TL;DR
This paper introduces a novel defense mechanism against adversarial attacks using a regularized, quantized latent space in generative models, which enhances robustness across attack types and is computationally efficient.
Contribution
It proposes a generalized, attack-agnostic defense leveraging variational inference and latent space quantization, improving adversarial resilience without needing classifier access.
Findings
Outperforms state-of-the-art defenses in multiple attack scenarios
Provides near real-time adversarial robustness
Effective against both black-box and white-box attacks
Abstract
Despite their tremendous success in modelling high-dimensional data manifolds, deep neural networks suffer from the threat of adversarial attacks - Existence of perceptually valid input-like samples obtained through careful perturbation that lead to degradation in the performance of the underlying model. Major concerns with existing defense mechanisms include non-generalizability across different attacks, models and large inference time. In this paper, we propose a generalized defense mechanism capitalizing on the expressive power of regularized latent space based generative models. We design an adversarial filter, devoid of access to classifier and adversaries, which makes it usable in tandem with any classifier. The basic idea is to learn a Lipschitz constrained mapping from the data manifold, incorporating adversarial perturbations, to a quantized latent space and re-map it to the…
Click any figure to enlarge with its caption.
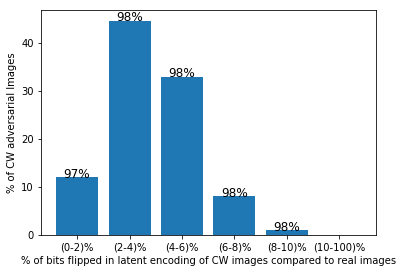 Figure 1
Figure 1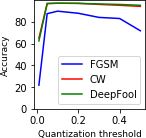 Figure 2
Figure 2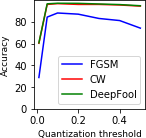 Figure 3
Figure 3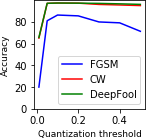 Figure 4
Figure 4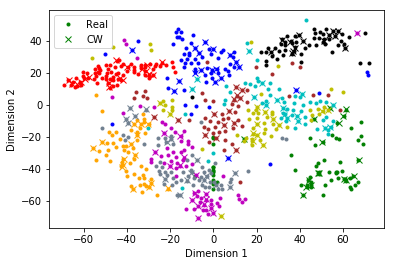 Figure 5
Figure 5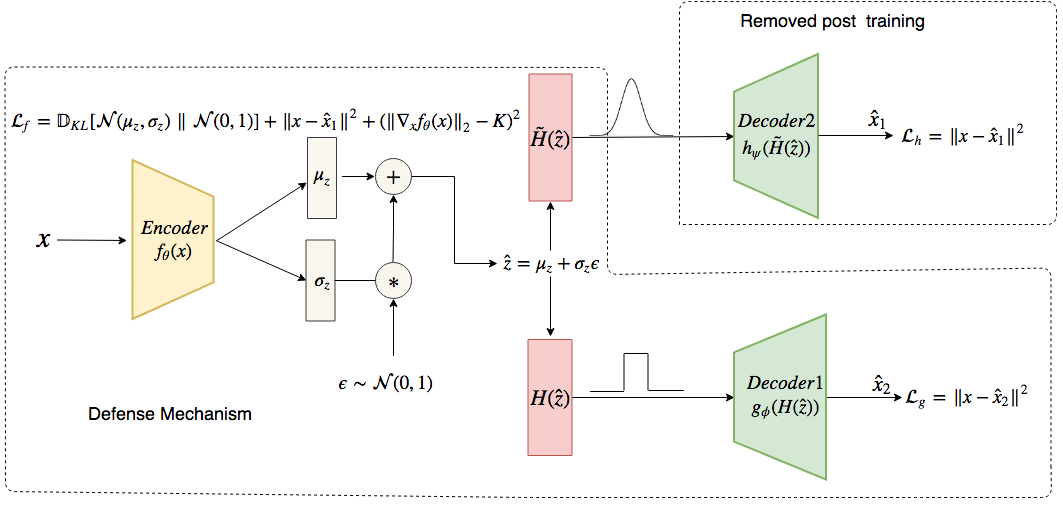 Figure 6
Figure 6| Attack | Model | No Attack | No Defense | LQ-VAE | Defense-GAN | Madry | Adv Tr |
| FGSM | A | 92.76 | 11.50 | 77.00 | 69.75 | 78.87 | 53.72 |
| B | 91.17 | 10.14 | 69.41 | 56.72 | 76.94 | 59.79 | |
| C | 89.06 | 11.60 | 67.07 | 56.34 | 64.16 | 66.43 | |
| Deepfool | A | 92.76 | 5.29 | 79.30 | 77.48 | 57.17 | 6.52 |
| B | 91.17 | 6.54 | 79.41 | 74.97 | 52.58 | 14.74 | |
| C | 89.06 | 7.65 | 79.89 | 74.82 | 39.93 | 24.71 | |
| CW | A | 92.76 | 5.41 | 80.64 | 78.75 | 62.55 | 5.35 |
| B | 91.17 | 6.61 | 81.58 | 78.18 | 56.48 | 6.35 | |
| C | 89.06 | 7.89 | 82.31 | 78.58 | 43.72 | 8.00 | |
| Average | 91.00 | 8.07 | 77.40 | 71.73 | 59.15 | 27.29 |
| Attack | Model | No Attack | No Defense | LQ-VAE | Defense-GAN | Madry | Adv Tr |
| FGSM | A | 99.40 | 20.16 | 89.17 | 90.43 | 96.85 | 67.95 |
| B | 99.41 | 13.17 | 86.70 | 88.52 | 96.20 | 49.49 | |
| C | 98.37 | 5.66 | 83.02 | 86.7 | 84.71 | 80.75 | |
| Deepfool | A | 99.40 | 7.38 | 97.60 | 95.41 | 67.82 | 3.10 |
| B | 99.41 | 5.88 | 97.74 | 93.03 | 66.35 | 5.75 | |
| C | 98.37 | 48.24 | 97.42 | 92.32 | 62.38 | 10.97 | |
| CW | A | 99.40 | 8.85 | 97.66 | 94.37 | 69.15 | 1.20 |
| B | 99.41 | 5.07 | 97.20 | 90.56 | 71.35 | 1.45 | |
