Decomposition-Based Transfer Distance Metric Learning for Image Classification
Yong Luo, Tongliang Liu, Dacheng Tao, Chao Xu

TL;DR
This paper introduces a transfer learning approach for distance metric learning in image classification, leveraging source task information through a decomposition-based method to improve robustness with limited target data.
Contribution
The paper proposes a novel decomposition-based transfer DML method that learns a sparse combination of source metrics, reducing variables and improving efficiency in limited data scenarios.
Findings
Outperforms existing transfer metric learning methods on image classification tasks.
Requires fewer variables, leading to faster and more reliable solutions.
Effective in scenarios with limited side information for target tasks.
Abstract
Distance metric learning (DML) is a critical factor for image analysis and pattern recognition. To learn a robust distance metric for a target task, we need abundant side information (i.e., the similarity/dissimilarity pairwise constraints over the labeled data), which is usually unavailable in practice due to the high labeling cost. This paper considers the transfer learning setting by exploiting the large quantity of side information from certain related, but different source tasks to help with target metric learning (with only a little side information). The state-of-the-art metric learning algorithms usually fail in this setting because the data distributions of the source task and target task are often quite different. We address this problem by assuming that the target distance metric lies in the space spanned by the eigenvectors of the source metrics (or other randomly generated…
Click any figure to enlarge with its caption.
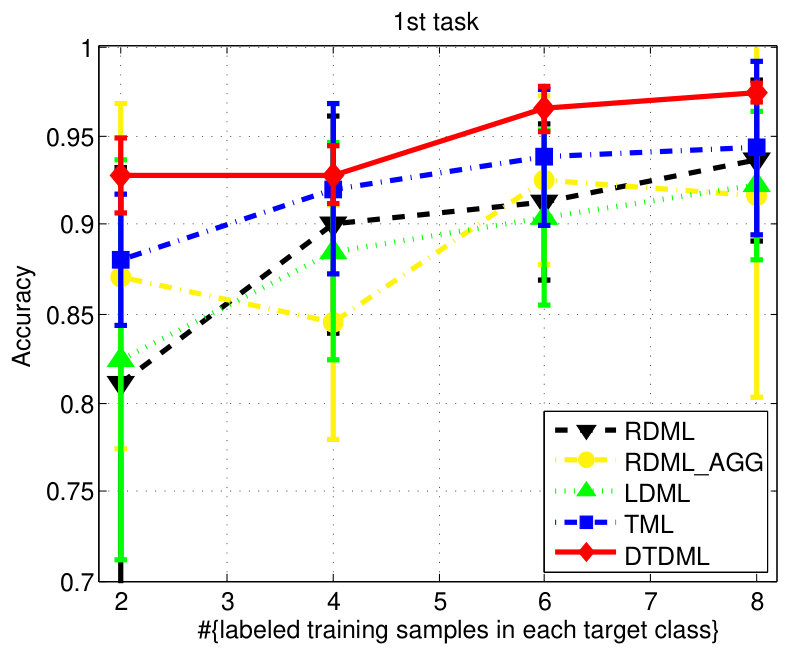 Figure 1
Figure 1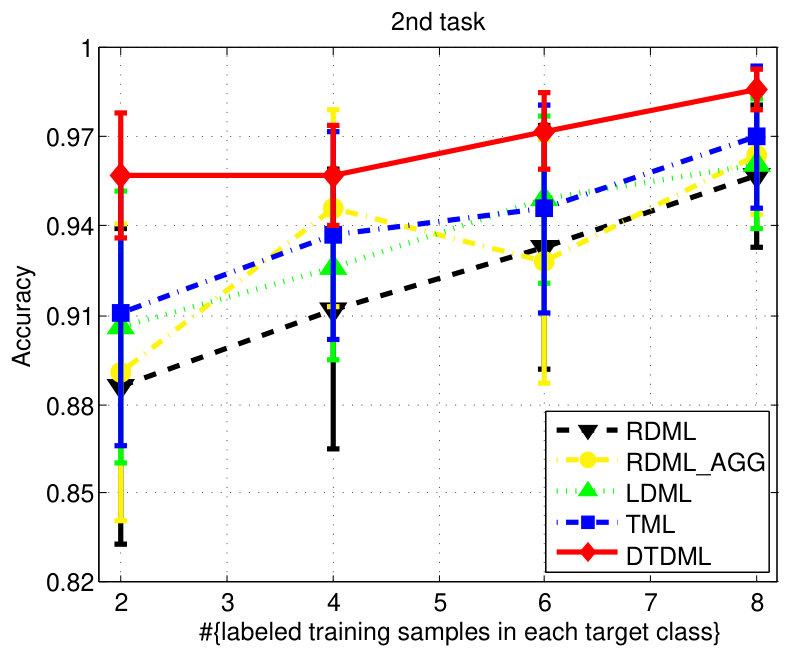 Figure 2
Figure 2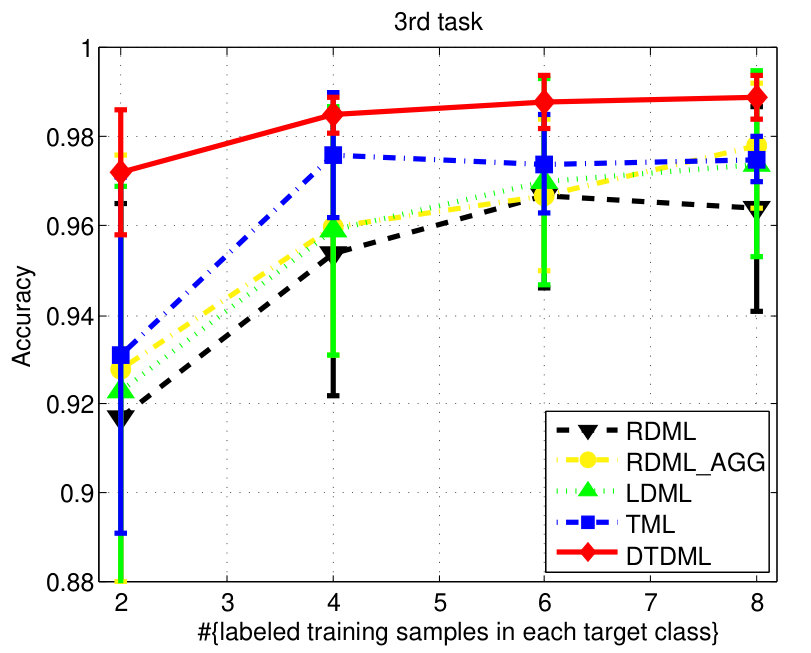 Figure 3
Figure 3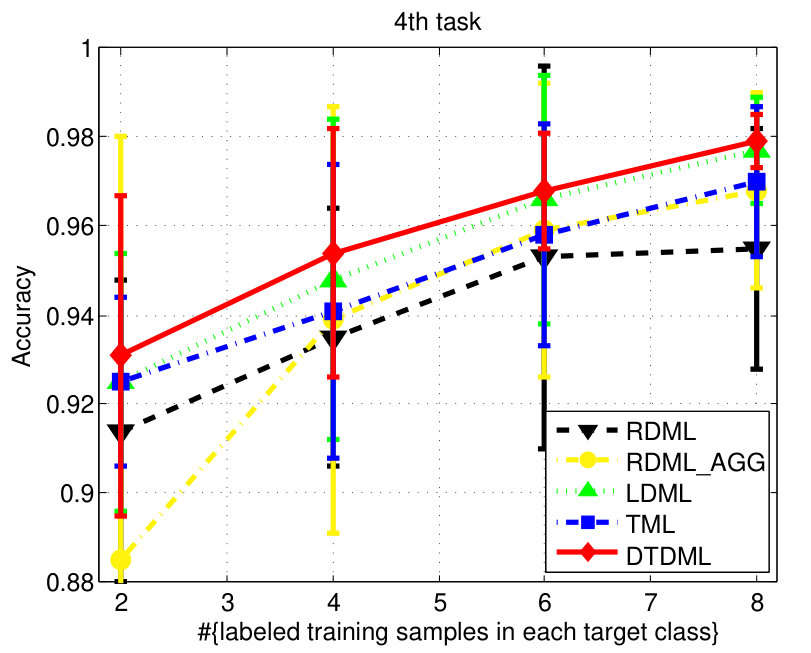 Figure 4
Figure 4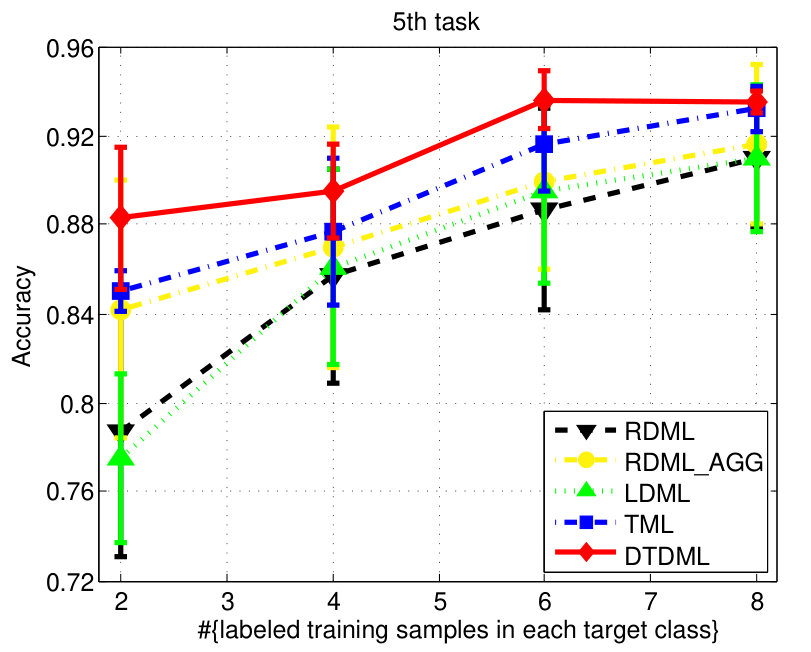 Figure 5
Figure 5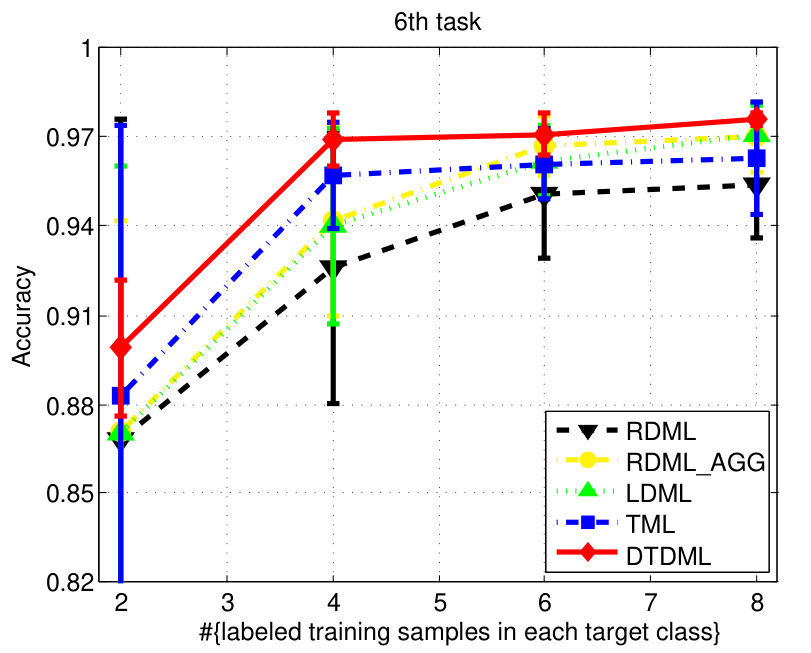 Figure 6
Figure 6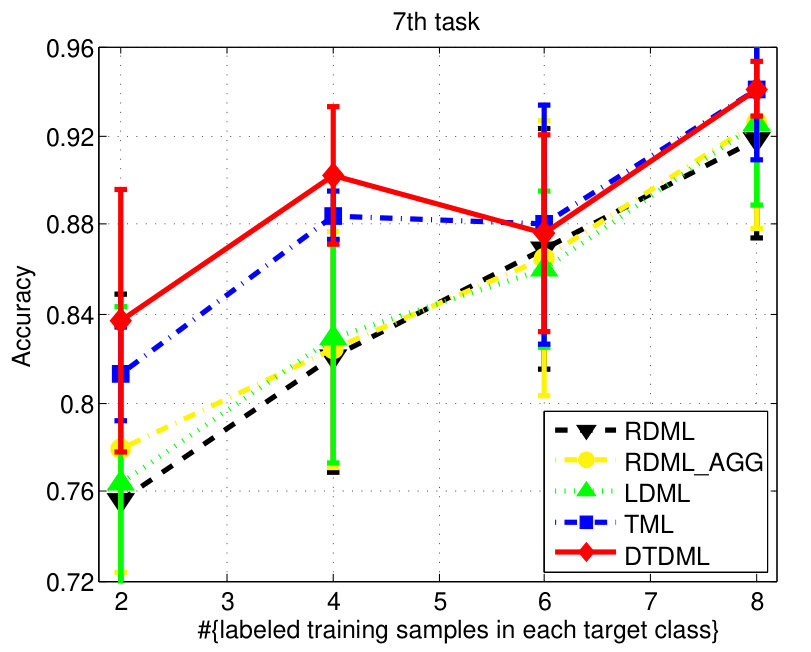 Figure 7
Figure 7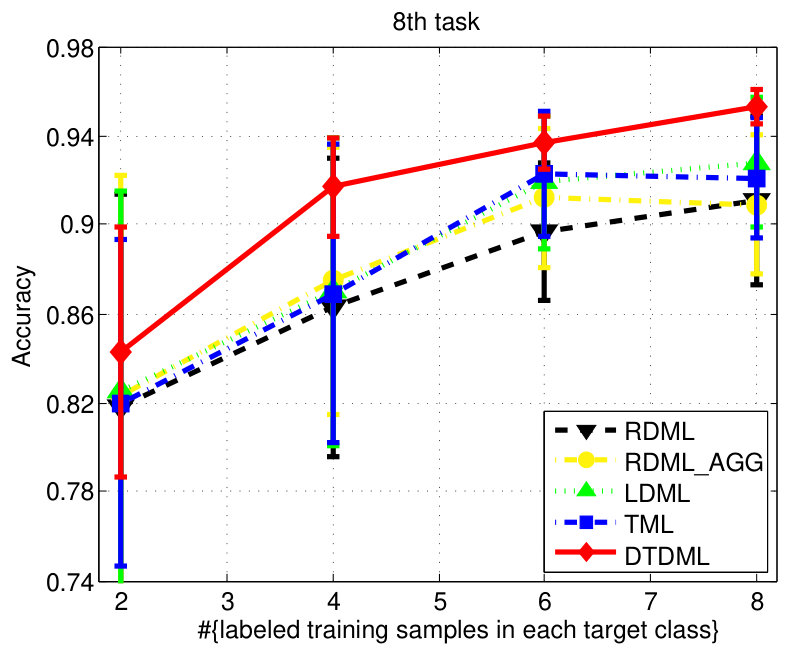 Figure 8
Figure 8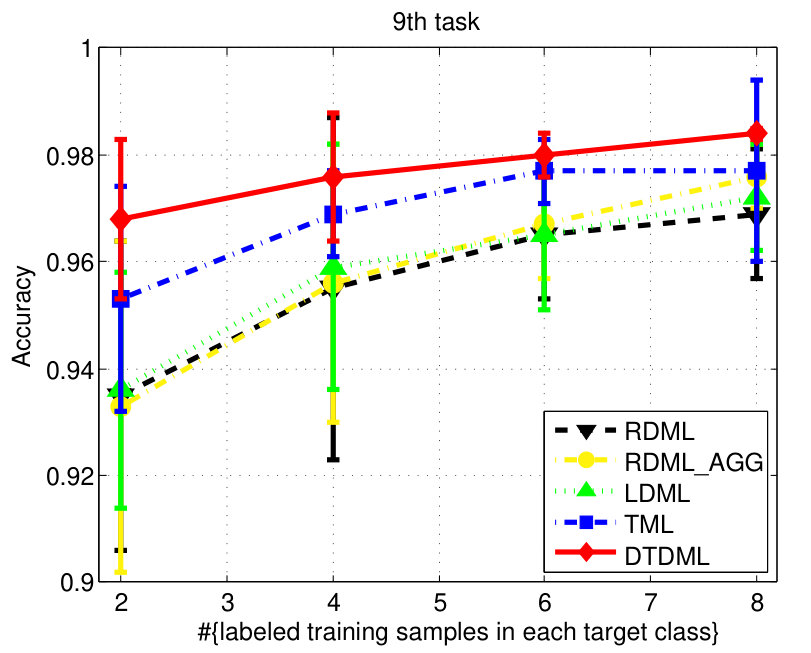 Figure 9
Figure 9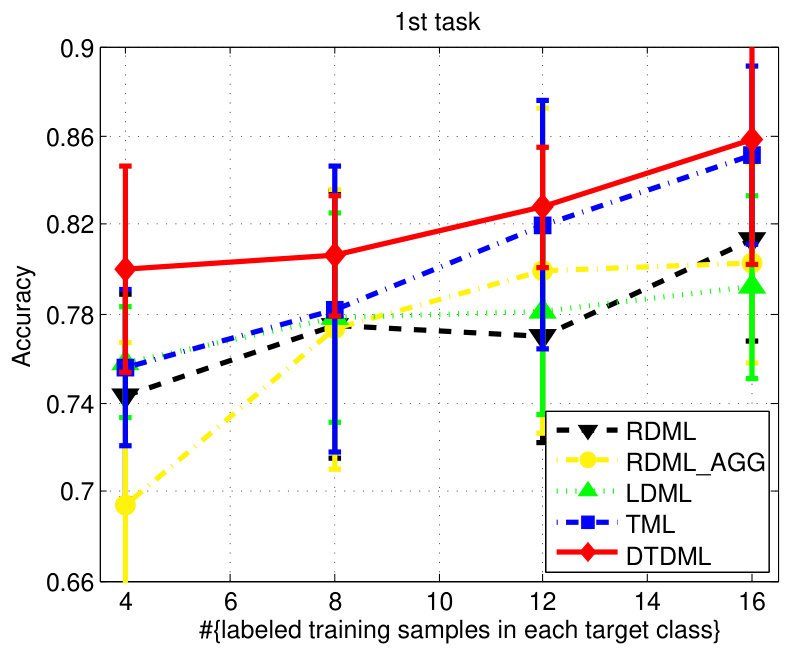 Figure 10
Figure 10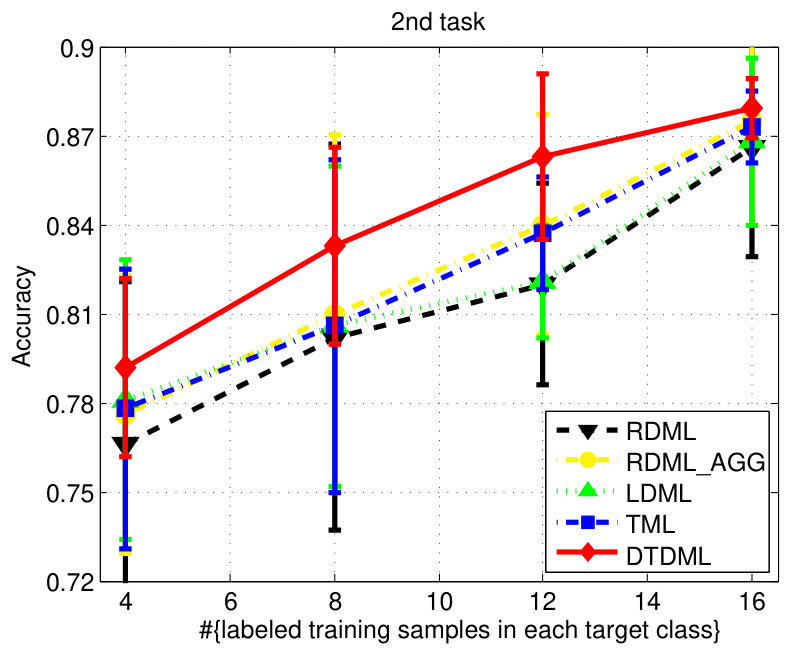 Figure 11
Figure 11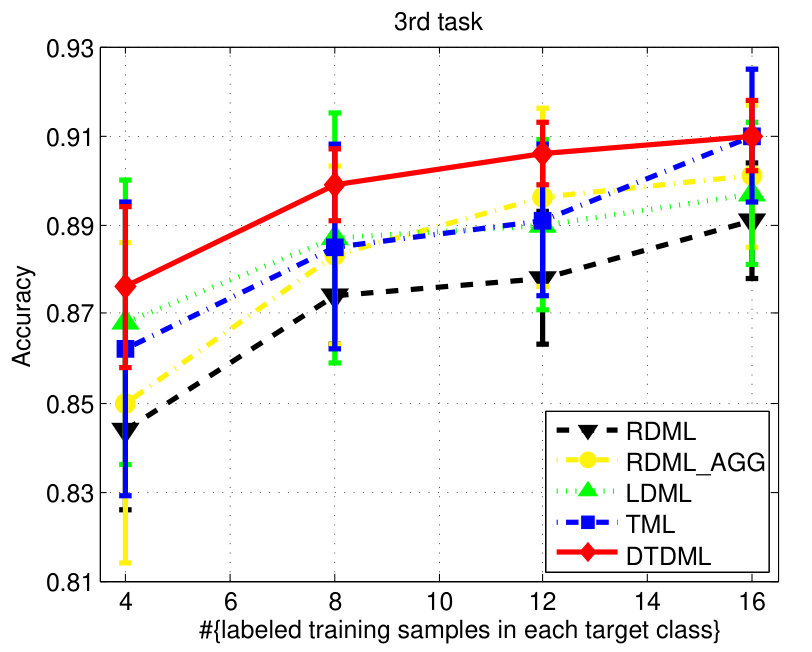 Figure 12
Figure 12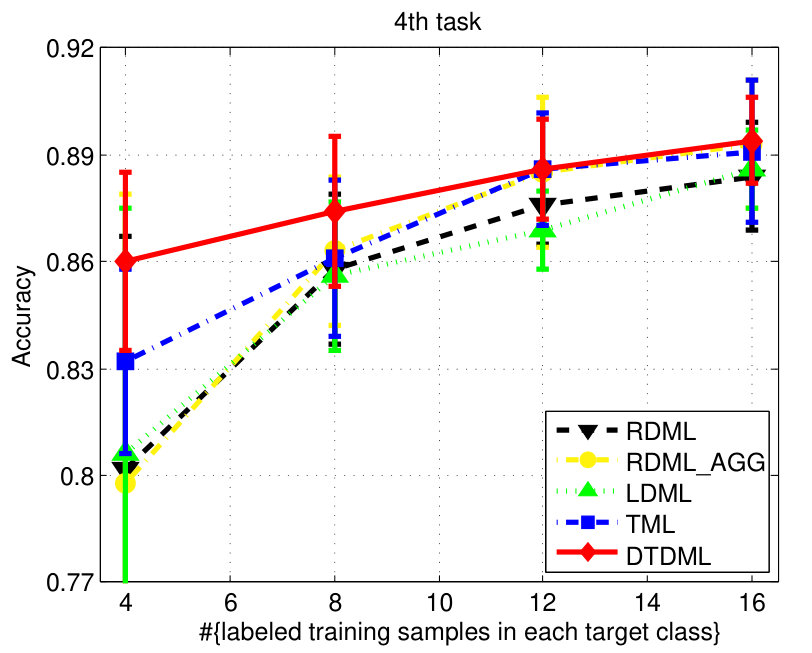 Figure 13
Figure 13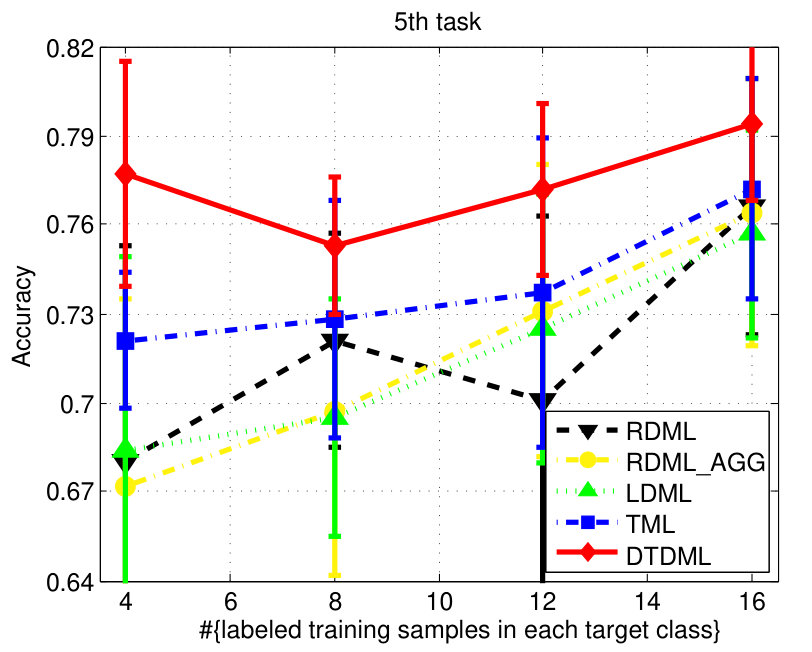 Figure 14
Figure 14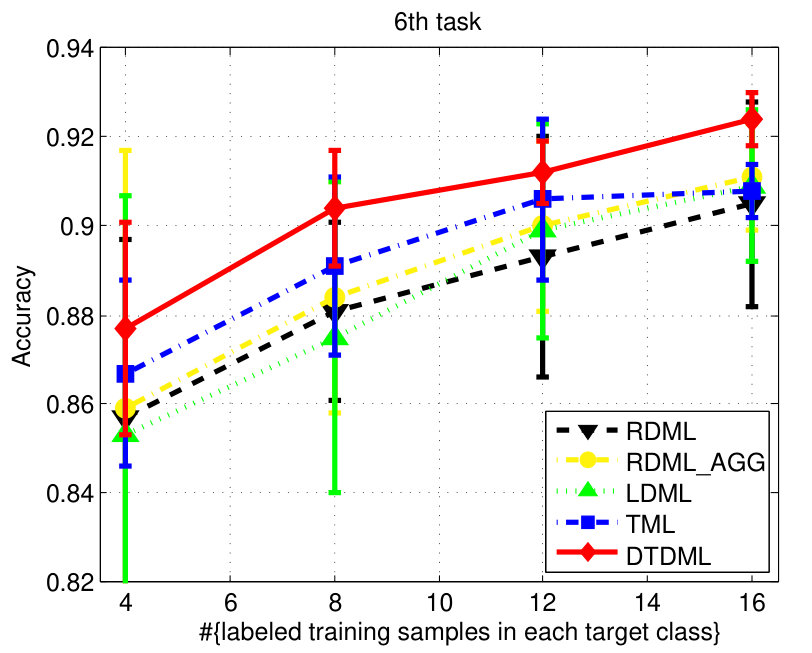 Figure 15
Figure 15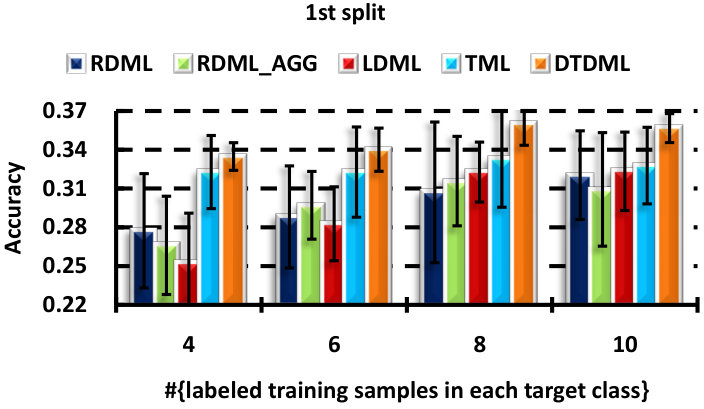 Figure 16
Figure 16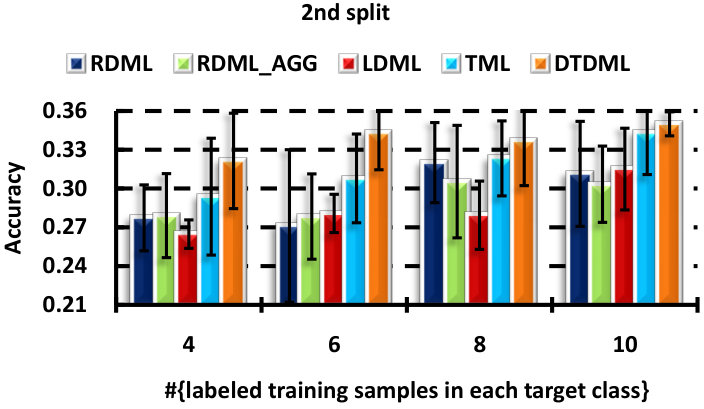 Figure 17
Figure 17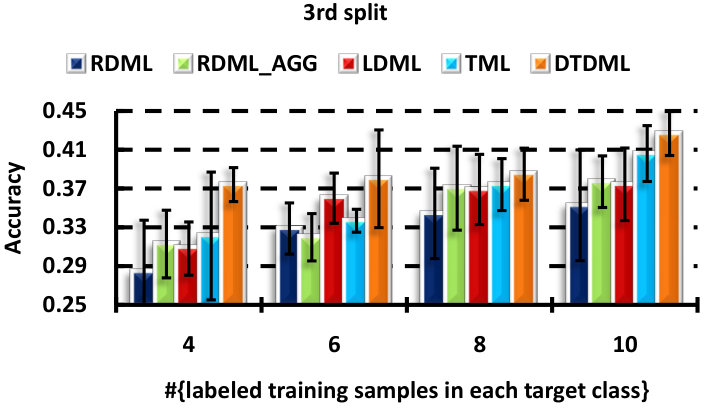 Figure 18
Figure 18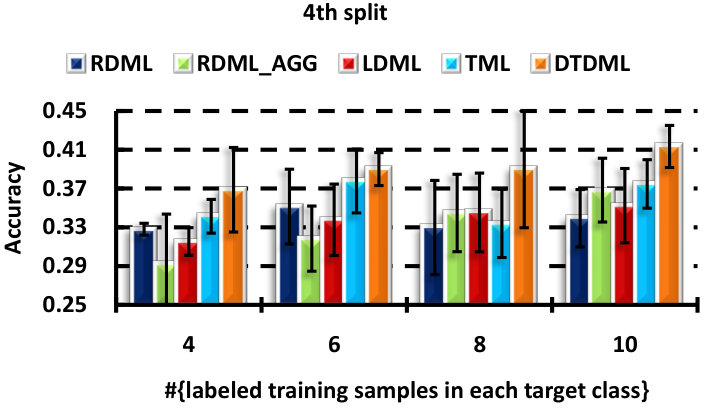 Figure 19
Figure 19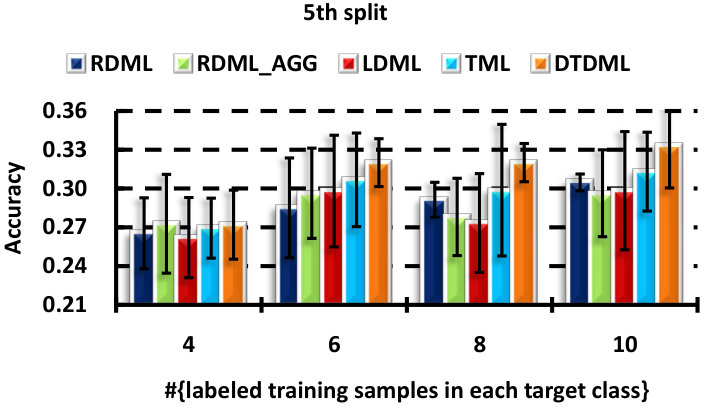 Figure 20
Figure 20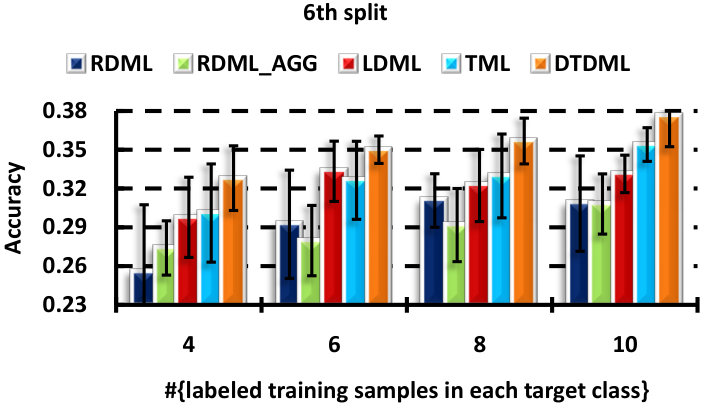 Figure 21
Figure 21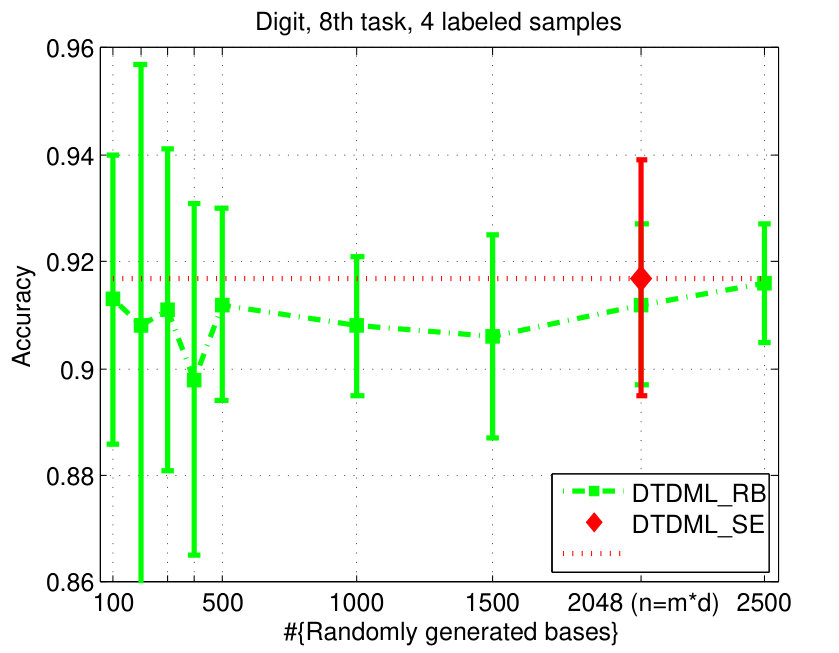 Figure 22
Figure 22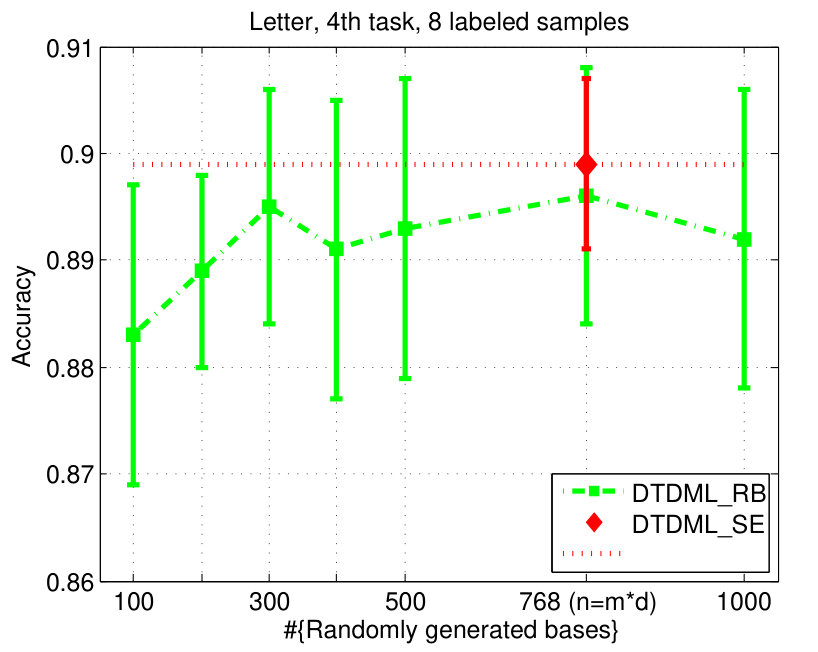 Figure 23
Figure 23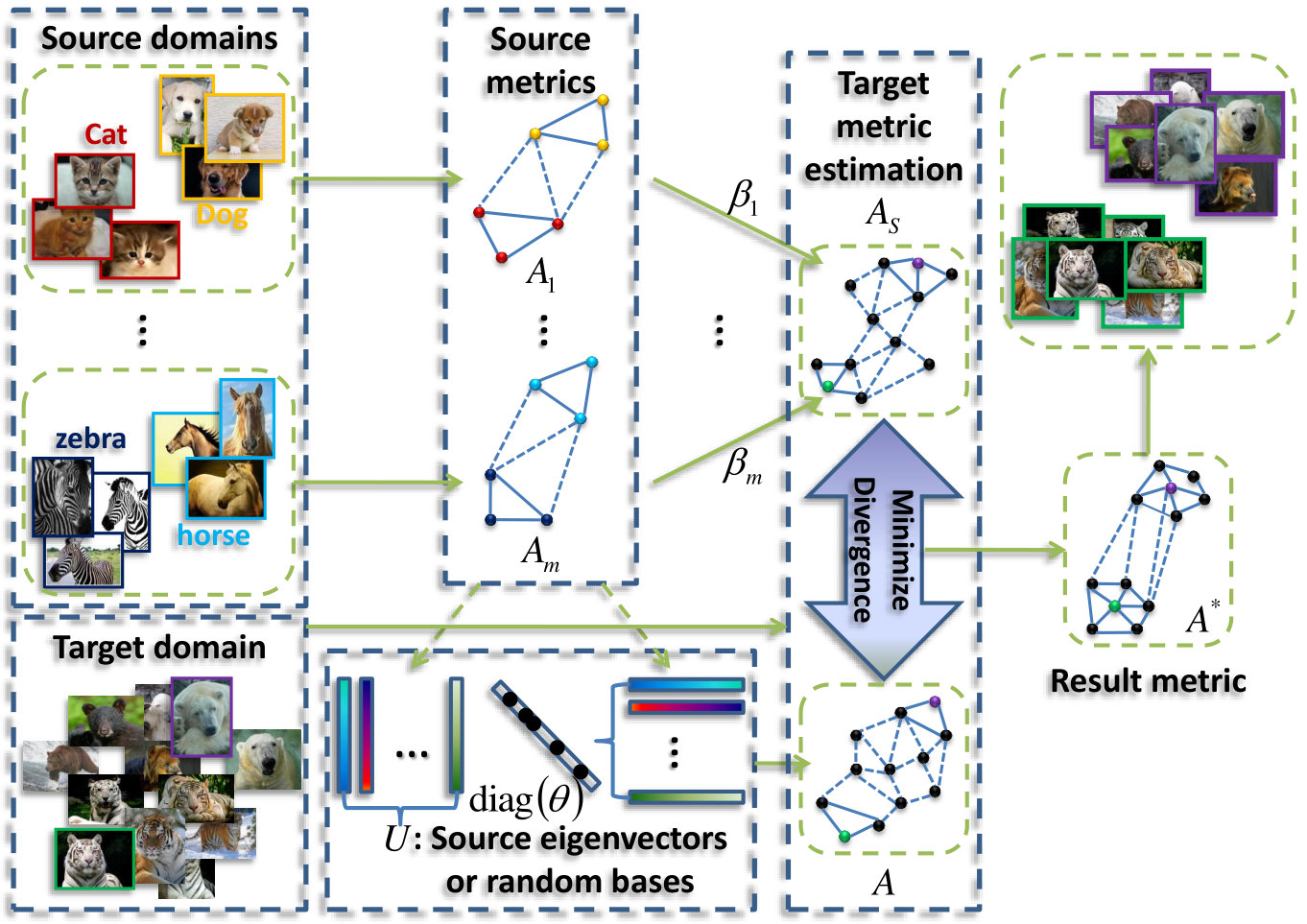 Figure 24
