TL;DR
This paper introduces JSIS3D, a novel approach combining multi-task pointwise networks and multi-value CRFs for joint semantic and instance segmentation of 3D point clouds, achieving state-of-the-art results.
Contribution
The paper presents a new joint segmentation framework that integrates deep learning with probabilistic graphical models for improved 3D scene understanding.
Findings
Robust joint semantic-instance segmentation on indoor datasets.
State-of-the-art performance in semantic segmentation.
Enhanced robustness over individual components.
Abstract
Deep learning techniques have become the to-go models for most vision-related tasks on 2D images. However, their power has not been fully realised on several tasks in 3D space, e.g., 3D scene understanding. In this work, we jointly address the problems of semantic and instance segmentation of 3D point clouds. Specifically, we develop a multi-task pointwise network that simultaneously performs two tasks: predicting the semantic classes of 3D points and embedding the points into high-dimensional vectors so that points of the same object instance are represented by similar embeddings. We then propose a multi-value conditional random field model to incorporate the semantic and instance labels and formulate the problem of semantic and instance segmentation as jointly optimising labels in the field model. The proposed method is thoroughly evaluated and compared with existing methods on…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1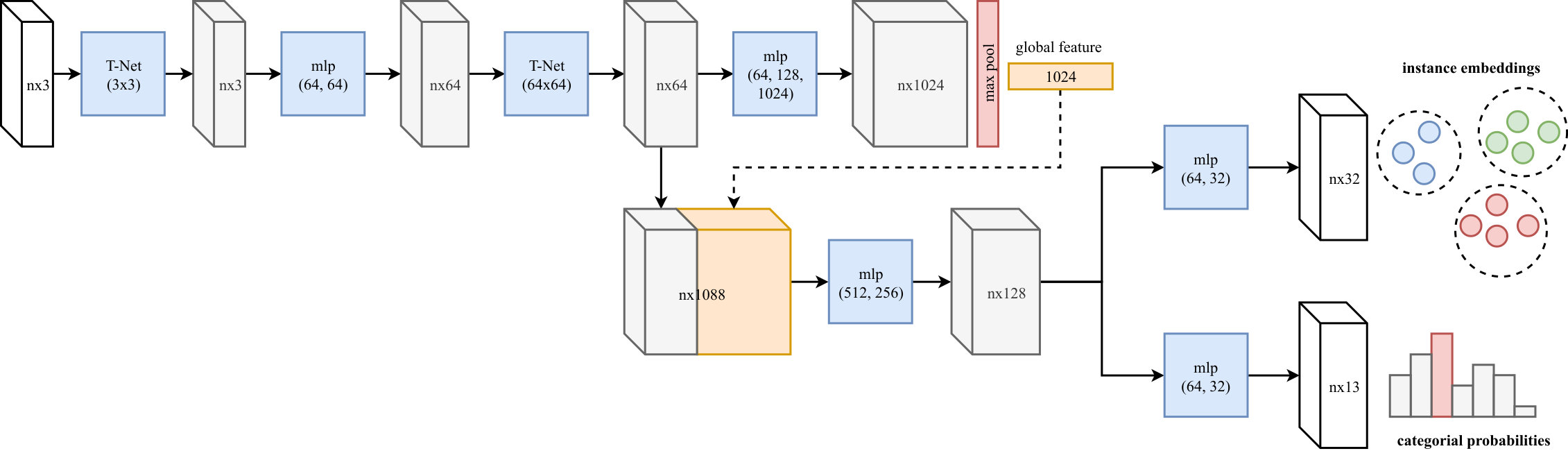 Figure 2
Figure 2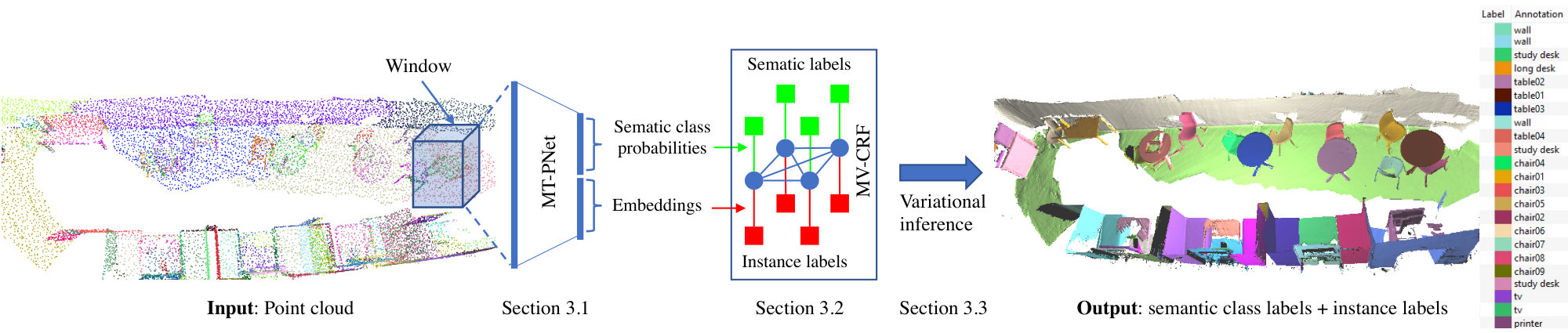 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26 Figure 27
Figure 27| (18) |
| (18) |
| (18) |
| (18) |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
JSIS3D: Joint Semantic-Instance Segmentation of 3D Point Clouds with
Multi-Task Pointwise Networks and Multi-Value Conditional Random Fields
Quang-Hieu Pham*†* Duc Thanh Nguyen*‡* Binh-Son Hua*⊳* Gemma Roig*†* Sai-Kit Yeung*⊲*
*†*Singapore University of Technology and Design
*‡*Deakin University *⊳*The University of Tokyo
*⊲*Hong Kong University of Science and Technology
Abstract
Deep learning techniques have become the to-go models for most vision-related tasks on 2D images. However, their power has not been fully realised on several tasks in 3D space, e.g., 3D scene understanding. In this work, we jointly address the problems of semantic and instance segmentation of 3D point clouds. Specifically, we develop a multi-task pointwise network that simultaneously performs two tasks: predicting the semantic classes of 3D points and embedding the points into high-dimensional vectors so that points of the same object instance are represented by similar embeddings. We then propose a multi-value conditional random