"Jam Me If You Can'': Defeating Jammer with Deep Dueling Neural Network Architecture and Ambient Backscattering Augmented Communications
Nguyen Van Huynh, Diep N. Nguyen, Dinh Thai Hoang, and Eryk Dutkiewicz

TL;DR
This paper introduces a deep dueling neural network-based anti-jamming method that learns jammer strategies quickly and adapts transmission, significantly improving throughput and reducing packet loss in wireless communications.
Contribution
It proposes a novel deep reinforcement learning algorithm with dueling neural networks to efficiently counter unknown jamming attacks, outperforming traditional Q-learning.
Findings
Achieves up to 426% increase in average throughput.
Reduces packet loss by 24%.
Enhances transmission success rate with increased jamming power.
Abstract
With conventional anti-jamming solutions like frequency hopping or spread spectrum, legitimate transceivers often tend to "escape" or "hide" themselves from jammers. These reactive anti-jamming approaches are constrained by the lack of timely knowledge of jamming attacks. Bringing together the latest advances in neural network architectures and ambient backscattering communications, this work allows wireless nodes to effectively "face" the jammer by first learning its jamming strategy, then adapting the rate or transmitting information right on the jamming signal. Specifically, to deal with unknown jamming attacks, existing work often relies on reinforcement learning algorithms, e.g., Q-learning. However, the Q-learning algorithm is notorious for its slow convergence to the optimal policy, especially when the system state and action spaces are large. This makes the Q-learning algorithm…
Click any figure to enlarge with its caption.
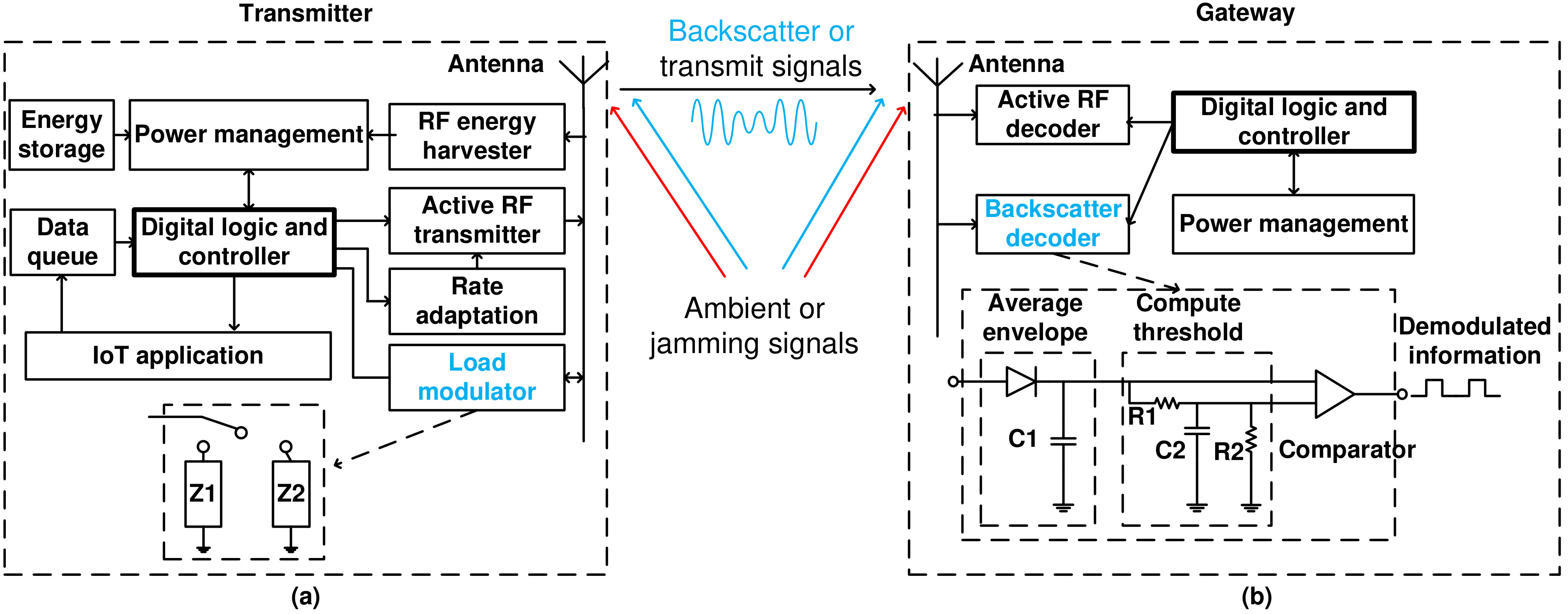 Figure 1
Figure 1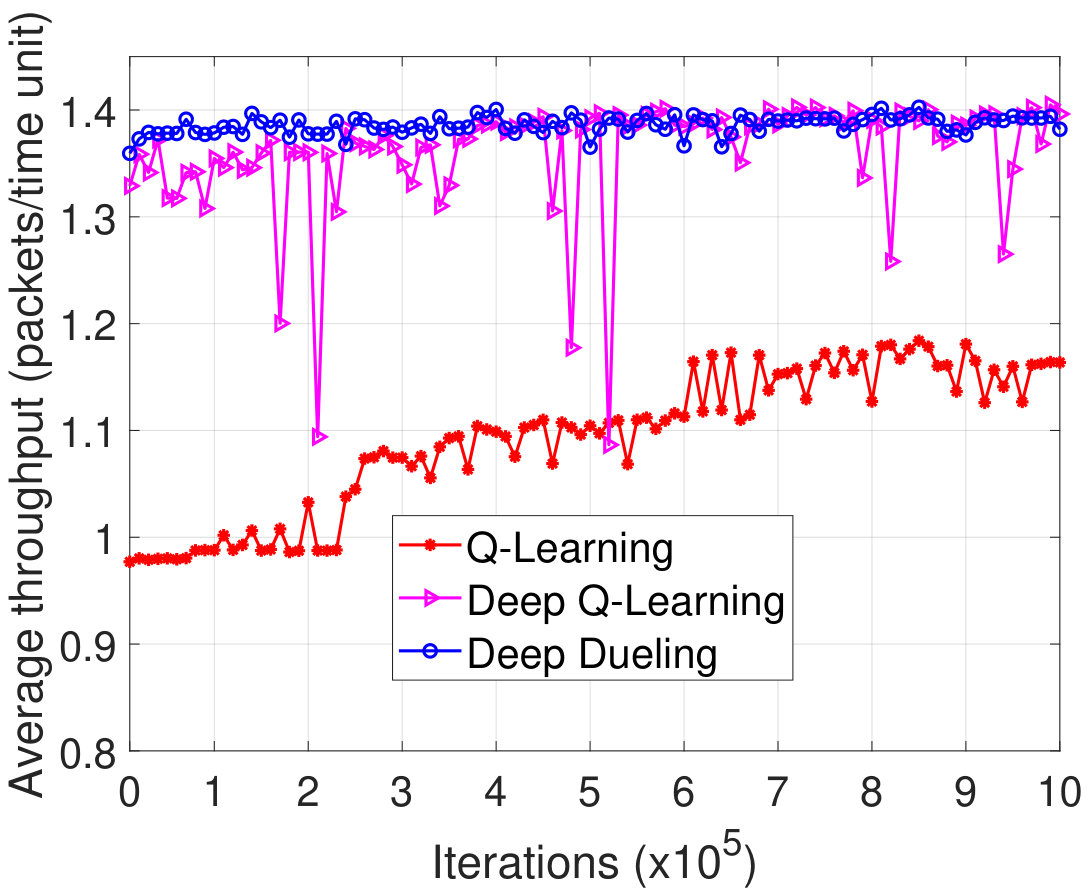 Figure 2
Figure 2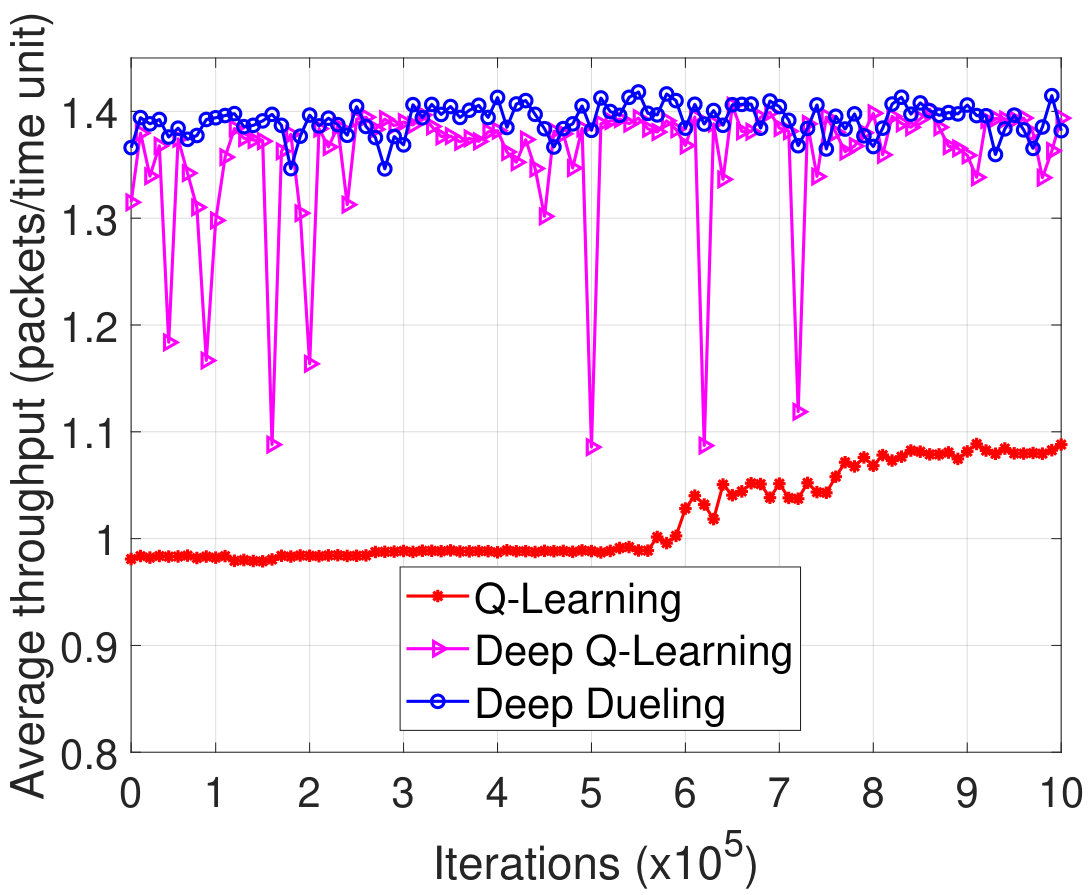 Figure 3
Figure 3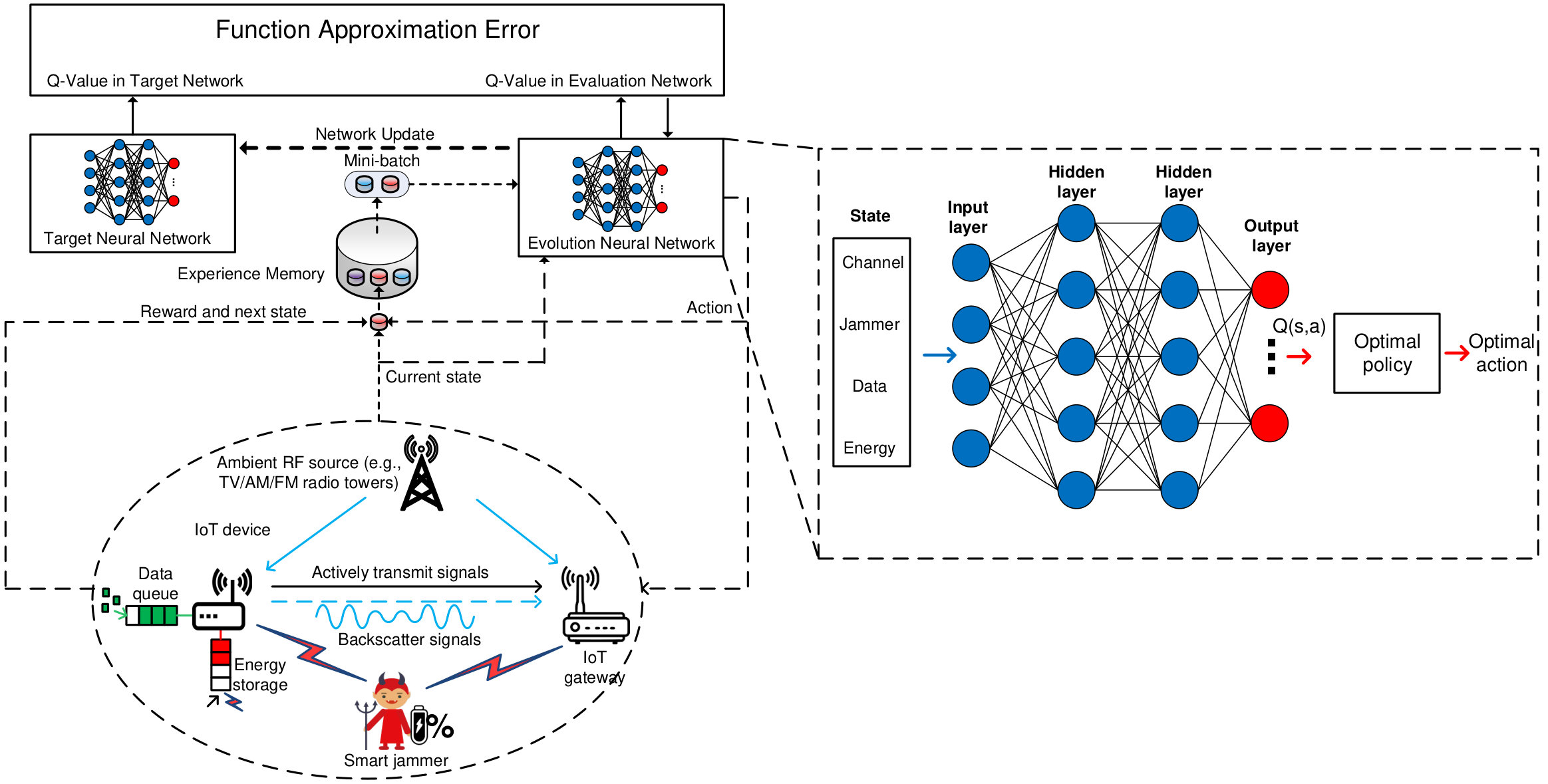 Figure 4
Figure 4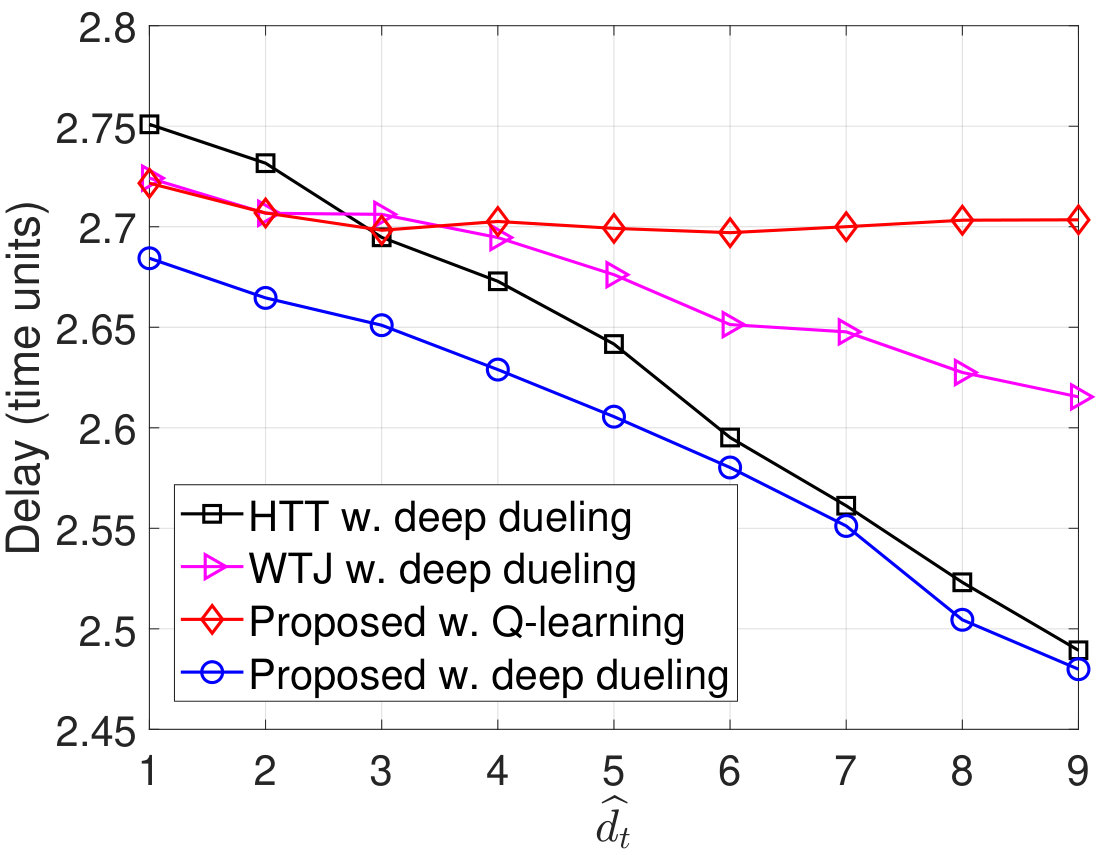 Figure 5
Figure 5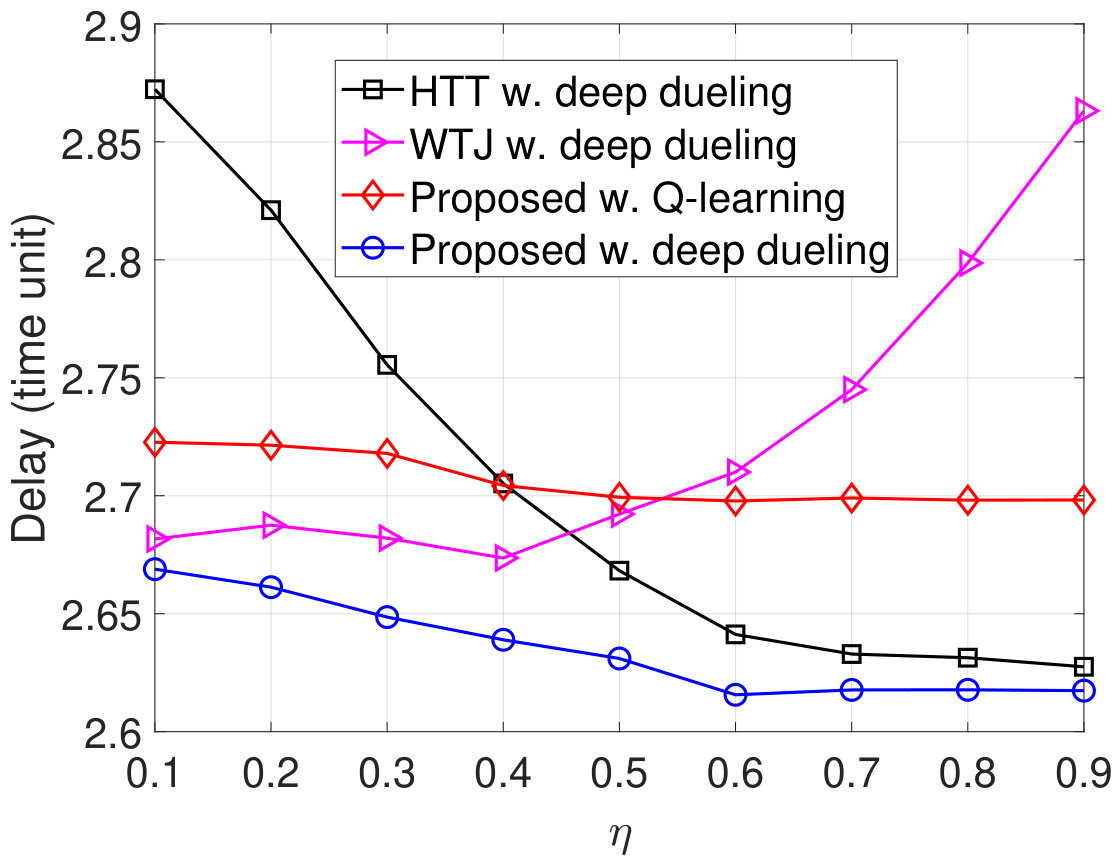 Figure 6
Figure 6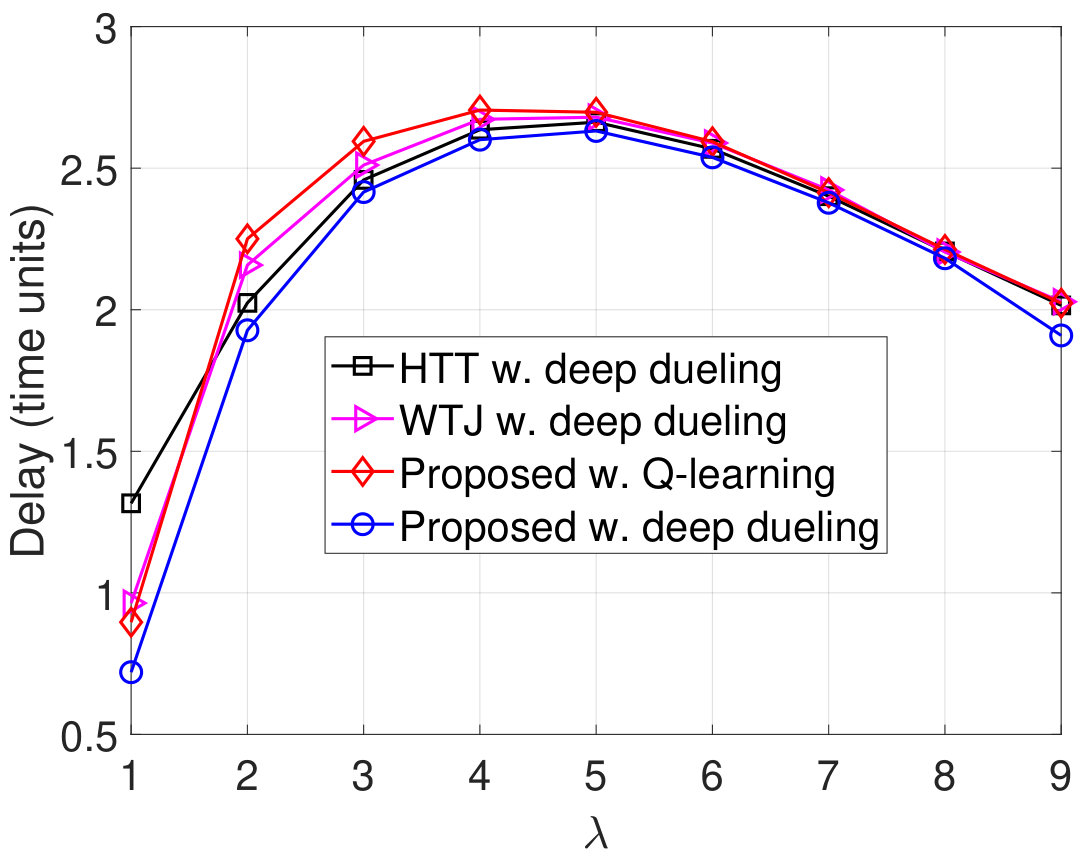 Figure 7
Figure 7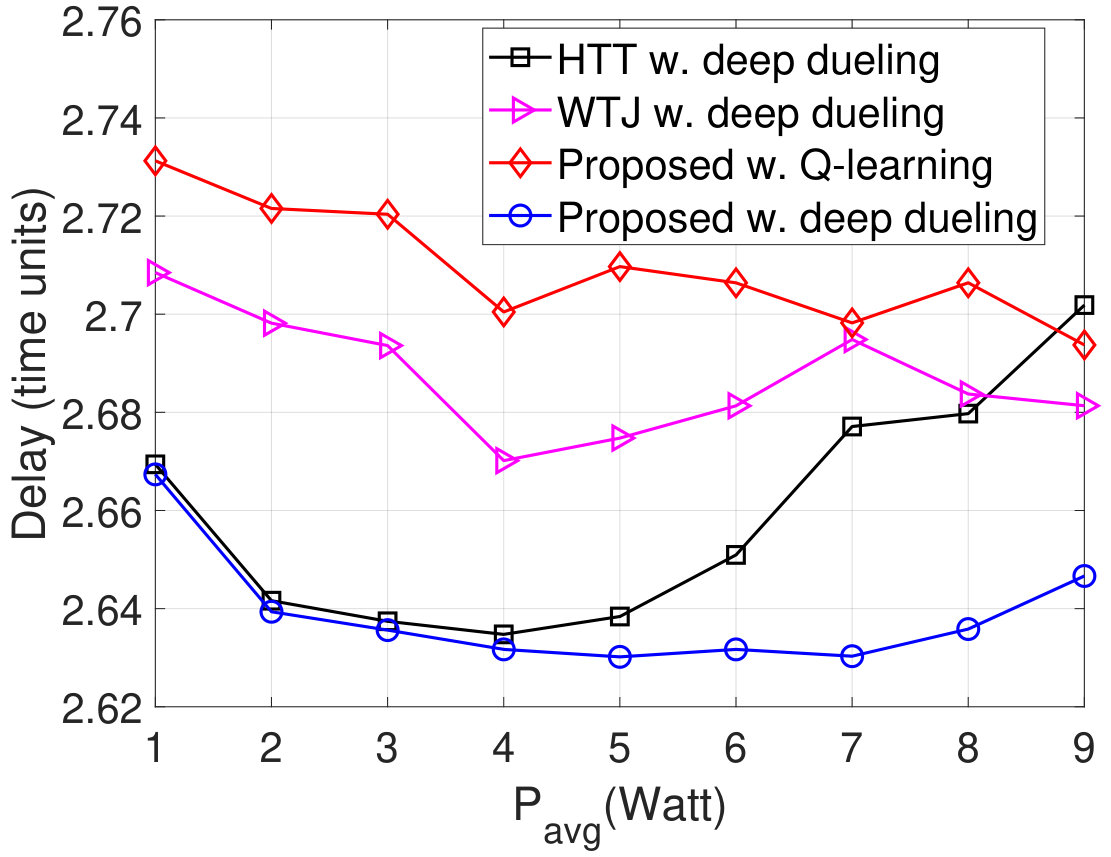 Figure 8
Figure 8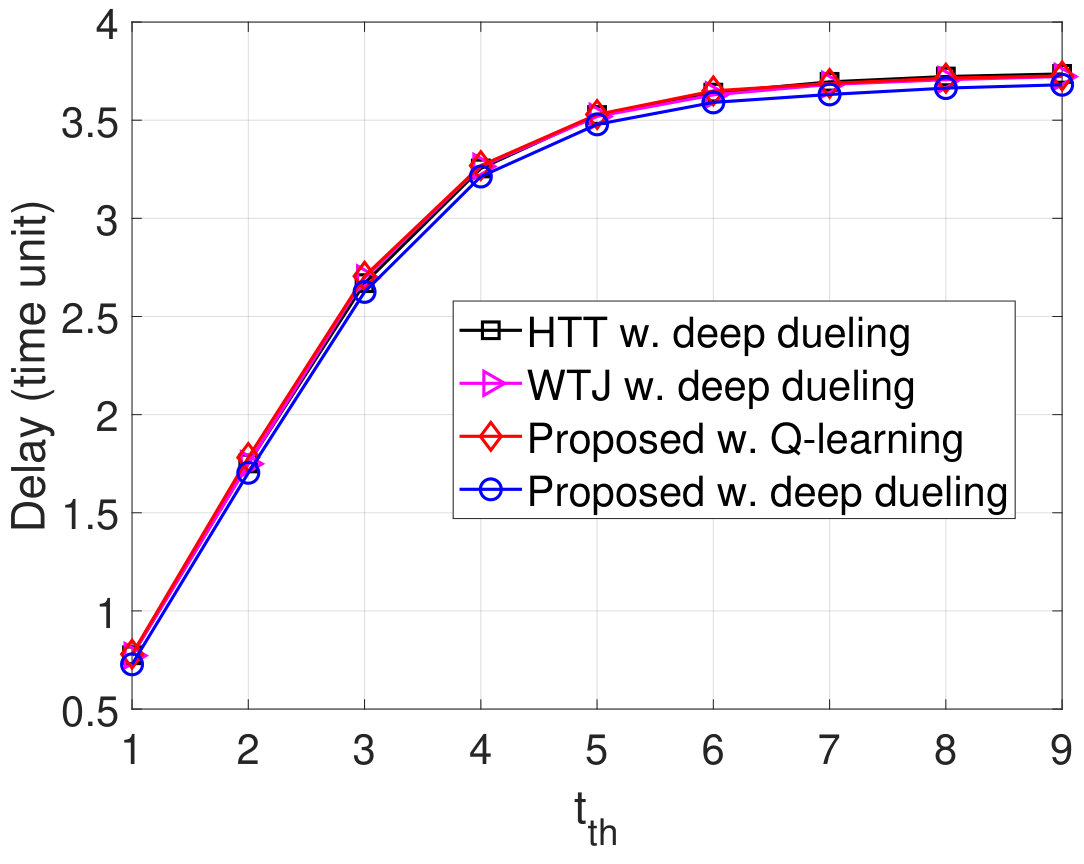 Figure 9
Figure 9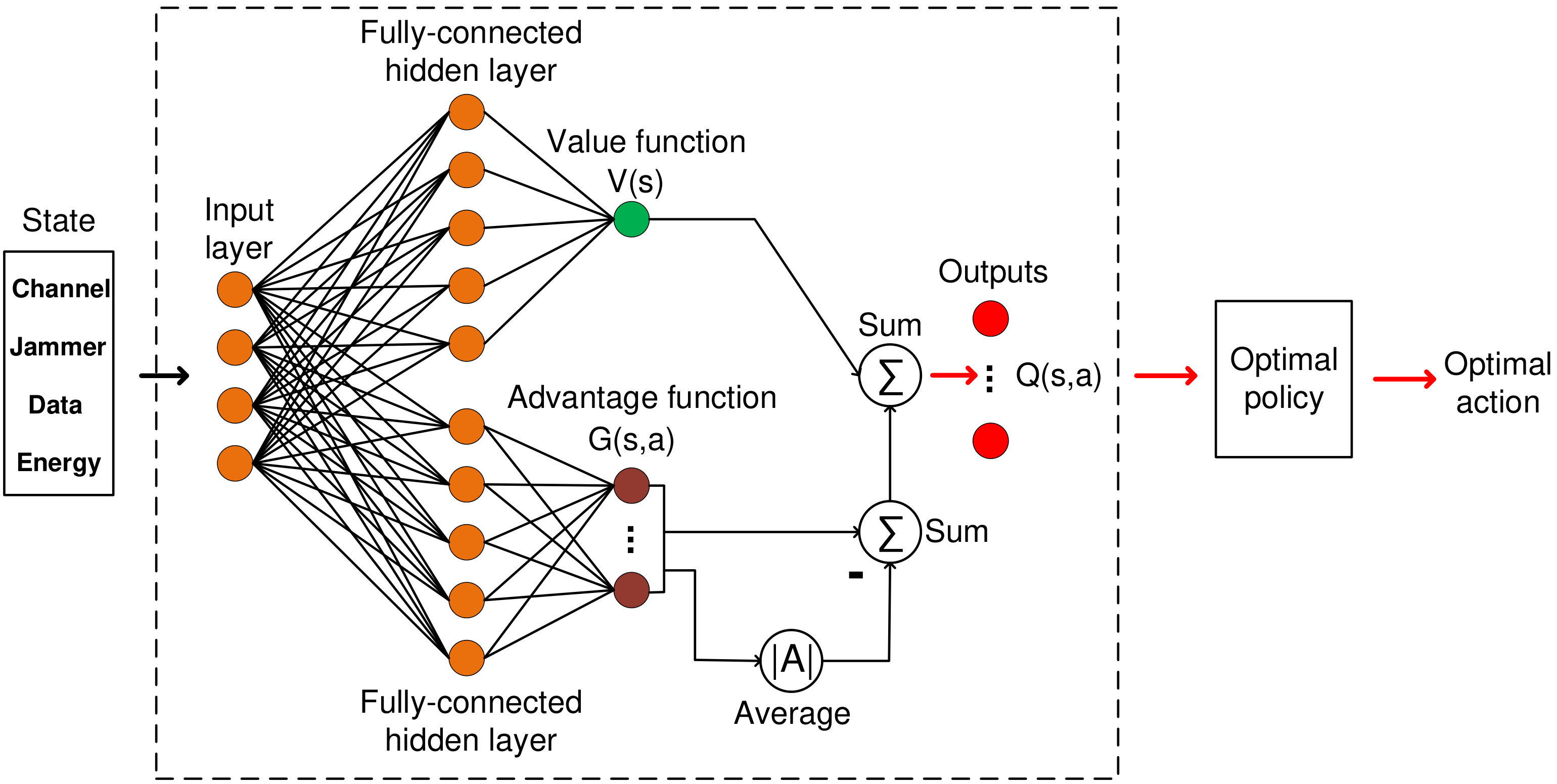 Figure 10
Figure 10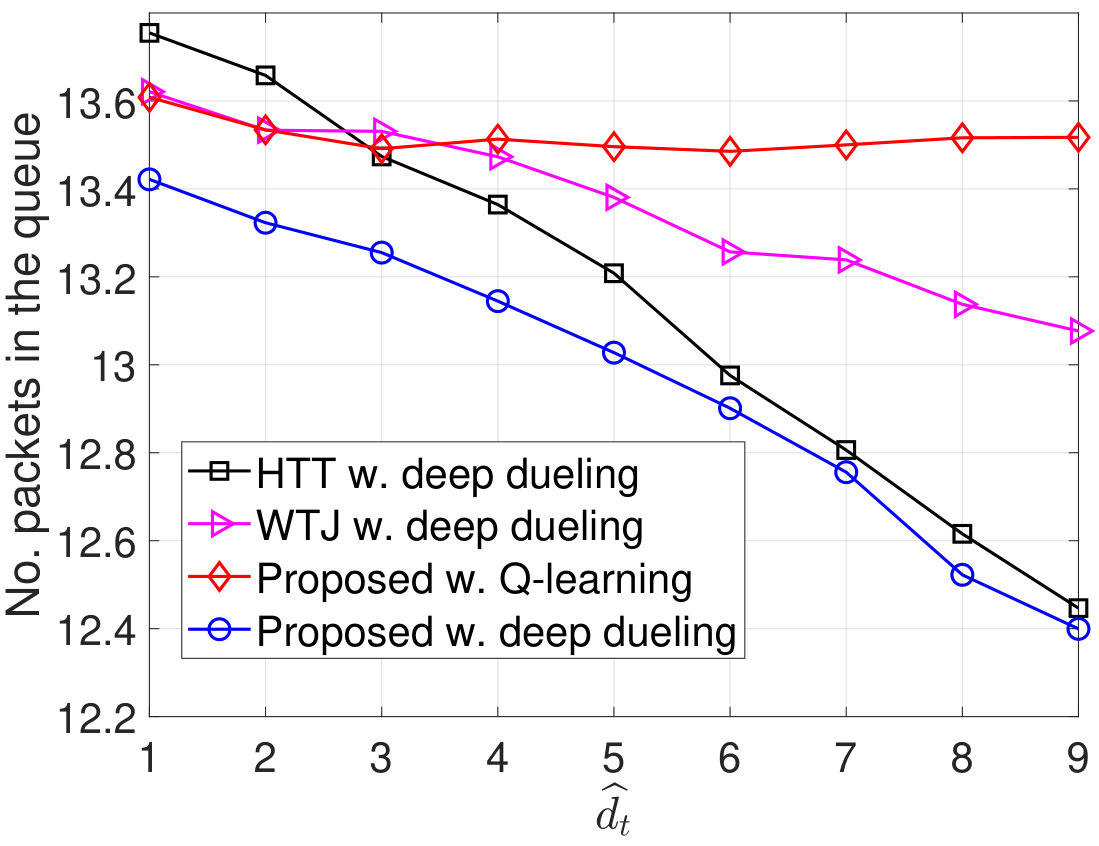 Figure 11
Figure 11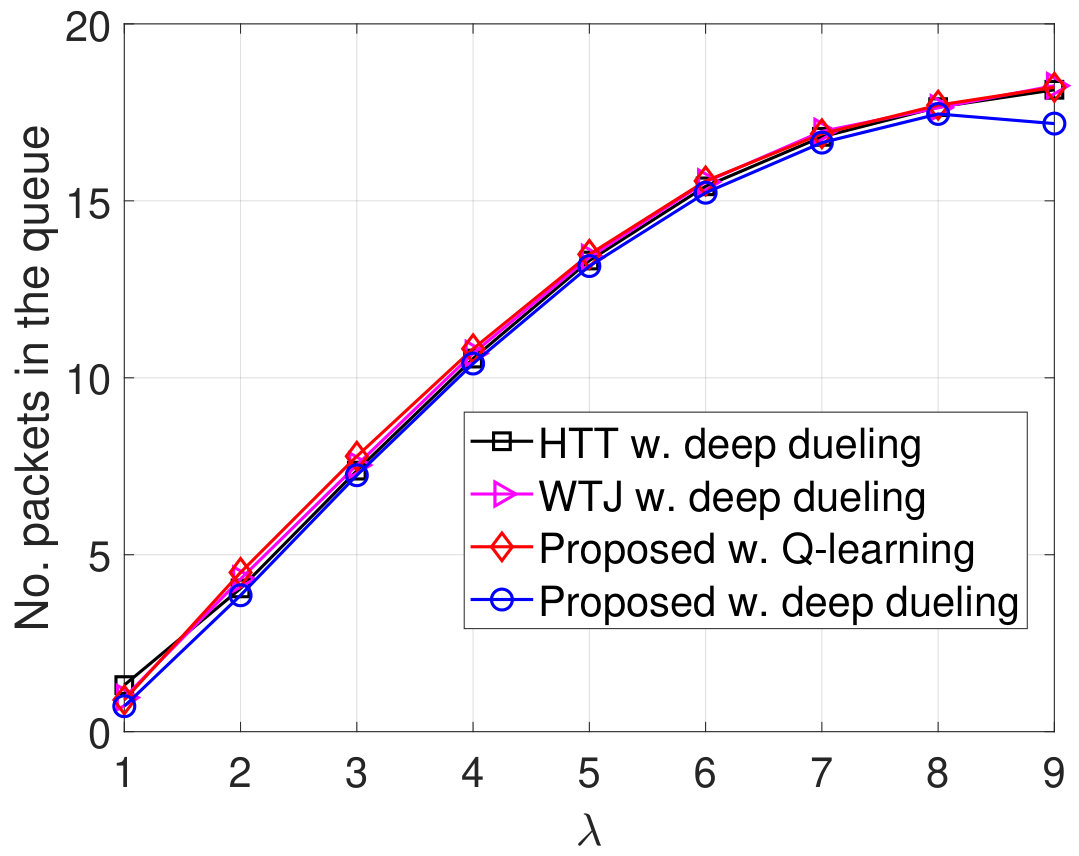 Figure 12
Figure 12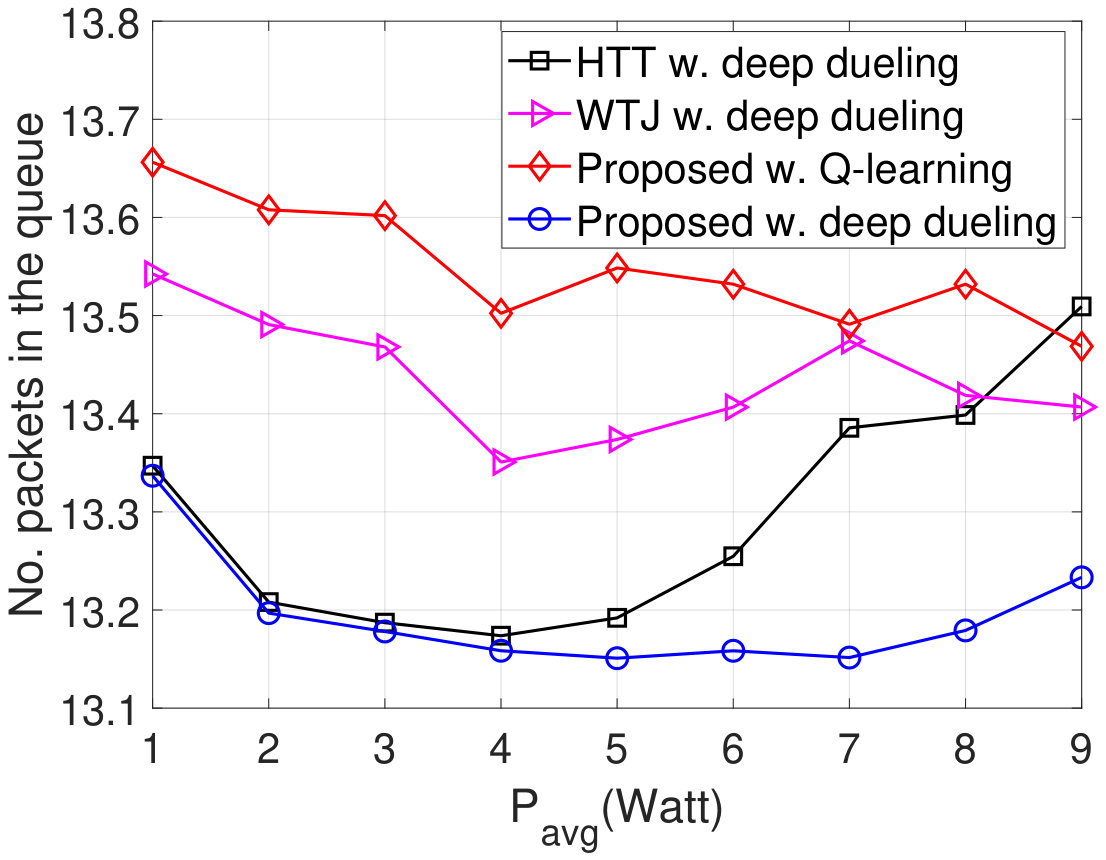 Figure 13
Figure 13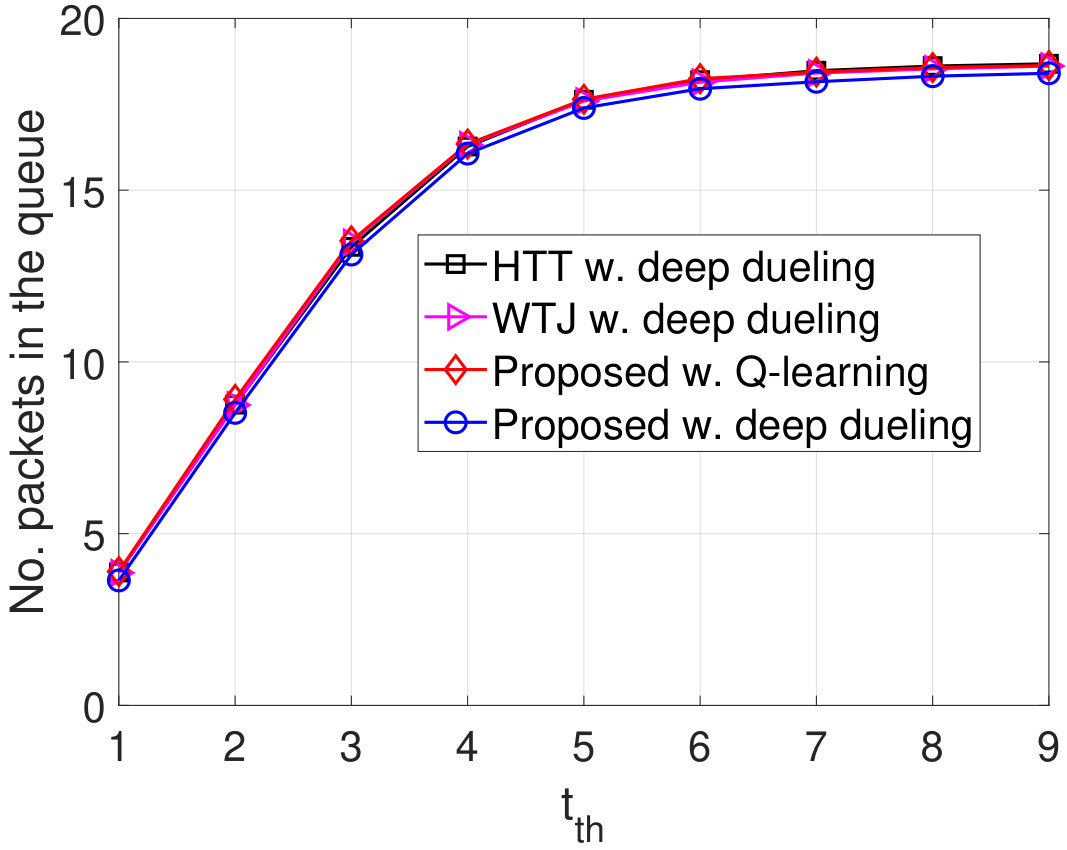 Figure 14
Figure 14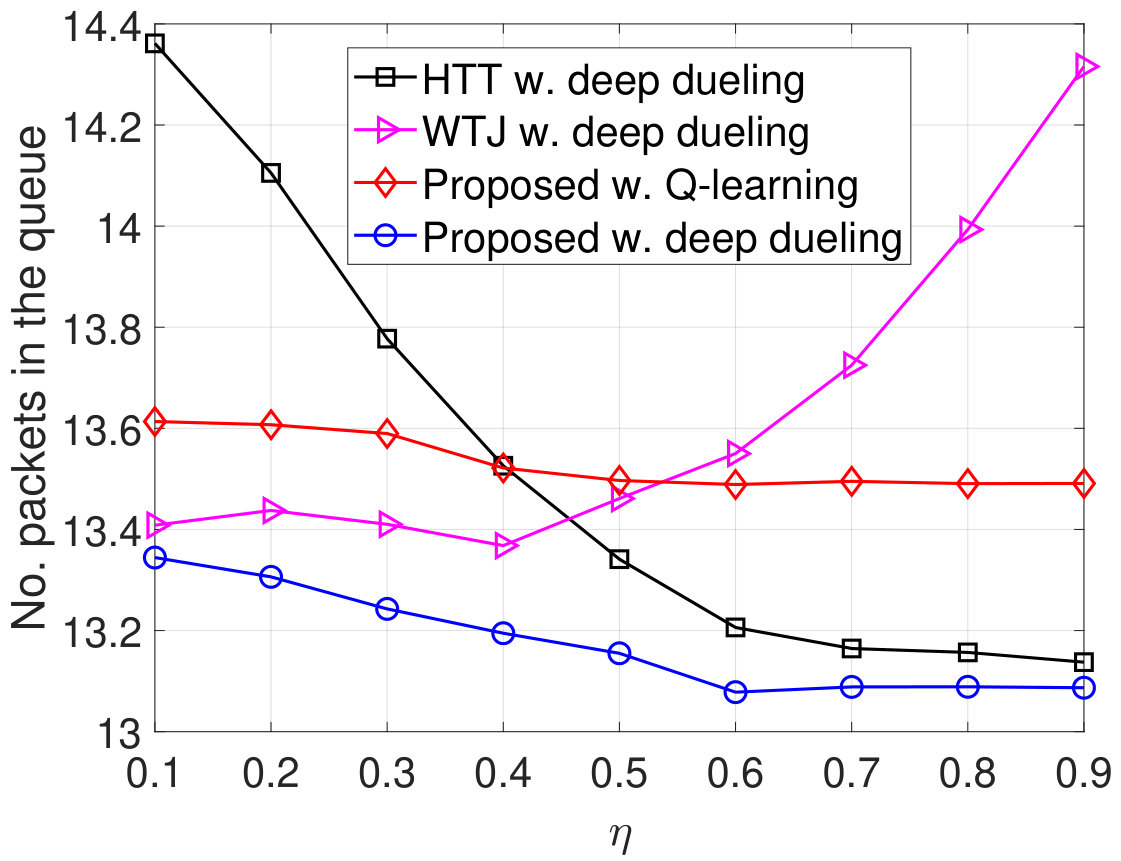 Figure 15
Figure 15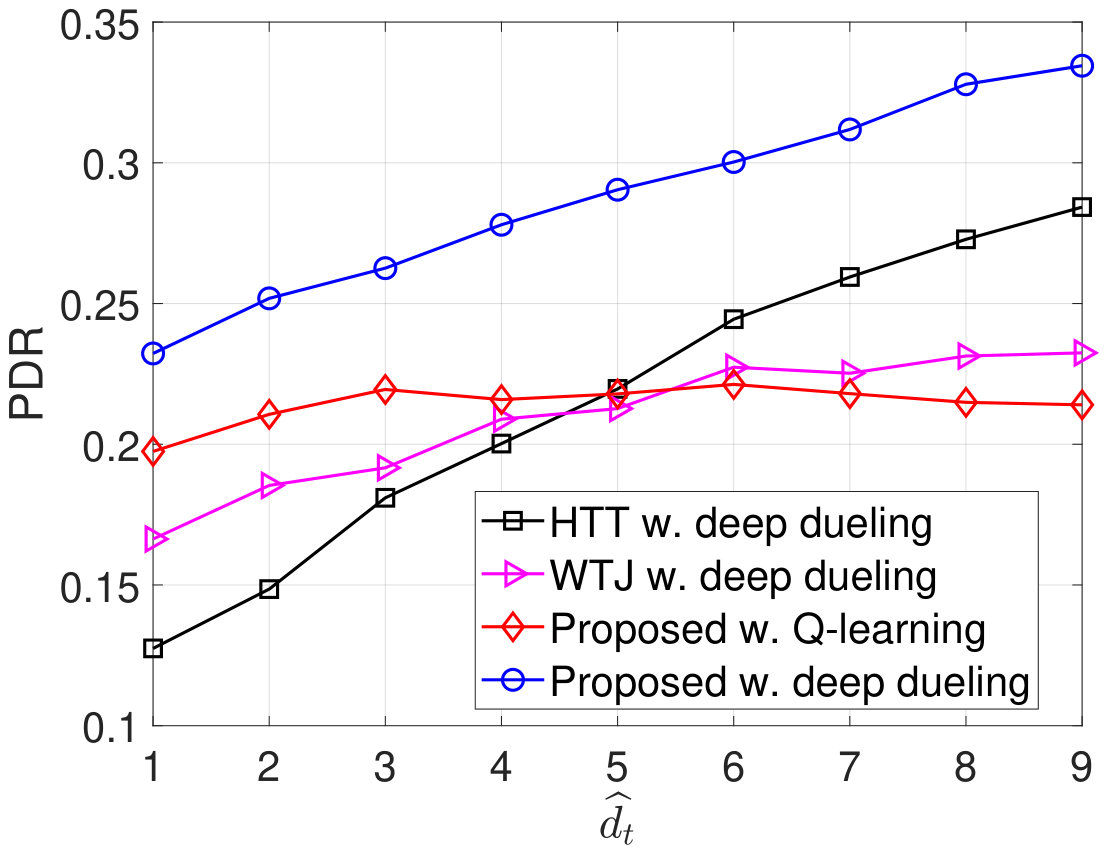 Figure 16
Figure 16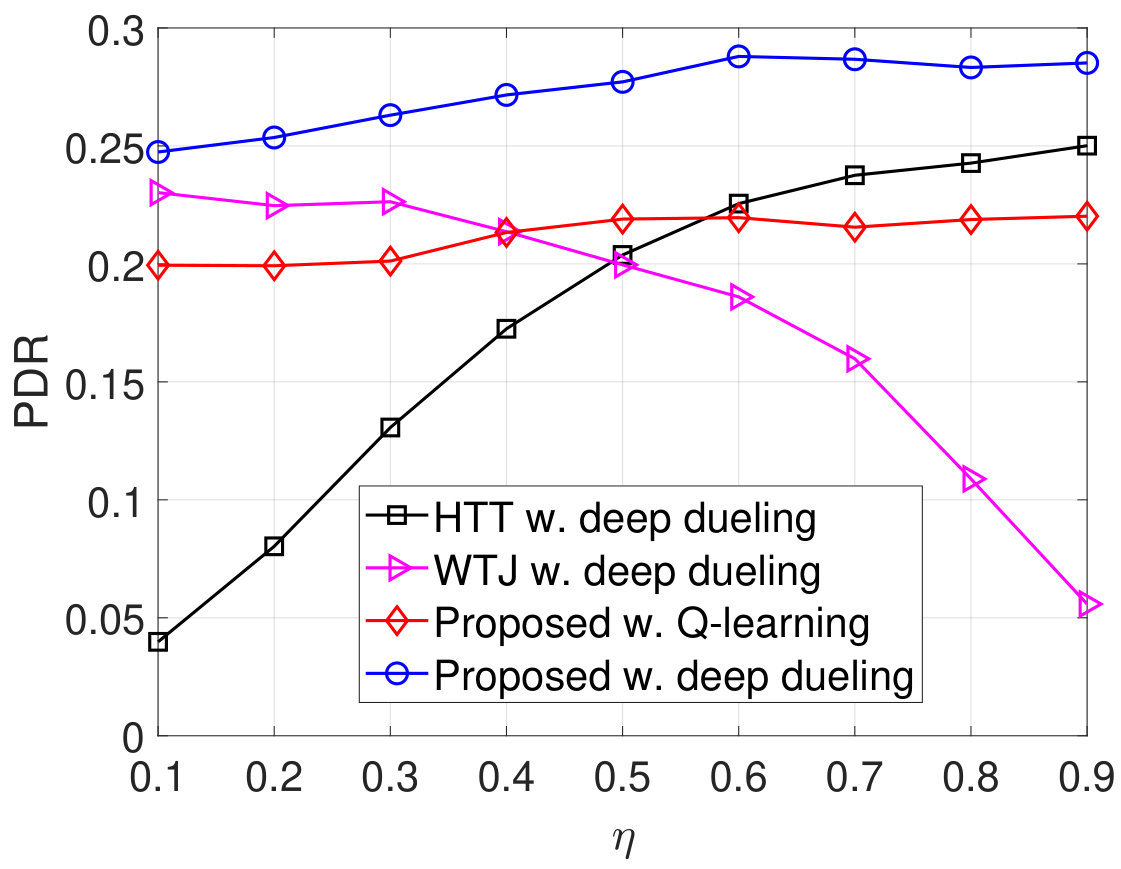 Figure 17
Figure 17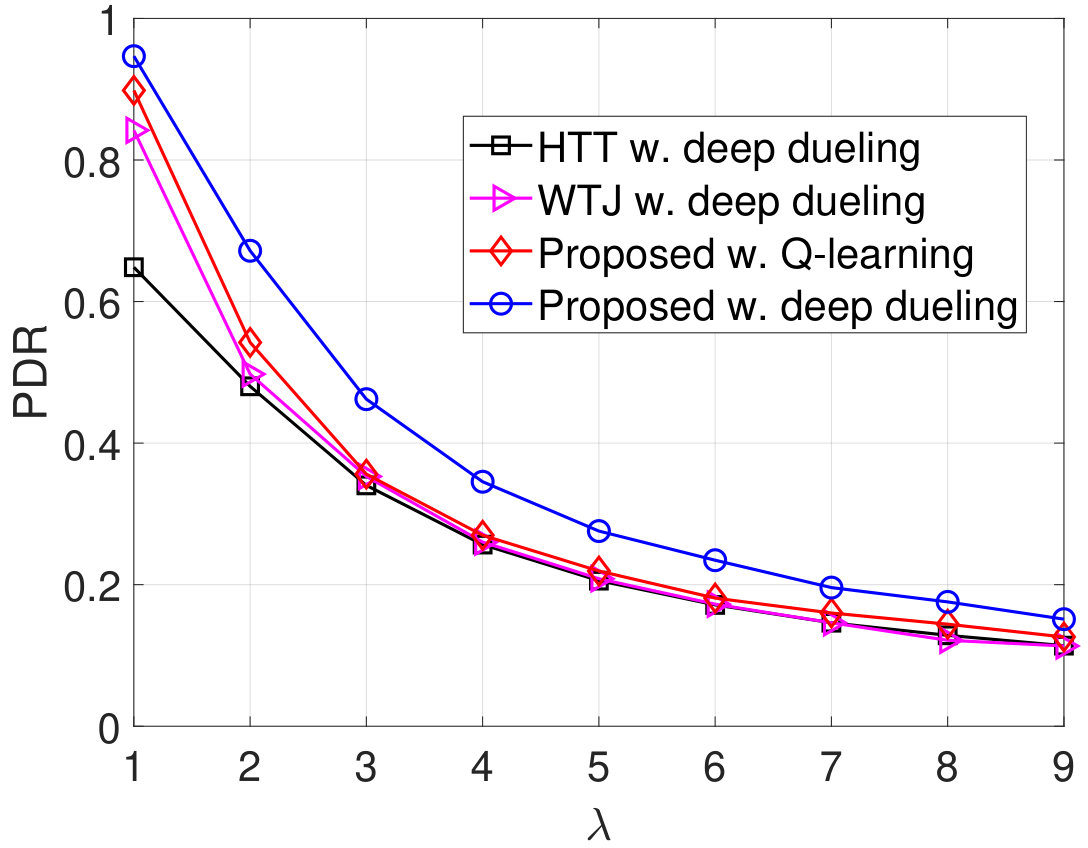 Figure 18
Figure 18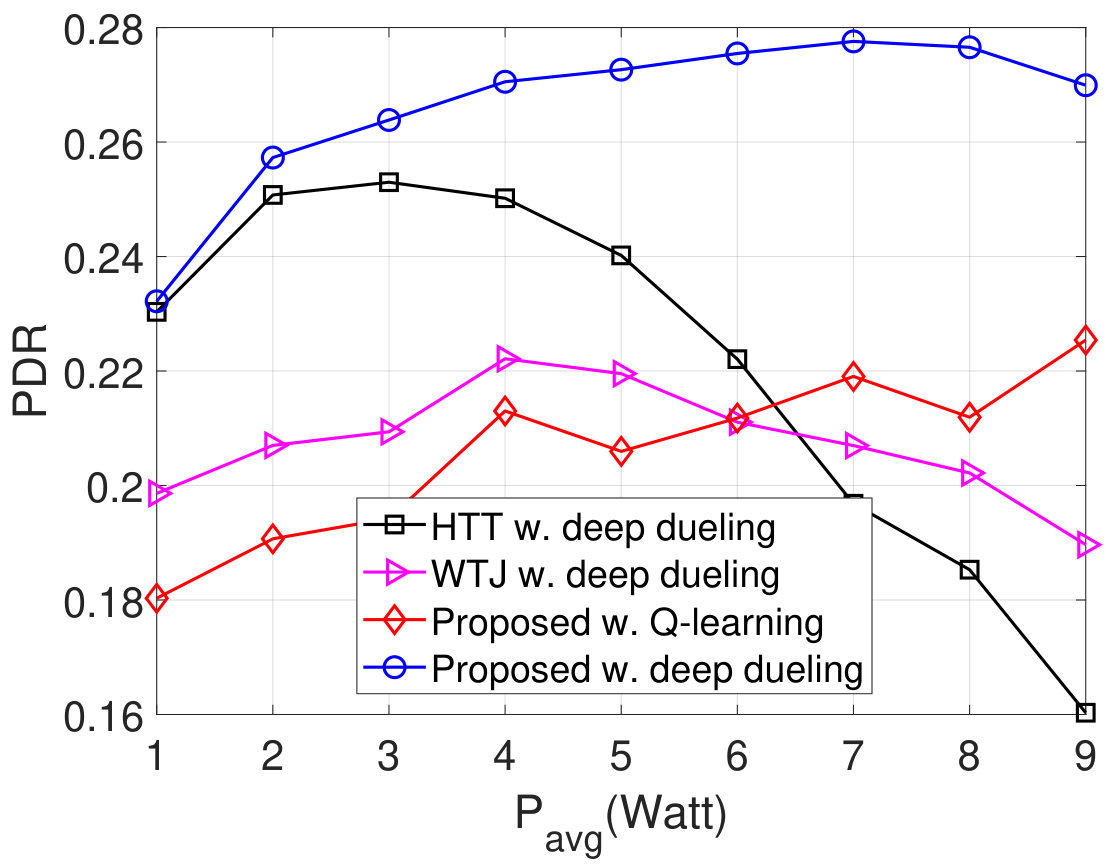 Figure 19
Figure 19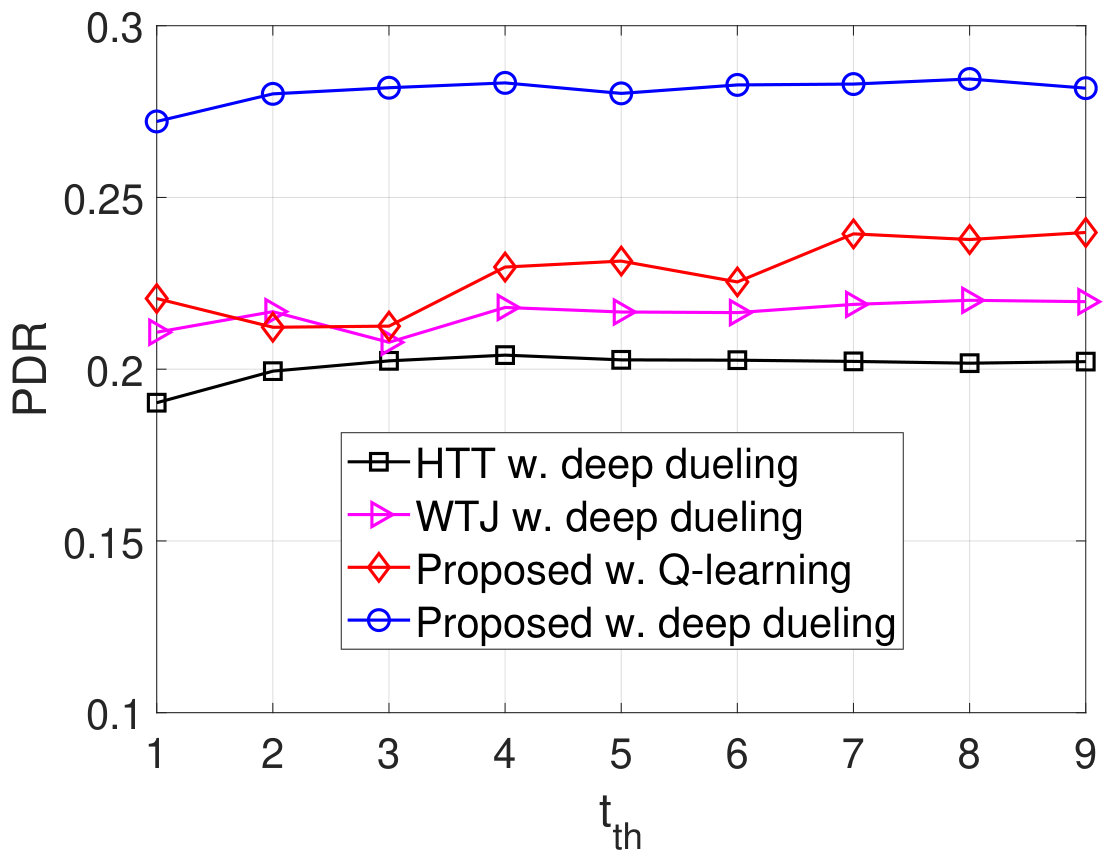 Figure 20
Figure 20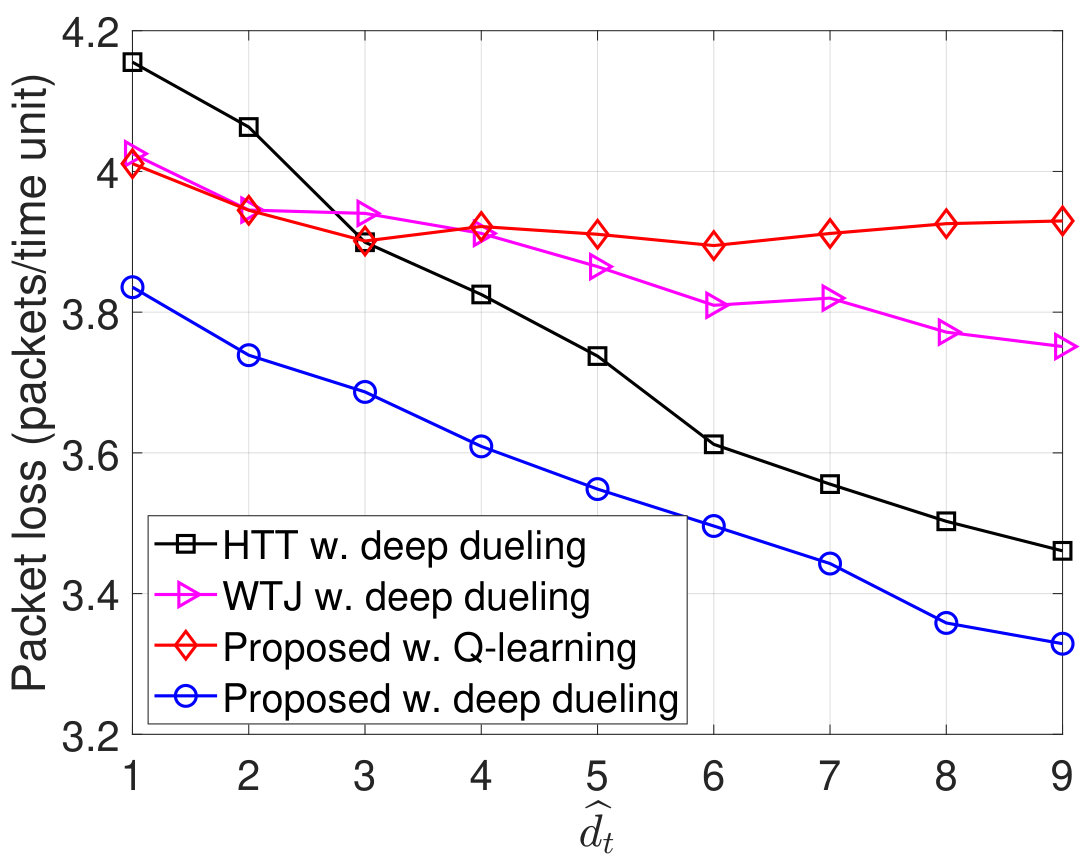 Figure 21
Figure 21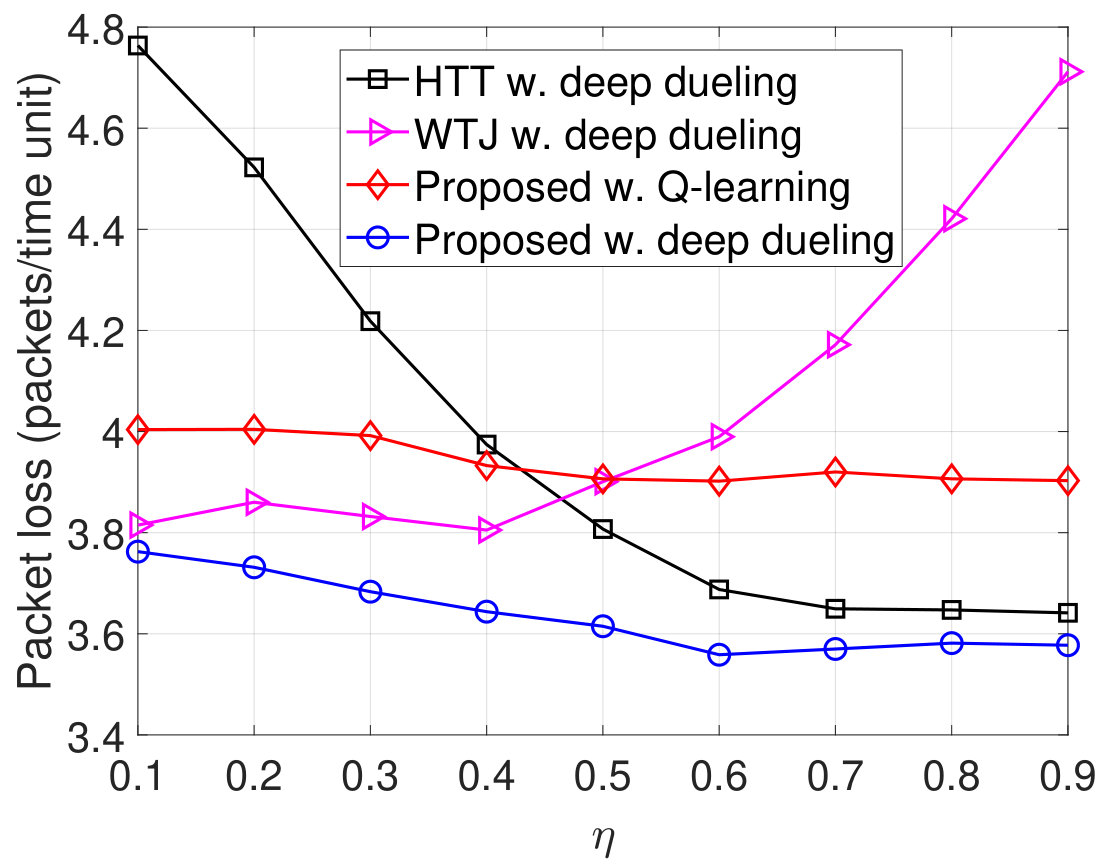 Figure 22
Figure 22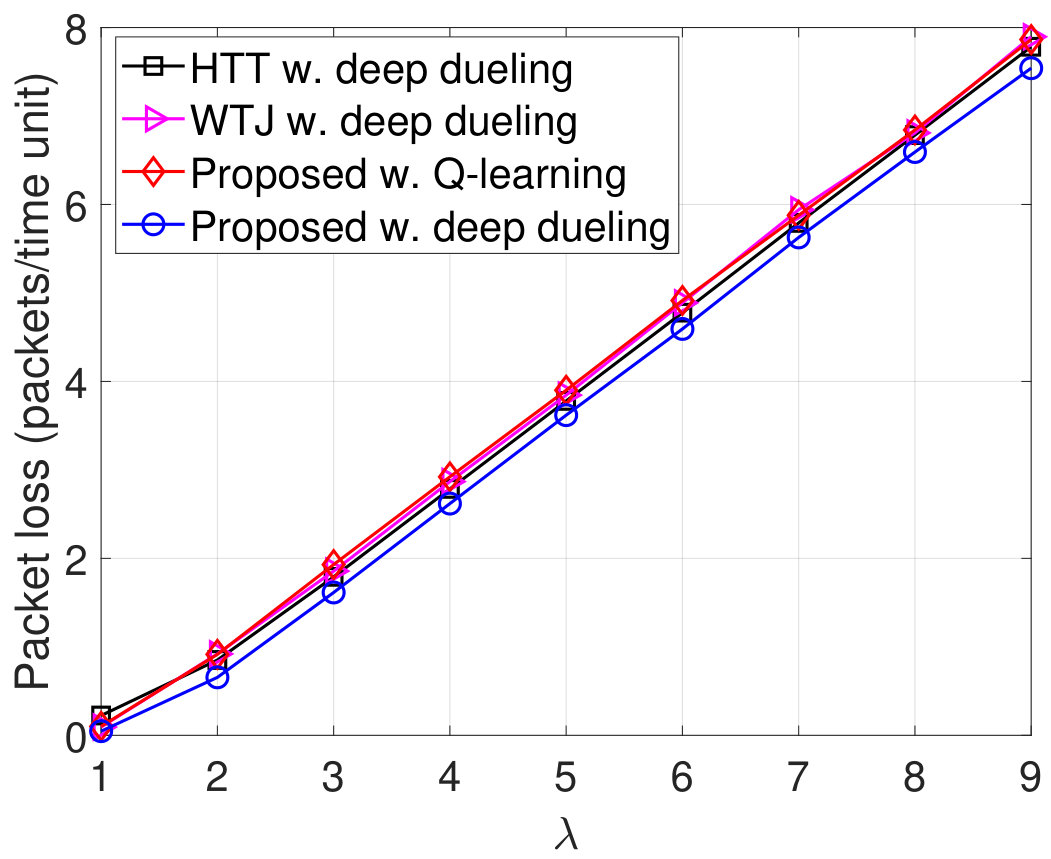 Figure 23
Figure 23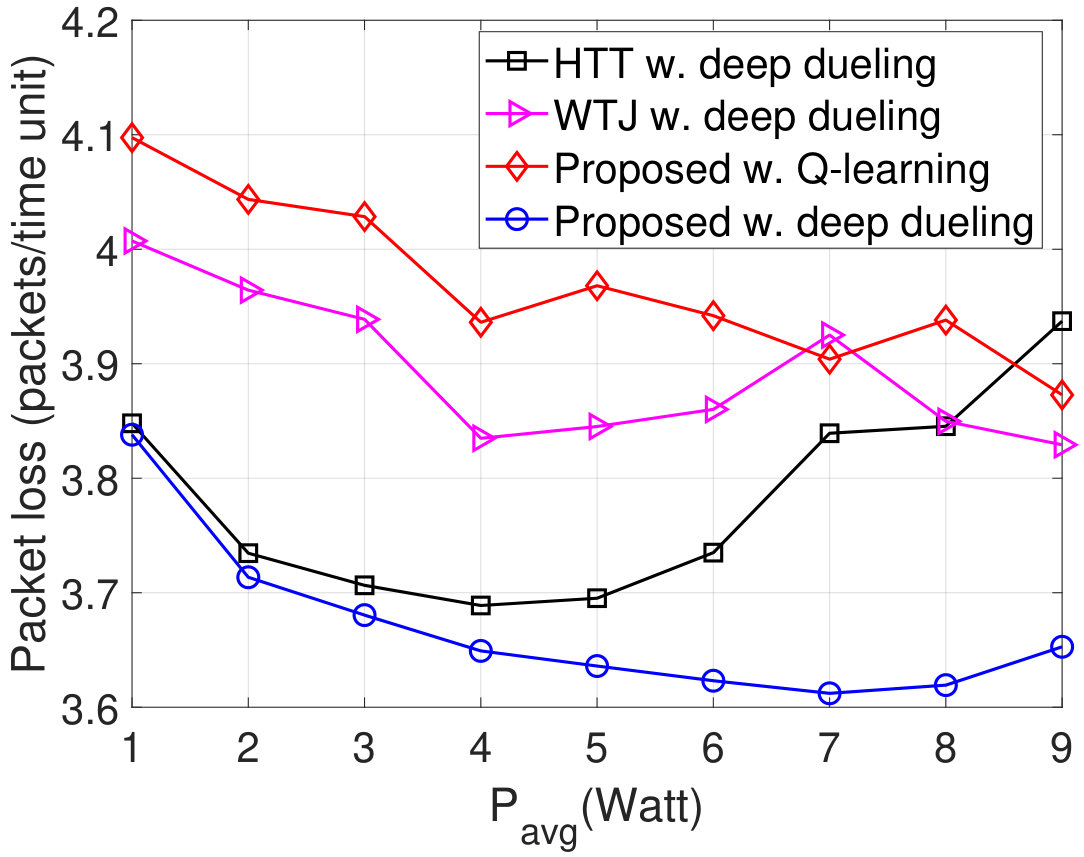 Figure 24
Figure 24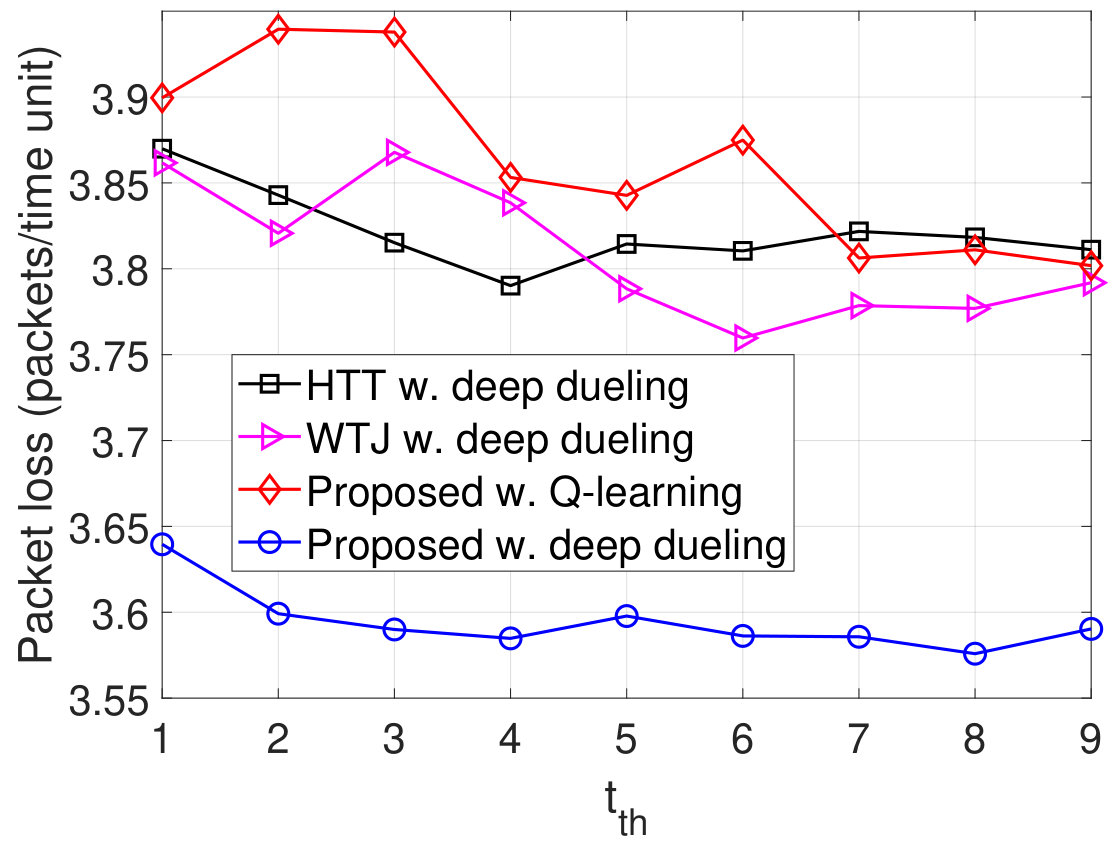 Figure 25
Figure 25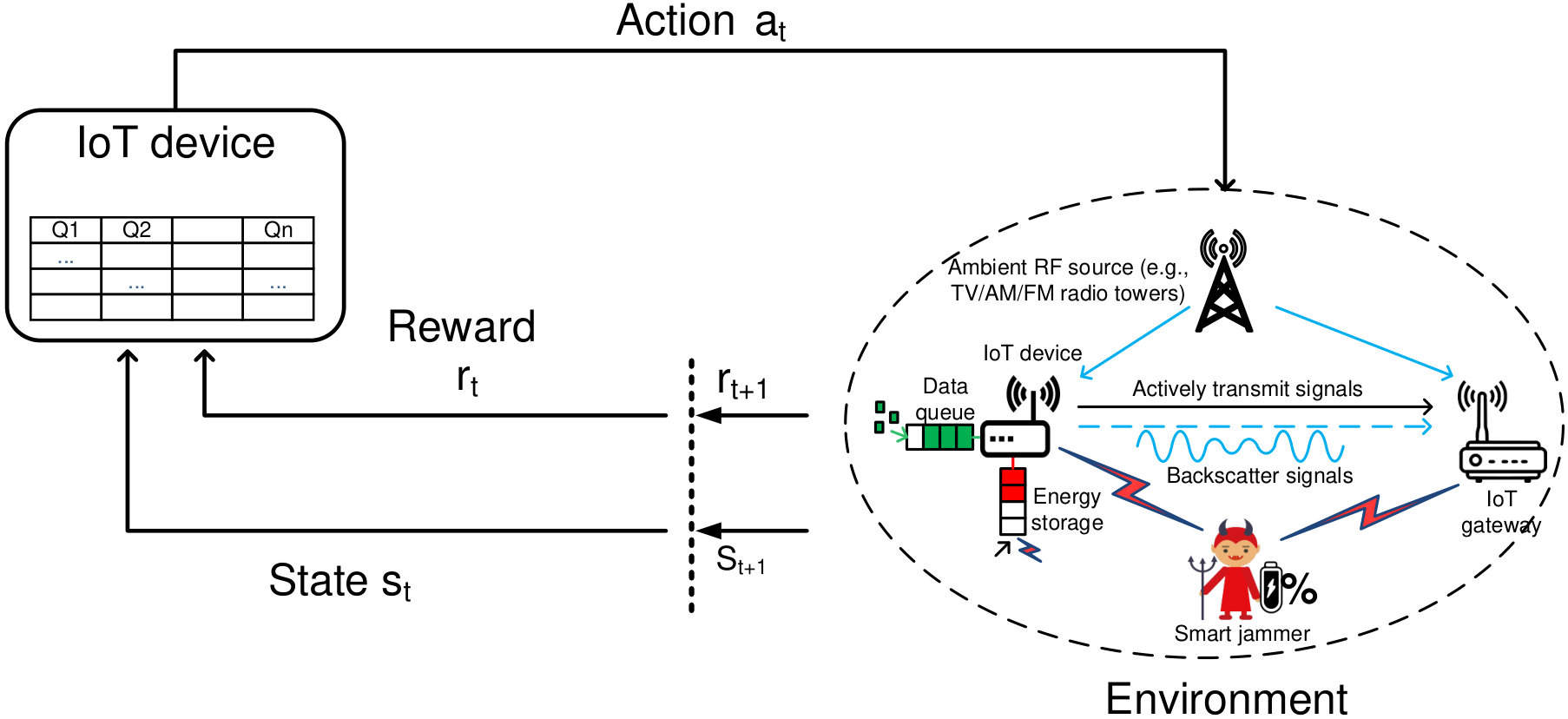 Figure 26
Figure 26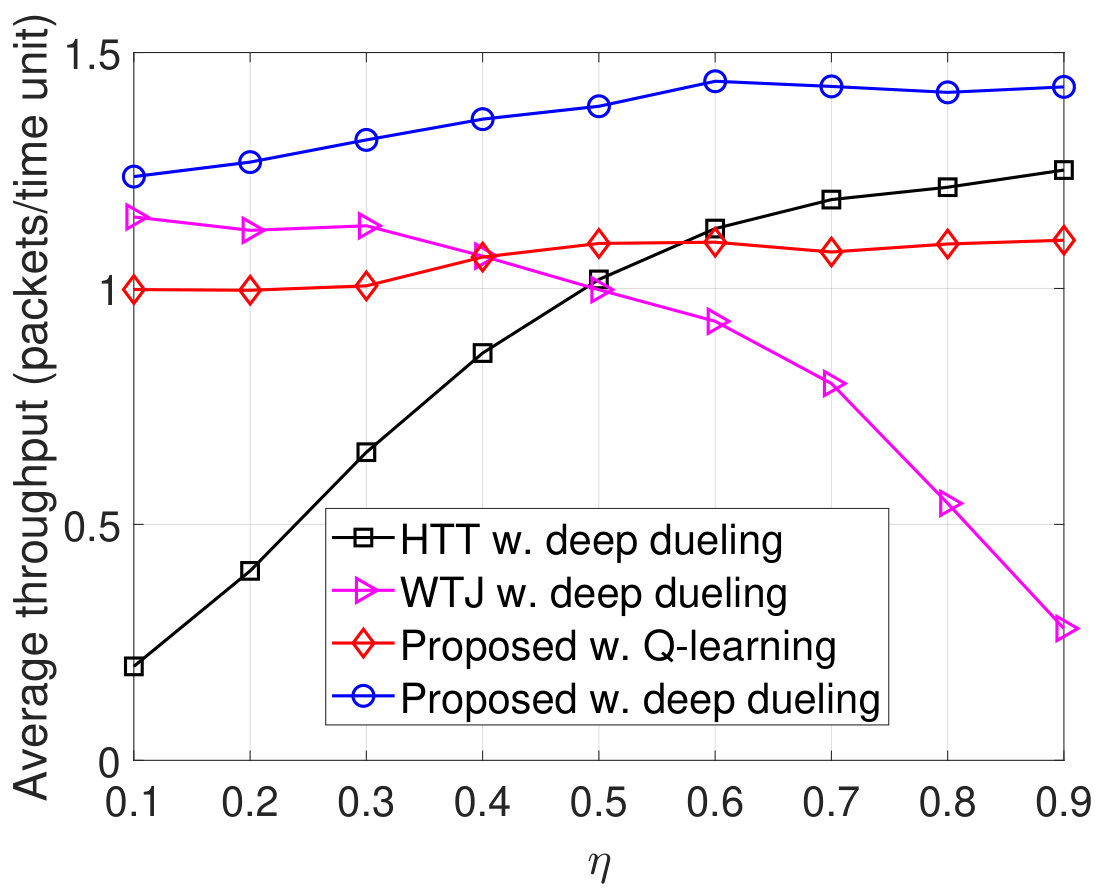 Figure 27
Figure 27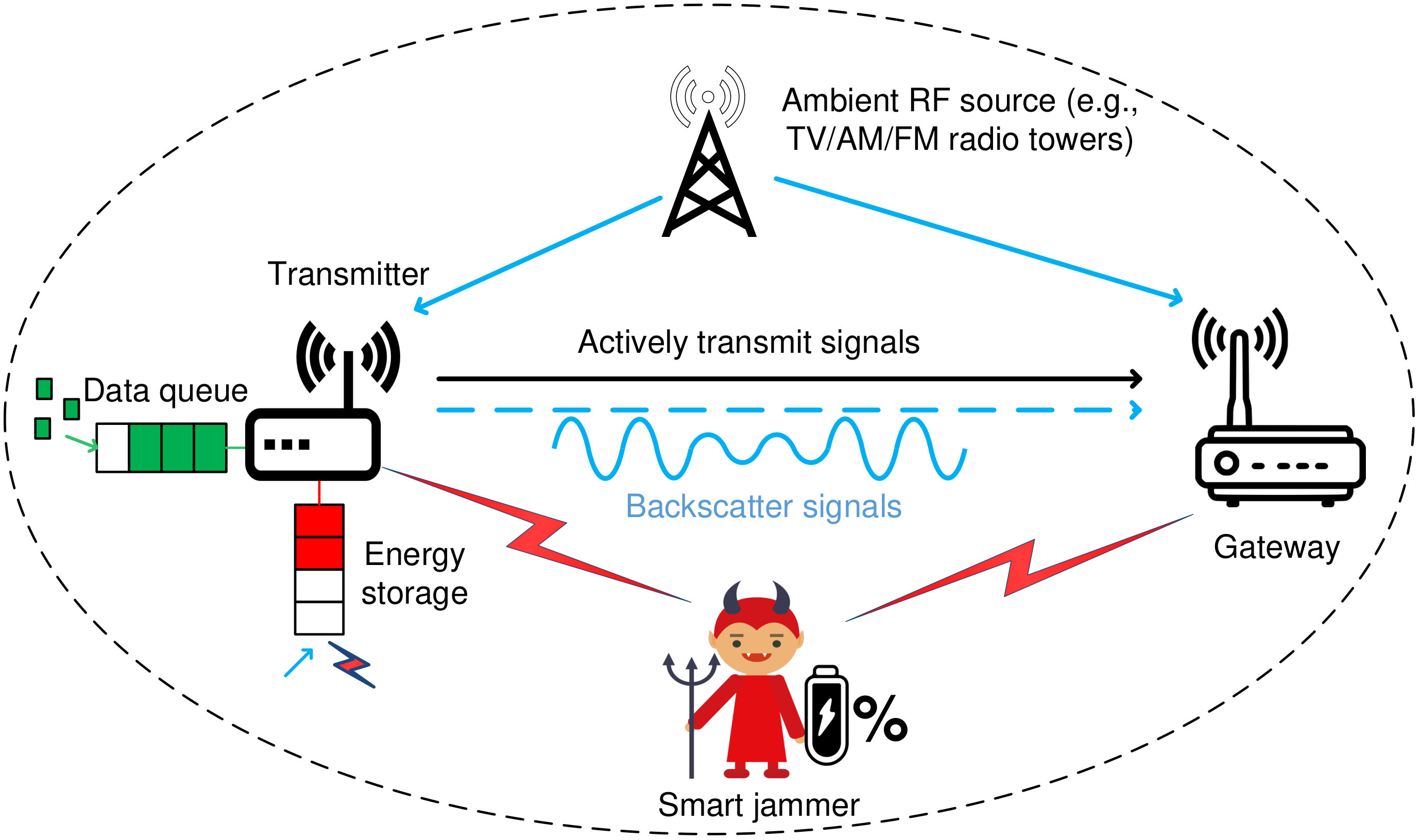 Figure 28
Figure 28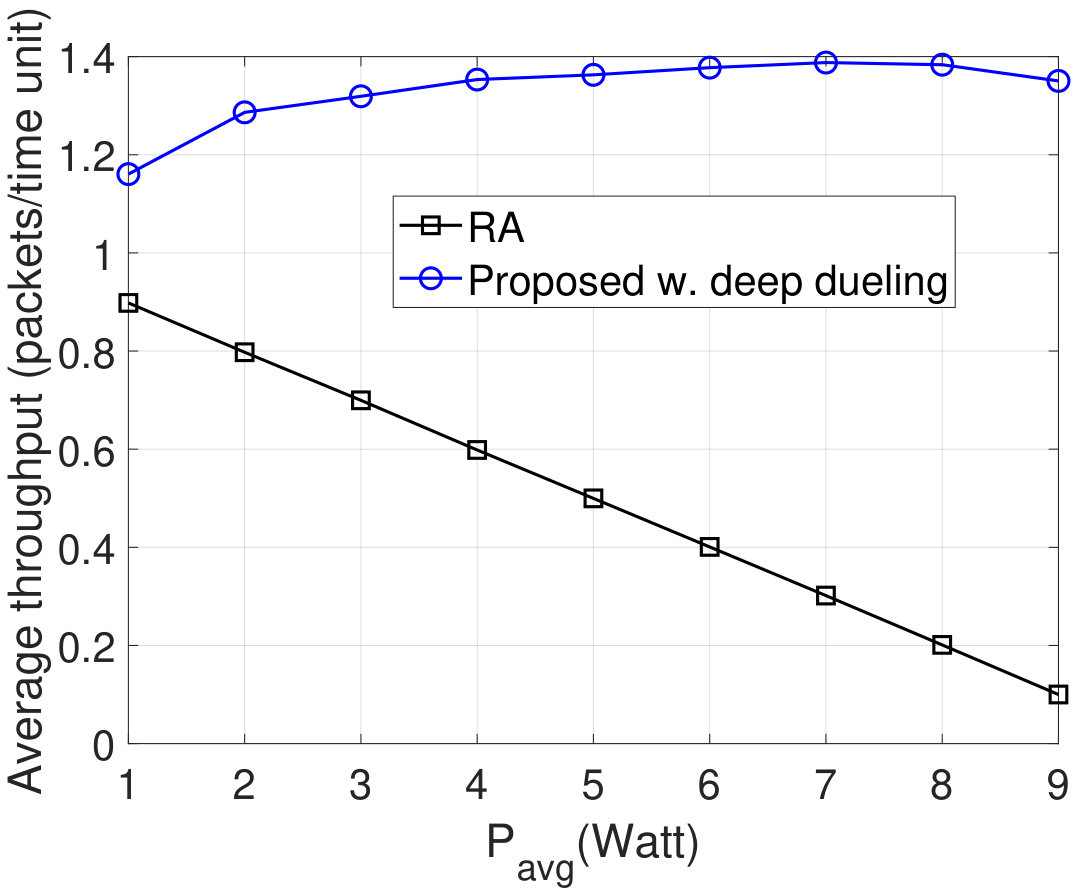 Figure 29
Figure 29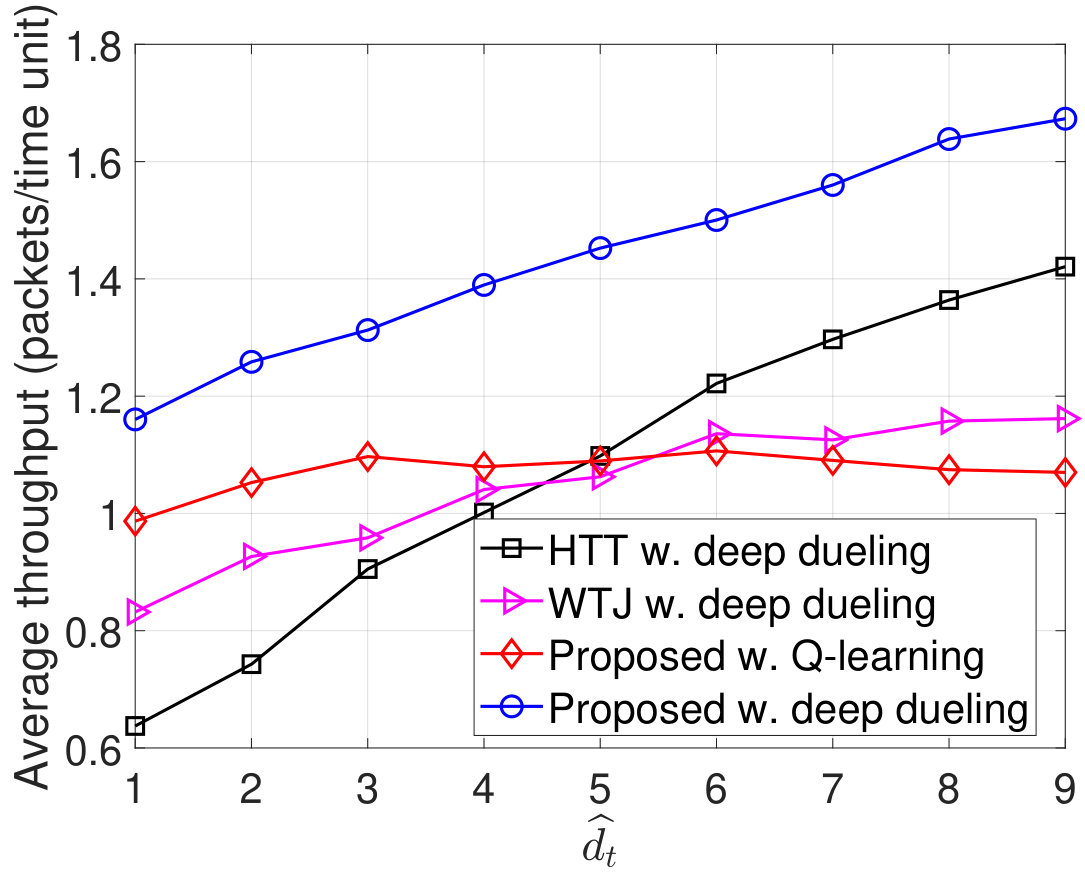 Figure 30
