TL;DR
This paper introduces a method using Chapman-Kolmogorov equations to analyze belief evolution in dynamic decision-making, enabling efficient comparison of models and empirical data in environments with stochastic changes.
Contribution
It presents a novel application of differential Chapman-Kolmogorov equations to model belief dynamics in stochastic, changing environments, facilitating model comparison and empirical analysis.
Findings
Belief distributions can be computed efficiently using Chapman-Kolmogorov equations.
Model performance assessed via accuracy and Kullback-Leibler divergence.
Optimal integration timescales increase with internal noise.
Abstract
Decision-making in dynamic environments typically requires adaptive evidence accumulation that weights new evidence more heavily than old observations. Recent experimental studies of dynamic decision tasks require subjects to make decisions for which the correct choice switches stochastically throughout a single trial. In such cases, an ideal observer's belief is described by an evolution equation that is doubly stochastic, reflecting stochasticity in the both observations and environmental changes. In these contexts, we show that the probability density of the belief can be represented using differential Chapman-Kolmogorov equations, allowing efficient computation of ensemble statistics. This allows us to reliably compare normative models to near-normative approximations using, as model performance metrics, decision response accuracy and Kullback-Leibler divergence of the belief…
Click any figure to enlarge with its caption.
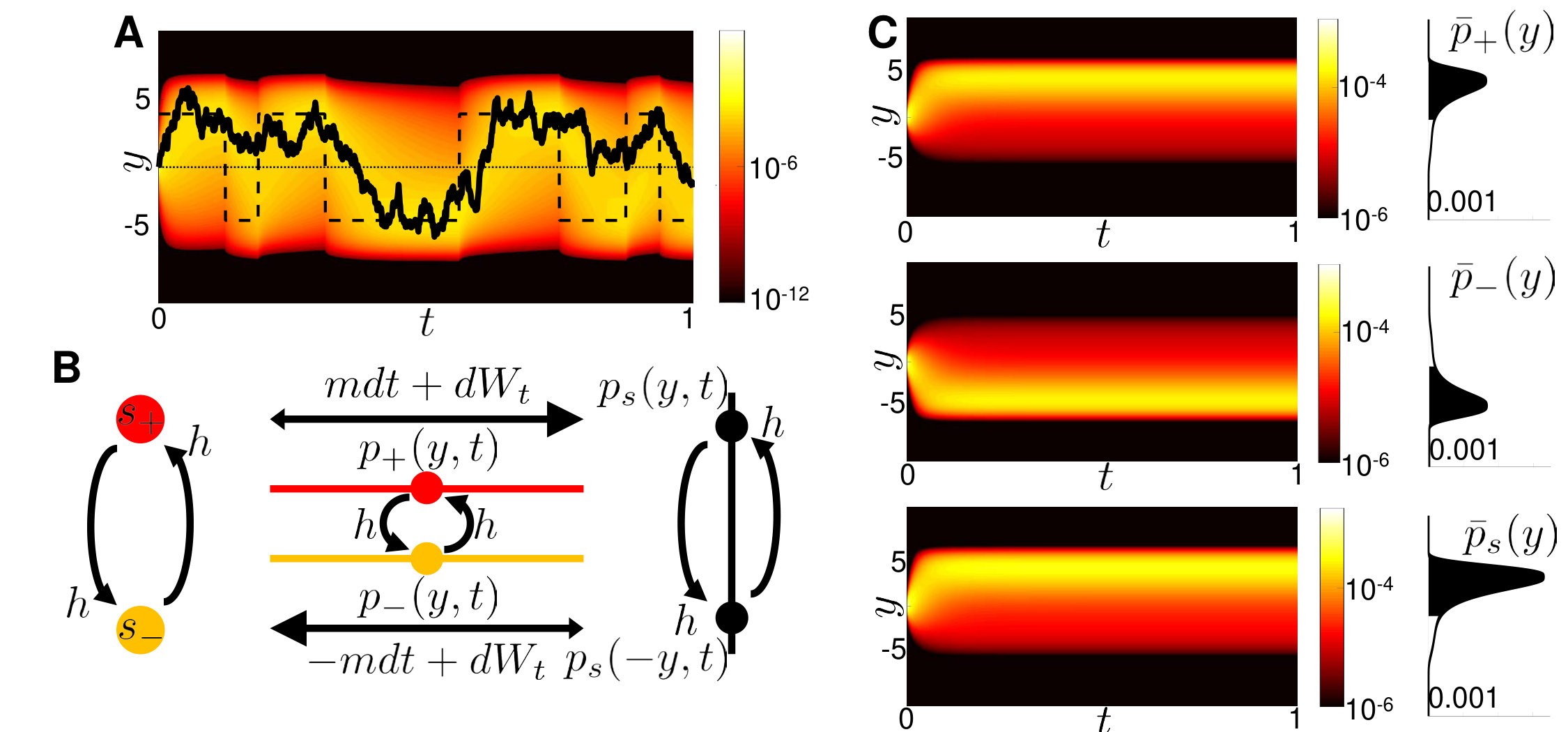 Figure 1
Figure 1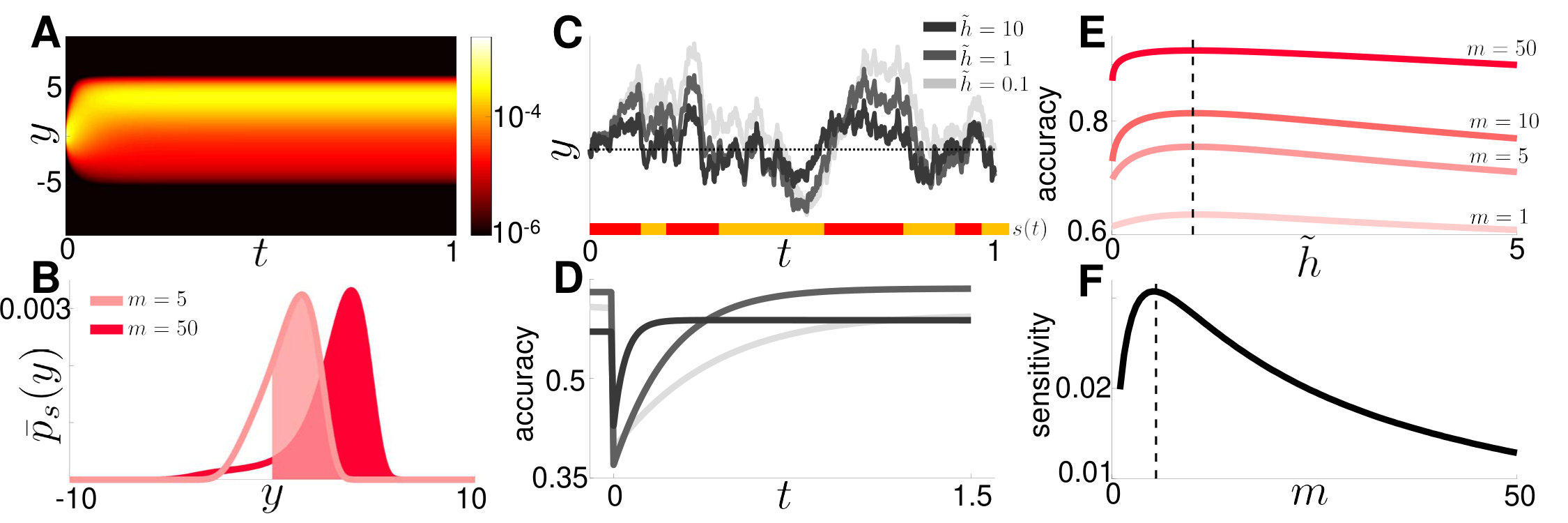 Figure 2
Figure 2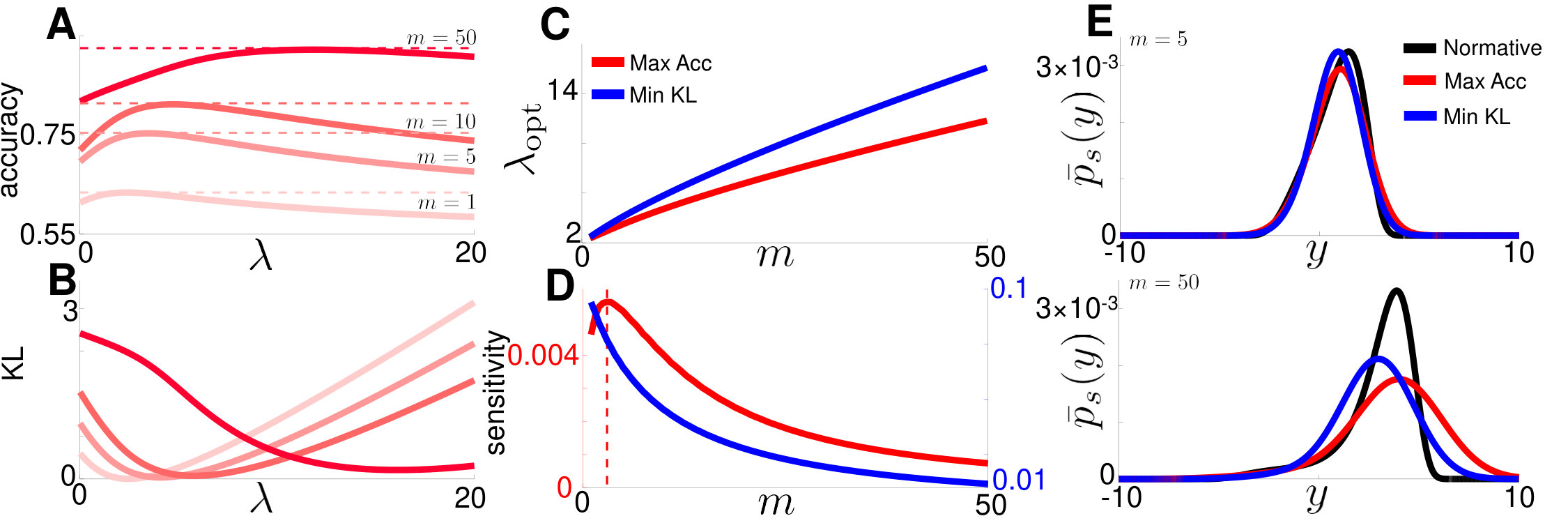 Figure 3
