TL;DR
This paper introduces the gammachirp envelope distortion index (GEDI), a new objective measure based on auditory modeling to predict speech intelligibility, especially under non-stationary noise, outperforming existing measures in various conditions.
Contribution
The study presents the novel GEDI index and its multi-resolution extension, demonstrating improved prediction of speech intelligibility over existing measures like STOI and ESTOI in noisy environments.
Findings
mr-GEDI outperforms STOI, ESTOI, and HASPI in pink-noise conditions
mr-GEDI provides more conservative and reliable intelligibility predictions
GEDI effectively predicts speech intelligibility for enhanced speech in non-stationary noise
Abstract
In this study, we propose a new concept, the gammachirp envelope distortion index (GEDI), based on the signal-to-distortion ratio in the auditory envelope, SDRenv to predict the intelligibility of speech enhanced by nonlinear algorithms. The objective of GEDI is to calculate the distortion between enhanced and clean-speech representations in the domain of a temporal envelope extracted by the gammachirp auditory filterbank and modulation filterbank. We also extend GEDI with multi-resolution analysis (mr-GEDI) to predict the speech intelligibility of sounds under non-stationary noise conditions. We evaluate GEDI in terms of speech intelligibility predictions of speech sounds enhanced by a classic spectral subtraction and a Wiener filtering method. The predictions are compared with human results for various signal-to-noise ratio conditions with additive pink and babble noises. The results…
Click any figure to enlarge with its caption.
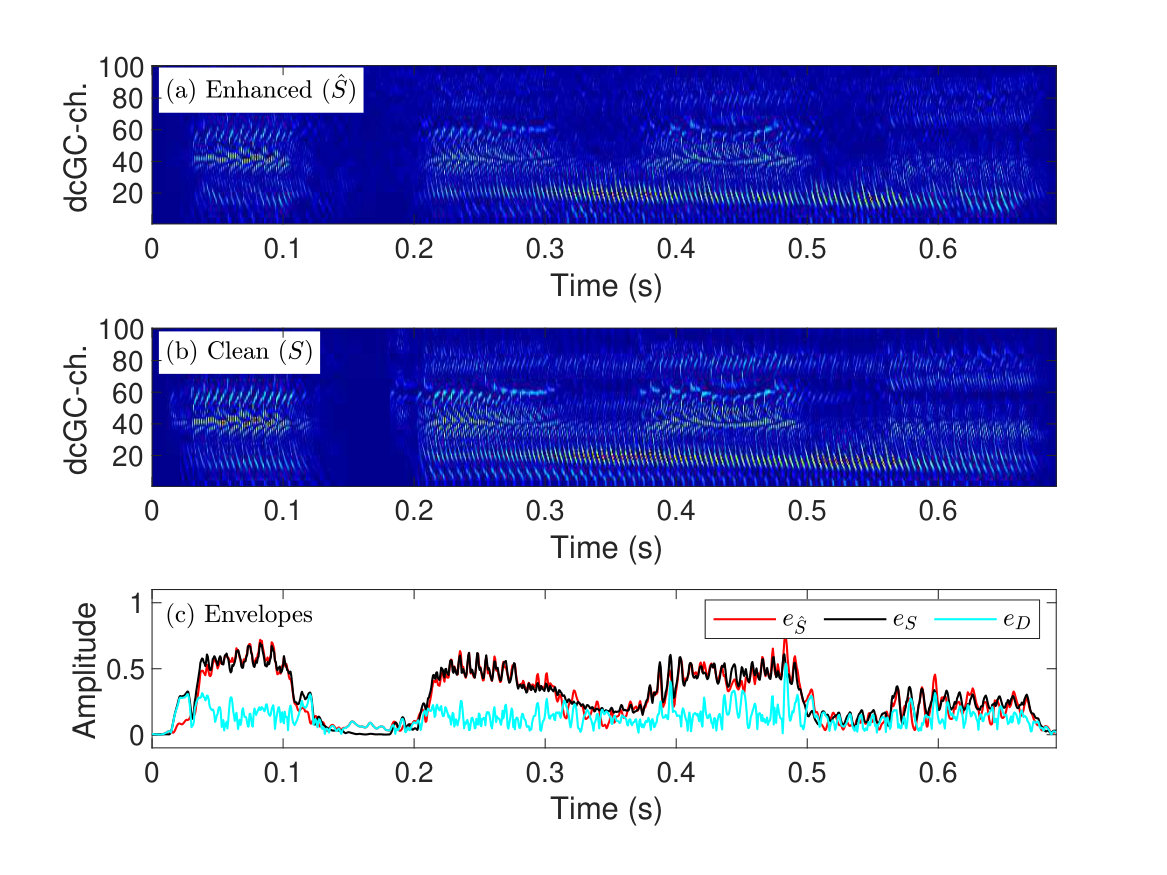 Figure 1
Figure 1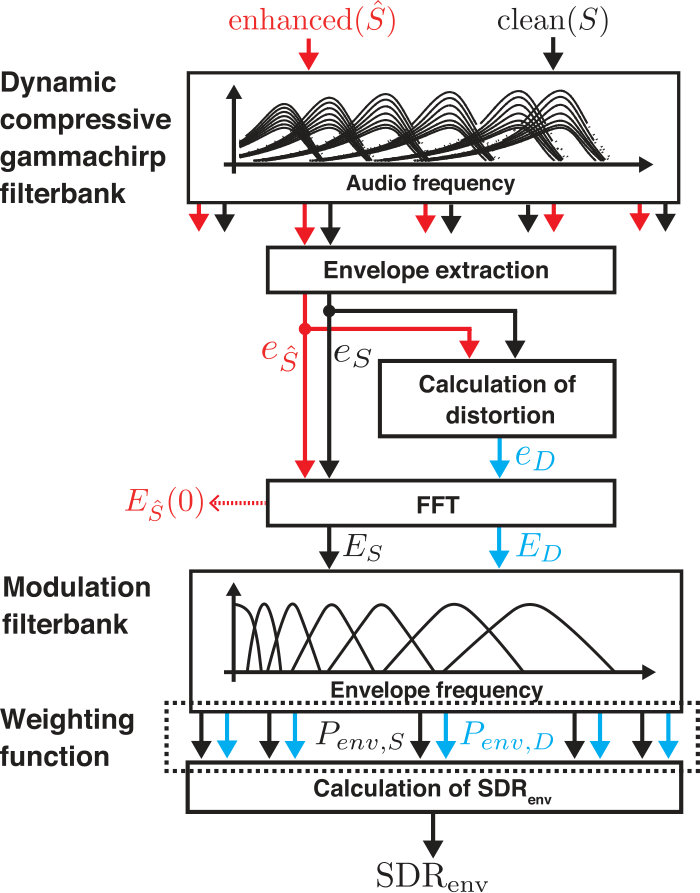 Figure 2
