DPTC -- an FPGA-based trace compression
G. Bruni, H. T. Johansson

TL;DR
This paper introduces DPTC, a lossless, FPGA-based trace compression algorithm that efficiently reduces storage and bandwidth needs for ADC trace data, suitable for real-time front-end electronics.
Contribution
The paper presents a novel, configuration-free lossless compression method for ADC traces, optimized for FPGA implementation and demonstrated on real detector data.
Findings
Achieves around 4-5 bits per sample compression
Comparable efficiency to popular general-purpose methods
Operates at multi-100 Msamples/s speeds
Abstract
Recording of flash-ADC traces is challenging from both the transmission bandwidth and storage cost perspectives. This paper presents a configuration-free lossless compression algorithm which addresses both limitations, by compressing the data on-the-fly in the controlling field-programmable gate array (FPGA). Thus the difference predicted trace compression (DPTC) can easily be used directly in front-end electronics. The method first computes the differences between consecutive samples in the traces, thereby concentrating the most probable values around zero. The values are then stored as groups of four, with only the necessary least-significant bits in a variable-length code, packed in a stream of 32-bit words. To evaluate the efficiency, the storage cost of compressed traces is modeled as a baseline cost including the ADC noise, and a cost for pulses that depends on their amplitude and…
Click any figure to enlarge with its caption.
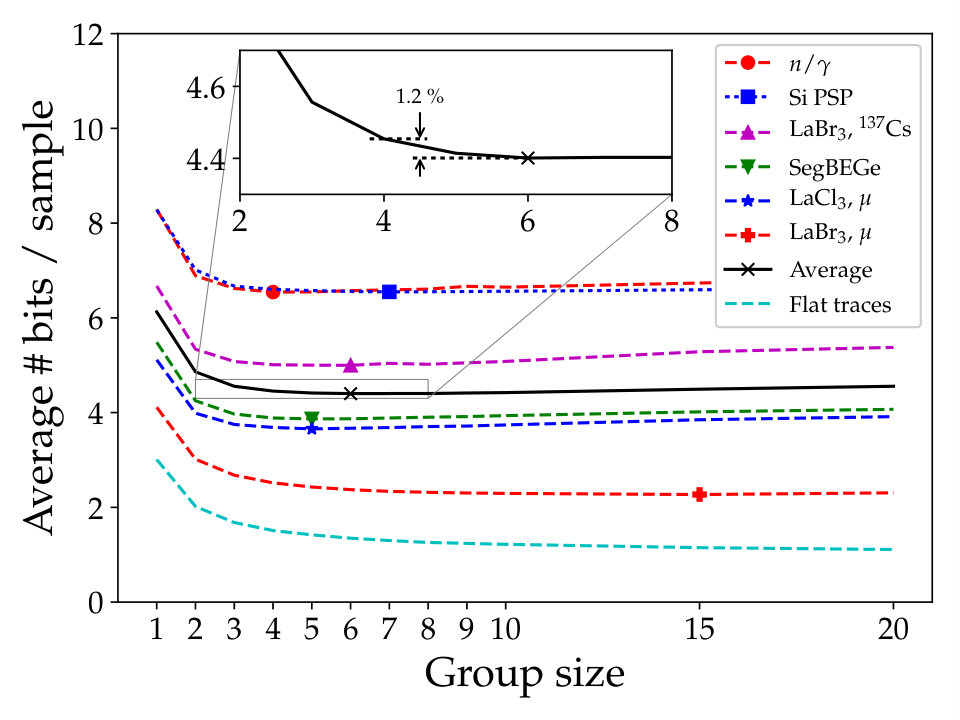 Figure 1
Figure 1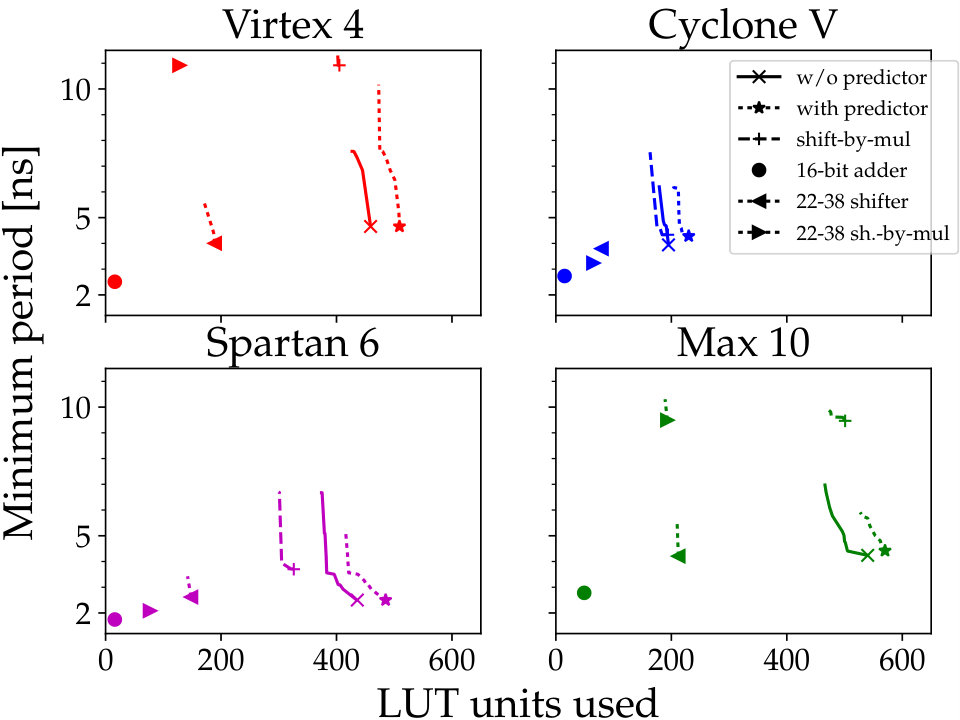 Figure 2
Figure 2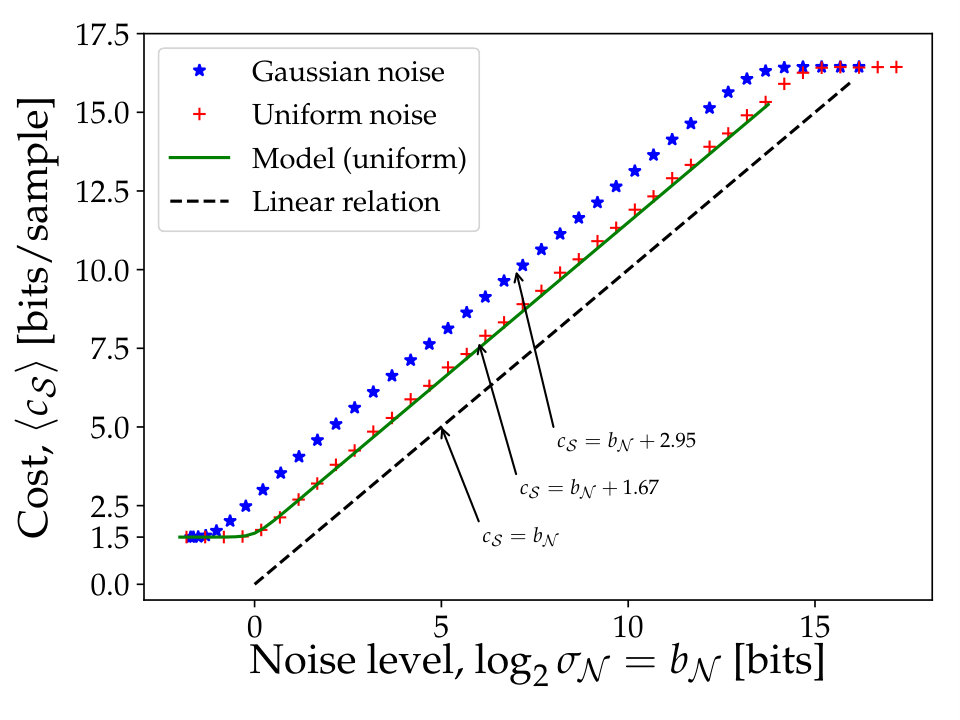 Figure 3
Figure 3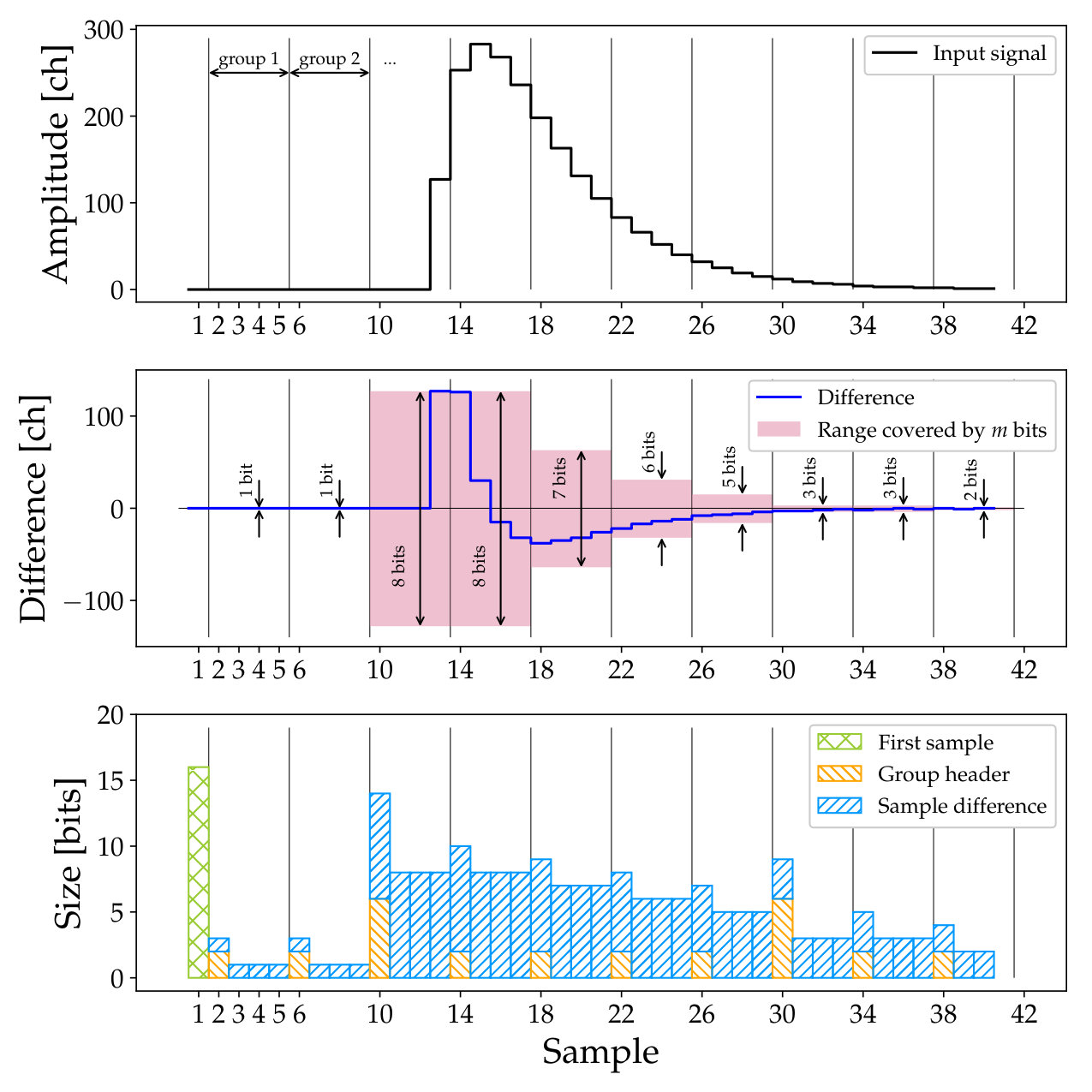 Figure 4
Figure 4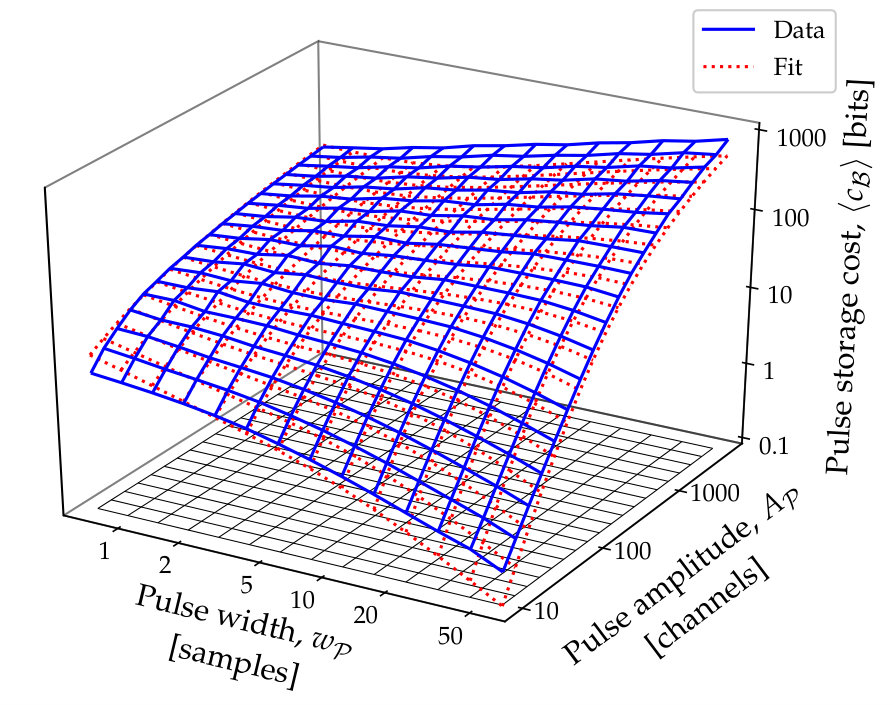 Figure 5
Figure 5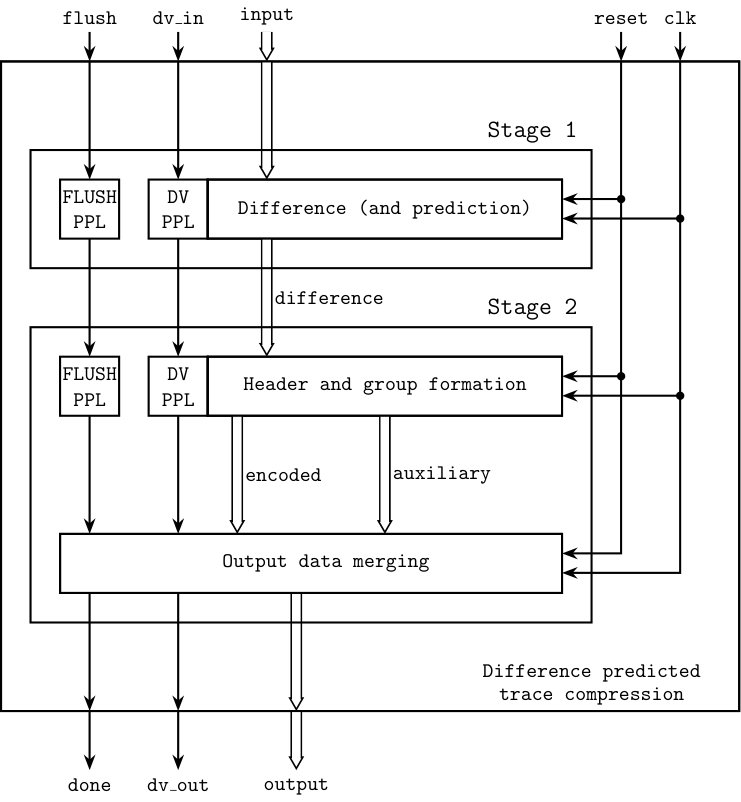 Figure 6
Figure 6| FPGA model | LUT | FF | Max clock frequency |
|---|---|---|---|
| occupation | occupation | ||
| Xilinx Virtex 4 | 427–459 | 265–301 | 210 |
| Xilinx Spartan 6 | 374–436 | 234–300 | 400 |
