Spectral Variability Aware Blind Hyperspectral Image Unmixing Based on Convex Geometry
Lucas Drumetz, Jocelyn Chanussot, Christian Jutten, Wing-Kin Ma, Akira, Iwasaki

TL;DR
This paper investigates the limitations of convex geometry-based hyperspectral unmixing methods under spectral variability and proposes an integrated unmixing approach that addresses these issues, validated on simulated and real data.
Contribution
It introduces a new unmixing chain that accounts for spectral variability within the convex geometry framework, based on an extended linear mixing model.
Findings
The proposed method improves unmixing accuracy under spectral variability.
Validation on datasets shows better performance than classical convex geometry methods.
The approach effectively handles endmember variability in hyperspectral data.
Abstract
Hyperspectral image unmixing has proven to be a useful technique to interpret hyperspectral data, and is a prolific research topic in the community. Most of the approaches used to perform linear unmixing are based on convex geometry concepts, because of the strong geometrical structure of the linear mixing model. However, two main phenomena lead to question this model, namely nonlinearities and the spectral variability of the materials. Many algorithms based on convex geometry are still used when considering these two limitations of the linear model. A natural question is to wonder to what extent these concepts and tools (Intrinsic Dimensionality estimation, endmember extraction algorithms, pixel purity) can be safely used in these different scenarios. In this paper, we analyze them with a focus on endmember variability, assuming that the linear model holds. In the light of this…
Click any figure to enlarge with its caption.
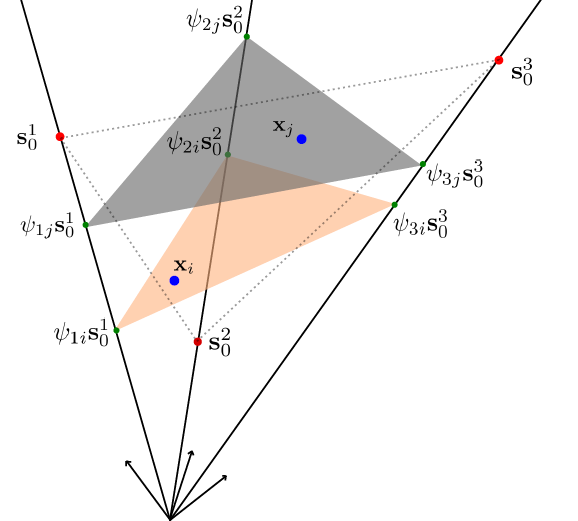 Figure 1
Figure 1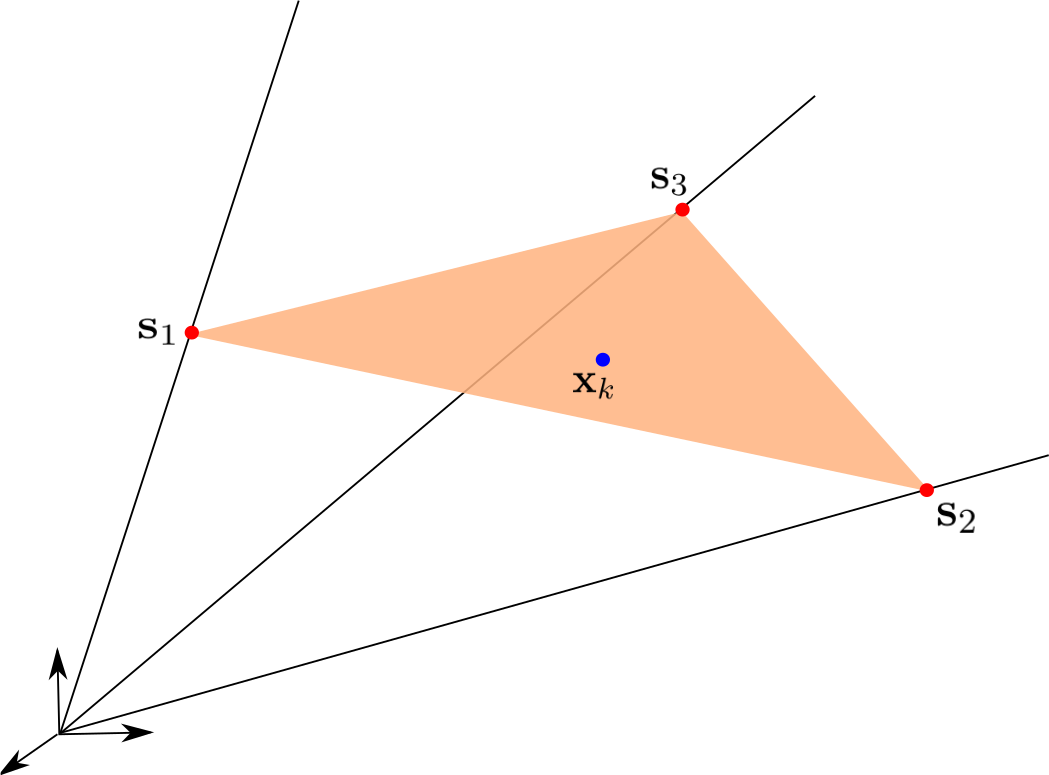 Figure 2
Figure 2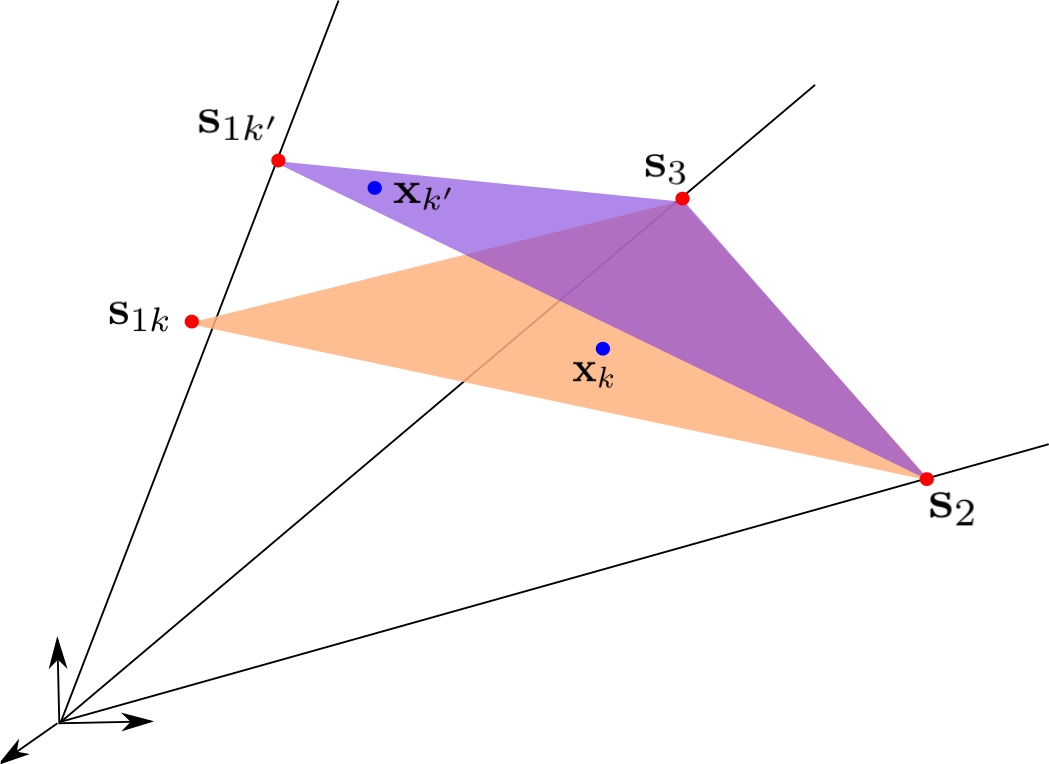 Figure 3
Figure 3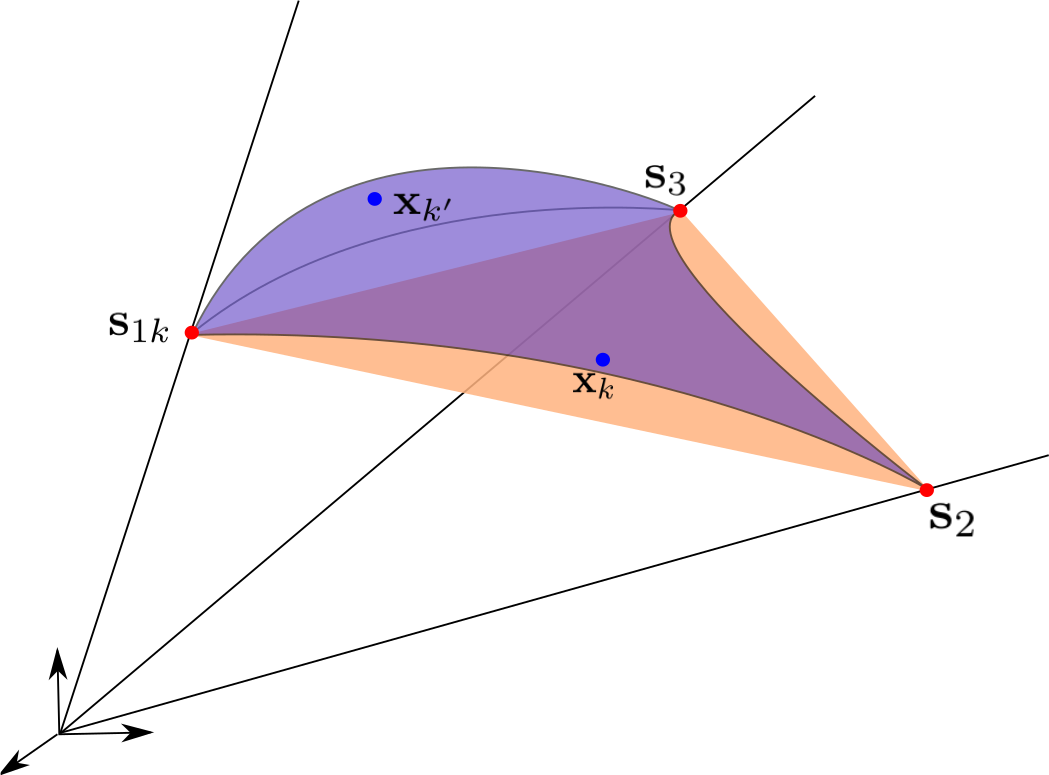 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6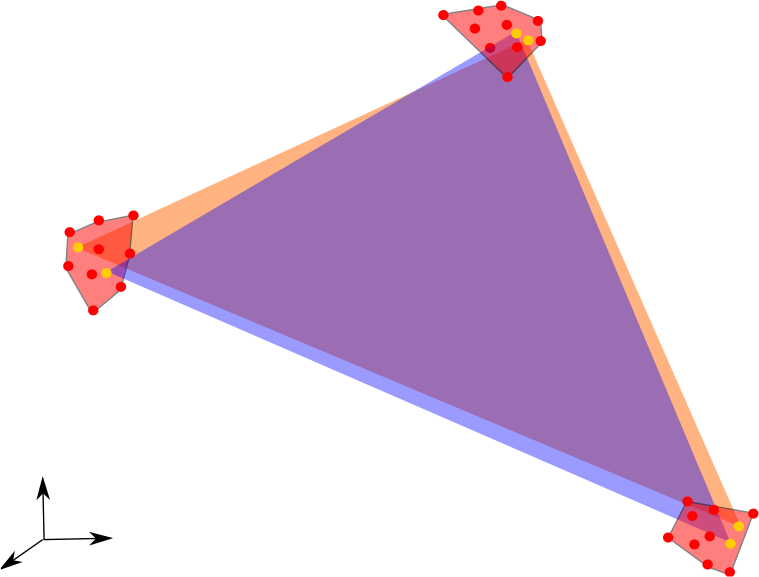 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9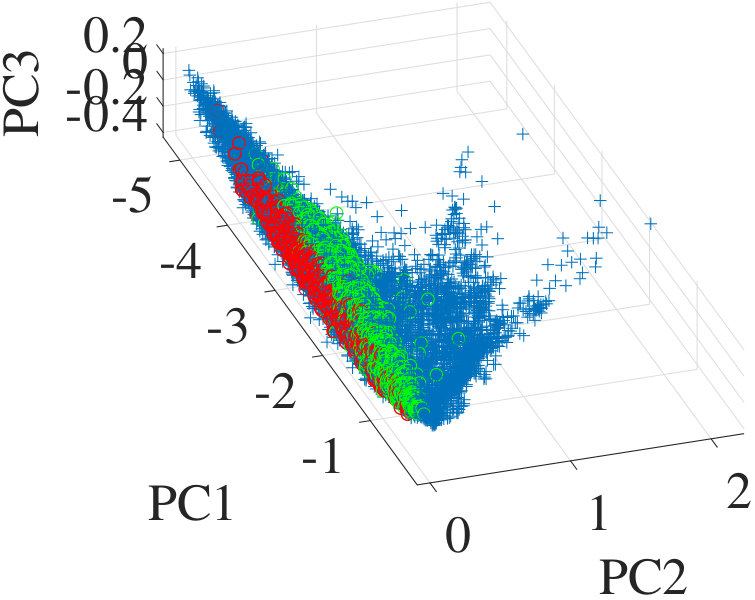 Figure 10
Figure 10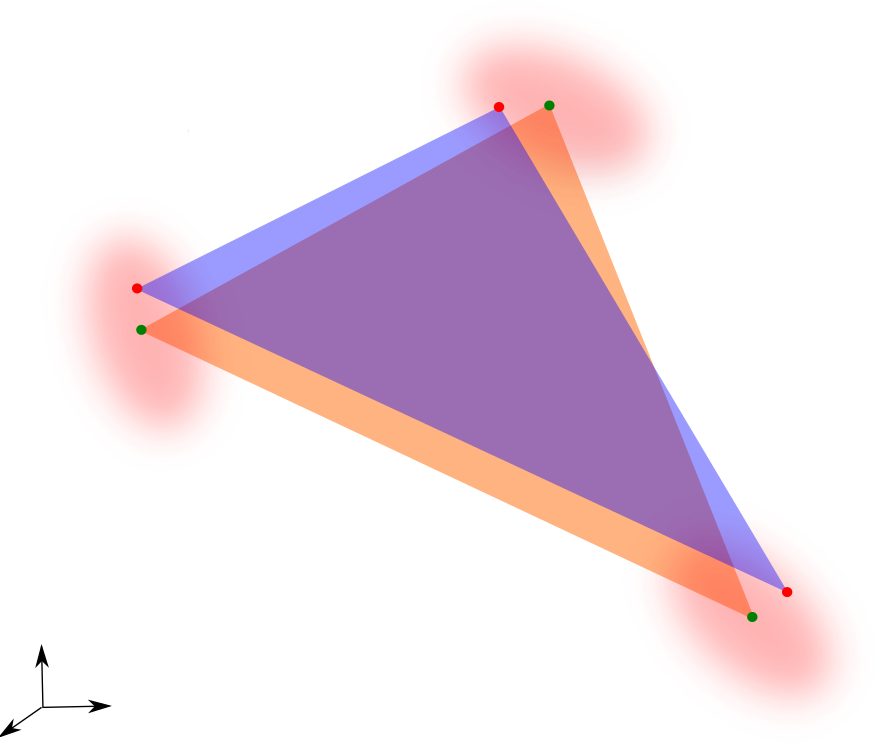 Figure 11
Figure 11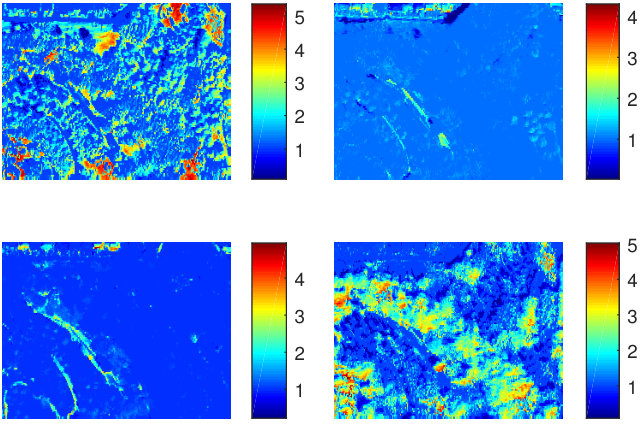 Figure 12
Figure 12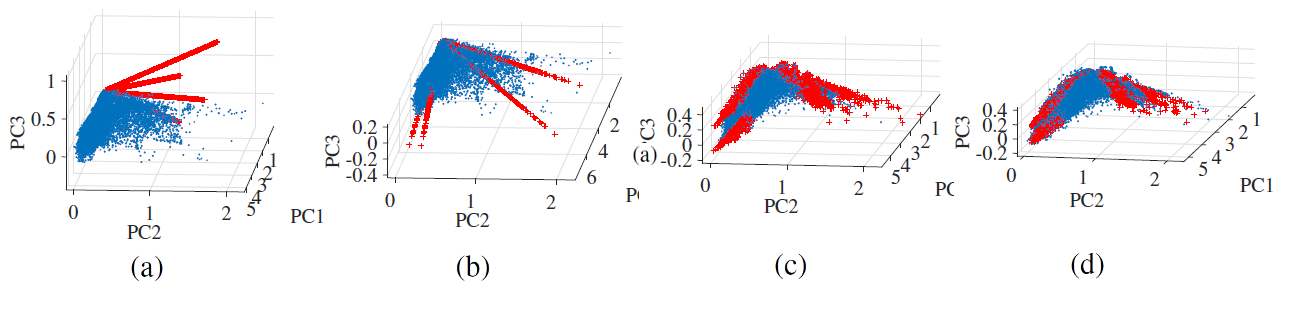 Figure 13
Figure 13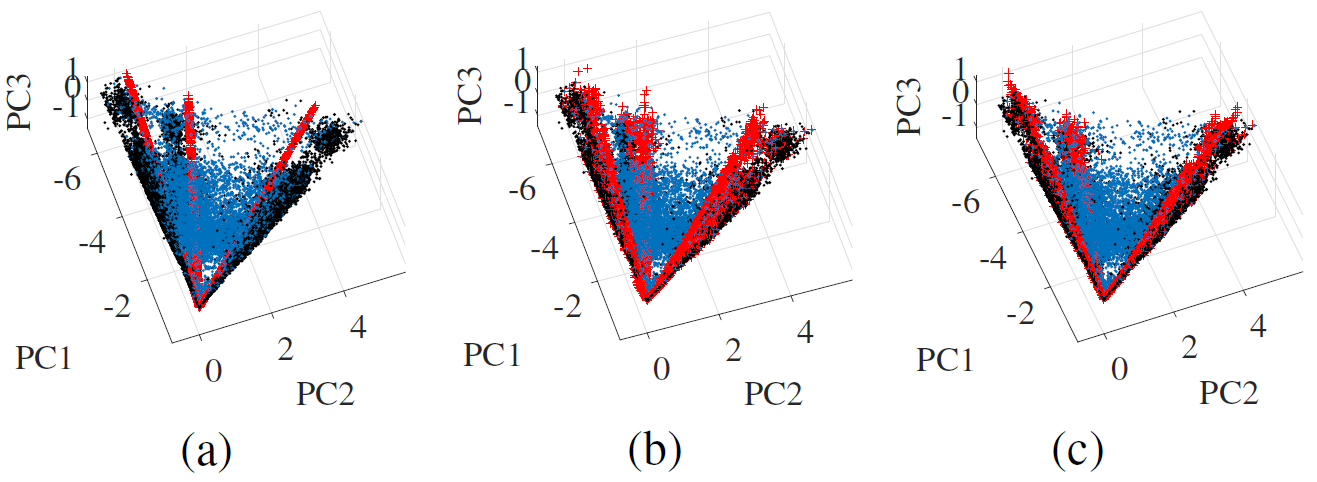 Figure 14
Figure 14| aRMSE | SAM (degrees) | Time (s) | |||
| VCA+SCLSU | 0.2075 | 54.4 | 3 | ||
| SCLSU | 0.0654 | 6.32 | 2 | ||
| ELMM | 0.01 | 0.0642 | 5.62 | 18 | |
| ELMM+SSD | 0.1 | 0.25 | 0.1718 | 10.41 | 88 |
| RELMM | 0.1 | 0.5 | 0.0560 | 3.48 | 428 |
| Time (s) | |||
|---|---|---|---|
| VCA+SCLSU | 9 | ||
| SCLSU | 11 | ||
| ELMM | 0.01 | 243 | |
| RELMM | 0.5 | 100 | 757 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Spectral Variability Aware Blind Hyperspectral Image Unmixing Based on Convex Geometry
