Multi-View Matrix Completion for Multi-Label Image Classification
Yong Luo, Tongliang Liu, Dacheng Tao, Chao Xu

TL;DR
This paper introduces a multi-view matrix completion framework that effectively combines multiple features for semi-supervised multi-label image classification, improving accuracy and robustness over single-view methods.
Contribution
It proposes a novel multi-view matrix completion approach with weighted feature combination and cross-validation for label prediction in multi-label image classification.
Findings
MVMC outperforms single-view methods on PASCAL VOC'07 and MIR Flickr datasets.
The approach effectively exploits complementary features for better label prediction.
Using AP loss enhances robustness in multi-label classification.
Abstract
There is growing interest in multi-label image classification due to its critical role in web-based image analytics-based applications, such as large-scale image retrieval and browsing. Matrix completion has recently been introduced as a method for transductive (semi-supervised) multi-label classification, and has several distinct advantages, including robustness to missing data and background noise in both feature and label space. However, it is limited by only considering data represented by a single-view feature, which cannot precisely characterize images containing several semantic concepts. To utilize multiple features taken from different views, we have to concatenate the different features as a long vector. But this concatenation is prone to over-fitting and often leads to very high time complexity in MC based image classification. Therefore, we propose to weightedly combine the…
Click any figure to enlarge with its caption.
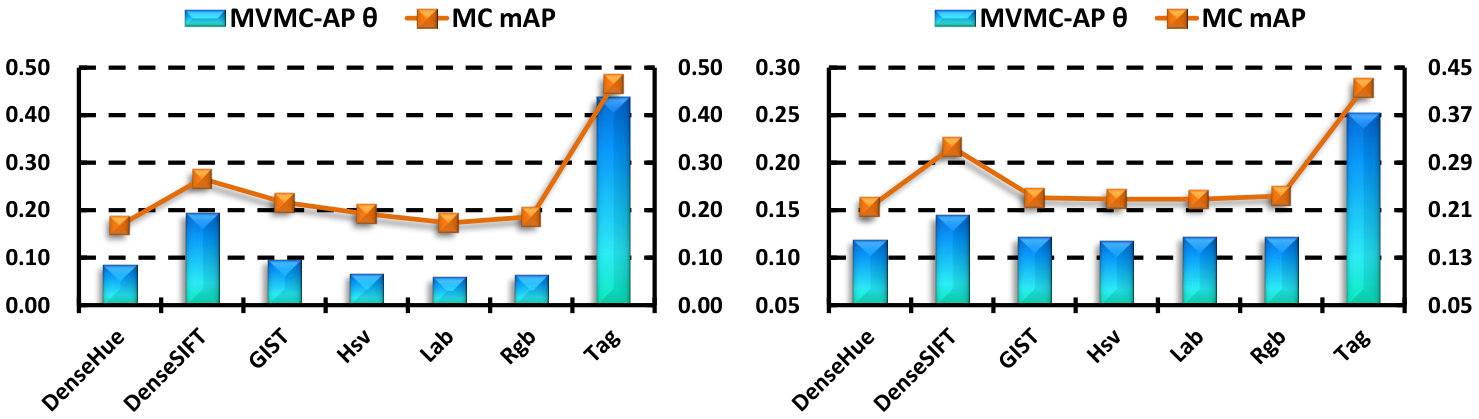 Figure 1
Figure 1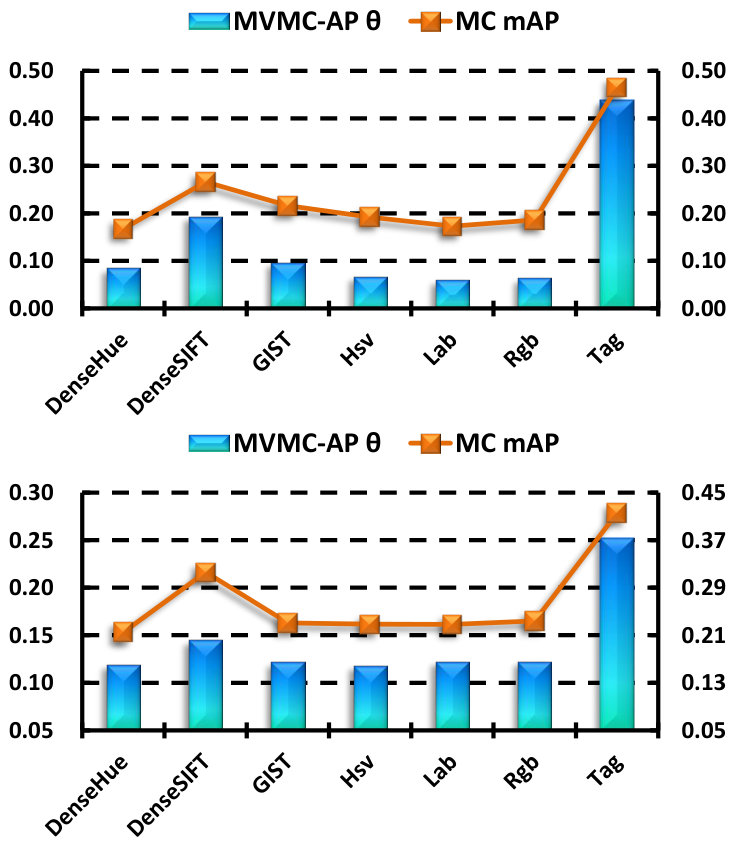 Figure 2
Figure 2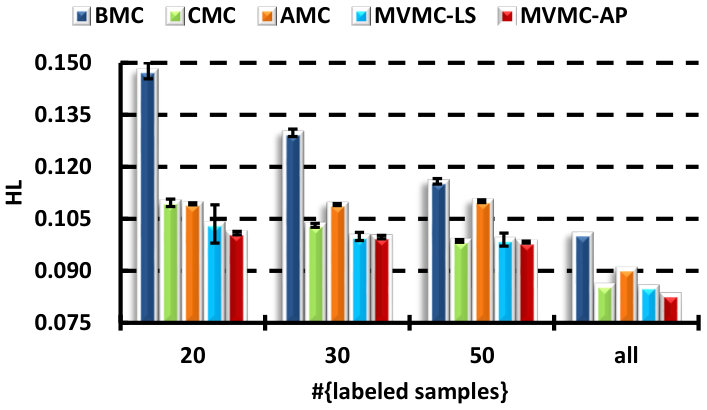 Figure 3
Figure 3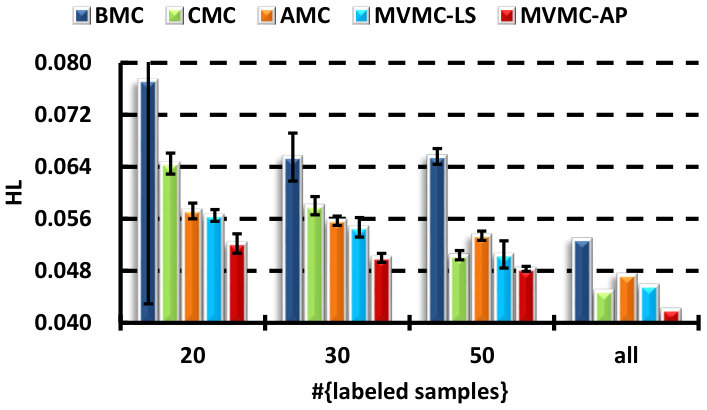 Figure 4
Figure 4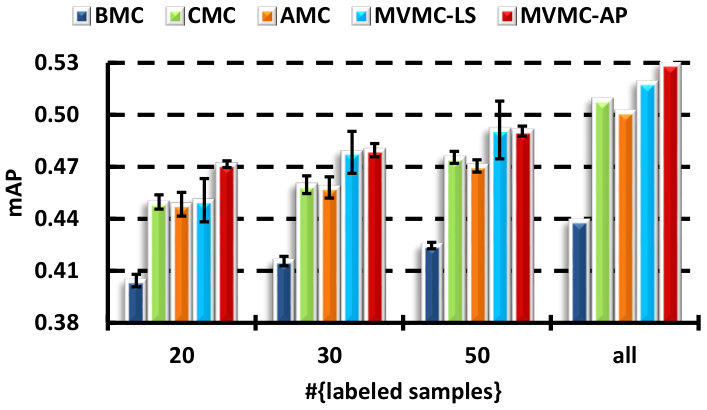 Figure 5
Figure 5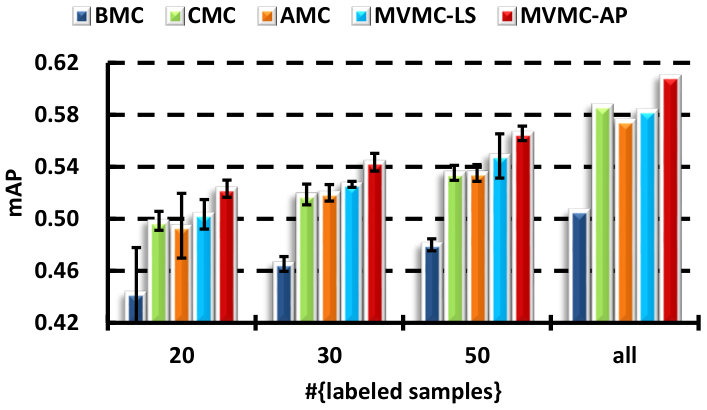 Figure 6
Figure 6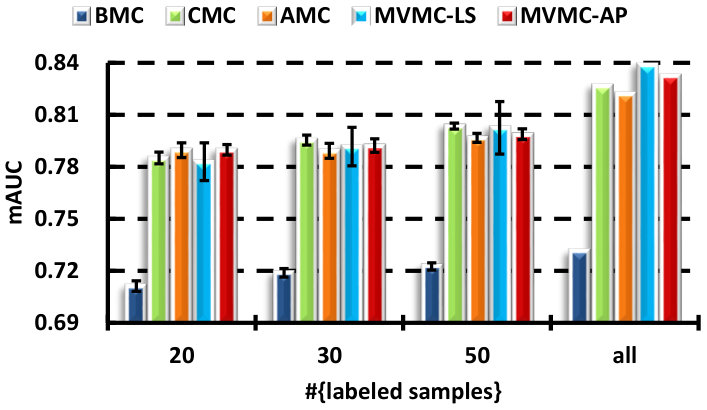 Figure 7
Figure 7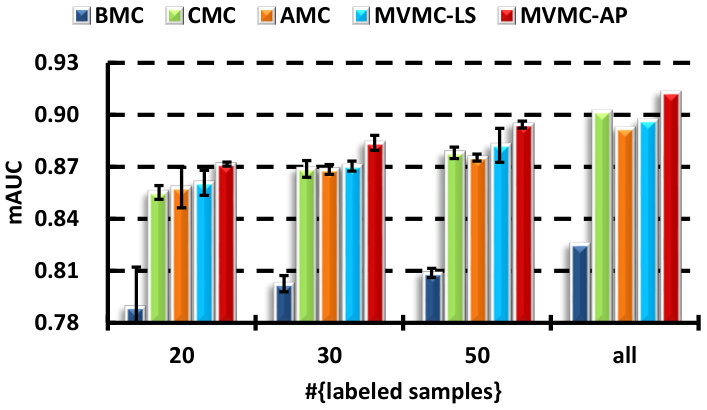 Figure 8
Figure 8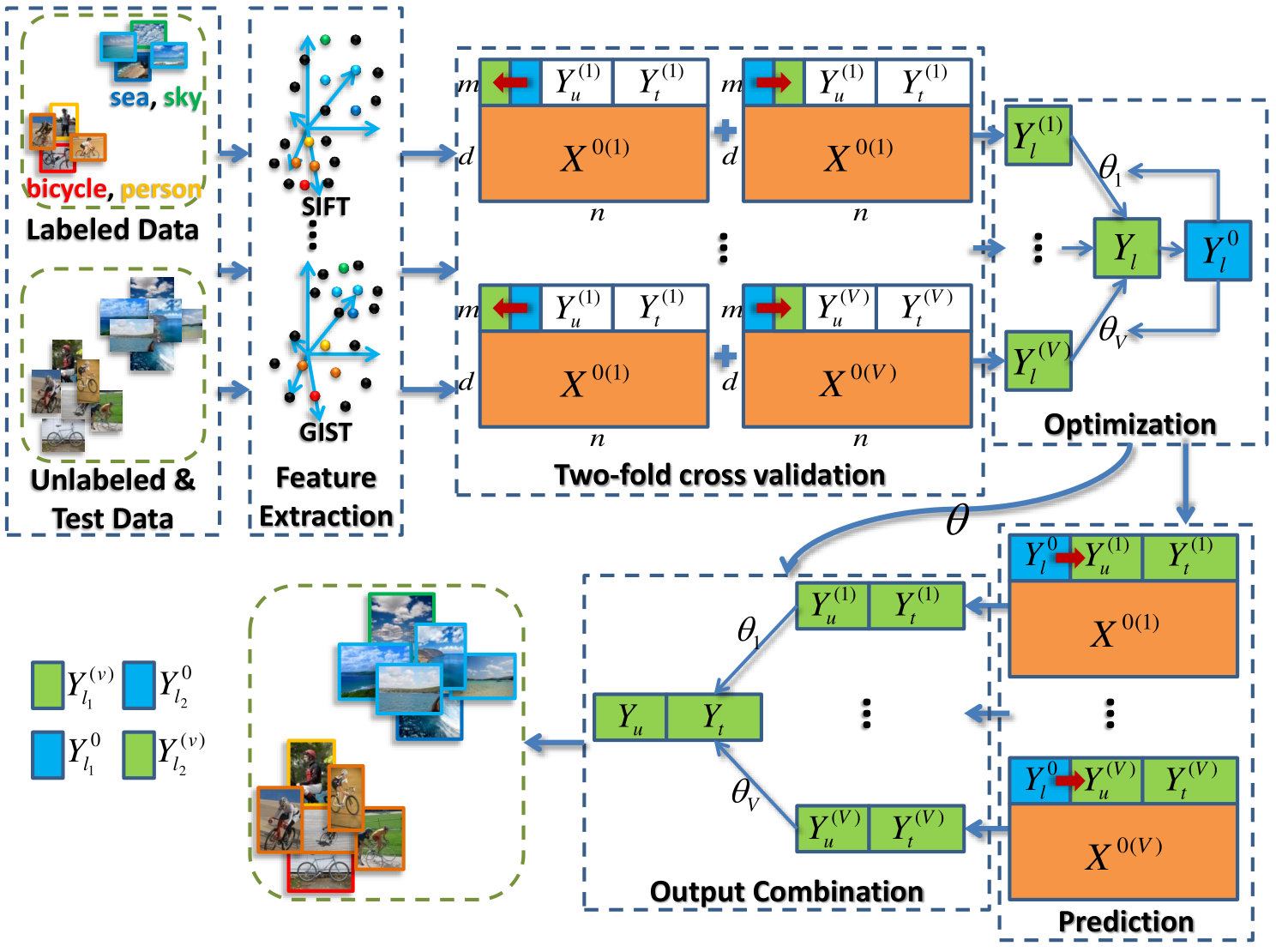 Figure 9
Figure 9| 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | |
|---|---|---|---|---|---|---|---|---|
| 0.4 | 0.3 | 0.2 | 0.1 | -0.1 | -0.2 | -0.3 | -0.4 | |
| 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | |
| -0.4 | -0.3 | -0.2 | -0.1 | 0.1 | 0.2 | 0.3 | 0.4 | |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| VOC mAP vs. #{labeled samples} | |||||
| Methods | 20 | 30 | 50 | all | Ranks |
| HierSVM [14] | 0.4590.032 (6) | 0.4880.026 (5) | 0.4990.020 (6) | 0.552 (4) | 5.25 |
| SimpleMKL [12] | 0.4900.006 (3) | 0.5130.004 (3) | 0.5410.005 (3) | 0.617 (2) | 2.75 |
| LpMKL [13] | 0.4980.008 (2) | 0.5150.006 (2) | 0.5530.005 (2) | 0.618 (1) | 1.75 |
| KLS-CCA [4] | 0.4700.011 (5) | 0.4870.010 (6) | 0.5120.005 (5) | 0.538 (5) | 5.25 |
