Polysemy and brevity versus frequency in language
Bernardino Casas, Antoni Hern\'andez-Fern\'andez, Neus Catal\`a, Ramon, Ferrer-i-Cancho, Jaume Baixeries

TL;DR
This study examines the relationship between word frequency, polysemy, and length across multiple languages, confirming that more frequent words tend to be more polysemous and shorter in various measures.
Contribution
It extends previous research by analyzing multiple languages and additional length measures, reinforcing the universality of Zipfian laws in language.
Findings
Meaning-frequency law holds across languages
Shorter words tend to be more frequent in all measures
Laws are robust across English, Dutch, and Spanish
Abstract
The pioneering research of G. K. Zipf on the relationship between word frequency and other word features led to the formulation of various linguistic laws. The most popular is Zipf's law for word frequencies. Here we focus on two laws that have been studied less intensively: the meaning-frequency law, i.e. the tendency of more frequent words to be more polysemous, and the law of abbreviation, i.e. the tendency of more frequent words to be shorter. In a previous work, we tested the robustness of these Zipfian laws for English, roughly measuring word length in number of characters and distinguishing adult from child speech. In the present article, we extend our study to other languages (Dutch and Spanish) and introduce two additional measures of length: syllabic length and phonemic length. Our correlation analysis indicates that both the meaning-frequency law and the law of abbreviation…
Click any figure to enlarge with its caption.
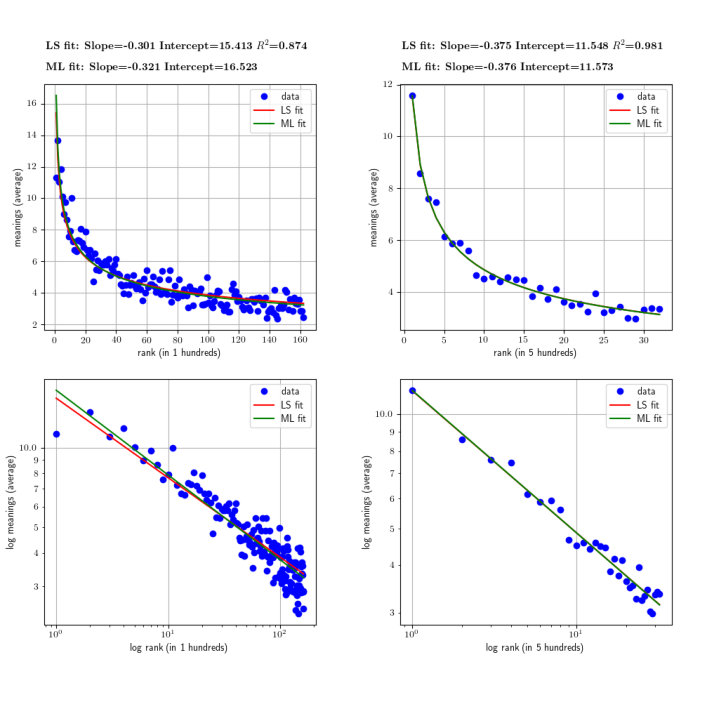 Figure 1
Figure 1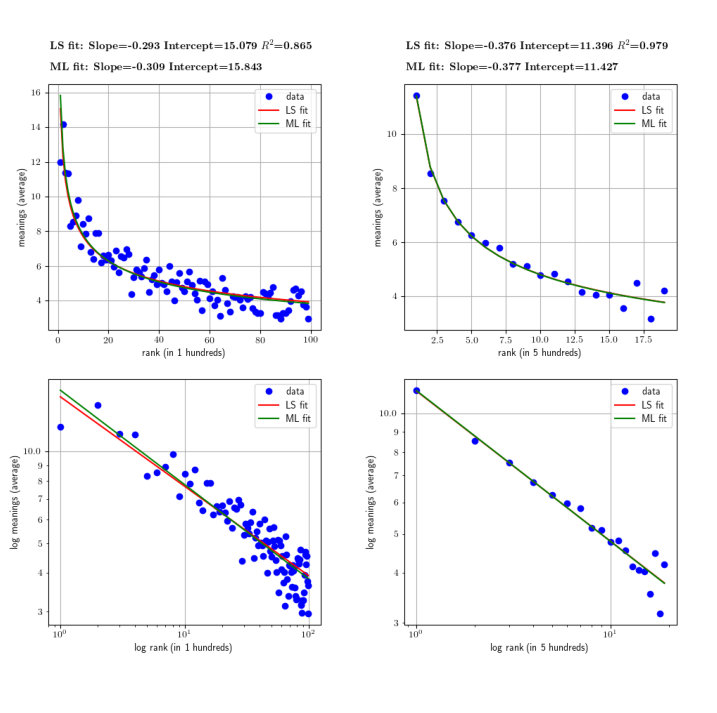 Figure 2
Figure 2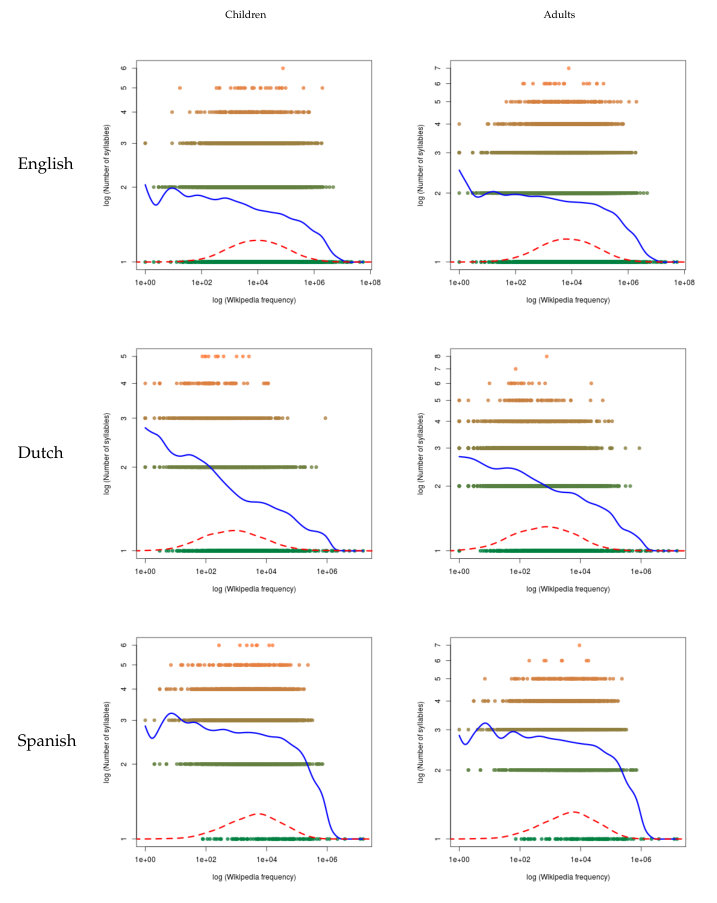 Figure 3
Figure 3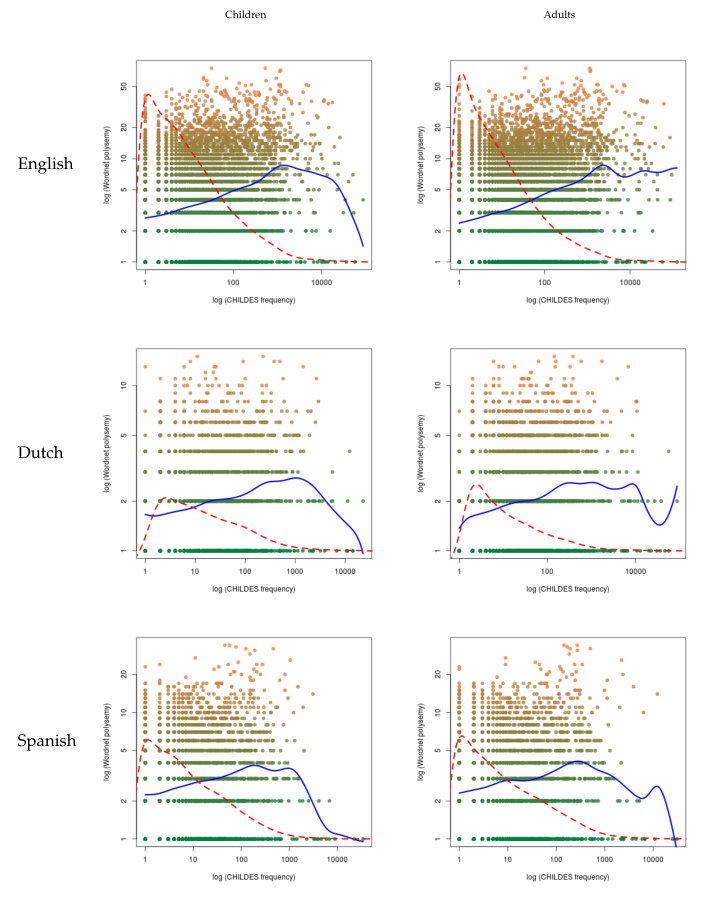 Figure 4
Figure 4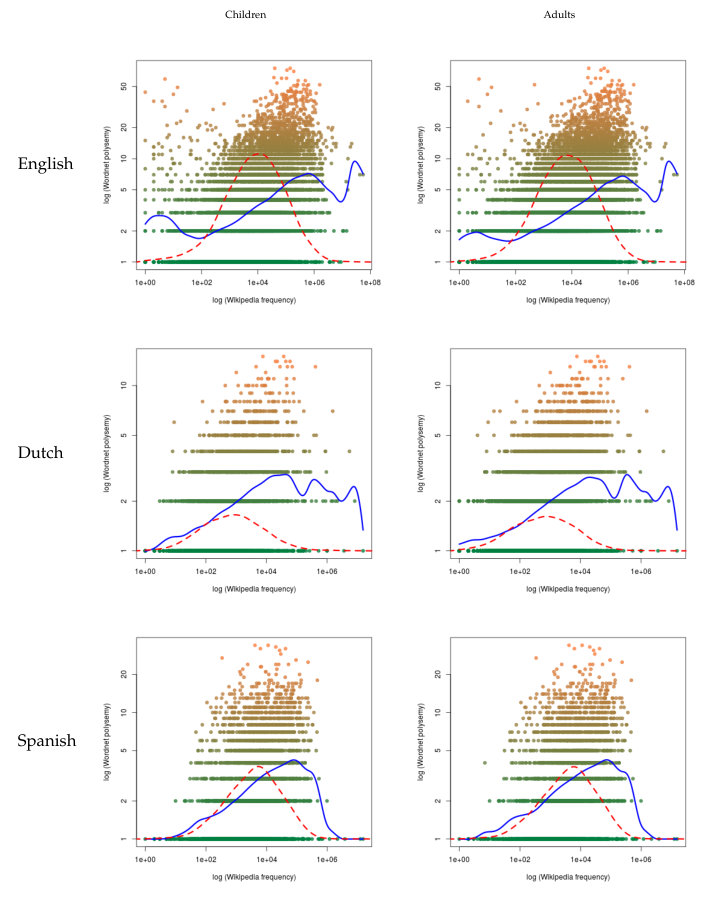 Figure 5
Figure 5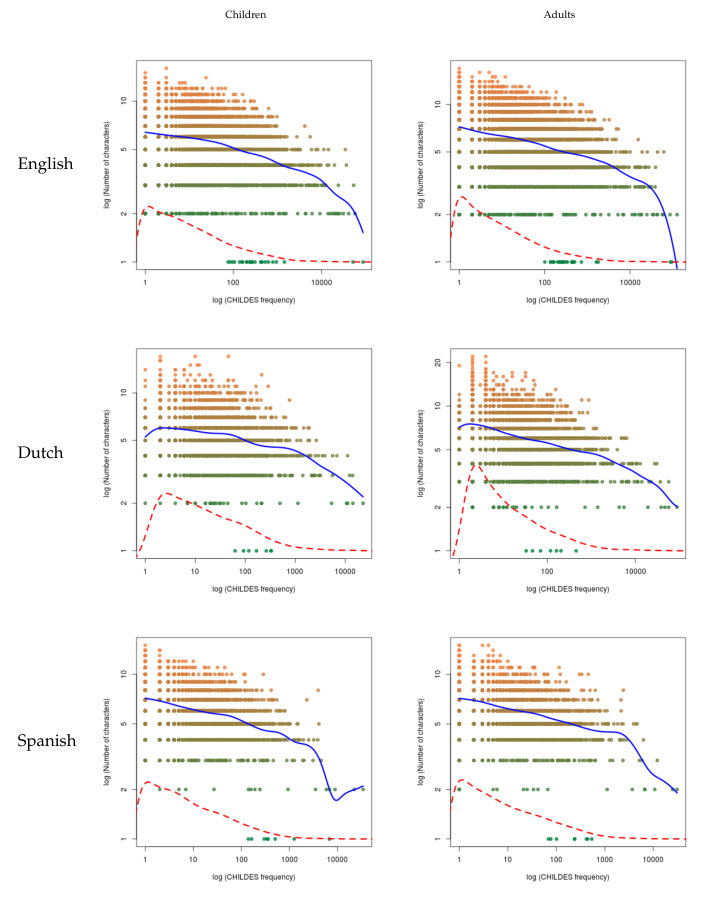 Figure 6
Figure 6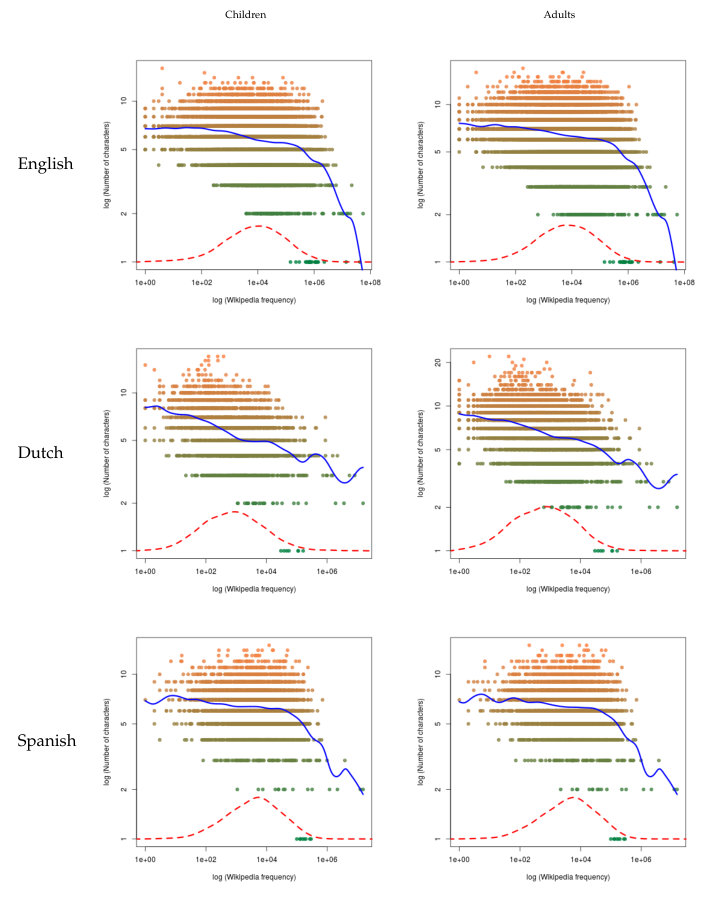 Figure 7
Figure 7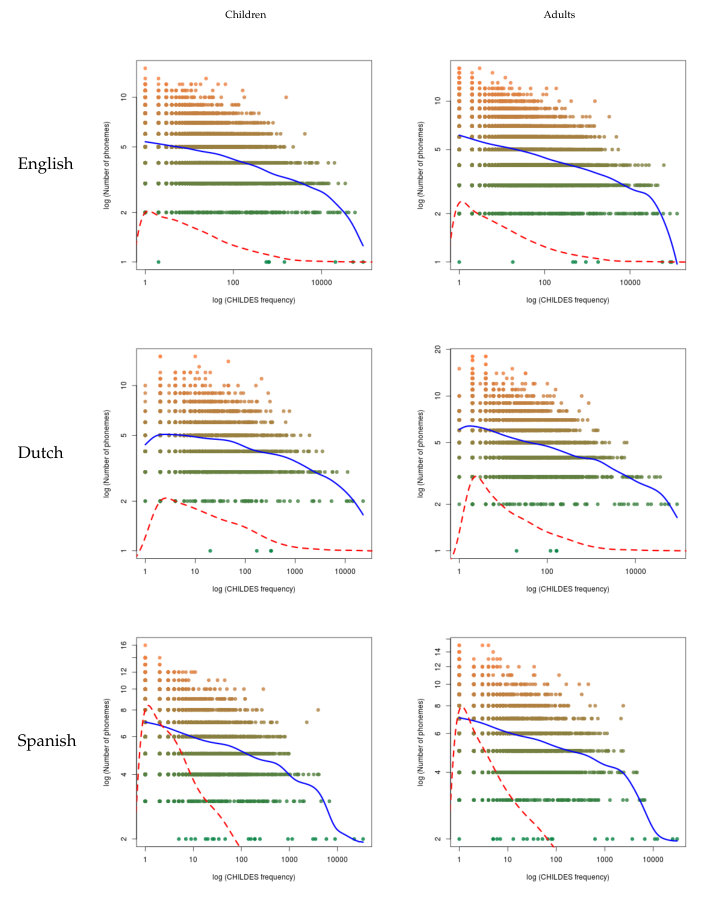 Figure 8
Figure 8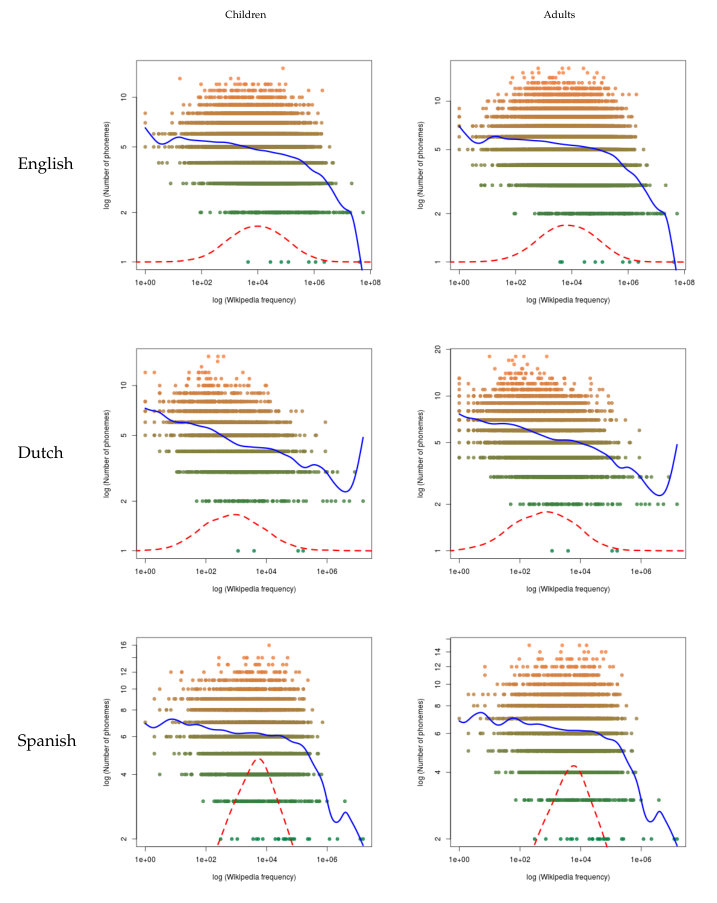 Figure 9
Figure 9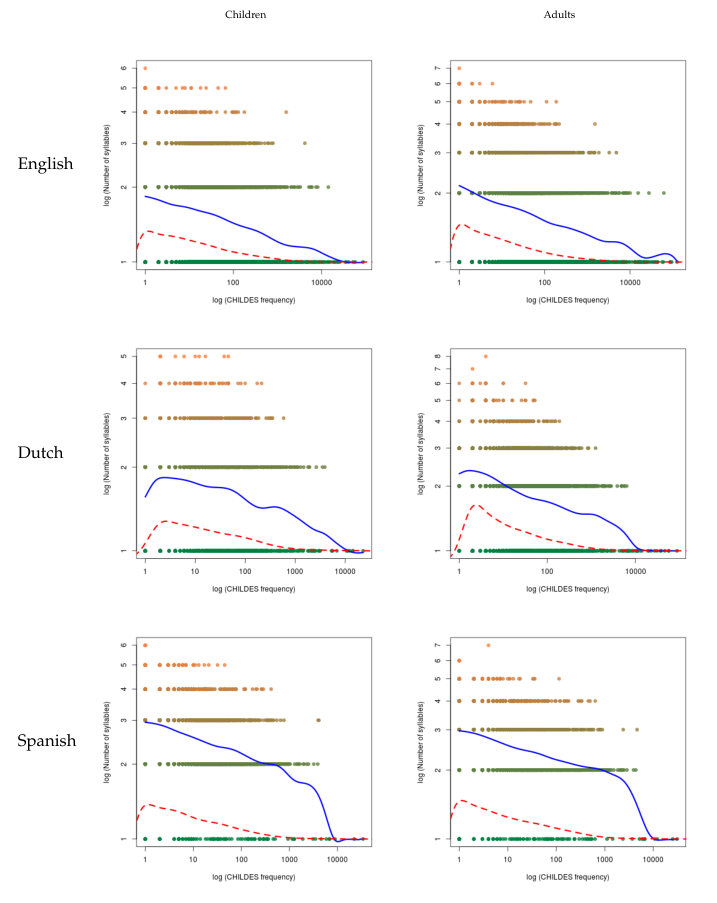 Figure 10
Figure 10| Language / role | N | Least squares | Maximum likelihood | |||
|---|---|---|---|---|---|---|
| slope | intercept | R-squared | slope | intercept | ||
| English/Adults | 162 | |||||
| English/Children | 99 | |||||
| Dutch/Adults | 52 | |||||
| Dutch/Children | 26 | |||||
| Spanish/Adults | 32 | |||||
| Spanish/Children | 35 | |||||
| Language / role | N | Least squares | Maximum likelihood | |||
|---|---|---|---|---|---|---|
| slope | intercept | R-squared | slope | intercept | ||
| English/Adults | 32 | |||||
| English/Children | 19 | |||||
| Dutch/Adults | 10 | |||||
| Dutch/Children | 5 | |||||
| Spanish/Adults | 6 | |||||
| Spanish/Children | 7 | |||||
| Lang. | Role | Types | Tokens | ||||
| analyzed | total | cover | analyzed | total | cover | ||
| English | Children | 9,930 | 29,017 | 34% | 1,596,726 | 2,308,675 | 69% |
| Adults | 16,235 | 25,135 | 64% | 3,008,148 | 4,584,213 | 65% | |
| Dutch | Children | 2,627 | 13,666 | 19% | 313,556 | 628,622 | 50% |
| Adults | 5,273 | 19,037 | 28% | 1,008,393 | 2,122,354 | 48% | |
| Spanish | Children | 3,520 | 27,167 | 13% | 253,145 | 864,603 | 29% |
| Adults | 3,217 | 19,975 | 16% | 288,660 | 997,901 | 29% | |
| Role | Frequency | Correlation | Char. vs Phon. | Phon. vs Syllables | Char. vs Syllables |
|---|---|---|---|---|---|
| Children | CHILDES | Pearson | |||
| Spearman | |||||
| Kendall | |||||
| Wikipedia | Pearson | ||||
| Spearman | |||||
| Kendall | |||||
| Adults | CHILDES | Pearson | |||
| Spearman | |||||
| Kendall | |||||
| Wikipedia | Pearson | ||||
| Spearman | |||||
| Kendall |
| Role | Frequency | Correlation | Char. vs Phon. | Phon. vs Syllables | Char. vs Syllables |
|---|---|---|---|---|---|
| Children | CHILDES | Pearson | |||
| Spearman | |||||
| Kendall | |||||
| Wikipedia | Pearson | ||||
| Spearman | |||||
| Kendall | |||||
| Adults | CHILDES | Pearson | |||
| Spearman | |||||
| Kendall | |||||
| Wikipedia | Pearson | ||||
| Spearman | |||||
| Kendall |
| Role | Frequency | Correlation | Char. vs Phon. | Phon. vs Syllables | Char. vs Syllables |
|---|---|---|---|---|---|
| Children | CHILDES | Pearson | |||
| Spearman | |||||
| Kendall | |||||
| Wikipedia | Pearson | ||||
| Spearman | |||||
| Kendall | |||||
| Adults | CHILDES | Pearson | |||
| Spearman | |||||
| Kendall | |||||
| Wikipedia | Pearson | ||||
| Spearman | |||||
| Kendall |
| Language | Role | Frequency | Polysemy | Number of characters | Number of phonemes | Number of syllables |
|---|---|---|---|---|---|---|
| English | Children | CHILDES | 18.2% | 20.9% | 21.4% | 35.4% |
| Wikipedia | 11.9% | 14.4% | 15.0% | 29.9% | ||
| Adults | CHILDES | 21.3% | 21.3% | 21.3% | 33.9% | |
| Wikipedia | 13.7% | 13.2% | 13.2% | 26.9% | ||
| Dutch | Children | CHILDES | 31.8% | 19.5% | 21.9% | 38.0% |
| Wikipedia | 26.9% | 13.1% | 15.6% | 33.0% | ||
| Adults | CHILDES | 36.1% | 21.8% | 23.3% | 37.0% | |
| Wikipedia | 28.2% | 11.1% | 12.7% | 28.4% | ||
| Spanish | Children | CHILDES | 24.0% | 21.4% | 21.0% | 38.7% |
| Wikipedia | 17.5% | 14.3% | 13.8% | 33.0% | ||
| Adults | CHILDES | 23.2% | 21.5% | 21.1% | 38.3% | |
| Wikipedia | 16.4% | 14.1% | 13.7% | 32.3% |
| Corpus | Age Range | # children | Comments |
|---|---|---|---|
| Bloom 1970 [68, 69, 70] | 1;9 – 3;2 | 2 | A large longitudinal study of one child with a few samples for another. Gia was excluded because age information is not reported for her. |
| Brown [71] | Adam 2;3 – 4;10 | 3 | Large longitudinal study |
| Eve 1;6 – 2;3 | of three children: Adam | ||
| Sarah 2;3 – 5;1 | 55 files, Eve 20 and Sarah 139 | ||
| Kuczaj [72] | 2;4 – 5;0 | 1 | Diary study in the home environment |
| MacWhinney [73] | Ross 2;6 – 8;0 | 2 | Diary study of the development of two brothers recorded in spontaneous situations |
| Mark 0;7 – 5;6 | |||
| Providence [74] | 1 – 3 | 5 | Ethan was excluded because he was diagnosed with Asperger’s Syndrome at the age of 5. |
| Sachs [75] | 1;1 – 5;1 | 1 | Longitudinal naturalistic study |