Figure 24Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsDomain Adaptation and Few-Shot Learning · Advanced Image and Video Retrieval Techniques · Multimodal Machine Learning Applications
Decomposition based Transfer Distance Metric Learning for Image Classification
Yong Luo, Tongliang Liu, Dacheng Tao, and Chao Xu, Y. Luo and C. Xu are with the Key Laboratory of Machine Perception (Ministry of Education), School of Electronics Engineering and Computer Science, Peking University, Beijing, 100871, China.T. Liu and D. Tao are affiliated with the Centre for Quantum Computation & Intelligent Systems and the Faculty of Engineering & Information Technology, University of Technology, Sydney, 235 Jones Street, Ultimo, NSW 2007, Australia.©20XX IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works.
Abstract
Distance metric learning (DML) is a critical factor for image analysis and pattern recognition. To learn a robust distance metric for a target task, we need abundant side information (i.e., the similarity/dissimilarity pairwise constraints over the labeled data), which is usually unavailable in practice due to the high labeling cost. This paper considers the transfer learning setting by exploiting the large quantity of side information from certain related, but different source tasks to help with target metric learning (with only a little side information). The state-of-the-art metric learning algorithms usually fail in this setting because the data distributions of the source task and target task are often quite different. We address this problem by assuming that the target distance metric lies in the space spanned by the eigenvectors of the source metrics (or other randomly generated