TL;DR
This paper introduces a learned RGB-to-grayscale transformation inspired by color constancy theory to enhance long-term visual localization robustness against appearance changes, reducing the need for extensive experience data.
Contribution
It proposes a novel nonlinear RGB-to-grayscale mapping learned via neural networks to improve feature matching under varying conditions, enabling scalable long-term localization.
Findings
Significant performance improvements over day-night cycles.
Achieves continuous localization over 30 hours with a single experience.
Reduces data requirements for experience-based localization.
Abstract
Long-term metric self-localization is an essential capability of autonomous mobile robots, but remains challenging for vision-based systems due to appearance changes caused by lighting, weather, or seasonal variations. While experience-based mapping has proven to be an effective technique for bridging the `appearance gap,' the number of experiences required for reliable metric localization over days or months can be very large, and methods for reducing the necessary number of experiences are needed for this approach to scale. Taking inspiration from color constancy theory, we learn a nonlinear RGB-to-grayscale mapping that explicitly maximizes the number of inlier feature matches for images captured under different lighting and weather conditions, and use it as a pre-processing step in a conventional single-experience localization pipeline to improve its robustness to appearance change.…
Click any figure to enlarge with its caption.
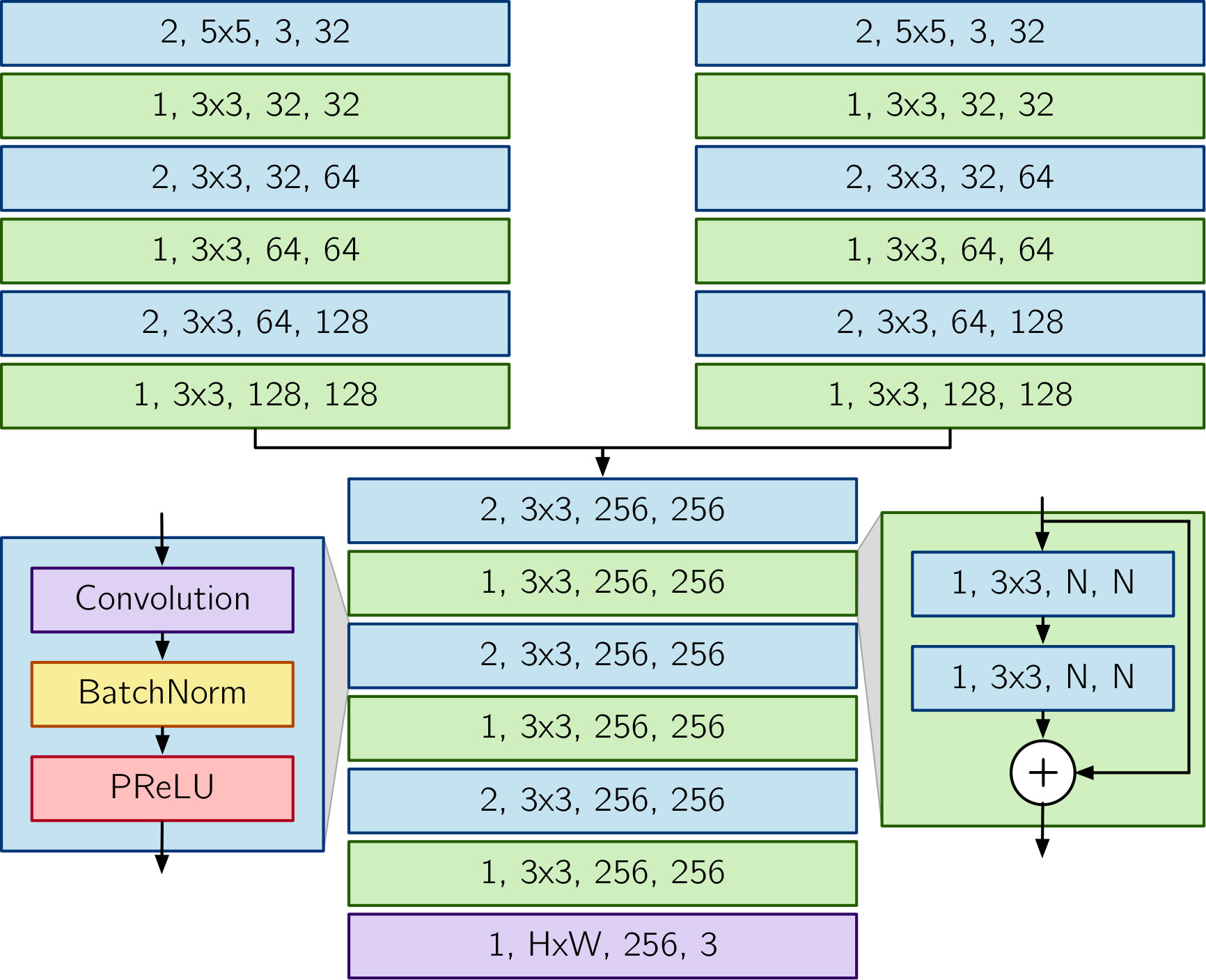 Figure 1
Figure 1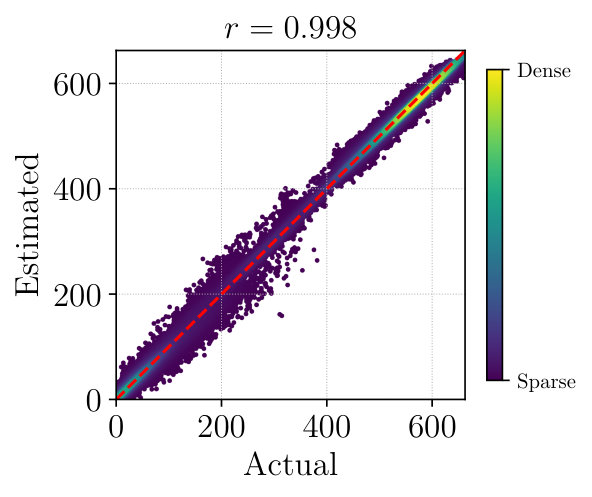 Figure 2
Figure 2 Figure 3
Figure 3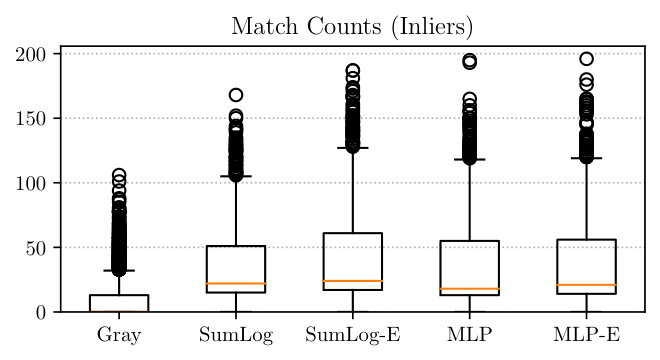 Figure 4
Figure 4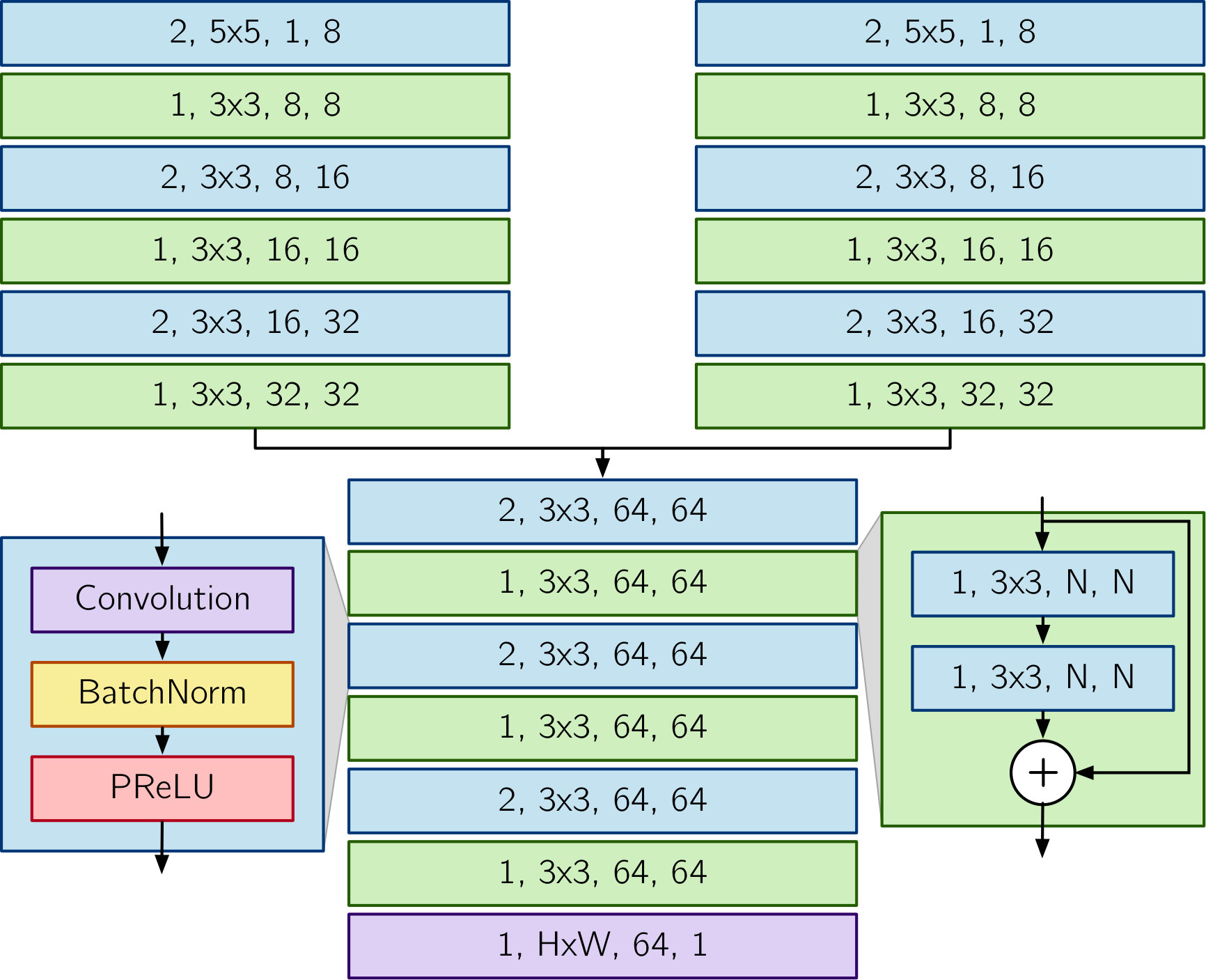 Figure 5
Figure 5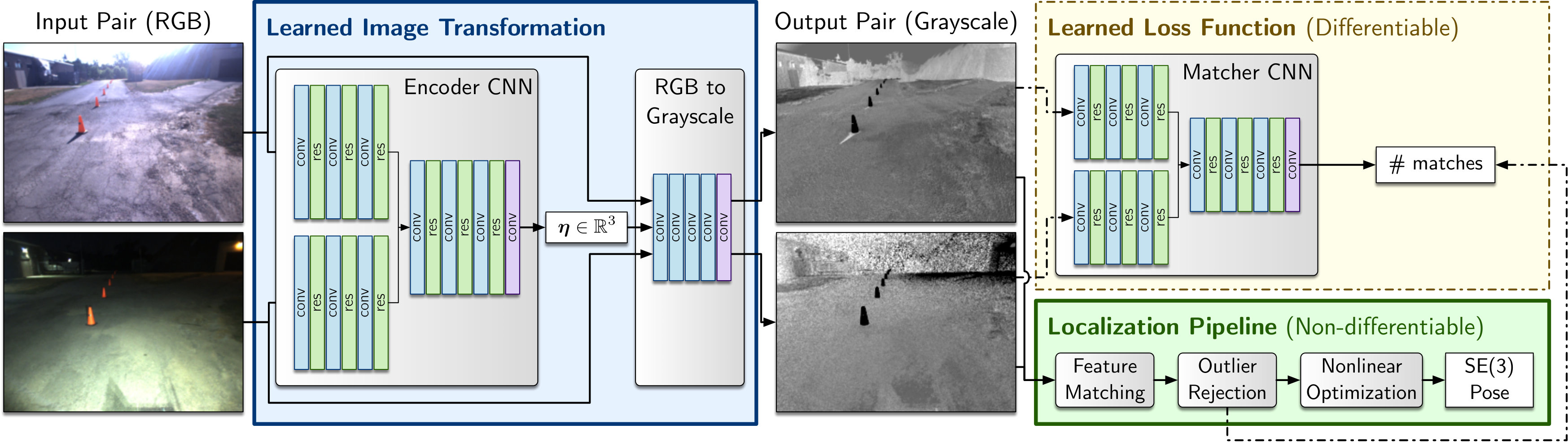 Figure 6
