Direct Modelling of Speech Emotion from Raw Speech
Siddique Latif, Rajib Rana, Sara Khalifa, Raja Jurdak, Julien Epps

TL;DR
This paper introduces a novel deep learning model combining parallel CNN layers with LSTM for raw speech emotion recognition, outperforming traditional feature-based methods on benchmark datasets.
Contribution
It proposes a parallel CNN architecture to better capture temporal resolutions in raw speech for emotion recognition, enhancing existing deep learning approaches.
Findings
Model achieves comparable performance to hand-engineered feature methods.
Parallel CNN layers improve contextual modeling in raw speech.
Results validated on IEMOCAP and MSP-IMPROV datasets.
Abstract
Speech emotion recognition is a challenging task and heavily depends on hand-engineered acoustic features, which are typically crafted to echo human perception of speech signals. However, a filter bank that is designed from perceptual evidence is not always guaranteed to be the best in a statistical modelling framework where the end goal is for example emotion classification. This has fuelled the emerging trend of learning representations from raw speech especially using deep learning neural networks. In particular, a combination of Convolution Neural Networks (CNNs) and Long Short Term Memory (LSTM) have gained great traction for the intrinsic property of LSTM in learning contextual information crucial for emotion recognition; and CNNs been used for its ability to overcome the scalability problem of regular neural networks. In this paper, we show that there are still opportunities to…
Click any figure to enlarge with its caption.
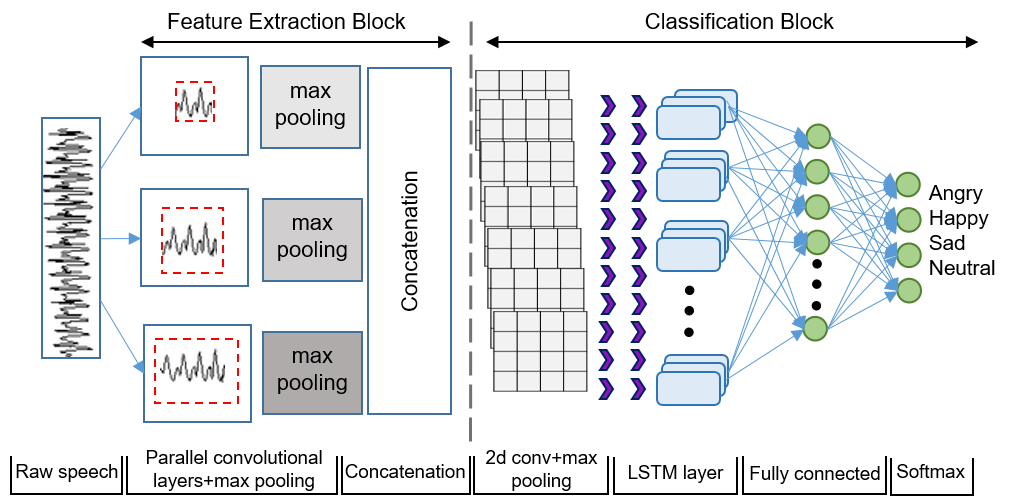 Figure 1
Figure 1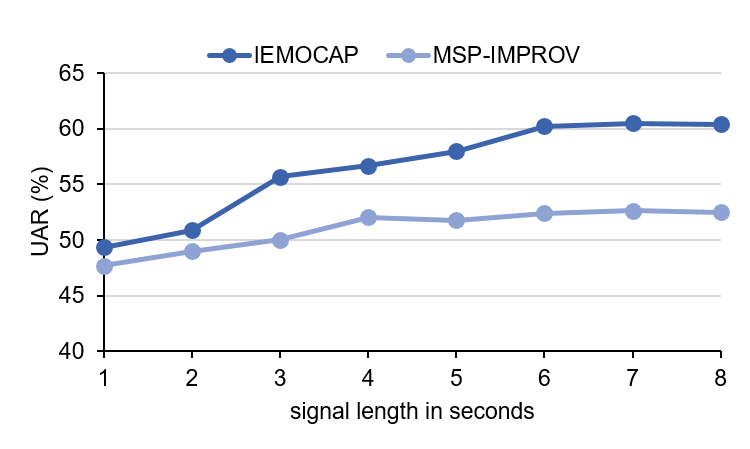 Figure 2
Figure 2| Method | UAR (%) | |
| IEMOCAP | MSP-IMPROV | |
| SVM+MFCC | 57.152.1 | 52.383.7 |
| SVM+LogMel | 58.162.6 | 52.543.1 |
| SVM+GeMAPS | 57.923.2 | 52.103.9 |
| SVM+eGeMAPS | 58.762.6 | 52.414.6 |
| CNN+MFBs [16] | 61.8 3.0 | 52.6 3.8 |
| Proposed+ raw | 60.233.2 | 52.43 4.1 |
| TDNN-LSTM+ raw (no aug) [12] | 48.84 | — |
| SimpleNet-CNN+ raw (no aug) [40] | 52.9 | — |
| Proposed+ raw (no aug) | 56.723.3 | 48.54 3.8 |
| Layers | UAR (%) | |
|---|---|---|
| IEMOCAP | MSP-IMPROV | |
| 1 | 57.362.3 | 48.363.1 |
| 2 | 58.322.8 | 50.123.5 |
| 3 | 60.233.2 | 52.434.1 |
| 4 | 59.133.1 | 52.214.0 |
| Pooling | UAR (%) | |
|---|---|---|
| IEMOCAP | MSP-IMPROV | |
