SAC-Net: Spatial Attenuation Context for Salient Object Detection
Xiaowei Hu, Chi-Wing Fu, Lei Zhu, Tianyu Wang, Pheng-Ann Heng

TL;DR
SAC-Net introduces a novel deep neural network that adaptively propagates and aggregates local and global image context features with variable attenuation, significantly improving salient object detection performance.
Contribution
The paper proposes the spatial attenuation context (SAC) module for adaptive context feature integration, enhancing salient object detection within a deep end-to-end network.
Findings
Outperforms 29 state-of-the-art methods on six benchmarks.
Achieves superior quantitative and visual detection results.
Effectively integrates local and global context features.
Abstract
This paper presents a new deep neural network design for salient object detection by maximizing the integration of local and global image context within, around, and beyond the salient objects. Our key idea is to adaptively propagate and aggregate the image context features with variable attenuation over the entire feature maps. To achieve this, we design the spatial attenuation context (SAC) module to recurrently translate and aggregate the context features independently with different attenuation factors and then to attentively learn the weights to adaptively integrate the aggregated context features. By further embedding the module to process individual layers in a deep network, namely SAC-Net, we can train the network end-to-end and optimize the context features for detecting salient objects. Compared with 29 state-of-the-art methods, experimental results show that our method…
Click any figure to enlarge with its caption.
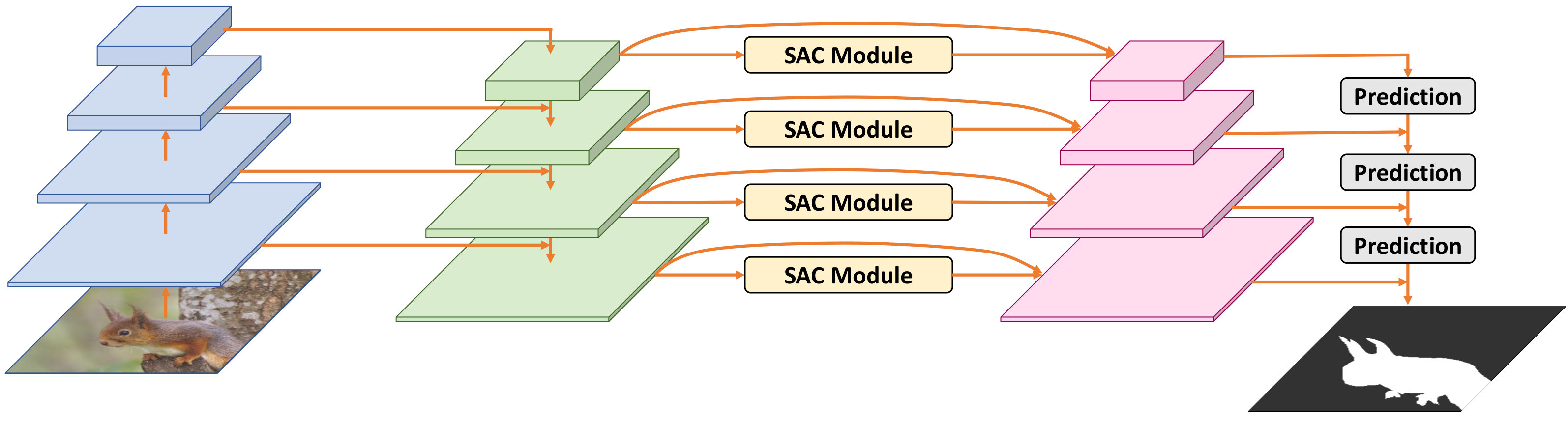 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32 Figure 33
Figure 33 Figure 34
Figure 34 Figure 35
Figure 35 Figure 36
Figure 36 Figure 37
Figure 37 Figure 38
Figure 38 Figure 39
Figure 39 Figure 40
Figure 40| Dataset | - | ECSSD [39] | PASCAL-S [53] | SOD [61] | HKU-IS [52] | DUT-OMRON [40] | DUTS-test [55] | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metric | Year | MAE | MAE | MAE | MAE | MAE | MAE | ||||||||||||
| SAC-Net* (ours) | - | 0.954 | 0.930 | 0.028 | 0.876 | 0.801 | 0.070 | 0.884 | 0.801 | 0.092 | 0.945 | 0.925 | 0.023 | 0.832 | 0.846 | 0.050 | 0.898 | 0.878 | 0.032 |
| PiCA-RC* [45] | 2018 | 0.940 | 0.916 | 0.035 | 0.870 | 0.789 | 0.073 | 0.867 | 0.780 | 0.094 | 0.929 | 0.905 | 0.031 | 0.828 | 0.826 | 0.054 | 0.871 | 0.849 | 0.040 |
| R3Net* [18] | 2018 | 0.935 | 0.910 | 0.040 | 0.845 | 0.749 | 0.100 | 0.847 | 0.761 | 0.124 | 0.916 | 0.900 | 0.036 | 0.805 | 0.817 | 0.063 | 0.833 | 0.823 | 0.058 |
| GNLB* [6] | 2018 | 0.931 | 0.900 | 0.045 | 0.840 | 0.758 | 0.096 | 0.837 | 0.744 | 0.127 | 0.917 | 0.886 | 0.037 | 0.800 | 0.817 | 0.058 | 0.830 | 0.811 | 0.058 |
| RADF* [20] | 2018 | 0.924 | 0.894 | 0.049 | 0.832 | 0.754 | 0.102 | 0.835 | 0.759 | 0.125 | 0.914 | 0.889 | 0.039 | 0.789 | 0.815 | 0.060 | 0.819 | 0.814 | 0.061 |
| DSS* [19] | 2017 | 0.916 | 0.882 | 0.053 | 0.829 | 0.739 | 0.102 | 0.842 | 0.746 | 0.118 | 0.911 | 0.881 | 0.040 | 0.771 | 0.790 | 0.066 | 0.825 | 0.812 | 0.057 |
| DCL* [21] | 2016 | 0.898 | 0.868 | 0.071 | 0.822 | 0.783 | 0.108 | 0.832 | 0.745 | 0.126 | 0.904 | 0.861 | 0.049 | 0.757 | 0.771 | 0.080 | 0.782 | 0.795 | 0.088 |
| SAC-Net (ours) | - | 0.951 | 0.931 | 0.031 | 0.879 | 0.806 | 0.070 | 0.882 | 0.809 | 0.093 | 0.942 | 0.925 | 0.026 | 0.830 | 0.849 | 0.052 | 0.895 | 0.883 | 0.034 |
| PoolNet-R [30] | 2019 | 0.944 | 0.921 | 0.039 | 0.865 | 0.794 | 0.080 | 0.869 | 0.801 | 0.100 | 0.934 | 0.912 | 0.033 | 0.830 | 0.836 | 0.056 | 0.886 | 0.871 | 0.040 |
| BASNet [48] | 2019 | 0.942 | 0.916 | 0.037 | 0.858 | 0.785 | 0.084 | 0.851 | 0.772 | 0.112 | 0.929 | 0.909 | 0.032 | 0.811 | 0.836 | 0.056 | 0.860 | 0.853 | 0.047 |
| CPD-R [29] | 2019 | 0.939 | 0.918 | 0.037 | 0.861 | 0.789 | 0.078 | 0.859 | 0.771 | 0.110 | 0.925 | 0.906 | 0.034 | 0.797 | 0.825 | 0.056 | 0.865 | 0.858 | 0.043 |
| AFNet [46] | 2019 | 0.935 | 0.917 | 0.042 | 0.866 | 0.792 | 0.076 | - | - | - | 0.925 | 0.905 | 0.036 | 0.820 | 0.826 | 0.057 | 0.867 | 0.855 | 0.045 |
| MLMSNet [32] | 2019 | 0.930 | 0.909 | 0.045 | 0.858 | 0.790 | 0.079 | 0.862 | 0.790 | 0.106 | 0.922 | 0.906 | 0.039 | 0.793 | 0.809 | 0.064 | 0.854 | 0.851 | 0.048 |
| CapSal [47] | 2019 | - | - | - | 0.868 | 0.769 | 0.079 | - | - | - | 0.889 | 0.849 | 0.057 | - | - | - | 0.845 | 0.808 | 0.060 |
