TL;DR
This paper investigates whether visual context enhances multimodal machine translation by showing that models can leverage visual information when textual context is limited, challenging previous assumptions about the modality's usefulness.
Contribution
The study provides a systematic analysis demonstrating that visual input improves translation quality in low-textual-context scenarios, contradicting prior beliefs about the irrelevance of visual data.
Findings
Visual modality benefits translation with limited textual context
Models can effectively utilize visual information when source text is sparse
Challenges the notion that visual features are ineffective in MMT
Abstract
Current work on multimodal machine translation (MMT) has suggested that the visual modality is either unnecessary or only marginally beneficial. We posit that this is a consequence of the very simple, short and repetitive sentences used in the only available dataset for the task (Multi30K), rendering the source text sufficient as context. In the general case, however, we believe that it is possible to combine visual and textual information in order to ground translations. In this paper we probe the contribution of the visual modality to state-of-the-art MMT models by conducting a systematic analysis where we partially deprive the models from source-side textual context. Our results show that under limited textual context, models are capable of leveraging the visual input to generate better translations. This contradicts the current belief that MMT models disregard the visual modality…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16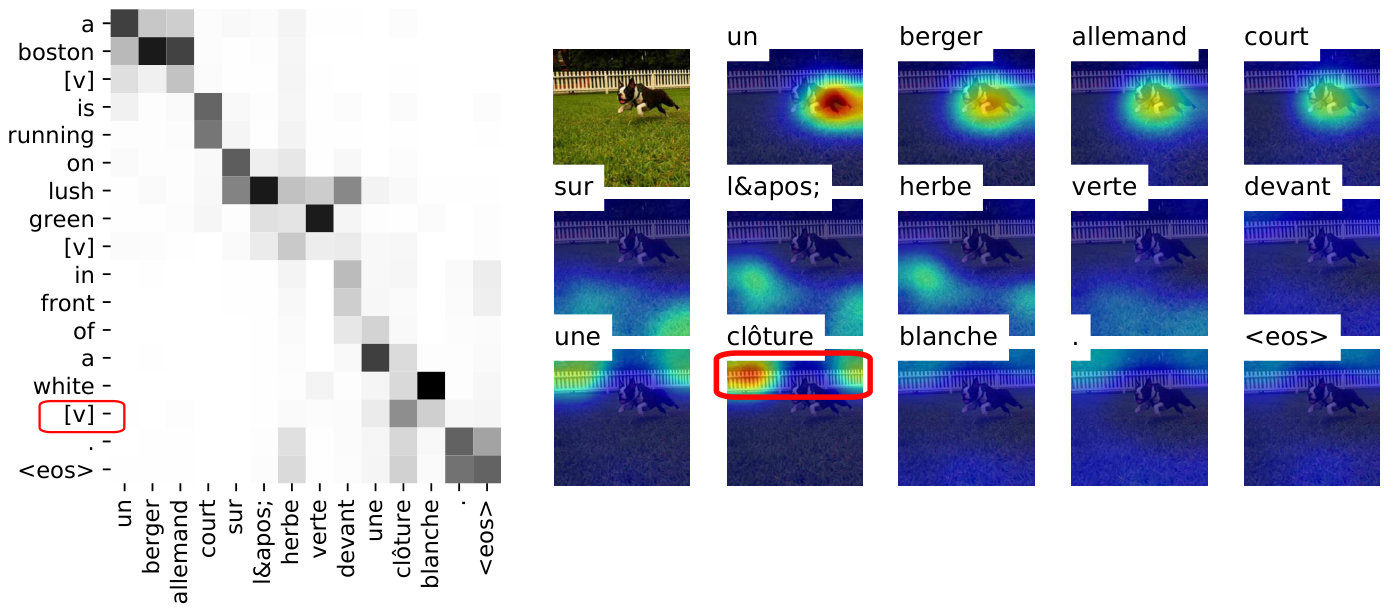 Figure 17
Figure 17 Figure 18
Figure 18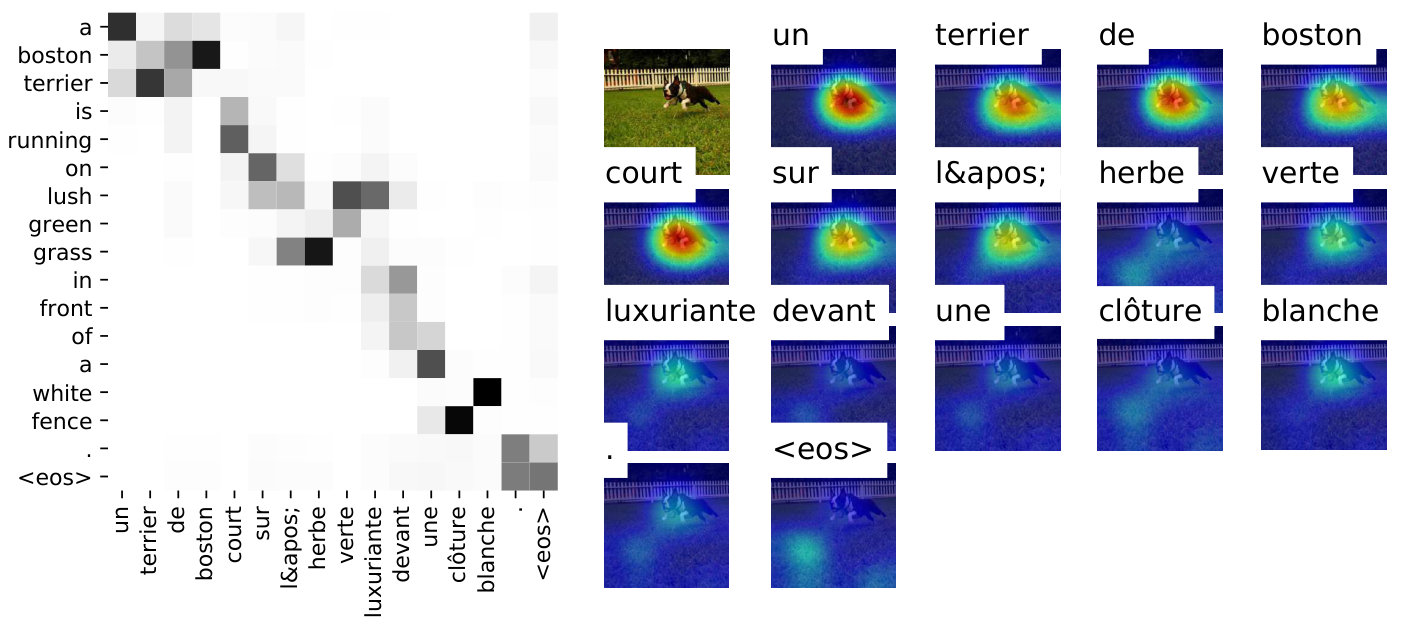 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24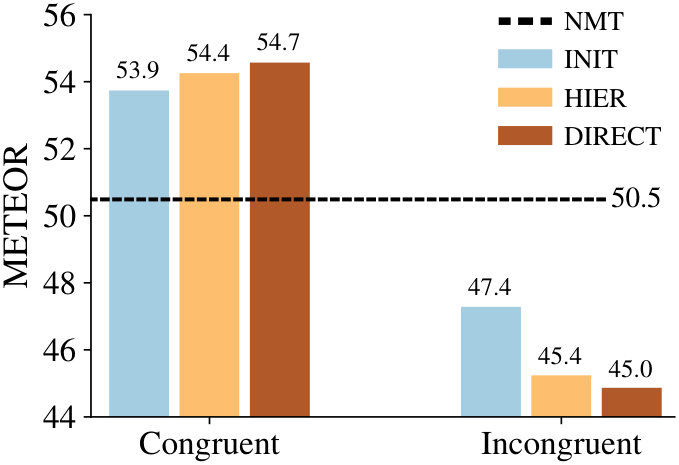 Figure 25
Figure 25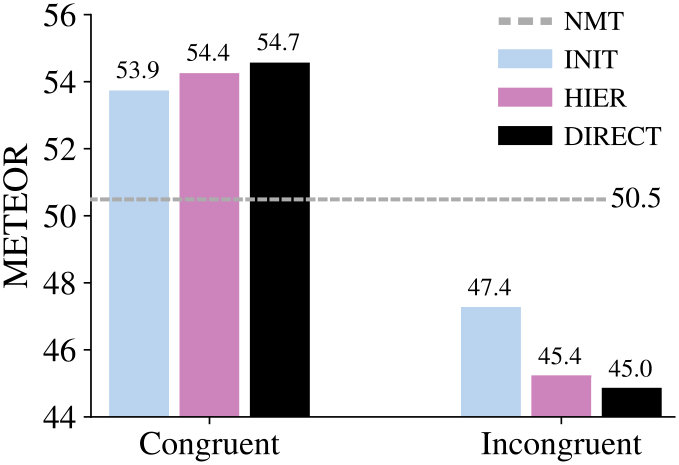 Figure 26
Figure 26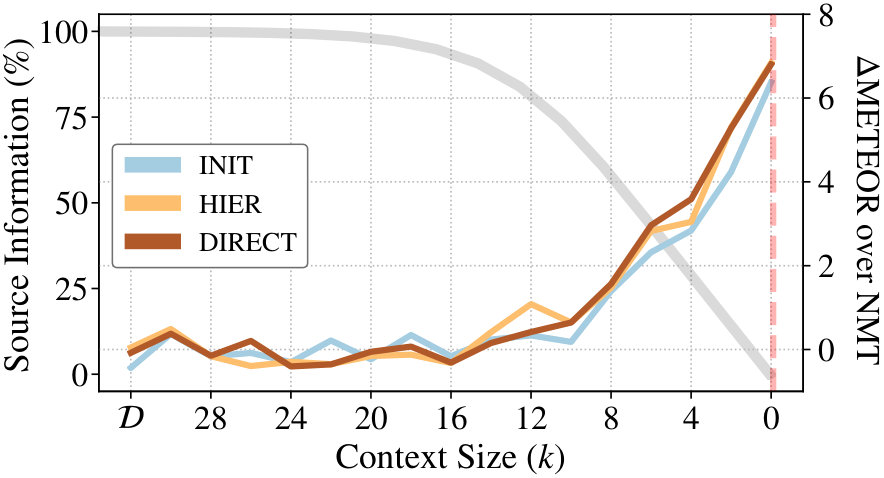 Figure 27
Figure 27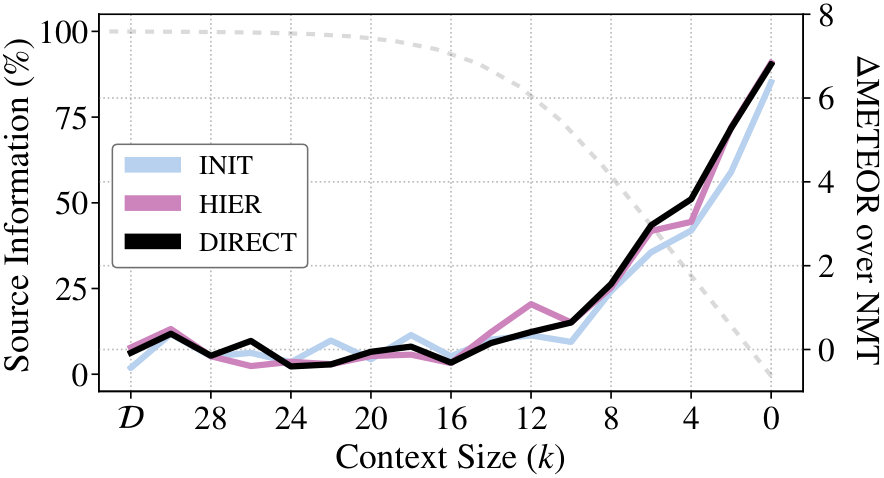 Figure 28
Figure 28| a | lady | in | a | blue | dress | singing | |
| a | lady | in | a | [v] | dress | singing | |
| a | [v] | in | a | blue | [v] | singing | |
| a | lady | in | a | [v] | [v] | [v] | |
| a | lady | [v] | [v] | [v] | [v] | [v] | |
| [v] | [v] | [v] | [v] | [v] | [v] | [v] |
| xxxxxxx NMT | 70.6 0.5 | 68.4 0.1 | ||
| INIT | 70.7 0.2 | 68.9 0.1 | ||
| HIER | 70.9 0.3 | 69.0 0.3 | ||