| C | 98.37 | 8.44 | 97.36 | 92.5 | 58.65 | 2.15 | |
| Average | 99.06 | 13.65 | 93.76 | 91.54 | 74.83 | 24.76 |
| Attack | Model | No Attack | No Defense | LQ-VAE | Defense-GAN | Madry | Adv Tr |
| FGSM | A | 96.34 | 3.65 | 81.04 | 74.13 | 62.35 | 4.53 |
| B | 96.60 | 3.40 | 64.74 | 67.06 | 71.42 | 72.88 | |
| C | 95.02 | 28.62 | 61.48 | 53.76 | 61.35 | 42.55 | |
| Deepfool | A | 96.34 | 3.56 | 85.89 | 83.87 | 52.86 | 6.26 |
| B | 96.60 | 2.43 | 83.81 | 83.65 | 49.39 | 14.17 | |
| C | 95.02 | 10.92 | 62.79 | 78.56 | 42.37 | 38.45 | |
| CW | A | 96.34 | 6.98 | 85.90 | 84.64 | 58.62 | 11.88 |
| B | 96.60 | 6.88 | 86.29 | 86.01 | 60.33 | 12.91 | |
| C | 95.02 | 10.92 | 79.20 | 78.56 | 45.02 | 38.45 | |
| Iter FGSM | A | 96.34 | 3.12 | 85.44 | 81.00 | 82.34 | 3.50 |
| B | 96.60 | 3.55 | 72.29 | 72.05 | 72.19 | 9.16 | |
| C | 95.02 | 11.92 | 52.12 | 42.13 | 90.87 | 19.47 | |
| Madry | A | 96.34 | 2.84 | 85.11 | 81.43 | 76.35 | 3.52 |
| B | 96.60 | 3.12 | 70.01 | 74.01 | 70.32 | 8.52 | |
| C | 95.02 | 8.57 | 54.00 | 45.11 | 84.09 | 18.59 | |
| Average | 95.99 | 7.37 | 74.01 | 72.40 | 65.32 | 20.32 |
| Classifier | No Attack | No Defense | LQ-VAE | Defense-GAN | Madry | Adv Tr |
|---|---|---|---|---|---|---|
| Substitute | ||||||
| A/B | 99.40 | 33.32 | 88.09 | 89.14 | 97.17 | 95.78 |
| A/C | 99.40 | 45.35 | 90.60 | 90.08 | 98.27 | 96.82 |
| B/A | 99.41 | 42.22 | 90.63 | 91.40 | 97.38 | 94.64 |
| B/C | 99.41 | 38.73 | 89.92 | 89.89 | 98.03 | 95.30 |
| C/A | 98.37 | 28.93 | 91.98 | 90.90 | 90.59 | 32.12 |
| C/B | 98.37 | 18.01 | 89.38 | 88.73 | 89.14 | 21.79 |
| Average | 99.06 | 34.43 | 90.10 | 90.02 | 95.10 | 72.74 |
| Classifier/ | No Attack | No Defense | LQ-VAE | Defense-GAN | Madry | Adv Tr |
|---|---|---|---|---|---|---|
| Substitute | ||||||
| A/B | 92.76 | 29.14 | 77.74 | 74.41 | 60.11 | 48.27 |
| A/C | 92.76 | 35.44 | 77.11 | 74.11 | 62.58 | 57.53 |
| B/A | 91.17 | 67.82 | 81.33 | 77.97 | 80.71 | 76.61 |
| B/C | 91.17 | 45.55 | 78.83 | 74.5 | 69.19 | 64.05 |
| C/A | 89.06 | 79.11 | 82.12 | 78.82 | 80.99 | 81.84 |
| C/B | 89.06 | 47.26 | 80.76 | 76.6 | 67.46 | 59.64 |
| Average | 91.00 | 50.72 | 79.65 | 76.07 | 70.17 | 64.66 |
| Classifier/ | No Attack | No Defense | LQ-VAE | Defense-GAN | Madry | Adv Tr |
|---|---|---|---|---|---|---|
| Substitute | ||||||
| A/B | 96.34 | 39.53 | 86.01 | 84.70 | 85.41 | 94.13 |
| A/C | 96.34 | 37.59 | 80.10 | 78.11 | 64.72 | 54.22 |
| B/A | 96.60 | 49.21 | 85.67 | 86.19 | 82.55 | 68.11 |
| B/C | 96.60 | 52.52 | 79.98 | 79.91 | 76.31 | 62.53 |
| C/A | 95.02 | 82.87 | 85.90 | 86.29 | 89.79 | 86.75 |
| C/B | 95.02 | 83.26 | 85.20 | 86.17 | 89.91 | 88.40 |
| Average | 95.99 | 57.50 | 83.81 | 83.56 | 81.45 | 75.69 |
| Dataset | LQ-VAE | Defense-GAN |
|---|---|---|
| MNIST | 83.70 | 55.17 |
| FMNIST | 57.41 | 39.41 |
| A | B | C |
|---|---|---|
| Conv(64, , 1) | Dropout(0.2) | FC(200) |
| ReLu | Conv(64, , 2) | ReLu |
| Conv(64, , 2) | ReLu | Dropout(0.5) |
| ReLu | Conv(128, , 2) | FC(200) |
| Dropout(0.25) | ReLu | ReLu |
| FC(128) | Conv(128, , 1) | FC() |
