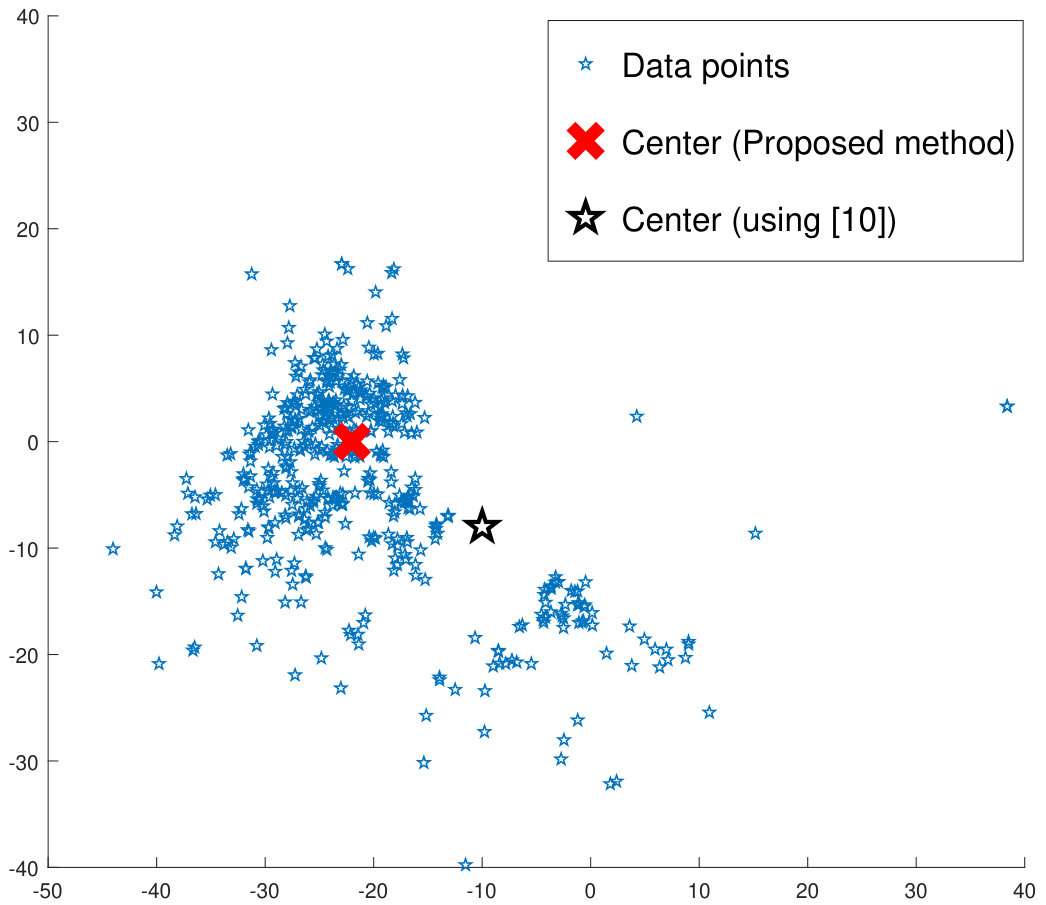 Figure 13
Figure 13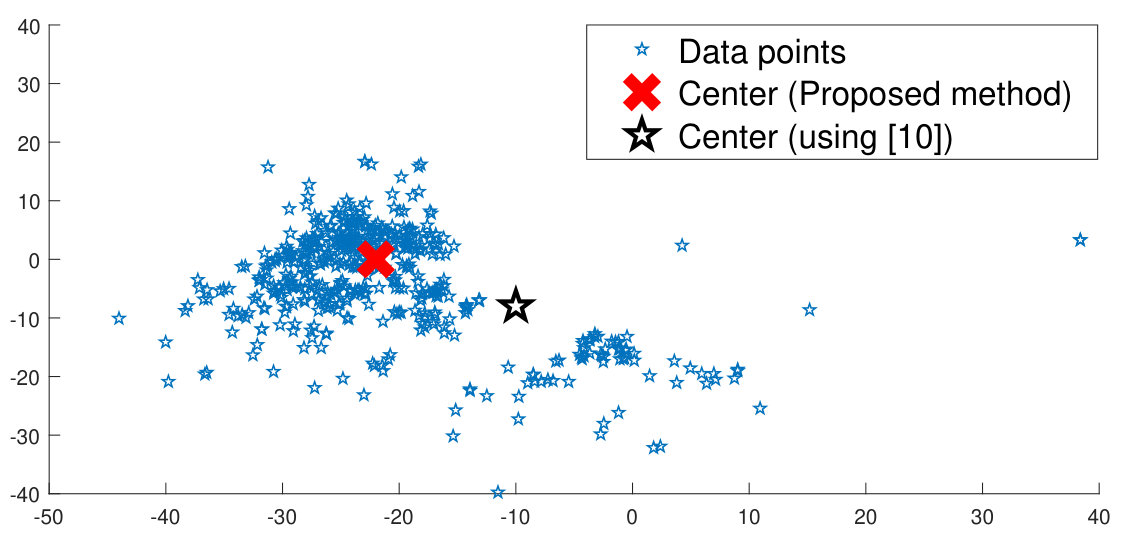 Figure 14
Figure 14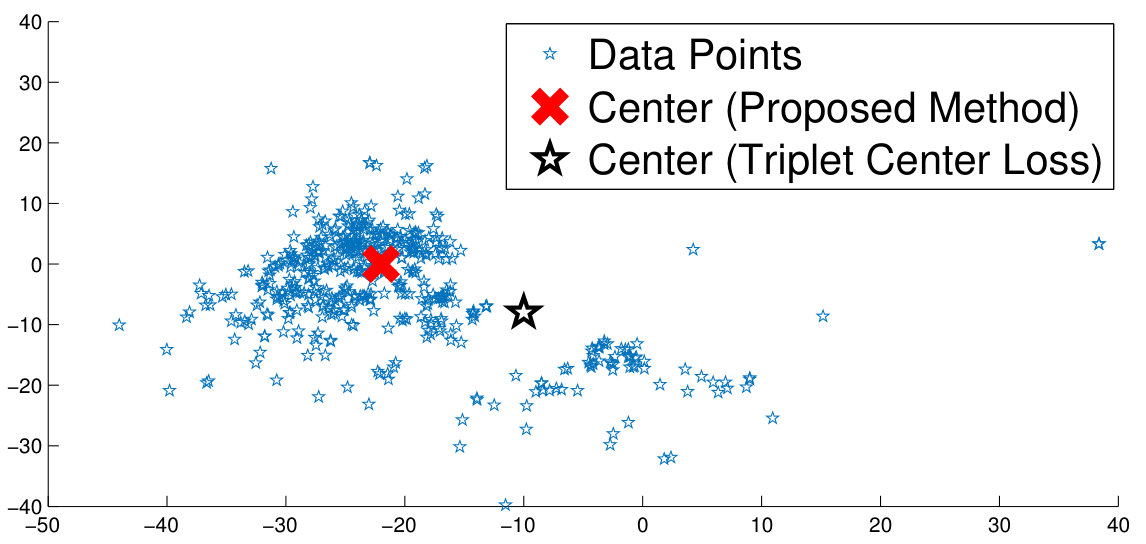 Figure 15
Figure 15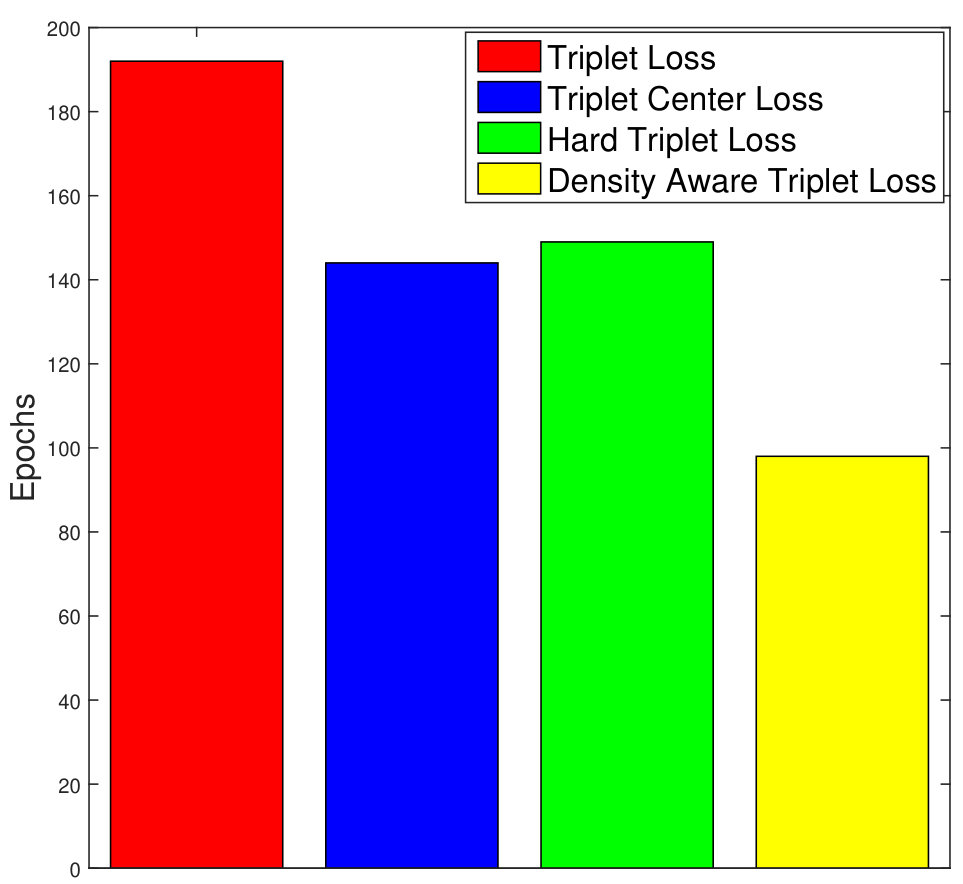 Figure 16
Figure 16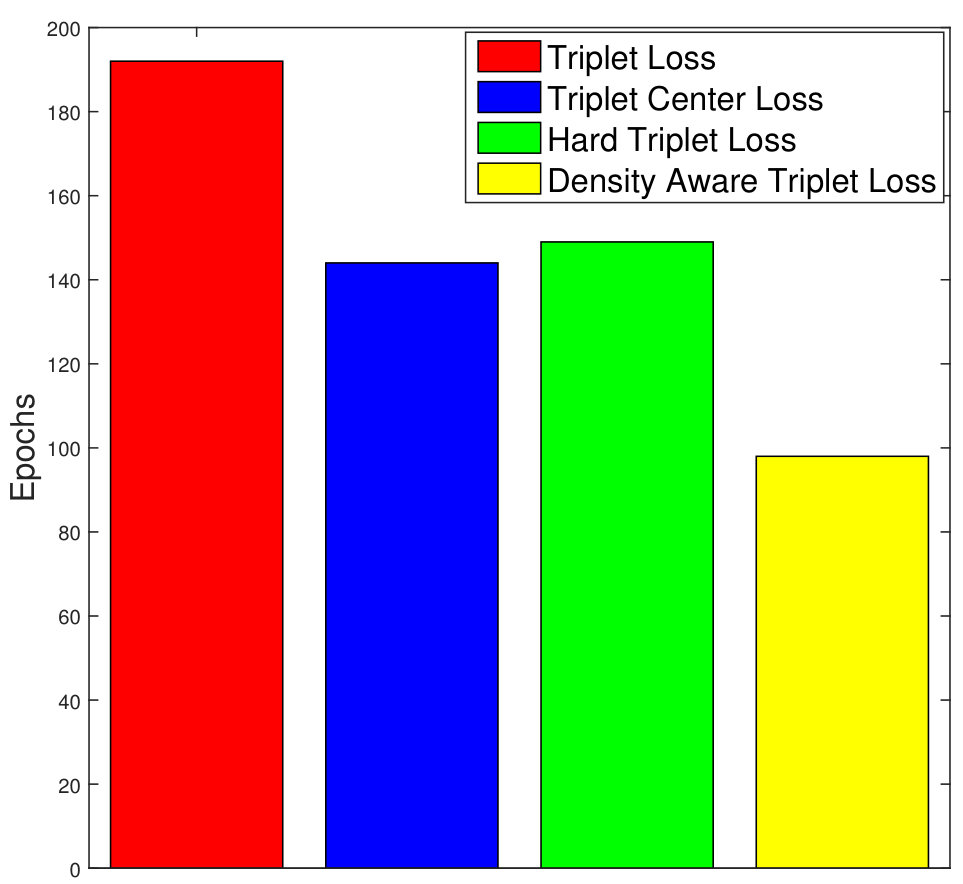 Figure 17
Figure 17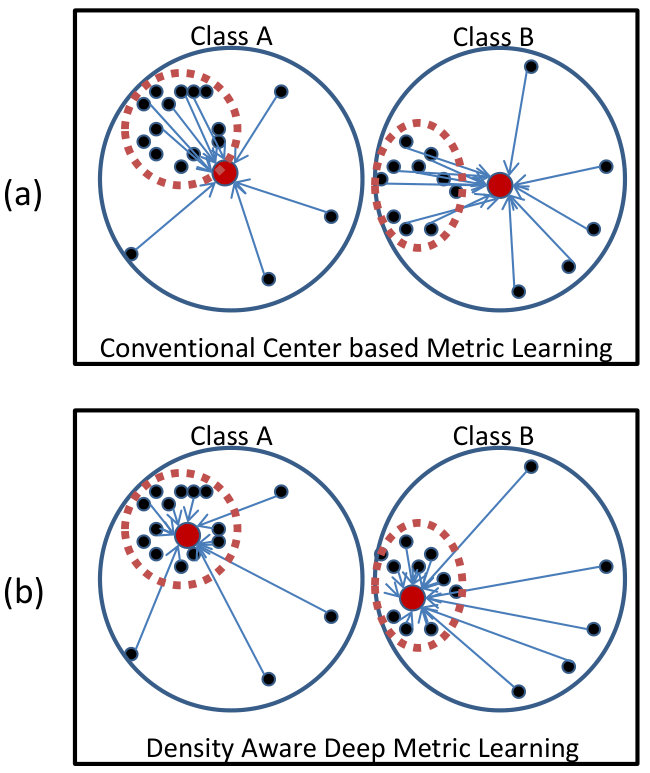 Figure 18
Figure 18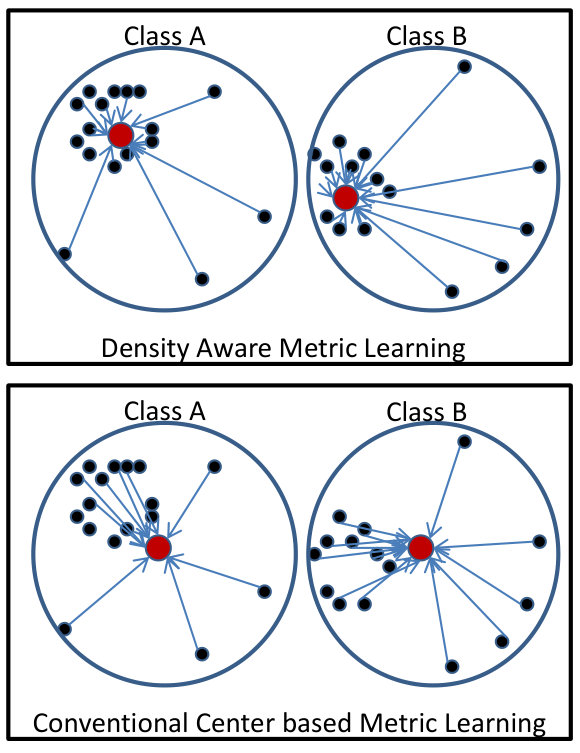 Figure 19
Figure 19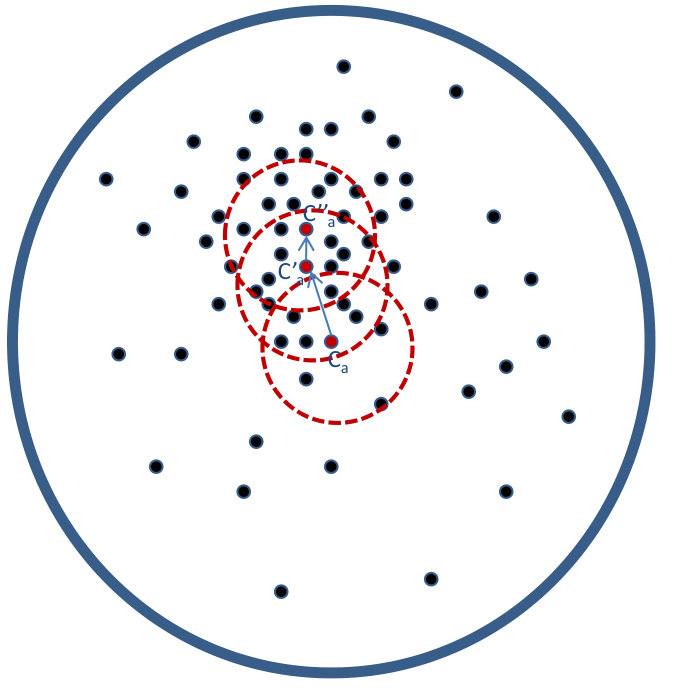 Figure 20
Figure 20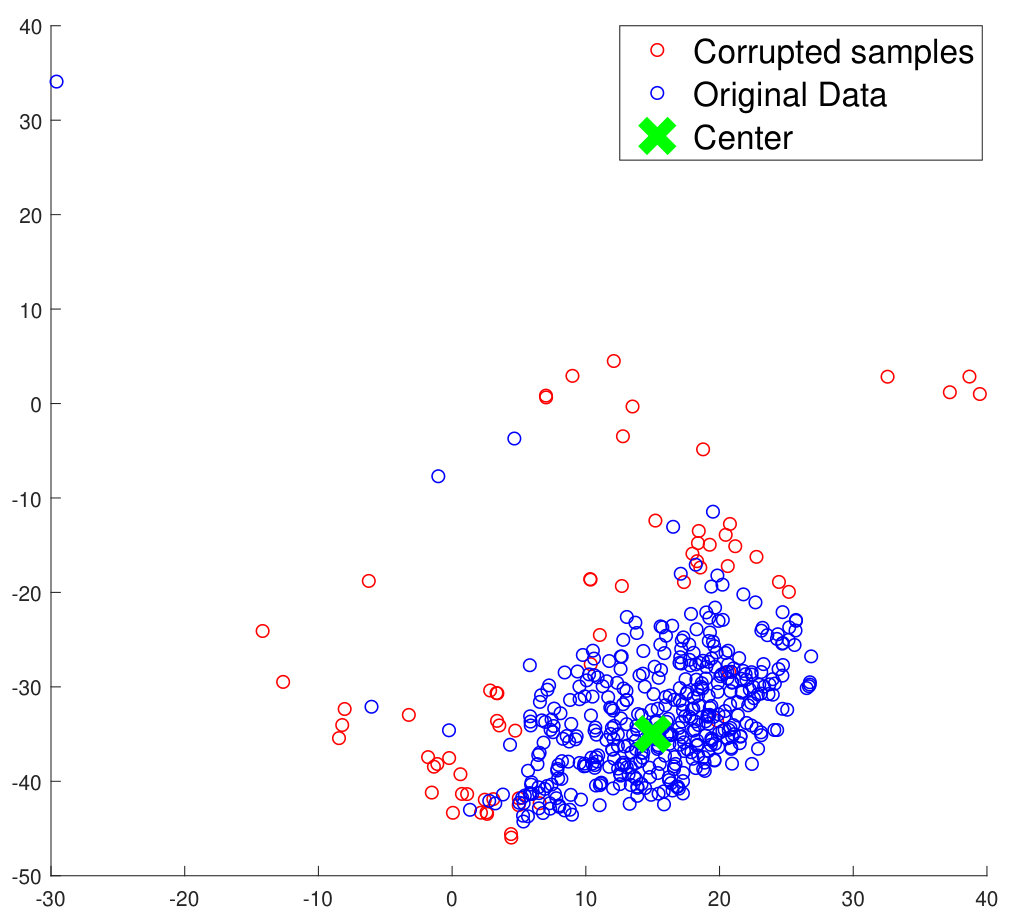 Figure 21
Figure 21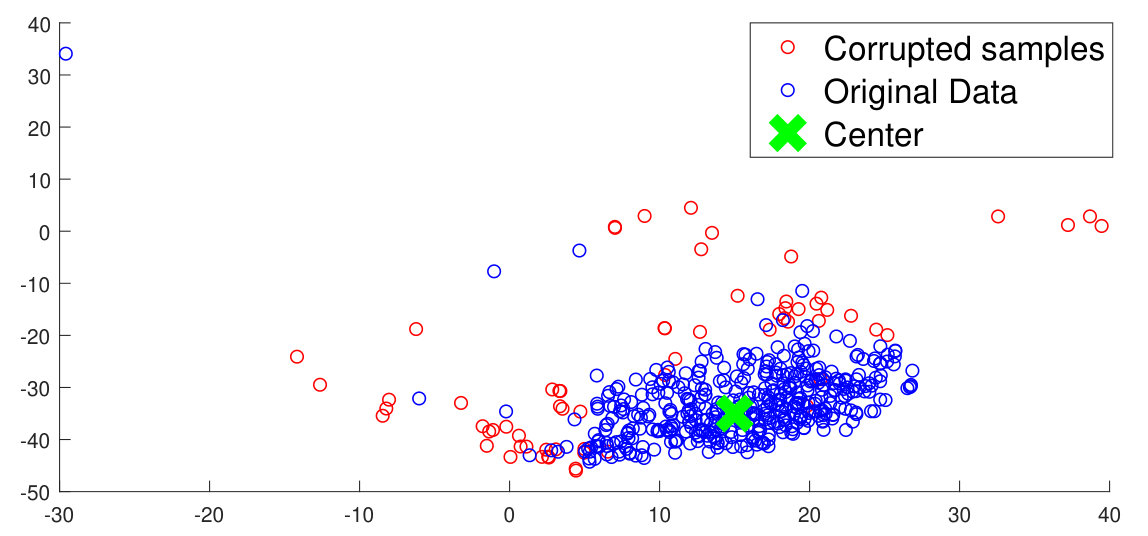 Figure 22
Figure 22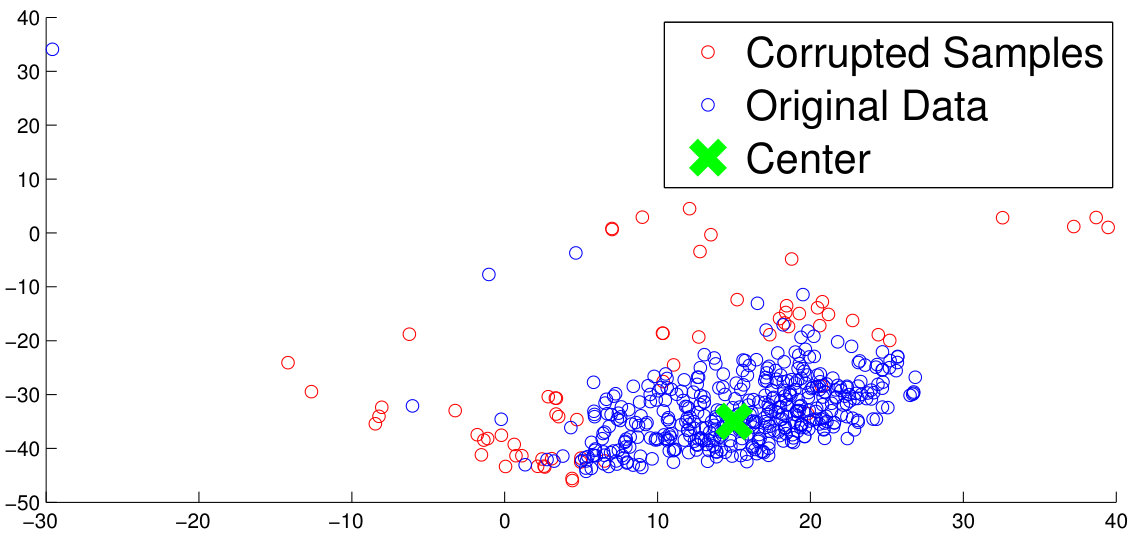 Figure 23
Figure 23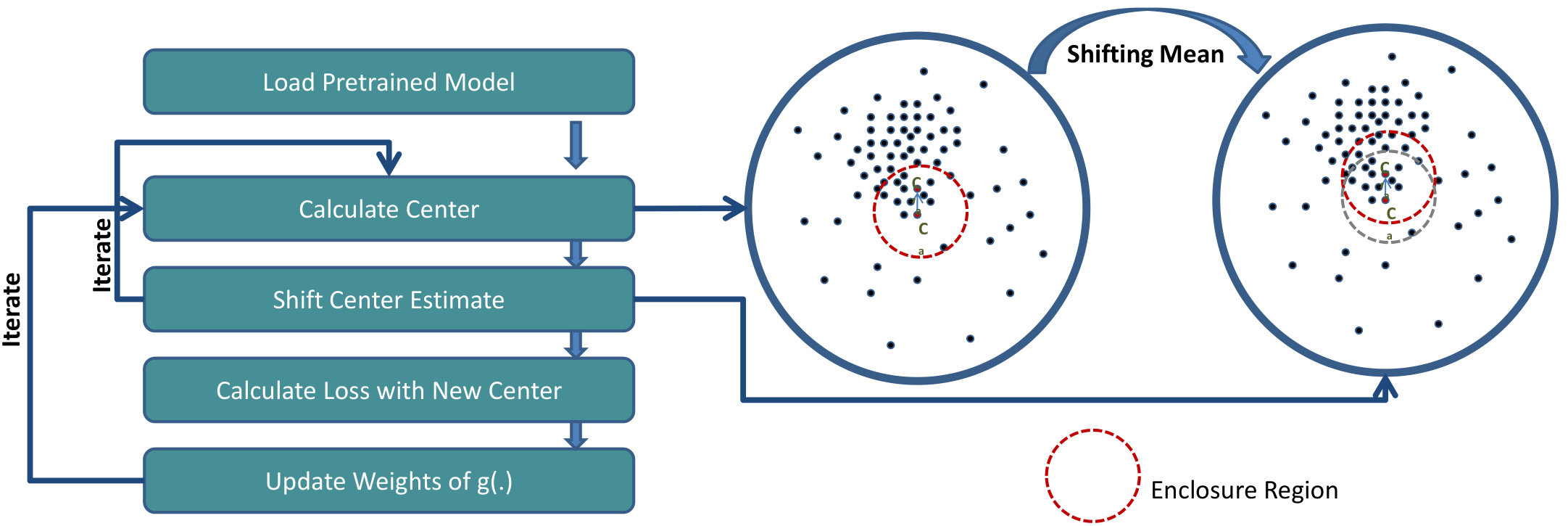 Figure 24
Figure 24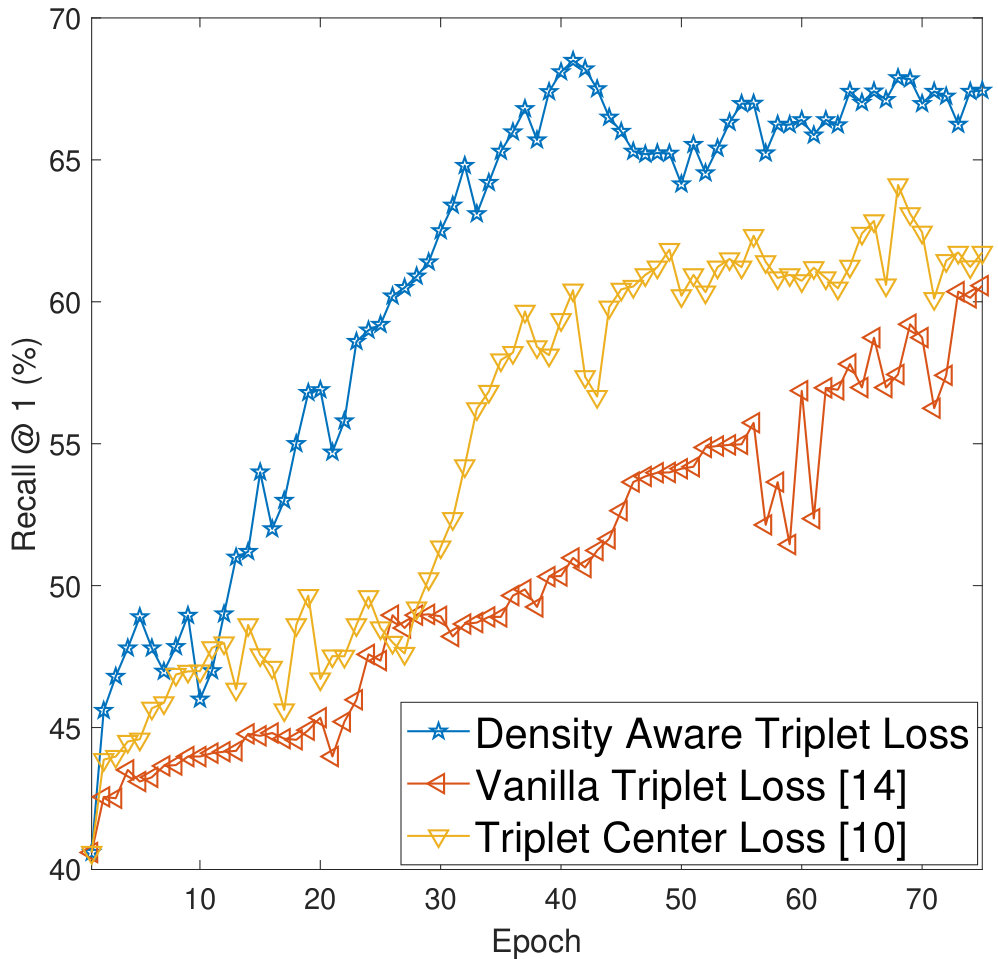 Figure 25
Figure 25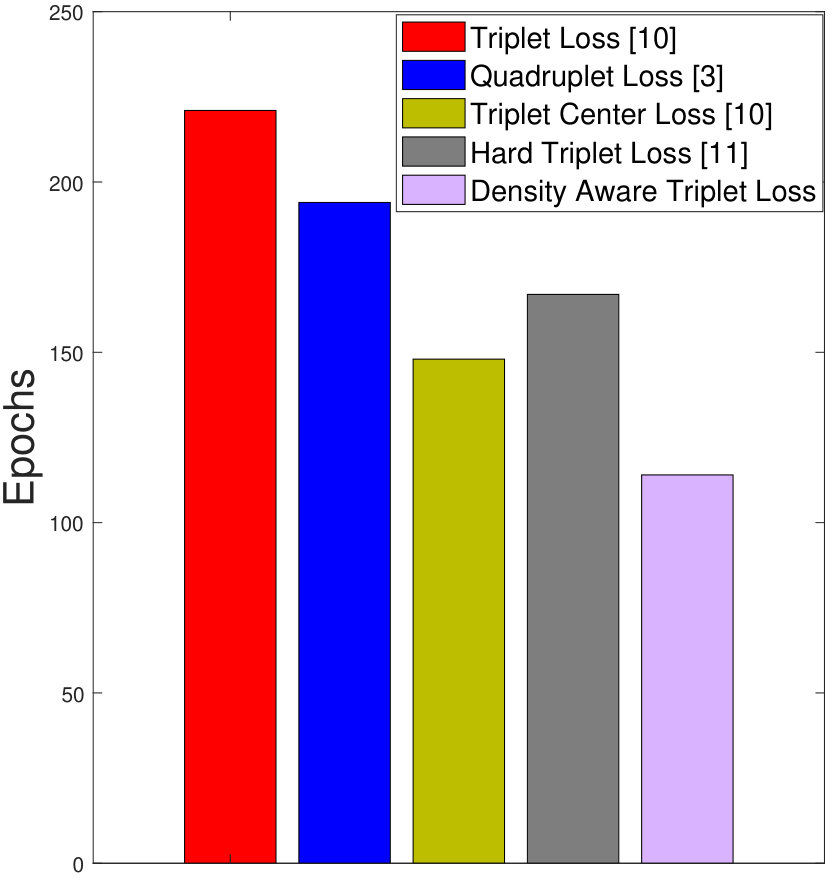 Figure 26
Figure 26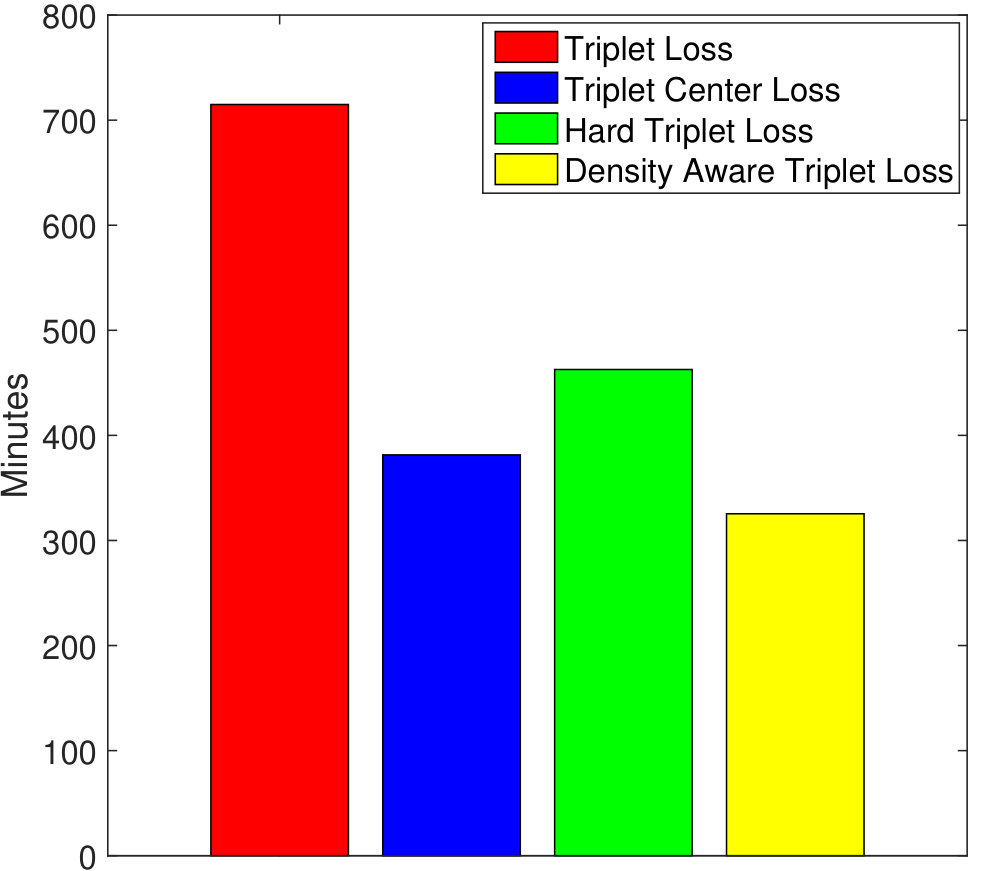 Figure 27
Figure 27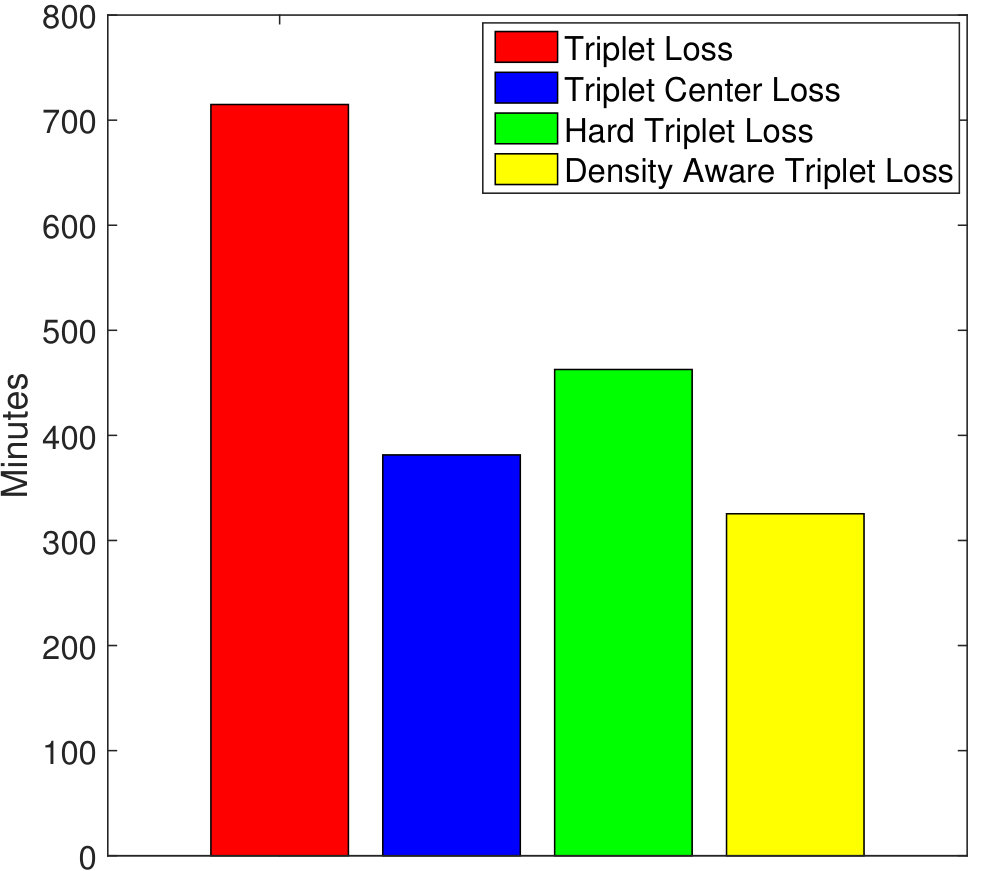 Figure 28
Figure 28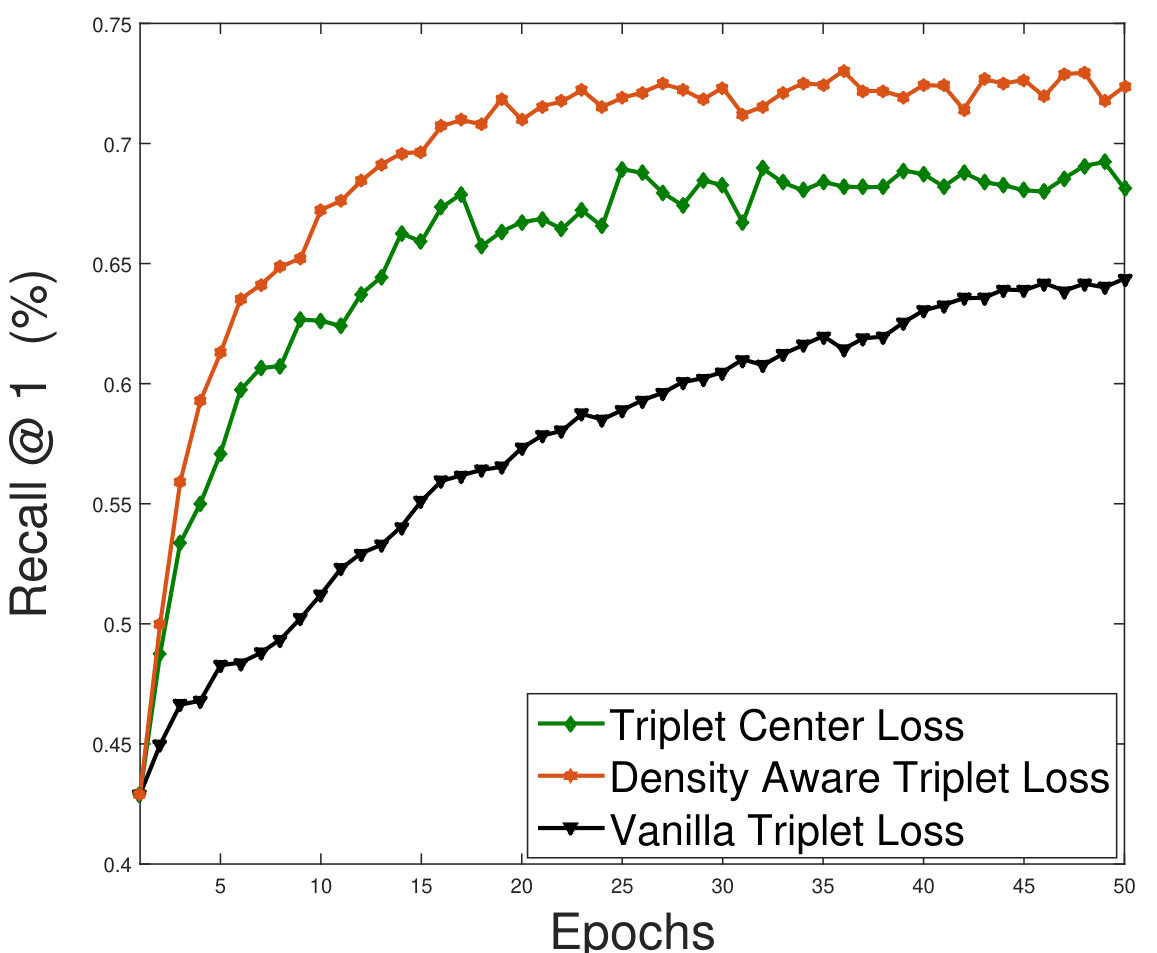 Figure 29
Figure 29| Method | Identification (%) (Rank 1) | |||
|---|---|---|---|---|
| 24 x 24 | 32 x 32 | 48 x 48 | ||
| MDS [2] | 64.87 | 70.48 | 76.14 | |
| Co-Transfer Learning [1] | 70.14 | 76.29 | 83.47 | |
| Res-Net [26] | 36.30 | 81.80 | 94.30 | |
| Coupled Res-Net [17] | 73.30 | 93.50 | 98.00 | |
| VGGFace [17] | 41.30 | 75.50 | 88.80 | |
| Coupled VGGFace [17] | 62.30 | 91.00 | 94.80 | |
| Coupled Light-CNN [17] | 50.50 | 85.00 | 94.00 | |
