TL;DR
This paper introduces a neural model that combines extraction and compression for text summarization, dynamically determining summary length and achieving state-of-the-art results on major datasets.
Contribution
The model uniquely integrates extraction and compression with dynamic length determination, improving summary conciseness and informativeness without requiring length constraints.
Findings
Achieves state-of-the-art results on CNN/DailyMail and Newsroom datasets.
Generates concise, informative summaries as confirmed by human evaluation.
Provides a new dataset of oracle compressive summaries.
Abstract
We present a new neural model for text summarization that first extracts sentences from a document and then compresses them. The proposed model offers a balance that sidesteps the difficulties in abstractive methods while generating more concise summaries than extractive methods. In addition, our model dynamically determines the length of the output summary based on the gold summaries it observes during training and does not require length constraints typical to extractive summarization. The model achieves state-of-the-art results on the CNN/DailyMail and Newsroom datasets, improving over current extractive and abstractive methods. Human evaluations demonstrate that our model generates concise and informative summaries. We also make available a new dataset of oracle compressive summaries derived automatically from the CNN/DailyMail reference summaries.
Click any figure to enlarge with its caption.
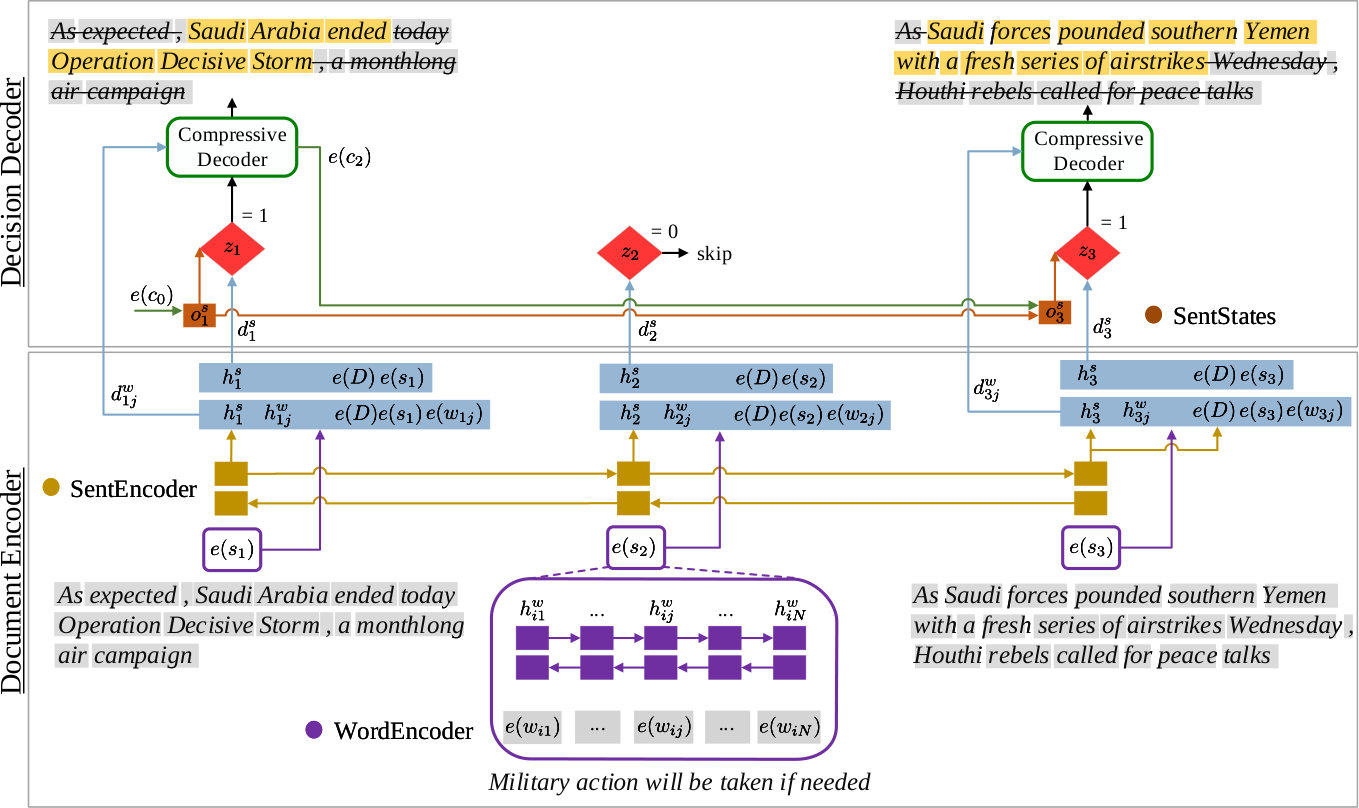 Figure 1
Figure 1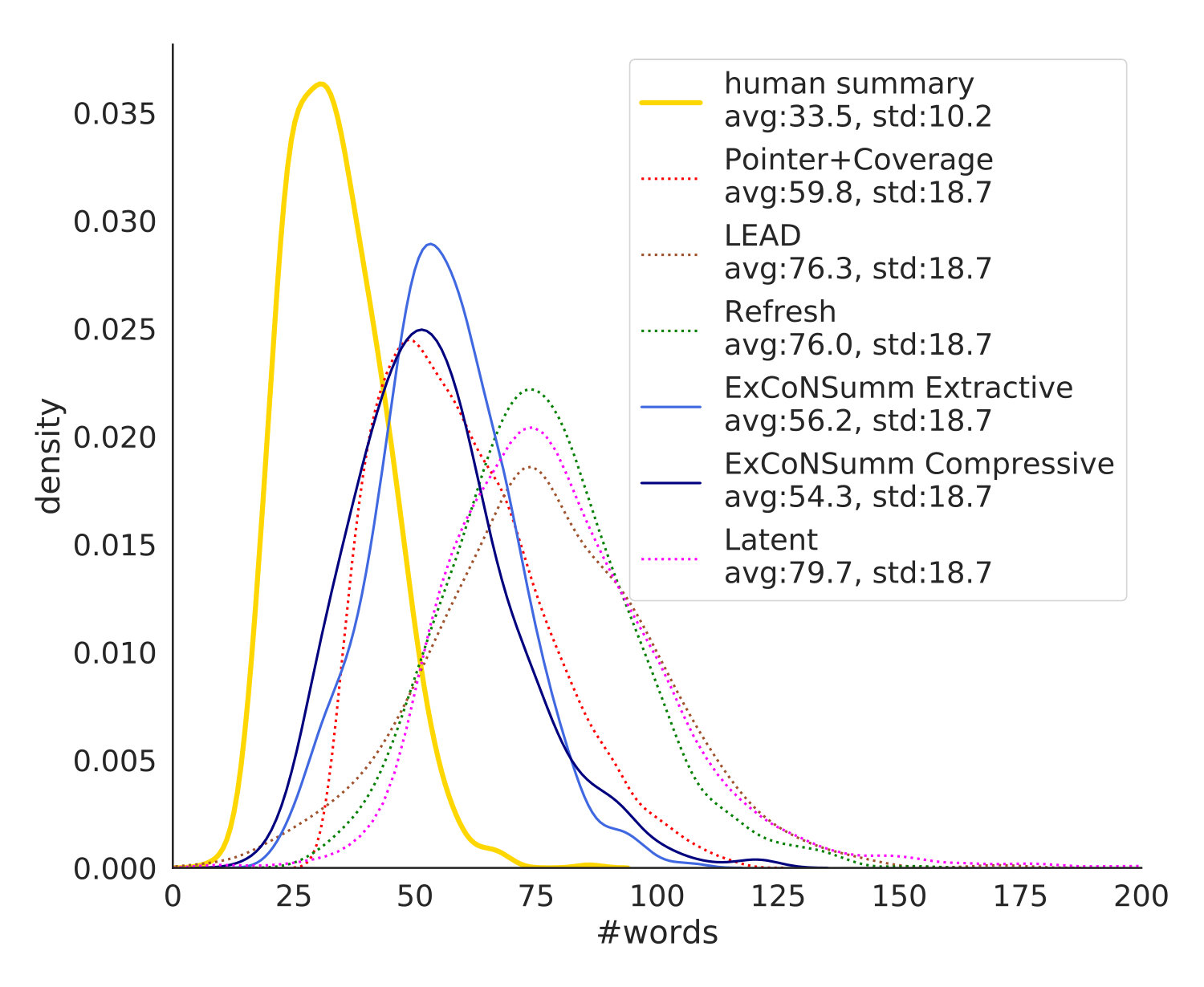 Figure 2
Figure 2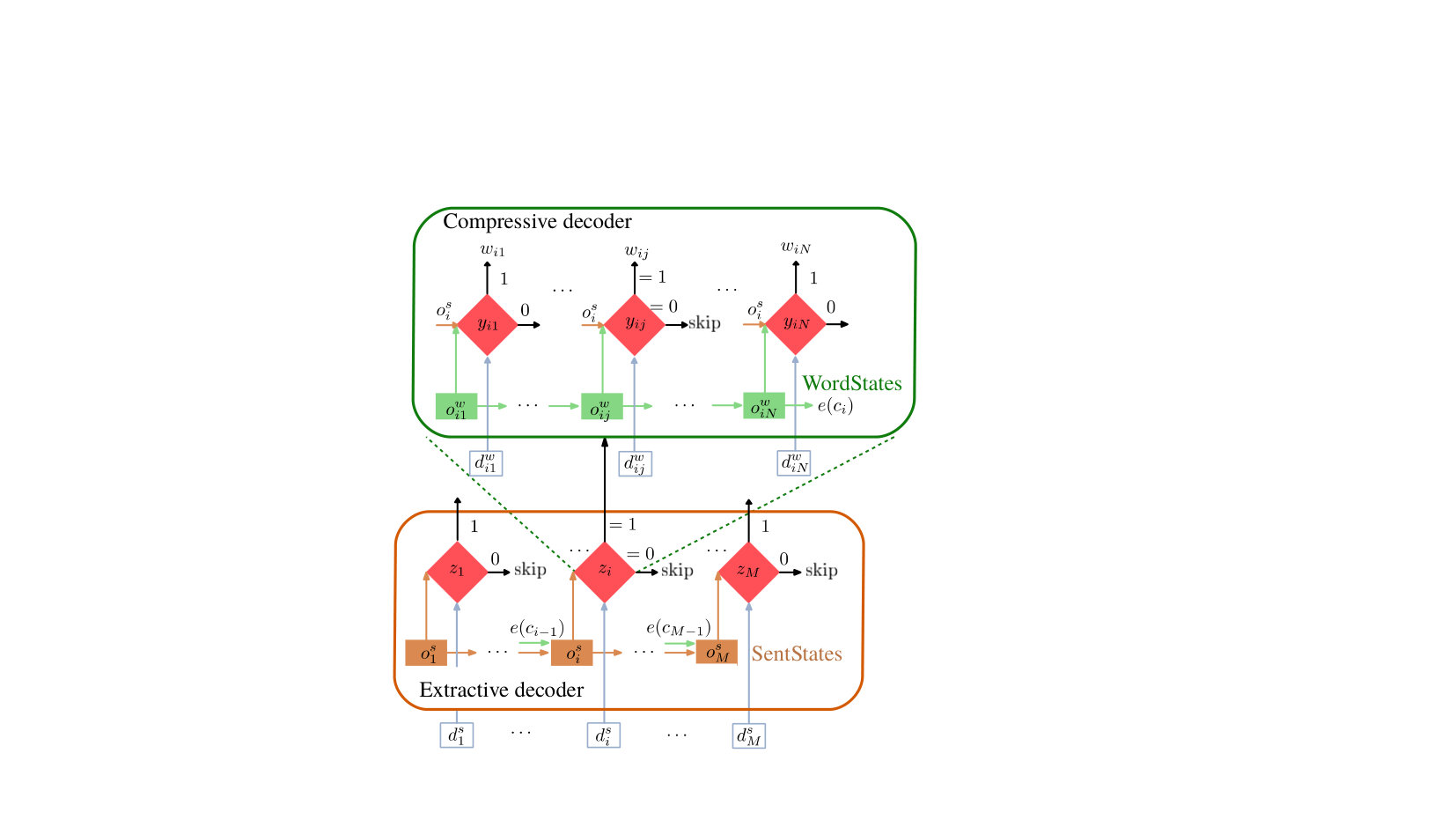 Figure 3
Figure 3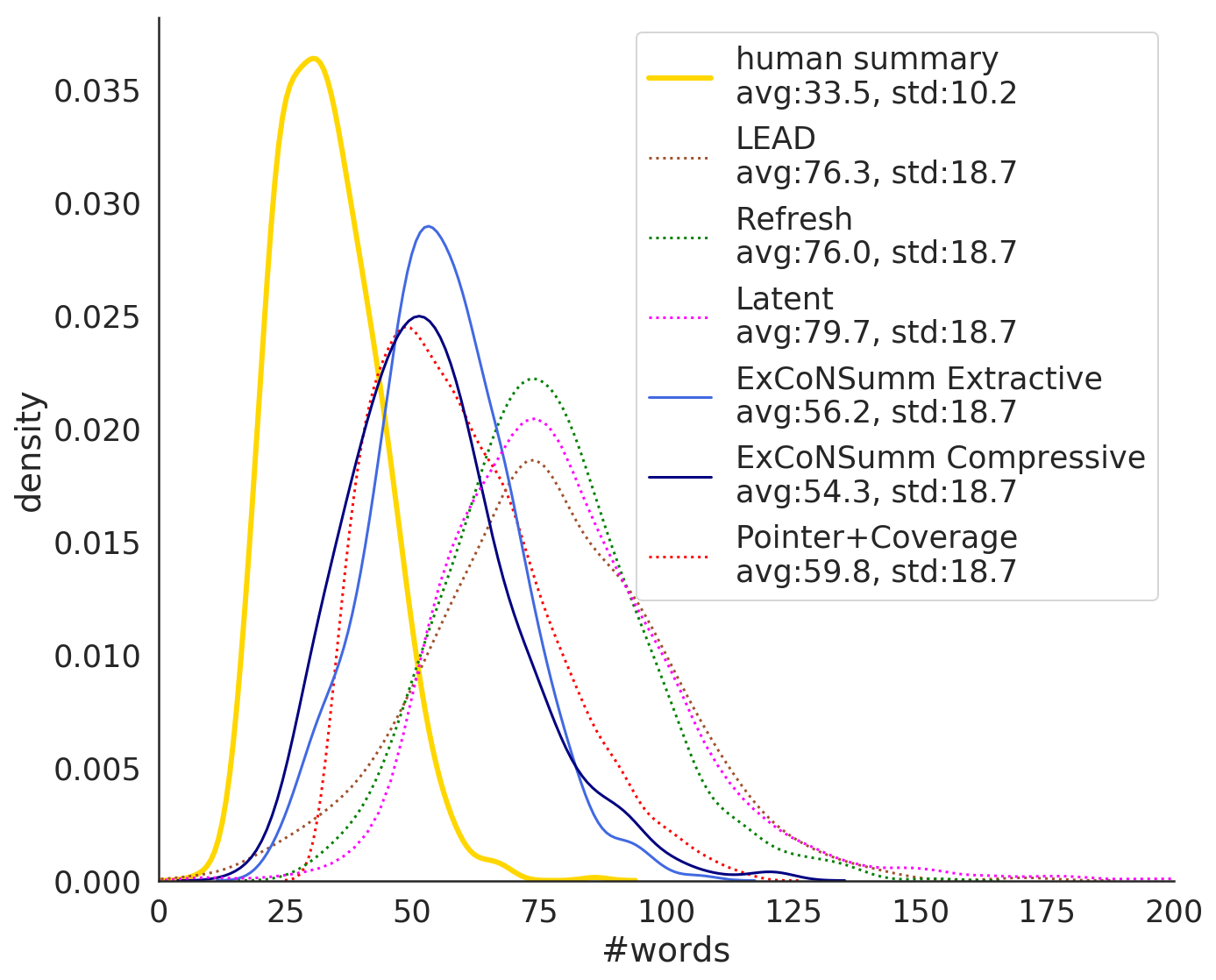 Figure 4
Figure 4| Oracle | R1 | R2 | RL |
|---|---|---|---|
| Extractive Oracle | 54.67 | 30.37 | 50.81 |
| Compressive Oracle | 57.12 | 32.59 | 53.27 |
| Models | CNN | DailyMail | Newsroom Ext. | Newsroom Mixed | Newsroom Abs. | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R1 | R2 | RL | R1 | R2 | RL | R1 | R2 | RL | R1 | R2 | RL | R1 | R2 | RL | |
| LEAD | 29.1 | 11.1 | 25.9 | 40.7 | 18.3 | 37.2 | 53.1 | 49.0 | 52.4 | — | — | — | 13.7 | 2.4 | 11.2 |
| Refresh | 30.0 | 11.7 | 26.9 | 41.0 | 18.8 | 37.7 | — | — | — | — | — | — | — | — | — |
