C2S2: Cost-aware Channel Sparse Selection for Progressive Network Pruning
Chih-Yao Chiu, Hwann-Tzong Chen, Tyng-Luh Liu

TL;DR
This paper introduces a cost-aware, progressive channel pruning method using a novel dual-format pruning layer to effectively compress deep neural networks while maintaining performance.
Contribution
It proposes a new pruning layer with dual real-valued and binary formats for end-to-end differentiable network pruning and channel selection.
Findings
Achieves competitive compression on image classification benchmarks.
Maintains network performance while reducing model size.
Progressive layer-wise pruning improves efficiency.
Abstract
This paper describes a channel-selection approach for simplifying deep neural networks. Specifically, we propose a new type of generic network layer, called pruning layer, to seamlessly augment a given pre-trained model for compression. Each pruning layer, comprising depth-wise kernels, is represented with a dual format: one is real-valued and the other is binary. The former enables a two-phase optimization process of network pruning to operate with an end-to-end differentiable network, and the latter yields the mask information for channel selection. Our method progressively performs the pruning task layer-wise, and achieves channel selection according to a sparsity criterion to favor pruning more channels. We also develop a cost-aware mechanism to prevent the compression from sacrificing the expected network performance. Our results for compressing several benchmark deep…
Click any figure to enlarge with its caption.
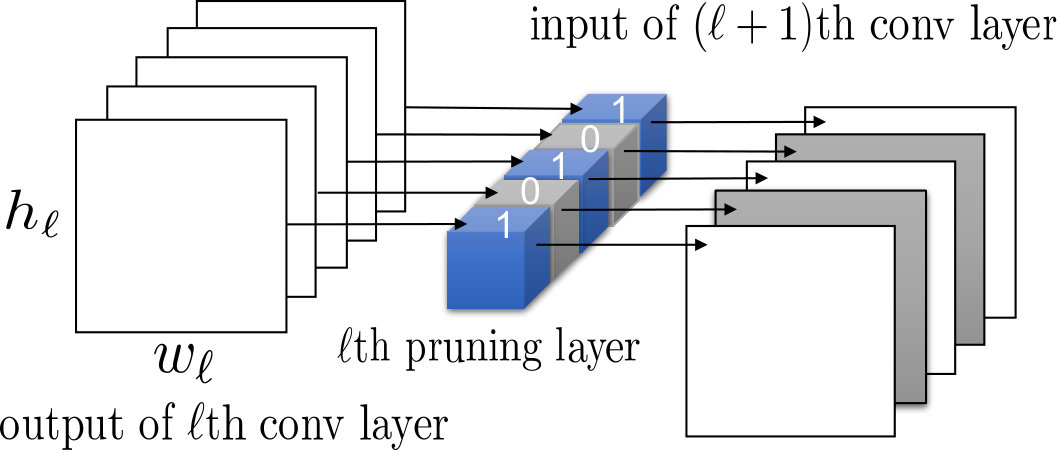 Figure 3
Figure 3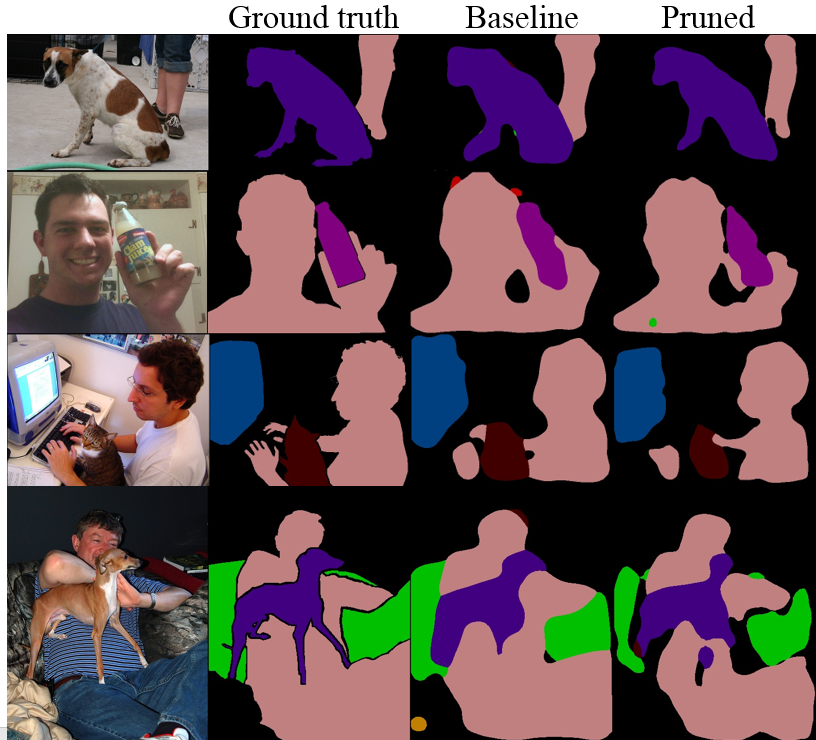 Figure 2
Figure 2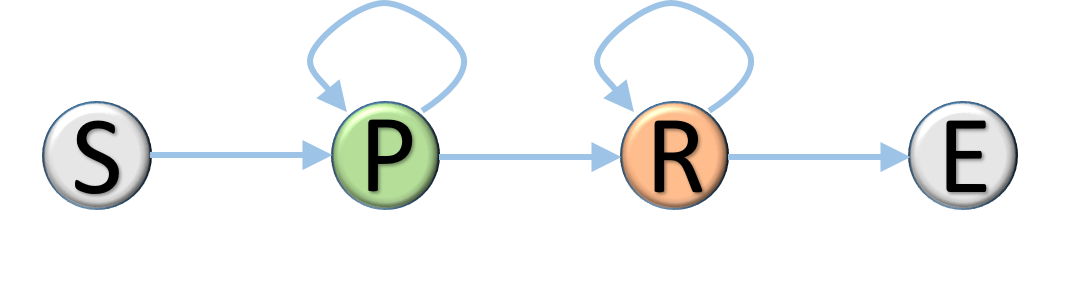 Figure 3
Figure 3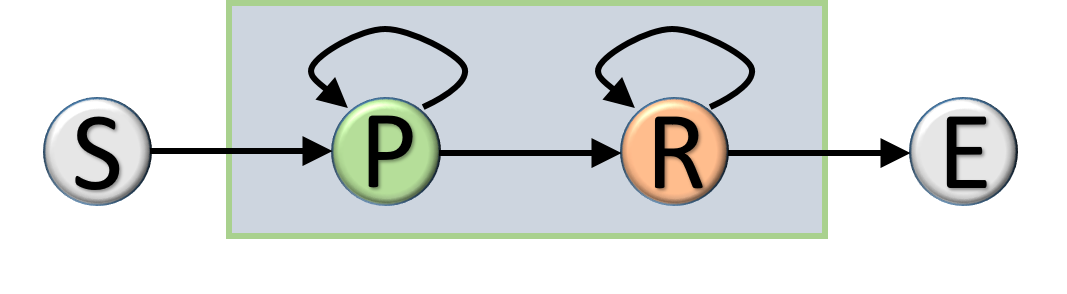 Figure 4
Figure 4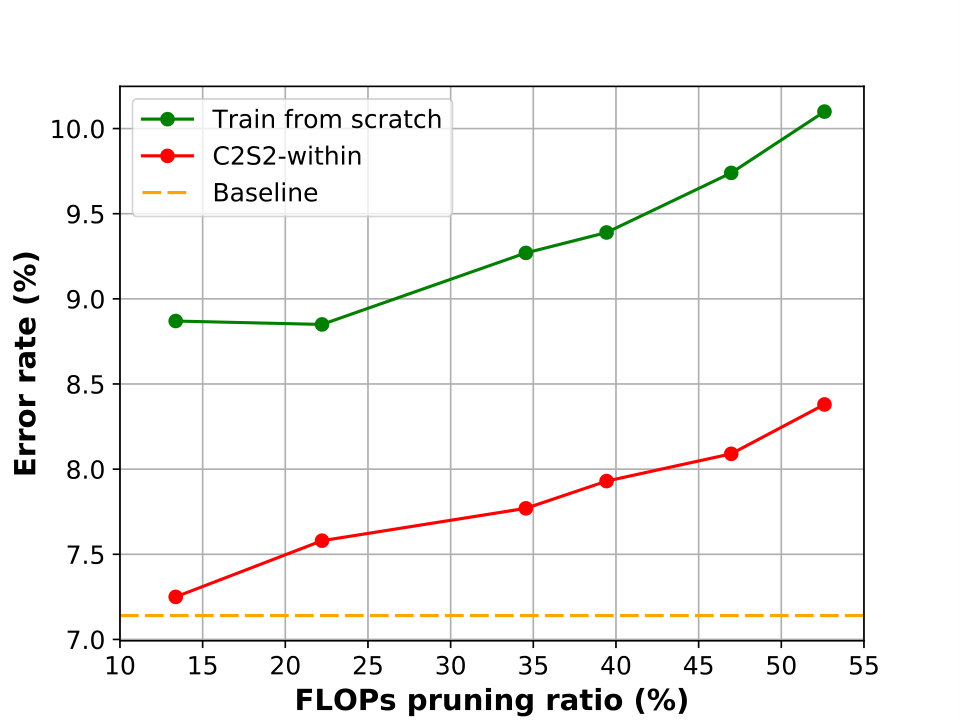 Figure 5
Figure 5 Figure 6
Figure 6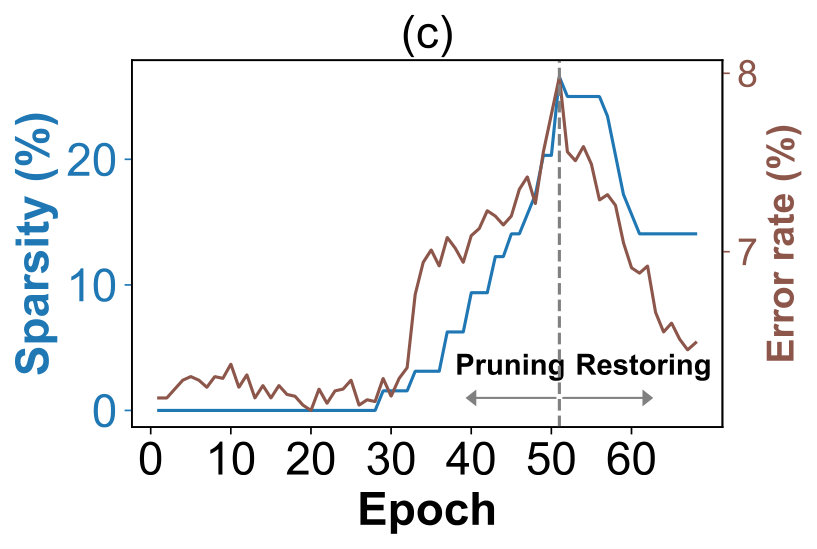 Figure 7
Figure 7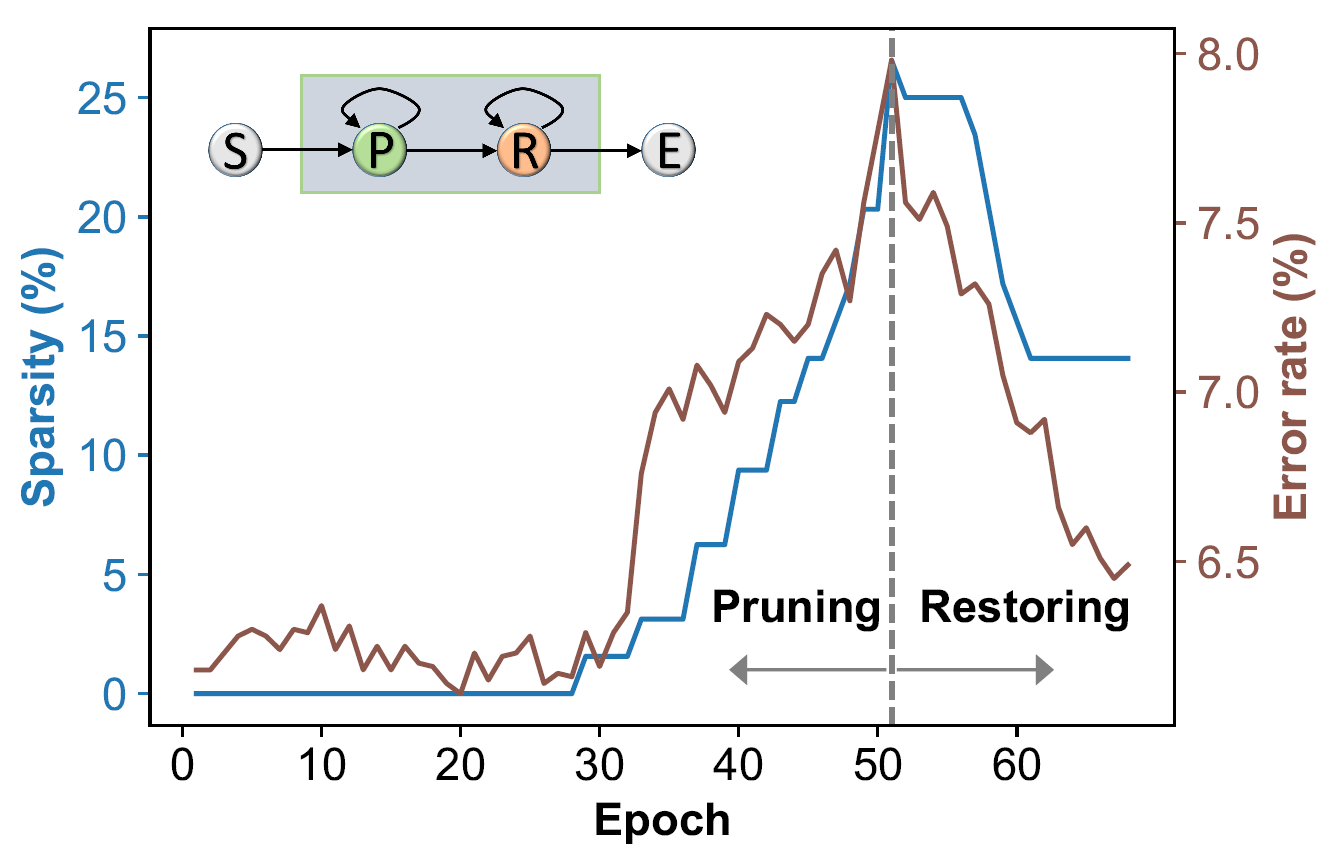 Figure 8
