A GPU-accelerated package for simulation of flow in nanoporous source rocks with many-body dissipative particle dynamics
Yidong Xia, Ansel Blumers, Zhen Li, Lixiang Luo, Yu-Hang Tang, Joshua, Kane, Hai Huang, Matthew Andrew, Milind Deo, Jan Goral

TL;DR
This paper introduces a GPU-accelerated simulation package using many-body dissipative particle dynamics for modeling fluid flow in complex nanoporous shale rocks, achieving high scalability and performance on supercomputers.
Contribution
The authors develop and validate a GPU-based simulation tool that significantly accelerates mesoscopic flow modeling in realistic shale pore geometries, enabling high-throughput analysis.
Findings
Nearly perfect strong and weak scaling up to 512 million particles on 512 GPUs
GPU performance surpasses CPU by up to 40% with NVLink
GPU implementation reduces computational resources compared to CPU clusters
Abstract
Mesoscopic simulations of hydrocarbon flow in source shales are challenging, in part due to the heterogeneous shale pores with sizes ranging from a few nanometers to a few micrometers. Additionally, the sub-continuum fluid-fluid and fluid-solid interactions in nano- to micro-scale shale pores, which are physically and chemically sophisticated, must be captured. To address those challenges, we present a GPU-accelerated package for simulation of flow in nano- to micro-pore networks with a many-body dissipative particle dynamics (mDPD) mesoscale model. Based on a fully distributed parallel paradigm, the code offloads all intensive workloads on GPUs. Other advancements, such as smart particle packing and no-slip boundary condition in complex pore geometries, are also implemented for the construction and the simulation of the realistic shale pores from 3D nanometer-resolution stack images.…
Click any figure to enlarge with its caption.
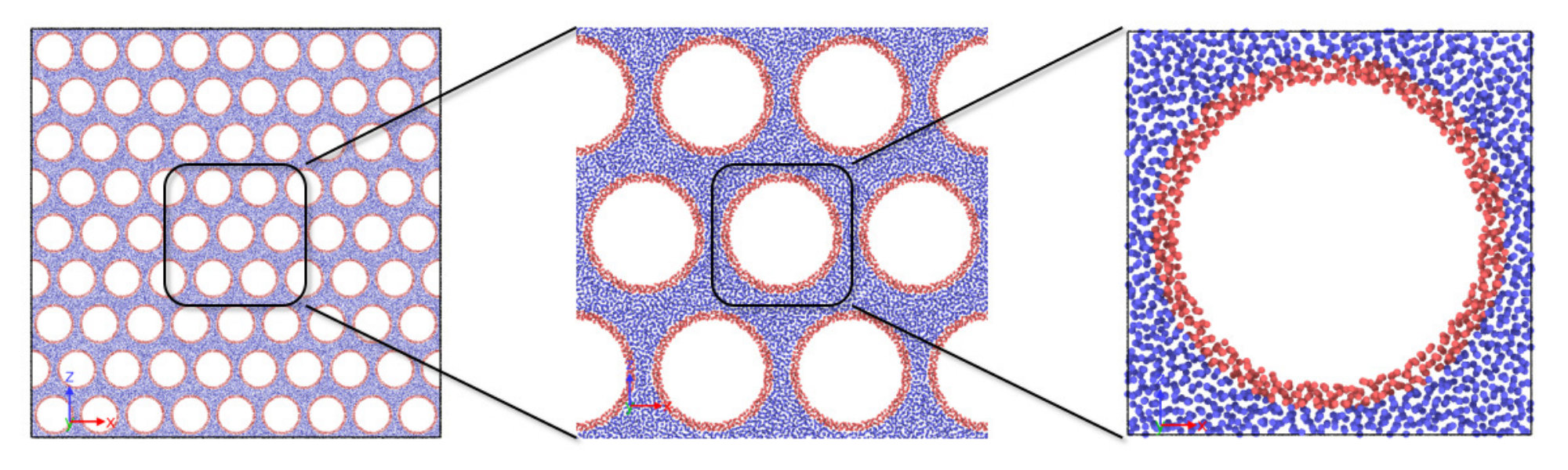 Figure 2
Figure 2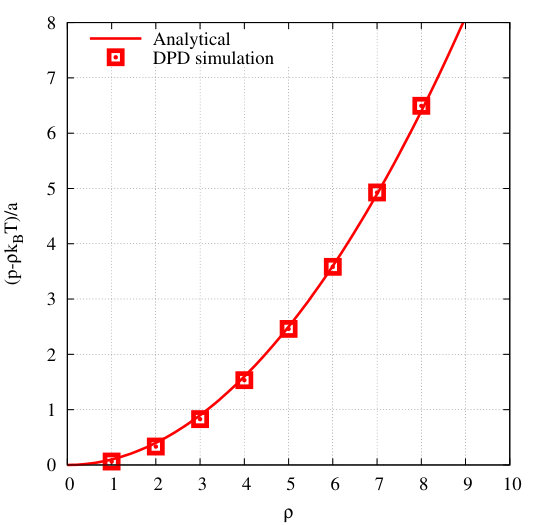 Figure 2
Figure 2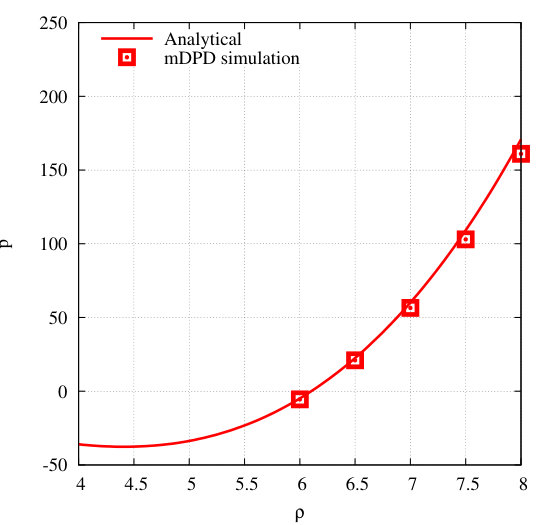 Figure 3
Figure 3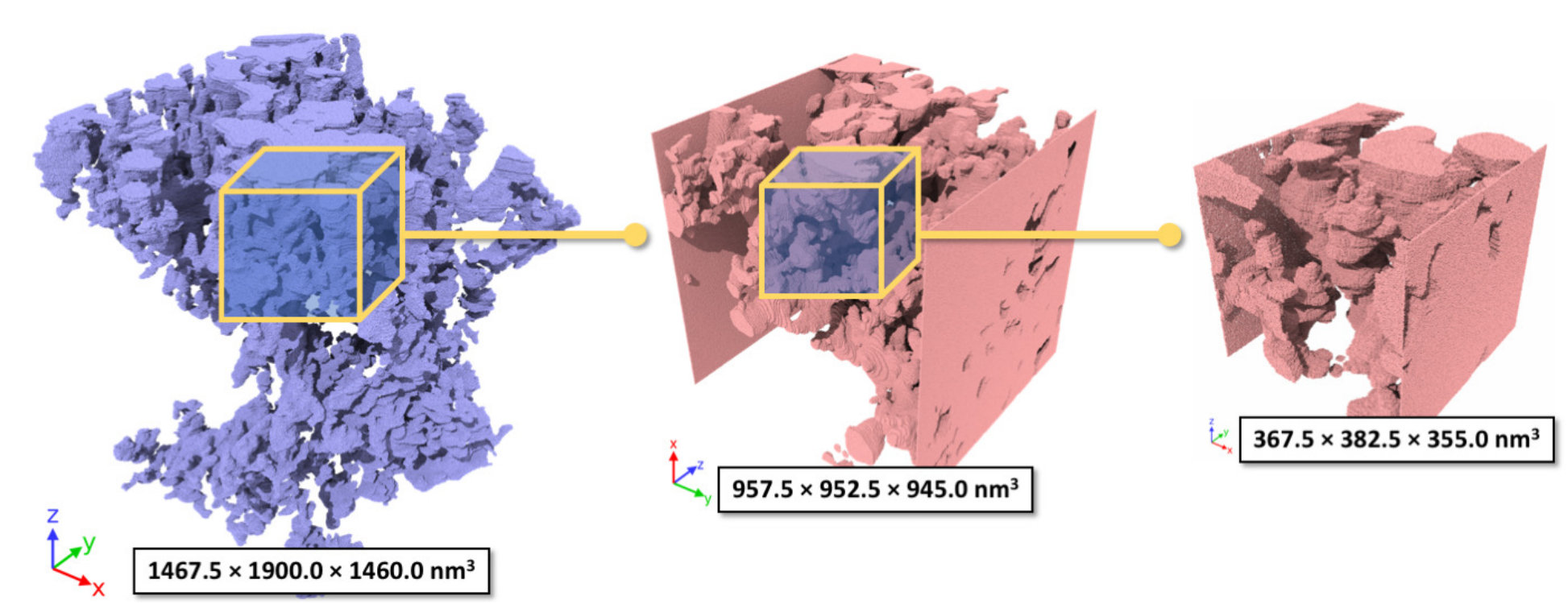 Figure 4
Figure 4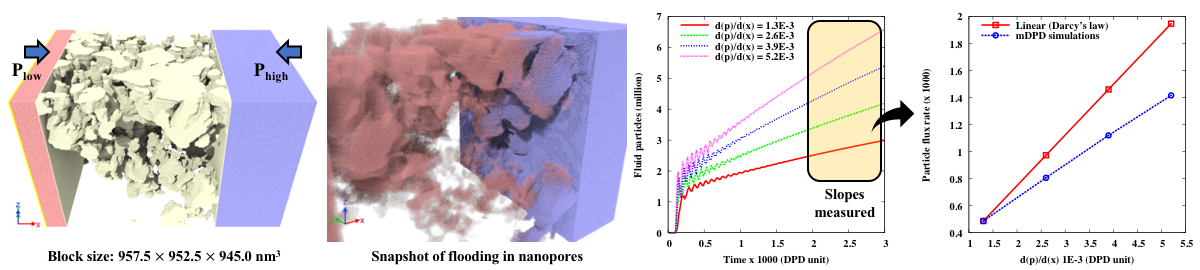 Figure 5
Figure 5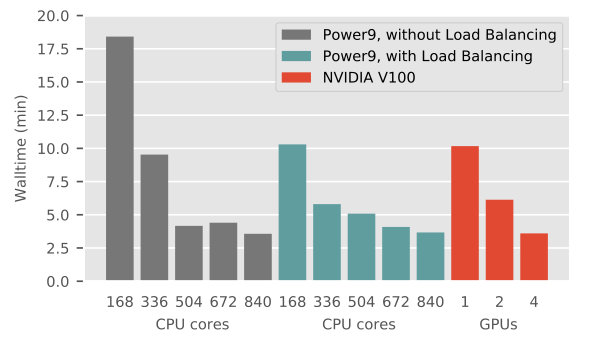 Figure 6
Figure 6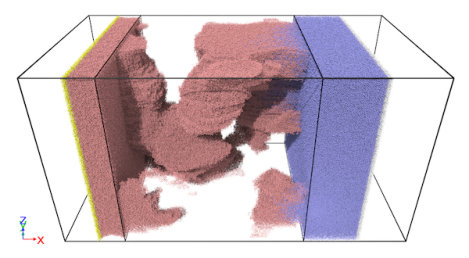 Figure 7
Figure 7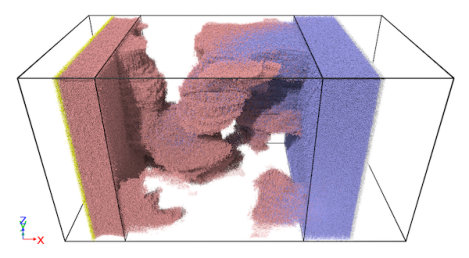 Figure 8
Figure 8 Figure 9
Figure 9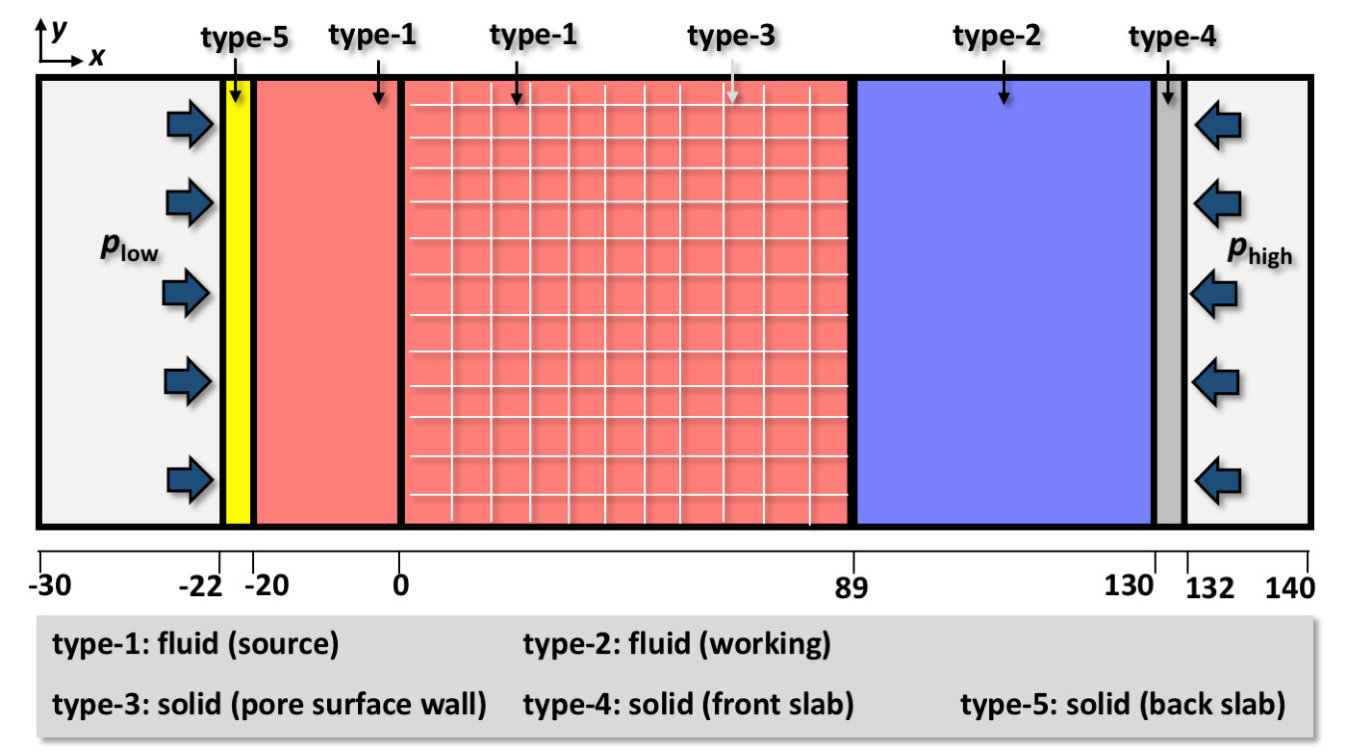 Figure 10
Figure 10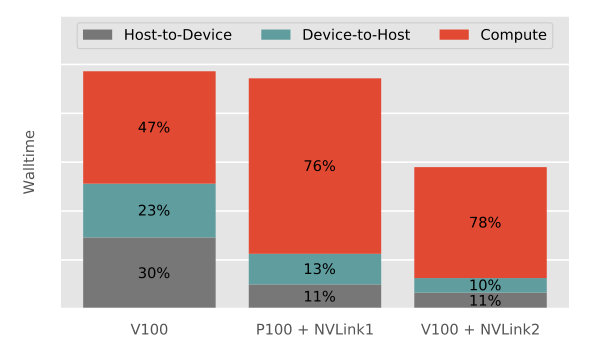 Figure 11
Figure 11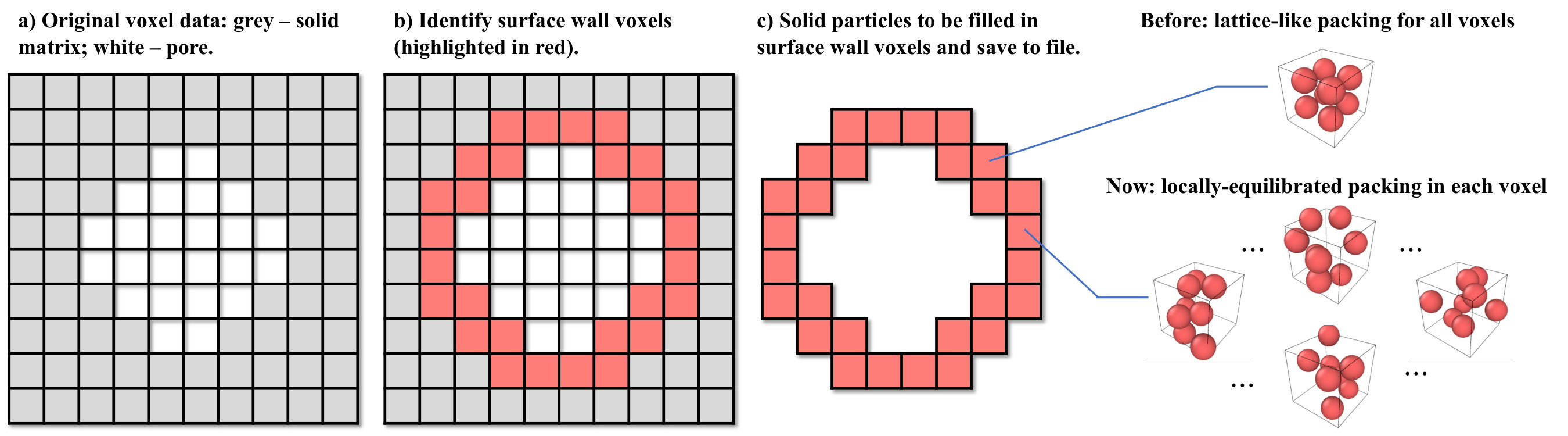 Figure 12
Figure 12 Figure 14
Figure 14 Figure 15
Figure 15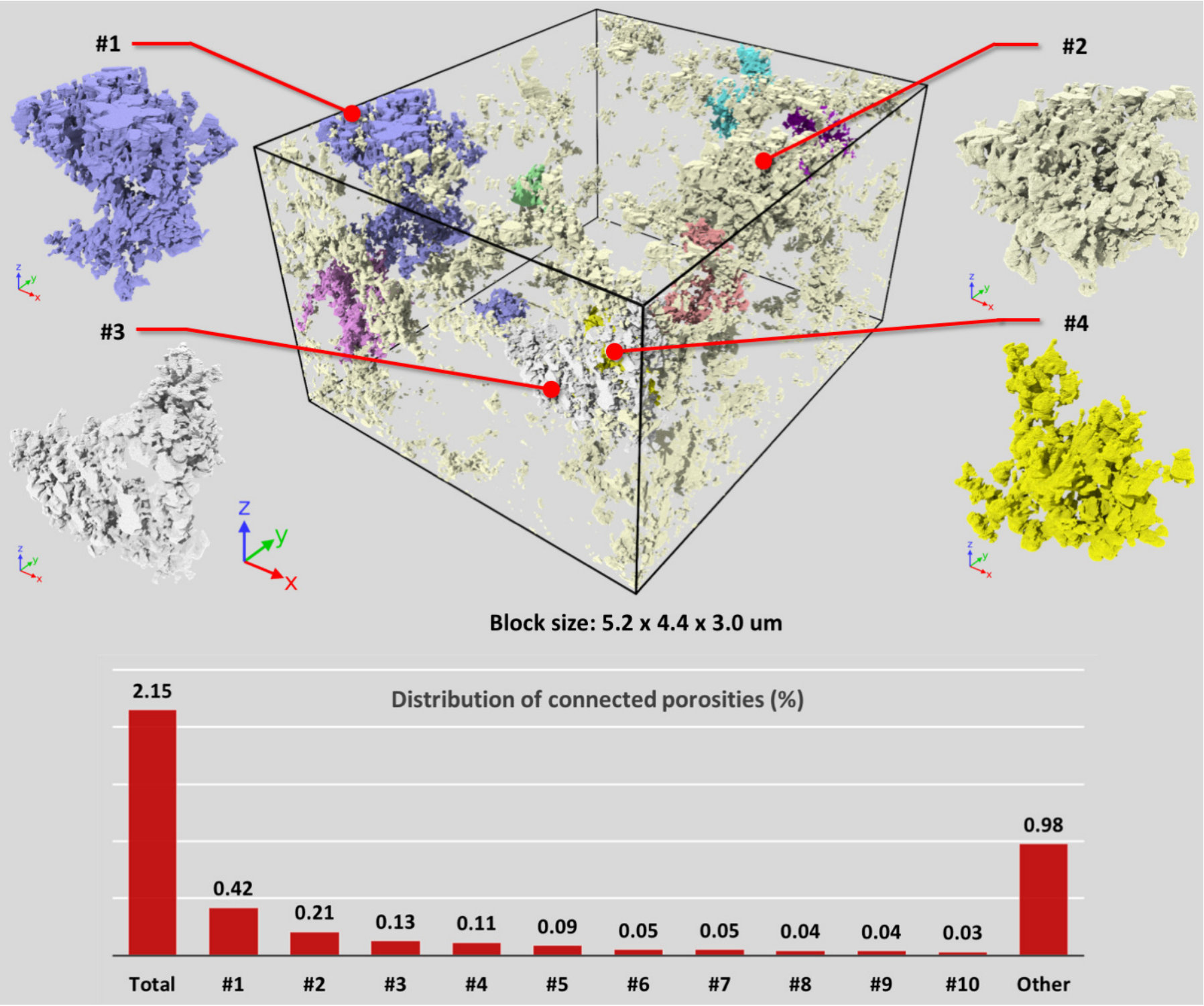 Figure 16
Figure 16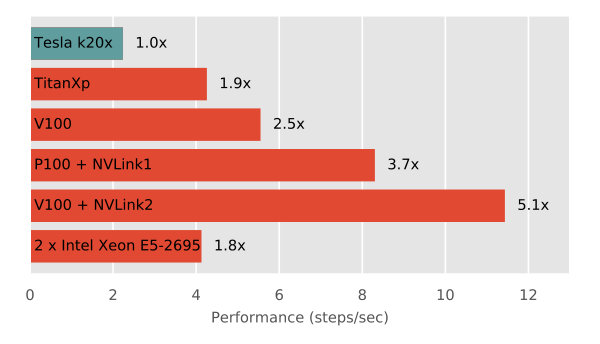 Figure 17
Figure 17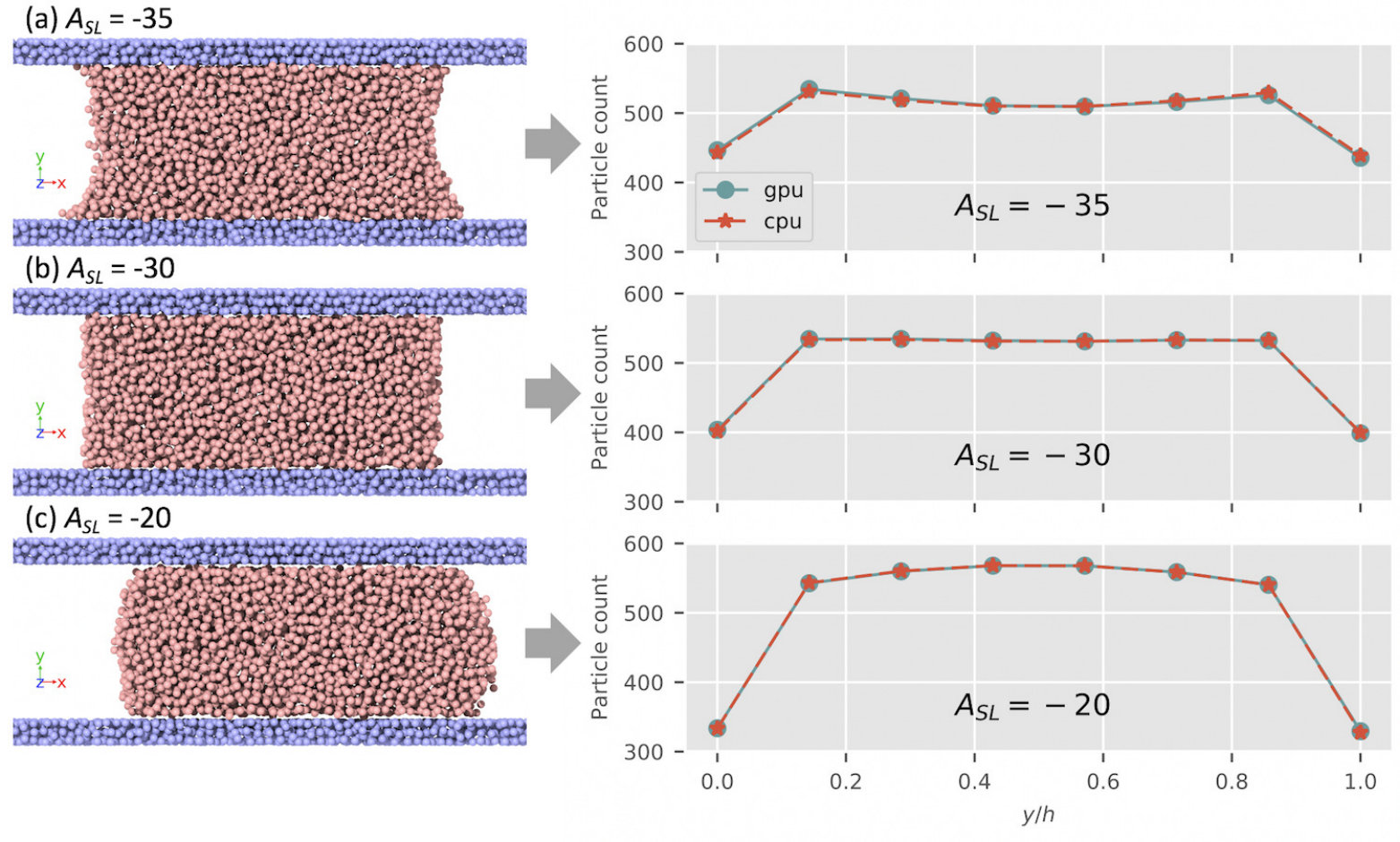 Figure 18
Figure 18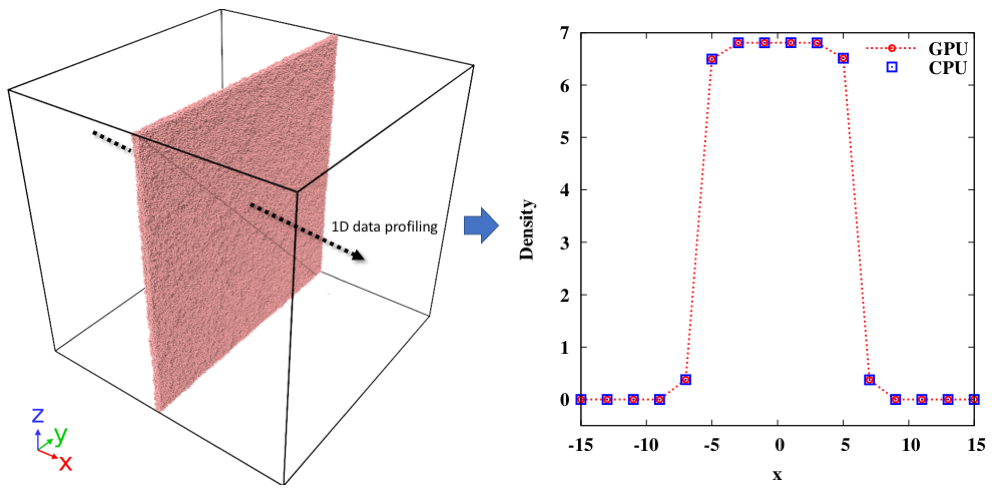 Figure 19
Figure 19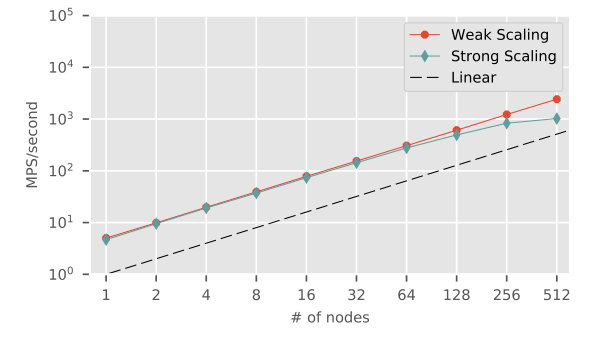 Figure 20
Figure 20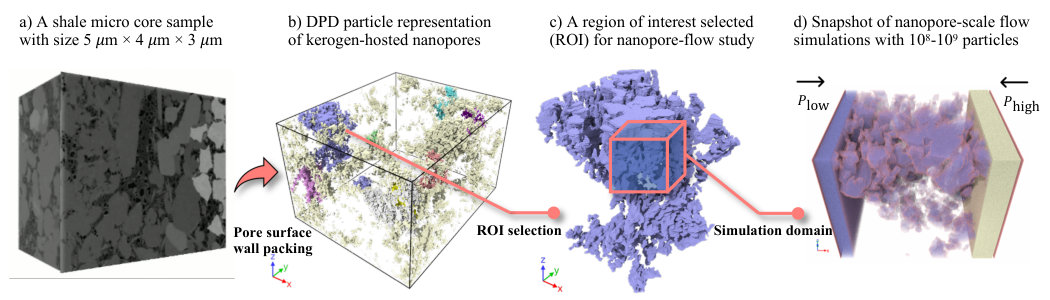 Figure 21
Figure 21| Solid | Lquid | |
|---|---|---|
| Solid | -40 | -40 |
| Liquid | -40 | -35; -30; -20 |
| Solid | Fluid | |
|---|---|---|
| Solid | — | -40 |
| Fluid | -40 | -40 |
