Prevention and Mitigation of Catastrophic Failures in Demand-Supply Interdependent Networks
Seyyedali Hosseinalipour, Jiayu Mao, Do Young Eun, Huaiyu Dai

TL;DR
This paper introduces a model for demand-supply interdependent networks, analyzing cascading failures caused by resource/load fluctuations, and proposes resource allocation and network adaptation strategies to prevent and mitigate such failures.
Contribution
It develops a generic model for demand-supply networks, identifies stress mechanisms, and proposes optimal resource allocation and adaptation methods to enhance network robustness.
Findings
Quantified network robustness under different resource configurations.
Designed optimal resource allocation strategies for various fluctuation scenarios.
Proposed network adaptation mechanisms to contain ongoing failures.
Abstract
We propose a generic system model for a special category of interdependent networks, demand-supply networks, in which the demand and the supply nodes are associated with heterogeneous loads and resources, respectively. Our model sheds a light on a unique cascading failure mechanism induced by resource/load fluctuations, which in turn opens the door to conducting stress analysis on interdependent networks. Compared to the existing literature mainly concerned with the node connectivity, we focus on developing effective resource allocation methods to prevent these cascading failures from happening and to mitigate/confine them upon occurrence in the network. To prevent cascading failures, we identify some dangerous stress mechanisms, based on which we quantify the robustness of the network in terms of the resource configuration scheme. Afterward, we identify the optimal resource…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4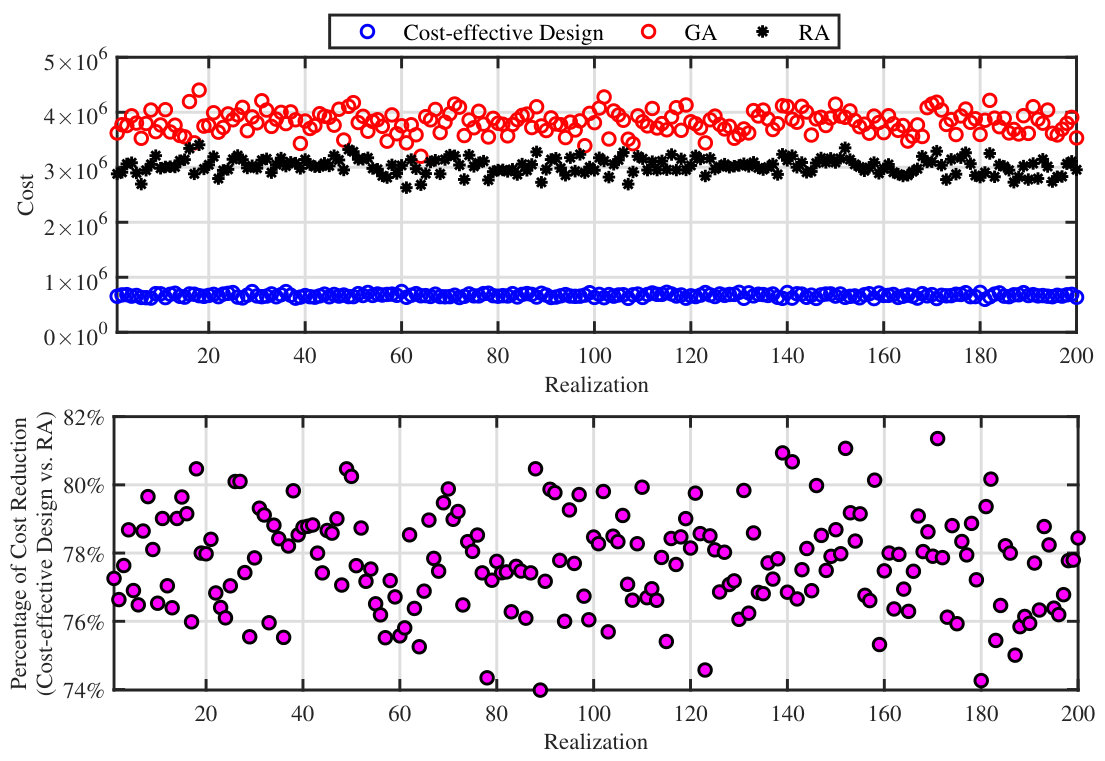 Figure 5
Figure 5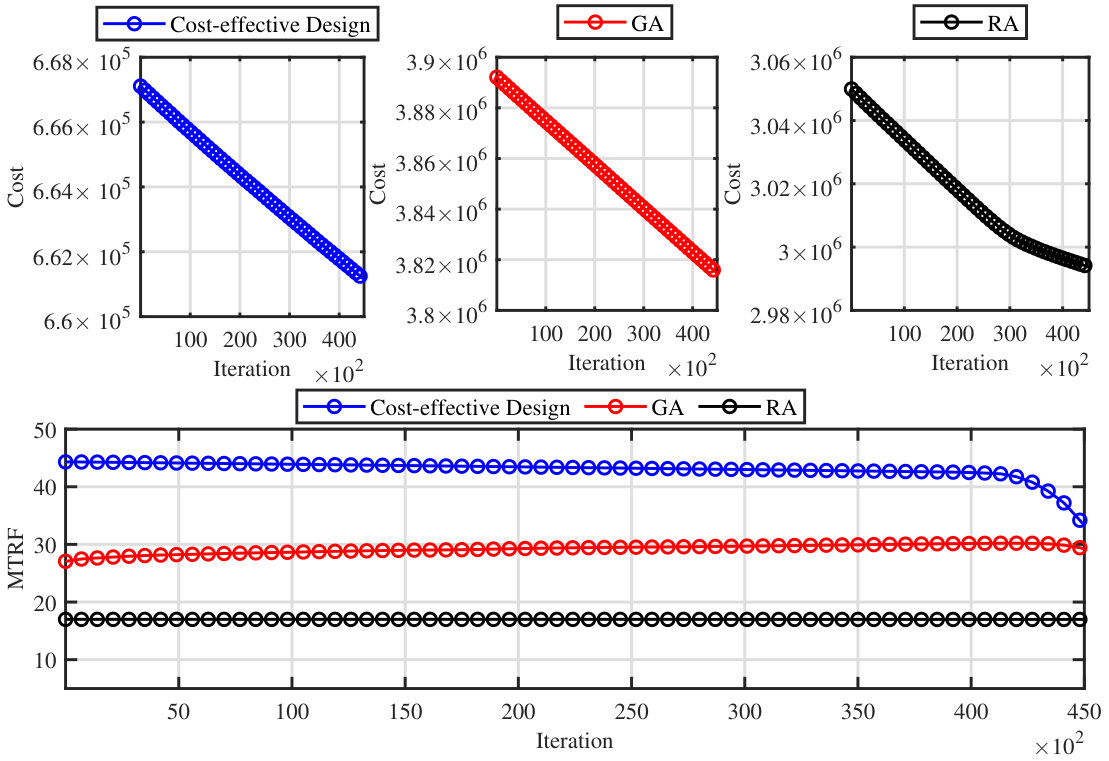 Figure 6
Figure 6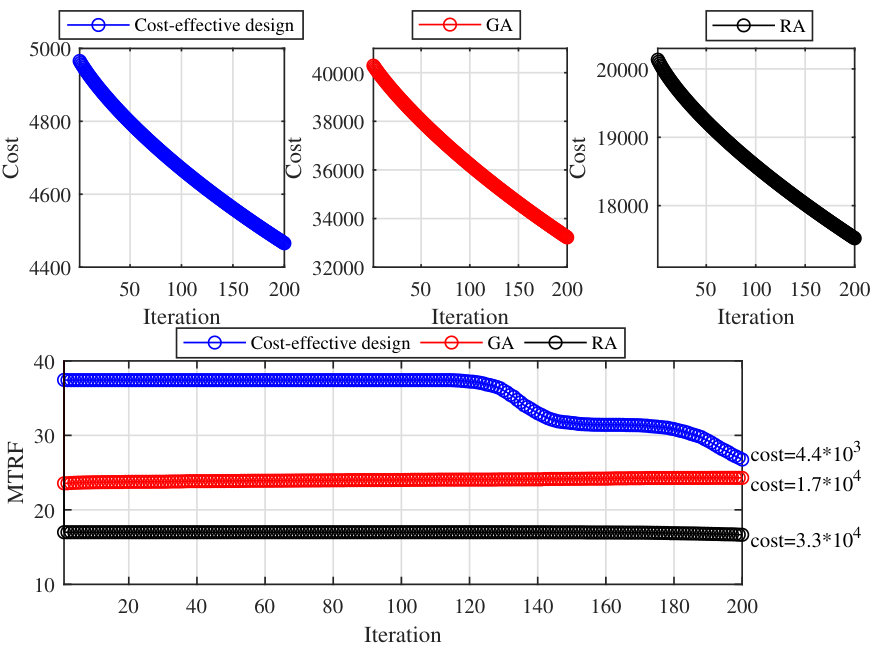 Figure 7