Figure 6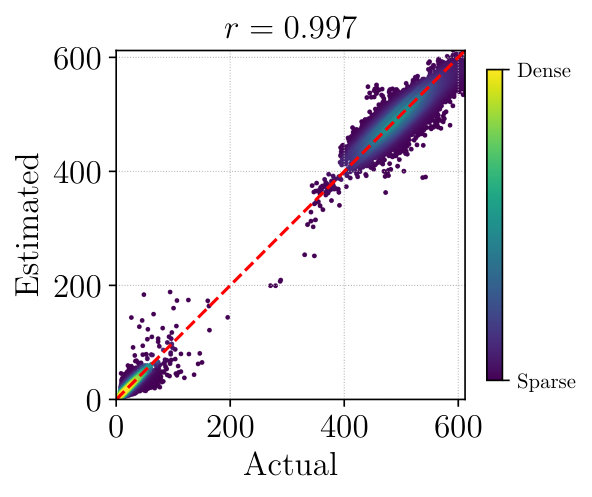 Figure 7
Figure 7 Figure 8
Figure 8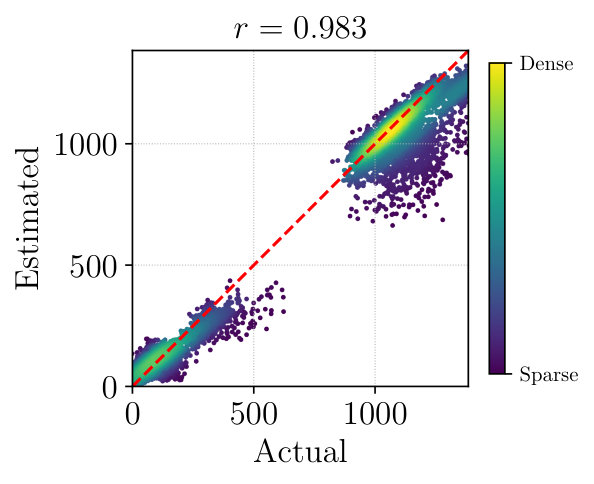 Figure 9
Figure 9 Figure 10
Figure 10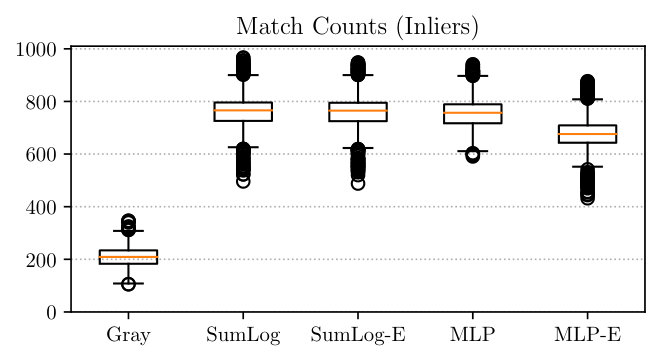 Figure 11
Figure 11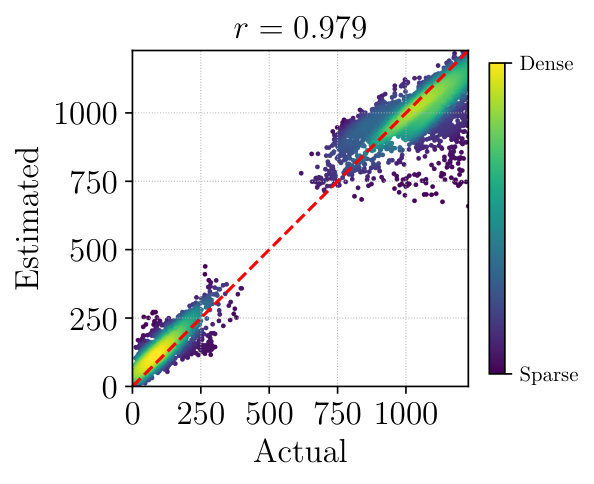 Figure 12
Figure 12| Inlier Feature Matches | ||||||
|---|---|---|---|---|---|---|
| Test Sequence | Gray | SumLog | SumLog-E | MLP | MLP-E | |
| VKITTI/0001 | ||||||
| Sunset-Morning | 262 (82) | 726 (136) | 689 (157) | 661 (108) | 623 (116) | |
| Overcast-Clone | 444 (58) | 790 (129) | 767 (125) | 747 (106) | 770 (107) | |
| VKITTI/0002 | ||||||
| Sunset-Morning | 240 (22) | 812 (67) | 803 (70) | 774 (65) | 702 (62) | |
| Overcast-Clone | 290 (41) | 739 (67) | 757 (76) | 755 (65) | 764 (84) | |
| VKITTI/0006 | ||||||
| Sunset-Morning | 125 (33) | 669 (44) | 735 (43) | 711 (37) | 642 (41) | |
| Overcast-Clone | 142 (33) | 647 (39) | 666 (43) | 566 (47) | 546 (38) | |
| VKITTI/0018 | ||||||
| Sunset-Morning | 234 (53) | 817 (36) | 816 (37) | 745 (37) | 731 (40) | |
| Overcast-Clone | 311 (46) | 548 (52) | 555 (50) | 450 (42) | 486 (39) | |
| VKITTI/0020 | ||||||
| Sunset-Morning | 210 (39) | 762 (69) | 758 (71) | 756 (62) | 675 (69) | |
| Overcast-Clone | 287 (78) | 716 (71) | 716 (72) | 718 (62) | 708 (64) | |
| InTheDark | ||||||
| Map (08:54) | - | - | - | - | - | |
| 0006 (09:46) | 178 (48) | 125 (56) | 165 (51) | 138 (52) | 158 (53) | |
| 0027 (18:36) | 9 (9) | 52 (29) | 57 (26) | 44 (25) | 48 (28) | |
| 0041 (21:48) | 10 (16) | 33 (25) | 39 (31) | 33 (29) | 35 (29) | |
| 0058 (05:48) | 99 (34) | 95 (47) | 114 (43) | 97 (44) | 113 (40) | |
| 0071 (09:18) | 181 (44) | 126 (52) | 167 (47) | 141 (48) | 161 (48) | |
| 0083 (14:01) | 53 (21) | 76 (39) | 83 (37) | 82 (37) | 83 (37) | |
| 0089 (16:43) | 45 (22) | 67 (35) | 70 (36) | 63 (31) | 68 (33) | |
| RobotCar | ||||||
