Enhanced Transfer Learning with ImageNet Trained Classification Layer
Tasfia Shermin, Shyh Wei Teng, Manzur Murshed, Guojun Lu, Ferdous, Sohel, Manoranjan Paul

TL;DR
This paper investigates the impact of using the ImageNet pre-trained classification layer during transfer learning, showing that including it can improve fine-tuning performance and network adaptability.
Contribution
It introduces a layer-wise fine-tuning method that incorporates the pre-trained classification layer, revealing its less category-specific nature and importance for better transfer learning.
Findings
Proposed fine-tuning outperforms traditional methods.
Pre-trained classification layer contains more global information.
Normalization and scaling are crucial for domain adaptation.
Abstract
Parameter fine tuning is a transfer learning approach whereby learned parameters from pre-trained source network are transferred to the target network followed by fine-tuning. Prior research has shown that this approach is capable of improving task performance. However, the impact of the ImageNet pre-trained classification layer in parameter fine-tuning is mostly unexplored in the literature. In this paper, we propose a fine-tuning approach with the pre-trained classification layer. We employ layer-wise fine-tuning to determine which layers should be frozen for optimal performance. Our empirical analysis demonstrates that the proposed fine-tuning performs better than traditional fine-tuning. This finding indicates that the pre-trained classification layer holds less category-specific or more global information than believed earlier. Thus, we hypothesize that the presence of this layer…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1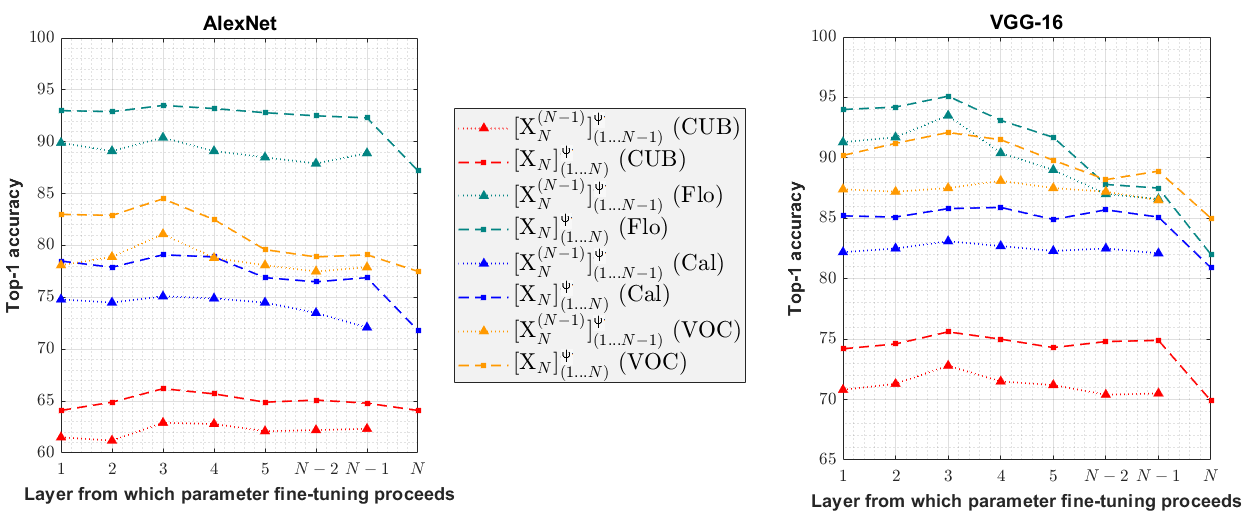 Figure 2
