DeepPoint3D: Learning Discriminative Local Descriptors using Deep Metric Learning on 3D Point Clouds
Siddharth Srivastava, Brejesh Lall
Department of Electrical Engineering
Indian Institute of Technology Delhi
[email protected], [email protected]
Abstract
Learning local descriptors is an important problem in computer vision. While there are many techniques for learning local patch descriptors for 2D images, recently efforts have been made for learning local descriptors for 3D points. The recent progress towards solving this problem in 3D leverages the strong feature representation capability of image based convolutional neural networks by utilizing RGB-D or multi-view representations. However, in this paper, we propose to learn 3D local descriptors by directly processing unstructured 3D point clouds without needing any intermediate representation. The method constitutes a deep network for learning permutation invariant representation of 3D points. To learn the local descriptors, we use a multi-margin contrastive loss which discriminates between similar and dissimilar points on a surface while also leveraging the extent of dissimilarity among the negative samples at the time of training. With comprehensive evaluation against strong baselines, we show that the proposed method outperforms state-of-the-art methods for matching points in 3D point clouds. Further, we demonstrate the effectiveness of the proposed method on various applications achieving state-of-the-art results.
1 Introduction
The ability to represent and uniquely match surface, regions and shape is a fundamental problem in computer vision. With 3D data, such problems are accompanied by many challenges in terms of size, complexity, quality and availability of sufficient data. The standard techniques for solving such a problem in 3D primarily involve keypoint identification, region alignment, construction of descriptors and matching of descriptors. Further, the extraction of a descriptor may use information from only the keypoint (point descriptor), its neighbourhood (local descriptor), or the entire 3D model (global descriptor). The primary aim is to be able to robustly encode the properties of the region being described. The state-of-the-art methods for computing global descriptors in 3D are based on deep networks [1, 2]. On the other hand, the most popular techniques for computing local descriptors are based on handcrafted techniques [3, 4, 5, 6]. Recently, efforts have been made to leverage deep networks to learn local descriptors from 3D data [7, 8] which derives motivation from similar efforts for 2D images [9]. However, these techniques do not work directly on the point cloud data, and instead, are based on extracting intermediate representations such as projections using multiple camera positions or histograms from the input 3D point cloud, that are passed into a deep network similar to a 2D convolutional neural network, from which the descriptor is obtained. Since these intermediate representations can result in loss of information, the resulting descriptor is not able to leverage the complete information available in the raw point cloud. Therefore, in this paper, we aim towards addressing this gap and using a deep network learn a local descriptor which can directly leverage from the point cloud representation of the 3D data.
The point cloud representation can usually be obtained directly as an output of the devices such as Kinect. The advantage of such a point cloud is that it represents the closest approximation of the captured surface as compared to a voxelized cloud or a RGB-D image, and is comparatively easier to process [10]. However, since such point clouds are unstructured i.e. do not have any defined ordering of points, it is difficult to process them with traditional deep learning based methods. Many efforts have been made to process 3D data and extract meaningful information using the deep learning pipeline [11]. Broadly, the deep networks that can process 3D data can be categorized into three types based on the type of input representation (i) Voxel based networks such as [1] which take as input a voxelized cloud and apply 3D operations (convolution etc.) in a pipeline similar to standard 3D Convolutional Neural Network (CNN) (ii) Networks based on standard 2D CNNs. There are two types of approaches with such networks. First, which take as input RGB and Depth images, and pass them into different networks prior to fusing them [12]. And second, which compute multiple intermediate representations and pass them into separate 2D CNNs prior to combining the feature vectors [7, 13] (iii) The last and the most recent approach directly processes the unstructured point clouds, and usually involves learning a permutation invariant representation of the point cloud prior to further processing [2, 14, 15].
Since, the point clouds considered in this paper are unstructured, the deep learning techniques based on traditional convolutional operation cannot be applied. Therefore, we use deep networks that directly process unstructured 3D point clouds as our base network. The input to the network is a point along with its neighbourhood. We then employ a discriminative loss function to distinguish between good and bad matches. A drawback of such loss functions is that they give each pair of negative samples equal weightage, which makes the network saturate early or not learn at all in some cases. Therefore, we introduce a multi-margin contrastive loss to leverage the extent of separation amongst the negative samples themselves, i.e. , we make the loss function incur a larger loss for hard negative examples, while a relatively lower loss is incurred for other (soft) negative examples. We compare the proposed technique against competing methods and strong baselines. Moreover, we show the generalization ability of the learned descriptors on several applications such as object classification, retrieval, binarization of descriptors, object discovery and drought stress classification of plants.
In view of the above, the contributions of this paper are
We propose a multi margin contrastive loss function leading to more discriminative learning as compared to other loss functions.
We directly process 3D input point clouds with deep networks to learn local geometric descriptors.
We construct a large scale 3D dataset for point correspondences.
We provide exhaustive experimental analysis and show that the proposed method outperforms the other competing deep learning based methods as well as traditional 3D descriptors.
The rest of the paper is organized as follows. Section 2 discusses various works related to classification and tag prediction. In Section 3, we describe the proposed methodology, while in Section 4, the experimental setup and results are detailed. In Section 5, we show the application of the proposed descriptors on several practical problems. Finally, the conclusion is provided in Section 6.
