Correlated Utility-based Pattern Mining
Wensheng Gan, Jerry Chun-Wei Lin, Han-Chieh Chao, Hamido Fujita and, Philip S. Yu

TL;DR
This paper introduces CoUPM, an efficient method for mining high-utility, positively correlated patterns in data, addressing limitations of previous utility-oriented mining by considering item correlation for more insightful results.
Contribution
The paper proposes a novel utility mining approach that incorporates item correlation, improving pattern relevance and computational efficiency over existing methods.
Findings
CoUPM outperforms state-of-the-art algorithms in efficiency.
Patterns mined are more insightful due to correlation consideration.
Experimental results confirm higher effectiveness of correlated high-utility patterns.
Abstract
In the field of data mining and analytics, the utility theory from Economic can bring benefits in many real-life applications. In recent decade, a new research field called utility-oriented mining has already attracted great attention. Previous studies have, however, the limitation that they rarely consider the inherent correlation of items among patterns. Consider the purchase behaviors of consumer, a high-utility group of products (w.r.t. multi-products) may contain several very high-utility products with some low-utility products. However, it is considered as a valuable pattern even if this behavior/pattern may be not highly correlated, or even happen by chance. In this paper, in light of these challenges, we propose an efficient utility mining approach namely non-redundant Correlated high-Utility Pattern Miner (CoUPM) by taking positive correlation and profitable value into account.…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1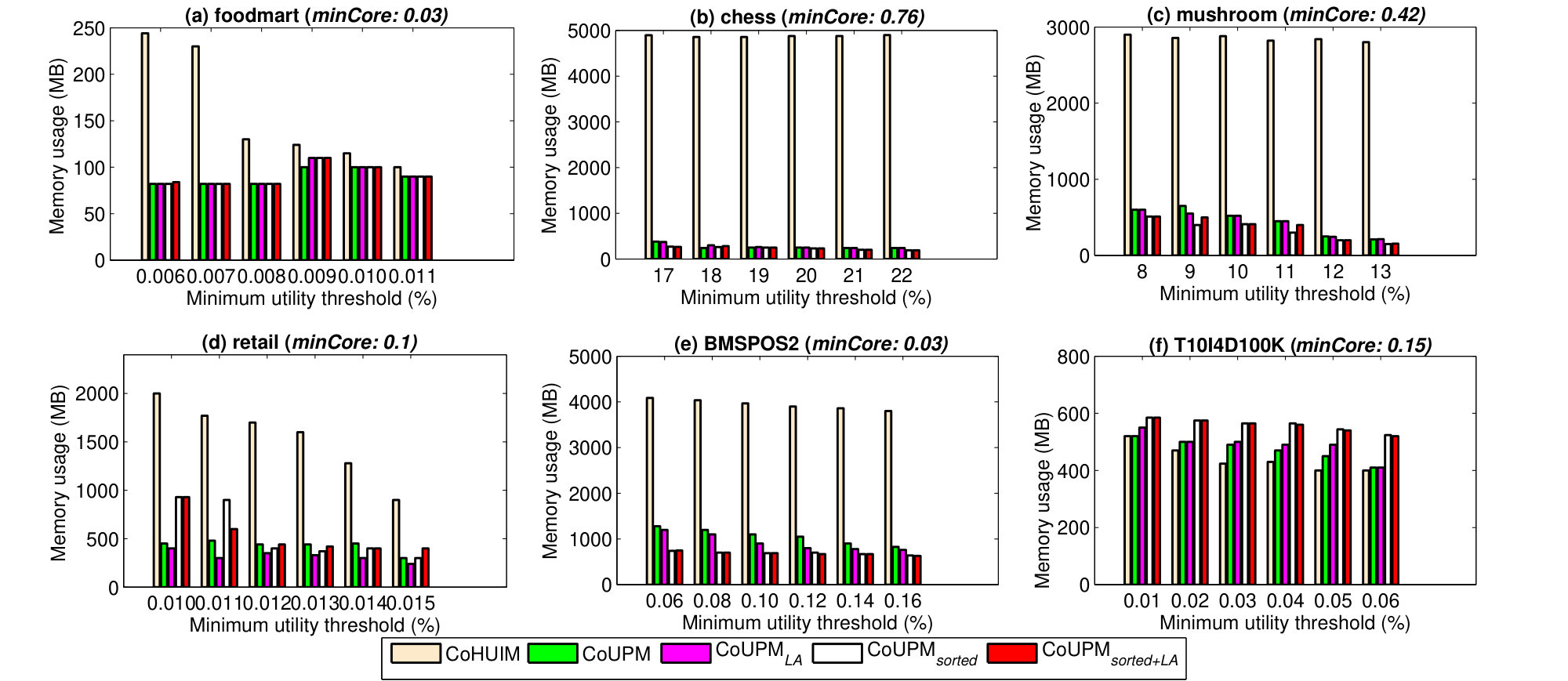 Figure 2
Figure 2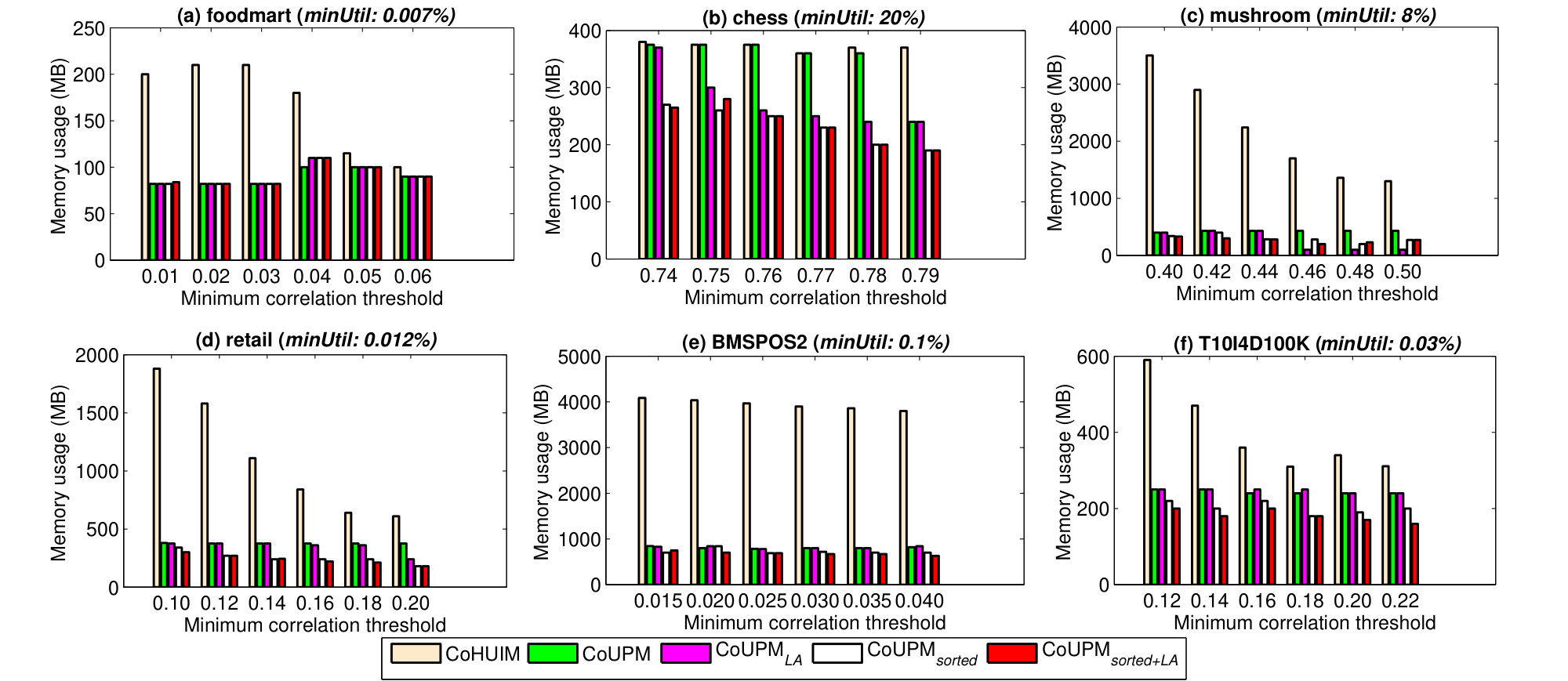 Figure 3
Figure 3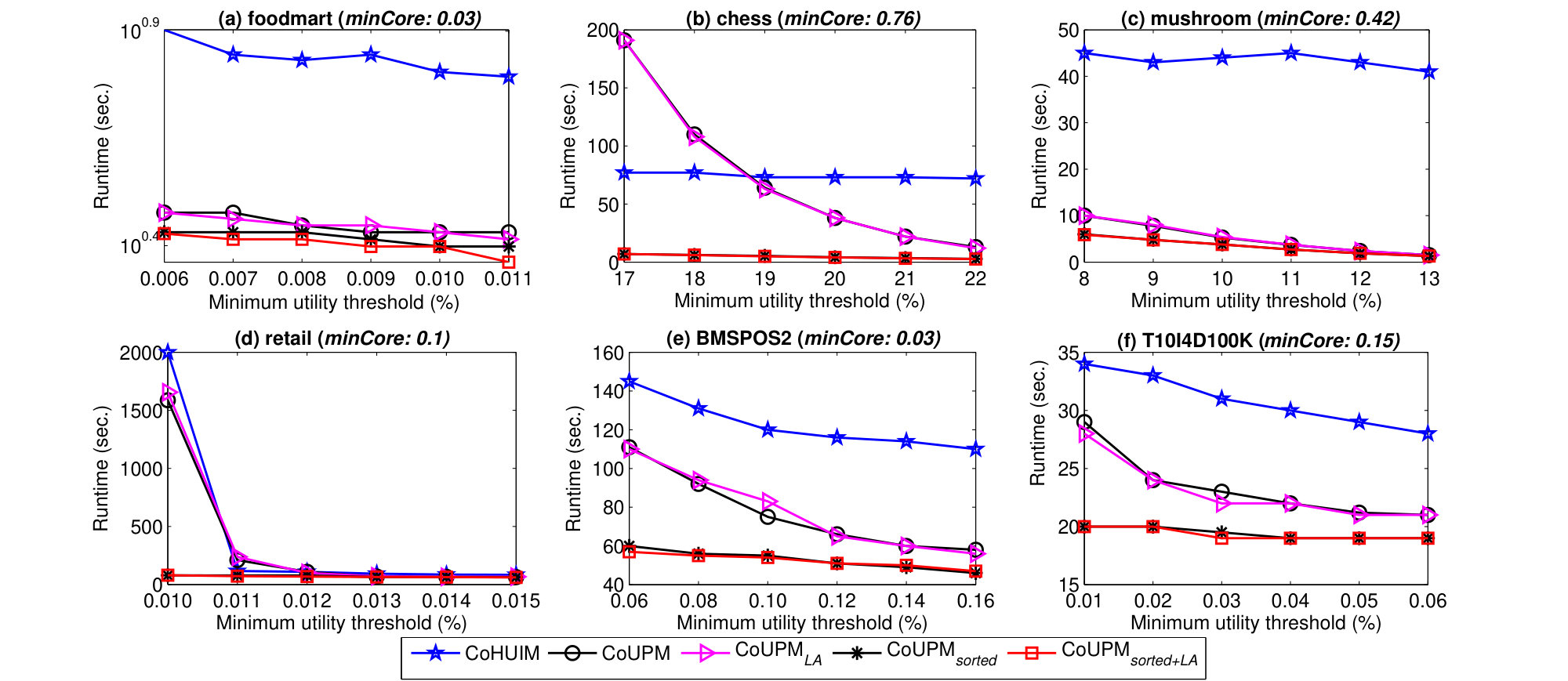 Figure 4
Figure 4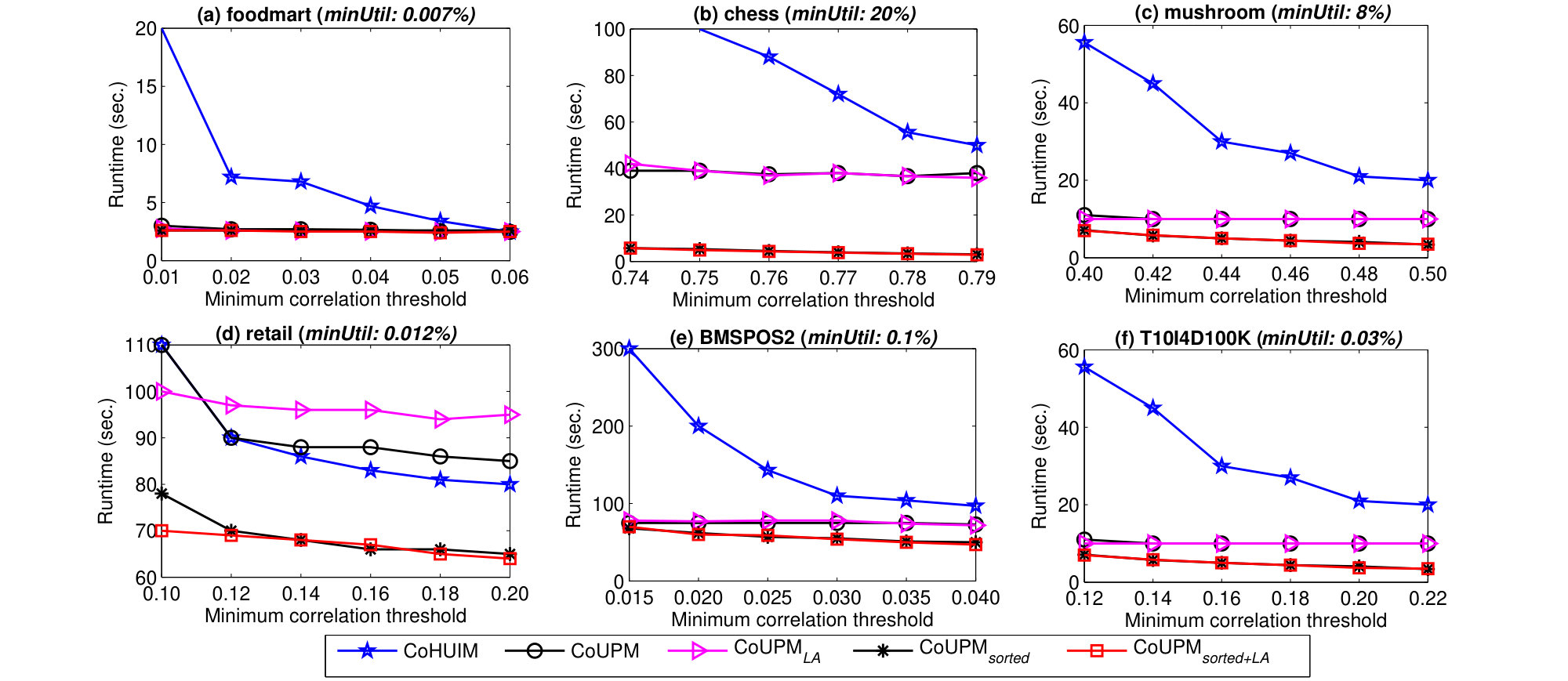 Figure 5
Figure 5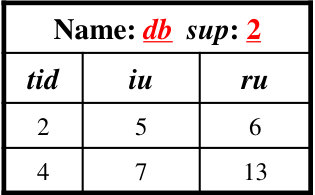 Figure 6
Figure 6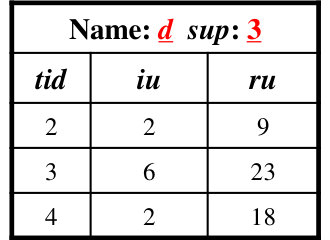 Figure 7
Figure 7| Tid | User | Timestamp | Purchase record |
|---|---|---|---|
| 07/12 10:05:30 | |||
| 07/12 10:11:10 | |||
| 07/12 10:15:48 | |||
| 07/12 10:18:00 | |||
| 07/12 10:25:20 |
| Product | |||||
|---|---|---|---|---|---|
| Profit ($) | 3 | 1 | 7 | 2 | 10 |
| Dataset | # Patterns | # patterns under different thresholds | |||||
|---|---|---|---|---|---|---|---|
| #HUIs | 93,418 | 49,821 | 26,176 | 14,156 | 8,364 | 5,365 | |
| #DHUIs | 33,621 | 16,285 | 8,712 | 5,277 | 3,644 | 2,778 | |
| # (minCor: 0.01) | 93,418 | 49,821 | 26,176 | 14,156 | 8,364 | 5,365 | |
| foodmart | # (minCor: 0.02) | 24,857 | 17,127 | 12,026 | 8,557 | 6,290 | 4,683 |
| # (minCor: 0.03) | 20,224 | 15,082 | 11,195 | 8,247 | 6,191 | 4,651 | |
| # (minCor: 0.04) | 6,869 | 5,675 | 4,682 | 3,831 | 3,222 | 2,764 | |
| # (minCor: 0.05) | 4,654 | 4,092 | 3,558 | 3,084 | 2,712 | 2,405 | |
| # (minCor: 0.06) | 2,644 | 2,501 | 2,344 | 2,204 | 2,065 | 1,944 | |
| #HUIs | - | - | 45,711,058 | 2,486,972 | 22,641 | 15,713 | |
| #DHUIs | 14,539 | 12,620 | 11,122 | 9,873 | 8,847 | 7,953 | |
| # (minCor: 0.10) | 11,510 | 10,244 | 9,252 | 8,474 | 7,836 | 7,301 | |
| retail | # (minCor: 0.12) | 10,221 | 9,224 | 8,402 | 7,735 | 7,170 | 6,686 |
| # (minCor: 0.14) | 8,734 | 7,922 | 7,239 | 6,676 | 6,187 | 5,783 | |
| # (minCor: 0.16) | 7,600 | 6,929 | 6,317 | 5,825 | 5,402 | 5,050 | |
| # (minCor: 0.18) | 7,081 | 6,469 | 5,909 | 5,455 | 5,063 | 4,732 | |
| # (minCor: 0.20) | 6,823 | 6,238 | 5,699 | 5,260 | 4,878 | 4,562 | |
| #HUIs | 198,920 | 89,933 | 39,281 | 16,848 | 7,141 | 2,969 | |
| #DHUIs | 0 | 0 | 0 | 0 | 0 | 0 | |
| # (minCor: 0.74) | 8,717 | 6,083 | 4,021 | 2,493 | 1,438 | 760 | |
| chess | # (minCor: 0.75) | 7,330 | 5,113 | 3,378 | 2,101 | 1,199 | 629 |
| # (minCor: 0.76) | 6,062 | 4,210 | 2,773 | 1,704 | 799 | 500 | |
| # (minCor: 0.77) | 4,987 | 3,464 | 2,282 | 1,401 | 799 | 415 | |
| # (minCor: 0.78) | 4,118 | 2,856 | 1,872 | 1,145 | 650 | 333 | |
| # (minCor: 0.79) | 3,316 | 2,287 | 1,483 | 891 | 503 | 252 | |
| #HUIs | 22,121 | 13,953 | 7,601 | 3,420 | 1,265 | 356 | |
| #DHUIs | 8 | 2 | 0 | 0 | 0 | 0 | |
| # (minCor: 0.40) | 8,732 | 5,320 | 2,723 | 1,145 | 435 | 138 | |
| mushroom | # (minCor: 0.42) | 7,126 | 4,422 | 2,374 | 1,046 | 413 | 129 |
| # (minCor: 0.44) | 5,962 | 3,778 | 2,060 | 928 | 362 | 106 | |
| # (minCor: 0.46) | 4,783 | 3,043 | 1,656 | 748 | 280 | 82 | |
| # (minCor: 0.48) | 3,595 | 2,236 | 1,176 | 508 | 195 | 61 | |
| # (minCor: 0.50) | 2,452 | 1,478 | 729 | 301 | 107 | 40 | |
| #HUIs | 370,624 | 167,972 | 91,529 | 56,326 | 37,381 | 26,385 | |
| #DHUIs | 49,762 | 25,080 | 14,922 | 9,762 | 6,836 | 5,042 | |
| # (minCor: 0.015) | 90,087 | 63,049 | 46,155 | 35,124 | 27,003 | 21,197 | |
| BMSPOS2 | # (minCor: 0.020) | 58,665 | 42,653 | 32,439 | 25,609 | 20,486 | 16,700 |
| # (minCor: 0.025) | 41,469 | 30,896 | 24,034 | 19,392 | 15,879 | 13,254 | |
| # (minCor: 0.030) | 30,857 | 23,459 | 18,537 | 15,182 | 12,584 | 10,652 | |
| # (minCor: 0.035) | 23,915 | 18,519 | 14,840 | 12,317 | 10,327 | 8,854 | |
| # (minCor: 0.040) | 19,116 | 14,970 | 12,146 | 10,144 | 8,563 | 7,413 | |
| #HUIs | 80,933 | 39,848 | 27,839 | 21,103 | 16,850 | 13,722 | |