| Altera Cyclone V | 179–195 | 262–324 | 250 |
| Altera Max 10 | 466–540 | 220–308 | 230 |
| CPU Model | Speed | Released | Time/sample | ||
|---|---|---|---|---|---|
| () | () | ||||
| Xeon E3-1285v6 | 2017 | – | |||
| Xeon E3-1276v3 | 2014 | – | |||
| Xeon X5450 | 2007 | – | |||
| PPC 7455 | 2002 | – | |||
| Label | Category | Details | Traces | Samples | DPTC | gzip | xz(LZMA) | Huff. | |||
| # | # | — — — — Bits/sample — — — — | |||||||||
| a | core signal | 40 | 5000 | 78.3 | 2.16 | 4.06 | 3.89 | 5.54 | 4.04 | 3.58 | |
| b | in segmented BEGe | segment 1 | 40 | 5000 | 27.3 | 2.16 | 4.06 | 3.86 | 4.87 | 3.89 | 3.55 |
| c | segment 5 | 40 | 5000 | 53.2 | 2.21 | 4.09 | 3.91 | 5.54 | 4.13 | 3.59 | |
| d | n/ discrimination | Ionisation chamber | 200 | 200 | 907 | 71.2 | 9.10 | 9.16 | 11.37 | 9.78 | 8.75 |
| e | -det. anode | 200 | 200 | 226 | 4.88 | 5.24 | 5.36 | 6.63 | 5.32 | 5.12 | |
| f | -det. cathode | 200 | 200 | 220 | 6.20 | 5.58 | 5.71 | 7.00 | 5.62 | 5.46 | |
| g | position-sensitive | -particles | 50 | 1000 | 852 | 29.7 | 7.84 | 7.81 | 11.07 | 8.10 | 7.38 |
| h | Si pin-diode | 40Ar | 50 | 1000 | 638 | 6.36 | 5.62 | 5.58 | 9.37 | 6.23 | 5.24 |
| i | no signal split | 100 | 200 | 534 | 5.30 | 5.36 | 5.55 | 7.91 | 6.33 | 5.47 | |
| j | from 137Cs | signal split 1:2 | 100 | 200 | 292 | 3.90 | 4.91 | 5.08 | 7.18 | 5.67 | 4.98 |
| k | in LaBr3 | signal split 1:4 | 100 | 200 | 194 | 3.23 | 4.64 | 4.81 | 6.69 | 5.24 | 4.68 |
| l | signal split 1:8 | 100 | 200 | 122 | 3.05 | 4.56 | 4.65 | 6.37 | 5.06 | 4.43 | |
| m | cosmic in LaBr3, varying HV of PMT | 350V a | 100 | 600 | 9.2 | 0.25 | 0.94 | 1.67 | 0.65 | 0.49 | 0.65 |
| n | 400V a | 100 | 600 | 19.4 | 0.25 | 0.94 | 1.67 | 0.84 | 0.63 | 0.78 | |
| o | 450V | 100 | 200 | 921 | 4.28 | 5.05 | 5.55 | 8.36 | 6.42 | 5.76 | |
| p | cosmic in LaCl3, different digitizers | CAEN DT5730 | 100 | 400 | 301 | 3.88 | 4.90 | 5.00 | 7.23 | 5.47 | 4.89 |
| q | CAEN DT5751 | 100 | 400 | 40.6 | 0.86 | 2.73 | 2.72 | 3.94 | 2.82 | 2.64 | |
| r | all values 0 | 1 | 1000 | 0 | 0 | - | 1.51 | 0.28 | 0.67 | 0.26 | |