| Label (machine) | CPU | NVIDIA GPU | Host-to-Device interconnect |
|---|---|---|---|
| Tesla K20X (ORNL Titan node) | AMD Opteron 6274 | Tesla K20X | PCIe |
| TITAN Xp (desktop workstation) | Intel i7-8700K | TTIAN Xp | PCIe |
| V100 (NVIDIA DGX-1 at INL) | Intel Xeon E5-2698 v4 | Tesla V100 | PCIe |
| P100 + NVLink1 (ORNL SummitDev node) | IBM Power8 | Tesla P100 | NVLink1 |
| V100 + NVLink2 (IBM AC922 node) | IBM Power9 | Tesla V100 | NVLink2 |
| 2 Intel Xeon E5-2695 (INL HPC node) | Intel Xeon E5-2695 | N/A | N/A |
| Subdomain | Fluids | Wall | Slabs | Total |
|---|---|---|---|---|
| 0 | 675,028 | 164,223 | 64,068 | 903,319 |
| 1 | 830,701 | 182,201 | 64,060 | 1,076,962 |
| 2 | 930,803 | 97,688 | 64,064 | 1,092,555 |
| 3 | 1,064,133 | 124,376 | 64,064 | 1,252,573 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
A GPU-accelerated package for simulation of flow in nanoporous source rocks with many-body dissipative particle dynamics*⋆*
Yidong Xiaa,,1, Ansel Blumersa,b,1, Zhen Lic,, Lixiang Luod, Yu-Hang Tange, Joshua Kanef, Hai Huanga, Matthew Andrewg, Milind Deoh, Jan Goralh
a** Energy and Environment Science & Technology, Idaho National Laboratory, Idaho Falls, ID
b Department of Physics, Brown University, Providence, RI
c Division of Applied Mathematics, Brown University, Providence, RI
d Center of Excellence at ORNL, IBM, Oak Ridge, TN
e Computational Research Division, Lawrence Berkeley National Laboratory, Berkeley, CA
f Materials and Fuels Complex, Idaho National Laboratory, Idaho Falls, ID
g Carl Zeiss X-ray Microscopy, Pleasanton, CA
h Department of Chemical Engineering, University of Utah, Salt Lake City, UT
Approved for external release: INL/JOU-19-52933
- Corresponding authors: [email protected] (Yidong Xia), [email protected] (Zhen Li)
1 These authors contributed equally to the work**
Abstract
Mesoscopic simulations of hydrocarbon flow in source shales are challenging, in part due to the heterogeneous shale pores with sizes ranging from a few nanometers to a few micrometers. Additionally, the sub-continuum fluid-fluid and fluid-solid interactions in nano- to micro-scale shale pores, which are physically and chemically sophisticated, must be captured. To address those challenges, we present a GPU-accelerated package for simulation of flow in nano- to micro-pore networks with a many-body dissipative particle dynamics (mDPD) mesoscale model. Based on a fully distributed parallel paradigm, the code offloads all intensive workloads on GPUs. Other advancements, such as smart particle packing and no-slip boundary condition in complex pore geometries, are also implemented for the construction and the simulation of the realistic shale pores from 3D nanometer-resolution stack images. Our code is validated for accuracy and compared against the CPU counterpart for speedup. In our benchmark tests, the code delivers nearly perfect strong scaling and weak scaling (with up to 512 million particles) on up to 512 K20X GPUs on Oak Ridge National Laboratory’s (ORNL) Titan supercomputer. Moreover, a single-GPU benchmark on ORNL’s SummitDev and IBM’s AC922 suggests that the