Time Domain Audio Visual Speech Separation
Jian Wu, Yong Xu, Shi-Xiong Zhang, Lian-Wu Chen, Meng Yu, Lei Xie,, Dong Yu

TL;DR
This paper presents a novel time-domain audio-visual speech separation architecture that extends previous models to improve target speaker extraction by integrating lip video data, achieving significant Si-SNR improvements.
Contribution
It introduces a new multi-modal time-domain architecture for speech separation that combines audio and visual cues, extending classical methods from frequency to time domain.
Findings
Achieves over 3dB Si-SNR improvement in two-speaker cases.
Achieves over 4dB Si-SNR improvement in three-speaker cases.
Outperforms audio-only and frequency-domain audio-visual models.
Abstract
Audio-visual multi-modal modeling has been demonstrated to be effective in many speech related tasks, such as speech recognition and speech enhancement. This paper introduces a new time-domain audio-visual architecture for target speaker extraction from monaural mixtures. The architecture generalizes the previous TasNet (time-domain speech separation network) to enable multi-modal learning and at meanwhile it extends the classical audio-visual speech separation from frequency-domain to time-domain. The main components of proposed architecture include an audio encoder, a video encoder that extracts lip embedding from video streams, a multi-modal separation network and an audio decoder. Experiments on simulated mixtures based on recently released LRS2 dataset show that our method can bring 3dB+ and 4dB+ Si-SNR improvements on two- and three-speaker cases respectively, compared to…
Click any figure to enlarge with its caption.
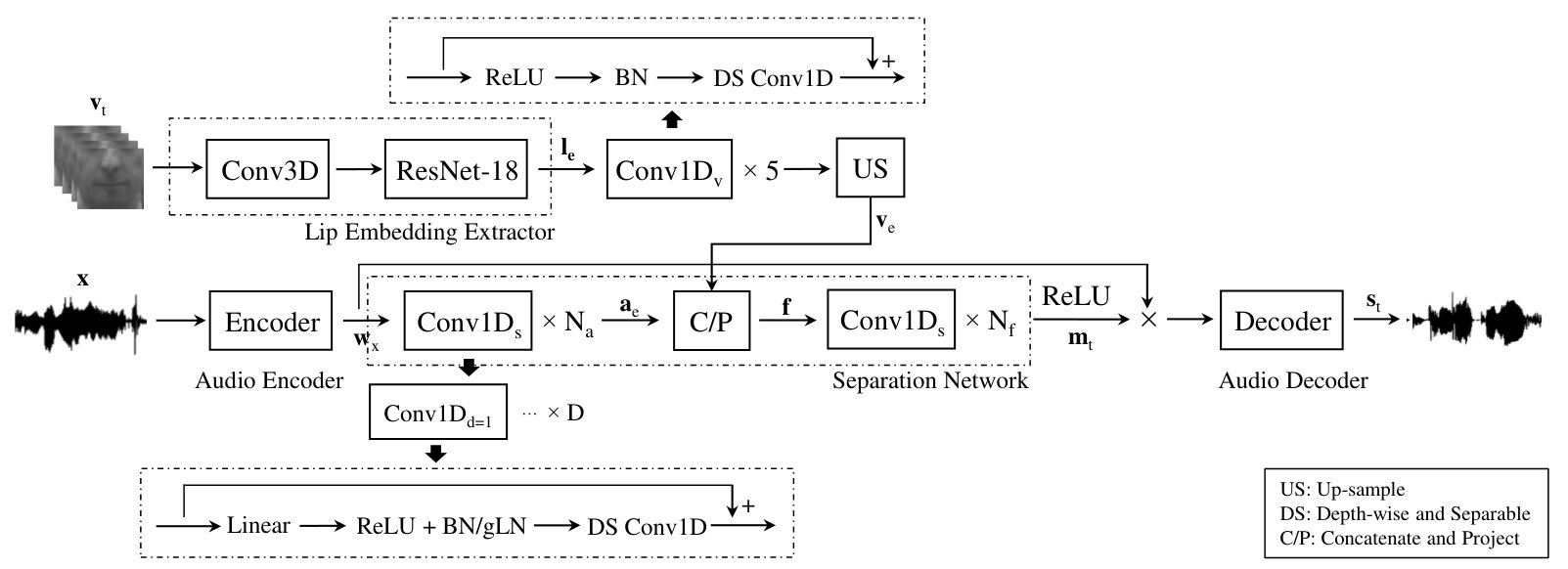 Figure 1
Figure 1| Dataset | #utts | Source | #simu |
|---|---|---|---|
| training | 16445 | training | 40k |
| validation | 3000 | training | 5k |
| test | 740 | validation+test | 3k |
| Method | Configuration | #Param | Si-SNR | |
|---|---|---|---|---|
| 2spkr | 3spkr | |||
| Mixed | - | - | 0.01 | -3.33 |
| Oracle PSM | 512/256/hann | - | 14.43 | 11.54 |
| Oracle IRM | 512/256/hann | - | 11.33 | 8.18 |
| uPIT-BLSTM222https://github.com/funcwj/setk/tree/master/egs/upit | 3600 | 22M | 7.13 | 1.20 |
| Conv-TasNet333https://github.com/funcwj/conv-tas-net | gLN | 13M | 10.58 | 5.67 |
| Dataset | #Param | Embeddings | Si-SNR | |
|---|---|---|---|---|
| BN | gLN | |||
| 2spkr | 10.09M | word | 12.53 | 13.01 |
| CI-phone | 12.76 | 13.04 | ||
| 3spkr | 10.09M | word | 7.52 | 8.25 |
| CI-phone | 8.36 | 9.41 | ||
| Dataset | Embeddings | Si-SNR | |
|---|---|---|---|
| 2spkr | 2 | CI-phone | 13.04 |