| Overcast-Night | 11(3) | 12 (2) | 12 (3) | 11 (2) | 11 (2) | |
| Overcast-Sunny | 26 (12) | 25 (12) | 25 (12) | 24 (9) | 71 (41) | |
| Maximum Distance on Dead Reckoning (m) | ||||||||||||||||||
| 10 Inliers | 20 Inliers | 30 Inliers | ||||||||||||||||
| G1 | S2 | S-E2 | M3 | M-E3 | G1 | S2 | S-E2 | M3 | M-E3 | G1 | S2 | S-E2 | M3 | M-E3 | ||||
| InTheDark | ||||||||||||||||||
| Map (08:54) | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | |||
| 0006 (09:46) | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.1 | 0.0 | 0.0 | 0.0 | |||
| 0027 (18:36) | 7.5 | 0.7 | 0.0 | 0.3 | 0.3 | 25.9 | 3.6 | 0.7 | 2.5 | 2.2 | 101.1 | 10.5 | 0.7 | 8.3 | 7.8 | |||
| 0041 (21:48) | 14.9 | 0.5 | 0.2 | 0.9 | 1.4 | 46.3 | 8.4 | 3.2 | 7.2 | 7.4 | 104.5 | 15.1 | 10.0 | 18.6 | 15.7 | |||
| 0058 (05:48) | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.2 | 0.0 | 0.2 | 0.0 | 0.0 | 0.6 | 0.3 | 0.6 | 0.0 | |||
| 0071 (09:18) | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | |||
| 0083 (14:01) | 0.0 | 0.2 | 0.0 | 0.0 | 0.0 | 0.4 | 0.5 | 0.3 | 0.2 | 0.0 | 2.2 | 4.0 | 0.3 | 0.4 | 0.5 | |||
| 0089 (16:43) | 0.3 | 0.3 | 0.2 | 0.0 | 0.0 | 4.8 | 1.0 | 3.7 | 1.2 | 0.8 | 6.1 | 6.1 | 4.7 | 2.9 | 2.9 | |||
| RobotCar | ||||||||||||||||||
| Map (Overcast) | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | |||
| Night | 27.0 | 7.6 | 3.7 | 27.3 | 27.3 | 307.1 | 307.1 | 245.9 | 400.8 | 398.9 | 740.5 | 541.5 | 740.5 | 697.3 | 740.5 | |||
| Sunny | 1.3 | 1.3 | 1.5 | 1.8 | 0.9 | 36.1 | 65.1 | 48.0 | 39.4 | 6.3 | 129.1 | 139.8 | 109.2 | 124.3 | 16.5 | |||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Learning Matchable Image Transformations for Long-term Metric Visual Localization