Figure 30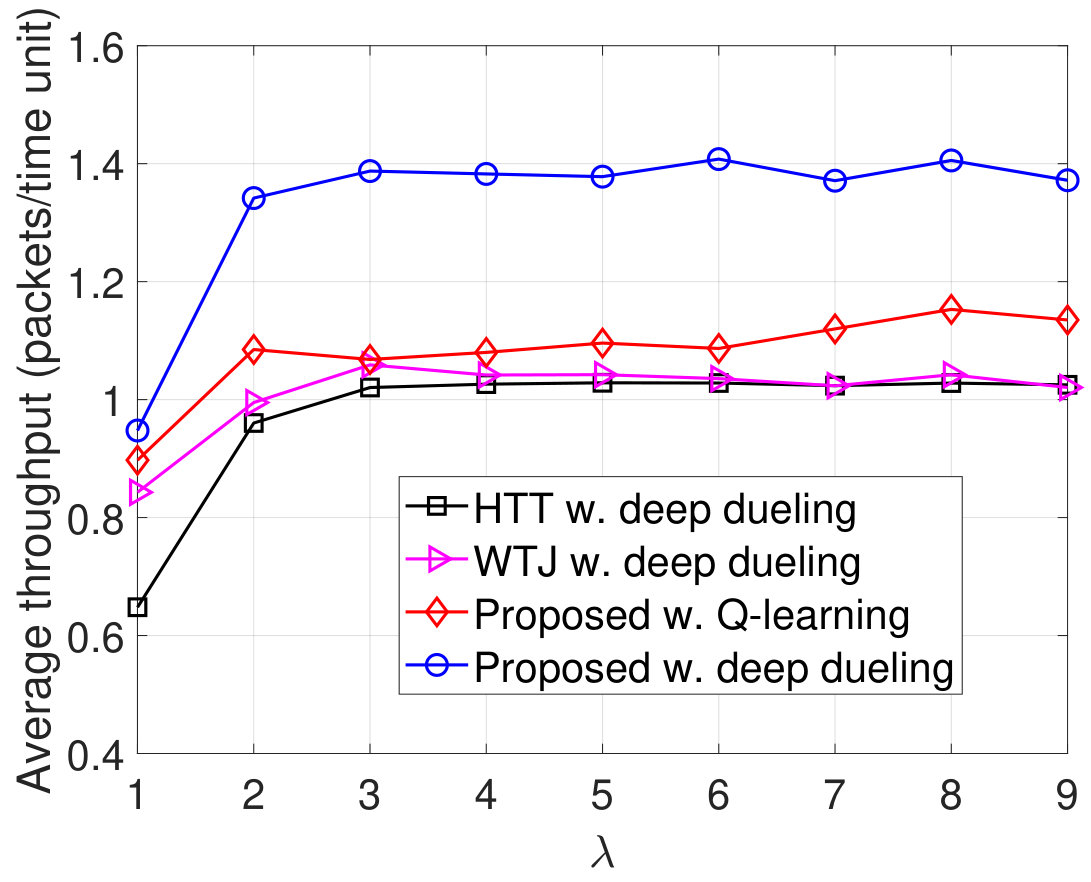 Figure 31
Figure 31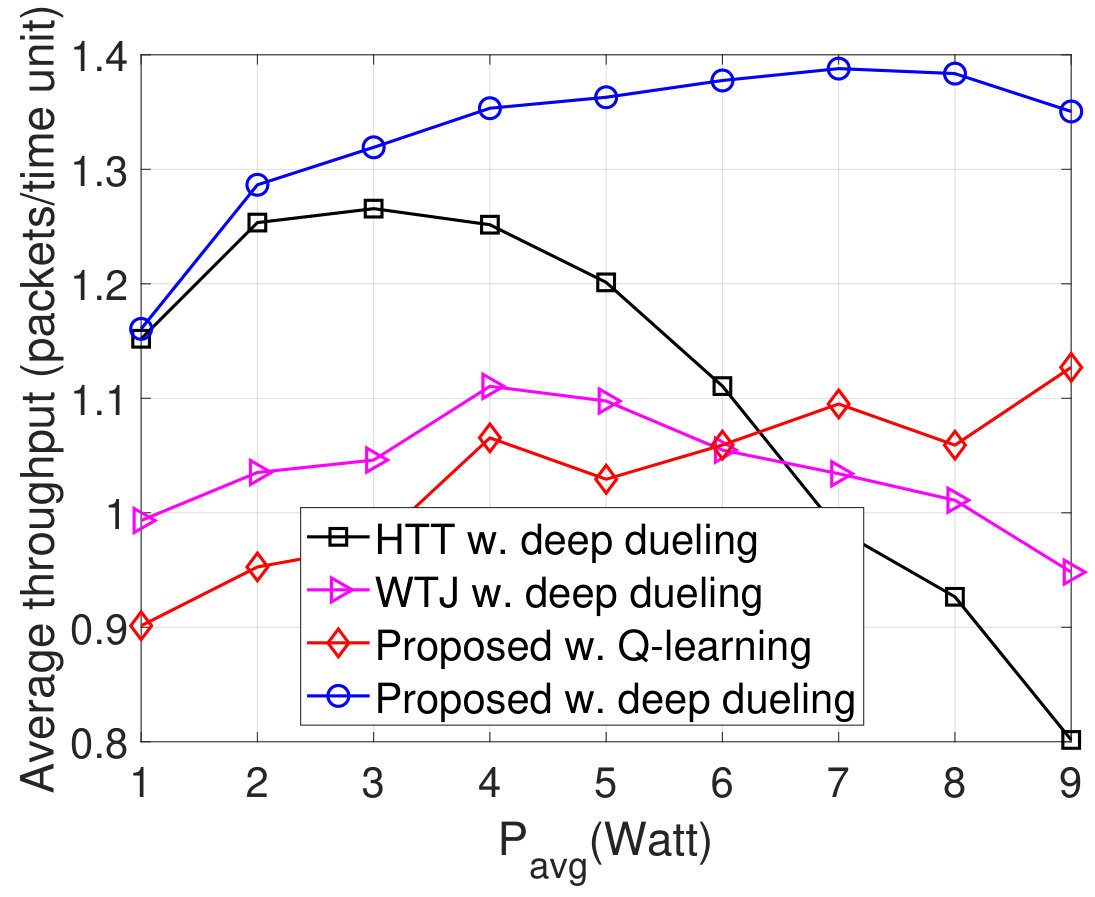 Figure 32
Figure 32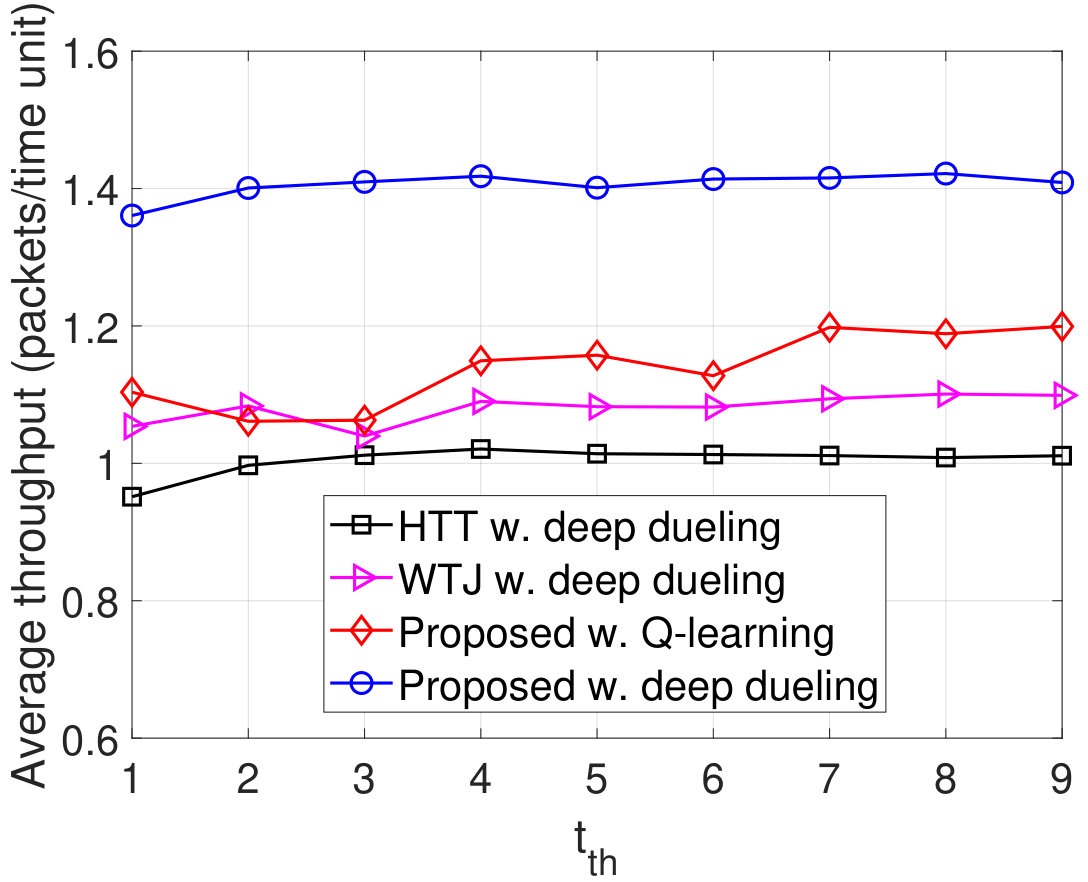 Figure 33
Figure 33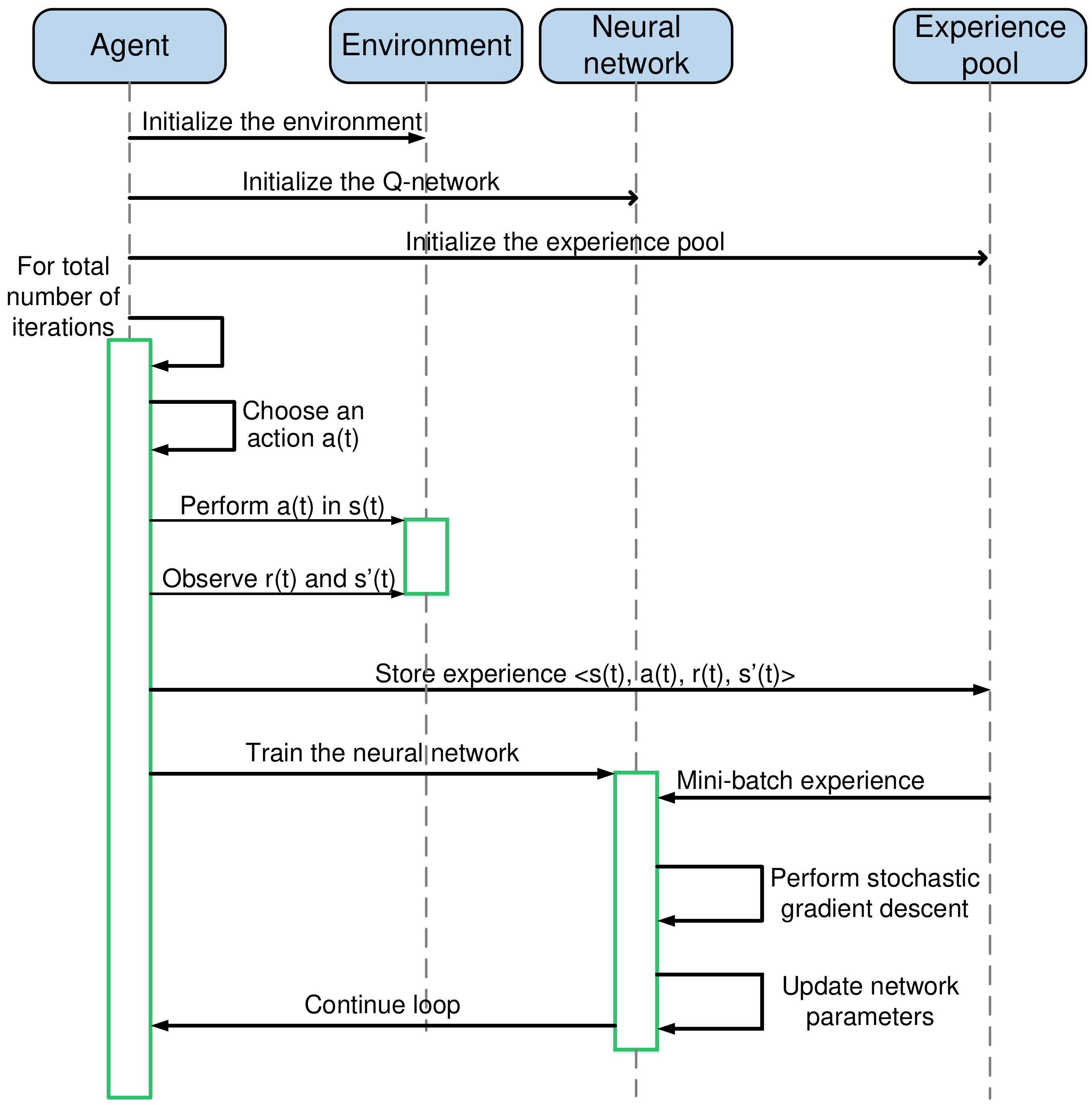 Figure 34
Figure 34Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
MethodsQ-Learning
“Jam Me If You Can”: Defeating Jammer with Deep Dueling Neural Network Architecture and Ambient Backscattering Augmented Communications
Nguyen Van Huynh, Diep N. Nguyen, Dinh Thai Hoang, and Eryk Dutkiewicz Nguyen Van Huynh, Diep N. Nguyen, Dinh Thai Hoang, and Eryk Dutkiewicz are with University of Technology Sydney, Australia. E-mails: [email protected], {Hoang.Dinh, Diep.Nguyen, and Eryk.Dutkiewicz}@uts.edu.au.The authors contributed equally to this work.
Abstract
With conventional anti-jamming solutions like frequency hopping or spread spectrum, legitimate transceivers often tend to “escape” or “hide” themselves from jammers. These reactive anti-jamming approaches are constrained by the lack of timely knowledge of jamming attacks (especially from smart jammers). Bringing together the latest advances in neural network architectures and ambient backscattering communications, this work allows wireless nodes to effectively “face” the jammer (instead of escaping) by first learning its jamming strategy, then adapting the rate or transmitting information right on the jamming signal (i.e., backscattering modulated information on the jamming signal). Specifically, to deal with unknown jamming attacks (e.g., jamming strategies, jamming power levels, and jamming capability), existing work often relies on reinforcement learning algorithms, e.g., Q-learning. However, the Q-learning algorithm is notorious for its slow convergence to the optimal policy, especially when the system state and action spaces are large. This makes the Q-learning algorithm pragmatically inapplicable. To overcome this problem, we design a novel deep reinforcement learning algorithm using the recent dueling neural network architecture. Our proposed algorithm allows the transmitter to effectively learn about the jammer and attain the optimal countermeasures (e.g., adapt the transmission rate or backscatter or harvest energy or stay idle) thousand times faster than that of the conventional Q-learning algorithm. Through extensive simulation results, we show that our design (using ambient backscattering and the deep dueling neural network architecture) can improve the average throughput (under smart and reactive jamming attacks) by up to 426% and reduce the packet loss by 24%. By augmenting the ambient backscattering capability on devices and using our algorithm, it is interesting to observe that the (successful) transmission rate increases with the jamming power. Our proposed solution can find its applications in both civil (e.g., ultra-reliable and low-latency communications or URLLC) and military scenarios (to combat both inadvertent and deliberate jamming).
Index Terms:
Anti-jamming, ambient backscatter, AI-powered rate adaptation, RF energy harvesting, deep dueling, deep neural networks, deep reinforcement learning, Q-learning.
I Introduction