Figure 2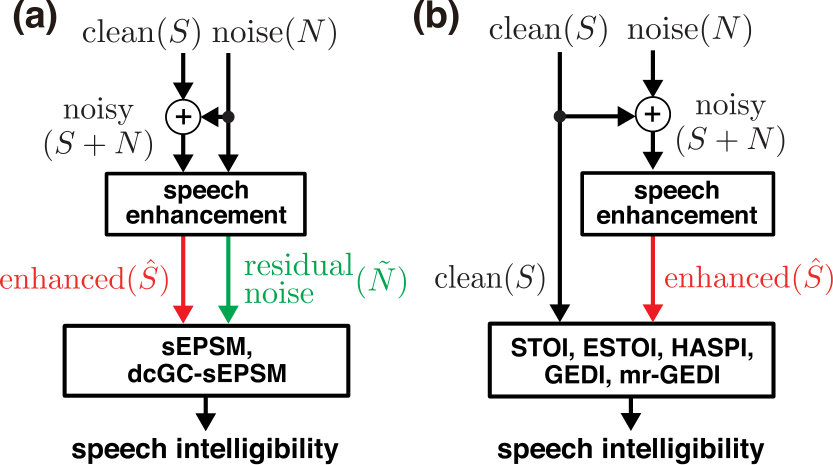 Figure 3
Figure 3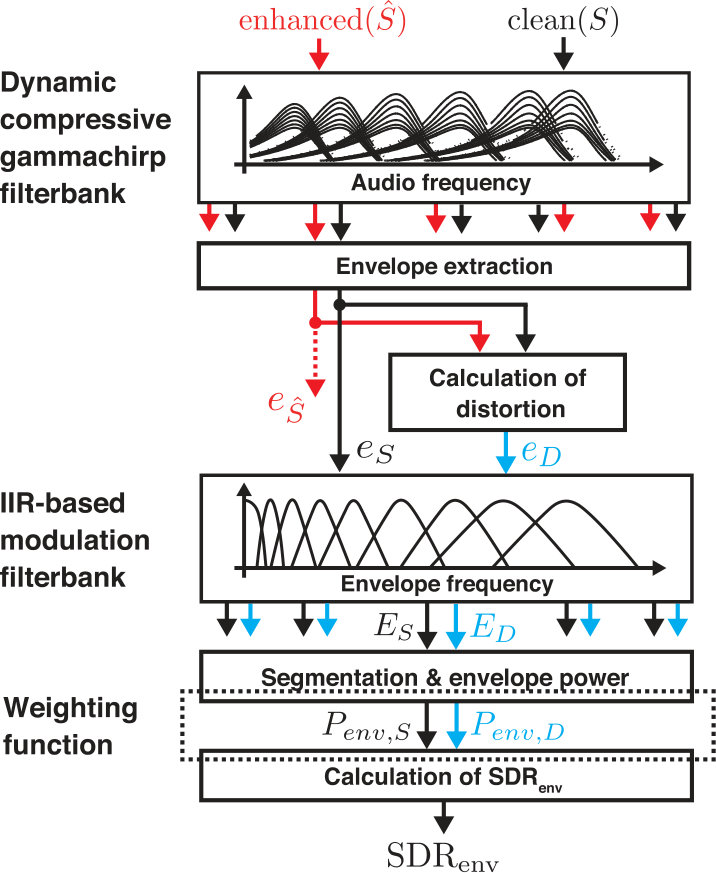 Figure 4
Figure 4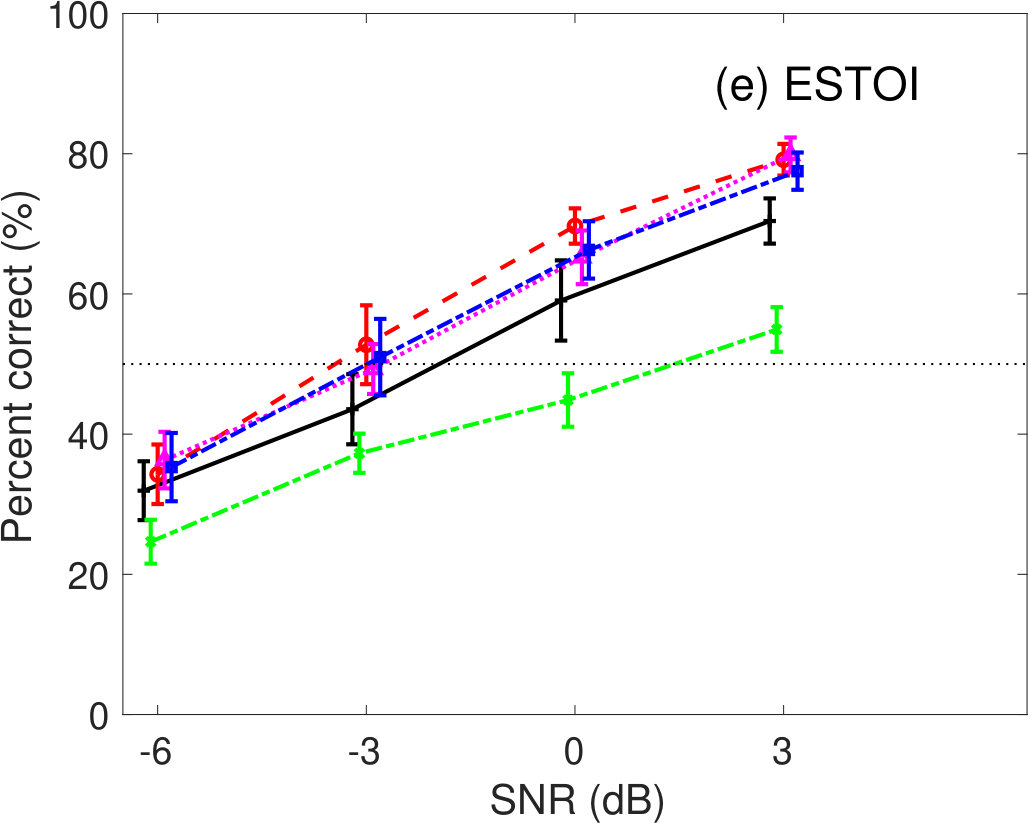 Figure 5
Figure 5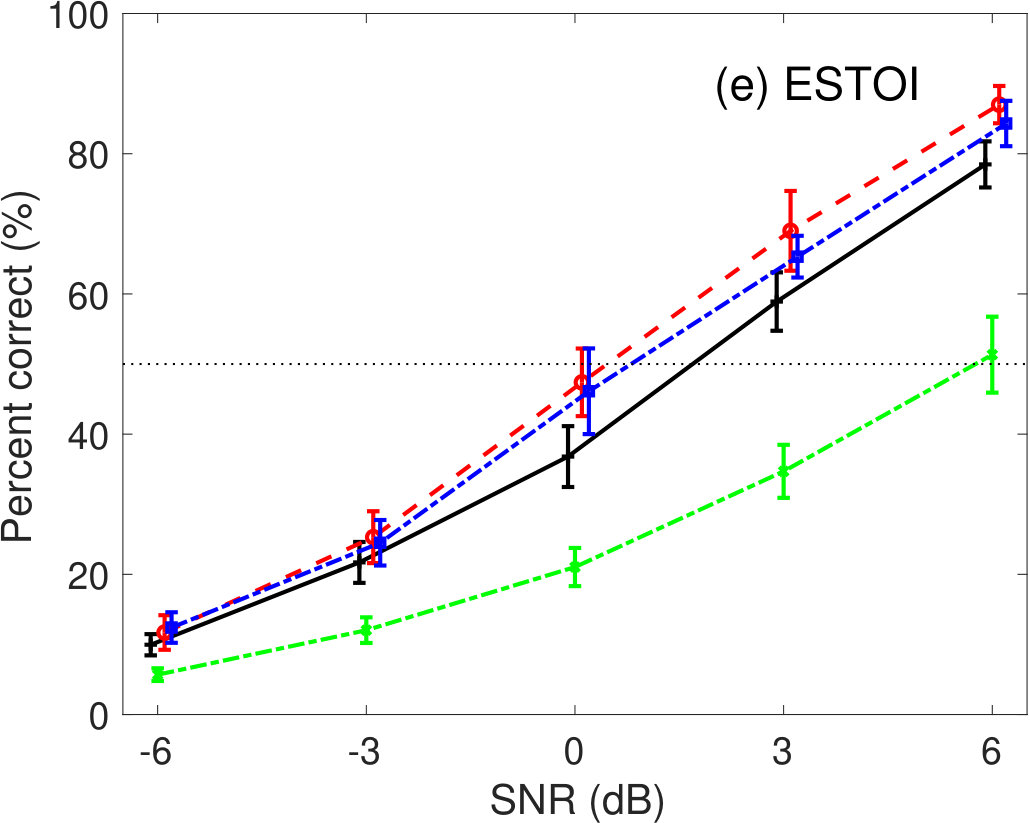 Figure 6
Figure 6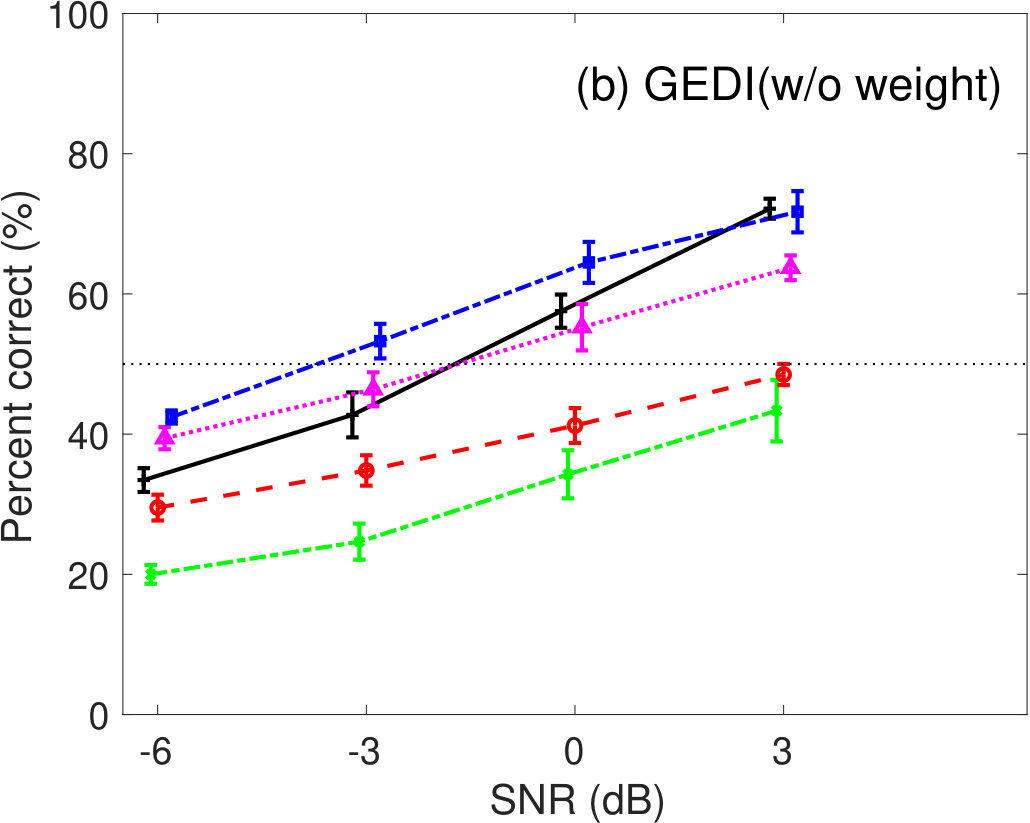 Figure 7
Figure 7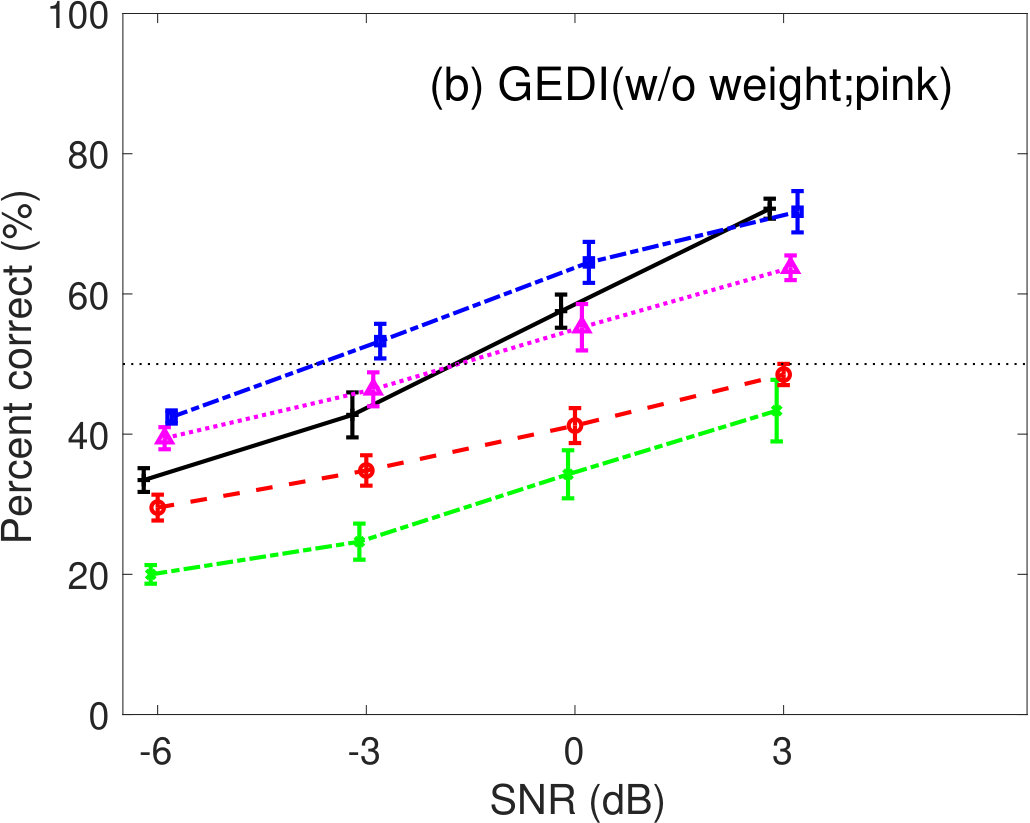 Figure 8
Figure 8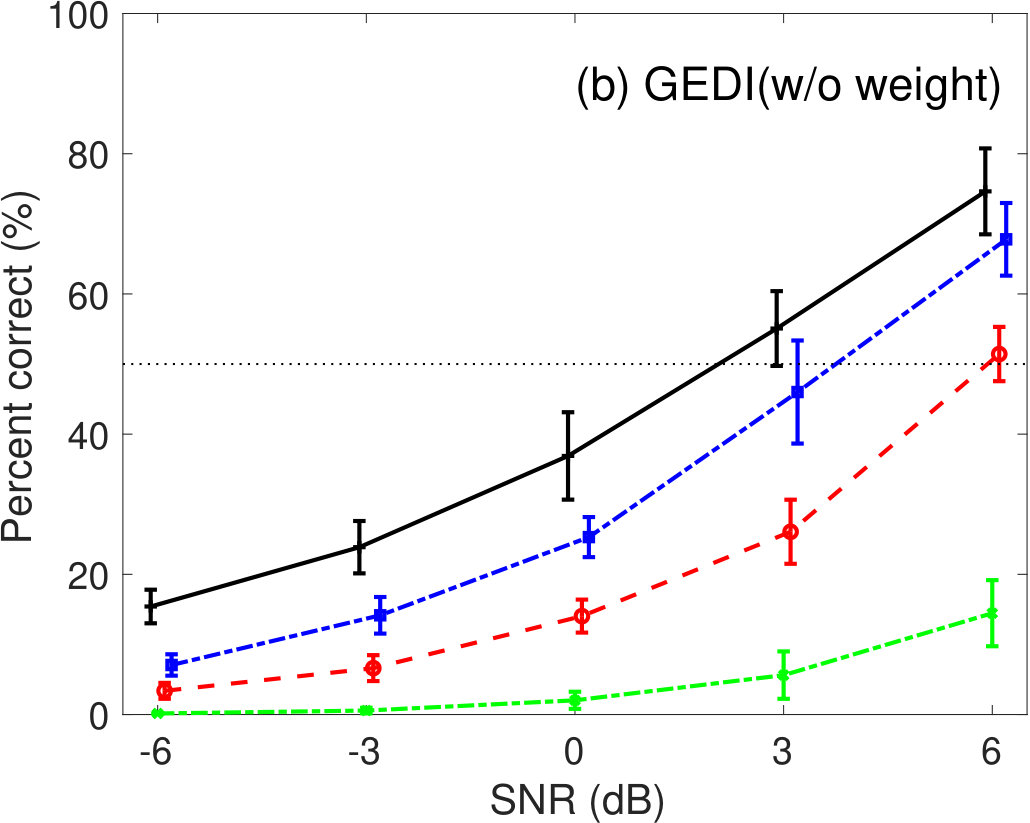 Figure 9
Figure 9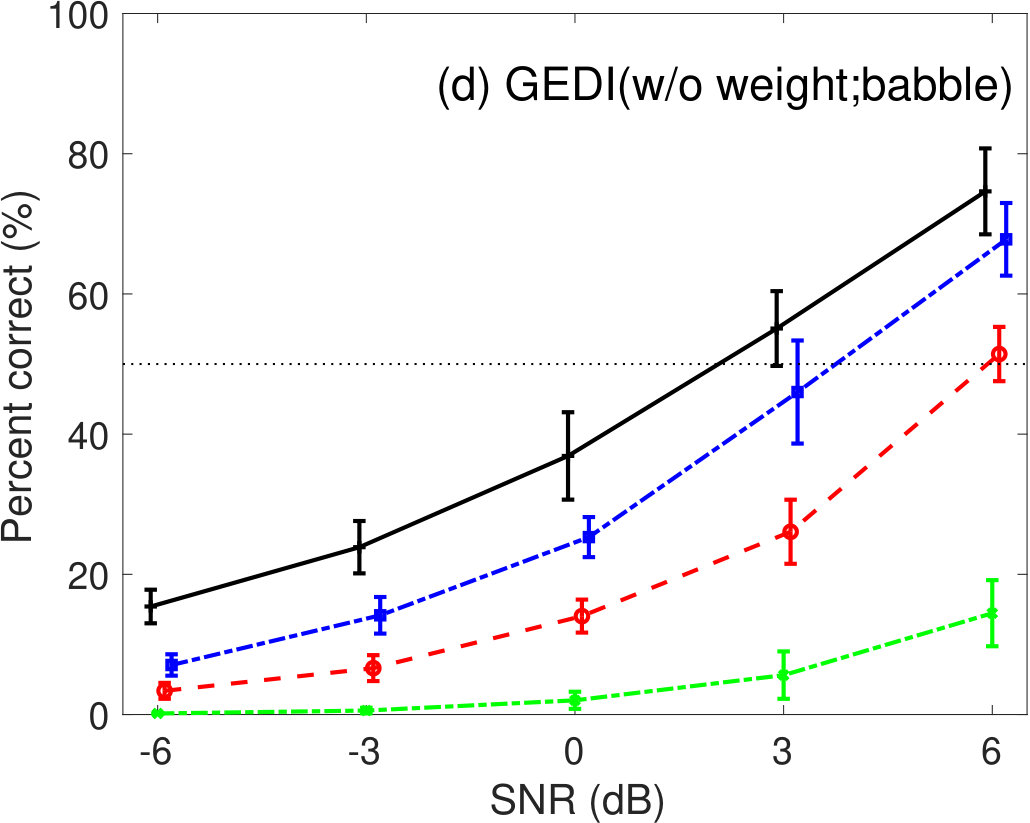 Figure 10
Figure 10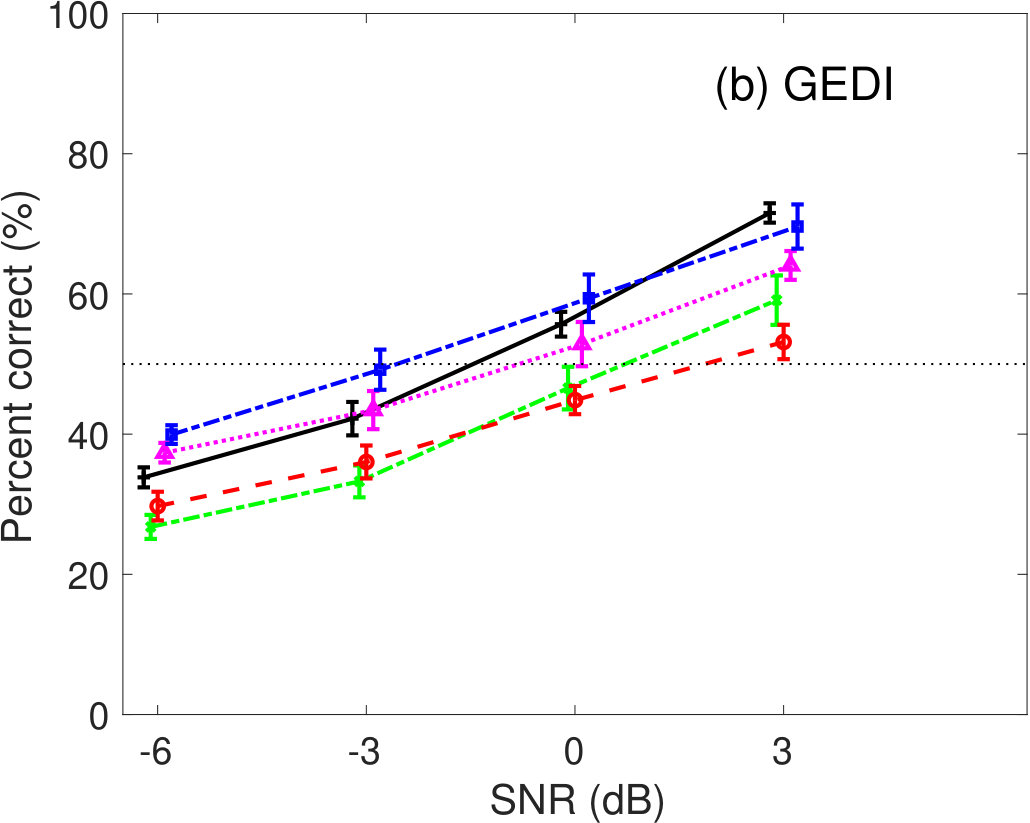 Figure 11
Figure 11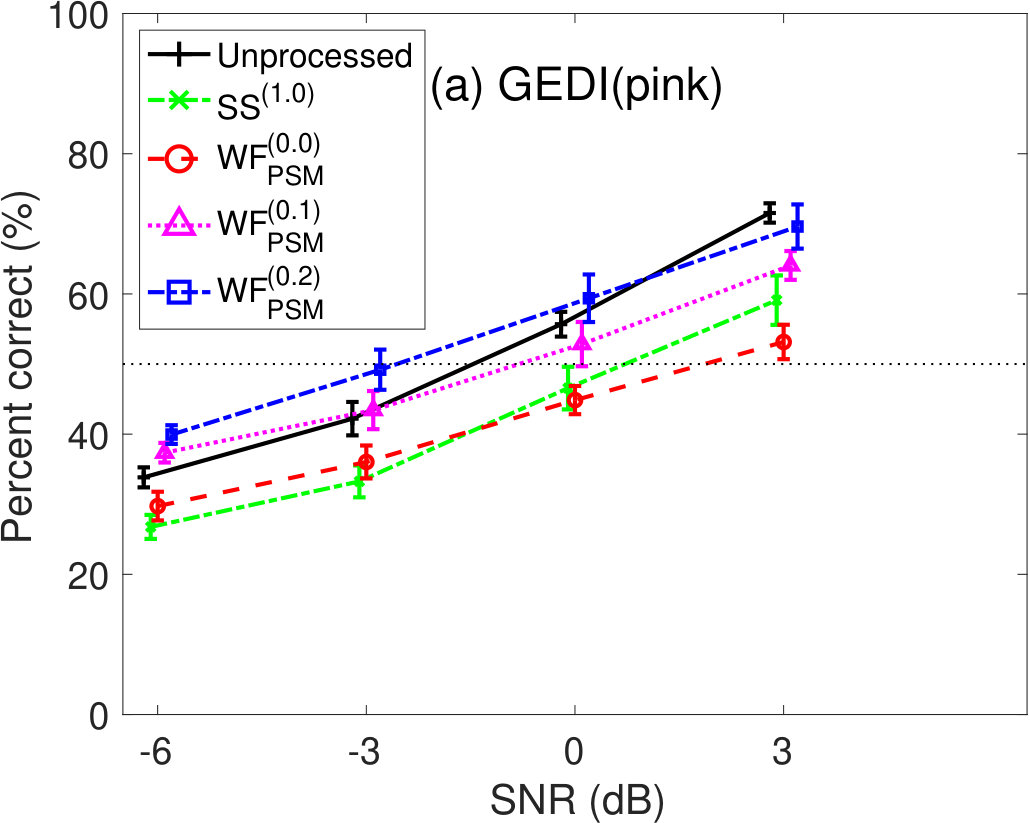 Figure 12
Figure 12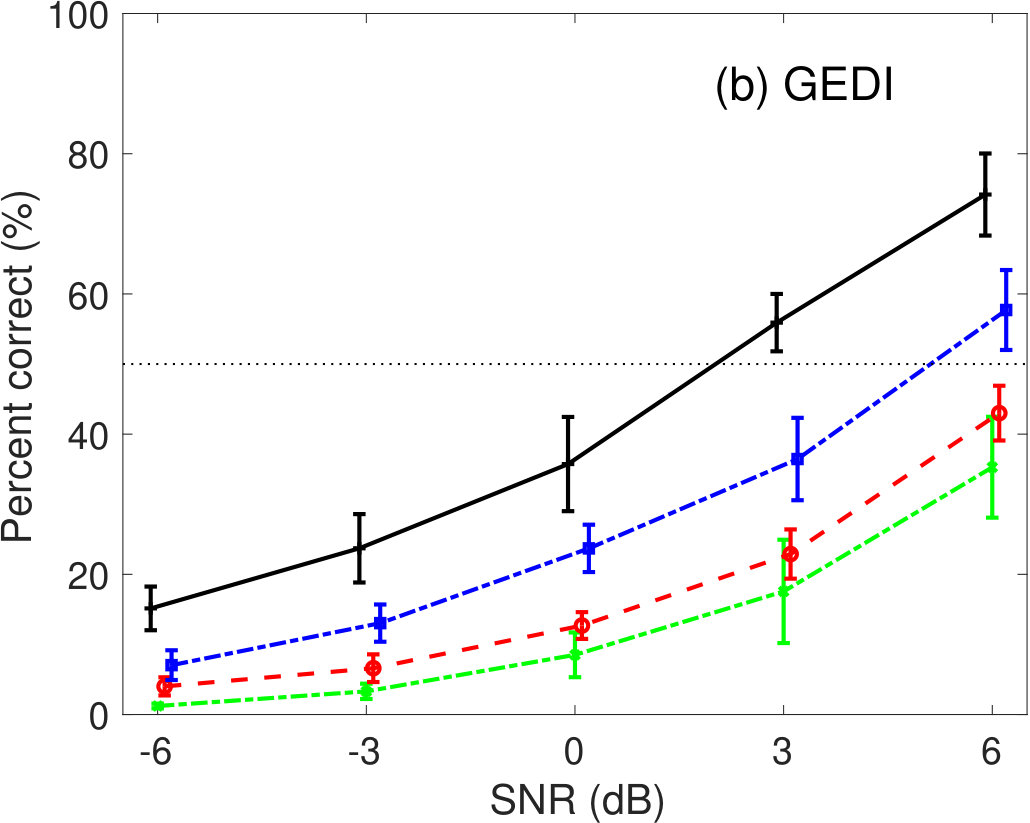 Figure 13
Figure 13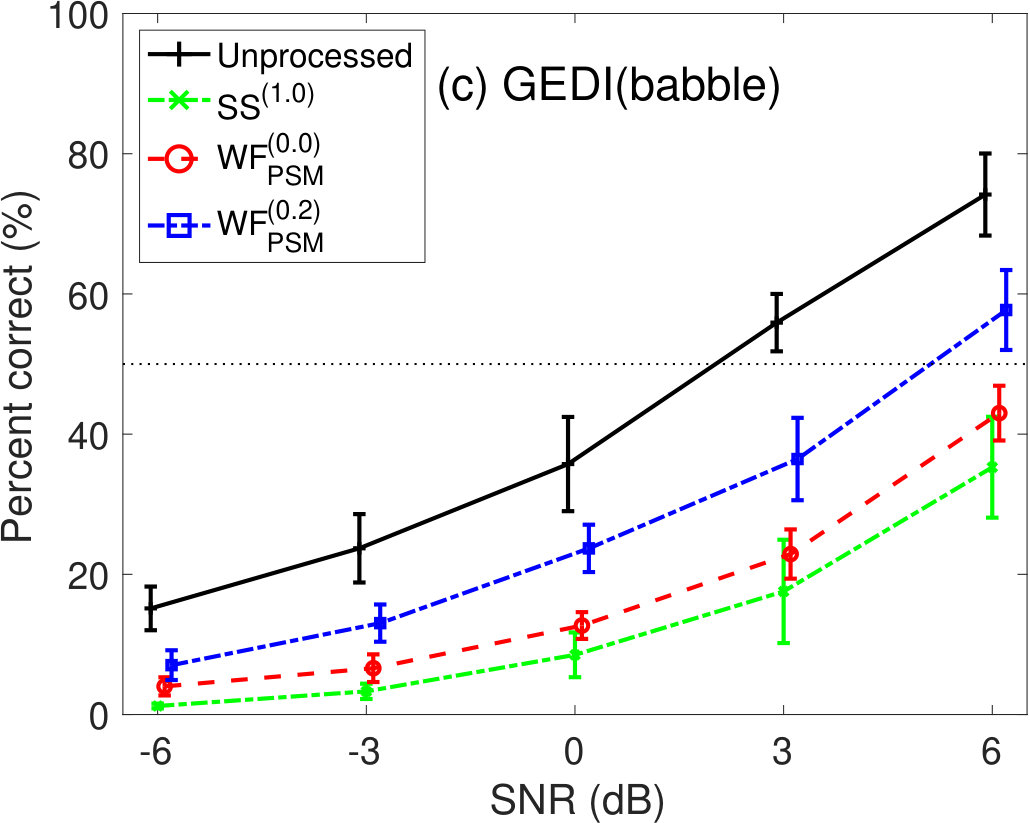 Figure 14
Figure 14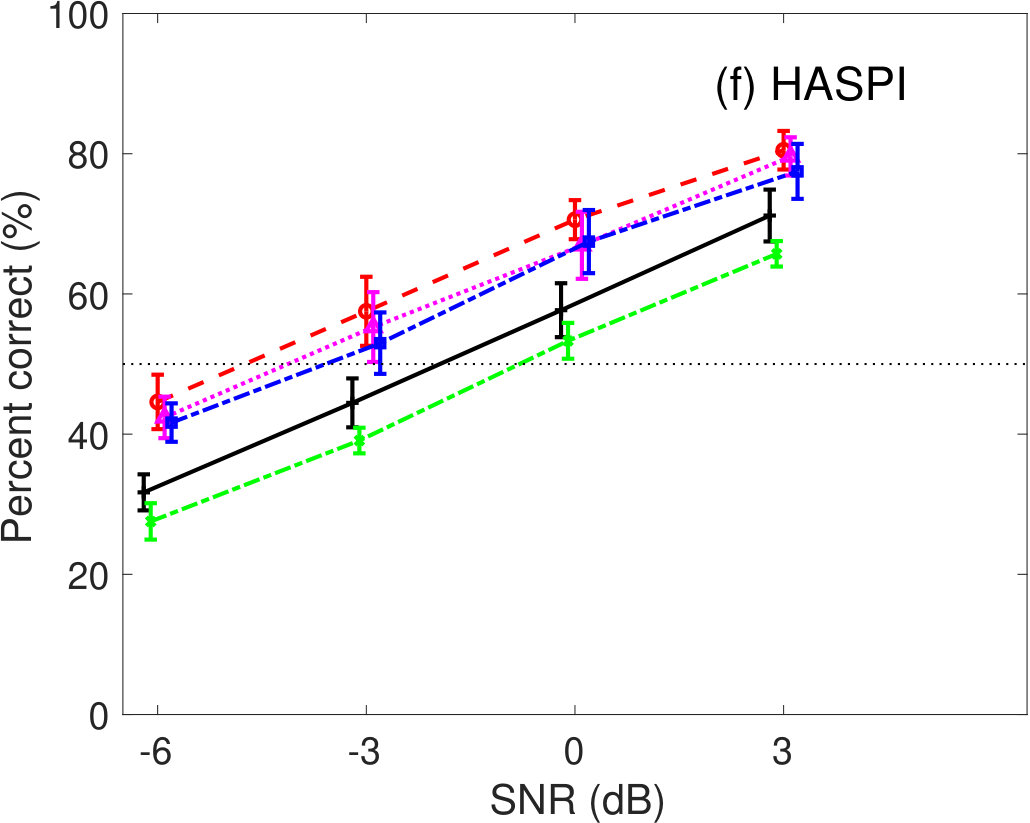 Figure 15
Figure 15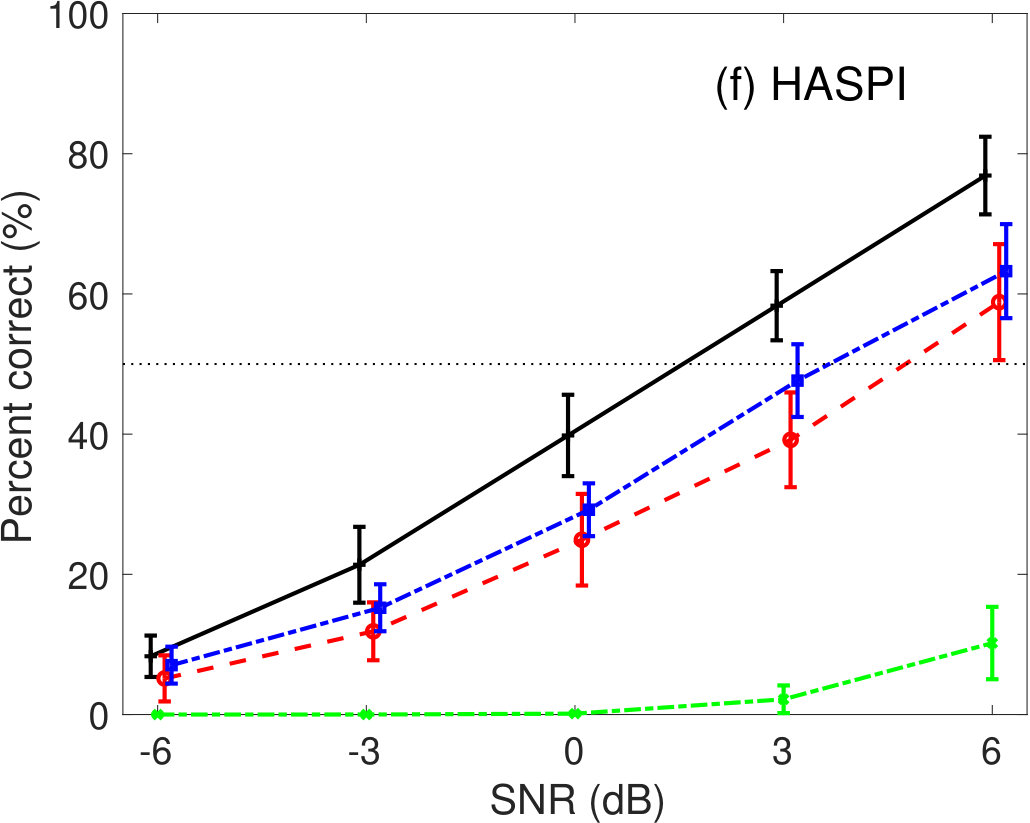 Figure 16
Figure 16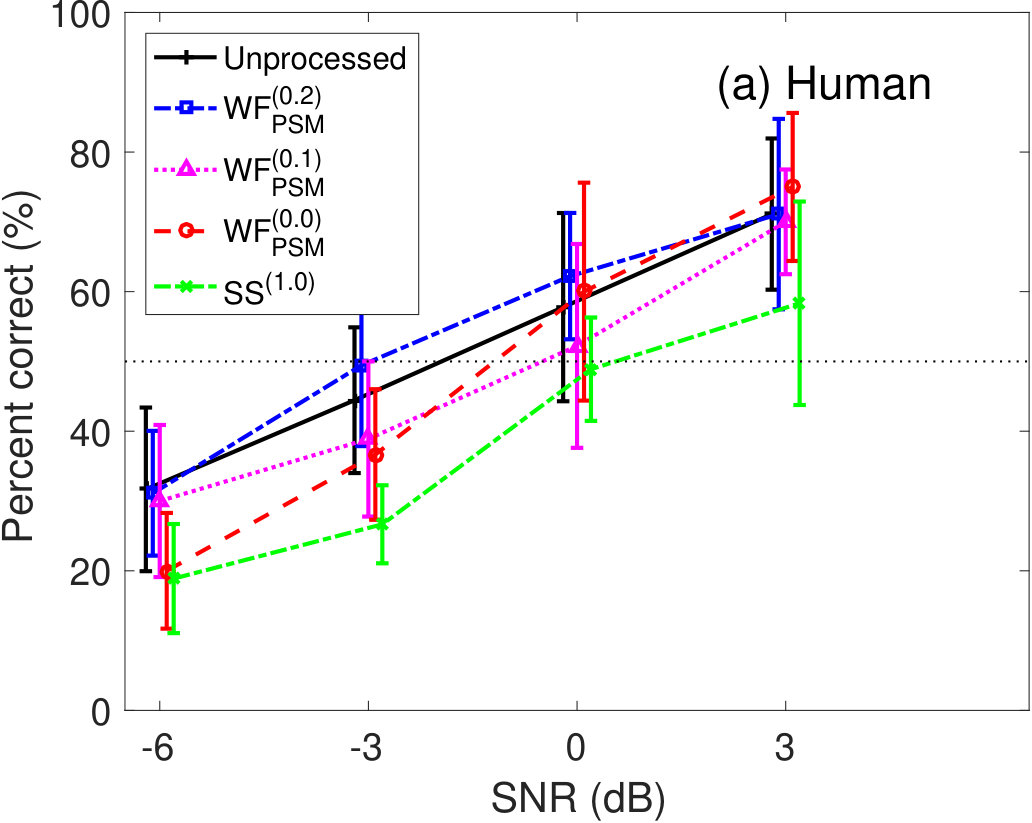 Figure 17
Figure 17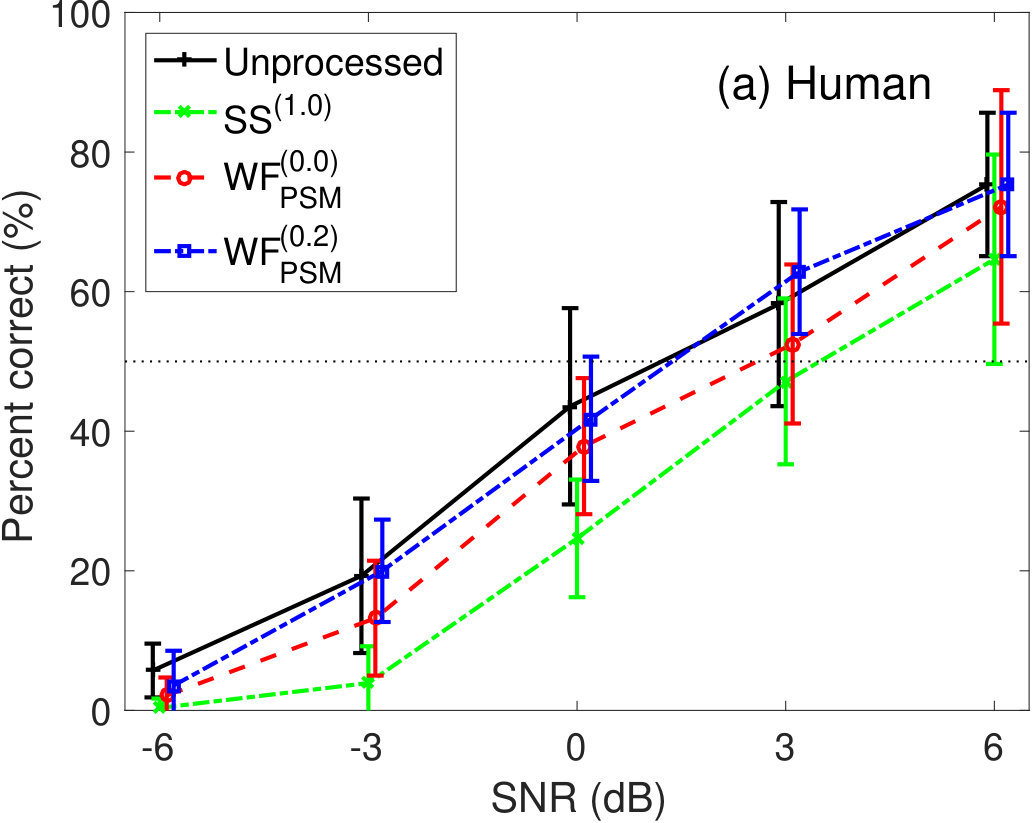 Figure 18
Figure 18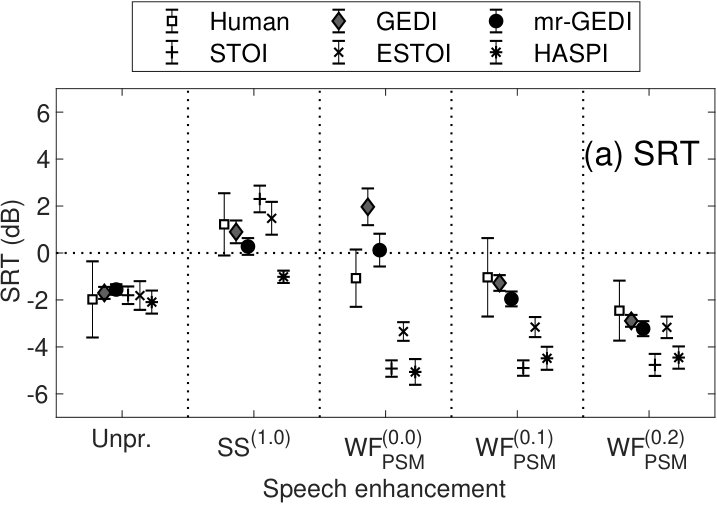 Figure 19
Figure 19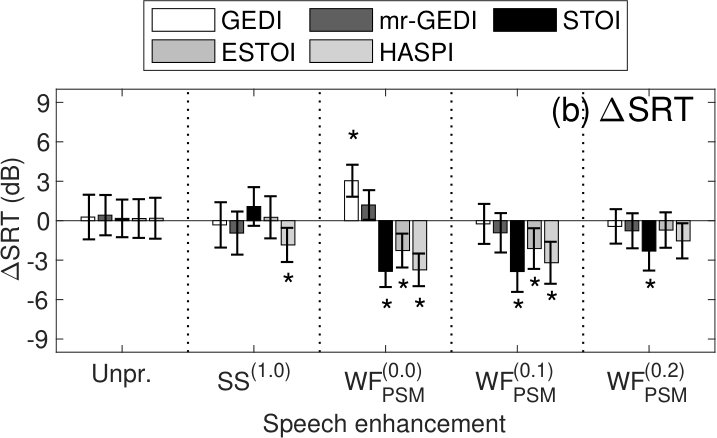 Figure 20
Figure 20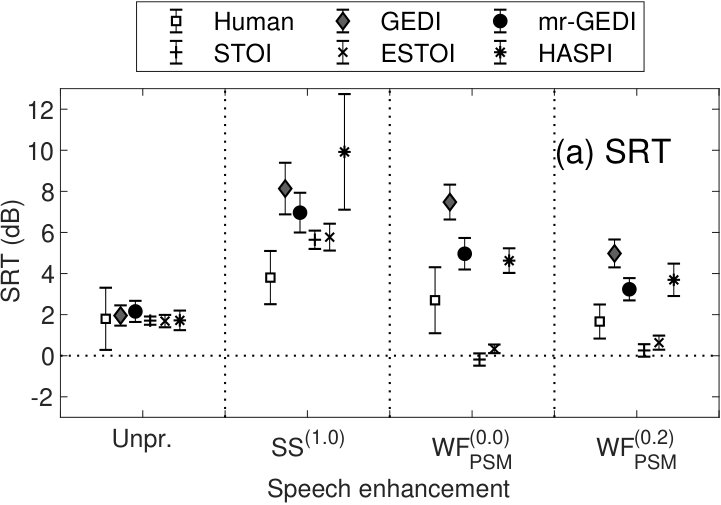 Figure 21
Figure 21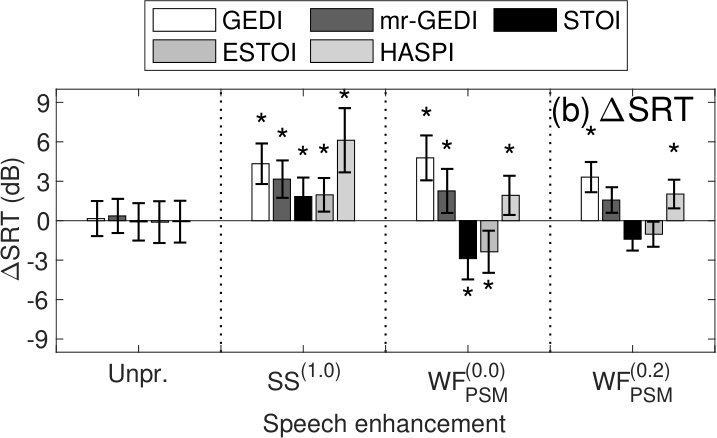 Figure 22
Figure 22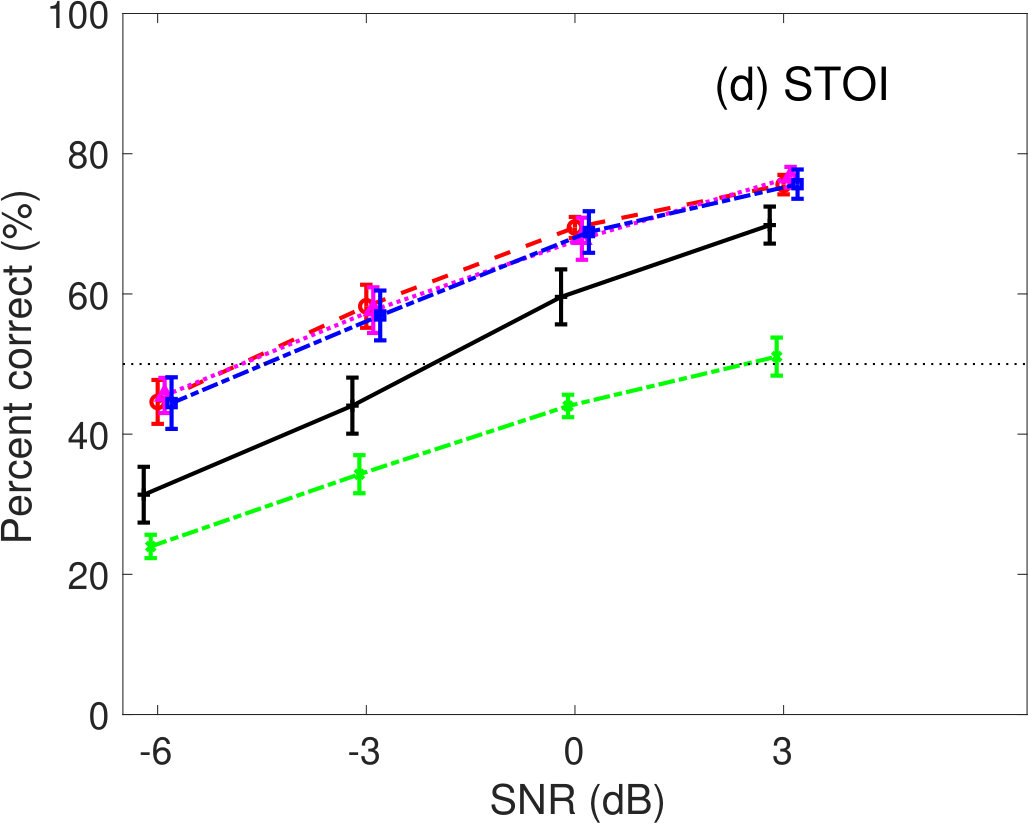 Figure 23
Figure 23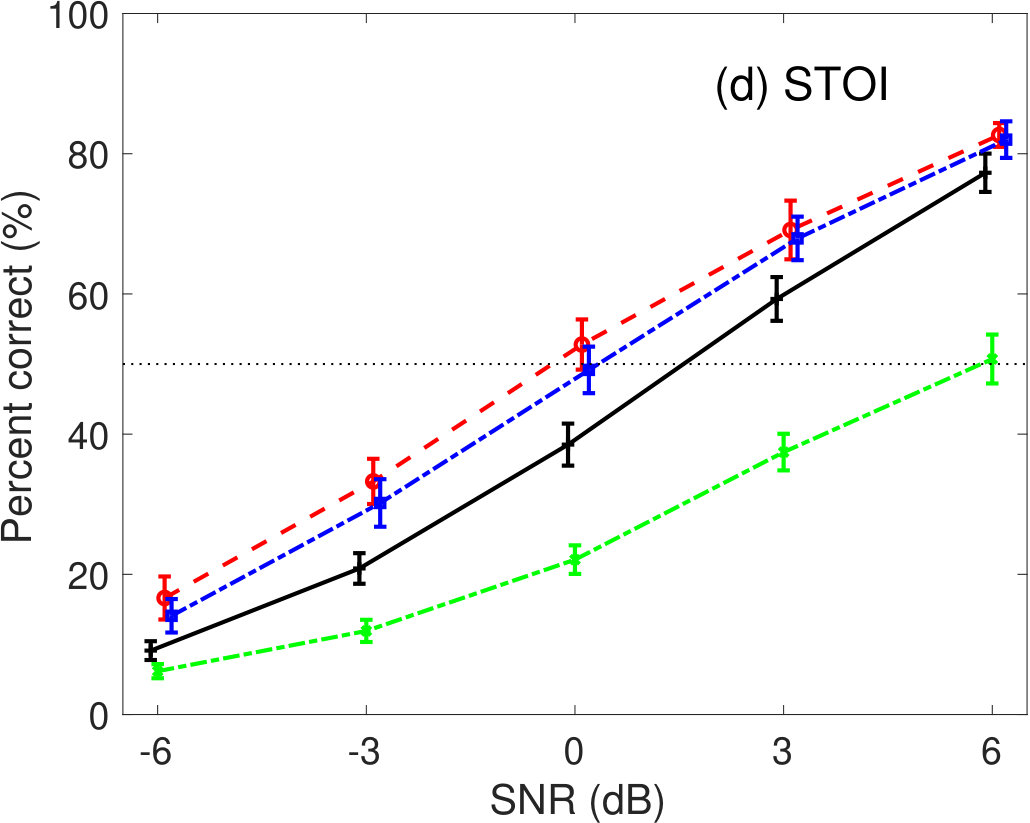 Figure 24
Figure 24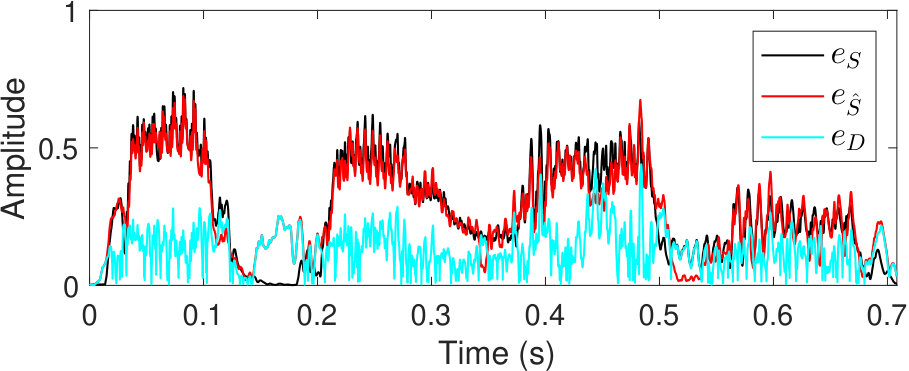 Figure 25
Figure 25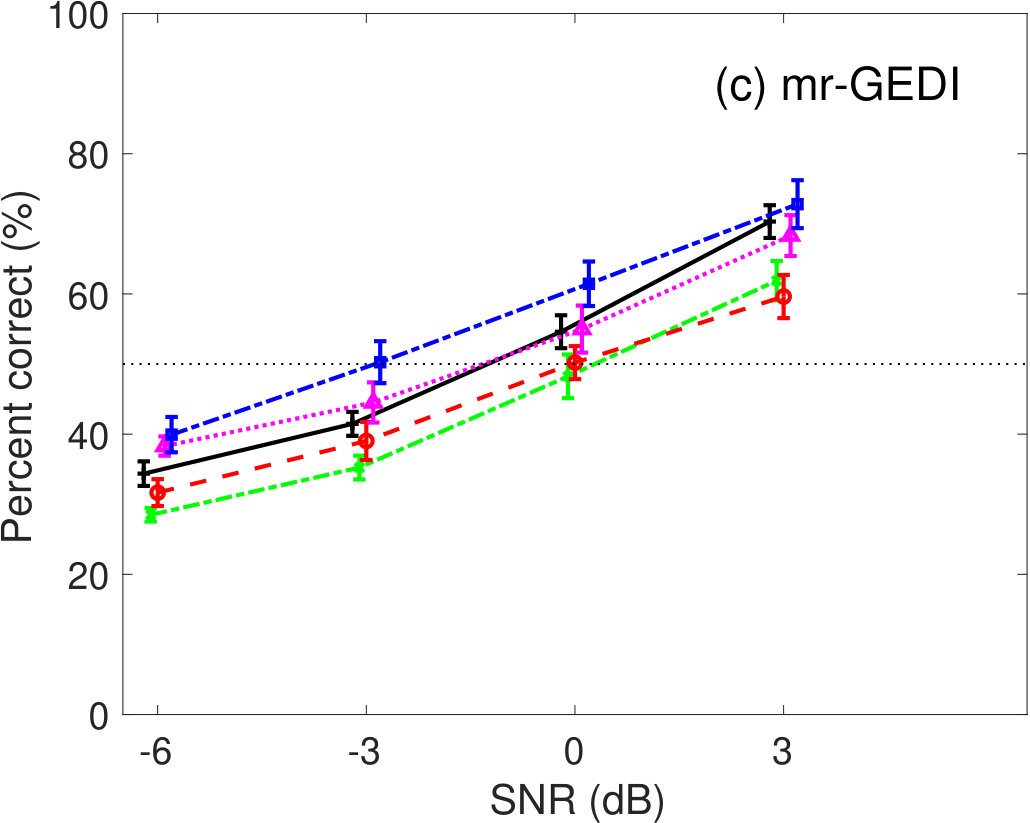 Figure 26
Figure 26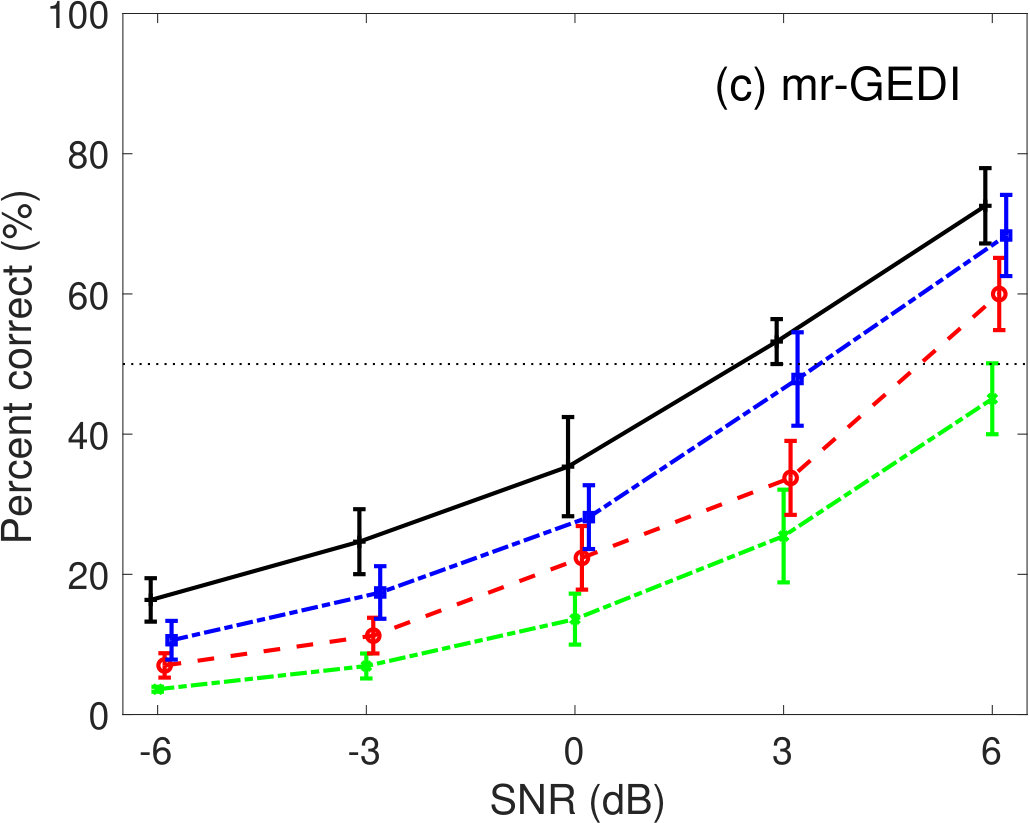 Figure 27
Figure 27
|
|
|
|
|||||||||
| Pink | ||||||||||||
| Babble |
| pink noise | babble noise | |||||
| GEDI | , | , | ||||
| mr-GEDI | , | , | ||||
| STOI | , | , | ||||
| ESTOI | , | , | ||||
| HASPI |
|
|
| GEDI | mr-GEDI | STOI | ESTOI | HASPI | |
|---|---|---|---|---|---|
| 10.8 | 10.9 | ||||
| 15.1 | 15.9 | ||||
| 11.4 | 11.1 | ||||
