Determining satisfiability of 3-SAT in polynomial time
Ortho Flint, Asanka Wickramasinghe, Jason Brasse, Christopher Fowler

TL;DR
This paper claims to present a deterministic polynomial time algorithm for solving 3-SAT, a problem previously thought to be NP-complete, suggesting a breakthrough in computational complexity theory.
Contribution
It introduces a novel polynomial time algorithm for 3-SAT, challenging the long-standing belief that 3-SAT is NP-complete.
Findings
Algorithm runs in polynomial time
Practical efficiency demonstrated on current hardware
Provides a serial implementation for testing
Abstract
In this paper, we provide a deterministic polynomial time algorithm that determines satisfiability of 3-SAT. The complexity analysis for the algorithm takes into account no efficiency and yet provides a low enough bound, that efficient versions are practical with respect to today's hardware. We accompany this paper with a serial version of the algorithm without non-trivial efficiencies (link: polynomial3sat.org).
Click any figure to enlarge with its caption.
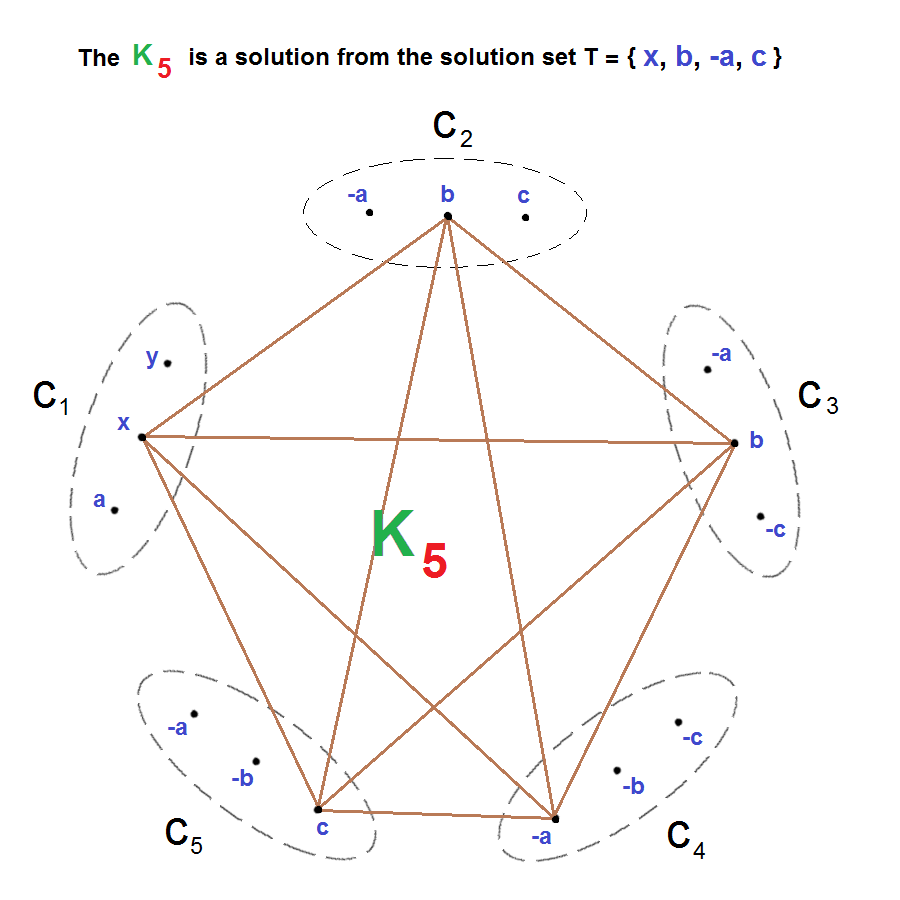 Figure 1
Figure 1 Figure 2
Figure 2 Figure 4
Figure 4Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsFormal Methods in Verification · graph theory and CDMA systems · semigroups and automata theory
Determining satisfiability of -SAT in polynomial time
Ortho Flint, Asanka Wickramasinghe, Jay Brasse, Chris Fowler
Abstract
In this paper, we provide a polynomial time (and space), algorithm that determines satisfiability of -SAT. The complexity analysis for the algorithm takes into account no efficiency and yet provides a low enough bound, that efficient versions are practical with respect to today’s hardware. We accompany this paper with a serial version of the algorithm without non-trivial efficiencies (link: polynomial3sat.org).
1 Introduction
The Boolean satisfiability problem (or SAT), was the first problem to be proven NP-complete by Cook in [1]. -SAT is one of Karp’s original NP-complete problems [2]. At last count, there are over NP-complete problems considered to be important. Any problem in NP can be presented as a SAT problem. A SAT problem can be transformed into a -SAT problem, where any increase in the number of clauses is a polynomial bound. We provide a deterministic polynomial time algorithm that decides satisfiability of -SAT. We also provide in Big O notation the complexity of the algorithm without efficiencies. The original serial version is called , by which we mean, none of the efficiencies that could be used for dramatic reductions in work are present. However, this version is quite useful for research, as we can attest. There are many non-trivial efficiencies that can be incorporated.
Note well, that the intent of an informal presentation of the algorithm, is to offer people that are outside the math/computer science community, a fairly straightforward explanation.
2 Preliminaries and Definitions
Definition 2.1**.**
A -SAT is a collection of literals or variables (usually represented by integers), in groups called clauses where no clause has more than literals, and at least one clause does have literals. If it’s possible to select exactly one literal from each clause such that no literal , and its negation (or denoted , meaning not ), appear in the collection of chosen literals, we say that the -SAT is satisfiable, otherwise we say it’s unsatisfiable. For satisfiability, the collection of literals chosen is called a solution, which is also known as a truth assignment. Note that the size of a solution set is smaller than the size of the collection, if the collection had at least two clauses of which the same literal was chosen.
It is important to note, that our definition of a solution (definition ), is inextricably tied to our constructs for a collection of clauses.
When we think of literals (also called atoms), we can consider an edge joining two vertices, each with an associated literal, if and only if, it’s not a literal and its negation. Under no circumstance would a literal and its negation be connected by an edge. There are also no edges between two literals from the same clause. So conceptually, there exist edges that connect every literal to every other literal with the two restrictions that were just stated. Then it follows, that a collection of literals for some solution is such that, a literal from each clause is connected to every other literal from that collection. In graph theory, such a graph is called a complete graph , being the number of vertices, which here it’s also the number of clauses. We shall denote this graph as: where is the number of clauses.
Definition 2.2**.**
An edge-sequence is an ordered sequence with elements and [math]. The ordering is an ordering of the clauses, with indexing: , , , , where a corresponding has its literals ordered the same way for each sequence constructed for a -SAT. An edge-sequence , for an edge with endpoints labelled and , where , the literals associated with the endpoints, is denoted by . The endpoints must always be from different clauses. We call the positions in that correspond to a clause the cell . The cells and containing the endpoints, and for have only one entry that is in the positions associated to and . When an edge-sequence is constructed, a given position in is if the associated literal is not or . The initial construction of is subject to certain rules defined in and , which may produce more zero entries. Lastly, removing one or more cells from is again a (sub) edge-sequence, denoted by , if the cells containing the endpoints for remain.*
Definition 2.3**.**
We call a literal , an edge-pure literal, if its negation does not appear in an edge-sequence. ie. there are zero entries in the positions associated with literal in the edge-sequence, or no exists. Note that the literals associated to the endpoints are necessarily edge-pure literals.
Definition 2.4**.**
We call a literal , an edge-singleton, if it has only one position in an edge-sequence. We say that only one position exists in each endpoint cell which correspond with the endpoints. And we call a literal a singleton, if it appears in only one clause for a given collection of clauses.
Definition 2.5**.**
A loner cell contains just one entry for some literal. And a loner clause contains just one literal.
Definition 2.6**.**
A vertex-sequence is an ordered sequence with elements and [math]. The ordering is an ordering of the clauses, with indexing: , , , , where a corresponding has its literals ordered the same way for each sequence constructed for a -SAT. A vertex-sequence , for a vertex associated with literal , is denoted by . We call the positions in that correspond to a clause the cell . The cell containing the vertex for has only one entry that is in the position associated to . When a vertex-sequence is constructed, a given position in is if the associated literal is not . The initial construction of is subject to certain rules defined in and , which may produce more zero entries. Removing one or more cells from is again a (sub) vertex-sequence, denoted by , if the cell containing remains.*
Definition 2.7**.**
When an entry in an edge-sequence or a vertex-sequence, becomes zero, we call it a bit-change. If a bit-change has occurred in an edge-sequence or a vertex-sequence, we say the sequence has been refined, or a refinement has occurred. A zero entry never becomes a entry.
It’s worth noting here that if an edge-sequence has a zero entry in some position for a literal , then there is no , using literals and together. In fact, this is what a bit-change is documenting in an edge-sequence.
Definition 2.8**.**
*The loner cell rule, LCR, is that no negation of a literal belonging to a loner cell can exist in an edge-sequence or vertex-sequence. If such a scenario exists in an edge-sequence or a vertex-sequence where is the loner cell literal, then all positions associated with literal incur a bit-change. If this action of a bit-change for , creates another loner cell where the negation of the literal in the newly created loner cell is still present in or the action of a bit-change for the negation is repeated. Hence, to be LCR compliant may be recursive, but all refinements are permanent for any edge or vertex sequence.
LCR compliancy is determined for an edge-sequence or a vertex-sequence if either or is being constructed. LCR compliancy is determined after any intersection between two of more edge-sequences is performed. LCR compliancy is determined if an edge-sequence or vertex-sequence incurred any refinement.
