Strategies that enforce linear payoff relationships under observation errors in Repeated Prisoner's Dilemma game
Azumi Mamiya, Genki Ichinose

TL;DR
This paper analytically investigates strategies in the repeated prisoner's dilemma with observation errors, revealing that only zero-determinant and unconditional strategies can enforce linear payoff relationships despite errors.
Contribution
It extends the understanding of linear payoff enforcement strategies to scenarios with observation errors, identifying the limited strategy sets capable of such enforcement.
Findings
Only ZD and unconditional strategies enforce linear payoffs with errors.
Numerical confirmation supports the analytical results.
Observation errors do not enable new strategies to enforce linear relationships.
Abstract
The theory of repeated games analyzes the long-term relationship of interacting players and mathematically reveals the condition of how cooperation is achieved, which is not achieved in a one-shot game. In the repeated prisoner's dilemma (RPD) game with no errors, zero-determinant (ZD) strategies allow a player to unilaterally set a linear relationship between the player's own payoff and the opponent's payoff regardless of the strategy that the opponent implements. In contrast, unconditional strategies such as ALLD and ALLC also unilaterally set a linear payoff relationship. Errors often happen between players in the real world. However, little is known about the existence of such strategies in the RPD game with errors. Here, we analytically search for all strategies that enforce a linear payoff relationship under observation errors in the RPD game. As a result, we found that, even in…
Click any figure to enlarge with its caption.
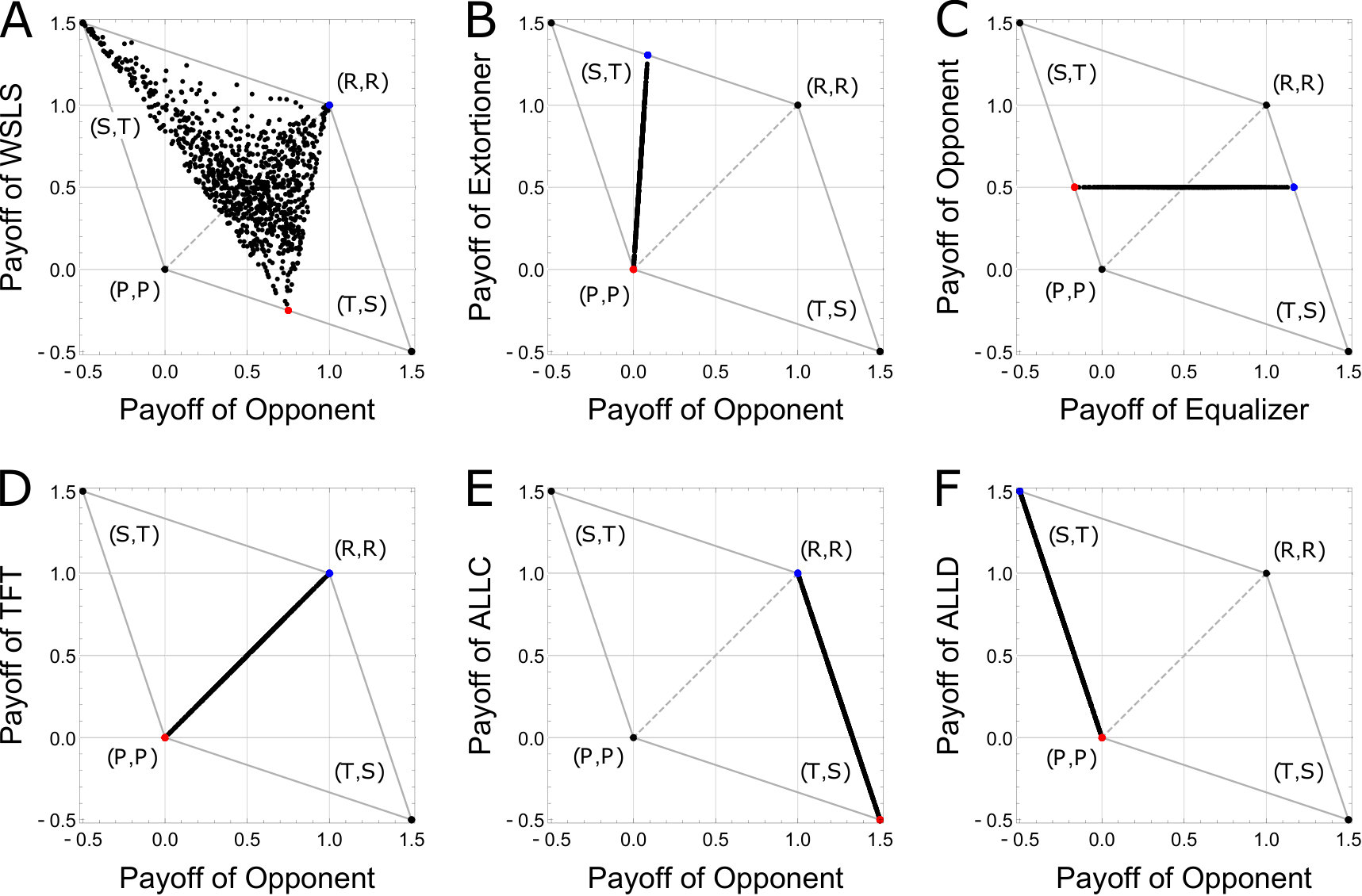 Figure 1