Figure 3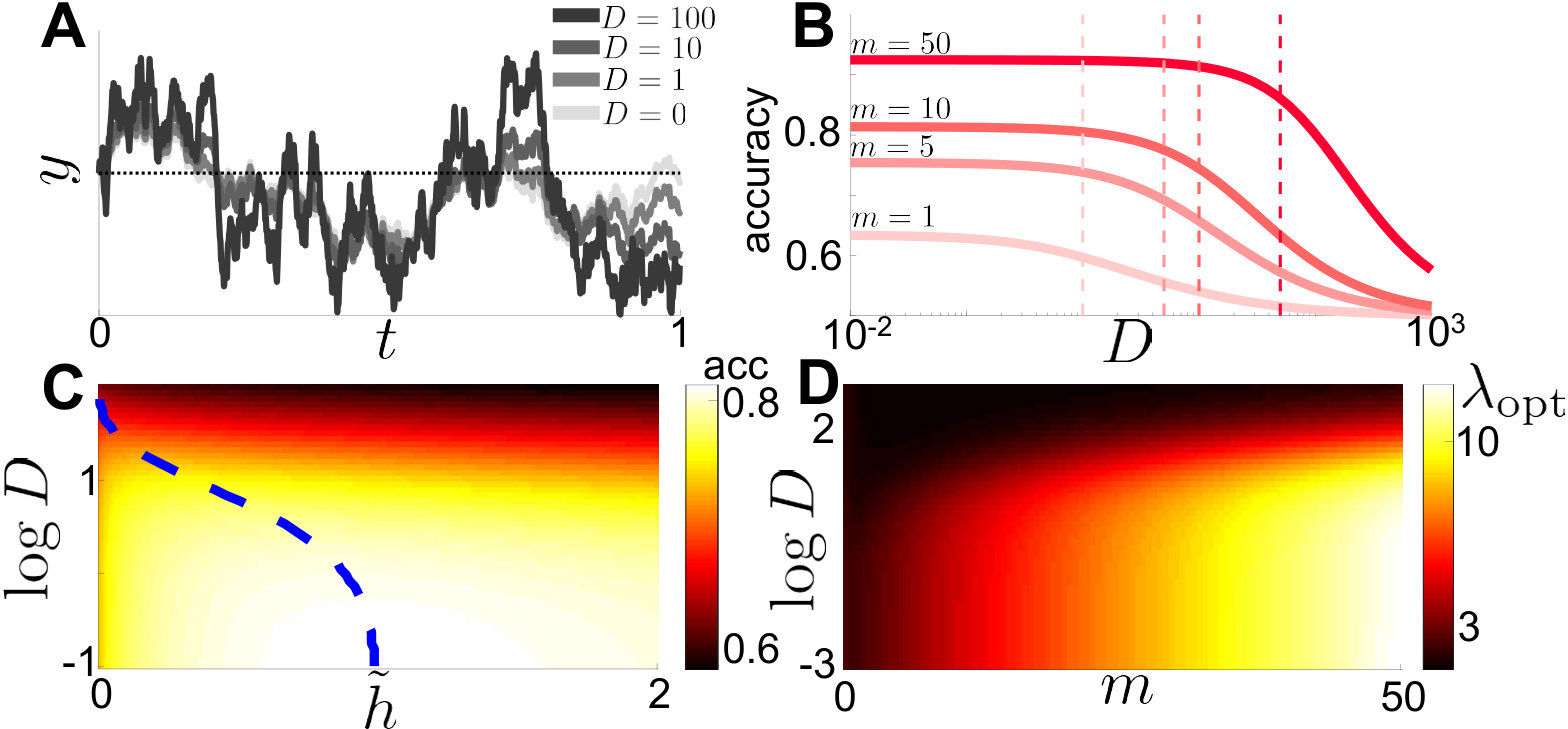 Figure 4
Figure 4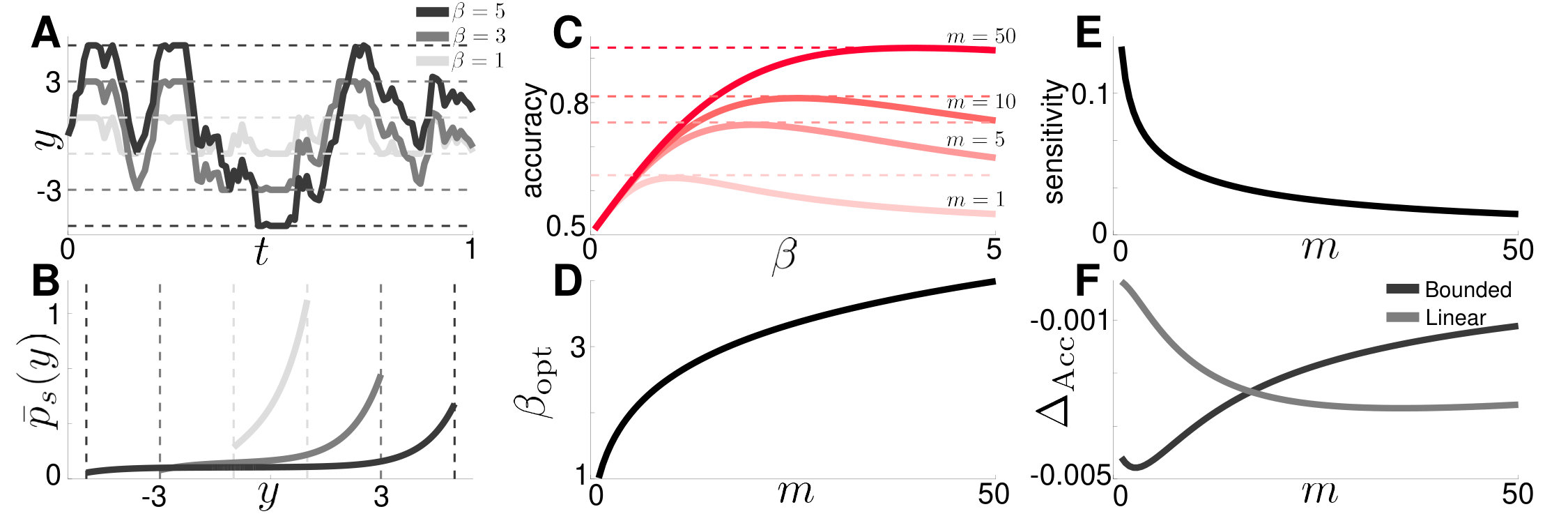 Figure 5
Figure 5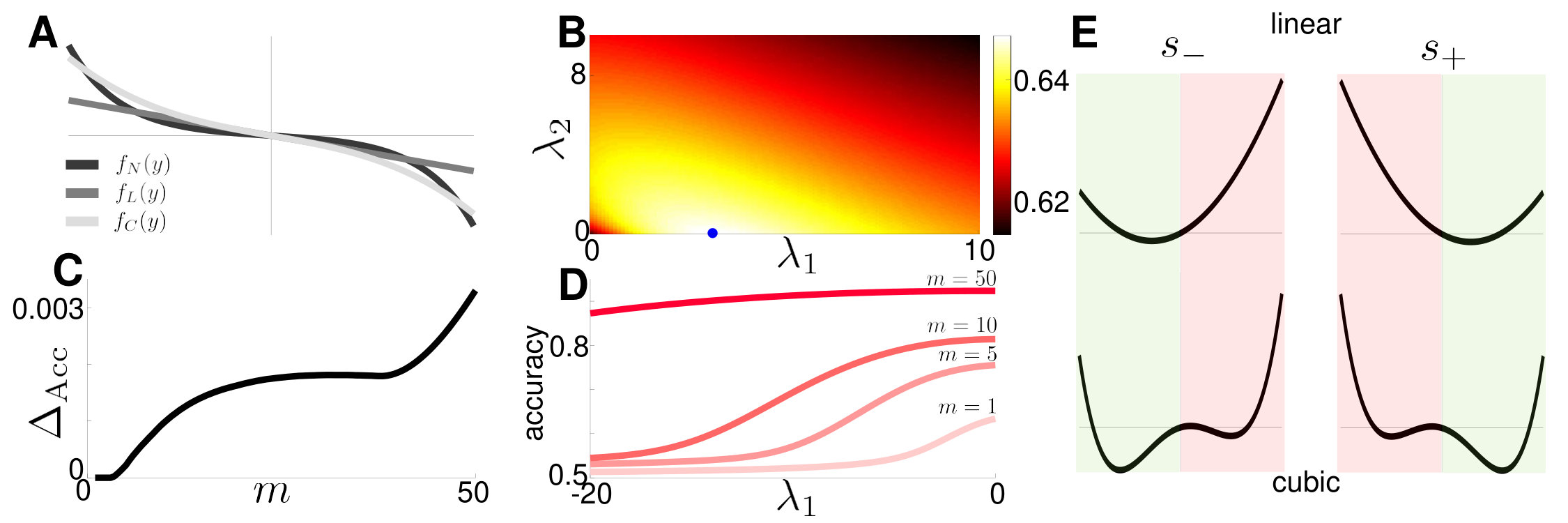 Figure 6
Figure 6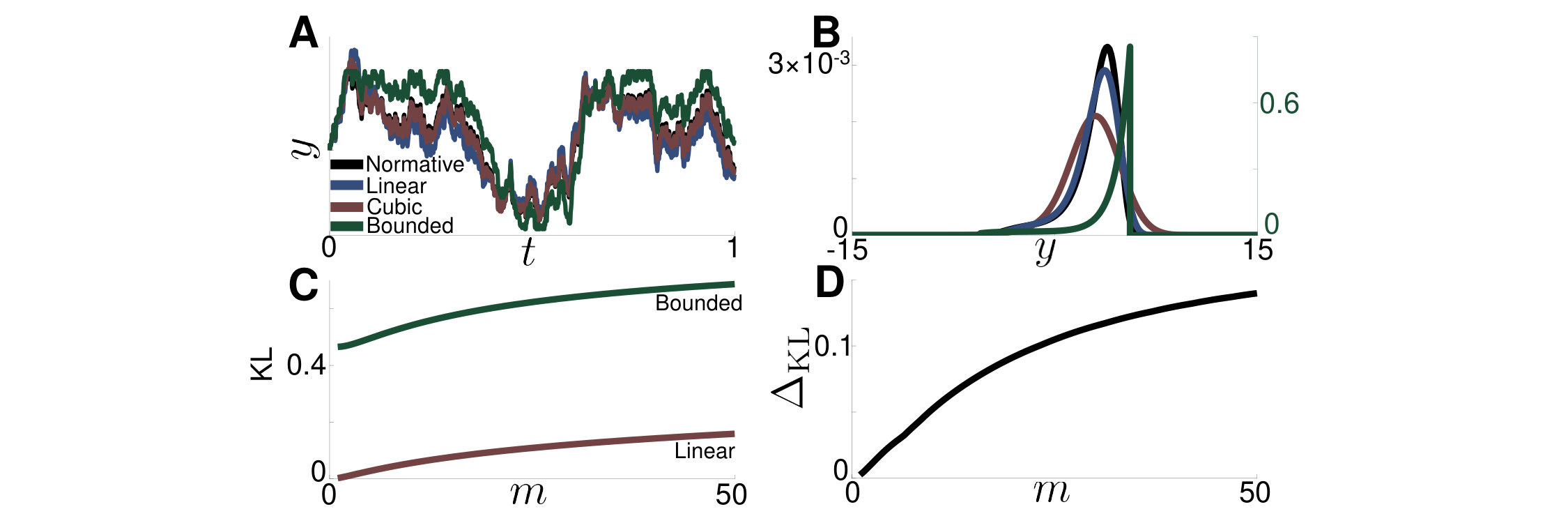 Figure 7
Figure 7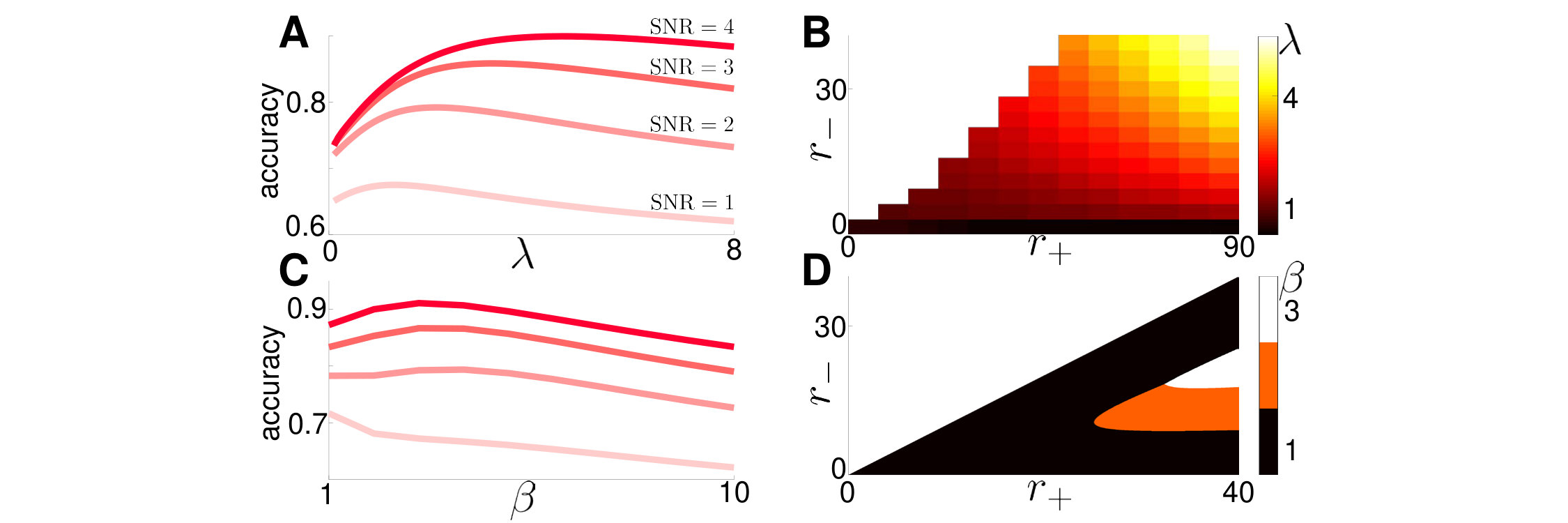 Figure 8
Figure 8 Figure 9
Figure 9Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
∎
11institutetext: N.W. Barendregt 22institutetext: Department of Applied Mathematics, University of Colorado Boulder
Boulder CO 80309 USA
22email: [email protected] 33institutetext: K. Josić 44institutetext: Department of Mathematics, University of Houston
Houston TX 77204 USA
44email: [email protected] 55institutetext: Z.P. Kilpatrick 66institutetext: Department of Applied Mathematics, University of Colorado Boulder
Boulder CO 80309 USA
66email: [email protected] 77institutetext: K. Josić and Z.P. Kilpatrick share equal authorship.