| #DHUIs | 45,994 | 24,115 | 15,961 | 10,503 | 6,626 | 4,434 | |
| # (minCor: 0.12) | 18,129 | 15,811 | 13,790 | 12,082 | 10,396 | 8,841 | |
| T10I4D100K | # (minCor: 0.14) | 15,260 | 13,283 | 11,664 | 10,287 | 8,884 | 7,594 |
| # (minCor: 0.16) | 12,824 | 11,107 | 9,772 | 8,629 | 7,457 | 6,424 | |
| # (minCor: 0.18) | 10,667 | 9,228 | 8,132 | 7,181 | 6,209 | 5,380 | |
| # (minCor: 0.20) | 8,917 | 7,685 | 6,767 | 5,986 | 5,186 | 4,498 | |
| # (minCor: 0.22) | 7,425 | 6,391 | 5,607 | 4,952 | 4,284 | 3,731 | |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Correlated Utility-based Pattern Mining
Wensheng Gan1,5, Jerry Chun-Wei Lin1,2**, Han-Chieh Chao3*, Hamido Fujita4 and Philip S. Yu5
1Harbin Institute of Technology (Shenzhen), Shenzhen, China
2Western Norway University of Applied Sciences, Bergen, Norway
3National Dong Hwa University, Hualien, Taiwan
4Iwate Prefectural University, Iwate, Japan
5University of Illinois at Chicago, Chicago, USA
Email: [email protected], [email protected], [email protected], [email protected], [email protected]
Abstract
In the field of data mining and analytics, the utility theory from Economic can bring benefits in many real-life applications. In recent decade, a new research field called utility-oriented mining has already attracted great attention. Previous studies have, however, the limitation that they rarely consider the inherent correlation of items among patterns. Consider the purchase behaviors of consumer, a high-utility group of products (w.r.t. multi-products) may contain several very high-utility products with some low-utility products. However, it is considered as a valuable pattern even if this behavior/pattern may be not highly correlated, or even happen by chance. In this paper, in light of these challenges, we propose an efficient utility mining approach namely non-redundant Correlated high-Utility Pattern Miner (CoUPM) by taking positive correlation and profitable value into account. The derived patterns with high utility and strong positive correlation can lead to more insightful availability than those patterns only have high profitable values. The utility-list structure is revised and applied to store necessary information of both correlation and utility. Several pruning strategies are further developed to improve the efficiency for discovering the desired patterns. Experimental results show that the non-redundant correlated high-utility patterns have more effectiveness than some other kinds of interesting patterns. Moreover, efficiency of the proposed CoUPM algorithm significantly outperforms the state-of-the-art algorithm.
keywords:
Economic, utility mining, positive correlation, pruning strategy
††journal: Information Science
1 Introduction
In many real-world applications, data mining [1, 2] turns a large collection of data into knowledge, and one of the common tasks of data mining is pattern mining [3, 4, 5]. For instance, to analyze the users’ click-stream or purchase behavior that contains auxiliary valuable with hidden information, pattern mining algorithms [3, 4] can be applied to identify embedded patterns and useful knowledge. In the past decades, numerous data mining frameworks and approaches, e.g., frequent pattern mining (FPM) [3, 4, 6] and association rule mining (ARM) [3], have been extensively studied. FPM extracts frequent patterns, and ARM aim at mining association rules. Besides, FPM is considered as the first step of ARM and more challenging. In general, these desired patterns represent interesting relationships among objects or patterns in different types of databases. Mining of insightful patterns has been successfully applied in many real-world applications. However, most of these pattern mining algorithms [3, 4, 5] mainly measure the interestingness of patterns based on the co-occurrence frequencies of patterns. Other implicit factors in data such as the weight, interest, risk or profit of patterns are not effectively utilized. Besides, all objects are considered to have equal importance, hence the objects/patterns that are real important to users may not be found effectively.
Therefore, some researchers are interested in incorporating both subjective measure (e.g., risk, interest and utility) and objective measures (e.g., correlation, frequency and confidence) for mining valuable patterns, such as itemsets and association rules. Among them, one utility-oriented data mining framework called high-utility pattern mining (HUPM) [7, 8, 9, 10] was proposed. Inspired by the utility theory [11], HUPM incorporates some useful factors, e.g., quantity, unit profit, and other useful factors, to identify the patterns which can bring valuable profits for retailers or managers in business. In general, the utility can also be other user-specified subjective measure, e.g., risk, interest, significance, satisfaction, and usefulness, etc. The concept of HUPM has been extended to utility mining [7, 8, 9, 10] and it serves as a critical role in data science. Up to now, utility mining has become an important branch of data analytics, which aims at utilizing the auxiliary information from data. It has been widely utilized to discover valuable information and hidden knowledge in recent decade since utility mining can bring more benefits in many real-life applications. Many studies of utility mining focus on developing the efficient algorithms, such as Two-Phase [7], IHUP [8], UP-growth [12], UP-growth+ [9], HUI-Miner [10], FHM [13], HUP-Miner [14], and EFIM [15]. At the same time, many studies focus on the effectiveness for mining utility-oriented patterns. For instance, mining high-utility patterns from uncertain data [16], dynamic data [17, 18], and big data [19].