Figure 1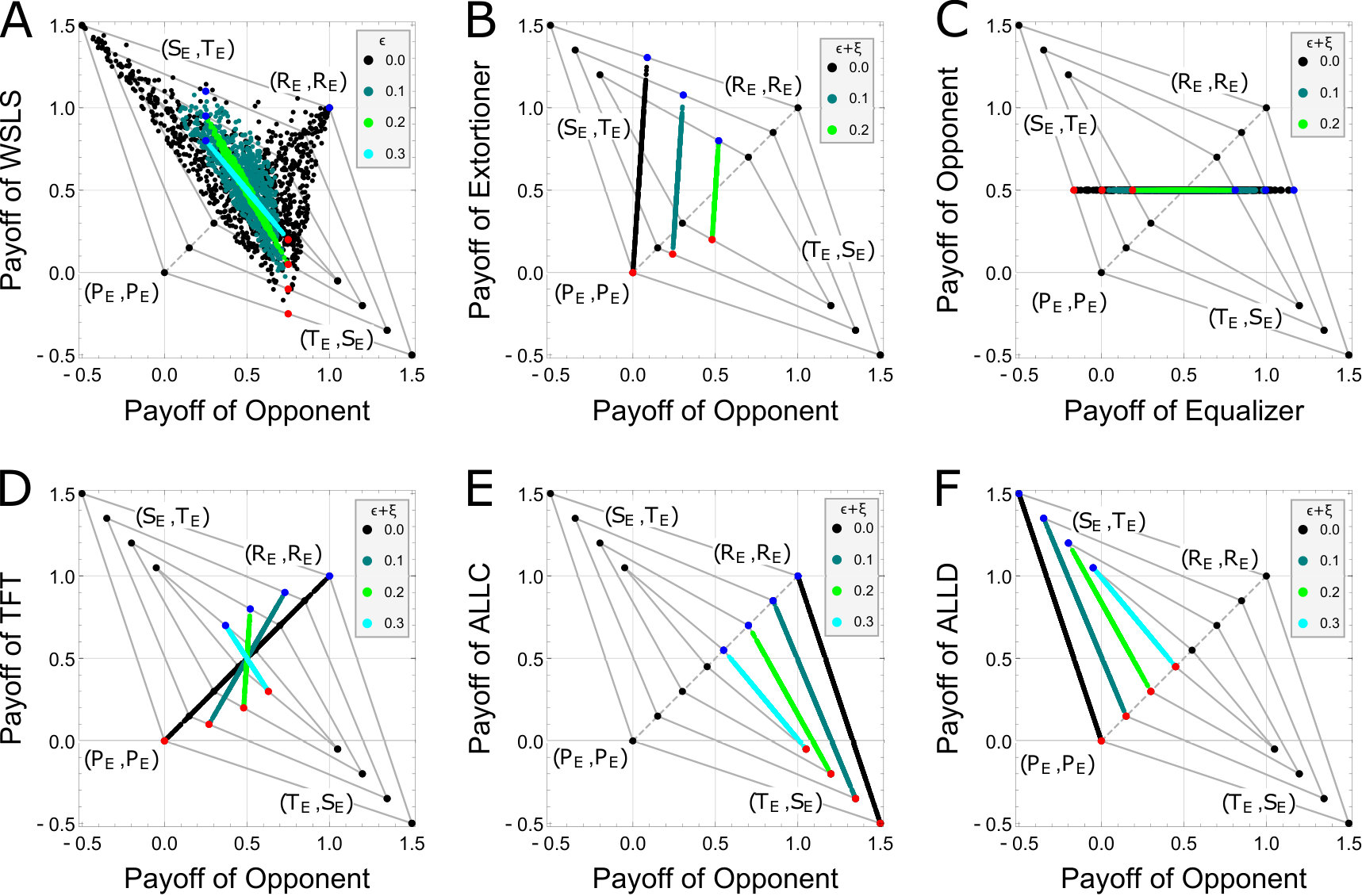 Figure 2
Figure 2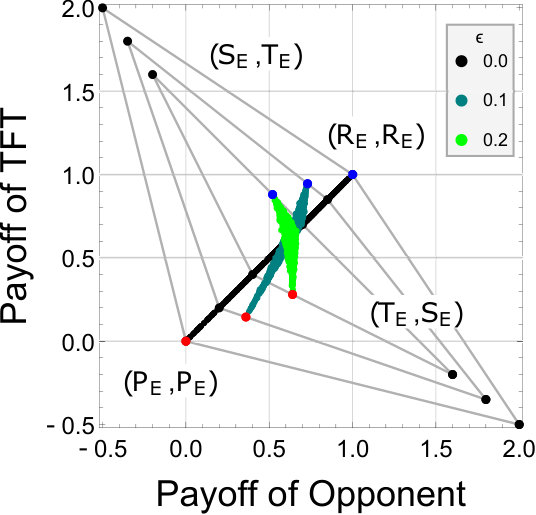 Figure 3
Figure 3Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsEvolutionary Game Theory and Cooperation · Experimental Behavioral Economics Studies · Mathematical and Theoretical Epidemiology and Ecology Models
Strategies that enforce linear payoff relationships under observation errors in Repeated Prisoner’s Dilemma game
Azumi Mamiya1 and Genki Ichinose1∗
1 Department of Mathematical and Systems Engineering, Shizuoka University,
3-5-1 Johoku, Naka-ku, Hamamatsu, 432-8561, Japan
∗ Corresponding author ([email protected])
Abstract
The theory of repeated games analyzes the long-term relationship of interacting players and mathematically reveals the condition of how cooperation is achieved, which is not achieved in a one-shot game. In the repeated prisoner’s dilemma (RPD) game with no errors, zero-determinant (ZD) strategies allow a player to unilaterally set a linear relationship between the player’s own payoff and the opponent’s payoff regardless of the strategy that the opponent implements. In contrast, unconditional strategies such as ALLD and ALLC also unilaterally set a linear payoff relationship. Errors often happen between players in the real world. However, little is known about the existence of such strategies in the RPD game with errors. Here, we analytically search for all strategies that enforce a linear payoff relationship under observation errors in the RPD game. As a result, we found that, even in the case with observation errors, the only strategy sets that enforce a linear payoff relationship are either ZD strategies or unconditional strategies and that no other strategies can enforce it, which were numerically confirmed.
