TL;DR
This paper introduces a novel method combining autoencoders and sparse regression to simultaneously discover optimal coordinates and governing equations from high-dimensional data, enhancing interpretability and model simplicity.
Contribution
It presents the first integrated approach to learn both coordinate transformations and sparse dynamical models simultaneously using deep learning and sparse regression.
Findings
Successfully applied to high-dimensional systems with low-dimensional dynamics
Achieves interpretable, parsimonious models
Demonstrates improved discovery of governing equations
Abstract
The discovery of governing equations from scientific data has the potential to transform data-rich fields that lack well-characterized quantitative descriptions. Advances in sparse regression are currently enabling the tractable identification of both the structure and parameters of a nonlinear dynamical system from data. The resulting models have the fewest terms necessary to describe the dynamics, balancing model complexity with descriptive ability, and thus promoting interpretability and generalizability. This provides an algorithmic approach to Occam's razor for model discovery. However, this approach fundamentally relies on an effective coordinate system in which the dynamics have a simple representation. In this work, we design a custom autoencoder to discover a coordinate transformation into a reduced space where the dynamics may be sparsely represented. Thus, we simultaneously…
Click any figure to enlarge with its caption.
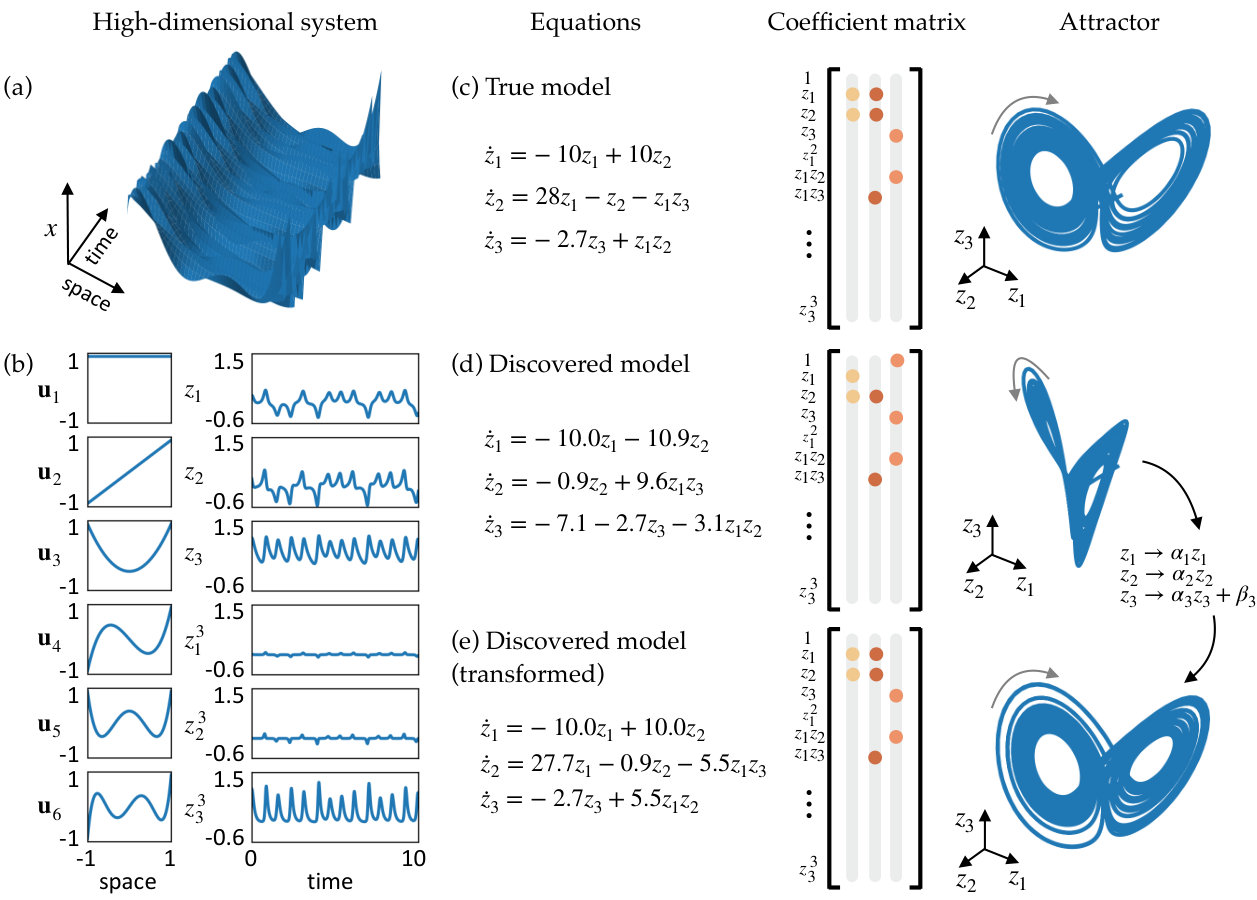 Figure 1
Figure 1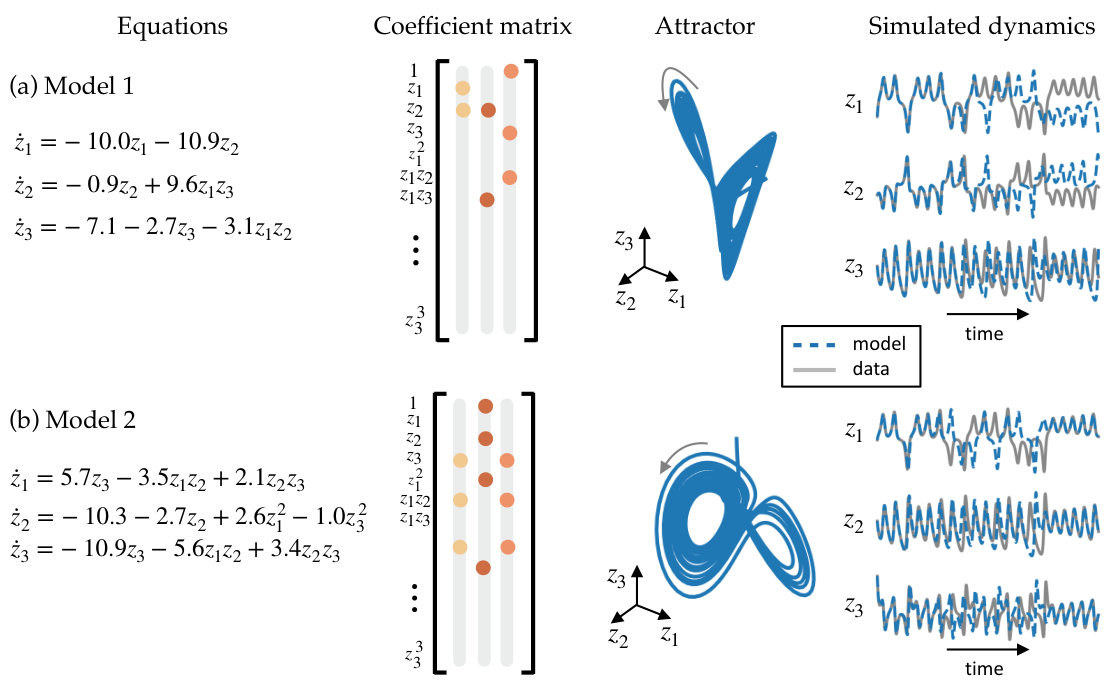 Figure 2
Figure 2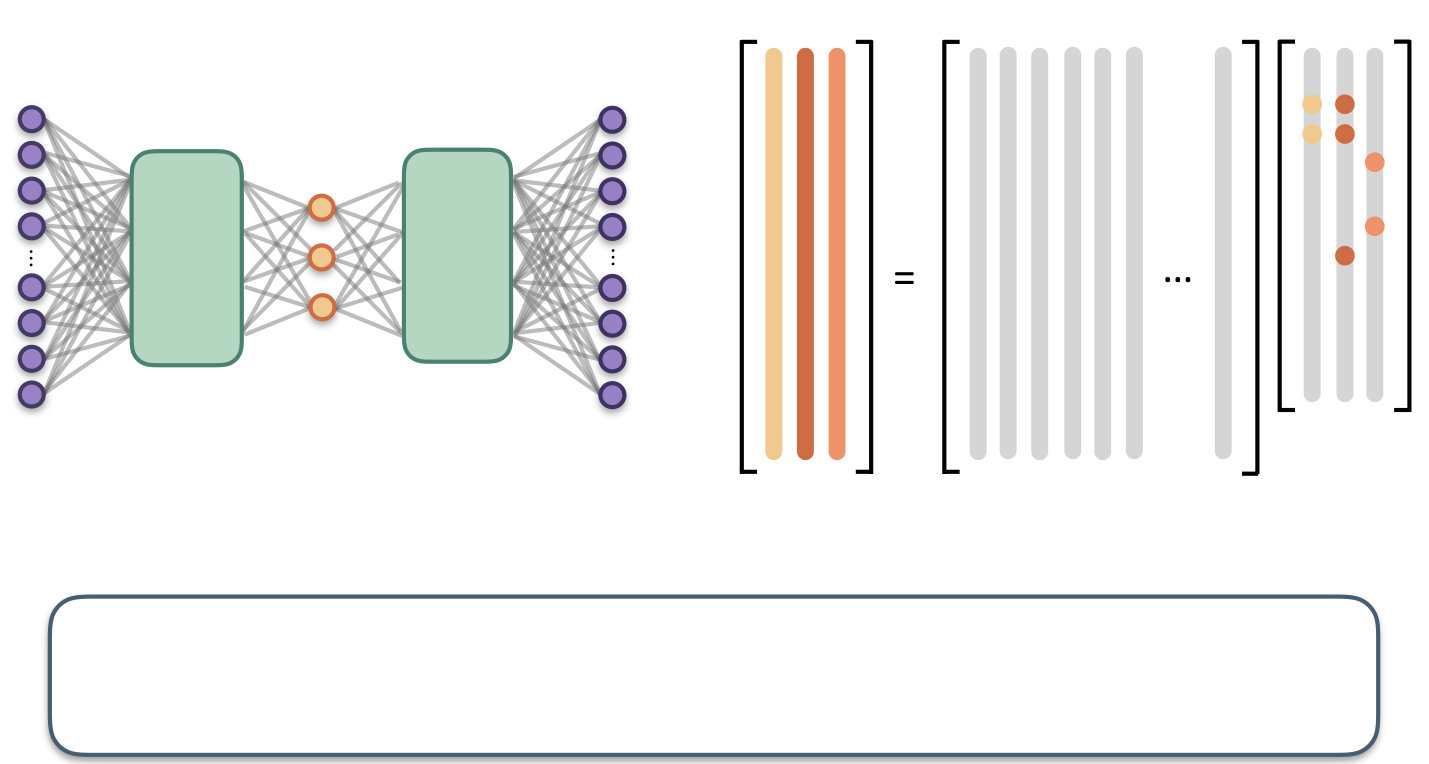 Figure 3
Figure 3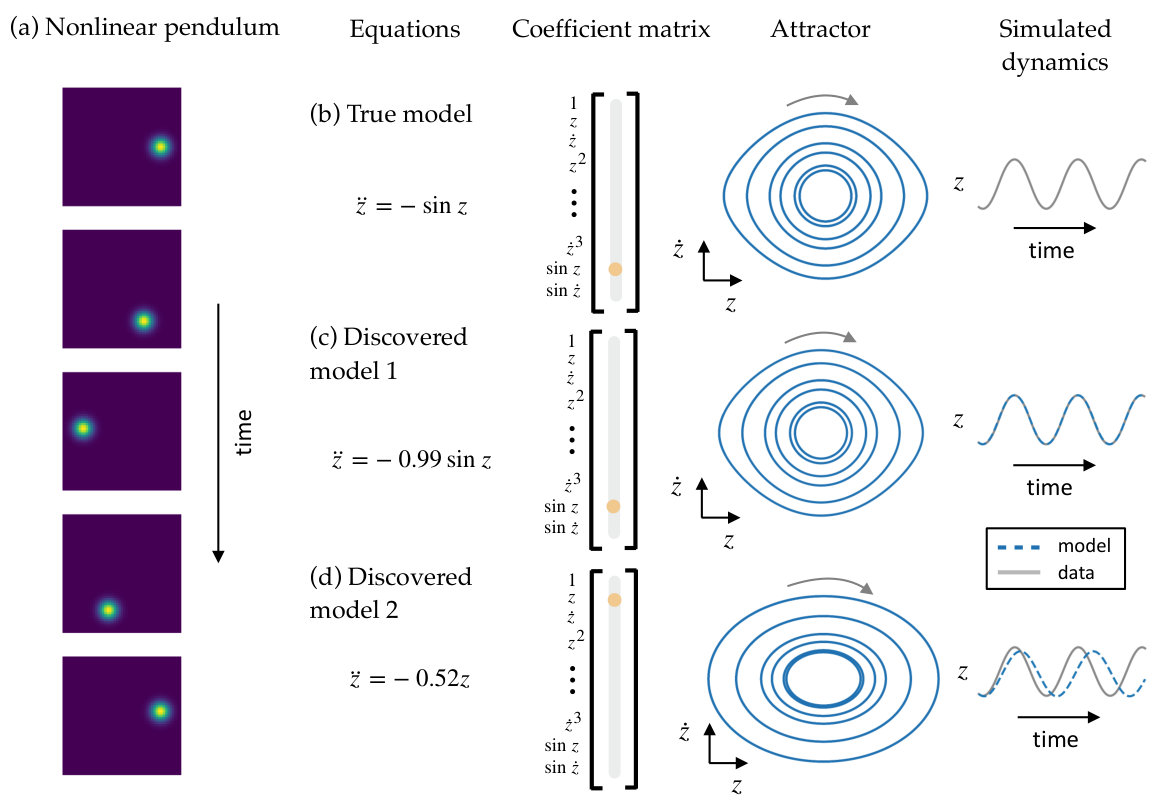 Figure 4