host-to-device NVLink can boost performance over PCIe by a remarkable 40%. Lastly, we demonstrate, through a flow simulation in realistic shale pores, that the CPU counterpart requires 840 Power9 cores to rival the performance delivered by our package with four V100 GPUs on ORNL’s Summit architecture. This simulation package enables quick-turnaround and high-throughput mesoscopic numerical simulations for investigating complex flow phenomena in nano- to micro-porous rocks with realistic pore geometries.
Keywords: digital rock physics; shale; GPU; dissipative particle dynamics; multiphase flow
Program summary
Program title: USERMESO 2.5
Licensing provisions: GNU General Public License 3
Programming language: CUDA C/C++ with MPI and OpenMP
Nature of problem: Particle-based simulation of multiphase flow and fluid-solid interaction in nano- to micro-scale pore networks of arbitrary pore geometries.
Solution method: Fluid particles and solid wall particles are modeled with a many-body dissipative particle dynamics (mDPD) model – a mesoscopic model for coarse-grained fluid and solid molecules. The pore surface wall boundary for arbitrary surface geometries is modeled with a no-slip boundary condition for fluid particles that prevents fluid particles from indefinitely penetrating in the walls. The time evolution of the system is integrated using the Velocity-Verlet algorithm.
Restrictions: The code is compatible with NVIDIA GPUs with compute capability 3.0 and above.
Unusual features: The code is implemented on GPGPUs with significantly improved speed.
1 Introduction
Approximately of the sedimentary rocks on Earth are clastic nanoporous tight rocks, which are often referred to as shale. Shale contains most of the world’s fossil energy sources (e.g. oil and natural gas). However, only a small fraction of the sources in shale can be recovered so far, in part due to the gaps of our knowledge in the relevant fundamental physics that ultimately control the dynamics of fluids in shale, which manifests extremely low permeability in the micro- to nano-Darcy range with average pore sizes from a few nanometers ( m) to a few micrometers ( m). Filling these knowledge gaps may help the development of more effective shale source recovery strategies. Most of the theories of fluid flow in geomaterials (and the predictive models built upon such theories) have been based on the concepts of classical continuum fluid dynamics and a rigid porous or fractured solid porous matrix, which assume ideal non-slip boundary conditions for fluid flow and transport [4]. Those concepts and models have proven adequate for developing the theories of single- and multi-phase flow in permeable porous media such as aquifers, soils, and conventional oil and gas reservoirs. Many pore-scale fluid flow models have been developed in either Eulerian or Lagrangian frame, based on the continuum computational fluid dynamics (CFD), e.g., the models based on lattice Boltzmann method (LBM) [41, 42], smoothed particle hydrodynamics (SPH) [51, 52], and volume-of-fluid finite volume method (VOF-FVM) [28, 