| s | Flat traces b | all values 10 | 1 | 1000 | 0 | 0 | - | 1.51 | 0.28 | 0.67 | 0.26 |
| t | all values 100 | 1 | 1000 | 0 | 0 | - | 1.51 | 0.28 | 0.67 | 0.26 | |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
DPTC—an FPGA-based Trace Compression
G. Bruni and H. T. Johansson G. Bruni and H. T. Johansson are with the Department of Physics, Chalmers University of Technology, SE-412 96 Göteborg, Sweden.This work was supported by the Swedish Research Council, the Scientific Council for Natural and Engineering Sciences under grant 2017-03839 and the Council for Research infrastructure under grant 822-2014-6644.
Abstract
Recording of flash-ADC traces is challenging from both the transmission bandwidth and storage cost perspectives. This work presents a configuration-free lossless compression algorithm, which addresses both limitations, by compressing the data on-the-fly in the controlling FPGA. Thus it can easily be used directly in front-end electronics. The method first computes the differences between consecutive samples in the traces, thereby concentrating the most probable values around zero. The values are then stored as groups of four, with only the necessary least-significant bits in a variable-length code, packed in a stream of 32-bit words. To evaluate the efficiency, the storage cost of compressed traces is modeled as a baseline cost including ADC noise, and a cost for pulses that depends on amplitude and width. The free parameters and the validity of the model are determined by compressing artificial traces with varying characteristics. The compression method was also applied to actual data from different types of detectors. A typical storage cost is around 4 to 5 bits per sample. Code for the FPGA implementation in VHDL and for the CPU decompression routine in C are available as open source software, both able to operate at speeds of 400 Msamples/s.
Index Terms:
Analog-to-digital conversion (ADC), data acquisition, data compression, field programmable gate array (FPGA), front-end electronics, lossless compression, real-time data acquisition, open source, variable-length code, VHDL.