| ExConSumm Extractive | 32.5 | 12.6 | 28.5 | 42.8 | 19.3 | 38.9 | 69.4 | 64.3 | 68.3 | 31.9 | 16.3 | 26.9 | 17.2 | 3.1 | 13.6 |
| ExConSumm Compressive | 32.5 | 12.7 | 29.2 | 41.7 | 18.5 | 38.4 | 68.4 | 62.9 | 67.3 | 31.7 | 16.1 | 27.0 | 17.1 | 3.1 | 14.1 |
| Pointer+Coverage ⋄ | — | — | — | — | — | — | 39.1 | 28.0 | 36.2 | 25.5 | 11.0 | 21.1 | 14.7 | 2.3 | 11.4 |
| Tan et al. (2017)∗ | 30.3 | 9.8 | 20.0 | — | — | — | — | — | — | — | — | — | — | — | — |
| Models | CNNDailyMail | ||
|---|---|---|---|
| R1 | R2 | RL | |
| LEAD | 39.6 | 17.7 | 36.2 |
| SummaRuNNer∗ | 39.6 | 16.2 | 35.3 |
| Refresh | 40.0 | 18.2 | 36.6 |
| Latent | 41.1 | 18.8 | 37.4 |
| ExConSumm Extractive | 41.7 | 18.6 | 37.8 |
| Latent+Compress | 36.7 | 15.4 | 34.3 |
| ExConSumm Compressive | 40.9 | 18.0 | 37.4 |
| Pointer+Coverage | 39.5 | 17.3 | 36.4 |
| ML + RL∗ | 39.9 | 15.8 | 36.9 |
| Tan et al. (2017)∗ | 38.1 | 13.9 | 34.0 |
| Li et al. (2018) | 39.0 | 17.1 | 35.7 |
| Chen and Bansal (2018) | 40.4 | 18.0 | 37.1 |
| Hsu et al. (2018) | 40.7 | 18.0 | 37.1 |
| Pasunuru and Bansal (2018) | 40.9 | 17.8 | 38.5 |
| Gehrmann et al. (2018) | 41.2 | 18.7 | 38.3 |
| Models | Bounded | Unbounded | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Human QA | ROUGE | Human QA | ROUGE | Pearson | |||||||
| score | rank | R1 | R2 | RL | score | rank | R1 | R2 | RL | r | |
| LEAD | 25.50 | 4rd | 30.9 | 11.9 | 29.1 | 36.33 | 5th | 31.6 | 13.5 | 29.3 | 0.40 |
| Refresh | 20.88 | 6th | 37.4 | 17.3 | 34.8 | 66.34 | 1st | 43.8 | 25.8 | 41.6 | 0.60 |
| Latent | 38.45 | 2nd | 38.9 | 19.6 | 36.4 | 53.38 | 4th | 40.7 | 22.0 | 38.1 | -0.02 |
| ExConSumm Extractive | 36.34 | 3rd | 38.4 | 18.5 | 35.9 | 54.93 | 3rd | 40.8 | 21.0 | 38.2 | 0.68 |
| ExConSumm Compressive | 39.44 | 1st | 38.8 | 19.0 | 37.0 | 57.32 | 2nd | 41.4 | 22.6 | 39.1 | 0.72 |
| Pointer+Coverage | 24.51 | 5th | 38.4 | 19.7 | 36.7 | 28.73 | 6th | 40.2 | 21.4 | 38.0 | 0.30 |
| State | ROUGE | ||
| R1 | R2 | RL | |
| ExConSumm Extractive | 32.5 | 12.6 | 28.5 |
| State averaging | 30.0 | 12.3 | 26.9 |
| ExConSumm Compressive | 32.5 | 12.7 | 29.2 |
| ExConSumm Ext+Comp oracle | 25.5 | 9.3 | 23.7 |
| Models | CNN | DailyMail | Newsroom Ext. | Newsroom Mixed | Newsroom Abs. | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R1 | R2 | RL | R1 | R2 | RL | R1 | R2 | RL | R1 | R2 | RL | R1 | R2 | RL | |