| Suppes [76] | 1;11 – 3;11 | 1 | Longitudinal study of a single child |
| Corpus | Age Range | # children | Comments |
|---|---|---|---|
| BolKuiken [77] | 1;7 – 3;7 | 47 | Dutch normal controls |
| CLPF [78, 79] | 1;0 – 2;11 | 12 | PHONBANK, longitudinal study with 20,000 utterances |
| Groningen [80] | 1;5 – 3;7 | 6 | ’Iris’ was removed because she subsequently displayed delay in language development due to hearing problems. ’Iri’ (ending with no ’s’) was also excluded (this person was very likely a misspelling of ’Iris’ because he/she was in the same subdirectory of ’Iris’ and was the only target child in the only file where it appeared). |
| Schaerlaekens [81] | 1;8 – 2;10 , 1;10 – 3;1 | 6 | |
| van Kampen [82] | Laura 1;9 – 5;10 | 2 | |
| Sarah 1;6.16 – 6;0 |
| Corpus | Age Range | # children | Comments |
|---|---|---|---|
| Aguirre [83] | 1;7-2;10 | 1 | |
| BecaCESNo | 3;6-11;6 | 40 | |
| ColMex | 6;0-7;0 | 30 | Mexican Spanish, picture and procedural description |
| DiezItza [84] | 3;0-3;11 | 20 | |
| FernAguado | 3;0-4;0 | 50 | |
| Hess [85] | 6;0-12;0 | 24 | |
| JacksonThal [86, 87] | 0;10-3;0 | 202 | Cross-sectional data from Queretaro, San Diego, and Santa Barbara |
| Linaza [88] | 2;0-4;0 | 1 | |
| LlinasOjea | 0;11-3;02 | 1 | Longitudinal study of two children in Asturias, but only Yasmin is considered. |
| Marrero | 1;8-8;0 | 3 | Longitudinal study of Spanish children from the Canaries |
| Nieva | 1;8-2;3 | 1 | |
| Ornat [89] | 1;7-4;0 | 1 | |
| Remedi | 1;11-2;10 | 1 | |
| Romero [90] | 2;0 | 1 | Mexican Spanish |
| SerraSole | 1;4-3;10 | 1 | |
| Shiro [91] | 6;0-9;0 | 113 | Narratives from Venezuelan children |
| Role | Pearson | Spearman | Kendall | size | |||
| p-value | p-value | p-value | |||||
| CHILDES frequency vs Wordnet polysemy | |||||||
| Children | 0.059 | 0.249 | 0.182 | 9,930 | |||
| Adults | 0.09 | 0.264 | 0.196 | 16,235 | |||
| CHILDES frequency vs Number of characters | |||||||
| Children | -0.122 | -0.27 | -0.202 | 9,930 | |||
| Adults | -0.115 | -0.324 | -0.243 | 16,235 | |||
| CHILDES frequency vs Number of phonemes | |||||||
| Children | -0.123 | -0.31 | -0.234 | 8,547 | |||
| Adults | -0.11 | -0.361 | -0.273 | 14,146 | |||
| CHILDES frequency vs Number of syllables | |||||||
| Children | -0.077 | -0.239 | -0.193 | 8,547 | |||
| Adults | -0.075 | -0.303 | -0.243 | 14,146 | |||
| Role | Pearson | Spearman | Kendall | size | |||
| p-value | p-value | p-value | |||||
| Wikipedia frequency vs Wordnet polysemy | |||||||
| Children | 0.059 | 0.415 | 0.301 | 9,975 | |||
| Adults | 0.068 | 0.422 | 0.307 | 16,286 | |||
| Wikipedia frequency vs Number of characters | |||||||
| Children | -0.106 | -0.241 | -0.172 | 9,975 | |||
| Adults | -0.094 | -0.2 | -0.142 | 16,286 | |||
| Wikipedia frequency vs Number of phonemes | |||||||
| Children | -0.1 | -0.242 | -0.176 | 8,548 | |||
| Adults | -0.084 | -0.171 | -0.122 | 14,149 | |||
| Wikipedia frequency vs Number of syllables | |||||||
| Children | -0.06 | -0.17 | -0.131 | 8,548 | |||
| Adults | -0.054 | -0.102 | -0.078 | 14,149 | |||
| Role | Pearson | Spearman | Kendall | size | |||
| p-value | p-value | p-value | |||||
| CHILDES frequency vs Wordnet polysemy | |||||||
| Children | 0.017 | 0.376 | 0.19 | 0.147 | 2,627 | ||
| Adults | 0.013 | 0.342 | 0.19 | 0.149 | 5,273 | ||
| CHILDES frequency vs Number of characters | |||||||
| Children | -0.13 | -0.187 | -0.138 | 2,627 | |||
| Adults | -0.113 | -0.347 | -0.259 | 5,273 | |||
| CHILDES frequency vs Number of phonemes | |||||||
| Children | -0.136 | -0.2 | -0.149 | 2,575 | |||
| Adults | -0.114 | -0.358 | -0.271 | 5,179 | |||
| CHILDES frequency vs Number of syllables | |||||||
| Children | -0.1 | -0.169 | -0.134 | 2,575 | |||
| Adults | -0.093 | -0.323 | -0.258 | 5,179 | |||
| Role | Pearson | Spearman | Kendall | size | |||
| p-value | p-value | p-value | |||||
| Wikipedia frequency vs Wordnet polysemy | |||||||
| Children | 0.002 | 0.931 | 0.377 | 0.286 | 2,634 | ||
| Adults | 0.008 | 0.574 | 0.395 | 0.302 | 5,289 | ||
| Wikipedia frequency vs Number of characters | |||||||
| Children | -0.079 | -0.4 | -0.285 | 2,634 | |||
| Adults | -0.07 | -0.347 | -0.244 | 5,289 | |||
| Wikipedia frequency vs Number of phonemes | |||||||
| Children | -0.077 | -0.389 | -0.282 | 2,579 | |||
| Adults | -0.067 | -0.315 | -0.224 | 5,190 | |||
| Wikipedia frequency vs Number of syllables | |||||||
| Children | -0.06 | 0.002 | -0.363 | -0.28 | 2,579 | ||
| Adults | -0.055 | -0.281 | -0.212 | 5,190 | |||
| Role | Pearson | Spearman | Kendall | size | |||
| p-value | p-value | p-value | |||||
| CHILDES frequency vs Wordnet polysemy | |||||||
| Children | -0.01 | 0.564 | 0.162 | 0.12 | 3,520 | ||
| Adults | 0.011 | 0.523 | 0.152 | 0.113 | 3,217 | ||
| CHILDES frequency vs Number of characters | |||||||
| Children | -0.125 | -0.367 | -0.276 | 3,520 | |||
| Adults | -0.136 | -0.362 | -0.272 | 3,217 | |||
| CHILDES frequency vs Number of phonemes | |||||||
| Children | -0.114 | -0.361 | -0.271 | 3,512 | |||
| Adults | -0.136 | -0.362 | -0.272 | 3,207 | |||
| CHILDES frequency vs Number of syllables | |||||||
| Children | -0.109 | -0.344 | -0.276 | 3,520 | |||
| Adults | -0.126 | -0.354 | -0.284 | 3,217 | |||
| Role | Pearson | Spearman | Kendall | size | |||
| p-value | p-value | p-value | |||||
| Wikipedia frequency vs Wordnet polysemy | |||||||
| Children | -0.003 | 0.849 | 0.385 | 0.282 | 3,524 | ||
| Adults | -0.007 | 0.698 | 0.359 | 0.262 | 3,220 | ||
| Wikipedia frequency vs Number of characters | |||||||
| Children | -0.085 | -0.144 | -0.103 | 3,524 | |||
| Adults | -0.088 | -0.167 | -0.119 | 3,220 | |||
| Wikipedia frequency vs Number of phonemes | |||||||
| Children | -0.078 | -0.122 | -0.087 | 3,516 | |||
| Adults | -0.081 | -0.145 | -0.103 | 3,210 | |||
| Wikipedia frequency vs Number of syllables | |||||||
| Children | -0.079 | -0.139 | -0.107 | 3,524 | |||
| Adults | -0.082 | -0.165 | -0.126 | 3,220 | |||
| Role | CHILDES Frequency | Wikipedia Frequency | size | ||||||
| Pearson | Spearman | Pearson | Spearman | size | |||||
| t | p-value | t | p-value | t | p-value | t | p-value | ||
| English | |||||||||
