Resource Optimization of Product Development Projects with Time-Varying Dependency Structure
Masaki Ogura, Junichi Harada, Masako Kishida, Ali Yassine

TL;DR
This paper introduces an analytical framework for optimizing resource allocation in product development projects with dependencies that change over time, using convex optimization and system modeling to reduce project durations.
Contribution
It develops a novel convex optimization-based approach for resource allocation in dynamic dependency structures, extending beyond static assumptions in prior work.
Findings
Optimal resource allocation can be efficiently computed via convex optimization.
The framework applies to asynchronous and aperiodic information exchange.
Boundary analyses offer managerial insights for empirical project processes.
Abstract
Project managers are continuously under pressure to shorten product development durations. One practical approach for reducing the project duration is lessening dependencies between different development components and teams. However, most of the resource allocation strategies for lessening dependencies place the implicit and simplistic assumption that the dependency structure between components is static (i.e., does not change over time). This assumption, however, does not necessarily hold true in all product development projects. In this paper, we present an analytical framework for optimally allocating resources to shorten the lead-time of product development projects having a time-varying dependency structure. We build our theoretical framework on a linear system model of product development processes, in which system integration and local development teams exchange information…
Click any figure to enlarge with its caption.
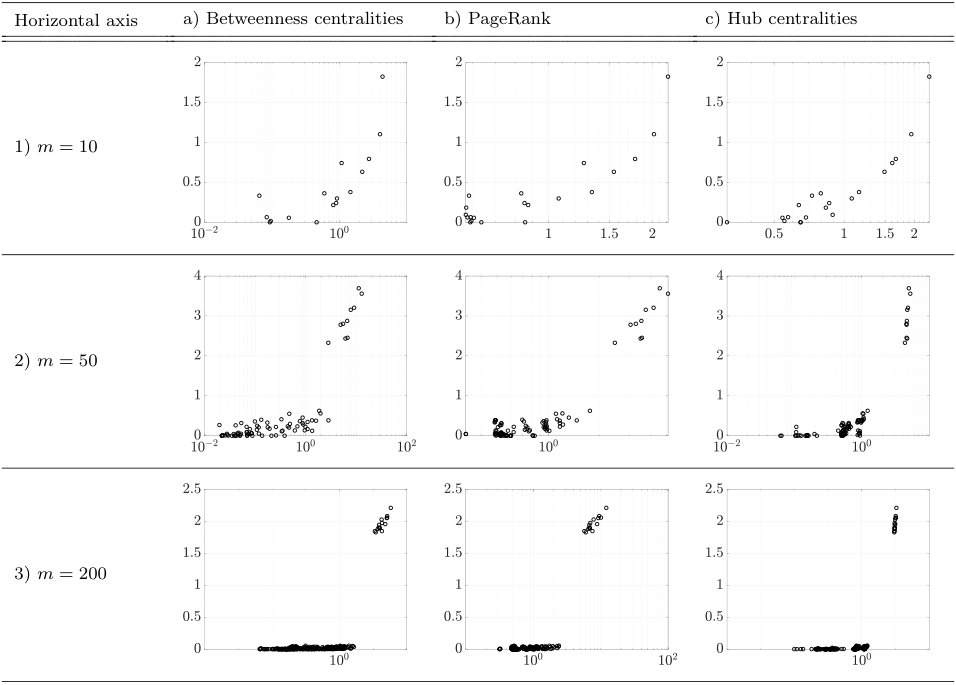 Figure 1
Figure 1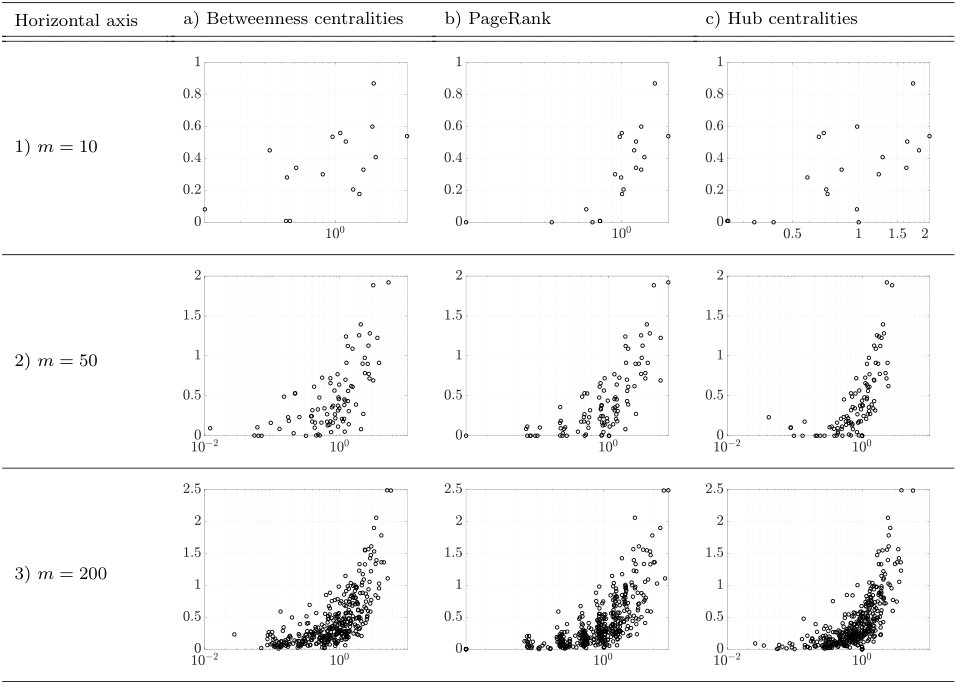 Figure 2
Figure 2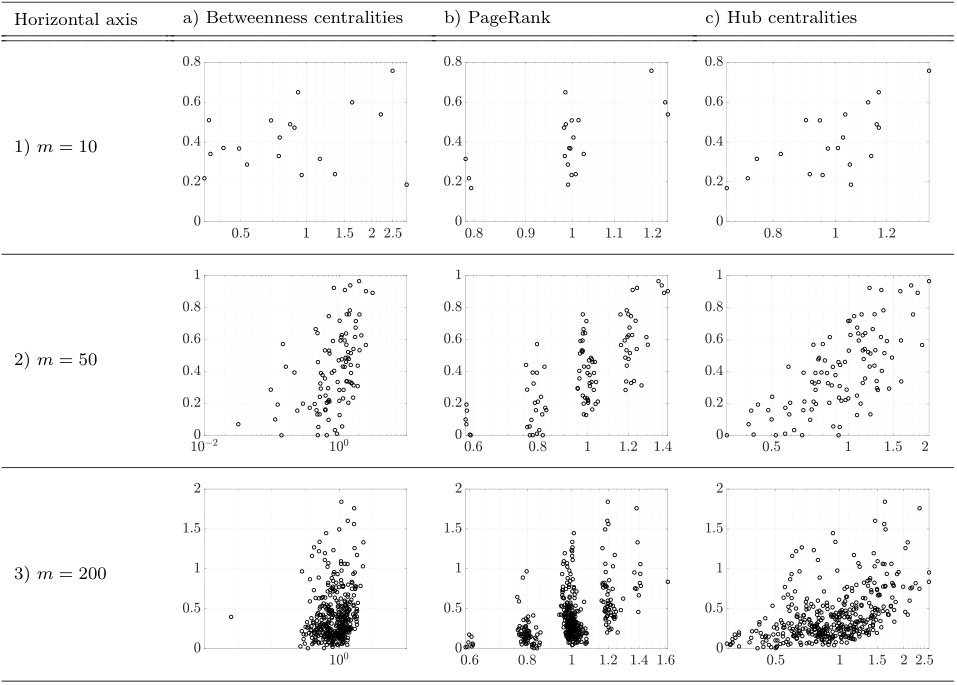 Figure 3
Figure 3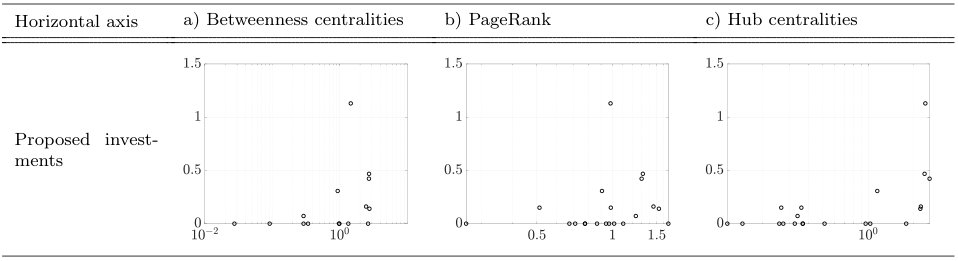 Figure 4
Figure 4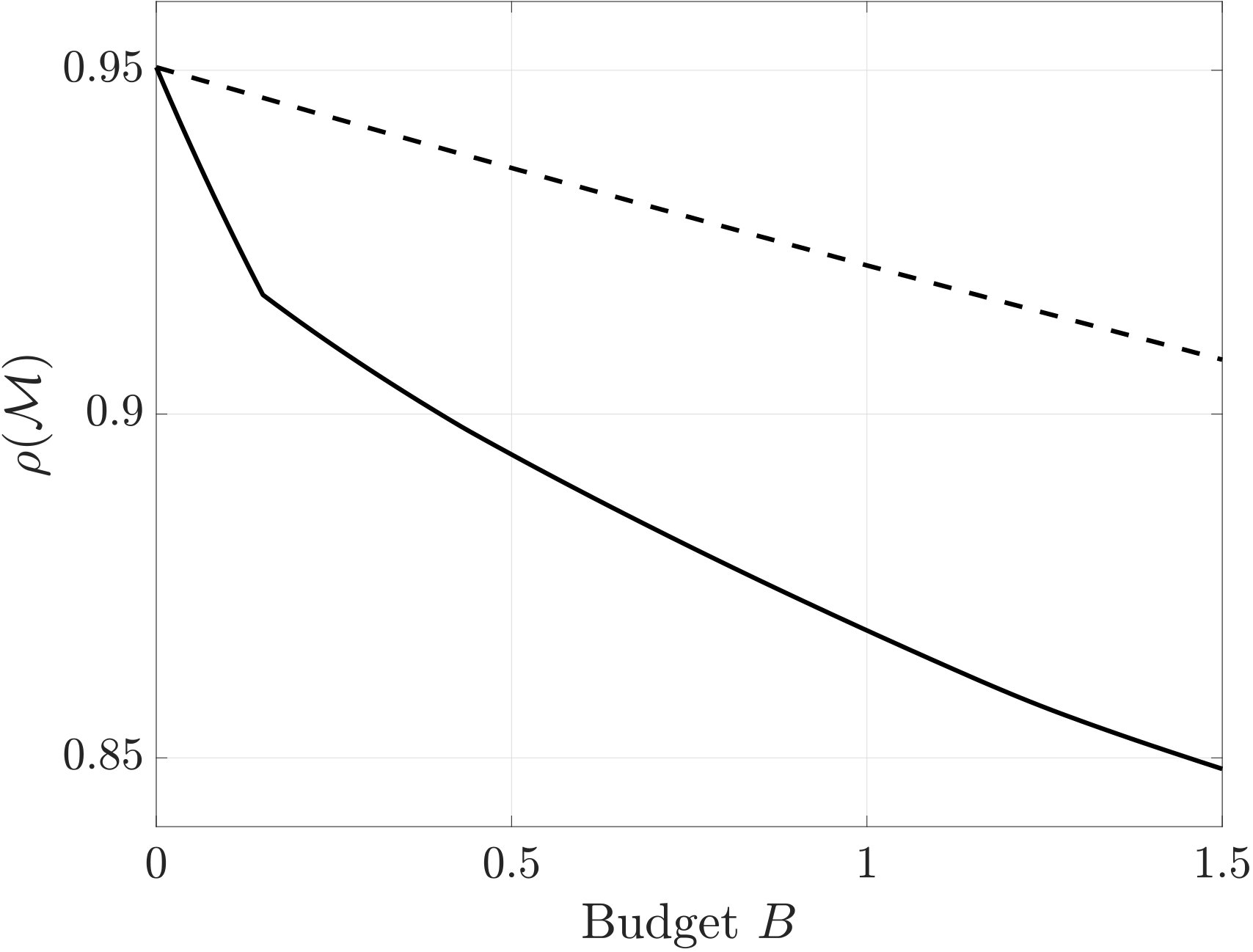 Figure 5
Figure 5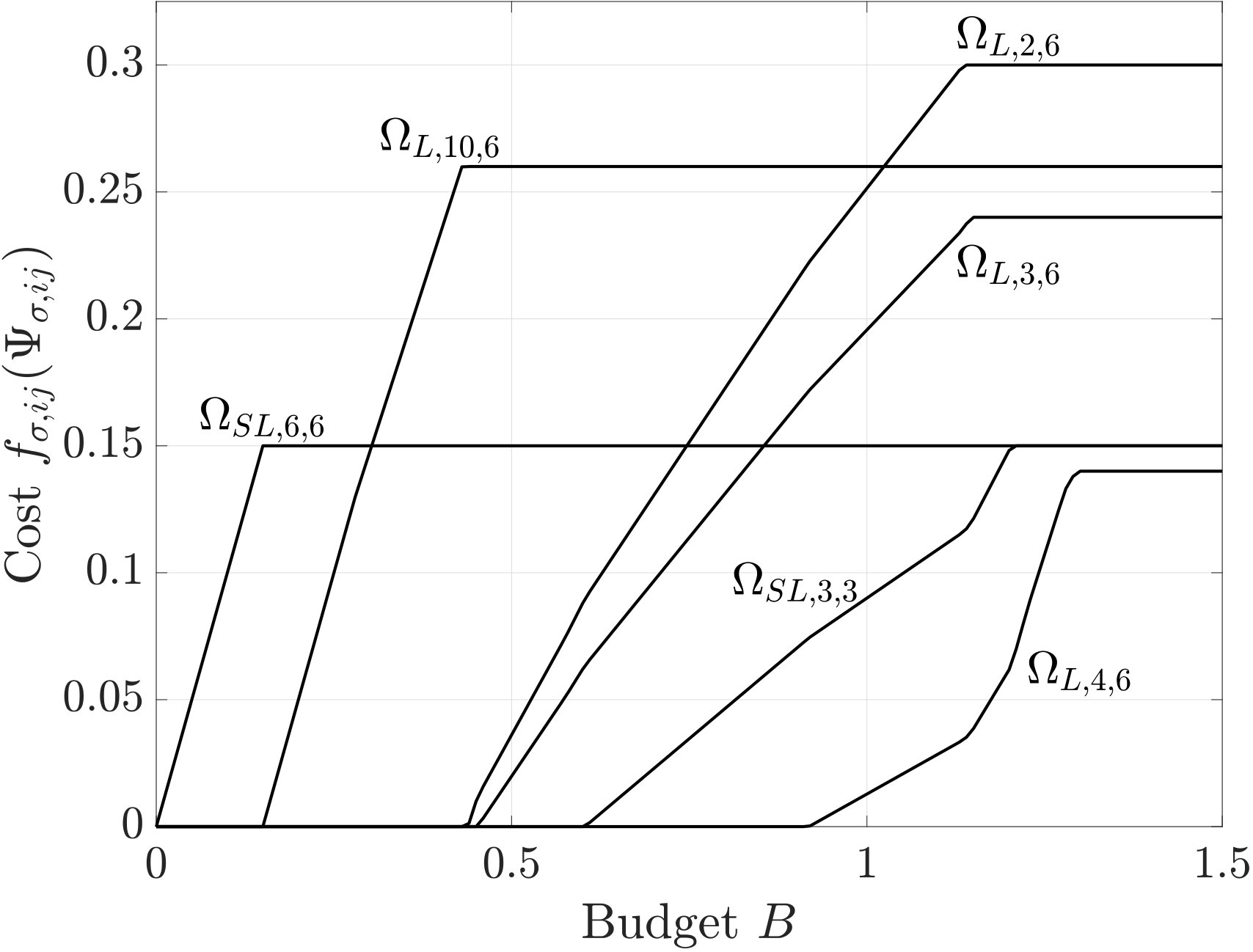 Figure 6
Figure 6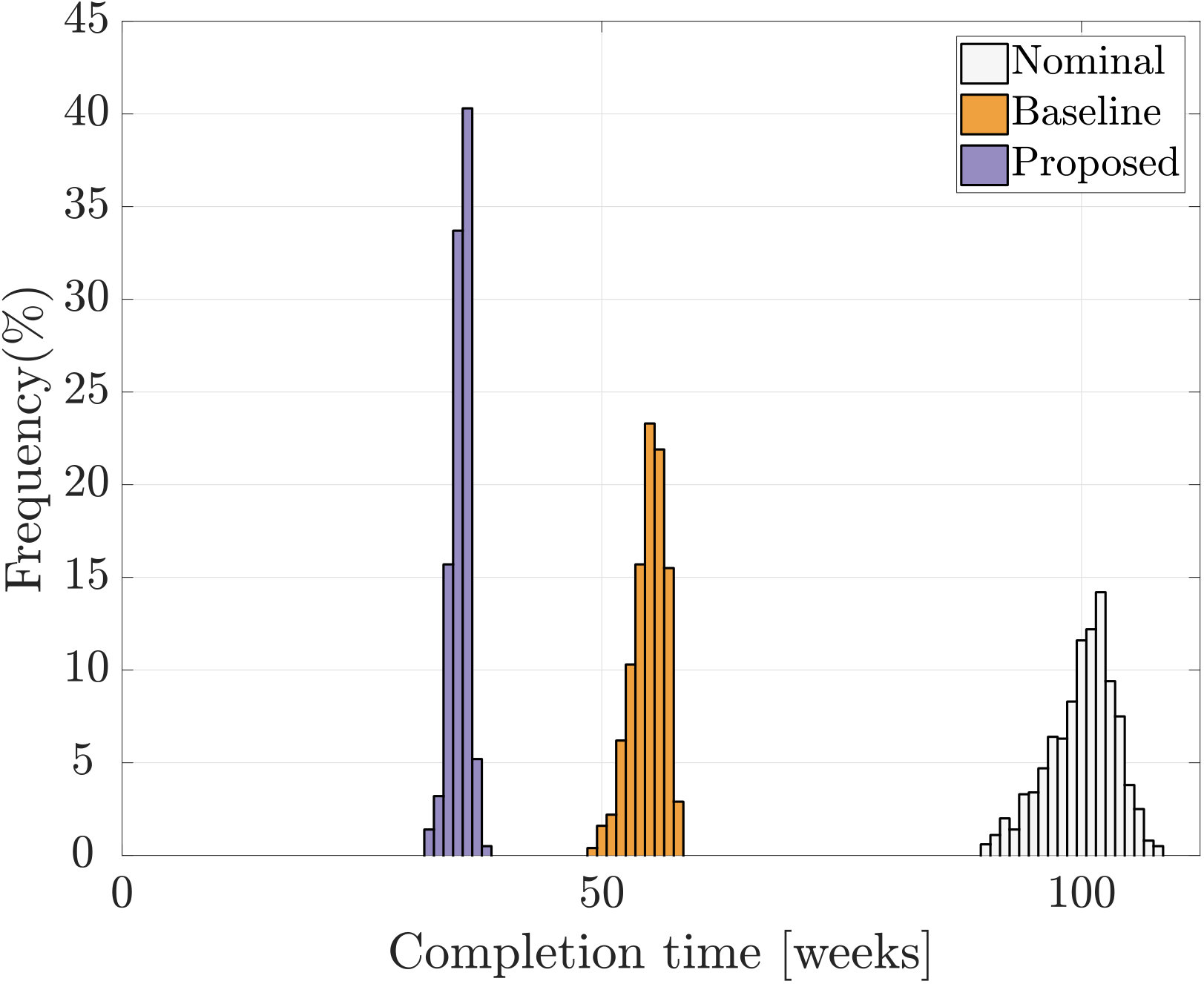 Figure 7
Figure 7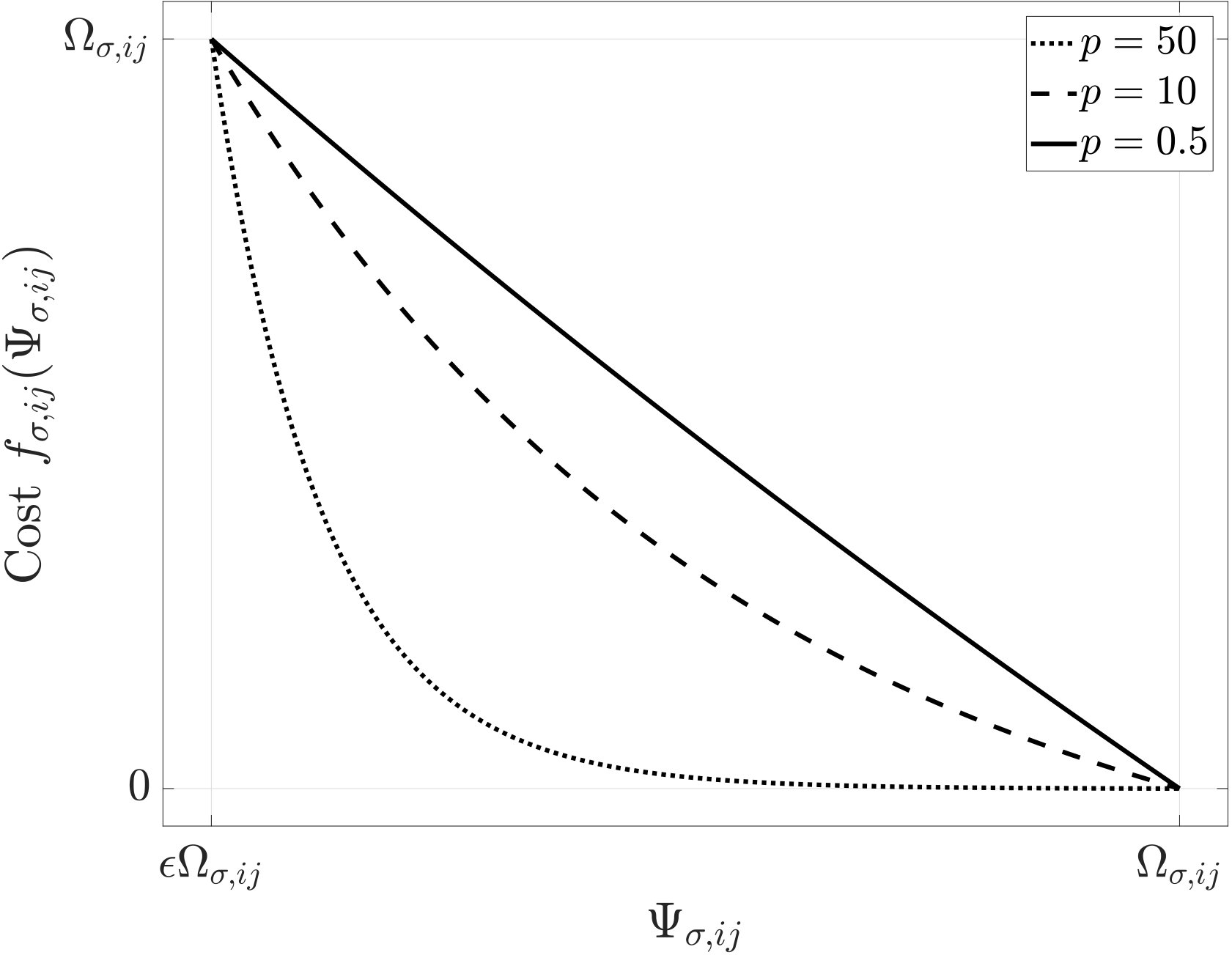 Figure 8
Figure 8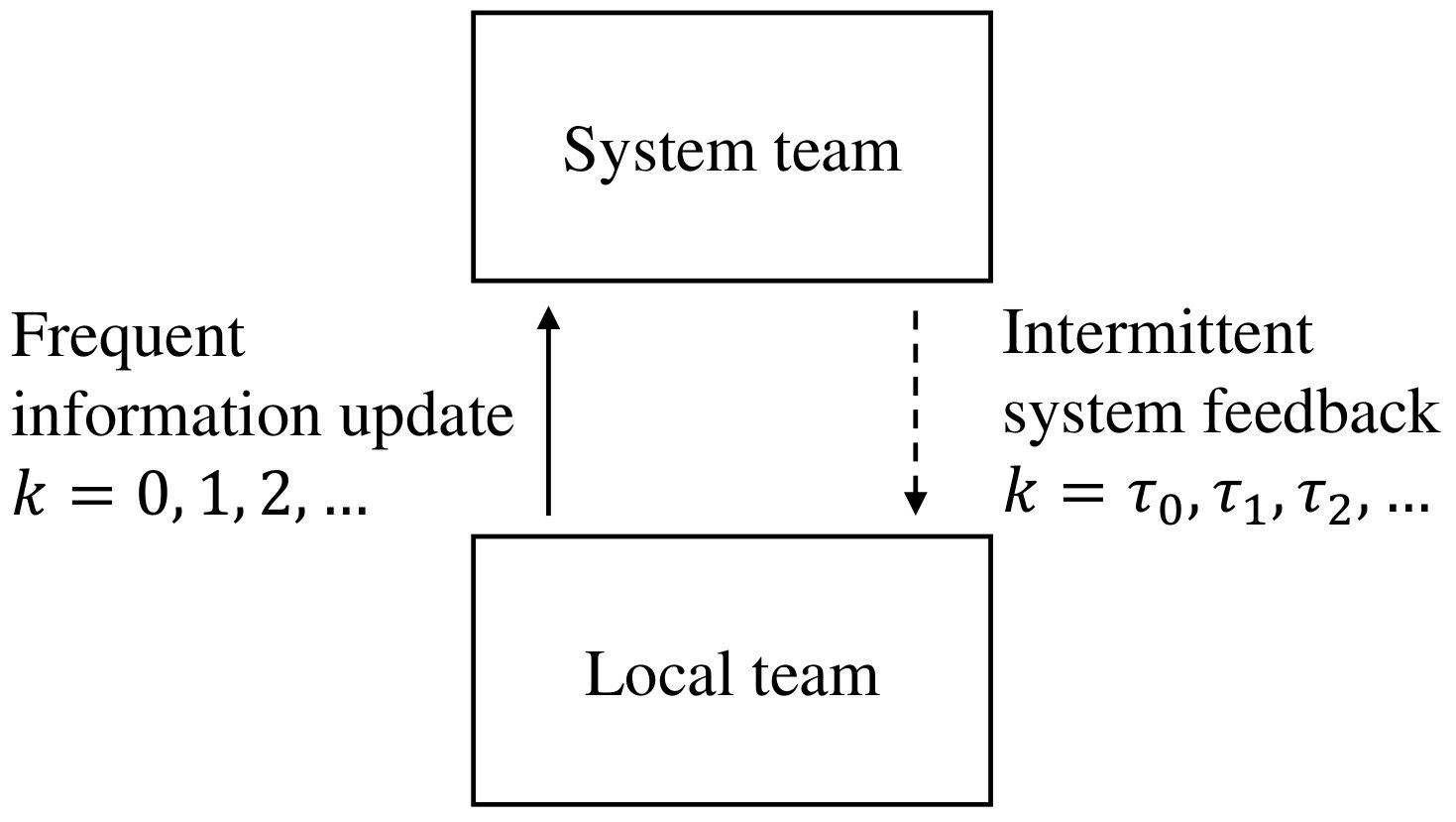 Figure 1
Figure 1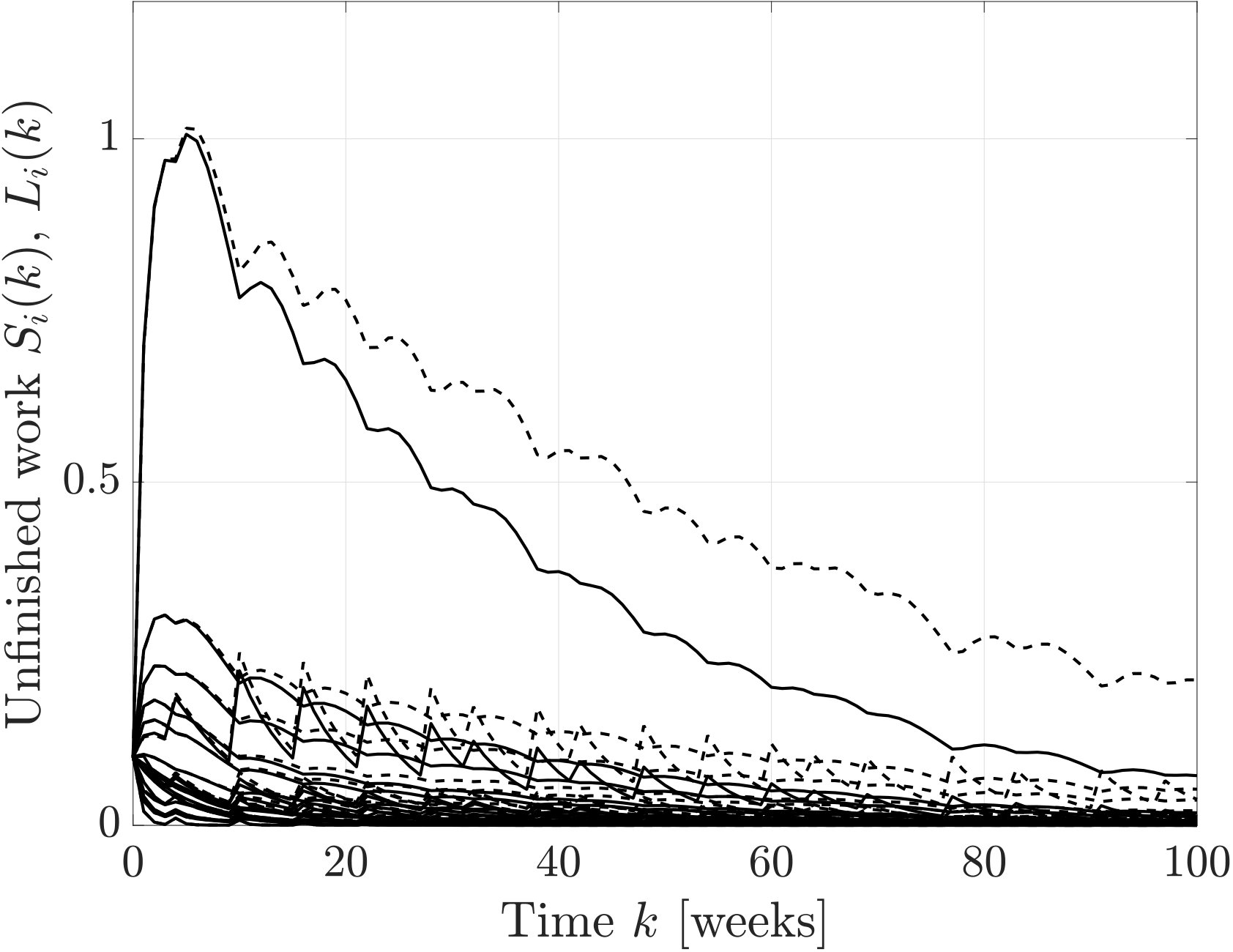 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsProduct Development and Customization · Resource-Constrained Project Scheduling · Systems Engineering Methodologies and Applications
∎
11institutetext: M. Ogura 22institutetext: Junichi Harada33institutetext: Division of Information Science, Nara Institute of Science and Technology, 8916-5 Takayama, Ikoma, Nara 630-0192, Japan
