Algebraic Channel Estimation Algorithms for FDD Massive MIMO systems
Cheng Qian, Xiao Fu, and Nicholas D. Sidiropoulos

TL;DR
This paper introduces an algebraic tensor-based channel estimation method for FDD massive MIMO systems that achieves accurate results with minimal training overhead, even when the number of paths exceeds the number of antennas.
Contribution
It proposes a novel algebraic framework using Vandermonde tensor algebra and a special training sequence to enable efficient, real-time channel estimation in challenging scenarios.
Findings
Effective channel estimation with small training overhead.
Handles more paths than antennas, surpassing traditional methods.
Lightweight algebraic operations enable real-time implementation.
Abstract
We consider downlink (DL) channel estimation for frequency division duplex based massive MIMO systems under the multipath model. Our goal is to provide fast and accurate channel estimation from a small amount of DL training overhead. Prior art tackles this problem using compressive sensing or classic array processing techniques (e.g., ESPRIT and MUSIC). However, these methods have challenges in some scenarios, e.g., when the number of paths is greater than the number of receive antennas. Tensor factorization methods can also be used to handle such challenging cases, but it is hard to solve the associated optimization problems. In this work, we propose an efficient channel estimation framework to circumvent such difficulties. Specifically, a structural training sequence that imposes a tensor structure on the received signal is proposed. We show that with such a training sequence, the…
Click any figure to enlarge with its caption.
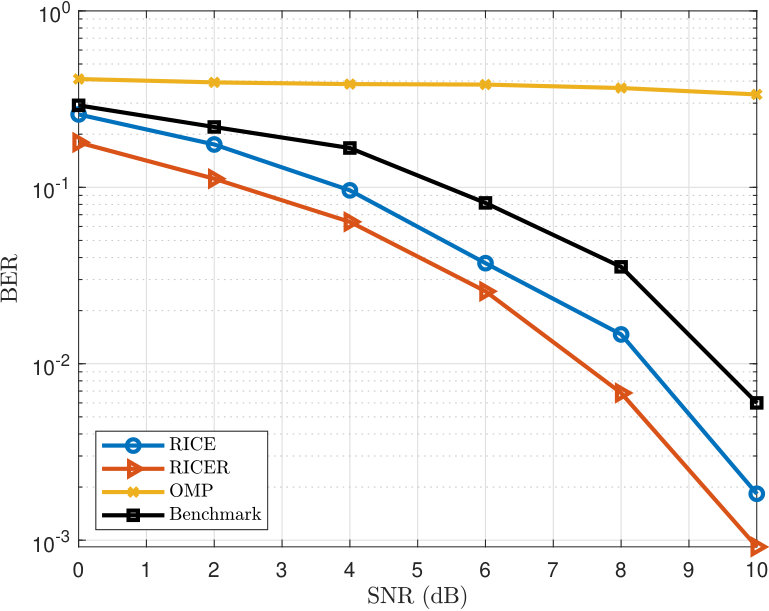 Figure 1
Figure 1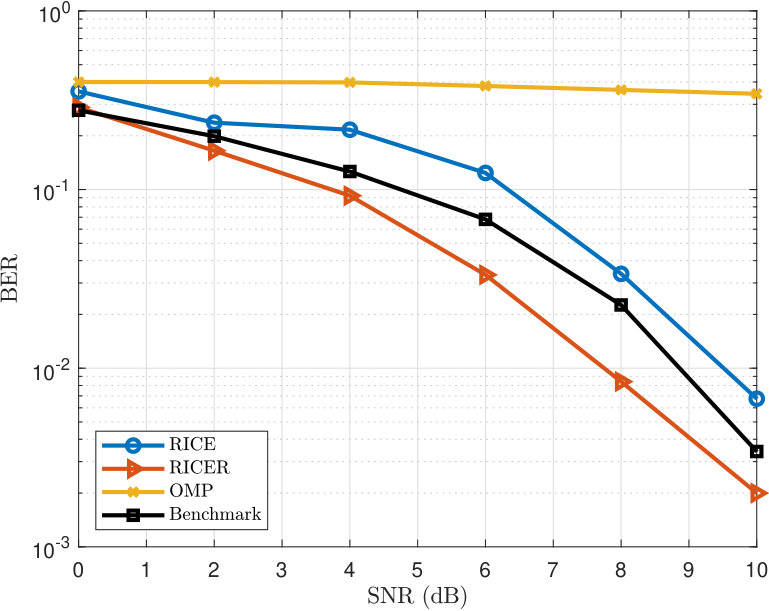 Figure 2
Figure 2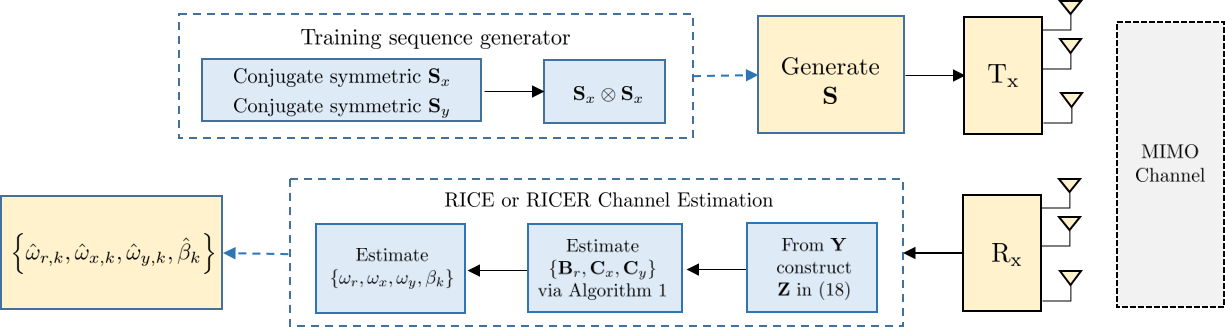 Figure 3
Figure 3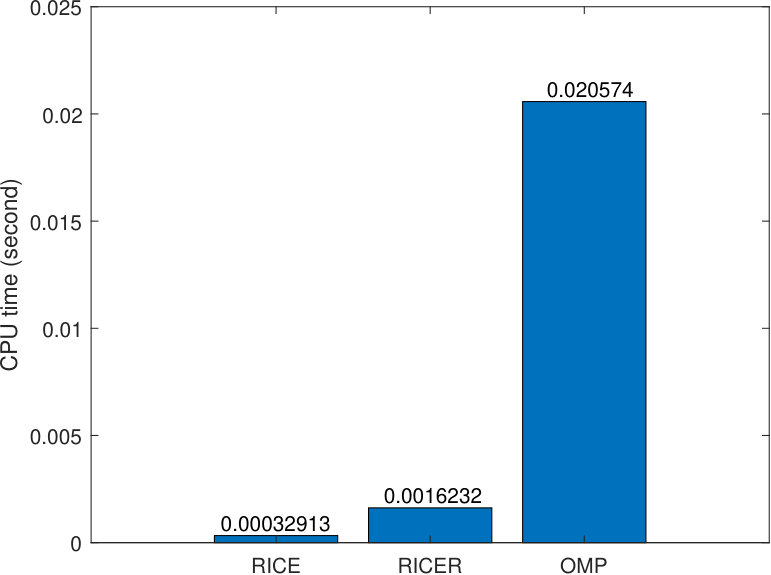 Figure 4
Figure 4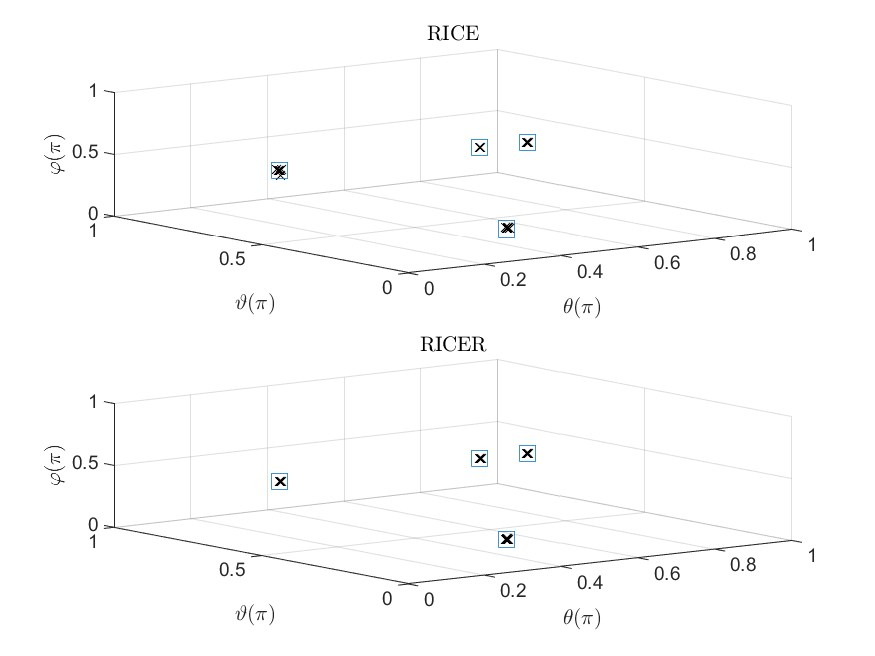 Figure 5
Figure 5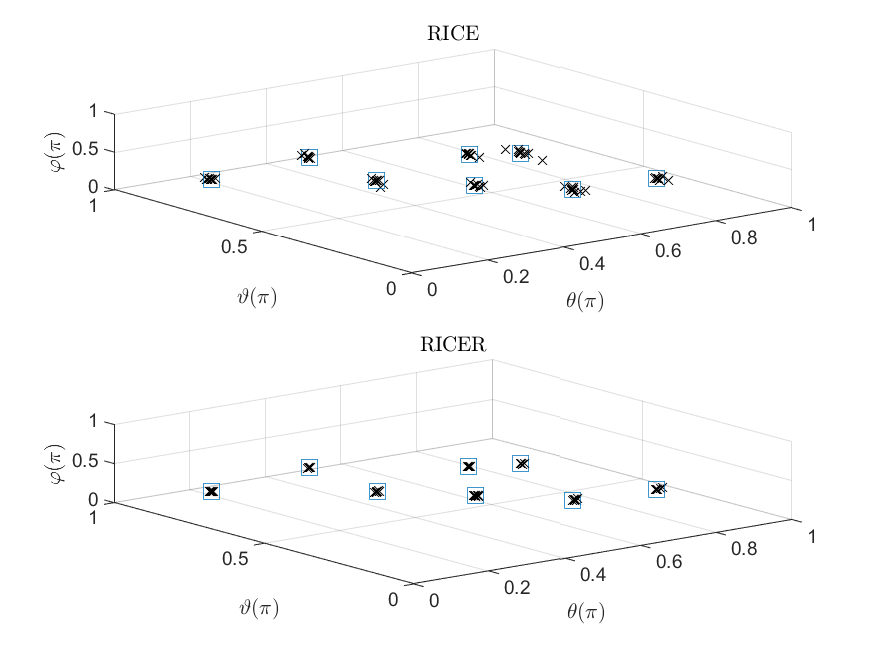 Figure 6
Figure 6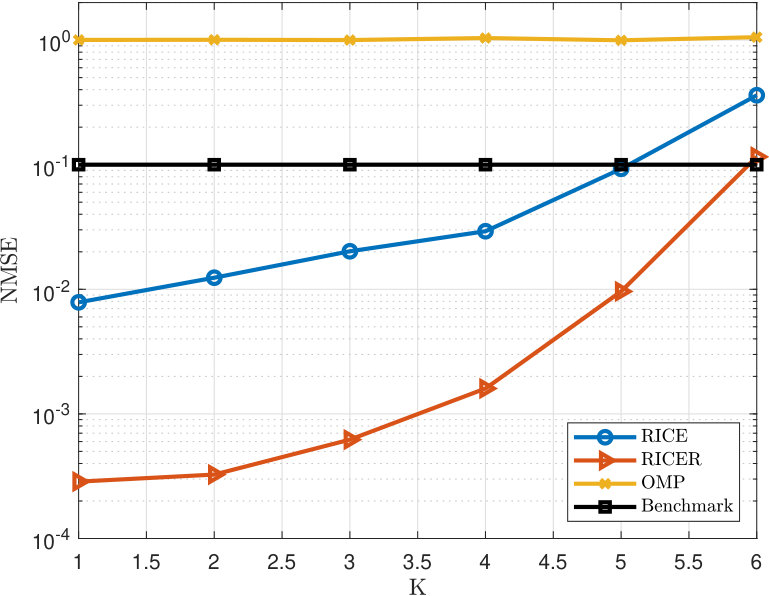 Figure 7
Figure 7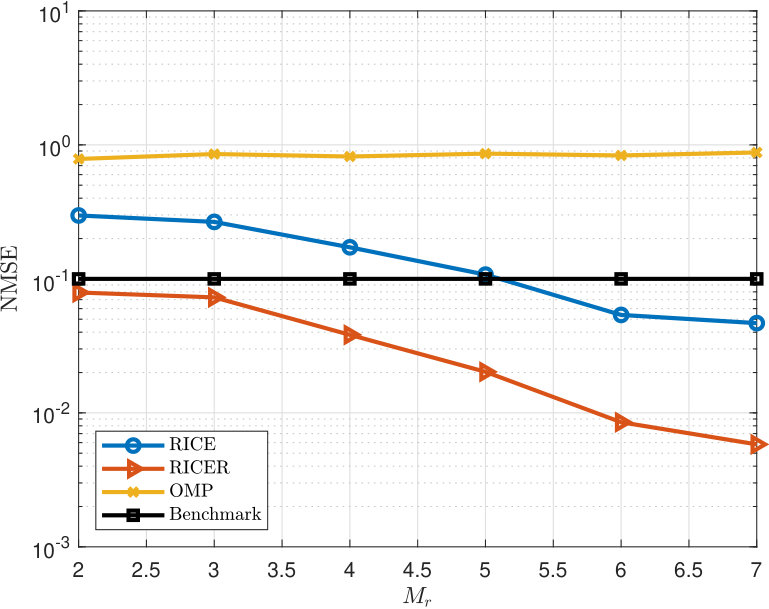 Figure 8
Figure 8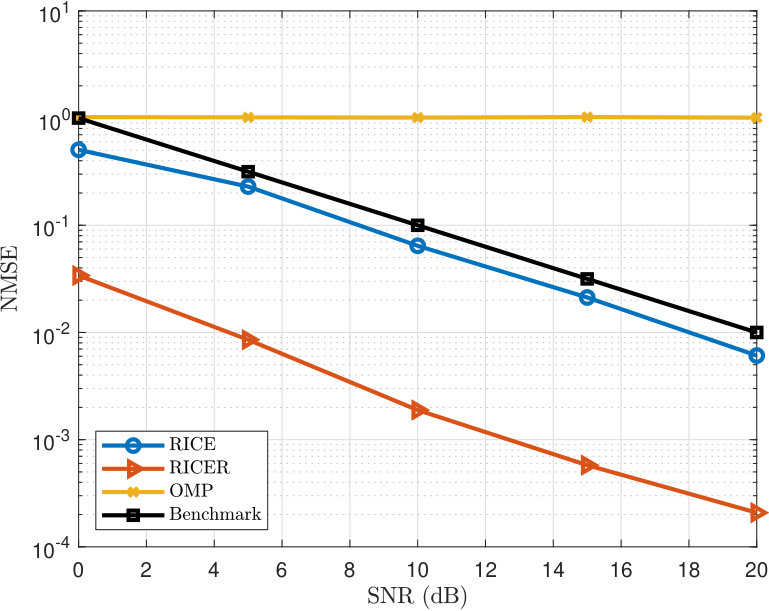 Figure 9
Figure 9Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Algebraic Channel Estimation Algorithms for FDD Massive MIMO systems
Cheng Qian, Member, IEEE, Xiao Fu, Member, IEEE, and Nikolaos D Sidiropoulos, Fellow, IEEE