| Children | -2.484 | 0.013 | 0.022 | 0.982 | -3.693 | -4.572 | 8,548 | ||
| Adults | -3.562 | 2.501 | 0.012 | -4.553 | -8.837 | 14,149 | |||
| Dutch | |||||||||
| Children | 0.395 | 0.693 | 1.417 | 0.157 | -0.472 | 0.637 | -1.049 | 0.294 | 2,579 |
| Adults | -0.251 | 0.802 | 1.624 | 0.104 | -0.793 | 0.428 | -6.491 | 5,190 | |
| Spanish | |||||||||
| Children | -0.861 | 0.389 | -0.391 | 0.696 | -1.203 | 0.229 | -3.596 | 3,516 | |
| Adults | 0.098 | 0.922 | 0.571 | 0.568 | -1.194 | 0.233 | -3.43 | 3,210 | |
| Role | CHILDES Frequency | Wikipedia Frequency | size | ||||||
| Pearson | Spearman | Pearson | Spearman | size | |||||
| t | p-value | t | p-value | t | p-value | t | p-value | ||
| English | |||||||||
| Children | -7.922 | -9.812 | -7.895 | -13.23 | 8,548 | ||||
| Adults | -9.045 | -9.3 | -8.817 | -19.092 | 14,149 | ||||
| Dutch | |||||||||
| Children | -3.277 | 0.001 | -2.051 | 0.040 | -2.01 | 0.045 | -3.519 | 2,579 | |
| Adults | -3.079 | 0.002 | -4.199 | -2.164 | 0.031 | -9.394 | 5,190 | ||
| Spanish | |||||||||
| Children | -1.775 | 0.076 | -2.704 | 0.007 | -0.701 | 0.483 | -0.491 | 0.623 | 3,524 |
| Adults | -1.139 | 0.255 | -1.006 | 0.314 | -0.691 | 0.490 | -0.28 | 0.780 | 3,220 |
| Role | CHILDES Frequency | Wikipedia Frequency | size | ||||||
| Pearson | Spearman | Pearson | Spearman | size | |||||
| t | p-value | t | p-value | t | p-value | t | p-value | ||
| English | |||||||||
| Children | -7.145 | -10.844 | -6.135 | -10.937 | 8,548 | ||||
| Adults | -7.67 | -12.544 | -6.581 | -14.275 | 14,149 | ||||
| Dutch | |||||||||
| Children | -3.488 | -2.901 | 0.004 | -1.662 | 0.097 | -2.628 | 0.009 | 2,579 | |
| Adults | -3.007 | 0.003 | -5.232 | -1.71 | 0.087 | -4.951 | 5,190 | ||
| Spanish | |||||||||
| Children | -1.093 | 0.274 | -2.413 | 0.016 | -0.09 | 0.929 | 1.19 | 0.234 | 3,516 |
| Adults | -1.162 | 0.245 | -1.227 | 0.220 | -0.102 | 0.918 | 1.281 | 0.200 | 3,210 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Polysemy and Brevity versus Frequency in Language
Bernardino Casas
Antoni Hernández-Fernández
Neus Català
Ramon Ferrer-i-Cancho
Jaume Baixeries
Complexity & Quantitative Linguistics Lab, Laboratory for Relational Algorithmics, Complexity and Learning (LARCA), Departament de Ciències de la Computació, Universitat Politècnica de Catalunya, Barcelona, Catalonia.
Complexity & Quantitative Linguistics Lab, Laboratory for Relational Algorithmics, Complexity and Learning (LARCA), Institut de Ciències de l*′*Educació, Universitat Politècnica de Catalunya, Barcelona, Catalonia.
Abstract
The pioneering research of G. K. Zipf on the relationship between word frequency and other word features led to the formulation of various linguistic laws. The most popular is Zipf’s law for word frequencies. Here we focus on two laws that have been studied less intensively: the meaning-frequency law, i.e. the tendency of more frequent words to be more polysemous, and the law of abbreviation, i.e. the tendency of more frequent words to be shorter. In a previous work, we tested the robustness of these Zipfian laws for English, roughly measuring word length in number of characters and distinguishing adult from child speech. In the present article, we extend our study to other languages (Dutch and Spanish) and introduce two additional measures of length: syllabic length and phonemic length. Our correlation analysis indicates that both the meaning-frequency law and the law of abbreviation hold overall in all the analyzed languages.
keywords:
Zipf’s laws , polysemy , brevity , word frequency
1 Introduction
The linguist George Kingsley Zipf (1902-1950) is known for his investigations on statistical laws of language [1, 2]. Perhaps the most popular one is Zipf’s law for word frequencies [1, 3], that states that the frequency of the -th most frequent word in a text follows approximately
[TABLE]
where is the frequency of that word, its rank or order and is a constant (). Zipf’s law is an example of power-law model for the relationship between two variables [4]. Zipf’s law for word frequencies can be explained by information theoretic models of communication [5] and is a robust pattern of language that presents invariance with text length in a sufficiently long text [6], and little sensitivity with respect to the linguistic units considered [7]. The focus of this paper is to test the robustness of two statistical laws in linguistics that have been studied less intensively:
Meaning-frequency law [3], the tendency of more frequent words to be more polysemous. Zipf predicted that the number of meanings of a word should follow
[TABLE]
where is the frequency of a word and . Zipf never tested the validity of this equation. He only derived it from Zipf’s law for word frequencies (Eq. 1) and the law of meaning distribution [3] (see [8] for a general derivation). The latter links with , namely, the frequency rank. Zipf proposed and tested [1, 3]
[TABLE]
where is a constant ().
- 2.
Zipf’s law of abbreviation [1, 9], the tendency of more frequent words to be shorter or smaller. In his pioneering research, Zipf made this observation but did not propose any mathematical formulae to model that dependency [1]. Power-law like functions were suggested later on by other researchers ([10]).
These laws are examples of laws where the predictor is the word frequency and the response is another word feature. These laws are regarded as universal although the only evidence of their universality is that they hold in every language where they have been tested so far [11]. Because of their generality, these laws have triggered modeling efforts that attempt to explain their origin and support their presumable universality with the help of abstract mechanisms or communication principles [12, 13], or exploring directly from voice those statistical patterns in levels under the phoneme scale [14]. Therefore, investigating the experimental conditions under which these laws surface is crucial.
In a previous work [15], we have studied these linguistic laws in a large corpus of child and adult language (CHILDES) [16]. We extracted semantic polysemy values from WordNet [17] and SemCor corpus 111http://multisemcor.fbk.eu/semcor.php, and defined word length simply as the number of characters per word.