field model to incorporate the semantic and instance labels and formulate the problem of semantic and instance segmentation as jointly optimising labels in the field model. The proposed method is thoroughly evaluated and compared with existing methods on different indoor scene datasets including S3DIS and SceneNN. Experimental results showed the robustness of the proposed joint semantic-instance segmentation scheme over its single components. Our method also achieved state-of-the-art performance on semantic segmentation.
1 Introduction
The growing popularity of low-cost 3D sensors (e.g., Kinect) and light-field cameras has opened many 3D-based applications such as autonomous driving, robotics, mobile-based navigation, virtual reality, and 3D games. This development also acquires the capability of automatic understanding of 3D data. In 2D domain, common scene understanding tasks including image classification, semantic segmentation, or instance segmentation, have achieved notable results [13, 3]. However, the problem of 3D scene understanding poses much greater challenges, e.g., large-scale and noisy data processing.
Literature has shown that the data of a 3D scene can be represented by a set of images capturing the scene at different viewpoints [14, 46, 42], in a regular grid of volumes [47, 26, 28], or simply in a 3D point cloud [33, 16, 45, 17, 24]. Our work is inspired by the point-based representation for several reasons. Firstly, compared with multi-view and volumetric representations, point clouds offer a more compact and intuitive representation of 3D data. Secondly, recent neural networks directly built on point clouds [33, 16, 24, 45, 17, 18, 22, 23, 48] have shown promising results across multiple tasks such as object recognition and semantic segmentation.
In this paper, we address two fundamental problems in 3D scene understanding: semantic segmentation and instance segmentation. Semantic segmentation aims to identify a class label or object category (e.g., chair, table) for every 3D point in a scene while instance segmentation clusters the scene into object instances. These two problems have often been tackled separately in which instance segmentation/detection is a post-processing task of semantic segmentation [31, 30]. However, we have observed that object categories and object instances are mutually dependent. For instance, shape and appearance features extracted on an instance would help to identify the object category of that instance. On the other hand, if two 3D points are assigned to different object categories, they unlikely belong to the same object instance. Therefore, it is desirable to couple semantic and instance segmentation into a single task. Towards the above motivations, we make the following contributions in our work.