| DIRECT | 70.9 0.2 | 68.8 0.3 |
| Gain ( Incongruence Drop) | |||
|---|---|---|---|
| INIT | HIER | DIRECT | |
| Czech | 1.4 ( 2.9) | 1.7 ( 3.5) | 1.7 ( 4.1) |
| German | 2.1 ( 4.7) | 2.5 ( 5.9) | 2.7 ( 6.5) |
| French | 3.4 ( 6.5) | 3.9 ( 9.0) | 4.2 ( 9.7) |
| DIRECT | 32.3 | 42.2 | 64.5 | 70.1 | 70.9 |
|---|---|---|---|---|---|
| Incongruent Dec. | 6.4 | 5.5 | 1.4 | 0.7 | 0.7 |
| Blinding | 3.9 | 2.9 | 0.4 | 0.5 | 0.3 |
| NMT | 3.7 | 2.6 | 0.6 | 0.2 | 0.3 |
| SRC: an older woman in [v][v][v][v][v][v][v][v][v][v][v] | |
| NMT: une femme âgée avec un t-shirt blanc et des lunettes de soleil est assise sur un banc | |
| NMT: (an older woman with a white t-shirt and sunglasses is sitting on a bank) | |
| MMT: une femme âgée en maillot de bain rose est assise sur un rocher au bord de l’eau | |
| MMT: (an older woman with a pink swimsuit is sitting on a rock at the seaside) | |
| REF: une femme âgée en bikini bronze sur un rocher au bord de l’océan | |
| REF: (an older woman in bikini is tanning on a rock at the edge of the ocean) | |
| SRC: a young [v] in [v] holding a tennis [v] | |
| NMT: un jeune garçon en bleu tenant une raquette de tennis | |
| NMT: (a young boy in blue holding a tennis racket) | |
| MMT: une jeune femme en blanc tenant une raquette de tennis | |
| REF: une jeune femme en blanc tenant une raquette de tennis | |
| MMT: (a young girl in white holding a tennis racket) | |
| SRC: little girl covering her face with a [v] towel | |
| NMT: une petite fille couvrant son visage avec une serviette blanche | |
| NMT: (a little girl covering her face with a white towel) | |
| MMT: une petite fille couvrant son visage avec une serviette bleue | |
| REF: une petite fille couvrant son visage avec une serviette bleue | |
| MMT: (a little girl covering her face with a blue towel) |
| SRC:... a girl in [v] is sitting on a bench | |
| NMT:... pink | |
| Init:.. pink | |
| Hier:.. black | |
| Direct: black | |
| SRC:... a man dressed in [v] talking to a girl | |
| NMT:... black | |
| Init:.. black | |
| Hier:.. white | |
| Direct: white | |
| SRC:... a [v] dog sits under a [v] umbrella | |
| NMT:... brown / blue | |
| Init:.. black / blue | |
| Hier:.. black / blue | |
| Direct: black / blue | |
| SRC:... a woman in a [v] top is dancing as a woman and boy in a [v] shirt watch | |
| NMT:... blue / blue | |
| Init:.. blue / blue | |
| Hier:.. red / red | |
| Direct: red / red | |