In this present article we extend our research in [15] by re-analyzing the behaviour of those linguistic laws in children and adults separately, using the transcripts in the CHILDES database, and exploring different definitions of word frequency, word polysemy and word length. In order to test the statistical validity of these linguistic laws, we also expand the number of languages to Dutch and Spanish, as well as English, which was the only language analyzed in [15]. Concerning word frequency, we consider two major sources of estimation: the CHILDES database [16] and Wikipedia [18]. Frequency estimates are computed separately for children and adults (comprising mothers, fathers and investigators). This division allows us to compare children and adults linguistic production: motherese also known as child-directed speech (CDS) or infant-directed speech (IDS) has been studied for many years and it is still a hot topic of research [19].
Concerning polysemy, we define the polysemy of a word as the number of different senses it has, based on the WordNet of its corresponding language (Princeton WordNet, Open Dutch WordNet and Multilingual Central Repository for Spanish). Hereafter, we will refer to this polysemy as WordNet polysemy. We assume that the polysemy measure provided by WordNet does not distinguish between different types of polysemy and we are aware of the inherent difficulties of borrowing this conceptual framework (see [20, 21, 22, 23]). Concerning word length, we consider three different units of measurement: a graphical unit (number of characters) and two phonetic units (number of phonemes and number of syllables). From the sources for obtaining word frequency and polysemy values and from the variety of measurement units for word length, we come up to eight major ways of investigating meaning-frequency law and law of abbreviation, for each language under study.
In this paper, we investigate these laws qualitatively using measures of correlation between two variables. Thus, the law of abbreviation is defined as a significant negative correlation between the frequency of a word and its length for any unit of measurement. The meaning-frequency law is defined as a significant positive correlation between the frequency of a word and its WordNet polysemy, a proxy for the number of meanings of a word. While our approach to these laws is non-parametric (we are not assuming any particular model for the relationship between two variables), traditional research on statistical laws of language is mostly parametric, assuming some sort of power law or generalizations of power laws [4, 10, 24].
We adopt these correlational definitions to remain agnostic about the actual functional dependency between the variables, which is currently under revision for various statistical laws of language [25, 26, 27]. We will show that a significant correlation of the right sign is found in the majority of combinations of conditions mentioned above, providing support for the hypothesis that these laws are originated from abstract mechanisms. We propose as well some hypotheses to explain why in some exceptional cases the analyzed variables do not correlate significantly.
The remainder of the article is organized as follows. Section 2 revises the power law model that Zipf proposed for the law of meaning distribution [1, 3] to illustrate the challenges of the parametric approach presented here. Then we justify the convenience of a non-parametric approach (and correlation analysis) that we have adopted in this article for statistical laws of language involving word frequency. Sections 3 and 4 present, respectively, the materials (databases) and the methods employed to analyze them. Section 5 presents the results of our analysis of the meaning-frequency law and the law of abbreviation. Section 6 discusses our findings and suggests future work.
2 Revisiting Zipf’s law of meaning distribution
To check if the equation that Zipf proposed for the law of meaning distribution (Eq. 3) holds on modern corpora, we have reproduced the computations exposed in [1] on a data set that we explore in depth in the next sections.
When plotting the relationship between number of meanings per word (on the ordinate) and frequency rank (abscissa), Zipf applied a linear binning technique to reduce noise. When using bins of length , the 1st bin is formed by the most frequent words, the 2nd bin is formed by the next most frequent words,… etc. Formally, the -th bin is defined by words whose rank satisfies
[TABLE]
Zipf plotted the relationship between the average number of meanings of the -th bin and [1, p. 30] and fitted a power law (Eq. 3). We follow the same method for a sample from the CHILDES database (see Section 3.5 for further details).
Figures 1 and 2 show two examples of these plots taking as input English words produced by adults and by children, respectively. Frequencies have been obtained from CHILDES for both data sets. For estimating the values of the parameters, the slope and the Y-intercept of the best regression line, we have used two different methods: non-linear least squares and maximum likelihood [28] on the original curve (in normal scale). The values shown at the top of each figure correspond to the parameters of the fitting in log-log scale, that define the regression line.
Tables 1 and 2 summarize the analyses performed over the whole data sets, that is, for the three languages (English, Dutch and Spanish) and for the two roles (adults and children). Table 1 corresponds to groupings of 100 words (the abscissa of a point represents 100 words and the value of its ordinate is the average number of meanings per word in this hundred). Table 2 corresponds to groupings of 500 words.
As shown in Tables 1 and 2, as groupings become larger, the slopes of the regression lines become closer to the expected value of [1, 11]. We want to note here that, especially in the case of English, groupings of 1000 words (as in Zipf’s work [1]) yield slopes of exactly .
