On evaluating CNN representations for low resource medical image classification
Taruna Agrawal, Rahul Gupta, Shrikanth Narayanan

TL;DR
This paper explores the use of CNN transfer learning for low-resource medical image classification, introduces a metric to predict CNN performance, and demonstrates its effectiveness in gastrointestinal landmark classification with limited data.
Contribution
It presents a novel metric to predict CNN test performance from training set representations and evaluates CNN transfer learning in low-resource medical imaging tasks.
Findings
CNN transfer learning outperforms knowledge-driven features.
The proposed metric correlates 87% with actual test performance.
CNN choice impacts classification success in low-resource settings.
Abstract
Convolutional Neural Networks (CNNs) have revolutionized performances in several machine learning tasks such as image classification, object tracking, and keyword spotting. However, given that they contain a large number of parameters, their direct applicability into low resource tasks is not straightforward. In this work, we experiment with an application of CNN models to gastrointestinal landmark classification with only a few thousands of training samples through transfer learning. As in a standard transfer learning approach, we train CNNs on a large external corpus, followed by representation extraction for the medical images. Finally, a classifier is trained on these CNN representations. However, given that several variants of CNNs exist, the choice of CNN is not obvious. To address this, we develop a novel metric that can be used to predict test performances, given CNN…
Click any figure to enlarge with its caption.
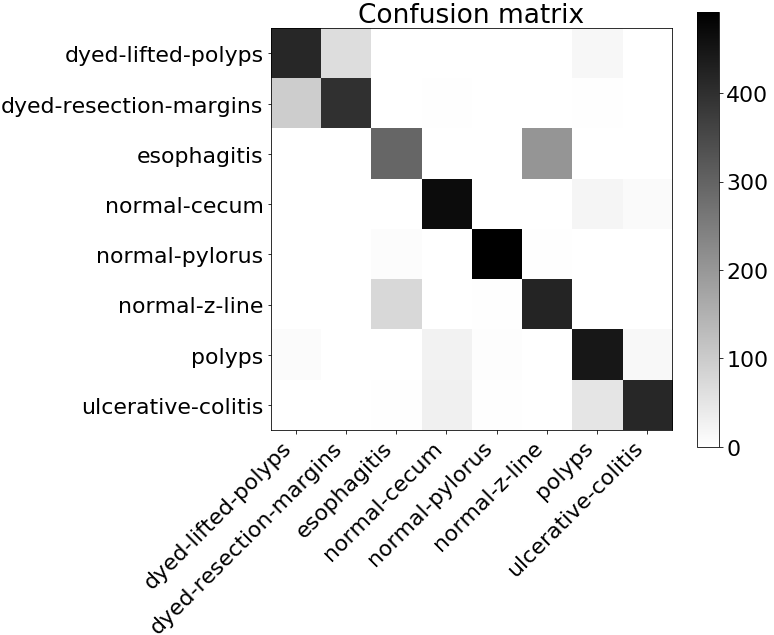 Figure 1
Figure 1 Figure 2
Figure 2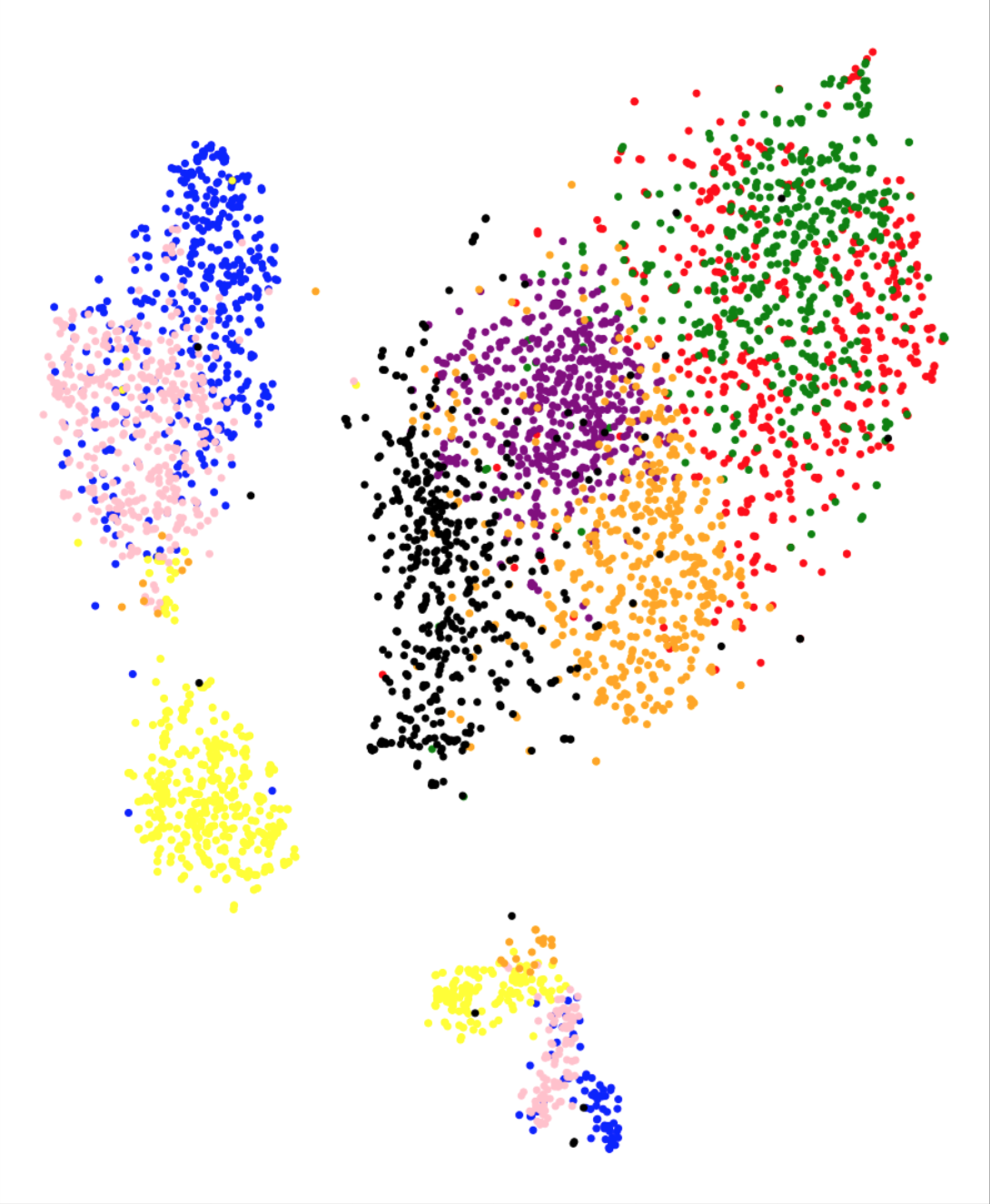 Figure 3
Figure 3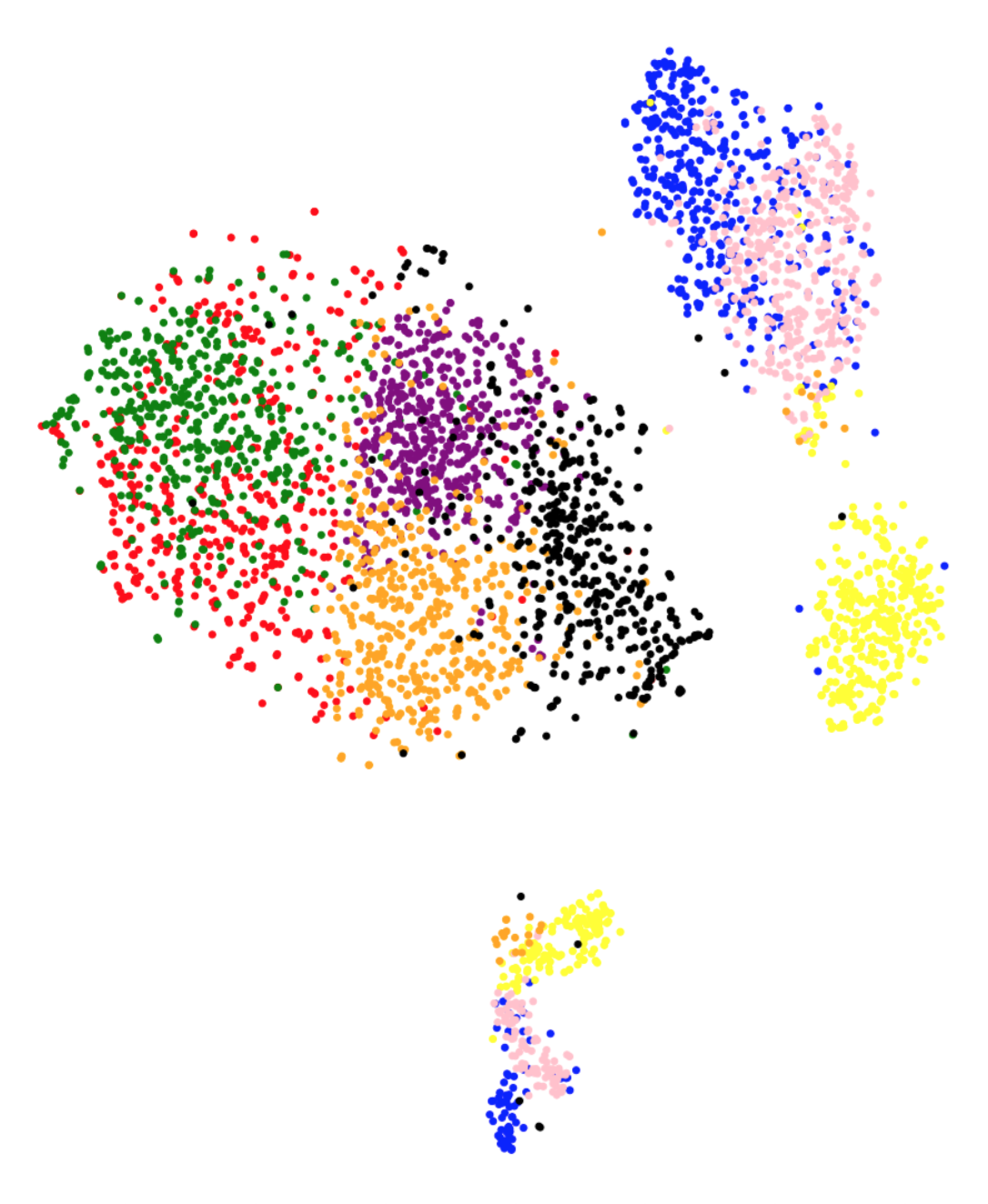 Figure 4
Figure 4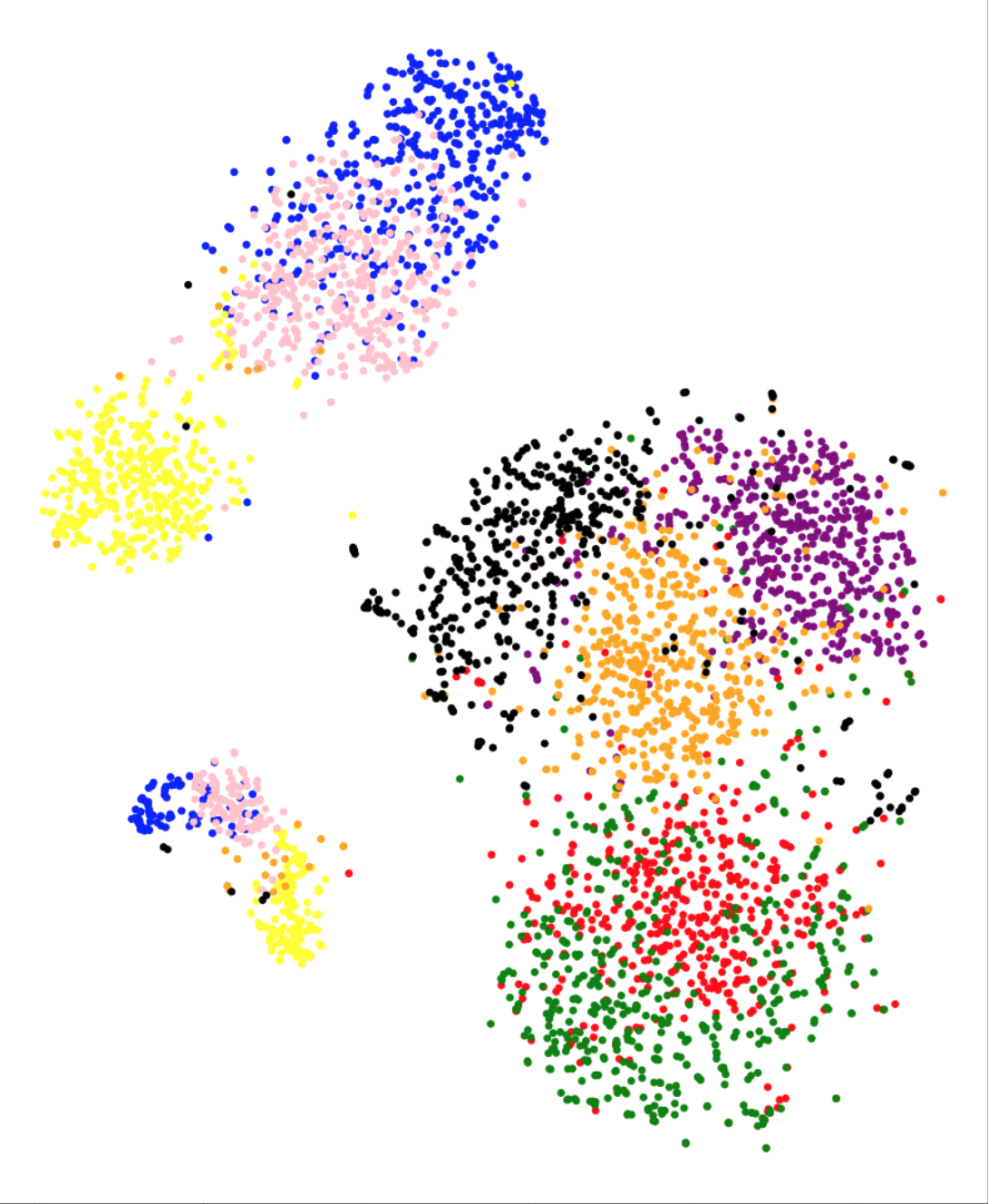 Figure 5
Figure 5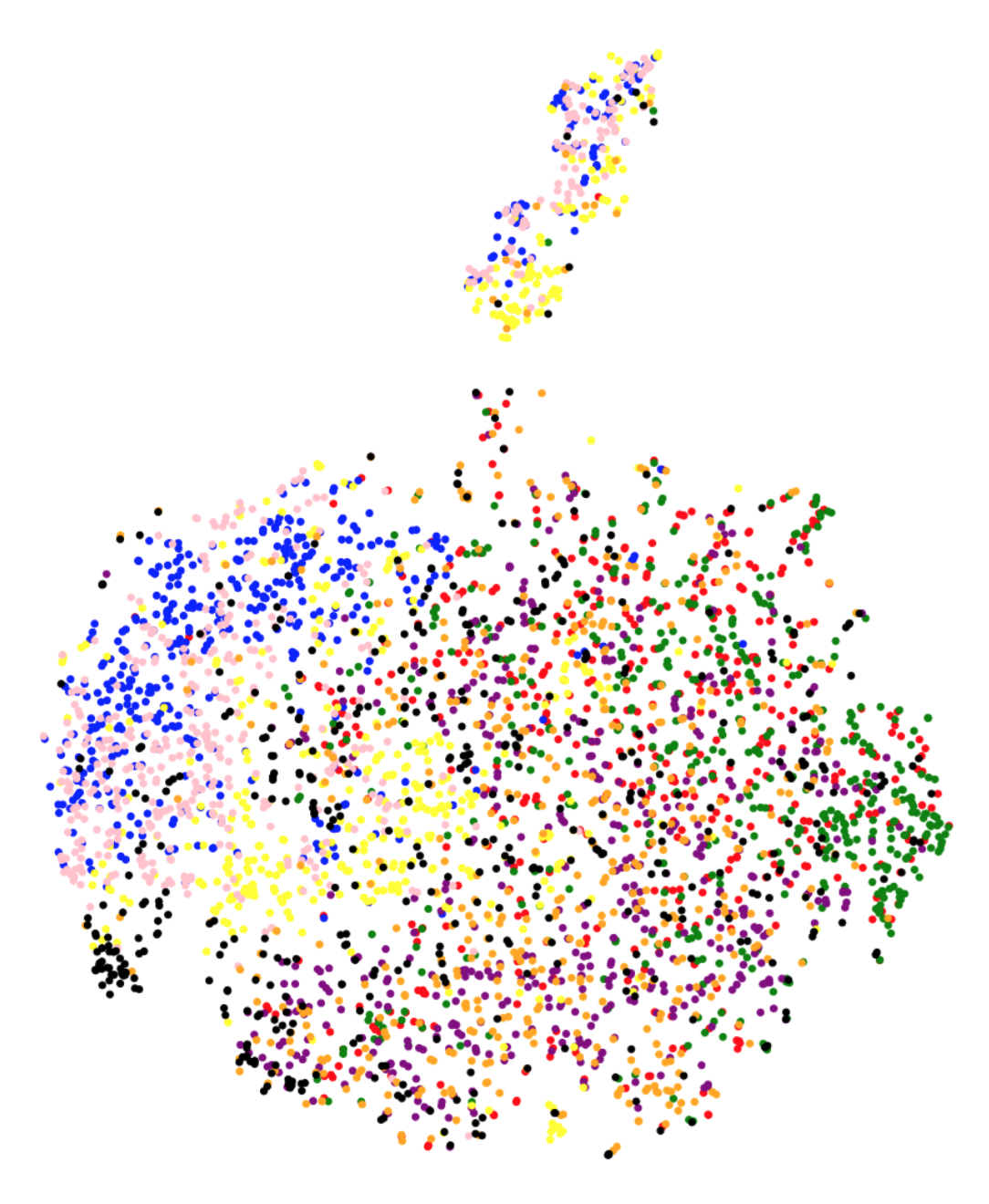 Figure 6
Figure 6 Figure 7
Figure 7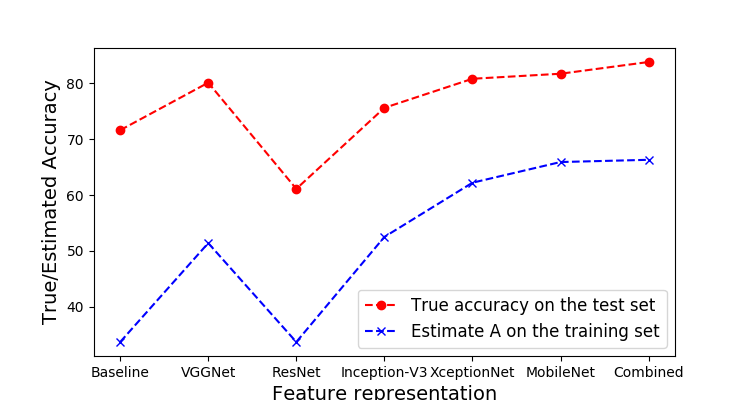 Figure 8
Figure 8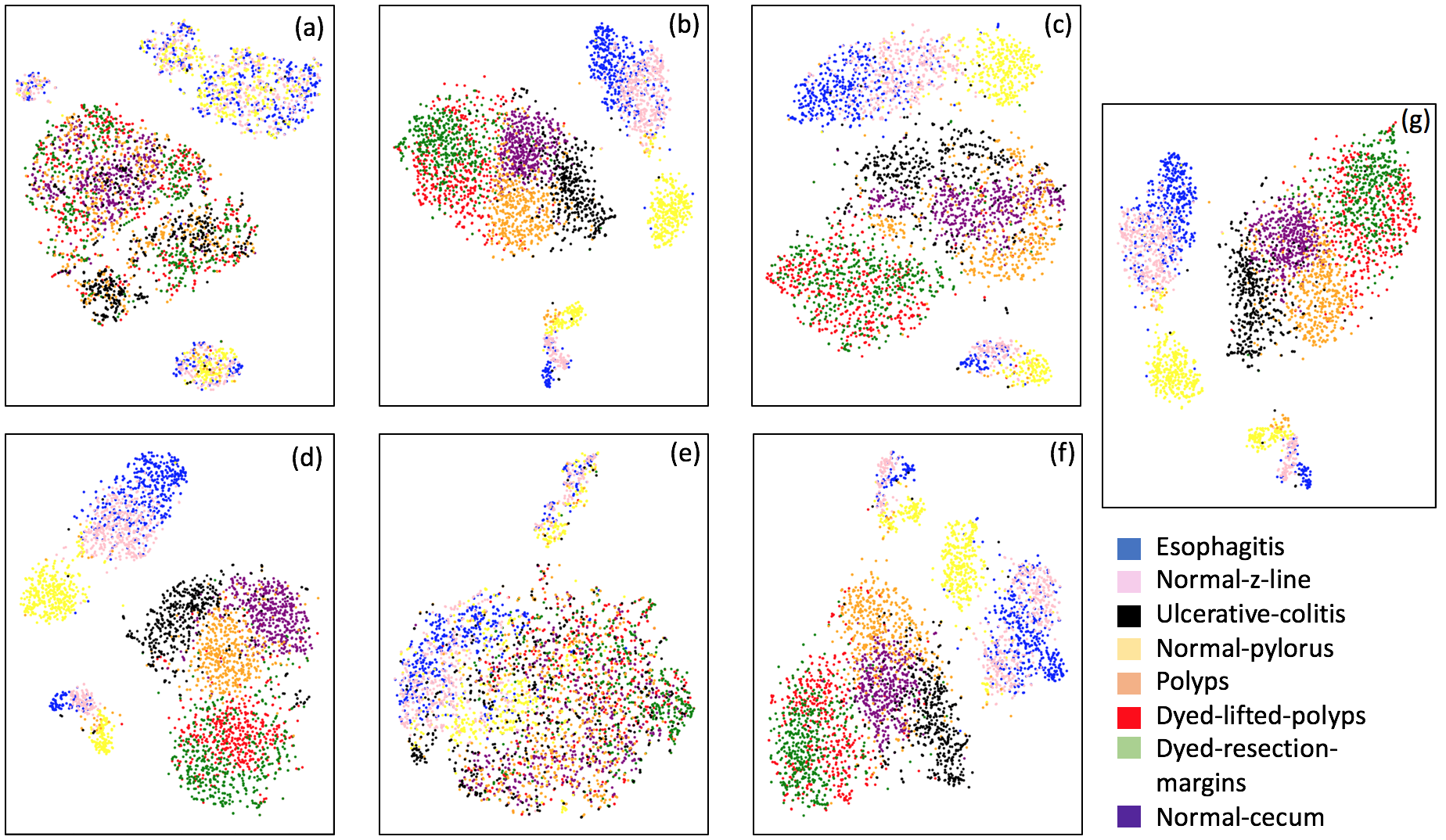 Figure 9
Figure 9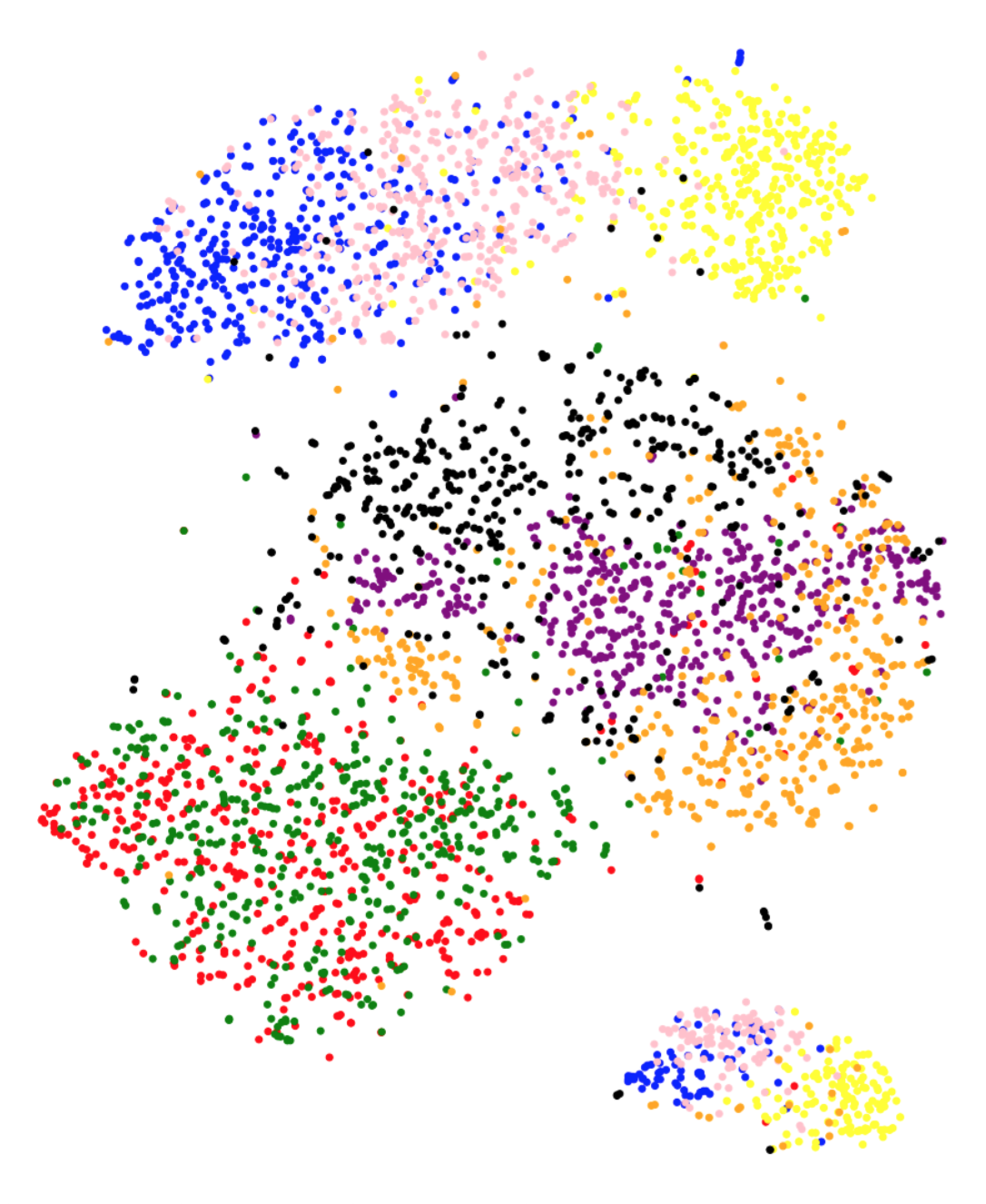 Figure 10
Figure 10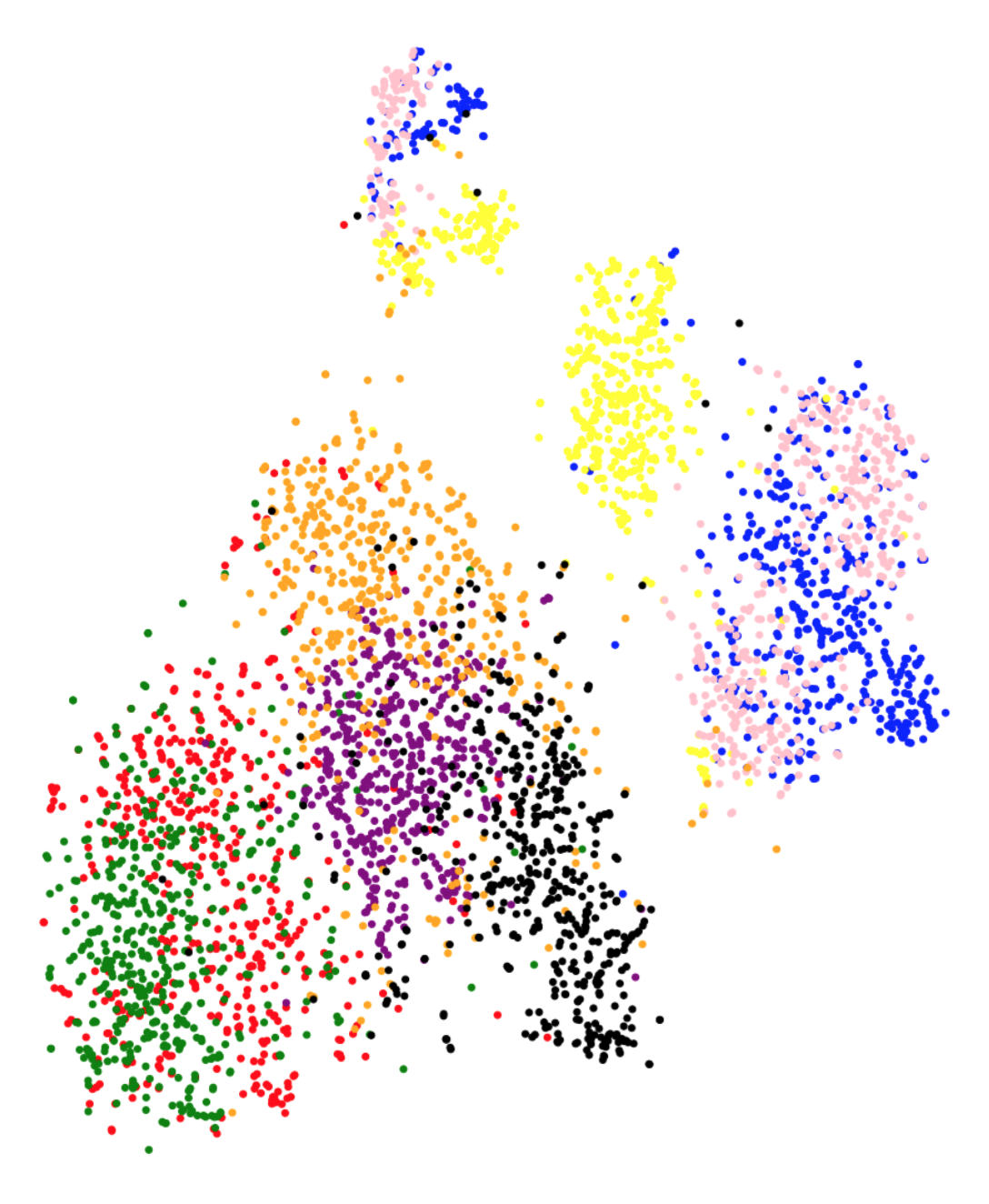 Figure 11
Figure 11| Feature : Description |
| Joint Composite Descriptor: Carries color and texture |
| information in a compressed format |
| Tamura: Features corresponding to human visual perception: |
| coarseness, directionality, line-likeness, regularity, and roughness |
| ColorLayour: Spatial distribution of color in the image |
| EdgeHistogram: Capture edge distribution in the image |
| AutoColorCorrelogram: Capture color correlation information |
| in the image |
| Pyramid Histogram of Oriented Gradients: Quantifies spatial |