Lee Clement1, Mona Gridseth2, Justin Tomasi1 and Jonathan Kelly1 Manuscript received: September 10, 2019; Revised December 2, 2019; Accepted December 31, 2019.This paper was recommended for publication by Editor Cesar Cadena Lerma upon evaluation of the Associate Editor and Reviewers’ comments.1Space and Terrestrial Autonomous Robotic Systems (STARS) Lab, University of Toronto Institute for Aerospace Studies (UTIAS), Canada. 2Autonomous Space Robotics Lab (ASRL), UTIAS, Canada. <firstname>.<lastname>@robotics.utias.utoronto.ca.Digital Object Identifier (DOI): see top of this page.
Abstract
Long-term metric self-localization is an essential capability of autonomous mobile robots, but remains challenging for vision-based systems due to appearance changes caused by lighting, weather, or seasonal variations. While experience-based mapping has proven to be an effective technique for bridging the ‘appearance gap,’ the number of experiences required for reliable metric localization over days or months can be very large, and methods for reducing the necessary number of experiences are needed for this approach to scale. Taking inspiration from color constancy theory, we learn a nonlinear RGB-to-grayscale mapping that explicitly maximizes the number of inlier feature matches for images captured under different lighting and weather conditions, and use it as a pre-processing step in a conventional single-experience localization pipeline to improve its robustness to appearance change. We train this mapping by approximating the target non-differentiable localization pipeline with a deep neural network, and find that incorporating a learned low-dimensional context feature can further improve cross-appearance feature matching. Using synthetic and real-world datasets, we demonstrate substantial improvements in localization performance across day-night cycles, enabling continuous metric localization over a 30-hour period using a single mapping experience, and allowing experience-based localization to scale to long deployments with dramatically reduced data requirements.