33email: [email protected], [email protected]: M. Kishida55institutetext: Principles of Informatics Research Division, National Institute of Informatics, Tokyo 101-8430, Japan
55email: [email protected] 66institutetext: A. Yassine 77institutetext: Department of Industrial Engineering and Management, American University of Beirut, Beirut 1107-2020, Lebanon
77email: [email protected]
Resource Optimization of Product Development Projects with Time-Varying Dependency Structure
††thanks: This work is funded in part by JSPS KAKENHI Grant Number 18K13777 and the open collaborative research program at National Institute of Informatics (NII) Japan (FY2018).
Masaki Ogura
Junichi Harada
Masako Kishida
Ali Yassine
(Received: date / Accepted: date)
Abstract
Project managers are continuously under pressure to shorten product development durations. One practical approach for reducing the project duration is lessening dependencies between different development components and teams. However, most of the resource allocation strategies for lessening dependencies place the implicit and simplistic assumption that the dependency structure between components is static (i.e., does not change over time). This assumption, however, does not necessarily hold true in all product development projects. In this paper, we present an analytical framework for optimally allocating resources to shorten the lead-time of product development projects having a time-varying dependency structure. We build our theoretical framework on a linear system model of product development processes, in which system integration and local development teams exchange information asynchronously and aperiodically. By utilizing a convexity result from the matrix theory, we show that the optimal resource allocation can be efficiently found by solving a convex optimization problem. We provide illustrative examples to demonstrate the proposed framework. We also present boundary analyses based on major graph models to provide managerial guidelines for improving empirical PD processes.
Keywords:
Project management resource management resource allocation systems time/cost/performance trade-offs project planning
1 Introduction