2 Related Works
2.1 Deep Learning based Global 3D Descriptors
Shapenet from Wu et al. [16] is a Convolutional Deep Belief Network for processing 3D data. The network has been used for shape completion and object recognition. Voxnet of Maturana et al. [1] takes as input a volumetric occupancy grid which can be constructed from LiDAR, RGB-D, Voxelized Clouds etc. The architecture for processing the volumetric occupancy grids comprises a 3D Convolutional Neural Network (3D-CNN) with a 128 dimensional feature vector as output. Qi et al. [17] evaluate various 3D-CNN architectures for volumetric data. They also introduce auxiliary learning tasks and long anisotropic kernels to improve object classification. Riegler et al. ’s [18] OctNet exploits the sparsity of 3D models by hierarchically partitioning them based on the density of the data. The convolutions are defined over these sub-partitions resulting in lower memory and computational requirements. This in turn enables the network to process inputs with higher resolutions as compared to other similar networks [1, 16]. Su et al. [13] (MVCNN) use multiple views of 3D models as inputs to multiple CNNs while pooling the outputs in an end-to-end learning framework to obtain robust descriptors.
While the above approaches work with voxelized clouds or projections of 3D models, Qi et al. ’s PointNet [2] works directly with unstructured 3D point clouds by learning a symmetric function on the input data. The network can also learn point level features by aggregating descriptors within a segmentation network. The point features thus generated have been used for the task of classification as well [19]. Qi et al. also propose an extension of PointNet i.e. PointNet++ [15] that applies hierarchical learning to
PointNet for obtaining geometrically robust features. Klokov et al. [14] propose
Kd-network where they construct a network of kd-trees for parameter learning and sharing. A major
advantage of these networks is that they avoid approximations introduced due to voxelization allowing them to capture fine details while also keeping the memory footprint low. Hence, in this work, we use these networks (specifically PointNet) to learn the local descriptors in 3D.
2.2 Deep Learning based Local 3D Descriptors
As discussed above, there are several deep architectures for processing complete 3D models. However, recently researchers have made efforts to learn local descriptors as well from 3D data. This line of research seems similar to learning 2D patch descriptors [9, 20], but unlike images, the 3D models have varying input representations such as voxels, point clouds, meshes etc., which impact the choice of underlying architecture as well as the subsequent applications. With the same analogy, Huang et al. [8] describe a local 3D region by learning an embedding where geometrically and semantically similar points lie closer. They work on carefully selected projection of 3D views and use an image based convolutional neural network arranged as a siamese network with contrastive loss. Khoury et al. [7] present an approach to learning features that represent the local geometry around a point in an unstructured point cloud. They construct a histogram by partitioning space around the point and providing as input, the resultant histogram, to a deep neural network mapping the histograms to low dimensional feature vectors. Zeng et al. [10] learn local descriptors using a siamese network where the input are volumetric 3D patches from RGB-D reconstructions. Srivastava et al. [21] learn features from supervoxels and use it for the task of object discovery. In contrast to these works, our method learns the local features directly from unstructured 3D point clouds.
3 Methodology
3.1 Overview
Figure 1 shows the proposed architectures for extracting 3D point local descriptors. The input to the networks are regions around a 3D keypoint extracted using ISS keypoint detector [22]. The training set consists of pairs of positive and negative 3D patches. For multi-margin contrastive loss, the negative training samples are also labelled as hard negatives and simple negatives. This is motivated by the intuition that since the complexity of data varies it is feasible for hard examples to make the learning stronger by optimizing the constraint using a larger margin. The other examples can be used to tune the network as is done with traditional loss functions. Once the networks have been trained, it can be used to generate a D-dimensional feature vector as output by feeding the keypoint as input to the network.
3.2 Network Input
The input to the network is a pair or a triplet of 3D patches. Each 3D local patch is a 3D keypoint extracted using ISS keypoint detector [22] and aligned using a Local Reference Frame [3] given as
[TABLE]
where p is keypoint in the 3D space, R is the radius of the support region around the keypoint, pi is a 3D point within a distance R from the keypoint, and di=∣∣pi−p∣∣2.
Once the surface is aligned, the standard method of defining the neighbourhood is to consider all points within a radius of R from the keypoint. However, the resulting regions consists of variable number of points. While PointNet can handle variable number of points, we also consider the possibility of providing a fixed number of points as inputs which can represent the properties of the surrounding regions. In order to achieve this, we the method recently proposed in [23] where the authors define the neighbourhood by selecting points separated by a certain angle in the 3D space(angular constraint) within a radius R. Therefore, the local region around the keypoint (3D patch) consists of N neighbours of the keypoint satisfying the angular constraint. The choice of neighbourhood is important as it captures the geometrical property around the point while also impacts the computational complexity. In our experiments, we found the angular constraint based method to perform better than considering all the points in a neighbourhood. Therefore, for all the experiments in Section 4, we report the results with neighbourhood constructed with angular constraint.
3.3 Loss Function
Various losses have been evaluated. These losses are described next, followed by the proposed Multi-Margin Contrastive Loss.
Hinge Loss: Hinge loss is aimed towards maximum-margin classification. It is given as
[TABLE]
The forward pass of the network is parameterized by Θ and is denoted as fΘ(⋅). (xi,xj) is the pair of 3D patches provided as input to the network and yij=+1 or −1 indicates if they belong to the set positive pairs or negative pairs. b∈R and m∈R+ represent the hyper-parameters bias and margin respectively.