Figure 2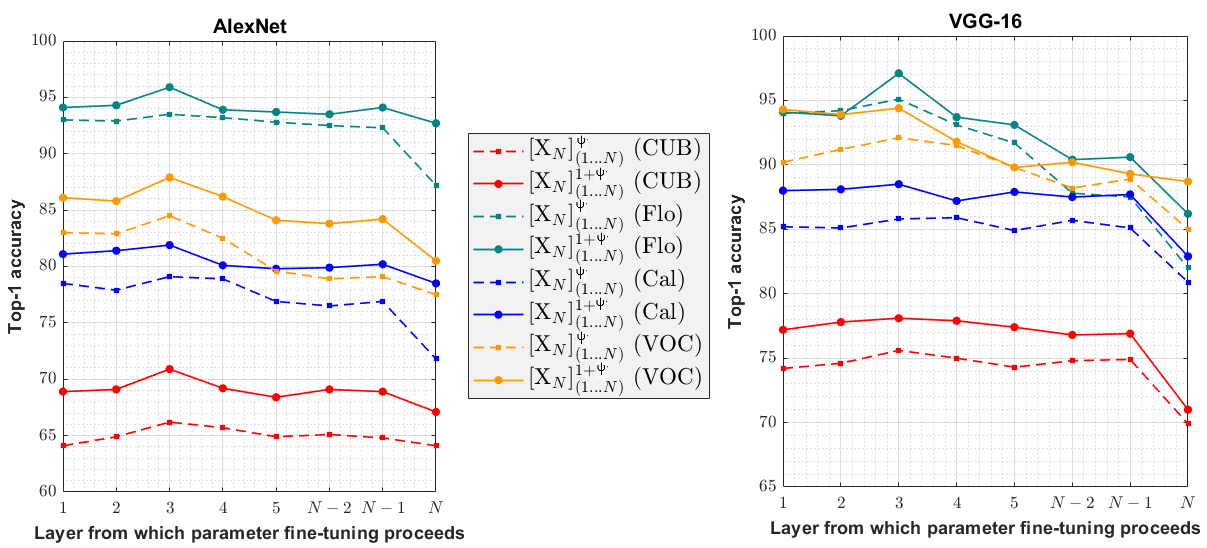 Figure 3
Figure 3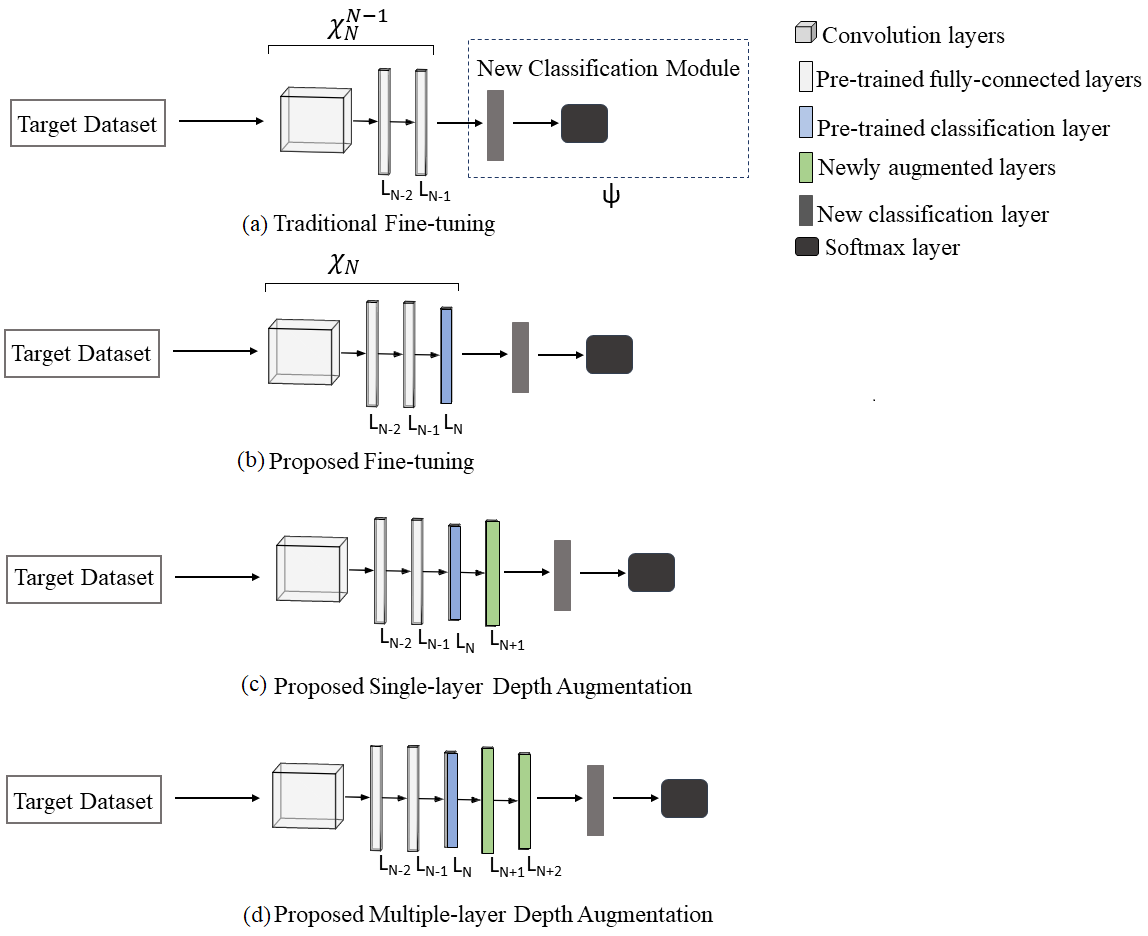 Figure 4
Figure 4 Figure 5
Figure 5| Type | Name | Images | Categories |
|---|---|---|---|
| Fine grained | 102 Flowers | 8189 | 102 |
| CUB 200-2011 | 11788 | 200 | |
| Stanford Dogs | 20580 | 120 | |
| Oxford Pets | 7400 | 37 | |
| Coarse | Caltech-256 | 30607 | 256 |
| Pascal VOC-07 | 9963 | 20 | |
| MIT-67 scenes | 15620 | 67 | |
| SUN-397 scenes | 108754 | 397 |
| Network | Dataset | All | |||||
|---|---|---|---|---|---|---|---|
| CUB 200-2011 | 512 | 65.2 | 66.5 | 66.9 | 67.8 | 67.2 | |
| 1024 | 66.2 | 67.5 | 68.9 | 69.9 | 68.4 | ||
| 2048 | 66.3 | 68.7 | 69.0 | 70.9 | 69.2 | ||
| 4096 | 66.7 | 68.1 | 67.1 | 68.1 | 66.8 | ||
| AlexNet | Caltech-256 | 512 | 75.5 | 78.2 | 78.6 | 79.5 | 79.1 |
| 1024 | 75.9 | 78.3 | 78.9 | 80.9 | 80.3 | ||
| 2048 | 75.2 | 77.9 | 78.5 | 81.9 | 81.1 | ||
| 4096 | 75.0 | 78.1 | 78.3 | 81.0 | 80.9 | ||
| CUB 200-2011 | 512 | 76.4 | 76.8 | 77.1 | 77.9 | 77.6 | |
| 1024 | 76.8 | 77.1 | 77.5 | 77.6 | 77.9 | ||
| 2048 | 76.7 | 77.6 | 77.9 | 78.1 | 77.1 | ||
| 4096 | 75.9 | 77.7 | 77.0 | 77.5 | 77.4 | ||
| VGG-16 | Caltech-256 | 512 | 85.5 | 86.1 | 87.7 | 87.9 | 87.1 |
| 1024 | 85.9 | 86.3 | 86.9 | 87.8 | 87.5 | ||
| 2048 | 85.5 | 87.8 | 88.0 | 88.4 | 88.1 | ||
| 4096 | 85.3 | 88.1 | 89.5 | 88.5 | 88.1 |
| Network | Dataset | Configuration | Accuracy (%) |
|---|---|---|---|
| CUB 200-2011 | 70.9 | ||
| 72.1 | |||
| 102 Flowers | 95.9 | ||
| 97.2 | |||
| AlexNet | Caltech-256 | 81.9 | |