These results suggest that using a similar methodology in [1], the analyzed data sets confirm Zipf’s meaning-frequency law. However, in this paper we want to present, an alternative way of confirming this law (as well as the Zipf’s law of abbreviation) by means of a correlation analysis.
The dependence of the exponent on bin size is a challenge for research on the law of meaning distribution. Paradoxically, when using the same bin size as Zipf did (), we get the number of non-empty bins reduced to a few for Spanish and Dutch (this is the reason why we exclude that bin size in the tables above). We can reduce the bin size to maximize the number of languages used but then the exponents deviate from the originally reported by Zipf in English. One also needs to control for the kind of binning. Logarithmic binning is often used when investigating power law relationships [29]. In addition, we are fitting Eq. 3 and estimating assuming that a power law holds. The validity of such assumption must be tested. The plots above suggest a deviation from the power law for high ranks.
Finally, we need to consider the role of the data source in the emergence of the power law. For instance, word frequency could be estimated from Wikipedia entries (see Section 4 for such a possibility). The magnitude of the whole challenge can easily be reduced with a non-parametric approach based on a correlation analysis that does not involve neither any kind of binning nor assuming an exact model (an equation), that may not be generally valid. So, after revisiting the classical Zipfian approach to the meaning-frequency law [1, 3], next sections develop our proposal of a correlation analysis between frequency, meaning and word length.
3 Materials
In this section we describe the different corpora and tools that have been used in this paper. We first describe the WordNet database which has been used to compute the polysemy measure. We also describe the tools used to convert text to phonetic transcription and to perform syllabic segmentation: CELEX database and SAGA. Finally, we describe the two different sources for calculating the frequency of words that are analyzed in this paper: CHILDES database and Wikipedia as reference corpora.
3.1 Open Multilingual Wordnet
The WordNet database can be seen as a set of senses (also called synsets) and relationships among them, where a synset is the representation of an abstract meaning, and it is defined as a set of words having (at least) the meaning that the synset stands for. Each pair word-synset is also related to a syntactic category. For instance, the pair book and the synset a written work or composition that has been published are related to the category noun, whereas the pair book and synset to arrange for and reserve (something for someone else) in advance are related to the category verb.
Open Multilingual WordNet [30] gives access to open wordnets in several languages. In this paper we use the Princeton WordNet for English, the Open Dutch WordNet for Dutch and the Multilingual Central Repository for Spanish.
Since each WordNet has been made by many different projects, they all vary notably in size and coverage. Table 3 shows some statistics for every WordNet used in this paper.
WordNet databases contain only four main syntactic categories: nouns, verbs, adjectives and adverbs. Words of other syntactic categories are not present in these databases (for instance, in English the article the or the preposition for). However, some words which should be considered as functional words, have been included in our analyses, because they can also be considered as content words (i.e. in English, the determiner a can also be a noun as in Letter A or Vitamin A).
3.2 CELEX database
CELEX [33] is the Dutch Centre for Lexical Information at the Max Planck Institute for Psycholinguistics. CELEX database comprises three different searchable lexical databases, Dutch, English and German. The lexical data contained in each database is divided into five categories: orthography, phonology, morphology, syntax (word class) and word frequency.
We use CELEX database to obtain the phonetic transcription and syllabic segmentation of Dutch and English speech transcripts. Using WebCelex222http://celex.mpi.nl/ we have created two lexicons, one for English and another for Dutch, by selecting from the English Wordforms and Dutch Wordforms databases the following items: Word (from the orthography category), and PhonSAM and PhonSylSAM (from the phonology category). The format of the phonetic transcription is SAMPA charset (Speech Assessment Methods Phonetic Alphabet333http://www.phon.ucl.ac.uk/home/sampa/index.html).
3.3 SAGA
SAGA is an automatic tool for phonetic transcription in Spanish, considering its multiple dialectal variants. The phonetic description is made in terms of the SAMPA alphabet. The tool is able to split the words into syllables and mark the prosodic stress.
SAGA is able to perform different kinds of transcriptions depending on the output settings (phonemes, semi-phonemes, syllables, semi-syllables). In addition, even Spanish has a mostly phonetic writing, there are some exceptions to the general phonetic rules as for example foreign words, archaic language or dialectal variants. To deal with these cases, SAGA contains dictionaries that can be modified to customize the phonetic transcriptions as desired.
We have used SAGA for Spanish conversations to perform both phonetic transcription and syllabic segmentation. This application is distributed under the terms of the GNU General Public License444Freely available at http://www.talp.upc.edu/index.php/technology/tools/signal-processing-tools/81-saga.
3.4 Wikipedia
Wikipedia is a free online encyclopedia built collaboratively and hosted by the non-profit Wikimedia Foundation. It exists in 295 languages, from which currently there is a total of 284 active ones, with the number of pages ranging from more than 5 million articles (English) to a few hundred articles (Zulu, Romani, Greenlandic…)555https://en.wikipedia.org/wiki/List_of_Wikipedias.
Wikipedia includes articles that span across many topics and it is updated with constant contributions. Thus, it turns out to be a useful resource as a reference corpus for getting word frequencies. Since we use two different sources for estimating word frequencies, we can compare the results obtained by using a general corpus (Wikipedia) with the use of a simpler one (CHILDES).
The contents of each Wikipedia can be downloaded and processed to calculate the frequency of every word that appears in Wikipedia [18]. We have downloaded from Gregory Grefenstette webpage the lexicons with the frequencies extracted from Wikipedia for English, Dutch and Spanish 666http://web.archive.org/web/20170205022929/http://pages.saclay.inria.fr:80/gregory.grefenstette/.
3.5 CHILDES database
The CHILDES database [16] is a set of corpora of transcripts of conversations between children and adults. The corpora included in this database are in different languages.
In this paper we have studied the conversations of 60 children in English, 73 children in Dutch and 490 children in Spanish. Detailed information on these conversations can be found in Table 9 for British English, Table 10 for American English, Table 11 for Dutch and 12 for Spanish in B. For each spoken word of these conversations the following values are given: CHILDES frequency (number of times this word appears in CHILDES, counted separately by children and adults), Wikipedia frequency (number of times this word appears in Wikipedia), number of synsets (according to the corresponding WordNet), number of characters, number of phonemes and number of syllables. Table 4 shows the number of different types and tokens obtained from the selected corpora. The number of analyzed tokens and types is smaller than the number of tokens and types initially extracted from the conversations, because only those words that are present in the correspondent WordNet have been retained.
4 Methods
We now describe the different numerical and computational methods that have been used in this paper.
4.1 Word Length Computation
There are several types of units to measure word length among which the most used are graphic and phonetic. Graphical units are usually characters or letters. Phonetic units are phonemes, syllables or sounds, and although they are highly correlated with graphical units there can be differences depending on the language.
Here, we have considered three different units of measurement: a graphical unit (number of characters) and two phonetic units (number of phonemes and number of syllables). When dealing with counting characters, numbers, blanks, separation characters and the like have not been taken into consideration. The resources used to obtain orthographic and phonetic information are described in Section 3.
4.2 Frequency
We have extracted word frequency values from two different sources. Thus, for each word that appears in the selected conversations of CHILDES, we obtain:
Wikipedia frequency, the frequency that the given word has in the Wikipedia dataset.
- 2.
CHILDES frequency, the frequency that the given word has in CHILDES according to the speaker’s role: children or adults (comprising mothers, fathers and investigators). For example, for the word book two different frequencies are given: the number of times this word appears uttered by children and uttered by adults, respectively.
4.3 Polysemy
From linguistics, polysemous words are words that have more than one meaning. Linguists distinguish between words with multiple meanings, where the meanings are unrelated (called homonyms), and words with multiple senses, where the senses are related. An example of the former is the word bank, having unrelated meanings such as a sloping land or a financial institution, whereas an example of the latter is honey, having related senses such as sweet yellow liquid produced by bees or a beloved person.
We have calculated the polysemy of a word as the number of different meanings provided by the WordNet database of its corresponding language. In WordNet, the different senses of a polysemous word are assigned to different synsets. Then, we have considered the number of synsets a word belongs to as the number of meanings it has. This count is what we call WordNet polysemy. We assume that the polysemy measure provided by WordNet does not differentiate between polysemy classes mentioned above.
We are aware that using the WordNet polysemy measure in the CHILDES corpora induces a bias. First, because we are assuming that the same meanings that are used in written text are also used in spoken language. Second, because we are using all possible meanings of a word. An alternative would have been to tag manually all corpora (which is currently an unavailable option) or to use an automatic tagger. But also in this latter case, the possibility of biases or errors would be present.
4.4 Statistical Methods
In the present work we have studied the relationship between (1) frequency and polysemy and (2) frequency and length. For the three variables, frequency, polysemy and word length, we have used different sources yielding us many combinations for evaluation.
For each language selected in the CHILDES corpora, we have calculated correlations between:
CHILDES frequency and WordNet polysemy 2. 2.
CHILDES frequency and number of characters 3. 3.
CHILDES frequency and number of phonemes 4. 4.
CHILDES frequency and number of syllables 5. 5.
Wikipedia frequency and WordNet polysemy 6. 6.
Wikipedia frequency and number of characters 7. 7.
Wikipedia frequency and number of phonemes 8. 8.
Wikipedia frequency and number of syllables
For each combination of two variables, we compute:
Correlation test. Pearson, Spearman and Kendall two-sided correlation tests [34], using the cor.test standardized R function. The traditional Pearson correlation is a measure of linear dependency while Spearman and Kendall correlations are to capture non-linear dependencies [35, 36]. 2. 2.
Plot, in logarithmic scale, that also shows the density of points. 3. 3.
Nonparametric regression, to obtain a smoothed curve for the cloud of points defined by the two variables. The smoothed curve is calculated using the locpoly standardized R function and added to the previous plot. 4. 4.
Probability density function using local polynomials. Proportional density function is calculated using the locpoly standardized R function and added to the previous plot.
On top of the correlation analysis we build another analysis where we compare pairs of correlations that have a variable in common. Our goal is to determine if the unit of measurement has some effect on the strength of a linguistic law. When we investigate the law of abbreviation (the correlation between the frequency of a word and its length), we keep the source used to estimate frequency while we vary the way length is measured: number of characters, number of phonemes or number of syllables. In particular, we determine if the difference between two dependent correlations sharing one variable is significant.
Suppose that we have two different length measures (which can be the number of characters, phonemes or syllables) and one frequency measure (which can be the CHILDES or Wikipedia frequency). Suppose that the correlation between and is and the correlation between and is , and that both correlations are negative. To determine if one of those correlations is significantly stronger that the other, we apply a two-tailed Steiger’s test [37] (we use the r.test standardized R function). If the p-value is below the significance level and , we can conclude that is more correlated to than . Else, if , we can conclude that is more correlated to than . Otherwise, if the test is non significant, we cannot conclude that one correlation is stronger than the other.
We note that the r.test standardized R function requires a single sample size as a parameter. For this reason, before performing the test, in order to compute and , we have selected from the dataset, those records that have a valid value on all three variables (). However, when we compute a correlation test two single variables and (or ), we select all those records that have a valid value in both and (), but not necessarily in all three of them. Therefore, the value computed for and in the Steiger’s test may yield a somehow different value from that in a single correlation test because of this constraint (inherent to the Steiger’s test).
As the theory of Steiger’s test is defined on Pearson correlation, this higher level analysis is performed only on Pearson correlations and Spearman correlations (Spearman correlation is a Pearson correlation on rank transformation of the random variables [34]). As far as we know, it is not warranted that the Steiger’s tests can be applied on Kendall correlations.