Figure 8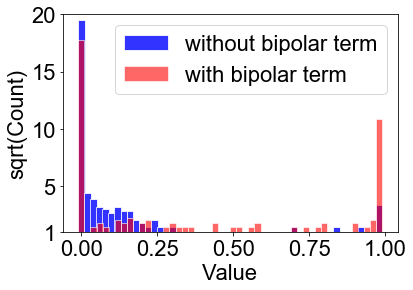 Figure 9
Figure 9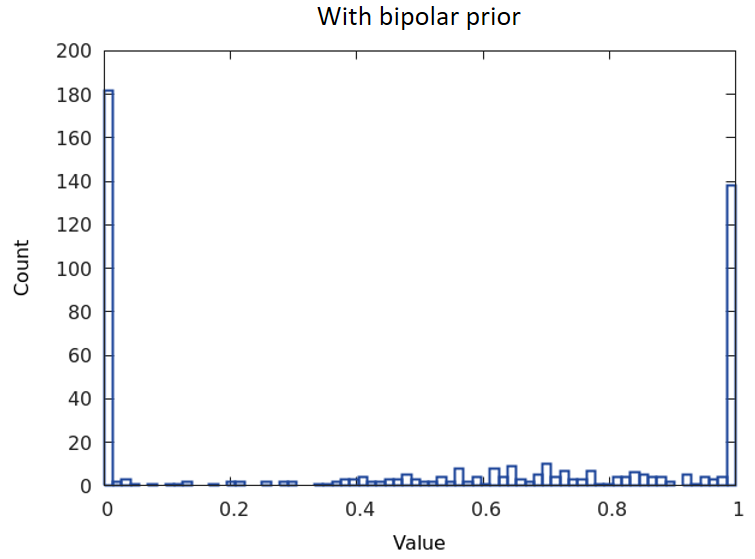 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12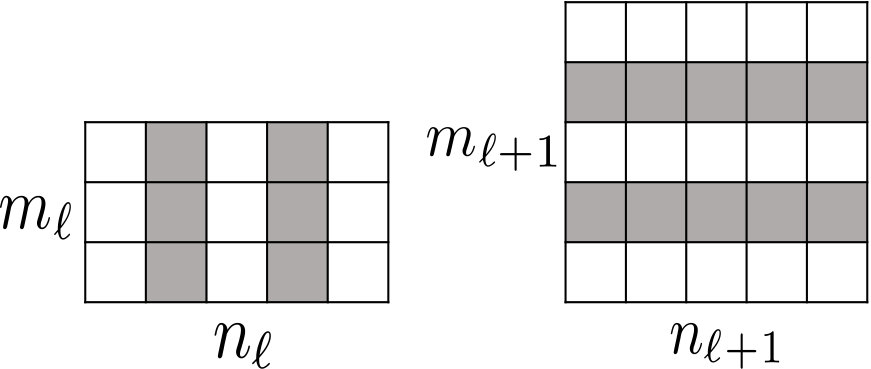 Figure 1
Figure 1 Figure 1
Figure 1 Figure 1
Figure 1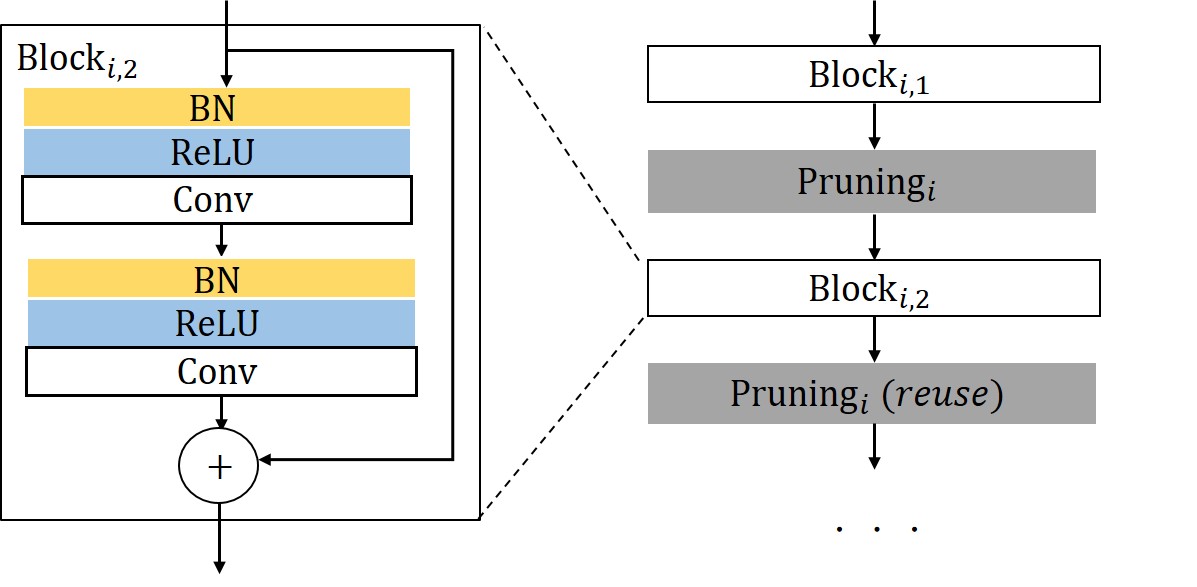 Figure 3
Figure 3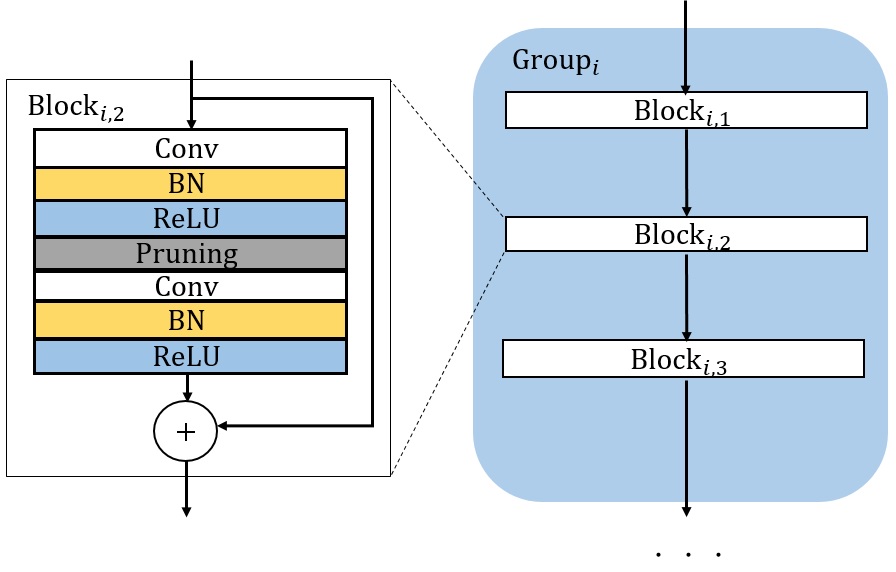 Figure 3
Figure 3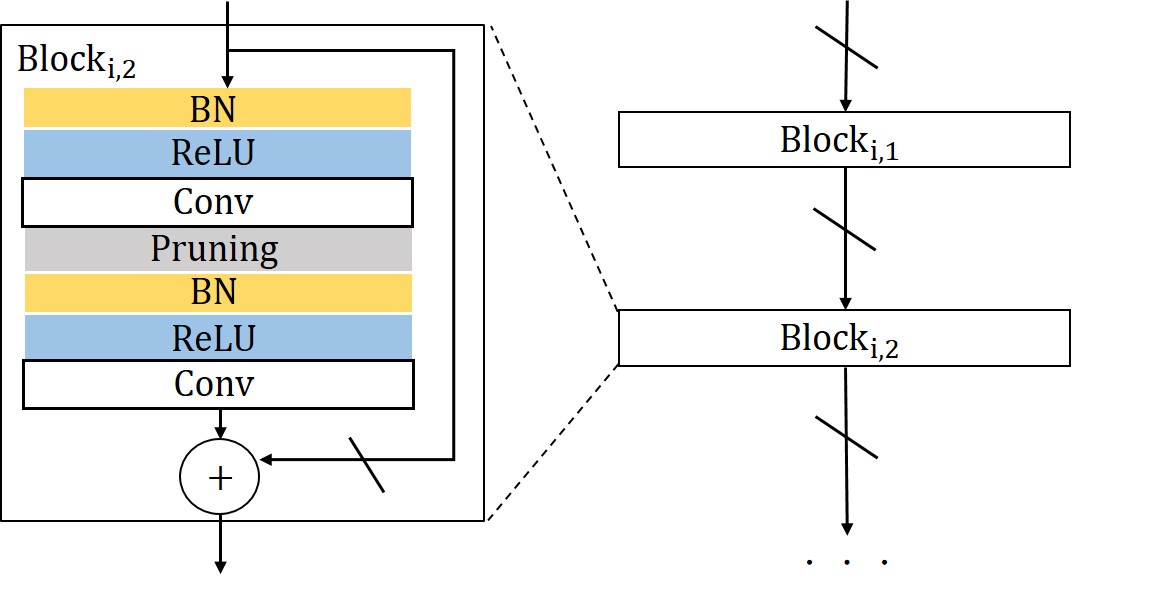 Figure 3
Figure 3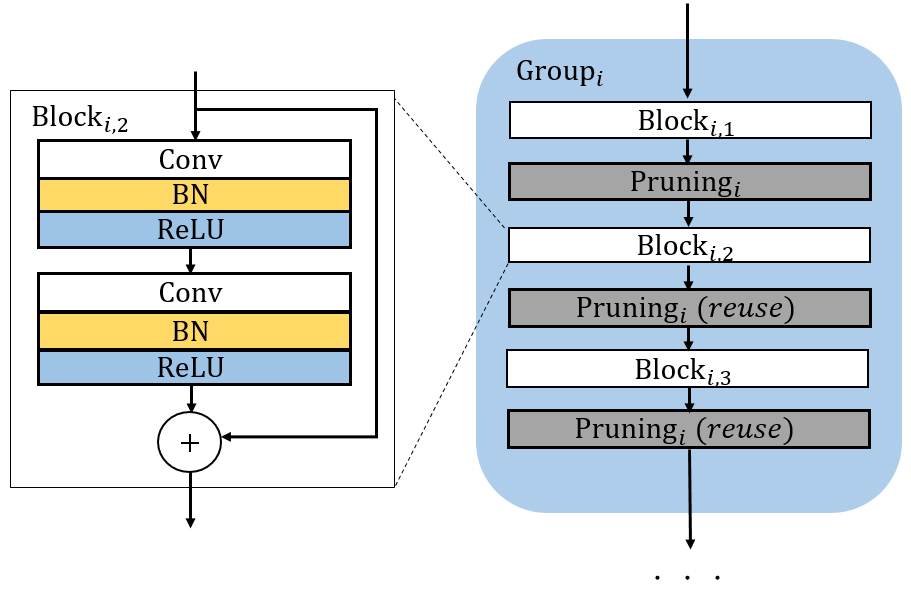 Figure 3
Figure 3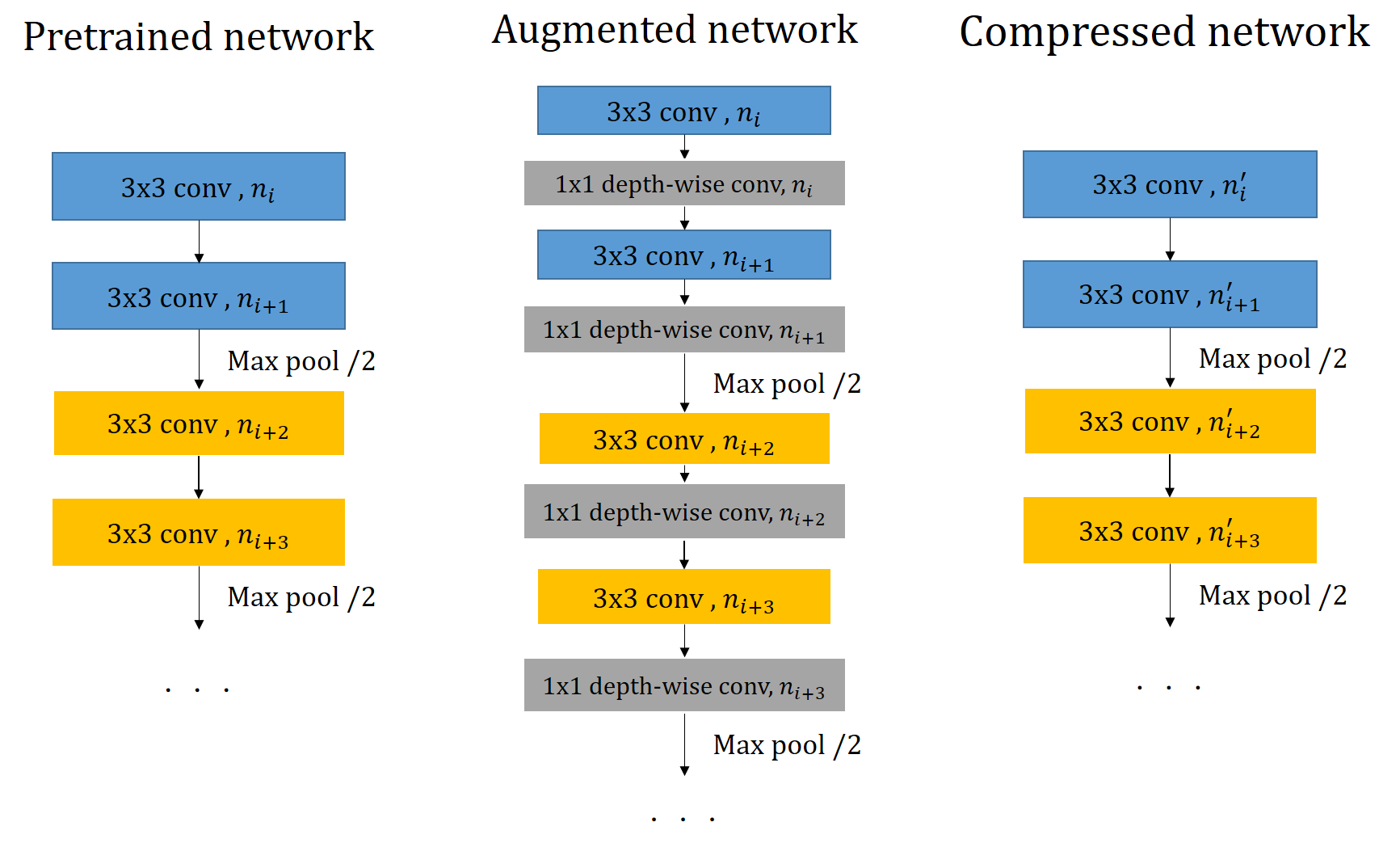 Figure 1
Figure 1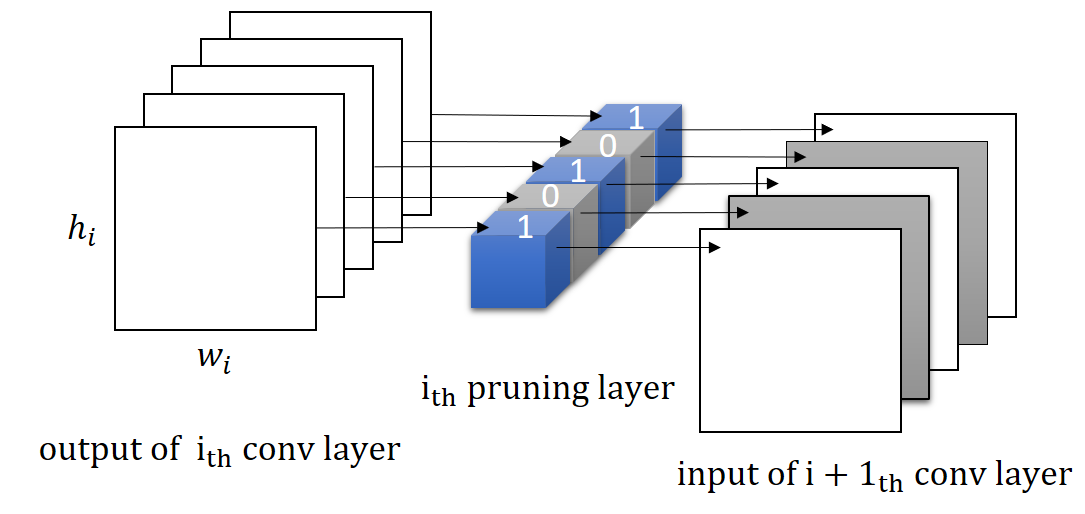 Figure 2
Figure 2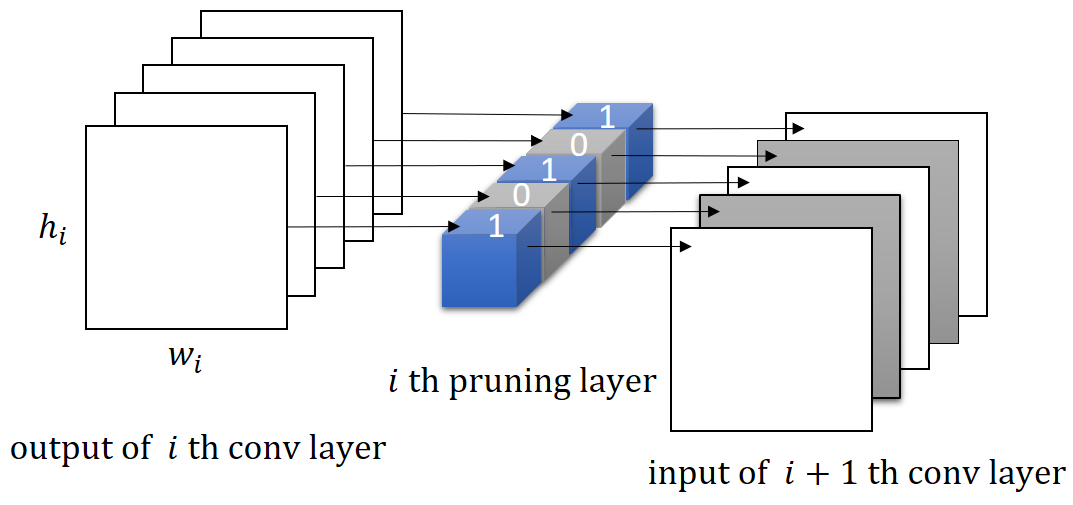 Figure 2
Figure 2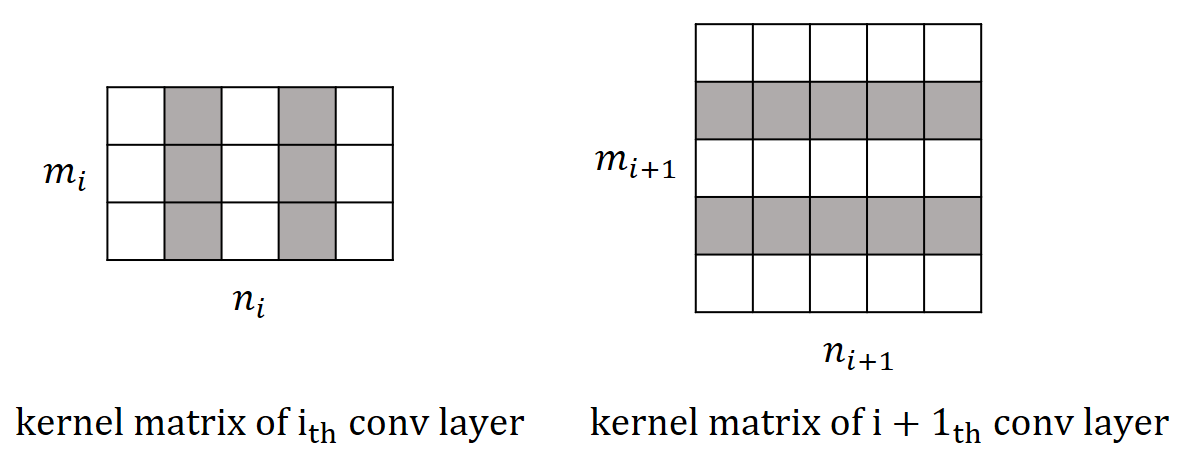 Figure 2
Figure 2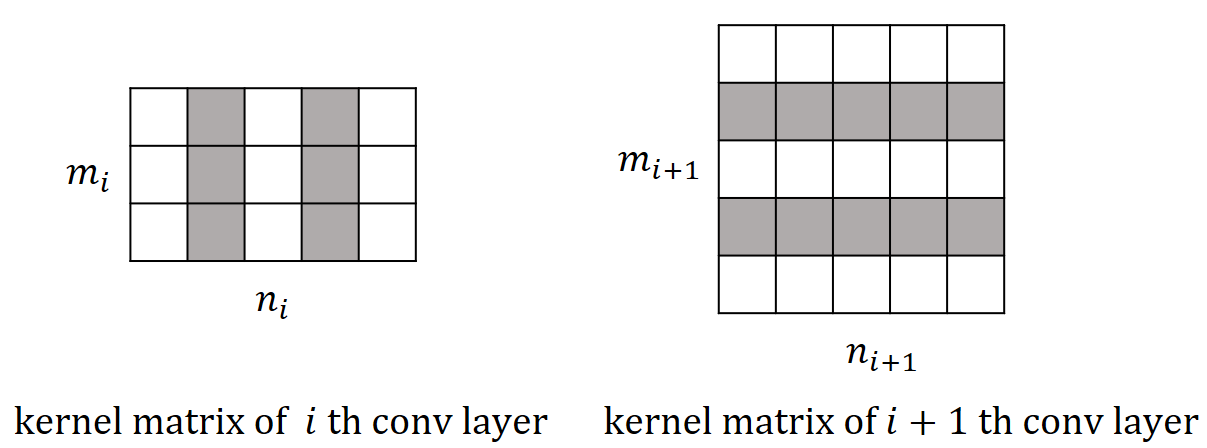 Figure 2
Figure 2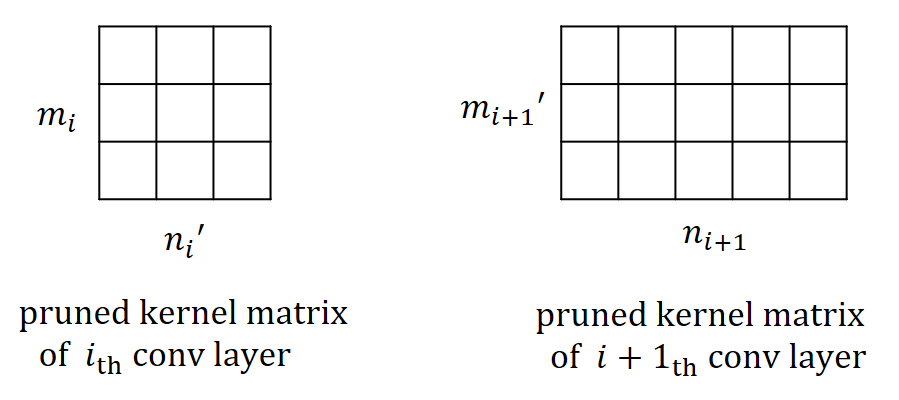 Figure 2
Figure 2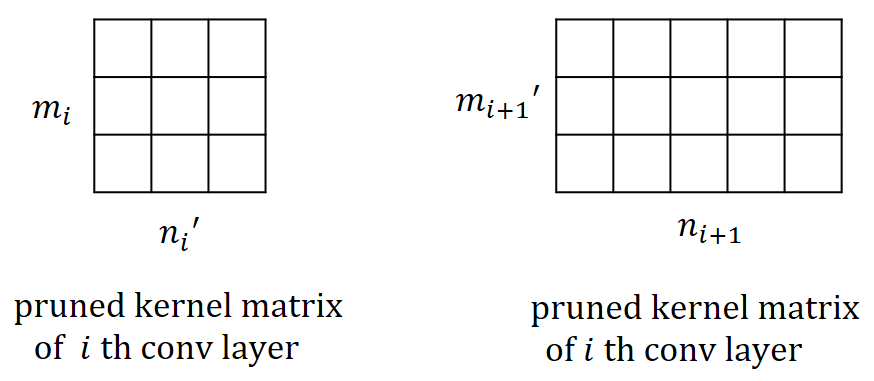 Figure 2
Figure 2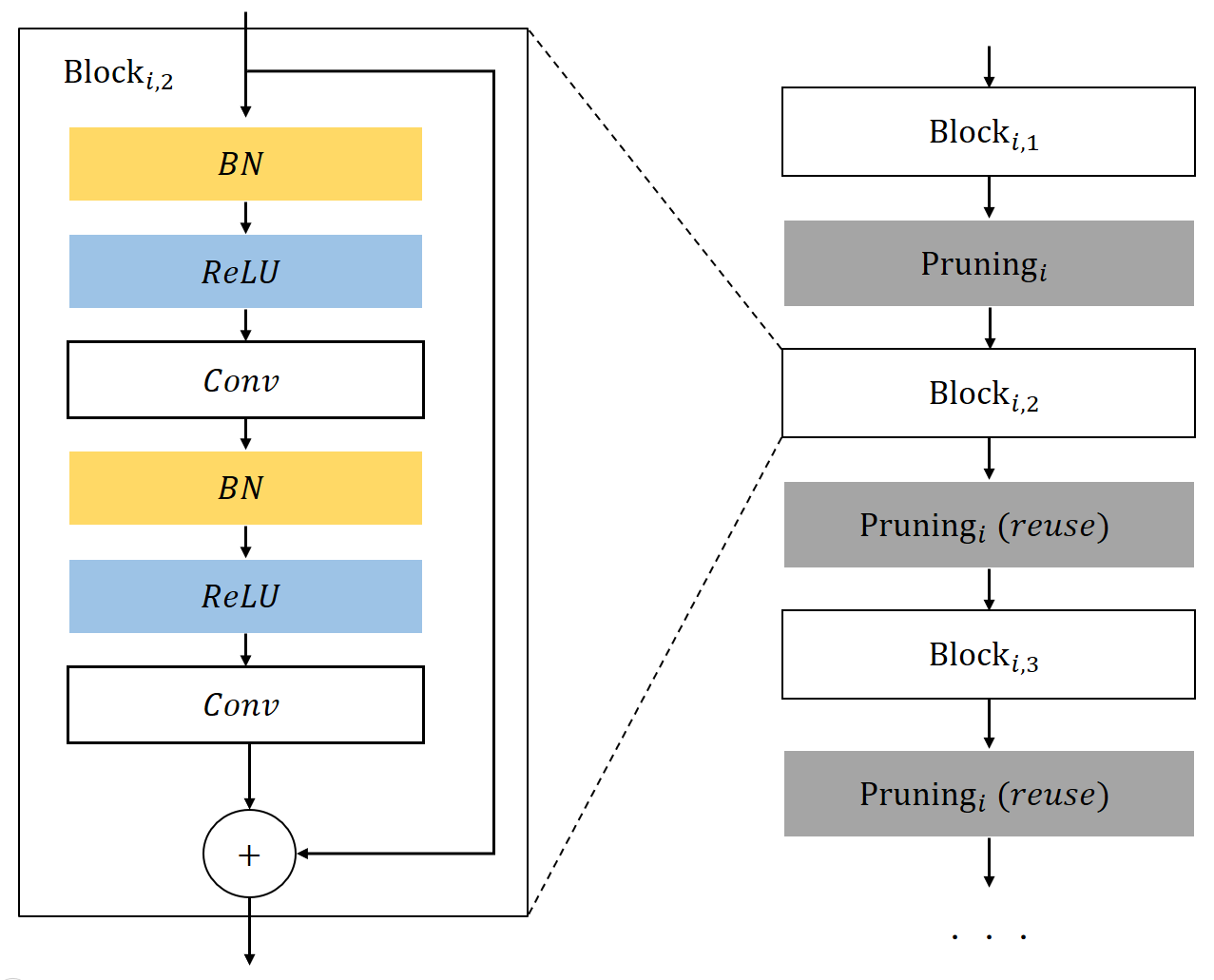 Figure 3
Figure 3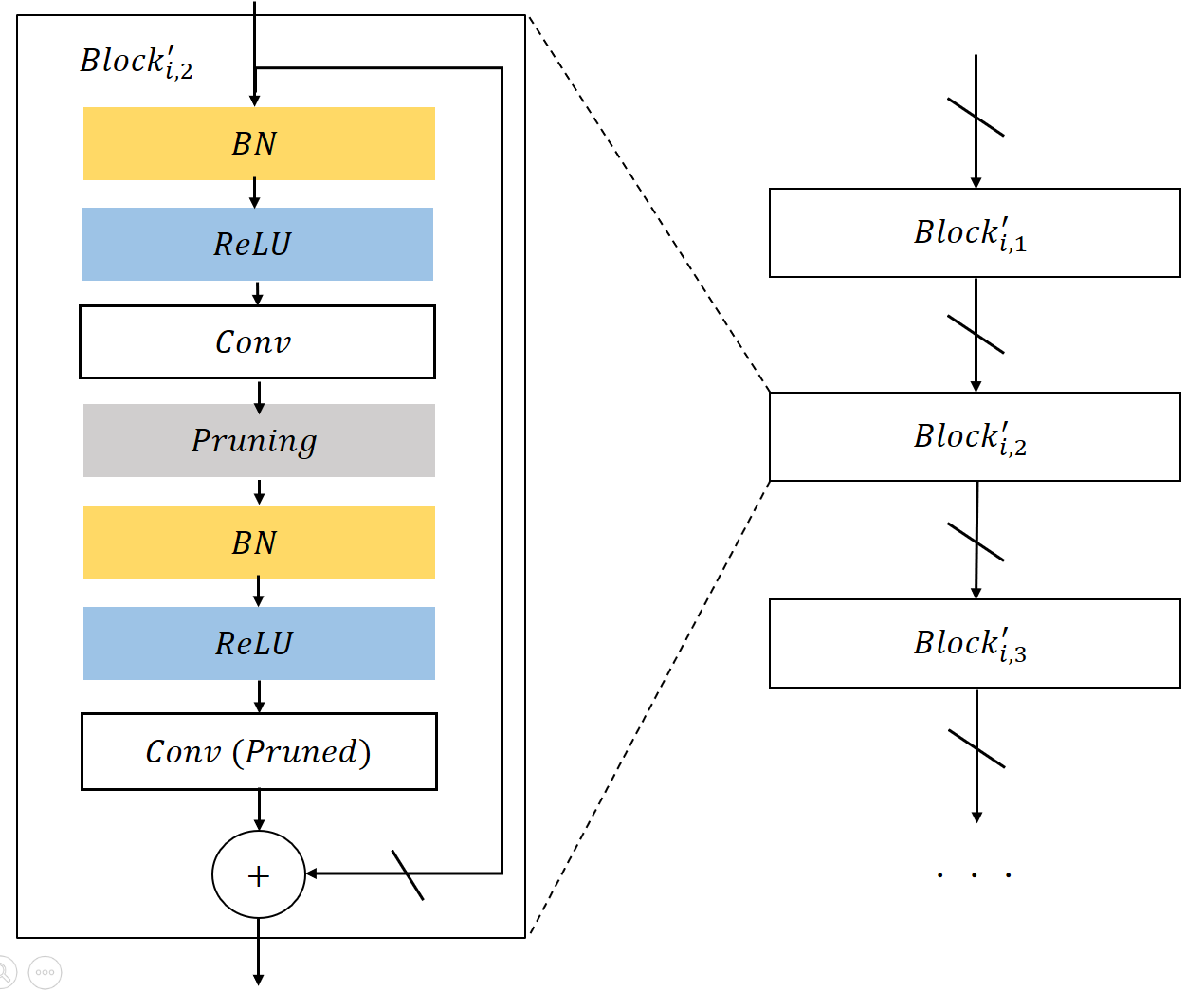 Figure 3