Definition 2.9**.**
*The -rule is that no cell from an edge-sequence or a vertex-sequence can have all zero entries. If this is the case, then or , equals zero, and is removed from its -set, or is removed from the vertex-sequence table. Note that their respective removals, is a refinement.
-rule compliancy is determined for an edge-sequence or a vertex-sequence , if either or are being constructed. -rule compliancy is determined after any intersection between two of more edge-sequences is performed. -rule compliancy is determined if an edge-sequence or vertex-sequence incurred any refinement. And finally, the -rule is violated if all the vertex-sequences associated with a clause, are zero. In such a case, it’s reported that the -SAT is unsatisfiable.
Before we work through an example, we must define what it means to take an intersection or union of two or more edge-sequences. No intersections or unions are taken with vertex-sequences.
Definition 2.10**.**
*We take the intersection or union of two length edge-sequences, and , by comparing position of and , using the Boolean rules for intersections (denoted by ), and unions (denoted by ), for all positions, 0,1,2,\ldots,n$$-1.
Recall that the entry for position of and , is either or [math].
*Then for an intersection, we have: *
* = = = [math]. And = . *
*And for a union we have: *
* = = = . And = [math].*
In general, an intersection or union between two or more edge-sequences, is a multi-edged sequence. There is one exception described in section , where an intersection or a union of intersections of edge-sequences, always produces an edge-sequence.
Definition 2.11**.**
An -set is a collection of edge-sequences whose endpoints are from two clauses, and where . The number of constructed edge-sequences to be an -set is minus the non edge-sequences of the form: . For -SAT, there can be at most 9 edge-sequences in an -set.
Definition 2.12**.**
A solution for a collection of clauses must have a corresponding collection of edge-sequences, for some . More precisely, the intersection of all the edge-sequences together, for a , does not equal zero. ie. A solution exists if [math], where and are every pair of endpoints from the collection of edges for a . A , , exists if the set of all sub edge-sequences for are such that the intersection of does not equal zero. ie. A exists if [math], where and are every pair of endpoints from the collection of edges for . It is to be understood that an edge-sequence for a or , means the edge-sequence associated with an edge for a or .*
Example
Figure : A -SAT with clauses
We believe it is useful to think of -SATs in terms of their corresponding graphs. For example, Figure (the only figure in the paper), depicts a -SAT with five clauses. The clauses are numbered and each clause has three literals. We say that a clause with three literals, thus three vertices, is size . For -SAT, clauses can only be of size , or . Although there would be an edge between any two literals not belonging to the same clause and not between a literal and its negation, we have chosen to show in Figure , just the edges for a from the solution set = .
Of course, the challenge when presented with a -SAT is to find at least one , when it’s a proper subgraph, or to determine that no exists.
This example is to demonstrate the construction of edge-sequences for an -set. We also provide one example of an intersection and another of a union between two edge-sequences.
For an -set with edge-sequences formed using clauses , we write: . Recall, that an edge’s endpoints are always labelled by their associated literals. Then the edge-sequence , for an edge with endpoints with labelling , is denoted by . Below, we add sub-subscripts for our example (Figure ), -SAT’s edge-sequences, to indicate which clauses the endpoints are from. And within the (ordered) sequences, the subscripts indicate which literal received a zero or a one.
Our example has -sets and at most edge-sequences in each. With respect to the sub-subscripts, all the edge-sequences are unique. We will show just the initial edge-sequences (there is no , a literal and its negation), for . We will also construct from for the purpose of showing intersections and unions of edge-sequences.
Then the constructed edge-sequences for , before and -rule determination is:
I_{a_{1},b_{2}}:(1_{a},0_{x},0_{y}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt0_{-a},1_{b},0_{c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt0_{-a},1_{b},1_{-c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt0_{-a},0_{-b},{\color[rgb]{0,1,0}1}_{-c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt0_{-a},0_{-b},{\color[rgb]{1,0,0}1}_{c})
I_{a_{1},c_{2}}:(1_{a},0_{x},0_{y}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt0_{-a},0_{b},1_{c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt0_{-a},{\color[rgb]{0,1,0}1}_{b},0_{-c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt0_{-a},{\color[rgb]{1,0,0}1}_{-b},0_{-c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt0_{-a},1_{-b},1_{c})
I_{x_{1},-a_{2}}:(0_{a},1_{x},0_{y}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt1_{-a},0_{b},0_{c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt1_{-a},1_{b},1_{-c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt1_{-a},1_{-b},1_{-c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt1_{-a},1_{-b},1_{c})
I_{x_{1},b_{2}}:(0_{a},1_{x},0_{y}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt0_{-a},1_{b},0_{c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt1_{-a},1_{b},1_{-c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt1_{-a},0_{-b},1_{-c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt1_{-a},0_{-b},1_{c})
I_{x_{1},c_{2}}:(0_{a},1_{x},0_{y}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt0_{-a},0_{b},1_{c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt1_{-a},1_{b},0_{-c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt1_{-a},1_{-b},0_{-c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt1_{-a},1_{-b},1_{c})
I_{y_{1},-a_{2}}:(0_{a},0_{x},1_{y}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt1_{-a},0_{b},0_{c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt1_{-a},1_{b},1_{-c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt1_{-a},1_{-b},1_{-c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt1_{-a},1_{-b},1_{c})
I_{y_{1},b_{2}}:(0_{a},0_{x},1_{y}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt0_{-a},1_{b},0_{c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt1_{-a},1_{b},1_{-c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt1_{-a},0_{-b},1_{-c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt1_{-a},0_{-b},1_{c})
I_{y_{1},c_{2}}:(0_{a},0_{x},1_{y}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt0_{-a},0_{b},1_{c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt1_{-a},1_{b},0_{-c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt1_{-a},1_{-b},0_{-c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt1_{-a},1_{-b},1_{c})
Observe below, that after and -rule is applied, edges and will be zero. Since the loner cells and in negate each other, applying to either cell (we apply to first encountered), causes the other cell to be an empty cell which violates the -rule. Similarly, the loner cells and in negate each other, producing the same outcome.
Then applying to , we have:
I_{a_{1},b_{2}}:(1_{a},0_{x},0_{y}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt0_{-a},1_{b},0_{c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt0_{-a},1_{b},1_{-c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt0_{-a},0_{-b},{\color[rgb]{0,1,0}1}_{-c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt0_{-a},0_{-b},{\color[rgb]{1,0,0}0}_{c})
Now, we apply -rule to , thereby [math]:
I_{a_{1},b_{2}}:(1_{a},0_{x},0_{y}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt0_{-a},1_{b},0_{c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt0_{-a},1_{b},1_{-c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt0_{-a},0_{-b},{\color[rgb]{0,1,0}1}_{-c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt{\color[rgb]{1,0,0}0}_{-a},{\color[rgb]{1,0,0}0}_{-b},{\color[rgb]{1,0,0}0}_{c})
Applying to , we have:
I_{a_{1},c_{2}}:(1_{a},0_{x},0_{y}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt0_{-a},0_{b},1_{c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt0_{-a},{\color[rgb]{0,1,0}1}_{b},0_{-c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt0_{-a},{\color[rgb]{1,0,0}0}_{-b},0_{-c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt0_{-a},1_{-b},1_{c})
Now, we apply -rule to , thereby [math]:
I_{a_{1},c_{2}}:(1_{a},0_{x},0_{y}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt0_{-a},0_{b},1_{c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt0_{-a},{\color[rgb]{0,1,0}1}_{b},0_{-c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt{\color[rgb]{1,0,0}0}_{-a},{\color[rgb]{1,0,0}0}_{-b},{\color[rgb]{1,0,0}0}_{-c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt0_{-a},1_{-b},1_{c})
The other edge-sequences of listed above, are and -rule compliant. Thus, the construction of the edge-sequences resulted in only edge-sequences for . We note here that if an -set had no edge-sequences after construction where and -rule was applied, it would mean there is no solution for the collection of clauses given. We show a in Figure , so all -sets must exist, because each -set has an edge-sequence for a .
Below, we show the result of doing and .
The and -rule compliant edge-sequence of is:
I_{b_{3},-c_{4}}:({\color[rgb]{1,0,0}0}_{a},1_{x},1_{y}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt1_{-a},1_{b},0_{c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt0_{-a},1_{b},0_{-c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt0_{-a},0_{-b},1_{-c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt{\color[rgb]{0,1,0}1}_{-a},0_{-b},0_{c})
And the and -rule compliant edge-sequence is:
I_{x_{1},c_{2}}:(0_{a},1_{x},0_{y}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt0_{-a},0_{b},1_{c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt1_{-a},1_{b},0_{-c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt1_{-a},1_{-b},0_{-c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt1_{-a},1_{-b},1_{c})
The intersection, is :
(0_{a},1_{x},0_{y}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt{\color[rgb]{1,0,0}0}_{-a},{\color[rgb]{1,0,0}0}_{b},{\color[rgb]{1,0,0}0}_{c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt0_{-a},1_{b},0_{-c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt{\color[rgb]{1,0,0}0}_{-a},{\color[rgb]{1,0,0}0}_{-b},{\color[rgb]{1,0,0}0}_{-c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt1_{-a},0_{-b},0_{c})
Recall that we always determine and -rule compliancy after any intersection. Thus, the intersection: = [math], because at least one cell violated the -rule. Here, both and violated the -rule.