Conference version of part of this work has been submitted to IEEE SPAWC 2019 [1]. This work was supported in part by the National Science Foundation under project NSF ECCS 1808159 and NSF ECCS 1608961. C. Qian and N. D. Sidiropoulos are with the Department of Electrical and Computer Engineering, University of Virginia, Charlottesville, VA 22904 USA (e-mail: [email protected], [email protected]).X. Fu is with the School of Electrical Engineering and Computer Science, Oregon State University, Corvallis, OR 97331 ([email protected]).
Abstract
We consider downlink (DL) channel estimation for frequency division duplex based massive MIMO systems under the multipath model. Our goal is to provide fast and accurate channel estimation from a small amount of DL training overhead. Prior art tackles this problem using compressive sensing or classic array processing techniques (e.g., ESPRIT and MUSIC). However, these methods have challenges in some scenarios, e.g., when the number of paths is greater than the number of receive antennas. Tensor factorization methods can also be used to handle such challenging cases, but it is hard to solve the associated optimization problems. In this work, we propose an efficient channel estimation framework to circumvent such difficulties. Specifically, a structural training sequence that imposes a tensor structure on the received signal is proposed. We show that with such a training sequence, the parameters of DL MIMO channels can be provably identified even when the number of paths largely exceeds the number of receive antennas—under very small training overhead. Our approach is a judicious combination of Vandermonde tensor algebra and a carefully designed conjugate-invariant training sequence. Unlike existing tensor-based channel estimation methods that involve hard optimization problems, the proposed approach consists of very lightweight algebraic operations, and thus real-time implementation is within reach. Simulation results are carried out to showcase the effectiveness of the proposed methods.
Index Terms:
Channel estimation, massive MIMO, training sequence design, tensor factorization, low-complexity.
I Introduction
Massive MIMO promises significant performance gains in terms of spectral efficiency, reliability and security over the existing communication systems [2, 3]. However, realizing many of these advantages in practice hinges on accurate estimation of the channel state information (CSI), which affects the performance of transmit beamforming at the transmitters and decoding accuracy at the receiver.