Lucas Drumetz, , Jocelyn Chanussot, , Christian Jutten, , Wing-Kin Ma, , and Akira Iwasaki L. Drumetz is with IMT Atlantique, Lab-STICC, UBL, Technopôle Brest-Iroise CS 83818, 29238 Brest Cedex 3, France (e-mail: [email protected])J. Chanussot and C. Jutten are with Univ. Grenoble Alpes, CNRS, Grenoble INP*, GIPSA-lab, 38000 Grenoble, France. * Institute of Engineering Univ. Grenoble Alpes (e-mail: {jocelyn.chanussot,christian.jutten}@gipsa-lab.grenoble-inp.fr).W-K. Ma is with the Chinese University of Hong Kong, Department of Electronic Engineering, Hong-Kong (e-mail: [email protected]).A. Iwasaki is with The University of Tokyo, RCAST, Department of Advanced Interdisciplinary Studies, (e-mail: [email protected])This work was partially funded by the Agence Nationale de la Recherche and the Direction Générale de l’Armement, by the project ANR-DGA APHYPIS, under grant ANR-16 ASTR-0027-01. L. Drumetz was also supported by a grant of the Summer Program of the Japanese Society for the Promotion of Science, JSPS-SP17206 and by a Campus France outgoing postdoctoral mobility grant, PRESTIGE-2016-4 0006.
Abstract
Hyperspectral image unmixing has proven to be a useful technique to interpret hyperspectral data, and is a prolific research topic in the community. Most of the approaches used to perform linear unmixing are based on convex geometry concepts, because of the strong geometrical structure of the linear mixing model. However, two main phenomena lead to question this model, namely nonlinearities and the spectral variability of the materials. Many algorithms based on convex geometry are still used when considering these two limitations of the linear model. A natural question is to wonder to what extent these concepts and tools (Intrinsic Dimensionality estimation, endmember extraction algorithms, pixel purity) can be safely used in these different scenarios. In this paper, we analyze them with a focus on endmember variability, assuming that the linear model holds. In the light of this analysis, we propose an integrated unmixing chain which tries to adress the shortcomings of the classical tools used in the linear case, based on our previously proposed extended linear mixing model. We show the interest of the proposed approach on simulated and real datasets.
Index Terms:
Hyperspectral imaging, remote sensing, spectral unmixing, endmember variability, convex geometry, nonnegative matrix factorization
I Introduction
Hyperspectral imaging, also known as imaging spectroscopy, is a technique which allows to acquire information in each pixel under the form of a spectrum of reflectance or radiance values for many – typically hundreds of – narrow and contiguous wavelengths of the electromagnetic spectrum, usually (but not exclusively) in the visible and infra-red domains [1]. The fine spectral resolution of these images allows an accurate identification of the materials present in the scene, since two materials can be considered to have distinct spectral profiles. However, this identification is made harder by the relatively low spatial resolution (significantly lower than panchromatic, color or even multispectral images). Therefore, many pixels are acquired with several materials in the field of view of the sensor, and the resulting observed signature is a mixture of the contributions of these materials. Spectral Unmixing is then a source separation problem whose goal is to recover the signatures of the pure materials of the scene (called endmembers), and to estimate their relative proportions (called fractional abundances) in each pixel of the image [2].