| ReLu | ReLu | Softmax |
| Dropout(0.5) | Dropout(0.5) | |
| FC() | FC() | |
| Softmax | Softmax |
| Encoder | Decoder1\Decoder2 |
|---|---|
| Conv(64, , 1) | FC(1024) |
| LeakyReLu(0.2) | LeakyReLu(0.2) |
| Conv(64, , 2) | FC(6272) |
| LeakyReLu(0.2) | LeakyReLu(0.2) |
| Conv(128, , 2) | ConvT(128,, 1) |
| LeakyReLu(0.2) | LeakyReLu(0.2) |
| Conv(128, , 1) | ConvT(128,, 2) |
| LeakyReLu(0.2) | LeakyReLu(0.2) |
| FC(1024) | ConvT(64,, 2) |
| LeakyReLu(0.2) | LeakyReLu(0.2) |
| FC(64), FC(64) | ConvT(1,, 1) |
| Encoder | Decoder1\Decoder2 |
|---|---|
| Conv(64, , 1) | FC(1024) |
| LeakyReLu(0.2) | LeakyReLu(0.2) |
| Conv(64, , 2) | FC(4096) |
| LeakyReLu(0.2) | LeakyReLu(0.2) |
| Conv(128, , 2) | ConvT(128,, 2) |
| LeakyReLu(0.2) | LeakyReLu(0.2) |
| Conv(128, , 2) | ConvT(128,, 2) |
| LeakyReLu(0.2) | LeakyReLu(0.2) |
| Conv(256, , 2) | ConvT(64,, 2) |
| LeakyReLu(0.2) | LeakyReLu(0.2) |
| FC(1024) | ConvT(64,, 2) |
| LeakyReLu(0.2) | LeakyReLu(0.2) |
| FC(64), FC(64) | ConvT(3,, 1) |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Variational Inference with Latent Space Quantization for Adversarial Resilience
Vinay Kyatham
SigTuple Technologies
Bangalore, India &Mayank Mishra11footnotemark: 1, Tarun Kumar Yadav,
**Deepak Mishra, Prathosh AP22footnotemark: 2
**Indian Institute of Technology Delhi
New Delhi, India Equal contributionEqual contribution
Abstract
Despite their tremendous success in modelling high-dimensional data manifolds, deep neural networks suffer from the threat of adversarial attacks - Existence of perceptually valid input-like samples obtained through careful perturbation that lead to degradation in the performance of the underlying model. Major concerns with existing defense mechanisms include non-generalizability across different attacks, models and large inference time. In this paper, we propose a generalized defense mechanism capitalizing on the expressive power of regularized latent space based generative models. We design an adversarial filter, devoid of access to classifier and adversaries, which makes it usable in tandem with any classifier. The basic idea is to learn a Lipschitz constrained mapping from the data manifold, incorporating adversarial perturbations, to a quantized latent space and re-map it to the true data manifold. Specifically, we simultaneously auto-encode the data manifold and its perturbations implicitly through the perturbations of the regularized and quantized generative latent space, realized using variational inference. We demonstrate the efficacy of the proposed formulation in providing resilience against multiple attack types (black and white box) and methods, while being almost real-time. Our experiments show that the proposed method surpasses the state-of-the-art techniques in several cases.
Introduction
