Mixing time of the adjacent walk on the simplex
Pietro Caputo, Cyril Labb\'e, Hubert Lacoin

TL;DR
This paper analyzes the mixing time of the adjacent walk on the simplex, showing a cutoff phenomenon with a precise spectral gap and extending results to log-concave distributions.
Contribution
It determines the spectral gap and mixing times for the adjacent walk on the simplex, revealing a cutoff phenomenon and extending to log-concave Beta distributions.
Findings
Spectral gap of the adjacent walk is explicitly determined.
Both total variation and separation distances exhibit cutoff.
Mixing times differ by a factor of 2.
Abstract
By viewing the -simplex as the set of positions of ordered particles on the unit interval, the adjacent walk is the continuous time Markov chain obtained by updating independently at rate 1 the position of each particle with a sample from the uniform distribution over the interval given by the two particles adjacent to it. We determine its spectral gap and prove that both the total variation distance and the separation distance to the uniform distribution exhibit a cutoff phenomenon, with mixing times that differ by a factor . The results are extended to the family of log-concave distributions obtained by replacing the uniform sampling by a symmetric log-concave Beta distribution.
Click any figure to enlarge with its caption.
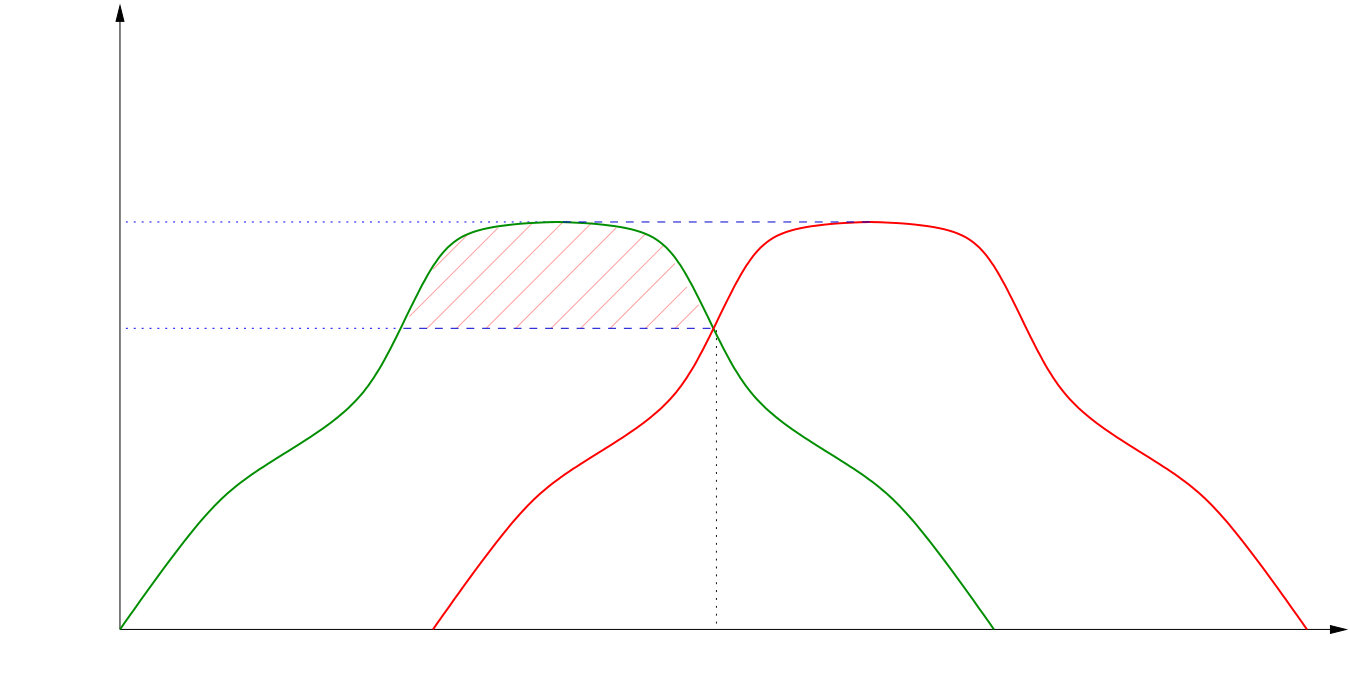 Figure 1
Figure 1Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Mixing time of the adjacent walk on the simplex
Pietro Caputo
Department of Mathematics and Physics, Roma Tre University, Largo San Murialdo 1, 00146 Roma, Italy.
,
Cyril Labbé
Université Paris-Dauphine, PSL University, Ceremade, CNRS, 75775 Paris Cedex 16, France.
and
Hubert Lacoin
IMPA, Estrada Dona Castorina 110, Rio de Janeiro, Brasil.
(Date: January 26, 2020)
Abstract.
By viewing the -simplex as the set of positions of ordered particles on the unit interval, the adjacent walk is the continuous time Markov chain obtained by updating independently at rate 1 the position of each particle with a sample from the uniform distribution over the interval given by the two particles adjacent to it. We determine its spectral gap and prove that both the total variation distance and the separation distance to the uniform distribution exhibit a cutoff phenomenon, with mixing times that differ by a factor . The results are extended to the family of log-concave distributions obtained by replacing the uniform sampling by a symmetric log-concave Beta distribution.
**MSC 2010 subject classifications: Primary 60J25; Secondary 37A25, 82C22.
Keywords: Spectral gap; Mixing time; Cutoff; Adjacent walk.**
Contents
- 1 Introduction
- 2 Preliminaries
- 3 Lower bound on total variation distance
- 4 Mixing time for the separation distance
- 5 Upper bound on total variation distance
- 6 From the top down to equilibrium
- A An extension of the Randall-Winkler upper bound
1. Introduction
Randomized algorithms based on Markov chains are commonly used for sampling points uniformly at random in a convex body and to simulate other log-concave distributions in -dimensional Euclidean space. The mixing time of the associated random walk in is often known to be polynomial in , see e.g. [DFK91, LV03]. In analogy with the setting of Markov chains with discrete state space, where the theory seems to be more advanced, see e.g. the monographs [AF02, LPW17], it is of interest to develop a finer analysis of the asymptotic growth of mixing times in high dimensions.
In this paper we address that question for a specific model, namely the adjacent walk on the -simplex. By viewing the -simplex as the set of positions of ordered particles on the unit interval, this is the process obtained by updating independently at rate 1 the position of each particle with a sample from the uniform distribution over the interval given by the two particles adjacent to it. The process defines a Gibbs sampler for the uniform distribution over the simplex.
The adjacent walk on the -simplex has been previously analysed in [RW05b], where the authors proved upper and lower bounds on the mixing time that are tight up to constant factors; see also [RW05a, Smi14, Smi13] for similar estimates in related models. A version of this model with open boundary conditions was introduced in [KMP82] to study the heat flow in a chain of one-dimensional oscillators.
Here we determine the mixing time to leading order and we establish the so-called cutoff phenomenon for the adjacent walk on the -simplex. We also show that the same results hold if the uniform distribution over the sampling interval is replaced by a symmetric log-concave Beta law, in which case the chain converges to a log-concave distribution over the simplex.
1.1. Model and results
It is convenient to replace the unit interval by the interval , that is to rescale the -simplex to the set of positions of ordered particles on the interval defined by
[TABLE]
We also set . An element in can be viewed as a non-decreasing interface connecting to : this viewpoint will be adopted throughout the article. Given an initial condition , we consider the process
[TABLE]
where , and independently for each , at rate , is resampled according to the uniform distribution on , where we use the convention and .
More formally, this is the continuous time Markov chain with generator
[TABLE]
where, given and , the transformation is defined by
[TABLE]
Let denote the uniform distribution over . Noting that coincides with the conditional expectation shows that the generator is a finite linear combination of orthogonal projections in . In particular, is a bounded self adjoint operator, and the Markov chain is reversible with respect to . Note that can be obtained by conditioning i.i.d. exponential random variables of parameter to have a sum equal to , and by taking the ’s to be their partial sums.
The generator is nonpositive definite and has the trivial eigenvalue zero associated to constant functions. Our first result is a characterization of the spectral gap, defined as the smallest nontrivial eigenvalue of .
Proposition 1**.**
For any , the spectral gap of the generator is given by
[TABLE]
and the corresponding eigenfunction is
[TABLE]
We are interested in the time needed for the total variation distance to equilibrium, starting from the “worst” initial condition, to pass below some given threshold . When this time is, to leading order in , insensitive to the choice of , one speaks of a cutoff phenomenon. More precisely, we set
[TABLE]
where is the law of , and for probability measures on , the total variation distance is given by
[TABLE]
the supremum ranging over all Borel subsets of . For any , the mixing time is defined by
[TABLE]
Our main result is the following.