Figure 7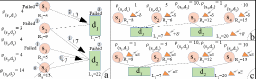 Figure 8
Figure 8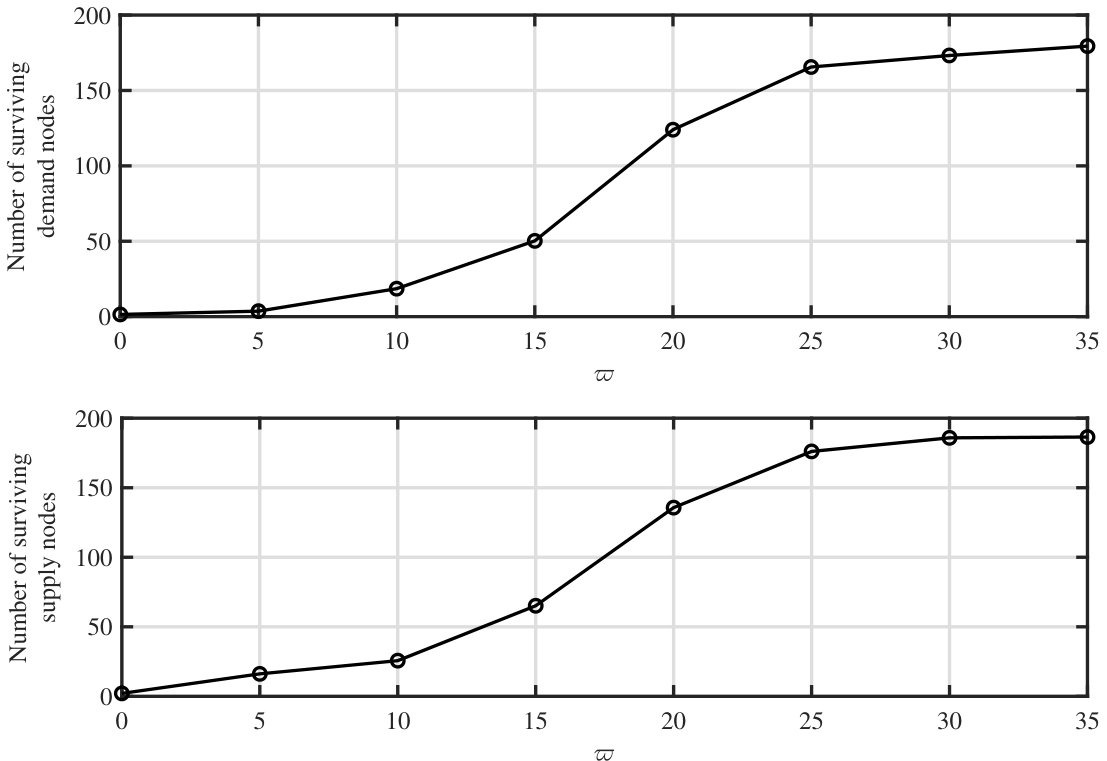 Figure 9
Figure 9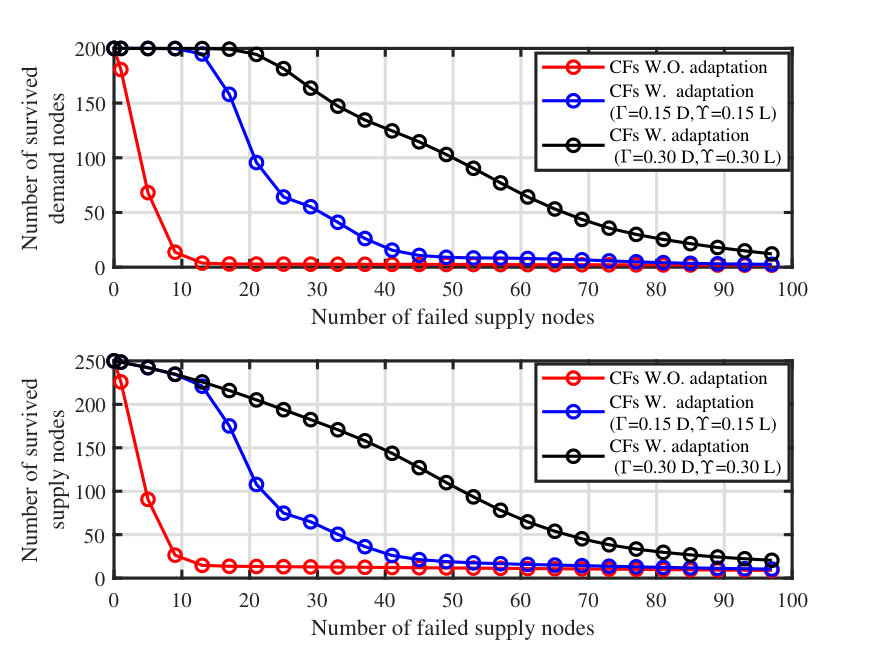 Figure 10
Figure 10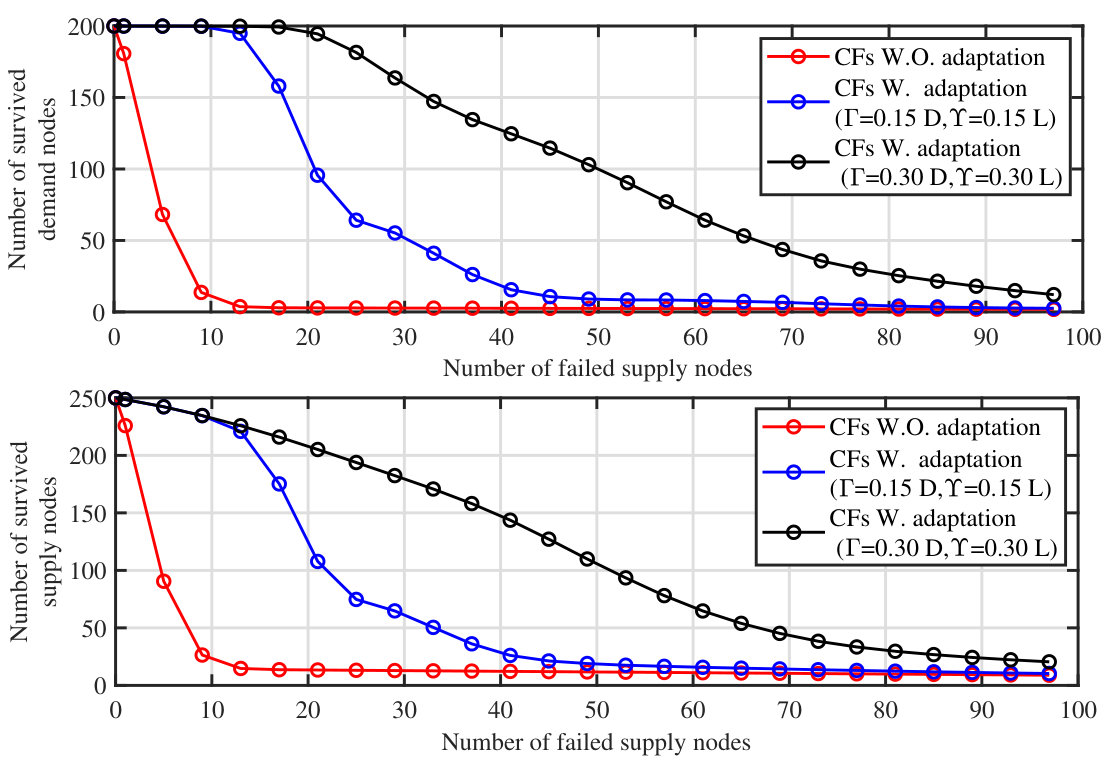 Figure 11
Figure 11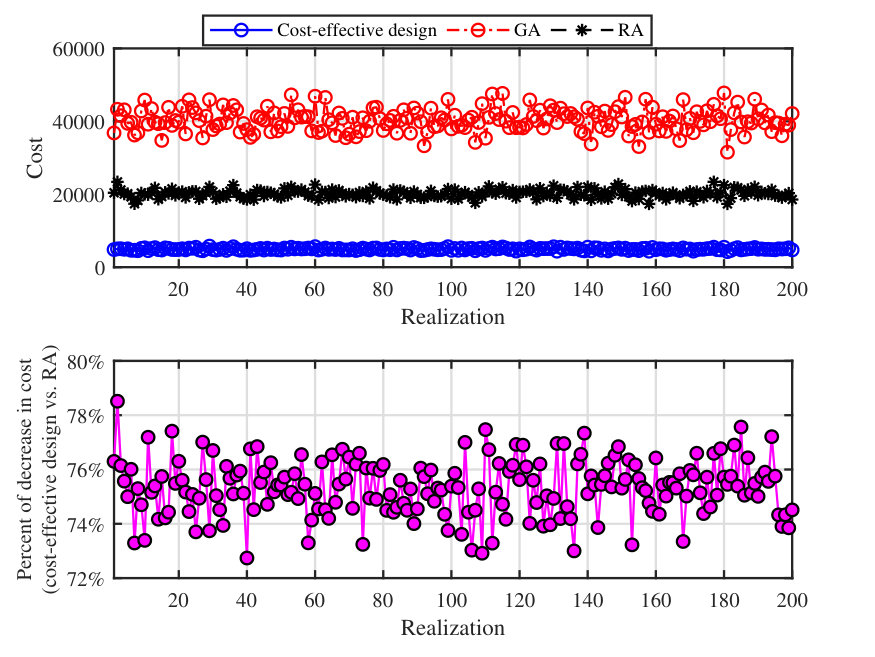 Figure 12
Figure 12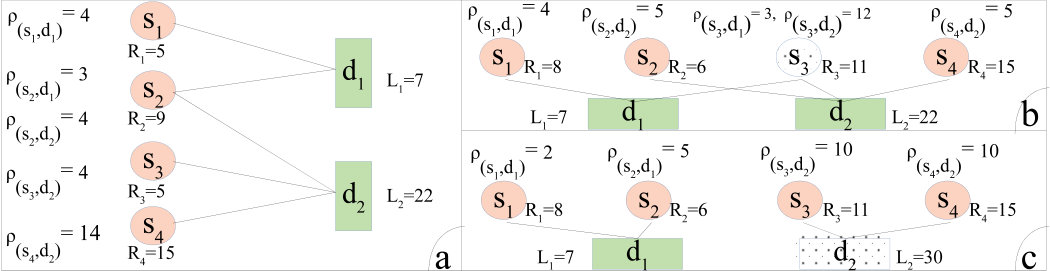 Figure 2
Figure 2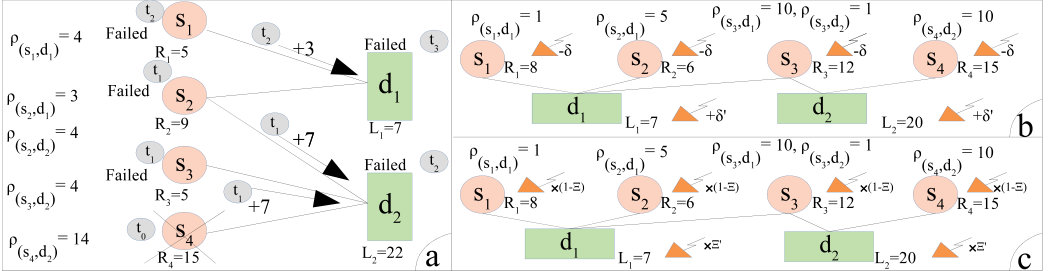 Figure 3
Figure 3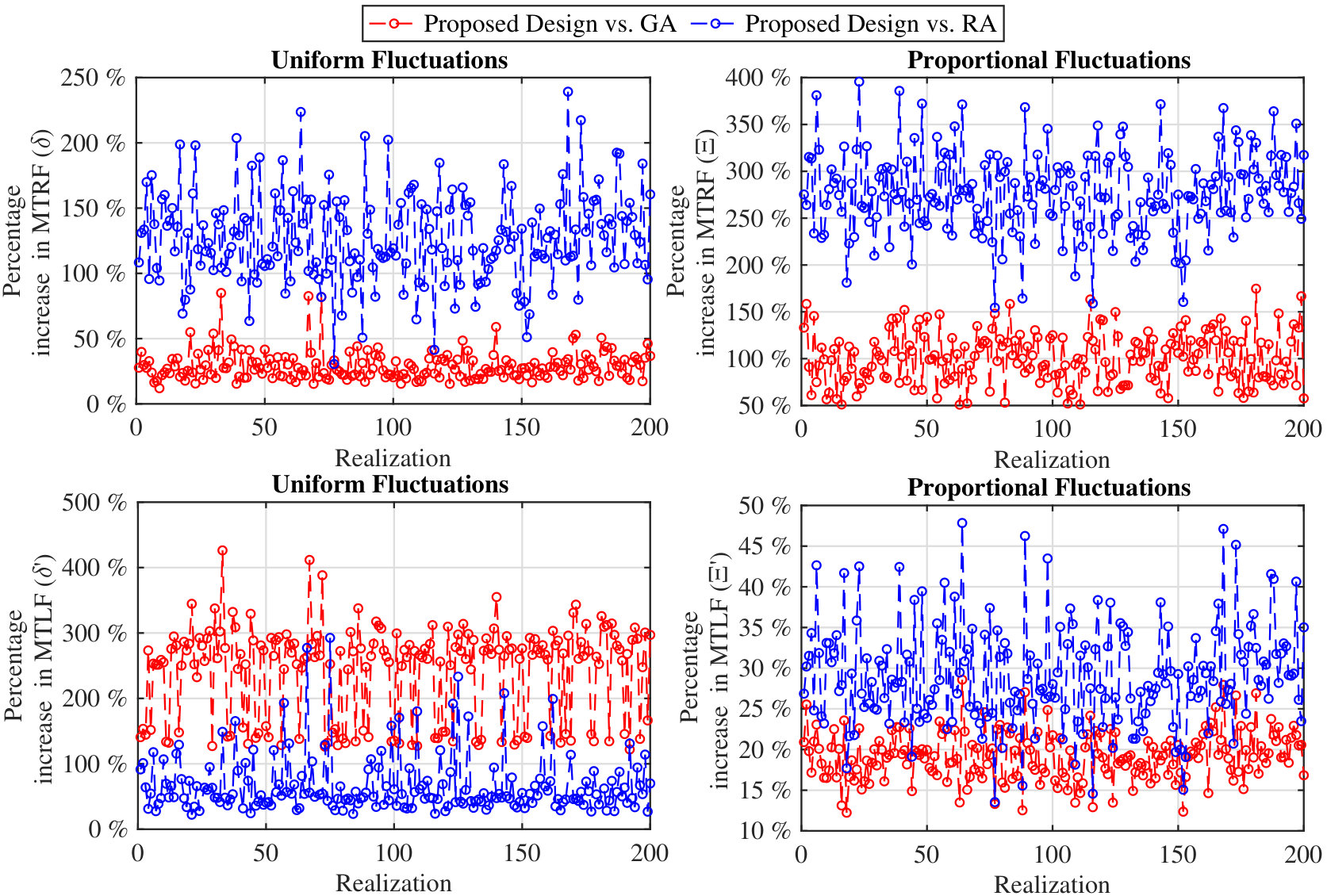 Figure 15
Figure 15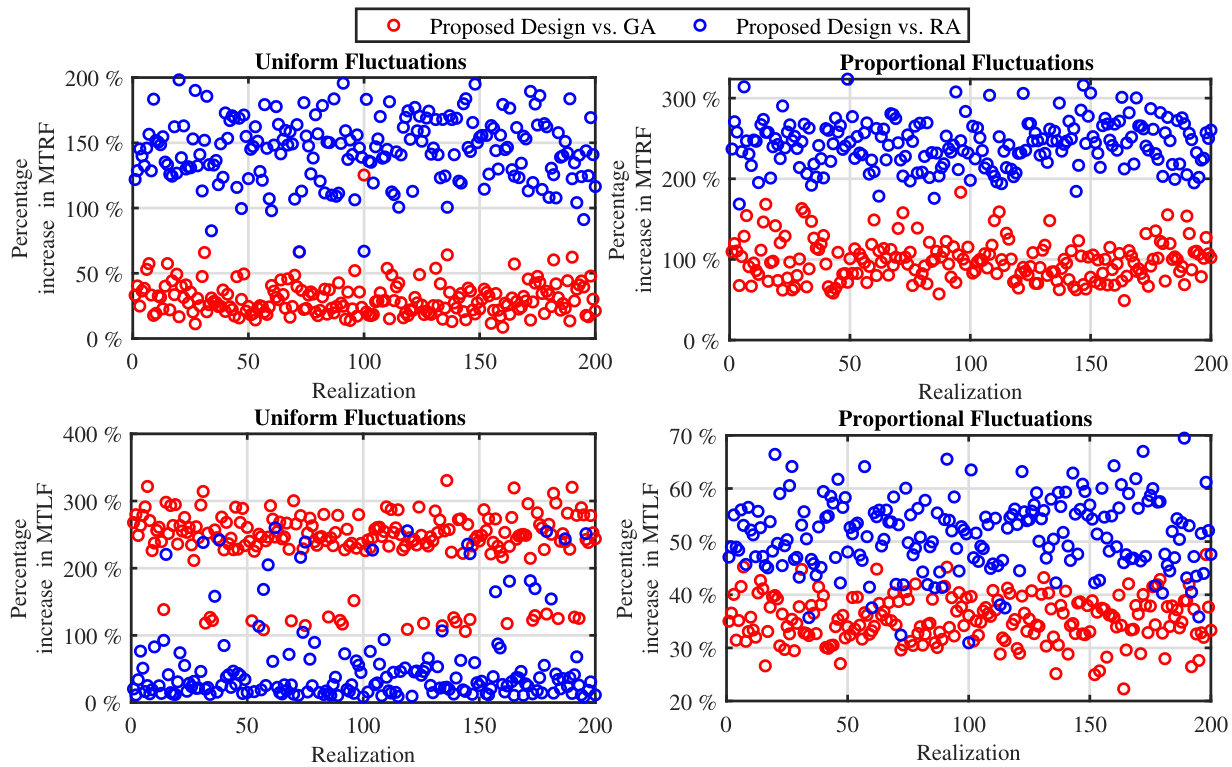 Figure 16
Figure 16 Figure 17
Figure 17Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Prevention and Mitigation of Catastrophic Failures in Demand-Supply Interdependent Networks
Seyyedali Hosseinalipour, Jiayu Mao, Do Young Eun, and Huaiyu Dai S. Hosseinalipour, D. Y. Eun and H. Dai are with the Department of Electrical and Computer Engineering, North Carolina State University, Raleigh, NC 27695 (Emails: shossei3,dyeun,[email protected]).