Due to its broadcast nature, wireless communications are particularly vulnerable to jamming attacks, especially in low-power wireless networks. By injecting interference to the wireless communication channel (i.e., deliberate jamming), a jammer can degrade the effective signal-to-interference-plus-noise ratio (SINR), thereby disrupting or even bringing down legitimate communications links. The jamming attacks can be easily launched by using commercial off-the-shelf products [1, 2] and have a significant detriment to wireless applications, especially for mission-critical systems (e.g., cyber-physical systems in traffic safety, industry automation or military missions). In practice, jamming signals can also come from inadvertent sources, e.g., due to device malfunctioning.
I-A Related Work and Motivation
Anti-jamming has a very rich literature, originating from the early days of wireless communications. With most conventional anti-jamming solutions like frequency hopping or spread spectrum, legitimate transceivers often tend to “escape” or “hide” themselves from jammers. As an example, frequency-hopping spread spectrum (FHSS) [4]-[11] allows a wireless device to quickly switch its operating frequency to other frequency channels. As soon as jammer attacks the channel, the device will quickly change its operating frequency, thereby avoiding the jamming attack. In [4], the authors proposed an integrated bit-level FHSS for low-power wireless communication systems. The key idea of this approach is exploiting the frequency agility of bulk acoustic wave resonators. In [5], the authors proposed a hybrid approach using FHSS and direct sequence spread spectrum (DSSS) to cope with fast-following jammers. Using a stochastic game framework, the authors of [7] studied the strategic interaction between jammers and legitimate users. In particular, the jammer and the transmitter are considered as two players playing with each other to obtain the optimal attack and defense strategies, respectively. Through the minimax-Q learning algorithm, the transmitter can gradually obtain the optimal defense policy, i.e., how to switch between different channels. The simulation results demonstrated that the proposed framework can maximize the spectrum-efficient throughput. Similarly, a game theory based anti-jamming framework for frequency hopping wireless communications was considered in [8]. Nevertheless, these game models require complete information of the jammer, which may not be available in advance in practice. In [9] and [10], the authors adopt the Q-learning and deep Q-learning algorithms that allow the transmitter to choose frequencies to hop when the jammer attacks the channel. In [11], the authors propose a mode-frequency hopping scheme which jointly uses the mode hopping and the traditional FH for anti-jamming in cognitive radio networks. However, the main limitation of the FHSS technique is that it requires extra spectrum resources (for hopping to evade the jammers). In addition, with powerful jammers which can attacks multiple channels simultaneously, FHSS may be less effective.
Besides the FHSS and DSSS techniques, the rate adaptation (RA) technique is also widely adopted, e.g., [12]-[14]. The key idea of the RA technique is to proactively or adaptively account for jamming attacks by operating at a lower transmission rate. In [12], the authors proposed an RA algorithm together with power control to mitigate jamming. Specifically, the algorithm consists of two modules: (i) a rate module for rate adaptation and (ii) a power control module for controlling the transmit power at legitimate transmitters. The experimental results demonstrated that the proposed algorithm can improve the network throughput by 150% under jamming