Figure 3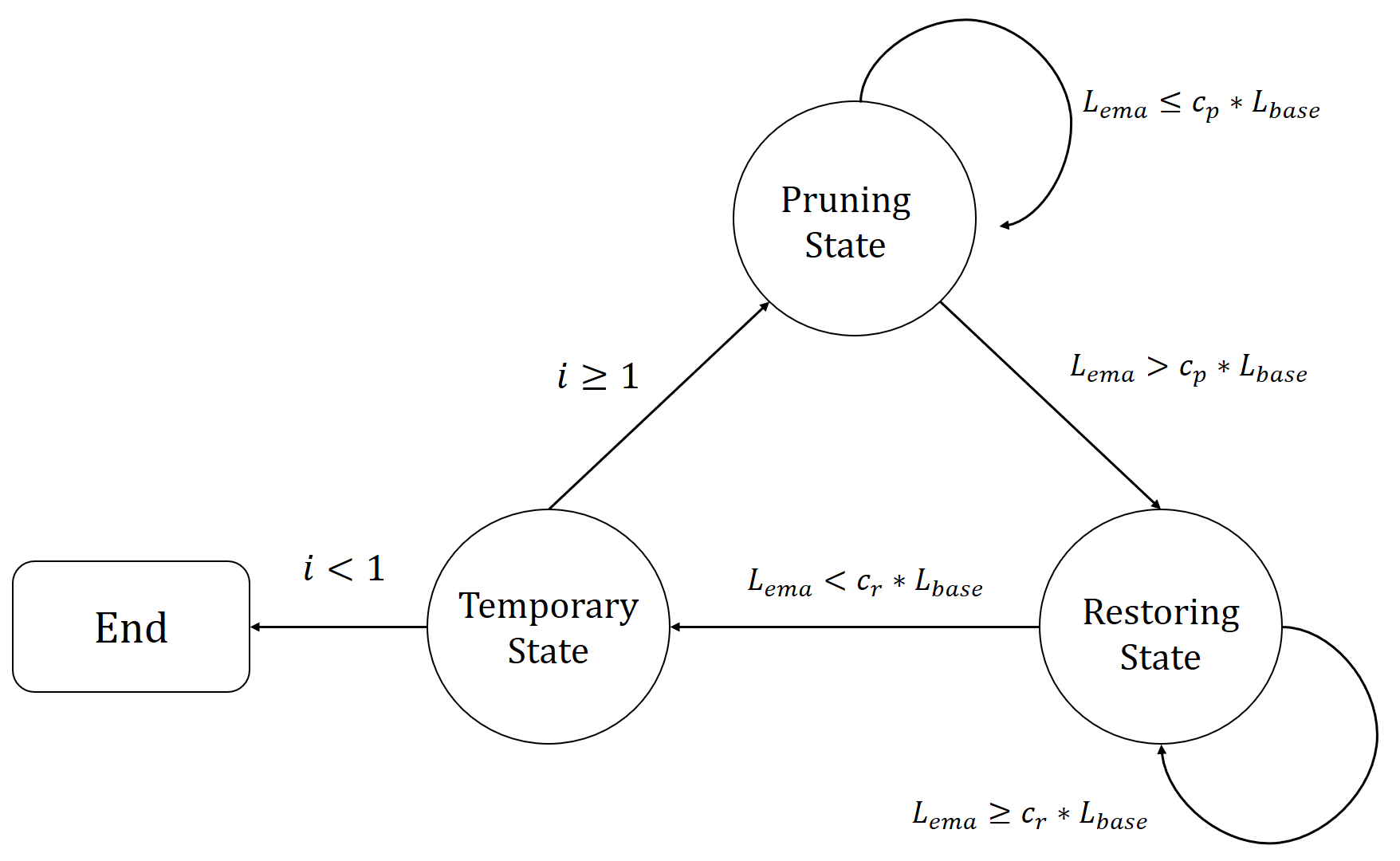 Figure 4
Figure 4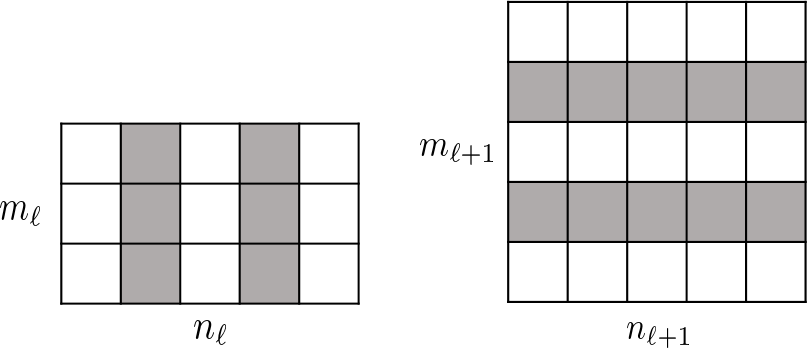 Figure 30
Figure 30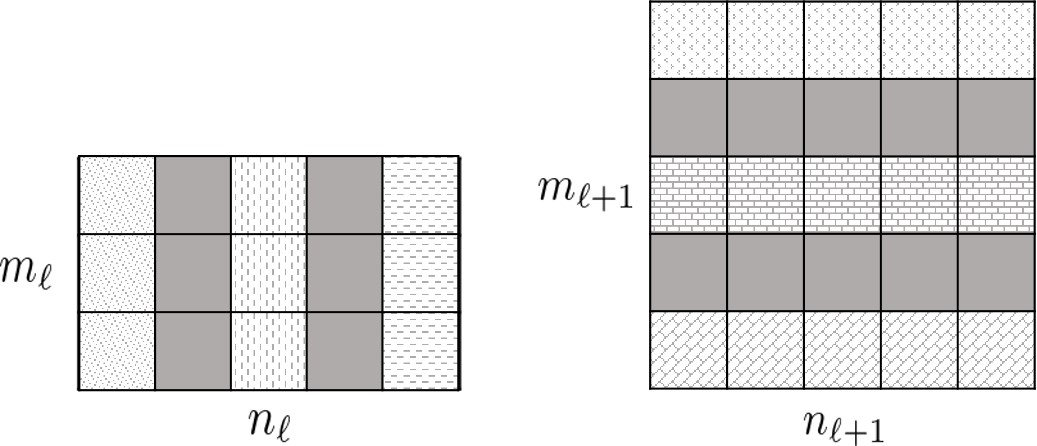 Figure 31
Figure 31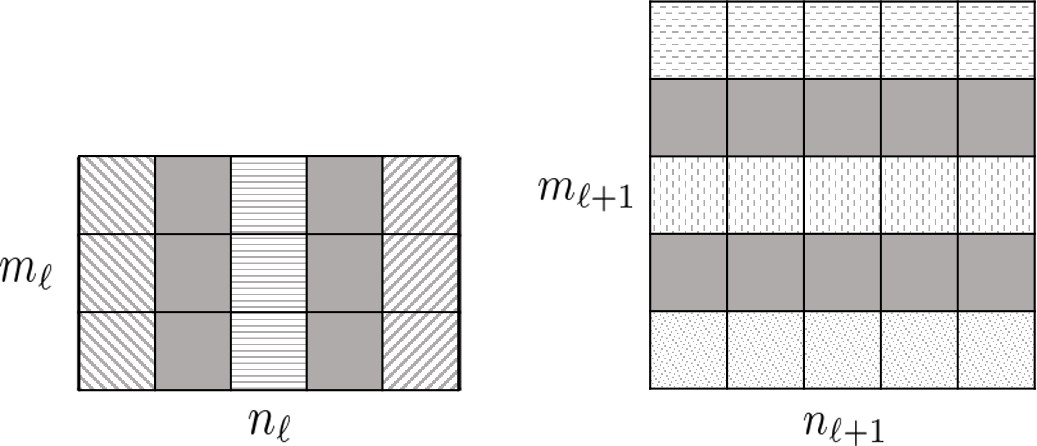 Figure 32
Figure 32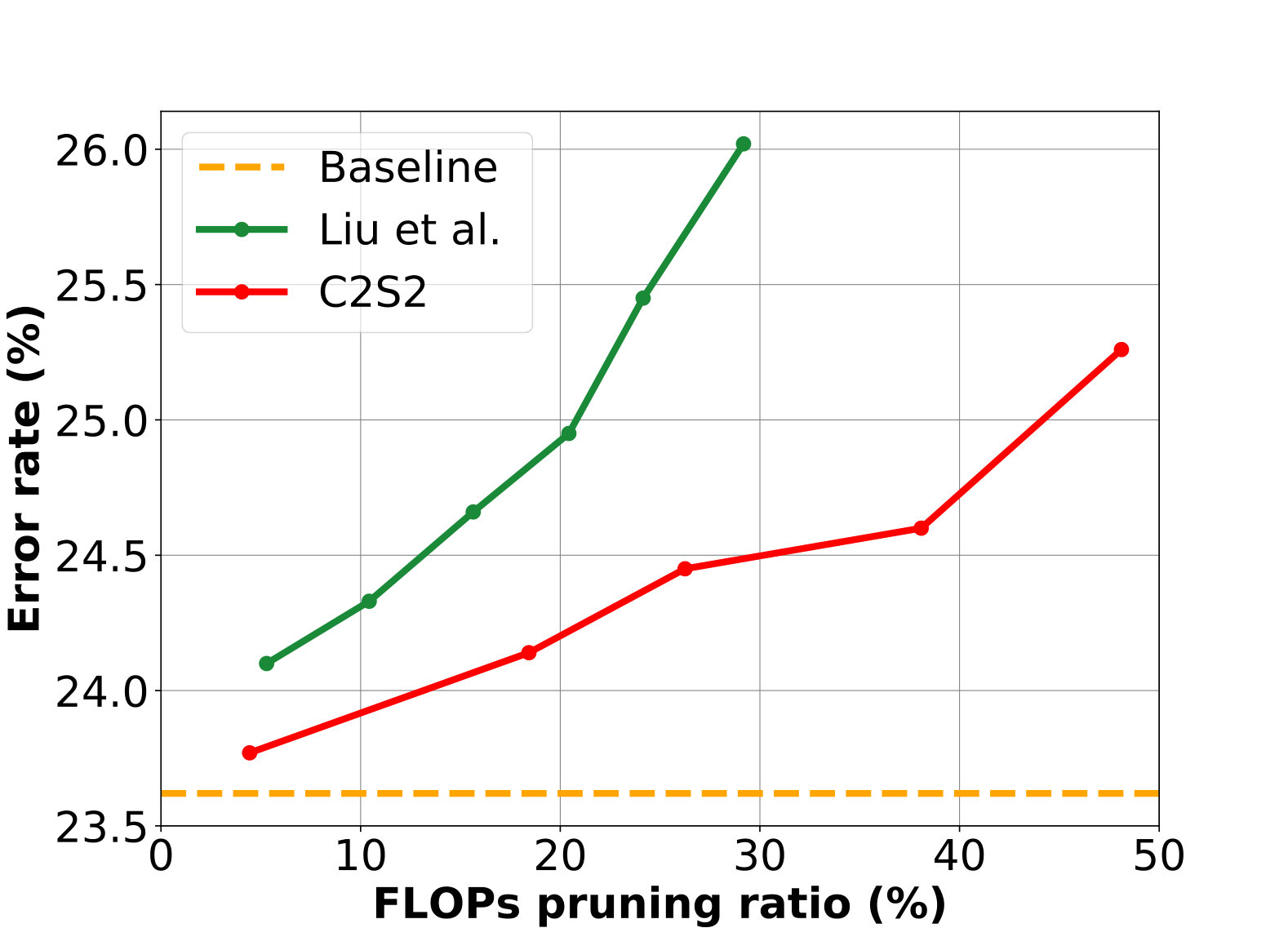 Figure 33
Figure 33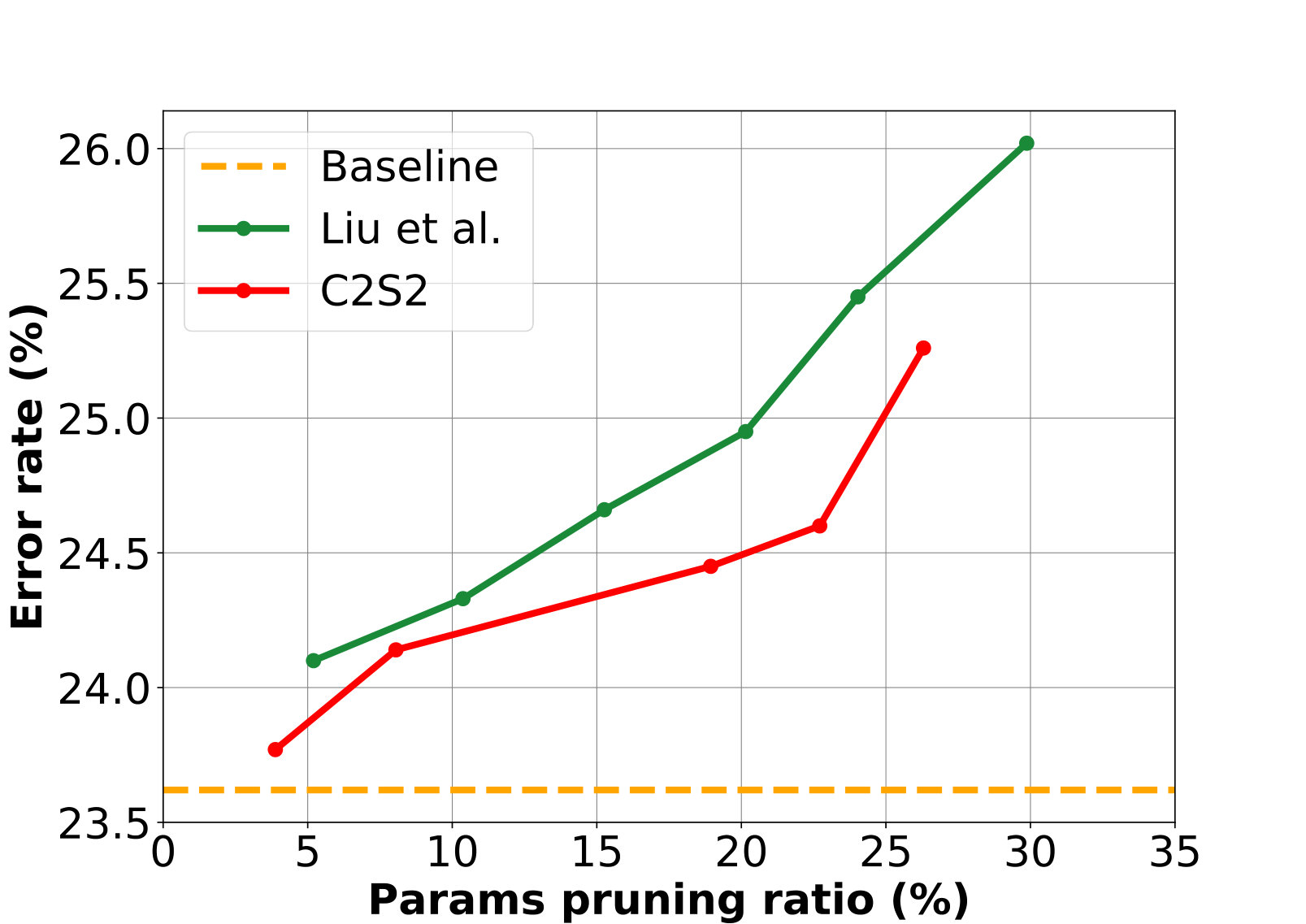 Figure 34
Figure 34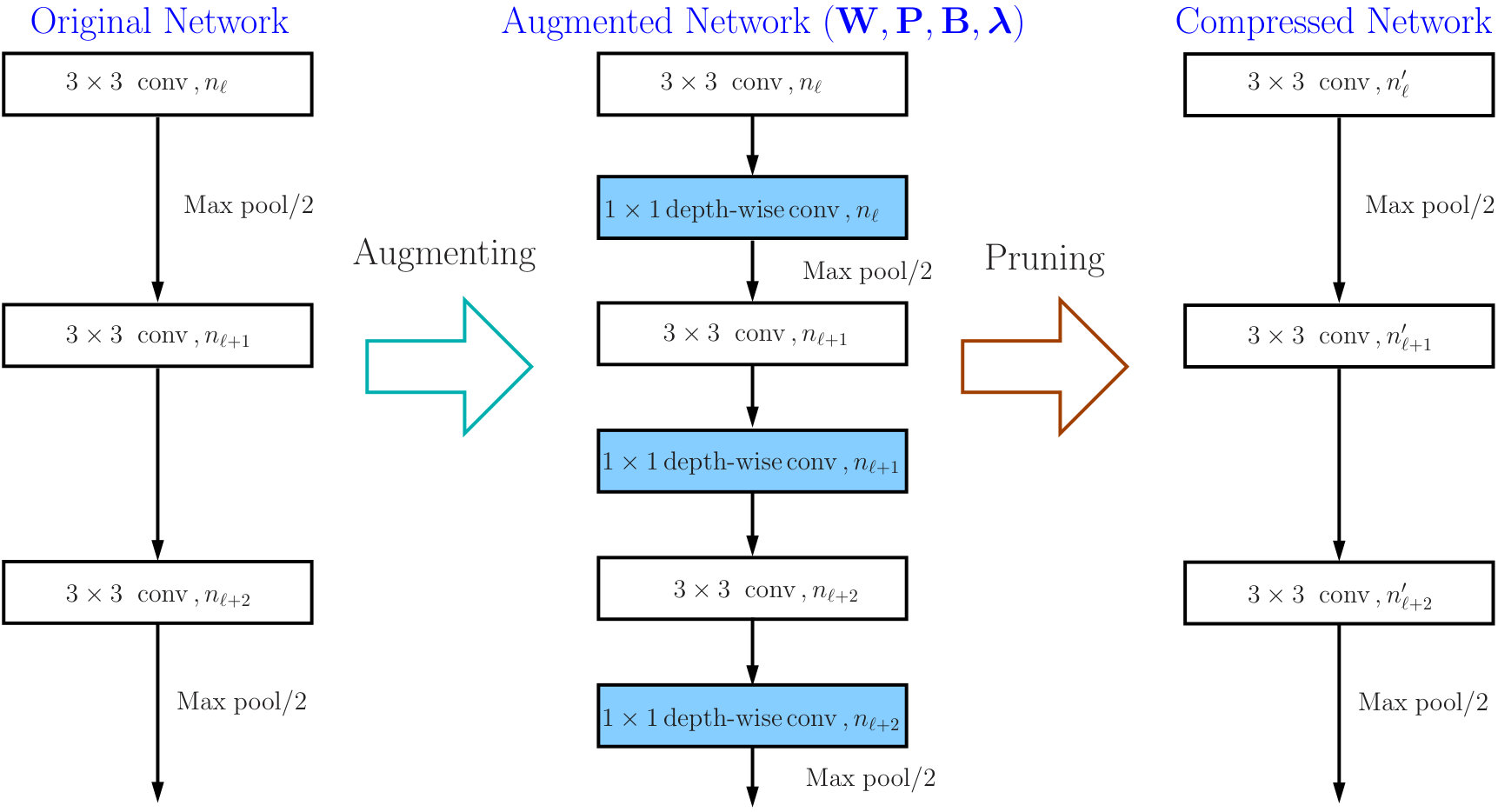 Figure 35
Figure 35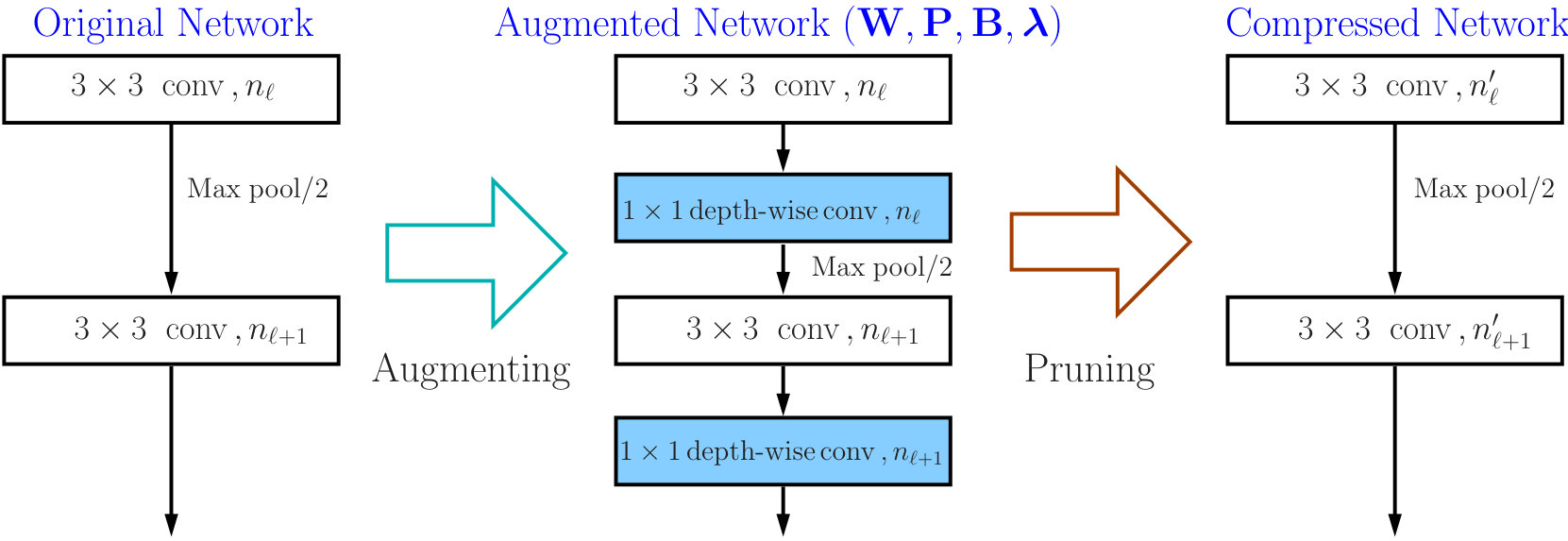 Figure 36
Figure 36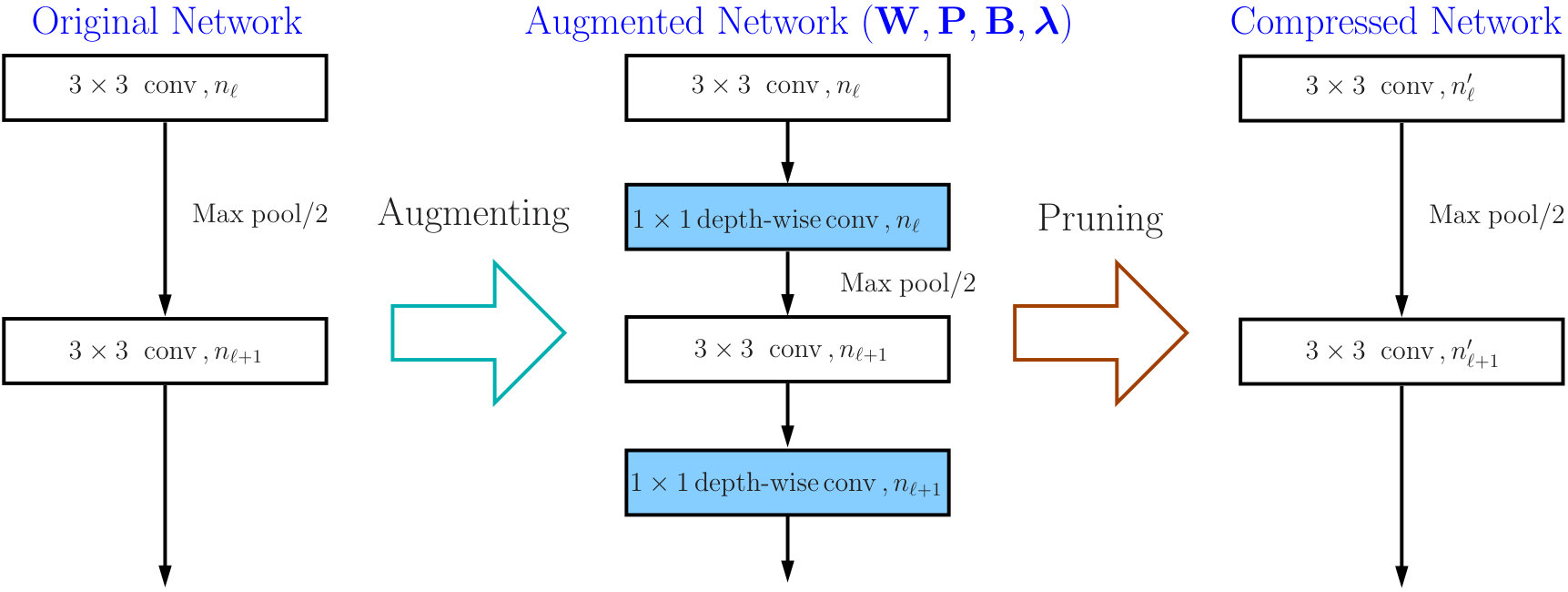 Figure 37
Figure 37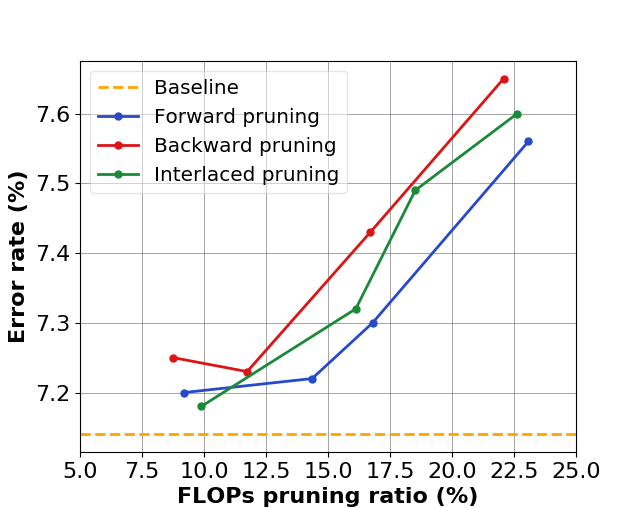 Figure 38
Figure 38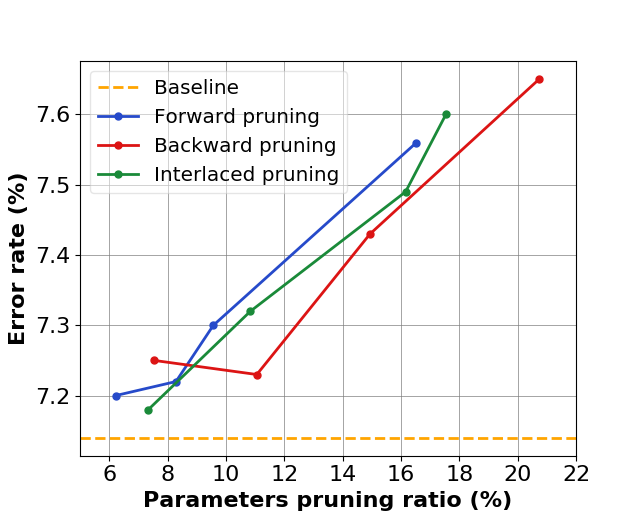 Figure 39
Figure 39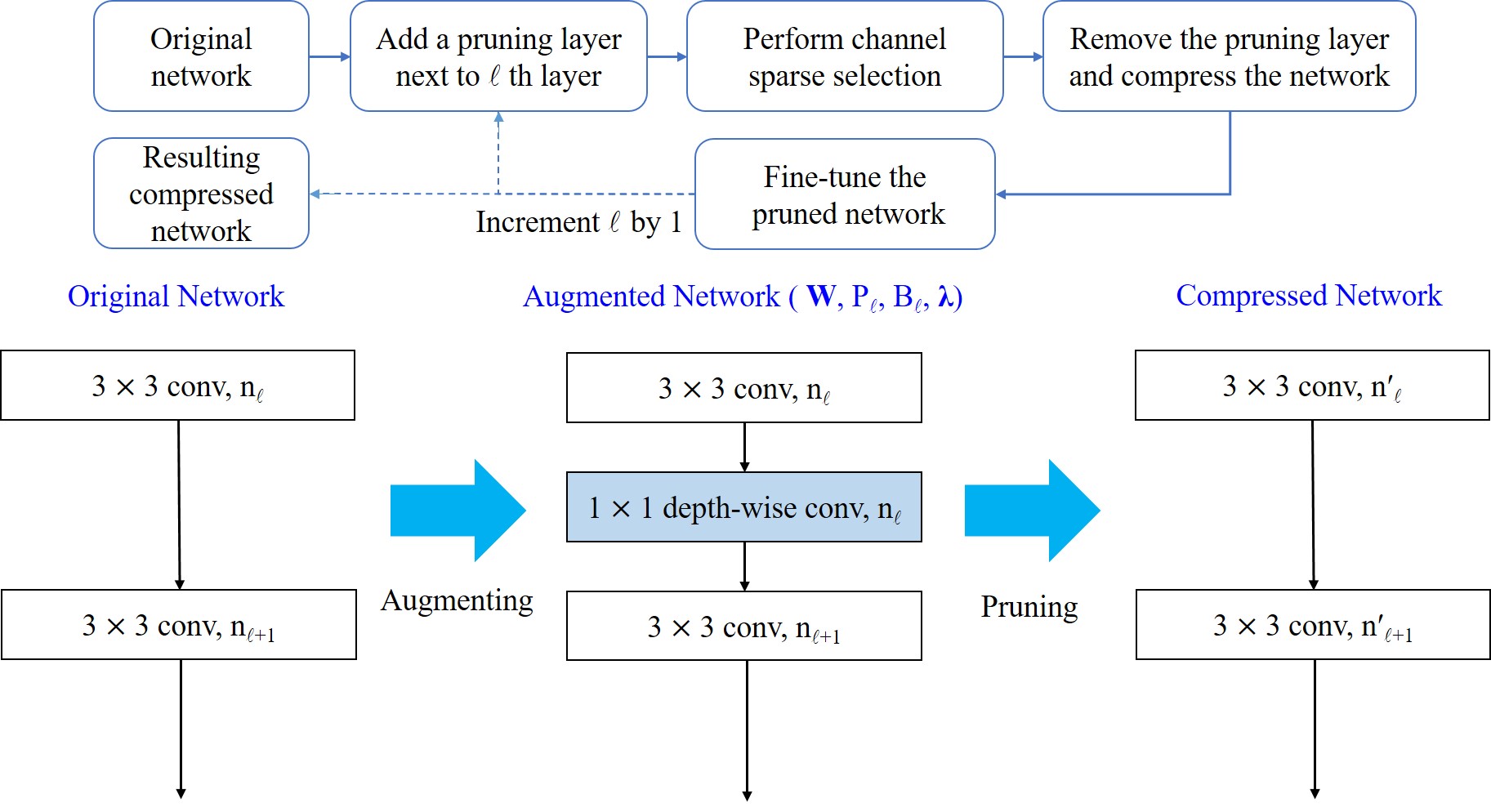 Figure 40
Figure 40| Model | Error | #channels | FLOPs | Params |
| Baseline | 17.9 | 32-32-64-10 | - | - |
| SSL | 17.9 | 16-23-63-10 | 69.8 | 38.4 |
| C2S2 | 17.8 | 11-16-52-10 | 73.0 | 63.8 |
| Method | Training dataset | Pruning T | Reduced T |
| [18] | ImageNet | 24hr, 27min | – |
| C2S2-within | ImageNet | 23hr, 11min | |