- •
A network architecture namely multi-task pointwise network (MT-PNet) that simultaneously performs two tasks: predicting the object categories of 3D points in a point cloud, and embedding these 3D points into high-dimensional feature vectors that allow clustering the points into object instances.
- •
A multi-value conditional random field (MV-CRF) model that formulates the joint optimisation of class labels and object instances into a unified framework, which can be efficiently solved using variational mean field technique. To the best of our knowledge, we are the first to explore the joint optimisation of semantics and instances in a unified framework.
- •
Extensive experiments on different benchmark datasets to validate the proposed method as well as its main components. Experimental results showed that the joint semantic and instance segmentation outperformed each individual task, and the proposed method achieved state-of-the-art performance on semantic segmentation.
The remainder of the paper is organised as follows. Section 2 briefly reviews related work. The proposed method is described in Section 3. Experiments and results are presented and discussed in Section 4. The paper is finally concluded in Section 5.
2 Related Work
This section reviews recent semantic and instance segmentation techniques in 3D space. We especially focus on deep learning-based techniques applied on 3D point clouds due to their proven robustness as well as being contemporary seminal in the field. For the sake of brevity, we later refer to the traditional, category-based semantic segmentation as semantic segmentation, and instance-based semantic segmentation as instance segmentation.
2.1 Semantic Segmentation
Recent availability of indoor scene datasets [37, 15, 5, 1] has sparked research interests in 3D scene understanding, particularly semantic segmentation. We categorise these recent works into three main categories based on their type of input data, namely multi-view images, volumetric representation, and point clouds.
Multi-view approach.
This approach often uses pre-trained models on 2D domain and applies them to 3D space. Per-vertex labels are obtained by back-projecting and fusing 2D predictions from colour or RGB-D images onto 3D space. Predictions on 2D can be done via classifiers, e.g., random forests [14, 36, 46, 42], or deep neural networks [27, 49, 30]. Such techniques can be implemented in tandem with 3D scene reconstruction, creating a real-time semantic reconstruction system. However, this approach suffers from inconsistencies between 2D predictions, and its performance might depend on view placements.
Volumetric approach.
The robustness of deep neural networks in solving several scene understanding tasks on images has inspired applying deep neural networks directly in 3D space to solve 3D scene understanding problem. In fact, convolutions on a regular grid, e.g., image structures, can be easily extended to 3D, which leads to deep learning with volumetric representation [47, 26, 28]. To support high-resolution segmentation and reduce memory footprints, a hierarchical data structure such as an octree was proposed to limit convolution operations only on free-space voxels [35]. It has been shown that the performance of semantic segmentation can be improved by solving the problem jointly with scene completion [39, 6].
Point cloud approach.
In contrast to volume, point cloud is a compact yet intuitive representation that directly stores attributes of the geometry of a 3D scene via coordinates and normals of vertices. Point clouds arise naturally from commodity devices such as multi-view stereos, depth, and LIDAR sensors. Point clouds can also be converted to other representations such as volumes [40] or mesh [41]. While convolutions can be done conveniently on volumes [40], they are not applicable straightforwardly on point clouds. This problem was first addressed in the work of Qi et al. [32], and subsequently explored by several others, e.g., [33, 16, 45, 17, 24, 23, 48]. Semantic segmentation can further be extended to graph convolution to handle large-scale point clouds [22], and with the use of kd-tree to address non-uniform point distributions [18, 12].
Conditional Random Fields (CRFs)
CRFs are often used in semantic segmentation of 3D scenes, e.g., [41, 14, 20, 46, 42, 27, 34]. In general, CRFs make use of unary and binary potentials capturing characteristics of individual 3D points [46] or meshes [41], and their co-occurrence. To enhance CRFs with prior knowledge, higher-order potentials are introduced [21, 11, 50, 2, 49, 10, 30]. Higher-order potentials, e.g., object detections [21, 2, 30], act as additional cues to help the inference of semantic class labels in CRFs.