29]. However, the behavior of fluids in nanoporous tight shale is very different, as the discreteness of molecules may impact flow and transport processes at higher scales, and the solid organic materials may play an important role as mechanical components, sorbents and sources of fluids. Besides, the large specific surface areas can make surface reactions and surface transport more profound. For example, in an ideal spherical pore of 100 nm diameter, about 6% of the fluid is within a distance of 1 nm from the solid surface, whereas in a pore of 10 nm diameter, over 49% of the fluid is within a distance of 1 nm, where the physical and chemical properties of the fluid can be significantly different from those of bulk fluids. A good understanding of large-scale flow and transport behaviors in shale requires robust and accurate multiscale computational models that can bridge the scale gaps between fluid molecular dynamics (MD) models and nanopore-scale fluid flow models.
Dissipative particle dynamics (DPD) constitutes a relatively new class of mesoscale models that can be used to simulate single- and multi-phase fluid flow [54, 25, 56, 34, 35, 36]. The DPD concept was originally introduced for microscopic hydrodynamics [27] with its theoretical foundation based on statistical mechanics [19, 38]. The various DPD models and their applications are summarized by Moeendarbary et al. [40] and Liu et al. [37], respectively. In DPD, a system can be simulated with a set of interacting particles, where each particle represents a small cluster of molecules instead of a single one. The particle-particle interaction force in a DPD embodiment consists of a “conservative” (non-dissipative) component, a dissipative component that represents the effect of viscosity, and a thermal component that represents fluctuation. The distinction between DPD and SPH is the thermally driven fluctuations that are only detectable on microscopic scales, e.g. pores with sizes in the nanometer ranges. Conversely, DPD fluids can recover the continuum Navier-Stokes equations on large scales (scales much greater than the particle size) with the effect of thermal fluctuations to be negligible. Furthermore, DPD conserves mass and momentum, and also the energy provided with special treatment [18, 49, 2, 32]), and allows much larger time steps than MD simulations. These features make DPD essentially a mesoscale method between the molecular and continuum hydrodynamic scales, and facilitates simulations of complex fluid systems with possible physical scales spanning a wide range. Recently, a so-called “many-body” DPD model [57], namely mDPD, has been found particularly suitable for multi-phase fluid systems, and thus has been applied for various multi-phase fluid simulation problems, including liquid-vapor interface, surface tension, and multi-component fluid flows in micro-scale channels [43, 8, 20, 9, 10]. In particular, mDPD manifests a unique multiscale modeling capability that can model fluid-fluid/solid interfaces in pores at both continuum- and sub-continuum-scales, as demonstrated in Figure 1.