Theorem 1**.**
For any ,
[TABLE]
As a consequence, the sequence of Markov chains displays a cutoff phenomenon.
In view of Proposition 1, the above theorem can be restated as
[TABLE]
Remark that if is as in (4) and we start with the extremal initial condition , then is exactly the time it takes for the expected value
[TABLE]
to drop from the initial value to a value , which is the typical size of fluctuations of at equilibrium.
Strikingly, Proposition 1 and Theorem 1 take the exact same form in the case of the symmetric simple exclusion process on the -segment; see [Wil04, Lac16].
1.2. Generalization to Beta-resampling
Given , the symmetric Beta distribution of parameter is the probability measure on with density
[TABLE]
We define a generalization of the process described in (2) by resampling points according to a Beta distribution
[TABLE]
While could be replaced by any probability on , the Beta laws are the only resampling laws that make the dynamics reversible with respect to probability measures with a product structure; see Remark 6 below. The associated equilibrium distribution is given by
[TABLE]
where is Lebesgue’s measure on . Since equals the conditional expectation , it follows that is a bounded self adjoint operator in . The following theorem extends the results of Proposition 1 and Theorem 1.
Theorem 2**.**
For any , the spectral gap and the corresponding eigenfunction are given by
[TABLE]
Moreover, for any the -mixing time associated with the Beta-resampling process satisfies
[TABLE]
In particular, the sequence of Markov chains displays a cutoff phenomenon.
Remark 2**.**
We have chosen so that average inter-particle spacing at equilibrium is one. However, this convention has no influence on the result and we may take as well or any other constant (the only effect of this change being a dilation or contraction of space). In the course of the proof it is sometimes convenient to consider also the case of a random (since the process leaves fixed this makes the dynamics non-irreducible in that case).
Remark 3**.**
The restriction is due to the fact that certain parts of our proof require log-concavity of the probability density , which in turn implies the validity of the FKG property for the equilibrium measure , see Section 2.2. However, we believe the result to be valid for all .
Remark 4**.**
The spectrum of restricted to the invariant subspace consisting of linear functions can be computed explicitly (see Section 2.3 below) and the fact that is equivalent to the statement that the spectral gap is attained within this subspace. As the following mean field example shows, this phenomenon is not always to be expected for the exchange dynamics obtained by replacing the segment with another graph. Consider for instance the exchange process on the complete graph with generator
[TABLE]
where
[TABLE]
and denotes the increment variables , . In other words, defines the mean field version of (7). Notice that is reversible w.r.t. . Using the arguments in [CCL03] or [Cap08] one can show that for each the spectral gap of satisfies
[TABLE]
and that the corresponding eigenfunction is the symmetric quadratic function
[TABLE]
1.3. Mixing time for the separation distance
Another distance for which mixing time can be considered is the separation distance (see [GS02]). Its use in the study of mixing times for Markovian systems was initially advocated by Aldous and Diaconis because of its appealing relation to strong-stationary times [AD87]. While to our knowledge, separation distance has been considered so far only for countable state spaces, it can be generalized to a continuous setup via the definition
[TABLE]
where
[TABLE]
and the infimum ranges over all Borel subsets of of positive Lebesgue measure. We can then define the separation mixing time associated with our chain as
[TABLE]
The separation mixing time is always larger than or equal to its total variation counterpart. It is known (cf. [LPW17, Lemma 19.3] in the discrete setup, and Section 4 below for an adaptation of the argument to the continuous case) that in the case of reversible chains, the separation mixing time is at most twice as large as that in total variation. Because of this factor , cutoff in total variation does not necessarily imply that the same phenomenon holds for the separation distance (see [HLP16] for counter-examples)
We prove nonetheless that our dynamics displays a cutoff phenomenon for the separation distance and that the associated mixing times are twice as large as those for the total variation distance.
Theorem 3**.**
For all and every , the -mixing time for the separation distance satisfies
[TABLE]
Here again, our result is analogous to the one obtained for the symmetric simple exclusion process [Wil04, Lac16].
Remark 5**.**
Note that another natural definition of the separation distance in the continuous setup would be
[TABLE]
*Using explicit bounds on the total-mass of the singular part of the law at time , see the proof of Lemma 38, one can prove that the two distances have a cutoff phenomenon at the same time. Because of the regularity of our setting, we strongly believe that , however this is certainly not true for every reversible Markov chain. *
1.4. Comments on the proof and related work
The cutoff phenomenon is a widely studied topic in Markov chain theory, see [Dia96, AF02, LPW17] for an introduction. Thanks to recent remarkable efforts, many interesting examples are known of Markov chains exhibiting this particular type of phase transition. Unfortunately, these seem to be mostly confined to the setting of Markov chains with discrete state space, see however [HJ17] for a recent exception. One of the reasons is possibly the fact that the analysis of total variation distance in a continuous state space is more demanding.
Let us briefly describe the main arguments used to establish the results of this article. Concerning the spectrum, the first observation is that when restricted to the invariant subspace of linear functions, the generator can be easily diagonalised. In particular, one finds that is an eigenfunction of with eigenvalue and therefore, for all , the spectral gap is at most . Proving that this is actually the spectral gap is more delicate. We prove it only in the case since we rely on the FKG inequality. In this case, using the strict monotonicity of , we show that any eigenfunction associated to an eigenvalue larger than needs to be non-decreasing as well, and the FKG inequality is then applied to conclude that the only such eigenfunction is the constant one; see Section 2.3 below. Concerning the case , we can only assert that the spectral gap is not smaller than for some constant . Indeed, this is a direct consequence of the mean field spectral gap (10) and a comparison argument (see e.g. [Cap08]).
To establish the lower bound on the mixing time of Theorem 2, we use Wilson’s method [Wil04]. For , this was already used in [RW05b] to obtain the weaker lower bound
[TABLE]
for some constant . Here we sharpen this, and obtain for any and for all
[TABLE]
see Proposition 11 below: note that we prove this result also for , but in this case is not defined as the spectral gap but simply as being . This suggests a cutoff window of order , but we do not have a corresponding upper bound. The proof of the above lower bound is based on Wilson’s method with a careful choice of the initial condition and a comparison argument which allows us to control the variance of ; see Section 3.
The proof of the upper bound on the mixing time of Theorem 2 is the most involved part of the paper, and is worked out in Section 5 and Section 6. Our strategy can be roughly outlined as follows; see Section 5.1 below for a more detailed overview. In [RW05b], and for , it was shown that
[TABLE]
for some constant . This upper bound was obtained by estimating, under some monotone grand coupling, the hitting time of [math] for the area comprised between the two extremal processes, that is, the processes starting from the highest () and the lowest () initial conditions. Note that under such a coupling this hitting time bounds from above the coalescing time starting from any two initial conditions. The proof consisted of two steps that we now briefly recall. First, using the decay of the heat equation solved by the expectation of the area, one can show that after a time , the area lies below with large probability. Choosing large enough, the second step relies on a brute force argument that shrinks the area to [math] in a time of order with large probability. In Appendix A, we give a proof of (13) in the general case : in contrast with the case , there is no simple monotone grand coupling for a general that achieves an efficient coalescing time of the two extremal processes. We are then lead to controlling the coalescing time of the stationary process and the process starting from some arbitrary initial condition.
The constant of (13) is dictated by the smallest value that one can take in the aforementioned strategy: since needs to be very large for the second step to apply, this value is much larger than desired. Our main contribution consists in introducing a sequence of intermediate steps that reduce the time necessary to bring the area to a small enough threshold from which a brute force argument can be applied. Namely, we use the first step above up to the target mixing time, which guarantees a shrinking of the expectation of the area down to (corresponding to ), and then present a coupling under which, through a sequence of successive stages, we are able to bring the area from down to within a time of order with large probability, that is, a time negligible compared to the target mixing time. The last step is then a (slightly different) brute force argument that shrinks the area to [math] with large probability within a time of order . This program is carried out in Section 5.
At a technical level, we use estimates on the derivative of the predictable bracket process associated to the evolution of the area together with diffusive estimates on supermartingales in order to upper bound the time needed for the area to descend through the intermediate values mentioned above. A key ingredient of these hitting time estimates, is the control of the gradients of the particle positions for the extremal processes, that is the process with maximal and minimal initial particle positions. The control of the gradients, in turn, is obtained by coupling the extremal processes with the stationary distribution. To this end we need to establish, with an independent argument, a sharp upper bound on the time needed for convergence to equilibrium of the two extremal processes.