2.2 Instance Segmentation
In general, there are two common strategies to tackle instance segmentation. The first strategy is to localise object bounding boxes using object detection techniques, and then find a mask that separates foreground and background within each box. This approach has been shown to work robustly with images [7, 13], while deemed challenging in 3D domain. This probably due to existing 3D object detectors are often not trained from scratch but make use of image features [9, 31, 25]. Extending such approaches with masks is possible but might lead to a sub-optimal and more complicated pipeline.
Instead, given the promising results of semantic segmentation on 3D data [32, 1, 16], the second strategy is to extend a semantic segmentation framework by adding a procedure that proposes object instances. In an early attempt, Wang et al. [44] proposed to learn a semantic map and a similarity matrix of point features based on the PointNet in [32]. Authors then proposed an heuristic and non-maximal suppression step to merge similar points into instances.
3 Proposed Method
In this section, we describe our proposed method for semantic and instance segmentation of 3D point clouds. Given a 3D point cloud, we first scan the entire point cloud by overlapping 3D windows. Each window (with its associated 3D vertices) is passed to a neural network for predicting the semantic class labels of the vertices within the window and embedding the vertices into high-dimensional vectors. To enable such tasks, we develop a multi-task pointwise network (MT-PNet) that aims to predict an object class for every 3D point in the scene and at the same time to embed the 3D point with its class label information into a vector. The network encourages 3D points belonging to the same object instance be pulled to each other while pushing those of different object instances as far away from each other as possible. Those class labels and embeddings are then fused into a multi-value conditional random field (MV-CRF) model. The semantic and instance segmentation are finally performed jointly using variational inference. We illustrate the pipeline of our method in Figure 1 and describe its main components in the following sub-sections.
3.1 Multi-Task Pointwise Network (MT-PNet)
Our MT-PNet is based on the feed forward architecture of PointNet proposed by Qi et al. in [32] (see Figure 2). Specifically, for an input point cloud of size , a feature map of size , where is the dimension of features for each point, is first computed. The MT-PNet then diverges into two different branches performing two tasks: predicting the semantic labels for 3D points and creating their pointwise instance embeddings. The loss of our MT-PNet is the sum of the losses of its two branches,
[TABLE]
The prediction loss is defined by the cross-entropy as usual. Inspired by the work in [8], we employ a discriminative function to present the embedding loss . In particular, suppose that there are instances and is the number of elements in the -th instance, is the embedding of point , and is the mean of embeddings in the -th instance. The embedding loss can be defined as follows,
[TABLE]
where
[TABLE]
[TABLE]
[TABLE]
where , and are respectively the margins for the pull loss and push loss . We set and in our implementation.
A simple intuition for this embedding loss is that the pull loss attracts embeddings towards the centroids, i.e., , while the push loss keeps these centroids away from each other. The regularisation loss acts as a small force that draws all centroids towards the origin. As shown in [8], if we set the margin , then each embedding will be closer to its own centroid than other centroids.
3.2 Multi-Value Conditional Random Fields (MV-CRF)
Let be the point cloud of a 3D scene obtained after 3D reconstruction. Each 3D vertex in the point cloud is represented by its 3D location , normal , and colour . By using the proposed MT-PNet, we also obtain an embedding for each point . Let be the set of semantic labels that need to be assigned to the point cloud , where represent the semantic class, e.g., chair, table, etc., of . Similarly, let be the set of instance labels of , i.e., all vertices of the same object instance will have the same instance label . The labels and are random variables taking values in and which are the set of semantic labels and instance labels respectively. Note that is predefined while is unknown and needs to be determined through instance segmentation.
We now consider each vertex as a node in a graph, two arbitrary nodes , are connected by an undirected edge, and each vertex is associated with its semantic and instance labels represented by the random variables and . Our graph defined over , , and is named multi-value conditional random fields (MV-CRF); this is because each node is associated to two labels taking values in . The joint semantic-instance segmentation of the point cloud thus can be formulated via minimising the following energy function,
[TABLE]
We note that our MV-CRF substantially differs from existing higher-order CRFs, e.g., [21, 11, 2, 30]. Specifically, in existing higher-order CRFs, higher-orders, e.g. object detections, are used as prior knowledge that helps to improve segmentation. In contrast, our MV-CRF treats instance labels and semantic labels equally as unknown and optimises them simultaneously.