| C2S2-within | ImageNet ( s=0.5 ) | 13hr, 15min | |
| C2S2-within | ImageNet ( s=0.25 ) | 7hr, 10min |
| C2S2-within | C2S2 | [18] | ||||||
| Error rate | FLOPs | Params | Error rate | FLOPs | Params | Error rate | FLOPs | Params |
| 7.25% | 13.37% | 11.69% | 7.31% | 18.65% | 17.28% | 7.33% | 10.40% | 10.00% |
| 7.58% | 22.22% | 19.14% | 7.55% | 27.25% | 25.50% | 7.76% | 22.22% | 18.34% |
| 7.77% | 34.55% | 27.43% | 7.76% | 38.99% | 31.75% | 8.01% | 31.75% | 27.54% |
| 7.93% | 39.43% | 38.59% | 7.90% | 42.02% | 40.68% | 8.46% | 40.28% | 38.86% |
| 8.09% | 46.97% | 44.86% | 8.15% | 51.64% | 50.58% | 8.77% | 48.41% | 48.59% |
| 8.38% | 52.61% | 49.54% | 8.37% | 54.99% | 54.31% | |||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Neural Network Applications · Domain Adaptation and Few-Shot Learning · Adversarial Robustness in Machine Learning
MethodsPruning
C2S2: Cost-aware Channel Sparse Selection for Progressive Network Pruning
Chih-Yao Chiu, Hwann-Tzong Chen, and Tyng-Luh Liu
Abstract
This paper describes a channel-selection approach for simplifying deep neural networks. Specifically, we propose a new type of generic network layer, called pruning layer, to seamlessly augment a given pre-trained model for compression. Each pruning layer, comprising depth-wise kernels, is represented with a dual format: one is real-valued and the other is binary. The former enables a two-phase optimization process of network pruning to operate with an end-to-end differentiable network, and the latter yields the mask information for channel selection. Our method progressively performs the pruning task layer-wise, and achieves channel selection according to a sparsity criterion to favor pruning more channels. We also develop a cost-aware mechanism to prevent the compression from sacrificing the expected network performance. Our results for compressing several benchmark deep networks on image classification and semantic segmentation are comparable to those by state-of-the-art.