Deep neural networks have shown tremendous success in various computer vision tasks. One of the primary factors contributing to their success is the availability of abundant data. This generally leads to an incomplete exploration of data space with the available training set, which in-turn results in loopholes in the data manifold (?; ?). Adversarial attacks exploit these gaps in the data manifold, unexplored by the classifier which leads to the failure of otherwise successful networks. This unexplored subspace, called adversarial subspace, contains adversarial samples generated using perturbation of original training samples with carefully designed synthetic noise (?; ?; ?; ?; ?). This is an important concern not only from a point of security but also from a generalization perspective (?). In the rest of the section, we will present an overview of the existing adversarial attacks, defense mechanisms along with the motivation for our work.
Adversarial attacks - General principles
An adversarial sample is obtained by perturbing the input sample with a small amount such that its perceptual quality is unaltered but the class label is changed under the classifier. Formally, let denote a sample from the natural data manifold and , denote a perturbation on with , being the space of all possible perturbations. Under a given distance metric and a classification scheme , the sample is called an adversarial example for if and . A large body of attacks consider a -norm based , with and norms being the significant ones, and solve an optimization problem on the loss function of to obtain the desired . Attacks can be targeted so that the classifier is misguided to a specific class or non-targeted so that it outputs an arbitrary class different from the original class. Further categorization of adversarial attacks is based on the level of access the attacker has about the classification and defense scheme. Specifically they are defined as white and black box attacks.
Attack methods
There is a gamut of literature on creating adversarial attacks. ? propose Fast Gradient Sign Method (FGSM) that performs a one step gradient update along the direction of sign of gradient of loss at each pixel. ? introduced Basic Iterative method (BIM) which runs FGSM for a few iterations. Deepfool (?) is another iterative attack which computes adversarial perturbations through an orthogonal projection of the sample on the decision boundary. Carlini-Wagner (CW) attack (?) is an optimization based attack that uses logits-based objective function instead of the commonly used cross-entropy loss. We choose these attacks since they cover a good breadth of the class of attacks.
Prior art on defense mechanisms
A large number of defense mechanisms to diminish the effect of adversarial attacks are available (?; ?; ?; ?; ?; ?; ?; ?). Broadly, these can be divided into the following categories -
Adversarial retraining - A natural way to make the classifier robust against the adversaries is to retrain the classifier using adversarial examples (?; ?). Several improvisations of adversarial retraining have been proposed (?; ?; ?). While adversarial retraining is a simple method for defense and is robust to first-order adversaries, it is shown to be ineffective towards DeepFool and CW attack (?) and also black-box attacks (?; ?; ?) 2. 2.