bases). The target metric is represented as a combination of the “base metrics”, which are computed using the decomposed components of the source metrics (or simply a set of random bases); we call the proposed method, decomposition based transfer DML (DTDML). In particular, DTDML learns a sparse combination of the “base metrics” to construct the target metric by forcing the target metric to be close to an integration of the source metrics. The main advantage of the proposed method compared to existing transfer metric learning approaches is that we directly learn the “base metric” coefficients instead of the target metric. To this end, far fewer variables need to be learned. We therefore obtain more reliable solutions given the limited side information and the optimization tends to be faster. Experiments on the popular handwritten image (digit, letter) classification and challenge natural image annotation tasks demonstrate the effectiveness of the proposed method.
Index Terms:
Distance metric learning, transfer learning, decomposition, base metric, image classification
I Introduction
The performance of computer vision, data mining and multimedia systems is heavily dependent on the distance metric between samples. For example, the simple -nearest neighbor (NN) classifier that uses a proper distance metric can be very competitive, and is sometimes superior to other well designed classifiers in many applications such as face recognition, image annotation, etc. In [1], the authors learn a distance metric for nearest neighbor classification so that the nearest neighbors tend to belong to the same class and the samples from different classes are separated by a large margin. The NN classifier based on the learned metric was shown to be comparable to the state-of-the-art multiclass support vector machine (SVM) in several applications including face recognition and text categorization. A weighted nearest neighbor model was proposed in [2] for image annotation that learned a discriminative distance metric. This model was demonstrated empirically to significantly out-perform the state-of-the-art annotation methods on three challenge datasets. Actually, distance metric learning (DML)is also critical to many other popular algorithms, e.g., -means clustering and kernel machines such as SVM.
It is therefore essential to learn a robust distance metric to reveal the data relationships. To achieve this goal, we need a large amount of side information [3] such as the constraints that indicate whether a pair of samples is similar or not. Real-world applications, e.g. image annotation [4, 5], usually have few training samples in the instance space of the target learning task due to the high labeling cost. However, we can easily obtain a large number of labeled samples from the instance spaces of different, but related learning tasks, or from the same instance space with different distribution. Therefore, we can leverage the samples from the related tasks for the target task learning. This is known as transfer learning, and the related tasks are usually called source tasks. This article focuses on utilizing the large quantity of side information in the source tasks to discover a reliable distance metric for the target task.