In the vast majority of the studies on hyperspectral unmixing, a linear mixing model (LMM) is assumed. Each observation (pixel) is modeled as a convex combination of reference signatures, representing the pure materials of the scene. The coefficients are the fractional abundances. This model is physically valid in the so-called checkerboard configuration, i.e. when the field of view of each pixel corresponds to a flat surface, on which the materials of interest each occupy a certain area (they are mixed at a macroscopic scale) [3, 4].
Let us denote a hyperspectral image by , gathering the pixels () in its columns, where is the number of spectral bands, and is the number of pixels in the image. The signatures of the endmembers considered for the unmixing are gathered in the columns of a matrix . The abundance coefficients for each pixel and material are stored in the matrix . With these notations, the LMM writes:
[TABLE]
where is an additive noise (usually assumed to be Gaussian distributed). denotes the useful signal, i.e. the noiseless data. Eq. (1) can be rewritten in a matrix form for the whole image:
[TABLE]
where comprises all the noise values. We keep in mind the constraints on the abundances: and .
With a linear mixture, one may be tempted to resort to Independent Component Analysis approaches, which have been shown to provide excellent results in many linear source separation problems in signal processing [5]. However, the main assumption of this class of techniques, i.e. the independence of the sources, is violated in the case of hyperspectral unmixing, whether we consider the sources to be the endmembers, or the abundances. In the former case, the spectra of different materials of interest are typically very correlated, all the more if the materials to be unmixed are close, for instance several types of vegetation or man made materials. In the latter case, the sum-to-one constraint on the abundances immediately breaks the independence assumption.
That is why other methodologies were defined to tackle the unmixing problem. The most common line of attack is to rely on the strong geometrical structure provided by the LMM: the (noiseless) data is assumed to lie in a simplex whose vertices are the endmembers [1]. The name comes from the fact that a simplex with vertices is the simplest -dimensional object that can be formed from affinely independent points embedded in a Euclidean space of dimension . We give the formal definition of a simplex:
Definition 1**.**
A subset is a -simplex if there exist affinely independent points such that , where this denotes the convex hull of , i.e. the set
[TABLE]
where denotes a vector of ones whose size is given in index.
