Learning Outside the Box: Discourse-level Features Improve Metaphor Identification
Jesse Mu, Helen Yannakoudakis, Ekaterina Shutova

TL;DR
This paper demonstrates that incorporating discourse-level features significantly enhances metaphor identification accuracy, achieving near state-of-the-art results without complex models by leveraging broader contextual information.
Contribution
It introduces the use of discourse-level features and document embeddings for metaphor detection, moving beyond sentence-level analysis.
Findings
Broader discourse features improve metaphor identification.
Gradient boosting classifiers with document embeddings achieve near state-of-the-art results.
Qualitative analysis confirms the importance of wider context in metaphor processing.
Abstract
Most current approaches to metaphor identification use restricted linguistic contexts, e.g. by considering only a verb's arguments or the sentence containing a phrase. Inspired by pragmatic accounts of metaphor, we argue that broader discourse features are crucial for better metaphor identification. We train simple gradient boosting classifiers on representations of an utterance and its surrounding discourse learned with a variety of document embedding methods, obtaining near state-of-the-art results on the 2018 VU Amsterdam metaphor identification task without the complex metaphor-specific features or deep neural architectures employed by other systems. A qualitative analysis further confirms the need for broader context in metaphor processing.
Click any figure to enlarge with its caption.
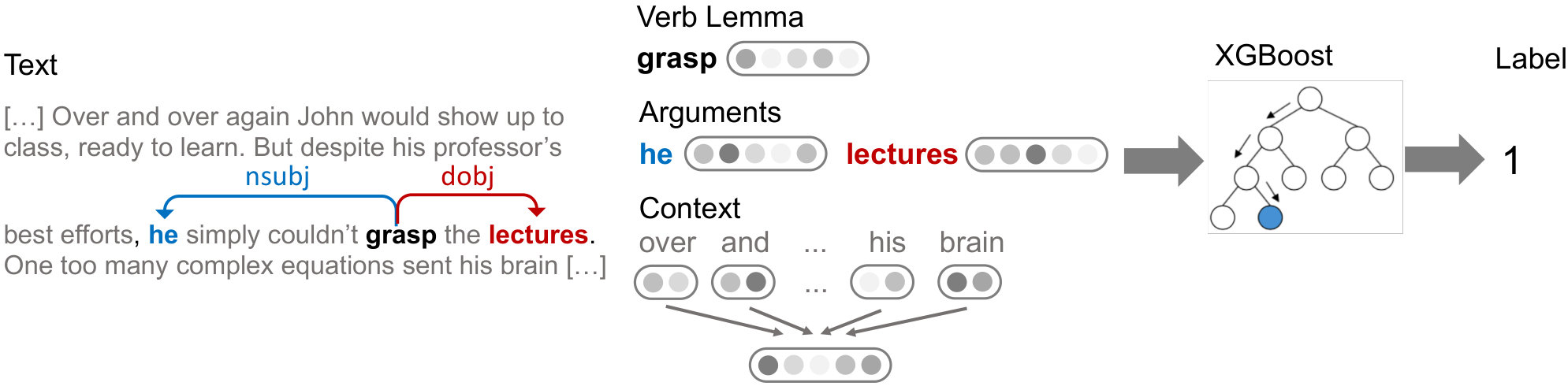 Figure 1
Figure 1
|
|||
|
| Model | P | R | F1 | |
| Baseline 1 (lemma) | 51.0 | 65.4 | 57.3 | |
| Baseline 2 (+WN, concrete) | 52.7 | 69.8 | 60.0 | |
| Stemle and Onysko (2018) | 54.7 | 77.9 | 64.2 | |
| Wu et al. (2018) | 60.0 | 76.3 | 67.2 | |
| GloVe | L (lemma) | 51.6 | 74.1 | 60.8 |
| LA (+ args) | 54.0 | 74.4 | 62.6*** | |
| LAC (+ ctx) | 56.7 | 76.8 | 65.2*** | |
| doc2vec | L | 48.8 | 72.1 | 58.2 |
| LA | 50.5 | 71.4 | 59.1** | |
| LAC | 52.7 | 72.2 | 60.9*** | |
| skip-thought | L | 53.5 | 76.1 | 62.8 |
| LA | 57.0 | 74.0 | 64.3*** | |
| LAC | 59.5 | 75.4 | 66.5*** | |
| ELMo | L | 51.3 | 74.9 | 60.9 |
| LA | 56.0 | 73.5 | 63.6*** | |
| LAC | 58.9 | 77.1 | 66.8*** | |
| Genre | Model | P | R | F1 |
|---|---|---|---|---|
| Academic | Baseline 2 | 70.7 | 83.6 | 76.6 |
| Wu et al. (2018) | 74.6 | 76.3 | 75.5 | |