Projects are indispensable and central in most of the industries for performing several types of work PMI2013 . For this reason, project management has been one of the major research themes in the field of engineering design during the last half-century. Since modern product structures are becoming increasingly complex due to global competition, technological advancements, and changing customer needs, the management of product development (PD) projects is of fundamental importance in various organizations. Despite this fact, there is still a lack of effective managerial methodologies for achieving PD project goals such as meeting prespecified deadlines, achieving desired performances, and keeping cost requirements Cicmil2006 ; Muller2012 . It is even reported that some of the PD projects achieving their goals are often considered to be not successful by stakeholders Cooke-Davies2002 ; Collyer2009 . Therefore, the development of effective methodologies for the modeling and planning of PD projects is highly anticipated by both managers and stakeholders.
Modularization is a widely adopted approach for effective understanding, management, and characterization of complex PD projects. Modularization consists of the following two steps: establishment of a modular architecture and development of design rules Baldwin2000 . In the first step, we divide a product into smaller building blocks called modules. This division is performed in such a way that dependencies among the components within individual modules are maximized while dependencies between modules are minimized. Therefore, modularization allows project managers to facilitate a PD project by independently improving individual modules within the product Yu2007 ; Borjesson2014 .
In practice, various technical, physical, and business constraints prohibit us from ignoring dependencies between modules and simply designing each module separately Holtta-Otto2007 . Therefore, in the second step of modularization, we seek for the possibility of minimizing or eliminating dependencies outside module boundaries Baldwin2000 . Such interdependencies can be reduced by investing in the design rules defining the connections or relationships between modules Loch1998 ; Lee1997 ; Ahmadi1999 . The reduction is achieved through either the creation of a higher level design rule in the design structure matrix (DSM) or internalizing the rule within the design of each module Baldwin2000 . This process helps us to develop a design rule as a mutual upfront agreement between modules Martin2002 ; Frenken2006 .
On the other hand, the current practice for investing in design rules is often based on project managers’ intuition or heuristic rules, which may not necessarily lead to the best outcome Adler1995 ; Loch1999 . Therefore, we find in the literature several decision support tools aimed at assisting the managers to cost-efficiently invest in design rules (see, e.g., Krishnan2001 ; Browning2007 ; Serrador2014 and references therein). A distinctive