| 3 | 13.33 | ||
| 3spkr | 2 | CI-phone | 9.41 |
| 3 | 9.50 | ||
| 4 | 9.30 | ||
| 3spkr | 2 | CD-phone | 9.23 |
| 3 | 9.47 | ||
| 4 | 9.06 |
| Dataset | Embeddings | #Param | Phase | Si-SNR |
|---|---|---|---|---|
| 2spkr | CI-phone | 10.03M | mix | 10.36 |
| oracle | 13.87 | |||
| 3spkr | CI-phone | 10.03M | mix | 6.16 |
| oracle | 9.65 |
| Training data | Norm | Si-SNR | ||
|---|---|---|---|---|
| 2spkr | 3spkr | |||
| 2spkr | 2 | BN | 12.76 | - |
| 3spkr | 11.52 | 8.36 | ||
| {2,3}spkr | 13.00 | 8.38 | ||
| 2spkr | 2 | gLN | 13.04 | - |
| 3spkr | 12.74 | 9.41 | ||
| {2,3}spkr | 13.65 | 9.40 | ||
| 2spkr | 3 | gLN | 13.33 | - |
| 3spkr | 12.86 | 9.50 | ||
| {2,3}spkr | 14.02 | 9.92 | ||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSpeech and Audio Processing · Music and Audio Processing · Advanced Adaptive Filtering Techniques
Time Domain Audio Visual Speech Separation
Abstract
Audio-visual multi-modal modeling has been demonstrated to be effective in many speech related tasks, such as speech recognition and speech enhancement. This paper introduces a new time-domain audio-visual architecture for target speaker extraction from monaural mixtures. The architecture generalizes the previous TasNet (time-domain speech separation network) to enable multi-modal learning and at meanwhile it extends the classical audio-visual speech separation from frequency-domain to time-domain. The main components of proposed architecture include an audio encoder, a video encoder that extracts lip embedding from video streams, a multi-modal separation network and an audio decoder. Experiments on simulated mixtures based on recently released LRS2 dataset show that our method can bring 3dB+ and 4dB+ Si-SNR improvements on two- and three-speaker cases respectively, compared to audio-only TasNet and frequency-domain audio-visual networks.
Index Terms: audio-visual speech separation, speech enhancement, TasNet, multi-modal learning
1 Introduction
The goal of speech separation is to separate each source speaker from the mixture signal. Although it has been studied for many years, speech separation is still a difficult problem, especially in noisy and reverberated environment. Several audio-only speech separation methods were recently proposed, such as uPIT [1], DPCL [2, 3], DANet [4] and TasNet [5]. However, in these approaches, the number of target speakers has to be known as a prior information and assumed to be unchanged during training and testing. In addition, the separation results of these systems cannot be associated to the speakers, which greatly limits their application scenarios.