Recently we developed an mDPD based nano to micro-scale pore flow model and applied it for multiphase flow simulations in source shale [58]. In that model, realistic shale pore geometries are constructed based on 3D voxel data of shale core samples, which are generated from a focused ion beam scanning electron microscopy (FIB-SEM) digital rock imaging process [23] with voxel resolution at tens of nanometers or even a few nanometers. Each voxel contains local composition information that can be used to identify phase boundaries in shale, e.g. interfaces between inorganic and organic solid matrices, between inorganic solid matrix and pores, and between organic solid matrix and pores. The integration of FIB-SEM to nano-pore flow simulations is a big step forward as compared with the earlier methods that used either manufactured or analytically described pore geometries [36]. Furthermore, it is worth noting that though FIB-SEM has been adopted for analyzing shale samples for a while [11, 12, 13, 14], most of the early flow simulation methods applied to shale were continuum CFD models (e.g. a finite element model by Dewers et al. [15]), whose theoretical legitimacy yet remain to be fully verified for heterogeneous nanoporous media like shale. In comparison, the mesoscopic nature of mDPD (as shown in Figure 1) makes the model a competent candidate for the nano- to micro-pore flow simulations in shale.
In order to use mDPD for predicting the critical material properties of shale micro core samples such as permeability and relative permeability, pore flow simulations must be conducted at meaningful space and time scales that may require simulations of a system with - particles and - timesteps. These simulations are computationally demanding and require significant computing resources. In early exercises we used the DPD package [31] in LAMMPS [47]. The package takes advantage of the parallel computing readiness of LAMMPS and delivers satisfying scalability for homogeneous porous systems. However, it is not the case for shale. Due to the highly non-uniform pore distributions in shale, load imbalance emerges as a result of non-uniform particle distributions and force calculations across the processing ranks and has been a serious bottleneck for the package to achieve desired scalability even with adaptive load balancing. Indeed, compared with the theoretical advances in multiphase DPD models, the development of efficient parallel strategies for those models is left behind, especially for heterogeneous porous systems at the appropriate physical scales. Efficient HPC strategies such as GPUs are highly encouraged. Because of the particular suitability of the general-purpose GPUs (GPGPUs) for MD and coarse-grained MD-like particle simulations, GPU computing has been widely adopted for mesoscale particle models such as SPH [17, 16, 59] and LBM [30, 7, 55]. Some basic DPD models have been implemented in GPU accelerated packages such as HOOMD-blue [22], GROMACS [1] and LAMMPS-GPU [6]. The implementation of more sophisticated DPD models is recently described by Tang and Karniadakis [50] and Blumers et al. [5]. Their GPU codes have demonstrated excellent strong- and weak-scalability for DPD simulations.
In this work, a generalized GPU-accelerated implementation of the mDPD based multiphase pore flow model with a solid wall boundary model for arbitrary pore geometries is developed to simulate flow dynamics in realistic source shale pores. The software features a tight integration of our earlier works including a mDPD pore flow model [58], an arbitrary-geometry wall boundary model [33] and a GPU-accelerated DPD simulator [50, 5], and delivers an efficient rock analysis throughput from digital rock imaging to pore flow simulations, as shown in Figure 2. With the new ability to model multiphase flow in arbitrary-shaped, nano- to micro-scale channels, the code package can be used to investigate the critical material properties of shale such as permeability and relative permeability with unprecedented time and length scales. Because a GPU can fit a workload comparable to many CPU codes, the use of GPUs can effectively reduce overhead in cross-rank/node communication. Consequentially the reduced rank-level parallelism is especially helpful for reducing load imbalance in mDPD flow simulations in non-uniform porous systems. For example, investing the same computing capacity, it requires a much smaller number of GPU cards than CPU cores, and hence much fewer ranks in GPU computing than CPU assuming one GPU card and one CPU core per rank. As a result, the use of GPUs would greatly reduce the number of domain decompositions in a non-uniform porous system, and thus is expected to improve load balance by substantially reducing cross-rank communication and latency in rank synchronization.
The rest of the paper is structured as follows. In section 2, we briefly describe the mDPD model, a solid wall boundary model and surface wall particle packing for arbitrary geometries. In section 3, we present the implementation and innovations of our program. In section 4, we validate the code with the verification problems. In section 5, we demonstrate the efficiency of our code by running benchmark cases for uniform and non-uniform nanoporous media. In section 6, we further demonstrate the capability of the software with pore flow simulations in realistic shale nanopore networks. Lastly, we conclude the paper in section 7.
2 Pore-scale fluid flow models
2.1 Many-body dissipative particle dynamics
In a generic formulation, DPD particles interact via pairwise central forces, i.e. , where represents a random force, a dissipative force, and a conservative force between particle and , respectively. If and are used to denote the position and velocity of particle , respectively, the random force and the dissipative force can be expressed as and , where , , and . These forces constitute a thermostat if the amplitude of the random variable and the viscous dissipation coefficient satisfy a fluctuation-dissipation theorem: and , where denotes the desired temperature in the unit of Boltzmann’s constant . In the original DPD model, the conservative force is defined as , where denotes the magnitude of the force, and the weight function vanishes when the inter-particle distance is larger than a cutoff range . The is usually derived from a soft and unspecific weight function , thus allowing for a fairly large integration time step. Different weight functions describe different material properties. A common choice for is and . The standard velocity Verlet algorithm can be employed to integrate the resulting equations of motion in time. A quadratic equation of state (EOS) is obtained with respect to the average particle density , as shown in Figure 3a. However, the original DPD model is not sufficient to model multiphase fluid flow phenomena such as liquid-vapor interfaces, liquid-liquid interfaces and free capillary surfaces. A more complex EOS needs to be represented with the DPD model. To achieve this, a long-range attractive and short-range repulsive conservative force is required. The multiphase fluid flow model employed in the present work is the so-called many-body DPD method [57], namely mDPD. In mDPD, the is augmented from the standard DPD method by density-dependent contributions, and the resulting model includes the van der Waals loop in the EOS, as shown in Figure 3b. In the mDPD model, the conservative force is expressed as
[TABLE]
which consists of a long-range attractive part that is density-independent, and a short-range repulsive part that depends on a weighted average of the local particle density. The attractive component can be obtained by simply turning the sign of the original force parameter (i.e., , with a cutoff range ). The term is a many-body repulsive component with , and shorter cutoff , where . The averaged local density, at the position of particle can be computed as , where the normalized weight function needs to satisfy . For a three-dimensional computational domain, the is defined as .
2.2 Solid wall conditions for arbitrary pore geometries
Because of the soft particle-to-particle interaction in DPD models, fluid particles may penetrate through solid matrix given a fluid-solid interface. Such penetration is not physically possible and must be avoided. Early development of solid wall boundary models were focused on imposing rigorous macroscopic boundary conditions, e.g., a non-slip boundary condition at sharply defined impenetrable solid surfaces. The idea was from a strict mesoscopic interpretation of DPD models, where a single DPD fluid particle represents a cluster of fluid molecules on scales well above the atomistic levels [24]. To model a non-slip boundary, additional forces must be exerted on fluid particles at the vicinity of solid-fluid interfaces with model parameters carefully calibrated to avoid spurious behaviors such as artificial slip [45], temperature oscillation [48] and particle layering [46]. To relax the strict non-slip requirement, Henrich et al. [26] proposed a boundary model, which imposes a weak external repelling force on fluid particles whenever they penetrate in solid matrix over a thin layer. However, most earlier boundary models are only suitable for solid surfaces that are either mostly flat, spherically curved, or at best analytically describable. A boundary model that can treat arbitrary pore geometries is required.
In this work, we adopt a new boundary model recently developed for DPD simulations involving arbitrarily complex geometries [33]. For simulating pore flow in source rocks, this model enables construction of DPD systems of realistic nano- to micro-pore channels directly from loading the 3D stack images, so that the many intermediate steps from scanning electron microscopy (SEM) or transmission electron microscopy (TEM) images to the corresponding numerical models, i.e., surface mesh reconstruction, mesh smoothing and remeshing can be avoided. In particular, this boundary model computes a boundary volume fraction of fluid particles and allows the fluid particles to detect solid boundaries on-the-fly based on local particle configurations. As a result, with a negligible extra computational cost, the moving fluid particles become autonomous to find the pore surfaces and infer the wall penetration. A predictor-corrector algorithm is then applied to perfectly prevent the fluid particles from penetrating the pore surfaces. In addition, it is important to point out that by calculating and controlling the effective dissipative interactions between fluid and solid particles, the no-slip or partially-slip boundary condition are imposed on rough/curved pore surfaces with negligible density and temperature fluctuations in the vicinity of the solid boundary.
2.3 Particle packing for pore surface geometries
To construct bounding walls in DPD based fluid flow simulations, most researchers (e.g. Meakin et al. [39], Chen et al. [8], Li et al. [33]) have followed a particle packing approach proposed in Liu et al. [36]. Using this packing approach, the whole simulation system will be first filled with DPD particles at a particle number density (e.g. ) for solid matrix and then equilibrated. Next, particles located in defined flow regions will be deleted. To reduce cost, particles located in solid matrix but away from fluid-solid interfaces by over a specified distance will also be deleted, as those particles will have no interaction with fluid particles. The remaining particles are the so-called surface wall particles, whose coordinates will be saved and used as input data in wall-bounded flow simulations. This approach, though easy to use for relatively small systems, is however challenging for production-scale systems because of a temporary spike of computational and memory cost in the step of initial whole-system packing. The highest memory temporarily needed could be over 100 times higher than it may be eventually required, making it hardly affordable for most end users. For example, a shale micro core sample with a meaningful domain size might need billions of or even over a trillion particles to fill the system temporarily, but at last require no more than 1% of them as surface wall particles because of the sample’s low porosity.