attacks. However, in [13], the authors revealed that the RA technique is not effective on a single channel. In [14], the authors investigated the performance of several state-of-the-art RA algorithms under different scenarios. The experimental results demonstrated that the existing RA algorithms are not effective to combat smart jamming attacks. Similar to the RA method, legitimate transmitters can also adapt (i.e., bump/push) their transmit power or beamforming vectors/matrices (to improve the effective SINR) to overcome or reject the effect of excessive interference. Nevertheless, this solution is either power-inefficient or not viable for low-power or hardware-constrained devices (e.g., in IoT applications).
In [1], the authors proposed a joint RA and FHSS technique to mitigate attacks from a reactive-sweep jammer. In particular, the jammer can sweep through a set of channels and sense the activities of legitimate transmitters to attack. To combat the jammer, the legitimate transmitters can either hop to a new channel and/or adapt their transmission rates. The authors modeled the system as a zero-sum Markov game and obtained the optimal policies for the transmitters by solving a constrained Nash equilibrium problem. Similar to [7, 8], this work also assumed complete information of the jammer in deriving the defense strategy. Another widely adopted approach in the literature is to use the ultra-wideband communications to hide the legitimate signals [3] in the noise.
It is worth noting that, to allow the transmitters to effectively escape or hide from the jammer, most aforementioned solutions require additional resources (in spectrum bandwidth, or transmit power, or hardware capability). This fact limits the practical applications of these conventional methods, especially for low-power and/or low-cost communications systems (e.g., in IoT). In this paper, we present a novel anti-jamming framework for these low-power and/or wireless-power communications devices. Such a framework allows these wireless transceivers to not only survive jamming attacks without requiring additional resources but also leverage the jamming signal to improve their transmission rate. To that end, we first observe that most existing anti-jamming solutions are reactive ones that are constrained by the lack of timely knowledge of jamming attacks (especially from smart jammers). Bringing together the latest advances in neural network architectures and ambient backscattering communications, this work allows wireless nodes to effectively “face” the jammer (instead of escaping) by first learning its jamming strategy, then adapting the rate and transmitting information right on the jamming signal (i.e., backscattering modulated information on the jamming signal). In our design, transmitters are augmented with an ambient backscattering communication circuit [16, 17] and an energy harvester. When a jammer attacks the communication channel, the transmitter can leverage the jamming signal to backscatter information to the gateway or harvest energy from the jamming signal.