A number of existing metric learning algorithms [3, 6, 1, 7, 8, 9] can be utilized to learn a useful distance metric for the source task with adequate training data. The training criterion is usually to minimize the distance between two samples if they are from the same class, and otherwise maximize their distance. However, directly applying the learned source metric to the target task may not result in good performance because it may be biased to the sample distribution of the source task, while the data distributions between the source task and target task maybe quite different. More sophisticated methods should therefore be developed to tackle the metric learning problem in the transfer scenario.
This paper proposes a decomposition-based method for transfer distance metric learning (DTDML) by assuming that the target metric (distance metric of the target task) lies in the space spanned by the eigenvectors of the source metrics, or other randomly generated bases. The target metric is represented as a combination of “base metrics” that are derived from the decomposition of the source metrics, or simply computed using the random bases. In particular, DTDML learns a sparse combination of the “base metrics” to construct the target metric by forcing the target metric to be close to an integration of the source metrics. The optimization is performed by alternating between the calculation of the “base metric” coefficients and source metric integration weights, and both of the two sub-problems can be solved efficiently.
Recent research on transfer metric learning includes the following. In [10], the target metric is learned by minimizing the log-determinant divergence between the source metrics and target metric. Zhang and Yeung [11] proposed to learn the task relationships in transfer metric learning, and therefore, allow modeling of negative and zero transfer. These two methods are also optimized using the alternating strategy. However, in each iteration of their alternating procedures, both rely on direct estimation of the target metric and have a large number of variables to be learned. Here, is the feature dimensionality, which is usually very high for an image, while in DTDML, the number of variables is only if we use the eigenvectors of source metrics to construct the ¡°base metrics¡±, and it is common for . Therefore, we can obtain more reliable solutions, given the limited side information in the target task, and the optimization tends to be faster because we have far fewer variables to be estimated. We adopt Nesterov’s optimal method [12] for optimization, so do not require costly semi-definite programming in the learning of the target metric, and have a rapid convergence rate. We performed extensive experiments on two popular handwritten image datasets and the challenge NUS-WIDE [13] Web image dataset. The results confirmed the effectiveness and efficiency of DTDML.
The article is organized as follows. We summarize closely related works in Section II. Section 3 includes the description, formulation, and some theoretical analysis of the proposed DTDML. Extensive experiments are presented in Section 4 and we conclude this paper in Section 5.
II Related Work
II-A Distance metric learning
The goal of distance metric learning (DML) [14] is to learn an appropriate distance function for a given problem.DML is very important for many learning models, e.g., the kNN rule and SVMs. A popular categorization of the DML methods is: supervised DML [3, 15, 6, 1, 7, 9] and unsupervised DML [16, 17], according to the underlying learning paradigm. There are also some semi-supervised works that combine these two paradigms [18, 19]. Our research is built on supervised metric learning, so we only review some representative works in this category.
A classical algorithm for supervised DML was presented in [3], where the authors proposed a constrained convex optimization problem for the metric learning. Relevant component analysis (RCA) [20] utilizes the so-called chunklets to learn a metric by reducing the weights of irrelevant dimensions and amplifying the weights of the relevant dimensions. In [15], the relative comparison constraints that can be easily obtained using the query feedbacks were introduced for DML. The formulation is a quadratic programming problem, which was solved by adapting the standard SVM solver. Neighborhood component analysis (NCA) [6] learns a metric that directly maximizes the nearest neighbor (NN) classification performance. This is achieved by optimizing the leave-one-out classification error on the training set with stochastic neighborhood selection. Large margin nearest neighbor (LMNN) [1] is also based on NN classification, but using a large margin strategy. From the perspective of information theoretic, Davis et al. [7] proposed to learn a Mahanobis matrix that is close to a given prior distance metric in the sense of differential relative entropy, and simultaneously satisfies the distance constraints s. In [9], an efficient online algorithm was presented for regularized DML, in which it was proved that the generalization error can be independent from the feature dimensionality if appropriate constraints are utilized.
II-B Transfer learning
Transfer learning [21] aims to utilize the knowledge obtained from source domains to help the target domain learning, because the training samples in the target domain are insufficient to train a robust model. Dozens of transfer learning algorithms have been proposed in the literature and can be roughly grouped into homogeneous and heterogeneous transfers. The former refers to samples in target and source domains that are drawn from the same instance space but different distributions [22, 23, 24], and the latter refers to samples in target and source domains that are drawn from different, but related instance spaces [25, 26, 27]. This research considers the homogeneous setting, and omits are view of the heterogeneous works.
According to [28], transfer learning can be grouped into instance transfer [23, 29], feature representation transfer [24, 30], parameter transfer [22] and relational knowledge transfer [31], based on “what to transfer”. A kernel mean matching (KMM) method was presented in [23] to match the data distribution of the target domain using the source domain samples. TrAdaboost [29] extends AdaBoost to leverage the abundant source data for the target task learning by iteratively filtering out “bad” source data. Argyriou et al. [24] presented a sparse representation based learning algorithm that learns (or selects) some common features shared across related tasks by using a -norm regularizer. In [30], an unsupervised approach called self-taught learning was proposed to learn features for transfer from unlabeled data. Evgeniou and Pontil [22] learned the parameters of the source and target task simultaneously by assuming the parameter for each task can be separated into two terms, one of which is shared between the source and target task. In [31], the relational knowledge represented with Markov logic networks (MLNs) was transferred from the source domain to the target domain by first constructing a predicate mapping, and then refining the mapped structure in the target domain. There are lots of other works on homogeneous and heterogeneous transfer learning, and we refer to [28] for a more comprehensive survey.
Despite the proposal of many transfer learning algorithms, to the best of our knowledge, only two [10, 11] consider homogeneous distance metric transfer. Zha et al. [10] developed two algorithms for learning a distance metric from a small number of training samples by transferring the prior knowledge from auxiliary data and using a large number of unlabeled samples. Zhang and Yeung [11] proposed a convex formulation for transferring the metric by encoding task relationships in a task covariance matrix. This matrix models positive, negative and zero task correlations. Both algorithms perform well on some applications, but the proposed DTDML will outperform them due the reasons discussed above in Section I. Before presenting the proposed DTDML, we first present certain notations that are used throughout this paper.
Notations: Let denotes the training set for the target task, wherein are vectors of dimension and indicates and are similar/dissimilar to each other. The number of target training samples is very small, so we are also given relevant source training sets, , each contains a large amount of training data. In the homogeneous transfer setting, belong to the same feature space as .
III Decomposition based transfer distance metric learning
Similar to [11], our method is also built on the regularized DML (RDML) [9] and we introduce it here. In DML, we intend to learn a distance function parameterized by a distance metric so that the similarity/dissimilarity between a new instance pair and is reflected by comparing with a constant threshold . In particular, the regularized distance metric learning (RDML) needs to learn a metric by the use of the following optimization problem:
[TABLE]
where is the distance between two samples and , and is the hinge loss, where is set to zero in [9]; The Frobenius norm of the metric A, i.e., is a regularizer that is used to control the model complexity, and is a trade-off parameter. The constraint means that is positive semi-definite.
An online method was presented in [9] to solve problem (1). However, when training data are limited, RDML performs poorly. Our decomposition based transfer distance metric learning (DTDML) method improves RDML by using training data from certain relevant source domains. As we know that, any metric can be decomposed as . This indicates that the optimal target metric can be represented as a linear combination of at most target “base metrics” . However, the target base metrics are not available. We thus propose to approximate the target base metric by combining some base metrics derived from the source metrics. This approximation is reasonable since the source tasks are related to the target task. Actually, we can also approximate the target base metric using some randomly generated bases and the effectiveness will be demonstrated empirically in our experiments. The proposed target metric learning strategy is advantageous compared to the traditional transfer metric learning algorithm, since we have fewer variables to be learned and thus can obtain more reliable solutions.
The diagram of the proposed DTDML is shown in Fig. 1. Given source domains with adequate labeled training data for each, we learn their corresponding metrics independently. These source metrics are weighted and integrated as , which is used for the target metric estimation later. At the same time, we apply singular value decomposition (SVD) to the obtained source metrics and obtain a set of source eigenvectors , with each . Alternatively, can be a set of randomly generated base vectors. We represent the target metric as , which is actually a combination of base metrics . Finally, we learn the source metric integration weights and the base metric combination coefficients simultaneously by minimizing the divergence between and , as well as leveraging the limited labeled training samples in the target domain. The result metric is given by , where is the learned coefficients. The technical details are given below.