If we can extract some target speaker dependent features, the task of speech separation will become the target speaker extraction problem. This has several clear advantages over the blind separation approaches. First, as the model only extracts one target speaker each time from the mixture, the prior knowledge about the number of speakers is no longer needed. Second, as the target speaker features were given to the model, the issue of label permutation is apparently avoided. These make separation of the target speaker more practical than the blind separation solutions.
Several target speaker separation approaches have been explored in the past [6, 7, 8]. In [8], the authors proposed a system named VoiceFilter that used d-vectors [9] as the embedding of target speaker for the separation network. Similarly [7] used a short anchor utterance as auxiliary input for target speaker separation. However, speaker or utterance based features are not robust enough, which could heavily affect system performance, especially when noise exists or same-gender speakers are mixed.
Alternatively, the visual information is acoustic noise insensitive and highly correlated to the speech content. Combining the audio and visual information has previously been investigated for automatic speech recognition (ASR) [10, 11, 12], speech enhancement [13, 14] and speech separation [15, 16]. The results have shown great potential of making use of visual features as complementary information source. For speech separation, [13] proposed an encoder-decoder model architecture to separate the voice of a visible speaker from background noise. The noisy spectrogram and center cropped video frames were used as the input of the audio/visual encoder respectively. [15] built a deeper network via stacking depth-wise separable convolution blocks, which includes a magnitude network to estimate Time-Frequency (TF) masks [17] and a phase network to predict clean phase from the mixture phase. The magnitude network used pre-trained lip embeddings [18] as visual features. Similarly [16] built a model based on dilated convolutions and LSTMs using face embeddings as visual features and yielded good results on a large scale audio-visual dataset.
Most of previous audio-visual separation systems have handled the audio stream in TF domain and thus the accuracy of the estimated TF-mask is the key to the success of those systems. On the other hand, the phase of signals is less considered, although it can significantly affect separation quality [19, 20, 21, 22]. To incorporate the phase information, [15] used a phase subnet to refine original noisy phase, and [16] adopted newly proposed complex masks [20] instead of traditional real masks (e.g., IRM [1], PSM [23] etc). Recently, [5, 24] proposed a new encoder-decoder framework named TasNet, directly separating speech on time-domain with impressive results on public WSJ0-2mix dataset. In this paper, we propose a new separation network that generalizes the TasNet to enable multi-modal fusion of auditory and visual signals. Given a raw waveform of mixture speech and the corresponding video stream of the target speaker, our audio-visual speech separation model can extract audio of the the target speaker directly.
The contribution of this work includes: 1) A new structure for multi-modal speech separation is proposed and to illustrate the effectiveness of the structure, a comprehensive comparison 111Audio samples of the compared systems can be checked out at https://funcwj.github.io/online-demo/page/tavs is performed with three typical separation models, uPIT [1] (frequency-domain audio-only), Conv-TasNet [5] (time-domain audio-only) and Conv-FavsNet (frequency-domain audio-visual). 2) To the best of our knowledge, this is the first work that performs audio-visual separation directly on the time-domain. Experiments on recently released in-the-wild videos [11] show that the proposed structure brings significant improvements compared to all other baseline models. 3) Previous visual features are not well designed for speech separation. In this work, the visual (lip) embeddings are specifically trained to represent the phonetic information. Different modeling units for the embedding network, such as words, phonemes (CI-phone) and context-dependent phones (CD-phone), are also investigated and compared.
2 Proposed system
This section will introduce the architecture of our proposed time-domain audio-visual speech separation network. Generally speaking, the network is fed with chunks of raw waveform and corresponding video frames, and predicts the speech of target speaker directly, as depicted in Figure 1. Scale-invariant source-to-noise ratio (Si-SNR) is used as the training objective function [5], which is defined as
[TABLE]
are estimated signal and target source respectively and are normalized to zero mean, where is an optimal scaling factor computed via
[TABLE]
We also use Si-SNR as the evaluation metric, which is thought to be a more robust measure of separation quality compared to the original SDR [25].