| max | 60.233.2 | 52.434.1 |
| 59.722.8 | 50.253.0 | |
| Average | 59.503.0 | 51.94 3.2 |
| Method | UAR (%) | |
|---|---|---|
| IEMOCAP | MSP-IMPROV | |
| DNN | 53.362.0 | 48.363.2 |
| LSTM-DNN | 56.322.6 | 49.583.0 |
| LSTM | 58.722.9 | 51.213.4 |
| CNN-DNN | 58.432.8 | 50.443.1 |
| CNN-LSTM | 59.233.0 | 52.363.6 |
| CNN-LSTM-DNN | 60.233.2 | 52.434.1 |
| CNN | 58.522.6 | 50.843.6 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Direct Modelling of Speech Emotion from Raw Speech
Abstract
Speech emotion recognition is a challenging task and heavily depends on hand-engineered acoustic features, which are typically crafted to echo human perception of speech signals. However, a filter bank that is designed from perceptual evidence is not always guaranteed to be the best in a statistical modelling framework where the end goal is for example emotion classification. This has fuelled the emerging trend of learning representations from raw speech especially using deep learning neural networks. In particular, a combination of Convolution Neural Networks (CNNs) and Long Short Term Memory (LSTM) have gained great traction for the intrinsic property of LSTM in learning contextual information crucial for emotion recognition; and CNNs been used for its ability to overcome the scalability problem of regular neural networks. In this paper, we show that there are still opportunities to improve the performance of emotion recognition from the raw speech by exploiting the properties of CNN in modelling contextual information. We propose the use of parallel convolutional layers to harness multiple temporal resolutions in the feature extraction block that is jointly trained with the LSTM based classification network for the emotion recognition task. Our results suggest that the proposed model can reach the performance of CNN trained with hand-engineered features from both IEMOCAP and MSP-IMPROV datasets.
Index Terms: speech emotion, raw speech, convolutional neural networks.
1 Introduction
Automatic speech emotion recognition has many important applications, such as diagnosis of depression [1], distress [2], monitoring mood state for bipolar patients [3, 4], and so on. However, emotion recognition from speech is a complex task as emotional expression could vary significantly due to a multitude of contextual factors including culture, age, gender, accent, surrounding environment and so on [5].