| PiCA-R [45] | 2018 | 0.935 | 0.917 | 0.047 | 0.868 | 0.800 | 0.078 | 0.864 | 0.793 | 0.103 | 0.919 | 0.904 | 0.043 | 0.820 | 0.832 | 0.065 | 0.863 | 0.859 | 0.050 |
| ASNet [62] | 2018 | 0.932 | 0.915 | 0.047 | 0.869 | 0.794 | 0.075 | 0.859 | 0.800 | 0.105 | 0.922 | 0.906 | 0.041 | - | - | - | 0.835 | 0.834 | 0.060 |
| R3Net [18] | 2018 | 0.929 | 0.910 | 0.051 | 0.842 | 0.761 | 0.103 | 0.839 | 0.770 | 0.131 | 0.914 | 0.897 | 0.046 | 0.802 | 0.819 | 0.073 | 0.831 | 0.829 | 0.067 |
| BDMPM [23] | 2018 | 0.928 | - | 0.044 | 0.862 | - | 0.074 | 0.851 | - | 0.106 | 0.920 | - | 0.038 | - | - | - | 0.850 | - | 0.049 |
| PAGRN [25] | 2018 | 0.927 | 0.889 | 0.061 | 0.849 | 0.749 | 0.094 | - | - | - | 0.918 | 0.887 | 0.048 | 0.771 | 0.775 | 0.071 | 0.854 | 0.825 | 0.055 |
| GNLB [6] | 2018 | 0.926 | 0.904 | 0.056 | 0.841 | 0.772 | 0.099 | 0.834 | 0.762 | 0.133 | 0.909 | 0.891 | 0.048 | 0.800 | 0.824 | 0.067 | 0.821 | 0.822 | 0.068 |
| DGRL [43] | 2018 | 0.925 | 0.906 | 0.045 | 0.850 | 0.796 | 0.080 | 0.846 | 0.777 | 0.104 | 0.914 | 0.897 | 0.037 | 0.779 | 0.810 | 0.063 | 0.834 | 0.836 | 0.051 |
| RAS [17] | 2018 | 0.916 | 0.893 | 0.058 | 0.842 | 0.735 | 0.122 | 0.847 | 0.767 | 0.123 | 0.913 | 0.887 | 0.045 | 0.785 | 0.814 | 0.063 | 0.831 | 0.828 | 0.059 |
| C2S [22] | 2018 | 0.911 | 0.896 | 0.053 | 0.845 | 0.793 | 0.084 | 0.821 | 0.763 | 0.122 | 0.898 | 0.889 | 0.046 | 0.759 | 0.799 | 0.072 | 0.811 | 0.822 | 0.062 |
| SRM [63] | 2017 | 0.917 | 0.895 | 0.054 | 0.847 | 0.782 | 0.085 | 0.839 | 0.746 | 0.126 | 0.906 | 0.888 | 0.046 | 0.769 | 0.798 | 0.069 | 0.827 | 0.825 | 0.059 |
| Amulet [24] | 2017 | 0.913 | 0.894 | 0.059 | 0.828 | 0.794 | 0.095 | 0.801 | 0.755 | 0.146 | 0.887 | 0.886 | 0.053 | 0.737 | 0.781 | 0.083 | 0.778 | 0.796 | 0.085 |
| UCF [15] | 2017 | 0.910 | 0.883 | 0.078 | 0.821 | 0.792 | 0.120 | 0.800 | 0.763 | 0.164 | 0.886 | 0.875 | 0.073 | 0.735 | 0.758 | 0.131 | 0.771 | 0.777 | 0.117 |
| NLDF [13] | 2017 | 0.905 | 0.875 | 0.063 | 0.831 | 0.756 | 0.099 | 0.810 | 0.759 | 0.143 | 0.902 | 0.879 | 0.048 | 0.753 | 0.770 | 0.080 | 0.812 | 0.815 | 0.066 |
| DHSNet [64] | 2016 | 0.907 | 0.884 | 0.059 | 0.827 | 0.752 | 0.096 | 0.823 | 0.752 | 0.127 | 0.892 | 0.870 | 0.052 | - | - | - | 0.807 | 0.811 | 0.067 |
| RFCN [14] | 2016 | 0.898 | 0.860 | 0.097 | 0.827 | 0.793 | 0.118 | 0.805 | 0.717 | 0.161 | 0.895 | 0.859 | 0.079 | 0.747 | 0.774 | 0.095 | 0.784 | 0.791 | 0.091 |
| ELD [65] | 2016 | 0.867 | 0.841 | 0.080 | 0.771 | - | 0.121 | 0.760 | - | 0.154 | 0.844 | - | 0.071 | 0.719 | 0.751 | 0.091 | 0.738 | 0.719 | 0.093 |
| MDF [52] | 2015 | 0.831 | 0.764 | 0.108 | 0.759 | 0.692 | 0.142 | 0.785 | 0.674 | 0.155 | - | - | - | 0.694 | 0.703 | 0.092 | 0.730 | 0.723 | 0.094 |
| LEGS [66] | 2015 | 0.827 | 0.787 | 0.118 | 0.756 | 0.682 | 0.157 | 0.707 | 0.661 | 0.215 | 0.770 | - | 0.118 | 0.669 | - | 0.133 | 0.655 | - | 0.138 |
| BSCA [67] | 2015 | 0.758 | 0.725 | 0.183 | 0.666 | 0.633 | 0.224 | 0.634 | 0.622 | 0.266 | 0.723 | 0.700 | 0.174 | 0.616 | 0.652 | 0.191 | 0.597 | 0.630 | 0.197 |
| DRFI [9] | 2013 | 0.786 | - | 0.164 | 0.698 | - | 0.207 | 0.697 | - | 0.223 | 0.777 | - | 0.145 | - | - | - | 0.647 | - | 0.175 |
| SAC-Net (Res50) | - | 0.945 | 0.924 | 0.034 | 0.871 | 0.805 | 0.072 | 0.872 | 0.804 | 0.093 | 0.936 | 0.920 | 0.028 | 0.808 | 0.832 | 0.057 | 0.881 | 0.873 | 0.037 |
| Dataset | - | ECSSD [39] | PASCAL-S [53] | SOD [61] | HKU-IS [52] | DUT-OMRON [40] | DUTS-test [55] | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metric | Year | MAE | MAE | MAE | MAE | MAE | MAE | ||||||||||||
| SAC-Net (ours) | - | 0.951 | 0.931 | 0.031 | 0.879 | 0.806 | 0.070 | 0.882 | 0.809 | 0.093 | 0.942 | 0.925 | 0.026 | 0.830 | 0.849 | 0.052 | 0.895 | 0.883 | 0.034 |
| PoolNet-R+ | 2019 | 0.947 | 0.924 | 0.032 | 0.867 | 0.801 | 0.071 | 0.872 | 0.798 | 0.097 | 0.937 | 0.919 | 0.026 | 0.813 | 0.834 | 0.052 | 0.883 | 0.873 | 0.035 |
| BASNet+ | 2019 | 0.919 | 0.894 | 0.049 | 0.825 | 0.761 | 0.101 | 0.825 | 0.754 | 0.126 | 0.912 | 0.893 | 0.040 | 0.795 | 0.819 | 0.064 | 0.822 | 0.821 | 0.061 |
| DSS+ [75] | 2019 | 0.906 | 0.862 | 0.074 | 0.819 | 0.721 | 0.115 | 0.831 | 0.735 | 0.144 | 0.904 | 0.869 | 0.054 | 0.783 | 0.799 | 0.070 | 0.819 | 0.809 | 0.067 |
| PiCA-R+ | 2018 | 0.940 | 0.914 | 0.037 | 0.863 | 0.791 | 0.076 | 0.864 | 0.768 | 0.101 | 0.931 | 0.905 | 0.031 | 0.816 | 0.828 | 0.068 | 0.868 | 0.844 | 0.043 |
| SC | TS | ECSSD | PASCAL-S | SOD | HKU-IS | DUT-OMRON | DUTS-test | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAE | MAE | MAE | MAE | MAE | MAE | |||||||||||||||