††publicationid: pubid: 0000–0000/00$00.00
I Introduction
This work is motivated by developments in data handling in nuclear and particle physics. However, its applicability is not limited to those fields. Experiments in nuclear and particle physics are growing, which implies an increasing amount of data that needs to be handled. This is caused by an increase in the number of detectors employed, finer segmentation and higher event rates. Of particular interest for this work is the recording of signal traces, because this is associated with a dramatic increase of data that need to be transferred, compared with a simple digitization of pulse amplitudes.
To illustrate the development of experimental setups, we consider two front-line particle physics experiments almost 30 years apart. We compare the ATLAS (A Toroidal LHC ApparatuS) experiment at LHC, CERN, which started data-taking in 2009, with the UA1 (Underground Area 1) experiment at Spp̄S, CERN, which started data-taking in 1981. Concerning data production, UA1 was designed to deliver around , mainly limited by the speed in writing to magnetic tape [1]. The data acquisition of ATLAS on the other hand stores around [2], with much higher internal data rates. The increase of a factor 100 in recorded data rate over a time span of 30 years is compensated by the substantial improvement of commercial development in both communication and storage.
Considering the evolution of Ethernet between 1980 and 2010, we have witnessed an increase of about a factor 20 every 10 years in bandwidth [3, 4], with the major increase in the latter half of the timespan. After 2010 however, a lower rate of growth, a factor 4 every 10 years, starts to appear.
For data storage, between 1980 and 2010, the increase was on average a factor 30 every 10 years, with a peak between 1990 and 2005 where the area density doubled and prices per byte fell by half on a yearly basis [5]. Also this pace has slowed down since around 2010, with instead a factor 4 every 10 years [6, 7].
