Generative Models For Deep Learning with Very Scarce Data
Juan Maro\~nas, Roberto Paredes, Daniel Ramos

TL;DR
This paper explores using Restricted Boltzmann Machines and Variational Auto-encoders to generate additional training data in scarce data scenarios, improving deep learning classification performance.
Contribution
It compares RBMs and VAEs for data augmentation in deep learning, demonstrating RBMs' superior sample generation for better classifier generalization.
Findings
RBMs outperform VAEs in sample quality for training
Data augmentation improves classification accuracy in scarce data scenarios
RBM-based augmentation surpasses semi-supervised ladder networks
Abstract
The goal of this paper is to deal with a data scarcity scenario where deep learning techniques use to fail. We compare the use of two well established techniques, Restricted Boltzmann Machines and Variational Auto-encoders, as generative models in order to increase the training set in a classification framework. Essentially, we rely on Markov Chain Monte Carlo (MCMC) algorithms for generating new samples. We show that generalization can be improved comparing this methodology to other state-of-the-art techniques, e.g. semi-supervised learning with ladder networks. Furthermore, we show that RBM is better than VAE generating new samples for training a classifier with good generalization capabilities.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3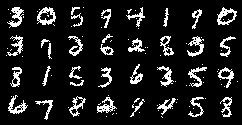 Figure 4
Figure 4 Figure 5
Figure 5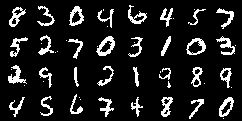 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11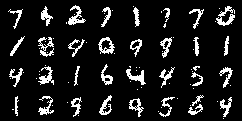 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15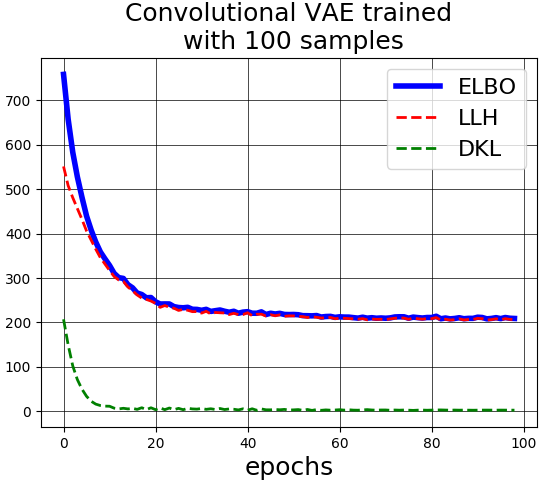 Figure 16
Figure 16 Figure 17
Figure 17| Labeled Samples | 10 | 100 | 1000 |
|---|---|---|---|
| Baseline | 58.88 | 28.39 | 7.25 |
| Ladder Network | 48.85 | 24.74 | 6.96 |
| RBM DA | 45.34 | 18.66 | 5.60 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
MethodsUSD Coin Customer Service Number +1-833-534-1729
Generative Models For Deep Learning with Very Scarce Data
Juan Maroñas [email protected] correspondence to: Juan Maroñas [email protected],[email protected]. Work published at 23th Iberoamerican Congress on Pattern Recognition Pattern Recognition and Human Language Technology, Universitat Politècnica de València, Valencia , Spain
Roberto Paredes [email protected]
Pattern Recognition and Human Language Technology, Universitat Politècnica de València, Valencia , Spain
Daniel Ramos [email protected]
AUDIAS , Universidad Autónoma de Madrid, Madrid, Spain
(November 2018)
Abstract
The goal of this paper is to deal with a data scarcity scenario where deep learning techniques use to fail. We compare the use of two well established techniques, Restricted Boltzmann Machines and Variational Auto-encoders, as generative models in order to increase the training set in a classification framework. Essentially, we rely on Markov Chain Monte Carlo (MCMC) algorithms for generating new samples. We show that generalization can be improved comparing this methodology to other state-of-the-art techniques, e.g. semi-supervised learning with ladder networks. Furthermore, we show that RBM is better than VAE generating new samples for training a classifier with good generalization capabilities.
Keywords: Data Scarcity, Generative Models, Data augmentation, Markov Chain Monte Carlo algorithms
1 Introduction
In the last few years deep neural networks have achieved state-of-the-art performance in many task such as image recognition [17], object recognition [13], language modeling [10], machine translation [16] or speech recognition [7]. One of the key facts that increased this performance is the great amount of available data. This amount of data together with the high expressiveness of neural networks as functions approximators and appropriate hardware lead us to an unprecedented performance in challenging problems.