Analyzing dynamic decision-making models using Chapman-Kolmogorov equations
Nicholas W. Barendregt
Krešimir Josić
Zachary P. Kilpatrick
(Received: date / Accepted: date)
Abstract
Decision-making in dynamic environments typically requires adaptive evidence accumulation that weights new evidence more heavily than old observations. Recent experimental studies of dynamic decision tasks require subjects to make decisions for which the correct choice switches stochastically throughout a single trial. In such cases, an ideal observer’s belief is described by an evolution equation that is doubly stochastic, reflecting stochasticity in the both observations and environmental changes. In these contexts, we show that the probability density of the belief can be represented using differential Chapman-Kolmogorov equations, allowing efficient computation of ensemble statistics. This allows us to reliably compare normative models to near-normative approximations using, as model performance metrics, decision response accuracy and Kullback-Leibler divergence of the belief distributions. Such belief distributions could be obtained empirically from subjects by asking them to report their decision confidence. We also study how response accuracy is affected by additional internal noise, showing optimality requires longer integration timescales as more noise is added. Lastly, we demonstrate that our method can be applied to tasks in which evidence arrives in a discrete, pulsatile fashion, rather than continuously.
Keywords:
decision-making drift-diffusion models continuous time Markov processes Chapman Kolmogorov equations
1 Introduction
Natural environments are fluid, and living beings need to accumulate evidence adaptively in order to make sound decisions (Behrens et al., 2007; Ossmy et al., 2013). Theoretical models suggest, and experiments confirm, that in changing environments animals use decision strategies that value recent observations more than older ones (Yu and Cohen, 2008; Brea et al., 2014; Urai et al., 2017). For instance, adaptive evidence accumulation has been explored using a dynamic version of the random dot motion discrimination (RDMD) task (Glaze et al., 2015). In this task, subjects must determine the predominant direction (left or right) of a field of randomly moving dots while this direction switches stochastically according to a continuous time Markov process. Since switches are unpredictable, an ideal observer discounts old information in favor of new evidence. Furthermore, this discounting rate increases with the rate of environmental changes. This strategy has been observed in humans and other animals performing dynamic tasks (Glaze et al., 2015; Piet et al., 2018; Glaze et al., 2018).
Normative models and their approximations have been used successfully to understand how subjects make decisions (Ratcliff, 1978; Gold and Shadlen, 2007). In simple cases these models are tractable and make concrete predictions about response statistics that can be compared to experimental data (Bogacz et al., 2006; Drugowitsch, 2016; Ratcliff and McKoon, 2008). However, determining when subjects use approximately normative decision strategies, and when and how they fail to do so, can be computationally challenging. For instance, one may wish to study how a subject’s estimate of the environmental timescale impacts their response accuracy, or how heuristic evidence-discounting strategies compare to optimal ones (Glaze et al., 2018; Radillo et al., 2019). To address these questions, previous work has primarily relied on Monte Carlo simulations (Veliz-Cuba et al., 2016; Piet et al., 2018), which can be computationally expensive.
Here, we show how to reframe dynamic decision models by deriving corresponding differential Chapman-Kolmogorov (CK) equations (See Eq. (6)). This approach allows us to quickly compute observer beliefs and performance, and compare models. Realizations of our models are described by stochastic differential equations with a drift term that switches according to a two-state Markov process, and leak terms that discount evidence. To describe these models using CK equations, we treat the switching process as a source of dichotomous noise, and condition on its state to track conditional belief densities. These methods allow us to quickly answer questions about how characteristics of optimal models and their approximations vary across ranges of task parameters.
Nonlinear, normative models can thus be compared to approximate linear and cubic discounting models, models with internal noise, and explicitly solvable bounded accumulation models with no flux boundaries. These models all can obtain near-optimal response accuracy, but each has very different belief distributions. This suggests that subject confidence reports could be used to distinguish subject decision strategies in data.
Detailed analyses, including belief distribution calculations, can be performed rapidly and accurately with our methods, allowing us to see why each approximate model performs better at different task difficulty levels. Monte Carlo methods fare much worse in terms of computation time and accuracy (See Fig. 9). Our methods also extend to tasks with pulsatile evidence, where drift and diffusion are replaced by jump terms. Our work thus demonstrates how partial differential equation descriptions of stochastic decision models, previously successful in understanding decision making in static environments (Busemeyer and Townsend, 1992; Moehlis et al., 2004; Bogacz et al., 2006), can be extended to dynamic environments.
2 Normative models for dynamic decision-making
We begin by considering the dynamic RDMD task (Glaze et al., 2015; Veliz-Cuba et al., 2016); an observer looks at a screen of dots which move, on average, right or left. The average direction of motion, which we call the state , switches in time between states (right-moving) and (left-moving) as a two-state continuous time Markov process with hazard rate , so . The observer is interrogated at a random time, , and reports their belief about the current direction of motion, . The most reliable state estimate is obtained by computing the log-likelihood ratio (LLR) between choices from (noisy) observations, , of the moving dot stimulus. Assuming the observer maintains a fixed estimate of the environmental hazard rate, , this evidence-accumulation process converges to a single stochastic differential equation (SDE) for the belief of the observer (See Veliz-Cuba et al. (2016) and Appendix A for modeling assumptions and details):
[TABLE]
where is a telegraph process that switches between two values, , with transition rate , providing evidence about the state, , is an increment of a Wiener process scaled by , and the observer’s assumed hazard rate, shapes the evidence discounting process. If we assume observations of the state are drawn from normal distributions, the input to the evidence accumulation model can be described by a single parameter (Veliz-Cuba et al., 2016). Combining our assumptions and rescaling time as , we obtain the following SDE for the observer’s belief (See Appendix A) in rescaled time (different from the units in Eq. (1)):
[TABLE]
where is a telegraph process with switching rate equal to 1. The parameter gives the mean information gain of the observer over the average length of time the environment remains the same ( in original units, in rescaled units). As increases the task becomes easier. Thus, we refer to as the evidence strength. If we take , the explicit dependence of Eq. (2) on vanishes, and, as we show, the observer obtains maximal response accuracy.
We are primarily interested in how variations of the evidence strength, , true hazard rate, , and the observer’s hazard rate estimate, impact the response accuracy of an observer whose belief is represented by Eq. (2). These quantities can be changed by varying psychophysical task parameters (Glaze et al., 2015; Piet et al., 2018; Glaze et al., 2018), and so provide a means of validating Eq. (2) and its approximations. In addition, a thorough understanding of the normative model’s performance can provide insights into task parameter ranges in which a subject’s belief, is sensitive to the strategy they use (Radillo et al., 2019). Obtaining statistics of the solutions to Eq. (2) requires estimating the distribution of the stochastically evolving belief across time. Monte Carlo approaches can require many realizations to accurately characterize belief distributions (See Fig. 9 in Appendix B), and can thus be computationally prohibitive.
2.1 Expressing models using differential Chapman Kolmogorov equations
An alternative to sampling is to derive differential CK equations corresponding to Eq. (2) and evolve them to obtain time-dependent probability distributions, of observer belief, directly. For instance, for a fixed realization of , the evolution of is described by the following differential CK equation:
[TABLE]
Here the drift terms involve non-autonomous forcing by and evidence discounting, while the diffusion term arises from the Wiener process. This equation could be useful for model fitting, since an experimenter would know the realization of , and could then fit the single free parameter using response data. A simulation using a fixed realization of shown in Fig. 1A, reveals how the belief density tracks the state changes, and the peak of the distribution tends towards the fixed points of Eq. (2) where .
The evolution of the belief and performance across trials is determined by extending our model to include the distribution of possible realizations of . Treating as dichotomous noise and defining the joint probability densities , we obtain a set of coupled differential CK equations (Gardiner, 2004):
[TABLE]
The jump terms that exchange probability between and in Eqs. (4) arise from the switches in state, as schematized in Fig. 1B. Eqs. (4) describe the joint evolution of the density of beliefs across all realizations of . We assume symmetric priors, . As we will show, this and the symmetry of Eq. (4) leads to symmetric solutions .