| FPN [60] | SGD | 0.926 | 0.904 | 0.056 | 0.859 | 0.780 | 0.085 | 0.846 | 0.772 | 0.124 | 0.913 | 0.898 | 0.046 | 0.805 | 0.825 | 0.065 | 0.858 | 0.852 | 0.052 | |
| SAC-Net | SGD | 0.949 | 0.928 | 0.036 | 0.878 | 0.805 | 0.072 | 0.874 | 0.806 | 0.099 | 0.938 | 0.923 | 0.030 | 0.828 | 0.849 | 0.055 | 0.888 | 0.879 | 0.038 | |
| Adam | 0.951 | 0.931 | 0.031 | 0.879 | 0.806 | 0.070 | 0.882 | 0.809 | 0.093 | 0.942 | 0.925 | 0.026 | 0.830 | 0.849 | 0.052 | 0.895 | 0.883 | 0.034 | ||
| with LSTM | SGD | 0.941 | 0.920 | 0.040 | 0.872 | 0.794 | 0.074 | 0.860 | 0.778 | 0.111 | 0.930 | 0.912 | 0.034 | 0.825 | 0.836 | 0.054 | 0.881 | 0.871 | 0.040 | |
| HKU-IS | DUT-OMRON | DUTS-test | ||||||||
| MAE | MAE | MAE | ||||||||
| 1 | learnable | 0.928 | 0.914 | 0.035 | 0.824 | 0.836 | 0.058 | 0.875 | 0.866 | 0.043 |
| 2 | learnable | 0.937 | 0.921 | 0.031 | 0.826 | 0.843 | 0.057 | 0.886 | 0.877 | 0.039 |
| 3 | learnable | 0.938 | 0.923 | 0.030 | 0.828 | 0.849 | 0.055 | 0.888 | 0.879 | 0.038 |
| 4 | learnable | 0.937 | 0.922 | 0.030 | 0.829 | 0.846 | 0.056 | 0.888 | 0.878 | 0.038 |
| 5 | learnable | 0.937 | 0.921 | 0.031 | 0.825 | 0.844 | 0.057 | 0.887 | 0.878 | 0.039 |
| 3 | fixed () | 0.936 | 0.921 | 0.031 | 0.825 | 0.846 | 0.056 | 0.887 | 0.877 | 0.039 |
| 3 | fixed () | 0.936 | 0.922 | 0.030 | 0.824 | 0.844 | 0.058 | 0.883 | 0.875 | 0.040 |
| 3 | fixed () | 0.935 | 0.920 | 0.032 | 0.826 | 0.846 | 0.057 | 0.884 | 0.875 | 0.041 |
| Models | HKU-IS | DUT-OMRON | DUTS-test | ||||||
|---|---|---|---|---|---|---|---|---|---|
| MAE | MAE | MAE | |||||||
| one-round | 0.933 | 0.920 | 0.032 | 0.824 | 0.845 | 0.056 | 0.883 | 0.875 | 0.040 |
| three-round | 0.937 | 0.922 | 0.031 | 0.828 | 0.848 | 0.055 | 0.886 | 0.879 | 0.039 |
| w/o left-right | 0.935 | 0.920 | 0.031 | 0.823 | 0.843 | 0.057 | 0.885 | 0.876 | 0.039 |
| w/o up-down | 0.936 | 0.921 | 0.031 | 0.824 | 0.843 | 0.056 | 0.886 | 0.877 | 0.039 |
| w/o attention | 0.934 | 0.919 | 0.032 | 0.824 | 0.844 | 0.055 | 0.884 | 0.876 | 0.039 |
| Ours | 0.938 | 0.923 | 0.030 | 0.828 | 0.849 | 0.055 | 0.888 | 0.879 | 0.038 |
| Dataset | ECSSD [39] | PASCAL-S [53] | SOD [61] | HKU-IS [52] | DUT-OMRON [40] | DUTS-test [55] | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metric | MAE | MAE | MAE | MAE | MAE | MAE | ||||||||||||
| SAC-Net (ours) | 0.951 | 0.931 | 0.031 | 0.879 | 0.806 | 0.070 | 0.882 | 0.809 | 0.093 | 0.942 | 0.925 | 0.026 | 0.830 | 0.849 | 0.052 | 0.895 | 0.883 | 0.034 |
| DSC [82, 83] | 0.948 | 0.929 | 0.036 | 0.877 | 0.801 | 0.072 | 0.872 | 0.801 | 0.100 | 0.935 | 0.920 | 0.031 | 0.830 | 0.847 | 0.053 | 0.886 | 0.878 | 0.038 |
| DeepLabv3+ [84] | 0.947 | 0.925 | 0.037 | 0.878 | 0.797 | 0.071 | 0.862 | 0.788 | 0.102 | 0.934 | 0.915 | 0.032 | 0.824 | 0.836 | 0.053 | 0.885 | 0.872 | 0.038 |
| PSPNet [85] | 0.940 | 0.917 | 0.042 | 0.877 | 0.795 | 0.071 | 0.860 | 0.777 | 0.111 | 0.927 | 0.911 | 0.036 | 0.819 | 0.829 | 0.056 | 0.881 | 0.869 | 0.040 |
| PSANet [86] | 0.940 | 0.917 | 0.042 | 0.873 | 0.796 | 0.073 | 0.858 | 0.778 | 0.112 | 0.928 | 0.912 | 0.036 | 0.816 | 0.831 | 0.056 | 0.879 | 0.869 | 0.041 |
| DeepLabv3 [87] | 0.939 | 0.917 | 0.042 | 0.873 | 0.793 | 0.073 | 0.862 | 0.775 | 0.111 | 0.926 | 0.909 | 0.037 | 0.821 | 0.827 | 0.056 | 0.877 | 0.865 | 0.042 |
| Non-local Network [34] | 0.936 | 0.915 | 0.044 | 0.874 | 0.795 | 0.072 | 0.858 | 0.776 | 0.112 | 0.924 | 0.906 | 0.037 | 0.809 | 0.826 | 0.059 | 0.873 | 0.865 | 0.043 |
| DeepLab [88] | 0.934 | 0.914 | 0.045 | 0.873 | 0.797 | 0.073 | 0.850 | 0.774 | 0.114 | 0.923 | 0.907 | 0.038 | 0.803 | 0.822 | 0.059 | 0.871 | 0.863 | 0.043 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
SAC-Net: Spatial Attenuation Context
for Salient Object Detection
Xiaowei Hu, Chi-Wing Fu, Lei Zhu, Tianyu Wang, and Pheng-Ann Heng
X. Hu, L. Zhu, and T. Wang are with the Department of Computer Science and Engineering, The Chinese University of Hong Kong, Hong Kong SAR, China. C.-W. Fu and P.-A. Heng are with the Department of Computer Science and Engineering, The Chinese University of Hong Kong, Hong Kong SAR, China and also with Shenzhen Key Laboratory of Virtual Reality and Human Interaction Technology, Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences, Shenzhen 518055, China.
Abstract