approach to address this problem can be found in the sequence of works Braha2004a ; Braha2004 ; Braha2007 , in which the authors identify the fact that performance, robustness, resilience, and fragility of complex design networks are heavily dependent on their underlying connectivity structures. The authors found, by analyzing empirical PD processes, that large-scale design networks are characterized by heavy-tail degree distributions with highly connected modules, while most modules have small degrees. This finding suggests Braha2007 that these degree connectivity patterns of complex design networks can be exploited and incorporated in a resource allocation for suppressing the amplification and propagation of design changes and errors through the engineering network.
However, most of the aforementioned decision support tools in the literature rely on an implicit assumption that the PD project architecture is static and, therefore, does not change over time. This assumption is not consistent with reality; for example, information hiding between development teams give rise to a time-varying dependency structure, which causes persistent recurrence of problems such that progress oscillates between being on schedule and falling behind Yassine2003 ; Lee1997 . Other sources of the time-variability include asynchronicity and random timing of task updates and information exchange Mihm2003 ; Huberman1993 and fluctuations in the amount of rework that a unit of rework in a module causes to other modules Huberman2005a . In fact, as firstly discovered in the seminal papers Braha2006 ; Braha2009 , time-variability of dependency structures or, in general, connectivity structures, can be found not only in PD projects but also in various other contexts such as human contact networks, online social networks, biological, and ecological networks (see, also, the monographs Holme2015b ; Masuda2016b for recent surveys on this subject).
In this paper, we present an optimization framework for making a cost-efficient investment in design rules when the underlying dependency structure between modules is changing over time. We illustrate our theoretical framework by focusing on the PD project model with asynchronous interaction between system integration and local development teams Yassine2003 . By using the stability theory of switched linear systems Lin2009 adopted from the systems and control theory, we show that the proposed model is feasible, i.e., the amount of unfinished work converges to zero, if and only if the magnitude of the eigenvalues of a generalized work transformation matrix (WTM) is strictly less than one.