Response accuracy – the probability of a correct response – is a common measure of subject performance in decision making tasks (Gold and Shadlen, 2007; Ratcliff and McKoon, 2008). Experimentally, response accuracy is defined as the fraction of correct responses at a specific interrogation time (Glaze et al., 2015; Piet et al., 2018). In our model, optimal observers make choices in accordance with the sign of their belief, , and response accuracy can be computed from solutions to Eq. (4) by computing
[TABLE]
The belief, is correct if it has the same sign as . This fact along with the inherent odd symmetry of Eqs. (4) suggests a change of variables in Eq. (4b). The sum, , then evolves according to
[TABLE]
The new density defines all belief values as correct, since the sign of beliefs in the state have been flipped, , while the sign of all beliefs in state remain the same. The density thus describes beliefs relative to the state, , with each environmental change flipping the sign of the belief, (See Fig. 1B). Eq. (5) can therefore be rewritten more simply as . By symmetry, we can recover the two original densities as .
Solving the CK equations numerically, we observe several notable features of and (Fig. 1C). First, the densities are reflections of one another () due to the symmetry of Eqs. (4). Second, all densities obtain stationarity on the timescale of the environment, so each is a unimodal function peaked on the correct side of . Stationary is reached due to the eventual equilibration between the drift and state switching. Most of the mass of the stationary densities is on the correct side of , and . The long tail of the distribution is due to both the constant transfer of probability from to due to the switching and the Wiener process noise. Both the nonlinear leak and switching cause the accuracy to saturate over time.
Before going further, we note that Eq. (6) satisfies the conditions for existence of an ergodic process (Gardiner, 2004): The nonzero jump probabilities, and a positive diffusion coefficient, ensure that the differential CK equation converges to a unique stationary density as . This occurs in a relatively short time period; we therefore focus the remainder of our study on steady-state cases. Typically, experimental dynamic decision trials are sufficiently long to make this assumption of stationarity reasonable (Glaze et al., 2015; Piet et al., 2018).
2.2 Evaluating accuracy for mistuned evidence-discounting
Subjects performing decision tasks often must learn the task parameters online to improve their performance. Our model can be extended to consider hazard rate learning (Radillo et al., 2017; Glaze et al., 2018), but for now we assume that the observer uses a fixed estimate of the hazard rate for their evidence discounting strategy (Glaze et al., 2015).
How does the response accuracy of an observer whose belief is described by Eq. (2) change when is mistuned? Veliz-Cuba et al. (2016) addressed this question using Monte Carlo sampling, but computational costs prevented a complete answer. Since Eq. (2) is rescaled, we take for the remainder of our investigation; all other cases can be recovered by rescaling time. Before asking how changing alters accuracy, we first briefly mention how accuracy varies with evidence strength, fixing . The density computed using Eq. (6) rapidly converges to the stationary solution, with most of its mass above zero (Fig. 2A). As , increases, more mass of the stationary distribution moves to positive values (Fig. 2B), but the total mass, equal to always saturates at a value less than 1 due to discounting and state switching.
When the observer misestimates the hazard rate, , we expect the long term accuracy to suffer. Effects on accuracy are subtle, but do follow a general pattern: overestimating the hazard rate () causes the observer to discount prior evidence too strongly, resulting in more errors driven by observation noise (Fig. 2C). On the other hand, observers that underestimate the hazard rate () discount evidence too slowly and are less adaptive to change points. Change point triggered response accuracy plots show both of these trends (Fig. 2D). Accuracy obtains a lower ceiling value during longer epochs without environmental changes when the discounting rate is too high. On the other hand, accuracy recovers more slowly following changes when the discounting rate is too low. This bias-variance tradeoff is common to binary choice experiments in dynamic environments (Glaze et al., 2015, 2018): Low discounting rates lead to averaging over longer sequences of observations thus reducing the effect of observational noise while increasing bias. On the other hand, high discounting rates decrease bias but increase susceptibility to observational noise, resulting in higher variability. An optimal observer balances these two sources of inaccuracy at a given environmental hazard rate.
An experimenter may not be able to change discounting rate a subject uses, but can control the strength of evidence the subject integrates. We therefore asked how the accuracy of both ideal and mistuned observers is impacted by changes in . Not surprisingly, accuracy increases as the strength of evidence increases (Fig. 2E). More interestingly, the sensitivity (or curvature) of the accuracy function at the optimum, where , varies nonmonotonically with , obtaining a peak at (Fig. 2F). Thus response accuracy is most sensitive to model mistuning for tasks of intermediate difficulty. Intuitively, an observer will always perform close to chance () when the task is hard ( is low), regardless of the they use. The observer will perform well (), again regardless of , if the task is easy ( is high). At intermediate values of , the observer’s performance is sensitive to changes in the model. See Radillo et al. (2019) for a similar analysis for a dynamic decisions using pulsatile evidence.
This example illustrates how CK equations can be used to obtain response accuracy statistics, and to compare normative models to related nonlinear models in which the evidence discounting is mistuned. Such approximate models may offer plausible descriptions of subject’s strategies, but only capture some of the possibilities. In the next section, we develop and analyze linear discounting models that approximate the adaptive evidence accumulation properties of the normative model and can be tuned to obtain near-optimal response accuracy.
3 Linear evidence discounting in dynamic environments
The nonlinear model defined by Eq. (2) describes the optimal evidence-accumulation strategy when the estimated hazard rate is correct. However, approximate models can also obtain response accuracy that is near-optimal. Glaze et al. (2015) and Veliz-Cuba et al. (2016) demonstrated this using a model that includes a linear leak term, in place of the nonlinearity in the normative model. The linear model is more tractable and can capture the dynamics of subjects’ beliefs in behavioral data (Ossmy et al., 2013; Glaze et al., 2015; Piet et al., 2018). We are interested in how well its statistics can be matched to that of the nonlinear model and how sensitive this match is to perturbations in the leak rate.
The linear discounting model is the doubly stochastic differential equation,
[TABLE]
where is a parameter we tune. As before, we can write differential CK equations corresponding to Eq. (7), and define to obtain the evolution equation
[TABLE]
As in the nonlinear model, an attracting stationary solution to Eq. (8) exists as long as (Gardiner, 2004). We thus focus on stationary solutions, , and make comparisons with the normative model. Our goal is to see how the leak rate, can be tuned so that the behavior of an observer whose belief evolves according tof Eq. (7) best matches that of an observer using the normative model, Eq. (2).
We use two metrics to compare our models: first, we consider the accuracy of the linear model
[TABLE]
and aim to tune so is maximized. Second, to quantify the distance between the belief distributions, we compute the Kullback-Leibler (KL) divergence
[TABLE]
between the stationary normative distribution, , obtained from Eq. (6), and the stationary distribution of the linear approximation, , obtained from Eq. (8). While it is possible for models to have nearby belief distributions but different realizations within trials, minimizing KL divergence still penalizes models with divergent belief distributions, sure to have distinct trial wise realizations. We show that choosing the leak rate, , that maximizes accuracy or minimizes the KL divergence leads to different biases (Fig. 3A,B).
Similar to the nonlinear model, the response accuracy of an observer using linear discounting varies nonmonotonically with (Fig. 3A). Observers using small adapt too slowly to change points, and those using a high exhibit more noise-driven errors in the state estimate. The optimal value of is achieved by balancing these error sources, obtaining response accuracy levels very close to those of the normative model. Furthermore, the that maximizes response accuracy increases as is increased, since evidence needs to be discounted more rapidly in environments with higher evidence strengths (Fig. 3C). The KL divergence also varies nonmonotonically with for all values of (Fig. 3B), obtaining a minimum at a value that also increases with , but is higher than . Understanding this result requires a more detailed analysis of the stationary densities of the normative and linear models, as we discuss below.
How important is it to tune in the linear model? If linear models are more sensitive to fine tuning for some task parameter ranges than the normative model, experimentalists could use these task parameter ranges to distinguish subjects’ strategies. When is small the belief distributions and are close whether or (Fig. 3C,E), but this agreement is sensitive to changes in (Fig. 3D). Thus, both the accuracy and KL divergence are sensitive to when is small. For large the two belief distributions are not close (Fig. 3E), and the KL divergence and difference in accuracy are insensitive to changes in . This disagreement in belief distribution at high is less important when optimizing the accuracy of the linear model, as we only need to maximize the mass of above .
