Fiducia: A Personalized Food Recommender System for Zomato
Mansi Goel, Ayush Agarwal, Deepak Thukral, Tanmoy Chakraborty

TL;DR
Fiducia is a personalized food recommendation system that analyzes Zomato reviews to identify relevant cafe items, assess sentiment, and suggest restaurants with high accuracy, improving upon existing baselines.
Contribution
The paper introduces Fiducia, a novel review processing pipeline that personalizes restaurant recommendations by item-specific sentiment analysis and similarity measures.
Findings
Sentiment analyzer accuracy exceeds 85%.
Recommender system achieves an RMSE of about 1.01.
Outperforms baseline recommendation methods.
Abstract
This paper presents Fiducia, a food review system involving a pipeline which processes restaurant-related reviews obtained from Zomato (India's largest restaurant search and discovery service). Fiducia is specific to popular cafe food items and manages to identify relevant information pertaining to each item separately in the reviews. It uses a sentiment check on these pieces of text and accordingly suggests an appropriate restaurant for the particular item depending on user-item and item-item similarity. Experimental results show that the sentiment analyzer module of Fiducia achieves an accuracy of over 85% and our final recommender system achieves an RMSE of about 1.01 beating other baselines.
Click any figure to enlarge with its caption.
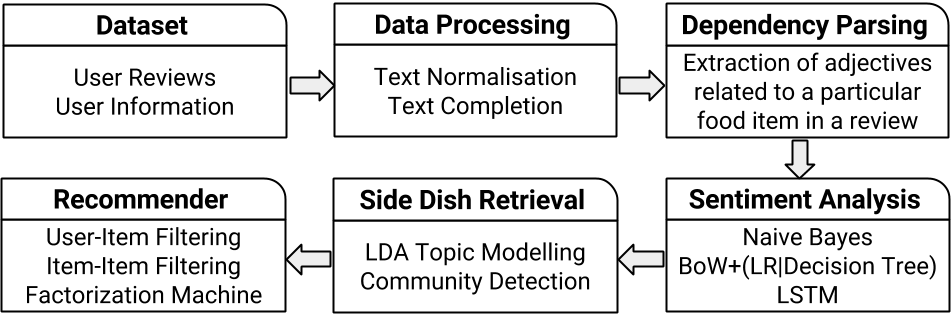 Figure 1
Figure 1| Data Set | Naive | BoW | BoW + | LSTM |
|---|---|---|---|---|
| Bayes | +LR | DT | ||
| Rated 2.0 | 0.77 | 0.81 | 0.86 | 0.81 |
| Rated 2.5 | 0.76 | 0.82 | 0.82 | 0.84 |
| Rated 3.0 | 0.74 | 0.79 | 0.81 | 0.83 |
| Manual | 0.80 | 0.84 | 0.86 | 0.90 |
| CF Method | RMSE | MAE | Precision |
|---|---|---|---|
| Baseline | 1.952 | 1.071 | 0.48 |
| User-Item Filter | 1.054 | 0.634 | 0.72 |
| Item-Item Filter | 1.059 | 0.661 | 0.70 |
| Factorization Machine | 1.010 | 0.609 | 0.74 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSentiment Analysis and Opinion Mining · Text and Document Classification Technologies · Spam and Phishing Detection
Fiducia: A Personalized Food Recommender System for Zomato
Mansi Goel, Ayush Agarwal, Deepak Thukral, Tanmoy Chakraborty
IIIT-Delhi, India
[mansi14062, ayush14029, deepak14036, tanmoy]@iiitd.ac.in
Abstract.
This paper presents Fiducia, a food review system involving a pipeline which processes restaurant-related reviews obtained from Zomato (India’s largest restaurant search and discovery service). Fiducia is specific to popular café food items and manages to identify relevant information pertaining to each item separately in the reviews. It uses a sentiment check on these pieces of text and accordingly suggests an appropriate restaurant for the particular item depending on user-item and item-item similarity. Experimental results show that the sentiment analyzer module of Fiducia achieves an accuracy of over 85% and our final recommender system achieves an RMSE of about beating other baselines.