| 82.8 | |||
| VOC-07 | 87.9 | ||
| 88.8 | |||
| CUB 200-2011 | 78.1 | ||
| 78.9 | |||
| 102 Flowers | 97.1 | ||
| 98.2 | |||
| VGG-16 | Caltech-256 | 88.5 | |
| 89.4 | |||
| VOC-07 | 94.4 | ||
| 95.9 |
| Network | Dataset | Norm | Accuracy (%) | ||||
|---|---|---|---|---|---|---|---|
| All | |||||||
| AlexNet | CUB 200-2011 | Standardization | 66.2 | 67.5 | 68.9 | 69.9 | 68.4 |
| 62.1 | 64.2 | 64.3 | 64.5 | 63.5 | |||
| VGG-16 | CUB 200-2011 | Standardization | 76.7 | 77.6 | 77.9 | 78.1 | 78.5 |
| 71.5 | 72.1 | 73.1 | 73.2 | 72.7 | |||
| CUB 200-2011 | 102 Flowers | Stan. Dogs | Oxf. Pets | Avg. | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| AlexNet | VGG-16 | AlexNet | VGG-16 | AlexNet | VGG-16 | AlexNet | VGG-16 | AlexNet | VGG-16 | |
| 3.3 | 2.8 | 3.1 | 1.6 | 1.4 | 1.6 | 4.2 | 2.0 | 3.0 | 2.0 | |
| 4.7 | 2.5 | 2.0 | 2.9 | 1.8 | 3.7 | 2.1 | 3.7 | 2.7 | 3.2 | |
| 1.2 | 0.8 | 1.3 | 1.1 | 0.4 | 1.2 | 1.0 | 0.9 | 1.0 | 1.0 | |
| Caltech-256 | VOC-07 | MIT-67 | SUN-397 | Avg. | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| AlexNet | VGG-16 | AlexNet | VGG-16 | AlexNet | VGG-16 | AlexNet | VGG-16 | AlexNet | VGG-16 | |
| 4.0 | 2.7 | 3.4 | 4.6 | 5.1 | 6.5 | 6.7 | 4.5 | 4.8 | 4.6 | |
| 2.8 | 2.7 | 3.4 | 2.3 | 3.6 | 3.8 | 2.0 | 3.5 | 3.0 | 3.1 | |
| 0.9 | 0.9 | 0.9 | 1.5 | 1.4 | 1.1 | 1.7 | 1.3 | 1.2 | 1.2 | |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
11institutetext: School of Science, Engineering and Information Technology
Federation University, Australia
11email: {t.shermin, shyh.wei.teng, manzur.murshed, guojun.lu}@federation.edu.au22institutetext: Murdoch University, Australia
22email: [email protected]