Previously, much attention has been devoted to the time division duplex (TDD) protocol, where channel reciprocity can be invoked to estimate the downlink (DL) CSI from uplink (UL) training. However, this convenient property does not hold under the frequency division duplex (FDD) protocol, where UL and DL channels are in different frequency bands, with generally different propagation characteristics. Hence, the DL channel is different from the UL one, and it must be estimated by the receiver and then fed back to the transmitter. On the other hand, FDD offers uninterrupted full-duplex transmission, and relaxed amplification and synchronization requirements which are critical factors affecting service and deployment costs. Hence it is of great interest to come up with lightweight training and feedback strategies that require few resources.
To alleviate the heavy burden of DL training and UL feedback, one possible way is to reduce the effective channel parameters by considering a specular multipath channel comprising a few dominant paths, each characterized by direction-of-arrival (DOA), direction-of-departure (DOD) and channel gain [3, 4, 5, 6]. Such a channel model is effective under certain conditions, e.g., when the base station (BS) antenna array is mounted on top of a tall building or cellular tower, such that the number of local scatterers is limited. In addition, when the carrier frequency is lifted to the millimeter wave regime, due to the severe path loss, only a few specular reflections reach the other end of the link [3, 7, 8]. Thus, the channel tends to exhibit a sparse structure in the angular domain. This allows for channel modeling using only DOA, DOD and channel gain. Under this model, the channel estimation problem for uniform transmit/receive arrays is related to multidimensional harmonic retrieval problems in classical array processing which have been well-studied in the past few decades [9]. Array processing algorithms (such as maximum likelihood [10] and subspace based approaches [11, 12]) can be employed to estimate multipath parameters. These methods are good fit for TDD systems but not for FDD. The reason is that array processing methods require a large array aperture for parameter estimation, where the array size should be greater than the number of paths in general—which is relatively easy to be satisfied in UL channels since the BS typically has many more antennas than the mobile station (MS), especially in massive MIMO scenarios. However, in FDD systems, the DL and UL channels have to be estimated separately. When the number of DL paths is larger than the number of receive antennas at the MS, conventional array processing methods will not work [13, 5].