Keywords
Prisoner’s dilemma, repeated games, observation errors, zero-determinant strategies, unconditional strategies
1 Introduction
The two-player repeated prisoner’s dilemma (RPD) game is a model for exploring the long-term relationships of players, which mathematically reveals how cooperation and competition arise among competitive players [1]. In the one-shot PD game, defection is the only Nash equilibrium. On the other hand, cooperation is possible in the RPD game because players can reward cooperating partners by cooperating in the future. Also, players can punish defecting partners by defecting in the future. This mechanism is called direct reciprocity [2, 3, 4] and makes it possible for players to mutually cooperate in the RPD game. In the context of the RPD game, theoretical biologists are interested in which strategies win in evolving populations. This question falls into the field of evolutionary games [5]. A series of the results of evolutionary games in the RPD game brought promising findings. Especially, with noise, generous tit-for-tat [6] and win-stay lose-shift [7, 8] were robust to various kinds of evolutionary opponents. In this way, theoretical biologists have traditionally focused on strong strategies obtained from evolutionary consequences. However, we can ask a question from a different point of view: Are there any strategies which always win against the opponent irrespective of the opponent’s strategy? Answering this question fosters greater understanding of the RPD game.
In 2012, Press and Dyson suddenly answered this question by finding a novel class of strategies which contain such ultimate strategies, called zero-determinant (ZD) strategies [9]. ZD strategies impose a linear relationship between the payoffs for a focal player and his opponent regardless of the strategy that the opponent implements. The discovery of ZD strategies inspired various relevant studies, including their evolution [10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25], multiplayer games [26, 19, 27, 28, 29], continuous action spaces [30, 28, 29, 31], alternating games [31], animal contests [32], human reactions to computerized ZD strategies [33, 34], and human-human experiments [35, 28, 36], which promote an understanding of the nature of human cooperation. For further understanding, see the recent elegant classification of strategies, partners (called “good strategies” in Ref. [11, 37]) and rivals, in direct reciprocity [38]. In contrast, unconditional strategies such as ALLC and ALLD can also unilaterally set a linear payoff relationship against the opponent [14, 39]. A previous study revealed that those two types of strategies are the only sets which enforce a linear payoff relationship in the RPD game [39].
These two types of strategies were found in the case of no errors. Errors (or noise) are unavoidable in human interactions and they may lead to the collapse of cooperation due to negative effects. Thus, the effect of errors has been considered in the literature of the RPD game [40, 41, 42, 43, 44, 45, 46, 47, 48]. However, except for [49], the effect of errors has not been considered for strategies that enforce a linear payoff relationship. There are typically two types of errors: perception errors [42] and implementation errors [43]. Hao et al. considered the former case of the errors where players may misunderstand their opponent’s action because the players can only rely on their private monitoring [40, 44] instead of their opponent’s direct action. They remarkably showed that ZD strategies can exist even in the case that such observation errors are incorporated [49]. In their model, they mathematically searched for one of the cases where determinants become zero in line with Press and Dyson’s formalism [9]. More specifically, they only searched for the case where the second and fourth columns of the determinant take the same value as Press and Dyson did in the case of no errors. They did not consider other possible strategies that make the determinant zero in the case of errors. In this study, from all possibilities, we mathematically searched for all of the cases where the determinant becomes zero. As a result, we found that only ZD strategies [9] and unconditional strategies [14, 39] are the two types which enforce a linear payoff relationship and that no other strategies exist to make the determinant zero. We also confirmed this result by numerical calculations.