III-A Problem formulation
The general formulation of the proposed DTDML for learning the target metric matrix is given by
[TABLE]
where , and the integrated metric . The term is a measure of the difference between and , which are expected to be close. Both and are used to control the model complexity. As depicted above, at most optimal base metrics are needed to construct the optimal target metric. In practice, most base metric combination coefficients are small and approximate to zero. Therefore, many input base metrics of the proposed model are redundant or noisy. We thus constraint the base metric coefficients to be sparse in order to suppress noisy [32]; , and are positive trade-off parameters.
Following [9], we choose and adopt the hinge loss [33] for , i.e., . Here, is set to be zero. Then we find the following optimization problem:
[TABLE]
For notation simplicity, we denote , and as , and respectively, where . We also set so that where with each . Then, the problem (3) becomes
[TABLE]
The solution can be obtained by alternating between two sub-problems (which correspond to the minimization w.r.t. and respectively) until convergence.
III-B Optimization procedure
For fixed , the optimization problem with respect to is formulated as
[TABLE]
where , and . The loss function is non-differentiable. Hence, we firstly smooth the loss and then use Nesterov’s optimal gradient method [12] to solve (5). According to [12], the smoothed version of the hinge loss can be given by
[TABLE]
where and is the smooth parameter. A larger induces a more smooth approximation with larger approximation error. On the other hand, a small induces a slow convergence rate, and thus leads to high time complexity. Therefore, the parameter should neither be too large nor too small, and we empirically set it as 5 in our implementation. The used here is served as a normalization, so that the appropriate value for parameter does not change too much for different . We refer to [34] for a comprehensive study of the smoothed hinge loss. By setting the objective function of (6) to become zero and then projecting on , we obtain the following solution,
[TABLE]
By substituting the solution (7) back into (6), we have the piece-wise approximation of , i.e.,
[TABLE]
We adopt the Nesterov’s method to solve the smoothed version of problem (5) since it can achieve the optimal convergence rate at , which indicates a low time complexity [12, 34]. To utilize Nesterov’s method for optimization, we have to compute the gradient of the smoothed hinge loss to determine the descent direction, as well as the Lipschitz constant to determine the step size of each iteration. We summarize the results in the following theorem.
Theorem 1
The gradient of the smoothed hinge loss is
[TABLE]
The sum of the gradient over all the samples is
[TABLE]
where and . The Lipschitz constant of is
[TABLE]
We leave the proof in the Appendix.
Similarly, let , so we have the following piece-wise approximation of with the smooth parameter :
[TABLE]
The gradient is given by with each and the Lipschitz constant .
In addition, the gradient of is given by
[TABLE]
where and .
Therefore, the gradient of the smoothed , is
[TABLE]
and the Lipschitz constant is
[TABLE]
Finally, based on the obtained gradient and Lipschitz constant, we apply Nesterov’s method to minimize the smoothed primal . In the ’th iteration round, two auxiliary optimizations are constructed and their solutions are used to build the solution of problem (5). We use , and to represent the solutions of DTDML w.r.t. and its two auxiliary optimizations at the ’th iteration round, respectively. The Lipschitz constant of is and the two auxiliary optimizations are,
[TABLE]
where is a guessed solution of . By directly setting the gradients of the two objective functions in the auxiliary optimizations as zeros, we can obtain and , respectively,
[TABLE]
The solution after the ’th iteration round is the weighted sum of and , i.e.,
[TABLE]
The stop criterion is . The initialization and guessed solution are set as the zero vectors.
For fixed , the optimization problem with respect to can be formulated as
[TABLE]
This is a standard quadratic programming problem and can be rewritten in compact form as
[TABLE]
where the constant term has been omitted, with each , and is a symmetric positive semi-definite matrix with the entry . This is a constrained quadratic optimization problem and can be solved efficiently using the coordinate descent algorithm. In each iteration, we select two elements and to update, and leave the others to be fixed. To satisfy the constraint , we have , where and are the solutions of the current iteration. In addition, by using the Lagrangian of (20), we obtain the following updating rule:
[TABLE]
where . The obtained or may violate the constraint , so we set
[TABLE]
III-C Automatic determination of the regularization parameters and
In the proposed model (4), we have three parameters , and to determine. Determination of all these parameters is nontrivial due to the limited number of labeled data available in the target task. Therefore, we present an automatic determination algorithm for the regularization parameters and . This algorithm is inappropriate for the determination of because the corresponding regularization term is a coupling of and .
The algorithm is based on the L-curve, which graphically displays the trade-off between approximation error and solution size as the regularization parameter varies [35, 36]. The proper regularization parameter value is associated with the corner of the curve, where both solution and approximation error have small norms. Following [36], we choose a tangency-based method [35] to find the L-corner since it has a convergence guarantee and the computation is fast. The procedure is shown in Algorithm 1, where and are slopes of the straight line that are tangent to the L-curves, and are set to be one, empirically, in this paper.
The stopping criterion for terminating the algorithm can be the difference of the objective value between two consecutive steps. Alternatively, we can stop the iterations when the variation of and are both smaller than a predefined threshold. Our implementation is based on the difference of the objective value, i.e., if the value is smaller than a predefined threshold, then the iteration stops, where is the objective value of the ’th iteration step.
III-D Theoretical analysis
The generalization error bound of the proposed DTDML algorithm is now provided. We derive the generalization bound using the uniform stability [37].
III-D1 Uniform Stability
Definition 1
(Uniform stability [37])**. An algorithm has uniform stability with respect to the loss function if the following holds
[TABLE]
where is the sample space, is the hypothesis function returned by the algorithm learning with the set of samples , and denotes a set of samples with the ’th element replaced by .
To obtain the uniform stability, we use the Bregman divergence [38]. Bregman divergence is defined for any convex and differentiable function as follows (here denotes the Hilbert space):
[TABLE]
For non-differential loss function, we use the generalized Bregman divergence. The sub-gradient of at (see e.g., [39]) is defined as
[TABLE]
Let be an arbitrary element of . The generalized Bregman divergence to is then defined as
[TABLE]
According to the definition of sub-gradient, we have and for any convex functions and . That is, the generalized Bregman divergence is non-negative and additive.
In addition, to derive the uniform stability, we need the following lemma cited from [9] (Proposition 2 therein):
Lemma 1
For any two distance metrics and , the following inequality holds for any sample and
[TABLE]
Then we present the uniform stability for our model.
Theorem 2
Let be the uniform stability of the developed algorithm for problem (2) and assume for any sample . Then,
[TABLE]
where is the Lipschitz constant of the function .
The detailed proof of Theorem 2 can be found in the Appendix. We then derive the generalization bound via the uniform stability.
III-D2 Generalization error bound
Let denote the sample set and . The empirical risk and expected risk can be defined as and , respectively. A probabilistic bound on the defect is called the generalization bound.
The bound can be derived by utilizing the obtained uniform stability and the following McDiarmid inequality [40].
Theorem 3
(McDiarmid inequality [40]).* Let be a set of independent random variables and assume that there exist such that satisfying*
[TABLE]
for all and any point . Let . Then, for all , the following holds:
[TABLE]
Then we present the generalization bound for our model.
Theorem 4
Let be a set of randomly selected samples and be the distance metric learned by solving (2). With probability at least , we have
[TABLE]
where
[TABLE]
Here, is a solution of and is the largest loss when the distance metric is .
To prove Theorem 4, we need an additional lemma:
Lemma 2
The following two inequalities hold: 1) and 2) .
The detailed proof of Theorem 4 for the bound can be found in the Appendix.
Remark 1
In the upper bound of generalization error, and are learned from the source data. They are the information that was transferred from the source data to the target data.
IV Experimental evaluation
This section outlines the validation of the effectiveness of the proposed DTDML empirically on two popular handwritten image datasets, and a challenging natural image dataset. The first two datasets are obtained from [11]. Specifically, we compare the following methods:
RDML [9]: an online algorithm that has been demonstrated empirically to be effective and quite efficient in learning a distance metric, and can handle high dimensional data. This algorithm serves as a baseline here since it learns only from the target task and leverages nothing from the source tasks.
RDML_AGG: a simple aggregation strategy, which is to learn the target metric by directly applying RDML on the training set that consists of data from both the source and target tasks.
LDML [10]: a transfer distance metric learning algorithm that is based on [7], and is formulated as:
[TABLE]
where and are matrices of the similar and dissimilar constraints. The above formulation contains a semi-definite programming (SDP) problem, and in our re-implementation it is solved using the SDPT3 solver. According to [10], the parameters can be set empirically as and . Therefore, only needs to be tuned.
TML [11]: a recently proposed transfer metric learning algorithm. Similar to [9], an online algorithm is developed to learn the target metric. The task relationship is learned for transfer by solving a second-order cone programming (SOCP) problem using the CVX solver. In addition, the parameters are automatically determined by adopting a Bayesian regularization scheme for the model.
DTDML: the proposed decomposition based transfer distance metric learning. The parameters and are determined automatically and we only need to optimize .