The above problem might be tackled by using compressive sensing (CS) methods. With a limited number of paths, the channel exhibits a sparse pattern in the angle domain, and thus channel estimation can be recast as a sparse regression problem [8, 14, 15, 16, 17, 18, 19, 20]. Many CS based algorithms have been developed. The authors of [8] employed CS for channel estimation and proved that if both BS and MS are equipped with uniform linear arrays (ULAs), a MIMO channel with dimension can be recovered from training samples with high probability, where is the number of paths, and and are the number of antennas at MS and BS, respectively. Since then a series of CS based techniques were proposed to enhance the channel estimation performance such as [16, 15]. The CS-based approach is elegant and works to some extent, but it also faces some challenges. CS-based methods rely on a discretized angle dictionary for parameter estimation, which is usually a very ‘fat’ matrix with many coherent columns. This may lead to unsatisfactory performance for sparse recovery. Since DOAs/DODs are continuous variables in space, how to alleviate the performance loss caused by angle discretization is another crucial issue. One way is to use gradient descent [21] or Newton’s method [22, 19, 18] to refine the angles. But this involves additional optimization and increases the complexity.
There are also matrix completion (MC) techniques employed for multipath channel estimation, e.g., [23, 24]. Fang et al., [24] employed MC to solve the channel estimation problem of a millimeter wave system with a single radio frequency chain, where they assumed that the number of dominant paths is much smaller than the number of the transmit and receive antennas. This method requires multiple communications between the BS and MS to collect enough data over time to form a low-rank data matrix. Such a protocol implicitly assumes that MS and scatterers remain static. Furthermore, the overall training overhead is still high and solving the MC problem is a non-trivial task in terms of computational complexity. Note that in the current FDD systems, the MS never communicates with the BS for DL channel estimation; instead, the BS acts more like a radio station and only broadcasts training sequences and its basic service information.
Another way to reduce the computational burden on the mobile end is to exploit the so-called spatial reciprocity [18, 19, 25, 26]. In this line of work, it is assumed that the UL and DL channels share the same propagation paths, and thus UL channel estimation yields important information for the DL channel as well. In this way, the DL estimation burden is shifted to the base station, which is anyway responsible for estimating the UL channel(s). This approach requires that the UL and DL operate on close-by carrier frequencies over similar bandwidths. The challenge is that in many FDD systems, the DL channel can have a much wider bandwidth using multiple carriers in different bands, whereas the UL channel is usually on a single carrier/band. This causes a wide frequency separation (e.g., 1 GHz) between the DL and UL channels, which may then exhibit very different propagation characteristics111See 5G UL and DL frequency allocations in https://www.everythingrf.com/community/5g-nr-new-radio-frequency-bands and https://en.wikipedia.org/wiki/5G_NR_frequency_bands..
In [5], an FDD massive MIMO system was considered with both BS and MS equipped with dual-polarized antennas. It has been shown that there is a hidden tensor structure in the received training data, and effective tensor factorization algorithms were proposed to estimate the multipath parameters. However, the techniques and parameter identifiability results therein are enabled by the special structure of dual-polarized multipath channels—how to generalize the technique to handle general multipath channels is unclear. In addition, the method in [5] is realized using computationally heavy optimization algorithms, which may not be realistic for mobile phones whose computational power is rather limited.
In this paper, we consider parameter estimation for general specular multipath channels. We aim to provide effective estimation schemes that entail very low DL training overhead and low complexity. Our detailed contributions are summarized as follows:
- •
Short Training Sequence Design
- We propose a new training sequence with a conjugate symmetric structure for FDD massive MIMO systems. As we will see, our judicious design enables simple and effective channel estimation with very low training overhead.
- •
Low complexity Algorithm
- We show that by using the proposed training sequence, the received data can be transformed to a low-rank tensor, and thus channel estimation can be recast as low-rank tensor decomposition. Two simple algebraic methods are then devised for channel estimation.
- •
Identifiability Analysis
- We analyze the multipath parameter identification problem for massive MIMO. We show that under mild conditions, all parameters of the channel are identifiable using the proposed training sequence and algorithms.
A short conference version of this work has been submitted to the IEEE SPAWC 2019 workshop [1]. This journal version includes a more advanced and accurate estimation method, fleshed out analysis, and more comprehensive experiments.
The remainder of this paper is organized as follows. In Section II we describe the signal model and multipath channel estimation problem. The major contributions of the paper appear in Sections III and IV; the former explains the design of a novel training sequence for frugal DL training, and the latter presents a computationally efficient channel estimation algorithm which incorporates the designed training sequence. Identifiability results are also provided in Section IV. Section V presents an improved channel estimator which incorporates the method proposed in Section IV and a root-finding technique to achieve higher estimation accuracy. Section VI presents our simulation results, and Section VII summarizes our conclusions.
Notation: Throughout the paper, superscripts , , , and represent transpose, complex conjugate, Hermitian transpose, matrix inverse and pseudo inverse, respectively. We use , , and for absolute value, Frobenius norm, -norm and -norm, respectively; denotes an estimate of , is a diagonal matrix holding the argument in its diagonal, is the vectorization operator and takes the phase of its argument; is the th element of a vector, is the entry of , and is the th column of . Symbols denote the Kronecker, Khatri-Rao, element-wise, and outer products, respectively; extracts the elements in rows to and columns to , extracts the elements in the columns to and extracts the elements in the rows to . is the identity matrix and is the zero matrix.
II Signal Model and Problem Statement
II-A Channel Model
We consider the DL of a FDD massive MIMO system, where a BS with transmit antennas sends signals to the MS that is equipped with receive antennas. After collecting temporal samples, the received data matrix at the MS is
[TABLE]
where is the DL channel matrix, is the training signal matrix, is i.i.d. circularly symmetric complex Gaussian noise with mean zero and covariance . When the BS employs a transmit array with many antennas and the carrier frequency goes to 60 GHz, it is reasonable to assume that there are a few scatterers between the transmitter and receiver [3, 6]. Under this assumption, the channel is modeled as
[TABLE]
where
[TABLE]
In the above, is the number of paths, , and denote the gain, transmit and receive steering vectors of the th path, respectively, where are the azimuth and elevation angles of DOA and are the azimuth and elevation angles of DOD. We assume that the BS is equipped with an element uniform rectangular array (URA), and the MS has a small uniform linear array (ULA) with antennas. In this case, the total number of transmit antennas is . The th steering vector of the MS is
[TABLE]
and the steering vector at the BS is
[TABLE]
where , and with and . Here, is the wavelength, and is the inter-element spacing distance between two adjacent antennas, which is assumed to be smaller than or equal to half-wavelength.
II-B Problem Statement and challenges
In an FDD system, the DL and UL channels are operated in different frequency bands, so the MS must estimate the DL channel first and then feed it back to the BS through a low-rate UL channel, where the number of feedback bits is limited. If the dimension of the channel is large, it is impractical to feed back the whole channel matrix. A more practical and economical way is to estimate and feed back the key parameters such as DOAs, DODs and path-losses that characterize the DL channel.