This paper presents a new deep neural network design for salient object detection by maximizing the integration of local and global image context within, around, and beyond the salient objects. Our key idea is to adaptively propagate and aggregate the image context features with variable attenuation over the entire feature maps. To achieve this, we design the spatial attenuation context (SAC) module to recurrently translate and aggregate the context features independently with different attenuation factors and then to attentively learn the weights to adaptively integrate the aggregated context features. By further embedding the module to process individual layers in a deep network, namely SAC-Net, we can train the network end-to-end and optimize the context features for detecting salient objects. Compared with 29 state-of-the-art methods, experimental results show that our method performs favorably over all the others on six common benchmark data, both quantitatively and visually.
Index Terms:
Spatial attenuation context, salient object detection, saliency detection, deep learning.
I Introduction
Salient object detection aims to distinguish the most visually distinctive objects from an input image and it is an effective pre-processing step in many image processing and computer vision tasks, e.g., object segmentation [1] and tracking [2], video compression [3] and abstraction [4], image editing [5], texture smoothing [6], as well as few-shot learning [7]. It is a fundamental problem in computer vision research and has been extensively studied in the past decade.
Early works attempt to detect salient objects based on low-level cues like contrast, color, and texture [8, 9, 10, 11]. However, relying on low-level cues is clearly inadequate to finding salient objects, which involve high-level semantics. Hence, most recent methods [12, 13, 14, 15, 16] employ convolutional neural networks (CNNs) and take a data-driven approach to the problem by leveraging both high-level semantics and low-level details extracted from multiple CNN layers [17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33]. However, since the convolution operator in CNN processes a local neighborhood in the spatial domain [34], existing methods tend to miss global spatial semantics in the results, e.g., they may misrecognize background noise as salient objects; see Section IV-B for quantitative and qualitative comparisons.
Essentially, salient objects are key elements that stand out from the background. Such an inference process [35] should involve not only the local image context within and around the salient objects, but also the global image context, as well as a suitable integration of the various context features. Ideally, after extracting context features per image pixel, if we can connect all these features and let them communicate with every other over the spatial domain, we can optimize the feature integration for maximized performance. However, it is computationally infeasible in practice. Hence, we present to propagate context features with different attenuation factors over the spatial domain of the image and learn to aggregate the resulting features adaptively; by then, our network can learn to detect salient objects by adaptively considering context features within, around, and even far from, the salient objects.
To achieve this, we present the spatial attenuation context, which is achieved by the following steps: (i) the image context is aggregated by propagating the information pixel by pixel over the whole feature maps; as a result, each pixel will obtain the global information from all other pixels of the feature maps; (ii) the propagation ability is affected by an attenuation factor, where a large attenuation factor reduces the information propagation and leads to a short-range context while a small attenuation factor improves the information propagation and leads to a long-range context; (iii) the image contexts with different ranges are dynamically merged by learning a set of attention weights. Fig. 1 shows a challenging example with the associated attention maps learned in our network for integrating the various image context: (c) long-range context aggregated with a small attenuation factor helps locate the global background; (d) medium-range context helps identify the image regions of the same object; and (e) short-range context aggregated with a large attenuation factor helps locate the boundary between salient and non-salient regions. Please see the supplementary material for detailed explanations with more illustrations.