| layout and local shapes within the image |
| Features | Description | Feature | Accuracy |
| dimensionality | |||
| Baseline | See Table 1 | 1179 | 71.6 |
| VGGNet [22] | 16 layer architecture, uses convolution pooling throughout the network. | 512 | 80.1 |
| ResNet50 [7] | 50 layer networks with shortcut connections. | 2048 | 61.1 |
| Inception-V3 [23] | Performs convolution with filters of dimensionality , and | 2048 | 75.6 |
| XceptionNet [24] | Extension of the Inception architecture with standard inception modules | 2048 | 80.8 |
| replaced by depthwise separable convolutions | |||
| MobileNet [6] | Uses depthwise separable convolution to build light weight deep neural networks | 1024 | 81.7 |
| Combined | 83.8 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsColorectal Cancer Screening and Detection · COVID-19 diagnosis using AI · AI in cancer detection
On Evaluating CNN representations for Low resource medical image classification
Abstract
Convolutional Neural Networks (CNNs) have revolutionized performances in several machine learning tasks such as image classification, object tracking, and keyword spotting. However, given that they contain a large number of parameters, their direct applicability into low resource tasks is not straightforward. In this work, we experiment with an application of CNN models to gastrointestinal landmark classification with only a few thousands of training samples through transfer learning. As in a standard transfer learning approach, we train CNNs on a large external corpus, followed by representation extraction for the medical images. Finally, a classifier is trained on these CNN representations. However, given that several variants of CNNs exist, the choice of CNN is not obvious. To address this, we develop a novel metric that can be used to predict test performances, given CNN representations on the training set. Not only we demonstrate the superiority of the CNN based transfer learning approach against an assembly of knowledge driven features, but the proposed metric also carries an 87% correlation with the test set performances as obtained using various CNN representations.
Index Terms: Convolutional Neural Networks, medical imaging, transfer learning
1 Introduction
Recent advances in the design of Convolutional Neural Networks (CNNs) has led to state of the art performances in several tasks, including image classification [1], object detection [2] and object tracking [3]. CNNs can be viewed as models that extract features from raw images using convolution and pooling operations, followed by a classification using fully connected layers [1]. However, training these models typically requires large amount of samples, given the large number of trainable parameters. Transfer learning is a promising approach in such cases, wherein CNN