| 10.7 | 10.4 | 10.7 |
| Human | GEDI | mr-GEDI | STOI | ESTOI | HASPI | |
|---|---|---|---|---|---|---|
| -13.0 | -10.8 | |||||
| -9.9 | -5.1 | |||||
| -1.4 | 1.3 | |||||
| 5.9 | 6.3 |
| GEDI | mr-GEDI | STOI | ESTOI | HASPI | |
|---|---|---|---|---|---|
| 13.4 | 13.4 | ||||
| 16.8 | 15.7 | ||||
| 12.0 | 11.3 |
| Human | GEDI | mr-GEDI | STOI | ESTOI | HASPI | |
|---|---|---|---|---|---|---|
| -15.3 | -16.2 | |||||
| -13.6 | -12.9 | |||||
| -6.0 | 5.4 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
GEDI: Gammachirp Envelope Distortion Index for Predicting Intelligibility of Enhanced Speech
Katsuhiko Yamamoto
Toshio Irino
Shoko Araki
Keisuke Kinoshita
Tomohiro Nakatani
Graduate School of Systems Engineering, Wakayama University, Sakaedani 930, Wakayama, Wakayama 640–8510, Japan
NTT Communication Science Laboratories, 2-4 Hikaridai, Seika-cho, Soraku-gun, Kyoto 619–0237, Japan
Abstract
In this study, we propose a new concept, the gammachirp envelope distortion index (GEDI), based on the signal-to-distortion ratio in the auditory envelope, , to predict the intelligibility of speech enhanced by nonlinear algorithms. The objective of GEDI is to calculate the distortion between enhanced and clean-speech representations in the domain of a temporal envelope extracted by the gammachirp auditory filterbank and modulation filterbank. We also extend GEDI with multi-resolution analysis (mr-GEDI) to predict the speech intelligibility of sounds under non-stationary noise conditions. We evaluate GEDI in terms of the speech intelligibility predictions of speech sounds enhanced by a classic spectral subtraction and a Wiener filtering method. The predictions are compared with human results for various signal-to-noise ratio conditions with additive pink and babble noises. The results showed