Our key idea is inspired by the latest advances in ambient backscattering communications (ABC) and RF energy harvesting. An ABC-capable transceiver can modulate/backscatter the RF ambient signals (e.g., FM, AM radio signals) to transmit its own information. Interested readers of ABC are referred to [16], [17] and therein references. Note that ABC, by contrast to bistatic backscattering communications, does not require a dedicated RF signal source. Specifically, in bistatic backscattering communications, e.g., [19], [41], [42], [43], backscatter devices transmit information by backscattering the RF signals generated by a dedicated RF source which is controllable. With the recent development of RF energy harvesting, the transmitter can harvest energy from RF signals with a high efficiency. In particular, in [33], [34], and [35], the authors propose novel designs for the rectenna, i.e., rectifier and antenna, and RF-DC converter to improve the amount of harvested RF energy from RF energy sources. The experimental results demonstrate that with the proposed rectenna, a tag can harvest RF energy and convert the harvested energy to DC with 70% efficiency under a wide range of input power. In [36], low power circuit designs for the voltage regulator and resistor to digital converter are also proposed. Differently, in [37] and [38], the authors aim to maximize the amount of harvested energy by considering the joint information and energy cooperative problem with channel constraints.
To deal with the uncertainty (or unknowns) of jamming attacks and ambient RF signals, existing work often relies on reinforcement learning algorithms, e.g,. Q-learning under the framework of a Markov decision process (MDP). However, the Q-learning algorithm is notorious for its slow convergence to the optimal policy, especially when the system state and action spaces are large. This makes the Q-learning algorithm pragmatically inapplicable. To overcome this problem, we design a novel deep reinforcement learning algorithm using a new dueling neural network architecture. Our proposed algorithm allows the transmitter to effectively learn about the jammer and attain the optimal countermeasures (e.g., adapt the transmission rate or backscatter or harvest energy or stay idle) thousand times faster than that of the conventional Q-learning algorithm. The transmitters not only successfully defeat jamming attacks, but also leverage jamming signal to significantly improve the performance for the system. Specifically, extensive simulation results show that our design (using ambient backscattering and the deep dueling neural network architecture) can improve the average throughput (under smart and reactive jamming attacks) by up to 426% and reduce the packet loss by 24%. By augmenting the ambient backscattering capability on devices and using our algorithm, it is interesting to observe that the (successful) transmission rate increases with the jamming power.
I-B Main Contributions
The major contributions of this paper can be summarized as follows.
- •
We propose a novel smart anti-jamming design using ambient backscatter, energy harvesting, and rate adaption techniques to defeat smart and reactive jammers. Based on this method, when a jammer attacks the channel, the transmitter can leverage jamming signal to transmit information using the ambient backscattering communication technique or harvest energy from the jamming signal. Alternatively, the transmitter can also choose to adapt the transmission rate to actively111It refers to the conventional radio transmission that is different from the ambient backscattering transmission. transmit data.
- •