††copyright: none
1. Introduction
Zomato111https://www.zomato.com/india is the largest Indian restaurant directory application used to suggest nearby restaurants according to the favored cuisines, prices and other amenities like home delivery. It hosts vast information about each restaurant which is not clustered properly according to the users’ convenience. If we manage to get a collection of restaurants recognized according to user preferences, the usability of the application will greatly increase. Zomato fails to provide details at the individual item level. A restaurant can be very popular but it might not be famous for a certain food item; whereas a less popular restaurant might excel in that. Usually customers need to go through the reviews to find out what’s the best the restaurant serves and what should be avoided.
Problem Definition: In this paper, we aim to design a system that maps customers’ choice of food to the place where they can be availed the best. The input of our system will be in the form of a preference food item of the user, and the recommendation generated will be based on restaurants which have a reviewed acclaim of that item. We also provide a peek into some of the side food items which go along well with the user’s choice of items.
System Description and State-of-the-art: Fiducia leverages complex and fine-tuned structures in the form of a Naive Bayes Classifier and LSTMs. Previous work in recommendation of the Yelp food review dataset has relied on techniques like clustering and graph projections, matrix decompositions and SVM Ranking models. Collaborative filtering (CF) approaches on the dataset have been explored in (Nikulin, 2014) while work in user preference based recommendation has been addressed in (Zeng et al., 2016). We do not rely on structured databases of recipes, in which a complete knowledge is available, but deal with fragmented information extracted solely from the user reviews of restaurants. Moreover, Fiducia deals with the problem of menu recommendation not in an abstract way, as a standalone problem, but contextualized to the user environment. Additionally, we also use techniques for topic modeling and community detection to determine suitable side dishes for user preference dishes.
To our knowledge, this is the first work to recommend restaurants based on fragmented individual food item reviews on Zomato.
2. System Architecture
Figure 1 shows the overall architecture of our system.
(i) Dataset: The Zomato API provides exhaustive information about each food joint by different filters like location, cuisine etc. However, it limits the number of reviews returned from every restaurant to 5. We collected 100 popular restaurant profiles including Name, Rating, Cuisine, Reviews along with the rating and reviewer identity of each review. Reviews on Zomato are written by common users mostly in code-mixed language (a mix of Hindi and English). We translated all such occurrences using Google Translate API to complete English text. Basic pre-processing steps included removing stop-words, assigning emoticons to its sentiment classes, replacing slangs with their intended meaning etc.
(ii) Dependency Parsing: Data extracted through Zomato contains a combined sentiment for multiple food items embedded in the same review. Object-wise sentiment detection problem is crucial for the recommender as it provides the user preferences for individual items especially in the cases of different sentiments for items expressed in the same review which would not be captured by the overall review sentiment. We use Stanford Dependency Parser(Chen and Manning, 2014) to identify the words intended for each item in a review. We create a vector of these fragments and use a sentiment analyzer framework on top of it to categorize the sentiment of each item.
(iii) Sentiment Analysis: We classify a fragment related to an item using three types of classifiers: (a) Naive Bayes Classifier gives us the probability of positive and negative sentiment for the item. (b) Bag of Words (BoW) model is used on each review as a document to make a dictionary containing the frequency of the vocabulary which is being built as we fit the data in the vectorizer. Through this we tokenize and count the word occurrences of a minimalistic corpus of reviews. Using the vocabulary we created a feature vector matrix of 0s and 1s according to the availability of a vocabulary element in that review. We tried training this vector with two classifiers - using Logistic Regression and using Decision Tree. (c) We also use Long Short Term Memory (LSTM). Simple RNNs are infamous for the vanishing gradient problem during backpropagation. This rises in cases of text snippets which are of longer length (similar to our case where the reviews, even for a single dish could be quite long). LSTMs preserve information for a long time using a circuit that implements an analog memory cell. Each review is mapped to a real vector domain in the embedding process which is the input to the network and the output consists of a number between (neg. class) and (pos. class) which denotes the sentiment.
(iv) Main Food Item Recommendation: We use two approaches in memory-based collaborative filtering – User-Item Filtering (Model 1) and Item-Item Filtering (Model 2). A user-item filtering takes a particular user, finds users that are similar to that user based on similarity of ratings as = and recommends items that those similar users liked. We use cosine similarity as the distance metric. Item-item filtering takes an item, finds users who liked that item, and searches for other items that those users or similar users also liked as = . To make the final prediction (Eqs. and ), we use similarity as a weight, and normalize it with similarity of the ratings to stay within and .