Contrastive Loss: The contrastive loss works by penalizing descriptors of positive pairs having large distance or descriptors of negative pairs having small distances. It is mathematically given as
[TABLE]
where yij=+1 for positive pairs and [math] for negative pairs. xi,xj is the pair of input 3D patches to the network.
Triplet Loss: A triplet loss computes the loss between an anchor, a positive and a negative patch with respect to the anchor patch. It aims to separate the positive and negative pairs by a specified distance margin.
The triplet loss is given as
[TABLE]
where x, x−, and x+ are anchor, negative and positive samples respectively while m is the margin.
Multi Margin Contrastive Loss
While the above loss functions are popular, they have various drawbacks when the data is too complicated (no convergence) or too simple (saturation). Therefore, we introduce a multiple margins to the contrastive loss which can leverage the variety in the training data and therefore the network can be made to learn as per the complexity of the data instead of treating all examples as the same. The proposed loss function consists of two margins m1 and m2, where each margin corresponds to a particular set of training examples in the negative set. The negative training examples are categorized as soft negatives (simple training examples) or hard negatives (difficult training examples). The margin corresponding to hard negatives is kept higher than that for soft negatives since they have higher potential of providing discriminative information to assist the learning. This is mathematically given as
[TABLE]
where yij=1 for positive pairs and [math] for negative pairs. xi,xj are input 3D patches. γ is 1 for hard negatives while [math] for soft negatives. m1 is the margin for hard negatives and m2 is the margin of soft negatives.
3.4 Proposed Networks
We have used PointNet and PointNet++ for directly processing the point clouds. To simplify the discussion, we would use Net to refer to the deep network used in the proposed architectures as shown in Figure 1. Various types of networks proposed are:
3DPatch triplet: It consists of Nets followed by a triplet loss function. The middle network is the anchor network while the first network is provided with the positive samples, and the third network is provided with the negative samples.
3DPatch Siamese: It consists of two Nets with tied parameters followed by hingle, contrastive or multi-margin contrastive loss.
Aggregated Siamese: This is motivated by the fact that PointNet provides features using just a cloud point. Therefore, we aggregate the features for each of the points with pooling and train a fully connected layer on top of intermediate features. The output of the fully connected layer is forwarded to the loss function. The network has been evaluated with both Contrastive and Multi-Margin Contrastive Loss.
3.5 Network Training
The parameters in the proposed architecture are computed by minimizing the loss functions discussed previously. To avoid the large parameter values, we include a regularization term to the minimization as provided below
[TABLE]
where \LRt is the regularized loss function, \Lt is the loss function of type t, i.e. , Hinge Loss, Contrastive Loss, Triplet Loss or Multi-Margin Contrastive Loss while χ represents the corresponding parameters of the loss function t. λ is the regularization parameter and W represents the weight vector.
Additionally, the initialization for the Nets has been done with the network trained for the task of part segmentation [2] on ShapeNet dataset.
4 Experiments
4.1 Dataset
We construct our dataset from the Shapenet Core dataset [24] with nearly 17,000 shapes from 16 categories. The dataset consists of labelled corresponding parts across various segmented 3D models. Therefore, we construct a set of corresponding pairs using the part-based registration from [8]. Further, we extract ISS keypoints [22] from the resultant parts and add to dataset, the points which have a corresponding keypoint in the corresponding pairs obtained previously. We construct the training set from 80% of the models, while 20% of the models are used for testing. For training the network, we need a set of positive and negative pairs. Therefore, to construct the set of positive pairs we add the matching keypoints from corresponding pairs across all the models. The negative pairs are constructed using two approaches, the first yields soft negatives, which are easier to distinguish, while the second results in hard negatives which are difficult to distinguish. We now describe both these approaches. The soft negatives are constructed by computing SHOT [3] descriptors for the points in the dataset and selecting points from distinct parts (same or different 3D models) which have a normalized Euclidean distance higher than a threshold. The intuition is that such points are keypoints (distinctive in their surroundings) and lie at a certain minimum distance in Euclidean space, they should be easy to distinguish in the embedding space as well. For hard negatives, we consider the neighbouring parts of same or similar 3D objects. For each such part, we compute the Nearest Neighbour Distance Ratio (NNDR) of the keypoints. The keypoints considered as a match are added to the set of hard negatives. Additionally, to introduce variation to the dataset, we randomly sample parts from different 3D models, and add the points which are a match as per NNDR criteria. However, as observed by [21], providing data at multiple resolutions augments the learning process from local 3D patches. Therefore, we sample point clouds at various mesh resolutions and add the resulting 3D patches to the dataset using the same methodology as described previously.
4.2 Evaluation Metrics
The results are provide on four metrics, i.e. Precision, Recall, Correspondence Accuracy and Cumulative Match Characteristics (CMC). These are explained below
Precision: It is given as the percentage of total matches which matched correctly to the ground-truth. Precision can be formulated as
[TABLE]
Recall: It is given as the correct matches out of the total matches estimated as correct by the proposed technique. Recall is formulated as
[TABLE]
Cumulative Match Characteristics (CMC): For each pair of shapes and input keypoint, we obtain a ranked list of matching points from one shape to the other shape as per the Euclidean distance amongst the descriptors of the points. Then we compute the fraction of ground-truth correspondences whose rank is less than k retrieved matches from the target shape. We report the average over all the pair of shapes for all the keypoints.