In details, we formulate the spatial attenuation context module, or SAC module for short, in a deep network to allow the image features in a CNN to propagate over variable spatial ranges by articulating different attenuation factors in the propagation. Our module has two rounds of recurrent translations to propagate and aggregate the image features. In each round, we propagate features independently using different attenuation factors towards different directions in the spatial domain; further, we formulate an attention mechanism to learn the weights to combine the aggregated features. Hence, we can adopt different attenuation factors (or influence ranges) for different image features. Furthermore, we deploy an SAC module in each layer of our network and predict a saliency map per layer based on the output from the SAC module and the convolutional features. Below, we summarize the major contributions of this work:
- •
We design the spatial attenuation context (SAC) module to recurrently propagate the image features over the whole feature maps with variable attenuation factors and learn to adaptively integrate the features through an attention mechanism in the module. Then, we adopt the SAC module in each layer of our network architecture to learn the spatial attenuation context in different layers, and train the whole network in an end-to-end manner for salient object detection.
- •
We evaluate our method and compare it against 29 state-of-the-art methods on six common benchmark data. Results show that our method performs favorably over all the others for all the benchmark data. Our code, trained models, and predicted saliency maps are publicly available at https://xw-hu.github.io/.
II Related Work
Rather than being comprehensive, we discuss mainly the methods on single-image salient object detection. Early methods use hand-crafted priors such as image contrast [9, 36], color [37, 38], texture [39, 40], and other low-level visual cues [41]; see [42] for a survey. Clearly, hand-crafted features are insufficient to capture high-level semantics, so methods based on them often fail for nontrivial inputs.
Recent works [12, 13, 16] exploit convolutional neural networks (CNN) to learn deep features for detecting salient objects. However, since these methods just take features at deep CNN layers, they tend to miss the details in the salient objects, which are captured mainly in the shallow layers. Several recent works [14, 15, 21, 19, 24, 20, 18, 23, 25, 22, 17, 43, 26] enhance the detection quality by further integrating features in multiple CNN layers to simultaneously leverage more global and local context in the inference process. Among them, Li et al. [21] explored the semantic properties and visual contrast of salient objects, Hou et al. [19] created short connections to integrate features in different layers, while Zhang et al. [24] derived a resolution-based feature combination module and a boundary-preserving refinement strategy. Hu et al. [20] recurrently aggregated deep features to exploit the complementary saliency information between the multi-level features and the features at each individual layer. Later, Deng et al. [18] adopted residual learning to alternatively refine features at deep and shallow layers. Zhang et al. [23] formulated a bi-directional message passing model to select features for integration. Zhang et al. [25] designed an attention-guided network to progressively select and integrate multi-level information. Li et al. [22] used a two-branch network to simultaneously predict the contours and saliency maps. Chen et al. [17] leveraged residual learning and reverse attention to refine the saliency maps. Li et al. [33] presented a contrast-oriented deep neural network, which adopts two network streams for both dense and sparse saliency inference. Zhang et al. [26] designed a symmetrical CNN to learn the complementary saliency information and presented a weighted structural loss to enhance the boundaries of salient objects. Wang et al. [43] explored the global and local spatial relations in deep networks to locate salient objects and refine the object boundary. Although the detection quality keeps improving, the exploration of global spatial context, particularly in the shallow layers, is still heavily limited by the convolution operator in CNN, which is essentially a local spatial filter [34].
Very recently, Liu and Han [44] incorporated global context and scene context by developing a deep spatial long short-term memory model. Liu et al. [45] aggregated the attended contextual features from a global/local view in feature maps of varying resolutions. Wang et al. [27] presented a pyramid attention structure and leveraged the salient edge information to better segment salient objects. Feng et al. [46] designed an attentive feedback network to further explore the boundaries of the salient objects. Zhao and Wu [28] used the dilated convolution and channel-wise & spatial attention to aggregate multi-scale context features. Wu et al. [29] proposed to discard the feature maps at shallow layers for acceleration and used the saliency map generated from one network branch to refine the features of another branch. Liu et al. [30] introduced two pooling-based modules to progressively refine the highly semantic features for detail enriched saliency maps. Wang et al. [31] predicted the saliency maps by iteratively aggregating the feature maps in the top-down and bottom-up manner. Zhang et al. [47] incorporated the semantic information of salient objects from the image captions. Qin et al. [48] formulated a boundary-aware salient object detection network by combining a deeply supervised encoder-decoder and a residual refinement module, and leveraged a hybrid loss to optimize the whole network. Wu et al. [32] jointly performed foreground contour detection and edge detection tasks by using multi-task intertwined supervision. Fu et al. [49] presented a Deepside to incorporate hierarchical CNN features and fused multiple side outputs based on a segmentation-based pooling. Li et al. [50] developed a multiscale saliency refinement network, which is used for instance-level salient object segmentation. Zhu et al. [51] learned the attentional dilated features to detect the salient objects. Even the detection performance continues to improve on the benchmarks [52, 53, 54, 55, 39, 40], current methods may still miss local parts in salient objects and misrecognize noises in non-salient regions as salient objects. Except the above works, Song et al. [56] presented a novel multi-scale attention network for accurate object detection. Peng et al. [57] proposed two-stream collaborative learning with a spatial-temporal attention approach for video classification. He et al. [58] developed a multi-scale and multi-granularity deep reinforcement learning approach for fine-grained visual categorization. Peng et al. [59] formulated an object-part attention model for weakly supervised fine-grained image classification.
The recent works [44, 45] that emphasize the importance of reasoning spatial context for salient object detection. Comparing with the PiCANet [44, 45], which aggregates the global context formation on the feature maps with small resolutions by adopting the expensive long short-term memory models and aggregates the local context information on the feature maps with large resolutions through convolutions, we leverage and selectively aggregate surrounding image context spatially in the same CNN layer by a new concept, i.e., spatial attenuation context, which attentively allows the context features to recurrently translate with varying attenuation factors (including local and global information) on the feature maps with any resolutions.