| SRC:... three female dancers in [v] dresses are performing a dance routine | |
| NMT:... white | |
| Init:.. white | |
| Hier:.. white | |
| Direct: blue |
| SRC: a [v] in a red [v] plays in the [v] | |
| NMT: un garçon en t-shirt rouge joue dans la neige | |
| NMT: (a boy in a red t-shirt plays in the snow) | |
| MMT: un garçon en maillot de bain rouge joue dans l’eau | |
| REF: un garçon en maillot de bain rouge joue dans l’eau | |
| MMT: (a boy in a red swimsuit plays in the water) | |
| SRC: a [v] drinks [v] outside on the [v] | |
| NMT: un homme boit du vin dehors sur le trottoir | |
| NMT: (a man drinks wine outside on the sidewalk) | |
| MMT: un chien boit de l’eau dehors sur l’herbe | |
| REF: un chien boit de l’eau dehors sur l’herbe | |
| MMT: (a dog drinks water outside on the grass) | |
| SRC: two [v] are driving on a [v] | |
| NMT: deux hommes font du vélo sur une route | |
| NMT: (two men riding bicycles on a road) | |
| MMT: deux voitures roulent sur une piste | |
| MMT: (two cars driving on a track/circuit) | |
| REF: deux voitures roulent sur un circuit | |
| SRC: a [v] turns on the [v] to pursue a flying [v] | |
| NMT: un homme tourne sur la plage pour attraper un frisbee volant | |
| NMT: (a man turns on the beach to catch a flying frisbee) | |
| MMT: un chien tourne sur l’herbe pour attraper un frisbee volant | |
| MMT: (a dog turns on the grass to catch a flying frisbee) | |
| REF: un chien tourne sur l’herbe pour poursuivre une balle en l’air | |
| MMT: (a dog turns on the grass to chase a ball in the air) | |
| SRC: a [v] jumping [v] on a [v] near a parking [v] | |
| NMT: un homme sautant à cheval sur une plage près d’un parking | |
| NMT: (a man jumping on a beach near a parking lot) | |
| MMT: une fille sautant à la corde sur un trottoir près d’un parking | |
| REF: une fille sautant à la corde sur un trottoir près d’un parking | |
| REF: (a girl jumping rope on a sidewalk near a parking lot) |
| SRC: a child [v][v][v][v][v][v] | |
| NMT: un enfant avec des lunettes de soleil en train de jouer au tennis | |
| NMT: (a child with sunglasses playing tennis) | |
| MMT: un enfant est debout dans un champ de fleurs | |
| MMT: (a child is standing in field of flowers) | |
| REF: un enfant dans un champ de tulipes | |
| REF: (a child in a field of tulips) | |
| SRC: a jockey riding his [v][v] | |
| NMT: un jockey sur son vélo | |
| NMT: (a jockey on his bike) | |
| MMT: un jockey sur son cheval | |