Correspondence Accuracy: For each pair of shapes, and input keypoint, the nearest point is found from one shape to the other shape. Then we calculate the Euclidean distance between the 3D position of the matched point and the ground-truth point. Finally, we compute the fraction of matched correspondences below a Euclidean error threshold τ.
Several 3D models in the dataset have symmetric shapes, such as wingtips of airplanes. In such cases, for a feature point from one of the wingtips can be considered a match for points on wingtips on either side. Since, we have constructed the dataset from part labels of the shapes, such matches may present challenge in certain scenarios. Therefore, to study the impact of models with symmetric points, we report results by considering both symmetric and non-symmetric matches.
4.3 Parameter Settings and Evaluation Setup
For comparing against the techniques of LMVCNN [8], CGF [7], 3DMatch [10], PCA [25], Spin Image [26], SHOT [3], Shape Context [27] and SDF [28] we use the publicly available code provided by the authors and those available in Point Cloud Library. For experiments using Hinge Loss, Contrastive Loss and Triplet Loss, we set m=1, while for MMCL, we use m1=2 and m2=1. The dataset of soft negatives and hard negatives is merged to a single negative set for evaluation of architectures not using MMCL. Following the protocol of [8], we also report result on training with single category and multiple category shapes. For single category training (Single Class), we train the network with the training correspondences obtained from a single class. For multiple category training, we train using correspondences from all 16 classes of ShapeNetCore (Mixed 16). Additionally, for fair comparison with competing work, we also report results when the network is trained upon 13 classes of ShapeNetCore by excluding airplanes, bikes, and chairs as reported by [8]. For reporting results with CMC and Correspondence Accuracy, we set the values of k as 100 and τ as 0.25.
4.4 Discussions
Quantitative Results
In Table 1, the results on the various proposed architectures are shown. It can be seen that 3D Patch Siamese with Multi Margin Contrastive Loss (MMCL) outperforms the next best candidate, Triplet Loss by nearly 8%, 6%, 10% and 11% respectively on CMC, Correspondence Accuracy, Precision and Recall (symmetric) for Single Class. Similarly, 3D Patch Siamese (MMCL) outperforms the other proposed architectures when trained on Mixed 16 classes as well. It can be seen that the network with triplet loss performs better than other siamese based approaches (except MMCL). This means that having more discriminative information aids learning of better descriptors. As 3D Patch Siamese with MMCL performs best amongst the proposed architectures, in the subsequent experiments we provide results and comparisons against the 3D Patch Siamese (MMCL) and refer to it as ’Ours’ throughout the text. Table 2 compares the matching performance of the best performing model amongst the proposed architectures, i.e. 3D Patch Siamese (MMCL) against other deep and hand-crafted local descriptors. It can be observed that the proposed method outperforms all the other methods, with nearly 3∼5% improvement on an average on all metrics over LMVCNN, the second best performing method amongst the evaluated techniques. This shows that the proposed network can effectively encode the structure from the input 3D patch, while being more robust to symmetric examples.
Ablation Studies
To further demonstrate the effectiveness of the proposed method against noisy and low resolution 3D models, we perform experiments by varying the mesh resolution (mr) of the input 3D models. The results are shown in Tables 3, 4, and 5. It can be observed that as the resolution increases from 0.25 to original (Table 2), the matching performance increases. We also noticed that on low resolutions, the orientation assignment may become noisy, however, in our experiments we did not find any significant difference on low resolutions by avoiding normal computation while at high resolutions, the orientation assignment resulted in a significant boost in the matching performance. It can also be noted that on low resolutions (0.25, 0.5) there is a significant drop in the performance of LMVCNN as compared to the same on higher resolutions. This is because LMVCNN uses projection of the point clouds to train the network and at low resolution, the generated projections become inaccurate inhibiting its performance. Similar trend is also observed for CGF. In other words, at lower resolution, the approaches based on intermediate representations i.e. projections or histograms, suffer from significant information loss while the proposed technique can exploit the available information (geometry etc. ) directly from the point cloud itself instead of any intermediate representation.
Figure 2 shows the impact of varying the size of the descriptor obtained using the proposed technique. It can be seen that with low descriptor size (such as 32, 64) the correspondence accuracy is very low. This means that the learned embedding is not able to generalize well for these sizes, while CGF provides better results with 32 bit vector. A possible reason is that in CGF, the learning is on the pre-processed patches where the network input is a histogram, while in the current setting the network input is the 3D patch itself. In our experiments, we found that making the network deeper (adding more layers), resulted in comparative performance with CGF having a descriptor size of 32 (since the current model was able to generalize well on the evaluated settings, we report results with the default architecture.)
Qualitative Results
Figure 3 shows the variation of the descriptors learned over models of chairs. The figure was plotted by following the strategy of [7] i.e. we extract descriptor of each point of the model and project it to a 3-dimensional RGB color space using PCA. Similar color on the surface indicates matching points in the two models. It can be observed that the correspondence is not only consistent but can also discriminate among various parts of the chairs such as the seat, back support and legs as indicated by similarity of colors on these parts. This is interesting as the method has not been trained explicitly to distinguish among parts. This also indicates that the network is able to learn the geometric structure of the surface. Moreover, the ground base of the first chair (left) has a bluish color, while such a color is not present in the second chair (right) indicating the absence of similar part (second chair does not have a base). This further demonstrates the disciminative ability of the learned features using the proposed model.