Jiayu Mao is with the Department of Electrical Engineering, Penn State University, State College, PA 16801 (Email: [email protected]).
Abstract
We propose a generic system model for a special category of interdependent networks, demand-supply networks, in which the demand and the supply nodes are associated with heterogeneous loads and resources, respectively. Our model sheds a light on a unique cascading failure mechanism induced by resource/load fluctuations, which in turn opens the door to conducting stress analysis on interdependent networks. Compared to the existing literature mainly concerned with the node connectivity, we focus on developing effective resource allocation methods to prevent these cascading failures from happening and to mitigate/confine them upon occurrence in the network. To prevent cascading failures, we identify some dangerous stress mechanisms, based on which we quantify the robustness of the network in terms of the resource configuration scheme. Afterward, we identify the optimal resource configuration under two resource/load fluctuations scenarios: uniform and proportional fluctuations. We further investigate the optimal resource configuration problem considering heterogeneous resource sharing costs among the nodes. To mitigate/confine ongoing cascading failures, we propose two network adaptations mechanisms: intentional failure and resource re-adjustment, based on which we propose an algorithm to mitigate an ongoing cascading failure while reinforcing the surviving network with a high robustness to avoid further failures.
Index Terms:
Interdependent networks, demand-supply networks, robustness, resource and load fluctuations, cascading failures.
1 Introduction
Interdependent networks are a relatively new concept in networking studies, which consist of two or more networks/layers with dependent functionality. Some well-known examples of these networks are i) smart power grid networks, where the functionality of the power-related sensors and the communication infrastructure are coupled [1], and ii) complex transportation systems consisting of multiple coupled transportation layers, e.g., railways and roadways [2]. The main motivation to study robustness, failure mechanisms, and fault propagation (we refer to all of them as robustness analysis for brevity) for these networks is their special failure mechanism called cascading failures [1].
Demand-supply networks are a category of interdependent networks, in which the functionality/operability of the nodes in one layer (demand layer) is contingent on receiving supplies from those in the other layer (supply layer). Due to the freshness of the topic, there is limited literature on conducting robustness analysis in the context of demand-supply networks. The most related works are [3, 4]. In [3], a model for demand-supply networks is proposed, where the functionality of the demand nodes depends on the number of connected supply nodes. Their model can be considered as an abstract representation of some real-world economic systems such as the network of financial firms and non-financial companies. In the proposed model, the operability of a demand node is examined by solely counting the number of supply nodes connected to it. Hence, there is no notion of resource as a shared quantity among the nodes. In [4], another model for demand-supply networks is proposed, where having at least a connection to the supply layer guarantees the operability of a demand node. Their model has some similarity to the cyber-physical networks and shared risk groups previously studied in [5, 6, 7]. In conclusion, in these works the functionality of a demand node is examined solely by counting the number of supply nodes supporting it, and the notion of resource as a quantitative value is overlooked. As a result, these works are mainly concerned with the connectivity among the nodes, while the underlying resource sharing/configuration mechanisms are ignored.
In this work, we conduct robustness analysis on a more generic model, in which the shared resource among the connected nodes is represented by a quantity that varies from one pair of nodes to another. In our model, demand nodes and supply nodes are associated with heterogeneous requested loads and heterogeneous resource provisioning capabilities, respectively. In this paradigm, the functionality of a demand node is examined by the total amount of resource received from those connected supply nodes. This leads to the existence of (infinitely) many choices for the configuration of shared resources, i.e., resource configuration, among the nodes for a network with a fixed node connectivity, all of which satisfying the requested loads of the demand nodes. This raises the following questions: i) is there any advantage in using a specific resource configuration? and if yes, ii) how important is the study of the resource configuration scheme to conduct robustness analysis? We demonstrate that the resource configuration scheme plays a key role in robustness analysis of our proposed model for demand-supply networks, which goes beyond the connectivity among nodes. One of the main advantages of our model is its adaptability to many real-world scenarios, e.g., allocation of infantry/capitals (considered as resources) to multiple divisions (considered as demand nodes with different requested loads) in battlefields, food/resources and humans in natural disasters, datacenters and users in a cloud network, banks and assets, and power plants and cities.
This paper can be broken down into two main parts: i) prevention of cascading failures, and ii) mitigation of ongoing cascading failures, in each of which we focus on studying the resource configuration schemes from a different angle. In the first part, considering quantitative values for the loads and resources, we analyze interdependent networks via stress analysis, which cannot be readily carried out using the system model of [3, 4]. We investigate the effect of fluctuations incurred on both the requested loads and the resource provisioning capabilities on the stability of the network. We then propose two metrics for the robustness of the network with regard to the resource configuration scheme. In this context, we aim to reinforce the network with a high robustness to prevent cascading failures from happening. In the second part, we target studying the distinct problem of stopping/confining ongoing cascading failures by solely re-adjusting the utilized resource configuration during the propagation of the failures. In particular, we extend the recently introduced concept of network adaptability in interdependent networks, e.g., [8, 9], to our model for demand-supply networks and propose effective mechanisms for adaptation of the resource configuration to stop cascading failures. For better comprehension, more discussion on the related works is postponed to Section 2.3.
Our contributions can be summarized as follows:
We provide a generic system model for demand-supply networks capturing heterogeneous resource provisioning capabilities of the supply nodes and heterogeneous requested loads of the demand nodes. In this paradigm, we reveal the effect of the resource sharing/configuration protocol on the reliability of the network and identify some dangerous stress mechanisms, which can lead to catastrophic failures. 2. 2.
As compared to the conventional cascading failures, we study an extended cascading failure process triggered by resource/load fluctuations, taking into account the overload of the supply nodes and resource deficiency of the demand nodes. 3. 3.
We quantify the robustness of the network with regard to its tolerability against fluctuations in both resource provisioning capabilities and requested loads under two resource/load fluctuation scenarios: i) uniform fluctuations and ii) proportional fluctuations. Afterward, we draw a connection between the prevention of cascading failures and maximization of the introduced robustness metrics. 4. 4.
We determine the optimal resource configuration protocol to maximize the robustness for each of the two aforementioned scenarios of resource/load fluctuations. We also address the cost-effective design achieving the highest robustness considering heterogeneous geographical constraints/limitations on resource sharing among the nodes reflected through heterogeneous resource sharing costs. Moreover, assuming a budget constraint, we propose an algorithm to decrease the cost of resource provisioning while maintaining a high robustness for the network. 5. 5.
We introduce a new perspective to the concept of network adaptability with respect to the underlying resource configuration protocol in demand-supply networks. In this regard, we propose two adaptability mechanisms: intentional failure and resource re-adjustment, based on which we develop a novel algorithm to confine/mitigate ongoing cascading failures and provide high robustness for the surviving network so as to avoid triggering of further failures.
2 Preliminaries
2.1 System model
We propose a model in which a demand-supply network comprises two layers: supply and demand layer. In the supply layer, there is a set of supply nodes denoted by , , where each supply node is associated with some resource units . In the demand layer, a set of demand nodes , , is considered, where each demand node is associated with a requested load . In our model, a supply node can distribute its resources among multiple demand nodes, each of which is capable of receiving resources from multiple supply nodes.111The geographical restrictions affecting the resource provisioning protocol are investigated in Section 4. For demand node , let denote the amount of resources received from supply node . We represent a demand-supply network as a weighted bipartite graph in which each supply node is connected to a demand node if .222We will define the weights of the edges with respect to different mechanisms of resource/load fluctuations in the following section.