2 Model
We consider the symmetric two-person RPD game with observation errors in line with the previous studies [44, 49]. Each player chooses an action . Each player cannot see what action the opponent chose. Instead, they can only observe a signal , where and denote good and bad signals, respectively. The signal cannot be observed by the other player, meaning that the signal is private information. Each player’s signal basically depends on the opponent’s action but is also affected by noise from the environment, which is a stochastic variable. In other words, a player observes (or ) when the other player chooses an action C (or D). However, when an error occurs, a player observes (or ) although the other player chooses an action C (or D) due to observation errors. We define as the probability that a signal profile is realized, given that an action profile occurs. Let be the probability that an error happens to one particular player but not to the other and be the probability that an error happens to both players. Then, the probability that an error occurs to neither player is . For example, when both players choose action C, we have , , and . The realized payoff for each player depends only on the action he chose and the signal he received, which is denoted by . Let , , , and be , and , respectively. Then the payoff matrix is given by
[TABLE]
The entries represent the payoffs that a focal player gains in a single round of the repeated game. Each row and column represents the action that the focal player chose and the signal he observed, respectively. In each stage, player ’s expected payoff value over all possible signals, when two players have an action profile , is represented by
[TABLE]
The expected payoffs under different action profiles ,,, and are denoted by , , and , respectively. According to Eq. (2), , , , and are derived as , , , , respectively. We assume that
[TABLE]
which dictates the prisoner’s dilemma condition. Both players expect a larger payoff by selecting D rather than C irrespective of the other’s action because and hold. We also assume that
[TABLE]
which guarantees that mutual cooperation is more beneficial than the two players alternating C and D in the opposite phase, i.e., CD, DC, CD, DC, , where the first and second letter represent the actions selected by and , respectively. The two players repeat the game whose payoff matrix in each round is given by Eq. (1).
Consider two players and that adopt memory-one strategies, with which they use only the outcomes of the last round to decide the action to be submitted in the current round. Even in the case of memory- strategies, errors can be considered. In fact, Hilbe et al. incorporated implementation errors in such a situation [48]. A memory-one strategy is specified by a 4-tuple; ’s strategy is given by a combination of
[TABLE]
where . The subscripts 1, 2, 3, and 4 of mean previous outcome C, C, D and D, respectively. In Eq. (5), is the conditional probability that cooperates when cooperated and observed signal in the last round, is the conditional probability that cooperates when cooperated and observed signal in the last round, is the conditional probability that cooperates when defected and observed signal in the last round, and is the conditional probability that cooperates when defected and observed signal in the last round. Note that, in this model, depends on ’s action and its private observation in the last round [44, 49]. Contrary, depends on ’s and ’s direct actions in the last round in the case of no errors. Similarly, ’s strategy is specified by a combination of
[TABLE]
where . Because both players adopt a memory-one strategy, the stochastic state of the two players in round is described by , where the subscripts 1, 2, 3, and 4 of mean the stochastic state (C,C), (C,D), (D,C), and (D,D), respectively. is the probability that both players cooperate in round , is the probability that cooperates and defects in round , and so forth. The state transition matrix of this noisy repeated game is given by
[TABLE]
where . Each row and column represents the previous states and the following states of the game, respectively. Then, the stochastic state of the two players in round is calculated by . The stationary distribution for is a vector such that
[TABLE]
Eq. (8) and yield
[TABLE]
Applying Cramer’s rule to matrix , we obtain
[TABLE]
where is the adjugate matrix of . Here, Eqs. (9) and (10) imply that every row of is proportional to . Therefore, is solely represented by the components of matrix . Choosing the fourth row of the matrix , we see that is composed of the determinant of the matrixes formed from the first three columns of . We add the first column of into the second and third columns. Even by this manipulation, this determinant is unchanged. The result of these manipulations is a formula for the dot product of an arbitrary vector with the stationary distribution vector , which can be represented by the form of the determinant
[TABLE]
where and . If we replace the arbitrary vector with ’s expected payoff vector , we obtain . Then, we divide it by . Finally, we can obtain player ’s per-round expected payoff in the form of the determinant as follows:
[TABLE]
where is needed for the normalization. Similarly, player ’s per-round payoff can be represented by the form of the determinant
[TABLE]
where is ’s expected payoff vector . Hereafter, we only consider the relationship between those two expected payoffs because they converge to certain expected values, respectively, if the stationary distributions exist in infinitely repeated games. In contrast, other types of the payoff are worth investigating in finitely repeated games.
Moreover, we can consider the linear combination of and , which can be given by the form of the determinant
[TABLE]
where , and , are arbitrary constant. The numerator of the right side of Eq. (14) is expressed in the following:
[TABLE]
If Eq. (15) is zero, the relationship between the two players’ payoffs becomes linear. In the next section, we search for all of the solutions which satisfy this condition.
3 Result
We search for strategies that impose a linear relationship between the two players’ payoffs regardless of their opponent’s strategies in the RPD game with observation errors, which satisfy the following equation:
[TABLE]
If the numerator of the right side of Eq. (14) is zero, Eq. (16) holds. In other words, if is satisfied, there is a linear payoff relationship between the two players’ payoffs.
Press and Dyson (without error) [9] and Hao et al. (with error) [49] only searched for the case that the second and fourth columns take the same value. This makes the determinant become zero. Here, from all possibilities, we search for all of the cases (including this case) that holds. The following determinant theorem gives such a condition.
Theorem 1
For an matrix A, the following holds:
[TABLE]
We define () as -th column vector of the determinant of Eq. (15). From the above theorem, if the columns of the determinant of Eq. (15) are linearly dependent vectors, there exist real numbers , and , except for the trivial solution (,), such that
[TABLE]
where vector denotes a zero vector.