5 Applications
In this section, we show the performance of the proposed descriptors on various basic as well as advanced tasks. The basic tasks involve classification, retrieval etc. The base problems have been chosen is to show the improvements obtained using the proposed technique when it is used as a drop-in replacement for handcrafted features in traditional pipelines. The advanced tasks are more specific tasks directly solving a practical real world problem.
5.1 Classification
Given an input 3D model, the objective is to identify the class to which the model belongs. To show the effectiveness of the proposed local descriptors against other local descriptors, we follow a standard pipeline of extracting keypoints from point clouds and describe them using various descriptors. Next, the descriptors are quantized using Fisher Vector [30] and classified using a Support Vector Machine. The classification is performed on Semantic3D[31] and ModelNet10[16] dataset. The Semantic3D provides point level labels, hence local descriptors are more suited for such classification. ModelNet10 does not provide point level labels, and hence in general, the global descriptors are preferred on ModelNet10 for evaluation. However, we provide results on ModelNet10 for two reasons. First, while it is amongst the most popular benchmarks, not many 3D local descriptors have been evaluated on it and hence, we provide a relative comparison of local descriptors on large 3D models and datasets. Second, since ModelNet10 does not provide point level labels, we use the network fine-tuned on Semantic3D for classification and still achieve better results than the compared local descriptors demonstrating the generalization ability of the proposed method.
For the results reported for classification, we use the pre-trained network from 3D Patch Siamese (MMCL) used in previous experiments, and fine tune it for classification task using the labelled training points provided by Semantic3D. The results are shown in Table 6 and Table 7 (a) for Semantic3D and ModelNet10 respectively. It can be seen that the proposed method outperforms the compared methods with LMVCNN lagging behind by 2% on Semantic3D and by 3.4% on ModelNet10. It can also be noticed that the deep descriptors consistently perform superior to the traditional hand-crafted descriptors e.g. RoPS lags behind the proposed descriptor by 7% on Semantic3D. This indicates that the learning based methods are able to encode, the local surface information, in a more robust manner, where the proposed architecture outperforms the deep learning based methods by ∼2.5% on Semantic3D and ∼3.8% on ModelNet10 on an average. The table also shows the results of a few state-of-the-art techniques on ModelNet10 dataset. These techniques provide global descriptors. It can be seen that the performance of state-of-the-art is greater than 95%, however, such techniques are usually based on alternate representations of point clouds such as projections [32] or ensemble of networks [33] to achieve such results instead of directly processing point clouds.
5.2 Retrieval
Retrieval aims at fetching, usually from a large repository, models similar to the input model. For efficient retrieval, the features need to robustly encode local information to differentiate among similarly structured models. The retrieval pipeline involves extracting features from keypoints obtained from the 3D models, quantizing them using Fisher Vector and then matching them with the quantized descriptors from the models in the repository. For evaluation we use the ModelNet10 dataset [16] and the results are shown in Table 7(b). It can be seen that the proposed method outperforms the compared methods by ∼7 on an average. Moreover, it significantly outperforms the handcrafted descriptors e.g. RoPS lags behind by 7.5% while SHOT is outperformed by 10.2%. An interesting observation here is that CGF performs better than LMVCNN while only slightly lagging behind the proposed method. This is because CGF is specifically designed to robustly encode the geometric information, while LMVCNN and our method rely on general purpose encoding of descriptors. This indicates that the proposed descriptor can effectively encode the geometric information into a compact descriptor.
5.3 Binarization
Compactness of feature plays an important role in scaling up the number of models that can be evaluated for a specific objective. However, at the same time it is also important to maintain the robustness of the original descriptor. Therefore, we binarize the descriptors and evaluate their performance on classification and retrieval tasks discussed above. The binarization for real-valued descriptors is achieved through Iterative Quantization [35] where the descriptors are reduced to 128 bits while CGF has been reduced to 32 bit (as maximum number of real values in the descriptor is 32). The results are shown in Table 8. It can be seen that the deep learning based descriptors consistently outperform handcrafted descritpors i.e. on an average the handcrafted descriptors lag behind by ∼20% from the proposed method. However, the 3D Binary Signatures [23] performs closer to the deep learning based descriptors, where 3DBS-64 i.e. 3DBS with 64 nearest neighbours, lags behind by only 5.5%. This shows that even with significant reduction in the descriptor size, the performance on classification and retrieval tasks is nearly the same as those of their respective real valued versions (Table 6, Table 7).