Differences between the two models become apparent if we interrogate observers about their confidence and not just their choice (Fig. 3E). We hypothesize that if one were to fit behavioral data using response accuracy, and compare them to fits using subject’s confidence reports, the second approach would result in stronger leak rates. Indeed, considerations of subject confidence as a proxy for LLR has been an important development in recent decision making studies (Kiani and Shadlen, 2009; Van Den Berg et al., 2016), and we will revisit this view in Section 7. However, most behavioral studies of decisions in dynamic environments do not include confidence reports, and so model fits are typically performed by considering accuracy data. We thus focus primarily on this measure for the remainder of our study.
4 Tuning evidence accumulation to account for internal noise
We next explore the impact of additional noise sources on the performance of both the nonlinear and linear models. Since the nervous system is inherently noisy (Faisal et al., 2008), it is important to consider sources of variability on top of the stochasticity of observations when developing and fitting decision models (Smith, 2010). Brunton et al. (2013) showed that the responses of humans and rats in an auditory clicks task are best described by models that include internally generated noise. Piet et al. (2018) showed that the same is the case in a dynamic clicks task. With this in mind, we extend our analysis to incorporate an additional independent noise source. Such variability could arise in early sensory areas or as part of the decision process (Bankó et al., 2011). For simplicity, we model the source of noise as an independent Wiener process, , with variance scaled by a parameter . The nonlinear model then takes the form,
[TABLE]
Adding internal noise means that Eq. (11) is no longer a normative model: When , noise corrupts state estimates (Fig. 4A), and maximal response accuracy is achieved when , as we show. The linear model is updated similarly,
[TABLE]
In either model, the Wiener processes, and , are independent.
As before, we can derive an evolution equation for the ensemble of realizations of these stochastic processes (See Appendix C). For the nonlinear Eq. (11), the corresponding differential CK equation is
[TABLE]
and the corresponding differential CK equation for Eq. (12) is
[TABLE]
Thus, only the constants scaling the diffusion term change as compared to the models without internal noise, Eqs. (6) and (8).
How should evidence accumulation be adjusted to maximize response accuracy as the evidence strength and internal noise change? As noted earlier, humans and rats integrate internal noise in addition to information obtained from the stimulus itself (Glaze et al., 2015; Piet et al., 2018). It is therefore plausible that they adjust their stimulus integration strategies to limit the impact of internal noise on performance. Increasing the magnitude of internal noise, reduces response accuracy in the nonlinear model (Fig. 4A,B), and there there is a steep drop off in response accuracy when slightly exceeds (Fig. 4B). This occurs whether is fixed or allowed to vary. When can be tuned, the value of that maximizes response accuracy decreases as is increased (Fig. 4C): The observer must integrate over longer timescales to average the increased internal noise and obtain a reliable estimate of the state. However, this is balanced by the need to adapt to change points as quickly as possible. Similarly, in the linear model the leak rate, that maximizes accuracy decreases as is increased (Fig. 4D). In general, as internal noise increases the observer must thus integrate over longer timescales to obtain the most accurate estimate of the state.
5 Discounting by bounding observer confidence
As an alternative to models that discount evidence with leak terms, we next consider models with no leak, and no-flux boundaries at (Glaze et al., 2015). This prevents the belief from straying outside of the range :
[TABLE]
Unlike classic DDMs for two alternative free response tasks (Smith and Ratcliff, 2004; Bogacz et al., 2006; Gold and Shadlen, 2007), the process does not terminate when the belief, , reaches one of the boundaries .
More careful treatments of the reflecting boundary are possible, by considering the limit of a discrete-time biased random walk on a lattice (Erban and Chapman, 2007), but we prefer the more intuitive description of Eq. (18), whose statistics we expect to match those of more detailed models. Fig. 5A shows example realizations of this stochastic process as the boundary location, is varied, illustrating how encounters with the no-flux boundaries serve to discount evidence.
The steady-state solution of the differential CK equations corresponding to Eq. (18) can be obtained exactly. The evolution equations are
[TABLE]
and the no flux (Robin) boundary conditions imply that
[TABLE]
Since Eq. (19) is an advection-diffusion equation, the proper reflecting boundary is a Robin boundary (Gardiner, 2004). It can be shown that the stationary solution to Eq. (19) restricted by the boundary conditions is
[TABLE]
The constants and and details of the derivation are given in Appendix D.
The distribution is more shallow for higher , as the stochastic trajectories spread over the admissible belief range (Fig. 5B). This is analogous to the sharpening (broadening) of the stationary distributions of the linear model that occurs as the leak rate is increased (decreased). Note here that decreasing strengthens the discounting effect of the reflecting boundaries.
To compute steady state accuracy of the bounded accumulator model, we can integrate Eq. (20) to obtain a formula that depends on and :
[TABLE]
For fixed , Eq. (21) varies nonmonotonically with , so there is a single which maximizes the accuracy (Fig. 5C). As increases, this optimal increases, suggesting that as the evidence is strengthened (Fig. 5D), less discounting is needed, in contrast to the linear discounting model. Accuracy is most sensitive to changes in when is small (Fig. 5E).
We also compare the performance of the bounded accumulator model with that of the linear discounting model (Fig. 5F). At low , linear discounting performs better than the bounded accumulator, obtaining accuracy closer to that of the normative model. The opposite is true at high , in which case the bounded accumulator model performs better. This may be related to the fact that linear discounting better approximates the local dynamics of the nonlinearity when is small (and thus is closer to 0), whereas a sharp boundary better approximates the strong discounting of the nonlinearity at higher values of (reached when is large) (Glaze et al., 2015). Both models perform quite close to the normative model when their discounting parameters are fine tuned.
Despite the bounded accumulator model’s near optimal response accuracy, it is important to note that the distributions of the bounded accumulator (Fig. 5B) are very different from those of the normative (Fig. 2B) or even the linear model (Fig. 3E,F). In this respect, fitting subject confidence reports using the bounded accumulator would give very different results; we return to this point in Section 7.
6 Generalized discounting functions with a cubic example
There are many combinations of discounting functions and boundaries that could be used to approximate the nonlinearity in the normative model (Wilson et al., 2010). To use our methods, we require discounting functions, that are (i) odd (), and (ii) negative for some half-infinite positive region of ( for where ); these conditions ensure convergence to non-trivial stationary distributions. For a general discounting function, the rescaled model then takes the form
[TABLE]
with the differential CK equation for given
[TABLE]
This family of evidence-discounting models could also incorporate boundary conditions as in the previous section.
A natural way to extend the linear is to introduce a cubic discounting function (Piet et al., 2018) which can be tuned to better match the nonlinearity of the normative model (Fig. 6A). As shown in Section 7, this vastly improves the agreement between the stationary probability density and that of the normative model, , though the model is more complex (Friedman et al., 2001). Since the linear model already obtains near-optimal accuracy (Fig. 3A), we find, as expected, that the best cubic model is only slightly more accurate. In fact, accuracy drops rapidly as is changed from its optimal value (Fig. 6B). We also calculated the difference between the accuracy of the optimal cubic model and optimal linear model, (Fig. 6C). Accuracy improves by incorporating the cubic term at high values, since nonlinear discounting is most needed at higher values.
However, mistuning the cubic model can considerably limit accuracy when the attractor structure of Eq. (22) with is qualitatively changed (Fig. 6D). Equilibria of the noise-free model are identified by fixing and solving the cubic equation . Fixing , we find a critical value, for which the attractor structure of the model switches from a single stable fixed point to two (Fig. 6E). Such bistable systems can be advantageous for working memory (Brody et al., 2003), but can hinder belief switches necessary in dynamic environments after state transitions. Fig. 6D shows that the accuracy of the model decreases as is decreased and the potential wells deepen. In these cases, the observer retains an erroneous belief long after the state has changed.
Thus, the cubic nonlinearity only marginally improves accuracy, but can have deleterious effects if mistuned. However, we may wish to use other measures of a subject’s belief to fit and validate models. In the next section we therefore ask how the full belief distribution changes with the choice of discounting function, and use KL divergence to quantify differences between different models.
7 Revisiting KL divergence for fitting observer belief distributions
Subject reports of confidence in decision-making tasks can be associated with LLRs of normative evidence accumulation models (Kiani and Shadlen, 2009). Thus, it may be possible to empirically estimate the belief distribution, represented by our models, by asking subjects to report confidence in their choice. This provides an additional advantage of our approach over Monte Carlo simulations, as using the latter to estimate belief distributions can be costly and inaccurate (See Fig. 9 in Appendix B). As we show here, a better understanding of how our normative and approximate models deviate from one another can be gleaned by comparing their belief distributions and computing KL divergence measures.