33institutetext: Charles Sturt University, Australia
33email: [email protected]
Enhanced Transfer Learning with ImageNet Trained Classification Layer
Tasfia Shermin 11
Shyh Wei Teng 11
Manzur Murshed 11
Guojun Lu 11
Ferdous Sohel 22
Manoranjan Paul 33
Abstract
Parameter fine tuning is a transfer learning approach whereby learned parameters from pre-trained source network are transferred to the target network followed by fine-tuning. Prior research has shown that this approach is capable of improving task performance. However, the impact of the ImageNet pre-trained classification layer in parameter fine-tuning is mostly unexplored in the literature. In this paper, we propose a fine-tuning approach with the pre-trained classification layer. We employ layer-wise fine-tuning to determine which layers should be frozen for optimal performance. Our empirical analysis demonstrates that the proposed fine-tuning performs better than traditional fine-tuning. This finding indicates that the pre-trained classification layer holds less category-specific or more global information than believed earlier. Thus, we hypothesize that the presence of this layer is crucial for growing network depth to adapt better to a new task. Our study manifests that careful normalization and scaling are essential for creating harmony between the pre-trained and new layers for target domain adaptation. We evaluate the proposed depth augmented networks for fine-tuning on several challenging benchmark datasets and show that they can achieve higher classification accuracy than contemporary transfer learning approaches.
Keywords:
CNNs Parameter fine-tuning Depth augmentation.