In practice, if the training sequences are orthogonal and both receive and transmit antennas are ULAs/URAs, the problem of estimating multipath parameters actually belongs to a class of multidimensional harmonic retrieval problems, which has been well-studied during the past few decades [27, 28, 29, 22]. To be specific, when , one can first estimate via
[TABLE]
which is a 3-D harmonic retrieval (HR) model [27, 28, 29, 30, 31, 32]. Then, the key parameters can be estimated from via various approaches such as [27, 28, 29, 30, 31, 32, 33], even when . However, the 3d-HR approach is computationally expensive, and using an orthogonal means that has to be satisfied. When the number of transmit antennas is large, this inevitably leads to high training overhead—which is undesired in massive MIMO systems, especially under mobility, where agile channel estimation is need. When and the training signal is non-orthogonal, i.e.,
[TABLE]
the matched filtering output
[TABLE]
is no longer a good approximation of the original channel, even without any noise. Under such circumstances, estimating the channel parameters becomes very challenging, and only a few cases are known to be resolvable. One major challenge is identifiability. Based on the existing identifiability results for array processing [13, 34], given and an unstructured , the number of paths that we can handle is about . In other words, once which is the case in practical scenarios, the channel parameters may not be identifiable. Even if , conventional array processing methods can only identify instead of , but how to efficiently estimate the DODs from this term is unclear. In [5], an iterative optimization algorithm was proposed to estimate the DODs from a similar term, but the complexity of the algorithm may be too high for a practical commercial smart phone. When , one may adopt CS based methods to estimate multipath parameters [8, 15, 16]. However, sparse methods also face serious challenges. Specifically, discretizing the angular space leads to sub-optimality and solving a large-scale sparse optimization with a semi-coherent dictionary is a challenge for practical implementation.
III Training Sequence Design
This work consists of two components for channel estimation: training sequence design and channel parameter estimation. Fig. 1 shows the block diagram of the proposed system. In this section, we will discuss the first part–training sequence design, which is critical for the subsequent channel estimation. We propose to design a “tall” training matrix which has certain structure to overcome the difficulties mentioned above.
III-A Tensor Preliminaries
To make the paper self-contained, we briefly present the definition of tensor rank and some useful theorems on the uniqueness of tensor decomposition in the following.
Definition 1
(Canonical Polyadic Decomposition (CPD)). A tensor is a multidimensional array indexed by three or more indices. Specifically, an third order tensor that has three latent factor matrices can be written as
[TABLE]
where and is a rank-1 tensor. The minimal such is the rank of tensor or the CPD rank of [35].
Definition 2
*(Unfolding). Tensor unfolding is obtained by taking the mode- slabs of the tensor (i.e., subtensors obtained by fixing the th index of the original tensor), vectorizing the slabs, and then stacking all the vectors from left to the right into a matrix *
CPD factors into a sum of rank-one tensors. It is known that the CPD is unique under mild conditions, up to scaling and permutation of the components. This is referred to as “essential uniqueness” of the latent factors in the literature, and formally defined as follows.
Definition 3
(Uniqueness). Given a -th order tensor of rank , its CPD is essentially unique if the rank-one terms in the decomposition are unique, i.e., there is no other way to decompose for the given number of rank-1 terms. If , for some , then there exists a permutation matrix and diagonal matrices such that
[TABLE]
where .
In some special cases, the factor matrices have special structure, e.g., they are Vandermonde. With this prior information, one can show stronger identifiability result. For example,
Theorem 1
[31]** Consider a third-order tensor , where , , , is Vandermonde with distinct nonzero generators. Assume that and are drawn from an absolutely continuous distribution. If
[TABLE]
where and are chosen from
[TABLE]
then , and are essentially unique with probability one.
III-B Conjugate Flipped Structure
Our idea is to use a Vandermonde structure-enabled algebraic tensor factorization algorithm to recover an channel matrix from the received signal matrix with dimension , where . Then we use a simple algorithm to recover the DOAs and DODs. Both steps are enabled via a judiciously designed training sequence. Let us first show how to transform to a tensor. It follows from that by defining
[TABLE]
can be written as
[TABLE]
where with its th column being , , , and with . Note that the scalar does not hurt the Vandermonde structure in , so is Vandermonde. According to Definitions 1 and 2, in (III-B) is the matrix form of a third-order tensor with rank defined as
[TABLE]
Before we continue, it is necessary to note that the essential uniqueness of tensor factorization makes the latent factors of a tensor identifiable under mild conditions [35]. In our case, the latent factors are and they are identifiable from up to column permutation and scaling ambiguity under some conditions. As we will see in Section IV, with the Vandermonde , these factor matrices can be efficiently identified by computing singular-value decomposition (SVD) of a small dimensional matrix, and hence avoiding the complicated optimization procedure as conventional tensor decomposition approaches do. However, our target is not the factor matrices but the angles and path-losses contained therein. The estimation of DOAs is relatively simple because is Vandermonde and we can estimate DOAs from the columns of . The difficulty here is the estimation of DODs and path-losses, where the former are contained in and while the latter are not even identifiable from standard tensor factorization approaches. In the following, we will show that by designing a specially structured training matrix , all the multipath parameters are identifiable from a simple algebraic method with identifiability guarantees.
Assume that we have already identified and . The remaining task is to identify azimuth and elevation angles from and . By definition, and , so the designs of and are the same. To simplify the analysis, let us temporally remove the subscripts and , and consider the design of for an -element ULA that has the steering vector as
[TABLE]
with . Assume that there is a training signal defined as
[TABLE]
where is the symbol transmitted by the th antenna element. The inner product between and is
[TABLE]
Taking the conjugate of and then flipping its nonzero elements yields
[TABLE]
which leads to
[TABLE]
where is the th element of . The above equation exhibits a “conjugate” rotational invariance (CRI) between and , which is slightly different from the standard rotational invariance (as in, e.g., ESPRIT [12]). The latter is usually built upon the forward and backward subarrays that are rotationally invariant by a factor of while CRI does not rely on subarrays and its invariant factor is the th element of the steering vector, i.e., . Note that the insight of constructing CRI appeared in MIMO radar beamparttern design [36], where a type of nonzero conjugately flipped waveform has been studied.
Let us rewrite (III-B) as
[TABLE]
We see that it provides a way for estimating the phase contained in , i.e., which contains the target . Nevertheless, for large and small , can be greater than , causing the so-called phase wrapping problem. Thus, we cannot find the exact from (10). This is also the problem of [36]. To solve the phase wrapping problem, we need at least two adjacent elements of since is Vandermonde. In (10), we have shown that a pair of and extracts the th element of . Provided that there exists another pair denoted by that takes the element of out, we may obtain a Vandermonde vector which consists of and , such that the phase can be estimated exactly through . Based on this observation, we vary from 1 to and collect all and in, respectively,
[TABLE]
Then the following equality holds
[TABLE]
where contains the last elements of , and hence it is Vandermonde.
The estimation of is now much easier. In practice, once and are identified222We will see later on how to identify them., we first estimate
[TABLE]
and then calculate the phase through
[TABLE]
III-C Design of and
Now let us return to the design of and . We first talk about the design of . To implement the above idea, the training signal must contain both and . One possible choice for is
[TABLE]
where , and are defined in (7) and (8), respectively; and have the same definitions as (11a) and (11b), respectively, and both of them have columns.