| DLP [5] | 0.4810.006 (4) | 0.4990.004 (4) | 0.5130.004 (4) | 0.533 (6) | 4.5 |
| MVMC-AP | 0.5230.007 (1) | 0.5440.007 (1) | 0.5660.006 (1) | 0.610 (3) | 1.5 |
| VOC mAUC vs. #{labeled samples} | |||||
| Methods | 20 | 30 | 50 | all | Ranks |
| HierSVM [14] | 0.8610.005 (2) | 0.8760.004 (2) | 0.8860.005 (3) | 0.912 (3.5) | 2.63 |
| SimpleMKL [12] | 0.8480.005 (5) | 0.8660.004 (4) | 0.8820.003 (4) | 0.912 (3.5) | 4.13 |
| LpMKL [13] | 0.8590.003 (3) | 0.8700.002 (3) | 0.8890.003 (2) | 0.913 (1.5) | 2.38 |
| KLS-CCA [4] | 0.8310.012 (6) | 0.8430.010 (6) | 0.8540.008 (6) | 0.861 (6) | 6 |
| DLP [5] | 0.8520.002 (4) | 0.8610.002 (5) | 0.8660.001 (5) | 0.877 (5) | 4.75 |
| MVMC-AP | 0.8720.001 (1) | 0.8840.004 (1) | 0.8940.002 (1) | 0.913 (1.5) | 1.13 |
| VOC HL vs. #{labeled samples} | |||||
| Methods | 20 | 30 | 50 | all | Ranks |
| HierSVM [14] | 0.0590.003 (4) | 0.0610.002 (3) | 0.0610.014 (5) | 0.058 (5) | 4.25 |
| SimpleMKL [12] | 0.0520.002 (1.5) | 0.0510.001 (2) | 0.0480.001 (1.5) | 0.043 (2) | 1.75 |
| LpMKL [13] | 0.0740.004 (5) | 0.0770.005 (5) | 0.0500.001 (3.5) | 0.050 (4) | 4.38 |
| KLS-CCA [4] | 0.0560.001 (3) | 0.0620.001 (4) | 0.0500.001 (3.5) | 0.048 (3) | 3.38 |
| DLP [5] | 0.2290.000 (6) | 0.2290.000 (6) | 0.2290.000 (6) | 0.229 (6) | 6 |
| MVMC-AP | 0.0520.002 (1.5) | 0.0500.001 (1) | 0.0480.001 (1.5) | 0.042 (1) | 1.25 |
| MIR mAP vs. #{labeled samples} | |||||
| Methods | 20 | 30 | 50 | all | Ranks |
| HierSVM [14] | 0.4220.011 (6) | 0.4380.012 (6) | 0.4500.014 (6) | 0.492 (6) | 6 |
| SimpleMKL [12] | 0.4490.003 (2) | 0.4560.005 (3) | 0.4700.003 (2) | 0.538 (1.5) | 2.13 |
| LpMKL [13] | 0.4440.007 (4) | 0.4540.008 (4) | 0.4680.009 (3) | 0.538 (1.5) | 3.13 |
| KLS-CCA [4] | 0.4360.007 (5) | 0.4480.008 (5) | 0.4570.008 (5) | 0.502 (4) | 4.75 |
| DLP [5] | 0.4470.002 (3) | 0.4570.005 (2) | 0.4640.007 (4) | 0.498 (5) | 3.5 |
| MVMC-AP | 0.4720.002 (1) | 0.4800.004 (1) | 0.4910.003 (1) | 0.529 (3) | 1.5 |
| MIR mAUC vs. #{labeled samples} | |||||
| Methods | 20 | 30 | 50 | all | Ranks |
| HierSVM [14] | 0.7920.008 (5) | 0.7990.006 (5) | 0.8020.005 (5) | 0.836 (5) | 5 |
| SimpleMKL [12] | 0.7950.004 (4) | 0.8010.005 (4) | 0.8120.003 (4) | 0.851 (2) | 3.5 |
| LpMKL [13] | 0.8090.003 (1.5) | 0.8100.003 (2.5) | 0.8180.003 (3) | 0.854 (1) | 2 |
| KLS-CCA [4] | 0.8050.006 (3) | 0.8100.006 (2.5) | 0.8210.003 (1) | 0.848 (3) | 2.38 |
| DLP [5] | 0.8090.002 (1.5) | 0.8150.003 (1) | 0.8190.001 (2) | 0.837 (4) | 2.13 |
| MVMC-AP | 0.7900.003 (6) | 0.7920.004 (6) | 0.7990.003 (6) | 0.833 (6) | 6 |
| MIR HL vs. #{labeled samples} | |||||
| Methods | 20 | 30 | 50 | all | Ranks |
| HierSVM [14] | 0.1050.009 (2) | 0.1030.006 (2) | 0.1020.005 (2) | 0.090 (2) | 2 |
| SimpleMKL [12] | 0.1110.001 (3) | 0.1190.001 (3) | 0.1140.001 (3) | 0.091 (3) | 3 |
| LpMKL [13] | 0.1700.005 (5) | 0.1670.005 (5) | 0.1420.004 (5) | 0.119 (4) | 4.75 |
| KLS-CCA [4] | 0.1230.000 (4) | 0.1230.000 (4) | 0.1230.000 (4) | 0.123 (5) | 4.25 |