| REF: un jockey sur son cheval | |
| MMT: (a jockey on his horse) | |
| SRC: girls are playing a [v][v][v] | |
| NMT: des filles jouent à un jeu de cartes | |
| NMT: (girls are playing a card game) | |
| MMT: des filles jouent un match de football | |
| REF: des filles jouent un match de football | |
| MMT: (girls are playing a football match) | |
| SRC: trees are in front [v][v][v][v][v] | |
| NMT: des vélos sont devant un bâtiment en plein air | |
| NMT: (bicycles are in front of an outdoor building) | |
| MMT: des arbres sont devant la montagne | |
| MMT: (trees are in front of the mountain) | |
| REF: des arbres sont devant une grande montagne | |
| REF: (trees are in front of a big mountain) | |
| SRC: a fishing net on the deck of a [v][v] | |
| NMT: un filet de pêche sur la terrasse d’un bâtiment | |
| NMT: (a fishing net on the terrace of a building) | |
| MMT: un filet de pêche sur le pont d’un bateau | |
| MMT: (a fishing net on the deck of a boat) | |
| REF: un filet de pêche sur le pont d’un bateau rouge | |
| REF: (a fishing net on the deck of a red boat) | |
| SRC: girls wave purple flags [v][v][v][v][v][v][v] | |
| NMT: des filles en t-shirts violets sont assises sur des chaises dans une salle de classe | |
| NMT: (girls in purple t-shirts are sitting on chairs in a classroom) | |
| MMT: des filles en costumes violets dansent dans une rue en ville | |
| MMT: (girls in purple costumes dance on a city street) | |
| REF: des filles agitent des drapeaux violets tandis qu’elles défilent dans la rue | |
| REF: (girls wave purple flags as they parade down the street) |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
Multimodal Machine Learning models do not work. Here is why. Part 1/2 – The SYMPTOMS· youtube
Probing the Need for Visual Context in Multimodal Machine Translation
Ozan Caglayan
LIUM, Le Mans University
&Pranava Madhyastha
Imperial College London
\ANDLucia Specia
Imperial College London
&Loïc Barrault
LIUM, Le Mans University
Abstract
Current work on multimodal machine translation (MMT) has suggested that the visual modality is either unnecessary or only marginally beneficial. We posit that this is a consequence of the very simple, short and repetitive sentences used in the only available dataset for the task (Multi30K), rendering the source text sufficient as context. In the general case, however, we believe that it is possible to combine visual and