Utility mining has been extensively studied and successfully applied in many real-world applications [18]. However, the existing studies of utility mining are mainly focused on the identification of high-utility patterns themselves, and thus the hidden correlation among the derived patterns is still limited. In other words, they ignore the inherent correlation of objects/items inside the patterns. This problem may easily lead to the identification of high-utility patterns with false negatives and false positives. Therefore, an important limitation of current utility mining algorithms is that a huge amount of patterns may be discovered while most of them contain many weakly correlated items. For example, it is common that retail stores cross-sell some products/items to improve the total revenue. Some products are usually sold with discount or free gifts to stimulate the sale of other related products/items. As shown in Figure 1111https://www.amazon.com, many products are bought together for cross-selling in Amazon. This example explains the reasons why correlation is an important factor, especially in utility mining. The really strongly correlated products (or purchase behaviors) are more useful for cross-selling; otherwise, those meaningless, redundant or non-discriminative patterns may be misleading for recommendation. Hence, it is a critical issue to address the effectiveness problem for discovering positively correlated and high-utility patterns based on the utility and correlation measures.
In the past few decades, some well-known correlation measures, e.g., the support [20, 21], confidence [21], all-confidence [22], frequency affinity [23], and coherence [22], have been studied in data mining. In the field of utility mining, the HUIPM [23] and FDHUP [24] algorithms were proposed to discover high-utility interesting patterns (HUIPs) with strong frequency affinity. The concept of affinity utility is introduced in HUIPM [23]. However, the tree-based HUIPM algorithm is time-consuming and may lead to the problem of combinatorial explosion. The faster FDHUP algorithm [24] utilizes two compact data structures and three pruning strategies to efficiently discover discriminative HUIPs. However, the co-occurrence frequency instead of inherent correlation is measured as the correlation factor in HUIPM [23] and FDHUP [24]. Recently, a projection-based approach namely CoHUIM [25] was developed to discover correlated high-utility patterns with consideration of the inherent correlation among items inside a pattern. It adopts a measure called Kulc [26, 27], which has the null (transaction)-invariant property, as the correlation factor. The discovered patterns have strong positive inherent correlation, and they can bring real benefits to utility mining. However, the projection-based CoHUIM may encounter the efficiency problem, and may cause a lot of memory consumption since it relies on the candidate generation-and-test mechanism.
In light of the above challenges, we propose an efficient utility mining framework, namely non-redundant Correlated high-Utility Pattern Miner (CoUPM) with the consideration of strong positive correlation and utility theory. CoUPM can not only extract non-redundant strongly correlated and profitable patterns, but also achieve better efficiency. We evaluate the effectiveness of the proposed CoUPM based on the correlation measure Kulc. For comparison, we take the well-known traditional HUPM model and the state-of-the-art CoHUIM algorithm into account to compare the designed algorithm for the correlated utility-based pattern mining problem. The major contributions of this paper are summarized as follows.
We adopt correlated significance as a key criterion for evaluating the high-utility patterns in the HUPM problem. Understanding such correlation can provide useful insights on the discovered results, and this makes utility mining with a higher effective performance than the existing HUPM models. The utility factor and relations among items/objects are taken into account for pattern evaluation.
- 2.
We design an efficient CoUPM algorithm for mining correlated and high-utility patterns from quantitative databases in one-phase. The revised utility-list structure is used to store the compact information of potential patterns from the processed database. This approach is able to early filter a large amount of unpromising patterns, and return the significant patterns in the mining process.
- 3.
We develop several pruning techniques in a depth-first search manner, which consist of the utilization of correlation property and utility property. Therefore, CoUPM can quickly discover a set of highly correlated and high-utility patterns.
- 4.