We provide intuition for the differences we will see by plotting single stochastic realizations of all four models (Fig. 7A). The linear and (even better) the cubic models closely track the belief trajectory of the normative model, while the bounded accumulator model strays the farthest. Comparing belief distributions of all four models that minimize KL divergence with the normative model at (Fig. 7B), we see that the cubic model matches the normative model far better than the linear model. This is due to the nonlinearity incorporated by the cubic term, which attenuates the tail of the distribution at high values. On the other hand, the best fit bounded accumulator distribution is far from that of the normative model.
Computing the KL divergence between models, we arrive at two main conclusions: First, despite the fact that the bounded accumulator obtains near optimal accuracy, the corresponding belief distribution, deviates from that of the normative model, at all evidence strength values, (Fig. 7C). On the other hand, though the cubic model only mildly increases response accuracy over the linear model, the corresponding belief distribution, matches that of the normative model, far better (Fig. 7D). Our differential CK framework allowed us to obtain these results quickly and accurately.
8 Chapman-Kolmogorov equations for clicks-task models
Thus far, we have been concerned with models that represent evidence accumulation in a RDMD task (Glaze et al., 2015), in which subjects receive a continuous flow of evidence during a trial. We next examine models of observers accumulating discretely timed, pulsatile evidence.
Piet et al. (2018) showed rats can perform an auditory clicks task of this type near-optimally. In this experiment, subjects are presented with two trains of clicks (one to the left ear, the other to the right), each generated by a Poisson process with instantaneous rates and . The rates evolve according to a two-state continuous time Markov process with hazard rate so that , always, and with . We define the state as . Observations are now comprised of the presence or absence of left or right clicks at each time . See Piet et al. (2018); Radillo et al. (2019) for details. At an interrogation time, , the observer must respond which side currently has the higher click rate .
The model for an ideal observer’s belief is given by
[TABLE]
where is the height of each evidence increment, and are the right and left click times, and is the hazard rate. Additionally, we define the inputs’ signal-to-noise ratio (SNR) as (Skellam, 1946). See Radillo et al. (2019) for a detailed discussion of how the SNR shapes model response accuracy.
Rather than carrying out another detailed analysis of several different approximations and perturbations to Eq. (23), we simply wish to show that our CK approach works and provides useful insights for click stimulus models. To sample the space of possible approximate models, we fix and focus on a linear discounting and bounded accumulator model. Since Piet et al. (2018) was specifically interested in internal noise perturbed versions of the linear model, we start with this example, and then consider a bounded accumulator without internal noise that affords us explicit results.
The linear model with internal noise takes the form (Piet et al., 2018)
[TABLE]
Here is the leak rate, is the strength of the internal noise, and is a Wiener process. We then define conditional densities and as before, writing coupled differential CK equations as
[TABLE]
Unlike our differential CK equations for models with continuously arriving evidence, the pulses flow probability between and , preventing us from combining with a change of variables and obtaining a single CK equation. Simulating Eq. (25) directly, we study how response accuracy depends on the leak and the click rates (Radillo et al., 2019). Similar to our linear model with a drift diffusion signal, accuracy varies nonmonotonically with (Fig. 8A), and is maximized at for a given pair as plotted in Fig. 8B. Fixing SNR does not fix as Radillo et al. (2019) showed for the normative model. As either or is increased, increases (Fig. 8B), suggesting that increasing the rate of true or erroneous pulses warrants stronger evidence discounting.
We also consider a bounded accumulator with no explicit discounting function. In parallel with Eq. (19), we define the model as
[TABLE]
The observer’s belief is restricted to the interval for some positive integer . The corresponding differential CK equations can be written as a discretized system since only visits integer multiples of between to . Rescaling yields the following system
[TABLE]
for , along with the boundary equations
[TABLE]
As with the continuum version of the bounded accumulator, the stationary solution can be obtained explicitly
[TABLE]
with constants , , , and and the derivation given in Appendix E.
The dependence of the optimal , which maximizes response accuracy, on and is nuanced. Fixing , for a given , there is an optimal maximizing response accuracy (Fig. 8C). However, there is a surprisingly large range of values within which is optimal (Fig. 8D). There is a range of for which the discounting timescale (breadth of the interval ) increases with task difficulty, as long as is sufficiently far from . However, when , , despite task difficulty. We conjecture this bound improves performance by instituting a “two click” strategy, in which the observer needs to only hear two clicks on the high click rate side to register a correct current belief. This limits the size of erroneous excursions wrong clicks can cause, as the bounds limit the effect of many misatributed clicks in a row.
Our methods thus extend to models with pulsatile evidence accumulation, illustrating their broad applicability. We can efficiently study model performance and its dependence on task parameters, and even explicitly analyze the resulting equations to determine how approximate models perform.
9 Conclusion
Decision-making models are key to understanding how animals integrate evidence to make choices in nature. Animals most likely use heuristic strategies in dynamic tasks as they can be easier to implement, and have utility that is close to optimal (Rahnev and Denison, 2018). Normative models are still useful, however, as subject performance can be benchmarked against them, allowing possible insights into how and why organisms fail to perform optimally (Geisler, 2003). Investigating optimal models and their approximations requires simulations across large parameter spaces; these necessarily require rapid simulation techniques to obtain refined results. Efficient computational methods are therefore essential for the analysis of evidence accumulation models, and their application to experiment design.
Using differential CK equations to describe ensembles of decision model realizations speeds up computation and describes the time-dependent probability density of an observer’s belief. Thus, traditional metrics of performance (e.g., accuracy) and other less common model comparison metrics (KL divergence) can be computed rapidly. This opens new avenues for comparing normative and heuristic decision making models, and for determining task parameter ranges to distinguish models. There is also hope that in high throughput experiments, sufficient data could be collected to specify subject confidence distributions, which could be fit, or compared to model predictions (Piet et al., 2019).
Doubly stochastic and jump-diffusion models appear in a number of other contexts in neuroscience and beyond (Hanson, 2007; Horsthemke and Lefever, 2006). For instance, dichotomous and white noise have been included in linear integrate and fire (LIF) models to model voltage or channel fluctuations (Droste and Lindner, 2014, 2017; Salinas and Sejnowski, 2002). The interspike interval statistics of these models can be analyzed directly by considering the corresponding differential CK equations. Unlike the models we consider here, the LIF model includes a single absorbing boundary and reset condition, which must be treated carefully when defining the flow of probability through state space.
We have studied a number heuristic models and computed how their performance depends on both task parameters and evidence discounting parameters. Well tuned heuristic models, such as the linear and bounded accumulator models, can in fact exhibit near-normative performance (Glaze et al., 2015; Veliz-Cuba et al., 2016; Radillo et al., 2019). There are specific parameter regimes (low versus high ) in which certain heuristic models perform better; our differential CK methods have allowed us to explore these regimes rapidly. Importantly, Brunton et al. (2013), and Piet et al. (2018) have shown that internal noise determines subject performance in decision tasks, in addition to the variability of the signal. We have confirmed that including internal noise causes optimal evidence-discounting to be weakened as noise increases, and that accuracy drops off precipitously once the amplitude of internal noise reaches that of the signal.
Our approach can also be used by experimentalists testing observer performance in dynamic-decision tasks. Models can thus guide one’s choice of task parameters when setting up experiments to determine the strategies subjects use to make decisions in dynamic environments. As in Radillo et al. (2019), we found that accuracy is most sensitive to one’s choice of model and tuning when tasks are of intermediate difficulty. In contrast, tasks that are easy (hard) are performed well (poorly) by most models. Also, the full belief distributions generated by our methods could be subsampled to produce randomized responses for comparison with subject data (Drugowitsch, 2016). It may also be feasible to use our differential CK equations to model trial-to-trial belief distributions of subjects, as affected by internal noise hidden to the experimentalist. This approach was recently developed in Piet et al. (2019) to account for for variability in subject responses.