III Methodology
Fig. 2 outlines the architecture of our spatial attenuation context network (SAC-Net), which takes a whole image as input and predicts the saliency map in an end-to-end manner. First, we use a CNN to generate feature maps in different resolutions and progressively propagate the image features at deep layers to feature maps at shallow layers to construct a feature pyramid [60]. After that, we use our SAC modules to harvest spatial attenuation context per layer and concatenate the module outputs with the corresponding convolutional features. Lastly, we predict a result per layer, upsample and merge it with the shallower-layer output, and take the result of the largest resolution as the final network output. In the following subsections, we first elaborate on the SAC module, and then present the strategies to train and test our network for salient object detection.
III-A Spatial Attenuation Context Module
Fig. 4 shows the architecture of the spatial attenuation context module, or SAC module, which takes a feature map as input and produces spatial attenuation context in the same resolution. As presented earlier, the spatial attenuation context contains image context aggregated by propagating local image context using varying attenuation factors via an attention mechanism; hence, we can disperse the local image context adaptively over the whole feature maps.
See again the SAC module in Fig. 4. First, we use a convolution on the input feature map to reduce the number of feature channels. Then, we adopt recurrent translations with varying attenuation factors () to disperse the local image features in four different directions; see the illustration in Fig. 3(b) & the detailed structure of recurrent translations in Fig. 4. At this moment, each pixel learns the spatial attenuation context along the four directions. After two rounds of recurrent translations, we adaptively disperse the local features over the 2D domain; see Fig. 3(c). Hence, each pixel knows the global spatial attenuation context over the entire feature map. More importantly, we learn the weights to combine the recurrently-aggregated results via an attention mechanism in an end-to-end manner (Fig. 4), so each pixel in the SAC module output can receive spatial context adaptively from its surroundings; please see the supplementary material for the detail explanations.
Recurrently-attenuating translation. To optimize the dispersal of local context, we first formulate a parametric model to recurrently aggregate the image features with attenuation. Given the feature map after a convolution (see Fig. 4), we recurrently translate its features using different attenuation factors in four principal directions: left, up, right, and down. Moreover, to ensure manageable memory consumption, we set the number of feature channels in each recurrently-aggregated feature map as , where is the number of different attenuation factors in the SAC module; see Table V for an experiment on .
Denoting as the feature at pixel in a feature map, our recurrently-attenuating translation process propagates features progressively over the spatial domain using the following equation (typically in the up direction) :
[TABLE]
where () is the attenuation factor, and is a learnable parameter in our recurrently-attenuating translation model.
In Eq. (III-A), we recurrently aggregate image features by using , where a smaller (close to zero) allows the features to propagate over a longer distance, while a larger (close to one) limits the propagation, so the related local features affect a smaller local area; see again the illustration in Fig. 3. Moreover, when , the first term in will become zero, and will be multiplied with . We define in Eq. (III-A) to reduce the feature magnitude when it is negative. Since we learn the value of for each feature channel, we can introduce nonlinearities when aggregating the spatial context and express more complex relations among the local features. Note that in our experiments, we initialize as for all the feature channels and learn it automatically during the network training process; in practice, we found that rarely goes beyond one in our experiments.
Attention mechanism.
After recurrently-translating the input feature map using different attenuation factors in four directions, we will obtain feature maps; see the feature maps with colored arrows in Fig. 4. As discussed earlier, the long-range image context reveals global semantics, while the short-range context helps identify the boundary between salient and non-salient regions. To adaptively leverage the complementary advantages of these aggregated spatial context features, we formulate an attention mechanism to learn the weights for selectively integrating them.
As shown at the top left corner in Fig. 4, we take the input feature map as the input to the attention mechanism and produce a set of unnormalized attention weights , each corresponding to a particular attenuation factor; superscript indicates that these weights are for the first round of recurrent translations. Then, we apply the Softmax function (Eq. (3)) to normalize the weights and produce the attention weight maps associated with different attenuation factors (see Fig. 4):
[TABLE]
where is the unnormalized attention weight at pixel for attenuation factor , are the normalized attention weights, and denotes the parameters learned by , which consists of two convolution layers and one convolution layer, and we apply the group normalization [68] and ReLU non-linear operation [69] after the first two convolution layers.
Next, we multiply with the corresponding context features aggregated after the recurrent translations:
[TABLE]
where denotes an element-wise multiplication, denotes the concatenation operator, and concatenates all the feature maps for different attenuation factors, after the feature maps are multiplied with the attention weights () by broadcasting the in a channel-wise manner. With the attention weights learned to select and integrate the context features aggregated with different attenuation factors (see again Fig. 1), our network can adaptively control the feature integration and allow the context features to be implicitly dispersed over varying spatial ranges.
Completing the SAC module. After concatenating the features, we complete the first round of recurrent translations in our SAC module and further apply a convolution to reduce the feature channels. Then, we repeat the same process in the second round of recurrent translation using another set of attention weights , which are also learnt through the attention mechanism; see again Fig. 4. After two rounds of recurrent translations, each pixel can obtain context features from the global domain adaptively aggregated with different attenuations; see Fig. 3(c). In the end, we further perform a convolution followed by the group normalization and ReLU non-linear operation on the integrated features to produce the SAC module output, i.e., the spatial attenuation context. Since two rounds of recurrent translations are able to obtain the global information, we set the number of rounds as two during the experiments.
III-B Training and Testing Strategies
We built our SAC-Net on ResNet-101 [70] and used the feature pyramid network (FPN) [60] (green blocks in Fig. 2) to enhance the feature’s expressiveness. Like [60], we set the channel number of each FPN or SAC layer as and did not use the feature maps at the first layer in both the FPN or SAC module due to the large memory footprint. This framework was implemented based on Caffe [71].
Objective function. We used the cross-entropy loss to train the network. Since we have multiple predictions over different layers (from deep to shallow) in our SAC-Net (see Fig. 2), the total loss is defined as the summation of the cross-entropy loss over all the predicted saliency maps:
[TABLE]
where is the layer index in network, is the ground truth value at pixel (i.e., one for salient regions, and zero, otherwise), and is the predicted saliency value at pixel on the result in the network’s -th layer.
Training parameters. We initialized the feature extraction part in our network (frontal blue blocks in Fig. 2) using weights of ResNet-101 [70] trained on ImageNet [72], and initialized other network parts using random noise. Moreover, we adopted two different training strategies to optimize the network. First, we used stochastic gradient descent (SGD) with a momentum value of and a weight decay of , and we set the learning rate as , adjusted it to be after training iterations, and stopped the training after iterations. Second, following [30], we used Adam [73] with the first momentum value of , second momentum value of , and weight decay of . We set the learning rate as and stopped the training after iterations. The first training strategy is fast while the second strategy achieves better results; see Section IV-C. Also, we horizontally flipped the input images for data argumentation in both training strategies. Lastly, we trained the network on a single NVidia Titan Xp GPU with a mini-batch size of one and updated the weights in every ten training iterations.