Extensive experiments on both real and synthetic datasets show that the proposed one-phase CoUPM algorithm has better effectiveness and efficiency than the existing algorithms.
The rest of this paper is organized as follows. Some related works of utility mining are briefly reviewed in Section 2. The key preliminaries and problem statement are given in Section 3. Details of the proposed CoUPM algorithm are described in Section 4. The evaluation of effectiveness and efficiency of CoUPM are provided in Section 5. Finally, conclusion and future work are drawn in Section 6.
2 Related Work
This research work is related to the studies in support-based pattern mining, utility-based pattern mining, and the development of pattern mining with consideration of affinity/correlation.
2.1 Utility-based Data Mining
In the past few decades, many pattern mining frameworks and algorithms have been developed and applied to various real-life applications. Most of these studies use support [3, 20] and confidence [20] to identify interesting patterns, e.g., frequent patterns [3, 4, 20]. These studies measure the interestingness of patterns mainly based on the co-occurrence frequency [3, 4]. Therefore, many interesting and high profitable patterns may not be found. To address these problems, a new data mining framework named utility-oriented pattern mining [9, 28, 29] is proposed. It aims at discovering the high-utility patterns rather than the support/confidence-based patterns. Utility mining considers the quantity and unit profit of objects/items, as well as other implicit factors. In the past decade, the problem of high-utility pattern mining (HUPM) has been extensively studied, such as Two-Phase [7], IHUP [8], UP-growth [12], UP-growth+ [9], and HUI-Miner [10]. There are mainly four categories of the existing HUPM algorithms, including Apriori-like, tree-based, utility-list-based, and hybrid approaches. The well-known Apriori-like approach for HUPM is the Two-Phase [7] algorithm which utilizes the transaction-weighted utilization (TWU) model [7]. Inspired by FP-growth [4], some tree-based algorithms are proposed to mining high-utility patterns, such as IHUP [8], UP-growth [12], UP-growth+ [9], and HUP-tree [30]. All of them outperform the Apriori-like algorithms. Liu et al. then introduced the HUI-Miner [10] by utilizing the utility-list structure and a new concept called remaining utility. Recently, many other utility-list based approaches have been developed, such as FHM [13], HUP-Miner [14], and EFIM [15].
The above mentioned HUPM algorithms focus on improving the mining efficiency, however, the effectiveness of utility mining task is also quite important. For example, how to develop different and flexible models to address the utility mining task in different types of data, constraints and applications are very necessary and challenging. Up to now, some studies that focus on the effectiveness of utility mining have been extensively developed, such as HUPM on uncertain data [16] or dynamic data [17, 18]. Lin et al. proposed a series of models to extract high-utility patterns from uncertain data [16, 31], temporal data [32], and dynamic data [17, 18, 33]. Based on the new concept of average utility [34], Wu et al. introduced a new upper bound for mining high average utility patterns [35]. Besides, several evolutionary computation approaches (e.g., HUIM-BPSO [36] and ACO-based HUIM-ACS [37]) are proposed to discover high-utility patterns. Tseng et al. introduced the concise representation [38] and top- issue [39] for HUPM. Different from the itemset-based models, other advanced models were extensively studied, including the association rule-based [40], sequence-based [41], and episode-based [42] utility mining models. Recently, Gan et al. proposed a new utility measure named utility occupancy to address the utility mining problem [43]. An overview of the current development of utility mining was presented recently [18].
2.2 Affinity/Correlation Pattern Mining
In the data mining literature, several association measures for association mining and analytics have been studied, such as confidence [20], lift [44], and the cosine measure [45]. Association analysis may generate many rules, while many of them are not useful or meaningful for decision-making. Different from association analysis, some studies have been explored for mining affinity patterns or correlation patterns. Omiecinski et al. first proposed three interesting measures for pattern mining called any-confidence [22], all-confidence [22], and bond [22]. To find strong affinity patterns which may contain low-support items, Kim et al. first introduced hyperclique pattern and hyperclique (h)-confidence [46]. The h-confidence is equivalent to the all-confidence. Wu et al. found that the degree of expectation-based correlation is highly influenced by the number of null transactions [27]. Thus, most of the existing measures, e.g., all-confidence [22], bond [22], cosine [45], are not suitable to evaluate correlation in large database that contains many and unstable null transactions. Due to the null (transaction)-invariant property, the correlation measure in Kulczynsky [26, 27] is independent of the dataset size. Besides, some other measures for the study of correlation have been proposed [21]. Different from the traditional data mining approaches which ignore the correlation among extracting results, the derived affinity/correlation patterns can return more insightful knowledge for decision-making.
2.3 Comparative Analysis with Previous Works
As mentioned before, the inherent correlation of items inside the patterns has not been considered in most of the HUPM algorithms yet. In the area of utility-oriented pattern mining, only few studies concern the utility and correlation together to derive the desired patterns. For instance, the HUIPM [23] and FDHUP [24] algorithms consider both frequency-affinity and utility as the two key measures to derive the desired patterns. However, the co-occurrence frequency of transactions is regarded as the correlation factor. Recently, Fournier-Viger et al. [47] introduced a FCHM model to extract correlated high-utility itemsets (CoHUIs). In the framework of FCHM, the bond measure [22] is used to evaluate the correlation value of items among a pattern. Moreover, the projection-based CoHUIM [25] algorithm has presented to take the correlation measure Kulc, which has null (transaction)-invariant property, into account for mining the interesting patterns. However, it may encounter the efficiency problem and may easily cause a lot of memory consumption. The reason is that CoHUIM firstly generates the complete correlated high-utility upper-bound itemsets (CHUUBIs) by recursively processing the projection, which uses the upper bound TWU [7] and Kulc measure. It then calculates actual utilities for all candidates in CHUUBIs to discover the final CoHUIs. In this paper, the proposed CoUPM method utilizes the revised utility-list structure and several powerful pruning strategies to significantly improve the mining efficiency.
3 Preliminaries and Problem Formulation
In this section, we first introduce some basic preliminaries of utility mining, and then discuss the differences between the addressed problem in this paper and the existing tasks. Finally, we provide a normal problem formulation of correlated high-utility pattern mining.
3.1 Database with Utility Factor
Note that we use the concept of utility to present the revenue for sellers. In the following contents, let = denote a combination/group of patterns/products, and is called a -itemset. In general, a unit profit of is associated to the cost price minus sell price. As mentioned before, the utility concept can be regarded as other user-specified subjective measure, e.g., risk, interestingness, satisfaction, usefulness, etc. According to the utility theory [11], we have the following concepts and formulation.
Example 1
Consider an e-commerce database as shown in Table 1, it is used as a running example in this paper. Similar to the e-commerce database provided by RecSys Challenge 2015222https://recsys.acm.org/recsys15/challenge/, this example database contains five purchase records (e.g., ) with auxiliary information. Behavior is occurred in timestamp “07/12 10:05:30”, and contains products , , and with a purchase quantity of 3, 1 and 2, respectively. Table 2 indicates that the unit profit (also called external profit) of these three products is a:\3}{:$1}{:$10}$, respectively. Note that the unit profit of each product is pre-defined by user/seller. In the addressed problem, this table is called profit-table.
3.2 Preliminaries of Utility Mining
Given a quantitative database such that = contains a set of quantitative transactions. Each transaction with a timestamp is a set of items/records. is a subset of and has a unique identifier called its Tid. Let be a set of distinct items, = . Each item is associated with a positive value namely its unit profit. For each item , a positive number is called occur quantity of . The utility contribution of a group of products, = , is related to the total utilities from each after marketing.
Definition 1
The utility of a group of products in a transaction is = , where is the utility/profit of a product in a transaction , and can be calculated as = . Thus, represents the utilities generated by all items in . Consider the entire database, let denote the total utility of in , then = .
Definition 2
Given a quantitative database , the transaction utility of a transaction , denoted as , can be calculated as = , where is the -th item in . Then the total utility of the entire is denoted as TU, and can be calculated as: TU = .
Example 2
In Table 1, the utility of in is = 2\times\1020, and the utility of in is = + = 3 \times10 = {d,e}u({d,e})u({d,e},T_{3})u({d,e},T_{4})26 + 38. Consider the first transaction in Table 1, = + + = 1 + 30. Then the transaction utilities of T1 to T5 are respectively calculated as tu(T1) = 18, tu() = T_{4}34, and tu() = 39. Thus, the total utility of in Table [1](#S3.T1) is TU30 + 29 + 39 = $150.
3.3 Correlation for Data Mining
As stated in introduction, the current HUPM algorithms have an important limitation that a huge amount of derived patterns may contain many items which are weakly correlated. HUIPM [23] and FDHUP [24] used a new measure called frequency affinity to evaluate the correlation of high-utility patterns. The minimum quantity among all quantities of items inside a pattern in each transaction is used to calculate the affinitive frequency. However, it is not enough to reveal the real inherent correlation of the desired patterns. In the past, the Kulczynsky (abbreviated as Kulc) measure [22, 26, 27] was widely used to evaluate the inherent correlation of a generalized pattern. Its definition is given as follows.
Definition 3
The pattern correlation evaluates the strength of the inherent correlation between its items. In general, there are three types of correlations among items in a pattern, including 1) positive correlation, 2) non-correlation, and 3) negative correlation.
Definition 4
The Kulc value is an interesting measure to evaluate the correlation between items inside a pattern. According to the previous studies [26, 27], the Kulc value of a group of patterns is defined as follows:
[TABLE]
where is the -item in = which totally contains distinct items.
Therefore, the range of Kulc value is [0, 1] and it can be easily used to evaluate whether the items in a specific pattern have a positive correlation or not. Clearly, the minimum correlation threshold for measuring Kulc value can be specified by user. Unlike other existing correlation measures, Kulc has the null (transaction)-invariant property. Previous studies [26, 27] have shown that Kulc value is more acceptable and suitable than other correlation measures to evaluate the correlation in data mining. The reason is that it is independent by the dataset size. Based on the above definitions, we have the following problem formulation.