| DLP [5] | 0.2310.000 (6) | 0.2310.000 (6) | 0.2310.000 (6) | 0.231 (6) | 6 |
| MVMC-AP | 0.1010.001 (1) | 0.1000.001 (1) | 0.0980.001 (1) | 0.083 (1) | 1 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Multi-View Matrix Completion for Multi-Label Image Classification
Yong Luo, Tongliang Liu, Dacheng Tao, and Chao Xu, Y. Luo and C. Xu are with the Key Laboratory of Machine Perception (Ministry of Education), School of Electronics Engineering and Computer Science, Peking University, Beijing, 100871, China.T. Liu and D. Tao are affiliated with the Centre for Quantum Computation & Intelligent Systems and the Faculty of Engineering & Information Technology, University of Technology, Sydney, 235 Jones Street, Ultimo, NSW 2007, Australia.©2015 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works.
Abstract
There is growing interest in multi-label image classification due to its critical role in web-based image analytics-based applications, such as large-scale image retrieval and browsing. Matrix completion has recently been introduced as a method for transductive (semi-supervised) multi-label classification, and has several distinct advantages, including robustness to missing data and background noise in both feature and label space. However, it is limited by only considering data represented by a single-view feature, which cannot precisely characterize images containing several semantic concepts. To utilize multiple features taken from different views, we have to concatenate the different features as a long vector. But this concatenation is prone to over-fitting and often leads to very high time complexity in MC based image classification. Therefore, we propose to weightedly combine the MC outputs of different views, and present the multi-view matrix completion (MVMC) framework for transductive multi-label image classification. To learn the view combination weights effectively, we apply a cross validation strategy on the labeled set. In particular, MVMC splits the labeled set into two parts, and predicts the labels of one part using the known labels of the other part. The predicted labels are then used to learn the view combination coefficients. In the learning process, we adopt the average precision (AP) loss, which is particular suitable for multi-label image classification, since the ranking based criteria are critical for evaluating a multi-label classification system. A least squares loss formulation is also presented for the sake of efficiency, and the robustness of the algorithm based on the AP loss compared with the other losses is investigated. Experimental evaluation on two real world datasets (PASCAL VOC’ 07 and MIR Flickr) demonstrate the effectiveness of MVMC for transductive (semi-supervised) multi-label image classification, and show that MVMC can exploit complementary properties of different features and output-consistent labels for improved multi-label image classification.