In other words, a -simplex is the convex hull of affinely independent points in .
An illustration of the geometrical interpretation of the LMM is given in Figure 1. From this observation, the typical unmixing processing chain is usually divided into three steps, which all rely on the convex geometry of the problem:
Estimating the number of endmembers to consider. This is a very hard and ill-posed problem in itself (because there is no such thing as an optimal number of endmembers in real data, among other reasons) and many algorithms have been considered in the community to try to obtain a good estimate [6]. The so-called Intrinsic Dimensionality (ID) of the data if often used as an estimate of the number of endmembers. The usual definition of the ID is that it is the dimension of the signal subspace, i.e. the dimension of the column space of the (noiseless) data matrix:
Definition 2**.**
The Intrinsic Dimension (ID) of a dataset, , is the dimension, , of the vector subspace spanned by the signals, .
In the noiseless linear case, if the LMM is valid, , and this indeed corresponds to the number of endmembers (if and have full column and row ranks, respectively, which is a quite reasonable assumption). One of the best-known algorithms to perform this estimation is the Hyperspectral Subspace Identification by Minimum Error (HySIME) [7]. 2. 2.
Extracting the spectra corresponding to the endmembers, a procedure referred to as endmember extraction. Then again, many Endmember Extraction Algorithms exist in the literature to tackle this problem, with various assumptions, the main one being the presence in the data of pure pixels, i.e. pixels in which only one material of interest is present [8]. These algorithms try to exploit the geometry of the problem by looking for extreme pixels in the data, which are the endmembers if the LMM holds. A popular endmember extraction algorithm using the pure pixel assumption is the Vertex Component Analysis (VCA) [9]. 3. 3.
Finally, estimating the abundances using the data and the extracted endmembers. This step is usually carried out by solving a constrained optimization problem:
[TABLE]
where denotes the Frobenius norm. Solving this problem is often referred to as Fully Constrained Least Squares Unmixing (FCLSU) [10]. Other methods based on Nonnegative Matrix Factorization (NMF) are able to jointly compute the abundances and refine the endmember estimation at the same time [11].
Over the years, several limitations of the LMM became apparent, the main ones being identified as nonlinearities in the mixing process, the intra-class variability of each material, and the dependence on pure pixels.
- •
Nonlinearities occur when the mixture of the materials takes place at an intimate level, e.g. in particulate media such as sand [12], or when the light undergoes multiple reflections before reaching the sensor, which can happen in tree canopies or urban scenarios [13, 14]. An example of the geometry of a nonlinear mixing model is shown in Fig. 2 (a).
- •
Considering endmember variability, on the other hand, simply means that we cannot reasonably assume that a single spectrum can fully represent a material in all its diversity. Several factors can indeed change the signature of a material, be it due to changing illumination conditions and topography, which locally change the geometry of the hyperspectral acquisitions, or the intrinsic variability of the materials, for instance the effect of a change in chlorophyll concentration in green vegetation [15, 16]. A geometrical interpretation of endmember variability is shown in Fig. 2 (b).
- •
When endmember extraction algorithms are used, one last issue is the necessity of pure pixels. Pure pixels are pixels whose abundance is one for one the materials and zero for the rest. Their presence is mandatory for geometry-based endmember extraction algorithms to work. Various methods have been designed to unmix data which do not satisfy this assumption [17, 18, 19]. They are based on minimizing the volume of the simplex used in the unmixing, so as to enclose the data in a simplex whose vertices are going to be the endmembers.
In this context, it is natural to wonder to what extent the linear unmixing chain still applies to the problem, and how each of the steps transfers to more complex mixing models. This question was never really adressed by the community, even though some statements about the robustess of certain algorithms to some of the aforementioned phenomena can be found here and there in the literature. For instance, concerning ID estimation, authors in [7] state that nonlinear models are still embedded in a linear subspace of dimension much lower than the number of spectral bands considered, and as such ID can still provide an upper bound for the number of endmembers. More information on the geometry of popular nonlinear models can be found in the recent overviews [13, 14]. In [14], endmember extraction algorithms are considered to be able to correctly identify endmembers in mildly nonlinearly mixed data because for many models, endmembers are still extreme points of the nonlinear data manifold. However, for certain models, the nonlinear manifolds have extremities which are not the linear endmembers anymore [13]. The pure pixel assumption has been the subject of several theoretical studies to determine in which configurations the endmembers could be identified in spite of the absence of pure pixels, and theoretical results on their efficiency can be derived, but then again, they are based on the LMM [20].
In this paper, we propose to discuss the validity of all these convex geometry-based techniques, in a context where the linear mixing model is still valid, but considering endmember variability. The reason for this choice is twofold: we consider that endmember variability generally affects the observations more than nonlinearities, which are predominant only in very specific cases, some of which are mentioned above. Second, with an appropriate modeling of endmember variability, the problem, although strictly speaking nonlinear, retains a strong geometrical structure, and thus theoretical results as well as geometrical concepts still apply with some modifications. In the nonlinear case, we will simply state that geometrical endmember extraction algorithms are still useful when the nonlinear model preserves the extreme nature of endmembers in the dataset, and ID estimation can still provide an upper bound of the number of endmembers to use. The efficiency of volume regularization is a more complex topic, but since the data manifold is no longer a simplex, it is likely that these methods will fail in strongly nonlinear scenarios. Even though theoretically powerful and appealing, combining nonlinear effects and endmember variability leads to very complex models whose efficiency in practice remain to be proven [21, 22]. Besides, the extended mixing model we will use throughout this paper to model brightness variations has recently been shown to be able to estimate the abundances of nonlinear mixing models modeling multiple interations to some extent, both theoretically and experimentally [23]. For all these reasons, we will consider nonlinear models out of the scope of the present paper.
Our contributions are as follows: we propose an analysis of the convex geometry based concepts used in hyperspectral image unmixing in the context of illumination induced, as well as intrinsic variability (with a precise perimeter for both these terms), in a LMM framework. We discuss ID estimation, endmember extraction, as well as pixel purity. Besides, with the insight gained from this analysis, we propose an integrated unmixing chain for this context, which is still based on convex geometry concepts, but adapts them to the new geometry induced by the presence of variable endmembers. We describe the proposed method (first outlined in [24]), and show its relevance on several datasets, both semi-synthetic and real, with quantitative and qualitative analyses of the results.
The remainder of this paper is organized as follows: Section II will review how spectral variability can be taken into account in the unmixing problem, and precise how we will consider it in this paper. Based on previous studies, Section III will provide an analysis of the behavior of different convex geometry concepts used in classical linear unmixing when endmember variability is considered. We will suggest some leads to circumvent the limitations of current approaches, which we will convert into an adapted unmixing chain and algorithm, as presented and described in Section IV. The results of the proposed approach on a synthetic and a real dataset are discussed in Section V. We gather some concluding remarks in Section VI.
II Endmember Variability
Endmember variability simply refers to the fact that one material cannot be completely represented by a single spectral signature, since many factors can induce modifications on the observed spectra corresponding to one material. The two main factors we consider here are the variations induced by changing illumination conditions (“extrinsic” variability) and all the modifications induced by changes in the physico-chemical composition of the materials (intrinsic variability). Before describing these two different types of variability and some of the existing approaches to tackle them, we formalize mathematically the notion of spectral variability in the unmixing problem, by restating the LMM as a space varying linear model. In this case, endmember variability essentially amounts to allow the endmember matrix to vary from one pixel to the other, within a linear model [16]:
[TABLE]
Of course, without further modeling on , this model is very general and solving the inverse problem of recovering endmembers and abundances is extremely ill-posed. We will not provide a full catalog of all the existing models and algorithms designed to tackle endmember variability, and refer to the recent reviews for the interested reader [25, 16]. Most of these models require to obtain reference endmembers from which the variability will be extrapolated. These are usually obtained using endmember extraction algorithms (designed for purely linear models). We will come back to this issue later in this paper.
II-A Illumination-induced variability
Changing illumination conditions can have a tremendous impact on the observed spectral signature of the materials, regardless of changes in their composition. Simple examples include shadowed materials, whose signatures are lower than if they were receiving full illumination from the sun. Besides, reflectance and radiance, the physical quantities used in hyperspectral imaging, are both dependent on the geometry of the acquisition, i.e. the incidence angle of the light with the material, and the viewing angle of the sensor. These are not fixed on all the support of a given image, since they are dependent on the topography of the scene, which locally changes the geometry of the acquisition. Complex radiative transfer models were designed to describe these physical phenomena, one of the most famous being the model derived by Hapke [12]. However, this model is much too complex to be directly used in blind unmixing, and also depends on many empirical parameters (the albedo of the materials, the acquisition angles, photometric parameters of each material), which are rarely (if at all) available in real scenarios.