Index Terms:
Model Compression, Network Pruning
1 Introduction
Techniques based on deep neural networks have been very successful for a wide variety of applications in artificial intelligence, but the good performance often comes at a price. A deep-net model typically comprises a huge number of parameters that may not be efficient for run-time computation and also take up large amounts of storage. Such concerns have not been mitigated by that most of the state-of-the-art deep learning methods tend to adopt deeper and complicated architecture to improve the accuracy. Meanwhile, there is also an immediate need for lightweight and efficient versions of deep networks that can be easily ported to and run on embedded systems or mobile devices. We are thus motivated to develop a cost-aware method that can reduce the complexity (e.g., size or FLOPs) of a given network significantly, without compromising its expected performance.
Weight quantization and network pruning are the two most popular ways to alleviate the storage requirement and the computational burden, or to reduce the number of parameters and the number of floating point operations for a deep-net model. This work focuses on devising a network-pruning method that removes redundant weights. A major challenge in pruning a deep network is that most of the weight parameters are correlated and finding the best combination of to-be-pruned weights is simply intractable. There is no general principle to decide directly which weights are negligible to the overall performance. While striving to avoid relying on heuristics, we instead develop a new type of generic network layer that can be plugged into a pre-trained network and then guides itself to systematically and effectively perform network pruning via a learning process.
The proposed new type of layer is called the pruning layer. Figure 1 illustrates the key idea about how it works. The pruning layer is implemented as a depth-wise convolutional layer with its binary-valued weights serving as the channel selection mask. Filtered by the binary weight values of the pruning layer, those channels that correspond to zero pruning weights will be excluded. As a result, kernels of the previous layer that produce these redundant channels will be removed, while kernels of the next layer will thus be slimmed according to the values of the pruning mask. To facilitate the pruning, we incorporate a sparsity term into the optimization objective to encourage each pruning layer to remove as many channels as possible. In addition, we also add a bipolar term so that the resulting pruning weights intrinsically tend to have values close to either [math] or , making it compelling to adopt as the unified threshold for all layer-wise binarizations.
With the proposed pruning layer, we further devise a cost-aware mechanism to avoid excessive pruning of weight parameters. The pruning layer is allowed to overshoot and remove more-than-enough channels. When the overshooting occurs, the training loss tends to be increasing and it may not be feasible to fine-tune the pruned model to yield comparable performance as the original network. The cost-aware pruning mechanism keeps monitoring the changes in the training loss to detect overshooting. When detected, the cost-aware mechanism stops the network-pruning step and rewinds the training process by restoring some pruned weights back to their previous values. The proposed cost-aware mechanism provides an effective way to compress deep-net models without paying the price of accuracy degradation. We apply our method to different network models, including VGG-Net, ResNet, MobileNet, and FCN. In particular, our method introduces the within-block and between-block pruning steps for ResNet. It is also worth noting that previous approaches to network pruning seldom try to compress deep-net models for tasks other than classification. Our method can efficiently compress FCN for the task of semantic segmentation by removing more than 95% parameters of the original model while producing comparable results. (See the Appendix.)
2 Related Work
Depending on the design principle, methods of compressing and accelerating deep neural networks could differ significantly. For example, several previous approaches involve learning a more efficient and lightweight network using different architecture or with additional data structures, such as distillation [1], LCNN [2], and MobileNet [3]. Our literature survey instead emphasizes those that directly compress existing pre-trained networks. For the ease of discussion, we categorize relevant techniques into two groups: weight quantization and weight pruning, and discuss more on the latter as our method for network compression is a pruning-based approach.
2.1 Weight Quantization
The technique by [4] can achieve nearly compression on several popular networks by quantizing weights into ternary values where and are learned for each layer. Subsequently, [5] present a quantization based method that uses a half-wave Gaussian quantizer for approximating the ReLU activation non-linearity. [6] quantize the full-precision weights into low-precision versions with the values constrained to powers of two or zero. Instead of considering all the weights jointly, they quantize only a portion of the weights of the given layer at a time and regain the accuracy by re-training. These quantization-based methods require specialized software libraries or hardware to accelerate the compressed networks, while our intended approach does not leverage such libraries or hardware for accelerating compressed networks.
2.2 Weight Pruning
The concept of weight pruning can be traced back to classic methods on reducing network complexity and improving generalization [7, 8], where second-derivative information is used to assess weight importance. Another early work on synaptic pruning [9] suggests to overgrow the synapses first and then prune them with respect to an optimal “minimal-value" deletion. [10] propose to measure the importance of a filter in each layer by its sum of absolute weights. Their method prunes the least useful filters according to sensitivity analysis for each layer. The drawback is that they have to conduct a series of analyses to determine how many filters can be pruned for each convolutional layer, which is time-consuming especially for very deep networks. Their strategy is to prune each layer independently and evaluate the accuracy. However, the sensitivity of a specific layer might change due to the pruning of other layers. In contrast, our cost-aware channel selection method prunes the network layer by layer and learns how many filters can be pruned without enforcing extra heuristics, which is more convenient and efficient.
In [11, 10, 12], the main idea is to evaluate the importance of weights by handcrafted criteria. Our method instead learns the importance of convolutional filters via a generic training process, and can automatically choose the crucial filters to keep without being guided by any handcrafted criteria.
Another line of research aims to learn a compact network by imposing sparsity constraints on the weights of convolutional layers. [13] propose to learn the number of neurons for each convolutional layer by including a group Lasso constraint on the weights. Structured Sparsity Learning (SSL) by [14] employs group Lasso constraints to multiple groups of weights for channel-wise, shape-wise, and depth-wise pruning. [15] propose the Net-Trim that uses convex optimization to prune the network layer-wise, and provide theoretical guarantees on how far the pruned model is from the original one. [16] introduce a coefficient vector for channel selection. They reduce the number of output channels for each layer by imposing an norm sparsity constraint on the corresponding coefficient vector. The pruning process is carried out via minimizing the reconstruction error on feature maps and the sparsity constraint. Our method, in comparison, directly minimizes the sparsity constraint and loss between the prediction and label, yielding a much simpler optimization problem. [17] develop the so-called ThiNet model for filter level pruning. It respects the network structure, and also performs filter pruning layer-by-layer. The pruning strategy is an iterative scheme that decides the pruning of layer based on the statistics of layer and optimizes a reconstruction error caused by the filter selection. However, in our method, the layer-wise pruning order can be arbitrary, and the pruning process is driven by preserving the network performance.
Network slimming by [18] shares a similar idea with our approach in that the common goal is to achieve channel-level sparsity and the insignificant channels are identified via a training process. They impose regularization on the scaling factors in batch normalization layers to achieve network compression. The key differences between their approach and ours are as follows: i) We introduce the cost-aware mechanism for recovering from over-pruning. The proposed Cost-aware Channel Sparse Selection (C2S2) method can automatically maintain the accuracy of the network during the process of progressive pruning. That is, it learns to generate the final compressed network in one pass by taking account of the trade-off between compression ratio and performance degradation. ii) Our approach includes a bipolar term in the loss function to enforce the convergence of pruning weights toward either [math] or for easy binarization using a fixed threshold (). iii) The proposed C2S2 carries out channel pruning layer by layer so that only kernels of a same layer are considered simultaneously. The strategy is more advantageous over global pruning for keeping the network architecture intact. In contrast, the method of [18] prunes channels by specifying a global percentile of sorted scaling factors across all layers. The pruning process is thus driven by the specified compression rate. It requires several full-fledged runs to decide the most suitable compression ratio that the resulting compressed network can still be fine-tuned to yield comparable performance to the original network. Our method instead performs channel selection with a cost-aware mechanism to layer-wise pursue most effective pruning with the constraint of maintaining the network performance. More discussions can be found in the Experiments.
3 Progressive Network Pruning
We explore the layer-wise architecture of deep network for network compression. The strategy, as we will describe below, could lead to not only a general framework but also an effective approach. At the core of our method is a new type of generic network layer called pruning layer that plays the crucial role of selecting and masking channels during the pruning process. The pruning layer is considered generic in that it is a flexible depth-wise module and can accommodate almost all types of neural networks. After inserting the pruning layers to a neural network, the function of each pruning layer is to select informative channels from its inputs, i.e., the outputs from its preceding layer. Hence the pruned channels can be either feature maps or simply neurons, depending on whether a pruning layer is positioned right after a convolutional layer or a fully-connected layer. However, in this study we restrict the use of pruning layers to expunging redundant feature maps from convolutional layers.
Given a pre-trained ConvNet with convolutional layers, we use to denote the set of relevant network parameters. The layer-wise outputs are expressed by , where tensor includes the feature maps yielded by the th convolutional layer. We augment the model with pruning layers, each of which follows right next to a convolutional layer. After performing channel sparse selection on the augmented network, we unplug the pruning layers and remove the masked channels to obtain a compressed network with that contains a reduced number of channels for each convolutional layer. We illustrate the overall pruning process in Figure 2a.
Specifically, each pruning layer comprises an array of depth-wise kernels, where the total number is specified by that of its input channels. We denote the real-valued weight tensor of the pruning layer following the th convolutional layer as . The goal of our network pruning is to optimize so that the real-valued weights can be automatically binarized with respect to a unified threshold to yield binary masks . With the above notations, the corresponding augmented network can be represented by a quadruplet , where are the weight parameters in the objective function (2) for the layer-wise pruning. (By a slight abuse of notation, in the quadruplet form indeed means to represent all trainable weights of the given ConvNet.) We can write the process of channel selection (network pruning) as
[TABLE]
where symbolizes the channel-wise product between and . From (1), we see that with its values from functions as the layer-wise binary channel selection mask.
3.1 Channel Sparse Selection
With the augmented network, the proposed channel selection algorithm starts with a training process that aims to learn the binary channel selection masks . To this end, we consider a progressive scheme that carries out the pruning task in a specific layer-wise order, which we have considered three implementations: forward , backward, and interlaced orderings. Since the channel selection process is analogous for each pruning layer, we omit the layer subscript in the following analysis for the sake of simplifying the notations.
Let the data ground truth for the underlying task that the given ConvNet aims to accomplish be . To perform channel selection for a specific pruning layer, our algorithm operates in two phases. In the first phase, the goal is to optimize the real-valued weights of the pruning layer, while all other network parameters are fixed. Then, in the second phase, while fixing , our algorithm optimizes all the remaining convolutional parameters according to the selection mask , which is derived from with respect to the threshold . We detail the two phases of performing network pruning below.
3.1.1 Phase 1
With fixed, we impose a sparsity constraint and a bipolar prior for optimizing , the real-valued weights of the pruning layer. Specifically, the objective function for layer-wise pruning can be written as
[TABLE]
where is the unit tensor with the same size of , and is a function (to be specified later) measuring the difference between ground-truth labels and phase-1 predictions . The term is to favor the sparsity of the pruning layer’s weights, i.e., to prefer pruning more channels. The second -norm term encourages the kernels of converging to [math] or , and thus computing the corresponding binary mask is not sensitive to the choice of threshold . So, in the first phase, we do forward propagation through the augmented network , and compute the total loss according to (2). Notice that is intentionally left out of the quadruplet notation since binary masks are not considered in the first phase. As a result, we have an end-to-end differentiable neural network. In back-propagation, only are updated with respect to the gradient feedback.
It is convenient to reshape the tensor into a 1-D vector , where is the number of output channels of the convolutional layer that the pruning layer is plugged right after. (See Figure 1 for illustration.) We then use to denote the th element of . In optimizing , although we do not enforce to clamp the value of each to fall between 0 and 1, the value can still be considered as the response for supporting the selection of convolutional output channel . It follows that each element of binary mask signals the channel selection for the th output channel of the preceding convolutional layer.
3.1.2 Phase 2
With fixed, the second phase of our algorithm begins by specifying the binary mask . Specifically, we compare with threshold to decide :
[TABLE]
In the second phase, we do forward propagation through the ConvNet architecture filtered by and obtain the predictions . As is fixed in phase two, the total loss in (2) is reduced to . During back-propagation, we fix the weights of each pruning layer and update the weights of each convolutional layer and each fully connected layer. In our implementation, phase one is carried out every 10 training steps, while phase two is done for each training step.
3.1.3 Channel Selection and Kernel Pruning/Slimming
The relation between channel selection and kernel pruning/slimming is illustrated in Figure 1. If a particular output channel is excluded by the binary mask, say, , the respective kernel of the th convolutional layer that produces this redundant channel will be pruned, while the kernels in the th layer will be slimmed by one input channel. In other words, the kernels of th layer that produce redundant channels will be removed, while kernels of th layer will be slimmed by the number of removed channels.