In Section III-B, we show that the estimation of is only related to the spatial structure of and but not their values. This provides more freedom on choosing the values for and . However, random and only guarantee the recovery of the phase but not the path loss. In order to estimate all the key parameters efficiently, we need one more constraint on choosing the values of and . We enforce the last elements in and to satisfy
[TABLE]
Due to the conjugate symmetric property between and , we also have .
It is instructive to showcase the structure of and by examples. Let us consider a setting where and . In this case, and are
[TABLE]
where the first two columns in are and the last two columns are ; similar to . When , for example , we may choose
[TABLE]
Remark 1
It is seen from the above examples that to construct and , we only need to generate different symbols . The minimum that guarantees the recovery of is 2, meaning that the minimum number of columns in and is . This also indicates that the minimum number of training samples for the above design is .
IV Channel Estimation
In this section, we derive a computationally efficient channel estimator. We first explain the details on how to efficiently estimate the factor matrices in (6). Then we derive closed-form solutions for multipath parameter estimation. Finally, we claim uniqueness condition for the identification of these parameters.
IV-A Identification of Factor Matrices
According to Definition 2, the matrix unfolding of along its third dimension takes the form of
[TABLE]
Since is Vandermonde, the spatial smoothing technique is applicable to further expand the dimension of . Specifically, defining a cyclic selection matrix and varying from 0 to , we have
[TABLE]
where .
Since are Vandermonde, given , we can follow [31, 5, 37] and employ an ESPRIT-like approach shown in Algorithm 1 to estimate , and .
IV-B DOA/DOD Estimation
The factor matrices identified from Algorithm 1 suffer column permutation and scaling ambiguity, implying that the estimates of are not exactly the original factors. Fortunately, this will not be an issue for angle estimation. Since the columns in are paired with each other and the scaling ambiguity does not affect the array manifold structure, we can estimate the th DOA and DOD from the th columns of , and , respectively.
Due to the one-by-one mapping between and , estimating DOA is equivalent to estimate the phase that is calculated as
[TABLE]
It is optional to estimate DOAs from
[TABLE]
The estimation of azimuth and elevation angles of DOD is different from DOA estimation due to the presence of and . To estimate them, it is necessary to know the phases contained in and . Toward this end, let us consider the estimation of the phase . Let and be submatrices of which contain the first and last half of the rows of , respectively. According to the definition of in (III-C), in the noiseless case, the explicit expressions for and are
[TABLE]
It follows from (13) that the top rows of the th column in equal to
[TABLE]
The corresponding phase is then calculated via
[TABLE]
Similarly, by splitting into and , we have
[TABLE]
where . It is optional to estimate the azimuth and elevation angles of DOD. If interested, we calculate them through
[TABLE]
IV-C Path-loss Estimation
The path-loss is merged into the factor matrices. Unlike DOA/DOD estimation which is insensitive to the column scaling ambiguity, the estimation of is seriously affected by such an ambiguity.
To estimate , let us find the explicit expression for estimating . Note that the column permutation in is not an issue, let us ignore it and consider only the scaling ambiguity to simplify the analysis. The reconstruction of from the estimated factor matrices is given by
[TABLE]
Since , by comparing it with (IV-C), we find
[TABLE]
where is the scaling ambiguity matrix corresponding to with its th diagonal entry being
[TABLE]
In the above, the scaling ambiguity corresponding to is estimated as
[TABLE]
where is constructed using . The only unknown in (30) is . We propose an efficient forward-backward average method to calculate it which only involves element-wise multiplication/division.
IV-C1 Forward Way
First, let us consider the forward way. Let
[TABLE]
be the and elements in , respectively.
In the presence of scaling ambiguity, is expressed as
[TABLE]
where contains scaling ambiguities with standing for the ambiguity between and . The estimates of and now become
[TABLE]
and
[TABLE]
It follows that
[TABLE]
where is replaced by its estimate . Then we have
[TABLE]
where the last equality is due to (16).
IV-C2 Backward Way
To maximize the information usage, for example, we may also calculate from the th and th rows of . The derivations are mostly the same as the forward way. The only difference is that is conjugate flipped from . We have the following relationship
[TABLE]
where and . Following the analysis in (32)–(35) yields
[TABLE]
Then based on (16), we have
[TABLE]
Finally, we substitute the average of (IV-C1) and (37) into (30) for final path-loss estimation.
Our method contains two main procedures: tensor decomposition and multipath parameter estimation. Both of them exploit the rotational invariance property which exists in the Vandermonde manifold matrices. Because of this reason, we name our method as rotationally invariant channel estimation (RICE) algorithm. Its detailed steps are summarized in Algorithm 2.
IV-D Identifiability Analysis
The last remaining question is identifiability, i.e., how many paths we can handle given the measurements in (1). Recall that the dimension of in (IV-A) is a function of and . Since and are fixed, by tuning and , we are able to find an optimal pair of such that the number of paths that our method is capable to cope with is maximized. Based on Theorem 1 [31], we have the following result.
Theorem 2
Assume that the DOAs and DODs in different paths are not identical, i.e., , and all the path-losses are jointly drawn from an absolutely continuous distribution. Then, given the measurements , all the multipath parameters are uniquely identifiable with probability one if
[TABLE]
where and are chosen from
[TABLE]
The proof of Theorem 2 is constructive, following the steps of Algorithm 1, meaning that this bound is achievable. In practice, once and are chosen, we first find the optimal by solving (39) and then cache them in the system to guarantee the identifiability. We note that the minimum is 16. If we choose , our method can uniquely identify up to eight paths, while the standard array processing methods can only handle three paths.
IV-E Complexity Analysis
The computational complexity for the proposed method mainly lies in Algorithm 1, where the SVD of in Step 2 costs about flops. Since and is usually no more than four according to nowadays technology, we have . On the other hand, because of the fact , by setting , the complexity of Step 2 becomes . After the factor matrices are obtained, the estimation of DOAs, DODs and path-losses are very simple. The DOA estimation in (21) requires about flops. The estimation of azimuth and elevation angles in (24)–(27) costs about flops where . In many cases is enough to achieve satisfactory performance. Thus, . The calculation of costs flops. The overall complexity of the proposed method is , which is quite low compared to the sparse regression methods such as orthogonal pursuit (OMP) that requires flops when DOD and DOA are quantized with bits.
Remark 2
The main advantages of the proposed method are its low-complexity and identifiability guarantees. As far as we know, there are very few uniqueness results available for MIMO channel estimation in the case of , i.e., when there are less training samples than the number of transmit antennas. And there is a serious lack of efficient and reliable channel estimation algorithms to handle such difficult cases especially when is small and is relatively large. In [5], we considered similar cases for a special type of MIMO systems with dual-polarized antennas, where we analyzed the identifiability and proposed algorithms for channel estimation. Unfortunately, the results in [5] are only valid for dual-polarized MIMO and hence, cannot be applied here. Therefore, the results in this paper are much more general—and also timely and meaningful as 5G system trials are beginning to roll out. It is worth highlighting that the proposed method can be generalized to the dual-polarized systems and similar closed-form solutions for multipath parameter estimation can be derived in a straightforward way.