2.1 Overview
The proposed structure is mainly inspired by the TasNet structure proposed in [24], which contains three parts, an audio encoder/decoder and a separation network. Given an audio mixture chunk ( means the chunk size), the audio encoder in the TasNet tries to encode mixture samples as some non-negative vector sequences , while the separation network estimates masks of each source defined on such space. The audio decoder is used to reconstruct each masked results into time-domain again. The total framework could be described as
[TABLE]
where
[TABLE]
denotes the Hadamard product. is the number of the speaker sources in the mixture. and represent the estimated masks and separation results of the -th speaker, respectively.
When the video stream is available, our motivation is to bias the separation network through feeding both audio representations and video encoded features . Thus the separator only generates masks of the target speaker, which could be written as
[TABLE]
means the image frame sequences of the target speaker, and represent the audio/video encoder. Finally, separated results could be obtained through the formula below:
[TABLE]
2.2 Video encoder
Video encoder is designed to extract the visual features from input image frame sequences. In our experiments, we only use the lip region because it encodes the context and phonetic information we need. Generally, the video encoder contains a lip embedding extractor, followed by several temporal convolutional blocks, as depicted in Figure 1 .
The lip embedding extractor consists of a 3D convolution layer and a 18-layer ResNet [26], similar to the work in [15]. The extractor outputs the fixed dimensional feature vectors for each video frame and is passed through the following temporal convolutional blocks. Each block consists of a temporal convolution, preceded by ReLU activation and batch normalization [27]. The residual connection is also included, although they do not have significant impact according to our results. To reduce the model parameters, we use depth-wise separable convolution [28] instead. In our setups, we use a 256 dimensional lip embeddings and choose 3 kernel size, 1 stride size and 512 channel size for all the blocks.
The lip embedding extractor is pre-trained separately with specific back-end, following the steps introduced in [18]. After that, the extractor is kept frozen. Apart from the word-level classification target used in [15], we also try the phoneme (CI-phone) and context dependent phone (CD-phone) from a view of ASR to improve the quality of the lip embeddings.
2.3 Audio encoder/decoder
Audio encoder and decoder perform the 1D convolution and deconvolution operation on the mixed audio signals and the masked encoded sequences, respectively. They can be represented as:
[TABLE]
and denote size of kernel and stride in 1D convolution operation, respectively. In this paper, we use and by default.
2.4 Separation network
Separation network is designed for estimating masks of the target speaker, conditioned on the encoded audio and visual features. It is stacked by several temporal dilated convolutional blocks and provides a simple mechanism to handle feature fusion and synchronization. The structure of the 1D dilated convolutional block in separation network is similar to the one used in Conv-TasNet. In this paper, we denote it as . Each has D sub-blocks with the exponential growth dilation factors , where , as shown in Figure 1. In our setups, we use .
The output of the audio encoder are firstly passed through convolutional blocks
[TABLE]
and then fused with visual features . The fusion process is performed through a simple concatenation operation over the convolution channel dimensions, followed by a position-wise projection to reduce the feature dimension. In order to synchronize the time resolution of audio and video features, up-sampling is done on video streams before concatenation if it’s necessary. The description above could be written as:
[TABLE]
Finally, the fused features are fed through convolutional blocks and target masks are estimated:
[TABLE]
here means an arbitrary non-linear function. We use ReLU in our experiments, without loss of generality.
We mainly utilize two normalization techniques in the separation network, batch normalization (BN) and global layer normalization (gLN). gLN normalizes the features on both time and channel dimensions. Although the modules applied gLN can not be a causal system, it brings better performance in the practice of the Conv-TasNet.
3 Experiments and results
3.1 Dataset
In the experiment, we created two-speaker and three-speaker mixtures using utterances from Oxford-BBC Lip Reading Sentences 2 (LRS2) dataset [11], which consists of thousands of spoken sentences from BBC television with their corresponding transcriptions. The training, validation and test sets are generated according to the broadcast date, and thus those sets are not overlapped.