Index Terms:
Image classification, transductive, multi-label, multi-view, matrix completion, average precision
I Introduction
Multi-label image classification, where multiple labels are assigned to a given image, is useful in many web-based image analytic-based applications. For example, keywords can be automatically assigned to an uploaded web image so that annotated images may be searched directly using text-based image retrieval systems.
Dozens of multi-label algorithms have been proposed in the past decade [1, 2, 3, 4, 5, 6]. However, none of these methods are able to handle missing features, or cases where parts of the training data labels are unknown. Many of the algorithms lack robustness to outliers and background noise. In order to overcome these limitations, matrix completion (MC) has recently been introduced as an alternative methodology for transductive (semi-supervised) multi-label classification [7, 8]. In particular, the MC-based multi-label classification concatenates the feature and label matrices, and then completes the unknown entries (either features or labels) in the concatenated matrix by the use of the rank minimization criterion. In this way, the MC-based methods can be used not only to infer labels of the unlabeled data, but also to estimate values of the missing features, and denoise the observed features and labels.
Although MC-based algorithms are robust for general transductive multi-label classification tasks, they cannot directly handle those image classification problems that include images represented by multi-view features. A popular solution has been to concatenate all the features into a long vector, but this strategy not only ignores the physical interpretations of different features, but also encounters an over-fitting problem given frequently limited labeled training samples and high dimensional image features. Besides, the feature concatenation often leads to a very large matrix to be completed. Thus the time cost is very high and sometimes intolerable [9].
To avoid these drawbacks, we propose to weightedly combine the MC based classification outputs of different views, and develop a new framework, namely, multi-view matrix completion (MVMC) for handling multi-view features in semi-supervised multi-label image classification. To learn the view combination coefficients, we firstly perform a two-fold cross validation procedure on the labeled set for each view. That is, we divide the labeled training samples into two (usually equal) sets. Labels in one set are assumed to be unknown and are completed using the label information in the other set. In fact the labeled training samples have been annotated, and thus we propose to linearly combine the predicted labels of all the views to approximate the ground-truth labels. In this way, we learn the combination coefficients of different views. In the learning of the coefficients, we propose to directly optimize average precision (AP), which is a critical criterion in evaluating a multi-label classification algorithm. We also present a formulation that adopts the least squares (LS) loss, which is quite efficient although not so proper as the AP loss for multi-label classification. Finally, for each view, the labels of the unlabeled and test data are predicted using matrix completion, and the obtained predictions of all the views are combined using the learned coefficients. The proposed algorithms tend to assign higher weight to the view carrying more discriminative information, and thus explore the complementary nature of different views.
In order to evaluate our MVMC algorithms (MVMC-LS and MVMC-AP), we have used two challenging datasets, PASCAL VOC’ 07 [10] and MIR Flickr [11]. To the best of our knowledge, there are no other algorithms which employ multi-view matrix completion. Therefore, in order to assess performance, we first compared our algorithms with the best single view (BMC), concatenation of all the views (CMC), and average the outputs of different views (AMC) in terms of mean average precision (mAP), mean area under the ROC curve (mAUC) and hamming loss (HL). To further verify the effectiveness of MVMC, we compared MVMC-AP with some popular and competitive feature-level [12, 13] and classifier-level [14] multi-view approaches, as well as some competitive multi-label classification methods [4, 5]. The experimental results show that our novel approach outperforms the current state-of-the-art.
The main contributions of this paper are: 1) the cross validation strategy that learns the view combination coefficients in the proposed multi-view matrix completion framework for multi-label image classification; 2) the developed solutions for the constrained optimization problems with the AP loss, as well as the LS loss. The former is particular suitable for multi-label classification, and the latter is for the sake of efficiency; 3) the robustness analysis of the AP loss compared with the LS and hinge loss in MVMC.
The rest of the paper is organized as follows. We firstly review some related work on matrix completion and multi-view learning in Section II. Section III summarizes the recent work on utilizing matrix completion for transduction and multi-label classification. In Section IV, we present the proposed MVMC framework, as well as the MVMC-LS and MVMC-AP algorithms by choosing different loss functions. Moreover, the robustness of the different algorithms is analyzed. The experimental results are presented in Section V. Finally, we conclude this paper in Section VI and prove the main theorem of this paper in Section VII.
II Related Work
II-A Matrix completion
Matrix completion (MC), as the name suggested, is to fill in the unknown entries of an uncompleted matrix . Without any assumption about the nature of the matrix, the completion is impossible. We usually assume the matrix we want to recover is of low-rank [15]. Then our goal is to find a matrix so that the errors between and on the known entries are as small as possible, and the rank of is minimized. The rank minimization [16] problem is NP-hard and thus is of little practical use [17]. Fortunately, can be replaced by its convex envelope, the nuclear norm , which is the sum of ’s singular values [18]. On the basis of this relaxation, dozens of methods have been proposed for matrix completion [17, 9, 19, 20]. A representative work was done by Candes and Recht [17]. They showed that the minimization of and has the same solution under broad assumptions of incoherence, and proved that a limited number of samples are needed to recover a low-rank matrix. Besides, a semi-definite programming (SDP) algorithm was proposed to efficiently solve the nuclear norm minimization problem. However, this algorithm cannot handle large size matrix, and thus a singular value thresholding (SVT) algorithm was developed in [9]. SVT can be expressed exactly as a linearized Bregman iteration, and the key step is the derived matrix shrinkage operation. Although SVT is shown to be efficient when completing large size matrices, it may fail (diverges, or does not solve the problems in a tolerate time, or yields a very inaccurate solution) for matrices which are not of very low-rank (e.g., an matrix of rank ). Therefore, a more robust algorithm, fixed point continuation (FPC) [19], was proposed. Similar to SVT, the matrix shrinkage is also utilized in FPC. The difference is that FPC employed an operator splitting technique. To reduce the complexity and improve recoverability (the ability to recover matrices of either small or moderate rank with tolerate error and speed), the authors further presented an approximate SVD based FPC (FPCA), which was demonstrated empirically to have much better recoverability than SDP (for MC) and SVT, etc. For example, the authors show that “for matrices of size and rank , FPCA can recover them with a relative error of , in about minutes by sampling only percent of the matrix elements”. But SDP and SVT, etc. do not have such a good recoverability property (since in these methods, the algorithm diverge, or the time cost is intolerant, or the solution is inaccurate).
To recovery a low-rank matrix corrupted with arbitrary large errors, a combination of the nuclear norm and the -norm should be minimized. Lin et al. [21] extended the classical augmented Lagrange multipliers (ALM) for solving this minimization problem efficiently. In particular, the exact ALM (EALM) method proposed in [21] was proved to have a pleasing convergence speed. The improved version, inexact ALM (IALM), was shown to be more precise and much faster than the state-of-the-art solvers, such as the accelerated proximal gradient (APG) algorithm [22]. Recently, matrix completion was introduced for transductive (semi-supervised) multi-label learning and we will depict it in section III.
II-B Multi-view learning
Multi-view learning is an active research topic in recent years. The multiple views can be the different viewpoints of an object in the camera, or the various descriptions of a given sample. We focus on the latter in this paper, and the goal is to learn to fuse the different descriptions. Lots of methods have been proposed in the recent decades for multi-view classification [23], retrieval [14], clustering [24], etc. In this section, we mainly review the classification methods [25, 26, 27], although most of them are also amenable for other applications. According to the level of the fusion being carried out, the multi-view classification methods can be grouped into two major categories: feature-level fusion and classifier-level fusion. We further divide them into four sub-categories: similarity fusion and unified subspace learning for the feature level, output/decision fusion and interactive fusion for the classifier level.
II-B1 Feature-level fusion
A direct strategy for feature-level fusion is to concatenate the different kinds of features into a long vector. This often leads to the curse of dimensionality problem and thus it is not practical. To this end, many sophisticated techniques are developed, which include those similarity space fusion (mostly kernel fusion by now) and multi-view subspace learning approaches.