Modified training - Here the idea is to tweak the training procedure and/or the training examples of the classifier so that the decision boundary learnt is robust to adversarial examples (?; ?; ?; ?; ?). However, ? demonstrate that most of these defenses are vulnerable because they capitalize on obfuscated gradients that can be mitigated. 3. 3.
Adversarial filtering - These defense mechanisms pre-process the adversarial examples to make them non-adversarial either by manifold projection or by using generative models. For example, MagNet (?) trains a collection of detector networks that differentiate between normal and adversarial examples. It also includes a reformer network (one or a collection of auto-encoders) to push adversarial examples close to the data manifold. A recent strategy called Defense-GAN (?) trains a generative adversarial network (GAN) (?) only on legitimate examples and uses it to denoise adversarial examples. At the time of inference, they find images from the range of generator that are near the input image but lie on the legitimate data manifold. This requires iterations of back propagation for random initializations to find the nearest legitimate image, typical value of L is 200 and R is 10. Other GAN based defences, for example, PixelDefend (?) and APE-GAN (?), perform image-to-image translation to convert an adversarial image into a legitimate image.
Problem setting and our contributions
As mentioned, while the existing defense mechanisms have their own merits, each of them suffer from aforementioned disadvantages. ? argue that most of these methods give a false sense of security since most of them capitalize on masking the gradients (obfuscated gradients) so that it is difficult to generate adversarial examples. However, they show that this can be circumvented using techniques such as approximation of derivatives by a differentiable approximation of the function, reparameterization and computation of expectations. In this paper, we propose a defense mechanism based on quantized latent variable generative autoencoders to alleviate the aforementioned issues. Our contributions are enlisted below:
Propose a quantized latent variable generative model based defense mechanism devoid of access to classifier and adversaries. 2. 2.
Construction of a Lipschitz constrained latent encoder that preserves the distances under a metric space on the latent and the data manifolds. 3. 3.
Constraining the latent space to follow a known distribution so that stochastic exploration of the latent neighbourhood corresponding to the data neighbourhood is possible. 4. 4.
Use of dual decoders with a quantization on the latent space so that a large neighbourhood around a data sample is explored and easily remapped back to the data point.
Proposed Method
Motivation
In many previous works it is hypothesized that the adversarial examples fall off the data manifold (?; ?). This suggests that a defense model could potentially be built by replacing an adversarial example with the nearest correctly-classified sample from the data manifold. However, searching in high-dimensional data manifolds is expensive, not generalizable and moreover, it has been found that the adversarial examples might fall on the data manifold too (?). Thus, a better approach could be to project the data manifold onto an explorable compact generative latent space and remap the latent codes back to the legitimate data. If the latent space projector is made to be Lipschitz constrained and compact, then one can hope that the adversarial examples adhere to a latent code that is invertible to the legitimate data.
Lipschitz constrained latent transformation
Let be a Lipschitz constrained function which maps a data point of dimension to a latent vector of dimension such that . For such an , if the adversarial perturbation on is bounded then the equivalent perturbation on is also bounded.
Since the goal is to learn mappings in high-dimensional spaces, we use Deep Neural Networks (DNNs) parameterized by , to approximate . There have been many methods proposed to make a DNN -Lipschitz including gradient clipping (?) and gradient norm penalty (?). We employ gradient norm penalty on the encoder since it is observed to be more stable.
Latent exploration via variational inference
As mentioned earlier, the goal is to explore the latent neighbourhood induced by perturbing a given input sample. This effectively means that one has to sample from the true conditional distribution . However since there is no direct access to we propose to use the principles of variational inference (?), where sampling from is facilitated by approximating it with a variational distribution on that is parameterized by the encoder network . Now minimizing the KL-divergence between and results in the maximization of the so-called evidence lower bound given as follows:
[TABLE]
where represents a probabilistic decoder network that maps the latent space back to the data space and is an arbitrary prior on which is usually a Normal distribution. We propose to sample from using the encoder network through the reparameterization trick (?). Thus, given a true data example, a cloud of perturbations is created around its latent representation obtained through Lipschitz constrained encoder , via variational sampling. The probabilistic decoder , parameterized using a neural network , is then tasked to map all the points within that cloud to a single input example through maximization of the likelihood term in (1), as shown in Figure 1. Mathematically, if the encoder embeds and to a and to a , such that then decoder learns . During inference, when the encoder is presented with an adversarial example, it will place it within the learned latent cloud so that the decoder converts it into a non-adversarial sample. This fact has been illustrated in Figure 2 where a 2D t-SNE plot of the latent encodings (from the Lipschitz constrained encoder) of the true and the CW attacked adversarial samples from the MNIST data is shown. It can be seen that embeddings of the adversaries are extremely close to those of the true samples.