The and -rule compliant union: is:
(0_{a},1_{x},1_{y}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt1_{-a},1_{b},1_{c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt1_{-a},1_{b},0_{-c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt1_{-a},1_{-b},1_{-c}\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt1_{-a},1_{-b},1_{c})
Observe that is a multi-edged sequence. We remark that if a collection of edge-sequences are and -rule compliant, then their union must also be and -rule compliant, so compliancy is assured after a union is performed. The reason is simply that there is no union of and -rule compliant edge-sequences, that could create a new scenario, or cause a violation of the -rule, via the Boolean rules.
3 Description of the algorithm
In this section we describe the basic algorithm. The description of the algorithm will consist of describing pre-processing and how the ordered sequences are compared with each other and what actions are to be taken based on those comparisons. The section to follow proves the correctness of this scheme and that it stops in polynomial time, when applied to any instance of -SAT.
Pre-processing
Pre-processing begins by building the first tables from a given DIMACS file. While doing this, we learn of redundancies that might as well be eliminated. However, it’s worth noting that the algorithm to process a -SAT does not require any redundancies to be removed.
Definition 3.1**.**
Let be a given collection of clauses. We call a literal , a pure literal, if its negation , does not appear in . ie. in .
Definition 3.2**.**
A clause of the form: , or is called a quantum clause. A quantum clause is a possible randomly generated clause.
To start, we order the literals represented by integers, within each clause. If there exists among the given clauses, two or more clauses which are the same clause, but the literals appear in a different order, it will be discovered. Only one copy of each unique clause is required to process a given -SAT. We learn if any clause has literal duplication: or or . Randomly generated clauses could be of this form, which we reduce to: , and , respectively. When we have ordered the clauses, we have also documented each literal and its negation, and to which clauses they are associated. At this point we will have discovered any literals. The clauses containing one or more literals, can be removed, where one of the , represents its clause. We can remove a clause with a because any solution found with the remaining clauses, can include all the , since no solution includes their negations. We will also discover any clauses, and they can be removed because any solution for the remaining clauses can always add a literal from a . For example, let a clause be , and there is a solution with the remaining clauses which may use or or neither. For neither, or can be selected to be part of the solution.
Removing and can be recursive, as it was for our example.
If there exists among the collection of clauses given, one or more clauses containing just one literal, we remove these clauses. Obviously, the single literal is the only literal to represent the clause for any solution. And since these literals must be in every solution, their negations are removed from the collection of clauses given. This action may also be recursive. If this action empties a clause of all its literals, then there is no solution for the collection of clauses given.
There is a possible redundancy that we ignore, which we call . Suppose among the given clauses, there exist two clauses: and . It’s clear that if a solution exists, then either literal or must be part of that solution, thus is redundant and could be removed. With respect to , in context of processing a -SAT, a cell may no longer have entries for every literal of clause . For example, let clause have three literals , and . Now, suppose after some processing, that the entry for in cell is zero, in all edge-sequences. Then cell can be removed from all sequences. And after all processing is complete, it can be determined if or will be representing clause .
Construction of the edge and vertex sequences
Let , where is the number of remaining clauses and is the sum of the sizes, for the clauses. Then after pre-processing, the vertex-sequences, grouped by clause association, are constructed first, as outlined in definition , and then and -rule is applied. It would be common practice to order the clauses, and the literals within each clause, and use this same ordering for both the edge and vertex sequences.
After pre-processing, the remaining clauses not removed, have at most, edge-sequences constructed from them pairwise. The edge-sequences are constructed as outlined in definition , and then and -rule is applied. Observe that the number of edge-sequences would be less than . It must always be less than, because we did not subtract the over count of non-existent edges with i) both endpoints in the same clause or ii) the non edge-sequences between a literal and its negation. Of course, if each clause had just one literal and there was a solution, pre-processing would have presented the solution or pre-processing removed all literals from at least one clause, establishing unsatisfiability. Either way, no edge-sequences would have been constructed. Each pair of clauses from the collection of clauses, forms an -set. Thus, the number of -sets is , where any -set contains at most, edge-sequences. We shall denote an -set with the indices of the two clauses used to construct its edge-sequences. ie. has edge-sequences whose endpoints are from clauses and .
Before we describe in detail the Comparing of -sets, we list the refinement rules. The refinement rules below, refer to a bit-change occurring, an edge removed from its -set, or a literal having a zero entry in every edge and vertex sequence, all being the result of the Comparing of -sets. Given a collection of clauses, if any of these refinements occurred that were not the result of the Comparing of -sets, it was the result of and -rule compliancy, while constructing the edge-sequences and vertex-sequences. We shall apply the actions outlined in the refinement rules even when constructing the vertex and edge sequences. The example demonstrated that certain edge-sequences were zero upon construction, as they failed and -rule compliancy. To be systematic, we would first construct all the vertex-sequences as described in definition . Then apply and -rule to all of the vertex-sequences. If the actions outlined in the refinement rules can be taken on any vertex-sequence, we do so. Next, we construct all the edge-sequences as described in definition . Then apply and -rule to all of the edge-sequences. If the actions outlined in the refinement rules can be taken on any vertex or edge sequence, we do so. This process may be recursive.
It is to be understood that an edge-sequence may be called just an edge for simplicity and that a vertex may be referred to by its associated literal. Also, an endpoint for an edge may be referred to as an endpoint for its corresponding edge-sequence and to say: a literal or an endpoint, in a cell , is to be understood as a entry in cell , associated to literal or an endpoint.
The Refinement Rules and
When a refinement occurs and one of the rules or actions are to be applied to an edge-sequence or a vertex-sequence, and -rule compliancy must always be determined afterward. Note that the actions for the refinement rules could be recursive and that all refinements are permanent.
**Rule 1: a bit-change occurred **
Let where denotes cell , and denotes cell , be an edge-sequence where at least, one entry for a position (occurrence) associated with literal became zero. Then we change entries to zero for all positions associated with in . If there was just one position for , then no action is taken.
Now, we consider all edges that are not . ie. at least one endpoint is not from either cell or . We will change a to zero for every occurrence of a literal who had at least one occurrence become zero in for all edge-sequences labelled . The result is all which of course includes have the same set of literals whose associated entries are zero.
**Rule 2: the follow up to a bit-change **
If has zero entries for , then will have zero entries for , and will have zero entries for . All three edge-sequences are documenting the same fact, namely, that there is no solution with , and together. So, if an edge-sequence for which at least one entry became zero, say for literal , we apply rule . Then in and we make all entries zero, that correspond to literals and , respectively.
**Rule 3: [math], and was removed from its -set **
Let be an edge that was removed from -set, . The sub-subscripts for the edge-sequence indicate that one endpoint is from cell , and the other endpoint is from cell . First, we remove all occurrences of where m$$+$$n i$$+$$j, from their respective -sets.
Next, we update all the vertex-sequences for literals and by: All the vertex-sequences for have all positions associated with incur a bit-change. And all the vertex-sequences for have all positions associated with incur a bit-change.
Recall, that any kind of refinement requires testing and -rule compliancy, even on vertex-sequences. This in turn could cause the vertex-sequence to equal zero. In such a case, we apply all actions outlined in rule .
We also ensure that all refined vertex-sequences for a literal , have the same set of literals whose associated entries are zero.
Now, all positions associated with incur a bit-change, in where is any literal that forms an edge with . Then all positions associated with incur a bit-change, in where is any literal that forms an edge with .
This whole process may cause another edge removal, in which case we apply rule , recursively if need be. This in turn could cause a vertex-sequence to equal zero. In such a case, we apply all actions outlined in rule .
**Rule 4: a literal’s vertex-sequence equals zero **
Let a literal be such that its vertex-sequence violates the -rule. Then its vertex-sequence , where belongs to cell is equal to zero.
If is now zero, then all vertex-sequences are now evaluated to be zero, and all of them are removed from the vertex-sequence table.
When a vertex-sequence equals zero we do: All positions associated with incurs a bit-change in every vertex and edge sequence. This action in turn causes all edge-sequences of the form: , where is any literal that forms an edge with , to equal zero.
This whole process may cause another edge-sequence (not of the form ), to be removed, in which case we apply rule , recursively if need be. This in turn could cause a vertex-sequence to equal zero. In such a case, we apply all actions outlined here, in rule .
The Comparing of the -sets
Essentially, the Comparing process is the algorithm. All data structures are simply updated based on the outcome of Comparing -sets with one another.
Definition 3.3**.**
When every -set has been Compared with every other -set, we say that a run has been completed. If clauses are considered, then there are -sets, thus the number of -set comparisons for a run is .
Definition 3.4**.**
A round is completed if the Comparing process stops because no refinement occurred during an entire run. We say that the -sets are equivalent when a round is completed.
We note that if the first round was not completed, it was the case that the vertex-sequences associated to a clause, were evaluated to be zero, so they were discarded. This violation of the -rule stops all processing, as there is no solution for the collection of clauses given.
To Compare, we take two -sets and determine if an edge-sequence from one of the -sets, can be refined by a union of the intersections between with each of the edge-sequences, from the other -set. Either the edge-sequence under determination, is refined or it remains the same. This is done for each edge-sequence from both of the -sets, in the same manner. As a matter of practice, we determine in turn, each edge-sequence from one -set first, and then we determine in turn, each edge-sequence from the other -set. Below, we construct two -sets to describe in more detail all the steps to be taken.
Let the -set: contain edge-sequences with endpoints from clauses: and giving: , , , , , , , ,
Let the -set: contain edge-sequences with endpoints from clauses: and giving: , , , , , , , ,
If and have edge-sequences each, then there were no negations between the literals in and , or between the literals in and , respectively.