The sharp upper bound for the extremal processes (by symmetry, we may consider only the highest process) is performed in Section 6. This part of the proof is based on a strategy developed in the discrete setting by [Lac16] for the adjacent transposition process. It relies on the FKG inequality and a version of the censoring inequality from [PW13]. Censoring inequalities are known to hold provided one has monotonicity of the density of the initial condition with respect to the invariant measure. While in the discrete setting this adapts well to the extremal process, in our context a nontrivial adaptation is required since the initial condition is singular with respect to the invariant measure.
2. Preliminaries
Let us consider a larger state-space where there is no constraint on
[TABLE]
The generator defines a dynamics also on this enlarged space. If we let
[TABLE]
denote the increments of , one can easily check that the distribution under which the increments are i.i.d. random variables with distribution , being an arbitrary parameter, is a reversible measure for the dynamics. Here stands for the Gamma distribution with mean and variance .
Remark 6**.**
We remark that the Beta resampling rule (6) is a natural choice in our context. Indeed, suppose we define a generator as in (7) with replaced by another probability on the unit interval. Then one can check that if is a probability measure on under which the increments are independent, the generator is reversible with respect to if and only if is the product of , and , for some . This rests on the well known fact that if are two independent random variables such that and are independent, then and must have the gamma distribution, see [Luk55].
2.1. Monotone grand coupling
There are two natural orders on associated with the dynamics. The coordinate order
[TABLE]
and the gradient order
[TABLE]
Here and below we use the notation for the integer interval . Note that the coordinate order is natural in both and , while the gradient order is only relevant for the unconstrained space . An important observation is that the Beta resampling dynamics preserves both orders in the following sense.
Proposition 7** (Existence of a grand coupling).**
For any , and , we can construct the trajectories of the Markov chain on with generator on the same probability space in such a way that -a.s, for all
[TABLE]
Proof.
The coupling invoked above is the usual graphical construction (see e.g. [Lig05]). To each we associate a Poisson clock process whose increments are i.i.d. rate one exponentials, and a sequence of i.i.d. symmetric Beta variables of paramenter . Then, for all , is chosen to be càd-làg and constant outside of the update times . At time , if the -th coordinate is updated as follows
[TABLE]
One then checks by inspection that the process generated in this manner is the desired Markov chain. Moreover, the above construction implies that it preserves the two above mentioned orders in the sense of (17). ∎
Let us finally introduce the maximal and minimal configurations for the coordinate order that we defined above:
[TABLE]
2.2. The FKG inequality
When , the equilibrum measure can be interpreted as a one dimensional gradient field associated with a convex potential. More precisely we can write
[TABLE]
where is the convex potential
[TABLE]
Below we use a standard application of Holley’s criterion (see [Pre74]) to show that satisfies the so-called FKG inequality which entails positive correlation between increasing functions.
We say that defined on is increasing if
[TABLE]
A subset is said to be increasing if is an increasing function. We let and denote the following operations in
[TABLE]
(Note that there is a little clash of notation with the maximal and minimal configurations introduced in (18): however we believe that this will never raise any confusion in the sequel).
Proposition 8** (FKG inequality).**
For any and , if and are increasing then
[TABLE]
Moreover, the inequality remains valid if is replaced by its restriction to any set which is stable under the operations and .
Proof.
Setting , the density of with respect to Lebesgue is given by and Holley’s criterion shows that the inequality holds provided that
[TABLE]
The inequality (22) can be deduced as a consequence of the convexity of see [Gia02, Appendix B1]. For the measure restricted to a set it is sufficient to check that (22) is valid when is replaced by
[TABLE]
which is an immediate consequence of (22) under our assumption on . ∎
Let us point out that the first inequality of Proposition 8 could be obtained directly from the monotonicity stated in Proposition 7, see for instance [LPW17, Th 22.16], and therefore does not require the convexity of the potential (that is, it holds also for ).
For two probability measures on , we write and say that is stochastically dominated by if for all increasing (in the sense of (20)) one has . Let us mention another application of Holley’s criterion which we are going to use in the proof.
Lemma 9**.**
Let and be two increasing subsets of such that
[TABLE]
Then
[TABLE]
Proof.
Let and . These probability measures have density proportional to and respectively, where the potentials are defined as in (23). The result then directly follows from [Pre74, Proposition 1] if one can show that for every
[TABLE]
This in turn follows from the inequality (22) for and our assumption on .
∎
2.3. Identification of the spectral gap
Here we prove the first statement of Theorem 2. Fix and , and write for the generator . Using the expression (7), the action of the generator on the coordinate map , , is given by
[TABLE]
where denotes the discrete Laplace operator
[TABLE]
Summation by parts and (25) then shows that for every the map
[TABLE]
is an eigenfunction of with the eigenvalue where
[TABLE]
In the case , we simply write for and for . We now turn to show that is actually the spectral gap.
It is not hard to check that for any , the set of all polynomials of degree at most in the variables is stable under the action of the generator. When restricted to any such set, the generator admits a finite complete decomposition into eigenvalues / eigenfunctions. By density of polynomials in , there exists an orthonormal basis of polynomial eigenfunctions and therefore the generator has pure point spectrum in .
maps to zero all constant functions and any nontrivial eigenvalue of must be associated with an eigenfunction with mean zero. Therefore it is sufficient to show that if is a normalized polynomial eigenfunction such that and , with , then . Since is polynomial, and since is strictly increasing in all its variables, there exists such that remains increasing in all its variables. Next, we define the following normalized function
[TABLE]
where denotes the semigroup generated by , and is the -norm. From our assumptions one has and
[TABLE]
with . It follows that as in . On the other hand, the semigroup preserves monotonicity by Proposition 7, so that is a non-decreasing function at any time . Thus, must be also non-decreasing. Notice that so far the argument is valid for any . We shall now use the assumption .
The FKG inequality and the orthogonality of and imply that the centered coordinate maps satisfy
[TABLE]
Indeed, by Proposition 8 one has and if this is positive for some , then .
Let be the event , with . Since both and are stable for the operations and introduced in (21), by Proposition 8 the restrictions and satisfy the FKG inequality. Therefore,
[TABLE]
The FKG inequality implies that both terms in the last expression are nonnegative: indeed, is increasing and therefore
[TABLE]
Hence the first term in the right hand side of (27) must be zero. Since , this is possible only if . However, that and the continuity of imply that the extremal configuration satisfies
[TABLE]
Hence for all and therefore . ∎
2.4. Absolute continuity
Recall that under , the r.v. sum up to . At several places in the proofs, it will be convenient to deal with independent r.v. instead. To that end, we use the following informal fact: for any , the law of under is uniformly over absolutely continuous w.r.t. the law of independent r.v. The formal version is stated below:
Lemma 10**.**
Fix . There exists a constant such that for all , writing , for any bounded measurable function we have
[TABLE]
where is the law on under which the ’s are IID r.v.
Proof.
Let be the density function of a centered Gaussian distribution of unit variance. Let be the density function of a centered r.v. By the Local Limit Theorem [Pet75, Th.VII.2.7], we have
[TABLE]
Using the above together with the fact that is maximized at [math], we have for all sufficiently large
[TABLE]
The result follows by tuning the value of to also include the first few values of . ∎
3. Lower bound on total variation distance
In this section we prove the lower bound on the mixing time displayed in Theorems 1 and 2. We obtain in fact a more quantitative lower bound which is valid for all values .
Proposition 11**.**
For any , for any there exists such that for all
[TABLE]
We are going to follow a variant of the method introduced by Wilson in [Wil04]: to obtain the lower bound (28), we select a specific test function and show that by time , the value is far from the equilibrium value with large probability. This is achieved by picking a suitable initial condition and by evaluating the first two moments of . As in the case of the exclusion process, we select , the eigenfunction appearing in Proposition 1. As noted in the proof of that proposition, is an eigenfunction with eigenvalue for all .
The initial condition is defined as follows. When we let be111In this section, we write for in order to alleviate notations. i.i.d. exponential random variables with mean conditioned on , and set for all . More generally, for arbitrary we choose the distribution of for to be i.i.d. , with the same conditioning on the sum, and set again for all . For the rest of this section, we let be the process starting from the random initial condition with increments ,
[TABLE]
We shall use for the corresponding probability measure and expectation, and for the associated variance. For later use we also prove a result concerning the variance of other Fourier coefficients of , namely the functions from (26).
Lemma 12**.**
For the process described above with initial condition (29), there exists such that for all and all large enough
[TABLE]
and for every
[TABLE]
With this lemma at hand, the proof of the lower bound is simple.
Proof of Proposition 11.
Define
[TABLE]
and note that for all :
[TABLE]
Chebyshev’s inequality and Lemma 12 imply that
[TABLE]
Similarly, noting that , one has
[TABLE]
Recalling that concludes the proof. ∎
We close this section with the proof of the lemma.
Proof of Lemma 12.