The application of Hapke model to generate variants of a given spectrum was theoretically and experimentally shown, however, to be reasonably approximated by (nonnegative) scaling variations of this signature [26, 27, 28, 29], i.e. we can reasonably model , where is a scaling factor accounting for brightness variations of a reference endmember matrix . Eq. (5) then becomes:
[TABLE]
Note that with this model, the product is no longer required to sum to one, which means in practice it can be simply estimated by nonnegative least squares (i.e. by dropping the usual sum-to-one constraint). Then, to split the product into abundances and scaling factors, one can simply sum these quantities over the materials, for a given pixel [30]:
[TABLE]
if we reintroduce the sum-to-one constraint on the actual abundances. Then the abundances can be reestimated by scaling the product , as . is never zero since at least one material is present in each pixel. This technique will be referred to as Scaled (partially) Constrained Least Squares Umixing (SCLSU) in the remainder of the paper.
In order to be able to explain material specific (i.e. photometry-related) effects on the spectra, the scaling factors can be further assumed to depend on the considered endmember, giving the so-called (full) Extended Linear Mixing Model (ELMM) [28]:
[TABLE]
In this case, we have , where is a diagonal matrix incorporating the scaling factors for each material on its diagonal.
The two scaling factor models can also be expressed globally in the whole image, connecting them to classical NMF models:
[TABLE]
where is the Schur-Hadamard (elementwise) product, gathers all the scaling factors, and . This formulation also reveals there is an inherent multiplicative ambiguity between abundances and scaling factors, and hence further assumptions are needed to split into two terms. SCLSU asssumes the scaling factor in a pixel to be the same for all endmembers, and the algorithm used in [28] for the full ELMM makes additional statistical assumptions.
Nevertheless, the model possesses a nice geometrical interpretation (shown in Fig. 3), generalizing the LMM: endmembers are no longer constrained to be single points, but can lie anywhere on lines joining the origin and the reference endmembers (the columns of ). In both cases, the data are no longer constrained to lie in a simplex, but in a convex cone spanned by the reference endmembers (or any scaled version of them, for that matter). More precisely, the data lie in a polyhedral cone:
Definition 3**.**
A subset is a polyhedral cone (or a finitely generated convex cone) with generators if there exist linearly independent points such that , where this denotes the conical hull of , i.e. the set
[TABLE]
On the edges of this cone, the scaling factors encode the position of the local endmembers w.r.t. the references.
II-B Intrinsic variability
If illumination related variability can be physically modeled in a tractable way for hyperspectral image unmixing, the situation is much more complex for the intrinsic variability of the materials, due to its material specific nature and to the numerous factors which should be taken into account for each different material. To cope with this inherent hurdle for the unmixing application, it hardly comes at a surprise that researchers have turned to statistical models to capture this phenomenon instead. One can categorize statistical models into two broad classes: bundle-based methods, and model-based methods. We briefly summarize some of these models below.
The concept of spectral bundles was introduced in [31], under the name “Automated Endmember Bundles” (AEB). The underlying idea is to represent endmember variability as a set of candidate signatures representing different instances of each material, and include each of them in the model as potential endmembers. In the context of blind unmixing, these candidates have to be extracted from the image.
To do that, several subsets of the image are randomly selected (possibly sampling without replacement to ensure that different endmember instances are selected every time). An endmember extraction algorithm is run on each of these subsets, to extract as many signatures as the number of endmembers considered globally. If there is at least one pure pixel in each subset for each material, then different instances of each endmember are likely to be selected. All the candidate endmembers are then gathered in a dictionary of candidate endmembers. However, since most endmember extraction algorithms are stochastic, the extracted sources are not aligned, i.e. the order of the endmembers is not the same from one subset to the other, and there is a priori no grouping of the different signatures into classes containing different instances of the same endmembers. To solve this problem, a clustering step is required, in order to group the signatures into bundles of candidate endmembers for the different materials. This can be done for instance with the k-means algorithm, usually using the Spectral Angle Mapper (SAM)
[TABLE]
as the similarity measure, since it is known to be insensitive to scaling variations (and hence to illumination related variability). It can be shown [32, 33] that pixelwise endmembers can be defined from the extracted abundances as convex or conical combinations (depending on the constraints used) of the candidates for each class, generalizing the LMM or even the ELMM by considering several signatures per class. A geometric interpretation of unmixing data using bundles with the LMM is shown in Fig. 4 (a).
Other purely statistical models can be used, where endmembers are explicitly modeled as drawn from various distributions (Gaussian [34] or Mixture of Gaussians [35], or other variants [36, 37]), or considered as additively perturbed instances of reference endmembers [38]. These models, although theoretically able to capture any type of variability, lack the interpretability of physics-based models. An illustration of these models is shown in Fig. 4 (b).
In this paper, we will model intrinsic variability via a simple Bayesian model. Let us assume that we have obtained a model for illumination variability allowing us to define pixelwise endmembers (such as the ELMM). We obtain the mixing model given in Eq. (5). Since intrinsic variability is really hard to model in a general way, one option is to define it statistically through assumptions on the prior distribution of . We model it as the sum of the variability given by the ELMM and a random variable :
[TABLE]
where we can take a simple uniform prior on , while is supposed to have been extracted beforehand. The residual can be modeled through a Gaussian prior:
[TABLE]
In addition, we also assume a spatially and spectrally white Gaussian model error and noise, i.e.
[TABLE]
where is the identity matrix. If one assumes in addition that the abundances are uniformly distributed in the simplex, then the Maximum A Posteriori (MAP) estimator of the parameters of model (5) is given, after straightforward computations, by:
[TABLE]
with the unit simplex with vertices.
With the physics-based illumination model for extrinsic variability, and the statistical model on intrinsic variability, we obtain a new derivation of the objective function advocated by the papers [28, 39], which first introduced the ELMM.
III Analysis of Convex Geometry Concepts for Hyperspectral Unmixing in the presence of endmember variability
The model on endmember variability introduced in the previous section is able to take into account multiple sources of variability, but two major caveats remain:
- •
The number of endmembers still has to be estimated in the presence of variability
- •
The endmember matrix has to be accurately estimated. Indeed, this parameter is critical since it conditions the whole unmixing chain.
In this section, we analyze three different key concepts for hyperspectral image unmixing based on convex geometry when endmember variability is considered, namely ID estimation, endmember extraction and the pure pixel assumption (as well as simplex volume regularization). We describe what endmember variability changes and how it affects a few popular dedicated algorithms designed for in the purely linear case.
III-A Intrinsic Dimensionality Estimation
The first step in purely blind unmixing is the determination of the number of endmembers to use. This is typically done by considering that the Intrinsic Dimensionality (Def. 2) of the data is equal to the number of endmembers. This is true when the LMM holds so long as the endmember matrix and the abundance matrix have full ranks, since in that case . In the case where illumination-induced variability is present, this result is unchanged since the noiseless data matrix can still be written as with a coefficient matrix with positive entries. In other words, the span of the conical and convex hulls of linearly independent points is the same.
If we consider in addition intrinsic variability, then the ID of the dataset is likely to change. If all the endmember candidates are stored in a new endmember matrix, the new ID is going to be equal to . Equality can happen, for instance, if all the candidate endmembers corresponding to the same class are the same, or if the abundances of all the instances of each material are zero on the whole support of the image, except for one per endmember. In most cases, the ID of the dataset is then going to be directly related to the total number of possible endmembers. In practice, for real data, where the notions of bundles and candidate endmembers do not really make sense a priori, the ID can still provide an upper bound for the number of endmembers, since we can expect pure materials to come in various configurations.
With this in mind, all the algorithms estimating ID as the dimension of the signal subspace such as HySIME [7] or the Random Matrix Theory (RMT) based algorithm of [40] remain useful to give an idea of the number of endmembers to consider. The Virtual Dimensionality (VD) (loosely defined as the “number of spectrally distinct signatures in the image”) concept of [41] follows the same logic and its value should also increase in the presence of intrinsic variability.
III-B Endmember Extraction
In this section, we analyze how geometrical endmember extraction algorithms based on pure pixel search behave in the presence of variability. Typical convex geometry based endmember extraction algorithms include NFINDR[42], the Successive Projection Algorithm (SPA) [43], and the Vertex Component Analysis (VCA) [9]. See [8] for a review. The NFINDR starts from random points in the dataset and iteratively inflates a simplex so as to obtain the simplex with maximum volume that is enclosed in the data. The SPA and VCA (as other algorithms not listed here) are both based on projections of the data on randomly generated vectors, with the assumption that extreme values of these projections are likely to correspond to extreme points in the data scatterplot. In addition, these two algorithms enforce some diversity in the extracted endmembers by projecting the dataset at each iteration to a subspace that is orthogonal to the previously determined endmembers.