We say that determining all edge-sequences from one -set first, is doing one direction denoted by: . And determining all edge-sequences once, for both -sets, is doing both directions, denoted by:
Suppose we determine of first. Then we have:
(I_{1,a}\cap{\color[rgb]{0,0,1}I_{4,d}})\cup(I_{1,b}\cap{\color[rgb]{0,0,1}I_{4,d}})\cup(I_{1,c}\cap{\color[rgb]{0,0,1}I_{4,d}})\cup(I_{2,a}\cap{\color[rgb]{0,0,1}I_{4,d}})\cup(I_{2,b}\cap{\color[rgb]{0,0,1}I_{4,d}})\hskip 1.42271pt\cup
(I_{2,c}\cap{\color[rgb]{0,0,1}I_{4,d}})\cup(I_{3,a}\cap{\color[rgb]{0,0,1}I_{4,d}})\cup(I_{3,b}\cap{\color[rgb]{0,0,1}I_{4,d}})\cup(I_{3,c}\cap{\color[rgb]{0,0,1}I_{4,d}})\hskip 2.84544pt\leq\hskip 2.84544pt{\color[rgb]{0,0,1}I_{4,d}}
The rule: Wrt. an intersection between and an edge-sequence from , suppose the intersection resulted with occurrences of literal and its negation , having zero entries, where at least one occurrence is not in any of the endpoint cells. Then the intersection can be evaluated to be zero, since if these two edge-sequences belonged to a solution together, they would also belong to two other solutions, one using and another using , if both and had occurrences not in the endpoint cells.
The one efficiency present even in the original version with no refinement rules, was eliminating any unnecessary intersections by one easy check. After an edge-sequence is selected for determination, say where , , the edge-sequences from the other -set in the Comparing, that do not have entries for the endpoints and when intersected with , will be zero. Recall, that the two cells containing the endpoints, only have a single entry corresponding to the two endpoints’ positions, in their respective cells. Thus, if the other edge-sequence does not have a entry for those same positions, the intersection will be zero, due to -rule violation. So, after the selection of an edge-sequence to be determined, we select the edge-sequences from the other -set, if they have entries in both positions corresponding to the endpoints of . Of course, we could also check to see if there are entries in corresponding to the endpoints of the other edge-sequence as well.
Let’s suppose then, that every edge-sequence in above, did have entries for both endpoints and of . Now suppose intersections become zero, after the intersections were taken and and -rule was applied to each intersection, and we now have:
0\cup(I_{1,b}\cap{\color[rgb]{0,0,1}I_{4,d}})\cup 0\cup(I_{2,a}\cap{\color[rgb]{0,0,1}I_{4,d}})\cup 0\cup 0\cup 0\cup 0\cup(I_{3,c}\cap{\color[rgb]{0,0,1}I_{4,d}})\hskip 2.84544pt\leq\hskip 2.84544pt{\color[rgb]{0,0,1}I_{4,d}}
which is equivalent to: (I_{1,b}\cap{\color[rgb]{0,0,1}I_{4,d}})\cup(I_{2,a}\cap{\color[rgb]{0,0,1}I_{4,d}})\cup(I_{3,c}\cap{\color[rgb]{0,0,1}I_{4,d}})\hskip 2.84544pt\leq\hskip 2.84544pt{\color[rgb]{0,0,1}I_{4,d}}
Now, we take their union. Of course, and -rule compliancy need not be checked for any union, since it would not have been possible to create a new loner cell scenario, nor a cell with all zero entries.
Then to complete the determination of we need to compare position by position, to see if has been refined. More precisely, if we have: (I_{1,b}\cap{\color[rgb]{0,0,1}I_{4,d}})\cup(I_{2,a}\cap{\color[rgb]{0,0,1}I_{4,d}})\cup(I_{3,c}\cap{\color[rgb]{0,0,1}I_{4,d}}) {\color[rgb]{0,0,1}I_{4,d}}, then is unchanged, and we move on to the next edge-sequence to be determined. Or instead, we have: (I_{1,b}\cap{\color[rgb]{0,0,1}I_{4,d}})\cup(I_{2,a}\cap{\color[rgb]{0,0,1}I_{4,d}})\cup(I_{3,c}\cap{\color[rgb]{0,0,1}I_{4,d}}) {\color[rgb]{0,0,1}I_{4,d}}, then has been refined. We need to know which literals incurred a bit-change, and then we apply the appropriate actions of the refinement rules, and as always, followed by testing and -rule compliancy.
To summarize, an edge-sequence to be determined, has possible scenarios.
-
[math], and is unchanged.
-
[math], and is refined. We determine which literals had a bit-change and follow all appropriate refinement rule actions, recursively if need be.
-
[math], because (I_{1,b}\cap{\color[rgb]{0,0,1}I_{4,d}})\cup(I_{2,a}\cap{\color[rgb]{0,0,1}I_{4,d}})\cup(I_{3,c}\cap{\color[rgb]{0,0,1}I_{4,d}})\hskip 2.84544pt\leq\hskip 2.84544pt{\color[rgb]{0,0,1}I_{4,d}} became zero after an appropriate refinement rule action was taken, and then and -rule was applied. In this case, edge-sequence is discarded, and the actions stated in refinement rule are taken, recursively if need be.
-
If each intersection: (I_{1,b}\cap{\color[rgb]{0,0,1}I_{4,d}}), (I_{2,a}\cap{\color[rgb]{0,0,1}I_{4,d}}) and (I_{3,c}\cap{\color[rgb]{0,0,1}I_{4,d}}) had also been zero at the outset, then [math]. And as with 3), is discarded and the actions stated in refinement rule are taken, recursively if need be. When an edge-sequence equals zero, it was the case that none of the edge-sequences from an -set could be part of a solution with the edge-sequence that was being determined. And every solution has an edge-sequence in every -set.
There are two observations worth noting with respect to the Comparing process. First, that the result of an intersection with just the edge-sequence to be determined, or the union of the intersections between the edge-sequence to be determined, with each of the allowed edge-sequences, from the other -set, is never a multi-edged sequence. Whether no refinement took place for the edge-sequence being determined, or a great deal of refinement took place, it is still the edge-sequence that is being determined and it does indeed represent an edge-sequence with two particular endpoints.
In section , we gave an example of an intersection and a union (from Figure ), but neither was for an edge-sequence determination. Recall, that the intersection violated the -rule, thus equals zero, but the union was not evaluated to be zero, and it’s properly defined as a multi-edged sequence.
The second observation is that the distributive law for unions and intersections does not apply here. Otherwise, for example, we could say that: (I_{1,b}\cap{\color[rgb]{0,0,1}I_{4,d}})\cup(I_{2,a}\cap{\color[rgb]{0,0,1}I_{4,d}})\cup(I_{3,c}\cap{\color[rgb]{0,0,1}I_{4,d}})\hskip 2.84544pt=\hskip 2.84544pt(I_{1,b}\cup I_{2,a}\cup I_{3,c})\cap{\color[rgb]{0,0,1}I_{4,d}} which is not true in general. In the algorithm, we provide a Comparing between two -sets that will do more than once in each direction. If doing the second direction, results in one or more bit-changes, we will do again. And if one or more bit-changes occur in we will do again, and so on until no bit-change occurs while doing a direction. An important note, is that we don’t have to do this. If we only did no matter how many bit-changes occurred while doing the second direction, it wouldn’t matter. Suppose doing would have had a bit-change. Then if that scenario still exists in the next run, meaning that some other Comparing of -sets didn’t do the refinement in question prior to returning to these two -sets Comparing, a bit-change would still occur for . We are assuming by doing more than just if prompted by a bit-change occurring during is an efficiency measure. Recall definition , that after all pairs of -sets have been compared with each other, a run has been completed, which is , for clauses. Another run will commence if any refinement occurred. Eventually, a run will incur no refinement, not even a bit-change, at which point a round has been completed, and the -sets are said to be equivalent, which implies satisfiability. Or, the algorithm stopped because unsatisfiability had been discovered during round . Discovering unsatisfiability is when every literal from some clause is such that their vertex-sequences equal zero.
An example of Comparing
The two Comparings shown in this example, produce the same outcome as the action for refinement rule .
Let the -set: contain edge-sequences with endpoints from clauses: and giving: , , , , , , , ,
Now suppose we have clause: . Then and Further suppose that incurred a bit-change for literal .
First we consider: where we determine
Observe that all edge-sequences: , , , , , have a zero entry for , so they are not selected for the determination of , again because their intersection would be just zero. Since, has zero entries for all occurrences of , then [math]. Thus, the only two edge-sequences from to determine is: and , both of which have a zero entry for . Therefore, the determination of is a refinement where at least has a zero entry. Then after refinement rule is applied, all occurrences of literal in are zero, assuming [math], after and -rule compliancy.
Similarly, we consider: where we determine
Observe that all edge-sequences: , , , , , have a zero entry for , so they are not selected for the determination of . Since, has zero entries for all occurrences of , then [math]. Thus, the only two edge-sequences from to determine is: and , both of which have a zero entry for . Therefore, the determination of is a refinement where at least has a zero entry. Then after refinement rule is applied, all occurrences of literal in are zero, assuming [math], after and -rule compliancy.