that mr-GEDI predicted the intelligibility curves better than short-time objective intelligibility (STOI) measure, extended-STOI (ESTOI) measure, and hearing-aid speech perception index (HASPI) under pink-noise conditions, and better than HASPI under babble-noise conditions. The mr-GEDI method does not present an overestimation tendency and is considered a more conservative approach than STOI and ESTOI. Therefore, the evaluation with mr-GEDI may provide additional information in the development of speech enhancement algorithms.
keywords:
Speech intelligibility; Objective measure; Speech enhancement
††journal: Speech Communication
1 Introduction
The development of objective speech intelligibility and quality measures is essential for speech communication technologies, such as assistive listening devices (e.g., smart headphones and hearing aids) [Falk et al., 2015]. International standards of objective intelligibility measures (OIM), the speech intelligibility index (SII) [ANSI S3-5, 1997], and the speech transmission index (STI) [ISO 9921, 2003] have been proposed to evaluate speech transmission qualities of public spaces and telecommunication lines assumed to be linear transmission systems. However, SII and STI cannot account for the effects of nonlinear processing, including noise reduction and speech-enhancement algorithms. For example, it was reported that STI failed to predict speech intelligibility of enhanced speech processed by a simple spectral subtraction (SS) algorithm [Jørgensen & Dau, 2011]. For the above reasons, the evaluation methodology of speech intelligibility still involves subjective listening tests. However, many noise reduction and speech-enhancement algorithms have been developed thus far without properly designed subjective listening tests evaluation.