3.1 Without errors (perfect monitoring)
3.1.1 Mathematical analysis
In this section, we search for all of the strategies that enforce a linear payoff relationship without errors ( and ). When there are no errors, the expected payoffs correspond to the original payoffs, i.e., and , respectively. In addition, by substituting and into Eq. (15), we obtain
[TABLE]
which is the same with Press and Dyson’s determinant [9]. By the extensive calculations provided in Appendix A, we found the only strategies that impose a linear payoff relationship between the two players’ payoffs are either
[TABLE]
or
[TABLE]
Equation (19) corresponds to ZD strategies without error ([9], Eq. (1) of [14], Eq. (1) of [13], and Eq. (3) of [38]). Equation (20) is called unconditional strategies [14]. Only these strategy sets can impose a linear relationship and no other strategies can impose it.
To conclude, in the RPD game under perfect monitoring, we showed that either ZD strategies or unconditional strategies can impose a linear relationship between the two players’ payoffs. This is consistent with the previous result in the case with a discount factor but no errors [39].
3.1.2 Numerical examples
We show numerical examples that ZD strategies and unconditional strategies can impose a linear relationship between the two players’ payoffs while others cannot in the RPD game without errors. Figure 1 shows the relationship between the two players’ expected payoffs per game with payoff vector . The gray quadrangle in each panel represents the feasible set of the payoffs. We fixed one particular strategy for player (vertical line) and randomly generate 1,000 strategies that satisfy for player (horizontal axis). Thus, each black dot represents the payoff relationship between two players. In addition, the blue and red are the particular cases for player . Red is the case that player is ALLD and blue is the case that player is ALLC.
Figure 1A shows the case with a Win-Stay-Lose-Shift (WSLS) strategy vs. strategies. As WSLS strategies are neither ZD nor unconditional strategies, the payoff relationships are not linear.
Numerical examples of ZD strategies
Equalizer [9], Extortioner [9], and Generous strategies [23] are known as the three most prominent ZD strategies. Here, we take up the first two as the numerical examples of ZD although Generous strategies play an important role in the evolution of cooperation. In contrast to Extortion, Generous strategies always obtain lower payoffs than the opponent except for mutual cooperation. Hence, Generous strategies are known as one of the cooperative ZD strategies. Because Extortion never loses in a one-to-one competition, Extortion is feasible in a small population. However, in a large evolving population, cooperative groups are more successful than the group of Extortioners. Thus, evolution leads from Extortion to Generous strategies [23]. In this sense, Generous strategies are important. Figure 1B is the case with an Extortioner strategy vs. strategies. Extortioner strategies are the subset of ZD strategies [9] (See Box 1 in [38] for a clear explanation of Extortioner (extortionate) strategies). Extortioner strategies can always gain a higher payoff than the one’s opponent, except for the point , regardless of the opponent’s strategies. When we set in Eq. (19), we obtain an Extortioner strategy, , with . In this particular case, the Extortioner strategy (player ) gains the payoff fifteen times higher than player .
Figure 1C is the case with an Equalizer strategy vs. strategies. Note that, only in this case, the vertical and horizontal axes are reversed. Thus, the horizontal axis is the payoff of Equalizer (player ) and the vertical axis is the payoff of player . Equalizer strategies are also the subset of ZD strategies [9]. If a player uses Equalizer strategies, he can fix the opponent’s payoff to be one particular value. When we set in Eq. (19), we obtain an Equalizer strategy, , which can fix the opponent’s payoff at irrespective of the opponent’s strategies.
Figure 1D is the case with TFT strategy vs. strategies. When we set in Eq. (19), we obtain TFT , which means that TFT is also the subset of ZD strategies. Actually, TFT is a special case of ZD strategies with called “fair strategies” [26]. Moreover, the strategies that including TFT can impose the linear payoff relationship . See Appendix B for the proof.
Numerical examples of unconditional strategies
Figure 1E is the case with ALLC vs. strategies. ALLC is one of the examples of unconditional strategies where . If we substitute and into Eq. (34), we obtain and we have a straight line represented by . We numerically see that the payoff of ALLC is always lower than the opponent’s payoff except for .
Figure 1F is the case with ALLD vs. strategies. ALLD is also one of the examples of unconditional strategies where . If we substitute and into Eq. (34), we obtain and we have a straight line represented by . We numerically see that the payoff of ALLD is always higher than the opponent’s payoff except for . Unlike ZD strategies, the slopes of the straight lines in Figure 1E and 1F are always negative [14].
3.2 With observation errors (imperfect monitoring)
3.2.1 Mathematical analysis
In the same way as no errors, we search for strategies that impose a linear relationship between the two players’ payoffs regardless of the opponent’s strategy in the RPD game with observation errors. If the numerator of the right side of Eq. (14) is zero, the following equation holds:
[TABLE]
In other words, if is satisfied, there is a linear payoff relationship between the two players’ payoffs. By the extensive calculations provided in Appendix C, we found the only strategies that impose a linear payoff relationship between the two players’ payoffs are either
[TABLE]
or
[TABLE]
Equation (22) is ZD strategies with observation errors. This is consistent with Hao et al.’s [49]. Equation (23) is unconditional strategies. Moreover, we analytically show the feasible payoff range for unconditional strategies. See Appendix D.
In summary, in the RPD game even with observation errors (imperfect monitoring), we showed that either ZD strategies or unconditional strategies can impose a linear relationship between the two players’ payoffs and that no other strategies can impose it. This is a new fact discovered in this study.