1 Introduction
Convolutional neural networks [1], [2], [4], [3] require a huge amount of labelled training data to yield optimal performance. Luckily, training CNNs on a large and diverse dataset (e.g. ImageNet) has been shown to enable the knowledge transfer across a wide range of tasks [5]. Parameter fine-tuning is one of the best performing transfer learning approaches used by the deep learning community. Parameter fine-tuning assists transferring learned knowledge to accomplish the target task with limited labelled data and increases the performance of the target model over random initialization [6]. The sequence of traditional parameter fine-tuning is to replace the classification layer of a CNN, pre-trained on a large and diverse dataset (e.g. ImageNet), with a randomly initialized new classification layer as per the target task. Then the new model undergoes forward-backward propagation to tune gradient descent on the target set. This transfer learning approach is exploited successfully by a number of contemporary transfer learning research [7], [8], [9], [10].
The intuition behind so far not using the pre-trained classification layer while fine-tuning is that this layer holds category-specific features [6] that may not generalize well to target sets. However, our research manifests that even the classification layers of CNNs pre-trained on ImageNet have of overlapping or neighbouring high-level features with the target sets of images of natural and artificial objects, since ImageNet consists of a massive amount of labelled images of natural and human-made objects. Fig. 1 shows the t-SNE [29] visualization of the relative distribution of extracted features from the classification layer of pre-trained AlexNet for widely used eight transfer learning target datasets (Section 4.1) and ImageNet (source). The t-SNE algorithm tries to minimize the divergence between two distribution by preserving the close or related clusters of high dimension in converted low dimension: one distribution is that measures pair-wise similarity in higher dimensional input data (in our case thousand dimensional features of source-target datasets) and the other distribution that measures pair-wise similarity in lower dimension (in our case two-dimensional space for visualization). We have used t-SNE for visualizing the relation or closeness between source and target features. The high intermingling or neighbouring between source and target feature distribution manifests that the classification layer of ImageNet pre-trained CNN may well assist the target network to adapt to the target domain via parameter fine-tuning. Also, by jointly adapting pre-trained classification and other representation layers for the target task, we could essentially bridge the domain shift underlying both the marginal distribution and the conditional distribution, which is pivotal for enhancing transfer learning [11]. Thus, we argue that the pre-trained classification layer is important for transfer learning and propose to include this layer in the fine-tuning procedure. In this work, we evaluate all fine-tuning approaches with our layer-wise fine-tuning scheme to observe fine-tuning from which layer produces optimal performance.
A significant number of works have experimented with incremental and lifelong learning [12], [13], [14]. For developmental transfer learning, in consistent with the traditional fine-tuning sequence, Wang et al. [15] and Oquab et al. [9] have discarded the pre-trained classification layer and appended new layers after the penultimate fully-connected (FC) layer of AlexNet. However, inspired by our empirical analysis of the transferability of the pre-trained classification layer (Section 4.3), we argue that the presence of the pre-trained classification layer is vital to increasing the network depth for transfer learning. Thus, we propose to consider this layer as the last FC layer and to append new layers beyond it for developmental transfer learning.
During fine-tuning, our proposed depth augmented networks might struggle from internal covariate shift of activations across pre-trained and new layers. Thus, to establish harmony between the learning of new and pre-trained layers, and to reduce sensitivity to random initialization, we introduce a normalization scheme to the network. We experiment with -norm normalization [15] and batch normalization [16] to search for the best performing normalization scheme for the proposed depth augmented networks.
The main contributions of the paper are as follows:
- •
We propose to include the pre-trained classification layer in fine-tuning and find that the transfer learning performance with the pre-trained classification layer is higher than the traditional fine-tuning approach without it.
- •
We investigate which layers should be frozen during fine-tuning for optimal performance.
- •
For developmental transfer learning, we propose to augment new layers beyond the pre-trained classification layer to adapt better to target task. We also investigate the best fit normalization scheme for our proposed depth augmented networks.
The rest of the paper is organized as follows. Our proposed approaches are presented in Section 2. Section 3 presents the setup and analysis of our experimentation. Section 4 summarizes the contributions of this paper.
2 Methodology
We introduce the architectural and notational details of the proposed and traditional fine-tuning, the proposed depth augmented networks, and the layer-wise fine-tuning scheme in this section. Let us assume be a CNN pre-trained with a large dataset (e.g. ImageNet) having layers , including the classification layer.