We then propose an analytical framework for optimally weakening the dependencies between different product components for accelerating PD projects. Since organizations seek for minimizing project lead-times under a predefined budget, time-cost trade-offs naturally arise in this context. In this paper, we consider the following two types of time-cost trade-off problems Hartmann2010 . The first one is the budget-constrained dependency optimization, where we distribute a fixed amount of resource across the project for minimizing its lead-time. The other problem is the performance-constrained dependency optimization, where we distribute resource for achieving a specified performance objective while minimizing the cost of the resource. We show that both problems can be efficiently solved via convex optimization techniques Boyd2004 , which is in contrast with other decision support tools relying on, e.g., non-convex optimizations Yassine2016 , genetic algorithms Peteghem2010 ; Alcaraz2003 , iterative procedures Boctor1996 , and backtracking procedures Patterson1990 .
The proposed framework is tailored to a dynamical PD project in which a local team passes their outcome to the system team for integration Joglekar2001 . We specifically consider the situation where, although the information update from the local team occurs regularly, the one from the system team occurs only intermittently Yassine2003 . Such asymmetry in the communication frequency can arise due to high communication cost or unbalanced integration and development times. A major source of high communication cost is poor communications between teams, which could even result in failed projects. On the other hand, when the development time is significantly different from the integration time, one of the teams would have to wait for the completion of the task in the other team. In this context, a typical application area of the proposed framework is the design and development of large-scale components in complex industrial products such as vehicles, vessels, and aircraft.
The rest of this paper is organized as follows. In Section 2, we describe our model of PD processes under asynchronous and aperiodic interactions between system integration and local development teams. After studying the feasibility of the proposed PD process model in Section 3, in Section 4 we develop an optimization framework for efficiently solving the time-cost trade-off problems. The obtained framework is illustrated with a real PD process in Section 5. Further boundary analyses based on major graph models are performed in Section 6. We finally provide the conclusion of the paper as well as some discussions in Section 7.
2 Asynchronous and aperiodic work transformation model
In this section, we review the asynchronous work transformation model presented in Yassine2003 . We then generalize the model to the case of random and aperiodic information exchange. We finally describe the problems of feasibility analysis and optimal resource allocation studied in this paper.
2.1 Asynchronous work transformation
In the asynchronous and periodic work transformation model Yassine2003 , there exist a pair of local and system teams working for the development of a product. The PD process contains tasks, and each task is separated into development and integration tasks that are performed by the local and system teams, respectively. As in Yassine2003 , we let and represent the amount of unfinished work in the th local and system task at time step , respectively. Let us define the vectors
[TABLE]
If the local and system teams exchange information at every time step, the above variables evolve over time by the following equation:
[TABLE]
where , , , and are WTMs having nonnegative entries. For example, is an entry-wise nonnegative matrix that captures the rework fraction created by system tasks for the corresponding local tasks . The other WTMs are understood in a similar manner.
As discussed and demonstrated by the authors in Yassine2003 , even though the local team may frequently provide the system team with local updates, the system team, on the other hand, may provide only intermittent feedback to the local team. To model this situation, they introduce the third variable, , denoting the amount of finished work in the th system task that is not yet transfered to the local team. When feedback from the system to local team occurs, the finished work will be cleared on the part of the system team and will be transferred to the local team. Also, until feedback occurs, the finished work keeps accumulating within the system team. In this situation, the vectorial variable
[TABLE]
dynamically evolves as
[TABLE]
where is a WTM from unfinished system tasks to finished system tasks. Similarly, the amount of unfinished work in the local team evolves by the following difference equation:
[TABLE]
Finally, notice that the amount of unfinished work in the system team evolves in the same way as in (1). Combining the above equations, we see that the joint state variable
[TABLE]
evolves over time as
[TABLE]
where the matrices and are given by
[TABLE]
In Yassine2003 , the authors considered the situation where feedbacks occur periodically. By using the Floquet theory for periodic linear dynamical systems, the authors clarified how intermittent feedback from the system team leads to persistent recurrence of PD problems called design churn effects, where progress oscillates between being on schedule and falling behind.
2.2 Specifications of WTMs
In this paper, we adopt the specification of WTMs proposed in Yassine2003 . Let and denote the DSMs within the local and system teams, respectively. For each , the diagonal elements of give work completion coefficients, while the off-diagonal elements ( with ) denote the amount of rework created for the task per unit of work done on the task . Also, for describing the dependency between the local and system teams, inter-component dependency matrices (IDMs) are introduced. Let denote the IDM, whose element represents the amount of rework created for system task per unit of work done on local task . The IDM is understood in the same manner.
Then, the authors in Yassine2003 have adopted the following formula for computing the WTMs from the DSMs and IDMs. In their formula, the WTM within the local team is given by
[TABLE]
The system WTM is computed in the same manner. Similarly, the IDMs are given by the formulas
[TABLE]
for all . Finally, they let .
2.3 Aperiodic work transformation
Let , , denote the times at which feedback from the system team to the local team occurs (see Fig. 1 for a schematic picture). Without loss of generality, we assume that . Let
[TABLE]
denote the interval between feedbacks. In Yassine2003 , it was assumed that the interval is constant. However, in practical PD processes, it is common that the interval of feedbacks fluctuates due to both intrinsic and exogenous factors. For this reason, in this paper, we consider a generalized work transformation model where the interval experiences stochastic fluctuations. Let and denote the minimum and maximum length of interval, i.e., we assume that
[TABLE]
We furthermore assume that the random intervals are independent and identically distributed with the probability
[TABLE]
which can be estimated by the manager from the past history of project management data. We remark that, under this formulation, we can no longer depend on the Floquet theory on periodic linear dynamical systems that was used in Yassine2003 because the dynamical system (2) is no longer a periodic linear system but a stochastic switched linear system in the context of systems and control theory.
In this paper, we address the following two fundamental questions on the PD process described above. The first question is about the feasibility of the PD process. Specifically, we are interested in if the state variable in (2) tends to [math] as . This feasibility analysis problem is investigated in Section 3. The other question is on the PD process optimization. Specifically, if the PD process turns out to be infeasible, or, feasible but too slow, we are interested in how to optimally improve the PD process by utilizing a limited budget. In Section 4, we study the problem of tuning the dependencies between different product components and development teams for optimally improving the process in a cost-efficient manner.
2.4 Literature review: Linear systems modeling
Before developing our framework in the next section, in this section we give a brief review of the linear systems modeling of PD processes and, then, state the contribution of this paper.
2.4.1 Static dependency structure
The linear systems approach for modeling PD processes dates back to the seminal work by Smith and Eppinger in Smith1995 , where the authors modeled the amount of unfinished work by a linear system having, as its transition matrix, the WTM of the development process. Based on the linear system model, the authors illustrated the critical role of eigenvalues and eigenvectors of the WTM for understanding the behavior of PD processes. They have also shown that the values of the dominating eigenvector of the WTM allow us to identify the design features that require a large number of iterations. This linear systems modeling was later extended to continuous-time models in terms of differential equations Joglekar2001 ; Ong2003 ; Kim2007a . Although a linear system model is an idealization of realistic PD processes, the model indeed allows us to obtain new knowledge to and identify the critical issues in PD processes Smith1995 . For this reason, the linear systems modeling has been adopted in other contexts of engineering management including value-based managements Hahn2012 , cash flow management Cui2010 , and the KPI analysis of supply chains Cai2009 .
When the analysis of a PD process indicates that the project is not feasible within a pre-specified period and, therefore, needs to be accelerated, the project manager would consider improving the process by allocating additional human or technological resources. In this direction, we can find in the literature several methodologies for tuning the values of WTMs for process improvements. Lee et al. Lee2004b presented an analytical framework for tuning the value of the WTM based on the pole-placement method developed in the systems and control theory. Cheng and Chu Cheng2012 extended this approach by using fuzzy numbers and proposed an optimization framework for assigning tasks to multi-skilled employees. Joglekar and Ford Joglekar2005 employed a more advanced control theoretical tool called the LQ optimal control, which allows us to find a resource allocation that optimizes the performance of the PD process over an infinite time-horizon.
2.4.2 Time-varying dependency architecture
Huberman and Wilkinson Huberman2005a proposed a general linear system model where the WTM randomly fluctuates over time. The sources of such fluctuations include asynchronicity of information exchange, uncertainty in performance evaluation, and fluctuations in the amount of development resources. Under the assumption that the fluctuations of the WTM are independent and identically distributed, the authors showed that the time-averaged dynamics of the PD process can be analyzed by the eigenvalues and eigenvectors of the time-average of the WTM. The authors also investigated the dependencies of the higher order moments of the work vectors on the parameters of the probability distributions of the fluctuations.
The authors in Xiao2011 considered a linear system model, in which reworks of tasks occur randomly. The authors proposed an analytical method, based on the eigendecomposition of the WTM, to mitigate the development process for minimizing the project duration. However, since their method is based on the analysis of the worst-case in which reworks occur with probability one, the mitigation strategy resulting from their methodology is not expected to be cost-effective.
Yassine et al. Yassine2003 investigated the effect of asynchronous information exchanges between local development teams and the system integration team in PD processes. The authors specifically modeled the asynchronicity by a time-varying linear system whose WTM changes periodically in accordance with the period of information exchanges. Using the Floquet theory of linear periodic systems Richards1983 , the authors have shown that the churn phenomena, which are frequently observed in realistic PD processes, are caused by the asynchronicity. The authors also suggested a heuristic methodology for improving the project development processes based on the eigendecomposition of a certain matrix following from the Floquet theory.