With a conical model such as the ELMM, endmembers are no longer extreme points in the dataset, but rather lines passing through the origin. However, they can be completely represented by any point (but the origin) on the lines which are the edges of the convex cone. For instance, an endmember is entirely determined by the point of the corresponding line that lies on the unit sphere, since one such point represents a direction in the feature space. It is one representative of an equivalence class for the projective space , defined as the quotient manifold , where the equivalence relation is . Note that in order to define this space, one has to remove the origin from , which suggests that dealing with the origin is going to be problematic with a conical model.
With illumination induced variability, the pure pixel assumption amounts to have at least one data point somewhere on the lines defining the endmembers. In [44], the pure pixel condition is reformulated in a more general NMF identifiability context and referred to as the separability condition, stating that at least one coefficient vector (for, say, pixel ), per column () of in the factorization should be equal to , where is the vector of the canonical basis of . If the sum to one constraint is considered in addition, the condition is the same except that should be equal to one.
However, with the classical notion of endmembers as extreme points of the data scatterplot, some extracted spectra would probably (although not in all configurations) include the points on each of those lines associated to the largest scaling factors. The main issue is that with a conical model, the origin itself becomes a salient point of the data, which may lead to the extraction of endmembers with very low amplitude, especially in the presence of shadows or very low brightness materials. Thus, the signal to noise ratio can be extremely low for these points and the resulting endmembers are spurious.
Nascimento and Bioucas-Dias, as far back as in 2005, were already conscious about the brightness variations entailed by changing illumination conditions and the possibility to model them as scaling variations [27, 9]. Thus, they made the VCA algorithm robust to these phenomena by incorporating a perspective projection [1] step prior to the endmember extraction (this is also sometimes called “Dark Fixed Point Transform” [45]). We define and describe this concept below.
Definition 4**.**
Let be a set and let be a vector which is not orthogonal to any vector of . The perspective projection of the set any onto the hyperplane is defined as
[TABLE]
This projection is not a linear operator, but possesses the property of not being affected by scaling variations. A consequence of this for our unmixing application is the following result, which is already alluded to in[46] (Eq.(4)), or [47] (note p.6), but important to bear in mind:
Theorem 1**.**
The perspective projection of a polyhedral cone on any compatible hyperplane is a simplex spanned by the perspective projection of the generators of the convex cone.
A proof is provided in the supplementary material to the paper. This theorem means that if the pure pixel hypothesis holds, after applying a perspective projection (VCA uses the mean of the data for ), the data lie in a simplex whose vertices can be identified with any geometrical endmember extraction algorithm. However, in practice, the problem of shadows is not solved, since low brightness pixels are likely to become extreme once projected on the hyperplane. Indeed, in that case, is very small, and hence the norm of the projection is going to be large. This makes these pixels still likely to be selected as endmembers, and as we have already pointed out, they are likely to be spurious because they typically have a low SNR. In real scenarios, problems are also to expect if there are zero or slightly nonnegative values in the data.
Another issue is that VCA and other algorithms use random vectors for the projection which are orthogonal to the previously identified endmembers. This makes endmember extraction difficult in cases where we are looking for very correlated endmembers, e.g. different types of vegetation. In summary, geometric endmember extraction algorithms can be used successfully in some cases of illumination induced variability, if a perspective projection step is carried out, and in the absence of very low brightness pixels.
If one wants to extract several instances for each endmember to model intrinsic variability through bundles, strategies such as the Automated Endmember Bundles (AEB) [31] can be used to obtain several instances per material.
III-C Pixel Purity and volume regularization
The availability of pure pixels is one of the crucial requirements for geometrical endmember extraction algorithms to work in the linear case. However, even in the absence of pure pixels, and in noiseless scenarios, in certain configurations, endmembers can still be perfectly recovered, by finding the simplex enclosing all data points which has minimum volume. The goal of this section is to recall a few results of the literature showing the relevance of resorting to volume regularization when there are no pure pixels, and when in addition endmember variability comes into play.
Note that all the discussion of this section applies only to the noiseless case. The study [20] defines the concept of Minimum Volume Enclosing Simplex (MVES) as the largest simplex (in terms of its volume [48]) which encloses all the data points.
In the linear case, when the pure pixel hypothesis is verified, finding the MVES is guaranteed to recover the true endmembers, with little surprise. However, it can be shown that the MVES actually recovers the true endmembers under milder conditions (provided we can find the global optimum of the nonconvex optimization problem – a highly nontrivial task) involving a quantity called the uniform pixel purity level. In a nutshell, the main result is that the MVES recovers the true simplex if there are enough pixels on the facets of that simplex, even if there are none on the vertices. Another identifiability condition of NMF (although completely different in its formulation) is stated in [44], defines for a coefficient matrix (the abundance matrix or the coefficient matrix , depending on the constraints) the notion of being “sufficiently scattered”. In the same paper, the two conditions are actually shown to be equivalent, even though the latter is less easy to interpret geometrically. Note that these conditions are only sufficient conditions. Before moving to the variability case, let us briefly review some algorithms which try to identify the MVES. The optimization problem is nonconvex and involves the determinant of a certain matrix related to the endmembers to compute the volume. This quantity is a hard to work with in optimization. The algorithm of [49], also referred to as MVES, directly tackles an equivalent formulation of the optimization problem. A different approach is to consider a Nonnegative Matrix Factorization (NMF) technique, where the endmembers are jointly estimated with the abundances, and a volume regularization is added. Examples include the Minimum Volume Constraint NMF (MVC-NMF) [50], where the actual volume of the simplex is replaced by a surrogate , which is slightly easier to manipulate, because it directly involves the endmember matrix. Other works propose to relax the optimization problem to make it more tractable or robust to noise. The Minimum Volume Simplex Analysis (MVSA) [51] replaces the hard constraint that the simplex must enclose all the data by a soft version to account for outliers. The Iterated Constrained Endmembers (ICE) is another NMF based-algorithm which relaxes the volume computation into a convex surrogate which sums all the pairwise distances between endmembers [17].
Again, a natural question is to wonder how these results can be extended, and the algorithms adapted when endmember variability comes into play. It turns out that the sufficient condition for perfect simplex recovery of the MVES is also valid in the conical case, with some adaptation due to the fact that the sum to one constraint is not enforced. The first necessary step is to define an equivalent to the uniform pixel purity level in the conical case [44]:
Definition 5**.**
The uniform pixel purity level for the extended linear mixing model is a quantity defined as
[TABLE]
where
[TABLE]
This definition is equivalent to
[TABLE]
which has a clear geometrical interpretation: is simply the set of vectors with nonnegative entries making an angle less than with the vector . With this definition, we have the following identifiability result – a mere reformulation of the criterion proven in [52]:
Theorem 2**.**
If there are at least three endmembers in the image (), and if , then solving the optimization problem
[TABLE]
guarantees the recovery of the true endmembers (up to scaling factors). In the case , this problem recovers the true cone if and only if the pure pixel hypothesis holds.
The condition is equivalent to , but this time the coefficient matrix has to appear explicitly, because there is a sum to one constraint on its rows (not columns, which would be the usual sum to one constraint on an abundance matrix). This constraint is only a technical constraint which ensures that minimizing the cost function leads to identify the edges of the cone. However, it breaks the geometrical interpretation of the model since the objective function cannot be interpreted anymore as the volume of a simplex such that the conical hull of its vertices enclose the data. However, without more constraints on the columns of (e.g. unit norm, which would make it impossible to satisfy the sum to one constraint on the rows of ) this quantity cannot be easily interpreted as an extension of the volume of a simplex to the associated polyhedral cone (such a measure should have some sort of scale invariance with respect to the columns of ). Once again, this criterion is only a sufficient condition, but empirical evidence suggests that it could also be a necessary condition for identifiability [47]. However, those results make us confident that volume regularization techniques could still help identify the lines of the endmembers in the case of illumination variability in practical scenarios, even in the absence of pure pixels.
When, in addition, we consider intrinsic variability, the analysis does not apply anymore. However, even if we consider intrinsic variability without illumination-induced variability, we are not so much interested in the extreme points of the data, as in the centroids of the convex hulls of each bundle, which allow us to define good reference endmembers. With a conical model, the rationale is the same, we do not want the edges of the convex cone anymore, but rather the center of the conical hulls of the candidate endmembers for each material. Hence the volume regularization still makes sense, but it might be preferable to resort to a minimum volume based algorithm with a soft constraint on the inclusion of the whole data in the cone, such as MVSA or ICE, simply adding the unit norm constraint on the reference endmembers.