For huge porous systems, to avoid the temporary but prohibitive computing and memory cost incurred during the solid particle packing process, we introduce a new approach as an improved version of our early approach [58]. Following our early version, a simulation system is determined based on voxel data of a shale micro core sample, in which each voxel records a numeric value for its local composition (e.g. pore, organic matter, or inorganic matter). An algorithm was developed to sweep through all the voxels to identify the so-called surface wall voxels, with the surface wall thickness equal to at least . In a second sweep, solid particles with a specified number density are created with a lattice-like distribution at locations corresponding to the surface wall voxels, and saved to data files for further use. Notice that the lattice-like packing of surface wall particles might cause undesired oscillations in fluid temperature in the vicinity of solid-fluid interfaces. Despite the known artifact, this approach had been probably the only affordable way for huge porous systems with arbitrary geometric complexity. To partially remedy the artifact, the present work proposes an improved particle insertion method. For each surface wall voxel, instead of employing the lattice-like packing, we use a locally equilibrated particle distribution that is randomly chosen from a database. The database is prepared in advance and is large enough for assembled pores to resemble sufficient randomness in pore surface roughness. Figure 4 is shown to illustrate this new packing method. Also notice that the idea of local equilibrium of the particles in each surface wall voxel makes the quality of packing closer to the one by Liu et al. [36], but meantime would potentially give rise to non-equilibrium in particles across two neighbor surface wall voxels. Further improvement of affordable particle packing for pore surface walls in huge porous systems is an open area in DPD research.
3 GPU implementation
The present USERMESO 2.5 package builds on USERMESO 2.0 [5], which is a successor to the original fully GPU-accelerated USERMESO package for DPD. USERMESO 2.0 expanded the capabilities of the package to simulate different flavors of DPD, as well as cellular dynamics. Although the new capabilities added in USERMESO 2.5 only require the original USERMESO [50] as base, we feel it more natural to name our software package USERMESO 2.5 as a progression from USERMESO 2.0 .
3.1 Core features
The original USERMESO [50] is a GPU-accelerated extension package to LAMMPS for DPD simulations. In the USERMESO framework, all computations and host-device communications are handled by the extension package while I/O related tasks such as inter-rank communications are attended by LAMMPS. By offloading computations to GPUs, USERMESO is able to achieves more than 20 times speedup for simple particle simulations [50]. The speedup over the CPU counterpart is made possible by technical innovations on, but not limited to, neighbor list constructions and particle reordering, which are intended to boost data locality and increases the chance of cache hit. Furthermore, data-layout is optimized for coalesced memory access. In LAMMPS, data are stored in an array-of-structure layout on host memory. To avoid strided access on device memory, data are stored in a structure-of-array layout. The conversion between the array-of-structure and structure-of-array layouts is carried out whenever data are transferred.
The notable innovative features of the original USERMESO from which USERMESO 2.5 has inherited include: 1) an atomics-free warp-synchronous neighbor list construction algorithm, 2) a two-level particle reordering scheme, which aligns with the cell list lattice boundaries for generating strictly monotonic neighbor list, 3) customized non-branching transcendental functions (sin, cos, pow, log, exp, etc.), 4) overlapping calculation (e.g. force evaluation) with communication (e.g. particle exchange) to reduce latency, and 5) radix sort with GPU stream support.
3.2 New capabilities
To simulate complex single- and multi-phase fluid flow phenomena in realistic nano- to micro-porous geometries, a number of new features have been implemented in USERMESO 2.5 .
A major contribution by USERMESO 2.5 is the capability to run mDPD simulations. To recall the formulation in Equation 1, the many-body density that appears in the mDPD conservative force term is needed to calculate the repulsive part of the conservative form. For each particle, is computed immediately prior to the force computation. Then an inter-rank communication takes place to synchronize for the partition-ghost particles, as demonstrated in Algorithm 1.
Another important feature that has been implemented in USERMESO 2.5 is the impenetrable wall boundary described in subsection 2.2 as a general solution to handle complex geometries in DPD simulations to treat pore surface walls of arbitrary geometric configuration. The main idea is to calculate the density of solid wall particles, , within a fluid-particle’s support, and then to add a correction force to the fluid particles to counter-react the artificial walls. Since is computed before the inter-rank communication, no synchronization is necessary as shown in Algorithm 1.
4 Code verification
In this section, we present two test problems to verify the implementation of the mDPD method and solid wall boundary condition in USERMESO 2.5 . The numerical results calculated by USERMESO 2.5 were verified with our CPU code, which is implemented based on the standard LAMMPS. Each problem underwent a comparative verification on two platforms: a workstation that has an Intel i7-8700K CPU and two NVIDIA TTIAN Xp GPUs, and a DGX-1 server that is equipped with two Intel Xeon E5-2698 v4 CPUs and eight NVIDIA Tesla V100 GPUs.
4.1 Liquid-vacuum interface
In this problem, a simulation of water liquid-vacuum interface is presented with the objective to assess whether USERMESO 2.5 accurately calculates properties of a specific type of fluid. The water density and surface tension calculated by USERMESO 2.5 will be checked against its CPU counterpart. We followed the problem setup similar to Ghoufi and Malfreyt [20], but used a large cubic simulation domain bounded by in each direction with a periodic boundary condition. The simulation was initialized with a face-centered cubic (fcc) based particle allocation in the region of and with a lattice spacing of in each direction, which resulted in a total of particles in the system. The mDPD force interaction parameters , , and were used in order to match the water properties reported in Ghoufi et al. [21]. With those parameters, one DPD particle represents approximately a cluster of three water molecules (i.e., ), and the size of one DPD particle corresponds to about 90 Å3. Details of conversion from the reduced units to their corresponding physical values can be found in Ghoufi and Malfreyt [20].
In the simulation, a total of timesteps were first carried out to equilibrate the system. An instantaneous snapshot of of the equilibrated system is displayed on the left side of Figure 5, depicting a thin liquid slab formed by the particles. Another timesteps were then run to calculate the time-averaged properties. With a 1D bin size of along the x axis, a density profile calculated by USERMESO 2.5 is compared with the one obtained by our CPU code on the right side of Figure 5. The density near (center of the slab) is for both USERMESO 2.5 and our CPU code, matching the value reported in Ghoufi and Malfreyt [20]. Moreover, thanks to the simple shape of the liquid slab, the interfacial tension between the water liquid and vacuum can be calculated by subtracting the mean tangential stresses and from the normal stress : . The calculated is for both USERMESO 2.5 and its CPU counterpart, again matching the value reported in Ghoufi and Malfreyt [20]. In addition, the values for water density and water-vacuum interfacial tension can be converted into the physical units with the equations: [Å], , and , where the superscript * denote values in the reduced unit, is the volume of one water molecule ( Å), is the molar weight of a water molecule ( ), is Avogadro’s number, and is Boltzmann’s constant, and is equal to K. Expressed in the converted physical units, the water density and liquid-vacuum interfacial tension are and , respectively, which agree well with the MD results [20]. Our result indicates that the implementation of the mDPD method in USERMESO 2.5 achieves consistency with its CPU counterpart, and delivers accurate predictions of thermodynamic properties for fluids of interest.
4.2 Static contact angle in a slit nano channel
The second test problem is the simulation of static contact angles formed between a single fluid and its bounding solid walls in a slit nano channel, which demonstrates the flexibility of the mDPD model to characterize the wetting properties of fluids in the nano-scale pores. In the mDPD model, the particle interaction force between two types of materials such as solid and liquid can be modified by adjusting the attractive force parameter , the repulsive force parameter , and the repulsive force cutoff range in Equation 1, where the subscript “S” and “L” denote solid and liquid, respectively. In a controlled study of the dependence of liquid wetting behavior on certain mDPD parameters such as , we selected three typical values for listed in Table 1, while imposing constant values for the rest of the parameters, i.e. and with a fixed relation between and as for all particle interactions.
The simulation domain in this problem is bounded by , and . A periodic boundary condition is prescribed in the x and z directions. The simulation consists of two steps. First, solid particles were initially placed in the two regions bounded by and , respectively, with a random spatial distribution. These two regions were treated as two subsystems to allow the solid particles to undergo sufficient timesteps with the mDPD method to reach equilibrium. The locations of the solid particles were then fixed to represent the bounding walls of the slit pore for the rest of the simulations. The width of the slit pore (along the y direction) is , corresponding to nm in the physical unit. Secondly, liquid particles were placed randomly in a region bounded by and . The whole system was run for time steps to reach equilibrium using the mDPD model along with the solid wall condition. Finally, timesteps were run to obtain the time-averaged properties of interest. This simulation was performed three times with the three values, respectively.
The instantaneous snapshots of the particle distributions corresponding to the values are displayed one the left side of Figure 6, demonstrating the transition of the fluid wettability in the slit pore from wetting to non-wetting. Note that in the latter case, the fluid had shifted slightly away from its initial location due to the coupled effect of non-smooth wall surface and strong non-wettability of the fluid. To validate the consistency of USERMESO 2.5 against its CPU counterpart, we plotted the profiles of the time-averaged fluid particle numbers versus the normalized pore width, and presented the GPU and CPU results on the right side of Figure 6. Eight bins were specified along the y direction, resulting in the eight data points in each profile. The GPU profiles agrees with their CPU references, indicating the numerical consistency. Furthermore, by dismissing the two near-wall points in those profiles, the curvatures of the profiles can be used to quantify the contact angles. For example, a higher such as led to a partially wetting fluid with a contact angle smaller than , whereas a lower such as led in a partially non-wetting fluid with a contact angle larger than . In the case of , the profile is almost a straight line, depicting the critical state of contact angle around . It is worth noting that a different choice in other parameters can result in a different dependency pattern of contact angle on ; for example, see a similar simulation in Pan [43].
5 Benchmark tests
In order to present a comprehensive performance benchmark, we tested USERMESO 2.5 with simulations of fluid flows in both simple homogeneous and complex heterogeneous pore networks. HPC resources at Oak Ridge National Laboratory (ORNL), IBM and Idaho National Laboratory (INL) were used to perform the tests. We used the NVIDIA NVCC compiler with -O3 optimization to compile the code. The CPU counterpart, which has also been implemented based on the standard LAMMPS in this work, is compiled with the GCC compiler with -O3 optimization as well. We first benchmarked our package on a manufactured, homogeneous pore network, which serves to verify the code integrity and identify any intrinsic bottlenecks. We then quantified the performance of the code with a miniature version of a realistic pore-network. For both cases, the walltimes are compared with their respective CPU counterparts.