Summary: Pre-processing begins with a DIMACS file submission, providing clauses, where each clause is at most size . The pre-processing entails ordering the literals within each clause (by any convention desired), and then removing duplicate clauses or literals within a clause. Next, the clauses to be removed have at least one literal, or they are quantum clauses. This may be a recursive process. Finally, clauses of size , a clause, are removed as are the negations of the literals from these clauses of size from all the other clauses that were given. This may also be recursive, as a negation may have been in a clause of size , thus its removal created a new loner clause. At this point, edge and vertex sequences are constructed from the remaining clauses. The edge-sequences are grouped in their respective -sets and the vertex-sequences are grouped by their clause association in the vertex-sequence table. When the vertex and edge sequences are and -rule compliant, the Comparing process begins. The Comparing process stops if: i) a clause was such that all its literals’ vertex-sequences are zero, where it’s reported that the given collection of clauses has no solution. Or, ii) one or more runs take place, where the last run had no refinement. This signals the end of a round, and the -sets are said to be equivalent, which implies satisfiability.
**Claim **: If a -SAT , with clauses (after pre-processing), has a solution , then the -sets for , will be equivalent at the completion of round , where each edge-sequence that appears, belongs to at least one solution. Moreover, an edge-sequence is such that any literal with a entry in belongs to at least one with and . Lastly, if at least one clause is such that all its literals’ vertex-sequences are zero, it means there is no solution for the collection of clauses that were processed, thus unsatisfiability has been discovered, which stops the processing of round .
In the next section we establish the claim. This is followed by proving that attaining -set equivalency is always achieved in polynomial time.
4 Proof of correctness and termination
Comparing and the Refinement rules
The actions of the refinement rules are taken if one of the four refinements occurred, by the Comparing process. We assert that: 1) If by Comparing, a bit-change occurred for one position of a literal in some edge-sequence , the Comparing process will eventually cause a bit-change for every position of in . 2) All edge-sequences have the same set of literals with zero entries via Comparing. 3) If by Comparing, an edge-sequence is evaluated to be zero, then all edge-sequences whose endpoints have the same associated literals, will be evaluated to be zero, by Comparing. And finally, 4) If by Comparing, a literal’s vertex-sequence is evaluated to be zero, then all vertex-sequences for literal belonging to other clauses, will be evaluated to be zero, by Comparing. Note that we have already shown in the Comparing example, that refinement rule is done by Comparing.
Since we intend to prove the algorithm that does use the refinement rules, then to determine if its actions are merely an efficiency isn’t warranted. Moreover, the argument to use the actions of the refinement rules ensures contradiction free edge-sequences. More precisely, if a bit-change occurred for one occurrence of literal in edge-sequence by Comparing, then with respect to literals, there is no solution using literals , and together. Therefore, if another occurrence of literal exists in it’s still the case that there is no solution using literals , and together. Thus, there would be no purpose for other occurrences of in to have entries. It follows, that if there exists another that belongs to another -set, that there would be no purpose for any occurrence of to have entries in this . And if by Comparing, [math], then with respect to literals, there is no solution using literals and together, so all edge-sequences whose endpoints are associated with literals and should be zero to be contradiction free. And finally, if a literal’s vertex-sequence [math], by Comparing, meaning no solution exists using literal , then with respect to literals, the vertex-sequence for every occurrence of should be zero to be contradiction free. We would provide the proof of the assertion if there should be any interest.
Another efficiency rule of note, but not part of our algorithm, is with respect to the vertex-sequences. Suppose during the Comparing process, it is determined that [math] say, and then at some later time in the Comparing process, it is determined that [math]. If were to be satisfiable, then as explained in the rule, a contradiction would exist. Therefore, must be unsatisfiable, so the processing can stop.
Lemma 4.1**.**
Let be a collection of -sets with and -rule compliant edge-sequences of length cells. Then no edge-sequence from , belonging to a , is removed by the Comparing process.
*Proof. *Suppose there exists a , . Then there exists an edge-sequence in each -set of , such that [math], where and are every pair of endpoints for the collection of edge-sequences of , by definition . So, if we take any edge-sequence , belonging to , it will still exist after the determination of from every other -set. The reason is that each -set , has an edge-sequence , call it , of , and the intersection , preserves all the entries for every literal that is part of the solution, by definition of . Thus, will not equal zero after and -rule compliancy, and the union of any additional intersections with , for any given determination, will be of no consequence. Additionally, may be refined due to refinement rules taken on it or on other edge-sequences, but this will not effect the entries for the literals that belong to . That is, if any entry in for a literal of , did incur a bit-change, it would imply that another edge or endpoint of , equals zero, a contradiction. In other words, every determination of with all the {c}\choose{2}$$- -sets will at most refine , since there is an edge-sequence belonging to , in every -set, and their intersection, , preserves the entries for every literal that is part of the solution . And no entry in for a literal of , is removed via the actions of the refinement rules on any edge-sequence, otherwise did not exist, a contradiction.
Observe that the proof for lemma establishes that if an edge-sequence and some literal belong to a , then does not incur a bit-change in by Comparing.
Lemma 4.2**.**
Let be a collection of equivalent -sets with edge-sequences of length cells, for a -SAT with clauses. Suppose an edge-sequence from , is such that its entries correspond to just edge-singletons or singletons, which includes and . Then belongs to at least one .
*Proof. *Let an edge-sequence be . Observe, that if there is a collection of entries, one from each cell, whose associated literals are such that no literal and its negation appear, then there is a solution by definition . And by lemma , the edges between those literals which did exist at the outset, will not be removed by the Comparing process, thus there is a corresponding . ie. a solution as defined in .
Let an edge-sequence with cells, that is and -rule compliant, be such that its entries correspond to just edge-singletons or singletons.
We shall construct a collection by first selecting the literals from all loner cells. This sub-collection is non-empty since endpoints and are in loner cells. Recall, that if is compliant, then the negations of the literals in loner cells do not exist in . Assume that the collection being constructed is not yet size . Note that at this point, there are only cells with at least two entries, from which to select a literal. For selecting literals from such cells, we make two cases to simplify the description of constructing a collection .
Case : For edge-sequence there are no edge-pure literals in cells with two or three entries.
Step 1: We select any cell and choose one of the literals, say , to represent the cell. Next, we find the cell that contains the entry for literal , say . If cell has a entry for the negation of a literal in , which is not representing then step stops. Suppose does not. Then there exist one or two entries for literals not , that are not the negations of any literal with a entry in . Choose one of these literals to represent cell and find the cell that contains the entry for the negation of the literal chosen to represent . If cell has a entry for the negation of a literal in or which is not representing or then step stops. If this is not the case, then continue step as described above, until a cell is finally selected which does have a entry for a literal which is the negation of some literal in a previously selected cell, that does not represent that cell. Should this never occur, then the last cell selected is the cell, and there exists at least one entry for a literal that is not the negation of any literal that represents a cell.
Step 2: Suppose step stops and all cells have not been selected. Then the last cell selected has at least one entry for literal say, which is the negation of some literal in a previously selected cell, that does not represent that cell. The literal will represent the last cell selected. Now, we will find all cells not yet selected, that contain the negations of literals in previously selected cells which did not represent their cells. These negations will be chosen to represent the cells in which they were found. Of course, should more than one negation belong to the same cell, we pick any one to represent the cell. Next, after selecting the cells that contain the negations of literals in previously selected cells, we check these cells to see if there are literals not representing their cells, that are not the negations of any literal among the cells selected thus far. If such literals exist, then we will find all cells not yet selected, that contain the negations of these literals. These negations will be chosen to represent the cells in which they were found. We repeat this part of step as just described, until there are no literals of this kind. At this point, if all cells have not been selected, then a exists, meaning the collection of selected cells (except the loner cells), contain a literal and its negation. If this is the case, the collection of cells not yet selected, contain a literal and its negation as well. Therefore, we apply step again on this remaining collection of cells which have no literal representing them. Observe that no literal from the cells of the are contained in these remaining cells. Step may stop again before all cells have been selected, in which case, step is applied. This may be recursive until each of the cells has a literal representing it, thus a of size will have been constructed.
Case : For edge-sequence there exist, one or more cells having two or three entries, that contain at least one edge-pure literal.
After selecting all literals from loner cells, we select all the edge-pure literals from cells having two or three entries. These literals will represent their cell and if a cell has entries for more than one edge-pure literal, any one can be chosen to represent that cell. So, selecting cells with an edge-pure literal may leave the cells with no representative as yet, with edge-pure literals among them. Thus, this process may be recursive. If this recursive process is not all cells, then it is a , otherwise the process would continue. We are now in case again, so we begin with step for the remaining cells which have no literal representing them thus far. Again, all of the above may be recursive until each of the cells has a literal representing it, producing a collection of size . Since we were able to construct a collection of size for the two possible cases outlined above, it follows that belongs to at least one .
Note well that lemma implies that if the stated scenario occurs, in a produced for a -SAT , then the remaining processing can finish with a linear time construction of a solution for .
**-set collections and refinements **
We claim that no for any collection of -sets with and -rule compliant edge-sequences of length cells, constructed from the clauses for a -SAT , exists. Suppose otherwise. Then let be a , and let clause be the clause that does not contain an endpoint for any edge of . Then at most, only two negations of the literals in could be used for , since all edge-sequences must be compliant. So, suppose and are endpoints for edges of . Then there exists an edge-sequence for . However, has a zero entry for every occurrence of literal , otherwise, would not be compliant, thus, by definition , can’t use literal . Since, there were edges between literal with every literal who is an endpoint for all the edges of , then by lemma , the edges between those literals which did exist at the outset, will not be removed by Comparing. This implies that , contradicting the assumption that was not contained. Observe, that the same argument holds, no matter which two literals of had their negations as endpoints for edges of . Also, if a uses only one or no negation of a literal from the clause that does not contain an endpoint for any edge of , then the is contained in some , by lemma .