Similarity space fusion: As far as we know, most of the current works on similarity space fusion are implemented in the form of kernel fusion. Multiple kernel learning (MKL) [28] is one of the most representative framework for kernel fusion. For example, in [29], a combination of different kernels built on different features sets were utilized for protein prediction. MKL was also used for dimensionality reduction of the multi-view data based on graph embedding [30]. McFee and Lanckriet [31] presented a method to combine multiple kernels in a proposed partial order embedding algorithm. The method learns a set of kernel mappings to induce a unified multi-modal similarity space, where the human perceptual information expressed by relative comparisons is incorporated. Kloft et al. [13] extended the traditional -norm MKL to arbitrary norms, and showed that the non-sparse MKL was superior to the state-of-the-art in combining different feature sets for biometrics recognition.
Unified subspace learning: In the feature-level fusion, another set of algorithms is on multi-view subspace learning. Canonical correlation analysis (CCA) [32] is one of the most popular methods for two-view learning, and seeks a subspace where the given two views are maximally correlated. SVM-2K [33] combines Kernel CCA (KCCA) and support vector machine (SVM) in a single optimization problem. Recently, White et al. [34] proposed a convex formulation for learning a shared subspace of multiple sources. In the learned subspace, conditional independence constraints are enforced.
II-B2 Classifier-level fusion
Schemes in this category either learn classifiers of different views independently or interactively.
Output or decision fusion: Individual classifiers are created for different views and then the outputs or decisions are fused. In [35], the SVM outputs are firstly converted to probabilistic scores, and then concatenated as the input of an SVM for final classification. This method was shown to outperform the simple feature concatenation, followed by an SVM. Such an approach was called hierarchical SVM in [14], and is compared with several other popular classifier fusion strategies, such as weighted sum of outputs and majority voting. Fumera and Roli [36] gave a theoretical analysis of the linear combination of multiple classifiers, and the effectiveness of their analytical model was confirmed by the experimental results. A thorough study on the weighted voting methods for classifier fusion was presented in [37], where the neural network was adopted to estimate the combination weights.
Interactive fusion: Methods in this sub-category communicate information with other views when learning classifier of the current view. Lots of these methods are semi-supervised and naturally two-view, such as co-training [38], co-regularization [39], etc. In the co-training framework, unlabeled samples classified by one view with high confidence were put in the labeled pool of the other view. Such a process was repeated until the classification performance on the validation dataset decreased. Although succeed empirically, co-training is based on the compatibility and class conditional independence assumptions, which are usually too restrictive to be satisfied [40]. The co-EM algorithm [41] bootstrapped samples in a similar way like co-training, but the unlabeled samples were labeled probabilistically in a batch mode using expectation-maximization (EM). By formulating the linear classifier in a probabilistic framework, SVM was introduced as the base classifier in co-EM [42]. In [39], classifiers of different views are enforced to be agreed on unlabeled data by the use of a regularization term, in a graph-based semi-supervised framework. This is called co-regularization and a similar idea was utilized in [43], under the theme of manifold regularization [44].
It was shown in [35, 14] that classifier-level fusion outperforms simple feature concatenation, while sophisticated feature-level fusion can usually be better than classifier-level fusion since the raw information is preserved [45]. The proposed MVMC method belongs to the classifier-level fusion, and is particular suitable for transductive (semi-supervised) multi-label classification. It was demonstrated empirically in this paper that MVMC can outperform some competitive classifier-level and feature-level multi-view learning approaches when limited labeled data are available. Experiments also show that MVMC is superior to competitive multi-label [4] and the recently proposed semi-supervised multi-label classification method [5].
III Transduction with matrix completion
This section briefly introduces the framework of utilizing matrix completion for transductive (semi-supervised) multi-label learning [7]. Given a set of samples with each , and the corresponding label vector . We construct the feature matrix and the label matrix . Some entries of may be missing, and our aim is to predict the unknown entries in . To solve this problem, we consider the linear classification model
[TABLE]
where is the weight matrix, is the bias vector, contains the soft labels of the ’th sample and the hard label can be obtained by . Then we can construct the underlying feature matrix , the soft label matrix , and concatenate them into an matrix . The stacked matrix is of low rank since each row of can be represented by a linear combination of the rows in , i.e., . Actually, the feature matrix can also be assumed to be of low rank, i.e., . This assumption is reasonable since high dimensional data typically lies on a manifold, and the assumption succeed in many component analysis techniques, e.g., principal component analysis (PCA) and Fisher’s linear discriminant analysis (FLDA).
Let and , be the set of known entries in and respectively. To recover the underlying feature matrix and predict the soft labels, Goldberg et al. [7] proposed to minimize the rank of , as well as the error between and for the entries in , . Thus the optimization problem, MC-1, is
[TABLE]
where is the nuclear norm (sum of singular values) of , and are the loss function for the features and labels respectively. Both and are the trade-off parameters. In [7], is chosen to be the least squares loss and is the log loss.
The problem (2) can be solved by a modified fixed point continuation (FPC) algorithm, which is to alternate between the gradient descent, , and the shrinkage . The step size can be easily computed according to [7, 8]. Here, is the iteration step and is the matrix gradient given by
[TABLE]
However, images are usually represented by feature histograms, which consist of positive values naturally. The formulation (2) will introduce negative values to the features. Therefore, in [8], all feature vectors are constrained to be positive or belong to a simplex, and the corresponding MC-Pos and MC-Simplex algorithms are induced. Besides, it is suggested in [8] to use the Pearson’s distance for to take the asymmetry of the feature histogram into consideration. For the labels, the authors used a generalized version of the log loss, i.e., , which is approximate to the hinge loss, and more suitable for classification than the original log loss.
IV Multi-view matrix completion
In this section, we first present our multi-view matrix completion (MVMC) framework, and then develop an algorithm that directly optimizes average precision for transductive (semi-supervised) multi-label image classification. The MVMC framework is depicted in Fig. 1. For all the labeled, unlabeled and test images, we extract different kinds of features, such as SIFT [46] and GIST [47]. Then we construct the stacked matrix for the ’th view. To combine the multiple views for matrix completion, a natural idea is to weightedly sum the different feature matrices , where is the number of views. However, the dimensionality of different views varies. Although we can utilize some dimensionality reduction algorithm, such as kernel PCA (KPCA), to preprocess the features, the summation of different matrices lacks physical interpretation. Therefore, we propose to combine the output label matrices of different views. KPCA is still employed to preprocess the features to significantly reduce the time complexity of the MC algorithm. The MC-1 algorithm is adopted to complete the matrix for each view since the processed features can be either positive or negative. We use the least squares loss for and the generalized log loss (a smooth approximation of the hinge loss) for . Subsequently, we proposed a two-step algorithm to learn the output combination coefficients of the different views:
Generate training data for each view. The training data we referred here is not the features to complete the matrix , but the output labels to learn the combination . We generate the data by assuming parts (e.g. half) of the labeled data as unlabeled, and predict their labels using the other parts. Such a process is then conducted conversely. In this way, we obtain the predicted labels of the labeled data, whose labels are actually known.
Learn the combination coefficients. In our formulation, the final output is a linear combination of the multiple outputs obtained from different views. Thus, we use the weighted summation to approximate the ground-truth . By minimizing the approximation error, we can learn the weight .
Finally, for each view, we predict the labels of the unlabeled and test data by utilizing all the labeled data. The multiple predictions are combined with the learned .
IV-A The general formulation for learning
To simplify the derivation, we convert the original two dimensional index of a sample to one dimensional by the use of vectorization. Let us define as the set of all the known labels’ entries, and as the set of generated data (predicted values of the labeled data) from the ’th view. Thus our prediction function can be written as , where is the predictions of all the views for the ’th sample. Then we have the following optimization problem,
[TABLE]
where is the number of entries in , which is equal to . Here, is the number of labeled samples. The regularization term is used to control the model complexity, and is the trade-off parameter. Here, is some pre-defined convex loss. It is easy to verify that the problem (4) is convex, and thus we can obtain the global solution. In this paper, we first choose to be the least squares (LS) loss, which will lead to a quite efficient solution.