| Triplet loss [16] | 70.69 | 95.42 | 97.02 | |
| Quadruplet loss [3] | 74.00 | 96.57 | 98.41 | |
| Hard triplet loss [13] | 72.65 | 96.12 | 98.05 | |
| Triplet Center Loss [12] | 75.45 | 96.10 | 98.50 | |
| Discriminative MDS [29] | 62.70 | 65.50 | 70.70 | |
| Proposed | DATL | 76.24 | 96.87 | 98.09 |
| DAQL | 77.25 | 96.58 | 98.14 | |
| Method | Resolution of Noisy Samples | ||||
| 24 x 24 | 32 x 32 | ||||
| Recall @ (%) | |||||
| =1 | =10 | =1 | =10 | ||
| Triplet Loss [20] | 54.12 | 58.00 | 68.45 | 72.58 | |
| Quadruplet Loss [3] | 56.51 | 59.77 | 68.74 | 73.01 | |
| Hard Triplet Loss [13] | 58.29 | 60.41 | 65.37 | 72.91 | |
| Triplet Center Loss [12] | 62.76 | 65.40 | 68.76 | 73.16 | |
| Proposed | DATL | 66.52 | 69.45 | 69.87 | 73.21 |
| DAQL | 65.47 | 69.80 | 68.52 | 75.40 | |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsFace recognition and analysis · Face and Expression Recognition · Video Surveillance and Tracking Methods
On Learning Density Aware Embeddings
Soumyadeep Ghosh, Richa Singh, Mayank Vatsa
IIIT-Delhi, India
{soumyadeepg, rsingh, mayank}@iiitd.ac.in
Abstract
Deep metric learning algorithms have been utilized to learn discriminative and generalizable models which are effective for classifying unseen classes. In this paper, a novel noise tolerant deep metric learning algorithm is proposed. The proposed method, termed as Density Aware Metric Learning, enforces