| ExConSumm Extractive | 32.5 | 12.6 | 28.5 | 42.8 | 19.3 | 38.9 | 69.4 | 64.3 | 68.3 | 31.9 | 16.3 | 26.9 | 17.2 | 3.1 | 13.6 |
| ExConSumm BOW | 33.5 | 12.4 | 30.0 | 42.5 | 17.8 | 38.8 | 68.7 | 59.8 | 67.6 | 32.0 | 15.2 | 27.3 | 19.1 | 2.8 | 16.5 |
| ExConSumm Compressive | 32.5 | 12.7 | 29.2 | 41.7 | 18.5 | 38.4 | 68.4 | 62.9 | 67.3 | 31.7 | 16.1 | 27.0 | 17.1 | 3.1 | 14.1 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Jointly Extracting and Compressing Documents
with Summary State Representations
Afonso Mendes*♠* Shashi Narayan*♢∗* Sebastião Miranda*♠*
** Zita Marinho*♡♠* André F. T. Martins*†♣* Shay B. Cohen*♢* **
♠Priberam Labs, Alameda D. Afonso Henriques, 41, 2o, 1000-123 Lisboa, Portugal
♢School of Informatics, University of Edinburgh, Edinburgh EH8 9AB, UK
♡ Instituto de Sistemas e Robótica, Instituto Superior Técnico, 1049-001 Lisboa, Portugal
†Instituto de Telecomunicações, Instituto Superior Técnico, 1049-001 Lisboa, Portugal
*♣*Unbabel Lda, Rua Visconde de Santarém, 67-B, 1000-286 Lisboa, Portugal
[email protected], [email protected], [email protected],
[email protected], [email protected], [email protected]
Abstract
We present a new neural model for text summarization that first extracts sentences from a document and then compresses them. The proposed model offers a balance that sidesteps the difficulties in abstractive methods while generating more concise summaries than extractive methods. In addition, our model dynamically determines the length of the output summary based on the gold summaries it observes during training, and does not require length constraints typical to extractive summarization. The model achieves state-of-the-art results on the CNN/DailyMail and Newsroom datasets, improving over current extractive and abstractive methods. Human evaluations demonstrate that our model generates concise and informative summaries. We also make available a new dataset of oracle compressive summaries derived automatically from the CNN/DailyMail reference summaries.111Our dataset and code is available at https://github.com/Priberam/exconsumm.
1 Introduction