Latent space quantization
A recent work by ? makes a very important observation - closeness from a correctly classified sample does not guarantee non-adversarial nature. In other words, since the latent space is real-valued it is impossible to explore it in its entirety. Thus, there is a high chance that a probabilistic decoder is unable to remove the adversarial noise even when the latent vector for an adversarial example falls within the seen latent cloud. We propose to address this issue by quantizing the latent space before it is input to the decoder. Specifically, we design a fixed discrete quantization function applied on each dimension of the real-output of the encoder as follows:
[TABLE]
where is the quantization threshold. thus converts into binary coded vectors thereby ensuring that the decoder receives a single latent code for all the input samples that map within a small neighbourhood of . In contrast to real , where has to learn a non-injective mapping, quantization allows it to learn a mapping close to injective since the same code vector is produced for all in this neighbourhood, hence making the training easier. This procedure potentially increases the robustness of the model too since the goal of an adversarial resilience model is not to exactly reproduce the non-adversarial version of a given sample but to produce an approximate version that is non-adversarial. Thus, it is imperative to just look for the presence or absence of the salient features that preserve the identity of a given example, which is accomplished by the binary quantization with the threshold being a hyperparameter whose value is chosen as, however not limited to, since it gives equal probability to a bit being +1 or -1. Thus, any deviation in the input sample falling outside the latent cloud leads to flipping of the bits in the quantized space.
Theorem 1
Let and be the latent encoding of and respectively. Let and be the corresponding quantizations. Then the probability of a particular bit being flipped is given by
[TABLE]
and the probability of () bit flips for dimensional latent space is which is significantly low, when is chosen such that both bits are equally likely, and (proof in supplementary material).
Figure 3 depicts the bit-flippings in the latent codes of the CW adversaries on the MNIST data - It can be seen that about 90 % of the total adversaries undergo less than 6% of bits being flipped resulting in high classification accuracy, confirming the effectiveness of the decoder in ignoring the bit-flippings. Further, the binary encoding layer ensures that gradient produced at that layer is either 0 or undefined, thereby making a gradient based attack on the defense mechanism impossible.
Adversarial resilience by LQ-VAE
As mentioned above, quantization prevents the flow of gradients through the encoder network that makes it non-trainable along with the decoder . We, therefore, create a copy of , say , which uses soft quantization in place of (called ) and enable the training of . A complete overview of the proposed method, called as Lisphitz-constrained quantized variational auto-encoder (LQ-VAE) is shown in Figure 1. Algorithm 1 gives the details of the LQ-VAE training procedure where the likelihood term in (1) is approximated using mean-squared error term between the input and the output. Note that the network is only used for training, not for inference. The defense scheme only contains the pipeline of .
Experiments and results
We consider MNIST (?), FMNIST111https://github.com/zalandoresearch/fashion-mnist, and CelebA (?) datasets and use three classifier architectures, named A, B, and C, for black box and white box experiments222Architectures of all the classifiers and LQ-VAE is included in supplementary material.. For MNIST and FMNIST, the standard 10 class classification task is considered, whereas for CelebA, a binary classification task of gender classification is taken, with accuracy as the metric. Five attack types namely, FGSM with (?), CW (?), Deepfool (?), iterative FGSM (?) and Madry (?), generated from cleverhans library (?), are considered for experimentation as they cover a good breadth of attack types. We compare our results with three defense strategies - Defense GAN (?), Madry (?) and Adversarial retraining (?) based on the following facts (i) Defense GAN is close to our work in spirit. Their method also employs a generative model (GAN) and does not train on adversarial examples, (ii) Madry retraining is claimed to be a robust defense against all first-order gradient computation based attacks and (iii) adversarial retraining is one of the earliest benchmark defenses created. We use the Adam optimizer () with a learning rate of to train LQ-VAE. We study different attack types, namely black box attacks, white box attack on classifier and end-to-end white box attack.