models are pre-trained on larger unrelated corpora, followed by a fine-tuning on the task of interest. The task of interest in this paper is the classification of gastro-intestinal (GI) tract images, given a few hundred training samples per class. A vanilla classification approach in this case would be extraction of a selected set of features, followed by learning a classifier. First, we establish the superiority of transfer learning approach using CNN models learnt on larger unrelated corpora against the vanilla classification approach. However, given that several variants of CNN architectures exist, it is not evident which CNN representation will yield the best performance. To address this, we also propose a metric that can inform the choice of CNN architecture.
Previous work: CNNs have revolutionized research in several fields such as image classification/detection [1], automatic speech recognition [4] and natural language understanding [5]. CNNs typically perform a set of convolution and pooling operations, variants of which have been proposed by several researchers [6, 7]. These variants are typically developed taking into consideration the task at hand. A few examples with custom CNN design include acoustic modeling for low resource languages [8], object and action classification [9] and remote sensing [10]. On the other hand, medical image classification [11] requires assignment of medical images (drawn from real world patients) to a medical landmark, phenomenon or a disease and often, obtaining large amounts of training data can be challenging. A few approaches for medical image classification include the use of decision trees [12], k-nearest-neighbors [13] and support vector machines [14]. Researchers have also applied CNNs for medical image classification using training from scratch [15] as well as transfer learning [16]. In their work, Tajbakhsh et al. [17] address questions regarding the choice between full training versus fine tuning based on empirical performance evaluation. Shin et al. [16] also simplify existing CNN architectures to reduce the number of parameters for training on medical imaging dataset. Recently the MediaEval challenge [18] garnered further interest in medical image classification, with proposals to use CNN based classifiers [19, 20]. All the above papers report performances using a CNN, however they fall short of describing a process that can inform selection of a CNN variant appropriate for the task at hand. First, we obtain performances on the KVASIR dataset [21] using transfer learning based approach. Using these results as an empirical testbed, we propose a metric that can predict performances on the test set. The goal of this metric is to inform the decisions regarding the choice of CNN architecture for transfer learning.