As we have reviewed so far in this subsection, although there exist various analytical methodologies for the improvement and optimization of fluctuation-free PD processes, we still find a lack of such methodologies tailored for the development processes subject to temporal fluctuations. An exception is a work by Yassine et al. Yassine2003 , where the authors proposed an eigenvector-based method for identifying design components requiring improvements. However, it remains to be an open question how much resources we should allocate when multiple such components are identified. We also remark that the optimality of resource allocations is rarely discussed in the literature as well.
3 Feasibility analysis
In this section, we analyze the feasibility of the PD process described in the last section. We specifically show that the PD process is feasible if and only if the magnitudes of the eigenvalues of a generalized WTM are strictly less than one.
We start our analysis by reviewing the results presented by the authors in Yassine2003 , in which they have considered the case of periodic feedbacks from the system team to the local team. Let the period of the feedback be denoted by . Also, let the dimension of the vector be denoted by . Then, by using the Floquet theory of periodic linear systems, the authors found that the state variable (2) admits the representation
[TABLE]
where is a matrix, is a vector, and , , , … is a sequence of matrices having period . By using the representation (8), the authors identified the following two sources of design churn effects: the one arising from the periodicity of the matrix sequence , and the one from the positions of the eigenvalues of the matrix . In their analysis, an important role is played by the monodromy matrix
[TABLE]
which represents the work transformation between feedback epochs, i.e., the transitions of the sub-sampled state variables
[TABLE]
In fact, the matrix in (8) is obtained from the diagonalization of the monodromy matrix (9).
However, in our case where the interval of feedbacks is stochastically modeled, the monodromy matrix (9) equals
[TABLE]
which is a random matrix. Due to the stochasticity of the monodromy matrix, we can no longer apply the Floquet theory to our PD process. However, we can still attempt to adopt the methodology based on the monodromy matrix. In order to illustrate the idea, let us define the random vectors
[TABLE]
As in (10), the random vector (12) represents the state right before the feedback from the system team. From (2) and (11), we see that the vectors satisfy the relationship
[TABLE]
Being a stochastic difference equation, Equation (13) is still not easy to analyze. In order to avoid the difficulty, let us take the mathematical expectation on both sides of the equation (13) to obtain
[TABLE]
Since the feedback interval is drawn from a distribution independent of the state variable , we can decompose the expectation on the right-hand side of (14) to obtain
[TABLE]
Let us introduce the vector
[TABLE]
Then, from (15), we obtain
[TABLE]
where the matrix is given by . Notice that, by (7), we can calculate the matrix by the formula
[TABLE]
where and are the minimum and maximum of the interval of two subsequent feedbacks and satisfy (6).
We can interpret equation (16) as representing the expected transformation of works between subsequent feedback epochs, with representing a generalized WTM. As is well-known, if the magnitudes of the eigenvalues of the matrix are all less than one, then , the expected state variable at the feedback epochs, converges to zero as tends to infinity. Notice that, due to the stochasticity of the feedback intervals, this convergence does not necessarily imply the convergence of the original state variable as tends to infinity. However, by utilizing the theory of switched linear systems Ogura2014d in the context of systems and control theory, we can prove that the condition on the magnitude of the eigenvalues of the generalized WTM is, in fact, sufficient for the feasibility of the PD process:
Theorem 3.1
The expected amounts of unfinished works, i.e., and , converge to [math] as tends to if and only if the magnitudes of the eigenvalues of are less than one.
Proof
Define the stochastic process by
[TABLE]
By the assumption that the intervals are independent and identically distributed, we can show that the stochastic process is regenerative (see Smith1955 for the details). Moreover, under this notation, the PD dynamics (3) admits the representation and, therefore, is a regenerative switched linear system defined in Ogura2014d . Moreover, we can easily confirm that the dynamics (3) satisfies the three conditions A1, A2, and A3 given in Ogura2014d . The dynamics satisfies A1 because the WTMs are nonnegative. Also, the conditions A2 and A3 are satisfied because is finite. Hence, Theorem 25 in Ogura2014d shows that Theorem 3.1 holds true.
By Theorem 3.1, the maximum magnitude of the eigenvalues of the matrix , i.e., the spectral radius , determines the feasibility of the PD project. Therefore, the quantity serves as an indicator for the PD manager to quickly predict the final consequence of his or her PD project. If the quantity is less than one, then the manager is assured about the validity of the current resource allocation in design rules. On the other hand, if the quantity is larger than one, then the manager should be warned and urged to reconsider the current practice. For this reason, we call the spectral radius the feasibility index of the PD project. In the next section, we present an analytical framework for cost-efficiently optimizing the feasibility index.
4 Optimizing dependencies
Based on the feasibility analysis in the last section, in this section, we study the problem of tuning the dependencies between distinct design components or teams to improve a nominal, possibly infeasible, PD process. We specifically consider the following PD optimization problem. Suppose that we can use resources for decreasing the dependencies. Assuming that the resources have an associated cost and that we are given a fixed budget, how should we distribute our resource throughout the local and system tasks to accelerate the PD process?
The purpose of this section is to present a resource allocation framework for tuning the dependency terms in the DSMs and IDMs to optimize the PD process under aperiodic interactions between the system integration and local development teams. We show that, under the assumption that the cost functions for tuning the dependencies are posynomials, we can transform the resource allocation problem to an equivalent convex optimization problem.
4.1 Problem formulation
In this paper, we shall focus on tuning the values of the inter-component or inter-team dependencies
[TABLE]
We assume that there is a cost associated with tuning the strength of dependencies. Let denote the cost of tuning the nominal dependency to . In other words, if we want to set the dependency of the th local component on the th local component to be , we need to pay monetary units. Since we do not need to consider improving the dependencies that are originally zero, the total cost for the improvement of the DSM equals
[TABLE]
Similarly, we introduce the cost functions , , and for tuning the nominal DSM and IDMs and , respectively. Then, the total cost for the improvement of the DSM and IDMs are given by
[TABLE]
Thus, the total cost for the improvement of the entire development process equals
[TABLE]
We impose the following two natural restrictions on the new DSMs and IDMs. First, the new matrices must be “better” than the nominal ones. In other words, we impose the following inequalities
[TABLE]
where denotes any one of the strings , , , and . Secondly, we assume that there is a certain management limitation in improving the values of the matrices, which we model by the inequality
[TABLE]
where is a constant dependent on projects. This inequality implies that the possible improvement of the values of the matrices is at most %. This implies that, since , we cannot completely eliminate a dependency that is present in the nominal PD process.
From our feasibility analysis in the last section, we know that the smaller the feasibility index, the faster the amounts of unfinished work decrease. For this reason, we formulate our first project optimization problem as follows:
Problem 1 (Budget-constrained dependency optimization)
Given cost functions , a constant , and a budget , find the new DSMs and IDMs that minimize the feasibility index of the PD project while satisfying the budget constraint on the cost (19)
[TABLE]
and the constraints (20) and (21).
We formulate another PD optimization problem of practical interest. In the budget-constrained dependency optimization problem, we need to distribute our resource in the PD process while keeping the corresponding cost within a given available budget. However, when the main KPI is in reducing the improvement cost, the manager would be interested in directly minimizing the cost, , while making sure that the PD process is feasible. From this perspective, we formulate an alternative optimization problem as follows:
Problem 2 (Performance-constrained dependency optimization)
Given cost functions , a constant , and a required performance , find the new DSMs and IDMs that minimize the cost (19) while satisfying the constraints (20) and (21) as well as the following requirement on the feasibility index:
[TABLE]
Mathematically, the budget-constrained dependency optimization problem is formulated as
[TABLE]
Also, the performance-constrained dependency optimization problem is formulated as
[TABLE]
4.2 Transformation to convex optimizations
The optimization problems (24) and (25) are not trivial to solve because the problems involve the spectral radius of the complicated matrix sum of the form (17). Although one may apply a heuristic optimization techniques such as the gradient descent method, such an approach can result in a solution that is only locally optimal, yielding a not necessarily effective allocation of resources. Therefore, it is desirable to establish a reliable method for obtaining a globally optimal solution to the optimization problems (24) and (25).
In this subsection, we shall show that the optimization problems can be efficiently solved if the cost functions belong to a wide class of functions called posynomials (see, e.g., Boyd2007 ), which we review below. Let be a real function defined for a positive scalar variable . We say that is a monomial if there exist and a real number such that . We say that is a posynomial if is a sum of monomials. For example, is a posynomial because , , and are monomials. The following lemma shows that posynomials exhibit a numerically good property with respect to the auxiliary variable
[TABLE]
Lemma 1 (Boyd2007 )
If the function is a posynomial, then the function defined by is a convex function of .
Besides the above mentioned numerical properties, there are developed algorithms Boyd2007 to fit posynomials to real data, possibly taken from past management histories. For these reasons, in this paper, we place the following reasonable assumption on the cost functions. We assume that, for each , , and , there exists a posynomial such that the cost function is of the form
[TABLE]
The essential part of the cost function is the first term , while the second term is for normalizing the cost function as , i.e., the zero investment yields the nominal interdependency matrix. Corresponding to the decomposition, let us define
[TABLE]
and
[TABLE]
Let
[TABLE]
Then, the total cost (19) is rewritten as
[TABLE]
We are now ready to state the first main result of this paper. As in (26), we introduce the auxiliary variable
[TABLE]
for all , , and . By using the celebrated convexity result of Kingman Kingman1961 , we can show that the optimization problem (24) for solving the budget-constrained dependency optimization problem can be transformed to a convex optimization problem, which can be efficiently and optimally solved by off-the-shelve softwares.