Text summarization is an important NLP problem with a wide range of applications in data-driven industries (e.g., news, health, and defense). Single document summarization—the task of generating a short summary of a document preserving its informative content Spärck Jones (2007)—has been a highly studied research topic in recent years Nallapati et al. (2016b); See et al. (2017); Fan et al. (2018); Pasunuru and Bansal (2018).
††∗ Now at Google London.
Modern approaches to single document summarization using neural network architectures have primarily focused on two strategies: extractive and abstractive. The former select a subset of the sentences to assemble a summary Cheng and Lapata (2016); Nallapati et al. (2017); Narayan et al. (2018a, c). The latter generates sentences that do not appear in the original document See et al. (2017); Narayan et al. (2018b); Paulus et al. (2018). Both methods suffer from significant drawbacks: extractive systems are wasteful since they cannot trim the original sentences to fit into the summary, and they lack a mechanism to ensure overall coherence. In contrast, abstractive systems require natural language generation and semantic representation, problems that are inherently harder to solve than just extracting sentences from the original document.
In this paper, we present a novel architecture that attempts to mitigate the problems above via a middle ground, compressive summarization Martins and Smith (2009). Our model selects a set of sentences from the input document, and compresses them by removing unnecessary words, while keeping the summaries informative, concise and grammatical. We achieve this by dynamically modeling the generated summary using a Long Short Term Memory (LSTM; Hochreiter and Schmidhuber, 1997) to produce summary state representations. This state provides crucial information to iteratively increment summaries based on previously extracted information. It also facilitates the generation of variable length summaries as opposed to fixed lengths, in previous extractive systems Cheng and Lapata (2016); Nallapati et al. (2017); Narayan et al. (2018c); Zhang et al. (2018). Our model can be trained in both extractive (labeling sentences for extraction) or compressive (labeling words for extraction) settings. Figure 1 shows a summary example generated by our model.