Model development can also help to inspire new experimental tasks, based on predictions and ideas that arise from mathematically describing subjects’ decision processes. One possible extension of the tasks we have discussed here could consider stochastic switches in evidence quality within trials. Past work has focused on both theoretical predictions and experimental results associated with task difficulty switching between trials (Drugowitsch et al., 2012; Zhang et al., 2014), suggesting subjects’ decision thresholds may vary with time as task difficulty is inferred throughout the trial. When both the state and difficulty switch stochastically within a trial, the effective state is governed by a multi-state continuous time Markov process. Details that could be introduced into such multi-state models, such as asymmetric evidence qualities and the ability to turn off evidence, offer a rich framework for applying the stochastic methods we have developed here. Another extension we could consider in our models is the recently developed click task model with stochastically drawn click heights (Piet et al., 2018; Radillo et al., 2019). Jumps would then be represented by an integral over the entire belief space, requiring new computational methods for efficient simulation of the associated differential CK equations.
In recent years, decision-making models and experiments have been developed to incorporate more naturalistic scenarios in which the environment changes in fluid yet predictable ways. The associated normative models can be complex, and efficient simulation techniques are important for evaluating performance across different models and interpreting experimental decision data from psychophysics tasks. It is also important to develop families of plausible heuristic models that subjects may be implementing, and to find ways to compare them with normative models. Our Chapman-Kolmogorov framework provides a straightforward and robust way to achieve these goals.
Code availability
Refer to https://github.com/nwbarendregt/DynamicDecisionCKEquations for the MATLAB finite difference code used to perform the analysis and generate figures.
Appendix A Normative evidence-accumulation in dynamic environments
Here we derive the continuum limit of the Bayesian update equation for continuous evidence accumulation in a changing environment. Starting with the discrete time model, we define as the probability of being in state at time assuming a sequence of observations . The state changes between evenly spaced time points (with ) at a hazard rate . The likelihood function is the conditional probability of observing sample given state , parameterized by .
We begin by assuming an ideal observer who knows the environmental hazard rate . Using Bayes’ rule and the law of total probability, we can relate to the probability at the previous time step according to the weighted sum (Veliz-Cuba et al., 2016)
[TABLE]
where . Defining , we can compute
[TABLE]
In search of the continuum limit of this equation, we assume , , and use the approximation to obtain
[TABLE]
Replacing the index with the time and applying the functional central limit theorem as in Billingsley (2008); Bogacz et al. (2006), we can write Eq. (30) as
[TABLE]
where is a random variable with a standard normal distribution and
[TABLE]
The drift and variance diverge unless are scaled appropriately in the limit. A reasonable assumption that can be made to compute and explicitly is to take observations to follow normal distributions with mean and variance scaled by (Bogacz et al., 2006; Veliz-Cuba et al., 2016)
[TABLE]
so we can compute the limits of Eq. (32) as
[TABLE]
where is a telegraph process with probability masses evolving as and remains constant. Therefore, the continuum limit () of Eq. (31) is
[TABLE]
where is a standard Wiener process. Eq. (34) provide the normative model of evidence accumulation for an observer who knows the hazard rate and wishes to infer the sign of at time with maximal accuracy (Glaze et al., 2015; Veliz-Cuba et al., 2016).
However, we are also interested in near-normative models in which the observer assumes an incorrect hazard rate . In such a case, the analysis proceeds as before, with the probabilistic inference process simply involving now rather than , and the result is
[TABLE]
Lastly, note that if indeed the original observations are drawn from normal distributions, Eq. (33) states where and . Rescaling time , we can then express Eq. (35) in terms of the following rescaled equation
[TABLE]
where and is a telegraph process with hazard rate 1, as shown in Eq. (2) of the main text.
Appendix B Finite difference methods for Chapman-Kolmogorov equations
We use a finite difference method to simulate the differential CK equations. The method is exemplified here for the normative CK equation from Eq. (6), but a similar approach is also used for the linear, cubic, and pulsatile equations. For stability purposes, our method uses centered differences in and backward-Euler in . This gives the following finite difference approximations of the functions and their derivatives in Eq. (6):
[TABLE]
where and are timestep and spacestep of the simulation, respectively. Substituting into Eq. (6) and solving for at each point on a mesh for gives the system of equations:
[TABLE]
where is tridiagonal with elements along the primary off-diagonal. This system can be inverted at each timestep and used to calculate the updates .
For the boundary conditions, we impose no-flux conditions at the mesh boundaries . For a standard drift-diffusion equation with drift and diffusion constant , this condition takes the form
[TABLE]
Using the finite difference approximations
[TABLE]
we can plug in to the appropriate replacement and use Eq. (37) to find the appropriate boundary terms for the system in Eq. (36).
Fig. 9 shows the results of Monte Carlo simulations compared against those from the CK equations; Monte Carlo simulations are less smooth (Fig. 9A), making optimality calculations less accurate. Furthermore, obtaining results that are close to those from the CK equations takes much longer to run (Fig. 9B).
Appendix C Deriving differential CK Equation with internal noise
Here we provide intuition for the form of the diffusion coefficient in Eq. (13) for the belief distribution of a normative observer strategy with additional internal noise of strength . Starting with the SDE in Eq. (12), because and are increments of independent Wiener processes, we can define a new Wiener process that has the same statistics as the original summed Wiener processes (Gardiner, 2004). To determine the appropriate effective diffusion constant , we note that
[TABLE]
and
[TABLE]
This requires , and means Eq. (12) can be rewritten as
[TABLE]
which following Gardiner (2004), has the differential CK equation given by Eq. (13).
Appendix D Steady state solution of the bounded accumulator model
Steady state solutions of Eq. (19) are derived first by noting that implies
[TABLE]
with boundary conditions . Eq. (38) has solutions \left(\begin{array}[]{c}\bar{p}_{+}(y)\\ \bar{p}_{-}(y)\end{array}\right)=\left(\begin{array}[]{c}A\\ B\end{array}\right){\rm e}^{\alpha y}, with characteristic equation . The characteristic roots are , where we define . For , we have , whereas for , the symmetry implies for and for . Lastly, defining the sum , we obtain
[TABLE]
The no flux boundary conditions along with the normalization requirement give explicit expressions for the constants
[TABLE]
and
[TABLE]
Appendix E Steady state solution of the clicks-task bounded accumulator model
Considering Eq. (26), we look for stationary solutions of the form , yielding the characteristic equation
[TABLE]
where . Solving Eq. (39) gives with eigenfunction and two roots of the quadratic . Superimposing the eigenfunctions, redefining constants, and defining gives the general solution
[TABLE]
The constants , , and can be determined by normalization and the stationary boundary conditions
[TABLE]
Long term accuracy of the bounded accumulator is then determined by the weighted sum .
Acknowledgements.
This work was supported by and NSF/NIH CRCNS grant (R01MH115557) and NSF (DMS-1517629). ZPK was also supported by NSF (DMS-1615737). KJ was also supported by NSF (DBI-1707400). We thank Sam Isaacson and Jay Newby for feedback on setting up the boundary value problem for the bounded accumulator model. We are also grateful to Adrian Radillo and Tahra Eissa for comments on a draft version of the manuscript.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Bankó et al. (2011) Bankó ÉM, Gál V, Körtvélyes J, Kovács G, Vidnyánszky Z (2011) Dissociating the effect of noise on sensory processing and overall decision difficulty. Journal of Neuroscience 31(7):2663–2674
- 2Behrens et al. (2007) Behrens TE, Woolrich MW, Walton ME, Rushworth MF (2007) Learning the value of information in an uncertain world. Nature neuroscience 10(9):1214
- 3Billingsley (2008) Billingsley P (2008) Probability and measure. John Wiley & Sons
- 4Bogacz et al. (2006) Bogacz R, Brown E, Moehlis J, Holmes P, Cohen JD (2006) The physics of optimal decision making: a formal analysis of models of performance in two-alternative forced-choice tasks. Psychological review 113(4):700
- 5Brea et al. (2014) Brea J, Urbanczik R, Senn W (2014) A Normative Theory of Forgetting: Lessons from the Fruit Fly. P Lo S Computational Biology 10(6):e 1003640
- 6Brody et al. (2003) Brody CD, Romo R, Kepecs A (2003) Basic mechanisms for graded persistent activity: discrete attractors, continuous attractors, and dynamic representations. Current opinion in neurobiology 13(2):204–211
- 7Brunton et al. (2013) Brunton BW, Botvinick MM, Brody CD (2013) Rats and humans can optimally accumulate evidence for decision-making. Science 340(6128):95–98
- 8Busemeyer and Townsend (1992) Busemeyer JR, Townsend JT (1992) Fundamental derivations from decision field theory. Mathematical Social Sciences 23(3):255–282