Inference. We took the highest-resolution prediction as the overall result and refined the salient object boundary using fully-connected conditional random field (CRF) [74].
IV Experimental Results
IV-A Datasets and Evaluation Metrics
We used six widely-used saliency benchmark datasets in our experiments: (i) ECSSD [39] has natural images with many semantically meaningful but complex structures; (ii) PASCAL-S [53] has images generated from the PASCAL VOC2010 segmentation dataset [76], where each image has several salient objects; (iii) SOD [61] has images selected from the BSDS dataset [54], where the salient objects are typically of low contrast or closely contact with the image boundary; (iv) HKU-IS [52] has images, where most images have multiple salient objects; (v) DUT-OMRON [40] has high-quality images, each with one or more salient objects; and (vi) DUTS [55] has a training set of images and a testing set (denoted as DUTS-test) of images, where the images contain various number of salient objects with large variance in scale. Among the datasets, HKU-IS, DUT-OMRON, and DUTS provide a large number of test images captured under different situations, enabling more comprehensive comparisons among different methods. Moreover, we follow the recent works on salient object detection [45, 43, 23, 25] to train our network model using the training set of DUTS [55].
Next, we used three common metrics for quantitative evaluation: F-measure (), structure measure () and mean absolute error (MAE). F-measure is a balanced average precision and recall computed from the predicted maps and the ground truth images:
[TABLE]
where is set as to improve the importance of the precision, as suggested in [77, 19]. S-measure [78] computes the object-aware and region-aware structural similarity between the predicted map and ground truth image :
[TABLE]
where and denote the object-aware and region-aware structural similarity, respectively; is a parameter, which balances the importance of structural similarities, and we followed [78] and set it as . Overall, a large or indicates a better result. MAE [36] is the average pixel-wise absolute difference between the predicted map and the ground truth image :
[TABLE]
where and are the width and height of or , respectively. Unlike the and , a small indicates a better result. Finally, we used the implementation of [78, 19] to compute , and MAE for all results.
IV-B Comparison with the State-of-the-arts
We compared our method with state-of-the-art methods; see the first column in Table I. Among the methods, to detect salient objects, BSCA [67] and DRFI [9] use hand-crafted features, while others employ deep neural networks to learn features. For a fair comparison, we obtained their results either by using the saliency maps provided by the authors or by producing the results using their implementations with the released training models.
Quantitative comparison. Table I summaries the quantitative results compared with the state-of-the-art methods in terms of , and MAE on detecting salient objects in the six benchmark datasets. Our SAC-Net performs favorably against all the others for almost all the cases, regardless of whether CRF is used as a post-processing step. Especially, our method without CRF (SAC-Net) already achieves the best performance compared with all the other methods with CRF for most datasets. This result demonstrates the strong capability of our method to deal with challenging inputs; see also the visual comparison results presented in Fig. 5.
Recent deep learning methods use different kinds of backbone networks for feature extraction. For a fair comparison, we retrained these methods (PoolNet [30], BASNet [48], and PiCA [45]) by using the same backbone network (ResNet-101) as our SAC-Net. We reported the results of DSS [75] using ResNet-101 by downloading the trained model from the authors’ website. These models are denoted as “XX+”. Table II shows the comparison results, where our method still outperforms the very recent salient object detection methods on all the benchmark datasets. We also re-train our method by taking ResNet-50 as the backbone network, and report the results “SAC-Net (Res50)” in the last row of Table I, where our method still achieves the best performance on most of the benchmark datasets.
Visual comparison. Fig. 5 presents salient object detection results produced by various methods, including ours. From the figures, we can see that other methods (d)-(h) tend to include non-salient backgrounds or miss some salient details, while our SAC-Net is able to produce results (c) that are more consistent with the ground truth images (b). Particularly, for challenging cases, such as (i) salient objects and non-salient background with similar appearance (see and rows), (ii) small salient objects (see and rows), (iii) complex background (see , , , , and rows), and (iv) multiple objects (see , , and to rows), our method can still predict more plausible saliency maps than the others, showing the robustness and quality of SAC-Net.
IV-C Evaluation on the Network Design
Component analysis. We performed an ablation study to evaluate the major components in SAC-Net. The first row of Table III shows the results from a basic model (FPN [60]) built with only the feature pyramid; see the green blocks in Fig. 2. By having the SAC modules in the network to adaptively aggregate spatial context, we can see clear improvements on all the benchmark datasets as compared with the FPN results; see the first two rows in the table.
Training strategy analysis. As mentioned in Section III-B, we adopted two different training strategies to optimize the network. The second and third rows in Table III show the comparison results, where using Adam achieves better results than using SGD. However, “Adam” took around hours to train the model, while “SGD” took only around hours. Hence, we adopted “SGD” to perform the following experiments to evaluate network design.
Compare with LSTM. The long short-term memory [79] (LSTM) is an efficient recurrent neural network to process sequence data by using a set of gates. The method has been extended to process 2D spatial information by some recent works on image classification [80] and saliency detection (s.t., DSCLRCN [44] and PiCA [45]). We performed another experiment by adopting the LSTMs in four principal directions with two rounds of recurrent translations to replace our recurrently-attenuating translation model in the SAC module; in detail, we replaced the feature maps with colored arrows in Fig. 4 by the LSTMs in corresponding directions.
The last row in Table III presents the LSTM results. Comparing with our results in the second row, we can see that our method performs better for , and MAE on all the benchmark data. We think the reason is that due to the limitation of the gate functions in LSTM [81], context features can only propagate over a short distance, thus limiting the dispersal of local context features in the spatial domain. On the other hand, the time complexity of computing LSTMs on 2D feature maps is very high. “with LSTM” took around hours to train the model, while our method took only around hours, which is more than times faster.
Parameter analysis. To build our network, we empirically determine the value of , which affects the number of attenuation factors and the number of feature channels in each aggregated feature map (); see Fig. 4. In general, a large allows the network to consider more variety of attenuation factors but each feature map would capture less information in return, since we keep the overall memory consumption to be manageable. Another parameter in our network is , where we automatically learn its value for regulating the magnitude of the negative part in Eq. (III-A).