the model to learn embeddings that are pulled towards the most dense region of the clusters for each class. It is achieved by iteratively shifting the estimate of the center towards the dense region of the cluster thereby leading to faster convergence and higher generalizability. In addition to this, the approach is robust to noisy samples in the training data, often present as outliers. Detailed experiments and analysis on two challenging cross-modal face recognition databases and two popular object recognition databases exhibit the efficacy of the proposed approach. It has superior convergence, requires lesser training time, and yields better accuracies than several popular deep metric learning methods.
1 Introduction
Classification models such as Convolutional Neural Networks (CNN) utilize deep metric learning based loss function for learning discriminative embeddings. The loss function attempts to bring the embeddings of the same classes close to each other in the output manifold. In this embedding space, a direct computation of the distance gives the dissimilarity score between the two images. Several different applications have investigated the use of deep metric learning algorithms such as person re-identification [4, 13, 21], 3D object retrieval [12], biometric recognition [7, 20, 23, 24], robot perception [15], patch matching [11, 31], and object recognition [18, 27].
In the literature, very efficient deep metric learning methods have been proposed such as triplet loss [20] and quadruplet loss [3]. However, a major limitation of these loss functions is their heavy dependence on mining of hard samples for training [13, 20, 21, 30]. In the triplet Loss [20], for training classes and samples in each class, the total number of triplets for training can be as high as , which increases the training time on large datasets significantly. Another limitation of these methods is slow convergence, this heavily depends on the appropriate choice of the training curriculum. Further, the presence of outliers (noisy/poor-quality samples) in the training data, and their participation in triplets may hurt the training process. To the best of our knowledge there has been no study to understand the effect of outliers and density distribution of the training data on the performance of deep metric learning algorithms.
As seen in Figure 1(a), conventional center loss based deep metric learning methods [12, 26] generate embeddings of each class that lie closer to the centroid of the samples of that particular class. However, they do not take into account the distribution of the training data. In cases where outliers are present, the convergence of such methods on large databases can be slow and the outliers/noisy training samples can adversely affect the training of a discriminative model. In order to mitigate this challenge, the