The energy function in (3.2) involves in a number of potentials that incorporate physical constraints (e.g., surface smoothness, geometric proximity) and semantic constraints (e.g., shape consistency between object class and instances) in both semantic and instance labeling. Specifically, the unary potential is defined over the semantic labels and computed directly from the classification score of MT-PNet as,
[TABLE]
where is a possible class label in and is the probability (e.g., softmax value) that our network classifies to the semantic class .
We have found that vertices of the same object class often share the same distribution of classification scores, i.e., . We thus model the pairwise potential via the classification scores of both and . Specifically, we define,
[TABLE]
where is obtained from the Pott compatibility as,
[TABLE]
The unary potential enforces embeddings belonged to the same instance to get as close to their mean embeddings as possible. Intuitively, embeddings of the same instance are expected to convert to their modes in the embedding space. Meanwhile, embeddings of different instances are encouraged to diverge from each other. Specifically, suppose that the instance label set includes instances. Suppose that the current configuration of assigns all the vertices in into these instances. For each instance label , we define,
[TABLE]
where and respectively denote the mean and covariance matrix of embeddings assigned to the label , and is an indicator.
The term in (3.2) represents the area of instance and is used to favour large instances. We have found that this term could help to remove tiny instances caused by noise in the point cloud.
The pairwise potential of instance labels captures geometric properties of surfaces in object instances and is defined as a mixture of Gaussians of the locations, normals, and colour of vertices and . In particular,
[TABLE]
where is presented in (9).
The term in (3.2) associates the semantic-based potentials with instance-based potentials and encourages the consistency between semantic and instance labels. For instance, if two vertices are assigned to the same object instance, they should be assigned to the same object class. Technically, if we compute a histogram of frequencies of semantic labels for all vertices of object instance , we can define based on the mutual information between and as,
[TABLE]
where is the frequency that semantic label occurs in vertices whose instance label is .
As shown in (12), given an instance label , the sum of over all semantic labels is the information entropy of the labels w.r.t. the object instance , i.e., . A good labeling, therefore, should minimise such entropy, leading to low variation of semantic labels within the same object instance. Since the energy in (3.2) sums over all semantic labels and instance labels , it would favour highly consistent labelings.
3.3 Variational Inference
The minimisation of in (3.2) is equivalent to the maximisation of the posterior conditional which is intractable to be solved using a naive implementation. In this paper, we adopt mean field variational approach to solve this optimisation problem [43]. In general, the idea of mean field variational inference is to approximate the probability distribution by a variational distribution that can be fully factorised over all random variables in , i.e., .
However, the factorisation of over all pairs in induces a computational complexity of per vertex. In addition, since our proposed MV-CRF model is fully connected, message passing steps used in conventional implementation of mean field approximation require quadratic complexity in the number of random variables (i.e., ). Fortunately, since our pairwise potentials, defined in (8) and (3.2), are expressed in Gaussians, message passing steps can be performed efficiently via applying convolution operations with Gaussian filters on downsampled versions of , followed by upsampling [19]. Truncated Gaussians can be also be used to approximate these Gaussian filters to further speed up the message passing process [29].
We first assume that and are independent in the joint variational distribution , and hence can be decomposed as,
[TABLE]
The assumption in (13) allows us to derive mean field update equations for semantic and instance variational distributions and .
Since the term in (3.2) is not expressed in relative to the index , for convenience to the computation of mean field updates, for each vertex , we define a new term as,
[TABLE]
By using , the term in (3.2) can be rewritten as,
[TABLE]
We then obtain mean field updates,
[TABLE]
and
[TABLE]
where is the partition function that makes a probability mass function during the optimisation.
4 Experiments
4.1 Experimental Setup
Our MT-PNet was implemented in PyTorch. We trained our network using the SGD optimiser. The learning rate was set to and decay rate was set to after every 50 epochs. The training took 10 hours on a single NVIDIA TITAN X graphics card.
For the joint optimisation of semantic and instance labeling, we initialised the semantic and instance labels for 3D vertices as follows. Semantic labels with associated classification scores were obtained directly from MT-PNet. Embeddings for all 3D vertices were also extracted. Initial instance labels were then determined by applying the mean shift algorithm [4] on the embeddings. The bandwidth of mean shift was set to the margin of the push force in (4). We set and found this setting achieved the best performance. In addition, when setting the bandwidth to lower values, our performance will drop due to over-segmentation. We note that the number of clusters generated by the mean shift algorithm may be much larger than the true number of instances since we allow over-segmentation. After the joint optimisation step, we only maintain instances that pertain at least one vertex.