However, deep learning lacks of success in scenarios where the amount of labeled data is scarce. In this work we aim at providing a methodology in order to apply deep learning techniques to problems with very scarce available data. Some techniques are proposed to deal with such data size problem: semi supervised learning techniques such as the ladder network [12], Bayesian modeling [5] and data augmentation (DA) [18]. In particular, data augmentation uses to be referred to the techniques where the practitioners know the most common data variability, as in image recognition, and these variations can be applied to the available data in order to obtain new samples. On the other hand, there are other methods not assisted by practitioners to generate new samples: generative adversarial networks, GANs [6], variational models such as variational auto-encoder VAE [14, 9] and autoregressive models [19].
In this work we study how we can apply deep learning techniques when the amount of data is very scarce. We simulate scenarios where not only the amount of labeled data is scarce, but all the available data. As mentioned before, some techniques can deal with such scenarios. Bayesian modeling incorporates the uncertainty in the model [3]. However Bayesian neural networks are a field under study and introduce several problems for which there is not a wide well established solution: Monte Carlo integration, variational approximations or sampling in high dimensional data spaces, among others.
On the other hand, semi supervised learning techniques need a great amount of unlabeled data to work well. For instance, the ladder network can achieve impressive results with only 100 labeled samples in the MNIST task but using 60000 unlabeled samples.
Finally, deep generative models (DGM) need great amounts of data to be able of generate good quality samples. Figure 1 shows a Variational Auto-encoder (VAE) trained with 100 and 60000 samples. We can see that although the reconstruction error is being minimized the VAE with few samples is unable to generate good samples.
To our knowledge, none of the above mentioned techniques (both semi supervised and DA with DGM) has been applied disruptively to train neural networks models in data scarce scenarios as the ones we propose. Moreover DA based on DGM has not achieved impressive results in neural networks training with lots of data.
In this work we show that simple generative models as the Restricted Boltzmann Machines (RBM) [1] clearly outperforms the ladder network and DA based on a Deep Convolutional Variational Auto-encoder.
2 Methodology
In this work we simulate very scarce data scenarios. We train binary VAE and RBM using all the available samples. Details on these models can be found at [1, 9, 14]. Once these models are trained, we perform a sample generation following a MCMC procedure.
2.1 Sample Generation
For sample generation we rely on the theory of MCMC algorithms and define our transition operator as:
[TABLE]
Where and represents the likelihood distribution of an observed sample given a latent variable and, the posterior distribution over the latent variable given an observed sample, respectively. We will assume that this transition operator generates an ergodic Markov Chain and thus as long as the number of generated samples goes to infinity we will be sampling from the model distribution [11, 3, 2]. In case of VAEs, where the posterior distribution is approximated, see [14] appendix F for a proof of correctness.
In our models the likelihood distribution is modeled with a Bernoulli distribution. The posterior distribution is modeled with a Bernoulli distribution for the RBM and with a factorized Gaussian distribution for the VAE. For generating a sample we follow the Contrastive Divergence [4] algorithm which is based on Gibbs Sampling but starting from an observed sample. As example for generating 100 samples we follow algorithm 1, where is a sample from our dataset from which we will be generating new samples and is the number of samples to generate.111In case of VAE is replaced by which is the Variational Distribution. Note that although a Gibbs sampler depends on all the previous generated dimensions of a sample, in this case we can sample all the feature dimensions in parallel and thus our method is highly efficient.
2.2 Labeling process
We use the generated samples in two ways. As we stated, our approach is based on training a classifier on a set of labeled samples using additional generated samples from a VAE or a RBM. We associate the generated samples with the same label as the sample from the data distribution. In a first approach we use all the generated samples (and denote this approach in the experiments with letter ). In the second approach we classify the samples from the chain (using the same classifier we are training) and only the correctly classified samples are used for training (we denote this approach in the experiments with letter ). This has a great impact, as shown in the experiments, because long Markov Chains are likely to generate samples from other classes, as shown in figure 2.
Moreover, in case of the RBM we train two kind of models, named B-RBM (”bad RBM”) and G-RBM (”good RBM”). The difference rely on the convergence of the model, i.e., how is the quality of the generated samples, see figure 3. We expect that with a B-RBM the injected noise is able to improve the generalization whereas the G-RBM is collapsing to a part of the model space where no generalization improvement will be obtained. Basically we do not let the model achieve the same minimum for the case of the B-RBM as we do with the G-RBM.
Finally, figure 4 shows images from the different trained models in this work. We can clearly see how the VAE is able to generate good quality samples only when more training samples are provided.
3 Experiments
For the experiments we use a binarized version from the MNIST database. This database has 60000 training samples and 10000 test samples. The pixels above are saturated to value and the rest are saturated to . In order to simulate a scarce data scenario, we randomly select a small set of samples, and assume that only a very small subset is labeled. We simulate three different scenarios with a total of , and samples where only , and are labeled respectively. Note that for the first scenario we have only labeled sample per class.