Index Terms:
Deep Learning in Robotics and Automation, Visual Learning, Visual-Based Navigation, Localization
I Introduction
Self-localization is an essential capability of autonomous mobile robots, and localization algorithms based on inexpensive commercial vision sensors have become useful and widespread. Despite this success, long-term metric localization, where the goal is to continuously estimate the 6-dof pose of the vehicle with respect to a visual map, remains challenging in the presence of appearance change caused by illumination variations over the course of a day, changes in weather conditions, or seasonal shifts. This difficulty is largely due to simplifying assumptions such as brightness constancy and feature descriptor invariance that, when violated, cause visual localization systems to fail. Ideally, we would like our systems to function across this ‘appearance gap’, immune to variations in environmental conditions.
Long-term maps based on multiple visual ‘experiences’ of an environment have proven to be effective tools for metric localization through daily and seasonal appearance change [1, 2, 3, 4]. In [3], consecutive visual experiences are recorded in a spatio-temporal pose graph, and localization against a privileged mapping experience proceeds by recalling a relevant experience and tracing through a chain of relative transformations in the graph. This process is often aided by a prior on the vehicle’s topological location in the graph, whether from dead reckoning, place recognition, or GNSS, which serves to limit the number of candidate vertices for metric localization. However, the number of intermediate ‘bridging’ experiences required for reliable long-term localization can be very large, and methods for compressing experience graphs are necessary for this approach to scale.
Recent work in [5, 6] has explored deep image-to-image translation [7, 8] as a means of directly bridging the ‘appearance gap’ and localizing with fewer experiences. However these methods rely at least in part on well-aligned training images, which are difficult to obtain at scale in the real world. Moreover, the losses used to train these models are not explicitly connected to a target localization pipeline, and provide few assurances that the learned image transformations will ultimately improve localization performance.
We address these limitations by learning an image transformation optimized for a given combination of localization pipeline, sensor, and operating environment. Rather than translating between arbitrary appearance conditions, we learn to map images to a maximally matchable representation (i.e., one which maximizes the number of inlier feature matches) for a given feature detection/matching algorithm. Specifically, we learn a drop-in replacement for the standard RGB-to-grayscale colorspace mapping used to pre-process RGB images for use with conventional feature detection/matching algorithms, which typically operate on single-channel images (Figure 1). This formulation builds upon prior work on color constancy theory [9], does not require well-aligned images for training, and naturally admits a self-supervised training approach as training targets can be generated on the fly by the localization pipeline. Our main contributions are:
a technique for improving the robustness of a conventional visual localization pipeline to appearance change using a learned image pre-processing step; 2. 2.
a method for optimizing the performance of a non-differentiable localization pipeline by approximating the pipeline using a deep neural network; 3. 3.
experimental results on synthetic and real long-term vision datasets showing that our method enables continuous 6-dof metric visual localization across day-night cycles using a single mapping experience; and 4. 4.
an open-source implementation of our method using PyTorch [10].111github.com/utiasSTARS/matchable-image-transforms
II Related Work
Appearance robustness in metric visual localization has previously been studied from the perspective of illumination invariance, with methods such as [11, 12, 13, 14] making use of hand-engineered image transformations to improve feature matching over time for a given feature detector and descriptor. Similarly, affine models and other simple analytical transformations have been used to improve the robustness of direct visual localization to illumination change [15, 16]. Other approaches such as [17, 18, 19, 20] have focused on learning feature descriptors that are robust to certain types of appearance change in autonomous route following applications. However, [17, 18] produce correspondences that are only weakly localized, and [19, 20] require sets of true and false point correspondences to train feature descriptors, which are challenging to obtain at scale over long periods.
Deep image-to-image translation [7, 8] has recently been applied to the problem of metric localization across appearance change. In [21] the authors train a convolutional encoder-decoder network to enhance the temporal consistency of image streams captured in environments with high dynamic range. Here the main source of appearance change is the camera itself as it automatically modulates its imaging parameters in response to the local brightness of a static environment. Other work has tackled the problem of localization across environmental appearance change, with [5] learning a many-to-one mapping onto a privileged appearance condition and [6] learning multiple pairwise mappings between appearance categories such as day and night. Image-to-image translation has also been applied to the related task of appearance-invariant place recognition [22, 23], which typically relies on patch matching or whole-image statistics to identify images corresponding to nearby physical locations rather than estimating the 6-dof pose of the vehicle. While [6, 21] include loss terms to maximize gradient information, these heuristics are not directly tied to the performance of the localization pipeline. Moreover, [5, 6, 21] require well-aligned training images exhibiting appearance variation, which are difficult to obtain at scale in the real world, and it is not clear how categorical appearance mappings such as [6, 22, 23] should be applied to continuous appearance change in long-term deployments.
Surrogate-based methods for approximating computationally expensive or non-differentiable objective functions are common in the numerical optimization literature [24]. Neural network surrogates in particular have found applications in a variety of domains including computer graphics [25] and computational oceanography [26], where high-fidelity physics simulations are available but expensive to compute. Our method of learning a differentiable loss function is similar in spirit to Generative Adversarial Networks (GANs) [27] in that a complex discriminator/loss function is trained using a comparatively simple analytical loss function. It also bears resemblances to perceptual losses [28], where the loss function is derived from the feature activations of a network trained on a proxy task such as image classification.
III Learning Matchable Colorspace Transformations
Our goal in this work is to learn a nonlinear transformation mapping the RGB colorspace onto a grayscale colorspace that explicitly maximizes a chosen performance metric of a vision-based localization pipeline. We investigate two approaches to formulating such a mapping: 1) a single function to be applied as a pre-processing step to all incoming images, similarly to [11, 13, 14]; and 2) a parametrized function tailored to the specific image pair to be used for localization, where the parameters of this function are derived from the images themselves. Additionally, the functional form of either mapping may be specified analytically (e.g., from physics) or learned from data using a function approximator such as a neural network.