First of all, since is an eigenfunction of associated with the eigenvalue , we have
[TABLE]
where the last bound follows from the fact that the initial condition satisfies
[TABLE]
To compute the variance at a fixed time (we focus on the case to keep the notation light and explain the general case at the end of the proof), we introduce the process
[TABLE]
Since , , it follows that is a martingale. The associated increasing predictable process, or angle bracket, is denoted , . In particular, we look for an upper bound on .
Note that independently of the value of , when an update is performed at coordinate , the value of varies at most by , where . Thus,
[TABLE]
Therefore,
[TABLE]
Now using monotonicity of the dynamics for the gradients (Proposition 7), we can replace by the gradients corresponding to a dynamics on starting from a larger initial condition for the order defined in (16). A natural choice is to pick an initial condition which is stationary for the dynamics so that the dependence in vanishes in the integral.
Let be i.i.d. variables with distribution , conditioned to
[TABLE]
and consider the dynamics on with initial condition . Note that one can construct and on the same probability space in such a way that for all by setting
[TABLE]
and , for . Indeed, by a standard property of the gamma distribution, the variables and are independent and therefore the defined in (31) has the correct distribution. Hence using Proposition 7 we can assume for all and thus in particular .
Finally let be (unconditioned) i.i.d. with distribution . Defining the dynamics with this initial condition one has
[TABLE]
By stationarity,
[TABLE]
Since the expected value of each is , the central limit theorem shows that the event has probability at least if is sufficiently large. In conclusion,
[TABLE]
Using this bound in (30) shows that uniformly in .
For , we repeat the above procedure for the martingale
[TABLE]
and obtain . This concludes the proof of Lemma 12.
∎
4. Mixing time for the separation distance
Here we prove Theorem 3. The main result of this section is the following lower bound.
Proposition 13**.**
For any , there exists such that for any and for all sufficiently large we have
[TABLE]
With this result at hand, and assuming the validity of Theorem 2, the derivation of the asymptotic of the separation mixing times is somewhat standard.
Proof of Theorem 3.
Proposition 13 gives the desired lower bound on the mixing times. Regarding the upper bound, we adapt the argument used in the discrete setup (see e.g [LPW17, Lemma 19.3]) to show that
[TABLE]
where denotes the positive part. Theorem 2 and (33) clearly imply the desired upper bound in Theorem 3.
Recalling the notation defined below (11) we notice that reversibility implies that and as a consequence
[TABLE]
Thus for any with positive Lebesgue measure, using the semigroup property at the first line and reversibility at the second line
[TABLE]
By Schwarz’ inequality, we have
[TABLE]
Let denote the normalized version of . From (34) it follows that and are the respective densities of and w.r.t. . Therefore, using the triangular inequality one has
[TABLE]
Taking the infimum over and yields (33). ∎
Proof of Proposition 13.
We are going to show that for all , there exists such that if
[TABLE]
then one can find measurable sets such that
[TABLE]
A natural choice to minimize is to choose as tiny neighbourhoods of the opposite extremal configurations. We define the neighbourhoods of our extremal configurations and as follows
[TABLE]
and we are going to prove
[TABLE]
We assume for simplicity that is even just for the sake of notation. The first step of the proof is to reduce (36) to a simple statement about the process at time
[TABLE]
and the second step is to prove (37).
Let us now show that (36) follows from (37) as a consequence of reversibility and the FKG inequality. The proof is in fact very similar to the one developped in [Lac16, Section 7.1] in a discrete setup. We have
[TABLE]
Now we can split the integral on into two contributions
[TABLE]
with and . Using reversibility and symmetry we have
[TABLE]
so that the right hand side of (38) is equal to
[TABLE]
Now according to the observations made in Section 6 (see Lemma 32), the measure
[TABLE]
has an increasing density with respect to (call it ). Also we observe that by monotone coupling is decreasing in . Hence using the FKG inequality (Proposition 8 for the restriction to the stable set ) we obtain that the quantity (40) satisfies
[TABLE]
Using stationarity we see that the second integral is smaller than
[TABLE]
Hence using the fact that and replacing by its definition we can conclude that
[TABLE]
This proves that (36) follows from (37). It remains to prove (37), or in other words that starting from a random initial condition in the probability that is small.
Note that (37) follows from a slightly stronger result for the maximal initial condition
[TABLE]
Indeed, with the grand coupling described in the proof of Proposition 7, for any , and any we have
Now by monotonicity we can replace by the dynamics with the random initial condition considered in Lemma 12.
The function can be decomposed on the orthonormal basis of the discrete Laplacian (endowed with Dirichlet b.c.). Using (26), we thus obtain
[TABLE]
Using the fact that , and observing that all the terms with become negligible, it follows that if the constant is large enough, then
[TABLE]
Now the important part is to control the variance of . Our control is uniform in time.
From the very rough bound valid for any sequence of random variables , and using Lemma 12 one obtains
[TABLE]
Then (43) can easily be deduced by combining the inequalities for the two first moments (45) and (46). ∎
5. Upper bound on total variation distance
5.1. Decomposition of the proof
In this section we prove the upper bound on the total variation mixing time displayed in Theorems 1 and 2. Given we set
[TABLE]
and we are going to prove that
[TABLE]
Since is arbitrary and this yields the desired upper bound. We establish this statement via two intermediate propositions. Firstly, we show that by time we can bring to equilibrium the extremal process started in the maximal configuration .
Proposition 14**.**
For any we have
[TABLE]
Secondly, we show that with large probability and for any given initial condition , we can couple the process starting form with the maximal process.
Proposition 15**.**
For any we have
[TABLE]
By the triangle inequality, (47) is an immediate consequence of the two propositions above.
Even though Proposition 14 is a consequence of Proposition 15, our proof of the latter will actually rely on the former result; see also Remark 42 below. Consequently, we will need an independent proof of Proposition 14 and this will be carried out in Section 6. The remainder of this section is concerned with the proof of Proposition 15.
From now on, is fixed; however all the constants that will appear below will be independent of this chosen . In the forthcoming Section 5.2, we construct the processes and on the same probability space in such a way that (recall (15))
[TABLE]
In the remainder of this proof denotes the probability associated with the probability space on which this coupling is constructed. We let denote the area comprised between the graphs of and :
[TABLE]
and we aim at bounding its hitting time of [math]
[TABLE]
As the ordering given by (48) implies that for , we have
[TABLE]
Of course the distribution of depends tremendously on the coupling. For instance, the reader can check that for the coupling provided by Proposition 7 which satisfies (48), we have with probability one. The coupling presented below is constructed with the aim of minimizing the merging time . The proof is split into three main steps:
- (1)
The area passes below by time with large probability. 2. (2)
Within an additional time of order , the area is very likely to decline from to . 3. (3)
The area goes from down to [math] within a time of order with large probability.
The above steps clearly ensure that the event has a small probability, which will conclude the proof of Proposition 15.
The first step is a rather simple consequence of the fact that is a solution of the discrete heat equation.
The third step is a brute force argument inspired by Randall and Winkler [RW05b]. More precisely, for this last step we build on the main idea of [RW05b], but we improve it in a quantitative manner using estimates on the minimum gradient of .
The second step above is by far the most delicate one. The strategy is to introduce a sequence of intermediate thresholds between the values and , and then analyse the associated hitting times for the area process. Our control of these hitting times relies on diffusive estimates for the supermartingale and on estimates on the corresponding angle bracket process. One of the ingredients of the latter estimates is a fine control of the gradients of , which is in turn derived from a combination of equilibrium estimates and Proposition 14.
5.2. The coupling and preliminary lemmas
We start by defining the coupling . For any and any configuration , we define the “interval of resampling of the -th coordinate” as and write for its length, where the “gradient” is defined by
[TABLE]
For simplicity we sometimes use the short-hand notation and . In our construction, we are going to try, at each resampling event, to couple and with the maximal probability. Letting denoting the distribution with density given by (when )
[TABLE]
we set
[TABLE]
and . In the case we have
[TABLE]
but there is no such simple expression for when ; however we will be able to provide good estimates for it (cf. Lemma 16).
Then, we define , , to be the probability measures with respective densities , and given by
[TABLE]
As a consequence of our assumption (which makes the functions unimodal), and the fact that by monotonicity both extremities of are larger than their counterparts in , the supports of and are intervals and , the lower extremity of being larger or equal than the upper extremity of . To see this it is sufficient to check that there exists at most one value such that the equation has at most one solution. We refer to Figure 1 for the case and to Figure 2 for the general case of a unimodal density.
Our coupled dynamics is defined as follows. Each pair of coordinates , , is updated with rate one independently, and when an update occurs at time then
- •
with probability , the two new coordinates are set to the same value drawn from the distribution ,
- •
with probability , the two new coordinates are sampled independently with respective distributions and , and therefore satisfy .