With respect to just literals, there is a scenario sometimes referred to as , which is: given a collection of clauses, there is a solution for any choice of m$$-1 clauses, but no solution for all clauses. However, the scenario never occurs with any , due to compliancy of the edge-sequences, as demonstrated above. ie. a that uses the negations of all the literals from the clause not containing an endpoint for the . In other words, by construction, all scenarios are eliminated.
So, if a literal is such that it does not belong to any for some with edge-sequences of length cells, then by the claim above, it’s known that does not belong to any of , as well. Moreover, does not belong to a , p<c$$-1, if there exist two or more clauses not having endpoints for any edge of the , where all together, they have no literal and its negation among them. For example, suppose there are two clauses and
, where the literals from and together, do not have a literal and its negation. Now, consider a , so a denoted , that has no endpoint for any of its edges in or . Suppose to the contrary that . Now, can at most, only use two negations for the literals of , and at most, only two negations for the literals of . Since, and together do not contain a literal and its negation, there exists a (an edge), between and for any possible choice of four negations of the literals from and which implies that , a contradiction.
Refinement Claim : Suppose a collection of -sets incurred one or more bit-changes called refinement , by Comparing, at some stage in the Comparing process. Now suppose we imposed in an arbitrary fashion, bit-changes to the edge-sequences of , and call it refinement , prior to any Comparing. Then the same refinement , would still occur by the Comparing of , or is fully or partly subsumed by .
Proof: We first note that refinements are due to the relationships between the edge-sequences and conversely, refinements cause relationships between the edge-sequences. So, if a collection of edge-sequences cause a bit-change for a literal , in some edge-sequence during some order of Comparing, then imposing a bit-change to any of the edge-sequences involved, prior to any Comparing, will still result with no possibility of a , using literals and together. More precisely, suppose an edge-sequence incurs a bit-change for a literal by some order of Comparing. Now suppose that before any Comparing, we imposed any arbitrary refinement . There are three cases to consider.
The first case is that refinement , played no role in the bit-change of in . So, proceeding with the same order of Comparing, still results in a bit-change for in .
The second case is when the refinement , does play a role, where during the same sequence of Comparing, causes the bit-change of in to occur sooner, during the same order of Comparing. The refinement may have also caused other refinements, including to during the same order of Comparing.
The third case is when the refinement , does play a role by subsuming some or all of . The most extreme would be that causes [math], during the same order of Comparing, which is the ultimate refinement of an edge-sequence. If [math], then there is no possibility of a , using literals , thus no , using literals and . ie. the bit-change to in was subsumed. The only note of interest for the third case is suppose an edge-sequence did play a role in the refinement of with no imposed bit-changes. ie. no . Now suppose that with , [math], during the same sequence of Comparing. In such a case, at least the bit-change of in still occurs during the same order of Comparing, because was just one edge-sequence that was part of a union of edge-sequences from its -set that refined either or it refined another edge-sequence which refined another, and so on, until some union of edge-sequences then refined . More generally, the remainder of the union of edge-sequences where [math], determining an edge-sequence when Comparing, will still refine , if the union that included had. Or, it is the case that the remainder of the union of edge-sequences determining an edge-sequence , can now refine , because [math]. The case being considered for above, is the former. In summary, refinements do not prevent other refinements, unless one is subsumed by another.
Additionally, it should be clear that if sub edge-sequences of length cells for some with edge-sequences of length cells, were to be Compared using just the -sets and a refinement occurred, that increasing the length of those sub edge-sequences to cells, prior to the same order of Comparing, will not prevent refinement , to occur, while processing the same -sets. This of course, assumes that some or all of refinement , was not subsumed while performing the same order of Comparing, due to the addition of k=c$$-p cells. ie. if the additional cells played no role wrt. refinement . The reason is simply that the refinements were due to the relationships between the first cells for those same edge-sequences, regardless of the size of . Remember that even a single bit-change always eliminates at least one possibility. So, if an edge-sequence incurs a bit-change in some position for a literal , then there is now, no possible, using literals and together, by definition . The theorem to follow establishes that Comparing produces bit-changes in an edge-sequence , for those literals that do not belong to a solution with the endpoints of , where a cell of zero entries eliminates .
Theorem 4.1**.**
*Let a collection of equivalent -sets with edge-sequences of length cells, be the result of Comparing a collection of -sets . Then an edge-sequence from , is such that a literal with a entry in belongs to at least one with and .
Recall that there is no collection of equivalent -sets if unsatisfiability is determined, which is discovered during the first round.
*Proof. *The proof is by induction on the number of clauses , and the base case shall be .
Let . Observe that the combinations of clause sizes, for three clauses are: i) ii) iii) iv) v) and vi) .
A -SAT with three clauses could have as many as edge-sequences, nine in each -set constructed or as few as edge-sequences for vi) above. Note that pre-processing would eliminate iv), v) and vi) due to the loner clauses, nor could edge-sequences be possible without the existence of literals. However, we exclude the pre-processing routine from the proof.
So, after the application of the and -rule to the newly constructed edge-sequences, and any applicable action of the refinement rules, the edge-sequences that remain will have one of the three possible number of entries:
1. {\color[rgb]{0,0,1}I_{x_{1},y_{2}}}:(1_{x},0,0\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt1_{y},0,0\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt1,0,0)
2. {\color[rgb]{0,0,1}I_{x_{1},y_{2}}}:(1_{x},0,0\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt1_{y},0,0\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt1,1,0)
3. {\color[rgb]{0,0,1}I_{x_{1},y_{2}}}:(1_{x},0,0\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt1_{y},0,0\hskip 4.26773pt{\color[rgb]{.75,.5,.25}|}\hskip 4.26773pt1,1,1)
, we can assume that the edge-sequence has its endpoints in the first and second cell. The third cell must have one, two or three entries, to be -rule compliant. In 1, literals and belong to one with some literal having a entry in the third cell, and in 2, and belong to a with each of the two literals in cell three having a entry. In 3, literals and belong to a with each of the three literals in cell three having a entry.
Claim: If the three -sets having edge-sequences with cells, require no more actions from the refinement rules to be taken and are , -rule compliant, then the -sets are already equivalent. ie. Only one run occurs.
Proof: Let literal be associated to cell , to cell and to cell . Suppose has a entry for . Then let have a entry for and have a entry for . Now, suppose instead that has a [math] entry for . Then by the action of refinement rule , will have a [math] entry for and will have a [math] entry for . Since, the edge-sequences were such that no actions of the refinement rules applied, it can not be the case. Then it is the case that [math], thus, these three edge-sequences belong to a . Therefore, an edge-sequence belonging to a collection of three equivalent -sets , is such that any literal with a entry in belongs to at least one with and .
Suppose now that c 3 is an integer for which the statement of the theorem is valid. We consider cases 1, 2 and 3.
Case 1i): Let a collection of -sets , be for a -SAT having c$$+1 clauses and a non-singleton literal that does not belong to any . ie. there is no solution using literal . Let be the -SAT formed with the clauses of less one clause: . Let be the collection of -sets for . If we apply Comparing to , either we determine unsatisfiability in which case, literal belongs to no solution, or a collection of equivalent -sets , is produced where the hypothesis holds. Suppose there are edge-sequences in of the form: where is any literal that forms an edge with . If contains even one edge-sequence of such a form, then belongs to a , for , so would also belong to a for , using from the c$$+1^{th} clause. Recall that the literals would have edges between them and the same literals, outside their respective cells, due to the refinement rules. Therefore, does not appear in any edge-sequence or vertex-sequence for which implies does not appear in any edge-sequence or vertex-sequence for as well. Because the same refinement would occur or be subsumed by another refinement when Comparing is applied to for , producing a collection of equivalent -sets .
Case 1ii): Let a collection of -sets , be for a -SAT , having c$$+1 clauses and a singleton literal that does not belong to any . Let be the -SAT formed with the clauses of less one clause: , where literal is a non edge-singleton wrt. of . Let be the collection of -sets for . If we apply Comparing to , either we determine unsatisfiability in which case, literal belongs to no solution, or a collection of equivalent -sets , is produced where the hypothesis holds. Suppose there is an edge-sequence from . If contains edge-sequence , then belongs to a , for , so would also belong to a for , using from the c$$+1^{th} clause as explained in 1i). It follows that does not appear in which implies it also does not appear in a collection of equivalent -sets for . Again, because the same refinement would occur or be subsumed by another refinement when Comparing is applied to a collection of -sets , for producing . If we construct other -SATs with the clauses of less one clause with the property of containing at least one literal that is a non edge-singleton wrt. of , we see that eventually all edge-sequences with one endpoint associated to is of the form: where is an edge-singleton or just a singleton, and every position associated to a non edge-singleton has a zero entry, due to the actions of refinement rule . And by lemma , if is such that its entries correspond to just edge-singletons or singletons, including and , then it belongs to at least one solution. Since does not belong to a solution, then there is no in , so it follows that [math].
Case 2i): Let a collection of -sets , be for a -SAT , having c$$+1 clauses and an edge-sequence that does not belong to any where is a non edge-singleton wrt. . We assume that and do belong to different solutions, otherwise we are in case 1. Let be the -SAT formed with the clauses of less one clause: . Let be the collection of -sets for . If we apply Comparing to , either we determine unsatisfiability in which case, belongs to no solution, or a collection of equivalent -sets , is produced where the hypothesis holds. Suppose exists in , then belongs to a , for , so would also belong to a for , using from the c$$+1^{th} clause. Therefore, does not appear in which implies does not appear in , again, because the same refinement would occur or be subsumed by another refinement when Comparing is applied to for .