IV-B A least squares formulation of MVMC (MVMC-LS)
If we choose to be the least squares loss, i.e. , then the optimization problem becomes
[TABLE]
Let and . The objective of the above problem can be written in a compact form as , and then the problem (5) can be reformulated as
[TABLE]
where the constant term has been omitted, is a semi-definite and usually full-rank matrix, and with each . Here, denotes the ’th row of the matrix , that is the prediction from the ’th view. To solve this problem, the coordinate descent algorithm is adopted. In each round of iteration, only two variables and are selected to update, while the others are fixed. We firstly only consider the constraint . By using the Lagrange method and note that do not change in the iteration, we have the following solution for updating and :
[TABLE]
where . By further taking the constraint into consideration, we have
[TABLE]
From solution (7), we can see that larger implies larger . This is because denotes the similarity between the prediction of the ’th view and the ground-truth.
In spite of the efficiency of the LS formulation, the LS loss is designed to optimize the accuracy performance, which is not appropriate for multi-label classification [48, 49]. Thus the obtained solution may be unsatisfactory. The hinge loss used in support vector machine (SVM) is not adopted for the same reason. Besides, the least squares and hinge loss are not robust loss functions [50, 51]. Therefore, we propose to directly optimize the average precision (AP), which is a critical criterion for evaluating the multi-label classification performance, and we can prove that the algorithm that utilizes the AP loss is more robust than that adopts the least squares or hinge loss. To this end, better view combination coefficients can be found hopefully. In the following, we first present the AP formulation of MVMC, and then give some theoretical analysis of the proposed algorithm, i.e., the robustness of the algorithm that adopts the AP loss compared with the least squares and hinge loss.
IV-C Optimizing average precision in MVMC (MVMC-AP)
Different from the least squares formulation, where the loss is point-wise and calculated on two scalar elements, the average precision (AP) loss is computed over two vectors for each label (category) and thus list-wise. Before presenting the AP loss, we first introduce the AP score. Suppose the input space is and the output space is (rankings111It should be noted that the ranking we refer to here is an ordered sequence and the rank value is a number in the sequence, not the notation “rank” of a matrix we used in Section III. over a corpus , each is a sample). In this paper (transductive multi-label classification), consists of the different labels (categories), which correspond to the possible queries in information retrieval [52]. For a certain label, if is a prediction vector for the samples in and is the corresponding ground-truth, then the AP score can be defined as
[TABLE]
where is a vector of rank values. The ground-truth ranking has only two rank values, i.e., for the positive samples and [math] otherwise. The prediction ranking is the sorting result of the predictions in , a larger prediction value corresponding to a higher rank value. Here, is the total number of positive samples, and is the percentage of positive samples in the top samples, where the samples in the corpus are assumed to have been sorted according to the prediction .
Table I is a toy example of two predictions. The AP scores are calculated as and respectively. However, the accuracy of the two predictions are both if we choose the threshold to be zero, and classify the samples predicted to be higher than the threshold as positive. We find that the accuracy is not appropriate in this case since the first classifier assigns much higher rank values to the positive samples than the second classifier, and thus performs much better. Such cases are common in multi-label classification since there are usually much more negative samples than the positive ones for each label. This is an intuition of why adopting the AP loss here, which is defined as
[TABLE]
Usually, the mean of the AP scores of all labels, i.e., mAP is adopted for evaluation. Therefore, the loss calculation will be preformed over all labels. In the following, we show how to incorporate the AP loss into an optimization problem for learning .
The central idea of optimizing AP in MVMC is to transform the multi-label classification into a retrieval problem, and regard each label as a query. Given a certain label , the aim is to find a ranking that maximizes the discriminant function:
[TABLE]
which is assumed to be linear (parameterized by ) in some combined feature representation given by:
[TABLE]
where and are the samples, and denote the set of positive and negative samples of for label . Here, the pairwise orderings is utilized, i.e., . For each , if is ranked ahead of , if and have equal rank, and otherwise. We assume that the rankings is complete, i.e., is either or (never [math]).
We can predict a ranking (of the samples) for label with a learned . However, this is not the point of this paper and we only concentrate on learning the weight vector . Here, we define the feature mapping function as . Each element of corresponds to the prediction of a certain view, and thus is a combined prediction of different views. For different labels, the feature mappings are the same, only the ground-truth orderings change. In this way, we can learn to combine different views by the use of the average precision (AP) loss.
Following [53], we use the structural SVM formulation to learn , where an additional simplex constraint is added:
[TABLE]
where is the ground-truth ranking for the label . , and we have defined . We propose to solve the problem (12) using an alternating algorithm in the dual formulation. Note that for , the constraint can be satisfied by a simple normalization, so we left this sum-to-one constraint to be considered later. By introducing the Lagrangian, we obtain
[TABLE]
Taking the partial derivatives of w.r.t. , and setting them to be zero,
[TABLE]
where and the second identity is equivalent to since the Lagrange multiplier . By substituting back into (12), we obtain the dual
[TABLE]
where . Let and with each , the problem (14) can be written in a compact form as
[TABLE]
We propose to solve this problem using the alternating optimization strategy. For fixed , the problem (15) becomes
[TABLE]
which is a structural SVM [54] formulation with the linear part . A cutting-plane algorithm is introduced to solve this problem and the most violated constraint can be found using the algorithm presented in [53]. For fixed , the problem (15) can be reformulated as
[TABLE]
This is a quadratic programming (QP) problem and can be solved quite efficiently using a standard SVM solver. It can be easily verified that the Hessian matrix of (15) H_{e}(\alpha,\zeta)=-\left[\begin{array}[]{cc}K&\delta\Psi^{T}\\ \delta\Psi&I_{V}\end{array}\right] is negative semi-definite, where is the identity matrix, and thus the problem (15) is jointly concave w.r.t. and . Besides, the sub-problems (16) and (17) are concave w.r.t. and respectively. Therefore, by alternatively solving (16) and (17), the algorithm will converge to the global solution of (15).
IV-D Complexity analysis
The complexity of MVMC has two parts: the first is determined by the MC-based classification of each view, and the second is determined by the learning of the view combination coefficients. In this paper, the MC-based classification is carried out by optimizing the MC-1 problem (2). We can reduce the complexity of the MC-based classification algorithm MC-1 [8] to by exploiting the approximate SVD based fixed point continuation (FPCA) [19] algorithm, where and are the number of class labels and all samples respectively, is the average feature dimension, is the iteration numbers, and is the number of elements in the sequence of the continuation step. In common, and . Thus, the adopted MC-1 can solve large matrix rank minimization problems efficiently.
With regard to the learning of the combination coefficients , we use the weighted summation to approximate the groundtruth . Weights are obtained by minimizing the approximation error. The size of each is , where is the number of labeled data. This means that the complexity of the proposed view combination procedure is not dependent on the amount of all samples, but only on the labeled sample size, which is usually small in transductive (semi-supervised) classification. For MVMC-LS, the time complexity is , where is the number of views and is usually smaller than . For MVMC-AP, structure SVM is exploited for optimization. According to [55], the time complexity of the cutting-plane method used in structural SVMs is linear in the number of training samples. Thus the computational time cost of learning the view combination coefficients is , where is the number of iterations and is independent on the number of samples [55]. To this end, the view combination procedure is also very efficient, and according to our experience, it is more efficient than the MC-based classification.
Therefore, the time complexity of MVMC-LS and MVMC-AP are and , respectively. The former is often more efficient since is usually small.
IV-E Robustness analysis
In this section, we aim to prove that AP loss is more robust than the least squares and hinge loss when learning for MVMC. That is, AP is more tolerate of noise. We present the definition of the robustness here for completeness.