Our contributions in this paper are three-fold:
- •
we present the first end-to-end neural architecture for EXtractive and COmpressive Neural SUMMarization (dubbed ExConSumm, see §3),
- •
we validate this architecture on the CNN/DailyMail and the Newsroom datasets Hermann et al. (2015); Grusky et al. (2018), showing that our model generates variable-length summaries which correlate well with gold summaries in length and are concise and informative (see §5), and
- •
we provide a new CNN/DailyMail dataset annotated with automatic compressions for each sentence, and a set of compressed oracle summaries (see §4).
Experimental results show that when evaluated automatically, both the extractive and compressive variants of our model provide state-of-the-art results. Human evaluation further shows that our model is better than previous state-of-the-art systems at generating informative and concise summaries.
2 Related Work
Recent work on neural summarization has mainly focused on sequence-to-sequence (seq2seq) architectures Sutskever et al. (2014), a formulation particularly suited and initially employed for abstractive summarization Rush et al. (2015). However, state-of-the-art results have been achieved by RNN-based methods which are extractive. They select sentences based on an LSTM classifier that predicts a binary label for each sentence Cheng and Lapata (2016), based on ranking using reinforcement learning Narayan et al. (2018c), or even by training an extractive latent model Zhang et al. (2018). Other methods rely on an abstractive approach with strongly conditioned generation on the source document See et al. (2017). In fact, the best results for abstractive summarization have been achieved with models that are more extractive in nature than abstractive, since most of the words in the summary are copied from the document Gehrmann et al. (2018).
Due to the lack of training corpora, there is almost no work on neural architectures for compressive summarization. Most compressive summarization work has been applied to smaller datasets Martins and Smith (2009); Berg-Kirkpatrick et al. (2011); Almeida and Martins (2013). Other non-neural summarization systems apply this idea to select and compress the summary. Dorr et al. (2003) introduced a method to first extract the first sentence of a news article and then use linguistically-motivated heuristics to iteratively trim parts of it. Durrett et al. (2016) also learns a system that selects textual units to include in the summary and compresses them by deleting word spans guided by anaphoric constraints to improve coherence. Recently, Zhang et al. (2018) trained an abstractive sentence compression model using attention-based sequence-to-sequence architecture Rush et al. (2015) to map a sentence in the document selected by the extractive model to a sentence in the summary. However, as the sentences in the document and in the summary are not aligned for compression, their compression model is significantly inferior to the extractive model.
In this paper, we propose a novel seq2seq architecture for compressive summarization and demonstrate that it avoids the over-extraction of existing extractive approaches Cheng and Lapata (2016); Dlikman and Last (2016); Nallapati et al. (2016a).
Our model builds on recent approaches to neural extractive summarization as a sequence labeling problem, where sentences in the document are labeled to specify whether or not they should be included in the summary Cheng and Lapata (2016); Narayan et al. (2018a). These models often condition their labeling decisions on the document representation only. Nallapati et al. (2017) tries to model the summary as the average representation of the positively labeled sentences. However, as we show later, this strategy is not the most adequate to ensure summary coherence, as it does not take the order of the selected sentences into account. Our approach addresses this problem by maintaining an LSTM cell to dynamically model the generated summary. To the best of our knowledge, our work is the first to use a model that keeps a state of already generated summary to effectively model variable-length summaries in an extractive setting, and the first to learn a compressive summarizer with an end-to end approach.
3 Summarization with Summary State Representation
Our model extracts sentences from a given document and further compresses these sentences by deleting words. More formally, we denote a document as a sequence of sentences, and a sentence as a sequence of words. We denote by , and the embedding of words, sentences and document in a continuous space. We model document summarization as a sequence labeling problem where the labeler transitions between internal states. Each state is dynamically computed based on the context, and it combines an extractive summarizer followed by a compressive one. First, we encode a document in a multi-level approach, to extract the embeddings of words and sentences (“Document Encoder”). Second, we decode these embeddings using a hierarchical “Decision Decoder.” The extractive summarizer labels each sentence with a label where indicates that the sentence should be included in the final summary and [math] otherwise. An extractive summary is then assembled by selecting all sentences with the label . Analogously, the compressive summarizer labels each word with a label , denoting whether the word in sentence is included in the summary or not. The final summary is then assembled as the sequence of words for each and . See Figures 2 and 3 for an overview of our model. We next describe each of its components in more detail.
3.1 Document Encoder
The document encoder is a two layer biLSTM, one layer encoding each sentence, and the second layer encoding the document. The first layer takes as input the word embeddings for each word in sentence , and outputs the hidden representation of each word . The hidden representation consist of the concatenation of a forward and a backward LSTM (WordEncoder in Figure 2). This layer eventually outputs a representation for each sentence that corresponds to the concatenation of the last forward and first backward LSTMs. The second layer encodes information about the document and is also a biLSTM that runs at the sentence-level. This biLSTM takes as input the sentence representation from the previous layer and outputs the hidden representation for each sentence in the document as (SentEncoder in Figure 2). We consider the output of the last forward LSTM over M sentences and first backward LSTM to be the final representation of the document .
The encoder returns two output vectors, associated with each sentence , and for each word at the specific state of the encoder .
3.2 Decision Decoder
Given that our model operates both at the sentence-level and at the word-level, the decision decoder maintains two state LSTMs denoted by and as in Figure 3. For the sentence-level decoder sentences are selected and the state of the summary gets updated by . For the word-level, all compressed word representations in a sentence are pushed to the word-level layer. In the compressive decoder, words that get selected are pushed onto the , and once the decoder has reached the end of the sentence, it pushes the output representation of the last state onto the sentence-level layer for the next sentence.
Extractive Decoder
The extractive decoder selects the sentences that should go to the summary. For each sentence at time step , the decoder takes a decision based on the encoder representation and the state of the summary , computed as follows:
[TABLE]
where the is modeled by an LSTM taking as input the already selected and compressed sentences comprising the summary so far . This way, at each point in time, we have a representation of the summary given by the LSTM that encodes the state of summary generated so far, based on the past sentences already processed by the compressive decoder (in ).222When using only the extractive model the summary state is generated from an LSTM whose inputs correspond to the sentence encoded embeddings instead of the previously generated compressed representations . The summary representation at step () is then used to determine whether to keep or not the current sentence in the summary ( or [math] respectively). The summarizer state subsumes information about the document, sentence and summary as:
[TABLE]
where is a model parameter, is the dynamic LSTM state, and is a bias term.
This modeling decision is crucial in order to generate variable length summaries. It captures information about the sentences or words already present in the summary, helping in better understanding the “true” length of the summary given the document.