We study the network behavior under the following stability conditions:
[TABLE]
where denotes the aggregate offered resources of supply node , and indicates the aggregate received resources of demand node . In our model, violations in (1) are regarded as overloading of the supply node(s), whereas violations in (2) are considered as resource deficiencies in the demand node(s). Since the system will always suffer from instability if the total available resources becomes less than the total requested loads, to avoid triviality, we assume throughout the paper. For a small network consisting of nodes, three examples of resource sharing/configuration among the nodes are depicted in Fig. 1. It can be verified that the stability conditions hold only for the left instance (Fig. 1 (a)).
We conduct stress analysis on demand-supply networks by classifying the potential stress mechanisms into the following categories: i) internal failure of demand nodes; ii) internal failure of supply nodes; iii) load fluctuations (increase/decrease) at the demand nodes; and iv) resource fluctuations (increase/decrease) at the supply nodes. In the following, harmless stresses are discussed first followed by the dangerous stresses. Considering the stability conditions ((1), (2)), the first stress mechanism is harmless since it neither overloads the resource nodes ((1) remains intact) nor affects the receiving loads of the other demand nodes ((2) keeps inviolate). Also, a reduction in the load of a demand node is harmless since it has no effect on the stability of the network. A similar reason makes increment in the resources of supply nodes harmless.
In contrast, internal failure of a supply node is potentially a dangerous stress causing , which may result in resource deficiencies in demand nodes (violation of (2)). Another dangerous stress mechanism is a reduction in resource of a supply node, which (potentially) promotes overloading of the supply node (violation of (1)) and, upon reduction in the amount of offered resources to stabilize the node, resource deficiencies in those connected demand nodes (violation of (2)). Similarly, an increase in the load of a demand node is dangerous since it may (potentially) lead to resource deficiency in the node (violation of (2)), and subsequently overloading of those connected supply nodes (violation of (1)). These stress mechanisms promote a unique cascading failure process, which spreads differently as compared to the conventional cascading failures [1], discussed in the following subsection.
2.2 Cascading failures triggered by dangerous stress mechanisms
An example of initialization and evolution of a cascading failure caused by instability of the nodes is depicted in the left diagram of Fig. 2 (Fig. 2 (a)), where the time indices written in gray circles indicate the order of actions (). The cascading failure is initially (at ) triggered with internal failure of the supply node resulting in resource deficiency in the demand node . To trace the evolution of the cascading failure, we check the stability conditions ((1), (2)) at each time instance. To compensate for the resource deficiency, demand node drains extra unit of resources from its adjacent/connected supply nodes. Assume that drains extra unit of resources from both and (more elaborations on this subject is given in Section 3). At , since and can only provide and extra unit of resources while being stable, they both fail resulting in resource deficiency in (violation of (2)). At , drains extra unit of resources from leading to the failure of due to overloading (violation of (1)). At the same time, fails due to failure of all of its connected supply nodes (violation of (2)). At the next time instant (), fails due to the same reason. In this example, the cascading failures led to failure of all the nodes; however, the influence could be different for another resource configuration scheme.
We consider two resource/load fluctuation mechanisms triggering cascading failures: uniform and proportional fluctuations, which are shown in diagram (b) and (c) of Fig. 2, respectively. In the uniform fluctuation scenario (diagram (b)), a portion of supply (demand) nodes experience the same amount of reduction (increment), denoted by () in the diagram, in their resources (loads). In this scenario, the fluctuation in the load of a demand node is distributed evenly among the connected supply nodes. This happens specially when there is an agreement among the supply nodes to evenly compensate for resource deficiencies on the demand layer. Two example of this scenario are i) equal compensation for infantry/capitals among divisions in the battlefield context using multiple backup supply sources, and ii) compensation for the overload of the running cloud servers by providing equal extra processing power from backup resources. It can be verified that for a slightly greater than both and become unstable and fail. Also, assuming to be for puts at the threshold of failure (see Section 3.1). In the proportional fluctuation scenario (diagram (c)), the amount of fluctuations of the resources/loads is proportional to their initial values, where nodes with larger resources (loads) experience larger reduction (increment), denoted by () in the diagram. In this scenario, the fluctuation in the load of a demand node is distributed among the connected supply nodes proportional to their initial offered resources. Two examples of this scenario are i) banks-assets network, in which the fluctuation in values of the assets affects the banks with respect to their amount of investment, and ii) power plants and cities, in which the fluctuation in the load of the cities distributes among multiple power plants according to their supplying powers. It can be seen that considering slightly larger than leads to failure of . Also, fails when is slightly larger than for both and (see Section 3.2). Note that, considering the mentioned dangerous stress mechanism, internal failures of supply nodes can be regarded as load fluctuations in the demand nodes, and thus omitted from our discussions.
2.3 Related work
2.3.1 Connectivity-based cascading failures
Robustness of interdependent networks is studied extensively in literature in the context of a special failure mechanism called cascading failures [1], most of which aim at designing robust interdependent networks against node/edge removals and studying the robustness with respect to the network characteristics, e.g., [10, 11, 12, 13, 14, 15]. There is a parallel trend of research in D2D networks pursuing the same goal, e.g., [16, 17]. In these works, the functionality of a node is merely examined based on its connectivity to the giant component in its layer and its dependent nodes on the other layer. Moreover, there are some similar works in the power-grid literature, e.g., [18, 19], which consider the cascade of failures between the power grid network and the communication network. In this literature, controlling the loads and the power generators in the power grid network is studied to suppress the impact of cascading failure. Nevertheless, the resource sharing/provisioning among the nodes between different layers is not studied in all the aforementioned works and most of contemporary literature.
2.3.2 Load-based cascading failures
Cascading failures caused by load (re-)distribution among the nodes are studied in literature (e.g., [20, 21, 22]), in which the load of the nodes are independent/decoupled to each other and load distribution only occurs upon failures of the nodes. However, in our model, there is a constant coupling between resources provided from the supply nodes and the load of the demand nodes. Hence, fluctuations of the resources/loads in one layer can lead to instability of the nodes in the other layer. Moreover, in our model, in the middle of a cascading failure, a demand node with resource deficiency drains extra resources from its adjacent supply nodes, which can result in either stability of the demand node or overloading of the supply nodes. This paradigm distinguishes our cascading failure mechanism and proposed robustness analysis from that literature.
2.3.3 Network adaptability
The authors in [23] provide some general ideas and approaches to prepare the telecommunication networks priori to natural disasters. In the single layer network context, [24] proposes network rewiring mechanisms aiming to achieve a higher robustness against cascading failures. The concept of network adaptability is recently investigated in the context of interdependent networks in [8, 9] in terms of rehabilitating a portion of failed nodes in the process of cascading failures. However, the system model and cascading failures mechanism considered in these works belong to the first enumerated category (Section 2.3.1) rendering them irrelevant to our work. In this paper, we provide a new perspective to the concept of network adaptability by incorporating the resource sharing mechanism into cascading failures. Our focus is on adaptation of resource allocations among the nodes to confine cascading failures. To this end, we propose two adaptation strategies: i) intentional failures of the demand nodes, and ii) resource re-adjustments (re-allocations) among the supply nodes, using which we propose an algorithm to confine cascading failures and provide high robustness for the surviving network.
2.3.4 Demand-supply networks
There are a few works studying interdependent networks in the context of demand-supply networks, among which the most related ones are [3, 4]. In these works, there is no notion of “resource” as a quantitative value and the demands of the demand nodes are merely identified by the required number of connected supply nodes. Consequently, studying the connectivity of the network is the main focus of these studies, e.g., extending the concept of the edge-cut problem ([25, 26]) to the node-cut problem in [4]. Also, the model in these works captures one-way dependency between the nodes, where the functionality of the supply nodes is presupposed irregardless of the demand layer situations. In this paper, considering resources/loads as coupled quantitative values imposes a two-way dependency among the nodes, where resources/loads fluctuations in one layer can lead to instability in the other. Also, in our model, two networks with the same connectivity (wiring) configuration may react to failures differently due to different resources/loads of the nodes. Due to these inherent differences, the cascading failure process of this work along with its proposed design/analysis is explicitly different from those works.
We would like to mention notable works of [27, 28] in economics literature, which propose bipartite interdependent network modeling of bank-asset networks. We contribute to this literature with our design framework achieving a high robustness against fluctuations and our network adaptation methods to confine cascading failures, which are complementary and can be integrated into their models.
Also, there is a body of works on modeling the load and capacity of the transmission lines in the power grid literature, the most relevant of which aim to model the cascading failures caused by load fluctuation on the transmission lines and propose effective network designs, e.g., [29, 30, 31]. In this literature, the network consists of multiple transmission lines; upon failure, the load of the failed lines will be redistributed among all the remaining ones. Hence, there is no notion of node (supply node/demand node) as an entity in the network. Consequently, the network is not considered as a two-layer interdependent network with resource provisioning among the nodes, making their model fundamentally different as compared to our bipartite network model. This fact makes our system model and cascading failure mechanism completely different from that literature.