5.1 Fluid flow in homogeneous nanoporous media
5.1.1 Problem description
To showcase the scaling performance of USERMESO 2.5 , body-force driven fluid flow was simulated in manufactured, homogeneous porous domains. Displayed in Figure 7, fluid flow in such a kind of domain is essentially two-dimensional, as the size of the domain in the y direction () is sufficiently small in comparison with the other two ( and ). This domain is created based on a cell with and , as shown on the right side of Figure 7. We followed the procedure described in Liu et al. [36] to create such a cell, in which a ring-shape surface wall is constructed by equilibrated solid particles (red) with an outer radius of ( nm) and an inner radius of ( nm). Outside the ring, the space is filled with equilibrated fluid particles (blue). The cell is duplicated in the x and z directions (e.g. , … cells) to assemble a series of quasi-2D square domains, in which the even-numbered rows of cells are translated over a horizontal distance of to finally form the domain for the flow simulations. For example, a domain consisting of cells is shown on the left side of Figure 7. These domains have a porosity of , with the narrowest pore width to be ( nm). The uniform pore distribution in this test minimizes load imbalance across the compute nodes. We thus consider it an appropriate problem to investigate the scalability of our code.
The mDPD force interaction parameters used in our previous work [58] is adopted in this study. The attractive interaction parameters are listed in Table 2, while the rest of the parameters used are , and for all the particle-particle interactions. The particle number densities are and for the solid and fluid particles, respectively, ensuring that the pores are saturated at an adequate fluid pressure. An acceleration of along the z direction is applied on the fluid particles to drive the flow. A periodic boundary condition is prescribed at all the three directions. A non-penetration boundary condition is prescribed at the solid particle wall surfaces. A timestep size of is used. In each timing test, timesteps are run first to allow the domain to reach equilibrium under the influence of the fluid body force. The walltime is then measured for every timesteps, until four walltimes are obtained to calculate an average value.
5.1.2 Benchmark results
The scalability of our code is characterized with the strong- and weak-scaling performed on Titan at ORNL, Each Titan node is equipped with an AMD Opteron 6274 CPU, and a NVIDIA Tesla K20X GPU (Kepler architecture) with CUDA cores and GB memory.
For the strong-scaling, the test was carried out in a simulation system consisting of cells and a total of about million particles ( million fluid particles and million solid particles). The system size was chosen to allow the memory of a single K20X GPU to accommodate the simulation. For the weak-scaling, the simulation system size was fixed at approximately million particles per node. The walltimes were obtained on systems consisting of , , , , , , , , and cells, respectively. To allow comparison across multiple platforms, the performance of our code was quantified with the metric “million-particle-steps per second”, or MPS/second for short [50]. As shown in Figure 8, our flow simulator scored a nearly perfect weak-scaling. On the other hand, the strong-scaling plot levelled off around nodes, when each node was loaded with approximately particles.
Besides the Tesla K20X, we benchmarked our code on a few more modern GPUs with advanced high-speed Host-to-Device interconnects to characterize the performance improvement brought by the latest hardware architectures. For clarity, the machines that have been tested are labelled and listed in Table 3 with the detailed hardware specifications. Of particular note is the IBM AC922 node that is equipped with IBM Power9 cores and NVIDIA V100 GPUs with the NVLink2 interconnect: the same architecture configuration as ORNL’s Summit supercomputer. To factor out Host-to-Host and/or node-to-node communication quality on different machines, we limited the comparative benchmark simulation running on one CPU core and one GPU on each machine. The walltime obtained on the Tesla K20X was used to serve as the baseline, while the performance of other machines was measured in terms of the relative speedup, as shown in Figure 9.
For the first, our test result has shown that the TITAN Xp (Pascal architecture, CUDA cores, GB memory), a top-tier consumer’s model, produced nearly twice the performance of the Tesla K20X. Furthermore, our test result has shown that the Tesla V100 (Volta architecture, CUDA cores, GB memory) on DGX-1 can output the computing power of the Tesla K20X. On the other hand, because our code keeps the host and device memories separate for performance optimization, the overall performance depends heavily on the data transfer speed between the hosts and devices. In this regard, a remarkable finding is that the high-speed interconnects such as NVLink can dramatically shorten the walltime in our simulations. Together with the NVLink2 (the second-generation NVLink) on an IBM AC922 node, the V100 delivered an astonishing speedup over an ORNL Titan node. In other words, the NVLink2 is able to help double the performance of the V100 in our benchmark simulations. Lastly, to compare with the performance of a CPU-only implementation of our simulator, we benchmarked the CPU counterpart on an INL HPC node fully utilizing its cores (2 Intel Xeon E5-2695 v4 CPUs, 18 cores per CPU), and have found that it is equivalent to the TITAN Xp GPU in performance.
With an interest to elaborate on the ramifications of the NVLink interconnect, we present a breakdown of the walltime on the GPU-related tasks in Figure 10, e.g., Host-to-Device transfer, Device-to-Host transfer and kernel computation. For the Telsa V100 with the PCIe interconnect (DGX-1 node), the transfers together took up of the GPU related tasks (i.e., by Host-to-Device data transfer and by Device-to-Host data transfer). In comparison, when NVLink2 interconnected the host and the device, the transfers took up only while the walltime of kernel computations remains almost the same. In other words, NVLink2 has helped reduce the walltime of the GPU related tasks by about for our benchmark simulation. The same test was performed on SummitDev at ORNL (a tester cluster mimicking Summit), which has the Tesla P100 (Pascal architecture, CUDA cores, GB memory) with NVLink1 (the first-generation NVLink). Our result indicates that NVLink independently reduces considerable walltime that is sufficient to compensate for P100 when compared with its successor V100 without NVLink.
Above all, this benchmark problem has successfully demonstrated the excellent scalability of our code. Furthermore, the use of NVLink can drastically improve the efficiency of our code and provides performance boost to data-transfer intensive applications like our particle simulator.
5.2 Fluid flow in heterogeneous nanoporous media
The objective of this problem is to assess and demonstrate the scaling performance of USERMESO 2.5 for simulations of fluid flow in realistic heterogeneous nanopores, i.e., the shale kerogen-hosted pores. In this study, the construction of kerogen-hosted pores for pore-flow simulations was based on the nano-resolution stack images of a Vaca Muerta shale micro core sample, which refers to the geologic formation located at Neuqun Basin in Argentina [3]. The procedures for digital imaging of shale core samples and image post-processing for our pore-flow simulations are briefly described in Appendix A for interested readers. Most hydrocarbons in shale are believed to be in kerogen-hosted pores before geotechnically processed. Massive hydrocarbon flow will not occur in kerogen with their natural low permeability [53]. Permeability enhancement like hydraulic fracturing creates micro-cracks in shale and create linked paths for flow through connected pores spanning multiple scales (e.g. from nano- to micro-scale). Such structural evolution of organic-matter-hosted pores as well as the flow within is challenging to reproduce and measure in laboratory because of the required physical conditions [44]. Our benchmark test is thus focused on flow simulations in kerogen-hosted pores, in order to present an efficient pore-network flow simulation package for relevant research.
5.2.1 Problem description
For our benchmarking purpose, pore flow simulations in the entire core sample is not necessary. Instead, we focus on a large pore (labeled #1) in Figure 18 and introduce an example of how to set up a simulation domain for pore flow driven by bulk pressure gradient, as shown in Figure 11. In the first step, the #1 pore is cropped to create a cubic block ( nm3), with two slabs perpendicular to a specified direction (e.g. x) added to the two ends of the block to allow fluid particles to move only inside the pore, as shown in Figure 11 (middle). For flow simulation in this block, it is estimated to require over 200 million particles and 400 million timesteps. To allow the required memory to fit in a single V100 GPU for strong-scaling test, we cropped the block to a miniature version ( nm3), as shown in Figure 11 (right).
The setup for our miniature version test is illustrated in Figure 12, which is general enough for applying to a system of any size. The simulation box extents from -30 to 140 in x, 0 to 91 in y, and 0 to 88 in z, respectively. A reflection wall condition is prescribed at all the box boundaries to prevent fluid particles from accidentally fleeing, which though did not occur in our simulations. The simulation depicts a pressure gradient driven flooding through a porous block located at . Five material types numbered from 1 to 5 are labeled for the particles. A total of 3,325,409 particles are created in the box, including 1,859,025 particles as type-1 fluid (source), 1,641,640 particles as type-2 fluid (working), 568,488 particles as type-3 solid (pore surface wall), and 128,128 particles for type-4 solid (front-pushing slab) and type-5 solid (back-pressure slab), respectively. Type-1 and 2 particles are assigned with the same mDPD model parameters as we consider single-phase flow in this study. Likewise, type-3, 4 and 5 particles represent solids of the same kind. The use of unique material types allows flexible change of model parameters.
5.2.2 Benchmark results
The initial condition for the flooding simulation takes a few separate simulations to prepare. For the first, type-1 fluid particles are created to saturate the porous block (type-3). Extra type-1 fluid particles outside the block are pushed against the block by a slab (type-5) in order to sustain the hydraulic pressure in the pore. This setup mimicks hydrocarbons trapped in organic-matter-hosted pores. For the second, type-2 fluid particles are pushed against the block on the other side by a slab (type-4) with a higher external pressure. A virtual wall is placed at the boundary of the block () to prevent type-2 fluid particles from entering the pore. At the beginning of the flooding simulation, the virtual wall is removed, and due to the bulk pressure difference between the two ends of the block, the type-2 fluid particles will be pushed into the pore gradually, while the type-1 fluid particles in the pore will be extracted. The mDPD model parameters and timestep size used in subsection 5.1 are adopted here. A series of snapshots for the simulated flooding process are shown in Figure 13, depicting the forced ejection of source fluid out of the pore.