Input of our MT-PNet is a point cloud of 4,096 points. To handle large-scale scenes, an input point cloud was divided into overlapping windows, each of which roughly contains 4,096 points. Each window was fed to our MT-PNet to extract instance embeddings. The embeddings from all the windows were merged using the BlockMerging procedure in SGPN [44]. Joint optimisation was then applied on the entire scene. Finally, we employ non-maximal suppression to yield the final semantic-instance predictions.
4.2 Datasets
We conducted all experiments on two datasets: S3DIS [1] and SceneNN [15]. S3DIS is a 3D scene dataset that includes large-scale scans of indoor spaces at building level. On this dataset, we performed experiments at the provided disjoint spaces, which were typically parsed to about 10–80 object instances. The objects were annotated with 13 categories. We followed the original train/test split in [1]. Since S3DIS does not include normals of 3D vertices, we simplified (3.2) with only location and colour.
SceneNN [15] is a scene meshes dataset of indoor scenes with cluttered objects at room scale. Their semantic segmentation follows NYU-D v2 [37] category set, which has 40 semantic classes. On this dataset, we followed the train/test split by Hua et al. [16]. Similar to S3DIS, the semantic and instance segmentation were done on overlapping windows.
4.3 Evaluation and Comparison
In this section, we provide a comprehensive evaluation of our method and its variants, and comparisons with existing methods in both semantic and instance segmentation tasks. Several results of our method are shown in Figure 3.
Ablation study.
We study the effectiveness of joint semantic-instance segmentation compared with its individual tasks. This study is done by investigating the role of potentials of the energy of our MV-CRF defined in (3.2). Specifically, for semantic segmentation, we investigate the use of unary potentials in (7) only and traditional CRFs combining (7) and (8). Similarly, for instance segmentation, we compare the use of (3.2) only and the combination of (3.2) and (3.2). We also measure the performance of the joint task, i.e., the whole energy of MV-CRF. Table 1 compares MV-CRF and its variants in both semantic and instance segmentation on S3DIS. Metrics include micro-mean accuracy (mAcc)111Micro-mean takes into account the size of classes in calculating the average accuracy and thus is often used for unbalanced data. In our context, micro-mean accuracy is equivalent to the overall accuracy that is often used in semantic segmentation. [38] for semantic segmentation and [email protected] for instance segmentation.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Iro Armeni, Ozan Sener, Amir R Zamir, Helen Jiang, Ioannis Brilakis, Martin Fischer, and Silvio Savarese. 3D semantic parsing of large-scale indoor spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages 1534–1543, 2016.
- 2[2] Anurag Arnab, Sadeep Jayasumana, Shuai Zheng, and Philip H. S. Torr. Higher order conditional random fields in deep neural networks. In European Conference on Computer Vision (ECCV) , pages 524–540, 2016.
- 3[3] Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Transactions on Pattern Analysis & Machine Intelligence (PAMI) , 40(4):834–848, 2018.
- 4[4] Dorin Comaniciu and Peter Meer. Mean shift: A robust approach toward feature space analysis. IEEE Transactions on Pattern Analysis & Machine Intelligence (PAMI) , (5):603–619, 2002.
- 5[5] Angela Dai, Angel X Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3D reconstructions of indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages 5828–5839, 2017.
- 6[6] Angela Dai, Daniel Ritchie, Martin Bokeloh, Scott Reed, Jürgen Sturm, and Matthias Nießner. Scancomplete: Large-scale scene completion and semantic segmentation for 3D scans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages 4578–4587, 2018.
- 7[7] Jifeng Dai, Kaiming He, and Jian Sun. Instance-aware semantic segmentation via multi-task network cascades. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages 3150–3158, 2016.
- 8[8] Bert De Brabandere, Davy Neven, and Luc Van Gool. Semantic instance segmentation with a discriminative loss function. ar Xiv preprint ar Xiv:1708.02551 , 2017.