| ELMo LAC | 65.4 | 86.8 | 74.6 | |
| Conversation | Baseline 2 | 30.1 | 82.1 | 44.1 |
| Wu et al. (2018) | 40.3 | 65.6 | 50.3 | |
| ELMo LAC | 42.6 | 56.0 | 48.4 | |
| Fiction | Baseline 2 | 40.7 | 66.7 | 50.6 |
| Wu et al. (2018) | 54.5 | 78.4 | 57.6 | |
| ELMo LAC | 48.2 | 63.0 | 54.6 | |
| News | Baseline 2 | 67.7 | 68.9 | 68.3 |
| Wu et al. (2018) | 69.4 | 74.4 | 71.8 | |
| ELMo LAC | 65.2 | 80.0 | 71.8 |
| Args | Sentence | Paragraph | |
|---|---|---|---|
| Overall | 40 | 49 | 11 |
| Model errors | |||
| ELMo L | 37 | 50 | 13 |
| ELMo LA | 36 | 49 | 15 |
| ELMo LAC | 39 | 53 | 8 |
| Sentence | Gold label | LA | LAC | |||
|---|---|---|---|---|---|---|
|
0 | 1 | 0 | |||
|
1 | 0 | 1 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsLanguage, Metaphor, and Cognition · Advanced Text Analysis Techniques · Natural Language Processing Techniques
Learning Outside the Box:
Discourse-level Features Improve Metaphor Identification
Jesse Mu1,3, Helen Yannakoudakis2, Ekaterina Shutova4
1Computer Science Department, Stanford University, USA
2The ALTA Institute, 3Dept. of CS & Technology, University of Cambridge, UK
4ILLC, University of Amsterdam, The Netherlands
[email protected], [email protected], [email protected]
Abstract
Most current approaches to metaphor identification use restricted linguistic contexts, e.g. by considering only a verb’s arguments or the sentence containing a phrase. Inspired by pragmatic accounts of metaphor, we argue that broader discourse features are crucial for better metaphor identification. We train simple gradient boosting classifiers on representations of an utterance and its surrounding discourse learned with a variety of document embedding methods, obtaining near state-of-the-art results on the 2018 VU Amsterdam metaphor identification task without the complex metaphor-specific features or deep neural architectures employed by other systems. A qualitative analysis further confirms the need for broader context in metaphor processing.
1 Introduction
From bottled up anger to the world is your oyster, metaphor is a defining component of language, adding poetry and humor to communication (Glucksberg and McGlone, 2001) and serving as a tool for reasoning about relations between concepts (Lakoff and Johnson, 1980). Designing metaphor processing systems has thus seen significant interest in the NLP community, with applications from information retrieval (Korkontzelos et al., 2013) to machine translation (Saygin, 2001).