Figure 4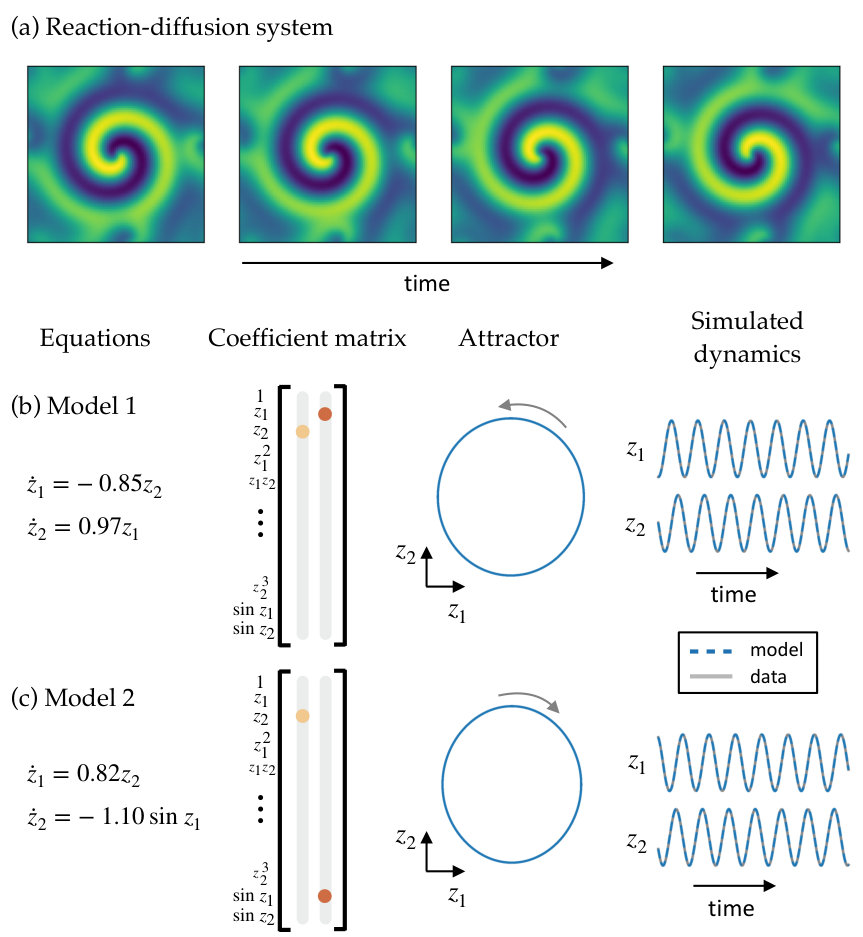 Figure 5
Figure 5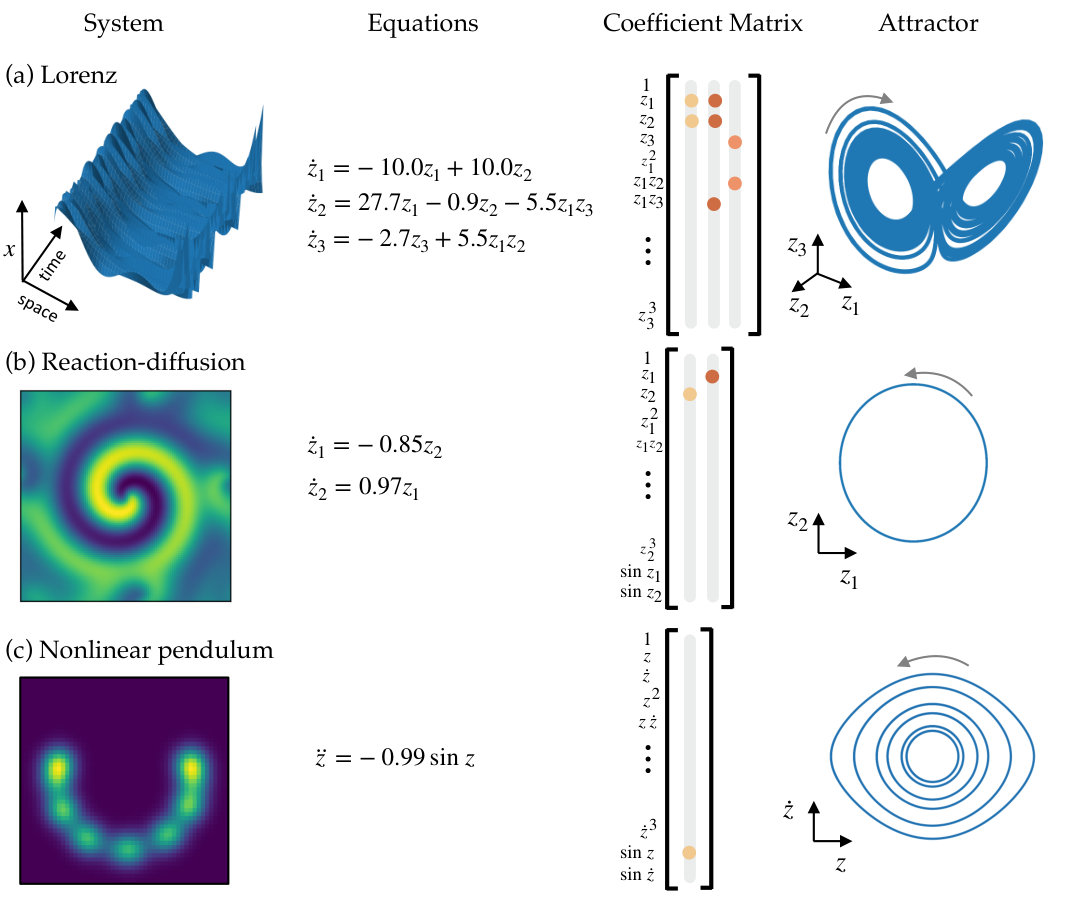 Figure 6
Figure 6| Parameter | Value |
|---|---|
| n | 128 |
| d | 3 |
| training samples | |
| batch size | 8000 |
| activation function | sigmoid |
| encoder layer widths | |
| decoder layer widths | |
| learning rate | |
| SINDy model order | 1 |
| SINDy library polynomial order | 3 |
| SINDy library includes sine | no |
| SINDy loss weight , | |
| SINDy loss weight , | |
| SINDy regularization loss weight, |
| Parameter | Value |
|---|---|
| n | |
| d | 2 |
| training samples | 8000 |
| batch size | 1024 |
| activation function | sigmoid |
| encoder layer widths | |
| decoder layer widths | |
| learning rate | |
| SINDy model order | 1 |
| SINDy library polynomial order | 3 |
| SINDy library includes sine | yes |
| SINDy loss weight , | |
| SINDy loss weight , | |
| SINDy regularization loss weight, |
| Parameter | Value |
|---|---|
| n | |
| d | 1 |
| training samples | |
| batch size | 1024 |
| activation function | sigmoid |
| encoder layer widths | |
| decoder layer widths | |
| learning rate | |
| SINDy model order | 2 |
| SINDy library polynomial order | 3 |
| SINDy library includes sine | yes |
| SINDy loss weight , | |
| SINDy loss weight , | |
| SINDy regularization loss weight, |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Simultaneous discovery of coordinates and parsimonious dynamics: SINDy autoencoders
Kathleen Champion1∗, Bethany Lusch2, J. Nathan Kutz1, Steven L. Brunton3
1 Department of Applied Mathematics, University of Washington, Seattle, WA 98195, United States
2 Argonne National Laboratory, Lemont, IL 60439, United States
3 Department of Mechanical Engineering, University of Washington, Seattle, WA 98195, United States