3.1.4 C2S2 for Residual Networks
Our method can also be used to compress residual networks [19]. Since residual blocks with the same number of output channels are distributed consecutively in a residual network, we thus divide them into (consecutive) residual groups with respect to the number of their output channels. Now consider an arbitrary group. If we prune any output channels of its last residual block, then, due to the design of identity shortcut, we also need to prune the corresponding input channels of that block to maintain the channel consistency. This will cause a chain effect such that the corresponding output channels of each residual block in the particular group must be removed accordingly. It implies that the pruning layers that we add right after each residual block of a common group must be made to yield the same binary mask. Further, to prevent the chain effect from propagating to the preceding groups, we implement the shortcut of the first residual block in each group as a convolutional layer. We thus propose a two-step pruning for each group. In the first step, as in Figure 2b, we insert a pruning layer after the first convolutional layer of each block and carry out within-block channel pruning. In the second step, we perform between-block pruning. Since all residual blocks within a group have the same number of output channels, they can be pruned by using a shared pruning layer. (See Figure 2c.) Likewise, we can obtain the final compressed residual network. The flexibility for performing between-block pruning is one of the key advantages of the proposed pruning layer, while other approaches, e.g., [18, 17], work solely on the original network architecture and are prevented from doing so due to the short-cut connections.
4 Cost-aware Mechanism
Previous work, e.g., [10] mainly estimates how many insignificant parameters can be pruned from each network layer by conducting a series of sensitivity analysis. In our approach, we attempt to automatically determine the proper sparsity for each convolutional layer via a cost-aware mechanism. As a result, our method can compress a given ConvNet in a much simpler and efficient way.
The cost-aware mechanism can be thought of as a simple case of two-state Markov decision process (MDP). As illustrated in Figure 3c, the process of channel selection has two (operation) states, namely, Pruning and Restoring, whereas the action to take at the former is to decide how many channels to prune, and at the latter is to estimate how many pruned channels should be restored. We now describe a greedy and heuristic approach to the process. To begin with, we run all the training examples with the given pre-trained ConvNet and obtain the average error rate . Then, with the augmented network, we maintain an incrementally updated error rate, denoted as , which is an exponential moving average of the training error rate .
At the beginning of pruning a specific convolutional layer, we trigger the state transition to move from Start to Pruning. Meanwhile, we set a scaling coefficient to form a tolerable upper bound that is used to prevent from increasing too much due to pruning too many channels. Specifically speaking, the process keeps returning to Pruning and the algorithm continues to prune redundant channels until exceeds . It signals the detection of excessive pruning and causes the process to make the state transition to Restoring.
Once the process is at Restoring state, our method automatically restores the pruned channels by changing the sign of . Particularly, we set a proper coefficient such that the algorithm continues to restore the pruned channels until is smaller than and then moves to the End state to conclude the channel selection for the convolutional layer. Detailed steps of the C2S2 algorithm for network compression are described in Algorithm 1 in the appendix.
5 Experiments
We evaluate our method on several popular ConvNets, including VGG-Net [20], ResNet [19], MobileNet [3] and FCN [21]. To decide the order of pruning, we carry out a pilot experiment on ResNet-20 with a model pre-trained on CIFAR-10 [22]. Next, we discuss results and comparisons for experiments on CIFAR-10, CIFAR-100, and ImageNet. Besides the various classification tasks, our method is also applied to the compression of ConvNets for semantic segmentation.
5.1 More on C2S2
We first provide some insightful observations to manifest the advantages of the two key components in C2S2, namely, the bipolar prior in (2) and the cost-aware mechanism. Figure 3b and Figure 3a show the distributions of pruning weights derived with or without using the bipolar term. It can then be inferred that the weight distributions by C2S2 entail a clear-cut fixed threshold at , while those from using only the sparsity constraint do not display such a favorable property. We next highlight the usefulness of pruning with the cost-aware mechanism that enables our method to perform channel selection under the constraint of maintaining network performance. As shown in Figure 3c, the proposed C2S2 can automatically detect the occurrence of over-pruning and makes the state transition from Pruning to Restoring so that the network performance after sparse channel selection for each layer is reasonably retained.
The two foregoing nice features enable our method to decompose the overall problem of channel selection into a sequence of layer-wise subproblems. At each layer, the task is to generate a binary mask based on the fixed threshold so that the resulting channel selection can be effectively achieved without degrading the expected accuracy.
Since we prune convolutional layers progressively, the effectiveness may be affected by the pruning order. We thus perform a pilot experiment on ResNet-20 pre-trained on CIFAR-10. The result is reported in Figure 4. The channel selection is done in three different orderings, namely, forward, backward, and interlaced. According to the results of this pilot experiment, we have found that forward pruning yields higher pruning ratios for low-level layers than high-level layers, which enables forward pruning to achieve higher FLOPs reductions than backward and interlaced pruning with roughly the same error rate. In contrast, backward pruning has higher pruning ratios for high-level layers than low-level layers, which results in higher parameters reductions than forward and interlaced pruning given roughly the same error rate. We choose to perform network pruning in forward direction for all our experiments since it attains the best accuracy-FLOPs trade-off (unless otherwise specified).
The overall pruning ratio and accuracy loss are mainly affected by the hyper-parameter , enforcing the training error rate of a pruned model to be under a certain level. In contrast, the impact of and on overall pruning ratio is negligible unless we use and of different orders. Note that and are fixed at 0.002 in all experiments.
5.2 VGG-Net on CIFAR-10
Our VGG-Net is a variant of VGG-16 [20]. We adopt the network architecture described in [18] and implement a VGG-Net that contains 16 convolutional layers and 1 fully connected layer. The detailed architecture of the VGG-Net can be found in Appendix. With the VGG-Net, the function in (2) is to measure the cross entropy between label and prediction .
From the results shown in Figure 6, we observe that C2S2 has the noticeable advantage over [18] in achieving pruning without degrading accuracy. In our experiment, C2S2 can easily perform pruning without degrading test accuracy by setting the hyper-parameter slightly larger than 1.0. As shown in the Appendix, C2S2 yields reduction of model parameters with improved accuracy by setting as 1.2. In contrast, the technique of [18] requires a pre-defined pruning ratio to do network pruning. However, there is no rule of thumb to choose a proper pruning ratio. In practice, it requires many time-consuming tries to decide the proper value of pruning ratio.
The other disadvantage from the model of [18] is about retaining the original network architecture. In the experiment, it reaches the highest pruning ratio of parameters at . When the pruning process continues to carry out and thus increases the pruning ratio, their technique would prune all output channels of the 12th convolutional layer and cause the model to break down. In contrast, C2S2 does not suffer from this problem because the cost-aware mechanism can prevent the pruning process from over-pruning.
Also detailed in the provided Appendix, the proposed method can obtain reduction of model parameters and reduction of FLOPs for VGG-Net without degrading test accuracy by performing channel sparse selection in forward direction. Our results of reduction in model parameters and FLOPs are superior to those of [18] under the same baseline accuracy and network settings.
5.3 ResNet-20 on CIFAR-10
The ResNet-20 architecture adopted in the comparison is the same as that described in [18]. The structure of residual block is plotted in Figure 2b. It is worth emphasizing that we use a convolutional layer to do projection mapping in the first residual block of each group. With the projection mapping, we can easily handle the dimension mismatch caused by channel pruning via reducing the output channels of convolutional layer. in (2) is to measure the cross entropy between labels and predictions. In the first step of C2S2 for residual network, we carry out within-block channel pruning. In the second step, we perform between-block pruning. In contrast, [18] performs only within-block channel pruning on ResNet.
As shown in Figure 7, the pruning result of C2S2 is clearly better than that of [18]. There is a growing trend of the difference between [18] and C2S2-within as the pruning ratio increases, which implies that our channel selection strategy is better than [18]. With parameters pruned, the accuracy drop of our pruned network and that of [18] are and respectively.
It is mentioned in [23] that fine-tuning a pruned model might lead to worse performance than re-training the pruned model with randomly re-initialized weights. Therefore, we compare the training results using the two strategies: i) fine-tuning and ii) re-training with randomly re-initialized weights. As shown in Figure 5, fine-tuning the pruned model achieves better performance than training from scratch. In other words, our pruning method is not just a kind of architecture search method. It indeed keeps the critical weights that are beneficial to achieving better performance.
5.4 Comparison with SSL on CIFAR-10
SSL [14] is one of the SOTA methods for network pruning which compresses networks by filter-wise, shape-wise and depth-wise pruning. For a fair comparison, we build the ConvNet described in Section 4.2 of SSL [14] and train it with CIFAR-10 from scratch. The error rate of baseline is 17.85 which is almost the same as that reported by SSL (17.9). The pruning results are reported in Table I. For the structured sparse model obtained by SSL, we report the output channel of each layer by assuming all the redundant convolution filters have been removed.
5.5 MobileNet on CIFAR-100
As our method focuses on channel pruning, we implement C2S2 in Torch so that we can accurately compare it with Network Slimming [18], the current SOTA but available only in Torch implementation. However, we cannot find a publicly available MobileNet pre-trained on ImageNet with Torch implementation. We thus choose to build and train the MobileNet from scratch on CIFAR-100, where its images are rescaled to with bicubic interpolation. The redundancy of MobileNet is limited since it is already a compact network. The proposed C2S2 achieves 38.1 reduction of FLOPs and 22.7 reduction of parameters with 1 accuracy loss. In comparison, Network Slimming [18] yields 15.6 reduction of FLOPs and 15.3 reduction of parameters with 1 accuracy loss.
5.6 ResNet-18 on ImageNet
We also conduct experiments with ResNet-18 on ImageNet, for further comparison with [18]. For the sake of comparison, we perform within-block compression with [18] and our method. We fine-tune each pruned model for ten epochs with learning rate changing from to . The results are plotted in Figure 9, while more detailed results can be found in the Appendix.
From Figure 9, we can reasonably infer that our method can achieve higher FLOPs reduction than [18] given the same error rate. We further observe that [18] tends to achieve high pruning ratios for high-level layers and low pruning ratios for low-level layers, which leads to less FLOPs reduction. In contrast, our method successfully learns the proper sparsity for each layer and achieves higher FLOPs reduction than [18] given the same error rate. In addition, our pruned model achieves lower error rate than [18] for high parameter reduction, owing to that C2S2 can prune those channels with lower impact on error rate especially for high compression ratios.
5.6.1 Runtime Analysis of C2S2
In order to compare the efficiency with [18], we measure the averaged time taken by C2S2 and [18] to finish the pruning process. The results are reported in Figure 10 and Table II. The averaged time taken by each algorithm is roughly the same, which makes us to think about how to compress the network faster and still achieve a good accuracy-FLOPs trade-off. We thus perform the pruning process by using a subset of original training set and measure the averaged time for pruning. We can save 42.8 time for pruning on averaged, while achieving better accuracy-FLOPs trade-off than [18] by using half of ImageNet training data during the pruning process. We further perform pruning with a quarter of ImageNet training data. The results are comparable to those of [18] but our processing speed is three times faster.
6 Conclusions
We present a channel selection method to prune redundant parameters of deep networks. Our method automatically identifies the insignificant channels of each layer via a generic learning process. Furthermore, our method can guide itself to learn proper sparsity for each layer with negligible accuracy degradation using the proposed cost-aware mechanism. When the pruning process is completed, we remove the augmented pruning layers and the identified insignificant channels to obtain a pruned model, which is ready for deployment. With C2S2 pruning, we have achieved state-of-the-art reductions in model parameters and FLOPs for all deep-net models evaluated in the experiments. The flexibility of pruning layer enables C2S2 to work with almost all variants of ConvNets, while its dual representations lead to end-to-end training for channel selection. Last but not least, the pruning strategy by C2S2 is driven by maintaining network accuracy, while other approaches accomplish the task by repeatedly exploring pre-specified compressed ratios.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] G. E. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,” Co RR , vol. abs/1503.02531, 2015. [Online]. Available: http://arxiv.org/abs/1503.02531
- 2[2] H. Bagherinezhad, M. Rastegari, and A. Farhadi, “LCNN: lookup-based convolutional neural network,” Co RR , vol. abs/1611.06473, 2016. [Online]. Available: http://arxiv.org/abs/1611.06473
- 3[3] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “Mobilenets: Efficient convolutional neural networks for mobile vision applications,” Co RR , vol. abs/1704.04861, 2017. [Online]. Available: http://arxiv.org/abs/1704.04861
- 4[4] C. Zhu, S. Han, H. Mao, and W. J. Dally, “Trained ternary quantization,” Co RR , vol. abs/1612.01064, 2016. [Online]. Available: http://arxiv.org/abs/1612.01064
- 5[5] Z. Cai, X. He, J. Sun, and N. Vasconcelos, “Deep learning with low precision by half-wave gaussian quantization,” Co RR , vol. abs/1702.00953, 2017. [Online]. Available: http://arxiv.org/abs/1702.00953
- 6[6] A. Zhou, A. Yao, Y. Guo, L. Xu, and Y. Chen, “Incremental network quantization: Towards lossless cnns with low-precision weights,” Co RR , vol. abs/1702.03044, 2017. [Online]. Available: http://arxiv.org/abs/1702.03044
- 7[7] Y. Le Cun, J. S. Denker, and S. A. Solla, “Optimal brain damage,” in Advances in Neural Information Processing Systems 2 , 1989, pp. 598–605.
- 8[8] B. Hassibi, D. G. Stork, and G. J. Wolff, “Optimal brain surgeon: Extensions and performance comparison,” in Advances in Neural Information Processing Systems 6 , 1993, pp. 263–270.