We use a binarized version of this database because, the expressions of the conditional distributions of the RBM models we use, are obtained assuming binary data distributions. Moreover, the VAE models for MNIST converge better when using Bernoulli decoders , ie binary cross entropy loss.
We trained 3 models, two fully connected (FC) and one convolutional (CNN). For fully connected we choose the following parameters, FC1: 784-1024-1024-10, FC2: 784-1000-500-250-250-250-10. For the convolutional counterpart we use, CONV1: 32@3x3-64@3x3-128@3x3-512-512-10. In all the topologies we inject Gaussian noise with in the input and we use batch norm (BN)[8] and dropout [15])
Tables 1, 2 and 3 show the error percentage with the here proposed data augmentation showing that the B-RBM clearly outperforms other approaches. We generate Markov chains of 500 and 1000 samples to increase the data set and train the classifier222convolutional models on 10 labeled samples are trained with 850 instead of 1000 samples. Convolutional models for 100 and 1000 samples use chains of 100 samples. VAE model on 100 and 1000 samples for all the schemes generates 100 samples. We found a GPU-memory bottleneck because we performed a parameter update per batch with all its generated samples. It is interesting to see that although the deep FC (FC2) has worse performance than FC1 with 10 and 100 samples without DA, we can achieve better results in case of 100 samples with FC2 when using our proposed method.
We also see that a significant improvement is obtained with the most scarce scenario (see table 1), where we are able to reduce 17% error on CONV1 (check B-RBM option 1000 samples) and more than 10% in FC models (check B-RBM option ), which is the main objective of this work.
Finally, Table 4 shows a comparison with the ladder network. Ladder network can be considered the state-of-the art on semi-supervised learning on this dataset333Recently other proposed methods have achieved better results, but they are based on GANs and we showed here that DGM are not suitable for these scenarios. For that reason we compare with ladder network.. As can be seen we obtain better results on the three scenarios.
4 Conclusions
We can draw several conclusions from this work. We first show that in data scarcity scenarios simple generative models outperform deep generative models (like VAEs). We also see that a B-RBM is incorporating noise that is improving generalization. We can check that G-RBM and VAE works better when we do not classify the generated sample and this is in fact another way to incorporate noise into the classifier. However B-RBM is the best of the three. This also means that a generative model trained in this way (where latent variables capture high detail) is unable to generate samples that improve generalization. The G-RBM generates better quality images but is unable to improve classification accuracy as the B-RBM does.
This can also be noted when we add more training samples, where the difference between the baseline and the here proposed DA is lower, as with CNN. This is because the samples generated do not incorporate additional information to the model and are either quite similar between them or quite similar to the labeled samples. A possible hypothesis is that the generative model is collapsing to a part of the data feature space.
VAEs results were unexpected because despite the poor quality images generated it can improve performance over the baseline. We got this improvement always without classifying images, model , and only in the case where few label samples are used. It is clear that the VAE is not a good model for these scenarios.
Finally, we also show that the here proposed approach outperforms and is clearly an alternative to semi supervised learning in data scarcity scenarios as shown in table 4. Another important advantage is that RBM is robust and has a stable learning whether the ladder network and GAN frameworks have several training challenges. The ladder network has many hyper-parameters and its performance is really sensible to little changes on them and the GANs are quite sensible to hyper-parameters as well.
5 Acknowledgment
We gratefully acknowledge the support of NVIDIA Corporation with the donation of two Titan Xp GPU used for this research. The work of Daniel Ramos has been supported by the Spanish Ministry of Education by project TEC2015-68172-C2-1-P. Juan Maroñas is supported by grant FPI-UPV.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Y. Bengio. Learning deep architectures for ai. Found. Trends Mach. Learn. , 2(1):1–127, Jan. 2009.
- 2[2] Y. Bengio et al. Generalized denoising auto-encoders as generative models. In Advances in Neural Information Processing Systems 26 , pages 899–907. Curran Associates, Inc., 2013.
- 3[3] C. M. Bishop. Pattern Recognition and Machine Learning . Springer-Verlag, 2006.
- 4[4] Carreira-Perpinan et al. On contrastive divergence learning. In Aistats , volume 10, pages 33–40. Citeseer, 2005.
- 5[5] Y. Gal and Z. Ghahramani. Bayesian convolutional neural networks with Bernoulli approximate variational inference. In 4th International Conference on Learning Representations (ICLR) workshop track , 2016.
- 6[6] I. Goodfellow et al. Generative adversarial nets. In Advances in Neural Information Processing Systems 27 , pages 2672–2680. Curran Associates, Inc., 2014.
- 7[7] G. Hinton et al. Deep neural networks for acoustic modeling in speech recognition. IEEE Signal Processing Magazine , 29:82–97, 2012.
- 8[8] S. Ioffe et al. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32Nd International Conference on International Conference on Machine Learning - Volume 37 , ICML’15, pages 448–456. JMLR.org, 2015.