V Exploiting full knowledge of
The RICE algorithm is based on the spatial structure of the training sequence for channel estimation but not the values. This means that only partial information of the training sequence has been used in RICE. Because of this reason, the complexity of RICE is maintained at a very low level, but at the expense of losing resolution ability in DOD estimation. In this section, we show that by fully utilizing the information in the training sequence, DODs can be estimated through a root-finding technique, and the performance of RICE can be further improved with a moderate increase of complexity. Toward this end, a joint RICE and Root-finding approach is developed. We name the new algorithm RICER.
In RICER, the estimation of DOA is the same as RICE, i.e., (21). The difference is in the estimation of DOD and path-loss. First, let us consider the estimation of from . Before we proceed, we claim that with the following Corollary, is identifiable from .
Corollary 1
[5]** Assume that , and that is Vandermonde with distinct generators, i.e., for . Then, can be uniquely identified almost surely from the system , where stands for column scaling and the elements in are jointly drawn from an absolutely continuous distribution.
We note that in the absence of noise,
[TABLE]
The above is interesting, indicating that although is fat, its null space does not contain any Vandermonde vector. The above also says that the orthogonal complement of is orthogonal to . Thus, we have
[TABLE]
Define
[TABLE]
Eq. (41) is then equivalent to
[TABLE]
In the noisy case, the equality in (43) approximately holds true. We can then estimate via
[TABLE]
which is similar to the cost of the classical MUSIC algorithm [38]. Thus, we may search the phase from to and report the one that minimizes the objective function in (44). The drawback is the complexity caused by the 1-D angular search which is approximately flops for each , where is the number of bins dividing . We may also derive a gradient descent method to handle (44) [5]. But due to the non-linearity and non-convexity in (44), optimizing the phase requires careful initialization which is not easy to be acquired in an efficient way.
Here, we employ a root-finding technique to estimate (24). Since is Vandermonde, we further express (43) as a polynomial:
[TABLE]
where
[TABLE]
There are totally roots after solving (45). The symmetric property of implies that half of the roots are inside the unit circle while another half are outside, and they appear in conjugate-reciprocal pairs. In other words, the outer roots are inverses of the inner roots. We are only interested in the inner roots, i.e., those inside the unit circle. Let us denote them as . The next problem is to judiciously select one from for estimating . It is well motivated from the philosophy of root-MUSIC [11] that one may find a root from that is closest to the unit circle. However, when SNR is low or sample size is small, the signal subspace might be heavily corrupted by a portion of noise subspace which causes the subspace leakage problem [39]. Once this happens, the root-MUSIC rule—selecting the root that is closest to the unit circle—is problematic; some irrelevant roots from the orthogonal complement of may be much closer to the unit circle than the true root. Such phenomenon happens oftentimes when we estimate since is noisy and the available degrees-of-freedom are only . Provided that the wrong root is selected, we can never reconstruct the channel correctly. Therefore, it is crucial to design a robust rule for final root determination.
One way to help alleviate the subspace leakage issue is as follows. Note that the RICE method relies more on the Vandermonde structure of but not the subspace , so RICE is robust for subspace leakage. As a result, we can use the estimate of from RICE for assistance. Specifically, let us calculate the phases in as . Let denote the estimate of from RICE, i.e., (24). We select one from that is closest to as the final estimate of .
Following the same way, we can calculate from . Finally, we update the path-loss as
[TABLE]
where is constructed from which are obtained from RICER. The detained steps for RICER are provided in Algorithm 3.
The identifiability of RICE and RICER is basically the same since both methods rely on Algorithm 1 for tensor decomposition. Their main difference lies in the estimation of DOD and path-loss. RICER uses the aid of RICE for determining and . Thus, its complexity is higher than RICE. We have phases in total. The related complexity for solving polynomials in (45) is flops. The complexity for updating the path-loss using (47) is flops. The total complexity for RICER is \mathcal{O}\big{(}M_{r}^{2}N^{1.5}+8K(M_{x}^{2}\log(M_{x})+M_{y}^{2}\log(M_{y}))+M_{r}M_{x}M_{y}NK\big{)} flops which is much higher than the complexity of RICE. In the next section, we will see that by paying this additional complexity, RICER achieves better performance than RICE.
V-A Special Case:
At this point, the reader might wonder whether the proposed framework can work in the case where only one antenna is available at the mobile end. The answer is affirmative. Let us first take a look at the signal model with a single receive antenna
[TABLE]
which can be reshaped into a matrix as
[TABLE]
We see that the tensor structure is no longer available in the received signal, and therefore uniqueness of the factor matrices seems to fail too. Since the RICE and RICER algorithms require the identification of and before performing parameter estimation, both of them will not work in the single antenna case. However, some further reflection shows that the RICER method can be modified for channel estimation even with a single receive antenna.
Note that when the training signals are orthogonal, channel estimation from (49) is indeed a 2-D harmonic retrieval problem, which is not our interest. Therefore, we only consider “tall” and , i.e., and . Let be the signal subspace of . Similar to (40), we have
[TABLE]
Then the following equation holds
[TABLE]
where
[TABLE]
Owing to the Vandermonde structure, we can also employ the root-finding technique to estimate by solving (45), where is replaced by . Then we pick the top roots inside of the unit circle and estimate as the phase of the th root. After that we use the estimates to construct and calculate
[TABLE]
Following (40)–(45), we can find the estimates of . Finally, estimate the path-losses as \big{(}\mathbf{S}_{y}^{H}\hat{\mathbf{A}}_{y}\odot\mathbf{S}_{x}^{H}\hat{\mathbf{A}}_{x}\big{)}^{\dagger}\tilde{\mathbf{y}}.
Note that the channel parameters can be identified via the above procedures if and are full column rank and .
VI Simulations
In the simulation, we assume that the multipath propagation gains are Rician distributed. All the results are averaged over 500 Monte-Carlo trials using a computer with 3.7 GHz Intel Core i7-8700 and 32 GB RAM. The normalized mean square error (NMSE) of channel estimates is computed from where denotes the channel that is reconstructed from the estimated multipath parameters from the th Monte-Carlo trial. The estimation of is beyond the scope of this paper. So in the simulations, to be fair, we assume that is known to all the algorithms.
Given the model in (1), array processing methods fail to work when . The existing methods which are qualified to handle large might be the class of CS based methods [8, 15, 16]. We choose the OMP method for performance comparison since it is hyper-parameter free and computationally efficient. To implement OMP, we quantize , and using 7 bits, so the resulting dictionary has size . We only consider “tall” , i.e., there are less samples than transmit antennas. Hence, the LS technique does not work. We are interested in how well the new methods perform with a ‘tall’ compared to the LS estimate with an orthogonal square . The best achievable NMSE of the LS channel estimate from orthogonal training is , where SNR is in dB. We include this value as a performance benchmark.