IV Proposed Unmixing Framework
In this section, with all the analyses of the previous sections in mind, we outline the core contribution of this paper, a full unmixing chain which applies all convex geometry concepts of linear unmixing to the case where both types of variability can be found in the data. The first step is to estimate an upper bound of the number of the dataset through ID estimation, using one’s favorite algorithm. The second step is endmember extraction to define reference endmembers, and the last one is abundance, refined reference endmember and variability estimation. This last step is an NMF step which is similar to the approach of [28], except that volume regularization is added in a way that is compatible with conical data, and which is robust to intrinsic variability. We describe the reference endmember extraction and the NMF step below.
IV-A Reference endmember extraction
We aim at extracting reference endmembers around which variability can be extrapolated on each pixel of the data. Even though both intrinsic variability and illumination-induced variability can be expected in real scenarios, in the absence of shadows and low brightness pixels, the perspective projection step of the VCA makes it a good candidate algorithm to use. However, if shadows or outliers are an issue, another way of extracting reference endmembers should be used. In such cases, we propose to cluster the data using a simple k-means algorithm with clusters, and the spectral angle as the similarity measure. We use the centroids as initial reference endmembers, which will then be refined in the next step.
The reason to resort to k-means with the cosine distance, instead of a geometrical extraction endmbmer is that it allows us to define the endmembers taking into account the statistics of the data, as well as their geometry. We expect to be able to capture correlated endmembers more easily than with the VCA, which, to identify a new endmember, iteratively projects the data on orthogonal vectors to the subspace spanned by the already identified endmembers (see [9] for details). Also, low brightness pixels are not given as much importance as with the VCA. Another theoretical motivation to use this strategy is that, as the regular k-means with the Euclidean distance can be interpreted as a hard assignment version of a Gaussian Mixture Model, the k-means algorithm can be interpreted as a hard assignment version of a mixture of Von Mises-Fisher distributions [53]. This distribution can be thought of as the equivalent of an isotropic Gaussian distribution on the sphere, i.e. for directional data, such as endmembers in a conical model [54]. The main drawback of using k-means is that it performs a hard assignment, and hence does not account for mixed pixels, and as a result, the centroids of the clusters can be too far in the conical hull of the data because very mixed pixels have to be assigned to one class only. This is why it is necessary to be able to adjust the endmembers during the abundance estimation step. The pure pixel assumption helps, but since the refrerence endmembers will be adjusted using a volume related criterion, it is not strictly mandatory in theory.
IV-B NMF estimation of the abundances, reference endmembers and variability
At this step, we have initial estimates for the reference endmembers, and we need to estimate the abundances, as well an endmember matrix for each pixel, accounting for both types of variability. We first define the cost function that we are going to minimize, by slightly extending the Bayesian variability model of Eq. (12). Since our goal is to reestimate adaptively, we include the following hyperprior on the reference endmembers:
[TABLE]
where tr denotes the trace of a matrix, and , such that
[TABLE]
i.e. the sum of pairwise Euclidean distances between reference endmembers. A derivation of this equality can be found in [17]. denotes the oblique manifold, i.e. the manifold of matrices with unit norm columns. With this additional hyperprior, the MAP estimator of the model (12) becomes
[TABLE]
where we have replaced the estimation of the standard deviations and of with regularization parameters to tune.
The new additional term allows to control the openness of the cone (depending on the value of ), with the convex approximation of the volume used in the ICE algorithm [17]. This term can really be thought of as an approximation for the volume of the cone, and we further constrain the endmembers to be normalized, treating them as directional data [54]. Without this, we compare endmembers which could have different magnitudes, which is not meaningful. The openness of the cone can then be tuned so that the reference endmembers are situated within the data (in the presence of pure pixels and with intrinsic variability), or outside of the dataset (if there are no pure pixels). The term , forces each local endmember to be close (but not equal) to scaled versions the (unit norm) representatives of the reference directions. The scaling factors capture illumination induced variability, while can further account for intrinsic variability effects, by allowing the local endmembers to drift away from the lines, depending on the value of . The fact that the reference endmembers are normalized also has the advantage of easily allowing to compare the magnitude of the scaling factors (and thus the impact of illumination induced variability) across different materials and images. Spatial regularizations could also be added if need be, as done in [28]. The novelty of the proposed criterion relies on the reference endmember term, together with the oblique manifold constraint to bridge the hitherto separate issues of volume regularization and endmember variability.
IV-B1 Optimization
Here, we propose an algorithm to obtain a stationary point of the cost function (23). This objective function is challenging for several reasons: it is nonconvex over all variables simultaneously, which usually calls for block coordinate descent methods to try and get a local minimum. In this case, this approach is made even more complex because the problem is not convex w.r.t. either, because of the nonconvex unit norm constraints. However, we will see we can still obtain a local minimum for this variable by taking advantage of the Riemannian manifold structure of the constraint set. Before detailing the different steps of the optimization, we will briefly describe how we initialize the algorithm. As mentioned above, if VCA is not used for the endmember extraction, we first run the k-means clustering algorithm (with the cosine similarity) to obtain centroids, which we normalize to initialize . We initialize by assigning the appropriate column of this matrix to the current pixel , depending on its clustering label. The other columns are initialized using the remaining centroids. The abundance and scaling factor matrices are initialized using the SCLSU algorithm with the centroids as references, which is very fast. This way, we hope to obtain a good local minimum in spite of the complexity of the problem.
The optimization w.r.t. is relatively easy, since the objective function is smooth, convex and the constraint set (unit simplex) is easy to project onto [55]. The global minimum of this subproblem can be then obtained pixel-by-pixel using (for instance) a projected gradient descent. The optimizations w.r.t to and are easy and enjoy closed form solutions (see [39] for details). Optimizing over is harder because of the unit sphere constraints, despite the smoothness and convexity of the objective. Using the fact that the constraint set has a Riemannian manifold structure for which a retraction mapping can be easily found, we perform a conjugate gradient descent on the oblique manifold [56] (we use the Manopt toolbox for MATLAB [57]– also available in Python).
Due to the nonconvex nature of the oblique manifold constraint, we cannot prove global convergence, even though we observe good performance in practice. However, if this constraint is dropped, we can find a closed form update for , and we can prove convergence of the algorithm to a stationary point. We use the result of [58] (Proposition 5) on block coordinate descent (BCD) techniques. This results states that if the objective function is continuously differentiable over the global optimization variable, is strictly quasiconvex w.r.t. of the considered blocks, and if the constraint set is convex, then BCD converges to a stationary point of the objective. In our case, our optimization algorithm can be seen as a 3-block BCD, using blocks , and . The objective function is obviously continuously differentiable, and is in addition strictly convex w.r.t. (so long as ). Indeed, for each , if we consider the variable to be (stacking the columns), the Hessian is equal to , where is the Kronecker product. This is a symmetric positive definite matrix for , and then the objective is a fortiori quasiconvex w.r.t. . Since we dropped the nonconvex normalization constraint, the result applies and the algorithm converges in that particular case.
We stop the algorithm whenever the relative variations between consecutive iterates of all blocks of variables go below (in norms). We note that the convergence is going to be slower than the original ELMM with fixed reference endmembers, because the latter are now iteratively updated and impact the whole geometry of the unmixing.
V Experimental Results
In this section, we present the unmixing results obtained on a synthetic dataset whose materials incorporate realistic variability features, as well as a challenging real dataset with very correlated endembers and the presence of a significant proportion of shadowed areas.
V-A Synthetic data
V-A1 Data Generation
To generate a synthetic dataset, we first use the ground truth of the well-known Pavia University dataset to provide us with labeled spectra (203 bands in the visible and near infrared domains) belonging to several classes of interest, incorporating their spectral variability. We consider three classes present in the image: vegetation, concrete and metallic roofs. Theses classes incorporate both illumination induced variability (roofs and trees locally have different orientations w.r.t. the sun) and more intrinsic variability sources (especially in concrete and vegetation). In each pixel, we choose the local endmembers to be a random sample within each of these classes (after a normalization to project them on the unit sphere).
Scaling factors have been simulated by drawing them from a mixture of 4 Gaussian distributions (fitted from the results of SCLSU on a subimage of the Pavia dataset), which reflects the fact that in real scenarios scaling factors often come from multimodal distributions (for example roofs with two different orientations, or areas with shadows).
The abundances have been designed to be relatively sparse, using a Dirichlet distribution such that the probability density is concentrated around the edges and vertices of the unit simplex (while still allowing a proportion of heavily mixed pixels), so in this case the pure pixel assumption holds.
The data was then generated using Eq. (6), adding Gaussian white (both spatially and spectrally) noise such that the signal to noise ratio is 30dB. The generated image then benefits from realistic statistical properties.