We use three different measures of correlations for the following reasons. Pearson correlation is included for its popularity and simplicity. Spearman and Kendall correlation are included for their capacity to capture non-linear dependencies. Spearman is needed for the Steiger’s tests (see Section 5) and Kendall correlation allows one to interpret the strength of a correlation based on the number of ties (this will be shown in Section 5.4).
We assume a significance level of 0.05 in all tests.
We remark that the analysis for the CHILDES corpora has been segmented into two roles: children and adults.
5 Results
We describe the results that have been obtained in three different languages (English, Dutch and Spanish) from the analysis of the relationship between:
Frequency and polysemy (meaning-frequency law). 2. 2.
Frequency and word length (Zipf’s law of abbreviation).
We use two different measures for frequency (CHILDES frequency and Wikipedia frequency), one measure for polysemy (WordNet polysemy) and three measures for word length (number of characters, phonemes and syllables) as previously explained in Section 4.
Here we present the results in two formats:
A table that contains the results of a correlation test between a frequency measure versus the following measures: WordNet polysemy, number of characters, number of phonemes and number of syllables. Each table shows the results of three (Pearson, Spearman and Kendall) correlation tests. For each language we have produced two tables: one table where the frequency measure is the CHILDES frequency, and another table where the frequency measure is the Wikipedia frequency. 2. 2.
A plot for each pair of variables that have been analyzed in the previous tables along with a nonparametric regression and a probability density function (see Section 4 for details).
We also present the results of the Steiger’s test that shed light on which of the three different length measures exhibits a stronger correlation with frequency. Finally, we include a subsection in which we examine the impact of ties in our analyses.
5.1 Frequency versus Polysemy
We now describe the results that analyze the relationship between frequency and polysemy. We remind the reader that we compare the two sources of frequency (CHILDES and Wikipedia) with WordNet polysemy.
In English, all correlations are significant and positive (Tables 13 and 14 in the C). In Dutch (Tables 15 and 16 in the C) and Spanish (Tables 17 and 18 in the C), Spearman and Kendall correlations are significant and positive and the Pearson correlations are non-significant with a correlation value close to zero.
A visual inspection of the graphics in Figure 3 in the A confirms the patterns that we have examined previously. When CHILDES frequency is analyzed, we see in English that, in all cases, the nonparametric regressions show a positive slope in the area where most of the points are concentrated. Where this concentration decreases, so does the nonparametric regression. In both Dutch and Spanish, the regression shows a similar pattern, but the increase is not as strong as in English. But, as in English, the regression decays significantly when it reaches the area with a smaller density of points.
When Wikipedia frequency is analyzed (Figure 4 in the A), we can observe two facts: points are distributed in a more compact way and the nonparametric regression has a steeper slope in English, and, to a lesser degree, in Dutch and Spanish.
To sum up, we can say that, in a vast majority of cases, the values of the significant correlations are always positive. Correlations are significant in English in all cases, and for all non-linear correlation measures in Dutch and Spanish.
5.2 Frequency versus Length
The analysis of the two measures of frequency versus the three measures of length are in Tables 13 and 14 in English, Tables 15 and 16 in Dutch, and Tables 17 and 18 in Spanish in the C. In this case, the results show a more compact behavior, since all correlations are significant and negative both for children and for adults.
As for the nonparametric regression in Figures 5, 6, 7, 8, 9 and 10, we have that the results are consistent with these previous patterns: in all cases, the regression shows a negative slope.
5.3 Steiger’s test
We have seen in the previous section that all three measures of length exhibit a negative correlation with respect to frequency. We now turn into the question of deciding which of these measures holds the strongest correlation with frequency by means of a Steiger’s test (see Section 4 for details about how this test has been computed).
In D we present, for each pair of length measures (which can be the number of characters, phonemes or syllables) a table that displays the analytical results of the Steiger’s test (the t and p-value) with respect to the two different sources of frequency (CHILDES or Wikipedia). Table 19 shows the results for the Steiger’s test between variables number of characters and number of phonemes, Table 20 shows the results between number of characters and number of syllables and Table 21 shows the results between variables number of phonemes and number of syllables.
We also provide a more compact way of seeing the results contained in those tables in a set of three different tables, one for each language: English in Table 5, Dutch in Table 6 and Spanish in Table 7. In these tables, for each analyzed language, we list all possible combinations of role, frequency measure and correlation type and, for each combination, we display the order relationship on the strength of the correlation for each pair of length variables. In the column Char. vs Phon. we show the relation between number of characters and number of phonemes, in the column Phon. vs Syllables we show the relation between number of phonemes and number of syllables, and in the column Phon. vs Syllables we show the relation between number of phonemes and number of syllables. For each pair, the relation may be or if the Steiger’s test has determined that the difference of the correlations is significant. If the test is not significant, then, the relation may be or . Since the Kendall correlation test is not analyzed with the Steiger’s test (see Section 4), we have adopted the convention of assuming that this test is always non-significant.
Tables 5, 6, and 7, provide the following results: in English most of the tests are significant, and the pattern that emerges more frequently is that of , this is, that the number of characters is the length measure most correlated to a frequency measure, followed by the number of phonemes and, then, by the number of syllables. In fact, the patterns and appear in the vast majority of cases. In Dutch, we observe that little can be said about the prominence of the number of phonemes or characters as the most correlated length variable for lack of significance. However, the two patterns and (as in English) appear in most of the cases. As for Spanish, nothing can be said because most of the relations are non-significant.
To sum up, the variables number of characters and number of phonemes show a stronger correlation with respect to frequency than the number of syllables when the Steiger’s test was significant. The results also reveal (in English) a slightly stronger correlation between the number of characters and frequency than between the number of phonemes and frequency.
5.4 Proportion of ties
Here we aim at shedding some light on the weakness of the correlation between frequency and other variables. We focus on the Kendall correlation because it allows for a simple analysis of the influence of tied values.
The Kendall correlation is defined as [34]
[TABLE]
where is the sample size and and are, respectively, the number of concordant and discordant pairs in the sample. We have that
[TABLE]
where is the number of tied pairs (pairs that are neither concordant nor discordant). Applying
[TABLE]
one can rewrite Eq. 5 equivalently as
[TABLE]
where
[TABLE]
is the proportion of tied pairs (). The fact that allows one to see that
[TABLE]
Put differently, the strongest negative Kendall that can be obtained is . The higher the number of ties, the weaker the maximum Kendall correlation that can be obtained. Table 8 shows the percentage of ties, namely , of frequency (CHILDES and Wikipedia) versus polysemy and the measures of length for every language and role.
It is possible to derive lower bounds for the Spearman correlation from that of Kendall correlation. Knowing that [38]
[TABLE]
and recalling Eq. 7, one obtains
[TABLE]
Similarly, knowing that [39]
[TABLE]
one obtains
[TABLE]
Combining, Eqs. 8 and 9, we get finally
[TABLE]
The lower bounds of above are likely to be looser than the original lower bound of because the former are derived from the latter.
In Sections 5.2 and 5.3, we have shown a tendency of syllabic length to be the unit of length that is the most weakly correlated with frequency. This could be due to the higher proportion of ties of syllabic length ties in general (Table 8), that reduces the potential strength of the correlation according to Eqs. 7 and 10.
6 Discussion and Future Work
In this paper, we have reviewed two linguistic laws that we owe to Zipf’s [3, 1] and that have probably been shadowed by the best-known Zipf’s law for word frequencies [1]. Our analysis of the correlation between brevity (measured in number of characters, phonemes and syllables) and polysemy (number of synsets) versus word frequency was conducted with three correlation tests with varying assumptions and robustness. Pearson correlation is a measure of linearity while the Spearman correlation and Kendall correlation are able to capture monotonic non-linear dependencies as we have explained in Section 4. Our analysis confirms that a positive correlation between the frequency of the words and the number of synsets (consistent with the meaning-frequency law [3]) and a negative correlation between the length of the words and their frequency (consistent with the law of abbreviation [1]) arises under different definitions of the variables. In all cases, we find correlations whose sign matches the expected sign. In addition, all correlations are significant except the Pearson correlations in the meaning-frequency law for Dutch and Spanish. This behaviour could be due to (a) the lower capacity of the Pearson correlation to detect non-linear dependencies compared to Spearman and Kendall correlations or, (b) the fact that English exhibits a larger sample size than those two languages (Table 4).
In optimization models of the law of abbreviation, length is regarded as a proxy for the energetic cost of the word [12, 40]. Then one expects that a better measure of energetic cost would give a stronger correlation with frequency. Our meta-analysis of the correlation between frequency and length has shown that this correlation is slightly stronger when length is measured with characters than in phonemes in most cases in English, and that characters and phonemes are stronger that syllables in both English and Dutch. In Spanish, no clear pattern arises, which is consistent with the classical view of Spanish as a more transparent language than English [41] or Dutch [42]. Thus, the grapheme to phoneme conversion is easier in Spanish than in English or Dutch [42]. The degree of transparency of a language is defined as the extent to which a language maintains one-to-one relations between units from different dimensions, e.g., phonemes versus graphemes. Transparency is tied to the notion of “simplicity" in accounting for acquisition data (see [42] for a review). Transparency facilitates reading. Then, learning to read in a transparent orthography imposes fewer constraints than learning to read in a more opaque writing system [43].
The fact that the correlation between frequency and number of syllables tends to be weaker than correlations with other measures of length does not imply that syllables are a worse measure of length or energetic cost. It could be simply due to the fact that ties of length values are easier to obtain with syllabic length, a fact that is expected to yield weaker correlations and higher p-values as we have shown in Section 5.4.
Interestingly, we have not found any remarkable qualitative difference in the analysis of correlations for adults versus children in the CHILDES database, suggesting that both child speech and the infant-directed speech or child-directed speech (the so-called motherese) [19] seem to show the same general statistical biases in the use of more frequent words (that tend to be shorter and more polysemous), confirming the results of our previous test in [15] where adults were split into three different roles, mother, father and investigator, instead of being considered together in a single class as in this present paper.
Our analyses have shown the robustness of these Zipfian patterns from the standpoint of a correlation analysis. Such robustness provides support to Zipf’s hypothesis that these laws originate from abstract principles, e.g., functional pressures (least effort as he would put it), that are consistent with modern formalizations as a compression principle for the law of abbreviation [12, 40] or a biased random walk over the mapping words into meanings for the origins of Zipf’s meaning frequency law [13]. This theoretical approaches strongly suggest that it might be possible to provide a coherent and parsimonious explanation for the laws we have examined in this article and other laws such as Zipf’s law for word frequencies [44] or Menzerath’s law [45]. The need for an abstract standpoint is not only suggested by our analyses but also by patterning consistent with these laws in human language in different conditions, e.g., sign language [46], Kanji or Chinese characters [47, 48], and also in animal communication [12, 49, 50].
Our work offers many possibilities for future research.
First, expanding the set of languages to include languages from other families (i.e. not Indo-European languages) and the set of lexical databases employed (e.g., [51]). As for the latter, the challenge is to find sources that allow to deal with different languages homogeneously.
Second, considering different definitions of the same variables. For instance, a limitation of our study is the fact that we define word length using discrete units: number of syllables, number of phonemes or number of characters. Future research could benefit from viewing length as a continuous variable, e.g. the (average) duration in time of the word, because that may yield a better estimate of the actual energetic cost of a word and also because our research on language laws is to some extend limited by the information that is transcribed and the writing conventions, that add some degree of arbitrariness. These limitations have been overcome to a large extent in novel investigations of language laws in pure voice [14].