2.1 Traditional and Proposed Fine-tuning
Let denote the sub-network comprising the first layers of , . Let denote a transfer-learning network (TLN) from the first , , layers of the pre-trained CNN , with parameter fine-tuning from layer onwards, , where is a classification module for new classes, which is a FC classification layer followed by a Softmax layer. Fig. 2(a) illustrates the block diagram of a TLN () which follows traditional fine-tuning sequence where the pre-trained classification layer is discarded before fine-tuning. On the contrary, we include the pre-trained classification layer in the proposed fine-tuning approach, as shown in Fig. 2 (b). Our proposed fine-tuning TLN which comprises of all the layers of , is denoted as , with parameter fine-tuning from layer onwards.
2.2 Proposed Depth Augmented Networks for Fine-tuning
We increase the depth capacity of the network by constructing new FC layers comprising neurons on top of the classification layer as shown in Fig. 2 (c) and (d). Let denote a depth augmented TLN from the pre-trained CNN augmented with , , additional FC layers , with parameter fine-tuning from layer onwards, , where is the new classification module, which has a FC classification layer with a Softmax layer. Appended layers are treated as adaptation layers to compensate for the different image statistics of the source and target sets. Moreover, they allow for suitable compositions of pre-existing parameters and avoid unwanted modifications to the parameters of pre-trained layers for their adaptation to the new task.
To maintain learning pace, we propose to include a normalization scheme in proposed depth augmented networks. We explore both -norm normalization and batch normalization. For the first normalization approach, consistent with [15], we apply -norm normalization to the input activations of new layers. In case of batch normalization, we standardize the mean and variance of the input activations of new layers for stabilizing the learning process. Finally, we employ the learnable scaling parameter to scale the normalized activations.
2.3 Layer-wise Fine-tuning Scheme
We evaluate all the approaches discussed above (Sections 2.1 and 2.2) using a two-step layer-wise fine-tuning scheme. At the first step, we initialize the transferred layers with pre-trained parameters and new layers randomly. In the second step, we start fine-tuning from the last transferred layer and freeze other layers. These two steps are repeated times with different setups ( is the number of transferred layers), i.e. each time we unfreeze one more penultimate layer. For instance, in the second setup, we start fine-tuning from the penultimate transferred layer onwards. It is worth mentioning that the fine-tuning setups are mutually exclusive and parameters of all the different setups are initialized according to Step 1. We record transfer learning performance for each of these fine-tuning setups to determine which setup yields optimal performance.
3 Performance Study and Analysis
This section describes the datasets used in our experiments, the implementation details, and our evaluation outcomes for proposed approaches.
3.1 Datasets and Implementation Details
We assembled eight different fine-grained and coarse target datasets, as stated in Table 1. Fine-grained datasets used in this work are 102 Flowers [17] with 102 categories, CUB 200-2011 [18] with 200 types of birds, Stanford Dogs [19] with 120 classes and Oxford Pets [20] with 37 classes. The Coarse or mixed semantic datasets are Caltech-256 [21] with 256 categories, Pascal VOC-07 [22] having 20 different classes, MIT-67 scenes [23] with 67 classes of indoor scenes and SUN-397 scenes [24] with 397 categories. We have used ImageNet as the source dataset.
We have used AlexNet [1] and VGG-16 [2] pre-trained on ImageNet as source networks. Networks with two different depths, i.e. AlexNet, and VGG-16 are used to observe whether proposed parameter fine-tuning has consistent performance across different architectures. For pre-processing the training dataset, input images are first randomly cropped, horizontally flipped, and then normalized. A split of 75% of target dataset is used for training, and the remaining 25% for testing. We execute 2000 iterations with a batch size of 100 and momentum 0.9 for fine-tuning. A global learning rate of 0.005 is used with a piece-wise scheduler which lowers down the learning rate by 10 times less than the previous one at every 10 epochs. We have used 10 times higher learning rate in the newly appended layers of proposed depth augmented networks.