Theorem 4.1
Let be the solution of the optimization problem
[TABLE]
Then, the DSMs and IDMs defined by
[TABLE]
solve the budget-constrained dependency optimization problem. Moreover, if the cost functions are posynomial, then the optimization problem (29) is convex.
Theorem 4.1 serves as an analytical decision support tool for PD managers. Specifically, the theorem allows PD managers to efficiently solve the budget-constrained dependency optimization problem (Problem 1) by using off-the-shelve software for convex optimization such as fmincon routine in the MATLAB programming language or the CVXOPT package for the Python programming language. This feature distinguishes the proposed framework from others relying on heuristic or non-convex optimization procedures Peteghem2010 ; Alcaraz2003 ; Boctor1996 ; Patterson1990 for the following two reasons. On the one hand, since the above solvers always provide globally optimal solutions, PD managers do not need to worry about the optimality of their investments. On the other hand, since the computational cost for solving the problem is relatively small (polynomial in the size of the project), PD managers can quickly assess and, if necessary, re-design their PD process even when their project is quite large.
In order to prove Theorem 4.1, we state the following celebrated result by Kingman Kingman1961 :
Proposition 1 (Kingman1961 )
Let be a square matrix function in positive variables , …, . Assume that the logarithm of each entry in the matrix is convex in the variables , …, . Then, , as a function of the variables , …, , is convex.
We can now prove Theorem 4.1:
Proof
It is easy to see that the dependency constraints (20), (21) and the budget constraint (22) in the optimization problem (24) are equivalent to the constraints (29a), (29b), and (29c), respectively.
Therefore, to prove Theorem 4.1, it is enough to show that the quantities and are convex with respect to the variables ( and ). To show the convexity of , notice that is a posynomial in the dependency variables
[TABLE]
by our assumption that the cost function is a posynomial for all , , and . Therefore, Lemma 1 shows the convexity of with respect to the variables .
Let us show the convexity of . By equation (17), each entry of the matrix is a posynomial in the elements of the WTMs. Moreover, by (4) and (5), each element of the WTMs is a posynomial in the dependency variables (31). Therefore, since a composition of posynomials is a posynomial, each entry of the matrix is a posynomial in the variables (31). Therefore, Lemma 1 shows that the logarithm of each entry of is convex with respect to the variables . Hence, Proposition 1 concludes the convexity of with respect to the variables , as desired.
Our second main result states that the performance-constrained dependency optimization problem can be also transformed to a convex optimization problem:
Theorem 4.2
Let be the solution of the optimization problem
[TABLE]
Then, the DSMs and IDMs defined by (30) solve the performance-constrained dependency optimization problem. Moreover, if the cost functions are posynomial, then the optimization problem (32) is a convex program.
Proof
We can prove Theorem 4.2 in the same way as in the proof of Theorem 4.1. The constraints (20), (21), and (23) are obviously equivalent to the constraints in the optimization problem (32). Also, since is given by equations (27) and (28) and, therefore, is a constant, the minimization of performed in the optimization problem (25) is equivalent to minimizing as in the optimization problem (32). This completes the proof of Theorem 4.2.
5 Case study: automotive appearance design
In this section, we illustrate our optimization framework presented in the last section by using a real PD process reported in McDaniel1996 . In Section 5.1, we give an overview of the nominal automotive appearance design process. In Section 5.2, we introduce the cost function used in this case study and also give the baseline resource allocation strategy based on the description in Yassine2003 . We illustrate the effectiveness of our optimization framework in Section 5.3.
5.1 Automotive appearance design
The automotive appearance design process reported in McDaniel1996 (and further investigated in Yassine2003 ) is a part of an automobile PD process and refers to the process of designing all interior and exterior automobile surfaces for better appearance, surface quality, and operational interface. The authors in Yassine2003 focused on the following pair of the system and local teams; the engineering (local) team responsible for the feasibility of designs, and the styling (system) team responsible for the appearance of the vehicle. Information exchanges occur not only on the cross-functional level but also within functional groups working with specific tasks on appearance design. The tasks are 1) carpet, 2) center console, 3) door trim panel, 4) garnish trim, 5) overhead system, 6) instrument panel, 7) luggage trim, 8) package tray, 9) seats, and 10) steering wheel. For the sake of completeness, we include the values of the DSMs and IDMs in Fig. 2.
During the project period, there occur two different types of information exchanges between the teams. One is a weekly feasibility meeting, where the engineering team feedbacks to the styling team on infeasible design conditions. The other ones are in terms of CAD data from the styling team to the engineering team and are scheduled to be roughly six-week intervals. In this paper, we consider the situation where the schedule of the meeting can be either brought forward or postponed at most two weeks due to random and unexpected circumstances. In order to realize this situation, we set the minimum and the maximum interval of feedbacks as and .
5.2 Resource allocation strategies
In the nominal DSMs and IDMs shown in Fig. 2, we identify 104 dependencies of the form (18). Since the DSM is diagonal and, therefore, does not contain dependency terms, we do not consider tuning the values of in this case study.
We consider the following requirements on the cost functions in this case study.
The cost function is decreasing, that is, the more we invest, the weaker dependencies become. 2. 2.
In order to achieve the full improvement and set the dependency to , we need to pay the cost , that is,
[TABLE]
The second requirement in particular implies that the cost for the full improvement is proportional to the strength of the nominal dependencies. In order to realize this situation, we use the following cost function:
[TABLE]
where is a parameter that should be appropriately set by the manager, and the constant is uniquely determined to satisfy the equation (33). Also, we use a positive to satisfy the first requirement. In Fig. 3, we show the shape of the cost function for various values of . We see that, by tuning the value of , we can recover the following two practical improvement regimes that appear in realistic PD process improvements. When is small, we obtain the regime of linear improvement where the magnitude of the improvement, , is proportional to the allocated resource. On the other hand, a large yields the regime of diminishing returns (see, e.g., Chen2012 ), where the incremental elimination of the dependency decreases as we allocate more resource.
To set the baseline strategy for resource distribution, we recall the strategy that was found to be most effective among the other strategies that were proposed by the authors in Yassine2003 . In this reference, the tasks , , and (i.e., the tasks for the center console, door trip panel, and instrument panel within the local team) were identified as “complex local components”. Then, the authors proposed that the project manager should focus on weakening the dependencies between these three local tasks and other tasks. Therefore, in terms of the DSMs and IDMs, it was recommended that we weaken the following dependencies:
[TABLE]
where . We choose to implement this recommendation in the following manner. In our implementation, we distribute the whole resource to the dependencies in (35) in such a way that the distributed resources are proportional to the strength of the nominal dependencies. Hence, in the baseline strategy, we distribute no resources to the dependencies that are not listed in (35).
5.3 Results
For simplicity of illustration, we first fix the probabilities (7) as , , , and . We set (i.e., a full investment eliminates 15% of the nominal dependency) and solve the budget-constrained dependency optimization problem with the budget . Using the baseline and proposed strategies, we obtain the two sets of resource distributions for weakening the strength of dependencies. The proposed strategy achieves the better performance compared with the baseline strategy . We show the obtained investments in Figs. 6 and 6. A remarkable difference between the proposed and baseline strategies can be found in the investments on ; although the proposed strategy invests no resource on , the baseline strategy spends more than the half of the budget in its improvement.
Let us then observe how the investment from the proposed strategy depends on the centrality metrics of the network underlying the PD process. For this purpose, we determine the aggregated amount of investments on an individual task by the total sum of investments on the dependencies involving the task. For example, the aggregated amount of investment on the task in the proposed strategy equals . On the other hand, to compute the centrality metrics of each task, we construct the extended DSM by the formula
[TABLE]
and consider the directed network whose adjacency matrix equals . We then compute the following three different centrality measures for the network ; the betweenness centrality, the PageRank, and the Hub centrality (see, e.g., Newman2010a ). Each centrality metric is normalized to sum to . In Fig. 6, we show how the amount of aggregated investments in the proposed strategy depend on the aforementioned centrality measures. Interestingly, we find that the dependencies of the proposed investments on the centrality measures are not very clear for any cases, which contradicts our intuition that, the bigger centrality a task has, the more investment the task should receive. This observation indicates that, for the improvement of the automotive PD project, the centrality measures are not necessarily an indicative measure. We shall revisit and discuss this counterintuitive result in Section 6.
We next observe how the amount of the available budget affects performance improvements. In Fig. 8, we show the optimized values of the spectral radius from the proposed and baseline strategies as we increase from [math] to . We confirm that the proposed strategy achieves improvement on the baseline strategy for any value of the budget. Then, in Fig. 8, we show the investments on the top six dependencies in Fig. 6 for various values of the budget . We observe that the amount of investment on each dependency is not necessarily related to the priority of the investment. For example, although the dependency receives the second least amount of investments with the budget , the dependency receives all the available investments when the budget is within the range . This phenomenon indicates that the dependency should be invested with the top priority. This nontrivial pattern of the optimal investment indicates the necessity of an analytical tool for PD managers to develop an appropriate resource allocation strategy.