textual information in order to ground translations. In this paper we probe the contribution of the visual modality to state-of-the-art MMT models by conducting a systematic analysis where we partially deprive the models from source-side textual context. Our results show that under limited textual context, models are capable of leveraging the visual input to generate better translations. This contradicts the current belief that MMT models disregard the visual modality because of either the quality of the image features or the way they are integrated into the model.
1 Introduction
Multimodal Machine Translation (MMT) aims at designing better translation systems which take into account auxiliary inputs such as images. Initially organized as a shared task within the First Conference on Machine Translation (WMT16) Specia et al. (2016), MMT has so far been studied using the Multi30K dataset Elliott et al. (2016), a multilingual extension of Flickr30K Young et al. (2014) with translations of the English image descriptions into German, French and Czech Elliott et al. (2017); Barrault et al. (2018).
The three editions of the shared task have seen many exciting approaches that can be broadly categorized as follows: (i) multimodal attention using convolutional features Caglayan et al. (2016); Calixto et al. (2016); Libovický and Helcl (2017); Helcl et al. (2018) (ii) cross-modal interactions with spatially-unaware global features Calixto and Liu (2017); Ma et al. (2017); Caglayan et al. (2017a); Madhyastha et al. (2017) and (iii) the integration of regional features from object detection networks Huang et al. (2016); Grönroos et al. (2018). Nevertheless, the conclusion about the contribution of the visual modality is still unclear: Grönroos et al. (2018) consider their multimodal gains “modest” and attribute the largest gain to the usage of external parallel corpora. Lala et al. (2018) observe that their multimodal word-sense disambiguation approach is not significantly different than the monomodal counterpart. The organizers of the latest edition of the shared task concluded that the multimodal integration schemes explored so far resulted in marginal changes in terms of automatic metrics and human evaluation Barrault et al. (2018). In a similar vein, Elliott (2018) demonstrated that MMT models can translate without significant performance losses even in the presence of features from unrelated images.