V-A2 Results
First, we ran the HySIME [7] and the RMT [40] algorithm on this dataset, which gave an ID value of 14, and 29, respectively, even though only 3 endmembers are considered. The reason for this is that all the endmember variants introduced in the data generation lead to a substantial increase in the ID value, as explained in Sec. III-A, and this experimentally confirms that the ID can be considered more as an upper bound of the number of endmembers, rather than an absolute truth.
We run the the SCLSU algorithm with VCA-derived endmembers, so as to get baseline unmixing results with variability. We show below that this approach fails in this configuration. Then we focus on testing two algorithms with k-means derived references: SCLSU and the ELMM algorithm, as presented in [39]. Also, we denote by ELMM-SSD (Sum of Squared Distances) the ELMM augmented with the convex volume regularization of the ICE algorithm, but without the oblique manifold constraint. Finally, we compare all those methods to one proposed in Sec. IV-B, denoted as RELMM (for Robust ELMM). Note that we do not compare the results to the classical Fully Constrained Least Squares Unmixing [10], because this algorithm assumes a simplex-based model and has been shown to fail in many endmember variability scenarios. For each algorithm, we empirically tune the regularization parameters to obtain the best possible performance (the chosen values are reported in Table I). Quantitative results are presented using two metrics: the abundance Root Mean Squared Error (aRMSE) between the true abundances and the recovered ones: , and the mean (over all pixels and materials) Spectral Angle Mapper (SAM) (Eq. (11)) between the true endmembers in each pixel and the recovered ones. These quantities are gathered in Table I.
VCA+SCLSU obtains very poor results both in abundance estimation and variability retrieval, because two of the extracted signatures are associated with pixels with small scaling factors, and have a very low magnitude. The reason for this behavior is explained in Sec III-B. Using k-means instead along with SCLSU leads to better results, but far from optimal because the variability is only explained by scaling factors, and hence intrinsic variability is not accounted for. The ELMM does even better because it addresses it using an additional Gaussian prior on the local endmembers, allowing them to drift away from the lines defining the reference endmembers. ELMM+SSD fails because the regularization term involves the comparison of references with possibly different scales, whereas introducing the constraint leads to the best results.
Fig. 5 shows qualitative results using 3D-scatterplots of the data (using the first principal components) along with the recovered and true endmembers for the best algorithms (for the other algorithms, the lines are much too far away from the true cone to be relevant). Similar conclusions can be drawn from this figure, showing that RELMM finds the best endmembers in each pixel. Geometrically, the local endmembers defined using the volume regularization allow us to position the references so they lie more or less in the center of cones spanned by the true endmembers corresponding to each class. The k-means endmembers are initially slightly too far within the data and need to be updated to improve the unmixing performance.
V-B Real data
The real dataset we use in this study was acquired in 2009 by Japan Space Systems over the Tama Forest Science Garden in the western region of Tokyo, Japan, with the CASI-3 sensor (72 spectral bands in the visible and near-infrared domains) [59]. The spatial resolution is 1m. The image we use is a subset of the whole scene. An RGB representation is shown in Fig. 6 (a). This dataset has been used for supervised classification of tree species, using a ground truth and LiDAR (Light Detection And Ranging) data as an additional classification feature, since the different tree species are spectrally very close to one another. The image also comprises many shadowed areas because of the tree crowns, which were an important hurdle in previous studies [59]. Furthermore, other non vegetation endmembers are present, such as man made roofs, roads, and soil. We show here that using k-means instead of the VCA allows to distinguish between conifer and broadleaf trees in a completely unsupervised way. Some labeled conifer and broadleaf trees are shown in Fig. 6 (b). We show the scatterplot of the data and labeled pure pixels in Fig. 6(c).
The HySIME algorithm estimated the ID of the data to be 14, the RMT algorithm estimated it the ID to be 21. Because of the important variability present in the image, and since we may want to group several macroscopic constituents of the man-made material into one endmember for easier unmixing an interpretation (roads, several types of roofs…), we unmix the data using materials using the above mentioned algorithms. We show in Fig. 7 the scatterplots of the data and recovered endmembers for VCA+SCLSU, SCLSU, ELMM, and RELMM. The abundance maps are shown in Fig. 8 (a). For the ELMM, we set , and for the RELMM, we set and . As in the synthetic data case, the endmembers recovered by VCA are spurious because of shadow patches of the image, and the corresponding abundances are meaningless. Most of the data is projected on the closest line in the identified cone, which represents vegetation. Using k-means instead allows to distinguish between conifer trees and broadleaf trees. Grass and shadows are also detected by large and low values of the scaling factors, respectively (see Fig 8 (b)). The abundances of SCLSU and the ELMM are rather similar, slightly sparser for the ELMM, because it is able to better capture variability effects than SCLU (as seen in Fig. 7 (c). The RELMM, thanks to being able to adjust the references, is able to obtain sparser abundance maps which closely match the ground truth of Fig. 6 (b). We see that the identified endmembers enclose the data very well and are the closest to the ground truth pixels of Fig. 6 (c). The values of the regularization parameters used and the running times are provided in Table II.
VI Conclusion
Blind unmixing is a problem of prime importance for the analysis of hyperspectral images. The classical linear unmixing chain relies heavily on convex geometry concepts to extract endmembers and abundances, but many recent works suggest that endmember variability should be taken into account for accurate unmixing. Hence, the geometrical assumptions of the linear mixing model have to be adapted. We analyzed the main steps of the typical unmixing chain, namely the estimation of the number of endmembers, and their extraction in the presence of pure pixels or not, as well as abundance estimation. We modeled variability in two complementary ways: illumination induced variability was modeled through the extended linear mixing model, allowing a local scaling of the endmembers, and intrinsic variability effects were modeled using a statistical approach. We found that the estimation of the Intrinsic Dimensionality of the data can theoretically still provide an upper bound of the number of endmembers to use, that the VCA algorithm is robust to illumination induced variability provided there are no very low britghness pixels in the image. Otherwise, we advocate the use of k-means clustering with the cosine similarity to obtain initial estimates of the endmembers. Both algorithms can also be used to extract endmember bundles. By gathering various results of the literature, we have extended the notion of pure pixels and minimum volume identifiability results to conical mixing models. We have also stressed that in the presence of pure pixels, these approaches should not include a hard constraint making the cone enclosing all the data, but should allow the extracted endmembers to be slightly inside the convex cone so as to be better representatives of each endmember class in when significant intrinsic variability is expected. With all these observations, we have proposed an algorithm to blindly unmix hyperspectral data in the presence of variability in difficult scenarios (correlated endmembers, shadow effects) and have shown its efficacy on a real and simulated dataset. Theoretical open questions include a rigorous study of the robustness of the volume regularization to noise and intrinsic variability of the endmembers. On the algorithmic part, future work will include a scheme to automatically estimate the regularization parameters of the algorithm.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] J. Bioucas-Dias, A. Plaza, G. Camps-Valls, P. Scheunders, N. Nasrabadi, and J. Chanussot, “Hyperspectral remote sensing data analysis and future challenges,” IEEE Geoscience and Remote Sensing Magazine , vol. 1, pp. 6–36, June 2013.
- 2[2] N. Keshava and J. F. Mustard, “Spectral unmixing,” IEEE Signal Processing Magazine , vol. 19, pp. 44–57, Jan 2002.
- 3[3] J. Bioucas-Dias, A. Plaza, N. Dobigeon, M. Parente, Q. Du, P. Gader, and J. Chanussot, “Hyperspectral unmixing overview: Geometrical, statistical, and sparse regression-based approaches,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , vol. 5, pp. 354–379, April 2012.
- 4[4] W. K. Ma, J. M. Bioucas-Dias, T. H. Chan, N. Gillis, P. Gader, A. J. Plaza, A. Ambikapathi, and C. Y. Chi, “A signal processing perspective on hyperspectral unmixing: Insights from remote sensing,” IEEE Signal Processing Magazine , vol. 31, pp. 67–81, Jan 2014.
- 5[5] P. Comon and C. Jutten, Handbook of Blind Source Separation: Independent component analysis and applications . Academic press, 2010.
- 6[6] A. Robin, K. Cawse-Nicholson, A. Mahmood, and M. Sears, “Estimation of the intrinsic dimension of hyperspectral images: Comparison of current methods,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , vol. 8, pp. 2854–2861, June 2015.
- 7[7] J. Bioucas-Dias and J. Nascimento, “Hyperspectral subspace identification,” IEEE Transactions on Geoscience and Remote Sensing , vol. 46, pp. 2435–2445, Aug 2008.
- 8[8] A. Plaza, P. Martinez, R. Perez, and J. Plaza, “A quantitative and comparative analysis of endmember extraction algorithms from hyperspectral data,” IEEE Transactions on Geoscience and Remote Sensing , vol. 42, pp. 650–663, March 2004.