We train the source metrics using the RDML method and all the available data in the source tasks. We split the data into equal training and test sets for the target task. The number of labeled samples that are chosen from the training set is gradually increased to see the performance variation w.r.t. the size of the labeled set. We evaluate the learned target metric by applying the 1-nearest-neighbor classifier on the test set. Ten random choices of the labeled samples are used in our experiments. Both the mean and standard deviation of the accuracies are reported.
IV-A Handwritten image classification
One of the handwritten image datasets we use is the well-known USPS digit dataset111http://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/multiclass.html#usps, which contains samples. Each sample is an image of size in raw pixels, and the feature dimension . We consider nine classification tasks, i.e., 0/6, 0/8, 1/4, 2/7, 3/5, 4/7, 4/9, 5/8, and 6/8, each corresponding to a classification of two digits. One of the nine tasks is treated as the target task and the others are the source tasks (each task is treated as the target task in turn).
The other is a handwritten letter dataset222http://ai.stanford.edu/~btaskar/ocr/, which is a little different from the dataset presented in [11] since it cannot be downloaded immediately, according to the web link provided. The letter dataset used in this paper consists of samples and the feature dimension is . Six binary classification problems, i.e., c/e, m/n, a/g, a/o, f/t, and h/n, are considered. For each task, we randomly select at most positive and negative samples from the dataset. The experimental settings are the same as for those of the digit classification.
IV-A1 A self-comparison of DTDML using source eigenvectors and random bases
As depicted in this paper, the “base metrics” that are utilized to construct the target metric can be derived from either the source eigenvectors, or other randomly generated bases. Therefore, we first investigate the performance of these two strategies, which are denoted as DTDML_SE and DTDML_RB, respectively. For DTDML_SE, the in problem (2) are eigenvectors of the source metrics, so the number of base metrics is fixed as . For DTDML_RB, each is an eigenvector of some random matrix, and thus we can generate arbitrary number of base metrics. We randomly select one task from each of the two handwritten datasets, and report the results in Fig. 2.
The results demonstrate that: 1) Even when the number of random bases is very small, e.g., , we can still obtain satisfactory accuracy; 2) The accuracy of DTDML_RB tends to be higher when is increased, but usually cannot outperform DTDML_SE. To this end, we adopt DTDML_SE in the following experiments. Another reason for choosing DTDML_SE is to avoid tuning the additional parameter .
IV-A2 A comparison with the other algorithms
The classification accuracies of different methods, under different settings on the digit dataset are shown in Fig. 3. We observe from the results that: 1) when the number of labeled training samples increases, the performance of all the compared methods tends to be better (higher mean accuracy and smaller variance); 2) the transfer metric learning algorithms (LDML, TML, DTDML) that utilize the source task information for target task learning are usually superior to RDML, which only learns on the target task. RDML is comparable to LDML on some tasks (e.g., the 5’th, 7’th, and 9’th task), which may be due to the finding of a bad local minima in LDML; 3) Overall, the performance of RDML_AGG, which directly utilizes both the source and target training data without transfer, is better than RDML but worse than the transfer methods. This indicates that the distributions of the source and target datasets are different but related; 4) TML is better than LDML and RDML in most cases, while the proposed DTDML consistently outperforms all of them. In addition, we present the average performance over all settings in Table I. The results indicate a significant improvement compared with TML when using two labeled training samples. The level of improvement drops when more labeled samples are available. This is because DTDML has far fewer variables to learn than TML. The significance of this advantage gradually decreases since variable estimation can be steadily improved with an increase of labeled training samples. This indicates that the proposed algorithm is more suitable for the transfer scenario, since the labeled sample size of the target task is usually very small.
We report the performance on the letter dataset in Fig. 4. Similar to the digit classification, LDML is comparable to RDML and RDML_AGG sometimes, and DTDML is superior to other methods significantly on almost all tasks. The average performance is presented in Table II and we observe a significant improvement compared against TML when using four labeled training samples.
IV-B Web image annotation
This section provides details of the experiments conducted on a natural image dataset NUS-WIDE [13] to further verify the effectiveness of the proposed algorithm. This dataset contains images and the features used in our experiments are -D bag of visual words based on SIFT [41] descriptors. To perform a meaningful transfer, we select animal concepts: bear, bird, cat, cow, dog, elk, fish, fox, horse, tiger, whale, and zebra. For each concept, samples were randomly selected from the dataset.
In this set of experiments, the source task requires annotation of six randomly selected concepts, and the target task requires annotation of all others. Both are multi-class problems, but there is no difference in training compared to the binary case since the sample pairs are used and only the pair labels are needed. A pair of samples is labeled as positive if they are from the same class, and negative otherwise.
We perform six random splits of the concept set, and show the result of each split in Fig. 5. Similar conclusions can be obtained as in the handwritten image classification. DTDML always performs the best for all splits and in particular, we obtain an improvement on the average performance over all splits compared with TML when using four labeled samples.
V Conclusion and Discussion
Existing transfer metric learning approaches usually learn entries of the target metric directly, so the amount of variables is large, especially for the high dimensional image features. To resolve this problem, we have presented a decomposition based method called DTDML that assumes the target metric can be represented as a combination of “base metrics”. DTDML has far less variables because we only have to learn the combination coefficients of the “base metrics”, so better solutions can be obtained. In addition, we adopt Nesterov’s optimal method to learn the coefficients and the optimization is quite efficient.
From the experimental validation on the popular handwritten image datasets and a challenging natural image dataset, we conclude that: 1) both source eigenvectors and random bases can be used to construct the target metric and the former performs a little better; 2) In the transfer scenario, using “base metrics” to induce the target metric is more effective than learning the target metric variables directly, even when the “base metrics” are randomly generated.
Appendix A Proof of Theorem 1
Proof:
According to (7) and (8), we can calculate the gradient of for the ’th sample as
[TABLE]
This leads to (9). Given function , for any and , the Lipschitz constant satisfies
[TABLE]
Hence the Lipschitz constant of can be calculated from
[TABLE]
According to (32), we have
[TABLE]
Therefore,
[TABLE]
To this end, the Lipschitz constant of is calculated as
[TABLE]
This completes the proof. ∎
Appendix B Proof of Theorem 2
Proof:
Let’s denote , where and . It is obvious that both and are convex. We assume and to be the minimizers of and , respectively, where is the collection of examples that replaces with another example .
Because the generalized Bregman divergence is non-negative and additive, we have
[TABLE]
Besides, , where is the subgradient of , so we can obtain
[TABLE]
where , and if and otherwise.
According to (38) and (39), we have
[TABLE]
The second equality holds because and are minimizers of and respectively, which implies that . The last inequality holds because of Lemma 1. By comparing the left and right side of (40), we obtain
[TABLE]
By further utilizing Lemma 1, i.e., , we have
[TABLE]
This completes the proof. ∎
Appendix C Proof of Lemma 2
Proof:
Because is a solution of , so we have
[TABLE]
This leads to
[TABLE]
since . Therefore, we have . The same procedure can be applied to bounding . ∎
Appendix D Proof of Theorem 4
Proof:
Let . It follows from [37] that . Besides,
[TABLE]
where is the largest loss when the distance metric is . The last inequality holds because of Lemma 2.
Given , using the McDiarmid inequality, with probability at least , we have
[TABLE]
In addition, we can conclude that :
[TABLE]
This completes the proof. ∎
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] K. Q. Weinberger, J. Blitzer, and L. K. Saul, “Distance metric learning for large margin nearest neighbor classification,” in Advances in Neural Information Processing Systems , 2005, pp. 1473–1480.
- 2[2] M. Guillaumin, T. Mensink, J. Verbeek, and C. Schmid, “Tagprop: Discriminative metric learning in nearest neighbor models for image auto-annotation,” in IEEE International Conference on Computer Vision , 2009, pp. 309–316.
- 3[3] E. P. Xing, M. I. Jordan, S. Russell, and A. Ng, “Distance metric learning with application to clustering with side-information,” in Advances in Neural Information Processing Systems , 2002, pp. 505–512.
- 4[4] Y. Aytar and A. Zisserman, “Tabula rasa: Model transfer for object category detection,” in IEEE International Conference on Computer Vision , 2011, pp. 2252–2259.
- 5[5] N. Sawant, J. Wang, and L. Jia, “Enhancing training collections for image annotation: an instance-weighted mixture modeling approach,” IEEE Transactions on Image Processing , vol. 22, no. 9, pp. 3562–3577, 2013.
- 6[6] J. Goldberger, S. Roweis, G. Hinton, and R. Salakhutdinov, “Neighbourhood components analysis,” in Advances in Neural Information Processing Systems , 2004, pp. 513–520.
- 7[7] J. V. Davis, B. Kulis, P. Jain, S. Sra, and I. S. Dhillon, “Information-theoretic metric learning,” in International Conference on Machine Learning , 2007, pp. 209–216.
- 8[8] K. Q. Weinberger and L. K. Saul, “Fast solvers and efficient implementations for distance metric learning,” in International Conference on Machine Learning , 2008, pp. 1160–1167.