These empirical findings seem to indicate that images are ignored by the models and hint at the fact that this is due to representation or modeling limitations. We conjecture that the most plausible reason for the linguistic dominance is that – at least in Multi30K – the source text is sufficient to perform the translation, eventually preventing the visual information from intervening in the learning process. To investigate this hypothesis, we introduce several input degradation regimes (Section 2) and revisit state-of-the-art MMT models (Section 3) to assess their behavior under degraded regimes. We further probe the visual sensitivity by deliberately feeding features from unrelated images. Our results (Section 4) show that MMT models successfully exploit the visual modality when the linguistic context is scarce, but indeed tend to be less sensitive to this modality when exposed to complete sentences.
2 Input Degradation
In this section we propose several degradations to the input language modality to simulate conditions where sentences may miss crucial information. We denote a set of translation pairs by and indicate degraded variants with subscripts. Both the training and the test sets are degraded.
Color Deprivation.
We consistently replace source words that refer to colors with a special token [v] ( in Table 1). Our hypothesis is that a monomodal system will have to rely on source-side contextual information and biases, while a multimodal architecture could potentially capitalize on color information extracted by exploiting the image and thus obtain better performance. This affects 3.3% and 3.1% of the words in the training and the test set, respectively.
Entity Masking.
The Flickr30K dataset, from which Multi30K is derived, has also been extended with coreference chains to tag mentions of visually depictable entities in image descriptions Plummer et al. (2015). We use these to mask out the head nouns in the source sentences ( in Table 1). This affects 26.2% of the words in both the training and the test set. We hypothesize that a multimodal system should heavily rely on the images to infer the missing parts.
Progressive Masking.
A progressively degraded variant replaces all but the first tokens of source sentences with [v] . Unlike the color deprivation and entity masking, masking out suffixes does not guarantee systematic removal of visual context, but rather simulates an increasingly low-resource scenario. Overall, we form 16 degraded variants (Table 1) where . We stop at since 99.8% of the sentences in Multi30K are shorter than 30 words with an average sentence length of 12 words. – where the only remaining information is the source sentence length – is an interesting case from two perspectives: a neural machine translation (NMT) model trained on it resembles a target language model, while an MMT model becomes an image captioner with access to “expected length information”.
Visual Sensitivity.
Inspired by Elliott (2018), we experiment with incongruent decoding in order to understand how sensitive the multimodal systems are to the visual modality. This is achieved by explicitly violating the test-time semantic congruence across modalities. Specifically, we feed the visual features in reverse sample order to break image-sentence alignments. Consequently, a model capable of integrating the visual modality would likely deteriorate in terms of metrics.
3 Experimental Setup
Dataset.
We conduct experiments on the EnglishFrench part of Multi30K. The models are trained on the concatenation of the train and val sets (30K sentences) whereas test2016 (dev) and test2017 (test) are used for early-stopping and model evaluation, respectively. For entity masking, we revert to the default Flickr30K splits and perform the model evaluation on test2016, since test2017 is not annotated for entities. We use word-level vocabularies of 9,951 English and 11,216 French words. We use Moses Koehn et al. (2007) scripts to lowercase, normalize and tokenize the sentences with hyphen splitting. The hyphens are stitched back prior to evaluation.
Visual Features.
We use a ResNet-50 CNN He et al. (2016) trained on ImageNet Deng et al. (2009) as image encoder. Prior to feature extraction, we center and standardize the images using ImageNet statistics, resize the shortest edge to 256 pixels and take a center crop of size 256x256. We extract spatial features of size 2048x8x8 from the final convolutional layer and apply L2 normalization along the depth dimension Caglayan et al. (2018). For the non-attentive model, we use the 2048-dimensional global average pooled version (pool5) of the above convolutional features.
Models.
Our baseline NMT is an attentive model Bahdanau et al. (2014) with a 2-layer bidirectional GRU encoder Cho et al. (2014) and a 2-layer conditional GRU decoder Sennrich et al. (2017). The second layer of the decoder receives the output of the attention layer as input.