An important first step in any metaphor processing pipeline is metaphor identification. To date, most approaches to its identification operate in restricted contexts, for instance, by only considering isolated verb–argument pairs (e.g. deflate economy) (Rei et al., 2017) or the sentence containing an utterance (Gao et al., 2018). However, wider context is crucial for understanding metaphor: for instance, the phrase drowning students can be interpreted as literal (in the context of water) or metaphorical (in the context of homework). Often the context required extends beyond the immediate sentence; in Table 1, coreferences (them) must be resolved to understand the arguments of a verb, and a game is metaphorical in a political context. Indeed, a rich linguistic tradition (Grice, 1975; Searle, 1979; Sperber and Wilson, 1986) explains metaphor as arising from violations of expectations in a conversational context.
Following these theories, in this paper we argue that metaphor processing models should expand beyond restricted contexts to use representations of wider discourse. We support this claim with two contributions: (1) we develop metaphor identification models which take as input an utterance, its immediate lexico–syntactic context, and broader discourse representations, and demonstrate that incorporating discourse features improves performance; (2) we perform a qualitative analysis and show that broader context is often required to correctly interpret metaphors. To the best of our knowledge, this is the first work to investigate the effects of broader discourse on metaphor identification.111Code and data available at https://github.com/jayelm/broader-metaphor.
2 Related work
Metaphor identification is typically framed as a binary classification task, either with (1) word tuples such as SVO triples (car drinks gasoline) or (2) whole sentences as input, where the goal is to predict the metaphoricity of a token in the sentence. Recent work has used a variety of features extracted from these two types of contexts, including selectional preferences (Shutova, 2013; Beigman Klebanov et al., 2016), concreteness/imageability (Turney et al., 2011; Tsvetkov et al., 2014), multi-modal (Tekiroglu et al., 2015; Shutova et al., 2016) and neural features (Do Dinh and Gurevych, 2016; Rei et al., 2017).
At the recent VU Amsterdam (VUA) metaphor identification shared task (Leong et al., 2018), neural approaches dominated, with most teams using LSTMs trained on word embeddings and additional linguistic features, such as semantic classes and part of speech tags (Wu et al., 2018; Stemle and Onysko, 2018; Mykowiecka et al., 2018; Swarnkar and Singh, 2018). Most recently, Gao et al. (2018) revisited this task, reporting state-of-the-art results with BiLSTMs and contextualized word embeddings (Peters et al., 2018). To the best of our knowledge, none of the existing approaches have utilized information from wider discourse context in metaphor identification, nor investigated its effects.
3 Data
Following past work, we use the Verbs subset of the VUA metaphor corpus (Steen et al., 2010) used in the above shared task. The data consists of training and test examples, equally distributed across 4 genres of the British National Corpus: Academic, Conversation, News, and Fiction. All verbs are annotated as metaphorical or literal in these texts. We sample examples randomly from the training set as a development set.
4 Models
For each utterance, our models learn generic representations of a verb lemma,222The lemmatized form of the verb has improved generalization in other systems (Beigman Klebanov et al., 2016). its syntactic arguments, and its broader discourse context. We concatenate these features into a single feature vector and feed them into a gradient boosting decision tree classifier (Chen and Guestrin, 2016).333We use the default parameters of the XGBoost package: a maximum tree depth of 3, 100 trees, and . By observing performance differences when using the lemma only (L), lemma + arguments (LA), or lemma + arguments + context (LAC), we can investigate the effects of including broader context.
To obtain arguments for verbs, we extract subjects and direct objects with Stanford CoreNLP (Manning et al., 2014). of verb usages in the dataset have at least one argument; absent arguments are represented as zero vectors. To obtain the broader context of a verb, we take its surrounding paragraph as defined by the BNC; the average number of tokens in a context is . Figure 1 depicts the feature extraction and classification pipeline of our approach.
To learn representations, we use several widely-used embedding methods:444These methods differ significantly in dimensionality and training data. Our intent is not to exhaustively compare these methods, but rather claim generally that many embeddings give good performance on this task.