Definition 1
(Robustness [56]) Let be the set that each sample is drawn from, and be a training sample set . A learning algorithm is robust, for and , if can be partitioned into disjoint sets, denoted by , such that the following holds for all :
[TABLE]
where represents the hypothesis learned using on the training set . The sets can be regarded as sets with elements having some similarity to each other, such as the distance.
Let , and denote the learning algorithms which adopt the AP loss, least squares loss and hinge loss in (4) respectively. It is well known that the ranking based criteria are critical for multi-label classification [57, 58, 49, 59], and we can also prove that is more robust than and when learning for MVMC. This is easy to understand since the AP loss is list-wise, while the LS and hinge loss are both point-wise.
Theorem 1
We can partition the sample space into disjoint sets such that is robust, is robust and is robust, where is a positive integer and . That is, the will tolerate to the noise which do not change the partition of the disjoint sets , while the and will not.
Remark 1
It can also be seen from a general perspective that is more robust than and . That is, for any partitions, the least squares and hinge loss based algorithms cannot be robust, where , while we can find at least one set of partition in which the AP loss based algorithm is robust.
Remark 2
In Theorem 1, the claim that is robust does not mean that for all instances in the training set, the corresponding objective function losses are equal to each other. Instead, is robust with respect to a particular partition , and such an assertion means that for all instances in a fixed set , the objective function losses are equal to each other. The central idea of Theorem 1 is that, as we stated in the proof, for every point in a fixed prediction space , there has been a finite number of different rankings. Thus, we can partition the prediction space into a finite number of sets such that all points in one set share the same ranking. This is why the objective function losses for all instances in a fixed set are equal to each other and is robust. However, and cannot be robust, where is a finite counting number. This is because the corresponding losses have infinitely different values and we could never find a finite number of sets such that all points in one particular set share the same loss value.
The following two lemmas are useful for proving Theorem 1.
Lemma 1
([56]) Fix and metric of , If algorithm satisfies
[TABLE]
and , then is robust.
Lemma 2
([60, 61]) Let be a ball of radius in an -dimensional Banach space and . There exists a subset such that and , with , where is the metric of the Banach space.
We defer the detailed proof of Theorem 1 in the last section.
V Experiments
In the experimental evaluation, we firstly compare the proposed MVMC-LS and MVMC-AP algorithms with the following MC-based strategies: 1) BMC, which is to use a single view that performs the best in MC; 2) CMC, which is to simply concatenate features of the multiple views in MC; 3) AMC, which is to average the MC outputs of the multiple views. Then we show the view combination coefficients learned by our MVMC-AP method. Finally, we compare MVMC-AP with some popular and competitive feature-level fusion [12, 13], and classifier-level fusion [14] algorithms, as well as some competitive multi-label [4] and recently proposed semi-supervised multi-label classification approaches [5]. Before all of these evaluations, we present the datasets and features we used, as well as our experimental settings.
V-A Datasets, features and the evaluation criteria
Our experiments are conducted on two popular datasets, PASCAL VOC’ 07 (VOC for short) [10] and MIR Flickr (MIR for short) [11]. There are around natural images ( training, test) from categories in the VOC dataset. The MIR dataset consists of images (half training, half test) and categories.
In natural image classification and web image annotation, the taxonomy of the images is very large and the category defined for a certain image may vary in different fields. Therefore, it is impossible to manually label abundant training images for every category, and it is common that limited labeled samples are given in natural image classification or annotation [49, 62], especially for the new defined or uncommon categories. One of the advantages of the proposed transductive algorithms is the ability to handle small labeled sample size, since it can effectively utilize the information contained in the images from different views. To empirically demonstrate the effectiveness of MVMC, for both datasets, we only randomly select samples for each category in the training set as labeled, and all the others unlabeled. The labels of the unlabeled and test data are then inferred by our algorithms. Five random choices of the labeled data are used in our experiments. We also present the results of using all the labeled training samples to compare the performance of the algorithms in the fully supervised scenario. Besides, twenty percent of the test data are used for validation, which means that the parameters corresponding to the best performance on the validation set are used for unlabeled and test inference.
The features we used here are from [49], where 15 different image representations and tags are provided. Actually, the 15 representations are constructed from six kinds of visual features, which include two kinds of local features (Hue [63], SIFT [46]), a global representation (GIST [47]), and three global color histograms (Hsv, Lab, Rgb). In this paper, we regard each kind of visual feature as a single view. Then we have seven different views in all, with a tag view included. The dimensionality of the SIFT features we used is , and the color features (Hsv, Lab, Rgb) is around . The existing MC algorithms either fail to recover such a large size matrix or the time cost is intolerable. Thus we preprocess the features by KPCA to reduce the time complexity in the MC based image classification. For all the compared methods in this paper, the result dimension after KPCA is fixed to be , since we found the different algorithms perform well under this setting.
In the VOC and MIR datasets, the positive and negative samples are quite unbalanced. Thus the traditional accuracy criterion is not proper any more, and we introduce three popular criteria in multi-label classification for evaluation. They are average precision (AP) [64], area under ROC curve (AUC) [65] and hamming loss (HL) [66]. In this paper, AP and AUC are the ranking performance computed under each label. Usually, the mean value over all labels, i.e., mAP and mAUC are reported. HL is utilized to evaluate the label set prediction for each instance. It is not a ranking based criterion but widely used in multi-label classification [58]. A smaller value in HL indicates a better performance.
V-B A comparison with the MC-based strategies
There are several direct strategies to make use of the different views in MC: BMC, CMC and AMC. In this section, we demonstrate that learning the output combination coefficients is superior to all of these approaches. In particular, the algorithms compared are:
BMC [7, 8]: using the best single view, i.e., one that achieves the best MC-based classification performance. The MC-based transductive multi-label classification is performed by optimizing (2), where is chosen to be the least squares loss for the KPCA processed features, is tuned with in . The candidate set for choosing is . The parameter is initialized as (: the largest singular value of ), and decreases with a factor in the continuation steps until .
CMC: feature-level fusion. Concatenating the normalized features of all the views into a very long vector, and then performing MC-based classification.
AMC: classifier-level fusion. Learning separate MC-based classifiers for different views, and then combining the outputs of all the classifiers uniformly. Before the combination, the outputs of each view are converted to the probability scores by the use of a sigmoid function .
MVMC-LS: the proposed multi-view MC algorithm, in which the least squares loss is utilized. Outputs are also converted to probability scores. The trade-off parameter is tuned on the set .
MVMC-AP: the proposed multi-view MC algorithm with the average precision (AP) loss.
The results for all the compared methods are presented in Fig. 2. A self-test with different number of labeled samples is carried out to see the performance variation with respect to the labeled training size. We can see that the performance of all the presented methods improve when the number of labeled samples increase. By fusing all the views, either in the feature-level or classifier-level, can always be superior to the use of only the best single view. The concatenation (CMC) and average outputs (AMC) methods are comparable with each other. Although the proposed MVMC-LS algorithm is superior to CMC and AMC in most cases, the improvement is not significant, except for the mAP performance on the MIR dataset, while MVMC-AP consistently outperforms them in terms of all the evaluated criteria on the VOC dataset, and usually has small deviations. This demonstrates the effectiveness of the learned coefficients using the AP loss. Similar results can be seen on the MIR dataset, only the mAUC performance of the compared combination methods is comparable. In the fully supervised case (the “all” column), we find that CMC is superior to AMC and comparable to MVMC sometimes. This is because when large amounts of labeled data are available, the curse-of-dimension problem caused by simple concatenation is alleviated.
V-C Analysis of the view combination coefficients
In Fig. 3, we show the combination coefficients learned by MVMC-AP, together with the mAP by using MC for each view. From the results, we find that the tendency of the weights is consistent with the corresponding mAP in general, i.e., the views with a higher classification performance tend to be assigned larger weights, taking the DenseSIFT (the 2nd view) and the tags (the last view) for example. The three color histogram views (Hsv, Lab, Rgb) have similar discriminative power on the VOC dataset, and thus the weights for them are almost equivalent.