5.4 Object Discovery in 3D
Object Discovery in 3D refers to finding never-before-seen objects in 3D scenes. For discovering objects, we follow the pipeline proposed by [21]. We use the pre-trained network proposed in this paper and fine-tune it on the Universal Training Set proposed by the authors. However, our pipeline differs in the following way. Instead of a voxel based 3d convolutional neural network, we use the network proposed in this work. Therefore, instead of voxelizing the supervoxels, we use the corresponding points (unstructured) as input to the network. Additionally, instead of using a hinge loss, we use the multi-margin contrastive loss proposed in the paper. We show results on the NYU Depth v2 dataset [37] in Figure 5. The proposed method outperforms VDML40 by 2.3% while also having lower over-segmentation (Fos) and under-segmentation (Fus) scores as compared to variations of VDML, local descriptors (SI, RoPS, SHOT, FPFH) as well as those of Gupta et al. [38], Silberman et al. [37] and Stein et al. [39].
Figure 4 shows qualitative results for object discovery using the proposed method on Object Segmentation Dataset [40] and Object Discovery Dataset[41] with a network pre-trained on NYU Depth v2. It can be observed that the proposed method provides better coverage of objects even with varying colors. For example, in first row, the vaccum cleaner is detected as two distinct objects (over-segmentation) by [21], while the proposed method classifies it as a single object. This can be attributed to the point based learning of neighbourhood information which allows it learn finer details within the objects, whereas, voxel based representation tends to loose such information. Similarly, in second row, the discovered objects have lesser over-segmentation for objects such as cup, bowl which have curved surfaces.
5.5 Drought Stress Classification
In this setting, the objective is to predict whether the input plant model is suffering drought or not. Visual identification of drought stress experienced by a plant in a non-invasive manner is an active area of research [42]. The characteristics exhibited by leaves of the plants vary significantly among plant phenotypes and genotypes which makes it difficult to develop general purpose hand-crafted descriptors for this task. To overcome this, Srivastava et al. [19] proposed to learn descriptors to distinguish between 3D models of drought stress experiencing plants and healthy plants. Their feature extraction pipeline involves first learning a global descriptor of a 3D plant model using PointNet, followed by aggregation of global descriptors with point features to obtain the final descriptor. However, instead of using the point features obtained from PointNet, we provide as input the features obtained from pre-trained model of 3DPatch Siamese (MMCL) which is fine-tuned on the training set of [19]. The results are shown in Table 9. It can be seen that the proposed architecture outperformed the best performing model of [19] by ∼4% while having a similar computation time.
Figure 6 shows qualitative results on drought classification. The figure shows a few images of the plant from which a 3D model is constructed. The plant is in mid stages of drought as indicated by presence of both green and dry leaves. The drought stress classification technique of [19] which is based on optimizing global descriptors followed by local descriptors, classifies the input 3D model as suffering drought with a confidence of 51%. On the other hand, the proposed technique classifies the input 3D model as suffering from drought with 86% confidence. This shows that while both the techniques are able to classify correctly, the proposed method provides higher confidence indicating that it is able to discriminate between the variation in the local structures characterizing the drought.
6 Conclusion
In this paper, we proposed a novel local 3d descriptor based on recent advances in 3d deep networks. We directly processed the input 3D patches using a deep network where the learning is made discriminative using a siamese network with a multi-margin contrastive loss. With exhaustive experiments we showed that the proposed technique outperforms competing methods. We also showed that the method is able to robustly encode the available information even when the mesh resolution is reduced, where the performance of the other methods rapidly degrades. This strengthens our hypothesis that learning directly from point cloud representations allows learning stronger and more robust descriptors. Moreover, the generalization ability and uniqueness of the proposed architecture was demonstrated with applications on classification, retrieval, binarization, object discovery and drought stress classification in plants. The experiments on classification and retrieval demonstrated that the proposed descriptor can be effectively used as a drop-in replacement for existing 3D local descriptors. On the other hand, binarization did not result in significant loss for deep learning based descriptors indicating that there is scope for learning more compact descriptors without any significant loss in robustness. Finally, we showed that the proposed descriptor can be successfully applied to real-world problem by achieving state-of-the-art results for object discovery and drought stress classification.