Third, our work can be extended including other linguistic variables such as homophony, i.e. words with different origin (and a priori different meaning) that have converged to the same phonological form. This extension would require to trace the history of each word, under a dynamical and lexical perspective, following the connection between brevity of words and homophony that Jespersen (1933) suggested in his seminal work [52] and that has been confirmed more recently [53, 54] as a strong association between shortness of words, token frequency and homophony [54]. If polysemy is taken to be a form of motivated homophony, by which a word has two or more related meanings, but with probably different representation than homophones (for which different meanings are "stored separately" [55]) in a semantic space, both phenomena will only be distinguishable if we analyze and segment directly voice signals or, as said before, we do that under a diachronic approach. In any case, we must be aware of the limitations of synchronic approaches when homophony or homography are studied, the later being indistinguishable from polysemy in the present article.
Fourth, a parametric study of these laws with the help of power-law like functions [4, 24]. In Section 2, we have shown some challenges of that kind of investigation. We do think that such investigation is very needed and worthwhile. We have just argued it is not as simple as commonly believed.
Finally, future work should bridge the gap between our classic Zipfian perspective and psycholinguistics. We suggest a couple of ways. First, an exploration of the structural differences between common and rare words [56]. Second, an application of our methodology to other magnitudes such as contextual diversity, which may be more relevant than the mere word frequency in some lexical tasks [57, 58].
Acknowledgments
The authors thank Pedro Delicado for his helpful comments. This research work was supported by the grant SGR2014-890 (MACDA) and the recognition 2017SGR-856 (MACDA) from AGAUR (Generalitat de Catalunya), and also the grants TIN2014-57226-P (APCOM), TIN2017-89244-R (MACDA) and TIN2016-77820-C3-3-R (GRAPH-MED) from MINECO (Ministerio de Economia, Industria y Competitividad).
Appendix A Figures
Figures 3, 4, 5, 6, 7, 8, 9 and 10 show the results obtained in this article for English, Dutch and Spanish.
In all these plots, frequency is placed on the x-axis for at least three reasons. First, frequency is given (frequency is assumed to be constant) while length is variable In information theory (coding theory in particular) [59]. In the problem of compression, one aims to minimize the average length of codes given probabilities (estimated as relative frequencies). Information theory predicts the length of a code as a function of its frequency [59, p. 111] or its frequency rank [40]. Therefore, when plotting length versus frequency, it makes sense to put it on the x-axis. Second, word frequency is a fundamental variable in psycholinguistics to predict language processing costs [60, 61]. The third reason comes from the popular Zipf’s law for word frequencies. Although Zipf’s law is usually plotted as frequency as function of rank (following Eq. 1), a sister (but not identical) plot, the so called frequency spectrum, consists of showing the number of distinct words as a function of frequency [62]. The second plot (frequency on the x-axis) is preferred by various authors for investigating the distribution of word frequencies (e.g., [63, p. 298], [64, p. 3]).
Appendix B Information about CHILDES
Tables 9, 10, 11 and 12 show the CHILDES corpora used in this article for English, Dutch and Spanish.
Appendix C Correlations
Tables 13, 14, 15, 16, 17 and 18 show the correlations between Frequency and Polysemy, and Frequency and Length measures for English, Dutch and Spanish.
Appendix D Tables of Steiger’s tests
Tables 19, 20 and 21 show the results of Steiger’s test between number of characters and number of phonemes, number of characters and number of syllables, and number of phonemes and number of syllables for English, Dutch and Spanish.
References
- [1]
G. K. Zipf, Human behaviour and the principle of least effort, Addison-Wesley, Cambridge (MA), USA, 1949.
- [2]
G. K. Zipf, The Psycho-Biology of Language: an Introduction to Dynamic Psychology, MIT Press, Cambridge, MA, USA, 1968, originally published in 1935 by Houghton Mifflin - Boston - MA - USA.
- [3]
G. K. Zipf, The Meaning-Frequency Relationship of Words, Journal of General Psychology 1945 (33) (1945) 251–256.
- [4]
S. Naranan, V. K. Balasubrahmanyan, Models for power law relations in linguistics and information science, J. Quantitative Linguistics 5 (1-2) (1998) 35–61.
- [5]
R. Ferrer-i-Cancho, Optimization models of natural communication, in: Journal of Quantitative Linguistics, Vol. 25, 2014.
URL http://arxiv.org/abs/1412.2486
- [6]
F. Font-Clos, G. Boleda, A. Corral, A scaling law beyond Zipf’s law and its relation to Heaps’ law, New Journal of Physics 15 (9) (2013) 093033.
URL http://stacks.iop.org/1367-2630/15/i=9/a=093033
- [7]
A. Corral, G. Boleda, R. Ferrer-i-Cancho, Zipf’s law for word frequencies: Word forms versus lemmas in long texts, PLoS ONE 10 (7) (2015) 1–23.
doi:10.1371/journal.pone.0129031.
- [8]
R. Ferrer-i-Cancho, The meaning-frequency law in Zipfian optimization models of communication, Glottometrics 35 (2016) 28–37.
- [9]
P. Grzybek, Contributions to the science of text and language: word length studies and related issues, Vol. 31, Springer Science & Business Media, 2006.
- [10]
U. Strauss, P. Grzybek, G. Altmann, Word length and word frequency, Springer, Dordrecht, 2007, pp. 277–294.
- [11]
B. Ilgen, B. Karaoglan, Investigation of Zipf’s “law-of-meaning” on Turkish corpora, in: 22nd International Symposium on Computer and Information Sciences (ISCIS 2007), 2007, pp. 1–6.
- [12]
R. Ferrer-i-Cancho, A. Hernández-Fernández, D. Lusseau, G. Agoramoorthy, M. J. Hsu, S. Semple, Compression as a universal principle of animal behavior, Cognitive Science 37 (8) (2013) 1565–1578.
- [13]
R. Ferrer-i-Cancho, M. Vitevitch, The origins of Zipf’s meaning-frequency law, Journal of the American Association for Information Science and Technology 69 (2018) 1369–1379.
- [14]
I. Gonzalez Torre, B. Luque, L. Lacasa, J. Luque, A. Hernandez-Fernandez, Emergence of linguistic laws in human voice, Scientific reports 7 (43862) (2017) 1–10.
URL http://www.nature.com/articles/srep43862
- [15]
A. Hernández-Fernández, B. Casas, R. Ferrer-i-Cancho, J. Baixeries, Testing the Robustness of Laws of Polysemy and Brevity Versus Frequency, Springer International Publishing, Cham, 2016, pp. 19–29.
doi:10.1007/978-3-319-45925-7_2.
URL http://dx.doi.org/10.1007/978-3-319-45925-7_2
- [16]
B. MacWhinney, The CHILDES project: tools for analyzing talk, 3rd Edition, Vol. 2: the database, Lawrence Erlbaum Associates, Mahwah, NJ, 2000.
- [17]
C. Fellbaum, WordNet: An Electronic Lexical Database, MIT Press, Cambridge, MA, 1998.
- [18]
G. Grefenstette, Extracting Weighted Language Lexicons from Wikipedia, in: N. Calzolari, K. Choukri, T. Declerck, S. Goggi, M. Grobelnik, B. Maegaard, J. Mariani, H. Mazo, A. Moreno, J. Odijk, S. Piperidis (Eds.), Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016), European Language Resources Association (ELRA), Paris, France, 2016.
- [19]
C. Saint-Georges, M. Chetouani, R. Cassel, F. Apicella, A. Mahdhaoui, F. Muratori, M.-C. Laznik, D. Cohen, Motherese in interaction: At the cross-road of emotion and cognition? (A systematic review), PLOS ONE 8 (10).
doi:10.1371/journal.pone.0078103.
URL http://dx.doi.org/10.1371%2Fjournal.pone.0078103
- [20]
N. Ide, Y. Wilks, Making Sense About Sense, Springer Netherlands, Dordrecht, 2006, pp. 47–73.
doi:10.1007/978-1-4020-4809-8_3.
URL http://dx.doi.org/10.1007/978-1-4020-4809-8_3
- [21]
A. Kilgarriff, Dictionary word sense distinctions: An enquiry into their nature, Computers and the Humanities 26 (5) (1992) 365–387.
URL http://dx.doi.org/10.1007/BF00136981
- [22]
B. Armstrong, C. Zugarramurdi, A. Cabana, J. Valle Lisboa, D. Plaut, Relative meaning frequencies for 578 homonyms in two Spanish dialects: A cross-linguistic extension of the English eDom norms, Behavior Research Methods 48.
doi:10.3758/s13428-015-0639-3.
- [23]
I. Fraga, I. Padrón, M. Perea, M. Comesaña, I saw this somewhere else: The Spanish Ambiguous Words (SAW) database, Lingua 185 (2017) 1 – 10.
doi:https://doi.org/10.1016/j.lingua.2016.07.002.
URL http://www.sciencedirect.com/science/article/pii/S0024384116300596
- [24]
G. Altmann, Prolegomena to Menzerath’s law, Glottometrika 2 (1980) 1–10.
- [25]
E. G. Altmann, M. Gerlach, Statistical Laws in Linguistics, Springer International Publishing, Cham, 2016, pp. 7–26.
doi:10.1007/978-3-319-24403-7_2.
URL http://dx.doi.org/10.1007/978-3-319-24403-7_2
- [26]
F. Font-Clos, A. Corral, Log-log convexity of type-token growth in Zipf’s systems, Phys. Rev. Lett. 114 (2015) 238701.
doi:10.1103/PhysRevLett.114.238701.
- [27]
R. Ferrer-i-Cancho, A. Hernández-Fernández, J. Baixeries, Ł. Dębowski, J. Mačutek, When is Menzerath-Altmann law mathematically trivial? A new approach, Statistical Applications in Genetics and Molecular Biology 13 (2014) 633–644.
- [28]
H. L. Seal, The maximum likelihood fitting of the discrete Pareto law, Journal of the Institute of Actuaries (1886-1994) 78 (1) (1952) 115–121.
- [29]
A. Corral, Dependence of earthquake recurrence times and independence of magnitudes on seismicity history, Tectonophysics 424 (2006) 177–193.
- [30]
F. Bond, R. Foster, Linking and Extending an Open Multilingual Wordnet, Sofia, 2013.
- [31]
M. Postma, E. van Miltenburg, R. Segers, A. Schoen, P. Vossen, Open Dutch WordNet, in: Proceedings of the Eight Global Wordnet Conference, Bucharest, Romania, 2016.
- [32]
A. Gonzalez-Agirre, E. Laparra, G. Rigau, Multilingual central repository version 3.0: upgrading a very large lexical knowledge base, in: Proceedings of the 6th Global WordNet Conference (GWC 2012), Matsue, 2012.
- [33]
R. H. Baayen, R. Piepenbrock, L. Gulikers, CELEX (1996).
- [34]
W. J. Conover, Practical nonparametric statistics, Wiley, New York, 1999, 3rd edition.
- [35]
J. D. Gibbons, S. Chakraborti, Nonparametric statistical inference, Chapman and Hall/CRC, Boca Raton, FL, 2010, 5th edition.
- [36]
P. Embrechts, A. McNeil, D. Straumann, Correlation and dependence in risk management: properties and pitfalls, in: M. A. H. Dempster (Ed.), Risk management: value at risk and beyond, Cambridge University Press, Cambridge, 2002, pp. 176–223.
- [37]
J. H. Steiger, Tests for comparing elements of a correlation matrix, Psychological Bulletin 87 (1980) 245–251.
- [38]
H. E. Daniels, Rank correlation and population models, Journal of the Royal Statistical Society, Series B 12 (1950) 171–81.
- [39]
J. Durbin, A. Stuart, Inversions and rank correlations, Journal of the Royal Statistical Society, Series B 13 (1951) 303–309.