Example 3
Consider the running example in Table 1, when the settings of minUtil and minCor are respectively 20% and 0.7, the desired CoHUIs are the set of PatternsCoHUI = {, , , , , , }, while the set of high-utility patterns derived by the exiting HUPM algorithms are PatternsHUI = {, , , , , , , , , , , , , , }. It is clearly seen that most of the patterns in PatternsHUI do not have a positive correlated relationship. For instance, the patterns and have their Kulc values as Kulc() 0.5833 and Kulc() 0.6333. What’s more, the desired interesting CoHUIs do not have the downward closure property [3]. For example, the pattern is not a CoHUI, while its supersets , , are the CoHUIs. Previous studies [7, 8, 9, 10, 29] have shown that the utility of a pattern may be higher, equal to, or lower than that of its super-pattern and/or sub-pattern. Consequently, many pruning techniques of search space that rely on the downward closure property of Apriori [3] cannot be directly applied to discover CoHUIs.
As far, we have pointed out the major differences between HUIs and CoHUIs. The models aims at finding different patterns regarding to varied problems. Based on above introduction, the addressed problem in this paper is formulated below.
3.4 Problem Formulation
Definition 5
A group of patterns X in a quantitative database is defined as a strongly correlated high-utility itemset (denoted as CoHUI) if it satisfies the following two criteria: 1) ; 2) . Otherwise, is not a CoHUI, it may have a low utility or a negative correlation. Here, is a minimum utility threshold and is a minimum positive correlation threshold; both of them can be specified by users’ subjective preferences. In this paper, is a percentage value with respect to the total utility of a quantitative database. Therefore, the problem of correlated utility-based pattern mining (abbreviated as correlated HUPM) is to discover the complete set of significant and insightful CoHUIs in the entire database.
HUPM has shown its powerful potential in many applications and achieved outstanding performance compared with the support/confidence based data mining methods. Based on the utility theory [11] and correlation measure, the importance of utility and relations among items/objects are simultaneously taken into account. The extracted results of CoHUIs are high corresponding to positive correlation and profitable values.
4 Proposed One-Phase Algorithm: CoUPM
In this section, we propose an one-phase CoUPM algorithm to discover useful patterns, which are not only strongly correlated but also high profitable. CoUPM utilizes a vertical data structure named revised utility-list. Moreover, several effective pruning strategies which utilize the correlation and utility factors are applied to prune the search space and reduce memory cost. Details of the revised utility-list, the adopted pruning strategies, and the main procedures of the proposed algorithm are respectively described below.
4.1 Properties of the CoHUI
Most existing studies have been demonstrated that both the Kulc measure [26, 27] and utility measure [7] are neither monotonic nor anti-monotonic. In other words, a pattern may have a lower, equal or higher Kulc value (or utility value) than that of its subsets. Without holding the anti-monotonicity, the search space of the addressed problem is hard to be efficiently reduced in the mining process. To hold the downward closure property for mining high-utility patterns, a concept called transaction-weighted utilization [7] is commonly used in previous studies.
Definition 6
Given a database and a specific pattern , the transaction-weighted utilization (TWU) [7] of is defined as the sum of the total utilities of transactions containing , as shown in the following equation:
[TABLE]
Example 4
Consider two patterns and in the running example, then = + + + = 29 + 39 = TWU({d,e})tu(T_{3})tu(T_{4})29 + 63.
Based on the definition of CoHUI and utility property, the CoHUI does not hold the anti-monotonicity. In other words, a CoHUI may have lower, equal or higher utility value (or Kulc value) than any of its subsets. The TWU concept solves the anti-monotonicity problem by overestimating the overall utility of patterns in entire database without missing any high-utility patterns. However, a huge number of low-utility patterns still may be regarded as candidates since TWU is a loose upper-bound.
4.2 Revised Utility-List with Correlation
In previous studies, several approaches [10, 13, 14] use the utility-list [10] structure as a component to store and calculate the necessary information. Thanks to the vertical data structure of utility-list [10], these approaches can efficiently discover high-utility patterns without multiple database scans. But the original utility-list only deals with utility value, and does not contain the support and correlation information. The addressed problem needs a more flexible version of calculating scheme to obtain the auxiliary information. In the proposed CoUPM algorithm, we revise the utility-list [10] to make it suitable for computing the correlation and utility. Besides, a concept called remaining utility [10] is applied to obtain the estimated upper bound on utility, which will be presented in next subsection. Inspired by the utility-list [10] structure, the revised utility-list structure is defined as follows.
Definition 7
Without loss of generality, assume that all items in every transaction are sorted in the lexicographic order. Let the total order on items is denoted as .
Definition 8
Let denote the remaining utility [10] of a group of items/products in a transaction . Then is the sum of the utility values of each item appearing after in according to the total order . Thus, the remaining utility of does not include the utilities of items in itself. It can be represented as:
[TABLE]
Definition 9
The revised utility-list of a pattern in a quantitative database consists of pattern name (name), support count (sup), and a set of tuples corresponding to the transactions where appears (tuple). Here, is the related support of that occurred in the entire database, and it is equal to the number of tuples in this vertical data structure. A tuple is defined as <$$\underline{tid},\underline{iu},\underline{ru}$$> for each transaction containing .
: the transaction identifier of ;
- 2.
: the actual utility of in , w.r.t. ;
- 3.
: the remaining utility of in , w.r.t. .
Example 5
Consider and two patterns and in Table 1. Assume the total order adopts the support ascending order of all 1-itemsets. Since the support values of all 1-items in Table 1 are {:5, :4, :2, :3, :4}, the total order is . Then we have that = + + = 10 + 18, and = = \prec(d) is *{*(T_{2}2, (T_{3}6, (T_{4}2, $18)}, and its total support is 3, as shown in Figure 2.
Unlike the original utility-list [10] only deals with utility value, our revised structure can deal with more rich information, including support, correlation and utility. We can perform a single database scan to create the all revised utility-lists of all 1-items in the processed database. After constructing the initial revised utility-list of each 1-item (denoted as ), for any -itemset (), its revised utility-list can be directly constructed using the already built revised utility-lists of its subsets. Note that this operation does not need to scan the database anymore, and the built revised utility-lists fit in main memory. Details of the construction procedure of the revised utility-list are similar to the construction of utility-list, which can be referred to [10]. The difference between them is that after the join operation of two common tids, the procedure in the CoUPM algorithm simultaneously updates the support information in the revised utility-list for pattern . This is denoted as ++. For example, the 2-itemset appears in and , and its revised utility-list is constructed based on and , as shown in Figure 3. Note that the construction keeps consistent with respect to the total order .
Note that for optimization, when finding the common tids of two itemsets from the two sets of tids in the revised utility-lists, we use the binary search to speed up the computational efficiency. For example, we can perform a binary search to find the element with a given tid in a target revised utility-list.
Definition 10
Based on the designed revised utility-list, let and respectively denote the sum of utility values and the sum of remaining utility values for a pattern X in the constructed revised utility-list of X. According to [16, 48], they can be calculated as follows:
[TABLE]
[TABLE]
Thus, of a pattern X equals to . Both and are the total utility of in the entire database.
4.3 Pruning Strategies for Searching CoHUIs
Similar to previous studies [7, 24], the complete search space of the addressed problem can be presented as a Set-enumeration tree [49]. This prefix-based tree structure represents all possible itemsets of where each tree node represents a subset of . It is important to notice that this tree structure is only a conceptual representation and not stored in entirety while performing the mining process. In worst case, this approach may have up to 2n final itemsets (i.e., all itemsets of the search space with ). Without downward closure property, the search space would be huge. To address this limitation, we present a prefix-based depth-first enumeration tree. It means that the node in this tree structure is searched in the depth-first manner.
To speed up performance, the existing CoHUIM algorithm utilizes the Kulc measure in non-decreasing order of support count that holds the sorted downward closure property [25]. By utilizing the revised utility-list, this sorted downward closure property of Kulc measure [25] can be applied in the proposed CoUPM algorithm. More importantly, the enumeration of potential patterns may be terminated earlier by Kulc value and upper bound on utility. Details of the pruning strategies are described below.
Lemma 1** (Sorted downward closure property of Kulc)**
If the items in the set are sorted in support-ascending order, i.e., , the Kulc measure has the sorted downward closure property. That is: [25].
Proof 1
A complete proof can be referred to [25].
Based on Lemma 1, the following sorted downward closure property of Kulc measure can be held.
Theorem 1
(Anti-monotonicity of Kulc with SDC property). For any rooted node/itemset in the search space of CoUPM, if a tree node is a correlated pattern, its parent node is also a correlated pattern in . Let be a -itemset (node), and be any of its child nodes (extension, (+1)-itemset). The Kulc measure with the SDC property is anti-monotonic: always holds.
Example 6
Since the support counts of all 1-items are {:5, :4, :2, :3, :4}, this set of 1-items is sorted in support-ascending order as {}. Based on the definition of Kulc value (c.f. Formula 1), we can calculate the Kulc values of the following patterns, , , and , as: Kulc() 0.833, Kulc() 0.722, Kulc() 0.333 and Kulc() 0.307.
Thus, the Kulc measure holds anti-monotonicity if the processed items are sorted in support-ascending order. Note that the total order of items in the Set-enumeration tree [49] for the proposed CoUPM algorithm adopts the support-ascending order. Thus, we can utilize the following properties to prune the search space, and the details are described below.
Lemma 2** (Upper bound on utility)**
For any rooted node/itemset in the search space of CoUPM, the sum of and in the revised utility-list of is always no less than the overall utility of any of its descendant nodes (extensions, denoted as ). It is an upper bound on utility, such that .
Proof 2
A complete proof of this lemma can be referred to [16, 48].
Thus, the sum of the utilities of in D would not greater than ( + ) of in D. In other words, ( + ) of is an upper bound on utility while evaluating the overall utility of a specific pattern.
Example 7
Consider the running example, assume we perform the depth-first manner in the search space with the support-ascending order as {}. When determining the nodes/patterns in the subtree rooted at node , we have: . = {c,d,b}RU19, thus . + . = 19 = {c,d,b}{c,d,b}{c,d,b,e}IU31, . = {c,d,b,e,a}IU42, all are less than $52.