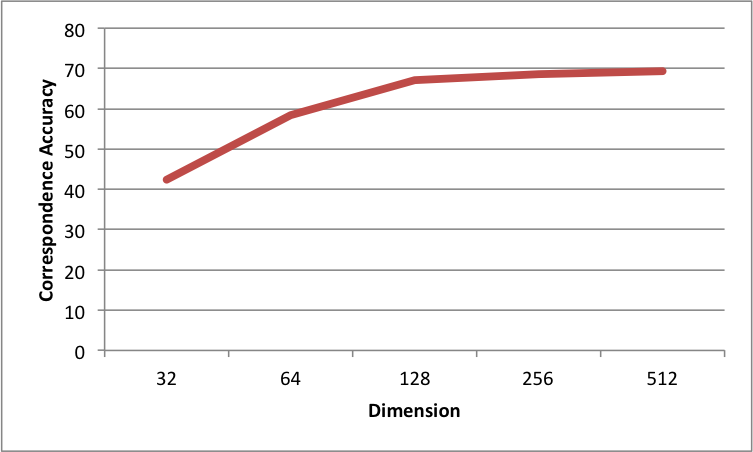 Figure 1
Figure 1 Figure 2
Figure 2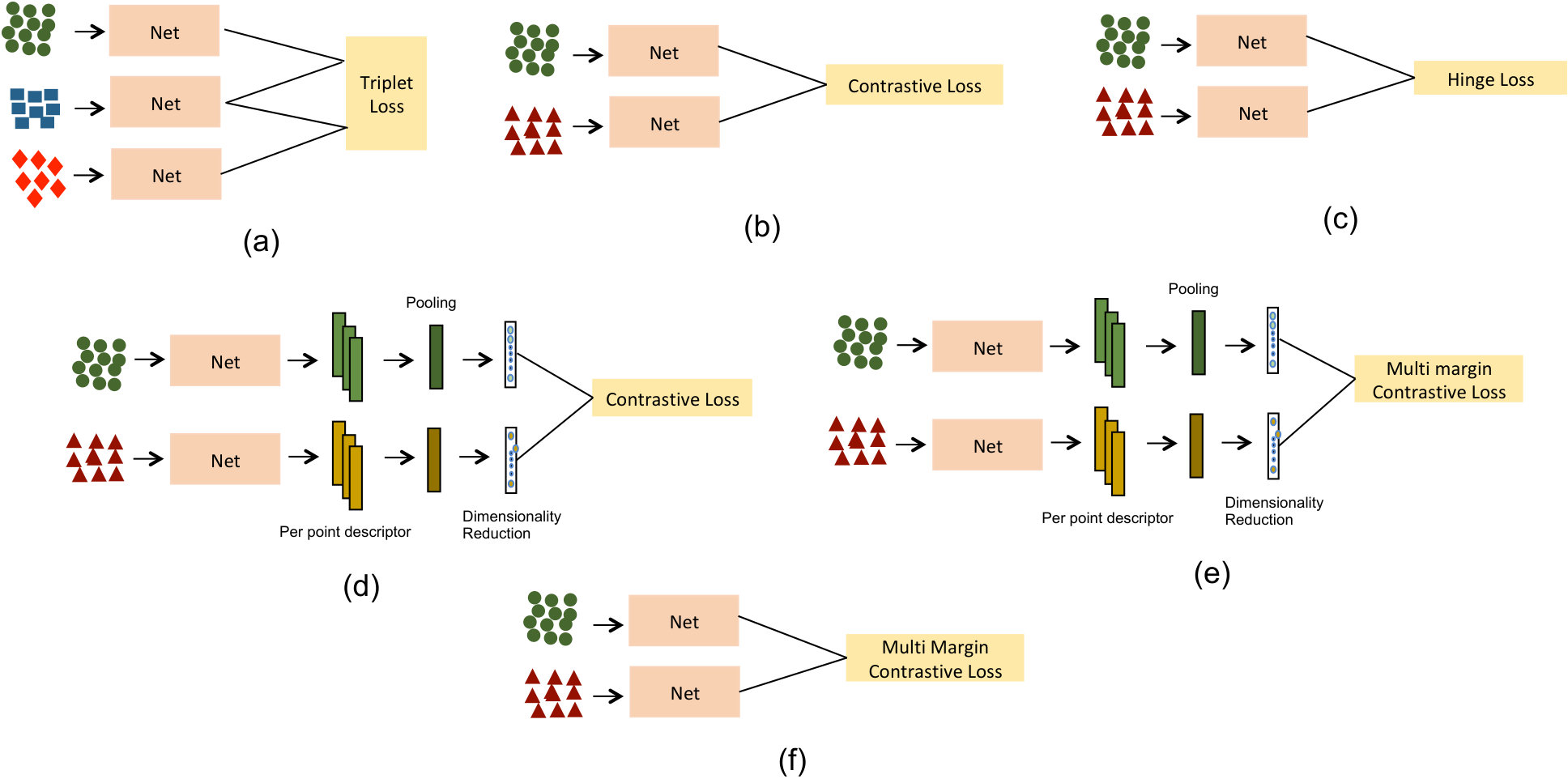 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10