1.1 Objective intelligibility measures for speech enhancement
To solve these problems, several human auditory-based models have been proposed. Rhebergen & Versfeld [2005] extended SII using short-time calculations of signal-to-noise ratios (SNRs) in the spectral domain. Kates & Arehart [2005] replaced the SNR with a signal-to-distortion ratio (SDR), calculated from the magnitude-squared coherence function using cross-spectrum between clean speech () and enhanced speech (). This method was referred to as the coherence speech intelligibility index (CSII). Cooke [2006] proposed the “glimpsing model” in human auditory models, which calculates local SNRs of spectro-temporal excitation patterns in the time-frequency domain.
Whereas the above models calculated indices in the spectral domain, there were alternative OIMs based on the calculation in the envelope modulation domain. They also used correlation analysis or SNR. Taal et al. [2011] proposed a short-time objective intelligibility (STOI) measure, which has often been used in evaluations of speech enhancement algorithms. STOI is based on the cross-correlation between the temporal envelopes of clean speech () and enhanced speech () at the output of a 1/3-octave filterbank. STOI assesses the intelligibility of speech processed by ideal time-frequency segregation (ITFS) [Kjems et al., 2009] and minimum mean-squared error estimate of short-time spectral amplitude algorithms [Ephraim & Malah, 1985, Erkelens et al., 2007]. STOI was evaluated under speech-shaped noise (SSN), cafeteria noise, noise from a bottling factory hall and noise conditions of the interior of a car [Taal et al., 2011]. Jensen & Taal [2016] proposed an extended version of STOI to account for highly modulated masker conditions, where STOI could not capture the spectral and temporal correlations of speech from the noise. Extended STOI (ESTOI) calculates the index from the spectral correlation of sub-band envelopes, whereas the original STOI calculated it directly from temporal correlations. It was reported that ESTOI demonstrated a performance comparable to STOI and also showed an overall improved prediction performance under the conditions of temporally modulated maskers [Dreschler et al., 2001, Gustafsson & Arlinger, 1994] and recorded noise in the Noisex corpus [Varga & Steeneken, 1993] and ICRA noises [Dreschler et al., 2001], where STOI did not perform well.
Kates & Arehart [2014] proposed a hearing-aid speech perception index (HASPI) for hearing-impaired (HI) and normal-hearing (NH) listeners as an extension of CSII [Kates & Arehart, 2005]. This measure combined two indices: the coherence between the outputs of an auditory filterbank for clean () with enhanced speech () and the cross-correlation between the temporal sequences of the cepstral coefficients of and . HASPI was said to account for nonlinear frequency compression, ITFS processing, and noise vocoded speech under multi-talker babble noise and SSN conditions.
Jørgensen & Dau [2011] proposed an alternative SNR-based model, referred to as the speech-based envelope power-spectrum model (sEPSM). sEPSM assumes that speech intelligibility is related to the SNR in the envelope domain, , which originates from , as shown in [Dubbelboer & Houtgast, 2008]. is calculated from the ratios between the envelope powers of the enhanced speech () and the residual noise () in the modulation frequency domain. sEPSM is intended to assess the intelligibility of speech sounds processed by SS. sEPSM was extended to a multi-resolution version to perform more accurate speech intelligibility estimations for speech affected by non-stationary noises [Jørgensen et al., 2013]. Chabot-Leclerc et al. [2014] extended sEPSM with a spectro-temporal receptive field to account for phase jitter [Chi et al., 1999]. sEPSM process is useful for developing a non-intrusive OIM, because sEPSM calculates the index without using an original clean signal. Santos et al. [2014] proposed a non-intrusive OIM to predict speech intelligibility in reverberant environments using the gammatone filterbank and the modulation filterbank. This is the speech-to-reverberation modulation ratio (SRMR) metric in which speech energy at low modulation frequencies related to speech information is separated from noise and distortion components on high modulation frequencies.
To incorporate characteristics of a human auditory filter, Yamamoto et al. [2019] extended sEPSM using a dynamic compressive gammachirp filterbank (dcGC-FB) [Irino & Patterson, 2006], in which the level-dependent frequency selectivity and gain of the auditory filter were reasonably determined by the data obtained from psychoacoustic masking experiments [Patterson et al., 2003]. For OIMs, it is important to introduce the appropriate level dependency to incorporate the well-known fundamental knowledge that speech intelligibility is lower as sound level decreases and that peripheral hearing loss decreases the intelligibility. Most of the existing OIMs, except for HASPI, use linear frequency analysis, which does not account for this factor. This model is referred to as dcGC-sEPSM, which predicted the human results of the Wiener filtering more accurately than the original sEPSM [Jørgensen & Dau, 2011], CSII [Kates & Arehart, 2005], STOI [Taal et al., 2011], and HASPI [Kates & Arehart, 2014].
The -based OIMs (i.e., sESPM and dcGC-sEPSM) present fundamental limitations. As shown in Fig. 1(a), the -based OIMs also require the residual noise (), estimated by a speech-enhancement algorithm. The definition of the residual noise was, however, not entirely clarified in the original article [Jørgensen & Dau, 2011]. This is an issue for most speech-enhancement algorithms, including recent non-linear speech-enhancement algorithms [Fujimoto et al., 2012, Weninger et al., 2014, Smaragdis & Venkataramani, 2017], because there are different techniques to estimate the residual noise as described in A. Therefore, the -based OIM approaches are restricted to speech enhancement algorithms (i.e., SS), which can estimate the residual noise uniquely and properly.
In many applications, it is preferable to use non-intrusive OIMs that do not use a reference signal. Yet, the prediction accuracy for speech-enhancement algorithms is still worse than that of intrusive OIMs [Falk et al., 2015]. A current alternative and practical choice is to use a clean signal as a reference, as shown in Fig. 1(b). As described above, there are several correlation-based OIMs, such as STOI, ESTOI, and HASPI.
The objective of this study is to develop a new OIM, based on a reliable level-dependent auditory filterbank. The developed OIM is designed to predict the speech intelligibility for NH listeners at moderate sound pressure levels (SPLs) with higher or comparable performance levels to the current OIM. The new OIM should have advantageous aspects and serve as a reliable base for future studies on speech intelligibility prediction for HI listeners or in conditions with a wide range of SPLs.
1.2 Proposed methods
In this paper, we demonstrate a new OIM called “gammachirp envelope distortion index (GEDI),” which calculates the signal-to-distortion ratio in the envelope domain () and uses clean speech () as the reference signal, as shown in Fig. 1(b). The internal representations in the proposed model are similar to those of dcGC-sEPSM and original sEPSM, which use . GEDI was initially proposed by Yamamoto et al. [2017] and evaluated under pink background-noise conditions. After preliminary experiments, GEDI was extended to include a weighting function to compensate for the envelope power across auditory filter channels. The unreported effect is presented here. Extended experiments were also performed to predict speech intelligibility under non-stationary, babble-noise conditions. The poor results urged us extend GEDI to a multi-resolutional version to improve predictability [Yamamoto et al., 2018].
In this paper, we thoroughly explain GEDI and mr-GEDI and perform experiments using speech intelligibility predictions. The prediction results of GEDI, STOI [Taal et al., 2011], ESTOI [Jensen & Taal, 2016], and HASPI [Kates & Arehart, 2015] are compared to human results by using speech materials produced by two speech-enhancement algorithms under pink- and babble-noise conditions.
In Section 2, we provide an overview of GEDI and mr-GEDI. In Sections 3 and 4, we describe the speech materials and experimental conditions of the evaluation, respectively. In Section 5, prediction results and human results are compared. In Section 6, some aspects of model development are discussed.
2 Proposed OIMs: GEDI and mr-GEDI
2.1 GEDI
Figure 2 shows a block diagram of GEDI. The input sounds to GEDI include enhanced speech () and clean speech (). The objective of GEDI is to calculate the distortion between the temporal envelopes of the clean and enhanced speech from the outputs of an auditory filterbank. We hypothesize that speech intelligibility becomes increasingly degraded as the temporal envelopes of the enhanced speech diverge from those of clean speech.
2.1.1 Auditory filterbank
The first stage is an auditory spectral analysis using dcGC-FB 111MATLAB code for the dcGC-FB is available in the GitHub repository [Irino & Yamamoto, 2019]. [Irino & Patterson, 2006], which has a number of 100 channels equally spaced along the -number [Moore, 2013] and covers the speech range between 100 and 6,000 Hz. This is the same as in with dcGC-sEPSM. The merit of dcGC-FB is that parameter values can also be estimated from psychoacoustic experiments of elderly listeners [Matsui et al., 2016] and NH listeners [Patterson et al., 2003]. Although NH parameters are used in this paper, they can be extended in that direction in the future.
Figures 3(a) and (b) show examples of auditory spectrograms of enhanced () and clean-speech signals (). The auditory filter changes the gain and bandwidth in accordance with the input level. Therefore, the dcGC-FB is carefully set to correspond to the SPL used for subjective listening experiments. With GEDI, the reference signal () and the test signal () are normalized to have the same SPL.
2.1.2 Distortion in the temporal envelope domain
The temporal envelopes of the enhanced () and clean speech () are calculated from the output of the individual auditory filter using a Hilbert transform and a low-pass filter with a cutoff frequency of 150 Hz. The absolute difference between the two power envelopes is calculated to determine the temporal “envelope distortion (),” as follows:
[TABLE]
where is the index of the dcGC-FB channel, is the total number, and is the sample number of the temporal envelope. Here, is a constant; we set this number as . Thus, the envelope distortion, , represents these differences as absolute values. Figure 3(c) shows an example of envelopes, and , and distortion, , calculated using Eq. 1. The use of the enhancement algorithms causes the envelope of the enhanced speech to either be emphasized or degraded relative to that of clean speech. The temporal envelope of the enhanced speech differs from that of clean speech. A new working hypothesis introduced by GEDI is that the envelope distortion, calculated by Eq. 1, is negatively correlated to speech intelligibility [Yamamoto et al., 2017, 2018]. That is, the relative distortion power is strongly related to speech intelligibility as speech intelligibility decreases when the power of the envelope distortion increases and vice versa.
2.1.3 in the envelope modulation domain
The modulation spectra of the envelope distortion () and the envelope of the clean speech () are calculated using the fast Fourier transform (FFT). A bank of modulation filters, defined in envelope frequency domain (), is applied to the spectra. There are seven modulation filters whose power spectra are for the modulation center frequency of , as illustrated in Figure 2 and described in previous studies [Jørgensen & Dau, 2011, Yamamoto et al., 2019]. The envelope power at the output of the modulation filter is calculated as
[TABLE]
where the asterisk () represents either or , and represents the 0-th order coefficient of the FFT (i.e., the direct-current (DC) component of the temporal envelope). Yamamoto et al. [2019] reported that normalization of the in dcGC-sEPSM was effective for speech intelligibility prediction of enhanced speech. The normalization has been inherited by GEDI which has the same filterbank structure as dcGC-sEPSM. The common denominator preserves the difference of levels between modulation components of the reference and enhanced speech sounds. In the original sEPSM [Jørgensen & Dau, 2011], it was assumed that there was internal noise in the modulation domain to restrict the lower limit of . The formula,
[TABLE]
was also used in GEDI. The total number of is 700, because the total number of the dcGC-FB channels, , is 100, and the total number of the modulation filters, , is 7.
The SDR in the modulation frequency domain () is calculated as the ratio of the modulation power spectra of clean speech, , to the distortion, . The individual, , for modulation filter channel, , is defined as the ratio of the powers summed across the dcGC-FB channel, , which can be written as
[TABLE]
where is a weighting function described in next subsection. The total, can be calculated as
[TABLE]
where is the index number of the modulation filter, .
2.1.4 with a weighting function
The weighting function, , in Eq. 4 was introduced to improve speech intelligibility prediction (see B for detail). The envelope power, , in Eq. 2 is proportional to the output power of the dcGC-FB, because it is linearly derived by the FFT and the modulation filterbank, as shown in Fig. 2. The output power of the individual auditory filter is proportional to the rectangular bandwidth, , [Moore, 2013] defined as
[TABLE]
where is the filter-center frequency in Hz, and the bandwidth is roughly proportional to above 500 Hz. Therefore, the average value of increases with the filter frequency. Moreover, the auditory filters in the dcGC-FB are distributed densely along the frequency axis with considerable overlapping, as described in Section 2.1.1.
In the series of studies [Yamamoto et al., 2017, 2018], claimed that the evaluation of speech spectrum uniformly on an -number axis provided better results. Thus, the frequency-dependent level difference must be compensated by a weighting function, , which is inversely proportional to the bandwidth of the filter at frequency , as
[TABLE]
Note that is normalized by at 1,000 Hz, which is near the center of dcGC filter frequencies.
2.1.5 Transformation to speech intelligibility
The following procedure is the same as the one used by the sEPSM algorithm [Jørgensen & Dau, 2011, Yamamoto et al., 2019], except that is used instead of . is converted to a sensitivity index, , of an “ideal observer” with
[TABLE]
where is a constant parameter determined empirically and described subsequently. In practice, they can be tuned such that the predicted speech intelligibility scores for the unprocessed noisy speech sounds approximately coincide with those of the human subjective score. Speech intelligibility as percentage correct, , is predicted from index using a multiple-alternative forced choice (mAFC) model [Green & Birdsall, 1988] with an unequal-variance Gaussian model [Mickes et al., 2007], and can be written as
[TABLE]
where denotes the cumulative normal distribution. The values of and are determined by response-set size, . The value of is fixed at 20,000 as reported in [Yamamoto et al., 2019]. The values of and are determined by Eqs. A1 and A2 from the Appendix of [Jørgensen & Dau, 2011]. The derived values are: and . These values are related to the ability of an ideal observer and are not affected by experimental conditions. The variable of is a parameter related to the redundancy of the speech material (e.g., meaningful sentences or monosyllables) and is determined based on the speech intelligibility experiment. The values of and are explained in Section 4.2.
2.2 Multi-resolution GEDI (mr-GEDI)
GEDI analyzes the modulation spectrum of the whole speech signal at once. Although it would be sufficient for stationary noise, it is difficult to separate the components of speech and non-stationary noise. Therefore, GEDI is extended to use multi-resolutional temporal frames dependent on the modulation frequency at the output of the modulation filterbank. High (low) modulation frequency characteristics are captured with short (long) frame. Such variable-frame processing has been demonstrated as beneficial for speech intelligibility predictions under non-stationary noise conditions [Jørgensen et al., 2013, Rhebergen et al., 2009, Taal et al., 2011].
The main differences between GEDI and mr-GEDI lie in the temporal processing using IIR filters, as described in Section 2.2.2, and segmentation using different frame lengths, as described in Section 2.2.3.
2.2.1 Front-end processing
Figure 4 shows a block diagram of mr-GEDI. The front-end processing, which includes the dcGC-FB, envelope extraction, and calculation of distortion, is common to the original GEDI, as shown in Fig. 2 and as described in Sections 2.1.1, 2.1.2, and 2.1.3.
2.2.2 IIR-based modulation filterbank
Temporal envelopes and distortion are filtered using an IIR-based modulation filterbank that includes a third-order low-pass modulation filter and eight second-order modulation bandpass filters. The octave-frequency space, the range, and the Q-value of the modulation filterbank are the same as in the mr-sEPSM study [Jørgensen et al., 2013].