Data-driven discovery of coordinates and governing equations
Kathleen Champion1∗, Bethany Lusch2, J. Nathan Kutz1, Steven L. Brunton3
1 Department of Applied Mathematics, University of Washington, Seattle, WA 98195, United States
2 Argonne National Laboratory, Lemont, IL 60439, United States
3 Department of Mechanical Engineering, University of Washington, Seattle, WA 98195, United States
Abstract
The discovery of governing equations from scientific data has the potential to transform data-rich fields that lack well-characterized quantitative descriptions. Advances in sparse regression are currently enabling the tractable identification of both the structure and parameters of a nonlinear dynamical system from data. The resulting models have the fewest terms necessary to describe the dynamics, balancing model complexity with descriptive ability, and thus promoting interpretability and generalizability. This provides an algorithmic approach to Occam’s razor for model discovery. However, this approach fundamentally relies on an effective coordinate system in which the dynamics have a simple representation. In this work, we design a custom autoencoder to discover a coordinate transformation into a reduced space where the dynamics may be sparsely represented. Thus, we simultaneously learn the governing equations and the associated coordinate system. We demonstrate this approach on several example high-dimensional dynamical systems with low-dimensional behavior. The resulting modeling framework combines the strengths of deep neural networks for flexible representation and sparse identification of nonlinear dynamics (SINDy) for parsimonious models. It is the first method of its kind to place the discovery of coordinates and models on an equal footing.