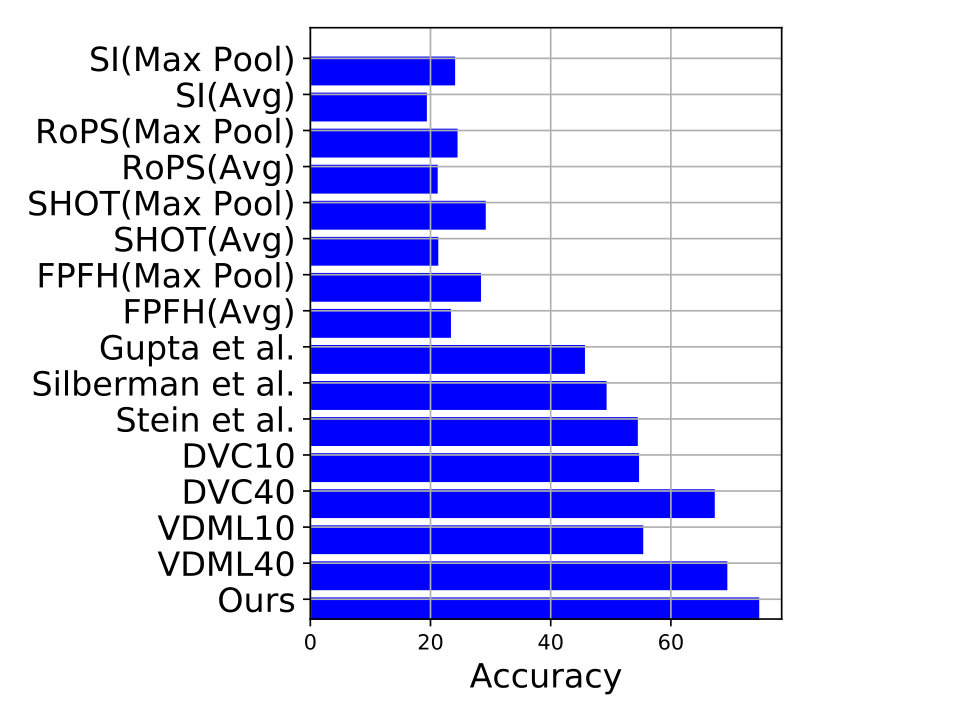 Figure 11
Figure 11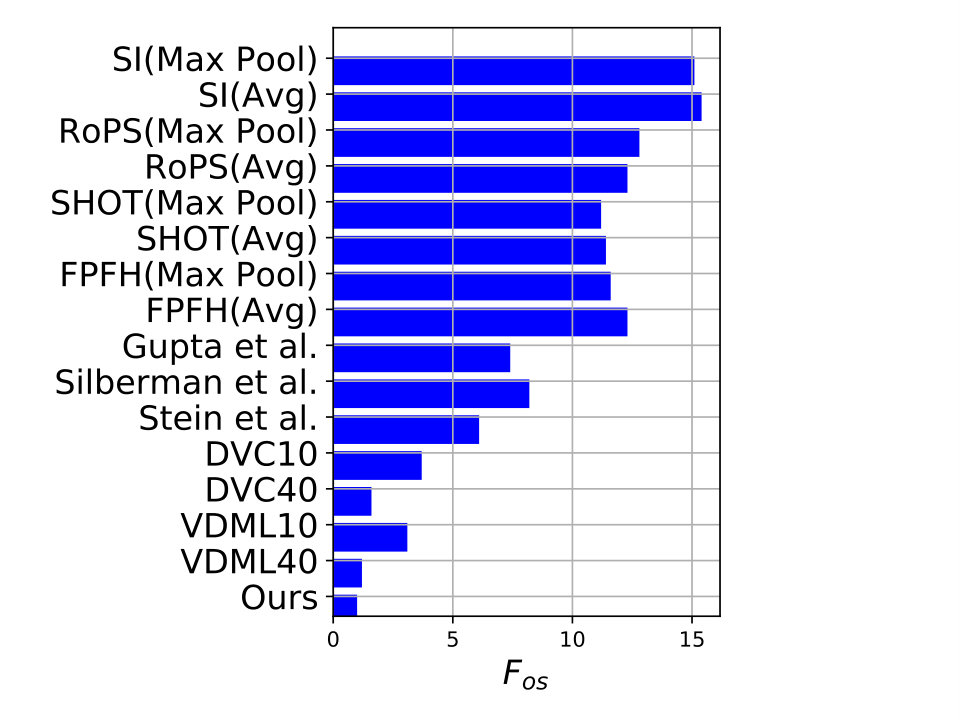 Figure 12
Figure 12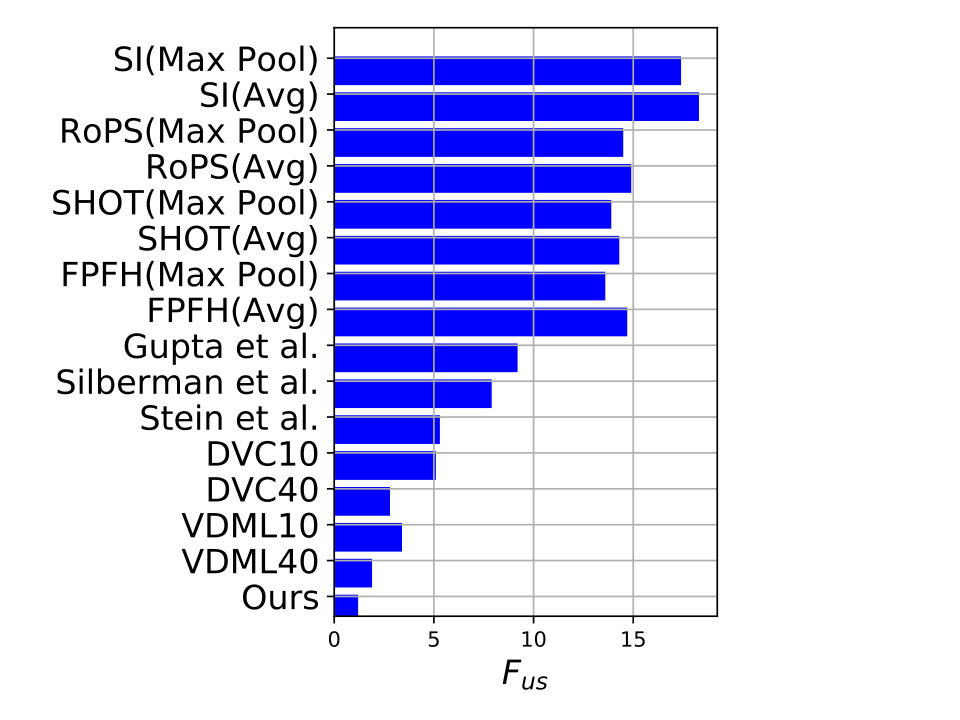 Figure 13
Figure 13