For convenience, we set
[TABLE]
(in the remainder of the proof as a positive parameter is not used anymore so that this should not yield confusion). We also introduce the “mean” interfaces and by setting
[TABLE]
and similarly for . Note that is the midpoint of the interval of resampling of the -th coordinate. We finally set
[TABLE]
We now collect a few facts on our coupling. We start by showing that the probability can be fairly approximated by
[TABLE]
and that, as soon as is close enough to , the overlap between the resampling intervals represents a small fraction of the largest resampling interval. This second bound will be convenient in order to bound from below the derivative of the bracket of the area, see the proof of Proposition 18.
Lemma 16**.**
For any , there is a constant (that depends on ) such that for all and
[TABLE]
Furthermore, there exists a constant such that
[TABLE]
(where the notation used is the one introduced below (50)).
Proof.
Note that (54) is simply a result concerning the total variation between two variables defined on two intervals and such that and . Recalling the definition (51)
[TABLE]
and (54) holds if we can prove (for a different constant ) that
[TABLE]
By symmetry, we can assume that is the largest of the two intervals and by scaling invariance we can assume without loss of generality that and , , , in which case
[TABLE]
We can further assume that as the result is trivially valid when .
For better readability of the proof we replace by a generic unimodal function which is positive on , integrates to and is symmetric around . We replace by with the convention that for .
We first let the reader check that is increasing in and simply because the integrand displays the same monotonicities.
For (55), we simply observe, using these monotonicities in and , that if then
[TABLE]
As a consequence, setting , we deduce that if , we have and thus yielding (55).
To prove (54), we show that for every
[TABLE]
which allows to prove (57) with . By monotonicity it is sufficient to check the upper-bound for . Figure 2 provides a graphical proof of the following inequality
[TABLE]
Now concerning the lower bound, using again the graphical proof of Figure 2 (by symmetry of the two curves intersect at ), we have for
[TABLE]
and thus the l.h.s. being increasing in we conclude that for all (the factor is present so that the inequality is also valid for )
[TABLE]
Using symmetry and invariance by translation at the first line and the triangle inequality for the total variation distance at the second line, we have
[TABLE]
This lower bound is also valid for by monotonicity in , thus completing the proof of (58). ∎
Remark 17**.**
Let us observe for latter use that the upper bound in (57) is also valid without the assumption , (at the cost of taking twice as large). This can be deduced from the other case. Indeed, assume without loss of generality that and set . Then, using the previous bounds for the pairs and ,
[TABLE]
Using the expression for the generator (25) and the fact that our coupling preserves monotonicity the reader can check that for every
[TABLE]
and hence that is a supermartingale for the filtration defined by . We write , for the associated angle bracket process, namely the increasing predictable process that compensates the square of the martingale part of .
Proposition 18**.**
There exists a constant such that for all large enough and for all , we have
[TABLE]
Remark 19**.**
The proof will actually establish the same bound but with replaced by the maximum of the latter and .
Proof.
First of all, recalling the coupling defined in Section 5.2, we have
[TABLE]
where is the mean square displacement corresponding to an instantaneous uncoupled jump of at time . We are going to prove a lower bound for each term in the sum, and as before we omit from now on the dependence in and . Without loss of generality we assume that .
We let and denote the two independent variables with respective distribution and (whose densities are described in Equation (52)) that are used in the coupling. We are going to prove first that
[TABLE]
This is achieved by computing explicitly (here denotes expectation for the pair of variables )
[TABLE]
Replacing by its value, observing that , and taking the minimum over all possible values for we obtain that the l.h.s. of (61) is larger than
[TABLE]
which is the desired result.
To conclude from (61), we consider from (55) in Lemma 16. If then the r.h.s. of (61) is larger than and we can conclude using the upper bound in (58).
When then we use (55) which ensures that
[TABLE]
so that with probability at least , coincides with a r.v. conditioned on being larger than its median . Since the variance of the latter conditional law is of order , so that for some adequate choice of we have we have
[TABLE]
which concludes the proof.
∎
5.3. Successive hitting times
To prove Proposition 15, our argument is to show that by time , the area has become very small (smaller than ) and then to use some brute force argument to show that cannot be much larger.
Our strategy to control the decay of the area requires several steps and we introduce the successive hitting times by the area of a sequence of well-chosen thresholds. For small, we define
[TABLE]
We first show that with large probability is equal to . Then setting , we show that the increments are small for all . The argument to control the increment differs for different ranges of so that it is practical for us to introduce the following intermediate thresholds
[TABLE]
We now introduce the following events which allow us to split our proof in four parts
[TABLE]
We prove in the forthcoming Sections 5.4, 5.7, 5.8, and 5.9 respectively that each of these four events holds with probability tending to 1. This implies in particular that
[TABLE]
In Section 5.10 we use this last statement to conclude the proof of Proposition 15. The remaining Sections 5.5-5.6 are dedicated to the introduction of technical material which is used throughout Sections 5.7-5.10.
5.4. Initial contraction of and control of
The probability of can be controlled using Markov’s inequality for the non-negative random variable . Indeed has an explicit expression in terms of the discrete heat equation. This argument does not exploit our specific coupling .
Lemma 20**.**
For any we have as
[TABLE]
In particular, if then .
Proof.
Let us set . From the expression (25), we deduce that
[TABLE]
In addition we have . Expanding on the orthonormal basis of the discrete Laplacian as in (44) and estimating all the corresponding eigenvalues by the main eigenvalue, it follows that
[TABLE]
By Cauchy-Schwarz’s inequality,
[TABLE]
Markov’s inequality then yields the asserted result. ∎
5.5. Technical preliminaries to control the probability of , ,
Before going into the specifics of each case let us introduce the common framework which allows us to control for . Our main idea is to exploit the fact that is a supermartingale for which we have a reasonable control on the jumps. For such processes the hitting time can be estimated if one can control the angle bracket of the martingale, as shown in the following result from [LL18].
Proposition 21**.**
Let be a pure-jump supermartingale with bounded jump rate and jump amplitude. Given and , set
[TABLE]
If the amplitude of the jumps of is bounded above by , then we have for any
[TABLE]
where denotes the bracket of (the predictable processes which compensates the square of the martingale part of ).
Proof.
The only difference with the statement of [LL18, Proposition 29] is that is not necessarily below . However, a careful inspection of the proof therein shows that the present statement holds (note that the proof therein relies on [LL18, Lemma 30] and this result does not need any modification to cover our setting). ∎
We apply the previous proposition to the supermartingale . Our idea is to combine the above result with estimates on the increments of the bracket of , in order to obtain upper-tail probability for the increments of the hitting times . The control of as a function of is technically involved. Our general strategy is to restrict ourselves to an event of large probability for which we have (for some adequate constant )
[TABLE]
The specific events that we have to consider is introduced in the following section.
5.6. Restriction to the right set of events
Our convenient event is the intersection of two events and that we now introduce (for these events and others we make the dependence in appear only when necessary). Regarding , we only impose that the increments of the higher interface are not too large “at all times”:
[TABLE]
That the probability of goes to will follow from the fact that the higher interface is close to equilibrium by Proposition 14 and from simple estimates under the invariant measure. To define , we introduce the following events that impose some restrictions on the interfaces at a given time . The events and require respectively the gradients of the higher interface to be not too small, and the distance between the two interfaces to be not too large:
[TABLE]
Given , we let be the increasingly ordered sequence of the values . Then we set
[TABLE]
Finally we define
[TABLE]
The event then requires that for a large proportion of the interval of time , the four events are satisfied:
[TABLE]
Note that the probability of still goes to if is replaced by any factor . However, for latter use we need this factor to be larger than , and this explains our particular choice .
Proposition 22**.**
We have .
Proof.
Recall that is the invariant measure of our dynamics, and let be the law on under which the ’s are independent r.v. Without further mention, we will apply Lemma 10 that allows us to bound some functionals under by the same functionals under .
We start with the event . We have (recall that )
[TABLE]
By Proposition 14, it follows that
[TABLE]
Therefore, it suffices to work with the process starting from the stationary measure : we denote by the law of such a process. Let us subdivide the interval into disjoint intervals of size : note that there are of order such intervals. Then, a standard argument on independent Poisson clocks ensures that the probability that on each interval there is no more than resampling event is larger than for some constant , hence on that event, at any time , is equal to some for some . Moreover, a simple union bound combined with (72) shows that the probability that for all and all , goes to . Therefore,
[TABLE]
We turn to the event . By Markov’s inequality, it suffices to show that for every
[TABLE]
To handle the events , and , Proposition 14 ensures that one can work under the stationary measure . We are going to make extensive use of the following tail estimates for the distribution:
[TABLE]
By Lemma 10, the bound is also valid under (with a different constant). To control the probability of it is sufficient to observe that by union bound and exchangeability of the increments
[TABLE]
We turn to . By union bound and exchangeability again we have
[TABLE]
for all . Since , it is simple to check that for small enough , we have which suffices to conclude.