Theorem 2
*(Anti-monotonicity of upper-bound on utility). *For any node/itemset in the search space of CoUPM, let denote any of ’s children (extension node). Then the sum of and in the revised utility-list of (equally in the entire database) is always larger than or equal to the sum of and of in the entire database. That is [16, 48]. **
Thus, the sum of total utilities and remaining utilities of in is always larger than or equal to the sum of utilities of its extension in the search space. This upper bound ensures that the downward closure property of transitive extensions. Based on the above observations, we can use the following filtering strategies.
Strategy 1
**Pruning strategy using the SDC property of Kulc value, abbreviated as SPK strategy. **Assume the total order of the processed items adopts the support-ascending order. While performing a depth-first search strategy in the search space, if the relative Kulc value of any node/itemset is less than , any of its child node is not a CoHUI, and these unpromising patterns can be regarded as irrelevant and pruned directly.
Strategy 2
**Pruning strategy using the upper bound on utility, abbreviated as UBU strategy. **After building the initial revised utility-lists for each 1-itemset, the CoUPM algorithm traverses the search space based on a depth-first search strategy. If the sum of and of any node/pattern is less than , any of its child node would not be a CoHUI, they can be regarded as irrelevant and pruned directly.
To further improve the mining efficiency, the LA-Prune strategy [14] with the upper bound on utility is extended to the proposed algorithm.
Lemma 3
Given two different pattern and (), neither nor any supersets of would be a high-utility itemset if X.IU + X.RU - [14].
Strategy 3
**LA-Prune strategy. **In the search space, let be a processed pattern (node), and be the right sibling node of . If the sum of (X.IU + X.RU) subtracts the utilities (X.iu + X.ru) of a set of transactions is less than minUtil, the combined pattern is not a HUI (also not a CoHUI), and any of child nodes of would not be a HUI (also not be a CoHUI). During the depth-first search progress, the construction of the revised utility-lists for the children nodes of is not necessary to be performed.
The improved construction procedure is similar to that of revised utility-list. It utilizes the LA-Prune strategy to avoid constructing a huge number of revised utility-lists of the unpromising patterns, as described in Algorithm 1.
4.4 Main Procedure
To clarify our methodology, we have illustrated the designed data structure, the key properties of utility and correlation with Kulc value, and the upper bound on utility so far. Utilizing the above technologies, the main procedure of the designed CoUPM algorithm is shown in Algorithm 2. It takes four parameters as input: 1) an e-commerce quantitative database, ; 2) a user-specified profit-table, ptable; 3) a minimum positive correlation threshold, minCor (0 1); and 4) a user-specified minimum utility threshold, minUtil (0 1). When minCor is set to 0, it means that CoUPM does not consider the correlation factor.
The CoUPM algorithm first scans the database once to calculate and construct the Tidset of each item in . The total utility of is also calculated. Here, the built Tidset of all 1-items can be used to sort the items and calculate the Kulc value in the later processes. Then all the 1-items which have TWU are put into the set of . Thereafter, all patterns do not in the candidate set will be ignored since they cannot be the part of CoHUIs. CoUPM then scans once again to build the initial revised utility-list of each item using the total order .
It is important to notice that the adopted order should be kept consistently after the construction of revised utility-list. In the designed CoUPM algorithm, the support-ascending order is used to hold the sorted downward closure property of Kulc value. In other words, without using this sorting order, we only can utilize the upper bound on utility w.r.t. Strategy 2 to prune the search space. In the next section of experimental results, we will conduct the proposed CoUPM algorithm with or without using the sorted downward closure property of Kulc value w.r.t. Strategy 1.
The procedure (as shown in Algorithm 3) takes as input: 1) a pattern , 2) extensions of having the form means that is obtained by appending a pattern to , 3) , and 4) . The search procedure operates as follows. It first obtains the and values from the built revised utility-list of (denoted as ) (Line 2). It also calculates the value using the built and Tidsets of all 1-items (Line 3 and Eq. (4)). As mentioned previously in Formula 1, the calculation of value of an itemset is based on all support count of the 1-items containing in this itemset. Notice that here the Tidsets of all 1-items just needs to be built once in the first database scan. Since the support count of a special itemset can be easily obtained from its revised utility-list w.r.t. support element, we can quickly calculate this value.
For each extension of , if the related correlation of is no less than , and the sum of the actual utility of (w.r.t. in revised utility-list) is no less than minUtil , then this pattern is output as a CoHUI (Lines 4 to 5). After that, the designed pruning strategies are used to determine whether the extensions of should be explored or not (Line 6, using Strategy 1 and Strategy 2). This is performed by merging with each extension of such that , to form extensions of the form (Lines 9 to 10). The revised utility-list of is then constructed by calling the Construct procedure to perform the join operation of the revised utility-lists of , and (Line 11, details of the construction have been described in Algorithm 1). To further filter the unpromising patterns, only the promising patterns with their revised utility-lists would be explored in next extension (Line 11). After all the extensions of the rooted are performed (Line 12), it recursively calls the Search procedure with extensionsOfXa to continually explore its extension(s) (Line 13).
5 Experimental Study
In this section, we conduct several experiments to demonstrate the effectiveness and efficiency of our proposed model.
Baseline algorithms. Note that we use one of the traditional HUPM algorithms (e.g., FHM [13]) and FDHUP to generate the different kinds of discovered results for pattern evaluation, while only the CoHUIM algorithm is compared for efficiency evaluation. The reason is that different kinds of patterns are related to different mining tasks, and they can be used to analyze the effectiveness and usefulness of the CoUPM framework. While the efficiency should be compared with those algorithms which focus on same mining task. Thus, it is unreasonable to evaluate the efficiency by comparing algorithms from different domains.
The CoUPM algorithm is compared with some baseline approaches, including traditional HUPM algorithm which does not consider correlation factor (e.g., HUI-Miner [10], FHM [13], and EFIM [15]), the frequency-affinity-based FDHUP algorithm [23], and the projection-based CoHUIM algorithm [24].
Variants of CoUPM algorithm. Additional to the baseline CoUPM algorithm which only utilizes the Strategy 2, three improved variants, e.g., CoUPMsorted (adopts Strategies 1 and 2), CoUPMLA (adopts Strategies 2 and 3), and CoUPMsorted+LA (adopts Strategies 1, 2 and 3), are used to evaluate the efficiency of the proposed algorithm.
5.1 Data Description and Experimental Setup
Datasets. Typically e-commerce datasets are proprietary and consequently hard to find among publicly available data. To conduct experiments, we use five publicly available real-world datasets (foodmart, chess333http://fimi.ua.ac.be/data/, mushroom3) and one synthetic dataset (T10I4D100K) in our experiments. The characteristics of used datasets are described below in details.
foodmart: this dataset is provided with Microsoft SQL Server. It contains 21,556 customer transactions and 1,559 distinct items from an anonymous chain store.
- 2.
chess: it is a dense dataset since it contains 3,196 transactions with 75 distinct items, and the average transaction length is 36 items.
- 3.
mushroom: it has 8,124 transactions with 120 distinct items, and the average transaction length is 23 items. Thus, it is also a dense dataset.
- 4.
retail: it contains 88,162 transactions with 16,470 distinct items. The average transaction length in retail is 10.3 items.
- 5.
BMSPOS2: it has 515,597 transactions with 1,657 distinct items, and the average transaction length is 6.53 items. It collects several years worth of point-of-sale data from a large electronics retailer.
- 6.
T10I4D100K: this is a synthetic dataset, which has 100,000 transactions with 870 distinct items, and the average transaction length is 10.1 items.
Note that the foodmart dataset already contains the quantity and a unit profit of each item, while chess and mushroom do not contain the quantitative and profit information. Therefore, we use a simulation method, which is widely adopted in previous studies [9, 10, 24], to generate the quantitative and profit information for each item in the chess and mushroom datasets. For the addressed utility-based mining problem, these used datasets having varied characteristics make the experimental results more convincing and acceptable.
Language and experimental environment. All the algorithms in the experiments were implemented in Java language and performed on a personal ThinkPad T470p computer with an Intel(R) Core(TM) i7-7700HQ CPU @ 2.80 GHz 2.81 GHz, 32 GB of RAM, and with the 64-bit Microsoft Windows 10 operating system.
Parameter settings. It is important to notice that both FHM [13] and FDHUP [23] are varied by one parameter , while the CoHUIM and CoUPM algorithms discover the CoHUIs by using two constraints: correlation and utility. Therefore, experiments are conducted on each dataset by varying . In addition, the is adjusted with six times on each dataset to evaluate the effectiveness of mining patterns. Specifically, as shown in Table 3, the six different thresholds are respectively set on each data. For instance, in foodmart, is varying from 0.01 to 0.06, such as 0.01, 0.02, 0.03, 0.04, 0.05, 0.06.
5.2 Effectiveness Analytics
The addressed problem aims at computing the satisfiable correlated and high profitable patterns. Thereby, the derived CoHUIs explicitly includes availability of the correlation and utility contribution. To further investigate the effectiveness of the addressed problem for correlated utility-based pattern mining, we plot in Table 3 with the results of different kinds of generated patterns under various parameter settings. Note that the #HUIs is the number of HUIs discovered by one of traditional HUIM algorithms (e.g., FHM), #DHUIs is the number of discriminative HUIs discovered by FDHUP, and the #CoHUIs (it is respectively denoted as # to # under six thresholds) is the number of correlated HUIs discovered by the CoHUIM and CoUPM algorithms. In Table 3, represents minUtil.
As shown in Table 3, it can be clearly observed that the number of CoHUIs is always different from that of #HUIs and #DHUIs under various minCor and minUtil thresholds on all test datasets under all parameter settings. More specifically, both the minCor and minUtil affect the results of CoHUIs, as shown from # to # on each dataset. In general, the numbers of DHUIs and CoHUIs are always smaller than that of HUIs. These results are reasonable since the DHUIs and CoHUIs are determined with not only the utility constraint, but also the correlation measure. Therefore, to derive desired patterns, more criteria can usually be applied to produce fewer patterns. The difference between #DHUIs and #CoHUIs indicates that the addressed problem with Kulc measure is more acceptable than the frequency-affinity-based utility mining framework. It is interesting to observe that the number of DHUIs in chess and mushroom datasets under various thresholds is close to zero.