To lay a theoretical foundation for our design, we develop a dynamic approach using the MDP framework and Q- and deep Q-learning algorithms to maximize the average long-term throughput for systems under the uncertainty of jamming attacks and ambient RF signals. Unlike existing rate adaption methods that require the explicit or implicit knowledge of the interference/jamming level, our reinforcement learning-based rate adaptation framework does not require such information. It is also worth emphasizing that such a rate adaptation method is not susceptible/subject to the imperfect estimation/observations of the jamming signal (e.g., misdetection or false alarms).
- •
To provide a practical solution for the theoretical Q-learning based approach above, we design a deep dueling neural network architecture which allows the system to quickly approach to the optimal defend policy. The key idea of this approach is implementing two streams of fully-connected hidden layers to separately and concurrently estimate the values of states and advantages of actions. As a result, the proposed deep dueling algorithm converges thousands times faster than Q-learning based algorithms.
- •
Finally, we perform extensive simulations with the aims of not only demonstrating the efficiency of proposed solutions in comparison with other conventional methods, but also providing insightful analytical results for the implementation of our framework.
The rest of paper is organized as follows. Section II and Section III describe the system model and the problem formulation, respectively. Section IV presents the Q-learning and deep Q-learning algorithms. Then, the deep dueling algorithm is presented in Section V. After that, the evaluation results are discussed in Section VI. Finally, conclusions are drawn in Section VII.
II System Model
We consider a wireless system considering of a gateway and a transmitter as illustrated in Fig. 1. The transmitter is equipped with a data buffer to store data before transmitting to the gateway. In addition, we assume that the transmitter is equipped with an energy harvesting circuit and an energy storage. The energy harvesting circuit is used to harvest energy from surrounding signals, and then the harvested energy will be stored in the energy storage for future use. We consider an ambient RF source, e.g., an FM radio tower, that is located near the system, and thus the transmitter can harvest energy from the RF energy source when the source is active, i.e., broadcasts signals. Then, the transmitter can use the harvested energy to transmit data to the gateway when the RF energy source becomes idle. This transmission scheme is also known as the harvest-then-transmit protocol that is well known in the literature [17].
II-A Smart and Reactive Jammer with Self-Interference Suppression Capability
We consider a222Note that our system model can be extended straightforwardly to the case with multiple jammers who perform attacks to the channel cooperatively, i.e., only one jammer attacks the channel at a time. smart and reactive jammer with self-interference suppression (SiS) capability. With the latest advances in SiS [7], the jammer can “listen” to the channel while jamming. That allows the jammer to instantaneously discern its jamming outcome and reactively optimize its jamming strategy to maximize the disruption of the victims. The SINR at the gateway is formally calculated as follows [1], [13]:
[TABLE]
where is the received power from the transmitter at the gateway, is the jamming power transmitted by the jammer, is the variance of additive white Gaussian noise, and expresses the jamming power received at the gateway in which is an attenuation factor.