3 Quantifying and Maximizing the Robustness Considering Load/Resource Fluctuations
3.1 Uniform resource/load fluctuations
For the uniform resource fluctuations, we pursue the worst-case design approach assuming , , (see Fig. 2 (b)). To study the stability of the supply nodes, we define the free capacity of the supply node as:
[TABLE]
We measure the robustness of the network in terms of the maximum tolerability of the network against resource fluctuations defined as:
[TABLE]
where
denotes the set of supply nodes involved in resource provisioning. In other words, is equal to the minimum amount of resource fluctuation that results in the instability of at least a supply node engaged in resource provisioning, which is equivalent to the minimum free capacity among the supply nodes offering resources to the demand layer. It can be construed that, upon uniform resource fluctuations, an increase in this parameter is directly linked to prevention of cascading failures. In the described demand-supply bipartite graph, we consider the weight of an edge connecting a pair of demand and supply nodes to be the amount of shared resources between them.
Our goal is then to find the optimal weighted adjacency matrix corresponding to a network with the maximum . One approach to achieve the largest is to minimize the offered resources used at each supply node, which leads to the maximum free capacity for each of them. On the other hand, simultaneously satisfying the loads of the demand nodes and minimizing the offered resources used at each supply node is equivalent to stabilizing the demand nodes by satisfying (see (2)). Using these facts, the resource configuration achieving the highest robustness against uniform resource fluctuations can be obtained by solving the following optimization problem:
[TABLE]
where (6) implies the stability of the supply nodes, (7) ensures the functionality of the demand nodes, and (8) guarantees a feasible allocation. In the following, we aim to solve this problem. Note that the objective function of is not a strict concave function. Hence, there can be multiple resource configuration schemes that are the solutions to . As further discussed in Remark 2 and Section 4 below, identifying a unique weighted adjacency matrix requires the knowledge of the cost of resource sharing among the nodes. The following fact serves as the basis to solve .
Fact 1**.**
If the sum of the offered resource to the demand layer is larger than or equal to the sum of the loads of the demand nodes while all the supply nodes are stable, there is at least a resource configuration scheme that leads to the stability of all the nodes.
With the above fact, we first focus on obtaining the optimal resource that supply nodes need to offer to the demand layer. The derivation of the optimal weighted adjacency matrix, i.e., the optimal resource configuration, is deferred to Section 4.
Lemma 1**.**
Assume that the resources of the supply nodes can be sorted as , , and define the dummy variable . Let denote the smallest index in which . Then, , and .
Proof.
Please refer to the supplementary materials. ∎
Remark 1**.**
The above lemma determines the resource nodes involved in the resource provisioning: . The main intuition behind the lemma is the fact that the is defined as the minimum free capacity of the resource nodes involved in resource provisioning. Hence, to maximize this metric those nodes with higher resources should be used. More explanation on this fact along with the examination of the case in which resource nodes may have equal amout of resources are given in the supplementary materials.
Theorem 1**.**
For the sorted resources and described in Lemma 1, the optimal resource offered from supply nodes is given by:
[TABLE]
Proof.
Assume that the set of resource nodes involved in the resource provisioning, according to Lemma 1, are given by: . Upon solving , assume that the free capacities of these nodes after resource provisioning are sorted as . Define the dummy variables , . Since , , we get . On the other hand, . Using these facts, the objective function of can be written as:
[TABLE]
From the last expression, it can be verified that the optimal solution is attained when . Since , this is achieved when , . This is equivalent to , , implying the same free capacity for those supply nodes involved in resource provisioning. Considering this result and (7), we get: , which implies , . Considering (3), we get: , , and the theorem is proved. ∎
So far, the resource fluctuations was the main concern of the design. Nevertheless, achieving a high robustness against uniform load fluctuations is a straightforward extension. We define the maximum tolerable load fluctuations as:
[TABLE]
where denotes the set of adjacent supply nodes of , . In other words, is the minimum value of increment in the load of demand nodes, which results in failure of (at least) one supply node under uniform spreading of the resource deficiencies. Using (9), it can be construed that the free capacities of all the supply nodes with non-zero offering resources to the demand layer is the same , . In this case, maximizing the value of , i.e., connecting each demand node to all the supply nodes, leads to the maximization of . For this purpose, after solving , the designer needs to consider a small value and allocate unit of resources from each supply node involved in the resource provisioning, i.e., , to all the demand nodes: .
Remark 2**.**
Note that (9) determines the total offered resources from each supply node without specifying the exact values of resources shared among different pairs of nodes. This is due to focusing on the free capacities of the nodes while assuming no difference in terms of resource sharing through different links. Hence, among the optimal solutions, any resource distribution strategy satisfying , can be deployed. Upon having heterogeneous costs associated with different links, the precise values of shared resources among the nodes can be derived (see Section 4). The same philosophy holds for the discussions in Section 3.2.
3.2 Proportional resource/load fluctuations
To capture the proportional distribution of load fluctuations among the supply nodes, we model the offered resources of supply node to demand node as , where denotes the weight of the edge between them determining the fraction of the load of offered via . In this case, the condition ensures the functionality of demand node . We design the system for the worst-case scenario, where the load of each demand node increases from to , , . In this case, to maintain the stability of the demand node , supply node should provide extra resources to the demand node. Hence, the requested resource that each supply should provide changes as . Also, in resource fluctuations scenario, the resources of each supply node decreases from to , , where . For this scenario, we define the and the as follows:
[TABLE]
In other words, in this case, and are the maximum amount of proportional load increment and the maximum amount of proportional resource reduction, for which the stability of all the supply nodes is guaranteed. In the following lemma and theorem, we identify the maximum attainable value of these parameters and propose a simple resource configuration scheme, which simultaneously achieves the maximum attainable values of both.
Lemma 2**.**
Given a demand-supply network, for any resource configuration scheme, and are bounded as follows: .
Proof.
The result can be derived using the proof by contradiction on the definitions of and considering the free capacities of the supply nodes. ∎
Theorem 2**.**
Any resource configuration satisfying the following criteria results in a network with the highest attainable values of both and :
[TABLE]
Proof.
Considering (14), , . By increasing the loads from to , where , the free capacity is given by , . The can be derived by solving , which results in . Also, can be obtained considering the free capacity of the supply nodes after resource decrement, , solving , results in . ∎
4 Resource Configuration under Heterogeneous Geographical Constraints
Consider a scenario in which allocation of resources among different pairs of demand and supply nodes is associated with different costs. The cost can represent geographical constraints or, in general, heterogeneous tendencies of supply nodes toward resource allocation among different demand nodes. We model the allocation cost between and with corresponding allocated resource as:
[TABLE]
where and are node specific parameters capturing the inherent heterogeneities. Note that our approach can be applied to any convex and increasing cost function and the cost modeling here is just for mathematical convenience.333The results provided in this section are revisited for another general family of cost functions in Section 3 of the supplementary materials. In the following, we first obtain the precise values of allocated resources among the nodes to achieve the highest robustness while minimizing the allocation cost. Afterward, we provide an algorithm to reduce the allocation cost of a given network via re-adjusting the resource configuration.
4.1 Achieving the highest robustness while minimizing the allocation cost
In (9) and (14) the total offered resources from each supply node is derived to achieve the highest robustness without specifying the exact resource configuration between each pair of supply and demand node. Considering the heterogeneous costs of resource allocation among the nodes, to identify the cost-effective resource configuration with the highest robustness, we propose the following optimization problem, which determines the precise value of allocated resources for all pairs of nodes :
[TABLE]
where the right hand side of the first constraint denotes the solutions obtained from the previous section for either uniform or proportional load/resource fluctuations scenario ((9), (14)). To obtain the solution, consider the Lagrangian multipliers associated with the first, the second, and the third constraint as , , and , respectively. The corresponding Lagrangian function of is given by:
[TABLE]
where . From the stationarity condition of KKT conditions [32], we get:
[TABLE]
which results in:
[TABLE]
As can be seen, is a function of the Lagrangian multipliers, the values of which can be found by applying the gradient descent method [32] on the following dual problem:
[TABLE]
where the dual function is given by:
[TABLE]
Since is a convex optimization problem with affine constraints, the optimal solution of the dual problem will coincide with the optimal solution of the original problem.
4.2 Cost reduction while incurring the least loss in robustness
For a given network, the network operator may need to reduce the resource allocation cost due to economical situations or upon change of link cost parameters among the nodes. In this situation, it is more reasonable to reduce the allocation cost by locally re-adjusting the resources offered through a portion of links as compared to (re-)designing the entire network. Moreover, to prevent cascading failures from initiation in the final network, it is desired to incur the least loss in the robustness while performing the resource re-adjustment. Let and denote the allocation cost of the initial network and the objective cost, respectively, and . We propose an iterative resource re-adjustment method, described in Algorithm 1, aiming to reduce the maximum attainable cost at each iteration while imposing the least impact on the robustness. At each iteration of this algorithm, first the partial derivatives of the link costs with respect to the allocated resources are obtained. Then, the resources allocated to the link with the highest derivative is decreased by a step-size variable . Note that for a given step-size variable , the resource reduction through that link is associated with the maximum attainable cost reduction among all the links. Afterward, the emerged resource deficiency of the associated demand node to that link is compensated through allocating extra resources from the supply node with the lowest associated cost derivative that has the highest tolerance of resource fluctuations (uniform or proportional depending on the context) obtained from (25). As can be construed, this resource compensation procedure ensures the smallest impact on the robustness of the network.