3.2 Evaluation and Analysis of Proposed Fine-tuning
To investigate the impact of pre-trained classification layer in parameter fine-tuning and to compare the performance of proposed fine-tuning with traditional fine-tuning, we utilize our layer-wise fine-tuning scheme (Section 2.3). Fig. 3 presents the results of two coarse (Caltech-256 and Pascal VOC-07) and two fine-grained datasets (CUB 200-2011, 102 Flowers). Traditional fine-tuning setup (dotted lines) lags far behind the proposed fine-tuning (dashed lines) consistently for almost all fine-tuning setups. This finding substantiates that fine-tuning pre-trained classification layer along with other transferred layers assist better transfer learning. Note that other datasets also perform similarly.
3.3 Layers to be Frozen for Optimal Performance
Proposed and traditional fine-tuning performance seems to increase when we continue to unfreeze and fine-tune more pre-trained layers according to different layer-wise fine-tuning setups (Section 2.3), as shown in Fig. 3 (a) and Fig. 3 (b). However, we observe a significant drop in performance when we tune initial convolutional layers, more specifically, convolutional layer 1 and 2 for AlexNet, and convolution block 1 and 2 for VGG-16. The intuition is that fine-tuning these generic layers might introduce noisy or unwanted modifications of parameters. That is, updating parameters would force the network to learn highly generic features of target set which are already learned from source set. The fine-tuning procedure has far fewer data and iterations than training from scratch, which might not let a vast number of pre-trained parameters of initial convolutional layers find another such equilibrium to interact with next convolutional layer in the same pace. Fig. 3(a) portrays that fine-tuning from the third convolution layer onwards of AlexNet yields the highest accuracy. Fig. 3(b) manifests that VGG-16 holds a similar trend for the third convolution block, which gives another perception that the first two convolution blocks of VGG-16 may contain highly generic or low-level features.
3.4 Performance Analysis of Proposed Depth Augmented Networks
We append a new FC layer on top of the pre-trained classification layer, employ normalization scheme to the augmented network, and perform layer-wise fine-tuning. We discuss details about our normalization scheme later in this section. Our results shown in solid lines of Fig. 4(a) and 4(b) present our best performing augmented networks with 2048 neurons and signify that parameter fine-tuning with increased network capacity paves the way to learn better. Our proposed single-layer depth augmented network performed better than fine-tuning with the pre-trained classification layer. This observation verifies the effectiveness of increasing model capacity beyond the pre-trained classification layer when adapting it to both fine-grained and coarse novel classification task. Considering the best layer-wise fine-tuning performance, CUB and 102 Flowers seem to achieve more gain than the other two.
A detailed analysis of our investigation with single-layer depth augmented networks having different combinations of neurons, such as 512, 1024, 2048, and 4096, is shown in Table 2. Our empirical results indicate that the increase in performance is proportional to the increase in the magnitude of the new layer; however, for 4096 neurons, it diminishes marginally. In proposed depth augmentation approach, the bridge between new and pre-trained layers is the layer consisting only 1000 neurons; it might suffer from an overabundance of parameters while propagating information through to four times larger neural layer. Single-layer depth augmentation with 2048 neurons happens to yield best performance. It is worth mentioning that our augmented networks also perform similarly for other datasets.
Comparison with Contemporary Transfer Learning Works To further prove the robustness of proposed single-layer depth augmented networks, we summarize the performance comparison with different existing transfer learning approaches from literature in Tables 3 and 4. The best outcomes among various combinations of our single-layer depth augmented AlexNet and VGG-16 evaluated by our layer-wise fine-tuning scheme are shown. For other approaches, the performance gap between our implementation and that reported by [5], [25], [26], [27], [15], [28] is due to different target sets, train-test splits, network architectures, and iterations. Note that we have used similar hyper-parameters, iterations, and train-test splits for all approaches in Tables 3 and 4 to maintain a fair comparison. Consistent superior outcomes validate that the presence of the pre-trained classification layer in increasing model capacity for parameter fine-tuning is effective for adjusting the network to a wide range of target tasks.