This slowdown in industry development poses new data acquisition challenges for both transmission speed and storage. A particular case when these are in high demand is when scientists are interested in storing entire traces, i.e. raw data directly from flash-ADCs, for example during testing or debugging of detectors and data processing procedures. In this case, the amount of data is much larger, easily by a factor 20–1000 [8].
One way to cope with these challenges is to increase capital expenditure to buy newer and better performing equipment. However the need to reduce costs leads to a different approach, where we aim to reduce the size of the data to be handled. This can be achieved through data compression.
A typical example of the traces considered is time-series data from flash-ADCs, which usually are slowly varying, with short intervals of larger variations due to pulses. The series data can also be information from adjacent channels, e.g. coupled strips of Si detectors, which can exhibit similar correlation characteristics.
If compression is employed as software running on a PC, only data which has already been sent from the signal acquisition unit can be reduced. This gives no reduction in the transfer rate demands. To address both limitations, an implementation of the compression directly on the FPGA, where the initial signal processing takes place, is needed. This article presents a simple yet effective lossless compression method, that can be applied to sequences of correlated data. The method allows a straightforward and fast implementation in FPGAs as well as CPUs, and is available as open source software.
This paper is structured in the following way: First, already available solutions are reviewed, followed by a description of the present routine. Optimisation possibilities, both regarding compression efficiency and resource utilisation are then discussed. This is followed by descriptions of the interfaces to the FPGA compression module and the CPU decompression code. The storage cost of both noise and pulses are then modeled, and verified using synthetic trace simulations. Finally, the achieved storage cost reduction is benchmarked using traces from actual detectors.
II Overview of available solutions
Ideas for data compression on front-end electronics are not new. Scientists working on large detectors have already faced the problem of how to efficiently compress data, albeit with different boundary conditions than in our case. Both lossy compressions, where a part of the initial information is lost to accomplish a reduction [9, 10]; and lossless compressions, where the initial information can be fully reconstructed, can be achieved following different approaches. One is to discard parts of the signal with no or little information (zero-suppression [11]). Another approach is to use a variable length coding [12], such as Huffman coding [13] as shown in [14] or Golomb-Rice coding, which is used in [15]. The effectiveness of such algorithms is based on the knowledge of the probability distribution of the original data values. Usually this knowledge is gained from inspecting the whole or a representative pool of the data undergoing compression. This requires to store and to analyse a representative sample of the data during setup, in order to tune the compression configuration to the signal and ADC operation parameters. As the signal characteristics have a tendency to change within and between calibration and production data, causing operational inconveniences, such approaches are not suitable for our purpose as a generic configuration-free compression method for traces, as it causes additional work when operating detectors.
In some cases, through a pre-processing of the incoming data, a more advantageous probability distribution can be exploited. A common approach is the calculation of differences between values [16, 17, 18, 19, 20]. These differences may be between sampled data and a model [16] or between sampled data and a reference value (base) [17, 18] or between consecutive samples [16, 18, 19]. When dealing with signal traces, which are sampled at rates high enough that consecutive samples have values close to each other, i.e. are correlated, the latter approach delivers a distribution dominated by small values.
III Operating principle
The difference predicted trace compression (DPTC) presented in this paper is based on preserving only those least significant bits which hold the information necessary to recover each value. Although this does not correspond to a real Huffman coding, the result is to encode the more common smaller values, i.e. closer to zero, with shorter sequences. This approach is quite similar to the one presented in [18], where one sample works as base value and the following three samples undergo the differencing treatment. The base value can be chosen arbitrarily. We use the first value of each trace, with all following samples subject to the difference processing. The resulting differences are organised in groups of four, and all the samples in one group are stored using the same number of bits. A small header containing information about the encoding is placed at the beginning of each group.
Our implementation is organised in two steps, as shown in Fig. 1. First, the procedure calculating the differences is applied to the input data. The original samples consist of a sequence of n-bit data words, where n is given by the bit resolution of the sampling ADC. The current design allows n to have any value in the range 5–16. The second stage is responsible for packing the differences into a stream of 32-bit words.
III-A Differencing procedure
The first stage treats each value according to the following rules:
Calculate the difference to the previous value. 2. 2.
The later storage is due to the binary encoding slightly asymmetric. With a certain number of bits, it can store one more negative value than positive. With e.g. 3 bits, the eight differences can be stored. For flat (noise-like) parts of a trace, any deviation from zero will generally be followed by a difference of the opposite sign. To make negative values more common than positive, a sign-changing scheme is applied: If a stored value is negative, the next non-zero value is stored with inverted sign; while, if positive, the next is stored as is. A value of zero does not change how to store following values.
Note that in all operations, only bits are considered, i.e. the differences are allowed to wrap (arithmetic is modulo-). This does not introduce any ambiguity.
III-B Group creation
The values are stored in groups of four, using the same number of bits, , for each value in a group. This is illustrated in Figs. 2 and 3. Since the stored values are differences, both positive and negative values must be representable (in two’s complement representation). Since each value may require a different number of bits to be represented, the widest representation needed by any value in a group is used. The number of bits used for values in each group is stored in a group header, placed before the actual data. Considering consecutive groups, it is worth noticing that the number of bits needed will often not change much and therefore a short and long encoding of the number of bits is employed, see Fig. 2. The short header consists of two bits: if the encoded value is 1, 2, or 3, the number of bits to use for the group is the same as for the previous group with a change of , [math] or bits, respectively. If the value of the two-bit short header is 0, the encoding is long and contains the full difference of bits stored per value. Since some values are already covered by the short encoding, an offset of 2 is applied to the full difference. This is encoded using bits, which is chosen such that any needed difference, at most , can be stored; , i.e. 1 bit for , 2 bits for , 3 bits for , and 4 bits for .