In the beginning, we examine the identifiability of our methods. Let us consider the following parameter setting: , , and SNR dB. We set the number of paths as the maximum number of identifiable paths calculated based on Theorem 2. Under this setting, we have . The phases are chosen as
[TABLE]
Fig. 2(a) plots the locations of each scatter based on their DOAs and DODs. It shows that RICE and RICER are able to resolve all the paths. Next we choose and SNR dB. According to Theorem 2, our methods can deal with paths in theory. To verify this, we set
[TABLE]
The results are shown in Fig. 2(b), where our algorithms still work well. However, some angle estimates of RICE slightly disperse around the true angles, while those of RICER are more concentrated.
Now let us study the NMSE performance of the proposed methods. We first compare the NMSE performance by varying SNR from 0 to 20 dB. We set , , and . Simulation results are provided in Fig. 3, where both RICE and RICER outperform the OMP and benchmark throughout the range of SNRs considered. Note that the benchmark here uses a training signal of length 100 (vs. 16 for RICE and RICER), but does not exploit the DOA-DOD path parametrization – this is why RICE can beat this benchmark. Also note that OMP, which leverages the DOA-DOD path parametrization, does not work well due to the lack of enough samples and the coherence in the dictionary. RICER has better accuracy than RICE but it is shown in Fig. 4 that this is at the expense of paying four times more complexity. The additional calculation time is caused by the root finding procedure for DOD estimation and LS for path-loss estimation. Notably, RICE is 62 times faster than OMP and RICER is 12 times faster.
Similar results can also be found in Fig. 5, where the number of paths varies from 1 to 6 and SNR is fixed at 10 dB. are generated by uniformly dividing the range into intervals. and are generated in the same way but from the range and , respectively. Again, OMP does not work, likely owing to the coherence of the ‘flat’ dictionary matrix whose dimension is . RICE and RICER offer satisfactory performance for small . However, when exceeds 5, RICE becomes a bit inferior to the benchmark but still acceptable for such a difficult setting—recovering 5 paths from 16 training samples, which indicates that using full knowledge of helps in achieving better estimation accuracy but at the expense of high complexity. Also we point out that according to Theorem 2, with the parameter settings of this example, our methods can resolve up to distinct paths. Therefore, the performance loss of RICE and RICER is due to the fact that the number of paths reaches the upper-bound that they can handle.
Next we evaluate the performance as a function of . We set , , SNR dB, and vary from 2 to 7. At the same time, we increase the number of paths for each in the range , i.e., . More specifically, if , , else if , , and so forth. DOAs, DODs and path-losses are generated in the same way as in Fig. 5. Fig. 6 shows the result, from which we can see that RICE and RICER work well. We find that in most cases, OMP can successfully resolve several paths but not all of them. It frequently mis-estimates one or two paths, which ultimately leads to unsatisfactory overall performance. Note that when , the maximum number of paths that the proposed methods can deal with is 6 which equals to the number of paths in this simulation. This validates the correctness of the identifiability analysis in Theorem 2.
In the last example, we examine the channel estimation performance by evaluating the bit error rate (BER) versus SNR. In the simulation, we first estimate the channel and then feed it back to the BS. Then we transmit QPSK symbols precoded using the zero-forcing precoding technique. We pass the coded signal through a white Gaussian channel and decode it at the MS. To simplify the analysis, we do not consider quantization error at the feedback step. The parameters are set as , and . According to Theorem 2, we can uniquely identify up to paths based on the setting. We consider two cases: and . The results are plotted in Fig. 7. Note that the benchmark curve is based on the least squares channel estimator with orthogonal pilots. We see that when , RICE and RICER outperform the benchmark and OMP. But the RICE algorithm performs worse than the benchmark when . We note that the benchmark achieving such performance is at the expense of huge training and feedback overhead, where the downlink training is based on a training signal and uplink feedback is with 600 real-valued numbers. However, the overhead of RICE and RICER is much lighter, where they only spend 16% of the training overhead of the benchmark and approximately 3.3% of the feedback overhead.
VII Conclusion
In this work, we designed a new non-orthogonal training sequence and proposed a novel tensor factorization framework to tackle the DL channel estimation problem for FDD massive MIMO from ‘frugal’ training. We showed that with the devised training sequence, the channel can be estimated accurately from a very small amount of training. Meanwhile, two computationally efficient algebraic methods were proposed for multipath parameter estimation. Compared to the existing approaches, the proposed methods have several advantages in terms of channel identification guarantees, estimation accuracy and computational complexity. Extensive simulations showed the effectiveness of the proposed methods. The most important take-away point is that RICE achieves similar or better performance than orthogonal training with a much shorter training sequence and using a computationally very attractive algebraic channel identification algorithm.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] C. Qian, X. Fu, and N. D. Sidiropoulos, “A simple algebraic channel estimation method for FDD massive MIMO systems,” in IEEE Int. Workshop on Signal Process. Advances in Wireless Commun. (SPAWC) , Cannes, France, July 2019, accepted.
- 2[2] E. G. Larsson, O. Edfors, F. Tufvesson, and T. L. Marzetta, “Massive MIMO for next generation wireless systems,” IEEE Commun. Mag. , vol. 52, no. 2, pp. 186–195, 2014.
- 3[3] R. W. Heath, N. Gonzalez-Prelcic, S. Rangan, W. Roh, and A. M. Sayeed, “An overview of signal processing techniques for millimeter wave MIMO systems,” IEEE J. Sel. Topics Signal Process. , vol. 10, no. 3, pp. 436–453, 2016.
- 4[4] A. Alkhateeb, O. El Ayach, G. Leus, and R. W. Heath, “Channel estimation and hybrid precoding for millimeter wave cellular systems,” IEEE J. Sel. Areas Commun. , vol. 8, no. 5, pp. 831–846, 2014.
- 5[5] C. Qian, X. Fu, N. D. Sidiropoulos, and Y. Yang, “Tensor-based channel estimation for dual-polarized massive MIMO systems,” IEEE Trans. Signal Process. , vol. 66, no. 24, pp. 6390–6403, Dec 2018.
- 6[6] A. Kammoun, H. Khanfir, Z. Altman, M. Debbah, and M. Kamoun, “Preliminary results on 3d channel modeling: From theory to standardization,” IEEE J. Sel. Areas Commun. , vol. 32, no. 6, pp. 1219–1229, 2014.
- 7[7] H. Xie, F. Gao, and S. Jin, “An overview of low-rank channel estimation for massive MIMO systems,” IEEE Access , vol. 4, pp. 7313–7321, 2016.
- 8[8] W. U. Bajwa, J. Haupt, A. M. Sayeed, and R. Nowak, “Compressed channel sensing: A new approach to estimating sparse multipath channels,” Proc. IEEE , vol. 98, no. 6, pp. 1058–1076, 2010.