[TABLE]
[TABLE]
where represents the rating of item m of a restaurant by a user a, is mean of all ratings provided by user k and is the mean of ratings provided to that item. We further use Factorization Machine which uses stochastic gradient descent with adaptive regularization as a learning method. It adapts the regularization automatically while training the model parameters. We use a learning rate of 0.001 with 100 iterations, and task regression in the model.
(v) Side Food Item Recommendation: Sometimes customers prefer to visit a restaurant where the sides frequented with the food items are equally good. An example of this can be observed in some reviews where the lack of a satisfactory serving of (say,) garlic bread with pasta is criticized. We aim to check the availability and quality of the side by employing two simple associative techniques.
Topic Modeling: Taking each review as a document, we collate them for every restaurant. We use Latent Dirchilet Allocation to train our model for constructed corpus of each restaurant. This way, top 10 topics are identified with each topic containing 10 words from which we identify the items separately. It not only provides us with the most common items being talked about in the reviews but also provides us with the possibility of a group of items preferred together if they appear in the same topic.
Community Detection: The concept of communities is applied to the graph of items appearing in reviews. Taking the items as nodes and edges according to their mentions in the reviews, a graph is constructed. On this graph, we then apply Louvain algorithm (Blondel et al., 2008; Chakraborty et al., 2017) for static community detection and obtain items appearing frequently together. Among dishes we have in total, we find 6 distinct communities.
We use this output as an additional feature in the recommender to evaluate the restaurant with respect to one of the primary items.
3. Evaluation and Results
Evaluation of Sentiment Analyzer: After preprocessing, we had a total reviews in our dataset. For the evaluation of the sentiment analyzers, we keep 80% (2504 samples) for training, and 20% (627 samples) for testing. We use F-score as our evaluation metric. If we rely on using thresholding on restaurant rating (scale of 1-5) provided by Zomato as ground-truth, in case of low-rated (¡2.0) restaurants we bias the evaluation with negative words, while the opposite happens in case of high-rated (¿3.0) restaurants. Therefore, we further manually annotated all reviews (annotations were done by annotators with an inter-annotator agreement of ). Table 1 shows that LSTM outperforms others across all the ground-truth datasets. Best performance ( F-score) is obtained on manually-annotated ground-truth dataset.
Evaluation of Recommender System: To evaluate our recommendation system, we use Root Mean Squared Error (RMSE), Mean Absolute Error (MAE) and precision. Depending on a person’s similarity with another user or the items in the reviews being similar, we make a recommendation for a restaurant w.r.t the person, and then evaluate it with the actual rating of the item in the person’s review. The baseline prediction is made by simply suggesting the restaurant with the highest number of positive reviews. Table 2 shows that Factorization Machine outperforms others with a precision of .
4. Conclusions
We designed Fiducia, a recommender system which suggests restaurants according to user’s food item preference based on the reviews received by Zomato about these restaurants. We also kept in mind the side items favored while making the recommendation. We believe that this information may be useful for the extensive review data available on such sites.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1(1)
- 2Blondel et al . (2008) V. D Blondel, J.-L. Guillaume, R. Lambiotte, and E. Lefebvre. 2008. Fast unfolding of communities in large networks. JSTAT 2008, 10 (2008), P 10008.
- 3Chakraborty et al . (2017) Tanmoy Chakraborty, Ayushi Dalmia, Animesh Mukherjee, and Niloy Ganguly. 2017. Metrics for Community Analysis: A Survey. ACM Comput. Surv. 50, 4 (Aug. 2017), 54:1–54:37.
- 4Chen and Manning (2014) Danqi Chen and Christopher Manning. 2014. A fast and accurate dependency parser using neural networks. In EMNLP . Doha, Qatar, 740–750.
- 5Nikulin (2014) Vladimir Nikulin. 2014. Hybrid Recommender System for Prediction of the Yelp Users Preferences. In ICDM . Springer, Dallas, TX, USA, 85–99.
- 6Zeng et al . (2016) Jun Zeng, Feng Li, Haiyang Liu, Junhao Wen, and Sachio Hirokawa. 2016. A Restaurant Recommender System Based on User Preference and Location in Mobile Environment. In IIAI-AAI . IEEE, Kumamoto, Japan, 55–60.