We now consider . We let denote the set of increasingly ordered values of . We are going to show that tends to zero where
[TABLE]
The same bound concerning the odd gradients is then sufficient to conclude. By union bound and exchangeability of the variables , we have
[TABLE]
Using Lemma 10 and (73) we obtain for some positive constant
[TABLE]
Regarding , we first show that for sufficiently large
[TABLE]
By symmetry, we can restrict to and by Lemma 10, it suffices to prove this bound under . For every the law of under is . Using a Chernoff bound for all large enough we obtain
[TABLE]
(Note that a finer upper bound would be for some small enough ). Consequently, (76) follows. By Proposition 14, we deduce that
[TABLE]
By symmetry the same is valid for . By Proposition 7 is stochastically dominated by and stochastically dominates . This implies that
[TABLE]
and the result is obtained by observing that is contained in the union of the two events in (77) and (78). ∎
5.7. Controlling the increments for
We are now ready to prove
Lemma 23**.**
The event satisfies
[TABLE]
Recall that for any , the area satisfies for some . Our proof relies then on the following observation.
Lemma 24**.**
For all , on the event we have
[TABLE]
Proof of Lemma 23.
Proposition 21 applied to the supermartingale (whose maximal jump size is ) with , yields that where
[TABLE]
To conclude we only need to show that
[TABLE]
We proceed by contradiction. On the event consider the smallest integer in such that . Applying Lemma 24 on the interval , on which we obtain
[TABLE]
where the last inequality uses the definition of to assert that
[TABLE]
∎
Proof of Lemma 24.
Since , we have for large enough
[TABLE]
Since we work on , we get
[TABLE]
The bound on the gradients given by ensures that
[TABLE]
so that for large enough we get
[TABLE]
and
[TABLE]
Consequently by Proposition 18 on the event
[TABLE]
The set over which the sum is taken on the r.h.s. can be decomposed into connected components of size at least . On , we thus deduce that there exists such that
[TABLE]
where in the last line we simply used (82). ∎
5.8. Controlling the increments for
We can prove now
Lemma 25**.**
We have
[TABLE]
We follow essentially the same line of proof as in the previous section, but using a different inequality for the bracket derivative. We also need an extra trick to control the maximal amplitude of jumps. Recall that for every , we have .
Lemma 26**.**
Fix . On the event , we have for all
[TABLE]
Proof of Lemma 25.
In order to diminish the restriction on imposed in Proposition 21 we introduce the following stopping times with the objective of considering a process with smaller jump amplitude
[TABLE]
We consider the supermartingale . For every , its maximal jump size up to time is bounded by
[TABLE]
Indeed, the maximal variation of the area due to an update of site at time is bounded above by
[TABLE]
We consider now the event
[TABLE]
with . The standard union bound and a supermartingale version of Doob’s maximal inequality (sometimes refered to as Ville’s inequality) show that , and hence converges to [math]. Now, applying Proposition 21 to with yields .
Our final step is to prove
[TABLE]
We place ourselves on the event and we proceed by contradiction. Consider the smallest element of such that (note that as we are on we must have ). Because we are on the event , the reader can check that we must have
[TABLE]
Hence by Lemma 26 , and imply that
[TABLE]
where for the inequality we proceed as in the proof of Lemma 23 to show that the integral is larger than . This yields the desired contradiction. ∎
We are left with proving Lemma 26. The first step is the following technical estimate.
Lemma 27**.**
Given , let be an increasing sequence of positive real numbers with , and an arbitrary sequence in with , and let us set , and . Then we have
[TABLE]
If we have
[TABLE]
Proof.
Let us start with the case when . Using that and are bounded by we have
[TABLE]
Now the reader can check that if is fixed, the r.h.s. is minimized when for , , and for . When , it is sufficient to check (88) when by monotonicity, and in that case we have
[TABLE]
∎
Proof of Lemma 26.
First assume that . As in the proof of Lemma 24, the bound on the gradients given by ensures that
[TABLE]
Consequently, if we let be an integer for which we get the bound
[TABLE]
By , we thus deduce that
[TABLE]
Next, assume that . Set . We apply Lemma 27 with being the ordered sequence of the and being the corresponding ’s. Since and since , the lemma combined with and Proposition 18 gives the following lower bound
[TABLE]
∎
5.9. Controlling the increments for
Following our plan we now prove
Lemma 28**.**
We have
[TABLE]
This time we use the following control for the martingale bracket, which is almost immediate to prove
Lemma 29**.**
On the event we have
[TABLE]
Proof.
Combining Proposition 18 and Lemma 27, we obtain
[TABLE]
∎
Proof of Lemma 28.
We only need to show that
[TABLE]
A contradiction can be obtained exactly as in the proof of Lemma 28. More precisely assuming that does not hold we obtain that for some
[TABLE]
∎
5.10. Proof of Proposition 15
We finally conclude the proof by proving
[TABLE]
We first need to restrict ourself to an adequate event of large probability. Using the fact that is a supermartingale, combinining the Martingale stopping theorem and Doob’s inequality we obtain that
[TABLE]
Since Lemma 20, 23, 25 and 28 assert that with large probability, we have where
[TABLE]
We also need to make sure that the gradients in our dynamics are not too small.
Lemma 30**.**
Setting
[TABLE]
we have
[TABLE]
Proof.
First of all, by Proposition 14 it suffices to control the probability of this event for the stationary process in the time interval , which we denote by for the rest of this proof. Recalling (73) we have
[TABLE]
Now for each , consider the ordered set of update times of the coordinate for our dynamics. We let be the number of updates of the site occurring in the time interval .
As the dynamics is of heat-bath type, for every and , is distributed like . This is also valid conditionally on the realization of the update times. Hence considering that can only be altered at times , from the union bound and (94),
[TABLE]
Taking the expectation of the above we obtain the desired result. ∎
For every site , let denote the random set of update times occurring in the interval . We set
[TABLE]
The probability of goes to one (by a standard coupon collector argument for the lower bound while the upper bound is a direct union bound) and one can thus safely restrict oneself to the event .
To conclude the proof, we are going to show that
[TABLE]
We are in fact going to prove an upper bound for this probability conditioned on both and the state of the system at the initial time . We use the short-hand notation for this conditional probability and the corresponding expectation.
Say that an update at time is successful if . The strategy is to work recursively on the successive update times, and to use the following fact. If all the previous updates have been successful, then using Lemma 16 the probability that the next update (occurring at site say) is not successful is bounded from above by (a constant times) divided by the largest gradient, this ratio being bounded by on the event . Since there are at most updates per site, since is bounded by twice the area and since the area is non-increasing as long as the updates are all successful, we deduce that the probability (95) that there exists an unsuccessful update is bounded by on the event . Thus, one can conclude. To put these heuristic observations on a firm ground, we need to introduce some notations.
Let be, among the set of update times , the time of the first unsuccessful update: on the event that there are no unsuccessful updates, we set arbitrarily . Note that the event is measurable w.r.t. the sigma-field generated by and the state of the system at the initial time . Since the probability of this event goes to , it suffices to show that
[TABLE]
in order to deduce that the merging time satisfies
[TABLE]
To prove (96), we set
[TABLE]
Then, almost surely
[TABLE]
The first term on the r.h.s. goes to [math] by Lemma 30. Regarding the second term, we argue as follows. Recall that is the sigma-field generated by the system up to time , and let . Using Lemma 16 at the second line, for all and we have
[TABLE]
Consequently,
[TABLE]
and on the event this last expression is bounded by
[TABLE]
for some new constant . This concludes the proof of (96).
6. From the top down to equilibrium
The goal of this section is to prove Proposition 14, that is: when started from the maximal configuration , setting , one has
[TABLE]
for any fixed .
Inspired by a strategy that was introduced in [Lac16] in the context of the adjacent interchange process, we shall base our proof on a two-scale argument, that can be roughly described as follows. For any integer , consider the particles with labels , . These will be called the special particles. The proof of (97) consists of three main steps.
Step 1. Starting from , after a time , if is fixed and tends to , then the joint distribution of the positions of the special particles
[TABLE]
is arbitrarily close to the corresponding equilibrium distribution, see Proposition 39 below. This step is based on a subtle use of the FKG inequality together with the control of the expected value of the variables .