Finally, the summarizer state is used to compute the probability of the action at time as:
[TABLE]
where is a model parameter and is a bias term for the summarizer action .
We minimize the negative log-likelihood of the observed labels at training time Dimitroff et al. (2013), where and represent the distribution of each class for the given sentences:333If or , we simply consider the whole term to be zero. Here represents the number of sentences in the document.
[TABLE]
where is the indicator function of class and represents all the training parameters of the sentence encode/decoder. At test time, the model emits probability , which is used as the soft prediction sequentially extracting the sentence . We admit sentences when .
Compressive Decoder
Our compressive decoder shares its architecture with the extractive decoder. The compressive layer is triggered every time a sentence is selected in the summary and is responsible for selecting the words within each selected sentence. In practice, LSTM (see Figure 3) is applied hierarchically after the sentence-level decoder, using as input the collected word embeddings so far:
[TABLE]
After making the selection decision for all words pertaining to a sentence, the final state of the , is fed back to of the extractive level decoder for the consecutive sentence, as depicted in Figure 3.
The word-level summarizer state representation depends on the encoding of words, document and sentence , on the dynamic LSTM encoding for the summary based on the selected words () and sentences () :
[TABLE]
where is a model parameter and is a bias term. Each action at time step is computed by
[TABLE]
with parameter and bias . The final loss for the compressive layer is
[TABLE]
where represents the set of all the training parameters of the word-level encoder/decoder, is the compressive layer loss over N words:
[TABLE]
The total final loss is then given by the sum of the extractive and compressive counterparts, .
4 Experimental Setup
We mainly used the CNN/DailyMail corpus Hermann et al. (2015) to evaluate our models. We used the standard splits of Hermann et al. (2015) for training, validation, and testing (90,266/1,220/1,093 documents for CNN and 196,961/12,148/10,397 for DailyMail). To evaluate the flexibility of our model, we also evaluated our models on the Newsroom dataset Grusky et al. (2018), which includes articles form a diverse collection of sources (38 publishers) with different summary style subsets: extractive (Ext.), mixed (Mixed) and abstractive (Abs.). We used the standard splits of Grusky et al. (2018) for training, validation, and testing (331,778/36,332/36,122 documents for Ext., 328,634/35,879/36,006 for Mixed and 332,554/36,380/36,522 for Abs.). We did not anonymize entities or lower case tokens.
4.1 Estimating Oracles
Datasets for training extractive summarization systems do not naturally contain sentence/word-level labels. Instead, they are typically accompanied by abstractive summaries from which extraction labels are extrapolated. We create extractive and compressive summaries prior to training using two types of oracles.
We used an extractive oracle to identify the set of sentences which collectively gives the highest ROUGE Lin and Hovy (2003) with respect to the gold summary Narayan et al. (2018c).
To build a compressive oracle, we trained a supervised sentence labeling classifier, adapted from the Transition-Based Chunking Model Lample et al. (2016), to annotate spans in every sentence that can be dropped in the final summary. We used the publicly released set of 10,000 sentence-compression pairs from the Google sentence compression dataset Filippova and Altun (2013); Filippova et al. (2015) for training. After tagging all sentences in the CNN and DailyMail corpora using this compression model, we generated oracle compressive summaries based on the best average of ROUGE-1 (R1) and ROUGE-2 (R2) F1 scores from the combination of all possible sentences and all removals of the marked compression chunks.
To verify the adequacy of our proposed oracles, we show in Table 1 a comparison of their scores. Our compressive oracle achieves much better scores than the extractive oracle, because of its capability to make summaries concise. Moreover, the linguistic quality of these oracles was preserved due to the tagging of the entire span by the sentence compressor trained on the sentence compression dataset.444We show examples of both oracles in Appendix §A.1. We believe that our dataset with oracle compression labels will be of significant interest to the sentence compression and summarization community.
4.2 Training Parameters
The parameters for the loss at the sentence-level were and and at the word-level, and . We used LSTMs with for all hidden layers. We performed mini-batch negative log-likelihood training with a batch size of 2 documents for 5 training epochs.We observed the convergence of the model between the 2nd and the 3rd epochs. It took around 12 hrs on a single GTX 1080 GPU to train. We evaluated our model on the validation set after every 5,000 batches. We trained with Adam Kingma and Ba (2015) with an initial learning rate of . Our system was implemented using DyNet Neubig et al. (2017).
4.3 Model Evaluation
We evaluated summarization quality using F1 ROUGE Lin and Hovy (2003). We report results in terms of unigram and bigram overlap (R1) and (R2) as a means of assessing informativeness, and the longest common subsequence (RL) as a means of assessing fluency.555We used pyrouge to compute the ROUGE scores. The parameters we used were “-a -c 95 -m -n 4 -w 1.2.” In addition to ROUGE, which can be misleading when used as the only means to assess summaries Schluter (2017), we also conducted a question-answering based human evaluation to assess the informativeness of our summaries in their ability to preserve key information from the document Narayan et al. (2018c).666We used the CNN/DailyMail QA test set of Narayan et al. (2018c) for evaluation. It includes 20 documents with a total of 71 manually written question-answer pairs. First, questions are written using the gold summary, we then examined how many questions participants were able to answer by reading system summaries alone, without access to the article.777See Appendix §A.2 for more details. Figure 5 shows a set of candidate summaries along with questions used for this evaluation.
4.4 Model and Baselines
We evaluated our model ExConSumm in two settings: Extractive (selects sentences to assemble the summary) and Compressive (selects sentences and compresses them by removing unnecessary spans of words). We compared our models against a baseline (LEAD) that selects the first leading sentences from each document,888We follow Narayan et al. (2018c) and set for CNN and for DailyMail. We follow Grusky et al. (2018) and set for Newsroom. three neural extractive models, and various abstractive models. For the extractive models, we used SummaRuNNer Nallapati et al. (2017), since it shares some similarity to our model, Refresh Narayan et al. (2018c) trained with reinforcement learning and Latent Zhang et al. (2018) a neural architecture that makes use of latent variable to avoid creating oracle summaries. We further compare against Latent+Compress Zhang et al. (2018), an extension of the Latent model that learns to map extracted sentences to final summaries using an attention-based seq2seq model Rush et al. (2015). All models, unlike ours, extract a fixed number of sentences to assemble their summaries. For abstractive models, we compare against the state-of-the art models of Pointer+Coverage See et al. (2017), ML+RL Paulus et al. (2018), and Tan et al. (2017) among others.