To investigate the scalability of USERMESO 2.5 on the flooding simulations in the realistic shale pore geometries, we carried out a set of strong-scaling tests using the Power9/V100 nodes on the IBM AC922 cluster. We chose the first 10,000 timesteps of the simulation for timing, during which the working fluid rushes into the pore. Shown in Figure 14, the benchmark results indicate that the almost linear strong scaling obtained in subsection 5.1 is no longer held true with the realistic nanopore geometries. This is because the fluid and solid particles are unevenly distributed in the simulation domain, unlike the uniform pore network described in subsection 5.1. When a simulation box is decomposed evenly based on the spatial dimensions, each subdomain has a distinctive particle composition tabulated in Table 4. As a result of the non-uniform particle distributions, the conventional spatial decomposition scheme does not offer a good strong scaling. Implementing a load balancing scheme such as the recursive coordinate bi-sectioning (RCB), the performance of the CPU code improved considerably, especially when fewer cores were used. For example, in our CPU timing with cores, the RCB cut the walltime almost in half. However, as more cores were engaged, the benefits of RCB subsided rapidly. This was observed in the CPU timing with cores, where the RCB failed to help reduce the walltime by a definitive amount. As for USERMESO 2.5 , the conventional spatial decomposition is enforced in the current implementation. Furthermore, as a GPU can hold a much larger subdomain than a CPU core, the effect of load imbalance is much less pronounced. Hence despite the lack of load balancing schemes, USERMESO 2.5 with V100 GPUs performed just as well as Power9 cores as seen in Figure 14, well demonstrating the superiority of GPU implementation for realistic complex geometries.
To further illuminate the scalability challenge for the particle flow simulations in heterogeneous nanoporous geometries, we present a breakdown of the GPU workloads with four V100 GPUs and track the number of particles in each subdomain over the timesteps, as shown in Figure 15. Recall that the simulation box is evenly divided into four subdomains with one per GPU. We also plotted the load imbalance factor, which is defined as the ratio of the largest GPU workload to the smallest among the subdomains. The workload imbalance is the largest at the beginning of the simulatiton, when subdomain 3 contained approximately more particles than subdomain 0, corresponding to a load imbalance factor of . As the working fluid rushed into the pore, the workloads became more even over time, and the factor descended to at most. Further investigation on the load balancing is not in the scope of this study. We intend to propose a general solution to control load imbalance on GPUs in a follow-up work.
6 Capability demonstration
Though it’s a common understanding that the Darcy’s law is no longer suitable for describing the flow and transport phenomena in nanoporous source shale rocks, so far no mature analytic formulation has been deduced experimentally to elaborate the source recovery processes in shale. Certain properties such as the permeability-fluid dependence (i.e. the correlation between the mass flow rate and bulk pressure gradient) are difficult to measure experimentally in the micro core samples. The USERMESO 2.5 package presented in this work provides an alternative to characterize the fluid-permeability dependency with mesoscopic flow simulations in digitized nanometer-resolution realistic shale pore geometries. To demonstrate the versatility of our package, the micro block ( nm3) shown in the middle of Figure 11 was used in the flooding simulations, with a brief depiction of the problem setup and a snapshot of the moving fluid particles on the left side of Figure 16. Again, for simplicity, we assumed single-phase flow by specifying the same model parameters for the working fluid (blue) and source fluid (red). The simulation box contained about 240 million particles. Four simulations corresponding to four successively increased bulk pressure gradients were performed. In each simulation, 3000 DPD time units were run to allow the mass flow rate to reach a stable status. A total of 2048 nodes on Titan at Oak Ridge National Laboratory were deployed for each simulation. The same simulation would take at least 15 times as long on the CPUs, deduced from our benchmark results.
Shown on the right side of Figure 16, the dependency of the flow rate on the bulk pressure gradient deviated from the Darcy’s law, indicating a non-constant permeability in shale, in part because of their heterogeneous porosity distributions and the sub-continuum solid-fluid interactions in the nanopores. The simulation results coincide with the general observation from shale reservoir operations that the increased injection rate does not necessarily help increase the source recovery rate. However, as a case of capability demonstration, such limited simulations cannot provide all but a rough depiction of the complicated source recovery processes. An inclusive understanding can only be established with flow simulations based on a sufficiently large ensemble of shale core samples and a careful calibration of model parameters for specific types of fluids and solids.
7 Summary
This work has presented a GPU-accelerated mesoscopic pore flow simulation package based on a many-body dissipative particle dynamics (mDPD) model to address the computational challenges in the numerical investigation of hydrocarbon flow in source shales. Leveraging mDPD’s ability to model the sub-continuum and continuum flow phenomena, the complex flow dynamics and fluid-solid interactions in multiscale pore networks with pore sizes ranging from a few nanometers to a few micrometers can be resolved simultaneously. The effective use of GPUs enhances simulation performance significantly: almost linear scaling on up to 512 nodes is achieved in both our strong and weak scaling benchmarks, while further speedup is possible even beyond 1024 nodes. Besides, the use of the advanced device-to-host interconnects such as NVLink2 brings remarkable additional speedup over PCIe. Additional advances including the implementation of solid wall boundary conditions for mDPD flow in complex pore geometries and solid wall particle packing for huge systems have facilitated flow simulations in realistic shale nano pore networks that are constructed from 3D nanometer-resolution stack images. Furthermore, we have calculated the speedup over CPU counterpart through a realistic shale pore flow test: it requires 840 Power9 CPU cores to match the performance of 4 V100 GPUs on the Summit architecture. In summary, this package enables quick-turnaround and high-throughput mesoscopic numerical simulations for investigating complex flow phenomena in nano- to micro porous rocks with realistic pore geometries. We made our software freely available on GitHub, following the link https://github.com/AnselGitAccount/USERMESO-2.0-mdpd.
Acknowledgment
The software development, validation and benchmark testing in this work is supported through the Idaho National Laboratory (INL) Laboratory Directed Research & Development (LDRD) Program under the U.S. Department of Energy Idaho Operations Office Contract DE-AC07-05ID14517.
The weak- and strong-scaling benchmarks and simulations for capability demonstration were primarily performed at Oak Ridge Leadership Computing Facility (OLCF) through the OLCF Director’s Discretion Program under project GEO124, which is supported by the Office of Science of the U.S. Department of Energy under Contract DE-AC05-00OR22725.
The benchmark testing also used resources in the High Performance Computing Center at INL, which is supported by the Office of Nuclear Energy of the U.S. Department of Energy and the Nuclear Science User Facilities under Contract No. DE-AC07-05ID14517.
The numerical investigation of permeability-fluid dependence in shale kerogen-hosted nanopores was supported as part of the EFRC-MUSE, an Energy Frontier Research Center funded by the U.S. Department of Energy, Office of Science, Basic Energy Sciences under Award No. DE-SC0019285.
Appendix A Digital imaging and post-processing of shale core samples
The Vaca Muerta shale micro core sample referred to in this work underwent a FIB-SEM process, which resulted in a stack of raw images with nm2 pixel resolution in each image and nm interval in scanning direction. Figure 17 displays one of such raw images to illustrate the complex constituents in the sample. In a simplistic manner, we categorized the shale constituents in four phases: 1) inorganic matters, 2) inorganic-matter-hosted pores, 3) organic matters, and 4) organic-matter-hosted pores (i.e. kerogen-hosted pores). The raw images were not readily usable to pore-flow simulations because they could contain digital noises that should be filtered out first.
The raw images were post-processed with the Dragonfly image processing toolkit. The processed images were used for the preparation of DPD-based pore flow simulations. A block region of interest that contains an abundance of kerogen-hosted pores was found in our micro core sample and selected for preparation of the pore-flow simulations reported in this work. This block region has a size of width = 5,232.50 nm in width, height = 4,400 nm, and depth = 3,030 nm, and is visualized in Figure 18, where the pore networks are represented with pore surface wall particles generated with the image-to-particle workflow described in subsection 2.2. In this block region, the ten largest pores that have no connectivity with others are each rendered with a unique color, and the rest of smaller isolated pores are colored in light yellow. The distribution of kerogen-hosted porosities in this block region is also reported in Figure 18, demonstrating the low-porosity feature of kerogen in shale as well as the discreteness of the pores.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Abraham et al. [2015] M.J. Abraham, T. Murtola, R. Schulz, S. Páll, J.C. Smith, B. Hess, and E. Lindahl. GROMACS: High performance molecular simulations through multi-level parallelism from laptops to supercomputers. Software X , 1:19–25, 2015.
- 2Avalos and Mackie [1999] J.B. Avalos and A.D. Mackie. Dynamic and transport properties of dissipative particle dynamics with energy conservation. The Journal of Chemical Physics , 111(11):5267–5276, 1999.
- 3Badessich et al. [2016] M. F. Badessich, D. E. Hryb, M. Suarez, L. Mosse, N. Palermo, S. Pichon, and L. Reynolds. Vaca Muerta Shale — Taming a Giant. Oilfield Review , 28(1):26–39, 2016.
- 4Bear [1973] J. Bear. Dynamics of Fluids in Porous Media . Dover, 1973.
- 5Blumers et al. [2017] Ansel L Blumers, Yu-Hang Tang, Zhen Li, Xuejin Li, and George E Karniadakis. GPU-accelerated red blood cells simulations with transport dissipative particle dynamics. Computer Physics Communications , 217:171–179, 2017.
- 6Brown et al. [2011] W.M. Brown, P. Wang, S.J. Plimpton, and A.N. Tharrington. Implementing molecular dynamics on hybrid high performance computers–short range forces. Computer Physics Communications , 182(4):898–911, 2011.
- 7Calore et al. [2016] E. Calore, A. Gabbana, J. Kraus, E. Pellegrini, S.F. Schifano, and R. Tripiccione. Massively parallel lattice–Boltzmann codes on large GPU clusters. Parallel Computing , 58:1–24, 2016.
- 8Chen et al. [2011] C. Chen, L. Zhuang, X. Li, J. Dong, and J. Lu. A many-body dissipative particle dynamics study of forced water–oil displacement in capillary. Langmuir , 28(2):1330–1336, 2011.