Keywords– model discovery, dynamical systems, machine learning, deep learning, autoencoder
††∗ Corresponding author ([email protected]).
1 Introduction
Governing equations are of fundamental importance across all scientific disciplines. Accurate models allow for fundamental understanding of physical processes, which in turn gives rise to an infrastructure for the development of technology. The traditional derivation of governing equations is based on underlying first principles, such as conservation laws and symmetries, or from universal laws, such as gravitation. However, in many modern systems, governing equations are unknown or only partially known, and recourse to first principles derivations is untenable. On the other hand, many of these modern systems have rich time-series data due to the emergence of sensor and measurement technologies (e.g. in biology and climate science). This has given rise to the new paradigm of data-driven model discovery. Indeed, the data-driven discovery of dynamical systems is the focus of intense research efforts across the physical and engineering sciences [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]. A central tension in model discovery is the balance between model efficiency and descriptive capabilities. Parsimonious models strike this balance, having the fewest terms required to capture essential interactions, and not more [1, 3, 9, 11]. Related to Occam’s razor, parsimonious models tend to be more interpretable and generalizable. However, obtaining parsimonious models is fundamentally linked to the coordinate system in which the dynamics are measured. Without knowledge of the proper coordinates, standard approaches may fail to discover simple dynamical models. In this work, we develop a machine learning approach that simultaneously discovers effective coordinates via a custom autoencoder [16, 17, 18], along with the parsimonious dynamical system model via sparse regression in a library of candidate terms [9]. The joint discovery of models and coordinates is critical for understanding many modern complex systems.
Numerous recent approaches leverage machine learning to identify dynamical systems models from data [19, 20, 21, 22, 23, 24, 25, 26], with many using neural networks to model time-series data [27, 28, 29, 30, 31, 32, 18, 33, 34, 35, 36, 37, 38]. When interpretability and generalizability are primary concerns, it is important to identify parsimonious models that have the fewest terms required to describe the dynamics, which is the antithesis of neural networks whose parametrizations are exceedingly large. A breakthrough approach used symbolic regression to learn the form of dynamical systems and governing laws from data [1, 3, 39]. Sparse identification of nonlinear dynamics (SINDy) [9] is a related approach that uses sparse regression to find the fewest terms in a library of candidate terms required to model a dynamical system. Because this approach is based on a sparsity-promoting linear regression, it is possible to incorporate partial knowledge of the physics, such as symmetries, constraints, and conservation laws [40]. Successful model identification relies on the assumption that the dynamics are measured in a coordinate system in which the dynamics may be sparsely represented. While simple models may exist in one coordinate system, a different coordinate system may obscure these parsimonious representations. For modern applications of data-driven discovery, there is no reason to believe that our sensors are measuring the correct variables to admit a parsimonious representation of the dynamics. This motivates the systematic and automated discovery of coordinate transformations to facilitate this sparse representation, which is the subject of this work.
The challenge of discovering an effective coordinate system is as fundamental and important as model discovery. Many key historical scientific breakthroughs were enabled by the discovery of appropriate coordinate systems. Celestial mechanics, for instance, was revolutionized by the heliocentric coordinate system of Copernicus, Galileo, and Kepler, thus displacing Ptolemy’s doctrine of the perfect circle, which was dogma for more than a millennium. Fourier introduced his famous transform to simplify the representation of the heat equation, resulting in a sparse, diagonal, decoupled linear system. Eigen-coordinates have been used more broadly to enable simple and sparse decompositions, for example in quantum mechanics and electrodynamics, to characterize energy levels in atoms and propagating modes in waveguides, respectively. Principal component analysis (PCA) is one of the most prolific modern coordinate discovery methods, representing high-dimensional data in a low-dimensional linear subspace [41, 42]. Nonlinear extensions of PCA have been enabled by a neural network architecture, called an autoencoder [16, 43, 17]. However, PCA coordinates and autoencoders generally do not take dynamics into account and, thus, may not provide the right basis for parsimonious dynamical models. In a related vein, Koopman analysis seeks to discover coordinates that linearize nonlinear dynamics [44, 45, 46, 47]; while linear models are useful for prediction and control, they cannot capture the full behavior of many nonlinear systems. Thus, it is important to develop methods that combine simplifying coordinate transformations and nonlinear dynamical models. We advocate for a balance between these approaches, identifying coordinate transformations where only a few nonlinear terms are present, as in the classic theory of near-identity transformations and normal forms [48, 12].
In this work we present a method for discovery of nonlinear coordinate transformations that enable associated parsimonious dynamics. Our method combines a custom autoencoder network with a SINDy model for parsimonious nonlinear dynamics. The autoencoder architecture enables the discovery of reduced coordinates from high-dimensional input data that can be used to reconstruct the full system. The reduced coordinates are found along with nonlinear governing equations for the dynamics in a joint optimization. We demonstrate the ability of our method to discover parsimonious dynamics on three examples: a high-dimensional spatial data set with dynamics governed by the chaotic Lorenz system, a spiral wave resulting from the reaction-diffusion equation, and the nonlinear pendulum. These results demonstrate how to focus neural networks to discover interpretable dynamical models. Critically, the proposed method is the first to provide a mathematical framework that places the discovery of coordinates and models on equal footing.
2 Background
2.1 Sparse identification of nonlinear dynamics
We review the sparse identification of nonlinear dynamics (SINDy) [9] algorithm, which is a mathematical regression technique for extracting parsimonious dynamics from time-series data. The method takes snapshot data and attempts to discover a best-fit dynamical system with as few terms as possible:
[TABLE]
The snapshots represent measurements of the state of the system in time , and the function constrains how the dynamics of the system evolve in time. We seek a parsimonious model for the dynamics, resulting in a function that contains only a few active terms: it is sparse in a basis of possible functions. This is consistent with our extensive knowledge of a diverse set of evolution equations used throughout the physical, engineering and biological sciences. Thus, the functions that comprise are typically known from our extensive modeling experience.