3.2.2 Numerical examples
As well as the case without errors, we show numerical examples that ZD strategies and unconditional strategies can impose a linear relationship between the two players’ payoffs while others cannot in the RPD game with errors. Figure 2 shows the relationship between the two players’ expected payoffs per game with payoff vector . The gray quadrangle in each panel represents the feasible payoff set. As error rates are increased, the size of the feasible payoff set becomes smaller. We fixed one particular strategy for player (vertical line) and randomly generate 1,000 strategies that satisfy for player (horizontal axis). Each black dot represents the payoff relationship between two players without errors (), the same as Figure 1. Moreover, green, light green, and light blue dots correspond to the cases of , and 0.3, respectively. We do not consider the case of because it does not satisfy the prisoner’s dilemma condition: . As in the case with no errors, red is the case that player is ALLD and blue is the case that player is ALLC.
Figure 2A shows the case with a Win-Stay-Lose-Shift (WSLS) strategy vs. strategies. In this case, is fixed and is varied to 0.1, 0.2 and 0.3. As in the case with no errors, the payoff relationships are not linear in this case because WSLS strategies are neither ZD nor unconditional strategies.
Numerical examples of ZD strategies
Figure 2B is the case with an Extortioner strategy vs. strategies. As shown in Figure 1, (black dots) is the extortion strategy without errors. In this case, player can always gain a higher payoff than the opponent (with the slope of 15), except for the point , regardless of the opponent’s strategies. (green) and (light green) are the extortion strategies when and 0.2, respectively. Unlike Extortioner without errors, there exists the region that the expected payoff of the Extortioner with errors is lower than the opponent’s payoff near .
Hao et al. already proved this fact [49]. They call it dominant extortion when the expected payoff of a focal player is always higher than the opponent except for . This is only possible when there are no errors. When there are errors, only contingent extortion can exist as Hao et al. proved. We assume that player adopts the contingent extortion. The contingent extortion implies that when player tries to increase his payoff, he will increase ’s payoff even more. However, in some regions near , ’s payoff is lower than ’s payoff. We mathematically restate the difference between dominant and contingent based on Hao et al.’s formalism [49]. We transform in Eq. (22) in line with Hilbe’s formalism [14]. We determine so that , are satisfied where is the slope of the line. Note that the inverse of is considered as the slope because, in Hilbe’s formalism, is the coefficient for player while in our and Hao’s formalism is the coefficient for player . Also, must satisfy . When (no error), if we set , we obtain in Eq. (22) and becomes (black dots in Figure 2B). In this case, the payoff of player is always higher than player except for the point . However, when , there is no solution in Eq. (22) when . Thus, is needed, which means that there are the cases that the payoff of player is lower than that of player . For instance, when are given, if we set and , (green in Figure 2B) (light green in Figure 2B) are obtained. In those cases, ’s payoff is lower than ’s payoff near although ’s increase leads to ’s increase even more.
Figure 2C is the case with an Equalizer strategy vs. strategies. Note that, only in this case, the vertical and horizontal axes are reversed. Thus, the horizontal axis is the payoff of Equalizer (player ) and the vertical axis is the payoff of player . As Hao et al. already suggested [49], there exist Equalizer strategies even if errors are incorporated. When (no error), if we set in Eq. (22), we obtain an Equalizer strategy, , which can fix the opponent payoff at irrespective of the opponent’s strategies as shown by black dots in Figure 2C. When , if we set , we obtain an Equalizer strategy, which can fix the opponent payoff at as shown by green dots in Figure 2C. Also, when , if we set , we obtain an Equalizer strategy, which can fix the opponent payoff at as shown by light green dots in Figure 2C. As error rates are increased, the payoff range for Equalizer becomes smaller.
Figure 2D is the case with TFT strategy vs. strategies. When (no error), if we set in Eq. (22), we obtain , which means that (black dots) in the case of TFT. When , and 0.3, if we set in Eq. (22), we obtain , , and , respectively. Thus, we obtain the corresponding lines, (green), (light green), and (light blue), respectively. When there are no errors, always holds. However, there are errors, this does not hold any more. As error rates are increased, the difference between and becomes larger. In general, when there are errors, unlike when there are no errors, TFT does not enforce a linear payoff relationship. Only when special payoff matrices are given, the linear payoff relationship remains. See Appendix E in detail.
Numerical examples of unconditional strategies
Figure 2E is the case with ALLC vs. strategies. ALLC is one of the examples of unconditional strategies where . When (no error), by Eq. (51), we obtain . Thus, the equation of the straight line is (black dots in Figure 2E) and the domain of becomes from Eq. (66). When , and 0.3, we obtain the corresponding lines, (green), (light green),and (light blue), respectively. We numerically see that the payoff of ALLC is always lower than the opponent’s payoff except for and all the dots are on the feasible lines , respectively.
Figure 2F is the case with ALLD vs. strategies. ALLD is also one of the examples of unconditional strategies where . When (no error), by Eq. (51), we obtain . Thus, the equation of the straight line is (black dots in Figure 2F) and the domain of becomes from Eq. (66). When , and 0.3, we obtain the corresponding lines, (green), (light green),and (light blue), respectively. We numerically see that the payoff of ALLD is always higher than the opponent’s payoff except for and all the dots are on the feasible lines , respectively.