In order to find an optimal colorspace transformation for a given application, we require an appropriate objective function to optimize, which should ideally be tied to the performance of the target localization pipeline. An intuitive choice of objective could be to directly minimize pose estimation error for the entire pipeline relative to ground truth if it is available. In the absence of accurate ground truth data, we might instead choose to maximize the number or quality of feature matches in the front-end of a feature-based localization pipeline. We adopt the latter approach in this work, since high-quality 6-dof ground truth is difficult to obtain over long time scales.
Although it is straightforward to choose a target performance metric to optimize, the most commonly used localization front-ends in robotics rely on non-differentiable components such as stereo matching, nearest-neighbors search, and RANSAC [29], which are incompatible with the gradient-based optimization schemes commonly used in deep learning. In this work we learn an objective function by training a deep convolutional neural network (CNN) to act as a differentiable proxy to the localization front-end. Specifically, we train a siamese CNN to predict the number of inlier feature matches for a given image pair, where the training targets are generated using a conventional non-differentiable feature detector/matcher algorithm based on libviso2 features [30]. This proxy network can then be used to define a fully differentiable objective function, allowing us to train a nonlinear colorspace mapping using gradient-based methods. Finally, the trained image transformation can be used as a pre-processing step in a conventional visual localization pipeline, enabling it to operate more reliably under appearance change. Figure 1 summarizes our full data pipeline pictorially.
III-A Differentiable Matcher Proxy
We consider the task of training a CNN , with parameters , to predict the number of inlier feature matches returned by a non-differentiable feature detector/matcher for a given image pair . This training objective is a convenient choice for our intended application as it is closely tied to the ability of our visual localization pipeline to operate across appearance change, however it is not by any means the only choice. For example, we could also train a CNN to predict a measure of localization accuracy such as geodesic distance from ground truth on the manifold, similarly to the estimator correction framework proposed in [31]. Importantly, this formulation admits a self-supervised training approach as training targets can be generated automatically by .
Figure 1 (right-hand side) summarizes the training setup for this task. A pair of single-channel images is fed into a conventional feature detection/matching algorithm (e.g., SURF [32], ORB [33], or libviso2 [30]), and a summary statistic is computed such as the quantity of RANSAC-filtered inlier feature matches. This summary statistic forms the training target for a CNN whose task is to predict the statistic for the same image pair. Given enough training pairs, the network should learn a set of convolutional filters that correspond to the types of features and patterns that best predict the performance of in a given environment. Critically, the proxy network is fully differentiable and can provide a gradient signal to train a nonlinear image transformation.
Our matcher proxy network (Figure 2) is a siamese network built from convolutional and residual [34] blocks using batch normalization [35] and PReLU non-linearities [36]. Each image in the input pair is processed by one of two feature detection branches, which share weights to ensure that both images are mapped onto a common feature space. The outputs of the feature detection branches are concatenated along the channel dimension to be further processed by the remainder of the network. Each non-residual convolution block downsamples the feature map by a factor of two, allowing for salient features to be learned at multiple scales. The final output is produced by a fully-connected layer, which projects the feature map to a scalar value. We train to fit in a least-squares sense by minimizing the mean squared error of the predicted match counts for a minibatch of image pairs:
[TABLE]
III-B Physically Motivated Transformations
Prior work in [9] has shown that under the assumptions of a single black-body illuminant and an infinitely narrow sensor response function, an appropriately weighted linear combination of the log-responses of a three-channel (e.g., RGB) camera represents a projection onto an invariant one-dimensional chromaticity space that is independent of both the intensity and color temperature of the illuminant, and depends only on the imaging sensor and the materials in the scene:
[TABLE]
where is the image of sensor responses at wavelength , the weights are subject to the constraints
[TABLE]
and the indices are chosen such that (i.e., red, green and blue channels, respectively).
The image formed from this pixel-wise linear combination of log-responses can then be rescaled to produce a valid grayscale image that can be further processed by a localization pipeline. Grayscale images generated using this procedure are somewhat resistant to variations in lighting and shadow, and have been shown to improve stereo localization quality in the presence of shadows and changing daytime lighting conditions [11, 13, 14], but have not been successful in adapting to nighttime navigation with headlights.
Given the constraints defined by Equation 3, the weights are completely specified as a function of the imaging sensor. However, in practice, these constraints are relaxed and the parameters are tuned to a specific environment, sensor, and feature matcher, where the theoretical values do not perform optimally. Indeed, [11, 14] used two sets of parameters tuned to maximize the stability of SURF features [32] in regions where grassy or sandy materials dominate.
We argue that environmental appearance is best thought of as continuous rather than categorical, and that a better approach to selecting the transformation parameters should take into account the content of the specific scene being imaged, rather than using the same parameters at every location within a large and potentially heterogeneous operating environment. Accordingly, we train a second encoder network , with parameters , to predict the optimal values of the transformation parameters (i.e., which yield the most inlier feature matches) for a given RGB image pair.
Furthermore, we relax the constraints in Equation 3 and generalize Equation 2 to be of the form
[TABLE]
where the parameters are computed for the image pair as
[TABLE]
and Equation 4 is applied to both and using the same set of parameters. Due to the need to rescale to form a valid single-channel image, a degree of freedom in is lost and represent the relative mixing proportions of the three color channels. We enforce using a normalization layer to ensure a consistent range of outputs.
Our encoder network follows a similar siamese architecture to , but takes pairs of 3-channel images as inputs and outputs a 3-dimensional vector. We train to maximize the mean number of inlier feature matches as predicted by , or equivalently, to minimize its negation:
[TABLE]
where are computed from input RGB images using Equations 4 and 5.
Rather than rescaling using the minimum and maximum response of each output image, we rescale by the joint mean and standard deviation of the output pair and apply a clamping operation to map the output onto the range :
[TABLE]
where we have used the notation . This rescaling scheme allows the model to saturate parts of the output images while still using the full range of valid pixel values. Moreover, it avoids introducing significant sparsity in the gradients through the and operators, which improves the flow of gradient information during training.