4.2.1 On the feasibility of cost reduction
Considering the resource satisfaction paradigm ((1), (2)), our algorithm is not capable of achieving any arbitrary desired cost . This parameter is lower-bounded with respect to the link cost parameters and the feasible resource configuration schemes. In the following proposition, we derive the minimum achievable resource sharing cost.
Proposition 1**.**
Assume , , and . The minimum attainable budget for successful cost reduction using Algorithm 1 is given by , where , for which the value of the coefficients can be found by applying the gradient descent method on the following optimization problem:444The mentioned value for is in fact the minimum achievable cost of allocation that guarantees the stability of the nodes.
[TABLE]
where
[TABLE]
Proof.
Please refer to the supplementary materials. ∎
5 Stopping/confining Cascading Failures while Maintaining a High Robustness
So far, the design goal was to prevent cascading failures from happening. In this section, we aim to develop an adaptation scheme tailored for demand-supply networks to confine ongoing cascading failures in the network. In particular, considering any arbitrary demand-supply network, once cascading failures start to propagate, we aim to achieve the following goals simultaneously: i) stopping/confining the ongoing cascading failures, ii) providing the surviving network with a high robustness to avoid further failures. To achieve this, we introduce and deploy two network adaptation mechanisms: intentional failure and resource re-adjustment. In the intentional failure mechanism, we deliberately cut all the edges connecting to the demand node with the largest resource deficiency, making it isolated from the supply layer. This can be thought as sacrificing a demand node to (potentially) save the rest of the network. The resource re-adjustment mechanism is composed of the following parts. i) We compensate for the resource deficiencies of the demand nodes via utilizing the spare resources of the supply nodes with the highest tolerance of resource fluctuations in an iterative manner. This procedure ensures the least impact on the robustness of the network while compensating for resource deficiencies. ii) By re-allocating the offered resources from the supply nodes with low tolerance of fluctuations to those with high tolerance (larger capacities), we modify the resource configuration scheme to achieve a higher robustness. This stage is performed to balance the free capacities of the nodes in the surviving network, which results in a higher robustness. As compared to the current state-of-the-art in adaptability of interdependent networks, e.g., [8, 9], which mainly focus on rehabilitating the failed nodes to confine cascading failures, our approach is fundamentally different due to the distinct cascading failure mechanism in demand-supply networks. Our approach can be recognized as smart failing of the nodes and sequential resource re-adjustment, which simultaneously confine cascading failures and enhance the robustness.
We consider a realistic scenario in which the network operator has a limited capability/ability to perform network adaptation mechanisms. In particular, we address the network operator’s capability by two parameters and indicating the number of intentional failures and the total amount of resource re-adjustments that can be executed at each time instant, respectively. The pseudo-code of our proposed network adaptation algorithm is given in Algorithm 2. At each stage of cascading failures, the algorithm first identifies the best set of candidates for intentional failures, which consists of those demand nodes with the highest resource deficiencies. Failing those demand nodes results in the minimum required amount of extra resource to stabilize the network. Afterward, if it predicts that the cascading failures can be stopped using the spare resources of the supply nodes, i.e., the resource deficiencies can be fulfilled via feasible resource re-adjustments, it performs the resource re-adjustments to stop cascading failures and continues the re-adjustments to balance the free capacities of the supply nodes using Algorithm 3. Note that at the current stage of cascading failures, if the algorithm predicts that it cannot confine the failures, it waits until next time instant to (possibly) handle less amount of resource deficiencies due to potential failures.
In the end, there are two worthwhile remarks regarding our proposed algorithm: i) The resource re-adjustment stage of the algorithm can be applied by itself to any demand-supply network to increase the robustness. ii) Instead of improving the robustness, after the cascading failures stop, the resource re-adjustment can also be implemented from an alternative perspective to minimize the associated costs, similar to Algorithm 1.
input : The network configuration (see Algorithm 2), maximum amount of resource re-adjustments , , , , load and resources of the nodes, tunable parameter .
output : Re-adjusted configuration
1
Satisfy the resource deficiencies using supply nodes with high tolerance of resource fluctuations:
2 while do
3 Select an element of at random. Let denote that element.
4 Find the operable supply node with the highest tolerance of resource fluctuations using (25) (break ties uniformly at random). Let denote the index of that node.
5 Choose a small step size such that
6
7
8
9 if then
10
11
Use the remaining capability of resource re-adjustments to increase the robustness:
12 while do
13 Find the operable supply node with the highest tolerance of resource fluctuations using (25) (break ties uniformly at random). Let denote the index of that node.
14 Find the operable supply node with the lowest tolerance of resource fluctuations with replacing with in (25) (break ties uniformly at random). Let denote the index of that node.
15
16 Re-allocate fraction of all the offered resources from supply node to supply node : 555The value of should be small enough to avoid overloading node .
17 .
18 .
Output .
Algorithm 3 Iterative resource re-adjustment procedure
Remark 3**.**
The intentional failure mechanism can also be studied considering heterogeneous importance of the demand nodes. In this case, there might be a tendency toward maintaining the functionality of important demand nodes regardless of their amount of resource deficiency.
Remark 4**.**
The problem of interest in this section can also be studied from the perspective of fault detection and mitigation. In that scenario, there might be intended (or unintended) misreports in the value of resources of the supply nodes and the requested loads of the demand nodes. Subsequently, the network manager’s goal will be the detection of these misreports and suppressing their potential catastrophic impacts on the network. A similar problem is studied in the context of smart grid networks with a different system model and failure assumptions, e.g., [33, 34, 35]. However, the model proposed in these works does not explicitly focus on the interdependency between the demand and the supply. Consequently, there is no robustness analysis considering the resource provisioning among the nodes in these works. Also, the corresponding effect of load fluctuations on the supply layer, resource fluctuations on the demand layer, the uniform/proportional mechanisms of resource/load fluctuations, and the cascading failure mechanism are not considered in these works. Another interesting problem is studying the network recovery after failures, e.g., [36, 37], in the context of demand-supply networks. We leave these interesting problems to future work.
5.1 On the feasibility of mitigating cascading failures in demand-supply networks
In this subsection, we provide some insights on the feasibility of the above-described methodology in some special scenarios with respect to the network operator’s capability and the network setting.
A) Capability of the network operator: In general, the capability of the network operator belongs to one of the following cases: i) performing both resource re-adjustment and intentional failures without any restrictions; ii) performing unlimited intentional failures and limited resource re-adjustments; iii) performing unlimited resource re-adjustments and limited intentional failures; iv) performing limited resource re-adjustments and intentional failures. In the following, we provide a discussion on the performance of Algorithms 2, 3 for each case. At any stage of cascading failure, let denote the set of resource deficiencies of those demand nodes having resource deficiency and assume that . In the first case, it is trivial to verify that no cascading failure will be spread upon using our proposed algorithms. In the second case, it can be verified that the cascading failure will not spread since all the demand nodes with resource deficiency can be isolated from the supply layer. However, failing of all the demand nodes is obviously not the best strategy. In this case, the capability of the network operator in performing resource readjustments identifies the minimum required number of failed demand nodes to stop an ongoing cascading failure. Mathematically, this parameter can be obtained as:
[TABLE]
In contrast, in the third case, the capability of the network operator in performing intentional failures identifies the minimum required amount of resource readjustments. Mathematically, in this case, at any stage of the cascading failure, if the following constraint is met, then the cascading failure can be absorbed by performing resource re-adjustments:
[TABLE]
In the fourth case, at any stage of cascading failures, the possibility of mitigation should be checked by assuming failure of the maximum number of demand nodes with resource deficiency using (29). If (29) holds, then the minimum number of required intentional failures can be found based on (28); otherwise, the algorithm waits for the next time instant for deployment of the adaptability schemes. Note that our proposed algorithms enjoy low computational complexities. In particular, the computational complexity of performing intentional failures in Algorithm 2 is , while the computational complexity of performing resource re-adjustments in Algorithm 3 is , where and are tuning parameters used in Algorithm 3. The aforementioned constraints ((28), (29)) also provide interesting insights for an attacker, especially in scenarios such as battlefields, who aims to attack some supply nodes or impose targeted resource deficiencies on some demand node by restraining the resource provisioning to them. In particular, they can identify the required amount of resource deficiencies on the demand layer to trigger cascading failures.