4 Conclusions
We analyzed strategies that enforce linear payoff relationships under observation errors in the RPD game. Press and Dyson firstly developed a new mathematical formalism for the expected payoffs of two players and found that if the second and fourth columns of the specific determinant take the same value, the determinant becomes zero, which implies the two players’ expected payoffs become linear [9]. Hao et al. used the same linear algebra technique and extended it to the case with observation errors [49]. Here, not just the case where the second and fourth columns of the determinant take the same value, we searched for all of the strategies which make the determinant zero under observation errors. As a result, we found that the only strategy sets that enforce a linear payoff relationship are either ZD strategies or unconditional strategies, which was consistent with the case of the RPD game with a discount factor [39]. We confirmed that the solutions are correct by showing some numerical calculations.
Press and Dyson first discovered strategies that make the determinant for the expected payoffs zero by finding that the second and fourth columns of the determinant take the same value [9]. They call these strategies “zero-determinant strategies” (original ZD strategies) and all subsequent studies also call them “zero-determinant strategies.” By searching for all possibilities, we found that not only these original ZD strategies but also unconditional strategies make the determinant zero with a different form and that no other strategies exist to make the determinant zero. In this sense, strictly speaking, both the original ZD strategies and unconditional strategies may be called “zero-determinant strategies.”
The original ZD strategies and the unconditional strategies are the only sets which impose a linear payoff relationship irrespective of the opponent strategies, not only in the case with a discount factor [39] but also in the case with observation errors as shown here. This result suggests that, in any case, those two sets are the only types of strategies that enforce a linear payoff relationship between two players. To investigate the inference, one possible direction of future research is analyzing the case of the RPD game with a discount factor under observation errors.
Appendix A Detailed calculations without errors
We substitute the column vectors of the determinant of Eq. (18) into Eq. (17) to obtain
[TABLE]
By taking out in Eq. (24), we obtain
[TABLE]
Here, we search for strategies which satisfy irrespective of ’s strategy , meaning that Eq. (25) must hold true irrespective of . Therefore, the coefficients of each element in Eq. (25) must equal to zero, that is, the following conditions are necessary:
[TABLE]
When Eq. (26) holds, the first terms of Eq. (25) are eliminated and we obtain
[TABLE]
If there exist real numbers, , and such that Eq. (26) and Eq. (27) are satisfied simultaneously, holds irrespective of . To solve Eq. (26), we subtract the fourth equation from the first three in Eq. (26):
[TABLE]
Then, we obtain or from the first equation. First, in the case that holds, the second and third equations automatically hold and we obtain from the fourth. Hence, we obtain and . Second, in the cases that and hold, we obtain and and from the second, third and fourth equations, respectively. Therefore, the solutions of Eq. (26) are either (1) and or (2) . Next, we check that these solutions can also satisfy Eq. (27) in the following.
Case (1) and :
In this case, we substitute and into Eq. (27) to obtain
[TABLE]
Here, when we set , either equation
[TABLE]
or
[TABLE]
must hold. When we set , we obtain the trivial solution . Also, we solve Eq. (31) and obtain the trivial solution . Hence, we do not have to consider the case of . Therefore, in the following, we only consider . Replacing constants , , and with , , and , we obtain,
[TABLE]
If there exist , and for satisfying Eq. (32), there must be solutions that Eq. (17) hold. This strategy set can impose a linear relationship. Eq. (32) corresponds to ZD strategies without error ([9], Eq. (1) of [14], Eq. (1) of [13], and Eq. (3) of [38]).
Case (2) :
In this case, let be , we substitute and into Eq. (27) to obtain
[TABLE]
There exist real numbers , and which satisfies Eq. (33) as follows:
[TABLE]
Because there exist real numbers , and such that Eq. (26) and Eq. (27) are satisfied, enforces a linear payoff relationship. This strategy set is called unconditional strategies [14]. By transforming into in Eq. (34), we obtain the following equations, which are the same as Eq. (16) of [14]:
[TABLE]
Appendix B Strategies that enforce without errors
We prove that strategies specified by and including TFT enforce a linear payoff relationship with under no errors. Equation (19) can be rewritten as follows by transforming into where is the slope of the straight line:
[TABLE]
which corresponds to Eq. (16) of [14]. When , we obtain
[TABLE]
This gives , hence, we obtain . Thus, strategies specified by and enforce a linear payoff relationship with .
Appendix C Detailed calculations with errors
We substitute the column vectors of the determinant of Eq. (15) into Eq. (17) to obtain
[TABLE]
By taking out in Eq. (38), we obtain
[TABLE]
Here, we search for strategies which satisfy irrespective of ’s strategy , meaning that Eq. (39) must hold true irrespective of . Therefore, the coefficients of each element in Eq. (39) must equal to zero, that is, the following conditions are necessary:
[TABLE]
When Eq. (40) holds, the first terms of Eq. (39) are eliminated and we obtain
[TABLE]
If there exist real numbers, , and such that Eq. (40) and Eq. (41) are satisfied simultaneously, holds irrespective of . To solve Eq. (40), we subtract the sixth equation from the first, the seventh from the second, the fifth from the third, and the eighth from the fourth in Eq. (40) to obtain:
[TABLE]
First, we solve the first four equations and obtain (1) , (2) and , (3) and . We further analyze whether these equations satisfy the last four equations and Eq. (41) by dividing into three cases as follows.