For the MMT model, we explore the basic multimodal attention (DIRECT) Caglayan et al. (2016) and its hierarchical (HIER) extension Libovický and Helcl (2017). The former linearly projects the concatenation of textual and visual context vectors to obtain the multimodal context vector, while the latter replaces the concatenation with another attention layer. Finally, we also experiment with encoder-decoder initialization (INIT) Calixto and Liu (2017); Caglayan et al. (2017a) where we initialize both the encoder and the decoder using a non-linear transformation of the pool5 features.
Hyperparameters.
The encoder and decoder GRUs have 400 hidden units and are initialized with 0 except the multimodal INIT system. All embeddings are 200-dimensional and the decoder embeddings are tied Press and Wolf (2016). A dropout of 0.4 and 0.5 is applied on source embeddings and encoder/decoder outputs, respectively Srivastava et al. (2014). The weights are decayed with a factor of . We use ADAM Kingma and Ba (2014) with a learning rate of and mini-batches of 64 samples. The gradients are clipped if the total norm exceeds 1 Pascanu et al. (2013). The training is early-stopped if dev set METEOR Denkowski and Lavie (2014) does not improve for ten epochs. All experiments are conducted with nmtpytorch111github.com/lium-lst/nmtpytorch Caglayan et al. (2017b).
4 Results
We train all systems three times each with different random initialization in order to perform significance testing with multeval Clark et al. (2011). Throughout the section, we always report the mean over three runs (and the standard deviation) of the considered metrics. We decode the translations with a beam size of 12.
We first present test2017 METEOR scores for the baseline NMT and MMT systems, when trained on the full dataset (Table 2). The first column indicates that, although MMT models perform slightly better on average, they are not significantly better than the baseline NMT. We now introduce and discuss the results obtained under the proposed degradation schemes. Please refer to Table 5 and the appendix for qualitative examples.
4.1 Color Deprivation
Unlike the inconclusive results for , we observe that all MMT models are significantly better than NMT when color deprivation is applied ( in Table 2). If we further focus on the subset of the test set subjected to color deprivation (247 sentences), the gain increases to 1.6 METEOR for HIER. For the latter subset, we also computed the average color accuracy per sentence and found that the attentive models are 12% better than the NMT (32.544.5) whereas the INIT model only brings 4% (32.536.5) improvement. This shows that more complex MMT models are better at integrating visual information to perform better.
4.2 Entity Masking
The gains are much more prominent with entity masking, where the degradation occurs at a larger scale: Attentive MMT models show up to 4.2 METEOR improvement over NMT (Figure 3). We observed a large performance drop with incongruent decoding, suggesting that the visual modality is now much more important than previously demonstrated Elliott (2018). A comparison of attention maps produced by the baseline and masked MMT models reveals that the attention weights are more consistent in the latter. An interesting example is given in Figure 2 where the masked MMT model attends to the correct region of the image and successfully translates a dropped word that was otherwise a spelling mistake (“son”“song”).
Czech and German.
In order to understand whether the above observations are also consistent across different languages, we extend the entity masking experiments to German and Czech parts of Multi30K. Table 3 shows the gain of each MMT system with respect to the NMT model and the subsequent drop caused by incongruent decoding444For example, the INIT system for French (Figure 3) surpasses the baseline (50.5) by reaching 53.9 (+3.4), which ends up at 47.4 ( 6.5) after incongruent decoding.. First, we see that the multimodal benefits clearly hold for German and Czech, although the gains are lower than for French555This is probably due to the morphological richness of DE and CS which is suboptimally handled by word-level MT.. Second, when we compute the average drop from using incongruent images across all languages, we see how conservative the INIT system is ( 4.7) compared to HIER ( 6.1) and DIRECT ( 6.8). This raises a follow-up question as to whether the hidden state initialization eventually loses its impact throughout the recurrence where, as a consequence, the only modality processed is the text.
4.3 Progressive Masking
Finally, we discuss the results of the progressive masking experiments for French. Figure 3 clearly shows that as the sentences are progressively degraded, all MMT systems are able to leverage the visual modality. When the multimodal task becomes image captioning at , MMT models improve over the language-model counterpart by 7 METEOR. Further qualitative examples show that the systems perform surprisingly well by producing visually plausible sentences (see Table 5 and the Appendix).
To get a sense of the visual sensitivity, we pick the DIRECT models trained on four degraded variants and perform incongruent decoding. We notice that as the amount of linguistic information increases, the gap narrows down: the MMT system gradually becomes less perplexed by the incongruence or, put in other words, less sensitive to the visual modality (Table 4).
We then conduct a contrastive “blinding” experiment where the DIRECT models are not only fed with incongruent features at decoding time but also trained with them from scratch. The results suggest that the blinded models learn to ignore the visual modality. In fact, their performance is equivalent to NMT models.