Research on speech emotion recognition primarily focuses on hand-engineered acoustic features as well as on designing efficient machine learning based models for accurate emotion prediction [6, 7]. In particular, building an appropriate feature representation and designing an appropriate classifier for these features have often been treated as separate problems in the speech recognition community. One drawback of this approach is that the designed features might not be best for the classification objective at hand. LogMel features have been the most popular feature to train Deep Neural Networks (DNNs) and their variants to date. The Mel filter bank is inspired by auditory and physiological evidence of how humans perceive speech signals [8]. However, based on the argument in [9] a filter bank that is designed from perceptual evidence is not always guaranteed to be the best filter bank in a statistical modelling framework where the end goal is emotion classification. These have led to a recent trend in the machine learning community towards deriving a representation of the input signal directly from raw, unprocessed data. The network learns an intermediate representation of the raw input signal automatically that better suits the task at hand and hence lead to improved performance compared to the classical methods.
A challenging issue in emotion recognition from speech is the efficient modelling of long temporal context [10]. This is because emotions are context-dependent [11] and emotion specific information is embedded in the long temporal contexts [12]. LSTM [13] can model a long range of contexts due to the presence of a special structure called the memory cell. This is why researchers frequently use LSTM for speech emotion recognition [14]. Interestingly, convolutional layer filters can also be used to capture contextual information, which has shown great success in natural language processing (NLP) for sentence classification [15]. In particular, multiple width filters can help improve performance because the model can simultaneously learn multiple contextual dependencies. This has also been validated for speech emotion recognition [16]. However, these studies have generally used multiple width filters in a single layer. Recent studies have shown that parallel convolutional layers can extract temporal information at multiple resolutions from the given data, which can improve the performance of the system [17, 18]. In contrast to using multiple filters in a single layer, in this paper we propose the use of parallel convolutional layers with different filter width to capture diverse contextual information from raw speech.
The key contribution of this paper is the proposed network that consists of a multi-temporal CNN stacked on LSTM. The proposed construct of CNN provides an additional layer for capturing contextual information at mulitple temporal resolutions and is designed to complement LSTM for modelling long-term contextual information from raw speech.
2 Related Work
Many studies have considered the use of Deep Neural Networks (DNN) models for processing raw waveforms directly, but the majority of these are in the field of automatic speech recognition (ASR). Dimitri et al. [19] used a framework of CNN for ASR and achieved competitive results to standard short-term spectral features. The authors showed that convolution layers act like a data-driven filterbank and can model spectral envelope of raw speech. The authors in [20] showed that CNN can learn more generalised features across different databases from raw speech compared to artificial neural networks and other feature-based approaches. The complementary approach of using CNN and LSTM jointly for raw speech has been evaluated in [9, 21]. The authors have shown that the use of LSTM with CNN, helps to reduce the word error rate and achieve competitive performance to the standard feature-based approaches. Besides ASR, researchers have highlighted the feature learning power of different DNN models from raw speech for many other tasks including environmental sound recognition [22], speaker identification [23, 24], and automatic tagging [25].
Few studies have attempted to model emotions using raw speech with results not quite matching feature-based methods. For instance, two studies [26, 14] used end-to-end models by combining CNN and LSTM layers for predicting valence-activation on RECOLA database [27] and achieved promising results. Sarma et al. [12] evaluated time-delay neural network (TDNN) based multiple architectures to model long term dependencies of speech emotion and provided promising results on IEMOCAP dataset. In [16] multi-width filter CNN was applied to hand-engineered features (Mel Filterbanks (MFBs) which provided competitive results to the systems trained on popular emotional feature sets. In contrast to previous studies [12, 14, 26], we propose a parallel configuration of convolutional layers with multiple filter lengths in feature extraction block to harness multiple temporal resolutions and simultaneously extract multiple contextual dependencies. The classification block is jointly optimised with the feature extraction block to achieve the emotion classification objective.
3 Model
Our model consists of two parts: a feature extraction block and a classification block, as shown in Figure 1.
3.1 Feature extraction block
In the feature extraction block, we use parallel convolutional layers with multiple filter lengths to capture both long-term and short-term interactions directly from raw speech. Given an input utterance, the convolutional layer identifies emotionally salient regions using finite impulse-response filters, since multiple filters with different lengths can capture diverse contextual dependencies simultaneously from the same region [16].