In practice, the jammer can adjust its pulse duty cycle factor to achieve the maximum degradation on the target channel while maintaining a time-average power constraint . Note that the average power should be less than the peak jamming power , i.e., [13]. Specifically, let denote the vector of discrete jamming power levels. In each time slot, the jammer can select any transmit power level as long as its the average power constraint is satisfied. If we denote as a probability vector, then the strategy space of the jammer, denoted by , can be defined as follows:
[TABLE]
To find the defense policy in the worst case, as mentioned above, we consider a smart jammer that would know the information of the transmitter, e.g., how many packets the transmitter can transmit/backscatter and how many packets it can bring down if the jamming is successful (thanks to the SiS capability). In such a case, based on this information and its given average power constraint , the jammer will find an optimal strategy to attack the channel in order to maximize the disruption. In particular, we assume that the jammer receives a reward if it attacks the channel with power level . can be referred as the number of packets that have been completely corrupted (i.e., not being successfully received/decoded, hence not ACKed by the receiver) if the jamming power is . Let denote the reward vector of the jammer. Thus, the objective function of the jammer can be defined as follows:
[TABLE]
Note that the ambient RF signal is an external source that is out of control of the jammer and the transmitter and also not impacted by neither the jammer or the node. Additionally, in this paper, we consider the case in which the transmitter operates as a secondary user that only actively transmits data when the ambient RF source is inactive. As such, Eq. (1) does not need to account for the ambient RF signals. Note that our analysis is also applicable for general cases in which both the ambient RF source and the transmitter are licensed devices operating on different licensed frequencies.
II-B Ambient Backscattering-Augmented Communications
To defeat the above smart and reactive jamming attack, we propose a novel communications scheme, namely “ambient backscatter-augmented communications”. Our high-level circuit architecture is shown in Fig. 2.
In Fig. 2(a), we show the proposed circuit diagram that allows the transmitter to be able to harvest energy, perform active RF transmission, and backscatter information. The circuit design for the integration of energy harvesting and backscattering communication has also been considered in several research works in the literature such as [16] and [18]. The architecture of transmitter consists of an antenna, a controller, an energy harvester, an RF transmitter for active transmissions, an energy storage, a data buffer, and a load modulator together with a backscatter decoder for ambient backscatter communications. The controller takes responsibilities to make decisions, e.g., stay idle, transmit data, backscatter data, and harvest energy, for the transmitter. When the ambient RF source is active and/or the jammer attacks the channel, if the transmitter chooses to harvest energy, it will use the energy harvester to harvest energy from the ambient signal or the jamming signal. The harvested energy is then stored in the energy storage and used when the transmitter decides to actively transmit data to the gateway. In contrast, if the transmitter chooses to backscatter to immediately transmit data to the gateway, the transmitter will modulate and reflect the ambient RF signal or the jamming signal by using the load modulator [16]. In particular, the load modulator consists of an RF switch, e.g., ADG902, directly connected to the antenna. The input of the load modulator is a stream of one and zero bits which is generated by the controller depending on the application. When the input bit is zero, the load modulator switches to load , and thus the transmitter is in the non-reflecting state. Otherwise, when the input bit is one, the load modulator turns to load , and thus the transmitter is in the reflecting state. By doing so, the transmitter can backscatter its data to the gateway. It is worth noting that while operating in the backscatter mode, the transmitter still can harvest energy (in the non-reflecting state), but the amount of the harvested energy is relatively small and only suitable for operations in the backscatter mode [16], [17].
To allow the gateway to decode backscattered signals, the transmitter backscatters information at a lower rate than the ambient signal, i.e., jamming signal and ambient signal. For completeness, we formally describe the principle as follows. Assuming that we have a digital receiver that samples the received signal at the Nyquist-information rate, e.g., using ADC [16]. The received signal at the gateway is sampled to as:
[TABLE]
where s are the samples of the ambient signal (i.e., the jamming signal, the ambient RF signal, or both of them) received at the gateway, is the noise, is the complex attenuation of the backscattered signal, and s are the bits transmitted by the transmitter (through the load modulator). If the transmitter sends information at a fraction of the rate, say , then are all equal for to [16]. Then, the gateway averages powers of received samples as follows:
[TABLE]
where takes a value of ‘0’ or ‘1’ depending on the non-reflecting and reflecting states, respectively. As is uncorrelated with the noise , (5) can be expressed as follows:
[TABLE]
Denote as the average power of the received jamming signal (or ambient signal). Ignoring the noise, the average power at the receiver is and when the backscatter transmitter is at the reflecting () state and the non-reflecting () state, respectively. Based on the differences between and , the backscatter receiver can decode the data from the backscattered signal with a conventional digital receiver [16].
However, the ADC consumes a significantly amount of power to sample the received signal. For a low-power design, in Fig. 2(b), we describe a circuit diagram using only analog components to decode the backscattered signal. In particular, the gateway is equipped with an antenna to receive information (either active transmission or backscatter information) from the transmitter. Based on the received signal, the gateway will decide to use a suitable mode to decode information from the transmitter. In particular, the active RF decoder is used to decode active transmission signal from the transmitter. If the transmitter transmits data by using the backscatter mode, the gateway will use the backscatter decoder to extract the information from the backscattered signal. Specifically, at the backscatter decoder, the backscattered signal is first smoothed by the envelope-averaging circuit. After that, the compute-threshold circuit produces an output voltage between low and high levels of the smoothed signal. Then, the comparator compares the signal with a predefined threshold to derive output bits zero and one properly. The more detailed information about hardware designs as well as decoding algorithms at the receiver can be found in [16].
Note that although we consider a single transmitter in this paper, the proposed model and analysis can be extended to the case with multiple transmitters. In such a case, one can adopt popular scheduling mechanisms, e.g., TDMA, to avoid the collision between transmitters. Another approach is that transmitters backscatter data at different rates [16], [17]. In this way, the gateway can decode the information in the backscattered signal by leveraging the difference in communication rates.
II-C System Operation
We denote the probability of the ambient RF source being idle in each time slot by . Due to the constraints on average power and maximum transmit power , the jammer may attack the channel with different power levels at different time. When the jammer attacks the channel and the ambient RF source is idle, the transmitter can choose one of the following actions (i) go to sleep mode, i.e., stay idle, (ii) harvest energy from the jamming signal, (iii) backscatter information based on the jamming signal, or (iv) adapt its transmission rate by using rate adaption (RA) techniques [1, 13]. Depending on the transmit power level of the jammer, the transmitter can harvest units of energy and backscatter maximum packets through the jamming signal. In practice, the more power the jammer uses to attack the channel, the more energy the transmitter can successfully harvest from the jamming signal 333Based on the Friis equation [15], we also can obverse the proportional relationship between the amount of harvested energy and the transmission power of energy source, i.e., the jammer.. In addition, through many real experiments and analysis on backscatter communication systems in the literature [16, 18, 19], it can be observed that the more power the jammer uses to attack the channel, the more energy per information bit the transmitter can backscatter to the gateway, and thus the less Bit Error Rate (BER) of backscatter communication is. This also implies that the more packets the transmitter can successfully transmit to the gateway by backscattering the jamming signal when the jammer uses higher power levels to attack. We denote as the amount of energy that the transmitter can successfully harvest from the jamming signal when the jammer attacks the channel with power level , respectively. Similarly we denote as the number of packets that the transmitter can successfully transmit to the gateway when the jammer attacks the channel with power level , respectively.
In practice, when the jammer attacks the channel and the ambient RF source does not transmit data, the transmitter still can transmit its data by reducing its data rate. Specifically, based on jamming power , the transmitter can actively transmit data at maximum rate . We then denote as the set of available transmission rates that the transmitter can choose to transmit data when the jammer attacks the channel. At each rate , the transmitter can transmit maximum packets. Note that, for , when with is the value of SINR, the gateway only can decode packets sent at rates , and the packets sent at rate or higher will be completely lost [1]. To detect the states of the ambient RF source and the jammer, several detection techniques can be adopted, e.g., energy detection [44], [45]. Note that there are miss detection and false alarm probabilities when detecting the states of channels. However, our proposed algorithm can learn these probabilities and dynamically adjust its optimal policy.
In this work, we define the packet delivery ratio (PDR) as the ratio of packets that are successfully delivered to the gateway over the total number of packets arriving at the system. The arrival data process follows the Poisson distribution with mean rate . The maximum data queue size and energy storage capacity are denoted by and , respectively. If a packet arrives at the system when the data queue is full, it will be dropped. To consider a low-latency system, if a packet stays in the queue longer than a latency threshold, i.e., , it will be discarded.
If at least one of the sources (i.e., either the ambient RF source, or the jammer, or both of them) is active, the transmitter can choose to backscatter data or harvest energy. The transmitter then observes the results of the taken action, i.e., the total number of packet backscattered or the total amount of harvested energy, and update the learning function. Based on the states of the ambient RF source and the jammer, the operations of our system can be expressed as follows:
- •
When the ambient RF source is idle and the jammer does not attack the channel: the transmitter can (i) transmit maximum packets if it has enough energy (each packet requires units of energy to be successfully transmitted) or (ii) stay idle.
- •
When the ambient RF source is idle and the jammer attacks the channel with power level : the transmitter can (i) use the RA technique to transmit maximum packets if it has enough energy, (ii) backscatter maximum packets, (iii) harvest units of energy, or (iv) stay idle.
- •
When the ambient RF source is active and the jammer does not attack the channel: the transmitter can choose to (i) backscatter maximum packets, (ii) harvest units of energy, or (iii) stay idle.
- •
When the ambient RF source is active and the jammer attacks the channel with the power level : the transmitter can choose to (i) backscatter packets with where and 444The backscatter rate when both sources are active, , should be in between the minimum of the backscatter rates of individual sources and the summation of them. In general, we assume that is unknown and captured by a random variable with a given distribution in the above range., (ii) harvest units of energy with where and [32]555The harvested energy when both sources are active, , should be in between the maximum of the energy harvested from each individual source and the summation of them. In general, we assume that is unknown and captured by a random variable with a given distribution in the above range., or (iii) stay idle.
In this paper, time is slotted. In each time slot, given a particular channel condition and states of the ambient RF source and the jammer, the amount of harvested energy and the number of backscattered/transmitted packets, i.e., , , , , , , , , can be observed after interacting with the environment. Our proposed deep dueling algorithm does not require this explicit information in advance. Instead, the algorithm learn these values and converge to the optimal policy for the transmitter.
III Problem Formulation
To deal with the uncertainty of jamming attacks and ambient RF signal, we adopt the Markov decision process (MDP) framework to formulate the optimization problem of the system. This framework allows the transmitter to dynamically make optimal actions based on its observations to maximize its average long-term reward. The MDP is defined by a tuple where is the state space, is the action space, and is the immediate reward of the system.
III-A State Space
We define the state space of the system as follows:
[TABLE]
where represents the state of the ambient RF channel, i.e., when the ambient RF channel is busy and otherwise. represents the state of the jammer, i.e., when the jammer is active and otherwise. and represent the number of packets in the data queue and the energy units in the energy storage of the transmitter, respectively. and are the maximum data queue size and energy storage capacity, respectively. The system state is then defined as a composite variable .
III-B Action Space
The transmitter can perform one of the actions, i.e., stay idle, actively transmit data, harvest energy from the ambient signals, backscatter data from the ambient signals, harvest energy from the jamming signals, backscatter data from the jamming signals, or actively transmit data when then channel is attacked with one of transmission rates by using the RA technique. Then, the action space of the transmitter can be defined by , where
[TABLE]
III-C Immediate Reward
We define the reward for the system as the number of packets that are successfully transmitted to the gateway. Thus, the immediate reward of the system after the transmitter makes an action at state can be defined as follows:
[TABLE]
In the above, when the ambient RF source is idle, the jammer does not attack the channel, and the number of data and energy units are sufficient for active transmission, the transmitter can actively transmit packets to the gateway (i.e, ). When the ambient RF source is active, the jammer is idle, and the transmitter has data to transmit, it can choose to backscatter packets(i.e., ). Similarly, when the jammer attacks the channel, the RF source is idle, and the transmitter has data to transmit, if it choose to backscatter, it can transmit maximum packets(i.e., ). If the ambient RF source is idle, the jammer attacks the channel, and the transmitter has enough energy and data in the queues, it can choose to adapt its rate (i.e., ) and actively transmit packets to the gateway. If both the jammer and the RF source are active, and the transmitter has data to transmit, if it choose to backscatter data, it can transmit to the gate way [32]. Finally, the immediate reward is equal to [math] if the transmitter cannot successfully transmit any packet to the gateway.
Note that after performing an action, the transmitter will observe the results from the environment including reward, i.e., number of packets that are successfully transmitted based on ACK messages sent from the gateway. In other words, , , , , and are the actually received packet at the gateway, i.e., successfully-ACKed packets. For that, the reward function captures the overall path between the source and the tag-receiver, e.g., fading, end-to-end SNR, BER, or the packet error rate.
III-D Optimization Formulation
We formulate an optimization problem to obtain the optimal policy, denoted by , that maximizes the average long-term reward for the system. Specifically, the optimal policy is a mapping from a state to an action taken by the transmitter. In other words, given the current system state, i.e., data queue, energy level, and channel states, the policy determines an optimal action to maximize the average long-term reward for the system. The optimization problem is then expressed as follows:
[TABLE]
where is the average reward of the transmitter under the policy and is the immediate reward under policy at time step . Clearly, the state space contains only one communicating class, i.e., from a given state the process can go to any other states after steps. In other words, the MDP with states in is irreducible. Thus, for every , the average throughput is well defined and does not depend on the initial state [20].
IV Learning about Jammer and Its Strategies with Reinforcement Learning Approaches
IV-A Q-Learning Approach
In the system under consideration, the transmitter cannot obtain the information about the jammer, e.g., jamming capacity, as well as the ambient RF signal, e.g., channel operation frequency, in advance to find the optimal policy. Thus, this section introduces Q-learning [21], a reinforcement learning algorithm, which can help the transmitter find the optimal policy without requiring prior information about the jammer as well as the channel. In particular, as illustrated in Fig. 3, the Q-learning algorithm implements a Q-table to store state-action pair values. Given a current state, the algorithm will select an action based on its current strategy. After performing the selected action, the Q-learning algorithm observes the immediate reward and next state, and updates the Q-values based on the Q-value function. In this way, the Q-learning algorithm can learn from its decisions, and it was proved that the Q-learning algorithm will converge to the optimal policy after a finite number of iterations [21].
In this paper, we aim to find the optimal policy , i.e., a mapping from states to their corresponding actions, for the transmitter to optimize its performance, i.e., maximize its long-term average throughput and minimize its packet loss, under the jamming attacks. Let’s denote as the expected value function obtained by policy from a state , that can be defined as follows:
[TABLE]
where is the discount factor which represents the importance of long-term reward [21]. Specifically, if is close to 0, the algorithm is likely to select actions to maximize its short-term reward. In contrast, when is close to 1, the algorithm will make actions such that its long-term reward is maximized. is the immediate reward achieved after performing action at state . To find the optimal policy , at each state, an optimal action has to be found through the following optimal value function.
[TABLE]
For all state-action pairs, the optimal Q-functions are denoted by:
[TABLE]
Then, the optimal value function can be written as By making samples iteratively, the problem is reduced to determining the optimal value of Q-function, i.e., , for all state-action pairs. In particular, the Q-function is updated according to (14).
[TABLE]
In particular, (14) is used to find the temporal difference between the predicted Q-value, i.e., and its current value, i.e., . The learning rate determines the impact of new information to the existing value. During the learning process, the learning rate can be adjusted dynamically, or it can be chosen to be a constant. However, to guarantee the convergence for the Q-learning algorithm, the learning rate is deterministic, nonnegative, and satisfies the following conditions [21]:
[TABLE]
The details of the Q-learning algorithm is provided in Algorithm 1. Specifically, from the current state , the algorithm will choose an action and observe results after performing this action. In practice, to select action , -greedy algorithm [22] is often adopted. In particular, this technique chooses a random action with probability , and selects an action that maximizes the with probability . After performing the chosen action, the Q-learning algorithm observes the next state and reward, and then updates the table entry for based on Eq. (14). When all -values converge or a certain number of iterations is reached, the learning process will be terminated. The Q-learning algorithm yields the optimal policy indicating an action to be taken at each state such that is maximized for all states in the state space, i.e., . Under the conditions of stated in Eq. (15), in Theorem 1, we show that the Q-learning algorithm will converge to the optimum action-values with probability one.
Theorem** 1****.**
Under the conditions of in Eq. (15), the Q-learning algorithm converges to the optimum action-values with probability one.
The proof of Theorem 1 is provided in Appendix A. It is worth noting that the Q-learning algorithm can converge to the optimal policy in a reasonable time when the state space and the action space are small. Nonetheless, for a complicated system with thousands of state-action pairs, the convergence rate of the Q-learning algorithm is usually slow. That makes the Q-learning algorithm practically inapplicable [23], especially for our considered system model which needs to learn activities from both the jammer and ambient RF source. Thus, in the following, we introduce deep Q-learning and deep dueling algorithms to quickly obtain the optimal defend policy for the transmitter, thereby effectively defeating the jamming attacks and optimizing performance for the system.
IV-B Deep Q-Learning based Adaptation
In this section, we propose the deep Q-learning algorithm [24] to cope with the low-convergence problem of the Q-learning algorithm introduced in Section IV. Intuitively, the deep Q-learning algorithm was introduced by Google DeepMind in 2015 [24] to teach machines to play games without human intervention. The deep Q-learning algorithm implements a deep neural network instead of the Q-table to find the approximated values of as illustrated in Fig. 4.
According to [24], the performance of reinforcement learning approaches might not be stable or even diverges when using a nonlinear function approximator. The reason is that with a small change of Q-values, the data distribution and correlations between the Q-values and the target values, i.e., , are varied, and thus the policy is greatly affected. To address this issue, we use three mechanisms, i.e., experience replay, target Q-network, and feature set.
- •
Experience replay mechanism: The algorithm implements a replay memory , i.e., memory pool, to store transitions instead of running on state-action pairs as they occur during experience. Random samples from the memory pool are then fed to the deep neural network for training. In this way, the algorithm can efficiently learn from previous experiences many times and remove the correlations between observations [24].
- •
Target Q-network: Obviously, the Q-values will be changed during the training process. As a result, the value estimations can be out of control if a constantly shifting set of values is used to update the Q-network resulting in the destabilization of the algorithm. To overcome this issue, the deep Q-learning algorithm implements a target Q-network to frequently but slowly update to the primary Q-network. As such, the correlations between the target and estimated Q-values are significantly eliminated, thereby stabilizing the algorithm.
- •
*Feature set: * For each state, we determine four features including the activities of the jammer and the ambient RF source, i.e., active or idle, as well as the status of data and energy queues of the transmitter. These features are then fed to the deep neural network to approximate Q-values for each state-action pair. Doing so, all aspects of each state are trained resulting in a high convergence rate.
Algorithm 2 provides the details of the deep Q-learning algorithm. In particular, as shown in Fig. 5, the training phase consists of multiple episodes. In each episode, given the current state, the algorithm chooses an action based on the epsilon greedy algorithm. The algorithm will start with a fairly randomized policy and later slowly move to a deterministic policy. In other words, at the first episode, is set at a large value, e.g., 0.9, and gradually decayed to a small value, e.g., 0.1. After that, the algorithm performs the selected action and observes results from taking this action, i.e., next state and reward. This transition is then stored in the replay memory for training process at later episodes.
In the learning process, random samples of transitions from the replay memory will be fed into the neural network. The algorithm then updates the neural network by minimizing the following lost function.
[TABLE]
where is the discount factor, are the parameters of the Q-networks at episode and are the parameters of the target network, i.e., . Differentiating the loss function in (17) with respect to the parameters of the neural networks, we have the following gradient:
[TABLE]
To minimize the loss function in (17), one can use the Stochastic Gradient Descent algorithm [25], which is very important algorithm to power nearly all of deep learning algorithms, to calculate the gradient in (18). In general, the cost function used by a machine learning algorithm is decayed by a sum over training examples of some per-example loss function. For instance, the negative conditional log-likelihood of the training data can be expressed as:
[TABLE]
where is the size of the memory pool. For these additive cost function, gradient descent requires computing as follows:
[TABLE]
The computational cost for the operation in Eq. (20) is . Thus, as the size of the replay memory is increased, the time to take a single gradient step becomes prohibitively long. As a result, in this paper, we adopt the stochastic gradient descent technique. The key idea of using stochastic gradient descent is that the gradient is an expectation. Clearly, the expectation can be approximately estimated by using a small set of samples. In particular, we can uniformly sample a mini-batch of experiences from the replay memory at each step of the algorithm. In general, the mini-batch size can be set to be relative small number of experiences, e.g., from one to a few hundred. As such, the training time is significantly fast. The estimate of the gradient under the stochastic gradient descent is then formulated as follows:
[TABLE]
where is the mini-batch size. The stochastic gradient descent algorithm then follows the estimated gradient downhill as in Eq. (22).
[TABLE]
where is the learning rate of the algorithm.
After every steps, the algorithm updates the target network parameters with the Q-network parameters . The target network parameters remain unchanged between individual updates. Fig. 5 shows the flowchart of the deep Q-learning algorithm.