SINDy frames model discovery as a sparse regression problem. Assuming snapshot derivatives are available, or can be calculated from data, the snapshots are stacked to form data matrices
[TABLE]
with . Although is unknown, we can construct an extensive library of potential candidate basis functions , where each is a candidate basis function or model term. We assume so that the number of data snapshots is much larger than the number of candidate library functions; it may be necessary to sample transient dynamics and multiple initial conditions to improve the condition number of . The choice of basis functions typically reflects some knowledge about the system of interest: a common choice is polynomials in as these are elements of many canonical models of dynamical systems [48]. The library is used to formulate a regression problem to approximately solve the overdetermined linear system of equations
[TABLE]
where the unknown matrix is the set of coefficients that determine the active terms from in the dynamics . Sparsity-promoting regression is used to find parsimonious models, ensuring that , or more precisely each , is sparse and only a few columns of are selected. For high-dimensional systems, the goal is to identify a low-dimensional state with dynamics , as in Sec. 3. The standard SINDy approach uses a sequentially thresholded least squares algorithm to find the coefficients [9], which is a proxy for optimization [49] and has convergence guarantees [50]. Yao and Bollt [2] previously formulated the dynamical system identification problem as a similar linear inverse problem, although sparsity-promoting regression was not used, so the resulting models generally included all terms in . In either case, an appealing aspect of this model discovery formulation is that it results in an overdetermined linear system of equations for which many regularized solution techniques exist. Thus, it provides a computationally efficient counterpart to other model discovery frameworks [3, 6].
SINDy has been widely applied to identify models for fluid flows [40, 51], optical systems [52], chemical reaction dynamics [53], convection in a plasma [54], structural modeling [55], and for model predictive control [56]. There are also a number of theoretical extensions to the SINDy framework, including for identifying partial differential equations [11, 57], multiscale physics [58], parametrically dependent dynamical models [59], hybrid (switching) dynamical systems [60], and models with rational function nonlinearities [61]. It can also incorporate partially known physics and constraints [40] and identify models based on physically realistic sensor measurements [51]. The algorithm can also be reformulated to include integral terms for noisy data [62] or handle incomplete or limited data [63, 64]. The selected modes can also be evaluated using information criteria for model selection [65]. These diverse mathematical developments provide a mature framework for broadening the applicability of the model discovery method.
2.2 Neural networks for dynamical systems
The success of neural networks (NNs) on problems such as image classification [66] and speech recognition [67] has led to the use of NNs to perform a wide range of tasks in science and engineering. One recent area of focus has been the use of NNs for studying dynamical systems, which has a surprisingly rich history [27]. In addition to improving solution techniques for systems with known equations [34, 35, 36, 37, 38], deep learning has been used for understanding and predicting dynamics for complex systems with potentially unknown equations [28, 29, 30, 31, 32, 18, 33]. Several recent methods have trained NNs to predict dynamics, including a time-lagged autoencoder which takes the state at time as input data and uses an autoencoder-like structure to predict the state at time [30]. Other approaches use a recurrent NN architecture, particularly long short-term memory (LSTM) networks, for applications involving sequential data [68, 69, 70]. LSTMs have recently been used to perform forecasting on chaotic dynamical systems [29]. Reservoir computing has also enabled impressive predictions [14]. Autoencoders are increasingly being leveraged for dynamical systems because of their close relationship to other dimensionality reduction techniques [43, 71, 72, 73].
Another class of NNs use deep learning to discover coordinates for Koopman analysis. Koopman theory seeks to discover coordinates that linearize nonlinear dynamics [44, 45, 46, 47]. Methods such as dynamic mode decomposition (DMD) [5, 4, 74, 10], extended DMD [75], kernel DMD [76], and time-delay DMD [77, 78] build linear models for dynamics, but these methods rely on a proper set of coordinates for linearization. Several recent works have focused on the use of deep learning methods to discover the proper coordinates for DMD and extended DMD [79, 31, 32]. Other methods seek to learn Koopman eigenfunctions and the associated linear dynamics directly using autoencoders [33, 18].
Despite their widespread use, NNs face three major challenges: generalization, extrapolation, and interpretation. The hallmark success stories of NNs (computer vision and speech, for instance) have been on data sets that are fundamentally interpolatory in nature. The ability to extrapolate, and as a consequence generalize, is known to be an underlying weakness of NNs. This is especially relevant for dynamical systems and forecasting, which is typically an extrapolatory problem by nature. Thus models trained on historical data will generally fail to predict future events that are not represented in the training set. An additional limitation of deep learning is the lack of interpretability of the resulting models. While attempts have been made to interpret NN weights, network architectures are typically complicated with the number of parameters (or weights) far exceeding the original dimension of the dynamical system. The lack of interpretability also makes it difficult to generalize models to new data sets and parameter regimes. However, NN methods still have the potential to learn general, interpretable dynamical models if properly constrained or regularized. In addition to methods for discovering linear embeddings [18, 33], deep learning has also been used for parameter estimation of PDEs [36, 37].
3 SINDy Autoencoders
We present a method for the simultaneous discovery of sparse dynamical models and coordinates that enable these simple representations. Our aim is to leverage the parsimony and interpretability of SINDy with the universal approximation capabilities of deep neural networks [80] in order to produce interpretable and generalizable models capable of extrapolation and forecasting. Our approach combines a SINDy model and a deep autoencoder network to perform a joint optimization that discovers intrinsic coordinates which have an associated parsimonious nonlinear dynamical model. The architecture is shown in Figure 1. We again consider dynamical systems of the form (1). While this dynamical model may be dense in terms of functions of the original measurement coordinates , our method seeks a set of reduced coordinates () with an associated dynamical model
[TABLE]
that provides a parsimonious description of the dynamics. This means that contains only a few active terms. Along with the dynamical model, the method provides coordinate transforms that map the measurement coordinates to intrinsic coordinates via (encoder) and back via (decoder).
The coordinate transformation is achieved using an autoencoder network architecture. The autoencoder is a feedforward neural network with a hidden layer that represents the intrinsic coordinates. Rather than performing a task such as prediction or classification, the network is trained to output an approximate reconstruction of its input, and the restrictions placed on the network architecture (e.g. the type, number, and size of the hidden layers) determine the properties of the intrinsic coordinates [17]; these networks are known to produce nonlinear generalizations of PCA [16]. A common choice is that the dimensionality of the intrinsic coordinates , determined by the number of units in the corresponding hidden layer, is much lower than that of the input data : in this case, the autoencoder learns a nonlinear embedding into a reduced latent space. Our network takes measurement data from a dynamical system as input and learns intrinsic coordinates , where is chosen as a hyperparameter prior to training the network.
While autoencoders can be trained in isolation to discover useful coordinate transformations and dimensionality reductions, there is no guarantee that the intrinsic coordinates learned will have associated sparse dynamical models. We require the network to learn coordinates associated with parsimonious dynamics by simultaneously learning a SINDy model for the dynamics of the intrinsic coordinates . This regularization is achieved by constructing a library of candidate basis functions, e.g. polynomials, and learning a sparse set of coefficients that defines the dynamical system
[TABLE]
While the functions in the library must be specified prior to training, the coefficients are learned along with the NN parameters as part of the training procedure. Assuming derivatives of the original states are available or can be computed, one can calculate the derivative of the encoder variables as and enforce accurate prediction of the dynamics by incorporating the following term into the loss function:
[TABLE]
This term uses the SINDy model along with the gradient of the encoder to encourage the learned dynamical model to accurately predict the time derivatives of the encoder variables. We include an additional term in the loss function that ensures SINDy predictions can be used to reconstruct the time derivatives of the original data:
[TABLE]
We combine (4) and (5) with the standard autoencoder loss function
[TABLE]
which ensures that the autoencoder can accurately reconstruct the input data. We also include an regularization on the SINDy coefficients , which promotes sparsity of the coefficients and therefore encourages a parsimonious model for the dynamics. The combination of the above four terms gives the following overall loss function:
[TABLE]
where the scalars are hyperparameters that determine the relative weighting of the three terms in the loss function.