GloVe
We use -dimensional pre-trained GloVe embeddings (Pennington et al., 2014) trained on the Common Crawl corpus as representations of a lemma and its arguments. To learn a context embedding, we simply average the vectors of the tokens in the context. Out-of-vocabulary words are represented as a mean across all vectors.
doc2vec
We use pretrained -dimensional paragraph vectors learned with the distributed bag-of-words method of Le and Mikolov (2014) (colloquially, doc2vec), trained on Wikipedia (Lau and Baldwin, 2016). Here, paragraph vectors are learned to predict randomly sampled words from the paragraph, ignoring word order. To extract representations for verbs and arguments, we embed one-word “documents” consisting of only the word itself.555Since some methods provide only document embeddings and not word embeddings, for consistency, in all methods we use the same embedding process even for single-word verbs and arguments. We use a learning rate and epochs to infer vectors.
Skip-thought
We use pretrained skip-thought vectors (Kiros et al., 2015) learned from training an encoder–decoder model to reconstruct the surrounding sentences of an input sentence from the Toronto BooksCorpus (Zhu et al., 2015). From this model, we extract -dimensional representations for verb lemma, arguments, and contexts.
ELMo
Finally, we use ELMo, a model of deep contextualized word embeddings (Peters et al., 2018). We extract -dimensional representations from the last layer of a stacked BiLSTM trained on Wikipedia and monolingual news data from WMT 2008–2012. To learn embeddings for verbs and arguments, we extract representations for sentences containing only the word itself. To learn context embeddings, we again average the constituent word embeddings.
5 Evaluation
For each embedding method, we evaluate the three configurations of features—L, LA, and LAC—on the VUA shared task train/test split, reporting precision, recall and F1 score. Since we are interested in whether incorporating broader context significantly improves identification performance, we compare successive model predictions (LAC vs. LA; LA vs. L) using the mid-p variant of McNemar’s test for paired binary data (Fagerland et al., 2013).
5.1 Comparison Systems
We first compare our models to the baselines of the VUA shared task (Leong et al., 2018): Baseline 1, a logistic regression classifier trained only on one-hot encodings of verb lemmas; and Baseline 2, the same classifier with additional WordNet class and concreteness features. We also compare to the best systems submitted to the VUA shared task: Wu et al. (2018), an ensemble of CNN-BiLSTMs trained on word2vec embeddings, part-of-speech tags, and word embedding clusters; and Stemle and Onysko (2018), a BiLSTM trained on embeddings from English language learner corpora.
5.2 Results
Results for our models are presented in Table 2. Interestingly, most of the simple lemma models (L) already perform at Baseline 2 level, obtaining F1 scores in the range –. This is likely due to the generalization made possible by dense representations of lemmas (vs. one-hot encodings) and the more powerful statistical classifier used. As expected, the addition of argument information consistently enhances performance.
Crucially, the addition of broader discourse context improves performance for all embedding methods. In general, we observe consistent, statistically significant increases of - F1 points for incorporating discourse. Overall, all LAC models except doc2vec exhibit high performance, and would have achieved second place in the VUA shared task. These results show a clear trend: the incorporation of discourse information leads to improvement of metaphor identification performance across models.
Table 3 displays the performance breakdown by genre in the VUA test set for our best performing model (ELMo LAC) and selected comparison systems. Echoing Leong et al. (2018), we observe that the Conversation and Fiction genres are consistently more difficult than the Academic and News genres across all models. This is partially because in this dataset, metaphors in these genres are rarer, occuring of the time in Academic and in News, but only in Conversation and in Fiction. In addition, for our model specifically, Conversation genre contexts are much shorter on average ( vs. ).
Our best performing model (ELMo LAC) is within F1 score of the first-place model in the VUA shared task (Wu et al., 2018). The GloVe LAC model would also have obtained second place at F1, yet is considerably simpler than the systems used in the shared task, which employed ensembles of deep neural architectures and hand-engineered, metaphor-specific features.
6 Qualitative analysis
To better understand the ways in which discourse information plays a role in metaphor processing, we randomly sample examples from our development set and manually categorize them by the amount of context required for their interpretation. For instance, a verb may be interpretable when given just its arguments (direct subject/object), it may require context from the enclosing sentence, or it may require paragraph-level context (or beyond). We also similarly analyze sampled errors made on the development set by the ELMo L, LA, and LAC models, to examine whether error types vary between models.