Step 2. Consider the censored dynamics obtained by freezing the positions of the special particles and letting the rest of the particles evolve as usual. We will show that if is taken proportional to , uniformly in the initial condition, the censored dynamics at time has essentially reached the conditional equilibrium given by conditioned on the positions of the special particles. For this step it will be sufficient to exploit an upper bound on the mixing time that is tight up to a constant factor as e.g. the one obtained in [RW05b] in the case , see (13) above.
Step 3. We combine the results in the previous two steps to obtain the desired conclusion. The key point is that the distance to equilibrium at time appearing in (97) satisfies
[TABLE]
where the distribution is obtained by running the standard dynamics, starting from , for a time and then by running from there the censored dynamics for a time . This step requires an adaptation to our continuous setting of the so called censoring inequality of Peres and Winkler [PW13].
We start developing the above program with a discussion of the censoring inequality. We then move to the proof of the mentioned steps in the given order.
6.1. Censoring lemma
The censoring inequality established by Peres and Winkler [PW13] allows one to compare the distance to equilibrium at time for the process under consideration with the distance to equilibrium at time for a censored process in which some of the updates have been omitted according to a given censoring scheme. In the context of Glauber dynamics for monotone, finite state spin systems, their argument rests on the following two key properties of a monotone dynamics: If the initial state has a distribution whose density w.r.t. the equilibrium measure is increasing, then for any , the distribution of the state at time satisfies
has an increasing density w.r.t. , 2. 2)
is stochastically lower than the distribution of the state of the censored dynamics, say , for any valid censoring scheme.
Properties 1 and 2 then allow one to prove the censoring inequality
[TABLE]
We shall follow the same line of reasoning here. However, a technical problem arises with respect to the usual discrete spin setting: to prove the censoring inequality (99) we need to start with the distribution which has no density w.r.t. equilibrium, while the strategy outlined above is crucially based on the existence of such a density. Notice also that has no density w.r.t. equilibrium at any time and so one cannot get around this problem by regularising the measure with a burn-in time. We shall need a more general version of the above properties which extends to a certain family of measures with a singular part.
We start by defining the latter. For , define the nested sets
[TABLE]
Thus is the maximal configuration, while is the whole set of particle positions. Let denote the probability measure supported on defined as the law of the random vector of the partial sums where are i.i.d. with distribution , for some arbitrary , conditioned to , while . Notice that this notation is consistent with our notation for the equilibrium measure on . If a probability measure supported on is absolutely continuous w.r.t. , we write for the corresponding density, and say that belongs to the family if is an increasing function. In particular, , while coincides with the set of distributions on with an increasing density with respect to equilibrium. Finally, we define the family of measures consisting of all probability measures on such that
[TABLE]
for some with . Notice that (102) is a decomposition into mutually singular measures, since if , then while . The following lemma is a key fact about the set .
Lemma 31**.**
If are two probability measures on such that and , then
[TABLE]
Proof.
Write
[TABLE]
where is singular w.r.t. while is absolutely continuous w.r.t. , with an increasing density . We have
[TABLE]
We then define . It is easy to check that this event maximises the second term on the r.h.s. of the last equation. Therefore, setting , and observing that one has and , , we deduce that
[TABLE]
Since and are increasing, the set is also increasing. Therefore, and
[TABLE]
∎
Let , , denote the orthogonal projection onto functions that do not depend on the position of the -th particle:
[TABLE]
If is a probability on , we write for the probability measure defined by
[TABLE]
This is the distribution obtained from after one update at .
Lemma 32**.**
If then for any
; 2. 2)
* is stochastically lower than .*
Proof.
Pick . If , then , since forces for all . If , writing , for any bounded measurable one has
[TABLE]
where we note that if and then , and therefore is self-adjoint in . Thus, has density w.r.t. . Recall the notation for the configuration updated at the -th particle. For any with , using for all , it follows that
[TABLE]
In other words is increasing, and if . When , observe that if , then . Therefore, if denotes the density of the marginal of on w.r.t. the marginal of on the same variables,
[TABLE]
This shows that is supported on and has density w.r.t. . A direct computation shows that
[TABLE]
for some positive constant . In particular, is increasing for any . It follows that if , then , for all . Taking a generic , by linearity the above implies that for any .
To prove the stochastic domination , for , it is sufficient to show that , for , for all . Pick for some and an increasing function on . We are going to show that for any . If then and there is nothing to prove. If , as above we may write
[TABLE]
Since is also increasing, the FKG inequality on , which is valid for any probability measure, implies that pointwise. Therefore
[TABLE]
Finally, if , then as before we have
[TABLE]
On the other hand, defining the function , one has
[TABLE]
Thus, the conclusion follows from the fact that . ∎
In the next lemma we consider the effect of a sequence of updates on a measure and compare it with the effect of another sequence obtained from the first by removing some of the updates.
Lemma 33**.**
Pick and fix a sequence . For any , if denotes the new measure
[TABLE]
then . Moreover, if denotes a sequence obtained from by removing some of the entries, then and
[TABLE]
Proof.
Lemma 32 shows that for any and any sequence . For the second part of the lemma, by a telescoping argument it is sufficient to consider the case where and differ by the removal of a single update, say , so that
[TABLE]
Let , and . Then and thus, by Lemma 32 one has . Moreover,
[TABLE]
where the inequality follows from the fact that each update preserves the monotonicity, see Proposition 7. The conclusion follows from Lemma 31. ∎
We can now state and prove the censoring inequality in our setup. A censoring scheme is defined as a càdlàg map
[TABLE]
where denotes the set of all subset of a set . The subset , at any time , represents the set of particles whose update is to be suppressed at that time. More precisely, given a censoring scheme , and an initial condition , we write for the law of the random variable obtained by starting at and applying the standard graphical construction (see Proposition 7) with the proviso that if the particle with label rings at time , then the update is performed if and only if . In particular, the uncensored evolution corresponds to when . Given a distribution on , we write
[TABLE]
Lemma 34**.**
For any , if , and is a censoring scheme, then for all :
* and ,* 2. 2)
* is stochastically higher than .*
Moreover, for all :
[TABLE]
Proof.
It is sufficient to prove 1) and 2) above, since the conclusion (106) is then a consequence of Lemma 31. To prove 1) and 2) note that by conditioning on the realization of the Poisson clocks , up to time in the graphical construction, one has that the uncensored and the censored evolution are measures of the form and respectively; see (104). By Lemma 33 one has and . Taking the expectation over shows that and , and that .
∎
6.2. Relaxation of the special particles
Here we show that special particles have reached equilibrium by time ; see Proposition 39. The key to this result will be Proposition 36 below. Recall the notation introduced in Section 6.1 for the set of probability measures on with an increasing density w.r.t. . Given a probability on , we write for the marginal of on the special particle positions .
Lemma 35**.**
If then is absolutely continuous w.r.t. and the corresponding density is increasing on .
Proof.
Let . The density of w.r.t. is given by the conditional expectation
[TABLE]
To prove that it is increasing, we have to show that whenever . The latter domination can be seen as follows. Let be the highest configuration of particle positions such that , , and let be the lowest configuration of particle positions such that , . Clearly, . Then use as initial conditions in the graphical construction (Proposition 7) for the censored dynamics where all updates of the special particles are suppressed. As time goes to infinity the two distributions converge weakly to respectively. Since and the graphical construction preserves the order, this shows that . ∎
We use the following notation for the centered height of the special particles:
[TABLE]
and write for the expected value of . Note that at equilibrium, for large, the vector behaves roughly as a normal vector, and the fluctuations of are of order for each fixed . The results below are valid for all .
Proposition 36**.**
For any , , there exists such that for all , one has:
[TABLE]
Proof.
We follow [Lac16, Section 5], where a similar statement was proved in the context of random permutations. Given a constant , define the events
[TABLE]
Let us first show that for any ,
[TABLE]
Let denote the density . The sets and are stable under the operations and introduced in (21), and the FKG inequality applied to shows that
[TABLE]
Similarly, the FKG inequality for shows that
[TABLE]
Therefore, using :
[TABLE]
Since and are increasing and since , one has and therefore
[TABLE]
Consider the function
[TABLE]
Then is increasing, and applying FKG we obtain
[TABLE]
Summing in (109),
[TABLE]
This proves (108). Next, let us show that for any ,
[TABLE]
The sets satisfy the assumptions of Lemma 9. Therefore,
[TABLE]
If , then
[TABLE]
From Lemma 35 we know that is increasing. If are two particle configurations such that and , then , for all . Since are measurable w.r.t. the variables, we write for the corresponding subsets of , so that and . Thus, we have
[TABLE]
Integrating over w.r.t. in the above inequality one finds
[TABLE]
where we have used the assumption . In conclusion,
[TABLE]
Finally, we need a lower bound on the probability and an upper bound on the probability . At equilibrium is approximately normal with mean zero and variance , and therefore
[TABLE]
for all , , for some constants as and for all . As for the lower bound on observe that by the FKG inequality one has
[TABLE]
On the other hand,
[TABLE]
Then, for any , any fixed , taking large enough, we find that there exists a constant such that
[TABLE]
Once we have (108), (110) and (112) we can conclude as follows. Suppose that . If , then by (108) and (112) one must have . Therefore by (110) and (112)
[TABLE]
The desired conclusion follows by taking . ∎
Next, we address the problem of controlling the expected value of at time when started from the maximal configuration.