III-C Learned Nonlinear Transformations
While the assumption of a single black-body illuminant in [9] is reasonable for daytime navigation where the dominant light source is the sun, it does not hold in many common navigation scenarios such as nighttime driving with headlights. Moreover, the assumption of an infinitely narrow sensor response is unrealistic for real cameras. As an alternative to the physically motivated colorspace transformation outlined in Section III-B, we investigate the possibility of learning a bespoke nonlinear mapping that maximizes matchability for a particular combination of imaging sensor, estimator and environment. We parametrize this mapping using a small neural network , with parameters , operating independently on each pixel of each input RGB image. We structure as a multilayer perceptron (MLP) implemented using convolutions and PReLU nonlinearities.
We consider two versions of this MLP-based transformation, both with and without incorporating an additional pairwise context feature obtained from encoder network using Equation 5. In the case where is used, the input to becomes the concatenation of the input RGB image and the parameters along the channel dimension, and the first convolutional layer of is modified accordingly. We train and (if used) jointly by minimizing a similar loss function to Equation 6, where in place of Equation 4, we have
[TABLE]
Similarly to the physically motivated transformations described in Section III-B, we rescale to fill the range of valid grayscale values by applying Equation 7.
IV Experiments
We conducted experiments on synthetic and real-world long-term vision datasets to validate and compare each approach. Specifically, we evaluated the ability of our matcher proxy network to capture the performance of libviso2 feature matching across viewpoint and appearance changes, as well as the effect of each image transformation on feature matching and localization performance. When evaluating feature matching, we assumed that we had a prior on the vehicle’s topological location in the map, such that we could reliably identify the nearest vertex in the pose graph. This is typical for autonomous visual route-following systems such as [4], where the topological prior is derived by dead reckoning from a previous successful localization, or using place recognition or GNSS in the event that the system becomes lost.
We refer to the generalized color-constancy model of [9] (Section III-B) as “SumLog” and “SumLog-E” , where the latter uses Equation 5 to derive the parameters per image pair, and the former uses a constant that maximizes inlier feature matches over the training set (similarly to [11, 14]). Analogously, we refer to the learned multilayer perceptron models (Section III-C) as “MLP” and “MLP-E”, where the latter incorporates and the former does not . We refer to the standard RGB-to-grayscale transformation as “Gray”.222We refer specifically to the ITU-R 601-2 luma transform implemented by the Pillow library: .
Training proceeds in two stages. First, we pre-train using standard grayscale images. Training labels are generated using the open-source libviso2 library [30] to detect and match features, and the eight-point RANSAC algorithm to reject outlier matches. Second, we train and/or using the matchability loss defined in Equation 6. To ensure that accurately predicts feature match counts for the output images, which differ significantly from standard grayscale images, we continue to train in an alternating fashion using the output images at each iteration. All models are implemented in PyTorch [10] and trained for 10 epochs with a batch size of 8, using the Adam optimizer [37] with default parameters and a learning rate of . We rescale all images to a height of 192 pixels for both training and testing.
IV-A Datasets
We evaluated our approach using both synthetic and real-world datasets exhibiting severe illumination change.
Virtual KITTI
The Virtual KITTI (VKITTI) dataset [38] is a synthetic reconstruction of a portion of the KITTI vision benchmark [39], consisting of five sets of non-overlapping trajectories with RGB-D imagery rendered under a variety of simulated illumination conditions. This dataset is a convenient validation tool as it provides perfect data association and a range of daytime illumination conditions. For each trajectory, we train models using image pairs from the others. Since each trajectory is non-overlapping, this spatial split allows us to evaluate how well our method generalizes to unseen environments. Further, since VKITTI provides corresponding images from identical viewpoints, we augmented the training data to ensure generalizability to viewpoint changes and dynamic objects by associating each training image in one condition with a window of nearby images in the other.
UTIAS In The Dark
The UTIAS In The Dark (InTheDark) dataset [3] provides stereo imagery of a 250 m outdoor loop traversed repeatedly over a 30-hour period using on-board headlights to illuminate the scene at night. We use the multi-experience localization system in [3] to obtain corresponding image pairs with overlapping fields of view but non-identical poses. We train our models using left-camera images from 66 traversals and test on 7 held-out traversals spanning a full day-night cycle (listed in Table I). This temporal split allows us to evaluate how well our method generalizes to multiple unseen illumination conditions.
Oxford RobotCar
We further evaluate our method using three sequences from the Oxford RobotCar (RobotCar) dataset [40], captured along the same 10 km route in overcast, nighttime, and sunny conditions.333“Overcast”, “Night”, and “Sunny” refer to 2014-12-09-13-21-02, 2014-12-10-18-10-50, and 2014-12-16-09-14-09, respectively. We find corresponding images using the GNSS/INS poses, and split the trajectory into two non-overlapping segments: the first 70% of the trajectory is used for training and the remaining 30% is used for testing.
IV-B Feature Matcher Approximation
We train in a self-supervised manner to predict the number of inlier feature matches for overlapping image pairs captured under different illumination conditions from nearby but different poses. Training labels are generated on the fly for each image pair using the open-source libviso2 library [30] in monocular flow matching mode with default parameters, using the eight-point RANSAC algorithm to reject outlier matches. In practice we train to minimize Equation 1 over all combinations of input images.
Figure 3 plots actual and estimated match counts for each dataset after ten epochs of pre-training on Gray images, aggregated over all test sequences. These include self-matches (same viewpoint, same appearance) and non-self-matches (different viewpoint, different appearance), which appear as clusters. In each case the test-time match counts predicted by are strongly correlated with the true performance of libviso2. This indicates that our approach generalizes well and that is capturing salient properties of feature matching rather than memorizing training examples.
IV-C Feature Matching Across Appearance Change
Figure 4 shows the outputs of each image transformation for sample RGB image pairs in the VKITTI/0020 Morning and Sunset sequences (Figure 4(a)) and the challenging sequence InTheDark/0041 (Figure 4(b)). We see that each model produced image pairs that are visually more consistent than standard Gray images, and that local illumination variations such as shadows, uneven lighting, and specular reflections were minimized by optimizing Equation 6.