2.2.3 Segmentation and envelope power
The output of the -th modulation filter channel, , is segmented into multi-resolution frames using a rectangular window without overlap and is denoted as . The duration of the window equals to the inverse of the center frequency of the corresponding modulation filter [Jørgensen et al., 2013]. For example, center frequencies at 2, 4, and 8 Hz, correspond to frame durations of 500, 250, and 125 ms, respectively. It is 1,000 ms for the low pass filter with the cutoff frequency of 1 Hz. Note that the maximum frame duration becomes the signal duration when it is less than 1,000 ms. This frame processing enables us to analyze the components with optimal resolution. The power of each frame, , is calculated from the squared sum of each temporal output of the modulation filterbank:
[TABLE]
where the asterisk () represents components from either the clean speech, “,” or the distortion, “.” is the frame index in the -th modulation filter, and the bar is the average operator over the duration of the input signal. is the sample number of temporal envelopes. The denominator, , in Eq.10 represents the normalization factor obtained using the DC component of the temporal envelope of the enhanced speech, . must be greater than dB (0.001 in linear terms), as suggested by Jørgensen et al. [2013].
2.2.4 Calculation of and speech intelligibility
The SDR in the temporal envelope domain () is calculated as the power ratio between the clean speech () and the distortion signal (). The individual, , for modulation filter channel and frame index is defined as the ratio of the powers summed across the dcGC-FB channel, , and can be written as
[TABLE]
where is a weight function described in section 2.1.4. The values of are averaged over the frames :
[TABLE]
The total is calculated by using Eq. 5, with as the number of modulation filter channels. The in Eq. 12 is transformed into speech intelligibility using Eqs. 8 and 9, which are the same as those used in GEDI.
3 Speech materials for evaluation
3.1 Speech data
Speech sounds made by Japanese 4-mora words spoken by a male speaker (label ID: mis) from a database of familiarity-controlled word lists from 2007 (FW07) [Kondo et al., 2007], used for subjective listening experiments and objective evaluations. The database comprises several word-familiarity ranks corresponding to the degree of lexical information. Speech sounds were obtained from the set having the lowest familiarity to prevent listeners from complementing answers with guesses. The dataset contains 400 words per single familiarity, and the average duration of a 4-mora word is approximately 700 ms. The sampling frequency of original speech sounds in the database is 48,000 Hz. The sounds are down-sampled to 16,000 Hz to remain consistent with the sampling frequency of speech-enhancement algorithms, used in the evaluation as described in Section 3.3.
3.2 Noise conditions
Pink noise and babble noise are used for the subjective listening experiments and objective predictions. Each noise is added to the clean speech to obtain noisy speech sounds, referred to as “unprocessed.” The babble noise has a temporal fluctuation in power preventing the perception of individual speech. A speech-babble noise is generated from the corpus of spontaneous Japanese (CSJ) data [Furui et al., 2000, Maekawa, 2003], generated as follows: 8-min sections randomly extracted from each file, all superimposed as babble noise. We mixed speech signals of 32 speakers after concatenating the sentences into a single-track sound. 32 was chosen so that verbal information of individual speech would not be discerned, and that the mixed sound would not be a steady noise.
Pink and babble noises were extracted from a random starting point before adding them to speech sounds. When making noise speech, we randomly cut out the start point from the noise, and the length is adjusted to the original speech sound. The SNR conditions range from to dB in -dB steps for pink-noise conditions, and from to dB for babble-noise conditions.
3.3 Speech-enhancement algorithms
In this study, we applied two speech enhancement algorithms to the unprocessed sounds. The first one was a simple SS algorithm [Berouti et al., 1979], used to ensure consistency with the method previously used to evaluate the original sEPSM method [Jørgensen & Dau, 2011]. The second one was a Wiener filter (WF)-based algorithm. It is commonly used in various systems because of its effectiveness with low computational costs. The WF achieves speech enhancement by changing signal gains adaptively in the time-frequency bins. As the characteristics of signals enhanced by the SS and the WF are substantially different, it is essential to investigate the difference between speech intelligibility predictions when using the two methods. In our experiments, we used a pre-trained speech model (PSM) based approach [Fujimoto et al., 2012] for estimating WF. The WF algorithm using the PSM is referred to as .
3.3.1 Spectral subtraction
The amplitude spectrum of clean speech, , was estimated using SS [Berouti et al., 1979], defined as:
[TABLE]
where represents the noise power spectrum () estimated from a non-speech segment, and is the power spectrum of noisy speech (). The parameter, , denotes the over-subtraction factor, (), and denotes the spectral flooring parameter, . The over-subtraction factor, , for the SS was fixed at 1.0 as a reference condition for comparison with the results presented in [Jørgensen & Dau, 2011]. We calculated the power and phase spectra using a short-time Fourier transform with a -point Hanning window and a % frame shift at a sampling frequency of 16,000 Hz. This method is referred to as “.”
3.3.2 Wiener filter with pre-trained speech model
The used in this study was estimated using a PSM of the clean speech and noise [Fujimoto et al., 2009, 2012]. The PSM is defined as a Gaussian mixture model defined in the Mel-spectrum domain using a VTS-based model combination algorithm. This algorithm can estimate the speech component of noisy speech based on the PSM, which represents the statistical distribution of the spectral features of clean speech. The PSM was trained using a large speech database comprising more than 30,000 sentences spoken by 180 speakers taken from the CSJ database [Furui et al., 2000, Maekawa, 2003]. In this evaluation, we used a PSM with a 24-channel Mel-filterbank and set the number of Gaussian mixture components for speech and noise to 64 and 1, respectively. The WF gain applied to the noisy speech in the linear frequency domain was calculated using frequency warping from the Mel-frequency domain.
In , the amount of residual noise can be controlled by the Wiener gain parameter, . The residual noise increases with the value of . The with values of 0, 0.1, and 0.2 are referred to as “,” “,” and “,” respectively. We used “,” “,” and “” models for pink-noise conditions and “” and “” for tests under babble noise conditions because of restrictions on the experimental condition.
4 Evaluation conditions
We performed subjective human experiments to estimate the intelligibility of enhanced speech described in Section 3. The proposed and conventional OIMs were evaluated based on how well they predicted the human results. Note that the speech materials used in the experiments were different for individual subjects. Therefore, the predictions were performed for the individual materials.
4.1 Subjective intelligibility
4.1.1 Sound presentation
For pink noise conditions, the sounds were presented diotically via a digital-to-analog (DA) converter (Fostex, HP-A8) over headphones (Sennheiser, HD-580) at a quantization level of 24 bits and a sampling frequency of 48,000 Hz after up-sampling from 16,000 Hz. The level of stimulus sounds was 65 dB in . Listeners were seated in a sound-attenuated room with a background noise level of approximately 26 dB in . For babble-noise conditions, the sounds were presented diotically via a DA converter (OPPO, HA-1) over headphones (OPPO, PM-1) at a sampling frequency of 48,000 Hz. The stimulus sound levels were 63 dB in .
4.1.2 Listeners
Nine young NH listeners (four males and five females) participated in the experiments under pink-noise conditions, and fourteen (eight male and six female) participated in experiments with babble-noise conditions. Their native language was Japanese. The participants had a hearing level of less than 20 dB between 125 and 8,000 Hz. They participated in the experiments only after providing informed consent. The participants were instructed to write down the words they heard using “hiragana,” which roughly corresponds to the Japanese morae or consonant-vowel syllables. The total number of presented stimuli was 400 words, comprising a combination of speech-enhancement algorithm conditions and SNR conditions with 20 words per condition. The details are listed in Table. 1. Note that the words for each condition corresponded to a set of 20 words in FW07. The total duration of the listening test was about 1 hour. To keep the listeners’ attention within a reasonable range, we restricted the maximum number of words as 400 to cover all SNR conditions and enhancement algorithms. Each subject listened to a different word set, assigned randomly to avoid bias caused by word difficulty.
4.2 Objective intelligibility measures
Model evaluations were performed for the prediction of human results under the conditions arising from the use of speech-enhancement algorithms and the existence of pink and babble noise conditions. STOI measure [Taal et al., 2011] was selected as a de facto standard OIM for the evaluation of state-of-the-art speech-enhancement algorithms. ESTOI measure [Jensen & Taal, 2016] is an extended version of STOI. Additionally, HASPI [Kates & Arehart, 2015] was selected as a competing model, because it performed better than other models in a previous study [Yamamoto et al., 2019]. Note that these models, including sEPSM [Jørgensen & Dau, 2011] and CSII [Kates & Arehart, 2005], have been used to evaluate dcGC-sEPSM in a previous study [Yamamoto et al., 2019]. Thus, sEPSM failed to predict speech intelligibility for the condition, and CSII could not predict speech intelligibility for . Thus, we only use STOI, ESTOI, and HASPI in this study.
We calculated speech intelligibility scores from the same speech sounds (3,600 words: 400 words 9 listeners) under pink-noise conditions and 5,600 words (400 words 14 listeners) under babble-noise conditions. This is because the individual subjects listened to different sets of speech sounds. Therefore, the OIM predictions were derived for the word sets provided to the individual listeners. In the following OIMs, several parameters were tuned, depending on the speech material used in the evaluation. In this study, for a fair comparison, the parameter values were determined by a least square error (LSE) method, such that the model predictions matched the intelligibility scores of human results of speech intelligibility for unprocessed conditions of all noise conditions. The capabilities of the OIMs to predict speech intelligibility based on the individual speech-enhancement algorithms were also investigated.
4.2.1 Parameters of GEDI and mr-GEDI
In GEDI, the values of the two parameters, and , in Eqs. 8 and 9, must be determined. The and were determined using the LSE method to minimize the mean-squared error of the “unprocessed” curves between human results and the model predictions, as described above. The optimized parameter values for GEDI and mr-GEDI are listed in the first and second rows of Table 2.
4.2.2 Parameters of STOI and ESTOI
The initial STOI process comprises one-third of the octave band analysis, envelope extraction, and calculation of the short-time correlation between the envelopes of clean and target sounds in each octave. Then, the internal index of speech intelligibility measure, , is obtained by averaging the inner products between sub-band temporal envelopes [Taal et al., 2011]. ESTOI [Jensen & Taal, 2016] shares its envelope extraction with STOI. The index, , is instead calculated from the average of correlation coefficients between short-time spectra across sub-bands.
The speech intelligibility index of STOI and ESTOI is derived as a percentage value using a logistic function:
[TABLE]
where and are parameters (See Eq. 8 of [Taal et al., 2011] and Eq. 10 of [Jensen & Taal, 2016]). For a fair comparison, the parameter values were adjusted to simulate human results in an unprocessed condition in our experiments (in section 5). The used values are listed in the third and fourth rows of Table 2.
4.2.3 Parameters of HASPI
HASPI was developed for speech intelligibility prediction of HI listeners using an extended version of the gammatone filterbank. This index is calculated from the normalized cross-correlation of the temporal sequences of cepstral coefficients with auditory coherence values. Speech intelligibility using HASPI is derived using a logistic function,
[TABLE]
as in Eqs. 1 and 7 in [Kates & Arehart, 2014]. The parameter, , is defined as a linear combination of feature values related to the cepstral correlations () and the three levels of auditory coherence (, , and ) with a bias component, and it can be calculated as
[TABLE]
The coefficients for this feature are denoted with capital letters: , , and . Note that coefficients and are set to zero, as described in Kates & Arehart [2014]. The remaining coefficients (i.e., , , and ) were determined using the LSE method. The fitted parameter values are listed in Table 2.
5 Results
5.1 Human and prediction results
5.1.1 Pink-noise conditions
Figure 5 shows the percent correct values of speech intelligibility as a function of the speech SNR. Panel(a) shows the human results. The other panels show the model predictions of (b) GEDI, (c) mr-GEDI, (d) STOI, (e) ESTOI, and (e) HASPI. The speech materials for evaluation were unprocessed and enhanced sounds, which were produced by and three levels of (i.e., , , and ). The percentage of correct values is the averaged value across the nine noisy speech sets used for both the subjective experiments nine listeners and their objective predictions.
For the human results (Figure 5(a)), the speech intelligibility curves for the and the were roughly the same as the curve for the unprocessed conditions. However, the curve for the was lower than the curve for the unprocessed conditions. The standard deviations across listeners. Multiple comparison analyses with the Tukey–Kramer HSD test [Hsu, 1996] () indicated that the speech intelligibility scores of the enhanced speech processed by were significantly lower than those of the unprocessed speech. There was no significant difference in any combination between the unprocessed and other enhancement methods.
Figure 5(b) illustrates the prediction results of GEDI. The predicted speech intelligibility curves for and are similar to the human result curves. In contrast, speech intelligibility for the above 0-dB SNR is lower than that of human.
The prediction results of mr-GEDI (Figure 5(c)) are comparable to the results of GEDI (Figure 5(b)) as mr-GEDI has an intended design work strategy similar to GEDI with stationary noise, e.g. pink noise.
The results of STOI in Fig 5(d) indicated higher speech intelligibility curves for , , and compared to of the unprocessed condition. These results are inconsistent to human results. In contrast, the speech intelligibility curve for is similar to human results.
The results of ESTOI in Fig 5(e) also show similar speech intelligibility curves as those of STOI in Fig 5(d). Although ESTOI slightly improved the prediction of STOI, the problem of predictions for the family still remains.
HASPI (Figure 5(f)) also predicted similar speech intelligibility as STOI (Figure 5(d)) and ESTOI (Figure 5(e)). HASPI has the same problem as the speech intelligibility curves of the family, which are higher than the curve for the unprocessed conditions. The curve for the is within the variability of that for the human results (Figure 5(a)).
5.1.2 Babble-noise conditions
Figure 6 shows the percent correct values of speech intelligibility as a function of the speech SNR under babble-noise conditions. Panel (a) shows the human results. The other panels indicate the results of (b) GEDI, (c) mr-GEDI, (d) STOI, (e) ESTOI, and (f) HASPI. The speech materials used for evaluation were unprocessed and enhanced sound samples produced by and two levels of (i.e., and ). Fourteen noisy speech sets were used for both subjective experiments and objective predictions.
In the human results (Figure 6(a)), the speech intelligibility curves for the and the were lower than the curve in the unprocessed speech condition. In the case of the , speech intelligibility was similar to the unprocessed condition in every SNRs. The intelligibility score curves for the enhancement algorithms were poorly parallel to the case of SNR conditions. Multiple comparison analyses (Tukey–Kramer HSD test, ) indicated a lower speech intelligibility scores for enhanced speech processed by compared with the unprocessed speech results. There were no significant differences between the other algorithms and unprocessed speech.
Prediction results of GEDI in Fig 6(b) are lower than the human results, because GEDI does not perform temporal analysis to handle non-stationary noise. This motivated us to develop mr-GEDI as described in Section 2.2.
The prediction results of mr-GEDI (Figure 6(c)) were improved from those of GEDI (Figure 6(b)). However, they remain lower than the human results (Figure 6(a)). Although improvements are necessary, the orders of the prediction curves are similar. The curve for the is the closest to the unprocessed curve. The curve is the most distant. The curve is in the achieved average results. The results may imply using mr-GEDI for further development.
In STOI (Fig 6(d)), the prediction curves of and were higher than that of the unprocessed condition. This is inconsistent with the human results (Fig 6(a)). The prediction curve of the was lower than that of human results.
The results of ESTOI in Fig 6(e) were similar to STOI results. The curves for the and the were higher than the unprocessed condition curve, although the distance was smaller. This suggests that ESTOI predicts in a manner similar to STOI. This means that STOI can deal with non-stationary noise in the current experiments sufficiently without any extension.
In HASPI (Fig 6(f)), the average intelligibility of the is less than 10%. This implies that HASPI completely failed to predict it. The curves for the and the were lower than the curve for the unprocessed condition. This result is similar to those of mr-GEDI.
5.2 RMS error and bias analysis
In the previous sections, comparisons between human and OIM results were performed qualitatively using Figures 5 and 6. In this section, quantitative comparisons are performed with two measures: RMS error between the intelligibility scores of human and OIMs for individual speech enhancement algorithms and the mean difference between the unprocessed and enhanced conditions to clarify whether the prediction score is higher or lower than the unprocessed score.
5.2.1 Pink-noise conditions
Table 3 compares the OIMs in terms of the RMS) error between human results and predicted results for individual speech-enhancement algorithms under pink-noise conditions. Bold and italic fonts indicate the smallest and second-smallest values of each row, respectively. The RMS error for the is the smallest of GEDI. The RMS errors for the , the , and the are the smallest of mr-GEDI. GEDI family successfully minimized RMS errors.