Proposition 37**.**
For any , any :
[TABLE]
In particular, if , then for all :
[TABLE]
Proof.
Defining
[TABLE]
one has for all :
[TABLE]
where
[TABLE]
Set , where
[TABLE]
Expanding the vector in the orthonormal basis , , one finds , where . Using (25) one finds
[TABLE]
In particular, , and
[TABLE]
Using it follows that
[TABLE]
If is such that then this implies . On the other hand if then clearly . Since , this proves the desired upper bound. ∎
Next we want to use the bound in Proposition 37 to obtain, via Proposition 36, the desired control on the convergence of special particles. However, again a technical problem arises due to the fact that has no density w.r.t. equilibrium. We overcome this by showing that the singular part of has very small mass if is large.
Lemma 38**.**
For any , the measure satisfies
[TABLE]
where , and , for some probability measure .
Proof.
We know from Lemma 34 that for all . Thus
[TABLE]
with for some coefficients , and some singular measure . It remains to show that . By conditioning on the realization of the Poisson clocks , up to time in the graphical construction, one has that the distribution of the particles at time is of the form , for some sequence of updates ; see (104). In the proof of Lemma 32 we have seen that if , then , and therefore if the sequence contains the full sweep as a subsequence, then . Let denote the event that contains as a subsequence. Since is stable under convex combinations, taking the expectation over one finds that . A rough lower bound on the latter can be obtained by dividing the interval in intervals and by requiring that for each the clock of particle with label rings during the -th time interval. This shows that . ∎
We are ready to accomplish the first and most delicate step in the program outlined at the beginning of this section.
Proposition 39**.**
Fix and . Let and let denote the marginal of on the special particle positions . If denotes the corresponding equilibrium distribution, for any fixed , with one has
[TABLE]
Proof.
From Lemma 38 it follows that
[TABLE]
where . Since , , from Proposition 36, (117) follows if we show that
[TABLE]
By Proposition 37 we know that
[TABLE]
On the other hand, Lemma 38 shows that
[TABLE]
∎
6.3. Relaxation of the censored dynamics
Here we establish the second step in the proof of Proposition 14. Consider the censored process obtained by suppressing all updates of the special particles. In other words, we use the censoring scheme such that , .
Proposition 40**.**
Fix . Let and let denote the equilibrium distribution given the special particle positions . For any small enough, setting , and , one has, for sufficiently large
[TABLE]
Proof.
By construction, the censored process corresponds to the product of independent adjacent walks each on the -simplex, with . The bound (120) implies that when is sufficiently large, the mixing time of a system of size satisfies for any given if is large enough. Therefore,
[TABLE]
for small enough. Thus if is the distance defined in (5), then
[TABLE]
as required. ∎
6.4. Proof of Proposition 14
With the previous results at hand it is relatively simple to conclude the proof of the desired estimate. We formulate the result as follows. Recall the notation .
Proposition 41**.**
Fix . For any ,
[TABLE]
Proof.
Set and let denote the censoring scheme defined by for and for . Let also denote the corresponding censored process. From Lemma 34 we have
[TABLE]
A coupling of and can be achieved as follows. Call . Use the optimal coupling attaining the total variation distance to couple the special particles at time . If the special particles are coupled at time and if is the configuration at that time, then couple the remaining particles at time with the optimal coupling attaining the total variation distance , where is as in Proposition 40. This shows that
[TABLE]
From Proposition 39 and Proposition 40,
[TABLE]
The distance is decreasing as a function of , and therefore we may take in the right hand side above to conclude. ∎
Remark 42**.**
Proposition 41 can be strengthened to obtain that for any ,
[TABLE]
for an arbitrary . Indeed, for any one has and and therefore the claim follows from Lemma 31. However, at this point we cannot infer that the same holds for arbitrary initial distribution without the requirement that it belongs to .
Appendix A An extension of the Randall-Winkler upper bound
As already discussed in the previous sections, one of the ingredients of our main results is the upper bound (13) on the mixing time that captures the right order of magnitude up to a multiplicative constant, which in the case was obtained by Randall and Winkler [RW05a]. In this section, we explain how one can extend that bound to the Beta-resampling case with . We are going to show more precisely that for any , if is sufficiently large, then
[TABLE]
Let us fix and construct a coupling of the two processes and , where has initial state and has initial distribution . Clearly,
[TABLE]
Our manner of coupling the two processes is time dependent and is as follows:
- (A)
For , we couple the two trajectories using the construction presented in the proof of Proposition 7.
- (B)
For , we couple the two trajectories according to the construction described in Section 5.2, namely we use a coupling that maximizes the probability of sticking at each update.
We first observe that at time the two processes have come close to one another:
[TABLE]
To see this, referring to the proof of Proposition 7, we consider the two processes , obtained by using the same clock processes and update variables as in the construction of and . Since this construction is order preserving, we necessarily have
[TABLE]
and (122) can be proved for repeating the computation leading to (65).
Now for , we remark that in contrast with Randall-Winkler’s case , the step B described above does not descend from a monotone grand coupling, and thus it is not sufficient to couple and by time to prove the desired mixing time bound.
Instead, we need to couple and for arbitrary . To this end we are going to repeat the recursive argument of Section 5.10 with replaced by . In particular, when we perform the update at a site , we have to replace the interval (see Section 5.2) by , which we define as the resampling interval of . As a consequence of this modification, the supports of the densities and presented in (52) are not necessarily intervals. Define the events
[TABLE]
From (122) and Markov’s inequality it follows that , and from the proof of Lemma 30 it follows that .
As in Section 5.10 we consider the probability of an unsuccessful update in the time interval . Let denote the event that each site is updated at least once and no more than times in this time interval. The probability of tends to 1 (cf. Section 5.10).
Using the upper bound (57) and recalling Remark 17, we see that conditioned on the realization of the update times in the time interval , on the event , the probability that there exists at least one unsuccessful update within is bounded above by . This shows that the probability that vanishes as , which implies (120). Note that the constant in this bound is not optimal.
Finally, we remark that the proof given above can be extended to the case , with replaced by a constant which depends on . However, this requires to prove an inequality that replaces the upper bound of (57), namely, that when there exists such that for any pair of intervals
[TABLE]
We leave the details of the adaptation as well as the proof of (123) to the interested reader.
Acknowledgements
H.L. is grateful to Werner Krauth for bringing to his knowledge the work of Randall and Winkler and for a stimulating discussion on the subject. This work was initiated during a stay of P.C. and C.L. at IMPA, and continued during a stay of P.C. and H.L. at Dauphine: we are grateful for hospitality and support provided by these two institutions. H.L. also acknowledges support from a productivity grant of CNPq and a JCNE grant from FAPERj. C.L. acknowledges support from the grant SINGULAR ANR-16-CE40-0020-01.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[AD 87] D. Aldous and P. Diaconis . Strong uniform times and finite random walks. Adv. in Appl. Math. 8 , no. 1, (1987), 69–97. doi:10.1016/0196-8858(87)90006-6 . · doi ↗
- 2[AF 02] D. Aldous and J. Fill . Reversible markov chains and random walks on graphs, 2002. URL https://www.stat.berkeley.edu/~aldous/RWG/book.pdf .
- 3[Cap 08] P. Caputo . On the spectral gap of the kac walk and other binary collision processes. Alea 4 , (2008), 205–222.
- 4[CCL 03] E. A. Carlen , M. C. Carvalho , and M. Loss . Determination of the spectral gap for kac’s master equation and related stochastic evolution. Acta mathematica 191 , no. 1, (2003), 1–54.
- 5[DFK 91] M. Dyer , A. Frieze , and R. Kannan . A random polynomial-time algorithm for approximating the volume of convex bodies. Journal of the ACM (JACM) 38 , no. 1, (1991), 1–17.
- 6[Dia 96] P. Diaconis . The cutoff phenomenon in finite markov chains. Proceedings of the National Academy of Sciences 93 , no. 4, (1996), 1659–1664.
- 7[Gia 02] G. Giacomin . Aspects of statistical mechanics of random surfaces . Lecture Notes for course given at IHP. 2002.
- 8[GS 02] A. L. Gibbs and F. E. Su . On choosing and bounding probability metrics. INTERNAT. STATIST. REV. 419–435.