Case (1) :
In this case, we substitute into Eq. (42) to obtain
[TABLE]
where and . The equations and do not hold at the same time. Therefore one of the solutions of Eq. (42) is and . Next, we check whether this solution satisfies Eq. (41). We substitute and into Eq. (41) to obtain
[TABLE]
Here, when we set , either equation
[TABLE]
or
[TABLE]
must hold. When we set , we obtain the trivial solution . Also, we solve Eq. (46) and obtain the trivial solution . Hence, we do not have to consider the case of . Therefore, in the following, we only consider . Replacing constants , , and with , , and , we obtain,
[TABLE]
If there exist , and satisfying Eq. (47), there must be solutions that Eq. (17) hold. This solution is ZD strategies with errors. This is consistent with Hao et al.’s [49].
Case (2) and :
In this case, the equations and lead to and . When and , the expected payoffs , and hold, which do not satisfy the condition of the prisoner’s dilemma game: . Hence, we can exclude this solution.
Case (3) and :
In this case, we substitute and into Eq. (42) to obtain
[TABLE]
The equations and do not hold at the same time. The following equations must hold.
[TABLE]
Therefore, we obtain the solution , which is the other solution of Eq. (42). Let be . Next, we check whether this solution satisfies Eq. (41). We substitute and into Eq. (41) to obtain
[TABLE]
There exist real numbers , and which satisfies Eq. (50) as follows:
[TABLE]
This strategy set is unconditional strategies . Therefore, the unconditional strategies enforce a linear payoff relationship in the RPD game with errors because there exist real numbers , and such that Eq. (40) and Eq. (41) are satisfied.
Appendix D The feasible payoff-range for unconditional strategies
In this section, we show the feasible expected payoff-range when a player takes unconditional strategies. We assume that player takes unconditional strategies, which is . By substituting unconditional strategies into Eq. (11), we obtain
[TABLE]
The equations and lead to
[TABLE]
By subtracting times the third column from the first, we obtain
[TABLE]
By subtracting the third row from the first and the fourth from the second, we obtain
[TABLE]
By subtracting times the first row from the third and the fourth from times the second, we obtain
[TABLE]
The Laplace expansion along the first column yields:
[TABLE]
Additionally, the Laplace expansion along the first column yields:
[TABLE]
Therefore ’s expected payoff can be calculated by the form of the determinant as follows:
[TABLE]
Let be and be to obtain
[TABLE]
where and because . In the case of , let be , where ( and ). Then, Eq. (64) leads to
[TABLE]
Here, by the conditions and , the is maximum if the function is minimum and the is minimum if the function is maximum. Then, the maximum of is and the minimum do not exist but . Hence, the range of in the case of is . Next, in the case of , holds. From the above, the feasible expected payoff-range for unconditional strategies is given by
[TABLE]
For instance, when is given, the expected payoffs become , and , respectively. If player is ALLD (), his expected payoff becomes by Eq. (66). Thus, when , and 0.3, the ranges become , , , and , respectively.
Moreover, we can even know the possible payoff range for when player takes by replacing with in Eq. (59).
Appendix E TFT can enforce a linear payoff relationship under errors only when special conditions are satisfied
In general, with errors, TFT can enforce a linear payoff relationship only when special conditions are satisfied. We prove it in this section.
As we showed in the main text, the only strategies that enforce a linear payoff relationship are either ZD or unconditional strategies with observation errors. Thus, TFT must be included in one of them. It is obvious that TFT is not classified as an unconditional strategy because it is specified by . Therefore, we check whether TFT can be classified as ZD strategies. If there exist strategies that satisfy Eq. (22), TFT is one of the ZD strategies.
By substituting into Eq. (22), we obtain
[TABLE]
We solve this equation and obtain the following two types of the solution:
[TABLE]
or
[TABLE]
which means that only in the case that there are no errors () as already proven in Appendix B or the case with , TFT can enforce a linear payoff relationship. Figure E.1 shows the case with . When there are no errors (black dots), TFT can enforce a linear payoff relationship. However, in the other cases (green and light green dots), the linear relationship collapses.
Acknowledgment
This study was partly supported by HAYAO NAKAYAMA Foundation for Science & Technology and Culture and JSPS KAKENHI Grant Number JP19K04903 (G.I.).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] J. Mailath and L. Samuelson. Repeated Games and Reputation . Oxford University Press, Oxford, 2006.
- 2[2] R. L. Trivers. The evolution of reciprocal altruism. Q. Rev. Biol. , 46:35–57, 1971.
- 3[3] M. A. Nowak. Evolutionary Dynamics . Harvard University Press, Cambridge, MA, 2006.
- 4[4] K. Sigmund. The Calculus of Selfishness . Princeton University Press, Princeton, NJ, 2010.
- 5[5] J. Maynard Smith. Evolution and the Theory of Games . Cambridge University Press, Cambridge, 1982.
- 6[6] M. A. Nowak and K. Sigmund. Tit for tat in heterogeneous populations. Nature , 355:250–253, 1992.
- 7[7] M. Nowak and K. Sigmund. A strategy of win-stay, lose-shift that outperforms tit-for-tat in the prisoner’s dilemma game. Nature , 364:56–58, 1993.
- 8[8] D. Kraines and V. Kraines. Learning to cooperate with Pavlov an adaptive strategy for the iterated Prisoner’s Dilemma with noise. Theory Decis. , 35:107–150, 1993.