For the task of GI landmark classification, we first establish the performances using two kinds of approaches (i) a kitchen sink feature extraction and classifier training and, (ii) extracting mid-level CNN representations followed by classification layer fine-tuning. We observe that the CNN based transfer learning based approach obtains significantly better test performances on the dataset of interest (described in Section 2) for a majority of CNN variants. However, in real world, choosing a CNN representation based on test performances is not feasible. To address this issue, we propose a metric that can be computed using the training set to predict performance on the test set. We aim for a one shot metric estimation that is robust to the absence of large training sets. We propose a metric whose computation entails projecting the training data-points into a lower dimension, followed by estimation of class confusions in the projected space. Given the various feature representations, the trends predicted by the proposed metric carries a correlation coefficient of 0.87 with the actual test accuracies.
2 Dataset
We use the KVASIR dataset [21] in our experiments. The dataset consists of 8000 images, equally drawn from eight different GI anatomical landmarks: (i) esophagitis, (ii) normal z-line, (iii) ulcerative-colitis, (iv) normal-pylorus, (v) polyps, (vi) dyed-lifted-polyps, (vii) dyed-resection-margins and, (viii) normal-cesum. The size of these images ranges between 720x576 to 1920x1072, each annotated by a professional endoscopist. In order to perform experiments, we use a training and testing set partition suggested in [18], with 4000 instances in each partition. The objective behind this dataset collection is to aid early discovery of lesions, that can prevent cancer progression. More information regarding the dataset can be obtained from [21, 18].
3 Classification Methodology
We obtain a representation for each GI image in the KVASIR dataset using two strategies: (i) a baseline kitchen sink feature extraction strategy and, (ii) feature representations obtained using CNNs trained on external corpora. These representations are then used to train a classifier on the available training data. We describe the feature extraction below, followed by the classification setup.
3.1 Baseline: kitchen sink feature extraction strategy
In this strategy, we use an assembly of knowledge driven features (as opposed to the data driven feature representations extracted in CNNs). We use a set of baseline features, as shown in Table 1. These features were motivated by Pogorelov et al. [21, 18] for application to the KVASIR dataset. These features are global descriptors of the images and are designed in a knowledge driven manner to capture a specific property of the images. The dimensionality of baseline feature representation is 1179.
3.2 CNN based feature extraction
In this strategy, we initially train CNN models on an external unrelated dataset, the ImageNet dataset [1]. We then obtain image representations yielded by these networks in the penultimate layer (layer right before the output layer) for the KVASIR dataset. We scale each image in the KVASIR dataset to a size of 224 224, equal to the size of images in the ImageNet dataset. These scaled images are then fed to the CNNs and we apply global average pooling to the outputs of last convolutional layer in each of the CNNs. We test five CNN architectures in our experiments, as described in Table 2.
3.3 Classification setup
After obtaining feature representations for an image, we train a multi-class Support Vector Machine (SVM) classifier for classifying image to one of the eight GI landmark labels. In case of feature representations obtained from CNNs, this training can also be seen as pre-training the CNNs on large datasets and fine tuning the final classification layer using a hinge loss on the KVASIR dataset. The hyper-parameters for the SVM classifier (kernel and box-constraint) are tuned using a five fold inner cross validation on the training set. We present the classification results in the next section.
3.4 Classification Results
Given that the classes are balanced in the training and testing partitions, we use accuracy as our evaluation metric. Table 2 presents the results for each image representation. We also present results for a case where we concatenate features representations from all the sources. In almost all the cases, representations yielded by CNN outperform the baseline features (except ResNet). This indicates that data driven representations obtained on external corpora can outperform knowledge based features. Research has shown that CNN tends to learn filters sensitive to geometrical patterns observed in the training data [25]. Since the CNNs are initially trained on a large set of images, our results suggest that they learn to encode geometrical patterns, which yield better classification results over knowledge based features. We also observe that the combined model performs the best, indicating that the features from various sources are complementary. We also plot the confusion matrix for the system using combination of all features in Figure 1, as obtained on the testing partition. The confusion matrix is indicative of the classes that the classifier tends to confuse (e.g. we observe a confusion between the dyed-lifted-polyps and dyed-resection-margins class). We refer back to the confusion matrix for further analysis in Section 4.2.
Although a majority of CNN representations yield better results than the baseline features, the choice amongst the CNN representations is not obvious during system design and training. Therefore, we need a mechanism to assess the discriminative capability of each representation during training. We address this by proposing a metric to estimate the accuracy yielded by a given feature representation in the next section.
4 Estimating accuracy yielded by feature representations
Given a feature representation (baseline or extracted from a CNN), we propose a metric to estimate the accuracy yielded by a classifier trained on those features. We design the metric such that it could be computed based on the training set. Furthermore, we should be able to obtain it using a one shot computation as opposed to estimation methods such as inner cross-validation on the training set. Such a method requires pre-selection of a classifier, hyper-parameter tuning and is computationally expensive. In particularly, on a small dataset as ours, results could vary from one cross-validation split to the other, leading to a noisy estimate. We outline the computation for the proposed metric in Algorithm 1.