The number of bits per stored difference is interpreted with a bias of 1, meaning that storing 0 bits per value is not supported. This is a conscious choice: supporting 0-bit values (i.e. minimal encoding of groups with all value differences 0) would make the code for CPU decompression (and compression) more complicated. Since ADCs usually are operated with noise in the least significant bit, it is also expected to have limited practical use.
The data values are then stored with the necessary number of bits for the group. Each data value is stored with a bias relative to the most negative value that can be stored with the given number of bits. This simplifies decoding, as the stored value only has to be unmasked, and the bias subtracted. This avoids a cumbersome sign extension operation by the CPU decoder.
As an exception to the above rules, the first data value is stored alone and fully, using n bits. This avoids storing the entire first group of data with many bits.
III-C Output word formation
The resulting stream of bits is then packed in 32-bit words, being filled from the least significant bits. When a value to store cannot fit, the completed output word is emitted and the remaining bits are stored in the next 32-bit output word.
Information about the number of original data values, number of data words produced by the compression and is needed by the decompression procedure. These values are not recorded by our routine, therefore it is the responsibility of the user to retain this information.
IV Optimisation
The algorithm described in the previous section can be optimised in different ways. However, the improvements obtained by applying additional procedures depend on many aspects, such as noise level, signal shape, and the distribution of signal amplitudes. Note that while improving for some characteristic, an optimisation will undermine other aspects. We present a few ideas together with a short analysis of each one, discussing advantages and disadvantages.
IV-A Compression factor optimisation
IV-A1 Linear predictor
With this additional pre-processing, the linear component of long sloped parts of a trace are removed by a second differencing of the data. This aims at a distribution of values more narrow around zero. However, for flat parts of a trace, which mainly contain noise, such a double difference leads to a wider distribution. Thus, in order to give an overall improvement, this procedure must only be applied for sufficiently long, sloped sequences. This is controlled by a heuristic using the observation that consecutive samples in unfavorable regions change sign often, or have 0 difference, and thus can be detected by a three-most-recent rule. The second differencing is switched off when at least one sign change or a zero has occurred for the previous three values.
While at first appearing to be promising for synthetic traces, from tests on actual traces, this optimisation does however not bring any improvement. This is connected to the fact that usually most of the pulses in the digitised traces only have small amplitudes, therefore the few improvements by this predictor are neutralised due to it activating spuriously in flat parts. The optimisation is implemented in the code, but deactivated by default.
IV-A2 Number of values in a group
The group size can also be varied to optimise the compression efficiency, see Fig. 4. Using smaller groups require more storage space due to the more frequent headers, while larger groups will encode unnecessary bits for more samples. The figure shows an optimum around six samples per group, with gradual losses at larger values, or steeply below three.
We have chosen to code four values in each group. The loss is about compared to groups of six values. Fixing the number as a power of two might be useful for a future parallelized unpack code. We choose four rather than eight as this leads to shorter pipelining in the group formation part of the circuit.
IV-B Circuit optimisation
IV-B1 Additional pipeline stages
The achievable minimum clock cycle period in a digital circuit depends on the propagation delay of the longest combinational logic chain between register latches.
In our case the circuit is described in VHDL, where the model and grade of the FPGA that is targeted will affect which logic expression becomes the longest. Adding pipeline stages to split the longest paths helps to lower the minimum clock cycle. At the same time however, introducing a pipeline stage causes more LUTs111Look-up table, a basic FPGA building block. The other basic unit is signal registers, i.e. flip-flops (FF). to be used, as well as flip-flops; leading to a trade-off between resource-usage and speed. In order to allow flexibility when using the code, a few generic parameters control a number of optional pipeline stages.
Since the synthesized code uses more LUTs than flip-flops, compared to the usually available ratio on FPGAs, we concentrate on the LUT usage for the circuit optimization comparisons.
By performing VHDL synthesis for all combinations of the optional pipeline stages, and directing the respective FPGA development toolchain to optimise for speed, the achievable performance as function of resource usage can be determined. The results are shown in Fig. 5 and summarized in Table I. Locations further down in the figure indicate that shorter clock periods can be used, and further to the left mean less resource consumption. For each circuit, only the results which improve the achievable clock frequency for a certain resource usage is kept, thus the short curves mainly show the improvements possible as more pipeline stages are enabled. To a smaller degree they also come from the ability of the toolchains to trade resource usage for speed. To compare with the most used constructions (adders, subtractors, comparators), 16-bit adders are also shown in the figure. The VHDL code allows the minimum period of the clock to be below (i.e. ) even on 10-year old FPGAs, and it can easily be configured to reach below with additional pipeline stages. On more modern FPGAs, going below seems rather easy.
If the compression circuit is operated continuously, directly fed by the data generator (e.g. flash-ADC), the speed needs to match the sampling period, since the circuit can process one sample per clock cycle. When compressing only selected traces which first have been recorded into temporary memory buffers, a slower clock can be used for the compression circuit.
The single most expensive component of the circuit is the barrel shifter, which aligns the encoded data at the next position in the output word. For , the shifter input is 22 bits wide, with the additional 6 bits coming from the potentially long encoded header. The shift amount is in the range 0 to 37, inclusive. 0 to 31 depends on how many bits already are used in the output word. The additional 0, 4, or 6 positions depend on the header (long, short, or none). This gives a 60 bit output. The cost and performance of the shifter units are also shown in Fig. 5.
IV-B2 Barrel shifter vs. multiplier units
A barrel shifter on FPGAs is normally realised as one multiplexer for each output bit (sharing some parts of the first stage selectors of each multiplexer). Since it also can be expressed as a multiplication of the input value with , where is the shift value, it can also be implemented using multiplier units in FPGAs. For the second factor, the input value is generated as , i.e. a one-hot encoding of the shift amount.
One could imagine this to be beneficial when generic LUT resources are scarce, however for the cases tested, it is not. The generation of the input value is rather expensive, as it requires individual selectors. Also the combination of the output values from the several multiplier units, often or wide, are rather expensive.