In our model, parallel convolutional layers take as input of raw speech and create different sequences of feature maps by convoluting with a set of filters of different lengths. The output of convoluting each layer consisting of filters having widths and strides are computed using (1).
[TABLE]
Here is the rectified linear function (ReLU) [28]. Another important component of our classification block is a nonlinear subsampling layer. For this purpose, we use max pooling layer over time which takes the output of each convolutional layer. Max pooling layer reduces the temporal resolution and selects the most salient features by locally aggregating the feature map of each convolutional layer. We then concatenate the outputs of these three pooling layers to get the features with multiple temporal resolutions and provide that to the classification block.
3.2 Classification Block
We construct our classification block by stacking CNN layer on LSTM. This is motivated by the fact that performance of LSTM can be improved by feeding it with a good representation [21]. LSTM is specialised to model a long range of contexts due to their gated architecture [29, 30]. Emotion in speech are context-dependent, therefore, the contexts modelling abilities of LSTM are utilised to learn the temporal structure of emotions from the given features maps. We pass the outputs of LSTM to the fully connected layers as it transforms the output of LSTM to a more discriminative space that helps the model for target prediction [21]. In this way, our classification block is jointly empowered by the convolutional layer to capture high-level abstraction, the LSTM layer for long-term temporal modelling, and finally the fully connected layer for learning discriminative representations.
4 Experimental Setup
4.1 Dataset
We evaluated our model on two popular datasets: MSP-IMPROV [31] and IEMOCAP [32]. Both of these datasets contain dyadic interactions between actors. We only used audio recordings from these datasets.
4.1.1 IEMOCAP
This corpus contains five sessions, where each session has utterances from two speakers (one male and one female). Overall, there are 10 unique speakers. We used four emotions including angry, happy, neutral and sad. To be consistent with previous studies [16], we merged excitement with happiness and considered one class, happy.
4.1.2 MSP-IMPROV
The MSP-IMPROV dataset contains six sessions, where each session comprises of utterances from two speakers, one male, and one female. There are four emotion categories in MSP-IMPROV: angry, neutral, sad, happy, all were used in the experiments.
4.2 Data Pre-processing and Augmentation
We used the data augmentation to increase the size of training set. In particular, we created two different copies of each utterance following the approach in [33]. For a given training utterance, we created two versions by applying the speed effect at the factors of and . Sox111http://sox.sourceforge.net/ audio manipulation tool was used for data augmentation. For both datasets, we removed the non-speech intervals at the beginning and end of each utterance as was done in [24].
4.3 Model Configuration
We implemented our model using Tensorflow library. In the front end, we selected three parallel striding convolutional layers with different filter widths using the validation data. We used one layer with filter window of 25ms with a shift of 10ms to match the standard frame size of emotional feature extraction process. Smaller and larger filters (than the standard) can also extract useful information from raw speech using CNNs [19, 23, 34]. Therefore, we also used two other layers with filter sizes 15ms and 100ms. The filter sizes were chosen using validation data. We used 40 filters in all three layers. We applied max pooling layer after each convolutional layer to extract the most descriptive features. The feature extraction was jointly optimised with the classification block where we used a combination of CNN and LSTM. First layer of classification block was a 2d convolutional layer, with filter size (2,2) and filter number 32, followed by the max pooling layer with the pooling size (2,2). The feature maps were then given to the LSTM layer with 128 cells for temporal modelling. Finally, we used one fully connected layer with 1024 units before the softmax layer.
Before applying non-linearity in each convolutional layer, we used batch normalisation (BN) [35] layers to alleviate the problem of exploding and vanishing gradients. For regularisation, we used dropout layer after LSTM layer, with a dropout rate of 0.3. We randomly initialised the weights of our network following the techniques in [36]. Similar to [16] we trained all models using the training set, and validation set was used for hyper-parameter selection. For minimisation of cross-entropy loss function, we used RMSProp optimiser [37], with an initial learning rate of . If the UAR on the validation set did not improve after 5 epochs, we halved the learning rate. We stopped the process if the UAR did not improve for 20 consecutive epochs. For each model used in this work, we repeated the evaluation 10 times and averaged their predictions.