proposed algorithm minimizes the effect of outliers by calculating the center, taking into account the most dense region of the respective clusters for each class (Figure 1(b)). Using the philosophy of the classical mean-shift algorithm [6], the estimate of the mean is shifted to a denser region from the initial estimate of the centroid. This shifted center embedding is used for learning a discriminative model. The research contributions of the paper can be summarized as follows:
- •
The proposed density aware deep metric learning algorithm provides a generalized framework which can be augmented with any deep metric learning method for effective training especially with noisy data.
- •
Detailed analysis and comparison with other popular deep metric learning methods on four challenging databases pertaining to face and object images show that the proposed approach gives better recognition accuracies, exhibits superior convergence with reduced training time and is resilient to noisy training data.
2 Related Work
Hadsell et al. [10] proposed the contrastive loss, which was one of the first deep metric learning methods for training a discriminative model with a deep neural network. They used a single loss function to pull positive pairs and push negative pairs in the output embedding space of the model. This method of training a discriminative neural network, popularly known as the Siamese Network, resulted in several extensions [18, 23, 24] which produced excellent results on a variety of image recognition problems. Recently, one of the most popular methods for deep metric learning is the triplet loss [20]. The triplet loss enforces the model to learn an embedding space where samples of similar classes are mapped closer to each other and that of other classes are pushed away. Wen et al. [26] used a combination of the softmax and the center loss for face recognition. Later, Chen et al. [3] proposed the quadruplet loss which used an extra negative sample in addition to the anchor, positive and the negative sample that were utilized by the triplet loss. They showed that the extra negative term helps to train a more generalizable model. Thereafter, several methods have attempted to improve upon the triplet and the quadruplet loss based methods. Yuan et al. [30] proposed an ensemble based technique for mining hard examples which are used for training a deep network using the contrastive loss. Hermans et al. [13] proposed a triplet mining technique, by selecting the hardest positive samples and hardest negative samples for each anchor image in a batch of randomly sampled images from the training set. Recently, He et al. [12] proposed the triplet center loss where the center of the set of anchors and the center of the nearest negative cluster were utilized in the loss function of the triplet loss, for person re-identification.