The resource usage for 22-bit, 38-position left-shifters implemented in the two ways are also compared in Fig. 5.
The results in Fig. 5 and Table I are for . Similar tests for give that for each bit removed, the needed number of LUTs shrinks on average by , and the attainable minimum period required decreases by , depending on FPGA model.
V VHDL module interface
The interface to the VHDL compression module is a single entity, with input and output signals as seen at the top and bottom of Fig. 1. Optional pipeline stages are configured using a generic map.
The circuit inputs are:
- •
clk: clock signal;
- •
reset: reset signal, given for at least as many cycles as the pipeline has stages;
- •
input: -bit data value to compress;
- •
dv_in: data valid signal: set to ’1’ every clock cycle an input value is provided;
- •
flush: flush signal: set to ’1’, after the last input value has been given. Held until done reported back. This forces the last output word to be emitted, especially when it is not fully occupied.
The output signals are:
- •
output: 32-bit output data word;
- •
dv_out: data valid signal: ’1’ every time the output word is filled, signaling the presence of a completed data word to be stored;
- •
done: informs that the last input value has been processed and the final output word was produced (possibly in the current cycle).
VI Decompression
The decompression is performed by one C function with the following parameters:
- •
compr: pointer to the 32-bit words of the compressed input buffer;
- •
ncompr: number of elements in the input buffer;
- •
output: pointer to a buffer of 16-bit items for the decompressed values;
- •
ndata: number of original/decompressed values;
- •
bits: number of bits of each value that was stored (). This must be the same as the number configured during compression.
On success, 0 is returned, otherwise a non-zero value.
The routine will report decompression failure on malformed compressed data, e.g. if there are non-zero bits left in the input buffer, or when entire words have not been used. The decompression routine will not read items beyond the end of the source buffer even if it runs out of data, e.g. due to a corrupted data stream. Table II shows the typical performance, which only has a small dependence on the actual data values.
VII Compression efficiency—Storage cost
The contributions to the compressed data size can be divided in two parts:
The cost of storing traces with no pulses, i.e. only containing the digitization noise. This is described as a cost per sample. 2. 2.
The cost of storing a pulse, described as an additional cost for the entire pulse.
There is a natural interplay between the two, as the noise affects the additional cost to store a pulse. This effect is also addressed below.
In the following, we use the variables for cost and for bits. To specify these, subscripts are used: for noise, for trace, for sample, for pulse, and for a small pulse (bump). Gaussian noise is described by its amplitude . The amplitude and width (std. dev.) of Gaussian-shaped pulses are given by and .
VII-A Bare trace cost
The cost of storing a trace without pulses has two parts: the size of the headers and the size of the encoded values, i.e. the differences.
The cost of storing the differences depends on the noise content, most easily expressed as the number of bits of noise .
Ignoring the pecularities of the first group, which may require a long header encoding, the estimated cost for a trace will be proportional to its length :
[TABLE]
The first sample has a fixed cost . The constant 15.5 accounts for the average number of unused bits in the last output word at the end of a trace. A first approximation, denoted by the tilde, for the average cost per noise sample is
[TABLE]
The first half bit comes from the short group header, using two bits every four samples. The additional one comes from differences encoding both positive and negative entries, i.e. effectively a sign bit. The term is an overhead, since the grouping of values causes some more bits than necessary to be used. To model the transition from very small noise levels, where the total cost is , to the proportional regime, a smooth transition function is used for , with . As wanted, as and for , while the parameter controls the smoothing. This yields:
[TABLE]
This is illustrated for Gaussian and uniform noise in Fig. 6, where good fits are achieved with .
For uniform noise, the range of differences is twice as large as the value distribution (due to also encoding negative entries), explaining the use of, on average, one more bit per sample in addition to the short header and . This is modeled by (3) shown as a solid line. For Gaussian noise, the distribution of differences between consecutive samples is wider by a factor than the original distribition, and any large value in a group of four leads to longer encodings. The further small fractional costs per sample are in both cases likely given by the occasional use of long group headers.
VII-B Pulse cost
The cost of a pulse is best described as the total cost of the pulse, and not a cost in bits per sample. For the following discussion, pulses are assumed to have a Gaussian shape, as opposed to the double exponential function considered in Fig. 3. Detector pulses can be considered as composed of two parts with different time constants (i.e. widths) for the rising and falling parts. Even if this may be a rather rough approximation of real pulses, especially for the trailing part, it is practical, since Gaussian functions are efficiently and familiarly described using their widths and amplitudes.
Since it is differences that are stored, the important parameter is not the amplitude of a pulse, but its steepest slope, which scales as . As a first approximation, denoted by the tilde, the cost is proportional to the number of bits needed to store these differences, as well as the width of the pulse,
[TABLE]
The scale is given by the proportionality constant . It turns out that this formula works rather well, if modified to account for the facts that even for small pulses, costs are not negative (by adding 1 inside the logarithm and control parameter ), and that very narrow pulses still will affect the storage size of at least one entire group ( within the square root):
[TABLE]
The modification is thus adjusted by the control parameters and .
VII-C Pulse-noise interaction
The above description 5 works in the limit where the pulse is large compared to the background noise. When this is not the case, the additional cost of storing the pulse will be smaller, since the pulse-associated part of the differences to some extent will be covered by the noise storage cost. This can be modeled by
[TABLE]
The correction is the cost of storing the noise for a stretch of samples proportional to the pulse width:
[TABLE]
is a proportionality constant.
VII-D Storage cost verification—synthetic traces
The storage cost described above and culminating in 6 has been verified by simulating a large number of traces with Gaussian pulses, where the parameters , , and were varied. A global fit suggests the following values for the control parameters: 5.6, $b=$1.3, 33, $d=$2.6 and 7.7$$, with a parameter uncertainty of up to . Fig. 7 shows the case.