B) Networks with a stubborn/fixed topology: Our proposed resource re-adjustment method in Algorithm 3 assumes the possibility of adding a link between a pair of nodes, which were previously sharing no resource, i.e., changing the weight of an edge with the zero initial weight. For a network with a fixed topology, or equivalently when the construction of a link takes forbidding efforts, this assumption may not be valid. In this case, the resource re-adjustments are limited to modifying the resources among the initially connected nodes, i.e., changing the weights of those edges with non-zero weights. For this scenario, we first provide a necessary condition for mitigating cascading failures upon having a limited capability of performing intentional failures and then provide the corresponding resource re-adjustment scenario.
Since the network corresponds to a bipartite graph, the adjacency matrix of the network can be written as follows:
[TABLE]
The matrix A has rows and columns, where row to corresponds to supply node to and rows to correspond to demand node to ; likewise for the columns. The rectangular matrix identifies the existence of a connection between a pair nodes, where if , and zero otherwise. In this case, upon existence of any resource deficiencies on the demand layer, let denote the extra resources needed to be allocated from node to demand node to satisfy the stability condition of that demand node. We group the supply nodes as , where denotes a group consisting of those supply nodes providing resources to demand node . A supply node may belong to multiple groups upon providing to multiple demand nodes. Consider the set with its elements as defined above and let denote those demand nodes with resource deficiencies and . It can be verified that the necessary condition for mitigating an ongoing cascading failure is then given by .
In this scenario, a suitable resource re-adjustment should satisfy the following set of equations:
[TABLE]
The left hand side of this system of equations can be written as the Hadamard product of matrices and . In Algebra, there is no known solution for the above equation holding for any matrix . Hence, the set of solutions of (31) must be found numerically. In that case, among the set of solutions, any solution satisfying , , satisfies the stability conditions on the demand and supply nodes, and thus terminates the propagation of cascading failures. It is obvious that upon applying intentional failures, some elements on the right hand side of (31) become zero.
6 Simulation Results
We consider a demand-supply network consisting of supply nodes and demand nodes. Simulations are conducted for realizations of the network, in each of which the resources and loads of the respective nodes are generated uniformly at random in the intervals and , respectively.
We consider two allocation strategies, greedy allocation (GA) and random allocation (RA), as baselines. The GA is an iterative algorithm, which is fed with the resource pool and the requested loads of the nodes. At each iteration, the GA chooses the supply node with the largest spare resource and fulfills the demands of the demand node with the largest unsatisfied load. In the RA, the adjacency matrix of the network is generated randomly fulfilling the stability conditions. In both methods, before realizing the resource configuration, we freeze/obstruct of the resources of each supply node to avoid having supply nodes at the threshold of failure. In the cost modeling, i.e., (15), for each pair of nodes, parameter is chosen uniformly at random between and , while is chosen uniformly at random between and . In Algorithm 1, we set .
Fig. 5 depicts the percentage increase in the values of and obtained by utilizing our proposed design methods as compared to the baselines under uniform and proportional resource/load fluctuations. From the two subplots on the top, it can be seen that on average our method exhibits around () performance gain in MTRF as compared to the baselines666These numbers are the average performance gains over the two baselines. upon uniform (proportional) resource fluctuations. Also, from the two subplots on the bottom, () performance gain in MTLF as compared to the baselines upon uniform (proportional) load fluctuations can be observed. We have observed that our proposed methods lead to significant performance gains as compared to the baselines for other network settings. However, the amount of achieved gains may vary form one parameter setting to another for different metrics and load fluctuation mechanisms. As can be seen from Fig. 5, the greedy algorithm often outperforms the random allocation, which is manifested by a closer performance to our optimal designs, except for MTLF with the uniform load fluctuations (bottom left subplot). This may be explained as follows: in the greedy algorithm most of the demand nodes are supplied by a few number of supply nodes. Hence, the amount of load fluctuation on the demand nodes does not spread among multiple supply nodes, which directly endangers those supply nodes with a small free capacity.
We depict the allocation cost of different resource configuration methods in Fig. 5. From the top plot of this figure, the clear superiority of our cost-effective design can be seen. Also, as can be seen, the RA results in a less allocation cost as compared to the GA. This is due to the resource congestion over the links connected to the supply nodes with large value of resources in the GA. To have a better comparison, the percent of decrease in cost upon using our cost-effective design as compared to the RA is shown in the bottom plot of this figure, which reveals a cost reduction (on average) upon using our method.
For the uniform resource fluctuations scenario, Fig. 5 demonstrates the average performance of our cost-reduction method (Algorithm 1). In the top plots, the cost is shown versus iteration demonstrating the cost reduction upon applying our algorithm to different resource allocation methods. The corresponding of the network is depicted in the bottom plot. As can be seen, our algorithm successfully reduces the allocation cost while maintaining a high robustness for the network. Also, as can be seen from the bottom plot, at the end of the last iteration although s for our cost-effective design and the baselines, especially GA, are close together, the cost of the cost-effective design is significantly lower.
The performance of confining cascading failures using our proposed network adaptability schemes is depicted in Fig. 6. In this simulation, we measure the number of surviving/stable nodes at the end of cascading failures triggered by failing various numbers of supply nodes. To have a fair performance measurement, we apply our algorithm to realizations of the network configured using RA. Each point in the figure represents the average performance over iterations comprising network realizations with different choices for the initially failed supply nodes for each realization. The simulations are conducted for two choices of the parameters for and (introduced in Section 5): i) , , and ii) , , which corresponds to a higher capability of performing demand nodes isolation and load re-adjustments as compared to the first case. As can be seen, implementing our network adaptation scheme can have a remarkable impact on the size of the surviving network, and thus the survivability of the network upon occurrence of cascading failures. Also, the impact of different network adaptation capabilities on the final size of the network upon occurrence of cascading failures is depicted in Fig. 7. In this simulation, initially, supply nodes are randomly failed and the results are obtained through averaging over Monte-Carlo iterations. It can be seen that as the capability of adapting the network increases, our proposed algorithm can save a significant number of nodes from failures.
7 Conclusion and Future Work
In this work, we studied the robustness of demand-supply networks by considering the resource as a quantitative value and incorporating the inherent resource sharing mechanism into our model. We studied the effect of different stress mechanisms on the network and investigated a suitable cascading failure mechanism. After quantifying the robustness considering different load/resource fluctuation scenarios, we proposed effective methods achieving the highest robustness to prevent cascading failures from happening. We further proposed a method that achieves the highest robustness under heterogeneous resource allocation costs among the nodes. We introduced an effective algorithm to reduce the resource allocation cost while maintaining a high robustness. Moreover, we extended the concept of network adaptability to our generic model. Along this direction, we proposed new network adaptability methods, using which we developed an algorithm to confine cascading failures. For the future work, one interesting direction is to study the demand-supply networks with uncertainties in available resources and requested loads of the nodes. This requires utilizing probabilistic methods to quantify the robustness and solve the optimization problems.
Acknowledgments
This work was supported in part by the National Science Foundation under grants ECCS-1444009 and CNS-1824518, and in part by Army Research Office under Grant W911NF-17-1-0087.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] S. V. Buldyrev, R. Parshani, G. Paul, H. E. Stanley, and S. Havlin, “Catastrophic cascade of failures in interdependent networks,” Nature , vol. 464, no. 7291, p. 1025, 2010.
- 2[2] P. Zhang, B. Cheng, Z. Zhao, D. Li, G. Lu, Y. Wang, and J. Xiao, “The robustness of interdependent transportation networks under targeted attack,” EPL (Europhysics Lett.) , vol. 103, no. 6, p. 68005, 2013.
- 3[3] M. Di Muro, L. Valdez, H. A. Rêgo, S. Buldyrev, H. Stanley, and L. Braunstein, “Cascading failures in interdependent networks with multiple supply-demand links and functionality thresholds,” Scientific Rep. , vol. 7, no. 1, p. 15059, 2017.
- 4[4] J. Zhang and E. Modiano, “Connectivity in interdependent networks,” IEEE/ACM Trans. Netw. , vol. 26, no. 5, pp. 2090–2103, Oct. 2018.
- 5[5] F. Poppe, J. Jones, S. Venkatachalam, S. Dharanikota, R. Jain, R. Hartani, D. Griffith, and Y. Xue, “Inference of shared risk link groups,” Internet Draft , 2001.
- 6[6] J. Q. Hu, “Diverse routing in optical mesh networks,” IEEE Trans. Commun. , vol. 51, no. 3, pp. 489–494, 2003.
- 7[7] D. Coudert, P. Datta, S. Pérennes, H. Rivano, and M.-E. Voge, “Shared risk resource group complexity and approximability issues,” Parallel Process. Lett. , vol. 17, no. 02, pp. 169–184, 2007.
- 8[8] M. Di Muro, C. La Rocca, H. Stanley, S. Havlin, and L. Braunstein, “Recovery of interdependent networks,” Scientific Rep. , vol. 6, p. 22834, 2016.