3 Density Aware Metric Learning
The proposed method presents a novel contribution to the deep metric learning paradigm by incorporating the density of data in the clusters during training. Before delving into the detailed formulation, a brief illustration of the background is discussed.
3.1 Background
In a classical pattern classification scenario, data from different classes is available, , where and are two images of the same class . Let the class contain number of training samples. The goal of a deep metric learning algorithm is to learn a function where is the dimensionality of the source data manifold, is the dimensionality of the output embedding space of the model , and represents the trainable parameters of the model. For illustration, let be the pair of points on the embedding manifold of the model . The distance metric function is defined as:
[TABLE]
In this paper, Euclidean distance is used as the distance metric, which can be defined as:
[TABLE]
Inspired from Large Margin Nearest Neighbor Classification [25], a typical deep metric learning loss can be used which is minimized by pulling intra-class embeddings together into one cluster and pushing the inter-class embeddings. From the training set , a 3-tuple is formed using three images, , which is a sample of the class , a positive sample , which is another image of the same class , and a negative sample which is an image of another class . The loss function can be expressed as:
[TABLE]
[TABLE]
where, is the set of all 3-tuples in the training data, , is the margin parameter and , and are sets of all the anchors, positive and negative samples, prepared from the training set.
3.2 Proposed Formulation
In order to present the proposed approach, the standard loss metric (Equation 3) is re-formulated where the anchor is replaced with the center of class . The center embedding is calculated as the mean of all the embeddings of class . Thus, the loss function may be expressed as:
[TABLE]
[TABLE]
represents the centroid of the cluster corresponding to class , containing training samples. However, depending on the density of the cluster (as shown in Figure 2), the mean-shift algorithm [6] may be applied to iteratively arrive at the mean driven by non-parametric density estimation of the cluster.
3.2.1 Shifting the Mean to a Denser Region
Reiterating, is the initial centroid of the cluster which is calculated by taking the mean of all the embeddings of class . Now, from , selecting the nearest points (in the embedding manifold of the model ) out of all the points in the cluster corresponding to class , we take the mean of only these points, where . We term the region of the embedding manifold containing these points around the centroid (the red dotted circle in Figure 2) as the enclosure region, and the set of these points as enclosure points. The estimate for the new center can be calculated as,
[TABLE]
where, is the point inside the enclosure region. Figure 2 shows the new mean , which is expected to be in a denser region of the cluster. The difference of the new mean and the old mean gives the mean shift vector which can be expressed as:
[TABLE]
This process is repeated iteratively until the mean shift is negligible, thus leading to convergence.
3.2.2 Weighted Mean Shift
The above calculation of the centroid does not take into account any weightage of the points around the mean that are considered. In order to give importance to the points nearer to the centroid, we can use a weight coefficient for every point in the enclosure region. The estimate of the center with respect to weights can be calculated as,
[TABLE]
being the estimate of the mean. The corresponding mean shift vector may be expressed as,
[TABLE]
Here, is the number of enclosure points for the iteration, and is the data point for the class .
3.3 Selecting weights using a Kernel Density Estimate (KDE)
In order to select weights for each point in the cluster represented by the centroid for a particular class , we can use a kernel density estimate that are generally used by non-parametric density estimation techniques. A uniform kernel for selecting the weights can be expressed as:
[TABLE]
where, gives the distance of the point from the cluster centroid for class . The uniform kernel assigns a weight to the point if it is within the enclosure region. The enclosure region has a radius of , thus all the points which are at a distance of or less from the centroid are assigned the same weight . Instead of directly using a parameter for the radius of the enclosure region, nearest enclosure points can also be considered out of all the points in the cluster for class . Algorithm 1 outline the steps of the proposed approach using the triplet loss.
4 Density Aware Deep Metric Learning in Triplet and Quadruplet Loss
The proposed Density Aware Metric Learning is a generic formulation and can be incorporated into any deep metric learning loss function. Here, we present the formulations of triplet and quadruplet loss based density aware metric learning:
4.1 Density Aware Triplet Loss (DATL)
Schroff et al. [20] proposed the triplet loss based deep metric learning technique where the loss is minimized by the same philosophy as discussed in Section 3.1. From the training set , a triplet is formed using an anchor , which is an image of the class , a positive sample , which is another image of the same class , and a negative sample which is an image of another class . The loss function is expressed as,
[TABLE]
[TABLE]
where , and are sets of all anchors, positive and negative samples, respectively, and is the set of all triplets in the training data. Using the proposed approach, the anchor is replaced with the center which is iteratively determined ( or , and so on) with an appropriate kernel density estimate. The loss function for the Density Aware Triplet Loss (DATL) is as follows:
[TABLE]
4.2 Density Aware Quadruplet Loss (DAQL)
The triplet loss is extended by Chen et al. [3] as the quadruplet loss where a second negative image is introduced. The loss function for the same in the proposed density aware paradigm can be expressed as,
[TABLE]
[TABLE]
where is the set of all the quadruplets prepared from the training set.
4.3 Experimental Setup and Implementation
The deep CNN architecture by Wu et al. [28] is utilized to learn a discriminative model with the proposed loss function. The weights are initialized from a network that is pretrained on the MS-Celeb 1M dataset. The model has convolutional layers, along with 10 Max-Feature-Map layers. The network has two fully connected layers at the end, producing embeddings of dimensionality . Training is performed using the Adam optimizer. The batch size is kept at and the learning rate of is used which is decreased gradually till . Hard mining is performed (steps 7-11 of Algorithm 1) for all the variants of triplet and quadruplet losses according to the Batch Hard scheme proposed by Hermans et al. [13]. The hard mining is only performed at the end of training (once the learning plateaus) to accelerate the training process. All the codes are implemented using the Pytorch platform on a machine with Intel Core i7 CPU, 64GB RAM and NVIDIA GTX 1080Ti GPU.
5 Experiments
The proposed algorithm is evaluated on the SCface [8] and FaceSurv [9] datasets for cross-modal face matching, and on the CIFAR10 [14] and STL-10 [5] datasets for object recognition.
5.1 Datasets
Details of the databases and experimental protocols are described in this section.
SCface [8] is a face dataset containing poor quality face images captured from surveillance cameras in indoor environment. The database contains 4160 images of 130 subjects. The images are captured with eight different cameras, out of which two cameras operated in night-vision mode and one camera is operated in Near-Infrared mode. The images are taken from three different stand-off distances namely 4.2 mts, 2.6 mts, and 1 mt. Out of the 130 subjects, images of 50 subjects are used for training and the remaining are used for testing. The classes/subjects in the train and test set are non overlapping.
FaceSurv [9] is a video face database where the subjects walk towards the camera from a distance of about 10 mts. It has 396 daytime and 365 nighttime videos of 240 subjects. The nighttime videos are captured in complete darkness with an NIR illuminator. Each video has about 200 frames on an average. Each subject has three gallery images which are captured in controlled scenarios from a standoff distance of 1 mt. Videos of only 39 subjects are used for training and the remaining are used for testing. The classes/subjects in train and test sets are disjoint.
CIFAR-10 [14] is a popular object recognition dataset consisting 60,000 images of 10 classes. The resolution of the images is . The training set contains 50,000 images (5,000 images of each class) and 10,000 images (1,000 per class) comprise the testing set.
STL-10 [5] contains 113,000 images of 10 different objects. The resolution of the images is . The total number of images for training and testing are 5,000 (500 per class) and 8,000 (800 per class), respectively. The remaining images are unlabeled and have not been used for the experiments.