Simulations were performed by building, for each set of parameters, a set of traces, each made of 500 samples, with Gaussian noise . In each, a Gaussian pulse (, ) was added to the trace. To average over discretisation effects, both the (noise) baseline and the center of the pulse were randomised, trace by trace, with fractional offsets.
Although Fig. 7 shows a good agreement between Equation 6 and the data, larger differences emerge for small values of and . These correspond to the limits handled by the modifications between 4 and 5, which are thus seen to only partly address these edge effects.
VII-E Storage cost verification—actual traces
Table III shows the compression efficiencies for some different collections of actual data. They are compared to the common gzip [22] and xz [23] generic compression routines (at their normal setting). For the generic routines, all data of each file was stored in a binary file with 16-bit values. For a fair comparison, the overhead size of storing an empty compressed file was subtracted. In general, the DPTC results are quite similar to the LZMA results, and well below the gzip results. The main exception are the LaBr3 collections marked a, where the data is very flat (virtually no noise) except for the pulses. Here the DPTC routine still uses its minimum of at least 1.5 bits/sample. This effect is also seen for the three synthetic traces marked b, which have constant values.
Since Huffman encoding [13] is a common approach for compression where the typical distribution of values is known, the actual traces have for comparison purposes also been compressed using this approach. It is applied after a difference stage, with the Huffman encodings individually optimised for each data set. To allow average costs below one bit per sample for very flat traces, encodings of up to four consecutive values using one symbol were also allowed, when such stretches of values would account for more than of the symbols. In these tests, the threshold was only passed for the cases marked a and b. Overall, the Huffman compression scheme delivers results slightly better than both the DPTC routine and the generic compression routines, but needs to be optimised to the characteristics of the signals.
Finally, note how close the costs per sample are to the expectations for only storing the respective noise content, showing that the storage cost contributions from pulses are negligible.
VII-F Caveat emptor—how to ignore ADC noise
In case the original data contains an excessive number of least-significant bits with noise that shall not be stored, they must be shifted out of the original data before the values are given to the DPTC compression routine. Just masking them out will not improve the compression efficiency, as the routine is looking for the most significant bit of the differences that need to be stored. On the other hand, using a compressor with larger than necessary causes little extra cost. Few, if any, extra bits will be used; since mainly will potentially be affected, see Fig. 2.
Note that the choice of omitting least-significant bits is delicate decision. The finally achievable resolution of a measurement may be improved by retaining some additional least-significant bits, since it may allow analysis of the later de-compressed traces to partially recover the effects of quantization error and differential non-linearity in the ADC, by averaging or fitting.
When applicable, in oversampled parts of a trace, much larger savings than obtained through omitting some least-significant bit may be obtained through downsampling the information by summing adjacent samples before compression, thus storing fewer samples, but with better resolution.
VIII Conclusion
A lossless compression routine which addresses both the transmission bandwidth and storage cost challenges associated with recording flash-ADC traces has been presented. The routine can be directly integrated in front-end electronics and can handle data streams on-the-fly at rates of in the controlling FPGA. Calculation of the differences between consecutive trace samples concentrated the most frequently occuring values around zero. The compression was concluded by storing the values in groups of four, yielding a simple yet effective variable-length code, by only storing the necessary least-significant bits, in a stream of 32-bit words.
A model for the storage cost was developed, by first considering the influence of the group headers as well as the retained ADC noise. The additional cost of storing a pulse was expressed in terms of its amplitude and width. By compressing a large set of artificial traces with varying characteristics, both the free parameters and the validity of the model were determined.
The method was then applied to actual data from different kinds of detectors. The compression efficiency was found to be comparable to popular general-purpose compression methods (gzip and xz). It was shown that the dominating cost of storing actual traces is generally given by the retained ADC noise, and not the pulses. It is therefore important for users to carefully assess how many least-significant bits shall be kept, in case they are noisy. Except for that, there are no parameters that need to be adapted, which is of particular interest for experiments employing hundreds or thousands of detector channels.
Computer code for the FPGA implementation in VHDL and for the CPU decompression routine in C are available for download [24] as open source software.
Acknowledgments
The authors would like to extend their thanks to O. Schulz, B. Löher, S. Storck, and P. Díaz Fernández for providing test data, and to A. Heinz and D. Radford for valuable discussions.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] A. Astbury et al. , “The UA 1 calorimeter trigger,” Nucl. Instrum and Methods in Phys. Res., Sect. A , vol. 238, no. 2, pp. 288–306, 1985.
- 2[2] ATLAS Collaboration. (2012, Jun.) ATLAS fact sheet. Accessed: 2018-12-05. [Online]. Available: http://cds.cern.ch/record/1457044/files/ATLAS fact sheet.pdf
- 3[3] V. S. Latha and D. S. B. Rao, “The evolution of the ethernet: Various fields of applications,” in 2015 Online Int. Conf. on Green Eng. and Technol. (IC-GET) , Nov. 2015.
- 4[4] Ethernet Alliance. (2018, Feb.) 2018 roadmap graphics. Accessed: 2018-12-06. [Online]. Available: https://ethernetalliance.org/the-2018-ethernet-roadmap/
- 5[5] R. J. T. Morris and B. J. Truskowski, “The evolution of storage systems,” IBM Syst. J. , vol. 42, no. 2, pp. 205–217, 2003.
- 6[6] R. Wood, “Future hard disk drive systems,” J. of Magnetism and Magnetic Materials , vol. 321, no. 6, pp. 555–561, 2009.
- 7[7] A. Nordrum, “The fight for the future of the disk drive,” IEEE Spectrum , vol. 56, no. 01, pp. 44–47, Jan. 2019.
- 8[8] S. Paschalis et al. , “The performance of the gamma-ray energy tracking in-beam nuclear array GRETINA,” Nucl. Instrum and Methods in Phys. Res., Sect. A , vol. 709, pp. 44–55, 2013.