Let us finally compare the amounts of reductions in project completion times. In Fig. 10, we show the trajectories of the amount of unfinished work when the proposed and baseline strategies are applied. We see that the proposed strategy achieves a faster decay in the amount of unfinished work. In order to further investigate the sensitivity of this analysis, we perform the following experiment. Let us suppose that the design project completes if the total amount of unfinished works across the project falls below a specified level, say, . In this case study, this level is set as (i.e., units of unfinished work within each task in average). In Fig. 10, we show the histogram of completion times of the nominal project, the project with the baseline investments, and the one with the proposed investments. To create the histogram, we randomly draw the numbers from a uniform distribution on the set . By following this procedure, we randomly generate a thousand probability distributions for the feedback intervals and, for each distribution, we find the resource allocation using the proposed and baseline strategies. We then simulate the design process and obtain one thousand sample paths for the nominal project, the project with the baseline investments, and the one with the proposed investments, from which we compute the completion times. From Fig. 10, we see that the proposed strategy can effectively reduce the project completion times.
6 Centrality metrics
In the case study that we performed in the previous section, we have observed that a task having a larger centrality does not necessarily receive a bigger investment at the optimality (see Fig. 6). On the other hand, it was shown in the reference Braha2007 that the dynamics and performance of engineering networks are dominated by a few highly central nodes. Specifically, it was observed in the reference that we can exploit such connectivity patterns of complex design networks to suppress the amplification and propagation of design changes and errors through the network. In order to explain this apparent contradiction and provide reliable and practical guidelines for resource investments in engineering design networks, in this section we analyze how the nominal boundary conditions on the DSMs and IDMs, i.e., the connectivity of the design networks, affects the dependence of the optimal investments on centrality measures.
For this purpose, we consider the cases where the structure of the PD network is determined by the following three major network models; the Erdős-Rényi ErdHos1959 , Watz-Strogatz Watts1998 , and Barabási-Albert Barabasi1999 graphs. The Erdös-Rényi graph is one of the earliest random graph models and commonly used in the literature, partly due to the fact that the model is easy to analyze. On the other hand, the Watz-Strogatz and Barabási-Albert graphs are more practical network models able to reproduce, respectively, the small-world and scale-free properties, which are frequently observed in empirical complex networks. For more detailed accounts on the graph models from the perspective of engineering design, we refer the readers to the references Braha2004a ; Braha2004 .
For each type of graph models, we construct a sample network (i.e., a realization) having nodes for , , and , respectively (recall that the PD process under our consideration contains components and each component is separately assigned into the local and system teams). Then, we set the extended DSM of the PD process, given in (36), by the formula , where is the adjacency matrix of the sample network and the constant is chosen in such a way that the generalized WTM, given by (17), has the spectral radius one, i.e., . Under this setting, the nominal PD project without resource allocations is (marginally) not feasible. For this nominal PD project, we solve the convex optimization problem (29) to obtain the optimal investments that solve the budget-constrained dependency optimization problem. In this optimization, we use the parameter and set the budget to be 10% of the full resource allocation. Also, we normalize the sum of the centralities to be equal to , as was done in the case study in the previous section.
In Fig. 11, we show the amount of the investments for individual tasks versus the centralities of the network for the case of Erdős-Rényi PD networks. We can observe a tendency that, when the network size is relatively large ( and ), tasks having bigger centralities tend to receive heavier investments. However, this tendency is not very strong for us to decide on investing towards only on the tasks having higher centralities, as there still exist some tasks receiving relatively heavy investments but having smaller centralities. We also note that, when the network size is small (), the amounts of investments seem not to have a significant correlation with any of the centrality measures. The above observations suggest that, when the network underlying a PD process exhibits a random-graph like structure, the proposed investment strategy could outperform the ones purely based on centrality measures. We can also draw a similar conclusion from Fig. 12 for the Watz-Strogatz network model.
However, the guidelines for the cases of Erdős-Rényi and Watz-Strogatz PD networks do not immediately extend to the last network model of Barabási-Albert graphs. In Fig. 13, we show the amount of investments on individual development tasks versus the centralities in the case of the Barabàsi-Albert graph. In contrast with the former two cases (Figs. 11 and 12), we see that the amounts of investments almost monotonically increase with the centralities, even for the small network size of . Furthermore, in the case of , most of the tasks receive almost zero investments, while a few high-centrality nodes are heavily invested for the improvement of the PD process, as previously reported in the reference Braha2007 .
Let us summarize our findings as follows. As can be observed from the second and third rows in Fig. 13, if a PD network has a scale-free property and is relatively large-scale, then heavily investing on high-centrality tasks would yield the best outcome, which coincides with findings in the literature. However, this natural investment strategy may not work well when the underlying PD networks are rather random or have a small-world property, as can be seen from Figs. 11 and 12. In such a case, the project managers are encouraged to consider not only high-centrality tasks but also the ones having ‘middle’ centralities to obtain the best outcome from investing in their PD projects. In fact, the PD network of our case study in Section 5 falls into this category; as Fig. 2 indicates, the underlying network structure is neither large-scale nor scale-free. This characteristics particularly explains the small correlation between the amount of the optimal investments and the centralities of the individual tasks.
7 Conclusion and discussion
In this paper, we have presented an analytical framework for optimizing the feasibility of PD projects having a time-varying architecture. We have focused on the specific but widely-observed situation in which system and local team asynchronously interact for development. By using a result from the systems and control theory, we first have derived the feasibility index of the project for determining the long-term feasibility of the project. Building on this analysis result, we have shown that the optimal resource distribution solving the budget-constrained and performance-constrained dependency optimization problems can be efficiently found by solving convex optimization problems. The effectiveness of the framework has been illustrated by the case study taking an automobile PD project as an example. We have furthermore analyzed how the boundary conditions on the DSMs and IDMs affect the optimal investment patterns by using major graph models from the Network Science.
It has long been implicitly assumed in most of the resource-allocation support tools that the dependency structure between modules is static (i.e., does not change over time) in PD projects. However, in several practical situations, the dependency structure experiences dynamical changes over time due to various endogenous and exogenous reasons. Despite this fact, little research effort has been spent on the issue of making optimal decisions on resource allocation for developing design rules. This is in great contrast with the research trend in the network science, in which the time-variability of network structures has been attracting growing attention Holme2015b ; Masuda2016b since their discovery Braha2006 ; Braha2009 . This paper is the first to shed a light on the issue somewhat overlooked in design engineering.
Several limitations of the proposed framework suggest fruitful directions for future research. One of the limitations of the current study stems from the fact that the framework allows the case in which the project has one and only one system and local teams. This limitation is mostly due to that of regenerative processes; if there are multiple system or local teams, then one can confirm that the work transformation between the teams cannot be described by a regenerative process. However, by employing more general results from systems and control theory such as the one in Ogura2015 , it would become possible to deal with such a general case.
Data availability is another issue that should be strengthened in future research. There exist established methodologies for the measurement of DSMs and WTMs in the literature (see, e.g., Browning2016 ). On the other hand, we have not addressed the details on measuring the distribution (7) of the interval between feedbacks. If past historical data of the same or similar projects is available to the PD manager, then it is realistic to estimate the distribution to a certain precision. However, if the PD project is completely new and, therefore, such past history is not available, then we would have to rely on a rough estimate by the PD manager, which could deteriorate the reliability of our framework. One of the possible approaches to solve this issue is to use robust control theoretical tools on switched linear systems (see. e.g., Lin2007 ; Ogura2015a ).
The current framework is tailored to large-scale, complex, and dynamical PD project in which communications between teams does not necessarily regularly occur but are asynchronous. For this reason, the current framework is not directly applicable to other widely-used frameworks such as Scrum for software development processes, in which communications between development members occur continuously and, therefore, the dependency structure within the project is not likely to change dynamically. However, it has been demonstrated in the network science literature that ignoring even a small temporality in dependency structure can lead to an ineligible error in our analysis Fefferman2007 ; Vazquez2007 ; Braha2006 ; Hill2010b . Such findings suggest that the currently widespread paradigm of “static dependency” for PD projects improvements may have to be carefully reconsidered.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1(1) Adler, P., Mandelbaum, A., Nguyen, V., Schwerer, E.: Project to process management: empirically-based framework for analyzing product development time. Management Science 41 (3), 458–484 (1995)
- 2(2) Ahmadi, R., Wang, R.H.: Managing development risk in product design processes. Operations Research 47 , 235–246 (1999)
- 3(3) Alcaraz, J., Maroto, C., Ruiz, R.: Solving the multi-mode resource-constrained project scheduling problem with genetic algorithms. Journal of the Operational Research Society 54 (6), 614–626 (2003)
- 4(4) Baldwin, C., Clark, K.: Design Rules: The Power of Modularity. MIT Press (2000)
- 5(5) Barabási, A.L., Albert, R.: Emergence of scaling in random networks. Science 286 (5439), 509–512 (1999)
- 6(6) Boctor, F.F.: A new and efficient heuristic for scheduling projects with resource restrictions and multiple execution modes. European Journal of Operational Research 90 (2), 349–361 (1996)
- 7(7) Borjesson, F., Hölttä-Otto, K.: A module generation algorithm for product architecture based on component interactions and strategic drivers. Research in Engineering Design 25 (1), 31–51 (2014)
- 8(8) Boyd, S., Kim, S.J., Vandenberghe, L., Hassibi, A.: A tutorial on geometric programming. Optimization and Engineering 8 (1), 67–127 (2007)