V Fighting Jammer with Deep Dueling Neural Network Architecture
V-A Deep Dueling Neural Network Architecture
According to [26], the convergence rate of the deep Q-learning algorithm is still limited due to the overestimation of optimizers, especially in systems with large action and state spaces as considered in this work. Therefore, we propose deep dueling algorithm [26], which was also originally developed by Google DeepMind in 2016, to further improve the system’s convergence speed. The key idea making the deep dueling superior to conventional approaches is its novel neural network architecture. Clearly, in many states, it is unnecessary to estimate the value of corresponding actions as the choice of these actions has no repercussion on what happens [26]. For example, the rate adaptation actions only matter when the jammer attacks the channels with low power levels. Hence, instead of estimating the action-value function, i.e., Q-function, the algorithm divides the deep neural network into two sequences, i.e., streams, of fully connected layers to separately estimate the values of states and advantages of actions666The value function represents how good it is for the system to be in a given state. The advantage function is used to measure the importance of a certain action compared with others [26].. The values and advantages are then combined at the output layer as shown in Fig. 6. In this way, the deep dueling algorithm can achieve more robust estimates of state value, and thus significantly improving its convergence rate as well as stability. It is worth noting that the flowchart of the deep dueling algorithm is the same as in the deep Q-learning. The main difference between the deep dueling algorithm and other conventional deep reinforcement learning algorithms is the deep dueling neural network. In the following, we present details of separating the Q-value into the value and the advantage functions.
Recall that given a stochastic policy , the values of state-action pair and state are as follows:
[TABLE]
The advantage function of actions can be expressed as:
[TABLE]
Specifically, the value function corresponds to how good it is to be in a particular state [26]. The state-action pair, i.e., Q-function, calculate the value of performing action in state . The advantage function decouples the state value from the Q-function to measure the importance of each action.
To estimate values of and functions, we use a dueling neural network in which one stream of fully-connected layers outputs a scalar and the other stream estimates an -dimensional vector , where and are the parameters of fully-connected layers. These two sequences are then combined at the output layer to obtain the Q-function by Eq. (25).
[TABLE]
Note that Eq. (25) applies to all instances. Thus, to express equation (25) in matrix form, one needs to replicate the scalar, , times. Importantly, is a parameterized estimate of the true Q-function, and given , we cannot obtain and uniquely. In other words, adding a constant to and subtracting the same constant from result in the same Q-value. Therefore, Eq. (25) is unidentifiable resulting in poor performance. To address this problem, the combining module of the network is implemented the following mapping:
[TABLE]
In this way, the advantage function estimator has zero advantage when choosing action. Intuitively, given , we have . Therefore, we can convert (26) into a simple form by replacing the max operator with an average as follows:
[TABLE]
Note that subtracting the mean in Eq. (27) solves the unidentifiable problem. However, it does not change the relative rank of the advantage function values, and hence the values for actions at each state.
Based on Eq. (27) and the advantages of the deep reinforcement learning, we propose the deep dueling algorithm as shown in Algorithm 3. It is worth noting that Eq. (27) is viewed and implemented as a part of the network and not as a separated algorithmic step [26]. In addition, and are estimated automatically without any extra supervision or modifications in the algorithm.
V-B Complexity Analysis and Implementation
Deep reinforcement learning (and deep learning in general) is well known for solving complicated and intractable problems with much higher performance compared to conventional methods. However, it typically requires many CPU and GPU resources, especially for large-scale and complex problems which require more hidden layers. To implement deep learning in resource-constrained IoT devices, several solutions have been proposed in the literature [30]. In [31], the authors proposed a novel method, called network compression, to convert a densely connected neural network into a sparsely connected network. In this way, the storage and computation load can be reduced by a factor of 10. The authors show that the network compression can allow deep learning algorithm to be implemented on commonly used IoT platforms from Qualcomm, Intel, and NVidia. Other approaches to reducing computational load such as approximate computing and deploy specialized accelerator hardware also make deep learning suitable to run on the transmitter [30]. Note that our proposed deep dueling algorithm only uses a simple deep neural network architecture with only one hidden layer for each stream. Together with recent advances in network compression, approximate computing, and accelerators, our proposed solution can be successfully implemented in common IoT devices.
Nevertheless, for ultra low-power transmitters, deep reinforcement learning might not be able to be implemented. To solve this problem, we use a central controller running on the gateway which has sufficient computing power to run the algorithm. Note that although the number of iterations is significant, this is the iterations for running the deep-Q learning algorithm, not the physical/real interactions between the transmitter and the gateway. As such, the computation and communication overhead are practically manageable. Specifically, at each state, given the current optimal policy, the transmitter will take an action and observe the results from the environment. It then stores this experience, i.e., , in a memory pool. After a certain period, e.g., a day, the transmitter will send experiences in the memory pool to the gateway. The gateway will use all these experiences to train the deep neural network, i.e., estimate the Q-value for each state-action pair, to obtain the optimal policy. Then, the optimal policy is sent back to the transmitter. This optimal policy is then stored at the transmitter to guide it in making real-time decisions. The proposed solution is thus also applicable to low-latency applications.
VI Performance Evaluation
VI-A Parameter Setting
In our system, the data queue of transmitter can store up to 20 packets with the packet size set at 300 bits [27]. The energy storage capacity is set to be 20 units. The fundamental energy unit is 60 [28]. When the ambient RF source/channel is active, the transmitter can either harvest two units of energy or backscatter one packet to the gateway. When the channel is idle and the jammer does not attack the channel, if the transmitter performs active transmission, it can successfully transmit packets. Each transmitted packet requires one unit of energy. The jammer has four transmit power levels, i.e., = {[math]W, W, W, W}, with = W [29]. As explained in the Section II, as the jamming power increases, the transmitter can successfully harvest more energy or transmit more packets by backscattering jamming signal, and thus we set and . In addition, when the jammer attacks the channel and the rate adaption technique is implemented, the transmitter can transmit {2, 1, 0} packets when the jammer attacks under power levels ={W, W, W}, respectively. In the case both the jammer and the ambient RF source are active, the total number of backscattered packets and the total amount of harvested energy follow the Poisson distribution with the means of and , respectively. The latency threshold is set at time units. Unless otherwise stated, the idle channel probability is and = W. Note that the reinforcement learning algorithms, i.e., Q-learning, deep Q-learning, and deep dueling, do not require the information about jammer, e.g., jamming strategy, and the channel activity, i.e., the idle channel probability, in advance. These information can be learned through the real-time learning process.
The architecture of the deep neural network significantly affects the performance of the deep reinforcement learning algorithms, and thus it requires a thoughtful design. In particular, the complexity of the algorithms increases when the number of hidden layers increases. Nevertheless, if the number of hidden layers is small, the algorithms requires a long time to converge to the optimal policy. Similarly, if the size of hidden layers, i.e., numbers of neutrons, and the mini-batch size are large, the algorithms will need more time to estimate the Q-function. For deep Q-learning algorithms, we adopt parameters based on the common settings for designing neural networks [24, 26]. Specifically, for the deep Q-learning algorithm, two fully-connected hidden layers are implemented together with input and output layers (as illustrated in Fig. 4). For the deep dueling algorithm, the neural network is divided into two streams. Each stream consists of a hidden layer connected to the input and output layers as illustrated in Fig. 6). The size of the hidden layers is . The mini-batch size is set at . The maximum size of the experience replay buffer is 10,000, and the target Q-network is updated every 1,000 iterations [24, 25]. All learning algorithms use the -greedy scheme with the initial value of set at and its final value set at [21].
To evaluate the proposed solutions, we compare their performance with two other schemes, i.e., HTT and WTJ. For the HTT scheme, the transmitter only implements harvest-then-transmit protocol without considering ambient backscatter communication technology. This scheme is to evaluate the impact of ambient backscatter communications to the system performance. For the WTJ, the transmitter can implement both harvest-then-transmit protocol and ambient backscatter communication technology only for the ambient RF signal. This scheme evaluates the system performance without leveraging the jamming signal. It is important to note that the optimal policies of both HTT and WTJ are also obtained by the deep dueling algorithm, i.e., Algorithm 3, presented in Section V.
VI-B Simulation Results
Compare with Non-machine Learning Rate Adaptation Technique
First, we compare our proposed solution with a non-machine learning technique, i.e., rate adaptation (RA). With RA technique, the transmitter has a fixed defend policy as follows: (i) when the jammer attacks the channel, the transmitter adapts its rate based on the power level of the jammer and (ii) otherwise, the transmitter harvests energy from the ambient RF signal. As shown in Fig. 7, the average throughput achieved by our proposed solution is much higher than that of the RA technique. The reason is that with RA technique, the transmitter transmits data at a low rate when the jammer attacks the channel with high power levels. Moreover, as stated in [13], with the RA technique, the jammer can force the transmitter to always operate at the lowest rate by merely randomizing its power levels, provided that the average jamming power is above a given threshold. When increases, i.e., the jammer has more opportunities to attack the channel with high power levels, the throughput achieved by the RA technique is significantly decreased. Our proposed solution, in contrast, can allow the transmitter to much more effectively adapt its defense strategy based on the environment condition and the attack strategy of the jammer. This is possible by implicitly learning the strategy of the jammer as well as unknown parameters that are often assumed to be available in the literature (e.g., the power constraint of the jammer, the jamming strategy…). Additionally, with the ambient backscatter capability, the transmitter can always transmit its data to the gateway by leveraging the strong jamming signal.
Performance Evaluation
Next, we perform simulations to evaluate and compare the performance of proposed solutions with those of the HTT and WTJ schemes in terms of average throughput, packet loss, delay, and PDR. For the HTT and WTJ schemes, we adopt the Deep Dueling algorithm (with iterations) to obtain the optimal policy for the transmitter. For the proposed solutions, we recruit both the Deep Dueling (with iterations) and Q-learning algorithms (with iterations).
In Fig. 8, we vary the idle channel probability of the ambient RF source and observe the performance of the system. Clearly, the throughput of the WTJ policy decreases when increases as shown in Fig. 8(a). This is stemmed from the fact that when the ambient RF source is likely to be idle, the WTJ has less opportunities to harvest energy and backscatter data from the ambient signal. This also leads to the increase of packet loss and number of packets in the data queue as shown in Fig. 8(b) and Fig. 8(c), respectively. In contrast, as the idle channel probability increases, the average throughputs obtained by the HTT policy and the proposed solution increase, and their packet loss and number of packets in the data queue will be reduced. The reason is that the transmitter has more opportunities to harvest energy from the jamming signal and use the harvested energy to actively transmit data when the channel is idle. Additionally, the proposed solution can also backscatter data through both the jamming and ambient signals, thereby its throughput is considerably higher than that of the HTT scheme. In Fig. 8(d), we observe the PDR of the system. Clearly, the proposed solution achieves the best PDR compared to the other schemes. It is worth noting that, the Q-learning algorithm cannot obtain the optimal policy in the first iterations, thereby the performance derived by the Q-learning algorithm is much lower than that of the Deep Dueling algorithm.
In Fig. 9, we vary to evaluate the average throughput, packet loss, number of packets in the data queue, and PDR of the system. Obviously, when increases from 1W to 3W, the throughput of the HTT and WTJ policies increases. The reason is that the transmitter has more chances to harvest energy from the strong jamming signal and uses the harvested energy to transmit data when the jammer and the ambient RF source are idle. However, when is large (e.g., higher than W), i.e., the jammer is more likely to attack the channel, the throughput of these policies decreases as the transmitter has less chance to actively transmit data to the gateway. In contrast, the throughput achieved by the proposed solution increases. The reason is that the proposed solution allows the transmitter to switch to the backscatter mode when the jammer is likely to attack the channel. Consequently, the proposed solutions achieve the best performance in terms of packet loss, number of packets in the queue, PDR, and delay as shown in Fig. 9(b), Fig. 9(c), Fig. 9(d), and Fig. 9(e), respectively. Again, the performance of the Q-learning algorithm is not as good as the Deep Dueling algorithm due to the slow-convergence problem.
Next, we vary the maximum number of packets that the transmitter can actively transmit to the gateway and evaluate the performance of the proposed solution as shown in Fig. 10. As shown in Fig. 10(a), as increases, the throughput of WTJ scheme also increases and remains the same when . This is due to the fact that the transmitter does not leverage the strong jamming signal (except when both the source are active), and thus the amount of harvested energy is limited. In contrary, the HTT policy allows the transmitter to harvest energy from both the ambient and jamming signal. As a result, its throughput increases and is higher than that of the WTJ policy. Importantly, by balancing the time for backscattering data and harvesting energy, the throughput achieved by the proposed solution is significantly higher than that of the HTT and WTJ schemes. This also leads to the reductions of the packet loss and number of packets waiting in the data queue as shown in Fig. 10(b) and Fig. 10(c), respectively. In Fig. 10, we observe the PDR of obtained by the three schemes. Clearly, the proposed solution continues to achieve the best PDR compared to other schemes.
In Fig. 11, we vary the packet arrival rate to evaluate the performance of the proposed solution. Clearly, when increases to 2 packets/time slot, the throughputs of all three schemes are increased as the transmitter can transmit more packets. However, when packets/time slot, the throughputs remain the same as the transmitter obtains the optimal policy. Note that with energy harvesting and backscattering capabilities, the proposed solution can achieve the highest throughput among three schemes. As the transmitter cannot transmit all the arrival packets, the packet loss and the number of packets waiting in the data queue increase when increases as shown in Fig. 11(b) and Fig. 11(c), respectively. With the total number of arrival packets increases, the PDRs of all three schemes are reduced as shown in Fig. 11(d). It is worth noting that in all cases the performance of the Q-learning algorithm is not as high as the Deep Dueling algorithm as it can not converge to the optimal policy within iterations.
Finally, we vary the latency threshold and investigate the performance of the proposed solution as shown in Fig. 12. Obviously, when the latency threshold increases from to time units, the throughputs and the PDRs obtained by all schemes increase as shown in Fig. 12(a) and Fig. 12(d), respectively, and the packet losses decreases as shown in Fig. 12(b). This is stemmed from the fact that with a very short period of latency, more packets will be discarded from the data queue resulting in lower throughputs. When the latency threshold is large, the throughputs remain the same as the deep dueling algorithm obtains the optimal solution to effectively utilize the ambient signal as well as the jamming signal. As the latency threshold increase, the arrival packets have more time to stay in the data queue. As such, the number of packets in the data queue increases as shown in Fig. 12(c). Note that the Deep Dueling algorithm always achieves the best performance in all cases. In contrast, the Q-learning algorithm cannot achieve the optimal policy for the transmitter due to the slow-convergence problem.
Convergence of Deep Reinforcement Learning Approaches
We first show the learning process and the convergence of the proposed deep reinforcement learning algorithms, i.e., deep Q-learning and deep dueling, in several scenarios. As shown in Fig. 13(a) and Fig. 13(b), when the maximum sizes of data and energy queues are set at and , respectively, after iteration, the average throughput obtained by the Q-learning algorithm is much lower than those of the deep reinforcement learning algorithms, especially in the first iterations. This implies that as the system state space increases, the Q-learning algorithm requires more time to be converged, and thus given a fixed short time period, the system performance obtained by the Q-learning algorithm cannot achieve the results as great as those of deep reinforcement algorithms (i.e., Deep Q-learning and Deep Dueling algorithms). Note that in Fig. 13, the performance obtained by Deep-Q learning algorithm is as close as that of Deep Dueling algorithm, however the average throughput obtained by the Deep-Q learning algorithm is very fluctuated compared with that of the Deep Dueling algorithm. This implies that the Deep-Q learning algorithm requires more time to be converged compared with that of the Deep Dueling algorithm.
VII Conclusion
In this paper, we have developed the optimal anti-jamming framework which allows the wireless transceivers to effectively defeat jamming attacks. In particular, with the ambient backscatter capability, while being attacked, the device can either adapt its transmission rate or backscatter its data to the gateway through the jamming signal or harvest energy from the jamming signal to support its operations. To effectively learn about the jamming attacks as well as the channel activities, we have proposed an optimal anti-jamming strategy based on MDP to obtain the optimal defend policy for the transmitter. Then, the reinforcement learning algorithms, i.e., Q-learning, deep Q-learning, and deep dueling, have been developed to maximize the long-term average throughput and minimize the packet loss. Extensive simulations have demonstrated that by using two streams of fully-connected hidden layers, the proposed framework using deep dueling algorithm can improve the average throughput up to 426% and reduce the packet loss by 24%. Importantly, with ambient backscatter and energy harvesting technology, jamming signal can be leveraged by the transmitter as the ambient RF signal, thereby effectively eliminating jamming attacks. To the best of our knowledge, this is the first anti-jamming solution that allows wireless transceivers to not only survive jamming attacks without requiring additional resources but also leverage the jamming signal to improve their transmission rate. The proposed ambient backscattering augmented communications framework can be applicable to both civil (e.g., ultra-reliable and low-latency communications or URLLC) and military scenarios (to combat both inadvertent and deliberate jamming).
Appendix A The proof of Theorem 1
Here, we prove that Q-learning converges to the optimum action-values with probability one, i.e., as . The main idea of the convergence proof is an artificial controlled Markov process called the action-replay process (ARP) [21], which is formulated from the learning rate and the episode sequence. In particular, the state space of the ARP is together with a special absorbing state, where is a state of the real process and is the level of the ARP. The action space is where is an action from the real process.
The stochastic reward and state transition consequence when action is taken at state are as follows:
[TABLE]
where is the index of the time action is taken at state . In this way, is the last time before episode where is executed in the real process. When , the reward is set as , and the ARP absorbs. Otherwise, let denote
[TABLE]
as the index of the episode that is replayed or taken. If , as above, the reward is set at , and the ARP absorbs. In contrary, when , the reward is , and a state transition is formed as .
As stated in [21], the ARP tends towards the real process. Thus, tends to , where and , is the optimal Q-value for the level of the ARP [21, Lemma A]. Without loss of generality, we assume that , where is the bound of the reward. Given , choose such that
[TABLE]
Based on Lemmas B.2, B.3, B.4 in [21], we can compare the value of taking actions in the ARP with of taking them in the real process as follows:
[TABLE]
Clearly, the effect of taking only actions makes a difference of less than for both the ARP and the real processes. As Eq. (32) can be applied to any set of actions, it applies perforce to a set of actions optimal for either the real process or the ARP. Thus, we have
[TABLE]
As a result, with probability 1, as .
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] M. K. Hanawal, M. J. Abdel-Rahman, and M. Krunz, “Joint adaptation of frequency hopping and transmission rate for anti-jamming wireless systems,” IEEE Transactions on Mobile Computing , vol. 15, no. 9, Sept. 2016, pp. 2247-2259.
- 2[2] W. Xu et al. , “The feasibility of launching and detecting jamming attacks in wireless networks,” In Proc. ACM Mobi Hoc , pp. 46-57, Urbana-Champaign, IL, USA, May 2005.
- 3[3] A. Mpitziopoulos, D. Gavalas, C. Konstantopoulos, and G. Pantziou, “A survey on jamming attacks and countermeasures in WS Ns,” IEEE Communications Surveys & Tutorials , vol. 11, no. 4, Fourth Quarter 2009, pp. 42-56.
- 4[4] R. T. Yazicigil, P. Nadeau, D. Richman, C. Juvekar, K. Vaidya, and A. P. Chandrakasan, “Ultra-fast bit-level frequency-hopping transmitter for securing low-power wireless devices,” 2018 IEEE Radio Frequency Integrated Circuits Symposium (RFIC) , PA, USA, Aug. 2018.
- 5[5] A. Mpitziopoulos, D. Gavalas, G. Pantziou, and C. Konstantopoulos, “Defending wireless sensor networks from jamming attacks,” IEEE PIMRC , Athens, Greece, Dec. 2007.
- 6[6] A. Sabharwal, P. Schniter, D. Guo, D. W. Bliss, S. Rangarajan, and R. Wichman, “In-band full-duplex wireless: Challenges and opportunities,” IEEE Journal on Selected Areas in Communications , vol. 32, no. 9, Jun. 2014, pp. 1637-1652.
- 7[7] B. Wang, Y. Wu, K. R. Liu, and T. C. Clancy, “An anti-jamming stochastic game for cognitive radio networks,” IEEE Journal on Selected Areas in Communications , vol. 29, no. 4, Apr. 2011, pp. 877-889.
- 8[8] Y. Gao, Y. Xiao, M. Wu, M. Xiao, and J. Shao, “Game theory-based anti-jamming strategies for frequency hopping wireless communications,” IEEE Trans. Wireless Commun. , vol. 17, no. 8, Aug. 2018, pp. 5314-5326.