In addition, the number of patterns discovered by the designed CoPUM algorithm under six always has: . When is fixed on a processed dataset, the larger is, the smaller the number of derived CoHUIs is. For instance, when is set as 19% on chess, #HUIs is 39,281, #DHUIs is 0, while the number of CoHUIs is changed from 4,021 to 1,483 (details are = 4,021, = 3,378, = 2,773, = 2,282, = 1,872, and = 1,483) when is varying from 0.74 to 0.79. It indicates that the adopted correlated Kulc measure is acceptable and useful to extract non-redundant correlated high-utility patterns from quantitative datasets.
5.3 Efficiency Analytics
From Table 3, we can observe that the mining results with the influence of minCor threshold and minUtil threshold. In this subsection, we continue to perform the evaluation of efficiency in terms of running time. To make fair comparison, we use the same parameter settings which are tested in Table 3. Both the minimum correlation threshold and the minimum utility threshold are used to evaluate the efficiency. We investigate the processing time of CoHUIM, CoUPM, and its three improved variants in six real datasets by varying and . When varying one threshold, another one is fixed on each dataset. The results of total execution time of the four variants are presented in Figure 4 and Figure 5, respectively. In particular, CoUPMsorted means the designed CoUPM algorithm with Strategy 1 which utilizes the sorted downward closure property of Kulc measure), while CoUPM is executed without using Strategy 1.
Firstly, CoUPM with or without Strategy 1 consistently outperforms the state-of-the-art CoHUIM approach, even up to 3 orders of magnitude. In particular, CoUPMsorted outperforms CoUPM in most cases under all parameter settings. For example, in the case in Figure 4(e), we can obviously observe the difference of the runtime between CoUPMsorted and CoUPM. When is set to 20% on chess dataset, the runtime of CoUPMsorted always closes to 4 seconds, while CoUPM approximately has its processing time as 40 seconds. This difference also can be observed from the other datasets. This observation indicates that the sorted downward closure property of Kulc measure plays an active role in pruning the search space of the correlation-based CoUPM algorithm.
Based on the observation of runtime between CoUPM and CoUPMLA, it indicates that the LA-Prune strategy also plays an active role in filtering the unpromising patterns in some cases. To summarize, the improved algorithms which utilize the powerful pruning strategies always have the best performance compared to the baseline CoUPM algorithm, as well as the CoHUIM algorithm.
It is important to notice that the projection-based CoHUIM algorithm may be very time-consuming on low thresholds or dense datasets. And this computational efficiency problem might be more easily happened in dense datasets, which can been seen in the view of Figure 4(b), Figure 4(c), Figure 5(b), and Figure 5(c), respectively. Overall, the proposed CoUPM algorithm significantly has better performance than the state-of-the-art CoHUIM algorithm in terms of running time and memory consumption. On dense datasets, i.e., chess and mushroom, the consumed memory of CoHUIM is very huge and can up to 50 times than that of CoUPM.
5.4 Memory Evaluation
In this subsection, we continue to evaluate the memory consumption of the compared algorithms. Results of the peak memory usage of CoHUIM and different variants of CoUPM on the all test datasets with the same parameter settings in Figure 4 and Figure 5 are shown in Figure 6 and Figure 7, respectively. Note that we use the Java API to calculate the peak memory consumption of each compared algorithm during the whole mining process.
As we can see, all the revised utility-list-based models perform significantly better than the projection-based CoHUIM algorithm, demonstrating the suitability of these models for dense datasets or large-scale datasets. For example, as shown in Figure 6, the peak memory consumption for CoUPM is significantly less than that of CoHUIM. In addition, the improved variants, e.g., CoUPMsorted, CoUPMLA and CoUPMsorted+LA, consume less memory than the baseline CoUPM algorithm that only adopts the pruning Strategy 2.
The peak memory consumptions under various values of parameters ( and ) are shown in Figure 6 and Figure 7, respectively. Note that the y-axis shows the peak memory consumption of the whole mining process corresponding to the choice of minimum utility threshold (minUtil) and minimum correlation threshold (minCore). As what can be seen, the proposed CoUPM model with several pruning strategies outperforms CoHUIM for all parameter settings. As mentioned previously, the advantage of CoUPM is that it is able to early filter a large amount of unpromising patterns by building the initial revised utility-lists. As the size of explored pattern increases, the revised utility-list size decreases, thus CoUPM exceeds the available main memory and its overall execution time decreases significantly. For instance, at mushroom (minCore = 0.42 and minUtil =10% at Figure 6), CoUPM has a peak memory consumption of 650 MB and requires 6s to discover the required information. For the same minimum thresholds, CoHUIM has a peak memory consumption of 2,900 MB and requires 43s for the mining task. This corresponds to a speed-up of 4.5x in memory, and speed-up of 7x in execution time. For dense data sizes (e.g., chess, mushroom), the speed-up increases further.
5.5 Summary and Discussion
For the proposed CoUPM, we have the following observations: (1) Best performance is achieved when all data structures (revised utility-lists) fit in main memory. (2) The performance degrades but still remains acceptable while dealing with dense dataset. (3) The low performance of projection-based CoHUIM model may be related to the huge memory consumption which is quite important in utility mining. In summary, we have the following observations of the results.
First, the filtered estimation of upper bound on utility takes a positive role in early pruning the unpromising patterns based on the revised utility-list to store the compact but complete information.
- 2.
Second, the designed CoUPM algorithm makes use of the compact data structure named revised utility-list. Thus, it can efficiently hold the “mining during the constructing” property, and the real search space and memory cost can be significantly reduced. On the contrast, the projection CoHUIM approach which recursively projects the sub-databases for next iteration may easily encounter a huge of memory cost, especially on dense datasets.
- 3.
Third, by utilizing the proposed pruning strategies with the properties of correlation and upper bound on utility, the search space and memory cost of the CoUPM algorithm is further reduced. The worse performance of the CoHUIM algorithm is caused by the candidate generation-and-test mechanism.
- 4.
In general, the upper bond on utility used in CoHUIM is not tight enough, and a huge number of candidates are required to be generated although the sorted downward closure property of Kulc is adopted in CoHUIM to prune the candidates in the search space.
6 Conclusion and Future Work
In this paper, we have presented an efficient utility mining framework named CoUPM for discovering non-redundant correlated high-utility patterns from quantitative databases. It studies the problem of utility-based pattern mining by measuring both correlation and availability of utility. Based on the revised utility-list, CoUPM does not need to scan the database with multiple times. It relies on several pruning strategies, which utilize the sorted downward closure of Kulc and upper bound on utility based on the concept of remaining utility. Moreover, CoUPM can directly discover the desired patterns from the quantitative databases by avoiding performing costly intersection operations of revised utility-lists. The extensive performance on several real-world datasets demonstrates the effectiveness and efficiency of the CoUPM algorithm.
For the future work, we plan to improve the mining efficiency by developing a new data structure instead of using the utility-list for the addressed problem. Secondly, we would focus on other practical effectiveness issues of utility mining. For example, we would like to conduct further research of the proposed model to deal with the dynamic utility mining [17, 18], utility mining on uncertain data [16], and privacy issue [50]. Lastly, it is also interesting to take the other interesting extensions and applications into account for our future studies.
Acknowledgment
This work was partially supported by the Shenzhen Technical Project under JCYJ 20170307151733005 and KQJSCX 20170726103424709. Specifically, Wensheng Gan was supported by the CSC (China Scholarship Council) Program during the study at University of Illinois at Chicago, IL, USA.
References
- [1]
M. S. Chen, J. Han, P. S. Yu, Data mining: an overview from a database perspective, IEEE Transactions on Knowledge and data Engineering 8 (6) (1996) 866–883.
- [2]
W. Gan, J. C. W. Lin, H. C. Chao, J. Zhan, Data mining in distributed environment: a survey, Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery 7 (6) (2017) e1216.
- [3]
R. Agrawal, R. Srikant, et al., Fast algorithms for mining association rules, in: Proceedings of the 20th International Conference on Very Large Data Bases, Vol. 1215, 1994, pp. 487–499.
- [4]
J. Han, J. Pei, Y. Yin, R. Mao, Mining frequent patterns without candidate generation: A frequent-pattern tree approach, Data Mining and Knowledge Discovery 8 (1) (2004) 53–87.
- [5]
W. Gan, J. C. W. Lin, P. Fournier-Viger, H. C. Chao, J. Zhan, Mining of frequent patterns with multiple minimum supports, Engineering Applications of Artificial Intelligence 60 (2017) 83–96.
- [6]
W. Gan, J. C. W. Lin, P. Fournier-Viger, H. C. Chao, P. S. Yu, A survey of parallel sequential pattern mining, arXiv preprint arXiv:1805.10515.
- [7]
Y. Liu, W. K. Liao, A. Choudhary, A two-phase algorithm for fast discovery of high utility itemsets, in: Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Springer, 2005, pp. 689–695.
- [8]
C. F. Ahmed, S. K. Tanbeer, B. S. Jeong, Y. K. Lee, Efficient tree structures for high utility pattern mining in incremental databases, IEEE Transactions on Knowledge and Data Engineering 21 (12) (2009) 1708–1721.
- [9]
V. S. Tseng, B. E. Shie, C. W. Wu, P. S. Yu, Efficient algorithms for mining high utility itemsets from transactional databases, IEEE Transactions on Knowledge and Data Engineering 25 (8) (2013) 1772–1786.
- [10]
M. Liu, J. Qu, Mining high utility itemsets without candidate generation, in: Proceedings of the 21st ACM International Conference on Information and Knowledge Management, ACM, 2012, pp. 55–64.