In addition to the regularization, to obtain a model with only a few active terms we also incorporate sequential thresholding into the training procedure as a proxy for sparsity [49]. This technique is inspired by the original algorithm used for SINDy [9], which combined least squares fitting with sequential thresholding to obtain a sparse dynamical model. To apply sequential thresholding during training, we specify a threshold that determines the minimum magnitude for coefficients in the SINDy model. At fixed intervals throughout the training, all coefficients below the threshold are set to zero and training resumes using only the terms left in the model. We train the network using the Adam optimizer [81]. In addition to the loss function weightings and SINDy coefficient threshold, training requires the choice of several other hyperparameters including learning rate, number of intrinsic coordinates , network size, and activation functions. Full details of the training procedure are discussed in Section S1.4.
4 Results
We demonstrate the success of the proposed method on three example systems: a high-dimensional system with the underlying dynamics generated from the canonical chaotic Lorenz system, a two-dimensional reaction-diffusion system, and a two-dimensional spatial representation (synthetic video) of the nonlinear pendulum. Results are shown in Figure 2, and additional details for each example are provided in Section S2.
4.1 Chaotic Lorenz system
We first construct a high-dimensional example problem with dynamics based on the chaotic Lorenz system. The Lorenz system is a canonical model used as a test case for many dynamical systems methods, with dynamics given by the following equations
[TABLE]
The dynamics of the Lorenz system are chaotic and highly nonlinear, making it an ideal test problem for model discovery. To create a high-dimensional data set based on this system, we choose six fixed spatial modes , given by Legendre polynomials, and define
[TABLE]
This results in a data set that is a nonlinear combination of the true Lorenz variables, shown in Figure 3a. The spatial and temporal modes that combine to give the full dynamics are shown in Figure 3b. Full details of how the data set is generated are given in Section S2.1.
Figure 3d shows the dynamical system discovered by the SINDy autoencoder. While the resulting model does not appear to match the original Lorenz dynamics, the discovered model is parsimonious, with only 7 active terms, and with dynamics that live on an attractor which has a two lobe structure similar to that of the original Lorenz attractor. Additionally, by choosing a suitable variable transformation the discovered model can be rewritten in the same form as the original Lorenz system. This demonstrates that the SINDy autoencoder is able to recover the correct sparsity pattern of the dynamics. The coefficients of the discovered model are close to the original parameters of the Lorenz system, up to an arbitrary scaling, which accounts for the difference in magnitude of the coefficients of in the second equation and in the third equation.
On a test data set of trajectories from 100 randomly chosen initial conditions, the mean square error of the decoder reconstruction is less than of the fraction of the variance of the input data. The fraction of the unexplained variance in predicting the derivatives and are and , respectively. Simulations of the resulting SINDy model are able to accurately reconstruct the dynamics of a single trajectory with less than 1% error over the duration of trajectories in the training data. Over longer durations, the trajectories start to diverge from the true trajectories. This result is not surprising due to the chaotic nature of the Lorenz system and its sensitivity to initial conditions. However, the dynamics of the discovered system match the sparsity pattern of the Lorenz system and the form of the attractor. Improved prediction over a longer duration could be achieved by increased parameter refinement or training the system with longer trajectories.
4.2 Reaction-diffusion
In practice, many high-dimensional data sets of interest come from dynamics governed by partial differential equations (PDEs) with more complicated interactions between spatial and temporal dynamics. To test the method on data generated by a PDE, we consider a lambda-omega reaction-diffusion system governed by
[TABLE]
with and . This set of equations generates a spiral wave formation, whose behavior can be approximately captured by two oscillating spatial modes. We apply our method to snapshots of generated by the above equations. Snapshots are collected at discretized points of the -domain, resulting in a high-dimensional input data set with .
We train the SINDy autoencoder with . The resulting model is shown in Figure 2b. With two modes, the network discovers a model with nonlinear oscillatory dynamics. On test data, the fraction of unexplained variance of both the input data and the input derivatives is . The fraction of unexplained variance of is . Simulation of the dynamical model accurately captures the low dimensional dynamics, with the fraction of unexplained variance of totaling .
4.3 Nonlinear pendulum
As a final example, we consider simulated video of a nonlinear pendulum in two spatial dimensions. The nonlinear pendulum is governed by the following second order differential equation:
[TABLE]
We simulate the system from several initial conditions and generate a series of snapshot images with a two-dimensional Gaussian centered at the center of mass, determined by the pendulum’s angle . This series of images is the high-dimensional data input to the autoencoder. Despite the fact that the position of the pendulum can be represented by a simple one-dimensional variable, methods such as PCA are unable to obtain a low-dimensional representation of this data set. A nonlinear autoencoder, however, is able to discover a one-dimensional representation of the data set.
For this example, we use a second-order SINDy model: that is, we use a library of functions including the first derivatives to predict the second derivative . This approach is the same as with a first order SINDy model but requires estimates of the second derivatives in addition to estimates of the first derivatives. Second order gradients of the encoder and decoder are therefore also required. Computation of the derivatives is discussed in Section S1.3.
The SINDy autoencoder is trained with . Of the ten training instances, five correctly identify the nonlinear pendulum equation. We calculate test error on trajectories from 50 randomly chosen initial conditions. The best model has a fraction of unexplained variance of for the decoder reconstruction of the input . The fraction of unexplained variance of the SINDy model predictions for and are and , respectively.
5 Discussion
We have presented a data-driven method for discovering interpretable, low-dimensional dynamical models and their associated coordinates for high-dimensional dynamical systems. The simultaneous discovery of both is critical for generating dynamical models that are sparse, and hence interpretable and generalizable. Our approach takes advantage of the power of NNs by using a flexible autoencoder architecture to discover nonlinear coordinate transformations that enable the discovery of parsimonious, nonlinear governing equations. This work addresses a major limitation of prior approaches for the discovery of governing equations, which is that the proper choice of measurement coordinates is often unknown. We demonstrate this method on three example systems, showing that it is able to identify coordinates associated with parsimonious dynamical equations. For the examples studied, the identified models are interpretable and can be used for forecasting (extrapolation) applications (see Figure S1).
A current limitation of our approach is the requirement for clean measurement data that is approximately noise-free. Fitting a continuous-time dynamical system with SINDy requires reasonable estimates of the derivatives, which may be difficult to obtain from noisy data. While this represents a challenge, approaches for estimating derivatives from noisy data such as the total variation regularized derivative can prove useful in providing derivative estimates [82]. Moreover, there are emerging NN architectures explicitly constructed for separating signals from noise [83], which can be used as a pre-processing step in the data-driven discovery process advocated here. Alternatively our method can be used to fit a discrete-time dynamical system, in which case derivative estimates are not required. Many methods for modeling dynamical systems work in discrete time rather than continuous time, making this a reasonable alternative. It is also possible to use the integral formulation of SINDy to abate noise sensitivity [62].