Black box attacks - The attacker neither has access to the original classifier nor the defense scheme, rather he has to generate adversarial examples on a substitute classifier (?). 2. 2.
White box attacks - We subdivide white box attacks into two further categories:
- (a)
White box attacks on classifier - In this case, it is assumed that the attacker has access to the original classifier but not the defense scheme and the adversarial examples are generated by computing gradients over the original classifier. 2. (b)
White box attacks with BPDA - The attacker has access to both the original classifier and the defense mechanism. In other words, the adversarial examples can be generated by computing gradients over the LQ-VAE - classifier combination. ? argue that such methods can be attacked using Backward Pass Differentiable Approximation (BPDA). We attack the defense mechanism by approximating the discretization function with given as follows:
[TABLE]
where is a non-negative hyperparameter. It can be seen that when .
Results on white box attacks on classifier
For MNIST and FMNIST, we use 60,000 real images for training the defense mechanisms and 10,000 adversarial images on the standard test set for testing. For CelebA, we use 90% images for training and remaining for testing. Classification accuracy of all three classifier models, A, B, and C, in presence and absence of defense mechanisms are listed in Table 1, 2, and 3 for MNIST, FMNIST, and CelebA, respectively. The attacks reduce classification accuracy of all the models drastically. Adversarial retraining is able to defend FGSM attack up to a certain extent but fails on the other attacks, since the retraining is performed using adversarial examples generated by FGSM attacks. Similarly Madry, which also uses first order gradients based adversarial images to retrain the classifiers, shows consistent performance against FGSM. However, for Deepfool and CW attack, its performance is lower than Defense-GAN and the proposed LQ-VAE. Both, Defense-GAN and LQ-VAE, do not require adversarial augmentation, however, we note that LQ-VAE consistently outperforms Defense-GAN.
Results on white box attacks with BPDA
Most of the defense mechanisms that rely on gradient obfuscation (?) are broken completely by attacking using BPDA. However, Defense-GAN still has 55% accuracy on MNIST after the attack since it does not rely on gradient obfuscation. Our work is similar in spirit to Defense-GAN in thse sense that it also does not rely on gradient obfuscation. We generate adversarial examples for the LQ-VAE - classifier combination via BPDA, however, passing these examples to the Lipschitz constrained encoder still results in these adversarial examples getting the same discrete latent codes (refer Figure 3 and Theorem 1) as their non-adversarial counterparts and thus their non-adversarial counterparts are successfully reconstructed by the decoder resulting in their correct classification (refer Table 7). We compare our results with Defense-GAN since ? show that it can also be attacked using BPDA.
Results on black box attacks
For black box experiments, we consider one attack each on a dataset as a representative set. Specifically, FGSM for MNIST, Deepfool for FMINST and CW for CelebA are considered with six-pairs of classifiers used for attacking and substitute. A similar trend is observed with the black box attacks as well, as seen in Tables 4, 5 and 6. Madry retraining performs the best on the FGSM attack because it is trained on a superset of first-order methods of which FGSM is a subset. However, the performance of LQ-VAE is consistent irrespective of the classifier pairs across all cases and is closely comparable (or better) to the best case. On Deepfool and CW, LQ-VAE outperforms the others in most of the cases. We hypothesize that this behaviour of LQ-VAE comes from the Lipschitz constraining, by which it becomes a strong defense when the attack alters fewer pixels of the input image yet changing the class, as in the case of CW and Deepfool, unlike in FGSM. In summary, the proposed method is invariant to white or black box attack types.