Case 2ii): Let a collection of -sets , be for a -SAT , having c$$+1 clauses and an edge-sequence that does not belong to any where and are edge-singletons wrt. . Again, we assume that and do belong to different solutions, otherwise we are in case 1. Let be the -SAT formed with the clauses of less one clause: , not containing or , where literal is a non edge-singleton wrt. . Let be the collection of -sets for . If we apply Comparing to , either we determine unsatisfiability in which case, the edge-sequence belongs to no solution, or a collection of equivalent -sets , is produced where the hypothesis holds. Suppose there is an edge-sequence from . If contains edge-sequence with a entry for , then also belongs to a for , using the literal from the c$$+1^{th} clause, contradicting that any . So if appears in it must have a zero entry for literal , and it follows that the same refinement would occur or be subsumed by another refinement when Comparing is applied to a collection of -sets , for producing . If we construct other -SATs with the clauses of less one clause not having or , with the property of containing at least one non edge-singleton wrt. for , we see that eventually all that could remain having a entry in are edge-singletons or singletons and every position associated to a non edge-singleton has a zero entry. And by lemma , if is such that its entries correspond to only edge-singletons or singletons, then it belongs to at least one solution for , a contradiction. Therefore, does not exist in . ie. by Comparing [math].
Case 3i): Let an edge-sequence from a collection of -sets , be for a -SAT , having c$$+1 cells, belong to at least one . First, consider any non edge-singleton literal wrt. ( is not or ). Let a collection of equivalent -sets having an edge-sequence be for . Let be the -SAT formed with the clauses of less one clause: . Let be the collection of -sets for . If we apply Comparing to , a collection of equivalent -sets , is produced where the hypothesis holds. We know that with will be produced because for , was produced having edge-sequence . So, if contains edge-sequence with a entry for , then also belongs to a for , using the literal from the c$$+1^{th} clause. If to the contrary, appeared in with a zero entry for literal , it would follow that the same refinement would occur, or be subsumed by another refinement when Comparing is applied to a collection of -sets , for producing , where literal would instead, have a zero entry.
Next, consider the cases where both and are non edge-singletons each occurring at least twice in or only is a non edge-singleton which occurs at least three times in , where we follow the same process as described in case 1i). For example, suppose and are non edge-singletons each occurring twice in . Then, there exists two clauses and containing and , respectively. Note that , , and are distinct clauses. We shall construct and and follow the process as outlined in 1i). For , we are able to determine the entries for all cells except cells and , when examining and . And for , we are able to determine the entries for all cells except cells and , when examining and . However, all together, every cell had its entries determined at size , where the hypothesis holds, which implies the entries are also known at size c$$+1, for these edge-sequences. Now, suppose that is a non edge-singleton which occurs three times in and is an edge-singleton wrt. . Then, there exists three distinct clauses , and containing . We shall construct and then follow the process as outlined in 1i). For , we are able to determine the entries for all cells except cell , when examining and . And for , we are able to determine the entries for all cells except cell , when examining and . Again, all together, every cell had its entries determined at size , where the hypothesis holds, so it follows that the entries are also known at size c$$+1 for these edge-sequences.
The edge-sequences: Observe that the edge-sequences whose endpoints correspond to the same literal such as , are never removed by Comparing, if belongs to at least one solution. Moreover, each instance of from any two clauses, and , will have the same vertex-sequences outside cells and . So, if a literal , with a entry in belongs to at least one solution with , then the edge-sequence must exist. Conversely, if Comparing produces [math], then there will be a zero entry corresponding to in due to the actions of refinement rule 3.
Case 3ii): Let a collection of -sets for a -SAT , with c$$+1 clauses have an edge-sequence , where , and a literal are edge-singletons wrt. such that there is no using , and together. We assume that belongs to at least one , otherwise we are in case 2ii). So, it must be established that Comparing will produce a zero entry for in .
There are two special cases of note. 1) Let be a -SAT formed with the clauses of less one clause not containing , or , where the collection of -sets for , does not possess a using , and together. Then Comparing will produce with a zero entry for , and by refinement rule , and incur bit-changes for and , respectively, and as explained in cases above, this implies the same outcome wrt. , and of for . 2) Since we do not exclude a -SAT with one or more literals, or even duplicate clauses, then if one of these should exist outside the clauses containing , and , simply process the collection of -sets for the -SAT formed with the clauses of less a clause that’s a duplicate, a or contains a . It must be the case that Comparing produces a bit-change for in of , and again, it will be the same outcome for of , having c$$+1 cells.
Next, a description is provided regarding the mechanics of edge-sequence intersections during Comparing resulting in a bit-change for an edge-sequence that is being determined. Consider a collection of -sets for a -SAT , with clauses, having an edge-sequence being determined by the edge-sequences from an -set . If there are zero entries for either or in the three (at most), edge-sequences with a common endpoint say, in , then determining by , results in a zero entry for in . It is possible that at least one of the three edge-sequences had a zero intersection with due to other cells and not because of zero entries for or . Note that if just one of or , had all the zero entries in the three edge-sequences with common endpoint , then or would be zero, again resulting in a zero entry for in . The two other possible ways that literal incurs a bit-change in would be if was not an endpoint to any edge-sequence in , but did have a zero entry in every edge-sequence in which had a non-zero intersection with . Or, if its negation , becomes a loner cell literal, so incurs a bit-change to ensure and -rule compliancy of .
The literal triples: Every collection of -sets , with edge-sequences of length , for a -SAT , have a set , consisting of all triples of literals from three distinct cells, for which no two are each other’s negation. There is a partition of by two sub-sets and , where are those that do belong to a together, and are those that do not belong to a together. If is the null set, then . If is not null, then the triples partition again into two sets and . Set are those triples which exist due to and -rule compliancy when constructing the edge-sequences for . More precisely, if three literals , and belong to clause , so cell as well, having negations in three distinct clauses, then edge-sequences , and have bit-changes to , and respectively, to be compliant, which makes the triple , and an set triple. Note well that membership of a triple to set implies Comparing did not produce this triple, thus they exist before any Comparing is done. Observe that in the case where a clause for has just two literals, say , then the triple: , and is an set triple, where is any literal that can form edges with and , with and incurring bit-changes to and respectively, but [math]. To see that an set triple must be from three distinct clauses, let a -SAT , have three clauses: , and , where , , , , and , are all singletons. Note that edge-sequences and do not incur bit-changes to and respectively, to be compliant, as they are in the endpoint cells, and does not exist. So, the triple , and is not an set triple because no refinements for compliancy occurred. Now, suppose a -SAT , has two clauses: and where , , , , and , are all singletons. Then no edge-sequences can be formed, thus no bit-change occurred, so the triple , and is not an set triple. If prior to any Comparing, we have that [math], then , and some other literal are set triples. If prior to any Comparing, we have that [math], then every pair of endpoints and are set triples. Set are those triples , and , that only by Comparing have edge-sequences , and with bit-changes to , and respectively. If by Comparing, an edge-sequence or vertex-sequence , equals zero, then bit-changes only occur to and or respectively, in the edge and vertex sequences that remain. To have a set requires the existence of a set . That is, without a set , there is no set , which means every triple of is in . Most importantly, it must be the case that the set triples which exist before any Comparing, determine which triples will become set triples, by Comparing. ie. the set triples in determine prior to Comparing, which three literals can belong to a solution together, where the ones who can not become set triples. Now observe that the negations of the literals from each clause of size , for a -SAT are a collection of set triples, if no or exist and no edge or vertex sequence became zero prior to Comparing. Suppose we have a -SAT with clauses and its collection of -sets contains an edge-sequence where , and are edge-singletons, in clause/cells , and , respectively. Let there be no solution using , and together. If we are not in special case 1) wrt. , then it’s the case that forming a -SAT by removing a clause which is not clause , or , results in a solution that uses , and together. Moreover, every solution using , and together, must also use the negations of the literals of . This is true for any clause removed that’s not , or . So, the solutions are distinct from one another assuming no clause is duplicated. Let the set be a collection of set triples with the property that no literal and its negation exists among them. We assert that the mechanics of edge-sequence intersections during Comparing resulting in a bit-change for in (or in or in ), is due solely to the existence of at least one wrt. the literal triple: , and , in . Suppose it’s true in general for every size . Then , let a clause: be for with c$$+1 clauses, where the negations for the literals of cell are in three distinct cells which are not the cells , and . Note that , or (all necessarily exist to be a non-trivial case), could be one of , or . Then let be the collection of -sets produced by removing all -sets of the form: where is any cell index not , from of , as well as removing cell from all the edge-sequences in the remaining -sets. Observe that there is no using , and together, in . Since a set wrt. the literal triple: , and exists in , which includes the set triple: , and , the relationship necessary to produce bit-changes to , and in , and , respectively, by Comparing , exists. The implication for all -SATs having a literal triple requiring another literal triple in order to be part of a solution, is that if the latter triple is turned into an set triple (imposed bit-changes), then the dependent triple must become a set triple, by Comparing. Note that the pair of triples could be co-dependent, in which case either could be the set triple while