We evaluated our network on the three largest datasets (HKU-IS, DUT-OMRON, and DUTS-test) using different and learnable/fixed . The results shown in Table IV reveal that when we aggregate the image context using two different attenuation factors (n$$=$$2), we achieve better results than using only one single long-range aggregation (n$$=$$1). The results further improve with larger and roughly stabilizes when reaches three, so we set n$$=$$3. On the other hand, comparing the results on the 3rd and last three rows (all with n$$=$$3) in table, we can see that automatically learning and adjusting gives better results than using a fixed (), or linearly aggregating the spatial features ().
Architecture analysis. To evaluate the effectiveness of our network design, we construct several variant models of our network. As shown in the Table V, first, we replace the two-round recurrent translations in our SAC module by one-round and three-round. The results show that our method with two-round recurrent translations achieves the best performance. Then, we build two modules, i.e., “w/o left-right” and “w/o up-down”, by removing the recurrent translations in the left and right or up and down directions, which leads to the worse results. Finally, we remove the attention mechanism in the SAC module to build “w/o attention”. Results show that our network design achieves the best performance.
Attention weight visualization. Figs. 1 & 6 visualize the learned attention weights for integrating the spatial context features. The long-range context (c) helps to locate the global background regions; the medium-range context (d) helps to identify the image regions of objects; and short-range context (e) helps to locate the boundary between salient and non-salient regions. Moreover, our attention mechanism selectively aggregates various spatial context and allows the context features to be implicitly dispersed over arbitrary spatial ranges.
Time performance. Our network is fast, since it has a fully convolutional architecture and employs an efficient recurrent translation module. We tested our network on a single GPU (TITAN Xp) using input images of size . It takes around seconds on average to test one image. If we remove the SAC modules from our network, it still needs seconds to process one image, which proves the efficiency of the proposed SAC module. Moreover, we compare the time performance of our SAC-Net with other methods for salient object detection. Table VII shows the results, where our method has comparable time performance with other methods that have worse detection accuracy than ours.
IV-D Shadow Detection
Our SAC model has the potential to be applied to other vision tasks. Here, we take the shadow detection as an example. We re-train our network as well as other salient object detection methods on the training set of SBU [91], which is a widely used dataset for shadow detection, and test them on the testing set of SBU. Moreover, we use the common metric BER for the quantitative comparisons among different shadow detectors. Table VIII reports the results, where our SAC-Net achieves the best performance among the methods designed for salient object detection and also outperforms most of the shadow detection methods.
V Discussion
There has been a lot of works on exploiting spatial context in deep CNNs for image analysis. Dilated convolution [88, 94] takes context from larger regions by inserting holes into the convolution kernels, but the context information in use still has a fixed range in a local region. ASPP [84, 87] and PSPNet [85] adopt multiple convolution kernels with different dilated rates or multiple pooling operations with different scales to aggregate spatial context using different region sizes; however, their designed kernel or pooling sizes are fixed, less flexible, and not adaptable to different inputs. DSC [82, 83] adopts the attention weights to indicate the importance of context features aggregated from different directions, but it only obtains the global context with a fixed influence range over the spatial domain. The non-local network [34] computes correlations between every pixel pair on the feature map to encode the global image semantics, but this method ignores the spatial relationship between pixels in the aggregation; for salient object detection, features of opposite semantics may, however, be important; see Fig. 1. PSANet [86] adaptively learns attention weights for each pixel to aggregate the information from different positions; however, it is unable to capture the context on lower-level feature maps in high resolutions due to the huge time and memory overhead. Compared to these methods, our SAC-Net explores and adaptively aggregates context features implicitly with variable influence ranges; it is flexible, fast, and computationally friendly for efficient salient object detection.
We performed an experiment by training these methods on the DUTS training set for salient object detection. For a fair comparison, we adopted ResNet-101 as the backbone network for all the methods. Table VI reports the results, where our method still achieves the best performance on all the benchmark datasets, which proves the effectiveness of the designed SAC module.
Lastly, we also analyzed the failure cases, for which we found to be highly challenging. For instance, our method may fail for (i) multiple salient objects in very different scales (see Fig. 7 (top)), where the network may regard the small objects as non-salient background; (ii) dark salient objects (see Fig. 7 (middle)), where there are insufficient context to determine whether the regions are salient or not; and (iii) salient objects over a complex background (see Fig. 7 (bottom)), where high-level scene knowledge is required to understand the image.
VI Conclusion
This paper presents a novel saliency detection network based on the spatial attenuation context. Our key idea is to recurrently propagate and aggregate image context with different attenuation factors and to integrate the aggregated features using weights learnt from an attention mechanism. Using our model, local image context can adaptively propagate over different ranges, and we can leverage the complementary advantages of these context to improve the saliency detection quality. In the end, we evaluated our method on six common benchmark datasets and compared it extensively with 29 state-of-the-art methods. Experimental results clearly show that our method performs favorably over all the others, both visually and quantitatively. In the future, we plan to explore the potential of our SAC module design for instance-level salient object detection and enhance its capability for detecting salient objects in videos.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] W. Wang, J. Shen, and F. Porikli, “Saliency-aware geodesic video object segmentation,” in CVPR , 2015, pp. 3395–3402.
- 2[2] S. Hong, T. You, S. Kwak, and B. Han, “Online tracking by learning discriminative saliency map with convolutional neural network,” in ICML , 2015, pp. 597–606.
- 3[3] H. Hadizadeh and I. V. Bajic, “Saliency-aware video compression,” IEEE Transactions on Image Processing , vol. 23, no. 1, pp. 19–33, 2014.
- 4[4] H. Zhao, X. Mao, X. Jin, J. Shen, F. Wei, and J. Feng, “Real-time saliency-aware video abstraction,” The Visual Computer , vol. 25, no. 11, pp. 973–984, 2009.
- 5[5] M.-M. Cheng, F.-L. Zhang, N. J. Mitra, X. Huang, and S.-M. Hu, “Repfinder: Finding approximately repeated scene elements for image editing,” in ACM Trans. on Graphics (SIGGRAPH) , vol. 29, no. 4. ACM, 2010, p. 83.
- 6[6] L. Zhu, X. Hu, C.-W. Fu, J. Qin, and P.-A. Heng, “Saliency-aware texture smoothing,” IEEE Transactions on Visualization and Computer Graphics , 2018.
- 7[7] H. Zhang, J. Zhang, and P. Koniusz, “Few-shot learning via saliency-guided hallucination of samples,” in CVPR , 2019, pp. 2770–2779.
- 8[8] M.-M. Cheng, N. J. Mitra, X. Huang, P. H. Torr, and S.-M. Hu, “Global contrast based salient region detection,” IEEE Transactions on Pattern Analysis and Machine Intelligence , vol. 37, no. 3, pp. 569–582, 2015.