Discussions and Conclusions
LQ-VAE and Defense-GAN fall into the same category of defense mechanisms in the sense that they both capitalize on the expressive capacity of generative models. Further, both of the models generalize better on the adaptive or unseen attacks (?) since both of them neither need access to the classifier nor train on a certain type of adversaries. However, LQ-VAE offers several advantages over Defense-GAN such as - (i) LQ-VAE does not involve a run-time search on the latent space unlike Defense-GAN which makes it orders of magnitude faster and independent of latent search parameters. Rather in LQ-VAE, the search in the latent space is implicitly done by effective encoding, quantization and decoding of the latent space. (ii) training a VAE is known to be easier and faster, yielding a better data likelihood than a GAN which is known to be difficult to be trained, especially on color datasets such as CelebA, (iii) LQ-VAE has a latent encoding followed by the re-mapping of the latent space to the data space which makes it invariant to attack types while Defense-GAN is shown to degrade in the case of black box attacks, (iv) as argued in (?), Defense-GAN can be attacked too by a method called the Backward Pass Differentiable Approximation (BPDA), in which case its defense on MNIST is reported at 55% (?). When the same technique is used to attack LQ-VAE, we get much better accuracy of 83% on the same task which can be ascribed to the use of latent space constraining and quantization. In summary, we proposed a technique called LQ-VAE as a filter for the adversarial examples using a constrained projection on to a quantized latent space followed by data reconstruction. It serves like a ‘black-box defense’ in the sense that it can be used to defend any attack and with any classifier. In principle, LQ-VAE can be re-trained using adversaries too, in which case the performance is observed to improve. For instance, it is observed that if one retrains LQ-VAE using Madry adversaries, its performance is enhanced by 5-10% on FGSM attacks. Future directions include exploration of the latent prior beyond a standard Normal distribution, studying the effect of different types of quantization other than a simple binary quantization and using LQ-VAE as an adversarial detector. We provide the code333The code used in this paper can be accessed at https://github.com/mayank31398/lqvae for further research.
Appendix A Appendix
Proof for Theorem 1
Let and be the latent encoding of and respectively. Let and be the corresponding quantizations with being the quantization threshold. Then the probability of a particular bit being flipped is given by:
[TABLE]
[TABLE]
which is obtained by using which is an even function. Similarly,
[TABLE]
Adding A and B we have,
[TABLE]
To give equal probability to taking the values -1 or 1 we have the following constraint:
[TABLE]
Solving this for , we have . Using this value of and we get where is the Lipschitz constant and is the perturbation in the input image. Thus, the probability of a bit being flipped is found to be which is a significantly low number. For a dimensional latent space, the probability of bit flips is which is found to be for () bit flips for a dimensional latent space.
Architectures of the classifier and substitute networks
The following table shows the neural network architectures used throughout the paper for classifier and substitute models. Terminology used:
- •
Conv() denotes a convolutional layer with m filters of size and stride
- •
ReLu is the Rectified Linear Unit Activation
- •
LeakyReLu() is the Leaky Rectified Linear Unit Activation with parameter
- •
Dropout() is a dropout layer with probability
- •
FC() denotes a fully connected layer with m neuron units
- •
ConvT() denotes a deconvolutional layer with filters of size and stride
Final Fully connected layer has 10 units for MNIST and FMNIST and 2 units for CelebA dataset.
LQ-VAE architecture
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[Arjovsky, Chintala, and Bottou 2017] Arjovsky, M.; Chintala, S.; and Bottou, L. 2017. Wasserstein gan. ar Xiv preprint ar Xiv:1701.07875 .
- 2[Athalye, Carlini, and Wagner 2018] Athalye, A.; Carlini, N.; and Wagner, D. 2018. Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples. ar Xiv preprint ar Xiv:1802.00420 .
- 3[Carlini and Wagner 2017] Carlini, N., and Wagner, D. 2017. Towards evaluating the robustness of neural networks. In 2017 IEEE Symposium on Security and Privacy (SP) , 39–57. IEEE.
- 4[Dhillon et al . 2018] Dhillon, G. S.; Azizzadenesheli, K.; Lipton, Z. C.; Bernstein, J.; Kossaifi, J.; Khanna, A.; and Anandkumar, A. 2018. Stochastic activation pruning for robust adversarial defense. ar Xiv preprint ar Xiv:1803.01442 .
- 5[Ding et al . 2019] Ding, G. W.; Lui, K. Y. C.; Jin, X.; Wang, L.; and Huang, R. 2019. On the sensitivity of adversarial robustness to input data distributions. ar Xiv preprint ar Xiv:1902.08336 .
- 6[Gilmer et al . 2018] Gilmer, J.; Metz, L.; Faghri, F.; Schoenholz, S. S.; Raghu, M.; Wattenberg, M.; and Goodfellow, I. 2018. Adversarial spheres. ar Xiv preprint ar Xiv:1801.02774 .
- 7[Goodfellow et al . 2014] Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; and Bengio, Y. 2014. Generative adversarial nets. In Advances in neural information processing systems , 2672–2680.
- 8[Goodfellow et al . 2016] Goodfellow, I.; Bengio, Y.; Courville, A.; and Bengio, Y. 2016. Deep learning , volume 1. MIT Press.