Short utterances (less than 2s) are dropped and 21075 utterances in total are used for data generation, with 19445 for training and the rest for validation and testing, respectively. The details of utterances used for simulation are summarized in Table 1. Two- and three-speaker mixtures are generated by randomly selecting different utterances and mixing them at various signal-to-noise ratios (SNR) between -5 dB and 5 dB. The sampling rate is 16kHz. To ensure the videos of each source are available in a mixture, longer sources are truncated to be aligned with the shortest one. The source segment is synchronous with the video stream in 25 fps. Finally, we simulated 40k (25h+ in total), 5k and 3k utterances for training, validation and test set, respectively.
3.2 Training details
Similar to [15], we first train the lip embedding extractor on the LRW dataset. This is a word-level classification task and we achieve 76.02% classification accuracy on the test set [18]. However, the LRW dataset does not provide utterance-level audio transcripts, which makes it unfeasible to replace the word-level training targets with smaller pieces, e.g., CD/CI-phones mentioned above. Instead, we choose LRS2’s pre-train set to train the phone-level lip embedding extractor.
The alignments are derived from the GMM acoustic models following the Kaldi’s [29] recipes and are sub-sampled to the video sampling rate before training. We choose 44 units from CMU dictionary for CI-phones and get 3048 units from alignments set for CD-phones. The video frames are transformed to grayscale and normalized with respect to the global mean and variance. The training progress is similar to the word-level task, except using frame-level cross-entropy loss instead of sequence-level.
The audio-visual network is trained with 2s audio/video chunks using Adam [30] optimizer for 80 epochs with early stopping when there is no improvement on validation loss for 6 epochs. Initial learning rate is set to and halved during training if there is no improvement for 3 epochs on validation loss.
3.3 Results and comparisons
On both datasets, we first report the results of two typical oracle masks as well as two conventional audio based methods: uPIT-BLSTM and Conv-TasNet [5] on frequency and time-domain, respectively. The results of oracle mask are the upper-bound of the corresponding mask-based methods. uPIT-BLSTM adopts a 3-layer Bi-LSTM structure and the PSM (phase sensitive mask [23]) is used as training target. For Conv-TasNet, we choose in audio encoder/decoder and a larger bottleneck size (384) in separation network in order to bring better performance. Results are shown in Table 2. It’s worth to mention that the audio streams in LRS2 are not as clean as WSJ0, so the results reported on those audio-only models are worse than previous results on WSJ0-2mix, especially when the number of speakers increases.
3.3.1 Results with different lip embeddings
In Table 3, we evaluate the proposed audio-visual models with the word-level lip embeddings trained on the LRW dataset, which already leads to significant improvements compared with the audio-only methods in Table 2. As the resolutions of the video frames on LRS2 dataset do not match with LRW, we crop the center 70 70 pixel region of the images and then re-sample them to 112 112. Replacing word-level targets with CI-phones leads to better results, particularly on difficult tasks, i.e., three-speaker test set as shown in Table 3.
Normalization techniques are also critical in our experiments. In Table 3, replacing batch normalization (BN) with global layer normalization (gLN) leads to improvement on both two and three-speaker mixture datasets. In our preliminary experiments, the residual connection in the video block affects less on the final results. And by increasing the number of blocks in video encoders, no significant improvement is achieved, possibly due to the well trained visual features.
3.3.2 Impact of separation networks
The final results largely depend on the target speaker masks produced by the separation network. In addition to the normalization techniques mentioned in Section 3.3.1, we also tuned the number of and in the separation network. By fixing the total number of blocks (4 used in this work), increasing the value of brings more context information of fused features. Table 4 illustrates that using and achieves the best performance.
Based on above discussion, we further compared CD/CI-phones on three-speaker dataset with different pair of and . Results show that using CD-phone as training targets brings slightly worse result, although they are more suitable for acoustic modeling task. We therefore choose CI-phone in the following experiments.