5 Results
5.1 Automatic Evaluation
Table 2 and 3 show results for the evaluations on the CNN/DailyMail and Newsroom test sets.
Comparison with Extractive Systems.
ExConSumm Compressive performs best on the CNN dataset and ExConSumm Extractive on the DailyMail dataset, probably due to the fact that the CNN dataset is less biased towards extractive methods than the DailyMail dataset Narayan et al. (2018b). We report similar results on the Newsroom dataset. ExConSumm Compressive tends to perform better for mixed (Mixed) and abstractive (Abs.) subsets, while ExConSumm Extractive performs better for the extractive (Ext.) subset. Our experiments demonstrate that our compressive model tends to perform better on the dataset which promotes abstractive summaries.
We find that ExConSumm Extractive consistently performs better on all metrics when compared to any of the other extractive models, except for the single case where it is narrowly behind Latent on R2 (18.6 vs 18.8) for the CNN/DailyMail combined test set. It even outperforms Refresh, which is trained with reinforcement learning. We hypothesize that its superior performance stems from the ability to generate variable length summaries. Refresh or Latent, on the other hand, always produces a fixed length summary.
Comparison with Compressive System.
ExConSumm Compressive reports superior performance compared to Latent+Compress (+4.2 for R1, +2.6 for R2 and +3.1 for RL). Our results demonstrate that our compressive system is more suitable for document summarization. It first selects sentences and then compresses them by removing irrelevant spans of words. It makes use of an advance oracle sentence compressor trained on a dedicated sentence compression dataset (Sec. 4.1). In contrast, Latent+Compress naively trains a sequence-to-sequence compressor to map a sentence in the document to a sentence in the summary.
Comparison with Abstractive Systems.
Both ExConSumm Extractive and Compressive outperform most of the abstractive systems including Pointer+Coverage See et al. (2017). When comparing with more recent methods Pasunuru and Bansal (2018); Gehrmann et al. (2018), our model has comparable performance.
rmed almost as well as the best abstractive model.
Summary Versatility.
We evaluate the ability of our model to generate variable length summaries. Table 4 show the Pearson correlation coefficient between the lengths of the human generated summaries against each unbounded model. Our compressive approach obtains the best results, with a Pearson correlation coefficient of 0.72 ().
Figure 4 also shows the distribution of words per summary for the models where predictions were available. Interestingly, both ExConSumm Extractive and Compressive follow the human distribution much better than other extractive systems (Lead, Refresh and Latent), since they are able to generate variable-length summaries depending on the input text. Our compressive model generates a word distribution much closer to the abstractive Pointer+Coverage model but achieves better compression ratio; the summaries generated by Pointer+Coverage contain 59.8 words, while those generated by ExConSumm Compressive have 54.3 words on average.
5.2 QA Evaluation
Table 4 shows results from our question answering based human evaluation. We elicited human judgements in two settings: the “Unbounded”, where participants were shown the full system produced summaries; and the “Bounded”, where participants were shown summaries that were limited to the same size as the gold summaries.
For the “Unbounded” setting, the output summaries produced by Refresh were able to answer most of the questions correctly, our Compressive and Extractive systems were placed at the 2nd and 3rd places respectively.999We carried out pairwise comparisons between all models to assess whether system differences are statistically significant. We found that there is no statistically significant difference between Refresh and ExConSumm Compressive. We use a one-way ANOVA with posthoc Tukey HSD tests with . The differences among Latent and both variants of ExConSumm, and between lead and Pointer+Coverage are also statistically insignificant. All other differences are statistically significant.
We observed that our systems were able to produce more concise summaries than those produced by Refresh (avg. length in words: 76.0 for Refresh, 56.2 for ExConSumm Extractive and 54.3 for ExConSumm Compressive; see Figure 4). Refresh is prone to generating verbose summaries, consequently it has an advantage of accumulating more information. In the “Bounded” setting, we aim to reduce this unfair advantage. Scores are overall lower since the summary sizes are truncated to gold size. The ExConSumm Compressive summaries rank first and can answer 39.44% of questions correctly. ExConSumm Extractive retains its 3rd place answering 36.34% of questions correctly.101010The differences among both variants of ExConSumm and Latent, and among lead, Refresh and Pointer+Coverage are statistically insignificant. All other differences are statistically significant. We use a one-way ANOVA with posthoc Tukey HSD tests with . These results demonstrate that our models generate concise and informative summaries that correlate well with the human summary lengths.111111App. §A.2 shows more examples of our summaries.
5.3 Summary State Representation
Next, we performed an ablation study to investigate the importance of the summary state representation w.r.t. the quality of the overall summary. We tested against a State averaging variant, where we replace by a weighted average, analogous to Nallapati et al. (2017), , where has the same form as but depends recursively on the previous summary state . Table 5 shows that using an LSTM state to model the current sentences in the summary is very important. The other ablation study shows how learning to extract and compress in a disjoint approach (ExConSumm Ext+Comp oracle) performs against a joint learning approach (ExConSumm Compressive). We compared summaries generated from our best extractive model and compressed them with a compressive oracle. Our joint learning model achieves the best performance in all metrics compared with the other ablations, suggesting that joint learning and using a summary state representation is beneficial for summarization.
6 Conclusions
We developed ExConSumm, a novel summarization model to generate variable length extractive and compressive summaries. Experimental results show that the ability of our model to learn a dynamic representation of the summary produces summaries that are informative, concise, and correlate well with human generated summary lengths. Our model outperforms state-of-the-art extractive and most of abstractive systems on the CNN and DailyMail datasets, when evaluated automatically, and through human evaluation for the bounded scenario. We further obtain state-of-the-art results on Newsroom, a more abstractive summary dataset.
Acknowledgments
This work is supported by the EU H2020 SUMMA project (grant agreement No 688139), by Lisbon Regional Operational Programme (Lisboa 2020), under the Portugal 2020 Partnership Agreement, through the European Regional Development Fund (ERDF), within project INSIGHT (No 033869), by the European Research Council (ERC StG DeepSPIN 758969), and by the Fundação para a Ciência e Tecnologia through contracts UID/EEA/50008/2019 and CMUPERI/TIC/0046/2014 (GoLocal).
Appendix A Appendices
A.1 Estimating Summary Oracles
We describe our method to estimate extractive and compressive oracle summaries prior to training using two types of oracles. We build these oracles in order to train our model with a supervised objective by minimizing a negative log-likelihood function. We create documents annotated with sentence-level and word-level extraction labels, which correspond to the gold values of both variables and respectively.