The mean differences of the speech intelligibility values between the unprocessed condition and the individual OIMs were calculated to quantify the relative locations of the curves, as shown in Figs. 5 and 6. This is a measure used to clarify the bias between unprocessed and speech-enhancement conditions. When the value is positive (negative), the mean score is higher (lower) than the unprocessed score. The values roughly correspond to the location of the prediction curves relative to that of the unprocessed curve. Table 4 shows the results. In , the mean difference for STOI is the
closest to that of human results, and ESTOI is the second closest. In , mr-GEDI is the
closest and GEDI is the second closest. In , GEDI is the
closest and mr-GEDI is the second closest. In , mr-GEDI is the
closest and ESTOI is the second closest. It is worth noting that the mean differences of STOI, ESTOI, and HASPI were positive in the and the , whereas those of the human results were negative. They overestimated the results for these two s.
In Table 3, the RMS errors between human and predicted results displayed in Fig. 5 are shown. Smaller values correspond to better predictions from human results. The errors in GEDI and mr-GEDI were always smaller than those in STOI, ESTOI, and HASPI. However, the differences are not very large. To further clarify the difference, statistical analysis was performed as described in section 5.3.
In Table 4, the mean differences between the unprocessed and enhanced speech curves in Fig. 5 are shown. This is a bias analysis similar to that in the Bland-Altman analysis [Bland & Altman, 1986]. The results show whether the results of the enhanced algorithms were better than those of unprocessed cases. In human results in the leftmost column, the value, 2.2 in was positive and slightly greater than that in the unprocessed results. This implies that improves human performance. In contrast, the values of , , and were all negative. This implies that these algorithms degrade performance. The objective index is better when the predicted values are closer to the human results. In the family, the values of GEDI or mr-GEDI were closest to the human results. In , the value of STOI is the closest. Even so, the values of GEDI or mr-GEDI were closer to the human results than the value of HASPI.
5.2.2 Babble-noise conditions
Table 5 shows a comparison of the OIMs in terms of the RMS error under babble-noise conditions. In , STOI and ESTOI possess the smallest RMS errors.
In , the RMS error of HASPI is the
smallest, and that of mr-GEDI is the
second smallest. In , the RMS error of ESTOI is the
smallest, and that of STOI was the
second smallest.
Table 6 shows the mean difference under babble-noise conditions. In the , STOI was the
closest to the human result, and ESTOI was the
second closest. In , HASPI was the
closest, and mr-GEDI was the second closest. In , ESTOI was the
closest, and mr-GEDI was the second closest.
One problem is observed from the results of STOI and ESTOI, as shown in Table 6. In the mean differences of STOI,
the value, in , is positive and greater than the value, in . This is inconsistent with human results, in which the value, in , was negative and smaller than the value, , in the . For human listeners, speech sounds processed by the were easier than those of . STOI and ESTOI predicted this oppositely, whereas it was not the case for GEDI, mr-GESI, and HASPI.
The results from this section imply that mr-GEDI, STOI, and ESTOI were competitive in predicting under babble conditions when evaluated in terms of RMS errors and mean differences. It is also clear that mr-GEDI was properly extended from GEDI.
5.3 Speech reception thresholds (SRT)
Speech reception thresholds (SRT) were calculated to analyze the difference between the human and predicted results. The SRT is defined as an SNR value where the intelligibility curve crosses the 50%-score line (dotted horizontal line in Figures 5 and 6. The values of the SRTs were calculated after fitting the prediction scores with a cumulative Gaussian function.
Moreover, was defined to clarify the difference between the human results and the predictions by the OIMs. For example, for the unprocessed condition is defined as
[TABLE]
In particular, is positive when the curve for the prediction of the OIM is located on the right side of the curve for the human result in Figures 5 and 6. The positive means the prediction was an under-estimation, and the negative means the prediction was an over-estimation.
5.3.1 Pink-noise conditions
Figure 7(a) summarizes the s for human results (), GEDI (), mr-GEDI (), STOI (), ESTOI (), and HASPI () under pink-noise conditions. Markers and error bars represent the mean and the standard deviations across subjects. In , the average SRTs of mr-GEDI, GEDI, STOI, and ESTOI were within the standard deviation of the human SRT. In , the SRT of mr-GEDI was closest to the human SRT. The SRTs of GEDI were much greater than the human SRTs, whereas the SRTs of STOI, ESTOI, and HASPI were much smaller than the human SRT. In , the SRTs of GEDI and mr-GEDI were within the standard deviation of the human SRT. The SRTs of STOI, ESTOI, and HASPI were again smaller than the human SRT. With , the average SRTs of GEDI, mr-GEDI, and ESTOI were within the standard deviation of the human SRT, whereas those of STOI and HASPI were smaller.
Figure 7(b) shows s calculated by Eq. 17 to clarify the difference between the SRTs of the OIM predictions and the human results shown in Figure 7(a). The mean, , in the unprocessed condition were virtually zero, because the parameters of the OIMs were optimized to simulate the results of listening experiments. Positive (negative) means the OIM tends to underestimate (overestimate) speech intelligibility relative to the human results.
Multiple-comparison analysis (Tukey–Kramer HSD test, ) was performed between of the unprocessed and enhanced conditions in each OIM. The asterisks in Figure 7(b) show different conditions from the corresponding unprocessed conditions i.e., virtually zero mean. The for GEDI was demonstrated positive results in , indicating that GEDI has an underestimation tendency for speech intelligibility. for STOI, ESTOI and HASPI in and were significantly negative, which means that these OIMs tend to overestimate speech intelligibility. In contrast, s for mr-GEDI in every speech-enhancement conditions were not significantly different from of the unprocessed condition. The results of the and the imply that mr-GEDI is better than STOI, ESTOI, and HASPI under pink-noise conditions.
The effect of the number of listeners (sample size ) on these results is discussed in C.
5.3.2 Babble-noise conditions
Figure 8(a) shows the s under babble-noise conditions. The s for every OIM are located inside the standard deviation of the human in the unprocessed condition because of parameter fitting, as described previously. In contrast, the s for all OIMs are located outside of the standard deviations of the human in every speech-enhancement condition. Thus, prediction by any of the OIMs is not highly successful.
Figure 8(b) shows the s. Multiple-comparison analysis (Tukey–Kramer HSD test, ) was performed between of the unprocessed and enhanced conditions within each OIM. The asterisks in Figure 8(b) show the conditions having significant difference from the unprocessed condition. There were only three conditions with no significant difference: mr-GEDI, STOI and ESTOI in . These results imply that mr-GEDI, STOI, and, ESTOI are competitive in intelligibility predictions under babble-noise conditions. But note that the s of STOI and ESTOI are negative for and . This implies there is overestimation tendency. In contrast, s of other OIMs are positive, which suggests an underestimation tendency.
5.3.3 Summary of SRT results
Under pink-noise conditions, mr-GEDI predicted the human results better than the other OIMs. Under babble-noise conditions, mr-GEDI, STOI, and ESTOI were competitive. The mr-GEDI algorithm evaluates speech intelligibility for more conservatively than STOI and ESTOI which overestimate as indicated by negative s in Figs. 7 and 8. Some speech enhancement algorithms (e.g., Wang et al. [2014]) have been proposed with the main evaluation of STOI and without subjective listening tests. However, precaution should be taken due to the overestimation fragility of STOI. The evaluation with mr-GEDI may provide additional information in the development. Furthermore, it is necessary to test mr-GEDI in a wider range of algorithms and noise conditions for a more generalized conclusion and is a direction of future works.
6 Discussion
6.1 Goodness of the model
It is essential to determine the parameter values of the OIMs in advance to predict the intelligibility of enhanced speech, as described in Section 4.2. In this study, the parameter values were derived via the LSE method to minimize the prediction error for the unprocessed conditions.
In modelling studies, goodness of model could also be measured with two factors: the number of parameters or the degree of freedom and the predictability or stability of parameter values across various conditions. The increment of parameters improves applicability to various types of data and goodness of fit to existing data. However, it does not necessarily result in improvement to performance on unknown data. A model with stable parameters is more useful in practical situations, which are more complex than laboratory conditions.
GEDI family and STOI family required two parameters, as defined in Eqs. 9 and 14, whereas HASPI required, at least, three parameters, as defined in Eq. 16. The number of parameters cannot be reduced because each parameter controls a different type of feature value. If one of the parameters were reduced, the prediction would fail completely.
Table 2 shows the parameter values used in the evaluation. In GEDI family, values were between 1.23 and 1.50 and not overly sensitive to noise conditions. values were about 1.8 for pink noise and about 0.7 for babble noise. was closely related to noise stationarity. It is an interesting topic to study on presetting a reasonable value with a minimized set of listening experiments.
Parameters and and in STOI and ESTOI were similar. Thus, for example, in STOI, was -6.44 and was 4.56 under pink-noise conditions. was -8.91 and was 5.84 under babble-noise conditions. The two parameters should be tuned to account for the different noise conditions. This differs from the characteristics of the parameters used in GEDI family. Although it would require a more sophisticated algorithm to preset the parameters, it would be advantageous to know that and were consistently negative and positive. In contrast, the three parameter values in HASPI were completely different under pink- and babble-noise conditions. Moreover, parameter flips the sign. It seems difficult to preset the parameter values, because there is no consistency.
6.2 Insights to improve GEDI and mr-GEDI
It does not seem that GEDI and mr-GEDI are attractive methods based on the evaluation for babble-noise conditions as shown in Tables 5 and 6. There are some causes which can be resolved through further modifications. One of them may be envelope fluctuations of babble noise used in the experiments. As described in section 3.2, the babble noise simulates a cocktail party situation by overlapping many speech sounds. Therefore, there remain envelope modulation components similar to those of clean speech sounds, particularly after the auditory filter analysis. This component may interfere in the estimation of .
One of potential solutions would be to limit the minimum value of as proposed in Jørgensen & Dau [2011], Jørgensen et al. [2013]. This may limit the output of channels where the modulation is overestimated. Another one is to modify the weighting function in Eq. 4 and to introduce an additional weighting function in 5 for optimization. However, it may require much larger amounts of data involving subjective results because of the increased number of parameters and complexity. Further study is necessary to make these modifications.
7 Conclusion
In this study, we proposed GEDI based on the signal-to-distortion ratio in the auditory envelope, . The main idea behind the proposed algorithm was to calculate the distortion between the temporal envelopes of enhanced and clean speech from the output of an auditory filterbank. Moreover, GEDI was extended with a multi-resolution analysis (mr-GEDI) to improve predictions for non-stationary noise conditions.
GEDI and mr-GEDI were evaluated against well-known OIMs: STOI, ESTOI, and HASPI. Predictability of human speech intelligibility scores were evaluated for speech sounds enhanced using a simple SS and a Wiener-filtering method. Speech sounds with additive pink and babble noises with various SNRs were used for evaluation. The prediction performance of mr-GEDI was better than those of STOI, ESTOI, and HASPI under pink-noise conditions and was better than that of HASPI under babble-noise conditions.
However, the differences were not very large. The main reason is that the differences in performance between speech enhancement algorithms were relatively small even in human experiments. This is unavoidable because the purpose of this study is to develop a new OIM to evaluate such advanced speech enhancement algorithms which may merely provide small but reliable steps of improvement. In this regard, mr-GEDI exhibited certain advantages. The mr-GEDI method did not overestimate speech intelligibility for the relatively new algorithm and, thus, the prediction was more conservative than that of STOI and ESTOI. Moreover, the parameter setting of mr-GEDI was more consistent and easier than that of HASPI.
Some of speech enhancement algorithms (e.g., Wang et al. [2014]) have been proposed with STOI evaluation and without subjective listening tests. The evaluation with more conservative mr-GEDI may provide additional information in the development.
Future work includes prediction evaluations using state-of-the-art speech enhancement algorithms (e.g., DNN-based approaches) and the prediction of speech intelligibility under the SPL or hearing loss conditions.
The software for GEDI and mr-GEDI is available online: https://github.com/AMLAB-Wakayama/GEDI.git.
Acknowledgments
This research was partially supported by JSPS KAKENHI: Grant Numbers JP25280063, JP16H01734, JP16K12464, and 17J04227. We thank anonymous reviewers for their very helpful comments and suggestions.
Appendix A Calculation of residual-noise components
The models shown in Figure 1(a), sEPSM [Jørgensen & Dau, 2011], mr-sEPSM [Jørgensen et al., 2013], and dcGC-sEPSM [Yamamoto et al., 2019] use the residual noise as the reference signal. During the initial speech enhancement stage, the inputs were noisy signals () and noises (), and the outputs were enhanced signals () and residual noises (). During the SS method, the power of noise components was subtracted with a power estimated from a non-speech segment of noisy speech, as in Eq. 13. The residual noise component, , can be calculated directly by subtracting the power of the estimated noise, , from the power of the original noise, , as in
[TABLE]
This provides a sufficiently simple and clear definition for the residual noise.
It is, however, difficult to define the residual noise uniquely using Wiener filtering methods. These methods use a gain function, , to enhance speech components. Thus, there is no direct estimation of noise components. We can assume at least two ways to define the residual noise, . The first candidate is
[TABLE]
Residual noise power is directly derived from the estimated noise power with the gain function used in speech enhancement. The second candidate is
[TABLE]
The power of the observed noisy signal, , is processed by the gain function, . The residual noise power is derived by subtracting this value from the original noise power. These definitions are not very convincing when compared to definitions in the SS. Moreover, there could be other definitions to consider.
The problem of this ambiguity motivated us to develop GEDI, which uses clean speech as the reference sound. However, models using residual noise would be useful when extending to non-intrusive OIMs while resolving the ambiguity problem.
Appendix B The effect of the weighting function in GEDI
The effect of the weighting function, , in Eq. 7 was evaluated for speech intelligibility prediction. Figure 1 shows the percent correct values of speech intelligibility as a function of speech SNR for pink- and babble-noise conditions. Left panels show the prediction results of GEDI (with weight), where the parameter values are listed in Table 2. Right panels show the prediction results of GEDI without the weighting function, where the parameter values were set as and for pink-noise conditions and and for babble-noise conditions after optimization. The prediction curves of GEDI (w/o weight) were more variable. When comparing Figures 5(a) and 6(a), GEDI (with weight) predicted the human results better. It is therefore clear that the weighting function, , in Eq. 7 is important for better prediction.
Appendix C Number of listeners and its effect on the results
The results of pink-noise conditions in Fig. 5 and babble-noise conditions in Fig. 6 were derived from experiments with nine and fourteen listeners, respectively (see section 4.1.2).The number was smaller in pink-noise conditions simply because the experiment was performed earlier [Yamamoto et al., 2016] than the experiment using babble noise [Yamamoto et al., 2017]. As it was difficult to increase the number later, we presented the results based on that experiment.
In this section, we consider the effect of sample size on the results described in section 5. When the population mean is , the mean and standard deviation of sample data are and , respectively, the confidence coefficient is , and the confidence interval of is derived (e.g. Altman et al. [2013]) from
[TABLE]
where is the appropriate value from the distribution of degrees of freedom associated with . The ratio between the ranges of 9 and 14 is calculated as when and the values of are the same222This assumption about is not so unreasonable because the standard deviations of human results were roughly the same in the pink-noise and babble-noise conditions as shown in Figs. 5(a) and 6(a).. This result means that the range of the CI is greater and the power of the test is smaller when than when . In the case of the statistical analysis of SRT under pink noise in Fig. 7, there were nine conditions, marked by asterisks (), which were significantly different from the unprocessed conditions. If we increased the number from 9 to 14 and the range of the CI is reduced, the hypotheses of these conditions would be more strictly rejected. In contrast, the conditions where zero is contained within the range of would not be affected much. Many of GEDI and mr-GEDI conditions exhibit these cases. In this sense, the current analysis would not be so unreliable even though . Even if the null hypothesis is not rejected statistically, it does not mean that the data was sampled from a population with zero-mean. But it is better than the rejected cases.
References
- Altman et al. [2013]
Altman, D., Machin, D., Bryant, T., & Gardner, M. (2013).
Statistics with confidence: confidence intervals and statistical guidelines.
(2nd ed.).
John Wiley & Sons.
- ANSI S3-5 [1997]
ANSI S3-5 (1997).
Methods for the calculation of the speech intelligibility index.
Washington DC: American National Standards Institute.
URL: https://webstore.ansi.org/RecordDetail.aspx?sku=ANSI%2FASA+S3.5-1997+(R2017)&source=blog.
- Berouti et al. [1979]
Berouti, M., Schwartz, R., & Makhoul, J. (1979).
Enhancement of speech corrupted by acoustic noise.
In IEEE International Conference on Acoustics, Speech, and Signal Processing (pp. 208–211).
Institute of Electrical and Electronics Engineers volume 4.
URL: http://ieeexplore.ieee.org/articleDetails.jsp?arnumber=1170788. doi:10.1109/ICASSP.1979.1170788.
- Bland & Altman [1986]
Bland, J. M., & Altman, D. (1986).
Statistical methods for assessing agreement between two methods of clinical measurement.
The lancet, 327, 307–310.