Figure 5 visually compares the distributions of actual libviso2 feature matches for each transformation, while Table I summarizes the results numerically. Each model significantly increased the mean number of inlier matches across most test sequences, with the greatest improvements generally obtained from the SumLog and SumLog-E transformations. Sequences InTheDark/0006 and InTheDark/0071 are exceptions in that the standard Gray transformation performed best. These sequences were recorded under similar conditions to the “Map” sequence, so feature matching can be expected to perform optimally on Gray images. We saw little improvement in match counts on the RobotCar/Overcast-Night experiment, which we attribute to motion blur in the nighttime images making feature matching exceptionally difficult. In contrast, the MLP-E method more than doubled the mean number of feature matches in the Sunny experiment.
We note that the pairwise encoder did not confer any significant benefit on the VKITTI sequences. These results are consistent with [11, 12, 13, 14], where one or two sets of parameter values were sufficient to achieve good performance across varying daytime conditions. In contrast, the encoder network provided a noticeable performance boost on most InTheDark and RobotCar sequences. We attribute this difference to more variation in illumination and terrain, as a single transformation is less likely to perform well under more varied conditions. We also note that the MLP-E transformation frequently performed similarly to the SumLog-E transformation, suggesting that, in spite of key assumptions being broken, a linear combination of log-responses as proposed by [9] may in fact be an optimal solution for this problem, and that a careful choice of weights is the key to obtaining good cross-appearance feature matching over day-night cycles.
IV-D Impact on Localization Performance
We evaluate localization performance in an autonomous route-following context by examining the maximum distances in each sequence that would have been navigated using dead reckoning (e.g., visual odometry) as a result of failing to localize against the map. These results are summarized in Table II for thresholds of 10, 20, and 30 inlier feature matches against the “Map” sequence. A typical criterion for requiring manual intervention is dead reckoning in excess of 10 meters, depending on the accuracy of the underlying dead reckoning system. Based on a relatively conservative threshold of 20 inlier feature matches against the “Map” sequence, we see that InTheDark/0027 (evening) and InTheDark/0041 (night) presented significant difficulty for localization, which was substantially alleviated using any of the four image transformations. In particular, the SumLog-E transformation yielded maximum dead reckoning distances below four meters across all illumination conditions. We see similar improvements using the SumLog-E method with a threshold of 10 inliers on the RobotCar dataset. Together, these results imply that near-continuous 6-dof visual localization over a full day-night cycle is achievable using only a single mapping experience and a simple image pre-processing step, representing a dramatic reduction in data requirements to scale experience-based localization to long deployments.
With more conservative thresholds (e.g., 30 inliers), localization failures became more common, as expected. However, the proposed image transformations continued to provide substantially more robust localization performance compared to standard grayscale images. For example, we achieved a maximum distance on dead reckoning of 10.0 m using the SumLog-E method on sequence InTheDark/0041 with a threshold of 30 inliers. In contrast, using the standard Gray method would have required the system to rely continuously on dead reckoning for approximately 40% of the route.
V Conclusions and Future Work
This paper presented a method for learning pixel-wise RGB-to-grayscale colorspace mappings that explicitly maximize the number of inlier feature matches for a given input image pair, feature detector/matcher and operating environment. Our key insight is that by training a deep neural network to predict the performance of a conventional non-differentiable feature detector/matcher, we can define a fully differentiable loss function that can be used to learn image transformations optimized for localization performance. We evaluated our approach using both physically motivated and data-driven transformations and demonstrated substantially improved feature matching and localization performance on synthetic and real long-term vision datasets exhibiting severe illumination change, allowing experience-based localization to scale to long deployments with dramatically fewer bridging experiences. We consistently achieved the best performance using a physically motivated weighted sum of log-responses with weights derived from a pairwise context encoder network. In future work we plan to explore alternative loss functions such as pose estimation error, the use of feature locations or photometric consistency as a more granular supervision signal, and the impact of context feature dimension on MLP-based transformations. We also intend to investigate the impact of our method on feature matching across seasonal appearance change.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] W. Churchill and P. Newman, “Experience-based navigation for long-term localisation,” Int. J. Robot. Res. , vol. 32, pp. 1645–1661, Dec. 2013.
- 2[2] C. Linegar, W. Churchill, and P. Newman, “Work smart, not hard: Recalling relevant experiences for vast-scale but time-constrained localisation,” in Proc. IEEE Int. Conf. Robot. Automat. (ICRA) , pp. 90–97, May 2015.
- 3[3] M. Paton, K. Mac Tavish, M. Warren, and T. D. Barfoot, “Bridging the appearance gap: Multi-experience localization for long-term visual teach and repeat,” in Proc. IEEE/RSJ Int. Conf. Intell. Robot. Syst. (IROS) , pp. 1918–1925, Oct. 2016.
- 4[4] M. Paton, K. Mac Tavish, L.-P. Berczi, S. K. van Es, and T. D. Barfoot, “I can see for miles and miles: An extended field test of visual teach and repeat 2.0,” in Proc. Field and Service Robot. (FSR) , pp. 415–431, 2018.
- 5[5] L. Clement and J. Kelly, “How to train a CAT: Learning canonical appearance transformations for direct visual localization under illumination change,” IEEE Robot. Automat. Lett. , vol. 3, no. 3, pp. 2447–2454, 2018.
- 6[6] H. Porav, W. Maddern, and P. Newman, “Adversarial training for adverse conditions: Robust metric localisation using appearance transfer,” in Proc. IEEE Int. Conf. Robot. Automat. (ICRA) , pp. 1011–1018, May 2018.
- 7[7] P. Isola, J. Y. Zhu, T. Zhou, and A. A. Efros, “Image-to-image translation with conditional adversarial networks,” in Proc. IEEE Conf. Comput. Vision and Pattern Recognit. (CVPR) , pp. 5967–5976, July 2017.
- 8[8] J. Zhu, T. Park, P. Isola, and A. A. Efros, “Unpaired image-to-image translation using Cycle-Consistent adversarial networks,” in Proc. IEEE Int. Conf. Comput. Vision (ICCV) , pp. 2242–2251, Oct. 2017.