Our analysis in Table 4 shows that of examples in the development set require paragraph-level context for correct interpretation. Indeed, while such examples are frequently misclassified by the L and LA models (, ), the error rate is halved when context is included ().
Table 5 further presents examples requiring at least paragraph-level context, along with gold label and model predictions. Out of the unique such examples identified in the above analyses, we found () requiring explicit coreference resolution of a pronoun or otherwise underspecified noun (e.g. Table 5 row 1) and () which reference an entity or event implicitly (ellipsis; e.g. Table 5 row 2). However, we also observed errors () due to examples with non-verbs and incomplete sentences and examples () where not even paragraph-level context was sufficient for interpretation, mostly in the Conversation genre, demonstrating the subjective and borderline nature of many of the annotations.
This analysis shows a priori the need for broader context beyond sentence-level for robust metaphor processing. Yet this is not an upper bound on performance gains; the general improvement of the LAC models over LA shows that even when context is not strictly necessary, it can still be a useful signal for identification.
7 Conclusion
We presented the first models which leverage representations of discourse for metaphor identification. The performance gains of these models demonstrate that incorporating broader discourse information is a powerful feature for metaphor identification systems, aligning with our qualitative analysis and the theoretical and empirical evidence suggesting metaphor comprehension is heavily influenced by wider context.
Given the simplicity of our representations of context in these models, we are interested in future models which (1) use discourse in more sophisticated ways, e.g. by modeling discourse relations or dialog state tracking (Henderson, 2015), and (2) leverage more sophisticated neural architectures (Gao et al., 2018).
Acknowledgments
We thank anonymous reviewers for their insightful comments, Noah Goodman, and Ben Leong for assistance with the 2018 VUA shared task data. We thank the Department of Computer Science and Technology and Churchill College, University of Cambridge for travel funding. Jesse Mu is supported by a Churchill Scholarship and an NSF Graduate Research Fellowship. Helen Yannakoudakis was supported by Cambridge Assessment, University of Cambridge. We thank the NVIDIA Corporation for the donation of the Titan GPU used in this research.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Beigman Klebanov et al. (2016) Beata Beigman Klebanov, Chee Wee Leong, E. Dario Gutierrez, Ekaterina Shutova, and Michael Flor. 2016. Semantic classifications for detection of verb metaphors. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages 101–106.
- 2Chen and Guestrin (2016) Tianqi Chen and Carlos Guestrin. 2016. XG Boost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , pages 785–794.
- 3Do Dinh and Gurevych (2016) Erik-Lân Do Dinh and Iryna Gurevych. 2016. Token-level metaphor detection using neural networks. In Proceedings of the Fourth Workshop on Metaphor in NLP , pages 28–33.
- 4Fagerland et al. (2013) Morten W Fagerland, Stian Lydersen, and Petter Laake. 2013. The Mc Nemar test for binary matched-pairs data: mid-p and asymptotic are better than exact conditional. BMC Medical Research Methodology , 13(1):91.
- 5Gao et al. (2018) Ge Gao, Eunsol Choi, Yejin Choi, and Luke Zettlemoyer. 2018. Neural metaphor detection in context. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages 607–613.
- 6Glucksberg and Mc Glone (2001) Sam Glucksberg and Matthew S Mc Glone. 2001. Understanding figurative language: From metaphor to idioms . Oxford University Press, Oxford.
- 7Grice (1975) Herbert P Grice. 1975. Logic and conversation. In Peter Cole and Jerry L Morgan, editors, Syntax and Semantics , volume 3, pages 41–58. Academic Press, New York.
- 8Henderson (2015) Matthew Henderson. 2015. Machine learning for dialog state tracking: A review. In Proceedings of The First International Workshop on Machine Learning in Spoken Language Processing .