- Chabot-Leclerc et al. [2014]
Chabot-Leclerc, A., Jørgensen, S., & Dau, T. (2014).
The role of auditory spectro-temporal modulation filtering and the decision metric for speech intelligibility prediction.
The Journal of the Acoustical Society of America, 135, 3502–3512. URL: http://asa.scitation.org/doi/10.1121/1.4873517. doi:10.1121/1.4873517.
- Chi et al. [1999]
Chi, T., Gao, Y., Guyton, M. C., Ru, P., & Shamma, S. (1999).
Spectro-temporal modulation transfer functions and speech intelligibility.
The Journal of the Acoustical Society of America, 106, 2719–2732. URL: http://asa.scitation.org/doi/10.1121/1.428100. doi:10.1121/1.428100.
- Cooke [2006]
Cooke, M. (2006).
A glimpsing model of speech perception in noise.
The Journal of the Acoustical Society of America, 119, 1562–1573. URL: http://scitation.aip.org/content/asa/journal/jasa/119/3/10.1121/1.2166600. doi:10.1121/1.2166600.
- Dreschler et al. [2001]
Dreschler, W. A., Verschuure, H., Ludvigsen, C., & Westermann, S. (2001).
ICRA Noises: Artificial Noise Signals with Speech-like Spectral and Temporal Properties for Hearing Instrument Assessment.
Audiology, 40, 148–157. URL: https://www.tandfonline.com/doi/abs/10.3109/00206090109073110. doi:10.3109/00206090109073110.
- Dubbelboer & Houtgast [2008]
Dubbelboer, F., & Houtgast, T. (2008).
The concept of signal-to-noise ratio in the modulation domain and speech intelligibility.
The Journal of the Acoustical Society of America, 124, 3937–3946. URL: http://scitation.aip.org/content/asa/journal/jasa/124/6/10.1121/1.3001713. doi:10.1121/1.3001713.
- Ephraim & Malah [1985]
Ephraim, Y., & Malah, D. (1985).
Speech enhancement using a minimum mean-square error log-spectral amplitude estimator.
IEEE Transactions on Acoustics, Speech, and Signal Processing, 33, 443–445. URL: http://ieeexplore.ieee.org/document/1164550/. doi:10.1109/TASSP.1985.1164550.
- Erkelens et al. [2007]
Erkelens, J. S., Hendriks, R. C., Heusdens, R., & Jensen, J. (2007).
Minimum Mean-Square Error Estimation of Discrete Fourier Coefficients With Generalized Gamma Priors.
IEEE Transactions on Audio, Speech, and Language Processing, 15, 1741–1752. doi:10.1109/TASL.2007.899233.
- Falk et al. [2015]
Falk, T. H., Parsa, V., Santos, J. F., Arehart, K., Hazrati, O., Huber, R., Kates, J. M., & Scollie, S. (2015).
Objective quality and intelligibility prediction for users of assistive listening devices: Advantages and limitations of existing tools.
IEEE Signal Processing Magazine, 32, 114–124. doi:10.1109/MSP.2014.2358871.
- Fujimoto et al. [2009]
Fujimoto, M., Ishizuka, K., & Nakatani, T. (2009).
A study of mutual front-end processing method based on statistical model for noise robust speech recognition.
In Proceedings of the Interspeech 2009 September 2009 (pp. 1235–1238).
- Fujimoto et al. [2012]
Fujimoto, M., Watanabe, S., & Nakatani, T. (2012).
Noise suppression with unsupervised joint speaker adaptation and noise mixture model estimation.
In IEEE International Conference on Acoustics, Speech and Signal Processing (pp. 4713–4716).
IEEE.
URL: http://ieeexplore.ieee.org/lpdocs/epic03/wrapper.htm?arnumber=6288971. doi:10.1109/ICASSP.2012.6288971.
- Furui et al. [2000]
Furui, S., Maekawa, K., & Isahara, H. (2000).
A Japanese National Project on Spontaneous Speech Corpus and Processing Technology.
In ASR2000 - Automatic Speech Recognition: Challenges for the new Millenium (pp. 244–248).
Paris, France.
URL: https://www.isca-speech.org/archive_open/asr2000/asr0_244.html.
- Green & Birdsall [1988]
Green, D. M., & Birdsall, T. G. (1988).
The Effect of Vocabulary Size on Articulation Score.
In J. A. Swets (Ed.), Signal Detection and Recognition by Human Observers: Contemporary Readings (pp. 609–619).
Peninsula Publishing.
URL: https://books.google.co.jp/books?id=-YMmPQAACAAJ.
- Gustafsson & Arlinger [1994]
Gustafsson, H. A., & Arlinger, S. D. (1994).
Masking of speech by amplitude-modulated noise.
The Journal of the Acoustical Society of America, 95, 518–529. doi:10.1121/1.408346.
- Hsu [1996]
Hsu, J. (1996).
Multiple comparisons: theory and methods.
Chapman and Hall/CRC.
- Irino & Patterson [2006]
Irino, T., & Patterson, R. D. (2006).
A Dynamic Compressive Gammachirp Auditory Filterbank.
IEEE transactions on audio, speech, and language processing, 14, 2222–2232. URL: http://www.pubmedcentral.nih.gov/articlerender.fcgi?artid=2661063&tool=pmcentrez&rendertype=abstract. doi:10.1109/TASL.2006.874669.
- Irino & Yamamoto [2019]
Irino, T., & Yamamoto, K. (2019).
gammachirp-filterbank.
URL: https://github.com/AMLAB-Wakayama/gammachirp-filterbank.
- ISO 9921 [2003]
ISO 9921 (2003).
Ergonomics – Assessment of speech communication.
Genève, Switzerland: International Organization for Standardization.
URL: https://www.iso.org/standard/33589.html.
- Jensen & Taal [2016]
Jensen, J., & Taal, C. H. (2016).
An Algorithm for Predicting the Intelligibility of Speech Masked by Modulated Noise Maskers.
IEEE/ACM Transactions on Audio, Speech, and Language Processing, 24, 2009–2022. doi:10.1109/TASLP.2016.2585878.
- Jørgensen & Dau [2011]
Jørgensen, S., & Dau, T. (2011).
Predicting speech intelligibility based on the signal-to-noise envelope power ratio after modulation-frequency selective processing.
The Journal of the Acoustical Society of America, 130, 1475–1487. URL: http://www.ncbi.nlm.nih.gov/pubmed/21895088. doi:10.1121/1.3621502.
- Jørgensen et al. [2013]
Jørgensen, S., Ewert, S. D., & Dau, T. (2013).
A multi-resolution envelope-power based model for speech intelligibility.
The Journal of the Acoustical Society of America, 134, 436–446. URL: http://www.ncbi.nlm.nih.gov/pubmed/23862819. doi:10.1121/1.4807563.
- Kates & Arehart [2014]
Kates, J., & Arehart, K. (2014).
The Hearing Aid Speech Perception Index (HASPI).
Speech Communication, 65, 75–93. URL: http://www.sciencedirect.com/science/article/pii/S0167639314000545?via%3Dihub. doi:https://doi.org/10.1016/j.specom.2014.06.002.
- Kates & Arehart [2005]
Kates, J. M., & Arehart, K. H. (2005).
Coherence and the speech intelligibility index.
The Journal of the Acoustical Society of America, 117, 2224–2237. doi:10.1121/1.1862575.
- Kates & Arehart [2015]
Kates, J. M., & Arehart, K. H. (2015).
Comparing the information conveyed by envelope modulation for speech intelligibility, speech quality, and music quality.
The Journal of the Acoustical Society of America, 138, 2470–2482. URL: http://asa.scitation.org/doi/10.1121/1.4931899. doi:10.1121/1.4931899.
- Kjems et al. [2009]
Kjems, U., Boldt, J. B., Pedersen, M. S., Lunner, T., & Wang, D. (2009).
Role of mask pattern in intelligibility of ideal binary-masked noisy speech.
The Journal of the Acoustical Society of America, 126, 1415–1426. doi:10.1121/1.3179673.
- Kondo et al. [2007]
Kondo, K., Amano, S., Suzuki, Y., & Sakamoto, S. (2007).
NTT-Tohoku University Familiarity-Controlled Word Lists 2007 (FW07).
URL: http://research.nii.ac.jp/src/en/FW07.html.
- Maekawa [2003]
Maekawa, K. (2003).
Corpus of Spontaneous Japanese: Its design and evaluation.
In ISCA and IEEE Workshop on Spontaneous Speech Processing and Recognition (SSPR2003) (pp. 7–12).
Tokyo, Japan.
URL: https://www.isca-speech.org/archive_open/sspr2003/index.html.
- Matsui et al. [2016]
Matsui, T., Irino, T., Inabe, H., Nishimura, Y., & Patterson, R. D. (2016).
Estimation of auditory compression and filter shape of elderly listeners using notched noise masking.
The Journal of the Acoustical Society of America, 140, 3274–3274. URL: http://asa.scitation.org/doi/10.1121/1.4970396. doi:10.1121/1.4970396.
- Mickes et al. [2007]
Mickes, L., Wixted, J., & Wais, P. (2007).
A direct test of the unequal-variance signal detection model of recognition memory.
Psychonomic Bulletin & Review, 14, 858–865. URL: http://dx.doi.org/10.3758/BF03194112%5Cnpapers2://publication/doi/10.3758/BF03194112. doi:10.3758/BF03194112.
- Moore [2013]
Moore, B. C. J. (2013).
An Introduction to the Psychology of Hearing.
(6th ed.).
Leiden, The Netherlands: Brill.
URL: http://www.brill.com/introduction-psychology-hearing-0.
- Patterson et al. [2003]
Patterson, R. D., Unoki, M., & Irino, T. (2003).
Extending the domain of center frequencies for the compressive gammachirp auditory filter.
The Journal of the Acoustical Society of America, 114, 1529–1542. URL: http://asa.scitation.org/doi/10.1121/1.1600720. doi:10.1121/1.1600720.
- Rhebergen & Versfeld [2005]
Rhebergen, K. S., & Versfeld, N. J. (2005).
A speech intelligibility index-based approach to predict the speech reception threshold for sentences in fluctuating noise for normal-hearing listeners.
The Journal of the Acoustical Society of America, 117, 2181–2192. doi:10.1121/1.1861713.
- Rhebergen et al. [2009]
Rhebergen, K. S., Versfeld, N. J., & Dreschler, W. A. (2009).
The dynamic range of speech, compression, and its effect on the speech reception threshold in stationary and interrupted noise.
The Journal of the Acoustical Society of America, 126, 3236–3245. URL: http://asa.scitation.org/doi/10.1121/1.3257225. doi:10.1121/1.3257225.
- Santos et al. [2014]
Santos, J., Senoussaoui, M., & Falk, T. (2014).
An improved non-intrusive intelligibility metric for noisy and reverberant speech.
In 2014 14th International Workshop on Acoustic Signal Enhancement (IWAENC) (pp. 55–59).
doi:10.1109/IWAENC.2014.6953337.
- Smaragdis & Venkataramani [2017]
Smaragdis, P., & Venkataramani, S. (2017).
A neural network alternative to non-negative audio models.
In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2017 (pp. 86–90).
New Orleans: IEEE.
URL: https://doi.org/10.1109/ICASSP.2017.7952123. doi:10.1109/ICASSP.2017.7952123.
- Taal et al. [2011]
Taal, C. H., Hendriks, R. C., Heusdens, R., & Jensen, J. (2011).
An algorithm for intelligibility prediction of time-frequency weighted noisy speech.
IEEE Transactions on Audio, Speech and Language Processing, 19, 2125–2136. doi:10.1109/TASL.2011.2114881.
- Varga & Steeneken [1993]
Varga, A., & Steeneken, H. J. M. (1993).
Assessment for automatic speech recognition: II. NOISEX-92: A database and an experiment to study the effect of additive noise on speech recognition systems.
Speech Communication, 12, 247–251. URL: http://www.sciencedirect.com/science/article/pii/0167639393900953. doi:https://doi.org/10.1016/0167-6393(93)90095-3.
- Wang et al. [2014]
Wang, Y., Narayanan, A., & Wang, D. (2014).
On Training Targets for Supervised Speech Separation.
IEEE/ACM Transactions on Audio, Speech, and Language Processing, 22, 1849–1858. doi:10.1109/TASLP.2014.2352935.
- Weninger et al. [2014]
Weninger, F., Le Roux, J., Hershey, J., & Watanabe, S. (2014).
Discriminative NMF and its application to single-channel source separation.
In Interspeech 2014 (pp. 865–869).
- Yamamoto et al. [2016]
Yamamoto, K., Irino, T., Matsui, T., Araki, S., Kinoshita, K., & Nakatani, T. (2016).
Speech intelligibility prediction based on the envelope power spectrum model with the dynamic compressive gammachirp auditory filterbank.
In Interspeech 2016 (pp. 2885–2889).
doi:10.21437/Interspeech.2016-652.
- Yamamoto et al. [2017]
Yamamoto, K., Irino, T., Matsui, T., Araki, S., Kinoshita, K., & Nakatani, T. (2017).
Predicting Speech Intelligibility Using a Gammachirp Envelope Distortion Index Based on the Signal-to-Distortion Ratio.
In Proceedings of the Interspeech 2017 (pp. 2949–2953).
URL: http://dx.doi.org/10.21437/Interspeech.2017-170. doi:10.21437/Interspeech.2017-170.
- Yamamoto et al. [2019]
Yamamoto, K., Irino, T., Matsui, T., Araki, S., Kinoshita, K., & Nakatani, T. (2019).
Speech intelligibility prediction with the dynamic compressive gammachirp filterbank and modulation power spectrum.
Acoustical Science and Technology, 40, 84–92. URL: https://www.jstage.jst.go.jp/article/ast/40/2/40_E1785/_article. doi:10.1250/ast.40.84.
- Yamamoto et al. [2018]
Yamamoto, K., Irino, T., Ohashi, N., Araki, S., Kinoshita, K., & Nakatani, T. (2018).
Multi-resolution Gammachirp Envelope Distortion Index for Intelligibility Prediction of Noisy Speech.
In Proc. Interspeech 2018 (pp. 1863–1867).
Hyderabad, India.
URL: http://dx.doi.org/10.21437/Interspeech.2018-1291. doi:10.21437/Interspeech.2018-1291.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Altman et al. [2013] Altman, D., Machin, D., Bryant, T., & Gardner, M. (2013). Statistics with confidence: confidence intervals and statistical guidelines . (2nd ed.). John Wiley & Sons.
- 2ANSI S 3-5 [1997] ANSI S 3-5 (1997). Methods for the calculation of the speech intelligibility index . Washington DC: American National Standards Institute. URL: https://webstore.ansi.org/Record Detail.aspx?sku=ANSI%2FASA+S 3.5-1997+(R 2017)&source=blog .
- 3Berouti et al. [1979] Berouti, M., Schwartz, R., & Makhoul, J. (1979). Enhancement of speech corrupted by acoustic noise. In IEEE International Conference on Acoustics, Speech, and Signal Processing (pp. 208–211). Institute of Electrical and Electronics Engineers volume 4. URL: http://ieeexplore.ieee.org/article Details.jsp?arnumber=1170788 . doi: 10.1109/ICASSP.1979.1170788 . · doi ↗
- 4Bland & Altman [1986] Bland, J. M., & Altman, D. (1986). Statistical methods for assessing agreement between two methods of clinical measurement. The lancet , 327 , 307–310.
- 5Chabot-Leclerc et al. [2014] Chabot-Leclerc, A., Jørgensen, S., & Dau, T. (2014). The role of auditory spectro-temporal modulation filtering and the decision metric for speech intelligibility prediction. The Journal of the Acoustical Society of America , 135 , 3502–3512. URL: http://asa.scitation.org/doi/10.1121/1.4873517 . doi: 10.1121/1.4873517 . · doi ↗
- 6Chi et al. [1999] Chi, T., Gao, Y., Guyton, M. C., Ru, P., & Shamma, S. (1999). Spectro-temporal modulation transfer functions and speech intelligibility. The Journal of the Acoustical Society of America , 106 , 2719–2732. URL: http://asa.scitation.org/doi/10.1121/1.428100 . doi: 10.1121/1.428100 . · doi ↗
- 7Cooke [2006] Cooke, M. (2006). A glimpsing model of speech perception in noise. The Journal of the Acoustical Society of America , 119 , 1562–1573. URL: http://scitation.aip.org/content/asa/journal/jasa/119/3/10.1121/1.2166600 . doi: 10.1121/1.2166600 . · doi ↗
- 8Dreschler et al. [2001] Dreschler, W. A., Verschuure, H., Ludvigsen, C., & Westermann, S. (2001). ICRA Noises: Artificial Noise Signals with Speech-like Spectral and Temporal Properties for Hearing Instrument Assessment. Audiology , 40 , 148–157. URL: https://www.tandfonline.com/doi/abs/10.3109/00206090109073110 . doi: 10.3109/00206090109073110 . · doi ↗