- [11]
A. Marshall, From principles of economics, in: Readings in the Economics of the Division of Labor: the Classical Tradition, World Scientific, 2005, pp. 195–215.
- [12]
V. S. Tseng, C. W. Wu, B. E. Shie, P. S. Yu, UP-Growth: an efficient algorithm for high utility itemset mining, in: Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ACM, 2010, pp. 253–262.
- [13]
P. Fournier-Viger, C. W. Wu, S. Zida, V. S. Tseng, FHM: Faster high-utility itemset mining using estimated utility co-occurrence pruning, in: Proceedings of the International Symposium on Methodologies for Intelligent Systems, Springer, 2014, pp. 83–92.
- [14]
S. Krishnamoorthy, Pruning strategies for mining high utility itemsets, Expert Systems with Applications 42 (5) (2015) 2371–2381.
- [15]
S. Zida, P. Fournier-Viger, J. C. W. Lin, C. W. Wu, V. S. Tseng, EFIM: a fast and memory efficient algorithm for high-utility itemset mining, Knowledge and Information Systems 51 (2) (2017) 595–625.
- [16]
J. C. W. Lin, W. Gan, P. Fournier-Viger, T. P. Hong, V. S. Tseng, Efficient algorithms for mining high-utility itemsets in uncertain databases, Knowledge-Based Systems 96 (2016) 171–187.
- [17]
J. C. W. Lin, W. Gan, T. P. Hong, A fast updated algorithm to maintain the discovered high-utility itemsets for transaction modification, Advanced Engineering Informatics 29 (3) (2015) 562–574.
- [18]
W. Gan, J. C. W. Lin, P. Fournier-Viger, H. C. Chao, T. P. Hong, H. Fujita, A survey of incremental high-utility itemset mining, Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery 8 (2) (2018) e1242.
- [19]
Y. C. Lin, C. W. Wu, V. S. Tseng, Mining high utility itemsets in big data, in: Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Springer, 2015, pp. 649–661.
- [20]
R. Agrawal, T. Imieliński, A. Swami, Mining association rules between sets of items in large databases, in: ACM SIGMOD Record, Vol. 22, ACM, 1993, pp. 207–216.
- [21]
L. Geng, H. J. Hamilton, Interestingness measures for data mining: a survey, ACM Computing Surveys 38 (3) (2006) 9.
- [22]
E. R. Omiecinski, Alternative interest measures for mining associations in databases, IEEE Transactions on Knowledge and Data Engineering (1) (2003) 57–69.
- [23]
C. F. Ahmed, S. K. Tanbeer, B. S. Jeong, H. J. Choi, A framework for mining interesting high utility patterns with a strong frequency affinity, Information Sciences 181 (21) (2011) 4878–4894.
- [24]
J. C. W. Lin, W. Gan, P. Fournier-Viger, T. P. Hong, H. C. Chao, FDHUP: fast algorithm for mining discriminative high utility patterns, Knowledge and Information Systems 51 (3) (2017) 873–909.
- [25]
W. Gan, J. C. W. Lin, P. Fournier-Viger, H. C. Chao, H. Fujita, Extracting non-redundant correlated purchase behaviors by utility measure, Knowledge-Based Systems 143 (2018) 30–41.
- [26]
S. Kulczyński, Die pflanzenassoziationen der pieninen, Imprimerie de l’Université, 1928.
- [27]
T. Wu, Y. Chen, J. Han, Re-examination of interestingness measures in pattern mining: a unified framework, Data Mining and Knowledge Discovery 21 (3) (2010) 371–397.
- [28]
H. Yao, H. J. Hamilton, Mining itemset utilities from transaction databases, Data & Knowledge Engineering 59 (3) (2006) 603–626.
- [29]
W. Gan, J. C. W. Lin, P. Fournier-Viger, H. C. Chao, V. S. Tseng, P. S. Yu, A survey of utility-oriented pattern mining, arXiv preprint arXiv:1805.10511.
- [30]
C. W. Lin, T. P. Hong, W. H. Lu, An effective tree structure for mining high utility itemsets, Expert Systems with Applications 38 (6) (2011) 7419–7424.
- [31]
J. C. W. Lin, W. Gan, P. Fournier-Viger, T. P. Hong, V. S. Tseng, Efficiently mining uncertain high-utility itemsets, Soft Computing 21 (11) (2017) 2801–2820.
- [32]
J. C. W. Lin, W. Gan, T. P. Hong, V. S. Tseng, Efficient algorithms for mining up-to-date high-utility patterns, Advanced Engineering Informatics 29 (3) (2015) 648–661.
- [33]
J. C. W. Lin, W. Gan, T. P. Hong, A fast maintenance algorithm of the discovered high-utility itemsets with transaction deletion, Intelligent Data Analysis 20 (4) (2016) 891–913.
- [34]
T. P. Hong, C. H. Lee, S. L. Wang, Effective utility mining with the measure of average utility, Expert Systems with Applications 38 (7) (2011) 8259–8265.
- [35]
J. M. T. Wu, J. C. W. Lin, M. Pirouz, P. Fournier-Viger, TUB-HAUPM: Tighter upper bound for mining high average-utility patterns, IEEE Access 6 (2018) 18655–18669.
- [36]
J. C. W. Lin, L. Yang, P. Fournier-Viger, T. P. Hong, M. Voznak, A binary PSO approach to mine high-utility itemsets, Soft Computing 21 (17) (2017) 5103–5121.
- [37]
J. M. T. Wu, J. Zhan, J. C. W. Lin, An ACO-based approach to mine high-utility itemsets, Knowledge-Based Systems 116 (2017) 102–113.
- [38]
V. S. Tseng, C. W. Wu, P. Fournier-Viger, P. S. Yu, Efficient algorithms for mining the concise and lossless representation of high utility itemsets, IEEE Transactions on Knowledge and Data Engineering 27 (3) (2015) 726–739.
- [39]
V. S. Tseng, C. W. Wu, P. Fournier-Viger, P. S. Yu, Efficient algorithms for mining top- high utility itemsets, IEEE Transactions on Knowledge and Data Engineering 28 (1) (2016) 54–67.
- [40]
T. Mai, B. Vo, L. T. Nguyen, A lattice-based approach for mining high utility association rules, Information Sciences 399 (2017) 81–97.
- [41]
G. C. Lan, T. P. Hong, V. S. Tseng, S. L. Wang, Applying the maximum utility measure in high utility sequential pattern mining, Expert Systems with Applications 41 (11) (2014) 5071–5081.
- [42]
Y. F. Lin, C. W. Wu, C. F. Huang, V. S. Tseng, Discovering utility-based episode rules in complex event sequences, Expert Systems with Applications 42 (12) (2015) 5303–5314.
- [43]
W. Gan, J. C. W. Lin, P. Fournier-Viger, H. C. Chao, P. S. Yu, HUOPM: High-utility occupancy pattern mining, IEEE transactions on cybernetics.
- [44]
S. Brin, R. Motwani, C. Silverstein, Beyond market baskets: generalizing association rules to correlations, in: ACM SIGMOD Record, Vol. 26, ACM, 1997, pp. 265–276.
- [45]
J. Wu, S. Zhu, H. Liu, G. Xia, Cosine interesting pattern discovery, Information Sciences 184 (1) (2012) 176–195.
- [46]
W. Y. Kim, Y. K. Lee, J. Han, CCMine: efficient mining of confidence-closed correlated patterns, in: Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Springer, 2004, pp. 569–579.
- [47]
P. Fournier-Viger, J. C. W. Lin, T. Dinh, H. B. Le, Mining correlated high-utility itemsets using the bond measure, in: Proceedings of the International Conference on Hybrid Artificial Intelligence Systems, Springer, 2016, pp. 53–65.
- [48]
W. Gan, J. C. W. Lin, P. Fournier-Viger, H. C. Chao, P. S. Yu, Beyond frequency: Utility mining with varied item-specific minimum utility, arXiv preprint arXiv:1902.09584.
- [49]
R. Rymon, Search through systematic set enumeration, Proceeding of the 3rd International Conference on Principles of Knowledge Representationand Reasoning (1992) 539–550.
- [50]
W. Gan, J. C. W. Lin, H. C. Chao, S. L. Wang, P. S. Yu, Privacy preserving utility mining: a survey, in: Proceedings of the IEEE International Conference on Big Data, IEEE, 2018, pp. 2617–2626.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] M. S. Chen, J. Han, P. S. Yu, Data mining: an overview from a database perspective, IEEE Transactions on Knowledge and data Engineering 8 (6) (1996) 866–883.
- 2[2] W. Gan, J. C. W. Lin, H. C. Chao, J. Zhan, Data mining in distributed environment: a survey, Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery 7 (6) (2017) e 1216.
- 3[3] R. Agrawal, R. Srikant, et al., Fast algorithms for mining association rules, in: Proceedings of the 20th International Conference on Very Large Data Bases, Vol. 1215, 1994, pp. 487–499.
- 4[4] J. Han, J. Pei, Y. Yin, R. Mao, Mining frequent patterns without candidate generation: A frequent-pattern tree approach, Data Mining and Knowledge Discovery 8 (1) (2004) 53–87.
- 5[5] W. Gan, J. C. W. Lin, P. Fournier-Viger, H. C. Chao, J. Zhan, Mining of frequent patterns with multiple minimum supports, Engineering Applications of Artificial Intelligence 60 (2017) 83–96.
- 6[6] W. Gan, J. C. W. Lin, P. Fournier-Viger, H. C. Chao, P. S. Yu, A survey of parallel sequential pattern mining, ar Xiv preprint ar Xiv:1805.10515.
- 7[7] Y. Liu, W. K. Liao, A. Choudhary, A two-phase algorithm for fast discovery of high utility itemsets, in: Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Springer, 2005, pp. 689–695.
- 8[8] C. F. Ahmed, S. K. Tanbeer, B. S. Jeong, Y. K. Lee, Efficient tree structures for high utility pattern mining in incremental databases, IEEE Transactions on Knowledge and Data Engineering 21 (12) (2009) 1708–1721.