- [40]
R. Ferrer-i-Cancho, C. Bentz, C. Seguin, Compression and the origins of Zipf’s law of abbreviation.
URL http://arxiv.org/abs/1504.04884
- [41]
R. Nash, Comparing English and Spanish: Patterns in Phonology and Orthography, Prentice Hall, 1977.
URL https://books.google.es/books?id=ke86OwAACAAJ
- [42]
S. Leufkens, Transparency in language: a typological study, LOT, 2015.
URL http://hdl.handle.net/11245/1.439561
- [43]
E. Ijalba, L. K. Obler, First language grapheme-phoneme transparency effects in adult second-language learning, Vol. 27, 2015, pp. 47–70.
- [44]
R. Ferrer-i-Cancho, Compression and the origins of Zipf’s law for word frequencies, Complexity 21 (2016) 409–411.
URL http://dx.doi.org/10.1002/cplx.21820
- [45]
M. L. Gustison, S. Semple, R. Ferrer-i-Cancho, T. Bergman, Gelada vocal sequences follow Menzerath’s linguistic law, Proceedings of the National Academy of Sciences USA 13 (2016) E2750–E2758.
- [46]
C. Börstell, T. Hörberg, R. Östling, Distribution and duration of signs and parts of speech in Swedish Sign Language, Sign Language & Linguistics 19 (2016) 143–196.
- [47]
H. Sanada, Investigations in Japanese historical lexicology, Peust & Gutschmidt Verlag, Göttingen, 2008.
- [48]
Y. Wang, X. Chen, Structural complexity of simplified Chinese characters, in: A. Tuzzi, J. M. M. Benesová (Eds.), Recent Contributions to Quantitative Linguistics, De Gruyter, 2015, pp. 229–239.
- [49]
R. Ferrer-i-Cancho, B. McCowan, A law of word meaning in dolphin whistle types, Entropy 11 (4) (2009) 688–701.
- [50]
C. Hobaiter, R. W. Byrne, The meanings of chimpanzee gestures, Current Biology 24 (2014) 1596–1600.
- [51]
A. Duchon, M. Perea, N. Sebastián-Gallés, A. Martí, M. Carreiras, EsPal: One-stop shopping for Spanish word properties, Behavior Research Methods 45 (4) (2013) 1246–1258.
- [52]
O. Jespersen, Monosyllabism in English, in: Linguistica: Selected Writings of Otto Jespersen, George Allen and Unwin LTD, London, UK, 2007, pp. 574–598.
- [53]
J. Ke, A cross-linguistic quantitative study of homophony, Journal of Quantitative Linguistics (2006) 129–159.
- [54]
G. Fenk-Oczlon, A. Fenk, Frequency effects on the emergence of polysemy and homophony, International Journal Information Technologies and Knowledge 4 (2) (2010) 103–109.
- [55]
I. Dautriche, E. Chemla, What homophones say about words, PLOS ONE 11 (9) (2016) 1–19.
doi:10.1371/journal.pone.0162176.
URL http://dx.doi.org/10.1371%2Fjournal.pone.0162176
- [56]
T. Landauer, L. Streeter, Structural differences between common and rare words: Failure of equivalence assumptions for theories of word recognition, Journal of Verbal Learning and Verbal Behavior 12 (2) (1973) 119 – 131.
doi:https://doi.org/10.1016/S0022-5371(73)80001-5.
URL http://www.sciencedirect.com/science/article/pii/S0022537173800015
- [57]
M. Vergara-Martínez, M. Comesaña, M. Perea, The ERP signature of the contextual diversity effect in visual word recognition, Cognitive, Affective, & Behavioral Neuroscience 17 (3) (2017) 461–474.
doi:10.3758/s13415-016-0491-7.
URL https://doi.org/10.3758/s13415-016-0491-7
- [58]
J. S. Adelman, G. D. Brown, J. F. Quesada, Contextual diversity, not word frequency, determines word-naming and lexical decision times, Psychological Science 17 (9) (2006) 814–823.
doi:10.1111/j.1467-9280.2006.01787.x.
- [59]
T. M. Cover, J. A. Thomas, Elements of information theory, Wiley, New York, 2006, 2nd edition.
- [60]
R. Brown, D. McNeill, The “tip of the tongue” phenomenon, Journal of Verbal Learning and Verbal Behavior 5 (4) (1966) 325 – 337.
- [61]
C. M. Connine, J. Mullennix, E. Shernoff, J. Yelen, Word familiarity and frequency in visual and auditory word recognition, Journal of Experimental Psychology: Learning, Memory and Cognition 16 (1990) 1084–1096.
- [62]
J. Tuldava, The frequency spectrum of text and vocabulary, J. Quantitative Linguistics 3 (1) (1996) 38–50.
- [63]
S. Naranan, V. K. Balasubrahmanyan, Information theoretic models in statistical linguistics - Part II: Word frequencies and hierarchical structure in language., Current Science 63 (1992) 297–306.
- [64]
I. Moreno-Sánchez, F. Font-Clos, A. Corral, Large-scale analysis of Zipf’s law in English texts, PLOS ONE 11 (1) (2016) 1–19.
- [65]
C. F. Rowland, S. L. Fletcher, The effect of sampling on estimates of lexical specificity and error rates, Journal of Child Language 33 (2006) 859–877.
- [66]
A. L. Theakston, E. V. M. Lieven, J. M. Pine, C. F. Rowland, The role of performance limitations in the acquisition of verb-argument structure: an alternative account, Journal of Child Language 28 (2011) 127–152.
- [67]
C. G. Wells, Learning through interaction: the study of language development, Cambridge University Press, Cambridge, UK, 1981.
- [68]
L. Bloom, L. Hood, P. Lightbown, Imitation in language development: If, when and why, Cognitive Psychology 6 (1974) 380–420.
- [69]
L. Bloom, P. Lightbown, L. Hood, M. Bowerman, M. Maratsos, M. P. Maratsos, Structure and variation in child language, Monographs of the Society for Research in Child Development (Serial no. 160) 40 (2) (1975) 1–97.
- [70]
L. Bloom, Language development: Form and function in emerging grammars, MIT Press, Cambridge, MA, 1970.
- [71]
R. Brown, A first language: the early stages, Harvard University Press, Cambridge, MA, 1973.
- [72]
S. Kuczaj, The acquisition of regular and irregular past tense forms, Journal of Verbal Learning and Verbal Behavior 16 (1977) 589–600.
- [73]
CHILDES, American English Corpora. CHILDES. The Database Manuals. Available at http://childes.psy.cmu.edu/manuals/02englishusa.doc. Accessed 17 December 2012., TalkBank (2012).
- [74]
K. Demuth, J. Culbertson, J. Alter, Word-minimality, epenthesis, and coda licensing in the acquisition of English, Language and Speech 49 (2006) 137–174.
- [75]
J. Sachs, Talking about the there and then: the emergence of displaced reference in parent-child discourse, in: Children’s language, Vol. 4, Lawrence Erlbaum Associates, Hillsdale, NJ, 1983, pp. 1–28.
- [76]
P. Suppes, The semantics of children’s language, American Psychologist 29 (1974) 103–114.
- [77]
G. Bol, F. Kuiken, Grammatical analysis of developmental language disorders: A study of the morphosyntax of children with specific language disorders, with hearing impairment and with Down’s syndrome, Clinical Linguistics & Phonetics 4 (1) (1990) 77–86.
arXiv:http://dx.doi.org/10.3109/02699209008985472, doi:10.3109/02699209008985472.
URL http://dx.doi.org/10.3109/02699209008985472
- [78]
P. Fikkert, On the Acquisition of Prosodic Structure, no. 6, The Hague: Holland Academic Graphics, 1994.
URL http://hdl.handle.net/2066/32125
- [79]
C. Levelt, On the Acquisition of Place, no. 8, The Hague: Holland Academic Graphics, 1994.
- [80]
G. W. Bol, Implicational scaling in child language acquisition: The order of production of Dutch verb constructions, in: M. Verrips, F. Wijnen (Eds.), Amsterdam series in child language development: Vol. 3. Papers from the Dutch-German Colloquium on Language Acquisition, Institute for General Linguistics, Amsterdam, 1995, pp. 1–13.
- [81]
A. M. Schaerlaekens, The two-word sentence in child language, Mouton, The Hague, 1973.
- [82]
J. Van Kampen, The learnability of the left branch condition, in: R. Bok-Bennema, C. Cremers (Eds.), Linguistics in the Netherlands 1994, John Benjamins, Amsterdam/Philadelphia, 1994, pp. 83–94.
- [83]
C. Aguirre, La adquisición de las categorías gramaticales en español, Ediciones de la Universidad Autónoma de Madrid, 2000.
- [84]
E. Diez-Itza, Procesos fonológicos en la adquisición del español como lengua materna, Actas del XI Congreso Nacional de Lingüística Aplicada (1995) 225–264.
- [85]
K. Hess Zimmermann, El desarrollo lingüístico en los años escolares: análisis de narraciones infantiles, Ph.D. thesis, El Colegio de México, México (2003).
- [86]
D. Jackson-Maldonado, D. Thal, Lenguaje y cognición en los primeros años de vida, Project funded by the John D. and Catherine T. MacArthur Foundation and CONACYT (1993).
- [87]
D. Thal, D. Jackson-Maldonado, Language and cognition in Spanish-speaking infants and toddlers, Project funded by the John D. and Catherine T. MacArthur Foundation (1993).
- [88]
J. Linaza, M. E. Sebastián, C. del Barrio, Lenguaje, comunicación y comprensión. La adquisición del lenguaje, Monografía de Infancia y Aprendizaje (1981) 195–198.
- [89]
S. L. Ornat, A. Fernández, P. Gallo, S. Mariscal, La adquisición de la lengua Española, Siglo XXI, Madrid, 1994.
- [90]
S. Romero, A. Santos, D. Pellicer, The construction of communicative competence in Mexican Spanish speaking children (6 months to 7 years), Mexico City: University of the Americas (1992).
- [91]
M. Shiro, Getting the story across: A discourse analysis approach to evaluative stance in Venezuelan children’s narratives, unpublished Doctoral Dissertation. Harvard University (1997).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] G. K. Zipf, Human behaviour and the principle of least effort, Addison-Wesley, Cambridge (MA), USA, 1949.
- 2[2] G. K. Zipf, The Psycho-Biology of Language: an Introduction to Dynamic Psychology, MIT Press, Cambridge, MA, USA, 1968, originally published in 1935 by Houghton Mifflin - Boston - MA - USA.
- 3[3] G. K. Zipf, The Meaning-Frequency Relationship of Words, Journal of General Psychology 1945 (33) (1945) 251–256.
- 4[4] S. Naranan, V. K. Balasubrahmanyan, Models for power law relations in linguistics and information science, J. Quantitative Linguistics 5 (1-2) (1998) 35–61.
- 5[5] R. Ferrer-i-Cancho, Optimization models of natural communication , in: Journal of Quantitative Linguistics, Vol. 25, 2014. URL http://arxiv.org/abs/1412.2486
- 6[6] F. Font-Clos, G. Boleda, A. Corral, A scaling law beyond Zipf’s law and its relation to Heaps’ law , New Journal of Physics 15 (9) (2013) 093033. URL http://stacks.iop.org/1367-2630/15/i=9/a=093033
- 7[7] A. Corral, G. Boleda, R. Ferrer-i-Cancho, Zipf’s law for word frequencies: Word forms versus lemmas in long texts, P Lo S ONE 10 (7) (2015) 1–23. doi:10.1371/journal.pone.0129031 . · doi ↗
- 8[8] R. Ferrer-i-Cancho, The meaning-frequency law in Zipfian optimization models of communication, Glottometrics 35 (2016) 28–37.