A major problem with deep learning approaches is that models are typically neither interpretable nor generalizable. Specifically, NNs trained solely for prediction may fail to generalize to classes of behaviors not seen in the training set. We have demonstrated an approach for using NNs to obtain classically interpretable models through the discovery of low-dimensional dynamical systems, which are well-studied and often have physical interpretations. Once the proper terms in the governing equations are identified, the discovered model can be generalized to study other parameter regimes of the dynamics. While the coordinate transformation learned by the autoencoder may not generalize to data regimes far from the original training set, if the dynamics are known, the network can be retrained on new data with fixed terms in the latent dynamics space. The problem of relearning a coordinate transformation for a system with known dynamics is greatly simplified from the original challenge of learning the correct form of the underlying dynamics without knowledge of the proper coordinate transformation.
The challenge of utilizing NNs to answer scientific questions requires careful consideration of their strengths and limitations. While advances in deep learning and computing power present a tremendous opportunity for new scientific breakthroughs, care must be taken to ensure that valid conclusions are drawn from the results. One promising strategy is to combine machine learning approaches with well-established domain knowledge: for instance physics-informed learning leverages physical assumptions into NN architectures and training methods. Methods that provide interpretable models have the potential to enable new discoveries in data-rich fields. This work introduced a flexible framework for using NNs to discover models that are interpretable from a standard dynamical systems perspective. In the future, this approach could be adapted using domain knowledge to discover new models in specific fields.
Acknowledgments
This material is based upon work supported by the National Science Foundation Graduate Research Fellowship under Grant No. DGE-1256082. The authors also acknowledge support from the Defense Advanced Research Projects Agency (DARPA PA-18-01-FP-125) and the Army Research Office (ARO W911NF-17-1-0306 and W911NF-17-1-0422). This work was facilitated through the use of advanced computational, storage, and networking infrastructure provided by AWS cloud computing credits funded by the STF at the University of Washington. This research was funded in part by the Argonne Leadership Computing Facility, which is a DOE Office of Science User Facility supported under Contract DE-AC02-06CH11357. We would also like to thank Jean-Christophe Loiseau and Karthik Duraisamy for valuable discussions about sparse dynamical systems and autoencoders.
S1 Network Architecture and Training
S1.1 Network architecture
The autoencoder network consists of a series of fully-connected layers. Each layer has an associated weight matrix and bias vector . We use sigmoid activation functions , which are applied at all layers of the network, except for the last layer of the encoder and the last layer of the decoder. Other choices of activation function, such as rectified linear units and exponential linear units, may also be used and appear to achieve similar results.
S1.2 Loss function
The loss function used in training is a weighted sum of four terms: autoencoder reconstruction , SINDy prediction on the input variables , SINDy prediction on the encoder variables , and SINDy coefficient regularization . For a data set with input samples, each loss is explicitly defined as follows:
[TABLE]
The total loss function is
[TABLE]
ensures that the autoencoder can accurately reconstruct the data from the intrinsic coordinates. and ensure that the discovered SINDy model captures the dynamics of the system by ensuring that the model can predict the derivatives from the data. promotes sparsity of the coefficients in the SINDy model.
S1.3 Computing derivatives
Computing the derivatives of the encoder variables requires propagating derivatives through the network. Our network makes use of an activation function that operates elementwise. Given an input , we define the pre-activation values at the th encoder layer as
[TABLE]
The first layer applies the weights and biases directly to the input so that
[TABLE]
The activation function is not applied to the last layer, so for an encoder with hidden layers the autoencoder variables are defined as
[TABLE]
Assuming that derivatives are available or can be computed, derivatives can also be computed:
[TABLE]
with
[TABLE]
For the nonlinear pendulum example, we use a second order SINDy model that requires the calculation of second derivatives. Second derivatives can be computed using the following:
[TABLE]
S1.4 Training procedure
We train multiple models for each of the example systems. Each instance of training has a different random initialization of the network weights. The weight matrices are initialized using the Xavier initialization: the entries are chosen from a random uniform distribution over where is the dimension of the input plus the dimension of the output [84]. The bias vectors are initialized to 0 and the SINDy model coefficients are initialized so that every entry is 1. We train each model using the Adam optimizer for a fixed number of epochs [81]. The learning rate and number of training epochs for each example are specified in Section S2.
To obtain parsimonious dynamical models, we use a sequential thresholding procedure that promotes sparsity on the coefficients in , which represent the dynamics on the latent variables . Every 500 epochs, we set all coefficients in with a magnitude of less than to 0, effectively removing these terms from the SINDy model. This is achieved by using a mask , consisting of 1s and 0s, that determines which terms remain in the SINDy model. Thus the true SINDy terms in the loss function are given by
[TABLE]
where is passed in separately and not updated by the optimization algorithm. Once a term has been thresholded out during training, it is permanently removed from the SINDy model. Therefore the number of active terms in the SINDy model can only be decreased as training continues. The regularization on encourages the model coefficients to decrease in magnitude, which combined with the sequential thresholding produces a parsimonious dynamical model.
While the regularization penalty on promotes sparsity in the resulting SINDy model, it also encourages nonzero terms to have smaller magnitudes. This results in a trade-off between accurately reconstructing the dynamics of the system and reducing the magnitude of the SINDy coefficients, where the trade-off is determined by the relative magnitudes of the loss weight penalties and the regularization penalty . The specified training procedure therefore typically results in models with coefficients that are slightly smaller in magnitude than those which would best reproduce the dynamics. To account for this, we add an additional coefficient refinement period to the training procedure. To perform this refinement, we lock in the sparsity pattern in the dynamics by fixing the coefficient mask and continue training for 1000 epochs without the regularization on . This ensures that the best coefficients are found for the resulting SINDy model and also allows the training procedure to refine the encoder and decoder parameters. This procedure is analagous to running a debiased regression following the use of LASSO to select model terms [85].
S1.5 Model selection
Random initialization of the NN weights is standard practice for deep learning approaches. This results in the discovery of different models for different instances of training, which necessitates comparison among multiple models. In this work, when considering the success of a resulting model, one must consider the parsimony of the SINDy model, how well the decoder reconstructs the input, and how well the SINDy model captures the dynamics.
To assess model performance, we calculate the fraction of unexplained variance of both the input data and its derivative . This error calculation takes into account both the decoder reconstruction and the fit of the dynamics. When considering parsimony, we consider the number of active terms in the resulting SINDy model. While parsimonious models are desirable for ease of analysis and interpretability, a model that is too parsimonious may be unable to fully capture the dynamics. In general, for the examples explored, we find that models with fewer active terms perform better on validation data (lower fraction of unexplained variance of ) whereas models with more active terms tend to over-fit the training data.
For each example system, we apply the training procedure to ten different initializations of the network and compare the resulting models. For the purpose of demonstration, for each example we show results for a chosen “best” model, which is taken to be the model with the lowest fraction of variance unexplained on validation data among models with the fewest active coefficients. While every instance of training does not result in the exact same SINDy sparsity pattern, the network tends to discover a few different closely related forms of the dynamics. We discuss the comparison among models for each particular example further in Section S2.