5 Experiments and Results
This section reports the experimental validation of the proposed model for speech emotion recognition. We used leave-one-speaker-out scheme for both datasets and report unweighted average recall (UAR) for both datasets. UAR is a widely used metric used for speech emotion recognition due to class imbalanced datasets. In each session, we used utterances from one speaker for testing and utterances from the other speaker for validation and early stopping [16]. The remaining utterances from all speakers were used for training the model. For fair comparison with [16], we used the same data augmentation technique [33] to increase the size of the training set.
For baseline results, we trained SVMs using well-known feature sets, such as, MFCC, LogMel, GeMAPS and eGeMAPS [38] for emotion classification. These features were extracted using openSmile toolkit [39]. We used an RBF kernel and performed grid search using validation data to pick the optimal hyper-parameters. For a fair comparison with our model, we used the same augmented data for all SVM experiments.
Table 1 shows the comparison of results using different methods, and also shows the comparison with previous studies [16, 12, 40]. A direct comparison with some of these studies is not possible due to the difference in data augmentation methods used in the studies, which may affect the results. For example, [12] used different data augmentation scheme, while Gong et al. [40] did not use any data augmentation. We therefore compare our results with these studies [16, 12, 40] without any data augmentation and separate from other results using a double line in Table 1.
6 Analysis and Discussion
6.1 Convolutional Layers Analysis
The convolutional layers play a crucial role in the performance of emotion recognition from raw speech [12, 24]. It is interesting to see the effect of using parallel convolutional layers for capturing multi-temporal resolution features from the raw speech in the feature extraction block. We evaluated different number (1,2,3,4) of parallel convolutional layers and reported the associated results in Table 2.
The results show that the proposed multi-temporal resolution model with parallel convolutional layers outperforms the single layer architecture. The best results are obtained using 3 parallel layers, which suggests that a suitable number of parallel layers needs to be determined empirically for specific problems.
6.2 Pooling Strategies
Since the pooling layer is used for generalisation of time-domain averaging [9], we evaluated three different pooling operations including max, and average. Table 3 shows that max pooling outperformed others. All results reported in this paper, therefore, use max pooling.
6.3 Analysing Classification Block
In this section, we analyse the effect of using different type of layers in the classification block. Results are reported in Table 4 for both datasets using different configuration of layers in the classification block. In all these setups, we use the same feature extraction block consisting of three parallel convolutional layers that provide multiple temporal dependencies. The architectural changes are only made on the classification block. We trained different configuration of classification blocks including three DNNs (1024-512-512), two LSTMs (256-256), and three CNN layers (256 feature map). We also evaluated other combinations, such as, LSTM-DNN (2 LSTM, 1 DNN), CNN-DNN (2 CNN, 1 DNN), CNN-LSTM (1 CNN, 2 LSTM), and CNN-LSTM-DNN (1 CNN, 1 LSTM, and 1 DNN). All these combinations were trained using the evaluation recipe described in Section 4.3.
In Table 4, we observe that only using DNN layers in classification block hurts the performance of the model. However, their combination with LSTM and CNN is beneficial for the model performance. We achieved the best performance with the classification block while using the combination of CNN, LSTM and DNN layer. This shows that our proposed construct of the classification block, where convolutional layer captures high-level abstraction, LSTM layer performs long-term temporal modelling, and the fully connected layer performs discriminative representations, offers improvements in the performance of emotion recognition.
6.4 Input Length Analysis
We evaluated the performance of our proposed model for different signal lengths. Results are presented in Figure 2.
Signal length is an important aspect since short signals create many small segments which need to be merged, whereas long signals can potentially cause buffer overflow in embedded systems with limited memory. For both IEMOCAP and MSP-IMPROV, UAR increases with the increase in speech signal length in general. When the signal length is small (1 or 2 seconds) emotion recognition can be performed with a small accuracy loss. However, we observe that speech utterance signal of 6 seconds offers the best UAR for both datasets.