the other the set triple. Of course, it must be established that a maximum sized wrt. the triple , and at c$$+1, results in bit-changes to , and in , and , respectively, by Comparing. So we define a sequence to be an edge-sequence less one or both of its endpoint cells. Recall that, a (sub) edge-sequence has one or more cells removed but neither cell containing the endpoints are removed. We also define a -set to be an -set with at most 9 sequences. In particular, we consider the sequences: I_{{\color[rgb]{1,0,0}z},\#_{7}}, I_{{\color[rgb]{1,0,0}x},\#_{2}} and I_{{\color[rgb]{1,0,0}y},\#_{3}}. Next we take - {}, - {} and - {} to produce the collections of equivalent -sets: , and , respectively, by Comparing. Observe that the -sets have edge-sequences of length c$$+1 cells and assume the bit-changes of interest did not occur in the , or cells. An intersection between an edge-sequence , from one of these -sets and a sequence will be zero, if has a zero entry for the truncated endpoint. Otherwise, assume a entry for the truncated endpoint and zero entries for the other two positions, for the intersection. And the sequences will have the same truncated endpoint cell for the Comparing to be done, so an intersection between them will be zero if they don’t have the same truncated endpoint. Now we Compare S_{{\color[rgb]{1,0,0}r},\#_{4}} with , S_{{\color[rgb]{1,0,0}s},\#_{5}} with and S_{{\color[rgb]{1,0,0}t},\#_{6}} with . We also assume that at no time will an edge-pure literal be produced that’s not in cells , or of the truncated edge-sequences: I_{{\color[rgb]{1,0,0}z},x}, I_{{\color[rgb]{1,0,0}z},y}, I_{{\color[rgb]{1,0,0}x},y}, I_{{\color[rgb]{1,0,0}x},z}, I_{{\color[rgb]{1,0,0}y},x} or I_{{\color[rgb]{1,0,0}y},z}. Else, the literal triple , and can be determined with just cells simply by removing a cell with such an edge-pure literal from the -sets and apply Comparing. We further assume that no refinement of , and due to the sequences of S_{{\color[rgb]{1,0,0}r},\#_{4}}, S_{{\color[rgb]{1,0,0}s},\#_{5}} and S_{{\color[rgb]{1,0,0}t},\#_{6}} occurred which led to , and becoming a set triple. Since all bit-changes by Comparing occur outside the endpoint cells (recall that the zero entries for all set triples using truncated endpoints exist in , and ), then the result will be a bit-change to at least one of the literals , or in one of the sequences of interest, which are treated as vertex-sequences with cells, and is wrt. their literal doubles: (, ), (, ) and (, ), which will become set doubles. Note that if a position for the negation of a truncated endpoint exists (having a zero entry), it can be part of a , as a literal of an set double (with the other endpoint of the sequence), even if the truncated endpoint belongs to an set for , because any solution represented in a sequence can always include the literal associated to the truncated endpoint. Another way to see that the bit-changes of interest will occur just by the assertion holding at size , is to replace all the -sets with an index of (or all with an index of ), in , with the -sets: S_{{\color[rgb]{1,0,0}r},\#_{4}} and apply Comparing again. The result will be a zero entry for and in I_{{\color[rgb]{1,0,0}z},x} and I_{{\color[rgb]{1,0,0}z},y}, respectively, even though they have a vertex-sequence structure wrt. the cells of truncation. Note that if a uses and together, it must necessarily allow including the negation of the truncated endpoint which is not possible in I_{{\color[rgb]{1,0,0}z},x} or I_{{\color[rgb]{1,0,0}z},y}. Similarly, or with their corresponding -sets could have been chosen. Therefore, Comparing produces zero entries in edge-sequences, for literals that do not belong to a with the endpoints of those edge-sequences. We conclude that the inductive statement is valid at c$$+1 which completes the proof of the induction step, and so the result follows.
Lemma 4.3**.**
The algorithm applied to any -SAT , determines satisfiability in polynomial time.
*Proof. *By theorem , a -SAT is known to be satisfiable at the completion of round without necessarily constructing a solution. To make the complexity analysis straightforward for determining satisfiability, we take into account no efficiencies. Further, the worst case scenario assumes redundancies that no -SAT would have throughout the processing. Let be the sum of the sizes for all clauses, that remained after pre-processing, for a given -SAT . Then . We shall assume that it always took an entire run to produce just one bit-change. We shall further assume that to determine satisfiability, it was required that every position in every edge-sequence incurred a bit-change, which of course, would never occur.
The number of edges is . Thus, the total number of positions:
[TABLE]
Recall, that the number of -sets = . And a run would be:
[TABLE]
Now, we need to determine the complexity for a comparison between two -sets. First, we point out that if only one bit-change was supposed to have occurred for each run, implies that for all Compares of two -sets, and just occurred. ie. every edge in was determined by the edges of and every edge in was determined by the edges of and no more was done between those two -sets. Of course, one Comparing did have a bit-change occur. In this case, at most, one more determination of every edge in was done with the edges of again, because the bit-change could have occurred during: . The worst case for Comparing in one direction: would be that every edge-sequence in have entries for both endpoints of every edge in . If we assume steps are required to compare position by position, two sequences of length , then all of the intersections and unions needed to process one edge is , which includes determining the particular refinement, if any. And if all edges are the same scenario, then it takes steps for one direction. Assuming we have the same scenario comparing in the other direction, it would be a total of steps. Let be the constant for the work to do compliancy. is clearly linear, since the work is a look-up and bit-changes for the negations of loner cell literals. -rule compliancy is known during the steps to compare positions, as is the discovery of new loner cells. Now, let be the constant + , where the , is for the steps for all Compares less one which might have used an additional steps. Then the work for comparing two -sets with no bit-change is . The additional work for: would be for an entire run. However, we could choose to make equal to + + , which says every Comparing of two -sets, did . It is important to note that the algorithm would produce the same result if only was done regardless if bit-changes occurred. The only computational difference is that it may cause more runs to occur, because no follow up Compares were done in the current run. However, if another bit-change would have occurred say doing: then that scenario awaits to be done in the next run, as explained in section . But with respect to the worst case, this is irrelevant, because we are assuming that the maximum number of runs possible, were done.
Finally, taking the product for: the work of comparing two -sets (), with the number of -sets compared per run (), and the most runs possible (), is the worst case. This gives a complexity of , in Big O notation.
It’s straightforward to show that a solution can be constructed with complexity . Just take any edge-sequence at the end of round , remove the cells containing an , and a third literal , who had a entry in . Then make all positions for a zero. Next, reconstruct a new -SAT with clauses matching the entries in the remaining cells in and apply the algorithm again. There will be equivalent -sets where again we can select an edge-sequence and repeat the above. This can only be done at most times. Thus, we have at most . However, it’s been established that an algorithm can construct a solution, also with complexity .
The most important empirical observation with respect to efficiency, is after processing many -SATs considered to be hard instances, our original version which had no efficiencies including the actions for the refinement rules, never approached to construct a complete solution, where is the number of clauses! Thus, we expect any version with one or more non-trivial efficiencies added, to do better than the bound observed empirically. That is why we expect that efficient versions will be practical with respect to today’s hardware. Still, it would be reasonable to expect a bound of on average, without efficiencies. However, there are numerous schemes that allow processing of a round to be much less work, than the work done by the algorithm presented. Of course, it had to be established first, that a general method exists, namely, the Comparing of the -sets until equivalency is reached.
5 Final comments
Most of our research was devoted to finding efficiencies for both general purpose solving and for specific classes of SATs. We have found dozens so far, and it’s clear many more can be developed. We observed empirically, that with respect to constructing a solution, the combined work done in subsequent rounds was only a fraction of the work done in round . This observation is not why the worst case bound remains unchanged for constructing a solution. One powerful efficiency that was developed, constructs a solution while dispensing with completing rounds altogether, so in particular round .
The algorithm described herein does not make use of all the information that is determined while Comparing -sets, that if used, would only increase the space complexity by adding at most for lookup tables, while reducing the number of runs and dramatically reducing the number of edge-sequence intersections performed. We are assuming that always doing a lookup is less work than performing every intersection when is sufficiently large. Additionally, well known efficiency schemes could take on new relevance with respect to processing edge-sequences, by providing analysis at relatively no cost. They will also become non-trivial efficiency schemes for many classes of -SATs.
We have developed a way for parallel implementation that requires no communication between the nodes that is not the master node, and at that, it only requires passing information to update the sequences, at specific times.
There is a natural generalization of the algorithm described in this paper for SAT. This could be exploited for efficiency purposes, by extracting information at chosen costs, for Comparing a SAT’s corresponding -SAT. It is the case that Comparing for SAT becomes more expensive as clause size increases relative to just converting to -SAT.
A lot of time was dedicated in the last few years for pre-processing analysis, to determine the best initial choices for Comparing -sets. We experimented by choosing certain -sets to Compare first, which in many cases had a dramatic effect on efficiency, and it was these observations that inspired one of our most powerful efficiency schemes.
Lastly, note that code with a few implementation modifications employed, has a complexity of \Omega$$(n^{3}) for -SATs of semi-primes.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Cook, Stephen The complexity of theorem proving procedures . Proceedings of the Third Annual ACM Symposium on Theory of Computing. pp. 151 151 151 - 158 158 158 , 1971.
- 2[2] Karp, Richard M. Reducibility Among Combinatorial Problems . Complexity of Computer Computations. New York: Plenum. pp. 85 85 85 - 103 103 103 , 1972.
- 3[3] Agrawal, Manindra; Kayal, Neeraj; Saxena, Nitin. PRIMES is in P . Annals of Mathematics. pp. 781 781 781 - 793 793 793 , 2004.