Extractive Oracle.
We followed Narayan et al. (2018c) and identified the set of sentences which collectively give the highest ROUGE Lin and Hovy (2003) with respect to the gold summary. More concretely, we assembled candidate summaries efficiently by first selecting sentences from the document which on their own have high ROUGE scores. We then generated all possible combinations of sentences subject to maximum length ( for CNN and for DailyMail) and evaluated them against the gold summary. We select the summary with the highest mean of ROUGE-1, ROUGE-2, and ROUGE-L F1 scores.
Compressive Oracle.
The primary challenge in building a compressive oracle lies in preserving the grammaticality of compressed sentences. Following the sentence compression literature McDonald (2006); Clarke and Lapata (2008); Berg-Kirkpatrick et al. (2011); Filippova and Altun (2013); Filippova et al. (2015), we train a supervised neural model to annotate spans in every sentence that can be dropped. In particular, we trained a supervised sentence labeling classifier adapted from Lample et al. (2016). To train our classifier, we used the publicly released set of 10,000 sentence-compression pairs from the Google sentence compression dataset Filippova et al. (2015); Filippova and Altun (2013). We removed the first 1,000 sentences as the development set and used the remaining ones as the training set.
After training our classifier for 30 epochs, it achieved a per-sentence accuracy of 21%, a word-based F-1 score of 78% and a compression ratio of 0.38. The parameters for the model were: 2 layers, dropout of 0.1, hidden dimension of size 400, action dimension of 20 and relation dimension of 20. We used the One Billion Word Benchmark corpus Chelba et al. (2013) to train word embeddings with the skip-gram model Mikolov et al. (2013) using context window size 6, negative sampling size 10, and hierarchical softmax 1. Same embeddings were used to train our summarization model also. For details of the evaluation metrics, please see Filippova et al. (2015).
After tagging all sentences in the CNN and DailyMail corpora using this compression model, we generated oracle compressive summaries based on the best average of ROUGE-1 and ROUGE-2 F1 scores from the combination of all possible sentences with all combinations of removals of the marked compression chunks. To solve this combinatorial problem, our algorithm recursively selects the possible sentences with the best accumulated score. Due to performance reasons, we used a simplified algorithm which uses unigrams and bigrams overlap computed incrementally at each recursion level, instead of the official ROUGE metric Lin and Hovy (2003). We only allow a maximum of seven compressed sentences per oracle. Our compressive oracle achieves much better scores than the extractive oracle because of its capability to make summaries concise (see Table 1 in the paper). Moreover, the linguistic quality of these oracles was preserved due to the tagging of the entire span by the sentence compressor. See Figure 6 for examples of our oracle summaries.
Baseline BOW Oracle.
Additionally, we also experimented with a bag-of-words oracle (BOW oracle), that serves as a baseline for creating a compressive oracle, in which labels are generated by simply dropping words if they do not appear in the gold summary. Unsurprisingly, oracle sentences compressed with this method are often ungrammatical (see Figure 6).
Our model ExConSumm trained with the BOW oracle (ExConSumm BOW) often score higher than the scores of the compressive model as shown in Table 6. However, looking at the example summaries in Figure 7, we find that the BOW compressive model is incapable of generating a fluent or grammatical summary. The ExConSumm Compressive summary, on the other hand, is fluent and grammatical. Our summary LSTMs ( and ) can preserve the fluency of the summaries if trained with the fluent Compressive oracle. This is not guaranteed when using the BOW oracle.
A.2 Human Evaluation Experiment Design
The main assumption behind this evaluation is that the gold summary highlights the most important content of the document. Based on this assumption, the questions are written using the GOLD summary. For this study, we used the same 20 documents (10 from CNN and 10 from DailyMail testsets) with an accompanying set of questions based on the gold summary from Narayan et al. (2018c).121212The test set for the QA evaluation is publicly available at https://github.com/EdinburghNLP/Refresh. We examined how many questions participants were able to answer by reading system summaries alone, without access to the article. The more questions a system can help to answer, the better it is at summarizing the document as a whole. We collected answers from five different participants for each summary and system pair. We marked a correct answer with a score of one, partially correct answers with a score of 0.5, and zero otherwise, the final score is an average of all these scores. Answers were elicited using Amazon’s Mechanical Turk crowd-sourcing platform. Examples of systems summaries used for this evaluation are shown in Figures 5, 8, 9, 10, 11, 12 and 13.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Almeida and Martins (2013) Miguel Almeida and Andre Martins. 2013. Fast and robust compressive summarization with dual decomposition and multi-task learning. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , volume 1, pages 196–206.
- 2Berg-Kirkpatrick et al. (2011) Taylor Berg-Kirkpatrick, Dan Gillick, and Dan Klein. 2011. Jointly learning to extract and compress. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies , pages 481–490, Portland, Oregon, USA. Association for Computational Linguistics.
- 3Chelba et al. (2013) Ciprian Chelba, Tomas Mikolov, Mike Schuster, Qi Ge, Thorsten Brants, and Phillipp Koehn. 2013. One billion word benchmark for measuring progress in statistical language modeling. Co RR , abs/1312.3005.
- 4Chen and Bansal (2018) Yen-Chun Chen and Mohit Bansal. 2018. Fast abstractive summarization with reinforce-selected sentence rewriting. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages 675–686. Association for Computational Linguistics.
- 5Cheng and Lapata (2016) Jianpeng Cheng and Mirella Lapata. 2016. Neural summarization by extracting sentences and words. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages 484–494, Berlin, Germany. Association for Computational Linguistics.
- 6Clarke and Lapata (2008) James Clarke and Mirella Lapata. 2008. Global inference for sentence compression: An integer linear programming approach. Journal of Artificial Intelligence Research (JAIR) , 31:399–429.
- 7Dimitroff et al. (2013) Georgi Dimitroff, Laura Tolosi, Borislav Popov, and Georgi Georgiev. 2013. Weighted maximum likelihood loss as a convenient shortcut to optimizing the f-measure of maximum entropy classifiers. In Proceedings of the International Conference Recent Advances in Natural Language Processing RANLP 2013 , pages 207–214, Hissar, Bulgaria. INCOMA Ltd. Shoumen, BULGARIA.
- 8Dlikman and Last (2016) Alexander Dlikman and Mark Last. 2016. Using machine learning methods and linguistic features in single-document extractive summarization. In DMNLP@PKDD/ECML .