6.5 Classification Performance Analysis
We compare the results of our proposed model with that of SVM trained on widely used state-of-art feature sets including MFCC, LogMel, GeMAPS, eGeMAPS in Table 1. It can be observed that our proposed architecture modelling multi-temporal feature from raw speech can achieve better performance compared to the powerful classifier SVM using state-of-the-art features.
We also compare our results with three relevant studies [16, 12, 40] and present the results in Table 1. In [16] authors used Mel Filterbank (MFB) features as the input to CNNs and showed that CNNs with these hand-engineered features can produce competitive results to the popular feature sets. In contrast, we used raw speech as input to the model and jointly optimised the feature extraction with the classification network. We achieved comparable results with this study on both datasets as presented in Table 1. This shows that capturing multi-temporal dependencies from the raw speech using parallel CNN layers helps to achieve comparable performance to CNNs trained on hand-engineered features. Two other recent studies [12, 40] used raw speech and evaluated their approach on IEMOCAP dataset. We are achieving better results compared to them when data augmentation is not used. Other recent studies [17, 41] used CNN based models and achieved UAR of 61.9% and 61.7% on IEMOCAP dataset using spectrograms as the input. Compared to these studies, we are achieving 60.23% directly using raw speech.
7 Conclusions
In this paper, using two widely used emotion corpus: IEMOCAP and MSP-IMPROV, we show that the proposed network of parallel multi-layer CNN stacked on an LSTM offers, (1) better accuracy when compared to existing methods using raw speech waveform for emotion recognition and (2) comparable accuracy to existing methods using state-of-the-art hand-engineered features. We claim that our proposed construct of CNN having parallel convolutional layers with multiple filter lengths capture both long-term and short-term interactions and help us achieve this performance. In our future studies, we aim to further investigate ways to improve emotion recognition accuracy using raw speech. We also aim to perform run-time and computational complexity comparisons between methods using raw-speech and hand-engineered features and report the accuracy-complexity trade-off.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Y. Zhu, Y. Shang, Z. Shao, and G. Guo, “Automated depression diagnosis based on deep networks to encode facial appearance and dynamics,” IEEE Transactions on Affective Computing , vol. 9, no. 4, pp. 578–584, 2018.
- 2[2] R. Rana, S. Latif, R. Gururajan, A. Gray, G. Mackenzie, G. Humphris, and J. Dunn, “Automated screening for distress: A perspective for the future,” European Journal of Cancer Care , p. e 13033, 2019.
- 3[3] J. Gideon, E. M. Provost, and M. Mc Innis, “Mood state prediction from speech of varying acoustic quality for individuals with bipolar disorder,” in 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2016, pp. 2359–2363.
- 4[4] R. Rana, “Context-driven mood mining,” in Mobi Sys 2016 Companion-Companion Publication of the 14th Annual International Conference on Mobile Systems, Applications, and Services . Association for Computing Machinery (ACM), 2016, p. 143.
- 5[5] R. Rana, M. Hume, J. Reilly, R. Jurdak, and J. Soar, “Opportunistic and context-aware affect sensing on smartphones,” IEEE Pervasive Computing , vol. 15, no. 2, pp. 60–69, Apr 2016.
- 6[6] B. W. Schuller, “Speech emotion recognition: Two decades in a nutshell, benchmarks, and ongoing trends,” Communications of the ACM , vol. 61, no. 5, pp. 90–99, 2018.
- 7[7] S. Latif, R. Rana, S. Younis, J. Qadir, and J. Epps, “Transfer learning for improving speech emotion classification accuracy,” ar Xiv preprint ar Xiv:1801.06353 , 2018.
- 8[8] S. Davis and P. Mermelstein, “Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences,” IEEE transactions on acoustics, speech, and signal processing , vol. 28, no. 4, pp. 357–366, 1980.