S2 Example Systems
S2.1 Chaotic Lorenz system
To create a high-dimensional data set with dynamics defined by the Lorenz system, we choose six spatial modes and take
[TABLE]
where the dynamics of are specified by the Lorenz equations
[TABLE]
with standard parameter values of . We choose our spatial modes to be the first six Legendre polynomials defined at 128 grid points on a 1D spatial domain . To generate our data set, we simulate the system from 2048 initial conditions for the training set, 20 for the validation set, and 100 for the test set. For each initial condition we integrate the system forward in time from to with a spacing of to obtain samples. Initial conditions are chosen randomly from a uniform distribution over , , . This results in a training set with 512,000 total samples.
Following the training procedure described in Section S1.4, we learn ten models using the single set of training data (variability among the models comes from the initialization of the network weights). The hyperparameters used for training are shown in Table S1. For each model we run the training procedure for epochs, followed by a refinement period of epochs. Of the ten models, two have 7 active terms, two have 10 active terms, one has 11 active terms, and five have 15 or more active terms. While all models have less than 1% unexplained variance for both and , the three models with 20 or more active terms have the worst performance predicting . The two models with 10 active terms have the lowest overall error, followed by models with 7, 15, and 18 active terms. While the models with 10 active terms have a lower overall error than the models with 7 terms, both have a very low error and thus we choose to highlight the model with the fewest active terms. A model with 10 active terms is shown in Figure S1 for comparison.
For analysis, we highlight the model with the lowest error among the models with the fewest active terms. The discovered model has equations
[TABLE]
While the structure of this model appears to be different from that of the original Lorenz system, we can define an affine transformation that gives it the same structure. The variable transformation , , gives the following transformed system of equations:
[TABLE]
By choosing , , , , the system becomes
[TABLE]
This has the same form as the original Lorenz equations with parameters that are close in value, apart from an arbitrary scaling that affects the magnitude of the coefficients of in (21b) and in (21c). The attractor dynamics for this system are very similar to the original Lorenz attractor and are shown in Figure 3c.
The learning procedure discovers a dynamical model by fitting coefficients that predict the continuous-time derivatives of the variables in a dynamical system. Thus it is possible for the training procedure to discover a model with unstable dynamics or which is unable to predict the true dynamics through simulation. We assess the validity of the discovered models by simulating the dynamics of the discovered low-dimensional dynamical system. Simulation of the system shows that the system is stable with trajectories existing on an attractor very similar to the original Lorenz attractor. Additionally, the discovered system is able to predict the dynamics of the original system. The fourth panel in Figure S1a shows the trajectories found by stepping the discovered model forward in time as compared with the values of obtained by mapping samples of the high-dimensional data through the encoder. Although this is done on a new initial condition, the trajectories match very closely up to , which is the duration of trajectories contained in the training set. After that the trajectories diverge, but the predicted trajectories remain on an attractor. The Lorenz dynamics are chaotic, and thus slight differences in coefficients or initial conditions cause trajectories to diverge quickly.
For comparison, in Figure S1b we show a second model discovered by the training procedure. This model has 10 active terms, as compared with 7 in the true Lorenz system. While the model contains additional terms not present in the original system, the dynamics lie on an attractor with a similar two lobe structure. Additionally, the system is able to predict the dynamics through simulation. This model has a lower error on test data than the original 7 term model, with a fraction of unexplained variance of for , for , and for .
S2.2 Reaction-diffusion
We generate data from a high-dimensional lambda-omega reaction-diffusion system governed by
[TABLE]
with and . The system is simulated from a single initial condition from to with a spacing of for a total of 10,000 samples. The initial condition is defined as
[TABLE]
over a spatial domain of discretized on a grid with 100 points on each spatial axis. The solution of these equations results in a spiral wave formation. We apply our method to snapshots of generated by the above equations, multiplied by a Gaussian centered at the origin to localize the spiral wave in the center of the domain. Our input data is thus defined as . We also add Gaussian noise with a standard deviation of to both and . Four time snapshots of the input data are shown in Figure S2a.
We divide the total number of samples into training, validation, and test sets: the last 1000 samples are taken as the test set, 1000 samples are chosen randomly from the first 9000 samples as a validation set, and the remaining 8000 samples are taken as the training set. We train ten models using the procedure outlined in Section S1.4 for epochs followed by a refinement period of epochs. Hyperparameters used for training are shown in Table S2. Nine of the ten resulting dynamical systems models have two active terms and one has three active terms. The dynamical equations, SINDy coefficient matrix, attractors, and simulated dynamics for two example models are shown in Figure S2b,c. The models with two active terms all have one of the two forms shown in the figure: three models have a linear oscillation and six models have a nonlinear oscillation. Both model forms have similar levels of error on the test set and are able to predict the dynamics in the test set from simulation, as shown in the fourth panel of Figure S2b,c.
S2.3 Nonlinear pendulum
The nonlinear pendulum equation is given by
[TABLE]
We generate synthetic video of the pendulum in two spatial dimensions by creating high-dimensional snapshots given by
[TABLE]
at a discretization of . We use 51 grid points in each dimension resulting in snapshots . To generate a training set, we simulate (24) from 100 randomly chosen initial conditions with and . The initial conditions are selected from a uniform distribution in the specified range but are restricted to conditions for which the pendulum does not have enough energy to do a full loop. This condition is determined by checking that .
Following the training procedure outlined in Section S1.4, we train ten models for epochs followed by a refinement period of epochs. Hyperparameters used for this example are shown in Table S3. Five of the ten resulting models correctly recover the nonlinear pendulum equation. These five models have the best performance of the ten models. The attractor and simulated dynamics for the best of these five models are shown in Figure S3. One model, also shown in Figure S3, recovers a linear oscillator. This model is able to achieve a reasonably low prediction error for but the simulated dynamics, while still oscillatory, appear qualitatively different from the true pendulum dynamics. The four remaining models all have two active terms in the dynamics and have a worse performance than the models with one active term.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Josh Bongard and Hod Lipson. Automated reverse engineering of nonlinear dynamical systems. Proceedings of the National Academy of Sciences , 104(24):9943–9948, 2007.
- 2[2] Chen Yao and Erik M Bollt. Modeling and nonlinear parameter estimation with Kronecker product representation for coupled oscillators and spatiotemporal systems. Physica D: Nonlinear Phenomena , 227(1):78–99, 2007.
- 3[3] Michael Schmidt and Hod Lipson. Distilling free-form natural laws from experimental data. Science , 324(5923):81–85, 2009.
- 4[4] C. W. Rowley, I. Mezić, S. Bagheri, P. Schlatter, and D.S. Henningson. Spectral analysis of nonlinear flows. J. Fluid Mech. , 645:115–127, 2009.
- 5[5] Peter J. Schmid. Dynamic mode decomposition of numerical and experimental data. Journal of Fluid Mechanics , 656:5–28, 2010.
- 6[6] W. X. Wang, R. Yang, Y. C. Lai, V. Kovanis, and C. Grebogi. Predicting catastrophes in nonlinear dynamical systems by compressive sensing. Physical Review Letters , 106:154101–1–154101–4, 2011.
- 7[7] Peter Benner, Serkan Gugercin, and Karen Willcox. A survey of projection-based model reduction methods for parametric dynamical systems. SIAM review , 57(4):483–531, 2015.
- 8[8] Benjamin Peherstorfer and Karen Willcox. Data-driven operator inference for nonintrusive projection-based model reduction. Computer Methods in Applied Mechanics and Engineering , 306:196–215, 2016.