3.3.3 Comparision with the frequency-domain networks
To further investigate the advances of the time-domain audio-visual approach, we trained a frequency-domain audio-visual separation model with a similar parameter size on the same dataset for comparison. We call it Conv-FavsNet in this paper. Conv-FavsNet removes the audio encoder from the proposed architecture and replaces the decoder with a linear layer, which transforms the output of convolutional blocks to TF-masks. We use linear spectrogram computed with 40ms hanning window and 10ms shift as input audio features and PSM as training target. The loss function for phase-sensitive spectrum approximation (PSA) is defined as:
[TABLE]
where denotes the estimated target speaker masks, and denote the magnitude of target speaker and mixture signal, respectively. Results are shown in Table 5. The noisy phase used in iSTFT certainly affects the quality of the reconstructed waveform as oracle phase can bring additional 3dB Si-SNR improvement which thus matches our time-domain audio-visual results.
3.3.4 Multi-speaker training
For the biased/informed separation system, we find that models trained on hard tasks can work well on easy tasks. For example, in our experiments, the model trained on the three-speaker dataset also performs well on the two-speaker mixture signals. This motivates us to train models with a blend of two and three-speaker mixtures, which is called multi-speaker training in [3].
In fact, the architecture of the target isolating network is independent of the number of speakers. The label of training samples is determined by auxiliary features, e.g., lip embeddings in this work. This is applicable to the real-world scenarios because at most time the number of speakers is difficult to be detected. The performace of the models trained on two-speaker mixtures only, on three-speaker mixtures only, and using the multi-speaker training, are shown in Table 6. The model trained on three-speaker mixtures could generalize to two-speaker scenarios, but a little worse than the performance of the two-speaker model. The multi-speaker training brings improvement on two-speaker test set across all the setups in Table 6. The best configurations with multi-speaker training achieves 14.02dB and 9.92dB Si-SNR on two and three-speaker test sets, respectively.
4 Conclusions
In this paper, we have proposed a time-domain audio-visual target speech separation architecture incorporating the raw waveform and the target speaker’s video stream to predict the target speech waveform directly. Lip embedding extractor is pre-trained for extracting movement information from the video streams. We find that word-level and phoneme-level lip embeddings effectively benefit the separation network. Compared with the audio-only methods and the frequency-domain audio-visual method, the proposed approach improves more than 3dB and 4dB in terms of Si-SNR on two and three-speaker test sets, respectively.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Morten Kolbæk, Dong Yu, Zheng-Hua Tan, Jesper Jensen, Morten Kolbaek, Dong Yu, Zheng-Hua Tan, and Jesper Jensen, “Multitalker speech separation with utterance-level permutation invariant training of deep recurrent neural networks,” IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP) , vol. 25, no. 10, pp. 1901–1913, 2017.
- 2[2] John R Hershey, Zhuo Chen, Jonathan Le Roux, and Shinji Watanabe, “Deep clustering: Discriminative embeddings for segmentation and separation,” in 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2016, pp. 31–35.
- 3[3] Yusuf Isik, Jonathan Le Roux, Zhuo Chen, Shinji Watanabe, and John R Hershey, “Single-channel multi-speaker separation using deep clustering,” ar Xiv preprint ar Xiv:1607.02173 , 2016.
- 4[4] Zhuo Chen, Yi Luo, and Nima Mesgarani, “Deep attractor network for single-microphone speaker separation,” in 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2017, pp. 246–250.
- 5[5] Yi Luo and Nima Mesgarani, “Tasnet: time-domain audio separation network for real-time, single-channel speech separation,” in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2018, pp. 696–700.
- 6[6] Katerina Zmolikova, Marc Delcroix, Keisuke Kinoshita, Takuya Higuchi, Atsunori Ogawa, and Tomohiro Nakatani, “Speaker-aware neural network based beamformer for speaker extraction in speech mixtures.,” in Interspeech , 2017, pp. 2655–2659.
- 7[7] Jun Wang, Jie Chen, Dan Su, Lianwu Chen, Meng Yu, Yanmin Qian, and Dong Yu, “Deep extractor network for target speaker recovery from single channel speech mixtures,” ar Xiv preprint ar Xiv:1807.08974 , 2018.
- 8[8] Quan Wang, Hannah Muckenhirn, Kevin Wilson, Prashant Sridhar, Zelin Wu, John Hershey, Rif A Saurous, Ron J Weiss, Ye Jia, and Ignacio Lopez Moreno, “Voicefilter: Targeted voice separation by speaker-conditioned spectrogram masking,” ar Xiv preprint ar Xiv:1810.04826 , 2018.