5.2 Evaluation Criteria
In this work, two different kinds of experiments have been performed: cross-modal face recognition (identification) and object recognition (retrieval). For face identification, the test set is partitioned into probe (query images) and gallery (reference set/database) sets. For every image of the probe set, matching is performed with each image of the gallery by a forward pass through the learned model (), followed by computing Euclidean distance between the embeddings of the probe and the gallery images to calculate the match score. Rank accuracy is the ratio (multiplied by to get a percentage) of the number of times the correct class is among the top matches to the number of matching attempts (once for each probe image). Recall @ is the average recall score for all the query images. Following the definition by Song et al. [22], the recall score is one if the relevant class is retrieved in the top matches with the gallery/database set, and is zero otherwise.
6 Results
The experiments have been performed by partitioning each database into the train and test sets. The CNN model is trained on the train set using the proposed density aware deep metric learning, i.e. the Density Aware Triplet Loss (DATL) and the Density Aware Quadruplet Loss (DAQL). Comparisons have been performed with the vanilla triplet and quadruplet losses, (their variants for cross-modal matching are implemented for the SCface and FaceSurv databases). In addition, the proposed algorithm is also compared with hard triplet loss [13] and recently proposed triplet center loss [12]. The former is a variant of the vanilla triplet loss using a moderate hard mining approach. Triplet center loss is a formulation which mimics the conventional center based triplet loss previously discussed (Equation 4).
For face recognition, Rank 1 accuracies for three different probe resolutions, namely , and are reported. As shown in table 1 on and resolutions, the proposed algorithm produces state-of-the-art results for the SCface database. It outperforms the vanilla triplet and the quadruplet losses and their variants on the FaceSurv database (Table 2) as well. Moreover, on the SCface database, we report published results from different cross-modal face recognition methods. As shown in Table 1, it can be observed that the proposed algorithm outperforms these existing algorithms, specifically for lower resolution levels.
For the object retrieval task, experiments are performed on the CIFAR-10 and STL-10 datasets. As shown in Table 3, on the CIFAR-10 dataset, the proposed algorithm outperforms both the triplet and the quadruplet losses and their variants for recall @ 1 and recall @ 10. However, for recall @ 100 it produces competitive accuracy with respect to the other algorithms. As shown in Table 4, on the STL-10 dataset, the proposed algorithm outperforms the vanilla triplet and quadruplet losses along with their variants on recall @1, 10 and 100.
7 Analysis and Discussion
This section analyzes the performance of the proposed algorithm with respect to training with noisy data, convergence, training time, and parameters.
7.1 Effect of Noisy Data during Training
One of the primary properties of the proposed method is the ability to ignore outliers during training. Such outliers may often be represented by noisy data (low resolution/quality and poor illumination). As shown in Figure 3a, these noisy data samples affect the training process of conventional deep metric learning based algorithms. Since the proposed method computes the cluster center only by using the points inside the enclosure region, the outliers are effectively ignored. On the other hand, conventional deep metric learning algorithms would consider all the points (including outliers) which may lead to unnecessary jitter in the convergence during training.
An experiment is performed on the STL-10 database by replacing 15% of samples from each class by low resolution variants ( and as two separate experiments) of the same. Such training samples are expected to be outliers and thus may have potential to hurt the training process. We use a no reference image quality score (BRISQUE [19]) (a lower score implies better image quality) for the original training samples of STL-10 which is 33.90 (average for training set). For the noisy samples, the score is 45.14 (for ) and 41.83 (for ). This infers that the low resolution data are of lower quality. As shown in Table 5, the proposed methods perform better than conventional deep metric learning techniques when noisy data is introduced in the training process. It also exhibits that performance improvement is greater for the experiment where higher amount of data corruption (adding images) is performed.
7.2 Size of the Enclosure Region
One important parameter of the proposed algorithm is the size of the enclosure region. For implementation, the enclosure region is determined by taking the nearest k% points from the current center embedding point. A region of 20% signifies that the nearest 20% points (with respect to all the points of the particular cluster) from the current center are considered to be inside the enclosure region.
Figure 4 shows the results for the proposed Density Aware Triplet Loss on the STL-10 and CIFAR-10 databases for four different enclosure regions. It can be seen that an enclosure region of 17% yields optimal results while larger or smaller enclosure region results in reduced accuracy on both the databases.
7.3 Training Time
Owing to better convergence properties of the proposed DATL, total training time required is much less as compared to the vanilla triplet loss and its variants. As shown in Figure 5(a), the total time needed to train the proposed algorithm is 325.4 minutes. On the other hand, the vanilla triplet loss, triplet center loss, and the hard triplet loss requires 714.9, 381.4, and 462.7 minutes, respectively on the STL-10 dataset. In terms of the number of epochs as well, the proposed density aware triplet loss requires much lesser number of epochs (98 epochs), whereas the triplet loss, triplet center loss, and the hard triplet loss takes 192, 144, and 149 epochs, respectively.
7.4 Convergence
The foremost advantage of the proposed density based deep metric learning approach is its ability to converge quickly as compared to the vanilla triplet and quadruplet loss methods. In addition, the proposed algorithm also converges much faster with respect to the triplet center loss [12] which uses the centroid of the cluster in the loss function (Equation 4). The proposed method avoids outliers and thus updates the weights of the model in such a way, so as to create embeddings in the most dense region of the clusters. This avoids large weight updates as the embeddings need not be shifted away from the dense region. As shown in Figure 6, the convergence of the proposed density aware triplet loss (on a validation set which is prepared by randomly selecting 10% samples from the training set) is superior than the vanilla triplet loss and the triplet center loss. For all the methods, convergence is defined as the stage when the validation accuracy does not improve for 50 epochs at a stretch.
7.5 Shifting of the Center
The proposed approach iteratively evaluates the center towards the most dense region of each class (Figure 3b). An analysis is performed showing the magnitude of center shift for each epoch. The average of the center shift for all the classes is used to plot the graph in Figure 7 which shows that the magnitude of the center shift is much higher for the SCface database which has a very large number of noisy training samples. It can be also observed that the magnitude of the center shift decreases as the training progresses, thereby producing more compact clusters.
8 Conclusion
The paper presents an elegant approach for density aware deep metric learning. The proposed approach can be augmented with any deep metric learning technique such as triplet and quadruplet loss, and its variants. It results in superior convergence and accuracies, thus providing an important enhancement in current deep metric learning strategies. The proposed DATL and DAQL have also shown to be resilient to noisy training data compared to other deep metric learning methods. Extensive experiments on four datasets showcase the superiority of the proposed DATL and DAQL over existing deep metric learning techniques.
9 Acknowledgements
M. Vatsa and R. Singh are partly supported by the Infosys Center for AI, IIIT Delhi. M. Vatsa is also supported through the Swarnajayanti Fellowship by Government of India. S. Ghosh is supported by TCS Research Fellowship.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Himanshu S Bhatt, Richa Singh, Mayank Vatsa, and Nalini K Ratha. Improving cross-resolution face matching using ensemble-based co-transfer learning. IEEE TIP , 23(12):5654–5669, 2014.
- 2[2] Soma Biswas, Gaurav Aggarwal, Patrick J Flynn, and Kevin W Bowyer. Pose-robust recognition of low-resolution face images. IEEE TPAMI , 35(12):3037–3049, 2013.
- 3[3] Weihua Chen, Xiaotang Chen, Jianguo Zhang, and Kaiqi Huang. Beyond triplet loss: a deep quadruplet network for person re-identification. In IEEE CVPR , 2017.
- 4[4] De Cheng, Yihong Gong, Sanping Zhou, Jinjun Wang, and Nanning Zheng. Person re-identification by multi-channel parts-based CNN with improved triplet loss function. In IEEE CVPR , pages 1335–1344, 2016.
- 5[5] Adam Coates, Andrew Ng, and Honglak Lee. An analysis of single-layer networks in unsupervised feature learning. In AISTATS , pages 215–223, 2011.
- 6[6] Dorin Comaniciu and Peter Meer. Mean shift: A robust approach toward feature space analysis. IEEE TPAMI , 24(5):603–619, 2002.
- 7[7] Rishabh Garg, Yashasvi Baweja, Richa Singh, Mayank Vatsa, and Nalini Ratha. Heterogeneity aware deep embedding for mobile periocular recognition. In IEEE BTAS , 2018.
- 8[8] Mislav Grgic, Kresimir Delac, and Sonja Grgic. Scface–surveillance cameras face database. Springer MTA , 51(3):863–879, 2011.