V-D Compared with other multi-view and multi-label algorithms
Our last set of experiments compare MVMC with some popular and competitive multi-view algorithms, where we learn a binary classifier for each label. Besides, extensive comparisons with the competitive and recently proposed multi-label classification algorithms are also performed. Specifically we compare MVMC-AP with the following methods:
HierSVM [14]: learning separate SVM classifiers for each view, and then fusing the results by using an additional SVM classifier. This is called hierarchical SVM, and the trade-off parameter for each SVM classifier is optimized over .
SimpleMKL [12]: a very popular and competitive SVM-based multiple kernel learning algorithm. Constructing a kernel for each view, and then learning a linear combination of the different kernels, as well as a classifier based on the combined kernel. The penalty factor is tuned on the set .
LpMKL [13]: a recent proposed MKL algorithm, which extend MKL to -norm with . The penalty factor is tuned on the set and we choose the norm from the set .
KLS-CCA [4]: a least-squares formulation of the kernelized CCA for multi-label classification. The ridge parameter is chosen from the candidate set . The different views are fused by combining the kernels (similarity matrices) with uniform weights.
DLP [5]: an improved label propagation algorithm that is proposed recently for transductive multi-label learning by considering the label correlation. The parameters and are optimized over the set and respectively. The parameter is chosen from . The different views are fused by combining the similarity matrices with uniform weights.
The performance of the compared methods on the VOC and MIR datasets are reported in Table II and III, respectively. Both the mean and standard deviation of the three criteria are presented. From the experimental results, we observe that: 1) the performance improves with an increase of the labeled samples; 2) the multi-label classification methods (KLS-CCA and DLP) are better than HierSVM, but is inferior to other multi-view learning algorithms overall; 3) DLP outperforms KLS-CCA in most cases since the unlabeled information is utilized in transduction. But when the number of labeled data is increased, the improvement deceases and sometimes KLS-CCA is better (e.g., the mAUC performance in the fully supervised case (the “all” column) on the MIR dataset), since the significance of the unlabeled information decreases; 4) On the VOC dataset, the mAP and HL scores of the SimpleMKL method are larger than HierSVM, while the mAUC performance of the latter is better. In general, LpMKL is superior to SimpleMKL and HierSVM. The proposed algorithm consistently outperforms the other three methods; 5) On the MIR dataset, the other methods are comparable with or superior to our algorithm in terms of mAUC, while their mAP and HL performance are poor. Under the HL criterion, SimpleMKL and HierSVM perform well on only one of the two datasets (VOC and MIR respectively), while the proposed MVMC-AP achieves the best performance consistently on both datasets. In particular, we obtain a significant , and improvement in terms of mAP compared with LpMKL, when , and labeled samples for each class are used, respectively; 6) In the fully supervised scenario (the “all” column), SimpleMKL and LpMKL are comparable to MVMC under the mAP and mAUC criteria, but the HL performance of our method is the best among all methods. Therefore, the proposed transductive classification approach is particular suitable for the small labeled sample size problem, and is comparable to the state-of-the-art methods when large amount of labeled data are available.
Besides, the average rank of the proposed alogrithm is smaller than all the other methods in terms of all the three criteria on the VOC dataset, as well as the mAP and HL criteria on the MIR dataset. According to the Friedman test [67], the statistics of mAP, mAUC and HL on the two datasets are , and respectively. We can see that all of them are larger than the critical value , so we reject the null-hypothesis (the compared algorithm perform equally well).
VI Conclusion
Matrix completion (MC) has recently been used in transductive (semi-supervised) multi-label classification. It has the advantageous of being efficient, robust to noise, and being able to handle missing data. In existing algorithms, only features from a single view can be used, but there is not a single feature perfect for image classification. We therefore present a multi-view framework to fuse different kinds of features for MC-based multi-label classification. Our framework has the advantage of being able to explore the complementary properties of different views. We have designed two algorithms under the framework, MVMC-LS and MVMC-AP, which differ by the choice of different losses. The robustness of the two algorithms is analyzed.
From the experimental validation on the challenging PASCAL VOC’ 07 and MIR Flickr datasets, we mainly conclude that: 1) The classifier-level fusion is better than simple feature concatenation, which is in line with [35, 14]; 2) The learning of the combination coefficients is critical in the classifier-level fusion. Although the least squares formulation is quite efficient for learning the coefficients, the performance is usually not satisfactory. Thus more sophisticated loss should be adopted, such as the average precision loss utilized in this paper. Future works may be to extend MVMC for optimizing other criteria, such as AUC [68, 69], by changing the loss in MVMC.
VII Proofs of Main Results
In this section, we prove Theorem 1.
Proof:
Let be the prediction space, which contains all the possible predictions. For a certain prediction , each column is a vector , which is the predictions of views for a certain sample, and a given label. The formulation (12) is to find a to combine all the views such that the combined prediction will have the largest mean average precision over all labels.
Let be a cover of , where is a -norm metric. Suppose that every prediction returned by matrix completion has the range . Then, according to Lemma 2, we have
[TABLE]
We can partition into disjoint sets such that if and belong to the same set, then , rankings of different views are the same and . Here, is the number of all possible rankings, and is the number of all possible labels (since the ground-truth label only takes two values). Note that if and have the same ranking for each view, the combination of all views will have the same ranking. Suppose that is the solution returned by (12), then we have
[TABLE]
That is, the algorithm is robust, where .
In the next, we will prove that is robust and is robust, but . Suppose that is the solution returned by (5), then we have
[TABLE]
The right side of the inequality is obtained by setting , and the inequality holds because is the minimizer of (5). We thus further obtain . For any and in the same set of a partition, we have
[TABLE]
where we have utilized that and . The second inequality follows from the Cauthy-Schwarz inequality. The last inequality holds because and . Therefore, is robust. We now prove that is not robust. Because is a vector of real values which are chosen from an infinite continuous space, there must exists a set that contains more than three different choices of in any partition. Then for some , the following inequality holds
[TABLE]
This is because there are at most two different that make while the choices of is more than two in the set .
According to (21) and (22), we conclude that is robust and cannot be [math]. Similarly, we can prove that is robust and . Therefore, the AP loss will tolerate to the small perturbation added to , as long as the perturbation does not change the partition of , while the least squares and hinge loss will not. This completes the proof. ∎
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] M. Boutell, J. Luo, X. Shen, and C. Brown, “Learning multi-label scene classification,” Pattern Recognition , vol. 37, no. 9, pp. 1757–1771, 2004.
- 2[2] G. Tsoumakas and I. Katakis, “Multi-label classification: An overview,” International Journal of Data Warehousing and Mining , vol. 3, no. 3, pp. 1–13, 2007.
- 3[3] B. Hariharan, L. Zelnik-Manor, S. Vishwanathan, and M. Varma, “Large scale max-margin multi-label classification with priors,” in International Conference on Machine Learning , 2010, pp. 423–430.
- 4[4] L. Sun, S. Ji, and J. Ye, “Canonical correlation analysis for multilabel classification: a least-squares formulation, extensions, and analysis,” IEEE Transactions on Pattern Analysis and Machine Intelligence , vol. 33, no. 1, pp. 194–200, 2011.
- 5[5] B. Wang, Z. Tu, and J. K. Tsotsos, “Dynamic label propagation for semi-supervised multi-class multi-label classification,” in IEEE International Conference on Computer Vision , 2013, pp. 425–432.
- 6[6] G. Sundaramoorthi and B.-W. Hong, “Fast label: Easy and efficient solution of joint multi-label and estimation problems,” in IEEE Conference on Computer Vision and Pattern Recognition , 2014, pp. 3126–3133.
- 7[7] A. Goldberg, X. Zhu, B. Recht, J. Xu, and R. Nowak, “Transduction with matrix completion: Three birds with one stone,” in Advances in Neural Information Processing Systems , 2010, pp. 757–765.
- 8[8] R. Cabral, F. De la Torre, J. Costeira, and A. Bernardino, “Matrix completion for multi-label image classification,” in Advances in Neural Information Processing Systems , 2011, pp. 190–198.