Our proposed algorithm first projects the feature representations from a high dimensional space into a lower dimension space using the projection function . This is followed by obtaining a Probability Distribution Function (PDF) of the projected data-points () based on the class of their membership. Projecting the data-points on to the lower dimensional space is desirable, as with limited data, the parameters estimation for class specific PDF, , is more robust. We chose to be a Gaussian distribution. In step 3, based on the estimated class distributions , we compute the probability that a point sampled from will yield highest PDF value from the same PDF. We term this estimate as and it is integral of in the space spanned by where . We average the from each class to obtain the final estimate (we chose averaging since the class distribution is uniform in the training set). We expect the metric to be indicative of the accuracy obtained when using the feature representation .
We considered multiple lower dimension projection techniques such as Principal Component Analysis, auto-encoders and t-SNE. Empirically, we observed that the t-SNE projections (in a 2-D space) yield good estimates for with different values for each class . estimates using other methods tend to be close, implying a high degree of overlap between class specific distributions in the projected space. Next, we present our findings on the success of the proposed metric in predicting the test accuracy.
4.1 Results
Figure 2 plots the accuracies obtained on the test set (as also presented in Table 2) against the estimate for each feature representation. We note that although that the estimate is off by certain points, the metric captures the accuracy trend on the testing set. We obtain a correlation of 87% between and accuracies on the test set. We argue that despite an error in prediction, high correlation with test accuracy is useful as it can inform what feature representation is likely to yield the highest accuracy. We acknowledge that the absolute value of itself may be off the actual accuracy estimate. Another point to note is that the algorithm to compute the metric was not informed of the type of classifier (SVM) used in our experiments. Therefore the estimation is performed independent of the final classifier and the associated hyper-parameters.
4.2 Analysis on t-SNE projections
To further analyze the high correlation between the metric and test performance, Figure 3 presents the t-SNE projections for each feature representation on the training set. The class-wise distribution trends in Figure 3 closely associate with the classification performances on the testing set. We observe that in the case of baseline feature representations, different classes gets clustered together in the t-SNE projection plot. The plot suggests that the t-SNE method deems images from different classes to be similar to each other, based on the baseline features. This is coherent with the poor performance observed using the baseline features. On the other hand, class separation is evident in the case of Inception-V3, VGG-16, MobileNet and XceptionNet CNN architectures. The t-SNE representations using ResNet do not cluster as per the eight GI landmark classes, which is in line with the low performance observed using these representations. Overall, the visual trends observed in Figure 3 correspond to the actual test performances, explaining the success of metric in predicting test accuracies.
Another question we aim to answer is if we can predict the class confusion amongst the eight classes using the t-SNE analysis. t-SNE plots in Figure 3 present promising trends with this regards as well. For instance in the confusion matrix (Figure 1), we observe that the class normal-pylorus has the least confusion with other classes. In the t-SNE plot in Figure 3(g), we observe that this class occurs as a separate cluster by itself. The clusters for three classes: ulcerative-colitis, normal-cecum and polyps, are close to each other, which does reflect as small amount of confusion amongst these three classes. A large confusion is observed between dyed-lifted-polyps and dyed-resection-margins and, esophagitis and normal-z-line classes. The clusters corresponding to these classes have fair amount of overlap in the t-SNE plots. We note that one could obtain a pairwise class confusion metric between two classes and as (we integrate over the region where dominates). We observed that this metric obtains mediocre performances in predicting class confusions (a correlation between 20% - 50%, depending upon the feature representation). Since the development of this particular metric needs further research, we do not present the detailed results in this paper and consider this as an avenue for future research.
5 Conclusion
Several variants of CNNs have been proposed in the past to address problems related to computer vision, speech recognition and natural language understanding. We test their application on a medical imaging problem involving identification of GI landmarks given an image. We use a set of baseline feature representations crafted to capture specific aspects of images as well as feature representations yielded by a set of five different CNN architectures. Classifier trained on four out of five CNN representations outperform the baseline features. Furthermore, we develop a novel metric to inform the choice of CNN architecture for obtaining these representations. We observe that we can foretell the relative performance on the test set by using the proposed metric obtained on the training set. We analyze that the success of the proposed metric stems from a robust lower dimension projection yielded by the t-SNE projections.
In the future, we aim to perform further investigations on the transfer learning approach with CNNs. As of now, we use representations as obtained from the penultimate layer. However, intermediate representations may contain further complementary information. One may also investigate additional low dimensional projection techniques to estimate performance on the testing set. Future work may include decision on classifier design itself based on the t-SNE plots. For instance, a mixture of experts [26] model can be used to distinguish classes using a specific set of features, which otherwise carry a significant overlap in other sets of feature representations.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” in Advances in neural information processing systems , 2012, pp. 1097–1105.
- 2[2] S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN: Towards real-time object detection with region proposal networks,” in Advances in neural information processing systems , 2015, pp. 91–99.
- 3[3] M. Kristan, J. Matas, A. Leonardis, M. Felsberg, L. Cehovin, G. Fernández, T. Vojir, G. Hager, G. Nebehay, and R. Pflugfelder, “The visual object tracking vot 2015 challenge results,” in Proceedings of the IEEE international conference on computer vision workshops , 2015, pp. 1–23.
- 4[4] O. Abdel-Hamid, L. Deng, and D. Yu, “Exploring convolutional neural network structures and optimization techniques for speech recognition.” in Interspeech , 2013, pp. 3366–3370.
- 5[5] Y. Kim, “Convolutional neural networks for sentence classification,” ar Xiv preprint ar Xiv:1408.5882 , 2014.
- 6[6] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “Mobilenets: Efficient convolutional neural networks for mobile vision applications,” ar Xiv preprint ar Xiv:1704.04861 , 2017.
- 7[7] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition , 2016, pp. 770–778.
- 8[8] T. Alumäe, S. Tsakalidis, and R. M. Schwartz, “Improved Multilingual Training of Stacked Neural Network Acoustic Models for Low Resource Languages.” in Interspeech , 2016, pp. 3883–3887.