5 Discussion and Conclusions
We presented an in-depth study on the potential contribution of images for multimodal machine translation. Specifically, we analysed the behavior of state-of-the-art MMT models under several degradation schemes in the Multi30K dataset, in order to reveal and understand the impact of textual predominance. Our results show that the models explored are able to integrate the visual modality if the available modalities are complementary rather than redundant. In the latter case, the primary modality (text) sufficient to accomplish the task. This dominance effect corroborates the seminal work of Colavita (1974) in Psychophysics where it has been demonstrated that visual stimuli dominate over the auditory stimuli when humans are asked to perform a simple audiovisual discrimination task. Our investigation using source degradation also suggests that visual grounding can increase the robustness of machine translation systems by mitigating input noise such as errors in the source text. In the future, we would like to devise models that can learn when and how to integrate multiple modalities by taking care of the complementary and redundant aspects of them in an intelligent way.
Acknowledgments
This work is a follow-up on the research efforts conducted within the “Grounded sequence-to-sequence transduction” team of the JSALT 2018 Workshop. We would like to thank Jindřich Libovický for contributing the hierarchical attention to nmtpytorch during the workshop. We also thank the reviewers for their valuable comments.
Ozan Caglayan and Loïc Barrault received funding from the French National Research Agency (ANR) through the CHIST-ERA M2CR project under the contract ANR-15-CHR2-0006-01. Lucia Specia and Pranava Madhyastha received funding from the MultiMT (H2020 ERC Starting Grant No. 678017) and MMVC (Newton Fund Institutional Links Grant, ID 352343575) projects.
Appendix A Qualitative Examples
In this appendix, we provide further translation examples for color deprivation (Table 6), entity masking (Table 7) and progressive masking (Table 8). Specifically for the entity masking experiments, we also give further examples to showcase the behavior of the visual attention in Figure 4 and Figure 5.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Bahdanau et al. (2014) Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2014. Neural machine translation by jointly learning to align and translate . Computing Research Repository , ar Xiv:1409.0473. Version 7.
- 2Barrault et al. (2018) Loïc Barrault, Fethi Bougares, Lucia Specia, Chiraag Lala, Desmond Elliott, and Stella Frank. 2018. Findings of the third shared task on multimodal machine translation . In Proceedings of the Third Conference on Machine Translation, Volume 2: Shared Task Papers , pages 308–327, Belgium, Brussels. Association for Computational Linguistics.
- 3Caglayan et al. (2017 a) Ozan Caglayan, Walid Aransa, Adrien Bardet, Mercedes García-Martínez, Fethi Bougares, Loïc Barrault, Marc Masana, Luis Herranz, and Joost van de Weijer. 2017 a. LIUM-CVC submissions for WMT 17 multimodal translation task . In Proceedings of the Second Conference on Machine Translation, Volume 2: Shared Task Papers , pages 432–439, Copenhagen, Denmark. Association for Computational Linguistics.
- 4Caglayan et al. (2018) Ozan Caglayan, Adrien Bardet, Fethi Bougares, Loïc Barrault, Kai Wang, Marc Masana, Luis Herranz, and Joost van de Weijer. 2018. LIUM-CVC submissions for WMT 18 multimodal translation task . In Proceedings of the Third Conference on Machine Translation, Volume 2: Shared Task Papers , pages 603–608, Belgium, Brussels. Association for Computational Linguistics.
- 5Caglayan et al. (2016) Ozan Caglayan, Loïc Barrault, and Fethi Bougares. 2016. Multimodal attention for neural machine translation . Computing Research Repository , ar Xiv:1609.03976.
- 6Caglayan et al. (2017 b) Ozan Caglayan, Mercedes García-Martínez, Adrien Bardet, Walid Aransa, Fethi Bougares, and Loïc Barrault. 2017 b. NMTPY: A flexible toolkit for advanced neural machine translation systems . Prague Bull. Math. Linguistics , 109:15–28. · doi ↗
- 7Calixto et al. (2016) Iacer Calixto, Desmond Elliott, and Stella Frank. 2016. DCU-Uv A multimodal MT system report . In Proceedings of the First Conference on Machine Translation , pages 634–638, Berlin, Germany. Association for Computational Linguistics.
- 8Calixto and Liu (2017) Iacer Calixto and Qun Liu. 2017. Incorporating global visual features into attention-based neural machine translation. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing , pages 992–1003, Copenhagen, Denmark. Association for Computational Linguistics.