Comparison of Single and Multiple-layer Depth Augmentation Augmenting two new layers beyond pre-trained classification layer is observed to be the cut-off point as performance starts to diminish after that. Table 5 shows the results of the best combination (i.e. =2048 and =1024) of two-layer and single-layer depth augmentation. Appending two new layers after the pre-trained classification layer facilitate network marginally over single-layer augmentation by increasing representational capacity. It is proven once again that the pre-trained classification layer holds prominent high-level features which are capable of propagating learned knowledge to multiple newly appended layers. This also manifests increasing network incrementally by augmenting depth is a stable parameterization for improving performance.
3.4.1 Best Fit Normalization Scheme
After exploring two types of normalization, we observe that standardization [16] assisted better learning for proposed single and multiple-layer depth augmented networks. We represent the results of diagnostic experiments with and standardization in Table 6. Results of the single-layer depth augmented AlexNet trained on CUB 200-2011 dataset show that the improvement of our depth augmented network is around 2% compared to traditional fine-tuning for -norm normalization, and more than 6% otherwise. A similar significant boost in performance is also noticed in other datasets, which are not stated in this paper for limited space. Increase in task performance states that standardization reduces the chances of the pre-trained activations to dominate the randomly initialized ones.
3.5 Average Performance Gain
Tables 7 and 8 show that in average both coarse and fine-grained target datasets leverage the presence of the pre-trained classification layer in proposed fine-tuning and depth augmentation. However, coarse datasets manifest slightly more significant performance gain than fine-grained ones. This suggests that this layer possesses general information to transfer to a wide range of datasets. Results show that both the networks gain significant improvement for single-layer augmentation while for two-layer, the increase is marginal. Moreover, less deep backbone network seems to be more benefited from depth augmentation.
4 Conclusion
In this paper, we demonstrate that the ImageNet and widely used transfer learning target sets have neighbouring high-level features, therefore, adapting the pre-trained classification layer which catches high-level features would help fine-tuning. We propose a novel fine-tuning approach with the pre-trained classification layer. We empirically establish that proposed fine-tuning approach outperforms traditional fine-tuning for all selected target datasets. Also, we notice on average, the coarse target datasets with ImageNet achieve more performance gain than fine-grained ones. For evaluating traditional and proposed fine-tuning approaches, we use our layer-wise fine-tuning scheme. Our layer-wise fine-tuning scheme manifests that freezing initial convolutional layers yield optimal fine-tuning performance for all target datasets.
Being inspired by developmental transfer learning and impact of the pre-trained classification layer in fine-tuning, we augment new layers beyond the pre-trained classification layer for a better adaptation of the target task. Moreover, to tune pre-trained and new parameters at a steady speed and to encourage better learning, we normalize and scale input activations of augmented layers. Assessment of the proposed depth augmented networks on eight different datasets show that they outperform existing transfer learning approaches. Our empirical study has provided practitioners strong justification to utilize the ImageNet pre-trained classification layer for fine-tuning and depth augmentation beyond it for adapting the network to target tasks.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Krizhevsky, A., Sutskever, I., Hinton, G.: Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems, pp. 1097–1105 (2012)
- 2[2] Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. ar Xiv preprint ar Xiv:1409.1556 (2014).
- 3[3] He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778 (2016).
- 4[4] Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., Rabinovich, A.:Going deeper with convolutions. Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1–9 (2015).
- 5[5] Sharif Razavian, A., Azizpour, H., Sullivan, J., Carlsson, S.: CNN features off-the-shelf: an astounding baseline for recognition. Proceedings of the IEEE conference on computer vision and pattern recognition workshops, pp. 806–813 (2014).
- 6[6] Yosinski, J., Clune, J., Bengio, Y., Lipson, H.: How transferable are features in deep neural networks? Advances in neural information processing systems, pp. 3320–3328 (2014).
- 7[7] Hariharan, B., Arbeláez, P., Girshick, R., Malik, J.: Hypercolumns for object segmentation and fine-grained localization. Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 447–456 (2015).
- 8[8] Yang, S., Ramanan, D.: Multi-scale recognition with DAG-CN Ns. Proceedings of the IEEE international conference on computer vision, pp. 1215–1223 (2015).